fixed conflict vl 0811
commit
17b1312e7c
|
|
@ -131,7 +131,7 @@ pip3 install dist/PPOCRLabel-1.0.2-py2.py3-none-any.whl -i https://mirror.baidu.
|
|||
|
||||
> 注意:如果表格中存在空白单元格,同样需要使用一个标注框将其标出,使得单元格总数与图像中保持一致。
|
||||
|
||||
3. **调整单元格顺序:**点击软件`视图-显示框编号` 打开标注框序号,在软件界面右侧拖动 `识别结果` 一栏下的所有结果,使得标注框编号按照从左到右,从上到下的顺序排列
|
||||
3. **调整单元格顺序**:点击软件`视图-显示框编号` 打开标注框序号,在软件界面右侧拖动 `识别结果` 一栏下的所有结果,使得标注框编号按照从左到右,从上到下的顺序排列,按行依次标注。
|
||||
|
||||
4. 标注表格结构:**在外部Excel软件中,将存在文字的单元格标记为任意标识符(如 `1` )**,保证Excel中的单元格合并情况与原图相同即可(即不需要Excel中的单元格文字与图片中的文字完全相同)
|
||||
|
||||
|
|
|
|||
|
|
@ -1,41 +1,78 @@
|
|||
[English](README_en.md) | 简体中文
|
||||
|
||||
# 场景应用
|
||||
|
||||
PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。
|
||||
|
||||
> 如需下载全部垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
|
||||
- [教程文档](#1)
|
||||
- [通用](#11)
|
||||
- [制造](#12)
|
||||
- [金融](#13)
|
||||
- [交通](#14)
|
||||
|
||||
- [模型下载](#2)
|
||||
|
||||
<a name="1"></a>
|
||||
|
||||
## 教程文档
|
||||
|
||||
<a name="11"></a>
|
||||
|
||||
### 通用
|
||||
|
||||
| 类别 | 亮点 | 模型下载 | 教程 |
|
||||
| ---------------------- | ------------ | -------------- | --------------------------------------- |
|
||||
| 高精度中文识别模型SVTR | 比PP-OCRv3识别模型精度高3%,可用于数据挖掘或对预测效率要求不高的场景。| [模型下载](#2) | [中文](./高精度中文识别模型.md)/English |
|
||||
| 手写体识别 | 新增字形支持 | | |
|
||||
|
||||
<a name="12"></a>
|
||||
|
||||
### 制造
|
||||
|
||||
| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
|
||||
| -------------- | ------------------------------ | -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| 数码管识别 | 数码管数据合成、漏识别调优 | [模型下载](#2) | [中文](./光功率计数码管字符识别/光功率计数码管字符识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/7d5774a273f84efba5b9ce7fd3f86e9ef24b6473e046444db69fa3ca20ac0986" width = "200" height = "100" /> |
|
||||
| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/901ab741cb46441ebec510b37e63b9d8d1b7c95f63cc4e5e8757f35179ae6373" width = "200" height = "100" /> |
|
||||
| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/d9e0533cc1df47ffa3bbe99de9e42639a3ebfa5bce834bafb1ca4574bf9db684" width = "200" height = "100" /> |
|
||||
| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/95d8e95bf1ab476987f2519c0f8f0c60a0cdc2c444804ed6ab08f2f7ab054880" width = "200" height = "100" /> |
|
||||
| 电表识别 | 大分辨率图像检测调优 | [模型下载](#2) | | |
|
||||
| 液晶屏缺陷检测 | 非文字字符识别 | | | |
|
||||
|
||||
<a name="13"></a>
|
||||
|
||||
### 金融
|
||||
|
||||
| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
|
||||
| -------------- | ------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
|
||||
| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/a3b25766f3074d2facdf88d4a60fc76612f51992fd124cf5bd846b213130665b" width = "200" height = "200" /> |
|
||||
| 增值税发票 | 尽请期待 | | | |
|
||||
| 印章检测与识别 | 端到端弯曲文本识别 | | | |
|
||||
| 通用卡证识别 | 通用结构化提取 | | | |
|
||||
| 身份证识别 | 结构化提取、图像阴影 | | | |
|
||||
| 合同比对 | 密集文本检测、NLP串联 | | | |
|
||||
|
||||
<a name="14"></a>
|
||||
|
||||
### 交通
|
||||
|
||||
| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
|
||||
| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
|
||||
| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English | <img src="https://ai-studio-static-online.cdn.bcebos.com/76b6a0939c2c4cf49039b6563c4b28e241e11285d7464e799e81c58c0f7707a7" width = "200" height = "100" /> |
|
||||
| 驾驶证/行驶证识别 | 尽请期待 | | | |
|
||||
| 快递单识别 | 尽请期待 | | | |
|
||||
|
||||
<a name="2"></a>
|
||||
|
||||
## 模型下载
|
||||
|
||||
如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
|
||||
|
||||
<div align="center">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
|
||||
如果您是企业开发者且未在上述场景中找到合适的方案,可以填写[OCR应用合作调研问卷](https://paddle.wjx.cn/vj/QwF7GKw.aspx),免费与官方团队展开不同层次的合作,包括但不限于问题抽象、确定技术方案、项目答疑、共同研发等。如果您已经使用PaddleOCR落地项目,也可以填写此问卷,与飞桨平台共同宣传推广,提升企业技术品宣。期待您的提交!
|
||||
|
||||
> 如果您是企业开发者且未在下述场景中找到合适的方案,可以填写[OCR应用合作调研问卷](https://paddle.wjx.cn/vj/QwF7GKw.aspx),免费与官方团队展开不同层次的合作,包括但不限于问题抽象、确定技术方案、项目答疑、共同研发等。如果您已经使用PaddleOCR落地项目,也可以填写此问卷,与飞桨平台共同宣传推广,提升企业技术品宣。期待您的提交!
|
||||
|
||||
## 通用
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------------------------- | -------- | ---------- | ------------ |
|
||||
| [高精度中文识别模型SVTR](./高精度中文识别模型.md) | 新增模型 | 手写体识别 | 新增字形支持 |
|
||||
|
||||
## 制造
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------------------------------------ | ------------------------------ | ------------------------------------------- | -------------------- |
|
||||
| [数码管识别](./光功率计数码管字符识别/光功率计数码管字符识别.md) | 数码管数据合成、漏识别调优 | 电表识别 | 大分辨率图像检测调优 |
|
||||
| [液晶屏读数识别](./液晶屏读数识别.md) | 检测模型蒸馏、Serving部署 | [PCB文字识别](./PCB字符识别/PCB字符识别.md) | 小尺寸文本检测与识别 |
|
||||
| [包装生产日期](./包装生产日期识别.md) | 点阵字符合成、过曝过暗文字识别 | 液晶屏缺陷检测 | 非文字字符识别 |
|
||||
|
||||
## 金融
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------ | ------------------------ | ------------ | --------------------- |
|
||||
| [表单VQA](./多模态表单识别.md) | 多模态通用表单结构化提取 | 通用卡证识别 | 通用结构化提取 |
|
||||
| 增值税发票 | 尽请期待 | 身份证识别 | 结构化提取、图像阴影 |
|
||||
| 印章检测与识别 | 端到端弯曲文本识别 | 合同比对 | 密集文本检测、NLP串联 |
|
||||
|
||||
## 交通
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------- | ------------------------------ | ---------- | -------- |
|
||||
| [车牌识别](./轻量级车牌识别.md) | 多角度图像、轻量模型、端侧部署 | 快递单识别 | 尽请期待 |
|
||||
| 驾驶证/行驶证识别 | 尽请期待 | | |
|
||||
<a href="https://trackgit.com">
|
||||
<img src="https://us-central1-trackgit-analytics.cloudfunctions.net/token/ping/l63cvzo0w09yxypc7ygl" alt="traffic" />
|
||||
</a>
|
||||
|
|
|
|||
|
|
@ -0,0 +1,251 @@
|
|||
# 基于PP-OCRv3的手写文字识别
|
||||
|
||||
- [1. 项目背景及意义](#1-项目背景及意义)
|
||||
- [2. 项目内容](#2-项目内容)
|
||||
- [3. PP-OCRv3识别算法介绍](#3-PP-OCRv3识别算法介绍)
|
||||
- [4. 安装环境](#4-安装环境)
|
||||
- [5. 数据准备](#5-数据准备)
|
||||
- [6. 模型训练](#6-模型训练)
|
||||
- [6.1 下载预训练模型](#61-下载预训练模型)
|
||||
- [6.2 修改配置文件](#62-修改配置文件)
|
||||
- [6.3 开始训练](#63-开始训练)
|
||||
- [7. 模型评估](#7-模型评估)
|
||||
- [8. 模型导出推理](#8-模型导出推理)
|
||||
- [8.1 模型导出](#81-模型导出)
|
||||
- [8.2 模型推理](#82-模型推理)
|
||||
|
||||
|
||||
## 1. 项目背景及意义
|
||||
目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高。针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。手写体在日常生活中较为常见,然而手写体的识别却存在着很大的挑战,因为每个人的手写字体风格不一样,这对于视觉模型来说还是相当有挑战的。因此训练一个手写体识别模型具有很好的现实意义。下面给出一些手写体的示例图:
|
||||
|
||||

|
||||
|
||||
## 2. 项目内容
|
||||
本项目基于PaddleOCR套件,以PP-OCRv3识别模型为基础,针对手写文字识别场景进行优化。
|
||||
|
||||
Aistudio项目链接:[OCR手写文字识别](https://aistudio.baidu.com/aistudio/projectdetail/4330587)
|
||||
|
||||
## 3. PP-OCRv3识别算法介绍
|
||||
PP-OCRv3的识别模块是基于文本识别算法[SVTR](https://arxiv.org/abs/2205.00159)优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。如下图所示,PP-OCRv3采用了6个优化策略。
|
||||
|
||||
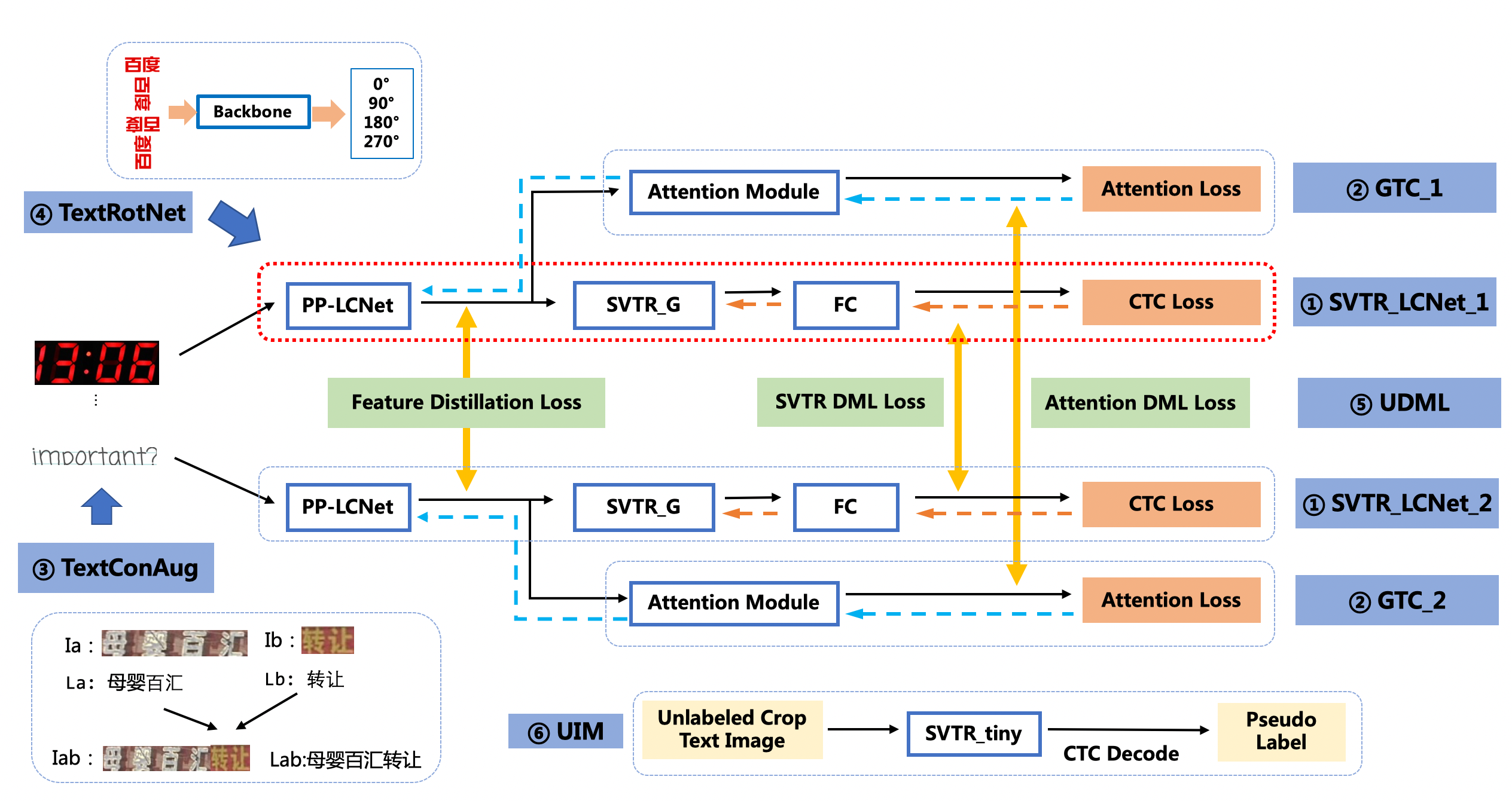
|
||||
|
||||
优化策略汇总如下:
|
||||
|
||||
* SVTR_LCNet:轻量级文本识别网络
|
||||
* GTC:Attention指导CTC训练策略
|
||||
* TextConAug:挖掘文字上下文信息的数据增广策略
|
||||
* TextRotNet:自监督的预训练模型
|
||||
* UDML:联合互学习策略
|
||||
* UIM:无标注数据挖掘方案
|
||||
|
||||
详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#3-%E8%AF%86%E5%88%AB%E4%BC%98%E5%8C%96)
|
||||
|
||||
## 4. 安装环境
|
||||
|
||||
|
||||
```python
|
||||
# 首先git官方的PaddleOCR项目,安装需要的依赖
|
||||
git clone https://github.com/PaddlePaddle/PaddleOCR.git
|
||||
cd PaddleOCR
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## 5. 数据准备
|
||||
本项目使用公开的手写文本识别数据集,包含Chinese OCR, 中科院自动化研究所-手写中文数据集[CASIA-HWDB2.x](http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html),以及由中科院手写数据和网上开源数据合并组合的[数据集](https://aistudio.baidu.com/aistudio/datasetdetail/102884/0)等,该项目已经挂载处理好的数据集,可直接下载使用进行训练。
|
||||
|
||||
|
||||
```python
|
||||
下载并解压数据
|
||||
tar -xf hw_data.tar
|
||||
```
|
||||
|
||||
## 6. 模型训练
|
||||
### 6.1 下载预训练模型
|
||||
首先需要下载我们需要的PP-OCRv3识别预训练模型,更多选择请自行选择其他的[文字识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B)
|
||||
|
||||
|
||||
```python
|
||||
# 使用该指令下载需要的预训练模型
|
||||
wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
|
||||
# 解压预训练模型文件
|
||||
tar -xf ./pretrained_models/ch_PP-OCRv3_rec_train.tar -C pretrained_models
|
||||
```
|
||||
|
||||
### 6.2 修改配置文件
|
||||
我们使用`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
|
||||
|
||||
```
|
||||
epoch_num: 100 # 训练epoch数
|
||||
save_model_dir: ./output/ch_PP-OCR_v3_rec
|
||||
save_epoch_step: 10
|
||||
eval_batch_step: [0, 100] # 评估间隔,每隔100step评估一次
|
||||
pretrained_model: ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy # 预训练模型路径
|
||||
|
||||
|
||||
lr:
|
||||
name: Cosine # 修改学习率衰减策略为Cosine
|
||||
learning_rate: 0.0001 # 修改fine-tune的学习率
|
||||
warmup_epoch: 2 # 修改warmup轮数
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data # 训练集图片路径
|
||||
ext_op_transform_idx: 1
|
||||
label_file_list:
|
||||
- ./train_data/chineseocr-data/rec_hand_line_all_label_train.txt # 训练集标签
|
||||
- ./train_data/handwrite/HWDB2.0Train_label.txt
|
||||
- ./train_data/handwrite/HWDB2.1Train_label.txt
|
||||
- ./train_data/handwrite/HWDB2.2Train_label.txt
|
||||
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_train_labels.txt
|
||||
- ./train_data/handwrite/HW_Chinese/train_hw.txt
|
||||
ratio_list:
|
||||
- 0.1
|
||||
- 1.0
|
||||
- 1.0
|
||||
- 1.0
|
||||
- 0.02
|
||||
- 1.0
|
||||
loader:
|
||||
shuffle: true
|
||||
batch_size_per_card: 64
|
||||
drop_last: true
|
||||
num_workers: 4
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data # 测试集图片路径
|
||||
label_file_list:
|
||||
- ./train_data/chineseocr-data/rec_hand_line_all_label_val.txt # 测试集标签
|
||||
- ./train_data/handwrite/HWDB2.0Test_label.txt
|
||||
- ./train_data/handwrite/HWDB2.1Test_label.txt
|
||||
- ./train_data/handwrite/HWDB2.2Test_label.txt
|
||||
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_val_labels.txt
|
||||
- ./train_data/handwrite/HW_Chinese/test_hw.txt
|
||||
loader:
|
||||
shuffle: false
|
||||
drop_last: false
|
||||
batch_size_per_card: 64
|
||||
num_workers: 4
|
||||
```
|
||||
由于数据集大多是长文本,因此需要**注释**掉下面的数据增广策略,以便训练出更好的模型。
|
||||
```
|
||||
- RecConAug:
|
||||
prob: 0.5
|
||||
ext_data_num: 2
|
||||
image_shape: [48, 320, 3]
|
||||
```
|
||||
|
||||
|
||||
### 6.3 开始训练
|
||||
我们使用上面修改好的配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,预训练模型,数据集路径,学习率,训练轮数等都已经设置完毕后,可以使用下面命令开始训练。
|
||||
|
||||
|
||||
```python
|
||||
# 开始训练识别模型
|
||||
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
|
||||
|
||||
```
|
||||
|
||||
## 7. 模型评估
|
||||
在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
# 评估预训练模型
|
||||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy"
|
||||
```
|
||||
```
|
||||
[2022/07/14 10:46:22] ppocr INFO: load pretrain successful from ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy
|
||||
eval model:: 100%|████████████████████████████| 687/687 [03:29<00:00, 3.27it/s]
|
||||
[2022/07/14 10:49:52] ppocr INFO: metric eval ***************
|
||||
[2022/07/14 10:49:52] ppocr INFO: acc:0.03724954461811258
|
||||
[2022/07/14 10:49:52] ppocr INFO: norm_edit_dis:0.4859541065843199
|
||||
[2022/07/14 10:49:52] ppocr INFO: Teacher_acc:0.0371584699368947
|
||||
[2022/07/14 10:49:52] ppocr INFO: Teacher_norm_edit_dis:0.48718814890536477
|
||||
[2022/07/14 10:49:52] ppocr INFO: fps:947.8562684823883
|
||||
```
|
||||
|
||||
可以看出,直接加载预训练模型进行评估,效果较差,因为预训练模型并不是基于手写文字进行单独训练的,所以我们需要基于预训练模型进行finetune。
|
||||
训练完成后,可以进行测试评估,评估命令如下:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
# 评估finetune效果
|
||||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy"
|
||||
|
||||
```
|
||||
|
||||
评估结果如下,可以看出识别准确率为54.3%。
|
||||
```
|
||||
[2022/07/14 10:54:06] ppocr INFO: metric eval ***************
|
||||
[2022/07/14 10:54:06] ppocr INFO: acc:0.5430100180913
|
||||
[2022/07/14 10:54:06] ppocr INFO: norm_edit_dis:0.9203322593158589
|
||||
[2022/07/14 10:54:06] ppocr INFO: Teacher_acc:0.5401183969626324
|
||||
[2022/07/14 10:54:06] ppocr INFO: Teacher_norm_edit_dis:0.919827504507755
|
||||
[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
|
||||
```
|
||||
|
||||
如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
<div align="left">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
将下载或训练完成的模型放置在对应目录下即可完成模型推理。
|
||||
|
||||
## 8. 模型导出推理
|
||||
训练完成后,可以将训练模型转换成inference模型。inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
|
||||
|
||||
|
||||
### 8.1 模型导出
|
||||
导出命令如下:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
# 转化为推理模型
|
||||
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy" Global.save_inference_dir="./inference/rec_ppocrv3/"
|
||||
|
||||
```
|
||||
|
||||
### 8.2 模型推理
|
||||
导出模型后,可以使用如下命令进行推理预测:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
# 推理预测
|
||||
python tools/infer/predict_rec.py --image_dir="train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg" --rec_model_dir="./inference/rec_ppocrv3/Student"
|
||||
```
|
||||
|
||||
```
|
||||
[2022/07/14 10:55:56] ppocr INFO: In PP-OCRv3, rec_image_shape parameter defaults to '3, 48, 320', if you are using recognition model with PP-OCRv2 or an older version, please set --rec_image_shape='3,32,320
|
||||
[2022/07/14 10:55:58] ppocr INFO: Predicts of train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg:('品结构,差异化的多品牌渗透使欧莱雅确立了其在中国化妆', 0.9904912114143372)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 可视化文字识别图片
|
||||
from PIL import Image
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
import os
|
||||
|
||||
|
||||
img_path = 'train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg'
|
||||
|
||||
def vis(img_path):
|
||||
plt.figure()
|
||||
image = Image.open(img_path)
|
||||
plt.imshow(image)
|
||||
plt.show()
|
||||
# image = image.resize([208, 208])
|
||||
|
||||
|
||||
vis(img_path)
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## 1. 简介
|
||||
|
||||
PP-OCRv3是百度开源的超轻量级场景文本检测识别模型库,其中超轻量的场景中文识别模型SVTR_LCNet使用了SVTR算法结构。为了保证速度,SVTR_LCNet将SVTR模型的Local Blocks替换为LCNet,使用两层Global Blocks。在中文场景中,PP-OCRv3识别主要使用如下优化策略:
|
||||
PP-OCRv3是百度开源的超轻量级场景文本检测识别模型库,其中超轻量的场景中文识别模型SVTR_LCNet使用了SVTR算法结构。为了保证速度,SVTR_LCNet将SVTR模型的Local Blocks替换为LCNet,使用两层Global Blocks。在中文场景中,PP-OCRv3识别主要使用如下优化策略([详细技术报告](../doc/doc_ch/PP-OCRv3_introduction.md)):
|
||||
- GTC:Attention指导CTC训练策略;
|
||||
- TextConAug:挖掘文字上下文信息的数据增广策略;
|
||||
- TextRotNet:自监督的预训练模型;
|
||||
|
|
|
|||
|
|
@ -6,11 +6,11 @@ Global:
|
|||
save_model_dir: ./output/re_layoutlmv2_xfund_zh
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2048
|
||||
seed: 2022
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
|
||||
save_res_path: ./output/re_layoutlmv2_xfund_zh/res/
|
||||
|
||||
|
|
@ -1,9 +1,9 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
epoch_num: &epoch_num 130
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/re_layoutxlm/
|
||||
save_model_dir: ./output/re_layoutxlm_xfund_zh
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
|
|
@ -12,7 +12,7 @@ Global:
|
|||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
|
||||
save_res_path: ./output/re/
|
||||
save_res_path: ./output/re_layoutxlm_xfund_zh/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
|
|
@ -81,7 +81,7 @@ Train:
|
|||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
batch_size_per_card: 2
