12 KiB
PaddleClas项目结构文档
该文档介绍了PaddleClas整体结构、代码组成以及运行逻辑,可以由本文档出发对PaddleClas项目进行学习。
目录
1. 项目整体介绍
PaddleClas是一个致力于为工业界和学术界提供运用PaddlePaddle快速实现图像分类和图像识别的套件库,能够帮助开发者训练和部署性能更强的视觉模型。同时,PaddleClas提供了数个特色方案:PULC超轻量级图像分类方案、PP-ShiTU图像识别系统、PP系列骨干网络模型和SSLD半监督知识蒸馏算法。

PaddleClas全景图
2. 代码解析
2.1 代码总体结构
项目代码总体结构可参考下图:

代码结构图
以下介绍各目录代码的作用。
2.1.1 benchmark
该目录存放了用于测试PaddleClas不同模型速度指标的shell脚本,如单卡训练速度指标、多卡训练速度指标等。以下是各脚本介绍:
- prepare_data.sh:下载相应的测试数据,并配置好数据路径。
- run_benchmark.sh:执行单独一个训练测试的脚本,具体调用方式,可查看脚本注释。
- run_all.sh: 执行所有训练测试的入口脚本。
具体介绍可以参考文档。
2.1.2 dataset
该目录用于存放不同的数据集。数据集文件中应当包含数据集图像、训练集标签文件、验证集标签文件、测试集标签文件;数据集标签文件使用txt格式保存,标签文件中每一行描述一个图像数据,包括图像地址和真值标签,中间用分隔符隔开(默认为空格),格式如下:
jpg/image_06765.jpg 0
jpg/image_06755.jpg 0
jpg/image_05145.jpg 1
jpg/image_05137.jpg 1
更详细的数据集格式说明请参考:图像分类任务数据集说明和图像识别任务数据集说明。
2.1.3 docs
该目录存放了PaddleClas项目的中英文说明文档和相关说明图,包括项目教程、方法介绍、模型介绍、应用实例介绍等。
2.1.4 ppcls
该目录存放了PaddleClas的核心代码,下面详细介绍该目录下各文件内容:
configs
该文件夹包含PaddleClas提供的官方配置文件,包括了对应不同模型、方法的配置,可以直接调用训练或作为训练配置的参考,详细介绍可参考:配置文件说明。以下简单介绍配置文件各字段功能:
| 字段名 | 功能 |
|---|---|
| Global | 该字段描述整体的训练配置,包括预训练权重、预训练模型、输出地址、训练设备、训练epoch数、输入图像大小等 |
| Arch | 该字段描述模型的网络结构参数,构建模型时主要调用该部分参数 |
| Loss | 该字段描述损失函数的参数配置,包括训练和验证损失函数,损失函数类型,损失函数权重等,构建损失函数时调用 |
| Optimizer | 该字段描述优化器部分的参数配置,构建优化器时调用 |
| DataLoader | 该字段描述数据处理部分参数配置,包括训练和验证过程的不同数据集读取方式、数据采样策略、数据增广方法等 |
| Metric | 该字段描述评价指标,包括训练和验证过程选择的评价指标及其参数配置 |
arch
该文件夹存放了与模型组网相关的代码,进行模型组网时根据配置文件中Arch字段的设置,选择对应的骨干网络、Neck、Head以及对应的参数设置,以下简单介绍各文件夹的作用:
| 文件夹 | 功能 |
|---|---|
| backbone | PaddleClas实现的骨干网络模型,,__init__.py中可以查看所有模型情况,具体骨干网络模型情况可参考:骨干网络预训练库 |
