9.8 KiB
图像分类常见问题汇总 - 2020 第1季
目录
第1期
Q1.1: PaddleClas可以用来做什么?
A:PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas提供了基于图像分类的模型训练、评估、预测、部署全流程的服务,方便大家更加高效地学习图像分类。具体地,PaddleClas中包含如下一些特性 。
- PaddleClas提供了24个系列的分类网络结构(ResNet, ResNet_vd, MobileNetV3, Res2Net, HRNet等)和训练配置,122个预训练模型和性能评估与预测,供大家选择并使用。
- PaddleClas提供了TensorRT预测、python inference、c++ inference、Paddle-Lite预测部署等多种预测部署推理方案,在方便在多种环境中进行部署推理。
- PaddleClas提供了一种简单的SSLD知识蒸馏方案,基于该方案蒸馏模型的识别准确率普遍提升3%以上。
- PaddleClas支持AutoAugment、Cutout、Cutmix等8种数据增广算法详细介绍、代码复现和在统一实验环境下的效果评估。
- PaddleClas支持在Windows/Linux/MacOS环境中基于CPU/GPU进行使用。
Q1.2: ResNet系列模型是什么?有哪些模型?为什么在服务器端如此推荐ResNet系列模型?
A: ResNet中创新性地引入了残差结构,通过堆叠多个残差结构从而构建了ResNet网络。实验表明使用残差块可以有效地提升收敛速度和精度,PaddleClas中,ResNet从小到达,依次有包含18、34、50、101、152、200层的ResNet结构,ResNet系列模型于2015年被提出,在不同的应用场景中,如分类、检测、分割等,都已经验证过其有效性,业界也早已对其进行了大量优化,该系列模型在速度和精度方面都有着非常明显的优势,对基于TensorRT以及FP16的预测支持得也很好,因而推荐大家使用ResNet系列模型;由于其模型所占存储相对较大,因此常用于服务器端。更多关于ResNet模型的介绍可以参考论文Deep Residual Learning for Image Recognition。