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
|
|
@ -6,13 +6,13 @@ Global:
|
|||
save_model_dir: ./output/ser_layoutlm_xfund_zh
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
|
||||
save_res_path: ./output/ser_layoutlm_xfund_zh/res/
|
||||
save_res_path: ./output/re_layoutlm_xfund_zh/res
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
|
|
@ -55,6 +55,7 @@ Train:
|
|||
data_dir: train_data/XFUND/zh_train/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_train/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
|
|
@ -27,6 +27,7 @@ Architecture:
|
|||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
key: "backbone_out"
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
|
|
@ -27,6 +27,7 @@ Architecture:
|
|||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
key: "backbone_out"
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
|
|
@ -1,18 +1,18 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
epoch_num: &epoch_num 130
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/re_layoutxlm_funsd
|
||||
save_model_dir: ./output/re_vi_layoutxlm_xfund_zh
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/FUNSD/testing_data/images/83624198.png
|
||||
save_res_path: ./output/re_layoutxlm_funsd/res/
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
|
||||
save_res_path: ./output/re/xfund_zh/with_gt
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
|
|
@ -21,6 +21,7 @@ Architecture:
|
|||
Backbone:
|
||||
name: LayoutXLMForRe
|
||||
pretrained: True
|
||||
mode: vi
|
||||
checkpoints:
|
||||
|
||||
Loss:
|
||||
|
|
@ -50,10 +51,9 @@ Metric:
|
|||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/training_data/images/
|
||||
data_dir: train_data/XFUND/zh_train/image
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/train_v4.json
|
||||
# - ./train_data/FUNSD/train.json
|
||||
- train_data/XFUND/zh_train/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
|
|
@ -62,8 +62,9 @@ Train:
|
|||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: True
|
||||
algorithm: *algorithm
|
||||
class_path: &class_path ./train_data/FUNSD/class_list.txt
|
||||
class_path: &class_path train_data/XFUND/class_list_xfun.txt
|
||||
use_textline_bbox_info: &use_textline_bbox_info True
|
||||
order_method: &order_method "tb-yx"
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
|
|
@ -79,22 +80,20 @@ Train:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations']
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 16
|
||||
batch_size_per_card: 2
|
||||
num_workers: 4
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/testing_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/test_v4.json
|
||||
# - ./train_data/FUNSD/test.json
|
||||
data_dir: train_data/XFUND/zh_val/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_val/val.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
|
|
@ -104,6 +103,7 @@ Eval:
|
|||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: *use_textline_bbox_info
|
||||
order_method: *order_method
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
|
|
@ -119,11 +119,11 @@ Eval:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations']
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
|
|
@ -0,0 +1,175 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 130
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/re_vi_layoutxlm_xfund_zh_udml
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_21.jpg
|
||||
save_res_path: ./output/re/xfund_zh/with_gt
|
||||
|
||||
Architecture:
|
||||
model_type: &model_type "vqa"
|
||||
name: DistillationModel
|
||||
algorithm: Distillation
|
||||
Models:
|
||||
Teacher:
|
||||
pretrained:
|
||||
freeze_params: false
|
||||
return_all_feats: true
|
||||
model_type: *model_type
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForRe
|
||||
pretrained: True
|
||||
mode: vi
|
||||
checkpoints:
|
||||
Student:
|
||||
pretrained:
|
||||
freeze_params: false
|
||||
return_all_feats: true
|
||||
model_type: *model_type
|
||||
algorithm: *algorithm
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForRe
|
||||
pretrained: True
|
||||
mode: vi
|
||||
checkpoints:
|
||||
|
||||
Loss:
|
||||
name: CombinedLoss
|
||||
loss_config_list:
|
||||
- DistillationLossFromOutput:
|
||||
weight: 1.0
|
||||
model_name_list: ["Student", "Teacher"]
|
||||
key: loss
|
||||
reduction: mean
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_5
|
||||
name: "loss_5"
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_8
|
||||
name: "loss_8"
|
||||
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
clip_norm: 10
|
||||
lr:
|
||||
learning_rate: 0.00005
|
||||
warmup_epoch: 10
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: DistillationRePostProcess
|
||||
model_name: ["Student", "Teacher"]
|
||||
key: null
|
||||
|
||||
|
||||
Metric:
|
||||
name: DistillationMetric
|
||||
base_metric_name: VQAReTokenMetric
|
||||
main_indicator: hmean
|
||||
key: "Student"
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/XFUND/zh_train/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_train/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: True
|
||||
algorithm: *algorithm
|
||||
class_path: &class_path train_data/XFUND/class_list_xfun.txt
|
||||
use_textline_bbox_info: &use_textline_bbox_info True
|
||||
# [None, "tb-yx"]
|
||||
order_method: &order_method "tb-yx"
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 2
|
||||
num_workers: 4
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/XFUND/zh_val/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_val/val.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: True
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: *use_textline_bbox_info
|
||||
order_method: *order_method
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
|
||||
|
|
@ -3,30 +3,38 @@ Global:
|
|||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutlm_funsd
|
||||
save_model_dir: ./output/ser_vi_layoutxlm_xfund_zh
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/FUNSD/testing_data/images/83624198.png
|
||||
save_res_path: ./output/ser_layoutlm_funsd/res/
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
|
||||
# if you want to predict using the groundtruth ocr info,
|
||||
# you can use the following config
|
||||
# infer_img: train_data/XFUND/zh_val/val.json
|
||||
# infer_mode: False
|
||||
|
||||
save_res_path: ./output/ser/xfund_zh/res
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutLM"
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutLMForSer
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
# one of base or vi
|
||||
mode: vi
|
||||
num_classes: &num_classes 7
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
key: "backbone_out"
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
|
|
@ -43,7 +51,7 @@ Optimizer:
|
|||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/FUNSD/class_list.txt
|
||||
class_path: &class_path train_data/XFUND/class_list_xfun.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
|
|
@ -52,9 +60,10 @@ Metric:
|
|||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/training_data/images/
|
||||
data_dir: train_data/XFUND/zh_train/image
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/train.json
|
||||
- train_data/XFUND/zh_train/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
|
|
@ -64,6 +73,8 @@ Train:
|
|||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: &use_textline_bbox_info True
|
||||
# one of [None, "tb-yx"]
|
||||
order_method: &order_method "tb-yx"
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
|
|
@ -78,8 +89,7 @@ Train:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
|
|
@ -89,9 +99,9 @@ Train:
|
|||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/FUNSD/testing_data/images/
|
||||
data_dir: train_data/XFUND/zh_val/image
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/test.json
|
||||
- train_data/XFUND/zh_val/val.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
|
|
@ -101,6 +111,7 @@ Eval:
|
|||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: *use_textline_bbox_info
|
||||
order_method: *order_method
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
|
|
@ -115,8 +126,7 @@ Eval:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
|
|
@ -0,0 +1,183 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_vi_layoutxlm_xfund_zh_udml
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 19 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: ppstructure/docs/vqa/input/zh_val_42.jpg
|
||||
save_res_path: ./output/ser_layoutxlm_xfund_zh/res
|
||||
|
||||
|
||||
Architecture:
|
||||
model_type: &model_type "vqa"
|
||||
name: DistillationModel
|
||||
algorithm: Distillation
|
||||
Models:
|
||||
Teacher:
|
||||
pretrained:
|
||||
freeze_params: false
|
||||
return_all_feats: true
|
||||
model_type: *model_type
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
# one of base or vi
|
||||
mode: vi
|
||||
checkpoints:
|
||||
num_classes: &num_classes 7
|
||||
Student:
|
||||
pretrained:
|
||||
freeze_params: false
|
||||
return_all_feats: true
|
||||
model_type: *model_type
|
||||
algorithm: *algorithm
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
# one of base or vi
|
||||
mode: vi
|
||||
checkpoints:
|
||||
num_classes: *num_classes
|
||||
|
||||
|
||||
Loss:
|
||||
name: CombinedLoss
|
||||
loss_config_list:
|
||||
- DistillationVQASerTokenLayoutLMLoss:
|
||||
weight: 1.0
|
||||
model_name_list: ["Student", "Teacher"]
|
||||
key: backbone_out
|
||||
num_classes: *num_classes
|
||||
- DistillationSERDMLLoss:
|
||||
weight: 1.0
|
||||
act: "softmax"
|
||||
use_log: true
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: backbone_out
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_5
|
||||
name: "loss_5"
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_8
|
||||
name: "loss_8"
|
||||
|
||||
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 10
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: DistillationSerPostProcess
|
||||
model_name: ["Student", "Teacher"]
|
||||
key: backbone_out
|
||||
class_path: &class_path train_data/XFUND/class_list_xfun.txt
|
||||
|
||||
Metric:
|
||||
name: DistillationMetric
|
||||
base_metric_name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
key: "Student"
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/XFUND/zh_train/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_train/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
# one of [None, "tb-yx"]
|
||||
order_method: &order_method "tb-yx"
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 4
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/XFUND/zh_val/image
|
||||
label_file_list:
|
||||
- train_data/XFUND/zh_val/val.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
order_method: *order_method
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
|
|
@ -0,0 +1,106 @@
|
|||
Global:
|
||||
use_gpu: true
|
||||
epoch_num: 8
|
||||
log_smooth_window: 200
|
||||
print_batch_step: 200
|
||||
save_model_dir: ./output/rec/r45_visionlan
|
||||
save_epoch_step: 1
|
||||
# evaluation is run every 2000 iterations
|
||||
eval_batch_step: [0, 2000]
|
||||
cal_metric_during_train: True
|
||||
pretrained_model:
|
||||
checkpoints:
|
||||
save_inference_dir:
|
||||
use_visualdl: True
|
||||
infer_img: doc/imgs_words/en/word_2.png
|
||||
# for data or label process
|
||||
character_dict_path:
|
||||
max_text_length: &max_text_length 25
|
||||
training_step: &training_step LA
|
||||
infer_mode: False
|
||||
use_space_char: False
|
||||
save_res_path: ./output/rec/predicts_visionlan.txt
|
||||
|
||||
Optimizer:
|
||||
name: Adam
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
clip_norm: 20.0
|
||||
group_lr: true
|
||||
training_step: *training_step
|
||||
lr:
|
||||
name: Piecewise
|
||||
decay_epochs: [6]
|
||||
values: [0.0001, 0.00001]
|
||||
regularizer:
|
||||
name: 'L2'
|
||||
factor: 0
|
||||
|
||||
Architecture:
|
||||
model_type: rec
|
||||
algorithm: VisionLAN
|
||||
Transform:
|
||||
Backbone:
|
||||
name: ResNet45
|
||||
strides: [2, 2, 2, 1, 1]
|
||||
Head:
|
||||
name: VLHead
|
||||
n_layers: 3
|
||||
n_position: 256
|
||||
n_dim: 512
|
||||
max_text_length: *max_text_length
|
||||
training_step: *training_step
|
||||
|
||||
Loss:
|
||||
name: VLLoss
|
||||
mode: *training_step
|
||||
weight_res: 0.5
|
||||
weight_mas: 0.5
|
||||
|
||||
PostProcess:
|
||||
name: VLLabelDecode
|
||||
|
||||
Metric:
|
||||
name: RecMetric
|
||||
is_filter: true
|
||||
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: LMDBDataSet
|
||||
data_dir: ./train_data/data_lmdb_release/training/
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- ABINetRecAug:
|
||||
- VLLabelEncode: # Class handling label
|
||||
- VLRecResizeImg:
|
||||
image_shape: [3, 64, 256]
|
||||
- KeepKeys:
|
||||
keep_keys: ['image', 'label', 'label_res', 'label_sub', 'label_id', 'length'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
batch_size_per_card: 220
|
||||
drop_last: True
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: LMDBDataSet
|
||||
data_dir: ./train_data/data_lmdb_release/validation/
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VLLabelEncode: # Class handling label
|
||||
- VLRecResizeImg:
|
||||
image_shape: [3, 64, 256]
|
||||
- KeepKeys:
|
||||
keep_keys: ['image', 'label', 'label_res', 'label_sub', 'label_id', 'length'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 64
|
||||
num_workers: 4
|
||||
|
||||
|
|
@ -1,125 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/re_layoutlmv2_funsd
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/FUNSD/testing_data/images/83624198.png
|
||||
save_res_path: ./output/re_layoutlmv2_funsd/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutLMv2"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutLMv2ForRe
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
|
||||
Loss:
|
||||
name: LossFromOutput
|
||||
key: loss
|
||||
reduction: mean
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
clip_norm: 10
|
||||
lr:
|
||||
learning_rate: 0.00005
|
||||
warmup_epoch: 10
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQAReTokenLayoutLMPostProcess
|
||||
|
||||
Metric:
|
||||
name: VQAReTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/training_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: True
|
||||
algorithm: *algorithm
|
||||
class_path: &class_path train_data/FUNSD/class_list.txt
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1./255.
|
||||
mean: [0.485, 0.456, 0.406]
|
||||
std: [0.229, 0.224, 0.225]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/testing_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/test.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: True
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1./255.