| gears | 包含特征提取网络的 Neck和Head部分代码,在识别模型中用于对骨干网络提取的特征进行转换和处理。 |
| distill | 包含知识蒸馏相关代码,详细内容可参考:知识蒸馏介绍和知识蒸馏实战 |
| slim | 包含模型量化相关代码,详细内容可参考算法介绍和使用介绍 |
data
该目录包含了对数据进行处理的相关代码用于构建dataloader,构建过程中会根据配置文件Dataloader字段内容,选择对应的dataset、sampler、数据增广方式以及对应的参数设置。以下简单介绍各文件夹作用:
| 文件夹 | 功能 |
|---|---|
| dataloader | 该目录包含了不同的数据集采样方法(dataset)和不同的采样策略(sampler) |
| preprocess | 该目录包含对数据的预处理和数据增广方法,包括对数据样本的处理(ops)和批数据处理方法(batch_ops),详细介绍可参考:数据增强实战 |
| postprocess | 对模型输出结果的后处理,输出对应的类别名、置信度、预测结果等 |
| utils | 其他常用函数 |
optimizer
该目录包含了不同优化器(optimizer.py)和不同学习率策略(learning_rate.py)的代码,构建过程会根据配置文件Optimizer字段内容选择对应的优化器和学习率策略以及对应的参数配置。
loss
该目录下包含了各种训练和验证过程损失函数的代码,构建损失函数过程会根据配置文件Loss字段内容选择对应的损失函数以及对应的权重和参数配置,并且会使用__init__.py中的CombinedLoss类将各个损失函数加权求和得到整体的损失函数。
metric
该目录包含了各种评价指标用于评估模型性能,构建评估指标时会根据配置文件Metric字段内容选择不同的评价指标在验证阶段进行模型评估。
engine
该目录包含PaddleClas训练和验证整体流程的代码,主要负责组织数据处理、模型准备和训练推理等流程,完成模型训练、模型推理和模型验证的整体串联流程。代码运行逻辑可参考:2.2 代码运行逻辑,以下简单介绍各文件夹作用:
| 文件或文件夹 | 功能 |
|---|---|
| train | 包含了训练过程代码,通过train.py中的train_epoch函数控制模型训练过程 |
| evaluation | 包含了验证过程代码,其中包括了不同的验证模式:分类、检索等 |
| engine.py | 整体训练、验证的启动类,其功能是串联训练模块构建、调用训练和验证过程 |
static
该目录包含了其他常用的函数,以下简单介绍其中几个文件作用:
| 文件 | 功能 |
|---|---|
| logger | logger打印相关函数。定义了一个全局变量_logger,并在需要打印的位置import该文件。 |
| ema | Exponential Moving Average,指数移动平均策略,用于根据参数加权历史均值更新当前参数。 |
| save_load | 保存、加载模型参数等操作。 |
2.1.5 deploy
该目录包含了PaddleClas模型部署以及PP-ShiTu相关代码。以下文档为模型部署以及PP-ShiTu相关介绍教程,可配合文档对相应代码进行理解:
2.1.6 test_tipc
该目录包含了PaddleClas项目质量监控相关的脚本,提供了一键化测试各模型的各项性能指标的功能,详细内容请参考:飞桨训推一体全流程开发文档
2.2 代码运行逻辑
代码运行逻辑如图,主要以训练过程为例介绍PaddleClas代码运行逻辑。