Q1.3: ResNet_vd和ResNet、ResNet_vc结构有什么区别呢?
A:
ResNet_va至vd的结构如下图所示,ResNet最早提出时为va结构,在降采样残差模块这个部分,在左边的特征变换通路中(Path A),第一个1x1卷积部分就行了降采样,从而导致信息丢失(卷积的kernel size为1,stride为2,输入特征图中 有部分特征没有参与卷积的计算);在vb结构中,把降采样的步骤从最开始的第一个1x1卷积调整到中间的3x3卷积中,从而避免了信息丢失的问题,PaddleClas中的ResNet模型默认就是ResNet_vb;vc结构则是将最开始这个7x7的卷积变成3个3x3的卷积,在感受野不变的情况下,计算量和存储大小几乎不变,而且实验证明精度相对于vb结构有所提升;vd结构是修改了降采样残差模块右边的特征通路(Path B)。把降采样的过程由平均池化这个操作去替代了,这一系列的改进(va->vd),几乎没有带来新增的预测耗时,结合适当的训练策略,比如说标签平滑以及mixup数据增广,精度可以提升高达2.7%。

Q1.4 如果确定使用ResNet系列模型,怎么根据实际的场景需求选用不同的模型呢?
A:
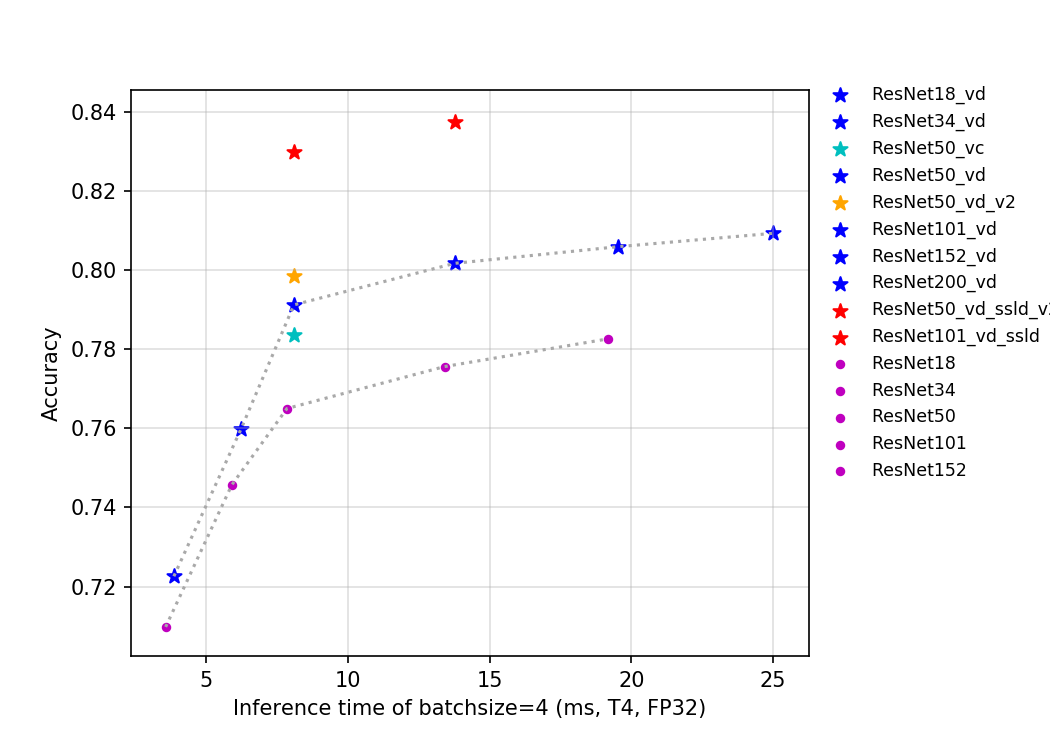
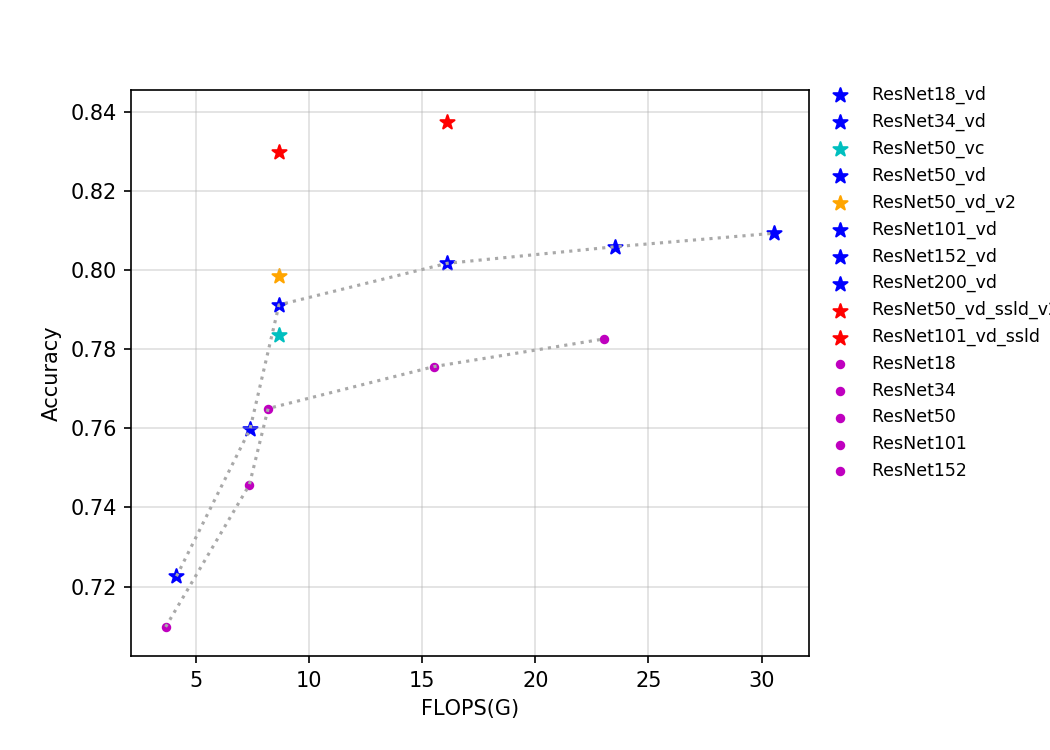
ResNet系列模型中,相比于其他模型,ResNet_vd模型在预测速度几乎不变的情况下,精度有非常明显的提升,因此推荐大家使用ResNet_vd系列模型。 下面给出了batch size=4的情况下,在T4 GPU上,不同模型的的预测耗时、flops、params与精度的变化曲线,可以根据自己自己的实际部署场景中的需求,去选择合适的模型,如果希望模型存储大小尽可能小或者预测速度尽可能快,则可以使用ResNet18_vd模型,如果希望获得尽可能高的精度,则建议使用ResNet152_vd或者ResNet200_vd模型。更多关于ResNet系列模型的介绍可以参考文档:ResNet及其vd系列模型文档。
- 精度-预测速度变化曲线
- 精度-params变化曲线

- 精度-flops变化曲线
Q1.5 在网络中的block里conv-bn-relu是固定的形式吗?