|
||||
mean: [0.485, 0.456, 0.406]
|
||||
std: [0.229, 0.224, 0.225]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
|
@ -1,124 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutlm_sroie
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 200 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/SROIE/test/X00016469670.jpg
|
||||
save_res_path: ./output/ser_layoutlm_sroie/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutLMForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 9
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/SROIE/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/SROIE/train
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/train.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: &use_textline_bbox_info True
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/SROIE/test
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/test.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
use_textline_bbox_info: *use_textline_bbox_info
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutlmv2_funsd
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 100 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/FUNSD/testing_data/images/83624198.png
|
||||
save_res_path: ./output/ser_layoutlmv2_funsd/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutLMv2"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutLMv2ForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 7
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path train_data/FUNSD/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/training_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/train.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/testing_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/test.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutlmv2_sroie
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 200 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/SROIE/test/X00016469670.jpg
|
||||
save_res_path: ./output/ser_layoutlmv2_sroie/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutLMv2"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutLMv2ForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 9
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/SROIE/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/SROIE/train
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/train.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/SROIE/test
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/test.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutxlm_funsd
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 57 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/FUNSD/testing_data/images/83624198.png
|
||||
save_res_path: output/ser_layoutxlm_funsd/res/
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 7
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/FUNSD/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/FUNSD/training_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/train.json
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/FUNSD/testing_data/images/
|
||||
label_file_list:
|
||||
- ./train_data/FUNSD/test.json
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 200
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutxlm_sroie
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 200 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data/SROIE/test/X00016469670.jpg
|
||||
save_res_path: res_img_aug_with_gt
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 9
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/SROIE/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/SROIE/train
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/train.txt
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/SROIE/test
|
||||
label_file_list:
|
||||
- ./train_data/SROIE/test.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -1,123 +0,0 @@
|
|||
Global:
|
||||
use_gpu: True
|
||||
epoch_num: &epoch_num 100
|
||||
log_smooth_window: 10
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/ser_layoutxlm_wildreceipt
|
||||
save_epoch_step: 2000
|
||||
# evaluation is run every 10 iterations after the 0th iteration
|
||||
eval_batch_step: [ 0, 200 ]
|
||||
cal_metric_during_train: False
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
seed: 2022
|
||||
infer_img: train_data//wildreceipt/image_files/Image_12/10/845be0dd6f5b04866a2042abd28d558032ef2576.jpeg
|
||||
save_res_path: ./output/ser_layoutxlm_wildreceipt/res
|
||||
|
||||
Architecture:
|
||||
model_type: vqa
|
||||
algorithm: &algorithm "LayoutXLM"
|
||||
Transform:
|
||||
Backbone:
|
||||
name: LayoutXLMForSer
|
||||
pretrained: True
|
||||
checkpoints:
|
||||
num_classes: &num_classes 51
|
||||
|
||||
Loss:
|
||||
name: VQASerTokenLayoutLMLoss
|
||||
num_classes: *num_classes
|
||||
|
||||
Optimizer:
|
||||
name: AdamW
|
||||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Linear
|
||||
learning_rate: 0.00005
|
||||
epochs: *epoch_num
|
||||
warmup_epoch: 2
|
||||
regularizer:
|
||||
name: L2
|
||||
factor: 0.00000
|
||||
|
||||
PostProcess:
|
||||
name: VQASerTokenLayoutLMPostProcess
|
||||
class_path: &class_path ./train_data/wildreceipt/class_list.txt
|
||||
|
||||
Metric:
|
||||
name: VQASerTokenMetric
|
||||
main_indicator: hmean
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/wildreceipt/
|
||||
label_file_list:
|
||||
- ./train_data/wildreceipt/wildreceipt_train.txt
|
||||
ratio_list: [ 1.0 ]
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: &max_seq_len 512
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: train_data/wildreceipt
|
||||
label_file_list:
|
||||
- ./train_data/wildreceipt/wildreceipt_test.txt
|
||||
transforms:
|
||||
- DecodeImage: # load image
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- VQATokenLabelEncode: # Class handling label
|
||||
contains_re: False
|
||||
algorithm: *algorithm
|
||||
class_path: *class_path
|
||||
- VQATokenPad:
|
||||
max_seq_len: *max_seq_len
|
||||
return_attention_mask: True
|
||||
- VQASerTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
scale: 1
|
||||
mean: [ 123.675, 116.28, 103.53 ]
|
||||
std: [ 58.395, 57.12, 57.375 ]
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
# dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'labels']
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 4
|
||||
|
|
@ -53,10 +53,11 @@ PP-OCRv3检测模型是对PP-OCRv2中的[CML](https://arxiv.org/pdf/2109.03144.p
|
|||
|
||||
|序号|策略|模型大小|hmean|速度(cpu + mkldnn)|
|
||||
|-|-|-|-|-|
|
||||
|baseline teacher|DB-R50|99M|83.5%|260ms|
|
||||
|baseline teacher|PP-OCR server|49M|83.2%|171ms|
|
||||
|teacher1|DB-R50-LK-PAN|124M|85.0%|396ms|
|
||||
|teacher2|DB-R50-LK-PAN-DML|124M|86.0%|396ms|
|
||||
|baseline student|PP-OCRv2|3M|83.2%|117ms|
|
||||
|student0|DB-MV3-RSE-FPN|3.6M|84.5%|124ms|
|
||||
|student1|DB-MV3-CML(teacher2)|3M|84.3%|117ms|
|
||||
|student2|DB-MV3-RSE-FPN-CML(teacher2)|3.6M|85.4%|124ms|
|
||||
|
||||
|
|
@ -184,7 +185,7 @@ UDML(Unified-Deep Mutual Learning)联合互学习是PP-OCRv2中就采用的
|
|||
|
||||
**(6)UIM:无标注数据挖掘方案**
|
||||
|
||||
UIM(Unlabeled Images Mining)是一种非常简单的无标注数据挖掘方案。核心思想是利用高精度的文本识别大模型对无标注数据进行预测,获取伪标签,并且选择预测置信度高的样本作为训练数据,用于训练小模型。使用该策略,识别模型的准确率进一步提升到79.4%(+1%)。
|
||||
UIM(Unlabeled Images Mining)是一种非常简单的无标注数据挖掘方案。核心思想是利用高精度的文本识别大模型对无标注数据进行预测,获取伪标签,并且选择预测置信度高的样本作为训练数据,用于训练小模型。使用该策略,识别模型的准确率进一步提升到79.4%(+1%)。实际操作中,我们使用全量数据集训练高精度SVTR-Tiny模型(acc=82.5%)进行数据挖掘,点击获取[模型下载地址和使用教程](../../applications/高精度中文识别模型.md)。
|
||||
|
||||
<div align="center">
|
||||
<img src="../ppocr_v3/UIM.png" width="500">
|
||||
|
|
|
|||
|
|
@ -69,6 +69,7 @@
|
|||
- [x] [SVTR](./algorithm_rec_svtr.md)
|
||||
- [x] [ViTSTR](./algorithm_rec_vitstr.md)
|
||||
- [x] [ABINet](./algorithm_rec_abinet.md)
|
||||
- [x] [VisionLAN](./algorithm_rec_visionlan.md)
|
||||
- [x] [SPIN](./algorithm_rec_spin.md)
|
||||
- [x] [RobustScanner](./algorithm_rec_robustscanner.md)
|
||||
|
||||
|
|
@ -91,6 +92,7 @@
|
|||
|SVTR|SVTR-Tiny| 89.25% | rec_svtr_tiny_none_ctc_en | [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_en_train.tar) |
|
||||
|ViTSTR|ViTSTR| 79.82% | rec_vitstr_none_ce | [训练模型](https://paddleocr.bj.bcebos.com/rec_vitstr_none_ce_train.tar) |
|
||||
|ABINet|Resnet45| 90.75% | rec_r45_abinet | [训练模型](https://paddleocr.bj.bcebos.com/rec_r45_abinet_train.tar) |
|
||||
|VisionLAN|Resnet45| 90.30% | rec_r45_visionlan | [训练模型](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar) |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | coming soon |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | coming soon |
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,154 @@
|
|||
# 场景文本识别算法-VisionLAN
|
||||
|
||||
- [1. 算法简介](#1)
|
||||
- [2. 环境配置](#2)
|
||||
- [3. 模型训练、评估、预测](#3)
|
||||
- [3.1 训练](#3-1)
|
||||
- [3.2 评估](#3-2)
|
||||
- [3.3 预测](#3-3)
|
||||
- [4. 推理部署](#4)
|
||||
- [4.1 Python推理](#4-1)
|
||||
- [4.2 C++推理](#4-2)
|
||||
- [4.3 Serving服务化部署](#4-3)
|
||||
- [4.4 更多推理部署](#4-4)
|
||||
- [5. FAQ](#5)
|
||||
|
||||
<a name="1"></a>
|
||||
## 1. 算法简介
|
||||
|
||||
论文信息:
|
||||
> [From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network](https://arxiv.org/abs/2108.09661)
|
||||
> Yuxin Wang, Hongtao Xie, Shancheng Fang, Jing Wang, Shenggao Zhu, Yongdong Zhang
|
||||
> ICCV, 2021
|
||||
|
||||
|
||||
<a name="model"></a>
|
||||
`VisionLAN`使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
|
||||
|
||||
|模型|骨干网络|配置文件|Acc|下载链接|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|VisionLAN|ResNet45|[rec_r45_visionlan.yml](../../configs/rec/rec_r45_visionlan.yml)|90.3%|[预训练、训练模型](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar)|
|
||||
|
||||
<a name="2"></a>
|
||||
## 2. 环境配置
|
||||
请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
|
||||
|
||||
|
||||
<a name="3"></a>
|
||||
## 3. 模型训练、评估、预测
|
||||
|
||||
<a name="3-1"></a>
|
||||
### 3.1 模型训练
|
||||
|
||||
请参考[文本识别训练教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练`VisionLAN`识别模型时需要**更换配置文件**为`VisionLAN`的[配置文件](../../configs/rec/rec_r45_visionlan.yml)。
|
||||
|
||||
#### 启动训练
|
||||
|
||||
|
||||
具体地,在完成数据准备后,便可以启动训练,训练命令如下:
|
||||
```shell
|
||||
#单卡训练(训练周期长,不建议)
|
||||
python3 tools/train.py -c configs/rec/rec_r45_visionlan.yml
|
||||
|
||||
#多卡训练,通过--gpus参数指定卡号
|
||||
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r45_visionlan.yml
|
||||
```
|
||||
|
||||
<a name="3-2"></a>
|
||||
### 3.2 评估
|
||||
|
||||
可下载已训练完成的[模型文件](#model),使用如下命令进行评估:
|
||||
|
||||
```shell
|
||||
# 注意将pretrained_model的路径设置为本地路径。
|
||||
python3 tools/eval.py -c configs/rec/rec_r45_visionlan.yml -o Global.pretrained_model=./rec_r45_visionlan_train/best_accuracy
|
||||
```
|
||||
|
||||
<a name="3-3"></a>
|
||||
### 3.3 预测
|
||||
|
||||
使用如下命令进行单张图片预测:
|
||||
```shell
|
||||
# 注意将pretrained_model的路径设置为本地路径。
|
||||
python3 tools/infer_rec.py -c configs/rec/rec_r45_visionlan.yml -o Global.infer_img='./doc/imgs_words/en/word_2.png' Global.pretrained_model=./rec_r45_visionlan_train/best_accuracy
|
||||
# 预测文件夹下所有图像时,可修改infer_img为文件夹,如 Global.infer_img='./doc/imgs_words_en/'。
|
||||
```
|
||||
|
||||
|
||||
<a name="4"></a>
|
||||
## 4. 推理部署
|
||||
|
||||
<a name="4-1"></a>
|
||||
### 4.1 Python推理
|
||||
首先将训练得到best模型,转换成inference model。这里以训练完成的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar)),可以使用如下命令进行转换:
|
||||
|
||||
```shell
|
||||
# 注意将pretrained_model的路径设置为本地路径。
|
||||
python3 tools/export_model.py -c configs/rec/rec_r45_visionlan.yml -o Global.pretrained_model=./rec_r45_visionlan_train/best_accuracy Global.save_inference_dir=./inference/rec_r45_visionlan/
|
||||
```
|
||||
**注意:**
|
||||
- 如果您是在自己的数据集上训练的模型,并且调整了字典文件,请注意修改配置文件中的`character_dict_path`是否是所需要的字典文件。
|
||||
- 如果您修改了训练时的输入大小,请修改`tools/export_model.py`文件中的对应VisionLAN的`infer_shape`。
|
||||
|
||||
转换成功后,在目录下有三个文件:
|
||||
```
|
||||
./inference/rec_r45_visionlan/
|
||||
├── inference.pdiparams # 识别inference模型的参数文件
|
||||
├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
|
||||
└── inference.pdmodel # 识别inference模型的program文件
|
||||
```
|
||||
|
||||
执行如下命令进行模型推理:
|
||||
|
||||
```shell
|
||||
python3 tools/infer/predict_rec.py --image_dir='./doc/imgs_words/en/word_2.png' --rec_model_dir='./inference/rec_r45_visionlan/' --rec_algorithm='VisionLAN' --rec_image_shape='3,64,256' --rec_char_dict_path='./ppocr/utils/dict36.txt'
|
||||
# 预测文件夹下所有图像时,可修改image_dir为文件夹,如 --image_dir='./doc/imgs_words_en/'。
|
||||
```
|
||||
|
||||

|
||||
|
||||
执行命令后,上面图像的预测结果(识别的文本和得分)会打印到屏幕上,示例如下:
|
||||
结果如下:
|
||||
```shell
|
||||
Predicts of ./doc/imgs_words/en/word_2.png:('yourself', 0.97076982)
|
||||
```
|
||||
|
||||
**注意**:
|
||||
|
||||
- 训练上述模型采用的图像分辨率是[3,64,256],需要通过参数`rec_image_shape`设置为您训练时的识别图像形状。
|
||||
- 在推理时需要设置参数`rec_char_dict_path`指定字典,如果您修改了字典,请修改该参数为您的字典文件。
|
||||
- 如果您修改了预处理方法,需修改`tools/infer/predict_rec.py`中VisionLAN的预处理为您的预处理方法。
|
||||
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++推理部署
|
||||
|
||||
由于C++预处理后处理还未支持VisionLAN,所以暂未支持
|
||||
|
||||
<a name="4-3"></a>
|
||||
### 4.3 Serving服务化部署
|
||||
|
||||
暂不支持
|
||||
|
||||
<a name="4-4"></a>
|
||||
### 4.4 更多推理部署
|
||||
|
||||
暂不支持
|
||||
|
||||
<a name="5"></a>
|
||||
## 5. FAQ
|
||||
|
||||
1. MJSynth和SynthText两种数据集来自于[VisionLAN源repo](https://github.com/wangyuxin87/VisionLAN) 。
|
||||
2. 我们使用VisionLAN作者提供的预训练模型进行finetune训练。
|
||||
|
||||
## 引用
|
||||
|
||||
```bibtex
|
||||
@inproceedings{wang2021two,
|
||||
title={From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network},
|
||||
author={Wang, Yuxin and Xie, Hongtao and Fang, Shancheng and Wang, Jing and Zhu, Shenggao and Zhang, Yongdong},
|
||||
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
|
||||
pages={14194--14203},
|
||||
year={2021}
|
||||
}
|
||||
```
|
||||
|
|
@ -65,7 +65,7 @@ python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/
|
|||
|
||||
```
|
||||
|
||||
上述指令中,通过-c 选择训练使用configs/det/det_db_mv3.yml配置文件。
|
||||
上述指令中,通过-c 选择训练使用configs/det/det_mv3_db.yml配置文件。
|
||||
有关配置文件的详细解释,请参考[链接](./config.md)。
|
||||
|
||||
您也可以通过-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001
|
||||
|
|
|
|||
|
|
@ -55,10 +55,11 @@ The ablation experiments are as follows:
|
|||
|
||||
|ID|Strategy|Model Size|Hmean|The Inference Time(cpu + mkldnn)|
|
||||
|-|-|-|-|-|
|
||||
|baseline teacher|DB-R50|99M|83.5%|260ms|
|
||||
|baseline teacher|PP-OCR server|49M|83.2%|171ms|
|
||||
|teacher1|DB-R50-LK-PAN|124M|85.0%|396ms|
|
||||
|teacher2|DB-R50-LK-PAN-DML|124M|86.0%|396ms|
|
||||
|baseline student|PP-OCRv2|3M|83.2%|117ms|
|
||||
|student0|DB-MV3-RSE-FPN|3.6M|84.5%|124ms|
|
||||
|student1|DB-MV3-CML(teacher2)|3M|84.3%|117ms|
|
||||
|student2|DB-MV3-RSE-FPN-CML(teacher2)|3.6M|85.4%|124ms|
|
||||
|
||||
|
|
@ -199,7 +200,7 @@ UDML (Unified-Deep Mutual Learning) is a strategy proposed in PP-OCRv2 which is
|
|||
|
||||
**(6)UIM:Unlabeled Images Mining**
|
||||
|
||||
UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
|
||||
UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%). In practice, we use the full data set to train the high-precision SVTR_Tiny model (acc=82.5%) for data mining. [SVTR_Tiny model download and tutorial](../../applications/高精度中文识别模型.md).
|
||||
|
||||
<div align="center">
|
||||
<img src="../ppocr_v3/UIM.png" width="500">
|
||||
|
|
|
|||
|
|
@ -68,6 +68,7 @@ Supported text recognition algorithms (Click the link to get the tutorial):
|
|||
- [x] [SVTR](./algorithm_rec_svtr_en.md)
|
||||
- [x] [ViTSTR](./algorithm_rec_vitstr_en.md)
|
||||
- [x] [ABINet](./algorithm_rec_abinet_en.md)
|
||||
- [x] [VisionLAN](./algorithm_rec_visionlan_en.md)
|
||||
- [x] [SPIN](./algorithm_rec_spin_en.md)
|
||||
- [x] [RobustScanner](./algorithm_rec_robustscanner_en.md)
|
||||
|
||||
|
|
@ -90,6 +91,7 @@ Refer to [DTRB](https://arxiv.org/abs/1904.01906), the training and evaluation r
|
|||
|SVTR|SVTR-Tiny| 89.25% | rec_svtr_tiny_none_ctc_en | [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_en_train.tar) |
|
||||
|ViTSTR|ViTSTR| 79.82% | rec_vitstr_none_ce | [trained model](https://paddleocr.bj.bcebos.com/rec_vitstr_none_none_train.tar) |
|
||||
|ABINet|Resnet45| 90.75% | rec_r45_abinet | [trained model](https://paddleocr.bj.bcebos.com/rec_r45_abinet_train.tar) |
|
||||
|VisionLAN|Resnet45| 90.30% | rec_r45_visionlan | [trained model](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar) |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | coming soon |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | coming soon |
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,135 @@
|
|||
# VisionLAN
|
||||
|
||||
- [1. Introduction](#1)
|
||||
- [2. Environment](#2)
|
||||
- [3. Model Training / Evaluation / Prediction](#3)
|
||||
- [3.1 Training](#3-1)
|
||||
- [3.2 Evaluation](#3-2)
|
||||
- [3.3 Prediction](#3-3)
|
||||
- [4. Inference and Deployment](#4)
|
||||
- [4.1 Python Inference](#4-1)
|
||||
- [4.2 C++ Inference](#4-2)
|
||||
- [4.3 Serving](#4-3)
|
||||
- [4.4 More](#4-4)
|
||||
- [5. FAQ](#5)
|
||||
|
||||
<a name="1"></a>
|
||||
## 1. Introduction
|
||||
|
||||
Paper:
|
||||
> [From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network](https://arxiv.org/abs/2108.09661)
|
||||
> Yuxin Wang, Hongtao Xie, Shancheng Fang, Jing Wang, Shenggao Zhu, Yongdong Zhang
|
||||
> ICCV, 2021
|
||||
|
||||
Using MJSynth and SynthText two text recognition datasets for training, and evaluating on IIIT, SVT, IC13, IC15, SVTP, CUTE datasets, the algorithm reproduction effect is as follows:
|
||||
|
||||
|Model|Backbone|config|Acc|Download link|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|VisionLAN|ResNet45|[rec_r45_visionlan.yml](../../configs/rec/rec_r45_visionlan.yml)|90.3%|[预训练、训练模型](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar)|
|
||||
|
||||
<a name="2"></a>
|
||||
## 2. Environment
|
||||
Please refer to ["Environment Preparation"](./environment_en.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone_en.md) to clone the project code.
|
||||
|
||||
|
||||
<a name="3"></a>
|
||||
## 3. Model Training / Evaluation / Prediction
|
||||
|
||||
Please refer to [Text Recognition Tutorial](./recognition_en.md). PaddleOCR modularizes the code, and training different recognition models only requires **changing the configuration file**.
|
||||
|
||||
Training:
|
||||
|
||||
Specifically, after the data preparation is completed, the training can be started. The training command is as follows:
|
||||
|
||||
```
|
||||
#Single GPU training (long training period, not recommended)
|
||||
python3 tools/train.py -c configs/rec/rec_r45_visionlan.yml
|
||||
|
||||
#Multi GPU training, specify the gpu number through the --gpus parameter
|
||||
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r45_visionlan.yml
|
||||
```
|
||||
|
||||
Evaluation:
|
||||
|
||||
```
|
||||
# GPU evaluation
|
||||
python3 tools/eval.py -c configs/rec/rec_r45_visionlan.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
|
||||
```
|
||||
|
||||
Prediction:
|
||||
|
||||
```
|
||||
# The configuration file used for prediction must match the training
|
||||
python3 tools/infer_rec.py -c configs/rec/rec_r45_visionlan.yml -o Global.infer_img='./doc/imgs_words/en/word_2.png' Global.pretrained_model=./rec_r45_visionlan_train/best_accuracy
|
||||
```
|
||||
|
||||
<a name="4"></a>
|
||||
## 4. Inference and Deployment
|
||||
|
||||
<a name="4-1"></a>
|
||||
### 4.1 Python Inference
|
||||
First, the model saved during the VisionLAN text recognition training process is converted into an inference model. ( [Model download link](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar)) ), you can use the following command to convert:
|
||||
|
||||
```
|
||||
python3 tools/export_model.py -c configs/rec/rec_r45_visionlan.yml -o Global.pretrained_model=./rec_r45_visionlan_train/best_accuracy Global.save_inference_dir=./inference/rec_r45_visionlan/
|
||||
```
|
||||
|
||||
**Note:**
|
||||
- If you are training the model on your own dataset and have modified the dictionary file, please pay attention to modify the `character_dict_path` in the configuration file to the modified dictionary file.
|
||||
- If you modified the input size during training, please modify the `infer_shape` corresponding to VisionLAN in the `tools/export_model.py` file.
|
||||
|
||||
After the conversion is successful, there are three files in the directory:
|
||||
```
|
||||
./inference/rec_r45_visionlan/
|
||||
├── inference.pdiparams
|
||||
├── inference.pdiparams.info
|
||||
└── inference.pdmodel
|
||||
```
|
||||
|
||||
|
||||
For VisionLAN text recognition model inference, the following commands can be executed:
|
||||
|
||||
```
|
||||
python3 tools/infer/predict_rec.py --image_dir='./doc/imgs_words/en/word_2.png' --rec_model_dir='./inference/rec_r45_visionlan/' --rec_algorithm='VisionLAN' --rec_image_shape='3,64,256' --rec_char_dict_path='./ppocr/utils/dict36.txt'
|
||||
```
|
||||
|
||||

|
||||
|
||||
After executing the command, the prediction result (recognized text and score) of the image above is printed to the screen, an example is as follows:
|
||||
The result is as follows:
|
||||
```shell
|
||||
Predicts of ./doc/imgs_words/en/word_2.png:('yourself', 0.97076982)
|
||||
```
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++ Inference
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="4-3"></a>
|
||||
### 4.3 Serving
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="4-4"></a>
|
||||
### 4.4 More
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="5"></a>
|
||||
## 5. FAQ
|
||||
|
||||
1. Note that the MJSynth and SynthText datasets come from [VisionLAN repo](https://github.com/wangyuxin87/VisionLAN).
|
||||
2. We use the pre-trained model provided by the VisionLAN authors for finetune training.
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@inproceedings{wang2021two,
|
||||
title={From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network},
|
||||
author={Wang, Yuxin and Xie, Hongtao and Fang, Shancheng and Wang, Jing and Zhu, Shenggao and Zhang, Yongdong},
|
||||
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
|
||||
pages={14194--14203},
|
||||
year={2021}
|
||||
}
|
||||
```
|
||||
|
|
@ -51,7 +51,7 @@ python3 tools/train.py -c configs/det/det_mv3_db.yml \
|
|||
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
|
||||
```
|
||||
|
||||
In the above instruction, use `-c` to select the training to use the `configs/det/det_db_mv3.yml` configuration file.
|
||||
In the above instruction, use `-c` to select the training to use the `configs/det/det_mv3_db.yml` configuration file.
|
||||
For a detailed explanation of the configuration file, please refer to [config](./config_en.md).