代码运行逻辑
注意:此处仅介绍整体运行逻辑,建议配合启动训练的快速体验文档进行代码运行逻辑部分的理解。
2.2.1 编写配置文件
设置训练过程中的配置参数和各个模块的构建参数,./ppcls/configs中包含了PaddleClas官方提供的参考配置文件。
2.2.2 启动训练
运行训练脚本./tools/train.py启动训练,该启动脚本首先对配置文件进行解析并调用Engine类进行各模块构建。

模块构建主要调用./ppcls文件夹下各模块的build函数(位于各模块的的__init__.py文件)以及配置文件中对应参数进行构建,如下图在Engine类中调用build_dataloader()函数构建dataloader。

训练脚本./tools/train.py调用Engine类完成训练所需的各个模块构建后,会调用Engine类中的train()方法启动训练,该方法使用./ppcls/engine/train/train.py中的train_epoch()函数进行模型训练。

3. 应用项目介绍
基于PaddleClas丰富的图像识别和图像分类算法功能,PaddleClas提供了两个具有产业特色的应用系统:PULC超轻量级图像分类方案和PP-ShiTu图像识别系统。
3.1 PULC超轻量级图像分类方案
PULC是PaddleClas为了解决企业应用难题,让分类模型的训练和调参更加容易,总结出的实用轻量图像分类解决方案(PULC, Practical Ultra Lightweight Classification)。PULC融合了骨干网络、数据增广、蒸馏等多种前沿算法,可以自动训练得到轻量且高精度的图像分类模型。详情请参考:PULC详细介绍
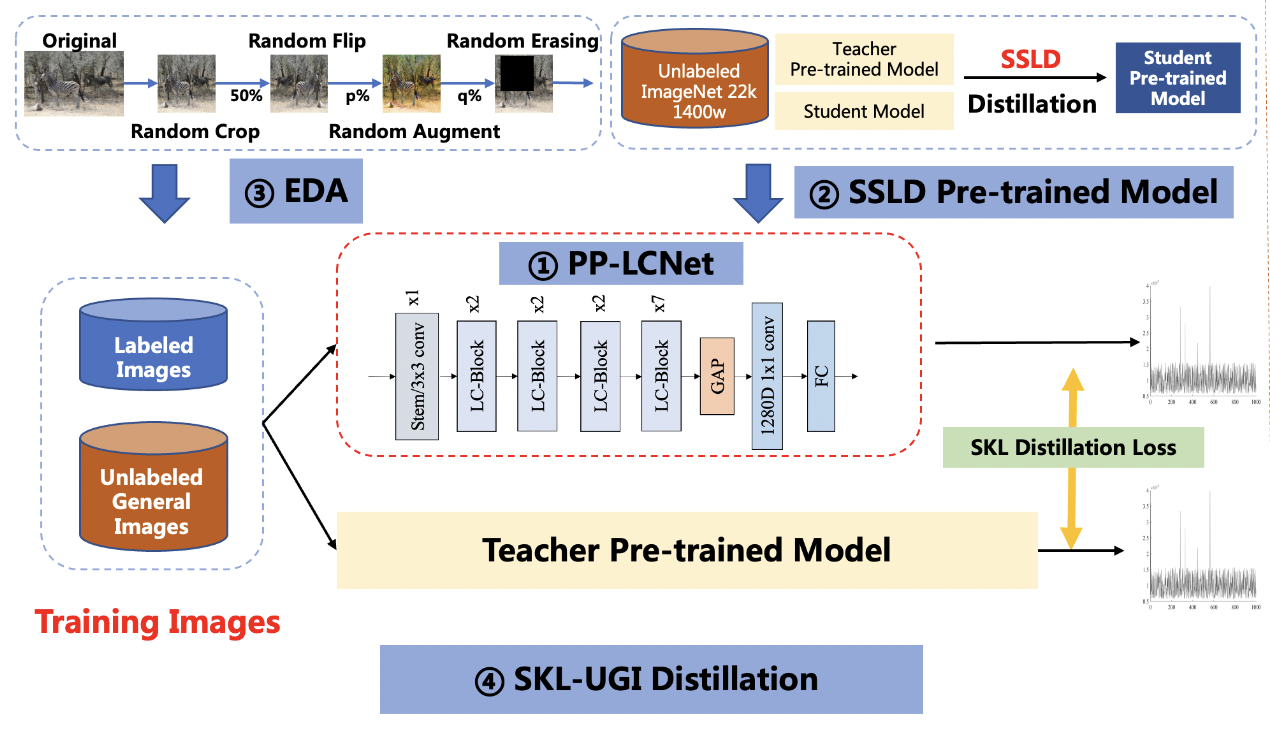
PULC超轻量级图像分类方案
3.2 PP-ShiTu图像识别系统
PP-ShiTuV2是一个实用的轻量级通用图像识别系统,主要由主体检测、特征学习和向量检索三个模块组成。该系统从骨干网络选择和调整、损失函数的选择、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型裁剪量化多个方面,采用多种策略,对各个模块的模型进行优化,PP-ShiTuV2相比V1,Recall1提升近8个点。更多细节请参考:PP-ShiTuV2图像识别系统

PULC超轻量级图像分类方案