mirror of
https://github.com/alibaba/EasyCV.git
synced 2025-06-03 14:49:00 +08:00
OCR algorithm
PP-OCRv3
We convert PaddleOCRv3 models to pytorch style, and provide end2end interface to recognize text in images, by simplely load exported models.
detection
We test on icdar2015 dataset.
| Algorithm | backbone | configs | precison | recall | Hmean | Download |
|---|---|---|---|---|---|---|
| DB | MobileNetv3 | det_model_en.py | 0.7803 | 0.7250 | 0.7516 | log-model |
| DB | R50 | det_model_en_r50.py | 0.8622 | 0.8218 | 0.8415 | log-model |
recognition
We test on on DTRB dataset.
| Algorithm | backbone | configs | acc | Download |
|---|---|---|---|---|
| SVTR | MobileNetv1 | rec_model_en.py | 0.7536 | log-model |
predict
We provide exported models contain weights and process config for easyly predict, which convert from PaddleOCRv3.
detection model
| language | Download |
|---|---|
| chinese | chinese_det.pth |
| english | english_det.pth |
| multilingual | multilingual_det.pth |
recognition model
| language | Download |
|---|---|
| chinese | chinese_rec.pth |
| english | english_rec.pth |
| korean | korean_rec.pth |
| japan | japan_rec.pth |
| chinese_cht | chinese_cht_rec.pth |
| Telugu | te_rec.pth |
| Canada | ka_rec.pth |
| Tamil | ta_rec.pth |
| latin | latin_rec.pth |
| cyrillic | cyrillic_rec.pth |
| devanagari | devanagari_rec.pth |
direction model
| language | Download |
|---|---|
| direction.pth |
usage
detection
import cv2
from easycv.predictors.ocr import OCRDetPredictor
predictor = OCRDetPredictor(model_path)
out = predictor([img_path]) # out = predictor([img])
img = cv2.imread(img_path)
out_img = predictor.show_result(out[0], img)
cv2.imwrite(out_img_path,out_img)

recognition
import cv2
from easycv.predictors.ocr import OCRRecPredictor
predictor = OCRRecPredictor(model_path)
out = predictor([img_path])
print(out)
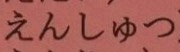
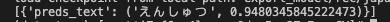
end2end
import cv2
from easycv.predictors.ocr import OCRPredictor
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/ocr/simfang.ttf
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/ocr/ocr_det.jpg
predictor = OCRPredictor(
det_model_path=path_to_detmodel,
rec_model_path=path_to_recmodel,
cls_model_path=path_to_clsmodel,
use_angle_cls=True)
out = predictor(img_path)
img = cv2.imread('ocr_det.jpg')
out_img = predictor.show(
out[0]['boxes'],
out[0]['rec_res'],
img,
font_path='simfang.ttf')
cv2.imwrite('out_img.jpg', out_img)
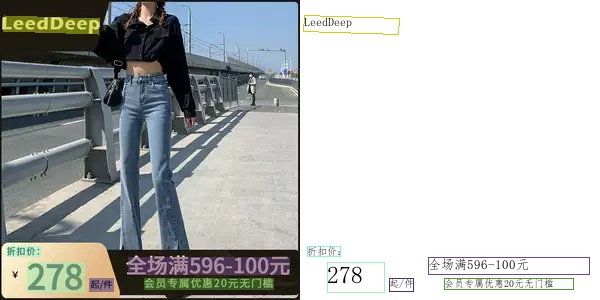
There are some ocr results.