|
||||
|
||||
You can also use `-o` to change the training parameters without modifying the yml file. For example, adjust the training learning rate to 0.0001
|
||||
|
|
|
|||
|
|
@ -25,8 +25,9 @@ from .make_pse_gt import MakePseGt
|
|||
|
||||
|
||||
from .rec_img_aug import BaseDataAugmentation, RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
|
||||
SRNRecResizeImg, GrayRecResizeImg, SARRecResizeImg, PRENResizeImg, \
|
||||
ABINetRecResizeImg, SVTRRecResizeImg, ABINetRecAug, SPINRecResizeImg, RobustScannerRecResizeImg
|
||||
SRNRecResizeImg, GrayRecResizeImg, SARRecResizeImg, PRENResizeImg, \
|
||||
ABINetRecResizeImg, SVTRRecResizeImg, ABINetRecAug, VLRecResizeImg, SPINRecResizeImg, RobustScannerRecResizeImg
|
||||
|
||||
from .ssl_img_aug import SSLRotateResize
|
||||
from .randaugment import RandAugment
|
||||
from .copy_paste import CopyPaste
|
||||
|
|
|
|||
|
|
@ -23,7 +23,10 @@ import string
|
|||
from shapely.geometry import LineString, Point, Polygon
|
||||
import json
|
||||
import copy
|
||||
from random import sample
|
||||
|
||||
from ppocr.utils.logging import get_logger
|
||||
from ppocr.data.imaug.vqa.augment import order_by_tbyx
|
||||
|
||||
|
||||
class ClsLabelEncode(object):
|
||||
|
|
@ -97,12 +100,13 @@ class BaseRecLabelEncode(object):
|
|||
def __init__(self,
|
||||
max_text_length,
|
||||
character_dict_path=None,
|
||||
use_space_char=False):
|
||||
use_space_char=False,
|
||||
lower=False):
|
||||
|
||||
self.max_text_len = max_text_length
|
||||
self.beg_str = "sos"
|
||||
self.end_str = "eos"
|
||||
self.lower = False
|
||||
self.lower = lower
|
||||
|
||||
if character_dict_path is None:
|
||||
logger = get_logger()
|
||||
|
|
@ -870,6 +874,7 @@ class VQATokenLabelEncode(object):
|
|||
add_special_ids=False,
|
||||
algorithm='LayoutXLM',
|
||||
use_textline_bbox_info=True,
|
||||
order_method=None,
|
||||
infer_mode=False,
|
||||
ocr_engine=None,
|
||||
**kwargs):
|
||||
|
|
@ -899,6 +904,8 @@ class VQATokenLabelEncode(object):
|
|||
self.infer_mode = infer_mode
|
||||
self.ocr_engine = ocr_engine
|
||||
self.use_textline_bbox_info = use_textline_bbox_info
|
||||
self.order_method = order_method
|
||||
assert self.order_method in [None, "tb-yx"]
|
||||
|
||||
def split_bbox(self, bbox, text, tokenizer):
|
||||
words = text.split()
|
||||
|
|
@ -938,6 +945,14 @@ class VQATokenLabelEncode(object):
|
|||
# load bbox and label info
|
||||
ocr_info = self._load_ocr_info(data)
|
||||
|
||||
for idx in range(len(ocr_info)):
|
||||
if "bbox" not in ocr_info[idx]:
|
||||
ocr_info[idx]["bbox"] = self.trans_poly_to_bbox(ocr_info[idx][
|
||||
"points"])
|
||||
|
||||
if self.order_method == "tb-yx":
|
||||
ocr_info = order_by_tbyx(ocr_info)
|
||||
|
||||
# for re
|
||||
train_re = self.contains_re and not self.infer_mode
|
||||
if train_re:
|
||||
|
|
@ -977,7 +992,10 @@ class VQATokenLabelEncode(object):
|
|||
info["bbox"] = self.trans_poly_to_bbox(info["points"])
|
||||
|
||||
encode_res = self.tokenizer.encode(
|
||||
text, pad_to_max_seq_len=False, return_attention_mask=True)
|
||||
text,
|
||||
pad_to_max_seq_len=False,
|
||||
return_attention_mask=True,
|
||||
return_token_type_ids=True)
|
||||
|
||||
if not self.add_special_ids:
|
||||
# TODO: use tok.all_special_ids to remove
|
||||
|
|
@ -1049,10 +1067,10 @@ class VQATokenLabelEncode(object):
|
|||
return data
|
||||
|
||||
def trans_poly_to_bbox(self, poly):
|
||||
x1 = np.min([p[0] for p in poly])
|
||||
x2 = np.max([p[0] for p in poly])
|
||||
y1 = np.min([p[1] for p in poly])
|
||||
y2 = np.max([p[1] for p in poly])
|
||||
x1 = int(np.min([p[0] for p in poly]))
|
||||
x2 = int(np.max([p[0] for p in poly]))
|
||||
y1 = int(np.min([p[1] for p in poly]))
|
||||
y2 = int(np.max([p[1] for p in poly]))
|
||||
return [x1, y1, x2, y2]
|
||||
|
||||
def _load_ocr_info(self, data):
|
||||
|
|
@ -1217,6 +1235,7 @@ class ABINetLabelEncode(BaseRecLabelEncode):
|
|||
dict_character = ['</s>'] + dict_character
|
||||
return dict_character
|
||||
|
||||
|
||||
class SPINLabelEncode(AttnLabelEncode):
|
||||
""" Convert between text-label and text-index """
|
||||
|
||||
|
|
@ -1229,6 +1248,7 @@ class SPINLabelEncode(AttnLabelEncode):
|
|||
super(SPINLabelEncode, self).__init__(
|
||||
max_text_length, character_dict_path, use_space_char)
|
||||
self.lower = lower
|
||||
|
||||
def add_special_char(self, dict_character):
|
||||
self.beg_str = "sos"
|
||||
self.end_str = "eos"
|
||||
|
|
@ -1248,4 +1268,68 @@ class SPINLabelEncode(AttnLabelEncode):
|
|||
|
||||
padded_text[:len(target)] = target
|
||||
data['label'] = np.array(padded_text)
|
||||
return data
|
||||
return data
|
||||
|
||||
|
||||
class VLLabelEncode(BaseRecLabelEncode):
|
||||
""" Convert between text-label and text-index """
|
||||
|
||||
def __init__(self,
|
||||
max_text_length,
|
||||
character_dict_path=None,
|
||||
use_space_char=False,
|
||||
lower=True,
|
||||
**kwargs):
|
||||
super(VLLabelEncode, self).__init__(
|
||||
max_text_length, character_dict_path, use_space_char, lower)
|
||||
self.character = self.character[10:] + self.character[
|
||||
1:10] + [self.character[0]]
|
||||
self.dict = {}
|
||||
for i, char in enumerate(self.character):
|
||||
self.dict[char] = i
|
||||
|
||||
def __call__(self, data):
|
||||
text = data['label'] # original string
|
||||
# generate occluded text
|
||||
len_str = len(text)
|
||||
if len_str <= 0:
|
||||
return None
|
||||
change_num = 1
|
||||
order = list(range(len_str))
|
||||
change_id = sample(order, change_num)[0]
|
||||
label_sub = text[change_id]
|
||||
if change_id == (len_str - 1):
|
||||
label_res = text[:change_id]
|
||||
elif change_id == 0:
|
||||
label_res = text[1:]
|
||||
else:
|
||||
label_res = text[:change_id] + text[change_id + 1:]
|
||||
|
||||
data['label_res'] = label_res # remaining string
|
||||
data['label_sub'] = label_sub # occluded character
|
||||
data['label_id'] = change_id # character index
|
||||
# encode label
|
||||
text = self.encode(text)
|
||||
if text is None:
|
||||
return None
|
||||
text = [i + 1 for i in text]
|
||||
data['length'] = np.array(len(text))
|
||||
text = text + [0] * (self.max_text_len - len(text))
|
||||
data['label'] = np.array(text)
|
||||
label_res = self.encode(label_res)
|
||||
label_sub = self.encode(label_sub)
|
||||
if label_res is None:
|
||||
label_res = []
|
||||
else:
|
||||
label_res = [i + 1 for i in label_res]
|
||||
if label_sub is None:
|
||||
label_sub = []
|
||||
else:
|
||||
label_sub = [i + 1 for i in label_sub]
|
||||
data['length_res'] = np.array(len(label_res))
|
||||
data['length_sub'] = np.array(len(label_sub))
|
||||
label_res = label_res + [0] * (self.max_text_len - len(label_res))
|
||||
label_sub = label_sub + [0] * (self.max_text_len - len(label_sub))
|
||||
data['label_res'] = np.array(label_res)
|
||||
data['label_sub'] = np.array(label_sub)
|
||||
return data
|
||||
|
|
|
|||
|
|
@ -205,6 +205,38 @@ class RecResizeImg(object):
|
|||
return data
|
||||
|
||||
|
||||
class VLRecResizeImg(object):
|
||||
def __init__(self,
|
||||
image_shape,
|
||||
infer_mode=False,
|
||||
character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
|
||||
padding=True,
|
||||
**kwargs):
|
||||
self.image_shape = image_shape
|
||||
self.infer_mode = infer_mode
|
||||
self.character_dict_path = character_dict_path
|
||||
self.padding = padding
|
||||
|
||||
def __call__(self, data):
|
||||
img = data['image']
|
||||
|
||||
imgC, imgH, imgW = self.image_shape
|
||||
resized_image = cv2.resize(
|
||||
img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
|
||||
resized_w = imgW
|
||||
resized_image = resized_image.astype('float32')
|
||||
if self.image_shape[0] == 1:
|
||||
resized_image = resized_image / 255
|
||||
norm_img = resized_image[np.newaxis, :]
|
||||
else:
|
||||
norm_img = resized_image.transpose((2, 0, 1)) / 255
|
||||
valid_ratio = min(1.0, float(resized_w / imgW))
|
||||
|
||||
data['image'] = norm_img
|
||||
data['valid_ratio'] = valid_ratio
|
||||
return data
|
||||
|
||||
|
||||
class SRNRecResizeImg(object):
|
||||
def __init__(self, image_shape, num_heads, max_text_length, **kwargs):
|
||||
self.image_shape = image_shape
|
||||
|
|
@ -259,6 +291,7 @@ class PRENResizeImg(object):
|
|||
data['image'] = resized_img.astype(np.float32)
|
||||
return data
|
||||
|
||||
|
||||
class SPINRecResizeImg(object):
|
||||
def __init__(self,
|
||||
image_shape,
|
||||
|
|
@ -267,7 +300,7 @@ class SPINRecResizeImg(object):
|
|||
std=(127.5, 127.5, 127.5),
|
||||
**kwargs):
|
||||
self.image_shape = image_shape
|
||||
|
||||
|
||||
self.mean = np.array(mean, dtype=np.float32)
|
||||
self.std = np.array(std, dtype=np.float32)
|
||||
self.interpolation = interpolation
|
||||
|
|
@ -303,6 +336,7 @@ class SPINRecResizeImg(object):
|
|||
data['image'] = img
|
||||
return data
|
||||
|
||||
|
||||
class GrayRecResizeImg(object):
|
||||
def __init__(self,
|
||||
image_shape,
|
||||
|
|
|
|||
|
|
@ -13,12 +13,10 @@
|
|||
# limitations under the License.
|
||||
|
||||
from .token import VQATokenPad, VQASerTokenChunk, VQAReTokenChunk, VQAReTokenRelation
|
||||
from .augment import DistortBBox
|
||||
|
||||
__all__ = [
|
||||
'VQATokenPad',
|
||||
'VQASerTokenChunk',
|
||||
'VQAReTokenChunk',
|
||||
'VQAReTokenRelation',
|
||||
'DistortBBox',
|
||||
]
|
||||
|
|
|
|||
|
|
@ -16,22 +16,18 @@ import os
|
|||
import sys
|
||||
import numpy as np
|
||||
import random
|
||||
from copy import deepcopy
|
||||
|
||||
|
||||
class DistortBBox:
|
||||
def __init__(self, prob=0.5, max_scale=1, **kwargs):
|
||||
"""Random distort bbox
|
||||
"""
|
||||
self.prob = prob
|
||||
self.max_scale = max_scale
|
||||
|
||||
def __call__(self, data):
|
||||
if random.random() > self.prob:
|
||||
return data
|
||||
bbox = np.array(data['bbox'])
|
||||
rnd_scale = (np.random.rand(*bbox.shape) - 0.5) * 2 * self.max_scale
|
||||
bbox = np.round(bbox + rnd_scale).astype(bbox.dtype)
|
||||
data['bbox'] = np.clip(data['bbox'], 0, 1000)
|
||||
data['bbox'] = bbox.tolist()
|
||||
sys.stdout.flush()
|
||||
return data
|
||||
def order_by_tbyx(ocr_info):
|
||||
res = sorted(ocr_info, key=lambda r: (r["bbox"][1], r["bbox"][0]))
|
||||
for i in range(len(res) - 1):
|
||||
for j in range(i, 0, -1):
|
||||
if abs(res[j + 1]["bbox"][1] - res[j]["bbox"][1]) < 20 and \
|
||||
(res[j + 1]["bbox"][0] < res[j]["bbox"][0]):
|
||||
tmp = deepcopy(res[j])
|
||||
res[j] = deepcopy(res[j + 1])
|
||||
res[j + 1] = deepcopy(tmp)
|
||||
else:
|
||||
break
|
||||
return res
|
||||
|
|
|
|||
|
|
@ -35,6 +35,7 @@ from .rec_sar_loss import SARLoss
|
|||
from .rec_aster_loss import AsterLoss
|
||||
from .rec_pren_loss import PRENLoss
|
||||
from .rec_multi_loss import MultiLoss
|
||||
from .rec_vl_loss import VLLoss
|
||||
from .rec_spin_att_loss import SPINAttentionLoss
|
||||
|
||||
# cls loss
|
||||
|
|
@ -63,7 +64,7 @@ def build_loss(config):
|
|||
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
|
||||
'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
|
||||
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss',
|
||||
'TableMasterLoss', 'SPINAttentionLoss'
|
||||
'TableMasterLoss', 'SPINAttentionLoss', 'VLLoss'
|
||||
]
|
||||
config = copy.deepcopy(config)
|
||||
module_name = config.pop('name')
|
||||
|
|
|
|||
|
|
@ -63,18 +63,21 @@ class KLJSLoss(object):
|
|||
def __call__(self, p1, p2, reduction="mean"):
|
||||
|
||||
if self.mode.lower() == 'kl':
|
||||
loss = paddle.multiply(p2, paddle.log((p2 + 1e-5) / (p1 + 1e-5) + 1e-5))
|
||||
loss = paddle.multiply(p2,
|
||||
paddle.log((p2 + 1e-5) / (p1 + 1e-5) + 1e-5))
|
||||
loss += paddle.multiply(
|
||||
p1, paddle.log((p1 + 1e-5) / (p2 + 1e-5) + 1e-5))
|
||||
p1, paddle.log((p1 + 1e-5) / (p2 + 1e-5) + 1e-5))
|
||||
loss *= 0.5
|
||||
elif self.mode.lower() == "js":
|
||||
loss = paddle.multiply(p2, paddle.log((2*p2 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
|
||||
loss = paddle.multiply(
|
||||
p2, paddle.log((2 * p2 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
|
||||
loss += paddle.multiply(
|
||||
p1, paddle.log((2*p1 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
|
||||
p1, paddle.log((2 * p1 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
|
||||
loss *= 0.5
|
||||
else:
|
||||
raise ValueError("The mode.lower() if KLJSLoss should be one of ['kl', 'js']")
|
||||
|
||||
raise ValueError(
|
||||
"The mode.lower() if KLJSLoss should be one of ['kl', 'js']")
|
||||
|
||||
if reduction == "mean":
|
||||
loss = paddle.mean(loss, axis=[1, 2])
|
||||
elif reduction == "none" or reduction is None:
|
||||
|
|
@ -154,7 +157,9 @@ class LossFromOutput(nn.Layer):
|
|||
self.reduction = reduction
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
loss = predicts[self.key]
|
||||
loss = predicts
|
||||
if self.key is not None and isinstance(predicts, dict):
|
||||
loss = loss[self.key]
|
||||
if self.reduction == 'mean':
|
||||
loss = paddle.mean(loss)
|
||||
elif self.reduction == 'sum':
|
||||
|
|
|
|||
|
|
@ -24,6 +24,9 @@ from .distillation_loss import DistillationCTCLoss
|
|||
from .distillation_loss import DistillationSARLoss
|
||||
from .distillation_loss import DistillationDMLLoss
|
||||
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
|
||||
from .distillation_loss import DistillationVQASerTokenLayoutLMLoss, DistillationSERDMLLoss
|
||||
from .distillation_loss import DistillationLossFromOutput
|
||||
from .distillation_loss import DistillationVQADistanceLoss
|
||||
|
||||
|
||||
class CombinedLoss(nn.Layer):
|
||||
|
|
|
|||
|
|
@ -21,8 +21,10 @@ from .rec_ctc_loss import CTCLoss
|
|||
from .rec_sar_loss import SARLoss
|
||||
from .basic_loss import DMLLoss
|
||||
from .basic_loss import DistanceLoss
|
||||
from .basic_loss import LossFromOutput
|
||||
from .det_db_loss import DBLoss
|
||||
from .det_basic_loss import BalanceLoss, MaskL1Loss, DiceLoss
|
||||
from .vqa_token_layoutlm_loss import VQASerTokenLayoutLMLoss
|
||||
|
||||
|
||||
def _sum_loss(loss_dict):
|
||||
|
|
@ -322,3 +324,133 @@ class DistillationDistanceLoss(DistanceLoss):
|
|||
loss_dict["{}_{}_{}_{}".format(self.name, pair[0], pair[1],
|
||||
idx)] = loss
|
||||
return loss_dict
|
||||
|
||||
|
||||
class DistillationVQASerTokenLayoutLMLoss(VQASerTokenLayoutLMLoss):
|
||||
def __init__(self,
|
||||
num_classes,
|
||||
model_name_list=[],
|
||||
key=None,
|
||||
name="loss_ser"):
|
||||
super().__init__(num_classes=num_classes)
|
||||
self.model_name_list = model_name_list
|
||||
self.key = key
|
||||
self.name = name
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
loss_dict = dict()
|
||||
for idx, model_name in enumerate(self.model_name_list):
|
||||
out = predicts[model_name]
|
||||
if self.key is not None:
|
||||
out = out[self.key]
|
||||
loss = super().forward(out, batch)
|
||||
loss_dict["{}_{}".format(self.name, model_name)] = loss["loss"]
|
||||
return loss_dict
|
||||
|
||||
|
||||
class DistillationLossFromOutput(LossFromOutput):
|
||||
def __init__(self,
|
||||
reduction="none",
|
||||
model_name_list=[],
|
||||
dist_key=None,
|
||||
key="loss",
|
||||
name="loss_re"):
|
||||
super().__init__(key=key, reduction=reduction)
|
||||
self.model_name_list = model_name_list
|
||||
self.name = name
|
||||
self.dist_key = dist_key
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
loss_dict = dict()
|
||||
for idx, model_name in enumerate(self.model_name_list):
|
||||
out = predicts[model_name]
|
||||
if self.dist_key is not None:
|
||||
out = out[self.dist_key]
|
||||
loss = super().forward(out, batch)
|
||||
loss_dict["{}_{}".format(self.name, model_name)] = loss["loss"]
|
||||
return loss_dict
|
||||
|
||||
|
||||
class DistillationSERDMLLoss(DMLLoss):
|
||||
"""
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
act="softmax",
|
||||
use_log=True,
|
||||
num_classes=7,
|
||||
model_name_pairs=[],
|
||||
key=None,
|
||||
name="loss_dml_ser"):
|
||||
super().__init__(act=act, use_log=use_log)
|
||||
assert isinstance(model_name_pairs, list)
|
||||
self.key = key
|
||||
self.name = name
|
||||
self.num_classes = num_classes
|
||||
self.model_name_pairs = model_name_pairs
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
loss_dict = dict()
|
||||
for idx, pair in enumerate(self.model_name_pairs):
|
||||
out1 = predicts[pair[0]]
|
||||
out2 = predicts[pair[1]]
|
||||
if self.key is not None:
|
||||
out1 = out1[self.key]
|
||||
out2 = out2[self.key]
|
||||
out1 = out1.reshape([-1, out1.shape[-1]])
|
||||
out2 = out2.reshape([-1, out2.shape[-1]])
|
||||
|
||||
attention_mask = batch[2]
|
||||
if attention_mask is not None:
|
||||
active_output = attention_mask.reshape([-1, ]) == 1
|
||||
out1 = out1[active_output]
|
||||
out2 = out2[active_output]
|
||||
|
||||
loss_dict["{}_{}".format(self.name, idx)] = super().forward(out1,
|
||||
out2)
|
||||
|
||||
return loss_dict
|
||||
|
||||
|
||||
class DistillationVQADistanceLoss(DistanceLoss):
|
||||
def __init__(self,
|
||||
mode="l2",
|
||||
model_name_pairs=[],
|
||||
key=None,
|
||||
name="loss_distance",
|
||||
**kargs):
|
||||
super().__init__(mode=mode, **kargs)
|
||||
assert isinstance(model_name_pairs, list)