A: 在batch-norm出现之前,主流的卷积神经网络的固定形式是conv-relu。在现阶段的卷积神经网络中,conv-bn-relu是大部分网络中block的固定形式,这样的设计是相对鲁棒的结构,此外,DenseNet中的block选用的是bn-relu-conv的形式,ResNet-V2中也使用的是这种组合方式。在MobileNetV2中,为了不丢失信息,部分block中间的层没有使用relu激活函数,选用的是conv-bn的形式。
Q1.6 ResNet34与ResNet50的区别?
A: ResNet系列中有两种不同的block,分别是basic-block和bottleneck-block,堆叠较多这样的block组成了ResNet网络。basic-block是带有shortcut的两个3x3的卷积核的堆叠,bottleneck-block是带有shortcut的1x1卷积核、3x3卷积核、1x1卷积核的堆叠,所以basic-block中有两层,bottleneck-block有三层。ResNet34和ResNet50中堆叠的block数相同,但是堆叠的种类分别是basic-block和bottleneck-block。
Q1.7 大卷积核一定可以带来正向收益吗?
A: 不一定,将网络中的所有卷积核都增大未必会带来性能的提升,甚至会有有损性能,在论文MixConv: Mixed Depthwise Convolutional Kernels 中指出,在一定范围内提升卷积核大小对精度的提升有正向作用,但是超出后会有损精度。所以考虑到模型的大小、计算量等问题,一般不选用大的卷积核去设计网络。
第2期
Q2.1: PaddleClas如何训练自己的backbone?
A:具体流程如下:
- 首先在ppcls/modeling/architectures/文件夹下新建一个自己的模型结构文件,即你自己的backbone,模型搭建可以参考resnet.py;
- 然后在ppcls/modeling/__init__.py中添加自己设计的backbone的类;
- 其次配置训练的yaml文件,此处可以参考configs/ResNet/ResNet50.yaml;
- 最后启动训练即可。
Q2.2: 如何利用已有的模型和权重对自己的分类任务进行迁移?
A: 具体流程如下:
- 首先,好的预训练模型往往会有更好的迁移效果,所以建议选用精度较高的预训练模型,PaddleClas提供了一系列业界领先的预训练模型,建议使用;
- 其次,要根据迁移的数据集的规模来确定训练超参数,一般超参数需要调试才可以寻找到一个局部最优值,如果没有相关经验,建议先从learning rate开始调起,一般来说,规模较小的数据集使用较小的learning rate,如0.001,另外,建议学习率使用warmup策略,避免过大的学习率破坏预训练模型的权重。在迁移过程中,也可以设置backbone中不同层的学习率,往往从网络的头部到尾补学习率逐渐减小效果较好。在数据集规模较小的时候,也可以使用数据增强策略,PaddleClas提供了8中强有力的数据增强策略,为更高的精度保驾护航。
- 训练结束后,可以反复迭代上述过程,直到寻找到局部最优值。
Q2.3: PaddleClas中configs下的默认参数适合任何一个数据集吗?
A: PaddleClas中的configs下的默认参数是ImageNet-1k的训练参数,这个参数并不适合所有的数据集,具体数据集需要在此基础上进一步调试,调试方法会在之后出一个单独的faq,敬请期待。
Q2.4 PaddleClas中的不同的模型使用了不同的分辨率,标配的应该是多少呢?
A: PaddleClas严格遵循了论文作者的使用的分辨率。自2012年AlexNet以来,大多数的卷积神经网络在ImageNet上训练的分辨率为224x224,Google在设计InceptionV3的时候为了适应网络结构将分辨率调至299x299,之后其推出的Xception、InceptionV4也是使用的该分辨率。此外,在EfficeintNet中,作者分析了不同规模的网络应该使用不同的分辨率,所以该系列网络中每个不同大小的网络都使用了不同的分辨率。在实际使用场景中,推荐使用默认的分辨率,当然,层数较深或者宽度较大的网络也可以尝试使用更大的分辨率。
Q2.5 PaddleClas中提供了很多ssld模型,其应用的价值是?
A: PaddleClas中提供了很多ssld预训练模型,其通过半监督知识蒸馏的方法获得了更好的预训练权重,在迁移任务或者下游视觉任务中,无须替换结构文件、只需要替换精度更高的ssld预训练模型即可提升精度,如在PaddleSeg中,HRNet使用了ssld预训练模型的权重后,精度大幅度超越业界同样的模型的精度,在PaddleDetection中,PP-YOLO使用了ssld预训练权重后,在较高的baseline上仍有进一步的提升。使用ssld预训练权重做分类的迁移表现也很抢眼,在SSLD蒸馏策略部分介绍了知识蒸馏对于分类任务迁移的收益。