|
||||
self.key = key
|
||||
self.model_name_pairs = model_name_pairs
|
||||
self.name = name + "_l2"
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
loss_dict = dict()
|
||||
for idx, pair in enumerate(self.model_name_pairs):
|
||||
out1 = predicts[pair[0]]
|
||||
out2 = predicts[pair[1]]
|
||||
attention_mask = batch[2]
|
||||
if self.key is not None:
|
||||
out1 = out1[self.key]
|
||||
out2 = out2[self.key]
|
||||
if attention_mask is not None:
|
||||
max_len = attention_mask.shape[-1]
|
||||
out1 = out1[:, :max_len]
|
||||
out2 = out2[:, :max_len]
|
||||
out1 = out1.reshape([-1, out1.shape[-1]])
|
||||
out2 = out2.reshape([-1, out2.shape[-1]])
|
||||
if attention_mask is not None:
|
||||
active_output = attention_mask.reshape([-1, ]) == 1
|
||||
out1 = out1[active_output]
|
||||
out2 = out2[active_output]
|
||||
|
||||
loss = super().forward(out1, out2)
|
||||
if isinstance(loss, dict):
|
||||
for key in loss:
|
||||
loss_dict["{}_{}nohu_{}".format(self.name, key,
|
||||
idx)] = loss[key]
|
||||
else:
|
||||
loss_dict["{}_{}_{}_{}".format(self.name, pair[0], pair[1],
|
||||
idx)] = loss
|
||||
return loss_dict
|
||||
|
|
|
|||
|
|
@ -0,0 +1,70 @@
|
|||
# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
This code is refer from:
|
||||
https://github.com/wangyuxin87/VisionLAN
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import paddle
|
||||
from paddle import nn
|
||||
|
||||
|
||||
class VLLoss(nn.Layer):
|
||||
def __init__(self, mode='LF_1', weight_res=0.5, weight_mas=0.5, **kwargs):
|
||||
super(VLLoss, self).__init__()
|
||||
self.loss_func = paddle.nn.loss.CrossEntropyLoss(reduction="mean")
|
||||
assert mode in ['LF_1', 'LF_2', 'LA']
|
||||
self.mode = mode
|
||||
self.weight_res = weight_res
|
||||
self.weight_mas = weight_mas
|
||||
|
||||
def flatten_label(self, target):
|
||||
label_flatten = []
|
||||
label_length = []
|
||||
for i in range(0, target.shape[0]):
|
||||
cur_label = target[i].tolist()
|
||||
label_flatten += cur_label[:cur_label.index(0) + 1]
|
||||
label_length.append(cur_label.index(0) + 1)
|
||||
label_flatten = paddle.to_tensor(label_flatten, dtype='int64')
|
||||
label_length = paddle.to_tensor(label_length, dtype='int32')
|
||||
return (label_flatten, label_length)
|
||||
|
||||
def _flatten(self, sources, lengths):
|
||||
return paddle.concat([t[:l] for t, l in zip(sources, lengths)])
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
text_pre = predicts[0]
|
||||
target = batch[1].astype('int64')
|
||||
label_flatten, length = self.flatten_label(target)
|
||||
text_pre = self._flatten(text_pre, length)
|
||||
if self.mode == 'LF_1':
|
||||
loss = self.loss_func(text_pre, label_flatten)
|
||||
else:
|
||||
text_rem = predicts[1]
|
||||
text_mas = predicts[2]
|
||||
target_res = batch[2].astype('int64')
|
||||
target_sub = batch[3].astype('int64')
|
||||
label_flatten_res, length_res = self.flatten_label(target_res)
|
||||
label_flatten_sub, length_sub = self.flatten_label(target_sub)
|
||||
text_rem = self._flatten(text_rem, length_res)
|
||||
text_mas = self._flatten(text_mas, length_sub)
|
||||
loss_ori = self.loss_func(text_pre, label_flatten)
|
||||
loss_res = self.loss_func(text_rem, label_flatten_res)
|
||||
loss_mas = self.loss_func(text_mas, label_flatten_sub)
|
||||
loss = loss_ori + loss_res * self.weight_res + loss_mas * self.weight_mas
|
||||
return {'loss': loss}
|
||||
|
|
@ -17,26 +17,30 @@ from __future__ import division
|
|||
from __future__ import print_function
|
||||
|
||||
from paddle import nn
|
||||
from ppocr.losses.basic_loss import DMLLoss
|
||||
|
||||
|
||||
class VQASerTokenLayoutLMLoss(nn.Layer):
|
||||
def __init__(self, num_classes):
|
||||
def __init__(self, num_classes, key=None):
|
||||
super().__init__()
|
||||
self.loss_class = nn.CrossEntropyLoss()
|
||||
self.num_classes = num_classes
|
||||
self.ignore_index = self.loss_class.ignore_index
|
||||
self.key = key
|
||||
|
||||
def forward(self, predicts, batch):
|
||||
if isinstance(predicts, dict) and self.key is not None:
|
||||
predicts = predicts[self.key]
|
||||
labels = batch[5]
|
||||
attention_mask = batch[2]
|
||||
if attention_mask is not None:
|
||||
active_loss = attention_mask.reshape([-1, ]) == 1
|
||||
active_outputs = predicts.reshape(
|
||||
active_output = predicts.reshape(
|
||||
[-1, self.num_classes])[active_loss]
|
||||
active_labels = labels.reshape([-1, ])[active_loss]
|
||||
loss = self.loss_class(active_outputs, active_labels)
|
||||
active_label = labels.reshape([-1, ])[active_loss]
|
||||
loss = self.loss_class(active_output, active_label)
|
||||
else:
|
||||
loss = self.loss_class(
|
||||
predicts.reshape([-1, self.num_classes]),
|
||||
labels.reshape([-1, ]))
|
||||
return {'loss': loss}
|
||||
return {'loss': loss}
|
||||
|
|
@ -19,6 +19,8 @@ from .rec_metric import RecMetric
|
|||
from .det_metric import DetMetric
|
||||
from .e2e_metric import E2EMetric
|
||||
from .cls_metric import ClsMetric
|
||||
from .vqa_token_ser_metric import VQASerTokenMetric
|
||||
from .vqa_token_re_metric import VQAReTokenMetric
|
||||
|
||||
|
||||
class DistillationMetric(object):
|
||||
|
|
|
|||
|
|
@ -73,28 +73,40 @@ class BaseModel(nn.Layer):
|
|||
self.return_all_feats = config.get("return_all_feats", False)
|
||||
|
||||
def forward(self, x, data=None):
|
||||
|
||||
y = dict()
|
||||
if self.use_transform:
|
||||
x = self.transform(x)
|
||||
x = self.backbone(x)
|
||||
y["backbone_out"] = x
|
||||
if self.use_neck:
|
||||
x = self.neck(x)
|
||||
y["neck_out"] = x
|
||||
if self.use_head:
|
||||
x = self.head(x, targets=data)
|
||||
# for multi head, save ctc neck out for udml
|
||||
if isinstance(x, dict) and 'ctc_neck' in x.keys():
|
||||
y["neck_out"] = x["ctc_neck"]
|
||||
y["head_out"] = x
|
||||
elif isinstance(x, dict):
|
||||
if isinstance(x, dict):
|
||||
y.update(x)
|
||||
else:
|
||||
y["head_out"] = x
|
||||
y["backbone_out"] = x
|
||||
final_name = "backbone_out"
|
||||
if self.use_neck:
|
||||
x = self.neck(x)
|
||||
if isinstance(x, dict):
|
||||
y.update(x)
|
||||
else:
|
||||
y["neck_out"] = x
|
||||
final_name = "neck_out"
|
||||
if self.use_head:
|
||||
x = self.head(x, targets=data)
|
||||
# for multi head, save ctc neck out for udml
|
||||
if isinstance(x, dict) and 'ctc_neck' in x.keys():
|
||||
y["neck_out"] = x["ctc_neck"]
|
||||
y["head_out"] = x
|
||||
elif isinstance(x, dict):
|
||||
y.update(x)
|
||||
else:
|
||||
y["head_out"] = x
|
||||
final_name = "head_out"
|
||||
if self.return_all_feats:
|
||||
if self.training:
|
||||
return y
|
||||
elif isinstance(x, dict):
|
||||
return x
|
||||
else:
|
||||
return {"head_out": y["head_out"]}
|
||||
return {final_name: x}
|
||||
else:
|
||||
return x
|
||||
|
|
|
|||
|
|
@ -84,11 +84,15 @@ class BasicBlock(nn.Layer):
|
|||
|
||||
|
||||
class ResNet45(nn.Layer):
|
||||
def __init__(self, block=BasicBlock, layers=[3, 4, 6, 6, 3], in_channels=3):
|
||||
def __init__(self,
|
||||
in_channels=3,
|
||||
block=BasicBlock,
|
||||
layers=[3, 4, 6, 6, 3],
|
||||
strides=[2, 1, 2, 1, 1]):
|
||||
self.inplanes = 32
|
||||
super(ResNet45, self).__init__()
|
||||
self.conv1 = nn.Conv2D(
|
||||
3,
|
||||
in_channels,
|
||||
32,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
|
|
@ -98,18 +102,13 @@ class ResNet45(nn.Layer):
|
|||
self.bn1 = nn.BatchNorm2D(32)
|
||||
self.relu = nn.ReLU()
|
||||
|
||||
self.layer1 = self._make_layer(block, 32, layers[0], stride=2)
|
||||
self.layer2 = self._make_layer(block, 64, layers[1], stride=1)
|
||||
self.layer3 = self._make_layer(block, 128, layers[2], stride=2)
|
||||
self.layer4 = self._make_layer(block, 256, layers[3], stride=1)
|
||||
self.layer5 = self._make_layer(block, 512, layers[4], stride=1)
|
||||
self.layer1 = self._make_layer(block, 32, layers[0], stride=strides[0])
|
||||
self.layer2 = self._make_layer(block, 64, layers[1], stride=strides[1])
|
||||
self.layer3 = self._make_layer(block, 128, layers[2], stride=strides[2])
|
||||
self.layer4 = self._make_layer(block, 256, layers[3], stride=strides[3])
|
||||
self.layer5 = self._make_layer(block, 512, layers[4], stride=strides[4])
|
||||
self.out_channels = 512
|
||||
|
||||
# for m in self.modules():
|
||||
# if isinstance(m, nn.Conv2D):
|
||||
# n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
|
||||
# m.weight.data.normal_(0, math.sqrt(2. / n))
|
||||
|
||||
def _make_layer(self, block, planes, blocks, stride=1):
|
||||
downsample = None
|
||||
if stride != 1 or self.inplanes != planes * block.expansion:
|
||||
|
|
@ -137,11 +136,9 @@ class ResNet45(nn.Layer):
|
|||
x = self.conv1(x)
|
||||
x = self.bn1(x)
|
||||
x = self.relu(x)
|
||||
# print(x)
|
||||
x = self.layer1(x)
|
||||
x = self.layer2(x)
|
||||
x = self.layer3(x)
|
||||
# print(x)
|
||||
x = self.layer4(x)
|
||||
x = self.layer5(x)
|
||||
return x
|
||||
|
|
|
|||
|
|
@ -140,4 +140,4 @@ class ResNet_ASTER(nn.Layer):
|
|||
rnn_feat, _ = self.rnn(cnn_feat)
|
||||
return rnn_feat
|
||||
else:
|
||||
return cnn_feat
|
||||
return cnn_feat
|
||||
|
|
@ -22,13 +22,22 @@ from paddle import nn
|
|||
from paddlenlp.transformers import LayoutXLMModel, LayoutXLMForTokenClassification, LayoutXLMForRelationExtraction
|
||||
from paddlenlp.transformers import LayoutLMModel, LayoutLMForTokenClassification
|
||||
from paddlenlp.transformers import LayoutLMv2Model, LayoutLMv2ForTokenClassification, LayoutLMv2ForRelationExtraction
|
||||
from paddlenlp.transformers import AutoModel
|
||||
|
||||
__all__ = ["LayoutXLMForSer", 'LayoutLMForSer']
|
||||
__all__ = ["LayoutXLMForSer", "LayoutLMForSer"]
|
||||
|
||||
pretrained_model_dict = {
|
||||
LayoutXLMModel: 'layoutxlm-base-uncased',
|
||||
LayoutLMModel: 'layoutlm-base-uncased',
|
||||
LayoutLMv2Model: 'layoutlmv2-base-uncased'
|
||||
LayoutXLMModel: {
|
||||
"base": "layoutxlm-base-uncased",
|
||||
"vi": "layoutxlm-wo-backbone-base-uncased",
|
||||
},
|
||||
LayoutLMModel: {
|
||||
"base": "layoutlm-base-uncased",
|
||||
},
|
||||
LayoutLMv2Model: {
|
||||
"base": "layoutlmv2-base-uncased",
|
||||
"vi": "layoutlmv2-wo-backbone-base-uncased",
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
|
|
@ -36,42 +45,47 @@ class NLPBaseModel(nn.Layer):
|
|||
def __init__(self,
|
||||
base_model_class,
|
||||
model_class,
|
||||
type='ser',
|
||||
mode="base",
|
||||
type="ser",
|
||||
pretrained=True,
|
||||
checkpoints=None,
|
||||
**kwargs):
|
||||
super(NLPBaseModel, self).__init__()
|
||||
if checkpoints is not None:
|
||||
if checkpoints is not None: # load the trained model
|
||||
self.model = model_class.from_pretrained(checkpoints)
|
||||
elif isinstance(pretrained, (str, )) and os.path.exists(pretrained):
|
||||
self.model = model_class.from_pretrained(pretrained)
|
||||
else:
|
||||
pretrained_model_name = pretrained_model_dict[base_model_class]
|
||||
else: # load the pretrained-model
|
||||
pretrained_model_name = pretrained_model_dict[base_model_class][
|
||||
mode]
|
||||
if pretrained is True:
|
||||
base_model = base_model_class.from_pretrained(
|
||||
pretrained_model_name)
|
||||
else:
|
||||
base_model = base_model_class(
|
||||
**base_model_class.pretrained_init_configuration[
|
||||
pretrained_model_name])
|
||||
if type == 'ser':
|
||||
base_model = base_model_class.from_pretrained(pretrained)
|
||||
if type == "ser":
|
||||
self.model = model_class(
|
||||
base_model, num_classes=kwargs['num_classes'], dropout=None)
|
||||
base_model, num_classes=kwargs["num_classes"], dropout=None)
|
||||
else:
|
||||
self.model = model_class(base_model, dropout=None)
|
||||
self.out_channels = 1
|
||||
self.use_visual_backbone = True
|
||||
|
||||
|
||||
class LayoutLMForSer(NLPBaseModel):
|
||||
def __init__(self, num_classes, pretrained=True, checkpoints=None,
|
||||
def __init__(self,
|
||||
num_classes,
|
||||
pretrained=True,
|
||||
checkpoints=None,
|
||||
mode="base",
|
||||
**kwargs):
|
||||
super(LayoutLMForSer, self).__init__(
|
||||
LayoutLMModel,
|
||||
LayoutLMForTokenClassification,
|
||||
'ser',
|
||||
mode,
|
||||
"ser",
|
||||
pretrained,
|
||||
checkpoints,
|
||||
num_classes=num_classes)
|
||||
num_classes=num_classes, )
|
||||
self.use_visual_backbone = False
|
||||
|
||||
def forward(self, x):
|
||||
x = self.model(
|
||||
|
|
@ -85,62 +99,92 @@ class LayoutLMForSer(NLPBaseModel):
|
|||
|
||||
|
||||
class LayoutLMv2ForSer(NLPBaseModel):
|
||||
def __init__(self, num_classes, pretrained=True, checkpoints=None,
|
||||
def __init__(self,
|
||||
num_classes,
|
||||
pretrained=True,
|
||||
checkpoints=None,
|
||||
mode="base",
|
||||
**kwargs):
|
||||
super(LayoutLMv2ForSer, self).__init__(
|
||||
LayoutLMv2Model,
|
||||
LayoutLMv2ForTokenClassification,
|
||||
'ser',
|
||||
mode,
|
||||
"ser",
|
||||
pretrained,
|
||||
checkpoints,
|
||||
num_classes=num_classes)
|
||||
self.use_visual_backbone = True
|
||||
if hasattr(self.model.layoutlmv2, "use_visual_backbone"
|
||||
) and self.model.layoutlmv2.use_visual_backbone is False:
|
||||
self.use_visual_backbone = False
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_visual_backbone is True:
|
||||
image = x[4]
|
||||
else:
|
||||
image = None
|
||||
x = self.model(
|
||||
input_ids=x[0],
|
||||
bbox=x[1],
|
||||
attention_mask=x[2],
|
||||
token_type_ids=x[3],
|
||||
image=x[4],
|
||||
image=image,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
labels=None)
|
||||
if not self.training:
|
||||
if self.training:
|
||||
res = {"backbone_out": x[0]}
|
||||
res.update(x[1])
|
||||
return res
|
||||
else:
|
||||
return x
|
||||
return x[0]
|
||||
|
||||
|
||||
class LayoutXLMForSer(NLPBaseModel):
|
||||
def __init__(self, num_classes, pretrained=True, checkpoints=None,
|
||||
def __init__(self,
|
||||
num_classes,
|
||||
pretrained=True,
|
||||
checkpoints=None,
|
||||
mode="base",
|
||||
**kwargs):
|
||||
super(LayoutXLMForSer, self).__init__(
|
||||
LayoutXLMModel,
|
||||
LayoutXLMForTokenClassification,
|
||||
'ser',
|
||||
mode,
|
||||
"ser",
|
||||
pretrained,
|
||||
checkpoints,
|
||||
num_classes=num_classes)
|
||||
self.use_visual_backbone = True
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_visual_backbone is True:
|
||||
image = x[4]
|
||||
else:
|
||||
image = None
|
||||
x = self.model(
|
||||
input_ids=x[0],
|
||||
bbox=x[1],
|
||||
attention_mask=x[2],
|
||||
token_type_ids=x[3],
|
||||
image=x[4],
|
||||
image=image,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
labels=None)
|
||||
if not self.training:
|
||||
if self.training:
|
||||
res = {"backbone_out": x[0]}
|
||||
res.update(x[1])
|
||||
return res
|
||||
else:
|
||||
return x
|
||||
return x[0]
|
||||
|
||||
|
||||
class LayoutLMv2ForRe(NLPBaseModel):
|
||||
def __init__(self, pretrained=True, checkpoints=None, **kwargs):
|
||||
super(LayoutLMv2ForRe, self).__init__(LayoutLMv2Model,
|
||||
LayoutLMv2ForRelationExtraction,
|
||||
're', pretrained, checkpoints)
|
||||
def __init__(self, pretrained=True, checkpoints=None, mode="base",
|
||||
**kwargs):
|
||||
super(LayoutLMv2ForRe, self).__init__(
|
||||
LayoutLMv2Model, LayoutLMv2ForRelationExtraction, mode, "re",
|
||||
pretrained, checkpoints)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.model(
|
||||
|
|
@ -158,18 +202,27 @@ class LayoutLMv2ForRe(NLPBaseModel):
|
|||
|
||||
|
||||
class LayoutXLMForRe(NLPBaseModel):
|
||||
def __init__(self, pretrained=True, checkpoints=None, **kwargs):
|
||||
super(LayoutXLMForRe, self).__init__(LayoutXLMModel,
|
||||
LayoutXLMForRelationExtraction,
|
||||
're', pretrained, checkpoints)
|
||||
def __init__(self, pretrained=True, checkpoints=None, mode="base",
|
||||
**kwargs):
|
||||
super(LayoutXLMForRe, self).__init__(
|
||||
LayoutXLMModel, LayoutXLMForRelationExtraction, mode, "re",
|
||||
pretrained, checkpoints)
|
||||
self.use_visual_backbone = True
|
||||
if hasattr(self.model.layoutxlm, "use_visual_backbone"
|
||||
) and self.model.layoutxlm.use_visual_backbone is False:
|
||||
self.use_visual_backbone = False
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_visual_backbone is True:
|
||||
image = x[4]
|
||||
else:
|
||||
image = None
|
||||
x = self.model(
|
||||
input_ids=x[0],
|
||||
bbox=x[1],
|
||||
attention_mask=x[2],
|
||||
token_type_ids=x[3],
|
||||
image=x[4],
|
||||
image=image,
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
labels=None,
|
||||
|
|
|
|||
|
|
@ -36,6 +36,7 @@ def build_head(config):
|
|||
from .rec_spin_att_head import SPINAttentionHead
|
||||
from .rec_abinet_head import ABINetHead
|
||||
from .rec_robustscanner_head import RobustScannerHead
|
||||
from .rec_visionlan_head import VLHead
|
||||
|
||||
# cls head
|
||||
from .cls_head import ClsHead
|
||||
|
|
@ -50,7 +51,8 @@ def build_head(config):
|
|||
'DBHead', 'PSEHead', 'FCEHead', 'EASTHead', 'SASTHead', 'CTCHead',
|
||||
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
|
||||
'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
|
||||
'MultiHead', 'ABINetHead', 'TableMasterHead', 'SPINAttentionHead', 'RobustScannerHead'
|
||||
'MultiHead', 'ABINetHead', 'TableMasterHead', 'SPINAttentionHead',
|
||||
'VLHead', 'RobustScannerHead'
|
||||
]
|
||||
|
||||
#table head
|
||||
|
|
|
|||
|
|
@ -0,0 +1,468 @@
|
|||
# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
This code is refer from:
|
||||
https://github.com/wangyuxin87/VisionLAN
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import paddle
|
||||
from paddle import ParamAttr
|
||||
import paddle.nn as nn
|
||||
import paddle.nn.functional as F
|
||||
from paddle.nn.initializer import Normal, XavierNormal
|
||||
import numpy as np
|
||||
|
||||
|
||||
class PositionalEncoding(nn.Layer):
|
||||
def __init__(self, d_hid, n_position=200):
|
||||
super(PositionalEncoding, self).__init__()
|
||||
self.register_buffer(
|
||||
'pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
|
||||
|
||||
def _get_sinusoid_encoding_table(self, n_position, d_hid):
|
||||
''' Sinusoid position encoding table '''
|
||||
|
||||
def get_position_angle_vec(position):
|
||||
return [
|
||||
position / np.power(10000, 2 * (hid_j // 2) / d_hid)
|
||||
for hid_j in range(d_hid)
|
||||
]
|
||||
|
||||
sinusoid_table = np.array(
|
||||
[get_position_angle_vec(pos_i) for pos_i in range(n_position)])
|
||||
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
|
||||
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
|
||||
sinusoid_table = paddle.to_tensor(sinusoid_table, dtype='float32')
|
||||
sinusoid_table = paddle.unsqueeze(sinusoid_table, axis=0)
|
||||
return sinusoid_table
|
||||
|
||||
def forward(self, x):
|
||||
return x + self.pos_table[:, :x.shape[1]].clone().detach()
|
||||
|
||||
|
||||
class ScaledDotProductAttention(nn.Layer):
|
||||
"Scaled Dot-Product Attention"
|
||||
|
||||
def __init__(self, temperature, attn_dropout=0.1):
|
||||
super(ScaledDotProductAttention, self).__init__()
|
||||
self.temperature = temperature
|
||||
self.dropout = nn.Dropout(attn_dropout)
|
||||
self.softmax = nn.Softmax(axis=2)
|
||||
|
||||
def forward(self, q, k, v, mask=None):
|
||||
k = paddle.transpose(k, perm=[0, 2, 1])
|
||||
attn = paddle.bmm(q, k)
|
||||
attn = attn / self.temperature
|
||||
if mask is not None:
|
||||
attn = attn.masked_fill(mask, -1e9)
|
||||
if mask.dim() == 3:
|
||||
mask = paddle.unsqueeze(mask, axis=1)
|
||||
elif mask.dim() == 2:
|
||||
mask = paddle.unsqueeze(mask, axis=1)
|
||||
mask = paddle.unsqueeze(mask, axis=1)
|
||||
repeat_times = [
|
||||
attn.shape[1] // mask.shape[1], attn.shape[2] // mask.shape[2]
|
||||
]
|
||||
mask = paddle.tile(mask, [1, repeat_times[0], repeat_times[1], 1])
|
||||
attn[mask == 0] = -1e9
|
||||
attn = self.softmax(attn)
|
||||
attn = self.dropout(attn)
|
||||
output = paddle.bmm(attn, v)
|
||||
return output
|
||||
|
||||
|
||||
class MultiHeadAttention(nn.Layer):
|
||||
" Multi-Head Attention module"
|
||||
|
||||
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
|
||||
super(MultiHeadAttention, self).__init__()
|
||||
self.n_head = n_head
|
||||
self.d_k = d_k
|
||||
self.d_v = d_v
|
||||
self.w_qs = nn.Linear(
|
||||
d_model,
|
||||
n_head * d_k,
|
||||
weight_attr=ParamAttr(initializer=Normal(
|
||||
mean=0, std=np.sqrt(2.0 / (d_model + d_k)))))
|
||||
self.w_ks = nn.Linear(
|
||||
d_model,
|
||||
n_head * d_k,
|
||||
weight_attr=ParamAttr(initializer=Normal(
|
||||
mean=0, std=np.sqrt(2.0 / (d_model + d_k)))))
|
||||
self.w_vs = nn.Linear(
|
||||
d_model,
|
||||
n_head * d_v,
|
||||
weight_attr=ParamAttr(initializer=Normal(
|
||||
mean=0, std=np.sqrt(2.0 / (d_model + d_v)))))
|
||||
|
||||
self.attention = ScaledDotProductAttention(temperature=np.power(d_k,
|
||||
0.5))
|
||||
self.layer_norm = nn.LayerNorm(d_model)
|
||||
self.fc = nn.Linear(
|
||||
n_head * d_v,
|
||||
d_model,
|
||||
weight_attr=ParamAttr(initializer=XavierNormal()))
|
||||
self.dropout = nn.Dropout(dropout)
|
||||
|
||||
def forward(self, q, k, v, mask=None):
|
||||
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
|
||||
sz_b, len_q, _ = q.shape
|
||||
sz_b, len_k, _ = k.shape
|
||||
sz_b, len_v, _ = v.shape
|
||||
residual = q
|
||||
|
||||
q = self.w_qs(q)
|
||||
q = paddle.reshape(
|
||||
q, shape=[-1, len_q, n_head, d_k]) # 4*21*512 ---- 4*21*8*64
|
||||
k = self.w_ks(k)
|
||||
k = paddle.reshape(k, shape=[-1, len_k, n_head, d_k])
|
||||
v = self.w_vs(v)
|
||||
v = paddle.reshape(v, shape=[-1, len_v, n_head, d_v])
|
||||
|
||||
q = paddle.transpose(q, perm=[2, 0, 1, 3])
|
||||
q = paddle.reshape(q, shape=[-1, len_q, d_k]) # (n*b) x lq x dk
|
||||
k = paddle.transpose(k, perm=[2, 0, 1, 3])
|
||||
k = paddle.reshape(k, shape=[-1, len_k, d_k]) # (n*b) x lk x dk
|
||||
v = paddle.transpose(v, perm=[2, 0, 1, 3])
|
||||
v = paddle.reshape(v, shape=[-1, len_v, d_v]) # (n*b) x lv x dv
|
||||
|
||||
mask = paddle.tile(
|
||||
mask,
|
||||
[n_head, 1, 1]) if mask is not None else None # (n*b) x .. x ..
|
||||
output = self.attention(q, k, v, mask=mask)
|
||||
output = paddle.reshape(output, shape=[n_head, -1, len_q, d_v])
|
||||
output = paddle.transpose(output, perm=[1, 2, 0, 3])
|
||||
output = paddle.reshape(
|
||||
output, shape=[-1, len_q, n_head * d_v]) # b x lq x (n*dv)
|
||||
output = self.dropout(self.fc(output))
|
||||
output = self.layer_norm(output + residual)
|
||||
return output
|
||||
|
||||
|
||||
class PositionwiseFeedForward(nn.Layer):
|
||||
def __init__(self, d_in, d_hid, dropout=0.1):
|
||||
super(PositionwiseFeedForward, self).__init__()
|
||||
self.w_1 = nn.Conv1D(d_in, d_hid, 1) # position-wise
|
||||
self.w_2 = nn.Conv1D(d_hid, d_in, 1) # position-wise
|
||||
self.layer_norm = nn.LayerNorm(d_in)
|
||||
self.dropout = nn.Dropout(dropout)
|
||||
|
||||
def forward(self, x):
|
||||
residual = x
|
||||
x = paddle.transpose(x, perm=[0, 2, 1])
|
||||
x = self.w_2(F.relu(self.w_1(x)))
|
||||
x = paddle.transpose(x, perm=[0, 2, 1])
|
||||
x = self.dropout(x)
|
||||
x = self.layer_norm(x + residual)
|
||||
return x
|
||||
|
||||
|
||||
class EncoderLayer(nn.Layer):
|
||||
''' Compose with two layers '''
|
||||
|
||||
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
|
||||
super(EncoderLayer, self).__init__()
|
||||
self.slf_attn = MultiHeadAttention(
|
||||
n_head, d_model, d_k, d_v, dropout=dropout)
|
||||
self.pos_ffn = PositionwiseFeedForward(
|
||||
d_model, d_inner, dropout=dropout)
|
||||
|
||||
def forward(self, enc_input, slf_attn_mask=None):
|
||||
enc_output = self.slf_attn(
|
||||
enc_input, enc_input, enc_input, mask=slf_attn_mask)
|
||||
enc_output = self.pos_ffn(enc_output)
|
||||
return enc_output
|
||||
|
||||
|
||||
class Transformer_Encoder(nn.Layer):
|
||||
def __init__(self,
|
||||
n_layers=2,
|
||||
n_head=8,
|
||||
d_word_vec=512,
|
||||
d_k=64,
|
||||
d_v=64,
|
||||
d_model=512,
|
||||
d_inner=2048,
|
||||
dropout=0.1,
|
||||
n_position=256):
|
||||
super(Transformer_Encoder, self).__init__()
|
||||
self.position_enc = PositionalEncoding(
|
||||
d_word_vec, n_position=n_position)
|
||||
self.dropout = nn.Dropout(p=dropout)
|
||||
self.layer_stack = nn.LayerList([
|
||||
EncoderLayer(
|
||||
d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
|
||||
for _ in range(n_layers)
|
||||
])
|
||||
self.layer_norm = nn.LayerNorm(d_model, epsilon=1e-6)
|
||||
|
||||
def forward(self, enc_output, src_mask, return_attns=False):
|
||||
enc_output = self.dropout(
|
||||
self.position_enc(enc_output)) # position embeding
|
||||
for enc_layer in self.layer_stack:
|
||||
enc_output = enc_layer(enc_output, slf_attn_mask=src_mask)
|
||||
enc_output = self.layer_norm(enc_output)
|
||||
return enc_output
|
||||
|
||||
|
||||
class PP_layer(nn.Layer):
|
||||
def __init__(self, n_dim=512, N_max_character=25, n_position=256):
|
||||
|
||||
super(PP_layer, self).__init__()
|
||||
self.character_len = N_max_character
|
||||
self.f0_embedding = nn.Embedding(N_max_character, n_dim)
|
||||
self.w0 = nn.Linear(N_max_character, n_position)
|
||||
self.wv = nn.Linear(n_dim, n_dim)
|
||||
self.we = nn.Linear(n_dim, N_max_character)
|
||||
self.active = nn.Tanh()
|
||||
self.softmax = nn.Softmax(axis=2)
|
||||
|
||||
def forward(self, enc_output):
|
||||
# enc_output: b,256,512
|
||||
reading_order = paddle.arange(self.character_len, dtype='int64')
|
||||
reading_order = reading_order.unsqueeze(0).expand(
|
||||
[enc_output.shape[0], self.character_len]) # (S,) -> (B, S)
|
||||
reading_order = self.f0_embedding(reading_order) # b,25,512
|
||||
|
||||
# calculate attention
|
||||
reading_order = paddle.transpose(reading_order, perm=[0, 2, 1])
|
||||
t = self.w0(reading_order) # b,512,256
|
||||
t = self.active(
|
||||
paddle.transpose(
|
||||
t, perm=[0, 2, 1]) + self.wv(enc_output)) # b,256,512
|
||||
t = self.we(t) # b,256,25
|
||||
t = self.softmax(paddle.transpose(t, perm=[0, 2, 1])) # b,25,256
|
||||
g_output = paddle.bmm(t, enc_output) # b,25,512
|
||||
return g_output
|
||||
|
||||
|
||||
class Prediction(nn.Layer):
|
||||
def __init__(self,
|
||||
n_dim=512,
|
||||
n_position=256,
|
||||
N_max_character=25,
|
||||
n_class=37):
|
||||
super(Prediction, self).__init__()
|
||||
self.pp = PP_layer(
|
||||
n_dim=n_dim, N_max_character=N_max_character, n_position=n_position)
|
||||
self.pp_share = PP_layer(
|
||||
n_dim=n_dim, N_max_character=N_max_character, n_position=n_position)
|
||||
self.w_vrm = nn.Linear(n_dim, n_class) # output layer
|
||||
self.w_share = nn.Linear(n_dim, n_class) # output layer
|
||||
self.nclass = n_class
|
||||
|
||||
def forward(self, cnn_feature, f_res, f_sub, train_mode=False,
|
||||
use_mlm=True):
|
||||
if train_mode:
|
||||
if not use_mlm:
|
||||
g_output = self.pp(cnn_feature) # b,25,512
|
||||
g_output = self.w_vrm(g_output)
|
||||
f_res = 0
|
||||
f_sub = 0
|
||||
return g_output, f_res, f_sub
|
||||
g_output = self.pp(cnn_feature) # b,25,512
|
||||
f_res = self.pp_share(f_res)
|
||||
f_sub = self.pp_share(f_sub)
|
||||
g_output = self.w_vrm(g_output)
|
||||
f_res = self.w_share(f_res)
|
||||
f_sub = self.w_share(f_sub)
|
||||
return g_output, f_res, f_sub
|
||||
else:
|
||||
g_output = self.pp(cnn_feature) # b,25,512
|
||||
g_output = self.w_vrm(g_output)
|
||||
return g_output
|
||||
|
||||
|
||||
class MLM(nn.Layer):
|
||||
"Architecture of MLM"
|
||||
|
||||
def __init__(self, n_dim=512, n_position=256, max_text_length=25):
|
||||
super(MLM, self).__init__()
|
||||
self.MLM_SequenceModeling_mask = Transformer_Encoder(
|
||||
n_layers=2, n_position=n_position)
|
||||
self.MLM_SequenceModeling_WCL = Transformer_Encoder(
|
||||
n_layers=1, n_position=n_position)
|
||||
self.pos_embedding = nn.Embedding(max_text_length, n_dim)
|
||||
self.w0_linear = nn.Linear(1, n_position)
|
||||
self.wv = nn.Linear(n_dim, n_dim)
|
||||
self.active = nn.Tanh()
|
||||
self.we = nn.Linear(n_dim, 1)
|
||||
self.sigmoid = nn.Sigmoid()
|
||||
|
||||
def forward(self, x, label_pos):
|
||||
# transformer unit for generating mask_c
|
||||
feature_v_seq = self.MLM_SequenceModeling_mask(x, src_mask=None)
|
||||
# position embedding layer
|
||||
label_pos = paddle.to_tensor(label_pos, dtype='int64')
|
||||
pos_emb = self.pos_embedding(label_pos)
|
||||
pos_emb = self.w0_linear(paddle.unsqueeze(pos_emb, axis=2))
|
||||
pos_emb = paddle.transpose(pos_emb, perm=[0, 2, 1])
|
||||
# fusion position embedding with features V & generate mask_c
|
||||
att_map_sub = self.active(pos_emb + self.wv(feature_v_seq))
|
||||
att_map_sub = self.we(att_map_sub) # b,256,1
|
||||
att_map_sub = paddle.transpose(att_map_sub, perm=[0, 2, 1])
|
||||
att_map_sub = self.sigmoid(att_map_sub) # b,1,256
|
||||
# WCL
|
||||
## generate inputs for WCL
|
||||
att_map_sub = paddle.transpose(att_map_sub, perm=[0, 2, 1])
|
||||
f_res = x * (1 - att_map_sub) # second path with remaining string
|
||||
f_sub = x * att_map_sub # first path with occluded character
|
||||
## transformer units in WCL
|
||||
f_res = self.MLM_SequenceModeling_WCL(f_res, src_mask=None)
|
||||
f_sub = self.MLM_SequenceModeling_WCL(f_sub, src_mask=None)
|
||||
return f_res, f_sub, att_map_sub
|
||||
|
||||
|
||||
def trans_1d_2d(x):
|
||||
b, w_h, c = x.shape # b, 256, 512
|
||||
x = paddle.transpose(x, perm=[0, 2, 1])
|
||||
x = paddle.reshape(x, [-1, c, 32, 8])
|
||||
x = paddle.transpose(x, perm=[0, 1, 3, 2]) # [b, c, 8, 32]
|
||||
return x
|
||||
|
||||
|
||||
class MLM_VRM(nn.Layer):
|
||||
"""
|
||||
MLM+VRM, MLM is only used in training.
|
||||
ratio controls the occluded number in a batch.
|
||||
The pipeline of VisionLAN in testing is very concise with only a backbone + sequence modeling(transformer unit) + prediction layer(pp layer).
|
||||
x: input image
|
||||
label_pos: character index
|
||||
training_step: LF or LA process
|
||||
output
|
||||
text_pre: prediction of VRM
|
||||
test_rem: prediction of remaining string in MLM
|
||||
text_mas: prediction of occluded character in MLM
|
||||
mask_c_show: visualization of Mask_c
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
n_layers=3,
|
||||
n_position=256,
|
||||
n_dim=512,
|
||||
max_text_length=25,
|
||||
nclass=37):
|
||||
super(MLM_VRM, self).__init__()
|
||||
self.MLM = MLM(n_dim=n_dim,
|
||||
n_position=n_position,
|
||||
max_text_length=max_text_length)
|
||||
self.SequenceModeling = Transformer_Encoder(
|
||||
n_layers=n_layers, n_position=n_position)
|
||||
self.Prediction = Prediction(
|
||||
n_dim=n_dim,
|
||||
n_position=n_position,
|
||||
N_max_character=max_text_length +
|
||||
1, # N_max_character = 1 eos + 25 characters
|
||||
n_class=nclass)
|
||||
self.nclass = nclass
|
||||
self.max_text_length = max_text_length
|
||||
|
||||
def forward(self, x, label_pos, training_step, train_mode=False):
|
||||
b, c, h, w = x.shape
|
||||
nT = self.max_text_length
|
||||
x = paddle.transpose(x, perm=[0, 1, 3, 2])
|
||||
x = paddle.reshape(x, [-1, c, h * w])
|
||||
x = paddle.transpose(x, perm=[0, 2, 1])
|
||||
if train_mode:
|
||||
if training_step == 'LF_1':
|
||||
f_res = 0
|
||||
f_sub = 0
|
||||
x = self.SequenceModeling(x, src_mask=None)
|
||||
text_pre, test_rem, text_mas = self.Prediction(
|
||||
x, f_res, f_sub, train_mode=True, use_mlm=False)
|
||||
return text_pre, text_pre, text_pre, text_pre
|
||||
elif training_step == 'LF_2':
|
||||
# MLM
|
||||
f_res, f_sub, mask_c = self.MLM(x, label_pos)
|
||||
x = self.SequenceModeling(x, src_mask=None)
|
||||
text_pre, test_rem, text_mas = self.Prediction(
|
||||
x, f_res, f_sub, train_mode=True)
|
||||
mask_c_show = trans_1d_2d(mask_c)
|
||||
return text_pre, test_rem, text_mas, mask_c_show
|
||||
elif training_step == 'LA':
|
||||
# MLM
|
||||
f_res, f_sub, mask_c = self.MLM(x, label_pos)
|
||||
## use the mask_c (1 for occluded character and 0 for remaining characters) to occlude input
|
||||
## ratio controls the occluded number in a batch
|
||||
character_mask = paddle.zeros_like(mask_c)
|
||||
|
||||
ratio = b // 2
|
||||
if ratio >= 1:
|
||||
with paddle.no_grad():
|
||||
character_mask[0:ratio, :, :] = mask_c[0:ratio, :, :]
|
||||
else:
|
||||
character_mask = mask_c
|
||||
x = x * (1 - character_mask)
|
||||
# VRM
|
||||
## transformer unit for VRM
|
||||
x = self.SequenceModeling(x, src_mask=None)
|
||||
## prediction layer for MLM and VSR
|
||||
text_pre, test_rem, text_mas = self.Prediction(
|
||||
x, f_res, f_sub, train_mode=True)
|
||||
mask_c_show = trans_1d_2d(mask_c)
|
||||
return text_pre, test_rem, text_mas, mask_c_show
|
||||
else:
|
||||
raise NotImplementedError
|
||||
else: # VRM is only used in the testing stage
|
||||
f_res = 0
|
||||
f_sub = 0
|
||||
contextual_feature = self.SequenceModeling(x, src_mask=None)
|
||||
text_pre = self.Prediction(
|
||||
contextual_feature,
|
||||
f_res,
|
||||
f_sub,
|
||||
train_mode=False,
|
||||
use_mlm=False)
|
||||
text_pre = paddle.transpose(
|
||||
text_pre, perm=[1, 0, 2]) # (26, b, 37))
|
||||
return text_pre, x
|
||||
|
||||
|
||||
class VLHead(nn.Layer):
|
||||
"""
|
||||
Architecture of VisionLAN
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
out_channels=36,
|
||||
n_layers=3,
|
||||
n_position=256,
|
||||
n_dim=512,
|
||||
max_text_length=25,
|
||||
training_step='LA'):
|
||||
super(VLHead, self).__init__()
|
||||
self.MLM_VRM = MLM_VRM(
|
||||
n_layers=n_layers,
|
||||
n_position=n_position,
|
||||
n_dim=n_dim,
|
||||
max_text_length=max_text_length,
|
||||
nclass=out_channels + 1)
|
||||
self.training_step = training_step
|
||||
|
||||
def forward(self, feat, targets=None):
|
||||
|
||||
if self.training:
|
||||
label_pos = targets[-2]
|
||||
text_pre, test_rem, text_mas, mask_map = self.MLM_VRM(
|
||||
feat, label_pos, self.training_step, train_mode=True)
|
||||
return text_pre, test_rem, text_mas, mask_map
|
||||
else:
|
||||
text_pre, x = self.MLM_VRM(
|
||||
feat, targets, self.training_step, train_mode=False)
|
||||
return text_pre, x
|
||||
|
|
@ -77,11 +77,62 @@ class Adam(object):
|
|||
self.grad_clip = grad_clip
|
||||
self.name = name
|
||||
self.lazy_mode = lazy_mode
|
||||
self.group_lr = kwargs.get('group_lr', False)
|
||||
self.training_step = kwargs.get('training_step', None)
|
||||
|
||||
def __call__(self, model):
|
||||
train_params = [
|
||||
param for param in model.parameters() if param.trainable is True
|
||||
]
|
||||
if self.group_lr:
|
||||
if self.training_step == 'LF_2':
|
||||
import paddle
|
||||
if isinstance(model, paddle.fluid.dygraph.parallel.
|
||||
DataParallel): # multi gpu
|
||||
mlm = model._layers.head.MLM_VRM.MLM.parameters()
|
||||
pre_mlm_pp = model._layers.head.MLM_VRM.Prediction.pp_share.parameters(
|
||||
)
|
||||
pre_mlm_w = model._layers.head.MLM_VRM.Prediction.w_share.parameters(
|
||||
)
|
||||
else: # single gpu
|
||||
mlm = model.head.MLM_VRM.MLM.parameters()
|
||||
pre_mlm_pp = model.head.MLM_VRM.Prediction.pp_share.parameters(
|
||||
)
|
||||
pre_mlm_w = model.head.MLM_VRM.Prediction.w_share.parameters(
|
||||
)
|
||||
|
||||
total = []
|
||||
for param in mlm:
|
||||
total.append(id(param))
|
||||
for param in pre_mlm_pp:
|
||||
total.append(id(param))
|
||||
for param in pre_mlm_w:
|
||||
total.append(id(param))
|
||||
|
||||
group_base_params = [
|
||||
param for param in model.parameters() if id(param) in total
|
||||
]
|
||||
group_small_params = [
|
||||
param for param in model.parameters()
|
||||
if id(param) not in total
|
||||
]
|
||||
train_params = [{
|
||||
'params': group_base_params
|
||||
}, {
|
||||
'params': group_small_params,
|
||||
'learning_rate': self.learning_rate.values[0] * 0.1
|
||||
}]
|
||||
|
||||
else:
|
||||
print(
|
||||
'group lr currently only support VisionLAN in LF_2 training step'
|
||||
)
|
||||
train_params = [
|
||||
param for param in model.parameters()
|
||||
if param.trainable is True
|
||||
]
|
||||
else:
|
||||
train_params = [
|
||||
param for param in model.parameters() if param.trainable is True
|
||||
]
|
||||
|
||||
opt = optim.Adam(
|
||||
learning_rate=self.learning_rate,
|
||||
beta1=self.beta1,
|
||||
|
|
|
|||
|
|
@ -28,12 +28,13 @@ from .fce_postprocess import FCEPostProcess
|
|||
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
|
||||
DistillationCTCLabelDecode, NRTRLabelDecode, SARLabelDecode, \
|
||||
SEEDLabelDecode, PRENLabelDecode, ViTSTRLabelDecode, ABINetLabelDecode, \
|
||||
SPINLabelDecode
|
||||
SPINLabelDecode, VLLabelDecode
|
||||
from .cls_postprocess import ClsPostProcess
|
||||
from .pg_postprocess import PGPostProcess
|
||||
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess
|
||||
from .vqa_token_re_layoutlm_postprocess import VQAReTokenLayoutLMPostProcess
|
||||
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess, DistillationSerPostProcess
|
||||
from .vqa_token_re_layoutlm_postprocess import VQAReTokenLayoutLMPostProcess, DistillationRePostProcess
|
||||
from .table_postprocess import TableMasterLabelDecode, TableLabelDecode
|
||||
from .picodet_postprocess import PicoDetPostProcess
|
||||
|
||||
|
||||
def build_post_process(config, global_config=None):
|
||||
|
|
@ -45,7 +46,9 @@ def build_post_process(config, global_config=None):
|
|||
'SEEDLabelDecode', 'VQASerTokenLayoutLMPostProcess',
|
||||
'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode',
|
||||
'DistillationSARLabelDecode', 'ViTSTRLabelDecode', 'ABINetLabelDecode',
|
||||
'TableMasterLabelDecode', 'SPINLabelDecode'
|
||||
'TableMasterLabelDecode', 'SPINLabelDecode',
|
||||
'DistillationSerPostProcess', 'DistillationRePostProcess',
|
||||
'VLLabelDecode', 'PicoDetPostProcess'
|
||||
]
|
||||
|
||||
if config['name'] == 'PSEPostProcess':
|
||||
|
|
|
|||
|
|
@ -0,0 +1,250 @@
|
|||
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import numpy as np
|
||||
from scipy.special import softmax
|
||||
|
||||
|
||||
def hard_nms(box_scores, iou_threshold, top_k=-1, candidate_size=200):
|
||||
"""
|
||||
Args:
|
||||
box_scores (N, 5): boxes in corner-form and probabilities.
|
||||
iou_threshold: intersection over union threshold.
|
||||
top_k: keep top_k results. If k <= 0, keep all the results.
|
||||
candidate_size: only consider the candidates with the highest scores.
|
||||
Returns:
|
||||
picked: a list of indexes of the kept boxes
|
||||
"""
|
||||
scores = box_scores[:, -1]
|
||||
boxes = box_scores[:, :-1]
|
||||
picked = []
|
||||
indexes = np.argsort(scores)
|
||||
indexes = indexes[-candidate_size:]
|
||||
while len(indexes) > 0:
|
||||
current = indexes[-1]
|
||||
picked.append(current)
|
||||
if 0 < top_k == len(picked) or len(indexes) == 1:
|
||||
break
|
||||
current_box = boxes[current, :]
|
||||
indexes = indexes[:-1]
|
||||
rest_boxes = boxes[indexes, :]
|
||||
iou = iou_of(
|
||||
rest_boxes,
|
||||
np.expand_dims(
|
||||
current_box, axis=0), )
|
||||
indexes = indexes[iou <= iou_threshold]
|
||||
|
||||
return box_scores[picked, :]
|
||||
|
||||
|
||||
def iou_of(boxes0, boxes1, eps=1e-5):
|
||||
"""Return intersection-over-union (Jaccard index) of boxes.
|
||||
Args:
|
||||
boxes0 (N, 4): ground truth boxes.
|
||||
boxes1 (N or 1, 4): predicted boxes.
|
||||
eps: a small number to avoid 0 as denominator.
|
||||
Returns:
|
||||
iou (N): IoU values.
|
||||
"""
|
||||
overlap_left_top = np.maximum(boxes0[..., :2], boxes1[..., :2])
|
||||
overlap_right_bottom = np.minimum(boxes0[..., 2:], boxes1[..., 2:])
|
||||
|
||||
overlap_area = area_of(overlap_left_top, overlap_right_bottom)
|
||||
area0 = area_of(boxes0[..., :2], boxes0[..., 2:])
|
||||
area1 = area_of(boxes1[..., :2], boxes1[..., 2:])
|
||||
return overlap_area / (area0 + area1 - overlap_area + eps)
|
||||
|
||||
|
||||
def area_of(left_top, right_bottom):
|
||||
"""Compute the areas of rectangles given two corners.
|
||||
Args:
|
||||
left_top (N, 2): left top corner.
|
||||
right_bottom (N, 2): right bottom corner.
|
||||
Returns:
|
||||
area (N): return the area.
|
||||
"""
|
||||
hw = np.clip(right_bottom - left_top, 0.0, None)
|
||||
return hw[..., 0] * hw[..., 1]
|
||||
|
||||
|
||||
class PicoDetPostProcess(object):
|
||||
"""
|
||||
Args:
|
||||
input_shape (int): network input image size
|
||||
ori_shape (int): ori image shape of before padding
|
||||
scale_factor (float): scale factor of ori image
|
||||
enable_mkldnn (bool): whether to open MKLDNN
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
layout_dict_path,
|
||||
strides=[8, 16, 32, 64],
|
||||
score_threshold=0.4,
|
||||
nms_threshold=0.5,
|
||||
nms_top_k=1000,
|
||||
keep_top_k=100):
|
||||
self.labels = self.load_layout_dict(layout_dict_path)
|
||||
self.strides = strides
|
||||
self.score_threshold = score_threshold
|
||||
self.nms_threshold = nms_threshold
|
||||
self.nms_top_k = nms_top_k
|
||||
self.keep_top_k = keep_top_k
|
||||
|
||||
def load_layout_dict(self, layout_dict_path):
|
||||
with open(layout_dict_path, 'r', encoding='utf-8') as fp:
|
||||
labels = fp.readlines()
|
||||
return [label.strip('\n') for label in labels]
|
||||
|
||||
def warp_boxes(self, boxes, ori_shape):
|
||||
"""Apply transform to boxes
|
||||
"""
|
||||
width, height = ori_shape[1], ori_shape[0]
|
||||
n = len(boxes)
|
||||
if n:
|
||||
# warp points
|
||||
xy = np.ones((n * 4, 3))
|
||||
xy[:, :2] = boxes[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
|
||||
n * 4, 2) # x1y1, x2y2, x1y2, x2y1
|
||||
# xy = xy @ M.T # transform
|
||||
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8) # rescale
|
||||
# create new boxes
|
||||
x = xy[:, [0, 2, 4, 6]]
|
||||
y = xy[:, [1, 3, 5, 7]]
|
||||
xy = np.concatenate(
|
||||
(x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
|
||||
# clip boxes
|
||||
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
|
||||
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
|
||||
return xy.astype(np.float32)
|
||||
else:
|
||||
return boxes
|
||||
|
||||
def img_info(self, ori_img, img):
|
||||
origin_shape = ori_img.shape
|
||||
resize_shape = img.shape
|
||||
im_scale_y = resize_shape[2] / float(origin_shape[0])
|
||||
im_scale_x = resize_shape[3] / float(origin_shape[1])
|
||||
scale_factor = np.array([im_scale_y, im_scale_x], dtype=np.float32)
|
||||
img_shape = np.array(img.shape[2:], dtype=np.float32)
|
||||
|
||||
input_shape = np.array(img).astype('float32').shape[2:]
|
||||
ori_shape = np.array((img_shape, )).astype('float32')
|
||||
scale_factor = np.array((scale_factor, )).astype('float32')
|
||||
return ori_shape, input_shape, scale_factor
|
||||
|
||||
def __call__(self, ori_img, img, preds):
|
||||
scores, raw_boxes = preds['boxes'], preds['boxes_num']
|
||||
batch_size = raw_boxes[0].shape[0]
|
||||
reg_max = int(raw_boxes[0].shape[-1] / 4 - 1)
|
||||
out_boxes_num = []
|
||||
out_boxes_list = []
|
||||
results = []
|
||||
ori_shape, input_shape, scale_factor = self.img_info(ori_img, img)
|
||||
|
||||
for batch_id in range(batch_size):
|
||||
# generate centers
|
||||
decode_boxes = []
|
||||
select_scores = []
|
||||
for stride, box_distribute, score in zip(self.strides, raw_boxes,
|
||||
scores):
|
||||
box_distribute = box_distribute[batch_id]
|
||||
score = score[batch_id]
|
||||
# centers
|
||||
fm_h = input_shape[0] / stride
|
||||
fm_w = input_shape[1] / stride
|
||||
h_range = np.arange(fm_h)
|
||||
w_range = np.arange(fm_w)
|
||||
ww, hh = np.meshgrid(w_range, h_range)
|
||||
ct_row = (hh.flatten() + 0.5) * stride
|
||||
ct_col = (ww.flatten() + 0.5) * stride
|
||||
center = np.stack((ct_col, ct_row, ct_col, ct_row), axis=1)
|
||||
|
||||
# box distribution to distance
|
||||
reg_range = np.arange(reg_max + 1)
|
||||
box_distance = box_distribute.reshape((-1, reg_max + 1))
|
||||
box_distance = softmax(box_distance, axis=1)
|
||||
box_distance = box_distance * np.expand_dims(reg_range, axis=0)
|
||||
box_distance = np.sum(box_distance, axis=1).reshape((-1, 4))
|
||||
box_distance = box_distance * stride
|
||||
|
||||
# top K candidate
|
||||
topk_idx = np.argsort(score.max(axis=1))[::-1]
|
||||
topk_idx = topk_idx[:self.nms_top_k]
|
||||
center = center[topk_idx]
|
||||
score = score[topk_idx]
|
||||
box_distance = box_distance[topk_idx]
|
||||
|
||||
# decode box
|
||||
decode_box = center + [-1, -1, 1, 1] * box_distance
|
||||
|
||||
select_scores.append(score)
|
||||
decode_boxes.append(decode_box)
|
||||
|
||||
# nms
|
||||
bboxes = np.concatenate(decode_boxes, axis=0)
|
||||
confidences = np.concatenate(select_scores, axis=0)
|
||||
picked_box_probs = []
|
||||
picked_labels = []
|
||||
for class_index in range(0, confidences.shape[1]):
|
||||
probs = confidences[:, class_index]
|
||||
mask = probs > self.score_threshold
|
||||
probs = probs[mask]
|
||||
if probs.shape[0] == 0:
|
||||
continue
|
||||
subset_boxes = bboxes[mask, :]
|
||||
box_probs = np.concatenate(
|
||||
[subset_boxes, probs.reshape(-1, 1)], axis=1)
|
||||
box_probs = hard_nms(
|
||||
box_probs,
|
||||
iou_threshold=self.nms_threshold,
|
||||
top_k=self.keep_top_k, )
|
||||
picked_box_probs.append(box_probs)
|
||||
picked_labels.extend([class_index] * box_probs.shape[0])
|
||||
|
||||
if len(picked_box_probs) == 0:
|
||||
out_boxes_list.append(np.empty((0, 4)))
|
||||
out_boxes_num.append(0)
|
||||
|
||||
else:
|
||||
picked_box_probs = np.concatenate(picked_box_probs)
|
||||
|
||||
# resize output boxes
|
||||
picked_box_probs[:, :4] = self.warp_boxes(
|
||||
picked_box_probs[:, :4], ori_shape[batch_id])
|
||||
im_scale = np.concatenate([
|
||||
scale_factor[batch_id][::-1], scale_factor[batch_id][::-1]
|
||||
])
|
||||
picked_box_probs[:, :4] /= im_scale
|
||||
# clas score box
|
||||
out_boxes_list.append(
|
||||
np.concatenate(
|
||||
[
|
||||
np.expand_dims(
|
||||
np.array(picked_labels),
|
||||
axis=-1), np.expand_dims(
|
||||
picked_box_probs[:, 4], axis=-1),
|
||||
picked_box_probs[:, :4]
|
||||
],
|
||||
axis=1))
|
||||
out_boxes_num.append(len(picked_labels))
|
||||
|
||||
out_boxes_list = np.concatenate(out_boxes_list, axis=0)
|
||||
out_boxes_num = np.asarray(out_boxes_num).astype(np.int32)
|
||||
|
||||
for dt in out_boxes_list:
|
||||
clsid, bbox, score = int(dt[0]), dt[2:], dt[1]
|
||||
label = self.labels[clsid]
|
||||
result = {'bbox': bbox, 'label': label}
|
||||
results.append(result)
|
||||
return results
|
||||
|
|
@ -668,6 +668,7 @@ class ABINetLabelDecode(NRTRLabelDecode):
|
|||
dict_character = ['</s>'] + dict_character
|
||||
return dict_character
|
||||
|
||||
|
||||
class SPINLabelDecode(AttnLabelDecode):
|
||||
""" Convert between text-label and text-index """
|
||||
|
||||
|
|
@ -681,4 +682,106 @@ class SPINLabelDecode(AttnLabelDecode):
|
|||
self.end_str = "eos"
|
||||
dict_character = dict_character
|
||||
dict_character = [self.beg_str] + [self.end_str] + dict_character
|
||||
return dict_character
|
||||
return dict_character
|
||||
|
||||
|
||||
class VLLabelDecode(BaseRecLabelDecode):
|
||||
""" Convert between text-label and text-index """
|
||||
|
||||
def __init__(self, character_dict_path=None, use_space_char=False,
|
||||
**kwargs):
|
||||
super(VLLabelDecode, self).__init__(character_dict_path, use_space_char)
|
||||
self.max_text_length = kwargs.get('max_text_length', 25)
|
||||
self.nclass = len(self.character) + 1
|
||||
self.character = self.character[10:] + self.character[
|
||||
1:10] + [self.character[0]]
|
||||
|
||||
def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
|
||||
""" convert text-index into text-label. """
|
||||
result_list = []
|
||||
ignored_tokens = self.get_ignored_tokens()
|
||||
batch_size = len(text_index)
|
||||
for batch_idx in range(batch_size):
|
||||
selection = np.ones(len(text_index[batch_idx]), dtype=bool)
|
||||
if is_remove_duplicate:
|
||||
selection[1:] = text_index[batch_idx][1:] != text_index[
|
||||
batch_idx][:-1]
|
||||
for ignored_token in ignored_tokens:
|
||||
selection &= text_index[batch_idx] != ignored_token
|
||||
|
||||
char_list = [
|
||||
self.character[text_id - 1]
|
||||
for text_id in text_index[batch_idx][selection]
|
||||
]
|
||||
if text_prob is not None:
|
||||
conf_list = text_prob[batch_idx][selection]
|
||||
else:
|
||||
conf_list = [1] * len(selection)
|
||||
if len(conf_list) == 0:
|
||||
conf_list = [0]
|
||||
|
||||
text = ''.join(char_list)
|
||||
result_list.append((text, np.mean(conf_list).tolist()))
|
||||
return result_list
|
||||
|
||||
def __call__(self, preds, label=None, length=None, *args, **kwargs):
|
||||
if len(preds) == 2: # eval mode
|
||||
text_pre, x = preds
|
||||
b = text_pre.shape[1]
|
||||
lenText = self.max_text_length
|
||||
nsteps = self.max_text_length
|
||||
|
||||
if not isinstance(text_pre, paddle.Tensor):
|
||||
text_pre = paddle.to_tensor(text_pre, dtype='float32')
|
||||
|
||||
out_res = paddle.zeros(
|
||||
shape=[lenText, b, self.nclass], dtype=x.dtype)
|
||||
out_length = paddle.zeros(shape=[b], dtype=x.dtype)
|
||||
now_step = 0
|
||||
for _ in range(nsteps):
|
||||
if 0 in out_length and now_step < nsteps:
|
||||
tmp_result = text_pre[now_step, :, :]
|
||||
out_res[now_step] = tmp_result
|
||||
tmp_result = tmp_result.topk(1)[1].squeeze(axis=1)
|
||||
for j in range(b):
|
||||
if out_length[j] == 0 and tmp_result[j] == 0:
|
||||
out_length[j] = now_step + 1
|
||||
now_step += 1
|
||||
for j in range(0, b):
|
||||
if int(out_length[j]) == 0:
|
||||
out_length[j] = nsteps
|
||||
start = 0
|
||||
output = paddle.zeros(
|
||||
shape=[int(out_length.sum()), self.nclass], dtype=x.dtype)
|
||||
for i in range(0, b):
|
||||
cur_length = int(out_length[i])
|
||||
output[start:start + cur_length] = out_res[0:cur_length, i, :]
|
||||
start += cur_length
|
||||
net_out = output
|
||||
length = out_length
|
||||
|
||||
else: # train mode
|
||||
net_out = preds[0]
|
||||
length = length
|
||||
net_out = paddle.concat([t[:l] for t, l in zip(net_out, length)])
|
||||
text = []
|
||||
if not isinstance(net_out, paddle.Tensor):
|
||||
net_out = paddle.to_tensor(net_out, dtype='float32')
|
||||
net_out = F.softmax(net_out, axis=1)
|
||||
for i in range(0, length.shape[0]):
|
||||
preds_idx = net_out[int(length[:i].sum()):int(length[:i].sum(
|
||||
) + length[i])].topk(1)[1][:, 0].tolist()
|
||||
preds_text = ''.join([
|
||||
self.character[idx - 1]
|
||||
if idx > 0 and idx <= len(self.character) else ''
|
||||
for idx in preds_idx
|
||||
])
|
||||
preds_prob = net_out[int(length[:i].sum()):int(length[:i].sum(
|
||||
) + length[i])].topk(1)[0][:, 0]
|
||||
preds_prob = paddle.exp(
|
||||
paddle.log(preds_prob).sum() / (preds_prob.shape[0] + 1e-6))
|
||||
text.append((preds_text, preds_prob))
|
||||
if label is None:
|
||||
return text
|
||||
label = self.decode(label)
|
||||
return text, label
|
||||
|
|
|
|||
|
|
@ -49,3 +49,25 @@ class VQAReTokenLayoutLMPostProcess(object):
|
|||
result.append((ocr_info_head, ocr_info_tail))
|
||||
results.append(result)
|
||||
return results
|
||||
|
||||
|
||||
class DistillationRePostProcess(VQAReTokenLayoutLMPostProcess):
|
||||
"""
|
||||
DistillationRePostProcess
|
||||
"""
|
||||
|
||||
def __init__(self, model_name=["Student"], key=None, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
if not isinstance(model_name, list):
|
||||
model_name = [model_name]
|
||||
self.model_name = model_name
|
||||
self.key = key
|
||||
|
||||
def __call__(self, preds, *args, **kwargs):
|
||||
output = dict()
|
||||
for name in self.model_name:
|
||||
pred = preds[name]
|
||||
if self.key is not None:
|
||||
pred = pred[self.key]
|
||||
output[name] = super().__call__(pred, *args, **kwargs)
|
||||
return output
|
||||
|
|
|
|||
|
|
@ -93,3 +93,25 @@ class VQASerTokenLayoutLMPostProcess(object):
|
|||
ocr_info[idx]["pred"] = self.id2label_map_for_show[int(pred_id)]
|
||||
results.append(ocr_info)
|
||||
return results
|
||||
|
||||
|
||||
class DistillationSerPostProcess(VQASerTokenLayoutLMPostProcess):
|
||||
"""
|
||||
DistillationSerPostProcess
|
||||
"""
|
||||
|
||||
def __init__(self, class_path, model_name=["Student"], key=None, **kwargs):
|
||||
super().__init__(class_path, **kwargs)
|
||||
if not isinstance(model_name, list):
|
||||
model_name = [model_name]
|
||||
self.model_name = model_name
|
||||
self.key = key
|
||||
|
||||
def __call__(self, preds, batch=None, *args, **kwargs):
|
||||
output = dict()
|
||||
for name in self.model_name:
|
||||
pred = preds[name]
|
||||
if self.key is not None:
|
||||
pred = pred[self.key]
|
||||
output[name] = super().__call__(pred, batch=batch, *args, **kwargs)
|
||||
return output
|
||||
|
|
|
|||
|
|
@ -53,8 +53,12 @@ def load_model(config, model, optimizer=None, model_type='det'):
|
|||
checkpoints = global_config.get('checkpoints')
|
||||
pretrained_model = global_config.get('pretrained_model')
|
||||
best_model_dict = {}
|
||||
is_float16 = False
|
||||
|
||||
if model_type == 'vqa':
|
||||
# NOTE: for vqa model, resume training is not supported now
|
||||
if config["Architecture"]["algorithm"] in ["Distillation"]:
|
||||
return best_model_dict
|
||||
checkpoints = config['Architecture']['Backbone']['checkpoints']
|
||||
# load vqa method metric
|
||||
if checkpoints:
|
||||
|
|
@ -78,6 +82,7 @@ def load_model(config, model, optimizer=None, model_type='det'):
|
|||
logger.warning(
|
||||
"{}.pdopt is not exists, params of optimizer is not loaded".
|
||||
format(checkpoints))
|
||||
|
||||
return best_model_dict
|
||||
|
||||
if checkpoints:
|
||||
|
|
@ -96,6 +101,9 @@ def load_model(config, model, optimizer=None, model_type='det'):
|
|||
key, params.keys()))
|
||||
continue
|
||||
pre_value = params[key]
|
||||
if pre_value.dtype == paddle.float16:
|
||||
pre_value = pre_value.astype(paddle.float32)
|
||||
is_float16 = True
|
||||
if list(value.shape) == list(pre_value.shape):
|
||||
new_state_dict[key] = pre_value
|
||||
else:
|
||||
|
|
@ -103,7 +111,10 @@ def load_model(config, model, optimizer=None, model_type='det'):
|
|||
"The shape of model params {} {} not matched with loaded params shape {} !".
|
||||
format(key, value.shape, pre_value.shape))
|
||||
model.set_state_dict(new_state_dict)
|
||||
|
||||
if is_float16:
|
||||
logger.info(
|
||||
"The parameter type is float16, which is converted to float32 when loading"
|
||||
)
|
||||
if optimizer is not None:
|
||||
if os.path.exists(checkpoints + '.pdopt'):
|
||||
optim_dict = paddle.load(checkpoints + '.pdopt')
|
||||
|
|
@ -122,9 +133,10 @@ def load_model(config, model, optimizer=None, model_type='det'):
|
|||
best_model_dict['start_epoch'] = states_dict['epoch'] + 1
|
||||
logger.info("resume from {}".format(checkpoints))
|
||||
elif pretrained_model:
|
||||
load_pretrained_params(model, pretrained_model)
|
||||
is_float16 = load_pretrained_params(model, pretrained_model)
|
||||
else:
|
||||
logger.info('train from scratch')
|
||||
best_model_dict['is_float16'] = is_float16
|
||||
return best_model_dict
|
||||
|
||||
|
||||
|
|
@ -138,19 +150,28 @@ def load_pretrained_params(model, path):
|
|||
params = paddle.load(path + '.pdparams')
|
||||
state_dict = model.state_dict()
|
||||
new_state_dict = {}
|
||||
is_float16 = False
|
||||
for k1 in params.keys():
|
||||
if k1 not in state_dict.keys():
|
||||
logger.warning("The pretrained params {} not in model".format(k1))
|
||||
else:
|
||||
if params[k1].dtype == paddle.float16:
|
||||
params[k1] = params[k1].astype(paddle.float32)
|
||||
is_float16 = True
|
||||
if list(state_dict[k1].shape) == list(params[k1].shape):
|
||||
new_state_dict[k1] = params[k1]
|
||||
else:
|
||||
logger.warning(
|
||||
"The shape of model params {} {} not matched with loaded params {} {} !".
|
||||
format(k1, state_dict[k1].shape, k1, params[k1].shape))
|
||||
|
||||
model.set_state_dict(new_state_dict)
|
||||
if is_float16:
|
||||
logger.info(
|
||||
"The parameter type is float16, which is converted to float32 when loading"
|
||||
)
|
||||
logger.info("load pretrain successful from {}".format(path))
|
||||
return model
|
||||
return is_float16
|
||||
|
||||
|
||||
def save_model(model,
|
||||
|
|
@ -166,15 +187,19 @@ def save_model(model,
|
|||
"""
|
||||
_mkdir_if_not_exist(model_path, logger)
|
||||
model_prefix = os.path.join(model_path, prefix)
|
||||
paddle.save(optimizer.state_dict(), model_prefix + '.pdopt')
|
||||
if config['Architecture']["model_type"] != 'vqa':
|
||||
paddle.save(optimizer.state_dict(), model_prefix + '.pdopt')
|
||||
if config['Architecture']["model_type"] != 'vqa':
|
||||
paddle.save(model.state_dict(), model_prefix + '.pdparams')
|
||||
metric_prefix = model_prefix
|
||||
else:
|
||||
else: # for vqa system, we follow the save/load rules in NLP
|
||||
if config['Global']['distributed']:
|
||||
model._layers.backbone.model.save_pretrained(model_prefix)
|
||||
arch = model._layers
|
||||
else:
|
||||
model.backbone.model.save_pretrained(model_prefix)
|
||||
arch = model
|
||||
if config["Architecture"]["algorithm"] in ["Distillation"]:
|
||||
arch = arch.Student
|
||||
arch.backbone.model.save_pretrained(model_prefix)
|
||||
metric_prefix = os.path.join(model_prefix, 'metric')
|
||||
# save metric and config
|
||||
with open(metric_prefix + '.states', 'wb') as f:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,130 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import os
|
||||
import sys
|
||||
|
||||
__dir__ = os.path.dirname(os.path.abspath(__file__))
|
||||
sys.path.append(__dir__)
|
||||
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '../..')))
|
||||
|
||||
os.environ["FLAGS_allocator_strategy"] = 'auto_growth'
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
import time
|
||||
|
||||
import tools.infer.utility as utility
|
||||
from ppocr.data import create_operators, transform
|
||||
from ppocr.postprocess import build_post_process
|
||||
from ppocr.utils.logging import get_logger
|
||||
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
|
||||
from ppstructure.utility import parse_args
|
||||
from picodet_postprocess import PicoDetPostProcess
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
class LayoutPredictor(object):
|
||||
def __init__(self, args):
|
||||
pre_process_list = [{
|
||||
'Resize': {
|
||||
'size': [800, 608]
|
||||
}
|
||||
}, {
|
||||
'NormalizeImage': {
|
||||
'std': [0.229, 0.224, 0.225],
|
||||
'mean': [0.485, 0.456, 0.406],
|
||||
'scale': '1./255.',
|
||||
'order': 'hwc'
|
||||
}
|
||||
}, {
|
||||
'ToCHWImage': None
|
||||
}, {
|
||||
'KeepKeys': {
|
||||
'keep_keys': ['image']
|
||||
}
|
||||
}]
|
||||
postprocess_params = {
|
||||
'name': 'PicoDetPostProcess',
|
||||
"layout_dict_path": args.layout_dict_path,
|
||||
"score_threshold": args.layout_score_threshold,
|
||||
"nms_threshold": args.layout_nms_threshold,
|
||||
}
|
||||
|
||||
self.preprocess_op = create_operators(pre_process_list)
|
||||
self.postprocess_op = build_post_process(postprocess_params)
|
||||
self.predictor, self.input_tensor, self.output_tensors, self.config = \
|
||||
utility.create_predictor(args, 'layout', logger)
|
||||
|
||||
def __call__(self, img):
|
||||
ori_im = img.copy()
|
||||
data = {'image': img}
|
||||
data = transform(data, self.preprocess_op)
|
||||
img = data[0]
|
||||
|
||||
if img is None:
|
||||
return None, 0
|
||||
|
||||
img = np.expand_dims(img, axis=0)
|
||||
img = img.copy()
|
||||
|
||||
preds, elapse = 0, 1
|
||||
starttime = time.time()
|
||||
|
||||
self.input_tensor.copy_from_cpu(img)
|
||||
self.predictor.run()
|
||||
|
||||
np_score_list, np_boxes_list = [], []
|
||||
output_names = self.predictor.get_output_names()
|
||||
num_outs = int(len(output_names) / 2)
|
||||
for out_idx in range(num_outs):
|
||||
np_score_list.append(
|
||||
self.predictor.get_output_handle(output_names[out_idx])
|
||||
.copy_to_cpu())
|
||||
np_boxes_list.append(
|
||||
self.predictor.get_output_handle(output_names[
|
||||
out_idx + num_outs]).copy_to_cpu())
|
||||
preds = dict(boxes=np_score_list, boxes_num=np_boxes_list)
|
||||
|
||||
post_preds = self.postprocess_op(ori_im, img, preds)
|
||||
elapse = time.time() - starttime
|
||||
return post_preds, elapse
|
||||
|
||||
|
||||
def main(args):
|
||||
image_file_list = get_image_file_list(args.image_dir)
|
||||
layout_predictor = LayoutPredictor(args)
|
||||
count = 0
|
||||
total_time = 0
|
||||
|
||||
repeats = 50
|
||||
for image_file in image_file_list:
|
||||
img, flag = check_and_read_gif(image_file)
|
||||
if not flag:
|
||||
img = cv2.imread(image_file)
|
||||
if img is None:
|
||||
logger.info("error in loading image:{}".format(image_file))
|
||||
continue
|
||||
|
||||
layout_res, elapse = layout_predictor(img)
|
||||
|
||||
logger.info("result: {}".format(layout_res))
|
||||
|
||||
if count > 0:
|
||||
total_time += elapse
|
||||
count += 1
|
||||
logger.info("Predict time of {}: {}".format(image_file, elapse))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main(parse_args())
|
||||
|
|
@ -32,15 +32,18 @@ def init_args():
|
|||
type=str,
|
||||
default="../ppocr/utils/dict/table_structure_dict.txt")
|
||||
# params for layout
|
||||
parser.add_argument("--layout_model_dir", type=str)
|
||||
parser.add_argument(
|
||||
"--layout_path_model",
|
||||
"--layout_dict_path",
|
||||
type=str,
|
||||
default="lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config")
|
||||
default="../ppocr/utils/dict/layout_pubalynet_dict.txt")
|
||||
parser.add_argument(
|
||||
"--layout_label_map",
|
||||
type=ast.literal_eval,
|
||||
default=None,
|
||||
help='label map according to ppstructure/layout/README_ch.md')
|
||||
"--layout_score_threshold",
|
||||
type=float,
|
||||
default=0.5,
|
||||
help="Threshold of score.")
|
||||
parser.add_argument(
|
||||
"--layout_nms_threshold", type=float, default=0.5, help="Threshold of nms.")
|
||||
# params for vqa
|
||||
parser.add_argument("--vqa_algorithm", type=str, default='LayoutXLM')
|
||||
parser.add_argument("--ser_model_dir", type=str)
|
||||
|
|
@ -87,7 +90,7 @@ def draw_structure_result(image, result, font_path):
|
|||
image = Image.fromarray(image)
|
||||
boxes, txts, scores = [], [], []
|
||||
for region in result:
|
||||
if region['type'] == 'Table':
|
||||
if region['type'] == 'table':
|
||||
pass
|
||||
else:
|
||||
for text_result in region['res']:
|
||||
|
|
|
|||
|
|
@ -216,7 +216,7 @@ Use the following command to complete the tandem prediction of `OCR + SER` based
|
|||
|
||||
```shell
|
||||
cd ppstructure
|
||||
CUDA_VISIBLE_DEVICES=0 python3.7 vqa/predict_vqa_token_ser.py --vqa_algorithm=LayoutXLM --ser_model_dir=../output/ser/infer --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --image_dir=docs/vqa/input/zh_val_42.jpg --output=output
|
||||
CUDA_VISIBLE_DEVICES=0 python3.7 vqa/predict_vqa_token_ser.py --vqa_algorithm=LayoutXLM --ser_model_dir=../output/ser/infer --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --image_dir=docs/vqa/input/zh_val_42.jpg --output=output
|
||||
```
|
||||
After the prediction is successful, the visualization images and results will be saved in the directory specified by the `output` field
|
||||
|
||||
|
|
|
|||
|
|
@ -215,7 +215,7 @@ python3.7 tools/export_model.py -c configs/vqa/ser/layoutxlm.yml -o Architecture
|
|||
|
||||
```shell
|
||||
cd ppstructure
|
||||
CUDA_VISIBLE_DEVICES=0 python3.7 vqa/predict_vqa_token_ser.py --vqa_algorithm=LayoutXLM --ser_model_dir=../output/ser/infer --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --image_dir=docs/vqa/input/zh_val_42.jpg --output=output
|
||||
CUDA_VISIBLE_DEVICES=0 python3.7 vqa/predict_vqa_token_ser.py --vqa_algorithm=LayoutXLM --ser_model_dir=../output/ser/infer --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --image_dir=docs/vqa/input/zh_val_42.jpg --output=output
|
||||
```
|
||||
预测成功后,可视化图片和结果会保存在`output`字段指定的目录下
|
||||
|
||||
|
|
|
|||
|
|
@ -153,7 +153,7 @@ def main(args):
|
|||
img_res = draw_ser_results(
|
||||
image_file,
|
||||
ser_res,
|
||||
font_path="../doc/fonts/simfang.ttf", )
|
||||
font_path=args.vis_font_path, )
|
||||
|
||||
img_save_path = os.path.join(args.output,
|
||||
os.path.basename(image_file))
|
||||
|
|
|
|||
|
|
@ -114,7 +114,7 @@ Train:
|
|||
name: SimpleDataSet
|
||||
data_dir: ./train_data/ic15_data/
|
||||
label_file_list:
|
||||
- ./train_data/ic15_data/rec_gt_train4w.txt
|
||||
- ./train_data/ic15_data/rec_gt_train.txt
|
||||
transforms:
|
||||
- DecodeImage:
|
||||
img_mode: BGR
|
||||
|
|
|
|||
|
|
@ -153,7 +153,7 @@ Train:
|
|||
data_dir: ./train_data/ic15_data/
|
||||
ext_op_transform_idx: 1
|
||||
label_file_list:
|
||||
- ./train_data/ic15_data/rec_gt_train4w.txt
|
||||
- ./train_data/ic15_data/rec_gt_train.txt
|
||||
transforms:
|
||||
- DecodeImage:
|
||||
img_mode: BGR
|
||||
|
|
|
|||
|
|
@ -52,8 +52,9 @@ null:null
|
|||
===========================infer_benchmark_params==========================
|
||||
random_infer_input:[{float32,[3,48,320]}]
|
||||
===========================train_benchmark_params==========================
|
||||
batch_size:128
|
||||
batch_size:64
|
||||
fp_items:fp32|fp16
|
||||
epoch:1
|
||||
--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
|
||||
flags:FLAGS_eager_delete_tensor_gb=0.0;FLAGS_fraction_of_gpu_memory_to_use=0.98;FLAGS_conv_workspace_size_limit=4096
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
===========================cpp_infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0
|
||||
model_name:ch_ppocr_mobile_v2_0
|
||||
use_opencv:True
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
infer_quant:False
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================ch_ppocr_mobile_v2.0===========================
|
||||
model_name:ch_ppocr_mobile_v2.0
|
||||
model_name:ch_ppocr_mobile_v2_0
|
||||
python:python3.7
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
infer_export:null
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================paddle2onnx_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0
|
||||
model_name:ch_ppocr_mobile_v2_0
|
||||
python:python3.7
|
||||
2onnx: paddle2onnx
|
||||
--det_model_dir:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0
|
||||
model_name:ch_ppocr_mobile_v2_0
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0
|
||||
model_name:ch_ppocr_mobile_v2_0
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================cpp_infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
use_opencv:True
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
infer_quant:False
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_infer
|
||||
infer_export:null
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================paddle2onnx_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python3.7
|
||||
2onnx: paddle2onnx
|
||||
--det_model_dir:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python3.7
|
||||
gpu_list:192.168.0.1,192.168.0.2;0,1
|
||||
Global.use_gpu:True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det
|
||||
model_name:ch_ppocr_mobile_v2_0_det
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_PACT
|
||||
model_name:ch_ppocr_mobile_v2_0_det_PACT
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================kl_quant_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_KL
|
||||
model_name:ch_ppocr_mobile_v2_0_det_KL
|
||||
python:python3.7
|
||||
Global.pretrained_model:null
|
||||
Global.save_inference_dir:null
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_FPGM
|
||||
model_name:ch_ppocr_mobile_v2_0_det_FPGM
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_FPGM
|
||||
model_name:ch_ppocr_mobile_v2_0_det_FPGM
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================cpp_infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_KL
|
||||
model_name:ch_ppocr_mobile_v2_0_det_KL
|
||||
use_opencv:True
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_klquant_infer
|
||||
infer_quant:False
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec_KL
|
||||
model_name:ch_ppocr_mobile_v2_0_det_KL
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_klquant_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_KL
|
||||
model_name:ch_ppocr_mobile_v2_0_det_KL
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_klquant_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================cpp_infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_PACT
|
||||
model_name:ch_ppocr_mobile_v2_0_det_PACT
|
||||
use_opencv:True
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_det_pact_infer
|
||||
infer_quant:False
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec_PACT
|
||||
model_name:ch_ppocr_mobile_v2_0_det_PACT
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_pact_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_det_PACT
|
||||
model_name:ch_ppocr_mobile_v2_0_det_PACT
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:./inference/ch_ppocr_mobile_v2.0_det_pact_infer/
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================cpp_infer_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
use_opencv:True
|
||||
infer_model:./inference/ch_ppocr_mobile_v2.0_rec_infer/
|
||||
infer_quant:False
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================paddle2onnx_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
python:python3.7
|
||||
2onnx: paddle2onnx
|
||||
--det_model_dir:
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================serving_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
python:python3.7
|
||||
trans_model:-m paddle_serving_client.convert
|
||||
--det_dirname:null
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
python:python3.7
|
||||
gpu_list:192.168.0.1,192.168.0.2;0,1
|
||||
Global.use_gpu:True
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
===========================train_params===========================
|
||||
model_name:ch_ppocr_mobile_v2.0_rec
|
||||
model_name:ch_ppocr_mobile_v2_0_rec
|
||||
python:python3.7
|
||||
gpu_list:0|0,1
|
||||
Global.use_gpu:True|True
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue