parent
4c6b03ad40
commit
ac79dadac9
|
|
@ -0,0 +1,652 @@
|
|||
# 基于PP-OCRv3的PCB字符识别
|
||||
|
||||
- [1. 项目介绍](#1-项目介绍)
|
||||
- [2. 安装说明](#2-安装说明)
|
||||
- [3. 数据准备](#3-数据准备)
|
||||
- [4. 文本检测](#4-文本检测)
|
||||
- [4.1 预训练模型直接评估](#41-预训练模型直接评估)
|
||||
- [4.2 预训练模型+验证集padding直接评估](#42-预训练模型验证集padding直接评估)
|
||||
- [4.3 预训练模型+fine-tune](#43-预训练模型fine-tune)
|
||||
- [5. 文本识别](#5-文本识别)
|
||||
- [5.1 预训练模型直接评估](#51-预训练模型直接评估)
|
||||
- [5.2 三种fine-tune方案](#52-三种fine-tune方案)
|
||||
- [6. 模型导出](#6-模型导出)
|
||||
- [7. 端对端评测](#7-端对端评测)
|
||||
- [8. Jetson部署](#8-Jetson部署)
|
||||
- [9. 总结](#9-总结)
|
||||
- [更多资源](#更多资源)
|
||||
|
||||
# 1. 项目介绍
|
||||
|
||||
印刷电路板(PCB)是电子产品中的核心器件,对于板件质量的测试与监控是生产中必不可少的环节。在一些场景中,通过PCB中信号灯颜色和文字组合可以定位PCB局部模块质量问题,PCB文字识别中存在如下难点:
|
||||
|
||||
- 裁剪出的PCB图片宽高比例较小
|
||||
- 文字区域整体面积也较小
|
||||
- 包含垂直、水平多种方向文本
|
||||
|
||||
针对本场景,PaddleOCR基于全新的PP-OCRv3通过合成数据、微调以及其他场景适配方法完成小字符文本识别任务,满足企业上线要求。PCB检测、识别效果如 **图1** 所示:
|
||||
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/95d8e95bf1ab476987f2519c0f8f0c60a0cdc2c444804ed6ab08f2f7ab054880', width='500'></div>
|
||||
<div align=center>图1 PCB检测识别效果</div>
|
||||
|
||||
注:欢迎在AIStudio领取免费算力体验线上实训,项目链接: [基于PP-OCRv3实现PCB字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4008973)
|
||||
|
||||
# 2. 安装说明
|
||||
|
||||
|
||||
下载PaddleOCR源码,安装依赖环境。
|
||||
|
||||
|
||||
```python
|
||||
# 如仍需安装or安装更新,可以执行以下步骤
|
||||
git clone https://github.com/PaddlePaddle/PaddleOCR.git
|
||||
# git clone https://gitee.com/PaddlePaddle/PaddleOCR
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 安装依赖包
|
||||
pip install -r /home/aistudio/PaddleOCR/requirements.txt
|
||||
```
|
||||
|
||||
# 3. 数据准备
|
||||
|
||||
我们通过图片合成工具生成 **图2** 所示的PCB图片,整图只有高25、宽150左右、文字区域高9、宽45左右,包含垂直和水平2种方向的文本:
|
||||
|
||||
<div align=center><img src="https://ai-studio-static-online.cdn.bcebos.com/bb7a345687814a3d83a29790f2a2b7d081495b3a920b43988c93da6039cad653" width="1000" ></div>
|
||||
<div align=center>图2 数据集示例</div>
|
||||
|
||||
暂时不开源生成的PCB数据集,但是通过更换背景,通过如下代码生成数据即可:
|
||||
|
||||
```
|
||||
cd gen_data
|
||||
python3 gen.py --num_img=10
|
||||
```
|
||||
|
||||
生成图片参数解释:
|
||||
|
||||
```
|
||||
num_img:生成图片数量
|
||||
font_min_size、font_max_size:字体最大、最小尺寸
|
||||
bg_path:文字区域背景存放路径
|
||||
det_bg_path:整图背景存放路径
|
||||
fonts_path:字体路径
|
||||
corpus_path:语料路径
|
||||
output_dir:生成图片存储路径
|
||||
```
|
||||
|
||||
这里生成 **100张** 相同尺寸和文本的图片,如 **图3** 所示,方便大家跑通实验。通过如下代码解压数据集:
|
||||
|
||||
<div align=center><img src="https://ai-studio-static-online.cdn.bcebos.com/3277b750159f4b68b2b58506bfec9005d49aeb5fb1d9411e83f96f9ff7eb66a5" width="1000" ></div>
|
||||
<div align=center>图3 案例提供数据集示例</div>
|
||||
|
||||
|
||||
```python
|
||||
tar xf ./data/data148165/dataset.tar -C ./
|
||||
```
|
||||
|
||||
在生成数据集的时需要生成检测和识别训练需求的格式:
|
||||
|
||||
|
||||
- **文本检测**
|
||||
|
||||
标注文件格式如下,中间用'\t'分隔:
|
||||
|
||||
```
|
||||
" 图像文件名 json.dumps编码的图像标注信息"
|
||||
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
|
||||
```
|
||||
|
||||
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
|
||||
|
||||
- **文本识别**
|
||||
|
||||
标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
|
||||
|
||||
```
|
||||
" 图像文件名 图像标注信息 "
|
||||
|
||||
train_data/rec/train/word_001.jpg 简单可依赖
|
||||
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
# 4. 文本检测
|
||||
|
||||
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)中的PP-OCRv3模型进行文本检测和识别。针对检测模型和识别模型,进行了共计9个方面的升级:
|
||||
|
||||
- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
|
||||
|
||||
- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
|
||||
|
||||
更多细节请参考PP-OCRv3[技术报告](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)。
|
||||
|
||||
|
||||
我们使用 **3种方案** 进行检测模型的训练、评估:
|
||||
- **PP-OCRv3英文超轻量检测预训练模型直接评估**
|
||||
- PP-OCRv3英文超轻量检测预训练模型 + **验证集padding**直接评估
|
||||
- PP-OCRv3英文超轻量检测预训练模型 + **fine-tune**
|
||||
|
||||
## **4.1 预训练模型直接评估**
|
||||
|
||||
我们首先通过PaddleOCR提供的预训练模型在验证集上进行评估,如果评估指标能满足效果,可以直接使用预训练模型,不再需要训练。
|
||||
|
||||
使用预训练模型直接评估步骤如下:
|
||||
|
||||
**1)下载预训练模型**
|
||||
|
||||
|
||||
PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
|
||||
|
||||
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|
||||
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
|
||||
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
|
||||
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
|
||||
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
|
||||
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
|
||||
|
||||
更多模型下载(包括多语言),可以参[考PP-OCR系列模型下载](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md)
|
||||
|
||||
这里我们使用PP-OCRv3英文超轻量检测模型,下载并解压预训练模型:
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
# 如果更换其他模型,更新下载链接和解压指令就可以
|
||||
cd /home/aistudio/PaddleOCR
|
||||
mkdir pretrain_models
|
||||
cd pretrain_models
|
||||
# 下载英文预训练模型
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar
|
||||
tar xf en_PP-OCRv3_det_distill_train.tar && rm -rf en_PP-OCRv3_det_distill_train.tar
|
||||
%cd ..
|
||||
```
|
||||
|
||||
**模型评估**
|
||||
|
||||
|
||||
首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
|
||||
```
|
||||
Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
|
||||
Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
|
||||
Eval.dataset.transforms.DetResizeForTest: 尺寸
|
||||
limit_side_len: 48
|
||||
limit_type: 'min'
|
||||
```
|
||||
|
||||
然后在验证集上进行评估,具体代码如下:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR
|
||||
python tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
|
||||
-o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
|
||||
```
|
||||
|
||||
## **4.2 预训练模型+验证集padding直接评估**
|
||||
|
||||
考虑到PCB图片比较小,宽度只有25左右、高度只有140-170左右,我们在原图的基础上进行padding,再进行检测评估,padding前后效果对比如 **图4** 所示:
|
||||
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/e61e6ba685534eda992cea30a63a9c461646040ffd0c4d208a5eebb85897dcf7' width='600'></div>
|
||||
<div align=center>图4 padding前后对比图</div>
|
||||
|
||||
将图片都padding到300*300大小,因为坐标信息发生了变化,我们同时要修改标注文件,在`/home/aistudio/dataset`目录里也提供了padding之后的图片,大家也可以尝试训练和评估:
|
||||
|
||||
同上,我们需要修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
|
||||
```
|
||||
Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
|
||||
Eval.dataset.label_file_list:指向验证集标注文件,/home/aistudio/dataset/det_gt_padding_val.txt
|
||||
Eval.dataset.transforms.DetResizeForTest: 尺寸
|
||||
limit_side_len: 1100
|
||||
limit_type: 'min'
|
||||
```
|
||||
|
||||
如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
<div align="left">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
将下载或训练完成的模型放置在对应目录下即可完成模型评估。
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR
|
||||
python tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
|
||||
-o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
|
||||
```
|
||||
|
||||
## **4.3 预训练模型+fine-tune**
|
||||
|
||||
|
||||
基于预训练模型,在生成的1500图片上进行fine-tune训练和评估,其中train数据1200张,val数据300张,修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml`中的以下字段:
|
||||
```
|
||||
Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
|
||||
Global.save_model_dir:模型保存路径
|
||||
Global.pretrained_model:指向预训练模型路径,'./pretrain_models/en_PP-OCRv3_det_distill_train/student.pdparams'
|
||||
Optimizer.lr.learning_rate:调整学习率,本实验设置为0.0005
|
||||
Train.dataset.data_dir:指向训练集图片存放目录,'/home/aistudio/dataset'
|
||||
Train.dataset.label_file_list:指向训练集标注文件,'/home/aistudio/dataset/det_gt_train.txt'
|
||||
Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[480,64]
|
||||
Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset/'
|
||||
Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
|
||||
Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
|
||||
limit_side_len: 64
|
||||
limit_type:'min'
|
||||
```
|
||||
执行下面命令启动训练:
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python tools/train.py \
|
||||
-c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
|
||||
```
|
||||
|
||||
**模型评估**
|
||||
|
||||
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
|
||||
-o Global.checkpoints="./output/ch_PP-OCR_V3_det/latest"
|
||||
```
|
||||
|
||||
使用训练好的模型进行评估,指标如下所示:
|
||||
|
||||
|
||||
| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
|
||||
| -------- | -------- | -------- | -------- | -------- |
|
||||
| 1 | PP-OCRv3英文超轻量检测预训练模型 | 64.64% | - | 提供的预训练模型具有泛化能力 |
|
||||
| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding | 72.13% |+7.5% | padding可以提升尺寸较小图片的检测效果|
|
||||
| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
|
||||
|
||||
|
||||
```
|
||||
注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
|
||||
```
|
||||
|
||||
# 5. 文本识别
|
||||
|
||||
我们分别使用如下4种方案进行训练、评估:
|
||||
|
||||
- **方案1**:**PP-OCRv3中英文超轻量识别预训练模型直接评估**
|
||||
- **方案2**:PP-OCRv3中英文超轻量检测预训练模型 + **fine-tune**
|
||||
- **方案3**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **公开通用识别数据集**
|
||||
- **方案4**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **增加PCB图像数量**
|
||||
|
||||
|
||||
## **5.1 预训练模型直接评估**
|
||||
|
||||
同检测模型,我们首先使用PaddleOCR提供的识别预训练模型在PCB验证集上进行评估。
|
||||
|
||||
使用预训练模型直接评估步骤如下:
|
||||
|
||||
**1)下载预训练模型**
|
||||
|
||||
|
||||
我们使用PP-OCRv3中英文超轻量文本识别模型,下载并解压预训练模型:
|
||||
|
||||
|
||||
```python
|
||||
# 如果更换其他模型,更新下载链接和解压指令就可以
|
||||
cd /home/aistudio/PaddleOCR/pretrain_models/
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
|
||||
tar xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
|
||||
cd ..
|
||||
```
|
||||
|
||||
**模型评估**
|
||||
|
||||
|
||||
首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
|
||||
|
||||
```
|
||||
Metric.ignore_space: True:忽略空格
|
||||
Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
|
||||
Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/rec_gt_val.txt'
|
||||
```
|
||||
|
||||
我们使用下载的预训练模型进行评估:
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR
|
||||
python3 tools/eval.py \
|
||||
-c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
|
||||
-o Global.checkpoints=pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
|
||||
|
||||
```
|
||||
|
||||
## **5.2 三种fine-tune方案**
|
||||
|
||||
方案2、3、4训练和评估方式是相同的,因此在我们了解每个技术方案之后,再具体看修改哪些参数是相同,哪些是不同的。
|
||||
|
||||
**方案介绍:**
|
||||
|
||||
1) **方案2**:预训练模型 + **fine-tune**
|
||||
|
||||
- 在预训练模型的基础上进行fine-tune,使用1500张PCB进行训练和评估,其中训练集1200张,验证集300张。
|
||||
|
||||
|
||||
2) **方案3**:预训练模型 + fine-tune + **公开通用识别数据集**
|
||||
|
||||
- 当识别数据比较少的情况,可以考虑添加公开通用识别数据集。在方案2的基础上,添加公开通用识别数据集,如lsvt、rctw等。
|
||||
|
||||
3)**方案4**:预训练模型 + fine-tune + **增加PCB图像数量**
|
||||
|
||||
- 如果能够获取足够多真实场景,我们可以通过增加数据量提升模型效果。在方案2的基础上,增加PCB的数量到2W张左右。
|
||||
|
||||
|
||||
**参数修改:**
|
||||
|
||||
接着我们看需要修改的参数,以上方案均需要修改配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml`的参数,**修改一次即可**:
|
||||
|
||||
```
|
||||
Global.pretrained_model:指向预训练模型路径,'pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy'
|
||||
Optimizer.lr.values:学习率,本实验设置为0.0005
|
||||
Train.loader.batch_size_per_card: batch size,默认128,因为数据量小于128,因此我们设置为8,数据量大可以按默认的训练
|
||||
Eval.loader.batch_size_per_card: batch size,默认128,设置为4
|
||||
Metric.ignore_space: 忽略空格,本实验设置为True
|
||||
```
|
||||
|
||||
**更换不同的方案**每次需要修改的参数:
|
||||
```
|
||||
Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
|
||||
Global.save_model_dir:指向模型保存路径
|
||||
Train.dataset.data_dir:指向训练集图片存放目录
|
||||
Train.dataset.label_file_list:指向训练集标注文件
|
||||
Eval.dataset.data_dir:指向验证集图片存放目录
|
||||
Eval.dataset.label_file_list:指向验证集标注文件
|
||||
```
|
||||
|
||||
同时**方案3**修改以下参数
|
||||
```
|
||||
Eval.dataset.label_file_list:添加公开通用识别数据标注文件
|
||||
Eval.dataset.ratio_list:数据和公开通用识别数据每次采样比例,按实际修改即可
|
||||
```
|
||||
如 **图5** 所示:
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/0fa18b25819042d9bbf3397c3af0e21433b23d52f7a84b0a8681b8e6a308d433' wdith=''></div>
|
||||
<div align=center>图5 添加公开通用识别数据配置文件示例</div>
|
||||
|
||||
|
||||
我们提取Student模型的参数,在PCB数据集上进行fine-tune,可以参考如下代码:
|
||||
|
||||
|
||||
```python
|
||||
import paddle
|
||||
# 加载预训练模型
|
||||
all_params = paddle.load("./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
|
||||
# 查看权重参数的keys
|
||||
print(all_params.keys())
|
||||
# 学生模型的权重提取
|
||||
s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
|
||||
# 查看学生模型权重参数的keys
|
||||
print(s_params.keys())
|
||||
# 保存
|
||||
paddle.save(s_params, "./pretrain_models/ch_PP-OCRv3_rec_train/student.pdparams")
|
||||
```
|
||||
|
||||
修改参数后,**每个方案**都执行如下命令启动训练:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
|
||||
```
|
||||
|
||||
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/eval.py \
|
||||
-c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
|
||||
-o Global.checkpoints=./output/rec_ppocr_v3/latest
|
||||
```
|
||||
|
||||
所有方案评估指标如下:
|
||||
|
||||
| 序号 | 方案 | acc | 效果提升 | 实验分析 |
|
||||
| -------- | -------- | -------- | -------- | -------- |
|
||||
| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
|
||||
| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% |-4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试)|
|
||||
| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
|
||||
| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
|
||||
|
||||
```
|
||||
注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)、2W张图片、添加公开通用识别数据集上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
|
||||
```
|
||||
|
||||
# 6. 模型导出
|
||||
|
||||
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
|
||||
|
||||
|
||||
```python
|
||||
# 导出检测模型
|
||||
python3 tools/export_model.py \
|
||||
-c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
|
||||
-o Global.pretrained_model="./output/ch_PP-OCR_V3_det/latest" \
|
||||
Global.save_inference_dir="./inference_model/ch_PP-OCR_V3_det/"
|
||||
```
|
||||
|
||||
因为上述模型只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/best_models/
|
||||
wget https://paddleocr.bj.bcebos.com/fanliku/PCB/det_ppocr_v3_en_infer_PCB.tar
|
||||
tar xf /home/aistudio/best_models/det_ppocr_v3_en_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 检测模型inference模型预测
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/infer/predict_det.py \
|
||||
--image_dir="/home/aistudio/dataset/imgs/0000.jpg" \
|
||||
--det_algorithm="DB" \
|
||||
--det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB/" \
|
||||
--det_limit_side_len=48 \
|
||||
--det_limit_type='min' \
|
||||
--det_db_unclip_ratio=2.5 \
|
||||
--use_gpu=True
|
||||
```
|
||||
|
||||
结果存储在`inference_results`目录下,检测如下图所示:
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/5939ae15a1f0445aaeec15c68107dbd897740a1ddd284bf8b583bb6242099157' width=''></div>
|
||||
<div align=center>图6 检测结果</div>
|
||||
|
||||
|
||||
同理,导出识别模型并进行推理。
|
||||
|
||||
```python
|
||||
# 导出识别模型
|
||||
python3 tools/export_model.py \
|
||||
-c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
|
||||
-o Global.pretrained_model="./output/rec_ppocr_v3/latest" \
|
||||
Global.save_inference_dir="./inference_model/rec_ppocr_v3/"
|
||||
|
||||
```
|
||||
|
||||
同检测模型,识别模型也只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
|
||||
|
||||
|
||||
```python
|
||||
cd /home/aistudio/best_models/
|
||||
wget https://paddleocr.bj.bcebos.com/fanliku/PCB/rec_ppocr_v3_ch_infer_PCB.tar
|
||||
tar xf /home/aistudio/best_models/rec_ppocr_v3_ch_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 识别模型inference模型预测
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/infer/predict_rec.py \
|
||||
--image_dir="../test_imgs/0000_rec.jpg" \
|
||||
--rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
|
||||
--rec_image_shape="3, 48, 320" \
|
||||
--use_space_char=False \
|
||||
--use_gpu=True
|
||||
```
|
||||
|
||||
```python
|
||||
# 检测+识别模型inference模型预测
|
||||
cd /home/aistudio/PaddleOCR/
|
||||
python3 tools/infer/predict_system.py \
|
||||
--image_dir="../test_imgs/0000.jpg" \
|
||||
--det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
|
||||
--det_limit_side_len=48 \
|
||||
--det_limit_type='min' \
|
||||
--det_db_unclip_ratio=2.5 \
|
||||
--rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
|
||||
--rec_image_shape="3, 48, 320" \
|
||||
--draw_img_save_dir=./det_rec_infer/ \
|
||||
--use_space_char=False \
|
||||
--use_angle_cls=False \
|
||||
--use_gpu=True
|
||||
|
||||
```
|
||||
|
||||
端到端预测结果存储在`det_res_infer`文件夹内,结果如下图所示:
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/c570f343c29846c792da56ebaca16c50708477514dd048cea8bef37ffa85d03f'></div>
|
||||
<div align=center>图7 检测+识别结果</div>
|
||||
|
||||
# 7. 端对端评测
|
||||
|
||||
接下来介绍文本检测+文本识别的端对端指标评估方式。主要分为三步:
|
||||
|
||||
1)首先运行`tools/infer/predict_system.py`,将`image_dir`改为需要评估的数据文件家,得到保存的结果:
|
||||
|
||||
|
||||
```python
|
||||
# 检测+识别模型inference模型预测
|
||||
python3 tools/infer/predict_system.py \
|
||||
--image_dir="../dataset/imgs/" \
|
||||
--det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
|
||||
--det_limit_side_len=48 \
|
||||
--det_limit_type='min' \
|
||||
--det_db_unclip_ratio=2.5 \
|
||||
--rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
|
||||
--rec_image_shape="3, 48, 320" \
|
||||
--draw_img_save_dir=./det_rec_infer/ \
|
||||
--use_space_char=False \
|
||||
--use_angle_cls=False \
|
||||
--use_gpu=True
|
||||
```
|
||||
|
||||
得到保存结果,文本检测识别可视化图保存在`det_rec_infer/`目录下,预测结果保存在`det_rec_infer/system_results.txt`中,格式如下:`0018.jpg [{"transcription": "E295", "points": [[88, 33], [137, 33], [137, 40], [88, 40]]}]`
|
||||
|
||||
2)然后将步骤一保存的数据转换为端对端评测需要的数据格式: 修改 `tools/end2end/convert_ppocr_label.py`中的代码,convert_label函数中设置输入标签路径,Mode,保存标签路径等,对预测数据的GTlabel和预测结果的label格式进行转换。
|
||||
```
|
||||
ppocr_label_gt = "/home/aistudio/dataset/det_gt_val.txt"
|
||||
convert_label(ppocr_label_gt, "gt", "./save_gt_label/")
|
||||
|
||||
ppocr_label_gt = "/home/aistudio/PaddleOCR/PCB_result/det_rec_infer/system_results.txt"
|
||||
convert_label(ppocr_label_gt, "pred", "./save_PPOCRV2_infer/")
|
||||
```
|
||||
|
||||
运行`convert_ppocr_label.py`:
|
||||
|
||||
|
||||
```python
|
||||
python3 tools/end2end/convert_ppocr_label.py
|
||||
```
|
||||
|
||||
得到如下结果:
|
||||
```
|
||||
├── ./save_gt_label/
|
||||
├── ./save_PPOCRV2_infer/
|
||||
```
|
||||
|
||||
3) 最后,执行端对端评测,运行`tools/end2end/eval_end2end.py`计算端对端指标,运行方式如下:
|
||||
|
||||
|
||||
```python
|
||||
pip install editdistance
|
||||
python3 tools/end2end/eval_end2end.py ./save_gt_label/ ./save_PPOCRV2_infer/
|
||||
```
|
||||
|
||||
使用`预训练模型+fine-tune'检测模型`、`预训练模型 + 2W张PCB图片funetune`识别模型,在300张PCB图片上评估得到如下结果,fmeasure为主要关注的指标:
|
||||
<div align=center><img src='https://ai-studio-static-online.cdn.bcebos.com/37206ea48a244212ae7a821d50d1fd51faf3d7fe97ac47a29f04dfcbb377b019', width='700'></div>
|
||||
<div align=center>图8 端到端评估指标</div>
|
||||
|
||||
```
|
||||
注: 使用上述命令不能跑出该结果,因为数据集不相同,可以更换为自己训练好的模型,按上述流程运行
|
||||
```
|
||||
|
||||
# 8. Jetson部署
|
||||
|
||||
我们只需要以下步骤就可以完成Jetson nano部署模型,简单易操作:
|
||||
|
||||
**1、在Jetson nano开发版上环境准备:**
|
||||
|
||||
* 安装PaddlePaddle
|
||||
|
||||
* 下载PaddleOCR并安装依赖
|
||||
|
||||
**2、执行预测**
|
||||
|
||||
* 将推理模型下载到jetson
|
||||
|
||||
* 执行检测、识别、串联预测即可
|
||||
|
||||
详细[参考流程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/Jetson/readme_ch.md)。
|
||||
|
||||
# 9. 总结
|
||||
|
||||
检测实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、验证集padding、 fine-tune 3种方案,识别实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、 fine-tune、添加公开通用识别数据集、增加PCB图片数量4种方案,指标对比如下:
|
||||
|
||||
* 检测
|
||||
|
||||
|
||||
| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
|
||||
| ---- | -------------------------------------------------------- | ------ | -------- | ------------------------------------- |
|
||||
| 1 | PP-OCRv3英文超轻量检测预训练模型直接评估 | 64.64% | - | 提供的预训练模型具有泛化能力 |
|
||||
| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估 | 72.13% | +7.5% | padding可以提升尺寸较小图片的检测效果 |
|
||||
| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
|
||||
|
||||
* 识别
|
||||
|
||||
| 序号 | 方案 | acc | 效果提升 | 实验分析 |
|
||||
| ---- | ------------------------------------------------------------ | ------ | -------- | ------------------------------------------------------------ |
|
||||
| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
|
||||
| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
|
||||
| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
|
||||
| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
|
||||
|
||||
* 端到端
|
||||
|
||||
| det | rec | fmeasure |
|
||||
| --------------------------------------------- | ------------------------------------------------------------ | -------- |
|
||||
| PP-OCRv3英文超轻量检测预训练模型 + fine-tune | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 93.3% |
|
||||
|
||||
*结论*
|
||||
|
||||
PP-OCRv3的检测模型在未经过fine-tune的情况下,在PCB数据集上也有64.64%的精度,说明具有泛化能力。验证集padding之后,精度提升7.5%,在图片尺寸较小的情况,我们可以通过padding的方式提升检测效果。经过 fine-tune 后能够极大的提升检测效果,精度达到100%。
|
||||
|
||||
PP-OCRv3的识别模型方案1和方案2对比可以发现,当数据量不足的情况,预训练模型精度可能比fine-tune效果还要高,所以我们可以先尝试预训练模型直接评估。如果在数据量不足的情况下想进一步提升模型效果,可以通过添加公开通用识别数据集,识别效果提升30%,非常有效。最后如果我们能够采集足够多的真实场景数据集,可以通过增加数据量提升模型效果,精度达到99.99%。
|
||||
|
||||
# 更多资源
|
||||
|
||||
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
|
||||
|
||||
- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
|
||||
|
||||
|
||||
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
|
||||
|
||||
# 参考
|
||||
|
||||
* 数据生成代码库:https://github.com/zcswdt/Color_OCR_image_generator
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 2.0 KiB |
|
|
@ -0,0 +1,30 @@
|
|||
5ZQ
|
||||
I4UL
|
||||
PWL
|
||||
SNOG
|
||||
ZL02
|
||||
1C30
|
||||
O3H
|
||||
YHRS
|
||||
N03S
|
||||
1U5Y
|
||||
JTK
|
||||
EN4F
|
||||
YKJ
|
||||
DWNH
|
||||
R42W
|
||||
X0V
|
||||
4OF5
|
||||
08AM
|
||||
Y93S
|
||||
GWE2
|
||||
0KR
|
||||
9U2A
|
||||
DBQ
|
||||
Y6J
|
||||
ROZ
|
||||
K06
|
||||
KIEY
|
||||
NZQJ
|
||||
UN1B
|
||||
6X4
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 145 B |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 141 B |
|
|
@ -0,0 +1,261 @@
|
|||
# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
This code is refer from:
|
||||
https://github.com/zcswdt/Color_OCR_image_generator
|
||||
"""
|
||||
import os
|
||||
import random
|
||||
from PIL import Image, ImageDraw, ImageFont
|
||||
import json
|
||||
import argparse
|
||||
|
||||
|
||||
def get_char_lines(txt_root_path):
|
||||
"""
|
||||
desc:get corpus line
|
||||
"""
|
||||
txt_files = os.listdir(txt_root_path)
|
||||
char_lines = []
|
||||
for txt in txt_files:
|
||||
f = open(os.path.join(txt_root_path, txt), mode='r', encoding='utf-8')
|
||||
lines = f.readlines()
|
||||
f.close()
|
||||
for line in lines:
|
||||
char_lines.append(line.strip())
|
||||
return char_lines
|
||||
|
||||
|
||||
def get_horizontal_text_picture(image_file, chars, fonts_list, cf):
|
||||
"""
|
||||
desc:gen horizontal text picture
|
||||
"""
|
||||
img = Image.open(image_file)
|
||||
if img.mode != 'RGB':
|
||||
img = img.convert('RGB')
|
||||
img_w, img_h = img.size
|
||||
|
||||
# random choice font
|
||||
font_path = random.choice(fonts_list)
|
||||
# random choice font size
|
||||
font_size = random.randint(cf.font_min_size, cf.font_max_size)
|
||||
font = ImageFont.truetype(font_path, font_size)
|
||||
|
||||
ch_w = []
|
||||
ch_h = []
|
||||
for ch in chars:
|
||||
wt, ht = font.getsize(ch)
|
||||
ch_w.append(wt)
|
||||
ch_h.append(ht)
|
||||
f_w = sum(ch_w)
|
||||
f_h = max(ch_h)
|
||||
|
||||
# add space
|
||||
char_space_width = max(ch_w)
|
||||
f_w += (char_space_width * (len(chars) - 1))
|
||||
|
||||
x1 = random.randint(0, img_w - f_w)
|
||||
y1 = random.randint(0, img_h - f_h)
|
||||
x2 = x1 + f_w
|
||||
y2 = y1 + f_h
|
||||
|
||||
crop_y1 = y1
|
||||
crop_x1 = x1
|
||||
crop_y2 = y2
|
||||
crop_x2 = x2
|
||||
|
||||
best_color = (0, 0, 0)
|
||||
draw = ImageDraw.Draw(img)
|
||||
for i, ch in enumerate(chars):
|
||||
draw.text((x1, y1), ch, best_color, font=font)
|
||||
x1 += (ch_w[i] + char_space_width)
|
||||
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
|
||||
return crop_img, chars
|
||||
|
||||
|
||||
def get_vertical_text_picture(image_file, chars, fonts_list, cf):
|
||||
"""
|
||||
desc:gen vertical text picture
|
||||
"""
|
||||
img = Image.open(image_file)
|
||||
if img.mode != 'RGB':
|
||||
img = img.convert('RGB')
|
||||
img_w, img_h = img.size
|
||||
# random choice font
|
||||
font_path = random.choice(fonts_list)
|
||||
# random choice font size
|
||||
font_size = random.randint(cf.font_min_size, cf.font_max_size)
|
||||
font = ImageFont.truetype(font_path, font_size)
|
||||
|
||||
ch_w = []
|
||||
ch_h = []
|
||||
for ch in chars:
|
||||
wt, ht = font.getsize(ch)
|
||||
ch_w.append(wt)
|
||||
ch_h.append(ht)
|
||||
f_w = max(ch_w)
|
||||
f_h = sum(ch_h)
|
||||
|
||||
x1 = random.randint(0, img_w - f_w)
|
||||
y1 = random.randint(0, img_h - f_h)
|
||||
x2 = x1 + f_w
|
||||
y2 = y1 + f_h
|
||||
|
||||
crop_y1 = y1
|
||||
crop_x1 = x1
|
||||
crop_y2 = y2
|
||||
crop_x2 = x2
|
||||
|
||||
best_color = (0, 0, 0)
|
||||
draw = ImageDraw.Draw(img)
|
||||
i = 0
|
||||
for ch in chars:
|
||||
draw.text((x1, y1), ch, best_color, font=font)
|
||||
y1 = y1 + ch_h[i]
|
||||
i = i + 1
|
||||
crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
|
||||
crop_img = crop_img.transpose(Image.ROTATE_90)
|
||||
return crop_img, chars
|
||||
|
||||
|
||||
def get_fonts(fonts_path):
|
||||
"""
|
||||
desc: get all fonts
|
||||
"""
|
||||
font_files = os.listdir(fonts_path)
|
||||
fonts_list=[]
|
||||
for font_file in font_files:
|
||||
font_path=os.path.join(fonts_path, font_file)
|
||||
fonts_list.append(font_path)
|
||||
return fonts_list
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--num_img', type=int, default=30, help="Number of images to generate")
|
||||
parser.add_argument('--font_min_size', type=int, default=11)
|
||||
parser.add_argument('--font_max_size', type=int, default=12,
|
||||
help="Help adjust the size of the generated text and the size of the picture")
|
||||
parser.add_argument('--bg_path', type=str, default='./background',
|
||||
help='The generated text pictures will be pasted onto the pictures of this folder')
|
||||
parser.add_argument('--det_bg_path', type=str, default='./det_background',
|
||||
help='The generated text pictures will use the pictures of this folder as the background')
|
||||
parser.add_argument('--fonts_path', type=str, default='../../StyleText/fonts',
|
||||
help='The font used to generate the picture')
|
||||
parser.add_argument('--corpus_path', type=str, default='./corpus',
|
||||
help='The corpus used to generate the text picture')
|
||||
parser.add_argument('--output_dir', type=str, default='./output/', help='Images save dir')
|
||||
|
||||
|
||||
cf = parser.parse_args()
|
||||
# save path
|
||||
if not os.path.exists(cf.output_dir):
|
||||
os.mkdir(cf.output_dir)
|
||||
|
||||
# get corpus
|
||||
txt_root_path = cf.corpus_path
|
||||
char_lines = get_char_lines(txt_root_path=txt_root_path)
|
||||
|
||||
# get all fonts
|
||||
fonts_path = cf.fonts_path
|
||||
fonts_list = get_fonts(fonts_path)
|
||||
|
||||
# rec bg
|
||||
img_root_path = cf.bg_path
|
||||
imnames=os.listdir(img_root_path)
|
||||
|
||||
# det bg
|
||||
det_bg_path = cf.det_bg_path
|
||||
bg_pics = os.listdir(det_bg_path)
|
||||
|
||||
# OCR det files
|
||||
det_val_file = open(cf.output_dir + 'det_gt_val.txt', 'w', encoding='utf-8')
|
||||
det_train_file = open(cf.output_dir + 'det_gt_train.txt', 'w', encoding='utf-8')
|
||||
# det imgs
|
||||
det_save_dir = 'imgs/'
|
||||
if not os.path.exists(cf.output_dir + det_save_dir):
|
||||
os.mkdir(cf.output_dir + det_save_dir)
|
||||
det_val_save_dir = 'imgs_val/'
|
||||
if not os.path.exists(cf.output_dir + det_val_save_dir):
|
||||
os.mkdir(cf.output_dir + det_val_save_dir)
|
||||
|
||||
# OCR rec files
|
||||
rec_val_file = open(cf.output_dir + 'rec_gt_val.txt', 'w', encoding='utf-8')
|
||||
rec_train_file = open(cf.output_dir + 'rec_gt_train.txt', 'w', encoding='utf-8')
|
||||
# rec imgs
|
||||
rec_save_dir = 'rec_imgs/'
|
||||
if not os.path.exists(cf.output_dir + rec_save_dir):
|
||||
os.mkdir(cf.output_dir + rec_save_dir)
|
||||
rec_val_save_dir = 'rec_imgs_val/'
|
||||
if not os.path.exists(cf.output_dir + rec_val_save_dir):
|
||||
os.mkdir(cf.output_dir + rec_val_save_dir)
|
||||
|
||||
|
||||
val_ratio = cf.num_img * 0.2 # val dataset ratio
|
||||
|
||||
print('start generating...')
|
||||
for i in range(0, cf.num_img):
|
||||
imname = random.choice(imnames)
|
||||
img_path = os.path.join(img_root_path, imname)
|
||||
|
||||
rnd = random.random()
|
||||
# gen horizontal text picture
|
||||
if rnd < 0.5:
|
||||
gen_img, chars = get_horizontal_text_picture(img_path, char_lines[i], fonts_list, cf)
|
||||
ori_w, ori_h = gen_img.size
|
||||
gen_img = gen_img.crop((0, 3, ori_w, ori_h))
|
||||
# gen vertical text picture
|
||||
else:
|
||||
gen_img, chars = get_vertical_text_picture(img_path, char_lines[i], fonts_list, cf)
|
||||
ori_w, ori_h = gen_img.size
|
||||
gen_img = gen_img.crop((3, 0, ori_w, ori_h))
|
||||
|
||||
ori_w, ori_h = gen_img.size
|
||||
|
||||
# rec imgs
|
||||
save_img_name = str(i).zfill(4) + '.jpg'
|
||||
if i < val_ratio:
|
||||
save_dir = os.path.join(rec_val_save_dir, save_img_name)
|
||||
line = save_dir + '\t' + char_lines[i] + '\n'
|
||||
rec_val_file.write(line)
|
||||
else:
|
||||
save_dir = os.path.join(rec_save_dir, save_img_name)
|
||||
line = save_dir + '\t' + char_lines[i] + '\n'
|
||||
rec_train_file.write(line)
|
||||
gen_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
|
||||
|
||||
# det img
|
||||
# random choice bg
|
||||
bg_pic = random.sample(bg_pics, 1)[0]
|
||||
det_img = Image.open(os.path.join(det_bg_path, bg_pic))
|
||||
# the PCB position is fixed, modify it according to your own scenario
|
||||
if bg_pic == '1.png':
|
||||
x1 = 38
|
||||
y1 = 3
|
||||
else:
|
||||
x1 = 34
|
||||
y1 = 1
|
||||
|
||||
det_img.paste(gen_img, (x1, y1))
|
||||
# text pos
|
||||
chars_pos = [[x1, y1], [x1 + ori_w, y1], [x1 + ori_w, y1 + ori_h], [x1, y1 + ori_h]]
|
||||
label = [{"transcription":char_lines[i], "points":chars_pos}]
|
||||
if i < val_ratio:
|
||||
save_dir = os.path.join(det_val_save_dir, save_img_name)
|
||||
det_val_file.write(save_dir + '\t' + json.dumps(
|
||||
label, ensure_ascii=False) + '\n')
|
||||
else:
|
||||
save_dir = os.path.join(det_save_dir, save_img_name)
|
||||
det_train_file.write(save_dir + '\t' + json.dumps(
|
||||
label, ensure_ascii=False) + '\n')
|
||||
det_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
# 场景应用
|
||||
|
||||
PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。
|
||||
|
||||
> 如需下载全部垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
|
||||
|
||||
<div align="center">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
|
||||
|
||||
> 如果您是企业开发者且未在下述场景中找到合适的方案,可以填写[OCR应用合作调研问卷](https://paddle.wjx.cn/vj/QwF7GKw.aspx),免费与官方团队展开不同层次的合作,包括但不限于问题抽象、确定技术方案、项目答疑、共同研发等。如果您已经使用PaddleOCR落地项目,也可以填写此问卷,与飞桨平台共同宣传推广,提升企业技术品宣。期待您的提交!
|
||||
|
||||
## 通用
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------------------------- | -------- | ---------- | ------------ |
|
||||
| [高精度中文识别模型SVTR](./高精度中文识别模型.md) | 新增模型 | 手写体识别 | 新增字形支持 |
|
||||
|
||||
## 制造
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------------------------------------ | ------------------------------ | ------------------------------------------- | -------------------- |
|
||||
| [数码管识别](./光功率计数码管字符识别/光功率计数码管字符识别.md) | 数码管数据合成、漏识别调优 | 电表识别 | 大分辨率图像检测调优 |
|
||||
| [液晶屏读数识别](./液晶屏读数识别.md) | 检测模型蒸馏、Serving部署 | [PCB文字识别](./PCB字符识别/PCB字符识别.md) | 小尺寸文本检测与识别 |
|
||||
| [包装生产日期](./包装生产日期识别.md) | 点阵字符合成、过曝过暗文字识别 | 液晶屏缺陷检测 | 非文字字符识别 |
|
||||
|
||||
## 金融
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------ | ------------------------ | ------------ | --------------------- |
|
||||
| [表单VQA](./多模态表单识别.md) | 多模态通用表单结构化提取 | 通用卡证识别 | 通用结构化提取 |
|
||||
| 增值税发票 | 尽请期待 | 身份证识别 | 结构化提取、图像阴影 |
|
||||
| 印章检测与识别 | 端到端弯曲文本识别 | 合同比对 | 密集文本检测、NLP串联 |
|
||||
|
||||
## 交通
|
||||
|
||||
| 类别 | 亮点 | 类别 | 亮点 |
|
||||
| ------------------------------- | ------------------------------ | ---------- | -------- |
|
||||
| [车牌识别](./轻量级车牌识别.md) | 多角度图像、轻量模型、端侧部署 | 快递单识别 | 尽请期待 |
|
||||
| 驾驶证/行驶证识别 | 尽请期待 | | |
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
46.39
|
||||
40.08
|
||||
89.52
|
||||
-71.93
|
||||
23.19
|
||||
-81.02
|
||||
-34.09
|
||||
05.87
|
||||
-67.80
|
||||
-51.56
|
||||
-34.58
|
||||
37.91
|
||||
56.98
|
||||
29.01
|
||||
-90.13
|
||||
35.55
|
||||
66.07
|
||||
-90.35
|
||||
-50.93
|
||||
42.42
|
||||
21.40
|
||||
-30.99
|
||||
-71.78
|
||||
25.60
|
||||
-48.69
|
||||
-72.28
|
||||
-17.55
|
||||
-99.93
|
||||
-47.35
|
||||
-64.89
|
||||
-31.28
|
||||
-90.01
|
||||
05.17
|
||||
30.91
|
||||
30.56
|
||||
-06.90
|
||||
79.05
|
||||
67.74
|
||||
-32.31
|
||||
94.22
|
||||
28.75
|
||||
51.03
|
||||
-58.96
|
||||
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,467 @@
|
|||
# 光功率计数码管字符识别
|
||||
|
||||
本案例将使用OCR技术自动识别光功率计显示屏文字,通过本章您可以掌握:
|
||||
|
||||
- PaddleOCR快速使用
|
||||
- 数据合成方法
|
||||
- 数据挖掘方法
|
||||
- 基于现有数据微调
|
||||
|
||||
## 1. 背景介绍
|
||||
|
||||
光功率计(optical power meter )是指用于测量绝对光功率或通过一段光纤的光功率相对损耗的仪器。在光纤系统中,测量光功率是最基本的,非常像电子学中的万用表;在光纤测量中,光功率计是重负荷常用表。
|
||||
|
||||
<img src="https://bkimg.cdn.bcebos.com/pic/a08b87d6277f9e2f999f5e3e1c30e924b899f35a?x-bce-process=image/watermark,image_d2F0ZXIvYmFpa2U5Mg==,g_7,xp_5,yp_5/format,f_auto" width="400">
|
||||
|
||||
目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
|
||||
|
||||
为实现智能读数,通常会采取文本检测+文本识别的方案:
|
||||
|
||||
第一步,使用文本检测模型定位出光功率计中的数字部分;
|
||||
|
||||
第二步,使用文本识别模型获得准确的数字和单位信息。
|
||||
|
||||
本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
|
||||
|
||||
本项目难点如下:
|
||||
|
||||
- 光功率计数码管字符数据较少,难以获取。
|
||||
- 数码管中小数点占像素较少,容易漏识别。
|
||||
|
||||
针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
|
||||
|
||||
aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
|
||||
|
||||
## 2. PaddleOCR 快速使用
|
||||
|
||||
PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
|
||||
|
||||

|
||||
|
||||
|
||||
官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
|
||||
|
||||
- 准备环境
|
||||
|
||||
```
|
||||
python3 -m pip install -U pip
|
||||
python3 -m pip install paddleocr
|
||||
```
|
||||
|
||||
|
||||
- 测试效果
|
||||
|
||||
测试图:
|
||||
|
||||
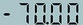
|
||||
|
||||
|
||||
```
|
||||
paddleocr --lang=ch --det=Fase --image_dir=data
|
||||
```
|
||||
|
||||
得到如下测试结果:
|
||||
|
||||
```
|
||||
('.7000', 0.6885431408882141)
|
||||
```
|
||||
|
||||
发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
|
||||
|
||||
下面就主要介绍如何在光功率计(数码管)场景上微调训练。
|
||||
|
||||
|
||||
## 3. 开始训练
|
||||
|
||||
### 3.1 数据准备
|
||||
|
||||
特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
|
||||
|
||||
数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
|
||||
|
||||
|
||||
- 合成数据
|
||||
|
||||
本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
```
|
||||
export https_proxy=http://172.19.57.45:3128
|
||||
git clone https://github.com/oh-my-ocr/text_renderer
|
||||
```
|
||||
|
||||
```
|
||||
import os
|
||||
python3 setup.py develop
|
||||
python3 -m pip install -r docker/requirements.txt
|
||||
python3 main.py \
|
||||
--config example_data/example.py \
|
||||
--dataset img \
|
||||
--num_processes 2 \
|
||||
--log_period 10
|
||||
```
|
||||
|
||||
给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
|
||||
|
||||
将收集好的语料存放在 example_data 路径下:
|
||||
|
||||
```
|
||||
ln -s ./fonts/DS* text_renderer/example_data/font/
|
||||
ln -s ./corpus/digital.txt text_renderer/example_data/text/
|
||||
```
|
||||
|
||||
修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
|
||||
|
||||
```
|
||||
python3 main.py \
|
||||
--config example_data/digital_example.py \
|
||||
--dataset img \
|
||||
--num_processes 2 \
|
||||
--log_period 10
|
||||
```
|
||||
|
||||
合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
|
||||
|
||||
查看合成的数据样例:
|
||||
|
||||

|
||||
|
||||
|
||||
- 真实数据挖掘
|
||||
|
||||
模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
|
||||
|
||||
|
||||
1. 数据搜集
|
||||
|
||||
使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
|
||||
|
||||
2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
|
||||
|
||||
PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
|
||||
|
||||

|
||||
|
||||
|
||||
收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
|
||||
|
||||
|
||||
最终 `data` 文件夹应包含以下几部分:
|
||||
|
||||
```
|
||||
|-data
|
||||
|- synth_train.txt
|
||||
|- real_train.txt
|
||||
|- real_eval.txt
|
||||
|- synthetic_data
|
||||
|- word_001.png
|
||||
|- word_002.jpg
|
||||
|- word_003.jpg
|
||||
| ...
|
||||
|- real_data
|
||||
|- word_001.png
|
||||
|- word_002.jpg
|
||||
|- word_003.jpg
|
||||
| ...
|
||||
...
|
||||
```
|
||||
|
||||
### 3.2 模型选择
|
||||
|
||||
本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
|
||||
|
||||
[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
|
||||
|
||||
[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
|
||||
|
||||
以上两个策略在自建中文数据集上的精度和速度对比如下:
|
||||
|
||||
| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
|
||||
|-----|-----|--------|----| --- |
|
||||
| 01 | PP-OCRv2 | 8M | 74.8% | 8.54ms |
|
||||
| 02 | SVTR_Tiny | 21M | 80.1% | 97ms |
|
||||
| 03 | SVTR_LCNet(h32) | 12M | 71.9% | 6.6ms |
|
||||
| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.6ms |
|
||||
| 05 | + GTC | 12M | 75.8% | 7.6ms |
|
||||
| 06 | + TextConAug | 12M | 76.3% | 7.6ms |
|
||||
| 07 | + TextRotNet | 12M | 76.9% | 7.6ms |
|
||||
| 08 | + UDML | 12M | 78.4% | 7.6ms |
|
||||
| 09 | + UIM | 12M | 79.4% | 7.6ms |
|
||||
|
||||
|
||||
### 3.3 开始训练
|
||||
|
||||
首先下载 PaddleOCR 代码库
|
||||
|
||||
```
|
||||
git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
|
||||
```
|
||||
|
||||
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
|
||||
|
||||
**Step1:下载预训练模型**
|
||||
|
||||
首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
|
||||
|
||||
```
|
||||
cd PaddleOCR/
|
||||
# 下载PP-OCRv3 中文预训练模型
|
||||
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
|
||||
# 解压模型参数
|
||||
cd pretrain_models
|
||||
tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
|
||||
```
|
||||
|
||||
**Step2:自定义字典文件**
|
||||
|
||||
接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
|
||||
|
||||
因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
|
||||
|
||||
```
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
-
|
||||
.
|
||||
```
|
||||
|
||||
word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
|
||||
|
||||
* 内置字典
|
||||
|
||||
PaddleOCR内置了一部分字典,可以按需使用。
|
||||
|
||||
`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
|
||||
|
||||
`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
|
||||
|
||||
* 自定义字典
|
||||
|
||||
内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
|
||||
|
||||
遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
|
||||
|
||||
```
|
||||
-
|
||||
.
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
8
|
||||
9
|
||||
B
|
||||
E
|
||||
F
|
||||
H
|
||||
L
|
||||
N
|
||||
T
|
||||
W
|
||||
d
|
||||
k
|
||||
m
|
||||
n
|
||||
o
|
||||
z
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
**Step3:修改配置文件**
|
||||
|
||||
为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
|
||||
|
||||
以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
|
||||
```
|
||||
Global:
|
||||
...
|
||||
# 添加自定义字典,如修改字典请将路径指向新字典
|
||||
character_dict_path: ppocr/utils/dict/digital_dict.txt
|
||||
...
|
||||
# 识别空格
|
||||
use_space_char: True
|
||||
|
||||
|
||||
Optimizer:
|
||||
...
|
||||
# 添加学习率衰减策略
|
||||
lr:
|
||||
name: Cosine
|
||||
learning_rate: 0.001
|
||||
...
|
||||
|
||||
...
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
|
||||
name: SimpleDataSet
|
||||
# 数据集路径
|
||||
data_dir: ./data/
|
||||
# 训练集标签文件
|
||||
label_file_list:
|
||||
- ./train_data/digital_img/digital_train.txt #11w
|
||||
- ./train_data/digital_img/real_train.txt #100
|
||||
- ./train_data/digital_img/dbm_img/dbm.txt #3w
|
||||
ratio_list:
|
||||
- 0.3
|
||||
- 1.0
|
||||
- 1.0
|
||||
transforms:
|
||||
...
|
||||
- RecResizeImg:
|
||||
# 修改 image_shape 以适应长文本
|
||||
image_shape: [3, 48, 320]
|
||||
...
|
||||
loader:
|
||||
...
|
||||
# 单卡训练的batch_size
|
||||
batch_size_per_card: 256
|
||||
...
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
# 数据集格式,支持LMDBDataSet以及SimpleDataSet
|
||||
name: SimpleDataSet
|
||||
# 数据集路径
|
||||
data_dir: ./data
|
||||
# 验证集标签文件
|
||||
label_file_list:
|
||||
- ./train_data/digital_img/real_val.txt
|
||||
transforms:
|
||||
...
|
||||
- RecResizeImg:
|
||||
# 修改 image_shape 以适应长文本
|
||||
image_shape: [3, 48, 320]
|
||||
...
|
||||
loader:
|
||||
# 单卡验证的batch_size
|
||||
batch_size_per_card: 256
|
||||
...
|
||||
```
|
||||
**注意,训练/预测/评估时的配置文件请务必与训练一致。**
|
||||
|
||||
**Step4:启动训练**
|
||||
|
||||
*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
|
||||
|
||||
```
|
||||
# GPU训练 支持单卡,多卡训练
|
||||
# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
|
||||
|
||||
#单卡训练(训练周期长,不建议)
|
||||
python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
|
||||
|
||||
#多卡训练,通过--gpus参数指定卡号
|
||||
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
|
||||
```
|
||||
|
||||
|
||||
PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
|
||||
|
||||
如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
|
||||
|
||||
### SVTR_Tiny 训练
|
||||
|
||||
SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
|
||||
|
||||
**Step1:下载预训练模型**
|
||||
|
||||
```
|
||||
# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
|
||||
# 解压模型参数
|
||||
tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
|
||||
```
|
||||
**Step2:自定义字典文件**
|
||||
|
||||
字典依然使用自定义的 digital_dict.txt
|
||||
|
||||
**Step3:修改配置文件**
|
||||
|
||||
配置文件中对应修改字典路径和数据路径
|
||||
|
||||
**Step4:启动训练**
|
||||
|
||||
```
|
||||
## 单卡训练
|
||||
python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
|
||||
-o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
|
||||
```
|
||||
|
||||
### 3.4 验证效果
|
||||
|
||||
如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
<div align="left">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
将下载或训练完成的模型放置在对应目录下即可完成模型推理
|
||||
|
||||
* 指标评估
|
||||
|
||||
训练中模型参数默认保存在`Global.save_model_dir`目录下。在评估指标时,需要设置`Global.checkpoints`指向保存的参数文件。评估数据集可以通过 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 修改Eval中的 `label_file_path` 设置。
|
||||
|
||||
```
|
||||
# GPU 评估, Global.checkpoints 为待测权重
|
||||
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.checkpoints={path/to/weights}/best_accuracy
|
||||
```
|
||||
|
||||
* 测试识别效果
|
||||
|
||||
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
|
||||
|
||||
默认预测图片存储在 `infer_img` 里,通过 `-o Global.checkpoints` 加载训练好的参数文件:
|
||||
|
||||
根据配置文件中设置的 `save_model_dir` 和 `save_epoch_step` 字段,会有以下几种参数被保存下来:
|
||||
|
||||
```
|
||||
output/rec/
|
||||
├── best_accuracy.pdopt
|
||||
├── best_accuracy.pdparams
|
||||
├── best_accuracy.states
|
||||
├── config.yml
|
||||
├── iter_epoch_3.pdopt
|
||||
├── iter_epoch_3.pdparams
|
||||
├── iter_epoch_3.states
|
||||
├── latest.pdopt
|
||||
├── latest.pdparams
|
||||
├── latest.states
|
||||
└── train.log
|
||||
```
|
||||
|
||||
其中 best_accuracy.* 是评估集上的最优模型;iter_epoch_x.* 是以 `save_epoch_step` 为间隔保存下来的模型;latest.* 是最后一个epoch的模型。
|
||||
|
||||
```
|
||||
# 预测英文结果
|
||||
python3 tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=test_digital.png
|
||||
```
|
||||
|
||||
预测图片:
|
||||
|
||||
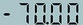
|
||||
|
||||
|
||||
得到输入图像的预测结果:
|
||||
|
||||
```
|
||||
infer_img: test_digital.png
|
||||
result: ('-70.00', 0.9998967)
|
||||
```
|
||||
|
|
@ -1,4 +1,33 @@
|
|||
# 1 项目说明
|
||||
# 多模态表单识别
|
||||
- [多模态表单识别](#多模态表单识别)
|
||||
- [1 项目说明](#1-项目说明)
|
||||
- [2 安装说明](#2-安装说明)
|
||||
- [3 数据准备](#3-数据准备)
|
||||
- [3.1 下载处理好的数据集](#31-下载处理好的数据集)
|
||||
- [3.2 转换为PaddleOCR检测和识别格式](#32-转换为paddleocr检测和识别格式)
|
||||
- [4 OCR](#4-ocr)
|
||||
- [4.1 文本检测](#41-文本检测)
|
||||
- [4.1.1 方案1:预训练模型](#411-方案1预训练模型)
|
||||
- [4.1.2 方案2:XFUND数据集+fine-tune](#412-方案2xfund数据集fine-tune)
|
||||
- [4.2 文本识别](#42-文本识别)
|
||||
- [4.2.1 方案1:预训练模型](#421-方案1预训练模型)
|
||||
- [4.2.2 方案2:XFUND数据集+finetune](#422-方案2xfund数据集finetune)
|
||||
- [4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据](#423-方案3xfund数据集finetune真实通用识别数据)
|
||||
- [5 文档视觉问答(DOC-VQA)](#5-文档视觉问答doc-vqa)
|
||||
- [5.1 SER](#51-ser)
|
||||
- [5.1.1 模型训练](#511-模型训练)
|
||||
- [5.1.2 模型评估](#512-模型评估)
|
||||
- [5.1.3 模型预测](#513-模型预测)
|
||||
- [5.2 RE](#52-re)
|
||||
- [5.2.1 模型训练](#521-模型训练)
|
||||
- [5.2.2 模型评估](#522-模型评估)
|
||||
- [5.2.3 模型预测](#523-模型预测)
|
||||
- [6 导出Excel](#6-导出excel)
|
||||
- [获得模型](#获得模型)
|
||||
- [更多资源](#更多资源)
|
||||
- [参考链接](#参考链接)
|
||||
|
||||
## 1 项目说明
|
||||
|
||||
计算机视觉在金融领域的应用覆盖文字识别、图像识别、视频识别等,其中文字识别(OCR)是金融领域中的核心AI能力,其应用覆盖客户服务、风险防控、运营管理等各项业务,针对的对象包括通用卡证票据识别(银行卡、身份证、营业执照等)、通用文本表格识别(印刷体、多语言、手写体等)以及一些金融特色票据凭证。通过因此如果能够在结构化信息提取时同时利用文字、页面布局等信息,便可增强不同版式下的泛化性。
|
||||
|
||||
|
|
@ -16,39 +45,37 @@
|
|||
<center><img src='https://ai-studio-static-online.cdn.bcebos.com/9bd844b970f94e5ba0bc0c5799bd819ea9b1861bb306471fabc2d628864d418e'></center>
|
||||
<center>图1 多模态表单识别流程图</center>
|
||||
|
||||
注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
|
||||
注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
|
||||
|
||||
## 2 安装说明
|
||||
|
||||
|
||||
|
||||
# 2 安装说明
|
||||
|
||||
|
||||
下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
|
||||
下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
|
||||
|
||||
|
||||
```python
|
||||
! unzip -q PaddleOCR.zip
|
||||
unzip -q PaddleOCR.zip
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 如仍需安装or安装更新,可以执行以下步骤
|
||||
! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
|
||||
# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
|
||||
# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
|
||||
# git clone https://gitee.com/PaddlePaddle/PaddleOCR
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 安装依赖包
|
||||
! pip install -U pip
|
||||
! pip install -r /home/aistudio/PaddleOCR/requirements.txt
|
||||
! pip install paddleocr
|
||||
pip install -U pip
|
||||
pip install -r /home/aistudio/PaddleOCR/requirements.txt
|
||||
pip install paddleocr
|
||||
|
||||
! pip install yacs gnureadline paddlenlp==2.2.1
|
||||
! pip install xlsxwriter
|
||||
pip install yacs gnureadline paddlenlp==2.2.1
|
||||
pip install xlsxwriter
|
||||
```
|
||||
|
||||
# 3 数据准备
|
||||
## 3 数据准备
|
||||
|
||||
这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
|
||||
|
||||
|
|
@ -59,7 +86,7 @@
|
|||
<center><img src="https://ai-studio-static-online.cdn.bcebos.com/0f84137778cd4ab6899c64109d452290e9c678ccf01744978bc9c0647adbba45" width="1000" ></center>
|
||||
<center>图2 数据集样例,左中文,右法语</center>
|
||||
|
||||
## 3.1 下载处理好的数据集
|
||||
### 3.1 下载处理好的数据集
|
||||
|
||||
|
||||
处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
|
||||
|
|
@ -69,13 +96,13 @@
|
|||
|
||||
|
||||
```python
|
||||
! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
|
||||
! tar -xf XFUND.tar
|
||||
wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
|
||||
tar -xf XFUND.tar
|
||||
|
||||
# XFUN其他数据集使用下面的代码进行转换
|
||||
# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
|
||||
# %cd PaddleOCR
|
||||
# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
|
||||
# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
|
||||
# %cd ../
|
||||
```
|
||||
|
||||
|
|
@ -119,7 +146,7 @@
|
|||
}
|
||||
```
|
||||
|
||||
## 3.2 转换为PaddleOCR检测和识别格式
|
||||
### 3.2 转换为PaddleOCR检测和识别格式
|
||||
|
||||
使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
|
||||
|
||||
|
|
@ -147,7 +174,7 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
|
|||
|
||||
|
||||
```python
|
||||
! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
|
||||
unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
|
||||
```
|
||||
|
||||
已经提供转换脚本,执行如下代码即可转换成功:
|
||||
|
|
@ -155,21 +182,20 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/
|
||||
! python trans_xfund_data.py
|
||||
python trans_xfund_data.py
|
||||
```
|
||||
|
||||
# 4 OCR
|
||||
## 4 OCR
|
||||
|
||||
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
|
||||
|
||||
|
||||
## 4.1 文本检测
|
||||
### 4.1 文本检测
|
||||
|
||||
我们使用2种方案进行训练、评估:
|
||||
- **PP-OCRv2中英文超轻量检测预训练模型**
|
||||
- **XFUND数据集+fine-tune**
|
||||
|
||||
### **4.1.1 方案1:预训练模型**
|
||||
#### 4.1.1 方案1:预训练模型
|
||||
|
||||
**1)下载预训练模型**
|
||||
|
||||
|
|
@ -195,8 +221,8 @@ PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/pretrain/
|
||||
! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
|
||||
! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
|
||||
tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
|
||||
% cd ..
|
||||
```
|
||||
|
||||
|
|
@ -226,7 +252,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR
|
||||
! python tools/eval.py \
|
||||
python tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
|
||||
-o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
|
||||
```
|
||||
|
|
@ -237,9 +263,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
| -------- | -------- |
|
||||
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
|
||||
|
||||
使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
|
||||
使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
|
||||
|
||||
### **4.1.2 方案2:XFUND数据集+fine-tune**
|
||||
#### 4.1.2 方案2:XFUND数据集+fine-tune
|
||||
|
||||
PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
|
||||
|
||||
|
|
@ -281,7 +307,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
|
|||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
|
||||
```
|
||||
|
||||
|
|
@ -290,12 +316,18 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
|
|||
<center><img src="https://ai-studio-static-online.cdn.bcebos.com/5a75137c5f924dfeb6956b5818812298cc3dc7992ac84954b4175be9adf83c77"></center>
|
||||
<center>图8 文本检测方案2-模型评估</center>
|
||||
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
|
||||
<div align="left">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
|
||||
将下载或训练完成的模型放置在对应目录下即可完成模型评估
|
||||
|
||||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! python tools/eval.py \
|
||||
python tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
|
||||
-o Global.checkpoints="pretrain/ch_db_mv3-student1600-finetune/best_accuracy"
|
||||
```
|
||||
|
|
@ -305,7 +337,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! python tools/eval.py \
|
||||
python tools/eval.py \
|
||||
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
|
||||
-o Global.checkpoints="pretrain/ch_db_mv3-student1600/best_accuracy"
|
||||
```
|
||||
|
|
@ -331,7 +363,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
|
|||
# 加载配置文件`ch_PP-OCRv2_det_student.yml`,从`pretrain/ch_db_mv3-student1600-finetune`目录下加载`best_accuracy`模型
|
||||
# inference模型保存在`./output/det_db_inference`目录下
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! python tools/export_model.py \
|
||||
python tools/export_model.py \
|
||||
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
|
||||
-o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \
|
||||
Global.save_inference_dir="./output/det_db_inference/"
|
||||
|
|
@ -374,12 +406,11 @@ use_gpu:是否使用GPU
|
|||
|
||||
| 方案 | hmeans | 结果分析 |
|
||||
| -------- | -------- | -------- |
|
||||
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有一定的泛化能力 |
|
||||
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有泛化能力 |
|
||||
| XFUND数据集 | 79.27% | |
|
||||
| XFUND数据集+finetune | 85.24% | finetune会提升垂类场景效果 |
|
||||
|
||||
|
||||
## 4.2 文本识别
|
||||
### 4.2 文本识别
|
||||
|
||||
我们分别使用如下3种方案进行训练、评估:
|
||||
|
||||
|
|
@ -387,8 +418,7 @@ use_gpu:是否使用GPU
|
|||
- XFUND数据集+fine-tune
|
||||
- XFUND数据集+fine-tune+真实通用识别数据
|
||||
|
||||
|
||||
### **4.2.1 方案1:预训练模型**
|
||||
#### 4.2.1 方案1:预训练模型
|
||||
|
||||
**1)下载预训练模型**
|
||||
|
||||
|
|
@ -401,8 +431,8 @@ use_gpu:是否使用GPU
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/pretrain/
|
||||
! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
|
||||
! tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
|
||||
tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
|
||||
% cd ..
|
||||
```
|
||||
|
||||
|
|
@ -424,7 +454,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml \
|
||||
-o Global.checkpoints=./pretrain/ch_PP-OCRv2_rec_train/best_accuracy
|
||||
```
|
||||
|
|
@ -435,9 +465,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
| -------- | -------- |
|
||||
| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% |
|
||||
|
||||
使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
|
||||
使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型具有泛化能力。
|
||||
|
||||
### **4.2.2 方案2:XFUND数据集+finetune**
|
||||
#### 4.2.2 方案2:XFUND数据集+finetune
|
||||
|
||||
同检测模型,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
|
||||
|
||||
|
|
@ -474,11 +504,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
```
|
||||
执行如下命令启动训练:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
|
||||
```
|
||||
|
||||
|
|
@ -493,7 +521,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
|
||||
-o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy
|
||||
```
|
||||
|
|
@ -506,7 +534,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
|
|||
|
||||
使用XFUND数据集+finetune训练,在验证集上评估达到72%左右,说明 finetune会提升垂类场景效果。
|
||||
|
||||
### **4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据**
|
||||
#### 4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据
|
||||
|
||||
接着我们在上述`XFUND数据集+finetune`实验的基础上,添加真实通用识别数据,进一步提升识别效果。首先准备真实通用识别数据,并上传到AIStudio:
|
||||
|
||||
|
|
@ -528,7 +556,7 @@ Train.dataset.ratio_list:动态采样
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/train.py \
|
||||
-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
|
||||
```
|
||||
|
||||
|
|
@ -538,11 +566,11 @@ Train.dataset.ratio_list:动态采样
|
|||
|
||||
<center>图16 文本识别方案3-模型评估</center>
|
||||
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
|
||||
使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
|
||||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
|
||||
-o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy
|
||||
```
|
||||
|
|
@ -580,7 +608,7 @@ Train.dataset.ratio_list:动态采样
|
|||
|
||||
|
||||
```python
|
||||
! python tools/infer/predict_system.py \
|
||||
python tools/infer/predict_system.py \
|
||||
--image_dir="./doc/vqa/input/zh_val_21.jpg" \
|
||||
--det_model_dir="./output/det_db_inference/" \
|
||||
--rec_model_dir="./output/rec_crnn_inference/" \
|
||||
|
|
@ -592,11 +620,11 @@ Train.dataset.ratio_list:动态采样
|
|||
|
||||
| 方案 | acc | 结果分析 |
|
||||
| -------- | -------- | -------- |
|
||||
| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型有一定的泛化能力 |
|
||||
| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型具有泛化能力 |
|
||||
| XFUND数据集+fine-tune |72.33% | finetune会提升垂类场景效果 |
|
||||
| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% | 真实通用识别数据对于性能提升很有帮助 |
|
||||
|
||||
# 5 文档视觉问答(DOC-VQA)
|
||||
## 5 文档视觉问答(DOC-VQA)
|
||||
|
||||
VQA指视觉问答,主要针对图像内容进行提问和回答,DOC-VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
|
||||
|
||||
|
|
@ -608,14 +636,13 @@ PaddleOCR中DOC-VQA系列算法基于PaddleNLP自然语言处理算法库实现L
|
|||
```python
|
||||
%cd pretrain
|
||||
#下载SER模型
|
||||
! wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
|
||||
#下载RE模型
|
||||
! wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
|
||||
%cd ../
|
||||
```
|
||||
|
||||
|
||||
## 5.1 SER
|
||||
### 5.1 SER
|
||||
|
||||
SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
|
||||
|
||||
|
|
@ -647,7 +674,7 @@ SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像
|
|||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR/
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
|
||||
```
|
||||
|
||||
最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/ser_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型。
|
||||
|
|
@ -664,7 +691,7 @@ SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像
|
|||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
|
||||
-c configs/vqa/ser/layoutxlm.yml \
|
||||
-o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
|
||||
```
|
||||
|
|
@ -684,7 +711,7 @@ SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像
|
|||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
|
||||
-c configs/vqa/ser/layoutxlm.yml \
|
||||
-o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \
|
||||
Global.infer_img=doc/vqa/input/zh_val_42.jpg
|
||||
|
|
@ -704,7 +731,7 @@ plt.figure(figsize=(48,24))
|
|||
plt.imshow(img)
|
||||
```
|
||||
|
||||
## 5.2 RE
|
||||
### 5.2 RE
|
||||
|
||||
基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
|
||||
|
||||
|
|
@ -729,7 +756,7 @@ plt.imshow(img)
|
|||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
|
||||
CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
|
||||
```
|
||||
|
||||
最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/re_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型
|
||||
|
|
@ -744,7 +771,7 @@ plt.imshow(img)
|
|||
|
||||
|
||||
```python
|
||||
! CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
|
||||
CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
|
||||
-c configs/vqa/re/layoutxlm.yml \
|
||||
-o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
|
||||
```
|
||||
|
|
@ -760,20 +787,14 @@ plt.imshow(img)
|
|||
|
||||
<center>图26 RE-模型预测</center>
|
||||
|
||||
使用OCR引擎 + SER + RE串联预测
|
||||
|
||||
使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例:
|
||||
|
||||
|
||||
使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例,
|
||||
|
||||
最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt。
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
%cd /home/aistudio/PaddleOCR
|
||||
! CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
|
||||
cd /home/aistudio/PaddleOCR
|
||||
CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
|
||||
-c configs/vqa/re/layoutxlm.yml \
|
||||
-o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \
|
||||
Global.infer_img=test_imgs/ \
|
||||
|
|
@ -787,10 +808,9 @@ plt.imshow(img)
|
|||
test_imgs/t131.jpg {"政治面税": "群众", "性别": "男", "籍贯": "河北省邯郸市", "婚姻状况": "亏末婚口已婚口已娇", "通讯地址": "邯郸市阳光苑7号楼003", "民族": "汉族", "毕业院校": "河南工业大学", "户口性质": "口农村城镇", "户口地址": "河北省邯郸市", "联系电话": "13288888888", "健康状况": "健康", "姓名": "小六", "好高cm": "180", "出生年月": "1996年8月9日", "文化程度": "本科", "身份证号码": "458933777777777777"}
|
||||
````
|
||||
|
||||
|
||||
展示预测结果
|
||||
|
||||
```python
|
||||
# 展示预测结果
|
||||
import cv2
|
||||
from matplotlib import pyplot as plt
|
||||
%matplotlib inline
|
||||
|
|
@ -800,7 +820,7 @@ plt.figure(figsize=(48,24))
|
|||
plt.imshow(img)
|
||||
```
|
||||
|
||||
# 6 导出Excel
|
||||
## 6 导出Excel
|
||||
|
||||
<center><img src="https://ai-studio-static-online.cdn.bcebos.com/ab93d3d90d77437a81c9534b2dd1d3e39ef81e8473054fd3aeff6e837ebfb827"></center>
|
||||
<center>图27 导出Excel</center>
|
||||
|
|
@ -859,7 +879,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
|
|||
workbook.close()
|
||||
```
|
||||
|
||||
# 更多资源
|
||||
## 更多资源
|
||||
|
||||
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
|
||||
|
||||
|
|
@ -869,7 +889,7 @@ workbook.close()
|
|||
|
||||
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
|
||||
|
||||
# 参考链接
|
||||
## 参考链接
|
||||
|
||||
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,832 @@
|
|||
# 一种基于PaddleOCR的轻量级车牌识别模型
|
||||
|
||||
- [1. 项目介绍](#1-项目介绍)
|
||||
- [2. 环境搭建](#2-环境搭建)
|
||||
- [3. 数据集准备](#3-数据集准备)
|
||||
- [3.1 数据集标注规则](#31-数据集标注规则)
|
||||
- [3.2 制作符合PP-OCR训练格式的标注文件](#32-制作符合pp-ocr训练格式的标注文件)
|
||||
- [4. 实验](#4-实验)
|
||||
- [4.1 检测](#41-检测)
|
||||
- [4.1.1 预训练模型直接预测](#411-预训练模型直接预测)
|
||||
- [4.1.2 CCPD车牌数据集fine-tune](#412-ccpd车牌数据集fine-tune)
|
||||
- [4.1.3 CCPD车牌数据集fine-tune+量化训练](#413-ccpd车牌数据集fine-tune量化训练)
|
||||
- [4.1.4 模型导出](#414-模型导出)
|
||||
- [4.2 识别](#42-识别)
|
||||
- [4.2.1 预训练模型直接预测](#421-预训练模型直接预测)
|
||||
- [4.2.2 预训练模型直接预测+改动后处理](#422-预训练模型直接预测改动后处理)
|
||||
- [4.2.3 CCPD车牌数据集fine-tune](#423-ccpd车牌数据集fine-tune)
|
||||
- [4.2.4 CCPD车牌数据集fine-tune+量化训练](#424-ccpd车牌数据集fine-tune量化训练)
|
||||
- [4.2.5 模型导出](#425-模型导出)
|
||||
- [4.3 计算End2End指标](#43-计算End2End指标)
|
||||
- [4.4 部署](#44-部署)
|
||||
- [4.5 实验总结](#45-实验总结)
|
||||
|
||||
## 1. 项目介绍
|
||||
|
||||
车牌识别(Vehicle License Plate Recognition,VLPR) 是计算机视频图像识别技术在车辆牌照识别中的一种应用。车牌识别技术要求能够将运动中的汽车牌照从复杂背景中提取并识别出来,在高速公路车辆管理,停车场管理和城市交通中得到广泛应用。
|
||||
|
||||
本项目难点如下:
|
||||
|
||||
1. 车牌在图像中的尺度差异大、在车辆上的悬挂位置不固定
|
||||
2. 车牌图像质量层次不齐: 角度倾斜、图片模糊、光照不足、过曝等问题严重
|
||||
3. 边缘和端测场景应用对模型大小有限制,推理速度有要求
|
||||
|
||||
针对以上问题, 本例选用 PP-OCRv3 这一开源超轻量OCR系统进行车牌识别系统的开发。基于PP-OCRv3模型,在CCPD数据集达到99%的检测和94%的识别精度,模型大小12.8M(2.5M+10.3M)。基于量化对模型体积进行进一步压缩到5.8M(1M+4.8M), 同时推理速度提升25%。
|
||||
|
||||
|
||||
|
||||
aistudio项目链接: [基于PaddleOCR的轻量级车牌识别范例](https://aistudio.baidu.com/aistudio/projectdetail/3919091?contributionType=1)
|
||||
|
||||
## 2. 环境搭建
|
||||
|
||||
本任务基于Aistudio完成, 具体环境如下:
|
||||
|
||||
- 操作系统: Linux
|
||||
- PaddlePaddle: 2.3
|
||||
- paddleslim: 2.2.2
|
||||
- PaddleOCR: Release/2.5
|
||||
|
||||
下载 PaddleOCR代码
|
||||
|
||||
```bash
|
||||
git clone -b dygraph https://github.com/PaddlePaddle/PaddleOCR
|
||||
```
|
||||
|
||||
安装依赖库
|
||||
|
||||
```bash
|
||||
pip install -r PaddleOCR/requirements.txt
|
||||
```
|
||||
|
||||
## 3. 数据集准备
|
||||
|
||||
所使用的数据集为 CCPD2020 新能源车牌数据集,该数据集为
|
||||
|
||||
该数据集分布如下:
|
||||
|
||||
|数据集类型|数量|
|
||||
|---|---|
|
||||
|训练集| 5769|
|
||||
|验证集| 1001|
|
||||
|测试集| 5006|
|
||||
|
||||
数据集图片示例如下:
|
||||

|
||||
|
||||
数据集可以从这里下载 https://aistudio.baidu.com/aistudio/datasetdetail/101595
|
||||
|
||||
下载好数据集后对数据集进行解压
|
||||
|
||||
```bash
|
||||
unzip -d /home/aistudio/data /home/aistudio/data/data101595/CCPD2020.zip
|
||||
```
|
||||
|
||||
### 3.1 数据集标注规则
|
||||
|
||||
CPPD数据集的图片文件名具有特殊规则,详细可查看:https://github.com/detectRecog/CCPD
|
||||
|
||||
具体规则如下:
|
||||
|
||||
例如: 025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
|
||||
|
||||
每个名称可以分为七个字段,以-符号作为分割。这些字段解释如下。
|
||||
|
||||
- 025:车牌面积与整个图片区域的面积比。025 (25%)
|
||||
|
||||
- 95_113:水平倾斜程度和垂直倾斜度。水平 95度 垂直 113度
|
||||
|
||||
- 154&383_386&473:左上和右下顶点的坐标。左上(154,383) 右下(386,473)
|
||||
|
||||
- 386&473_177&454_154&383_363&402:整个图像中车牌的四个顶点的精确(x,y)坐标。这些坐标从右下角顶点开始。(386,473) (177,454) (154,383) (363,402)
|
||||
|
||||
- 0_0_22_27_27_33_16:CCPD中的每个图像只有一个车牌。每个车牌号码由一个汉字,一个字母和五个字母或数字组成。有效的中文车牌由七个字符组成:省(1个字符),字母(1个字符),字母+数字(5个字符)。“ 0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O,而不是数字0。我们将O用作“无字符”的符号,因为中文车牌字符中没有O。因此以上车牌拼起来即为 皖AY339S
|
||||
|
||||
- 37:牌照区域的亮度。 37 (37%)
|
||||
|
||||
- 15:车牌区域的模糊度。15 (15%)
|
||||
|
||||
```python
|
||||
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
|
||||
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W','X', 'Y', 'Z', 'O']
|
||||
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
|
||||
```
|
||||
|
||||
### 3.2 制作符合PP-OCR训练格式的标注文件
|
||||
|
||||
在开始训练之前,可使用如下代码制作符合PP-OCR训练格式的标注文件。
|
||||
|
||||
|
||||
```python
|
||||
import cv2
|
||||
import os
|
||||
import json
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
|
||||
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
|
||||
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'O']
|
||||
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
|
||||
|
||||
def make_label(img_dir, save_gt_folder, phase):
|
||||
crop_img_save_dir = os.path.join(save_gt_folder, phase, 'crop_imgs')
|
||||
os.makedirs(crop_img_save_dir, exist_ok=True)
|
||||
|
||||
f_det = open(os.path.join(save_gt_folder, phase, 'det.txt'), 'w', encoding='utf-8')
|
||||
f_rec = open(os.path.join(save_gt_folder, phase, 'rec.txt'), 'w', encoding='utf-8')
|
||||
|
||||
i = 0
|
||||
for filename in tqdm(os.listdir(os.path.join(img_dir, phase))):
|
||||
str_list = filename.split('-')
|
||||
if len(str_list) < 5:
|
||||
continue
|
||||
coord_list = str_list[3].split('_')
|
||||
txt_list = str_list[4].split('_')
|
||||
boxes = []
|
||||
for coord in coord_list:
|
||||
boxes.append([int(x) for x in coord.split("&")])
|
||||
boxes = [boxes[2], boxes[3], boxes[0], boxes[1]]
|
||||
lp_number = provinces[int(txt_list[0])] + alphabets[int(txt_list[1])] + ''.join([ads[int(x)] for x in txt_list[2:]])
|
||||
|
||||
# det
|
||||
det_info = [{'points':boxes, 'transcription':lp_number}]
|
||||
f_det.write('{}\t{}\n'.format(os.path.join(phase, filename), json.dumps(det_info, ensure_ascii=False)))
|
||||
|
||||
# rec
|
||||
boxes = np.float32(boxes)
|
||||
img = cv2.imread(os.path.join(img_dir, phase, filename))
|
||||
# crop_img = img[int(boxes[:,1].min()):int(boxes[:,1].max()),int(boxes[:,0].min()):int(boxes[:,0].max())]
|
||||
crop_img = get_rotate_crop_image(img, boxes)
|
||||
crop_img_save_filename = '{}_{}.jpg'.format(i,'_'.join(txt_list))
|
||||
crop_img_save_path = os.path.join(crop_img_save_dir, crop_img_save_filename)
|
||||
cv2.imwrite(crop_img_save_path, crop_img)
|
||||
f_rec.write('{}/crop_imgs/{}\t{}\n'.format(phase, crop_img_save_filename, lp_number))
|
||||
i+=1
|
||||
f_det.close()
|
||||
f_rec.close()
|
||||
|
||||
def get_rotate_crop_image(img, points):
|
||||
'''
|
||||
img_height, img_width = img.shape[0:2]
|
||||
left = int(np.min(points[:, 0]))
|
||||
right = int(np.max(points[:, 0]))
|
||||
top = int(np.min(points[:, 1]))
|
||||
bottom = int(np.max(points[:, 1]))
|
||||
img_crop = img[top:bottom, left:right, :].copy()
|
||||
points[:, 0] = points[:, 0] - left
|
||||
points[:, 1] = points[:, 1] - top
|
||||
'''
|
||||
assert len(points) == 4, "shape of points must be 4*2"
|
||||
img_crop_width = int(
|
||||
max(
|
||||
np.linalg.norm(points[0] - points[1]),
|
||||
np.linalg.norm(points[2] - points[3])))
|
||||
img_crop_height = int(
|
||||
max(
|
||||
np.linalg.norm(points[0] - points[3]),
|
||||
np.linalg.norm(points[1] - points[2])))
|
||||
pts_std = np.float32([[0, 0], [img_crop_width, 0],
|
||||
[img_crop_width, img_crop_height],
|
||||
[0, img_crop_height]])
|
||||
M = cv2.getPerspectiveTransform(points, pts_std)
|
||||
dst_img = cv2.warpPerspective(
|
||||
img,
|
||||
M, (img_crop_width, img_crop_height),
|
||||
borderMode=cv2.BORDER_REPLICATE,
|
||||
flags=cv2.INTER_CUBIC)
|
||||
dst_img_height, dst_img_width = dst_img.shape[0:2]
|
||||
if dst_img_height * 1.0 / dst_img_width >= 1.5:
|
||||
dst_img = np.rot90(dst_img)
|
||||
return dst_img
|
||||
|
||||
img_dir = '/home/aistudio/data/CCPD2020/ccpd_green'
|
||||
save_gt_folder = '/home/aistudio/data/CCPD2020/PPOCR'
|
||||
# phase = 'train' # change to val and test to make val dataset and test dataset
|
||||
for phase in ['train','val','test']:
|
||||
make_label(img_dir, save_gt_folder, phase)
|
||||
```
|
||||
|
||||
通过上述命令可以完成了`训练集`,`验证集`和`测试集`的制作,制作完成的数据集信息如下:
|
||||
|
||||
| 类型 | 数据集 | 图片地址 | 标签地址 | 图片数量 |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| 检测 | 训练集 | /home/aistudio/data/CCPD2020/ccpd_green/train | /home/aistudio/data/CCPD2020/PPOCR/train/det.txt | 5769 |
|
||||
| 检测 | 验证集 | /home/aistudio/data/CCPD2020/ccpd_green/val | /home/aistudio/data/CCPD2020/PPOCR/val/det.txt | 1001 |
|
||||
| 检测 | 测试集 | /home/aistudio/data/CCPD2020/ccpd_green/test | /home/aistudio/data/CCPD2020/PPOCR/test/det.txt | 5006 |
|
||||
| 识别 | 训练集 | /home/aistudio/data/CCPD2020/PPOCR/train/crop_imgs | /home/aistudio/data/CCPD2020/PPOCR/train/rec.txt | 5769 |
|
||||
| 识别 | 验证集 | /home/aistudio/data/CCPD2020/PPOCR/val/crop_imgs | /home/aistudio/data/CCPD2020/PPOCR/val/rec.txt | 1001 |
|
||||
| 识别 | 测试集 | /home/aistudio/data/CCPD2020/PPOCR/test/crop_imgs | /home/aistudio/data/CCPD2020/PPOCR/test/rec.txt | 5006 |
|
||||
|
||||
在普遍的深度学习流程中,都是在训练集训练,在验证集选择最优模型后在测试集上进行测试。在本例中,我们省略中间步骤,直接在训练集训练,在测试集选择最优模型,因此我们只使用训练集和测试集。
|
||||
|
||||
## 4. 实验
|
||||
|
||||
由于数据集比较少,为了模型更好和更快的收敛,这里选用 PaddleOCR 中的 PP-OCRv3 模型进行文本检测和识别,并且使用 PP-OCRv3 模型参数作为预训练模型。PP-OCRv3在PP-OCRv2的基础上,中文场景端到端Hmean指标相比于PP-OCRv2提升5%, 英文数字模型端到端效果提升11%。详细优化细节请参考[PP-OCRv3](../doc/doc_ch/PP-OCRv3_introduction.md)技术报告。
|
||||
|
||||
由于车牌场景均为端侧设备部署,因此对速度和模型大小有比较高的要求,因此还需要采用量化训练的方式进行模型大小的压缩和模型推理速度的加速。模型量化可以在基本不损失模型的精度的情况下,将FP32精度的模型参数转换为Int8精度,减小模型参数大小并加速计算,使用量化后的模型在移动端等部署时更具备速度优势。
|
||||
|
||||
因此,本实验中对于车牌检测和识别有如下3种方案:
|
||||
|
||||
1. PP-OCRv3中英文超轻量预训练模型直接预测
|
||||
2. CCPD车牌数据集在PP-OCRv3模型上fine-tune
|
||||
3. CCPD车牌数据集在PP-OCRv3模型上fine-tune后量化
|
||||
|
||||
### 4.1 检测
|
||||
#### 4.1.1 预训练模型直接预测
|
||||
|
||||
从下表中下载PP-OCRv3文本检测预训练模型
|
||||
|
||||
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|ch_PP-OCRv3_det| 【最新】原始超轻量模型,支持中英文、多语种文本检测 |[ch_PP-OCRv3_det_cml.yml](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar)|
|
||||
|
||||
使用如下命令下载预训练模型
|
||||
|
||||
```bash
|
||||
mkdir models
|
||||
cd models
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
|
||||
tar -xf ch_PP-OCRv3_det_distill_train.tar
|
||||
cd /home/aistudio/PaddleOCR
|
||||
```
|
||||
|
||||
预训练模型下载完成后,我们使用[ch_PP-OCRv3_det_student.yml](../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml) 配置文件进行后续实验,在开始评估之前需要对配置文件中部分字段进行设置,具体如下:
|
||||
|
||||
1. 模型存储和训练相关:
|
||||
1. Global.pretrained_model: 指向PP-OCRv3文本检测预训练模型地址
|
||||
2. 数据集相关
|
||||
1. Eval.dataset.data_dir:指向测试集图片存放目录
|
||||
2. Eval.dataset.label_file_list:指向测试集标注文件
|
||||
|
||||
上述字段均为必须修改的字段,可以通过修改配置文件的方式改动,也可在不需要修改配置文件的情况下,改变训练的参数。这里使用不改变配置文件的方式 。使用如下命令进行PP-OCRv3文本检测预训练模型的评估
|
||||
|
||||
|
||||
```bash
|
||||
python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/det.txt]
|
||||
```
|
||||
上述指令中,通过-c 选择训练使用配置文件,通过-o参数在不需要修改配置文件的情况下,改变训练的参数。
|
||||
|
||||
使用预训练模型进行评估,指标如下所示:
|
||||
|
||||
| 方案 |hmeans|
|
||||
|---------------------------|---|
|
||||
| PP-OCRv3中英文超轻量检测预训练模型直接预测 |76.12%|
|
||||
|
||||
#### 4.1.2 CCPD车牌数据集fine-tune
|
||||
|
||||
**训练**
|
||||
|
||||
为了进行fine-tune训练,我们需要在配置文件中设置需要使用的预训练模型地址,学习率和数据集等参数。 具体如下:
|
||||
|
||||
1. 模型存储和训练相关:
|
||||
1. Global.pretrained_model: 指向PP-OCRv3文本检测预训练模型地址
|
||||
2. Global.eval_batch_step: 模型多少step评估一次,这里设为从第0个step开始没隔772个step评估一次,772为一个epoch总的step数。
|
||||
2. 优化器相关:
|
||||
1. Optimizer.lr.name: 学习率衰减器设为常量 Const
|
||||
2. Optimizer.lr.learning_rate: 做 fine-tune 实验,学习率需要设置的比较小,此处学习率设为配置文件中的0.05倍
|
||||
3. Optimizer.lr.warmup_epoch: warmup_epoch设为0
|
||||
3. 数据集相关:
|
||||
1. Train.dataset.data_dir:指向训练集图片存放目录
|
||||
2. Train.dataset.label_file_list:指向训练集标注文件
|
||||
3. Eval.dataset.data_dir:指向测试集图片存放目录
|
||||
4. Eval.dataset.label_file_list:指向测试集标注文件
|
||||
|
||||
使用如下代码即可启动在CCPD车牌数据集上的fine-tune。
|
||||
|
||||
```bash
|
||||
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams \
|
||||
Global.save_model_dir=output/CCPD/det \
|
||||
Global.eval_batch_step="[0, 772]" \
|
||||
Optimizer.lr.name=Const \
|
||||
Optimizer.lr.learning_rate=0.0005 \
|
||||
Optimizer.lr.warmup_epoch=0 \
|
||||
Train.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Train.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/train/det.txt] \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/det.txt]
|
||||
```
|
||||
|
||||
在上述命令中,通过`-o`的方式修改了配置文件中的参数。
|
||||
|
||||
|
||||
**评估**
|
||||
|
||||
训练完成后使用如下命令进行评估
|
||||
|
||||
|
||||
```bash
|
||||
python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/det.txt]
|
||||
```
|
||||
|
||||
使用预训练模型和CCPD车牌数据集fine-tune,指标分别如下:
|
||||
|
||||
|方案|hmeans|
|
||||
|---|---|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型直接预测|76.12%|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 fine-tune|99%|
|
||||
|
||||
可以看到进行fine-tune能显著提升车牌检测的效果。
|
||||
|
||||
#### 4.1.3 CCPD车牌数据集fine-tune+量化训练
|
||||
|
||||
此处采用 PaddleOCR 中提供好的[量化教程](../deploy/slim/quantization/README.md)对模型进行量化训练。
|
||||
|
||||
量化训练可通过如下命令启动:
|
||||
|
||||
```bash
|
||||
python3.7 deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \
|
||||
Global.save_model_dir=output/CCPD/det_quant \
|
||||
Global.eval_batch_step="[0, 772]" \
|
||||
Optimizer.lr.name=Const \
|
||||
Optimizer.lr.learning_rate=0.0005 \
|
||||
Optimizer.lr.warmup_epoch=0 \
|
||||
Train.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Train.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/train/det.txt] \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/det.txt]
|
||||
```
|
||||
|
||||
量化后指标对比如下
|
||||
|
||||
|方案|hmeans| 模型大小 | 预测速度(lite) |
|
||||
|---|---|------|------------|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 fine-tune|99%| 2.5M | 223ms |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 fine-tune+量化|98.91%| 1M | 189ms |
|
||||
|
||||
可以看到通过量化训练在精度几乎无损的情况下,降低模型体积60%并且推理速度提升15%。
|
||||
|
||||
速度测试基于[PaddleOCR lite教程](../deploy/lite/readme_ch.md)完成。
|
||||
|
||||
#### 4.1.4 模型导出
|
||||
|
||||
使用如下命令可以将训练好的模型进行导出
|
||||
|
||||
* 非量化模型
|
||||
```bash
|
||||
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/det/infer
|
||||
```
|
||||
* 量化模型
|
||||
```bash
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det_quant/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/det/infer
|
||||
```
|
||||
|
||||
### 4.2 识别
|
||||
#### 4.2.1 预训练模型直接预测
|
||||
|
||||
从下表中下载PP-OCRv3文本识别预训练模型
|
||||
|
||||
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|ch_PP-OCRv3_rec|【最新】原始超轻量模型,支持中英文、数字识别|[ch_PP-OCRv3_rec_distillation.yml](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)| 12.4M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
|
||||
|
||||
使用如下命令下载预训练模型
|
||||
|
||||
```bash
|
||||
mkdir models
|
||||
cd models
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
|
||||
tar -xf ch_PP-OCRv3_rec_train.tar
|
||||
cd /home/aistudio/PaddleOCR
|
||||
```
|
||||
|
||||
PaddleOCR提供的PP-OCRv3识别模型采用蒸馏训练策略,因此提供的预训练模型中会包含`Teacher`和`Student`模型的参数,详细信息可参考[knowledge_distillation.md](../doc/doc_ch/knowledge_distillation.md)。 因此,模型下载完成后需要使用如下代码提取`Student`模型的参数:
|
||||
|
||||
```python
|
||||
import paddle
|
||||
# 加载预训练模型
|
||||
all_params = paddle.load("models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
|
||||
# 查看权重参数的keys
|
||||
print(all_params.keys())
|
||||
# 学生模型的权重提取
|
||||
s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
|
||||
# 查看学生模型权重参数的keys
|
||||
print(s_params.keys())
|
||||
# 保存
|
||||
paddle.save(s_params, "models/ch_PP-OCRv3_rec_train/student.pdparams")
|
||||
```
|
||||
|
||||
预训练模型下载完成后,我们使用[ch_PP-OCRv3_rec.yml](../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml) 配置文件进行后续实验,在开始评估之前需要对配置文件中部分字段进行设置,具体如下:
|
||||
|
||||
1. 模型存储和训练相关:
|
||||
1. Global.pretrained_model: 指向PP-OCRv3文本识别预训练模型地址
|
||||
2. 数据集相关
|
||||
1. Eval.dataset.data_dir:指向测试集图片存放目录
|
||||
2. Eval.dataset.label_file_list:指向测试集标注文件
|
||||
|
||||
使用如下命令进行PP-OCRv3文本识别预训练模型的评估
|
||||
|
||||
```bash
|
||||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/rec.txt]
|
||||
```
|
||||
|
||||
如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
<div align="left">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
|
||||
|
||||
评估部分日志如下:
|
||||
```bash
|
||||
[2022/05/12 19:52:02] ppocr INFO: load pretrain successful from models/ch_PP-OCRv3_rec_train/best_accuracy
|
||||
eval model:: 100%|██████████████████████████████| 40/40 [00:15<00:00, 2.57it/s]
|
||||
[2022/05/12 19:52:17] ppocr INFO: metric eval ***************
|
||||
[2022/05/12 19:52:17] ppocr INFO: acc:0.0
|
||||
[2022/05/12 19:52:17] ppocr INFO: norm_edit_dis:0.8656084923002452
|
||||
[2022/05/12 19:52:17] ppocr INFO: Teacher_acc:0.000399520574511545
|
||||
[2022/05/12 19:52:17] ppocr INFO: Teacher_norm_edit_dis:0.8657902943394548
|
||||
[2022/05/12 19:52:17] ppocr INFO: fps:1443.1801978719905
|
||||
|
||||
```
|
||||
使用预训练模型进行评估,指标如下所示:
|
||||
|
||||
|方案|acc|
|
||||
|---|---|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测|0%|
|
||||
|
||||
从评估日志中可以看到,直接使用PP-OCRv3预训练模型进行评估,acc非常低,但是norm_edit_dis很高。因此,我们猜测是模型大部分文字识别是对的,只有少部分文字识别错误。使用如下命令进行infer查看模型的推理结果进行验证:
|
||||
|
||||
|
||||
```bash
|
||||
python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams \
|
||||
Global.infer_img=/home/aistudio/data/CCPD2020/PPOCR/test/crop_imgs/0_0_0_3_32_30_31_30_30.jpg
|
||||
```
|
||||
|
||||
输出部分日志如下:
|
||||
```bash
|
||||
[2022/05/01 08:51:57] ppocr INFO: train with paddle 2.2.2 and device CUDAPlace(0)
|
||||
W0501 08:51:57.127391 11326 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
|
||||
W0501 08:51:57.132315 11326 device_context.cc:465] device: 0, cuDNN Version: 7.6.
|
||||
[2022/05/01 08:52:00] ppocr INFO: load pretrain successful from models/ch_PP-OCRv3_rec_train/student
|
||||
[2022/05/01 08:52:00] ppocr INFO: infer_img: /home/aistudio/data/CCPD2020/PPOCR/test/crop_imgs/0_0_3_32_30_31_30_30.jpg
|
||||
[2022/05/01 08:52:00] ppocr INFO: result: {"Student": {"label": "皖A·D86766", "score": 0.9552637934684753}, "Teacher": {"label": "皖A·D86766", "score": 0.9917094707489014}}
|
||||
[2022/05/01 08:52:00] ppocr INFO: success!
|
||||
```
|
||||
|
||||
从infer结果可以看到,车牌中的文字大部分都识别正确,只是多识别出了一个`·`。针对这种情况,有如下两种方案:
|
||||
1. 直接通过后处理去掉多识别的`·`。
|
||||
2. 进行 fine-tune。
|
||||
|
||||
#### 4.2.2 预训练模型直接预测+改动后处理
|
||||
|
||||
直接通过后处理去掉多识别的`·`,在后处理的改动比较简单,只需在 [ppocr/postprocess/rec_postprocess.py](../ppocr/postprocess/rec_postprocess.py) 文件的76行添加如下代码:
|
||||
```python
|
||||
text = text.replace('·','')
|
||||
```
|
||||
|
||||
改动前后指标对比:
|
||||
|
||||
|方案|acc|
|
||||
|---|---|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测|0.2%|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测+后处理去掉多识别的`·`|90.97%|
|
||||
|
||||
可以看到,去掉多余的`·`能大幅提高精度。
|
||||
|
||||
#### 4.2.3 CCPD车牌数据集fine-tune
|
||||
|
||||
**训练**
|
||||
|
||||
为了进行fine-tune训练,我们需要在配置文件中设置需要使用的预训练模型地址,学习率和数据集等参数。 具体如下:
|
||||
|
||||
1. 模型存储和训练相关:
|
||||
1. Global.pretrained_model: 指向PP-OCRv3文本识别预训练模型地址
|
||||
2. Global.eval_batch_step: 模型多少step评估一次,这里设为从第0个step开始没隔45个step评估一次,45为一个epoch总的step数。
|
||||
2. 优化器相关
|
||||
1. Optimizer.lr.name: 学习率衰减器设为常量 Const
|
||||
2. Optimizer.lr.learning_rate: 做 fine-tune 实验,学习率需要设置的比较小,此处学习率设为配置文件中的0.05倍
|
||||
3. Optimizer.lr.warmup_epoch: warmup_epoch设为0
|
||||
3. 数据集相关
|
||||
1. Train.dataset.data_dir:指向训练集图片存放目录
|
||||
2. Train.dataset.label_file_list:指向训练集标注文件
|
||||
3. Eval.dataset.data_dir:指向测试集图片存放目录
|
||||
4. Eval.dataset.label_file_list:指向测试集标注文件
|
||||
|
||||
使用如下命令启动 fine-tune
|
||||
|
||||
```bash
|
||||
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams \
|
||||
Global.save_model_dir=output/CCPD/rec/ \
|
||||
Global.eval_batch_step="[0, 90]" \
|
||||
Optimizer.lr.name=Const \
|
||||
Optimizer.lr.learning_rate=0.0005 \
|
||||
Optimizer.lr.warmup_epoch=0 \
|
||||
Train.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Train.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/train/rec.txt] \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/rec.txt]
|
||||
```
|
||||
|
||||
**评估**
|
||||
|
||||
训练完成后使用如下命令进行评估
|
||||
|
||||
```bash
|
||||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/rec.txt]
|
||||
```
|
||||
|
||||
使用预训练模型和CCPD车牌数据集fine-tune,指标分别如下:
|
||||
|
||||
|方案| acc |
|
||||
|---|--------|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测| 0% |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测+后处理去掉多识别的`·`| 90.97% |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型 fine-tune| 94.54% |
|
||||
|
||||
可以看到进行fine-tune能显著提升车牌识别的效果。
|
||||
|
||||
#### 4.2.4 CCPD车牌数据集fine-tune+量化训练
|
||||
|
||||
此处采用 PaddleOCR 中提供好的[量化教程](../deploy/slim/quantization/README.md)对模型进行量化训练。
|
||||
|
||||
量化训练可通过如下命令启动:
|
||||
|
||||
```bash
|
||||
python3.7 deploy/slim/quantization/quant.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \
|
||||
Global.save_model_dir=output/CCPD/rec_quant/ \
|
||||
Global.eval_batch_step="[0, 90]" \
|
||||
Optimizer.lr.name=Const \
|
||||
Optimizer.lr.learning_rate=0.0005 \
|
||||
Optimizer.lr.warmup_epoch=0 \
|
||||
Train.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Train.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/train/rec.txt] \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/rec.txt]
|
||||
```
|
||||
|
||||
量化后指标对比如下
|
||||
|
||||
|方案| acc | 模型大小 | 预测速度(lite) |
|
||||
|---|--------|-------|------------|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型 fine-tune| 94.54% | 10.3M | 4.2ms |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型 fine-tune + 量化| 93.4% | 4.8M | 1.8ms |
|
||||
|
||||
可以看到量化后能降低模型体积53%并且推理速度提升57%,但是由于识别数据过少,量化带来了1%的精度下降。
|
||||
|
||||
速度测试基于[PaddleOCR lite教程](../deploy/lite/readme_ch.md)完成。
|
||||
|
||||
#### 4.2.5 模型导出
|
||||
|
||||
使用如下命令可以将训练好的模型进行导出。
|
||||
|
||||
* 非量化模型
|
||||
```bash
|
||||
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/rec/infer
|
||||
```
|
||||
* 量化模型
|
||||
```bash
|
||||
python deploy/slim/quantization/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec_quant/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/rec_quant/infer
|
||||
```
|
||||
|
||||
### 4.3 计算End2End指标
|
||||
|
||||
端到端指标可通过 [PaddleOCR内置脚本](../tools/end2end/readme.md) 进行计算,具体步骤如下:
|
||||
|
||||
1. 导出模型
|
||||
|
||||
通过如下命令进行模型的导出。注意,量化模型导出时,需要配置eval数据集
|
||||
|
||||
```bash
|
||||
# 检测模型
|
||||
|
||||
# 预训练模型
|
||||
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams \
|
||||
Global.save_inference_dir=output/ch_PP-OCRv3_det_distill_train/infer
|
||||
|
||||
# 非量化模型
|
||||
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/det/infer
|
||||
|
||||
# 量化模型
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
|
||||
Global.pretrained_model=output/CCPD/det_quant/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/det_quant/infer \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/ccpd_green \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/det.txt] \
|
||||
Eval.loader.num_workers=0
|
||||
|
||||
# 识别模型
|
||||
|
||||
# 预训练模型
|
||||
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams \
|
||||
Global.save_inference_dir=output/ch_PP-OCRv3_rec_train/infer
|
||||
|
||||
# 非量化模型
|
||||
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/rec/infer
|
||||
|
||||
# 量化模型
|
||||
python deploy/slim/quantization/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \
|
||||
Global.pretrained_model=output/CCPD/rec_quant/best_accuracy.pdparams \
|
||||
Global.save_inference_dir=output/CCPD/rec_quant/infer \
|
||||
Eval.dataset.data_dir=/home/aistudio/data/CCPD2020/PPOCR \
|
||||
Eval.dataset.label_file_list=[/home/aistudio/data/CCPD2020/PPOCR/test/rec.txt]
|
||||
```
|
||||
|
||||
2. 用导出的模型对测试集进行预测
|
||||
|
||||
此处,分别使用PP-OCRv3预训练模型,fintune模型和量化模型对测试集的所有图像进行预测,命令如下:
|
||||
|
||||
```bash
|
||||
# PP-OCRv3中英文超轻量检测预训练模型,PP-OCRv3中英文超轻量识别预训练模型
|
||||
python3 tools/infer/predict_system.py --det_model_dir=models/ch_PP-OCRv3_det_distill_train/infer --rec_model_dir=models/ch_PP-OCRv3_rec_train/infer --det_limit_side_len=736 --det_limit_type=min --image_dir=/home/aistudio/data/CCPD2020/ccpd_green/test/ --draw_img_save_dir=infer/pretrain --use_dilation=true
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型+fine-tune,PP-OCRv3中英文超轻量识别预训练模型+fine-tune
|
||||
python3 tools/infer/predict_system.py --det_model_dir=output/CCPD/det/infer --rec_model_dir=output/CCPD/rec/infer --det_limit_side_len=736 --det_limit_type=min --image_dir=/home/aistudio/data/CCPD2020/ccpd_green/test/ --draw_img_save_dir=infer/fine-tune --use_dilation=true
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型 fine-tune +量化,PP-OCRv3中英文超轻量识别预训练模型 fine-tune +量化 结果转换和评估
|
||||
python3 tools/infer/predict_system.py --det_model_dir=output/CCPD/det_quant/infer --rec_model_dir=output/CCPD/rec_quant/infer --det_limit_side_len=736 --det_limit_type=min --image_dir=/home/aistudio/data/CCPD2020/ccpd_green/test/ --draw_img_save_dir=infer/quant --use_dilation=true
|
||||
```
|
||||
|
||||
3. 转换label并计算指标
|
||||
|
||||
将gt和上一步保存的预测结果转换为端对端评测需要的数据格式,并根据转换后的数据进行端到端指标计算
|
||||
|
||||
```bash
|
||||
python3 tools/end2end/convert_ppocr_label.py --mode=gt --label_path=/home/aistudio/data/CCPD2020/PPOCR/test/det.txt --save_folder=end2end/gt
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型,PP-OCRv3中英文超轻量识别预训练模型 结果转换和评估
|
||||
python3 tools/end2end/convert_ppocr_label.py --mode=pred --label_path=infer/pretrain/system_results.txt --save_folder=end2end/pretrain
|
||||
python3 tools/end2end/eval_end2end.py end2end/gt end2end/pretrain
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型,PP-OCRv3中英文超轻量识别预训练模型+后处理去掉多识别的`·` 结果转换和评估
|
||||
# 需手动修改后处理函数
|
||||
python3 tools/end2end/convert_ppocr_label.py --mode=pred --label_path=infer/post/system_results.txt --save_folder=end2end/post
|
||||
python3 tools/end2end/eval_end2end.py end2end/gt end2end/post
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型 fine-tune,PP-OCRv3中英文超轻量识别预训练模型 fine-tune 结果转换和评估
|
||||
python3 tools/end2end/convert_ppocr_label.py --mode=pred --label_path=infer/fine-tune/system_results.txt --save_folder=end2end/fine-tune
|
||||
python3 tools/end2end/eval_end2end.py end2end/gt end2end/fine-tune
|
||||
|
||||
# PP-OCRv3中英文超轻量检测预训练模型 fine-tune +量化,PP-OCRv3中英文超轻量识别预训练模型 fine-tune +量化 结果转换和评估
|
||||
python3 tools/end2end/convert_ppocr_label.py --mode=pred --label_path=infer/quant/system_results.txt --save_folder=end2end/quant
|
||||
python3 tools/end2end/eval_end2end.py end2end/gt end2end/quant
|
||||
```
|
||||
|
||||
日志如下:
|
||||
```bash
|
||||
The convert label saved in end2end/gt
|
||||
The convert label saved in end2end/pretrain
|
||||
start testing...
|
||||
hit, dt_count, gt_count 2 5988 5006
|
||||
character_acc: 70.42%
|
||||
avg_edit_dist_field: 2.37
|
||||
avg_edit_dist_img: 2.37
|
||||
precision: 0.03%
|
||||
recall: 0.04%
|
||||
fmeasure: 0.04%
|
||||
The convert label saved in end2end/post
|
||||
start testing...
|
||||
hit, dt_count, gt_count 4224 5988 5006
|
||||
character_acc: 81.59%
|
||||
avg_edit_dist_field: 1.47
|
||||
avg_edit_dist_img: 1.47
|
||||
precision: 70.54%
|
||||
recall: 84.38%
|
||||
fmeasure: 76.84%
|
||||
The convert label saved in end2end/fine-tune
|
||||
start testing...
|
||||
hit, dt_count, gt_count 4286 4898 5006
|
||||
character_acc: 94.16%
|
||||
avg_edit_dist_field: 0.47
|
||||
avg_edit_dist_img: 0.47
|
||||
precision: 87.51%
|
||||
recall: 85.62%
|
||||
fmeasure: 86.55%
|
||||
The convert label saved in end2end/quant
|
||||
start testing...
|
||||
hit, dt_count, gt_count 4349 4951 5006
|
||||
character_acc: 94.13%
|
||||
avg_edit_dist_field: 0.47
|
||||
avg_edit_dist_img: 0.47
|
||||
precision: 87.84%
|
||||
recall: 86.88%
|
||||
fmeasure: 87.36%
|
||||
```
|
||||
|
||||
各个方案端到端指标如下:
|
||||
|
||||
|模型| 指标 |
|
||||
|---|--------|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型| 0.04% |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`| 78.27% |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune| 87.14% |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化 <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化| 88% |
|
||||
|
||||
从结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到78.27%,在CCPD数据集上进行 fine-tune 后指标进一步提升到87.14%, 在经过量化训练之后,由于检测模型的recall变高,指标进一步提升到88%。但是这个结果仍旧不符合检测模型+识别模型的真实性能(99%*94%=93%),因此我们需要对 base case 进行具体分析。
|
||||
|
||||
在之前的端到端预测结果中,可以看到很多不符合车牌标注的文字被识别出来, 因此可以进行简单的过滤来提升precision
|
||||
|
||||
为了快速评估,我们在 ` tools/end2end/convert_ppocr_label.py` 脚本的 58 行加入如下代码,对非8个字符的结果进行过滤
|
||||
```python
|
||||
if len(txt) != 8: # 车牌字符串长度为8
|
||||
continue
|
||||
```
|
||||
|
||||
此外,通过可视化box可以发现有很多框都是竖直翻转之后的框,并且没有完全框住车牌边界,因此需要进行框的竖直翻转以及轻微扩大,示意图如下:
|
||||
|
||||

|
||||
|
||||
修改前后个方案指标对比如下:
|
||||
|
||||
|
||||
各个方案端到端指标如下:
|
||||
|
||||
|模型|base|A:识别结果过滤|B:use_dilation|C:flip_box|best|
|
||||
|---|---|---|---|---|---|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型|0.04%|0.08%|0.02%|0.05%|0.00%(A)|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`|78.27%|90.84%|78.61%|79.43%|91.66%(A+B+C)|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune|87.14%|90.40%|87.66%|89.98|92.5%(A+B+C)|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化 <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化|88%|90.54%|88.5%|89.46%|92.02%(A+B+C)|
|
||||
|
||||
|
||||
从结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到91.66%,在CCPD数据集上进行 fine-tune 后指标进一步提升到92.5%, 在经过量化训练之后,指标变为92.02%。
|
||||
|
||||
### 4.4 部署
|
||||
|
||||
- 基于 Paddle Inference 的python推理
|
||||
|
||||
检测模型和识别模型分别 fine-tune 并导出为inference模型之后,可以使用如下命令基于 Paddle Inference 进行端到端推理并对结果进行可视化。
|
||||
|
||||
```bash
|
||||
python tools/infer/predict_system.py \
|
||||
--det_model_dir=output/CCPD/det/infer/ \
|
||||
--rec_model_dir=output/CCPD/rec/infer/ \
|
||||
--image_dir="/home/aistudio/data/CCPD2020/ccpd_green/test/04131106321839081-92_258-159&509_530&611-527&611_172&599_159&509_530&525-0_0_3_32_30_31_30_30-109-106.jpg" \
|
||||
--rec_image_shape=3,48,320
|
||||
```
|
||||
推理结果如下
|
||||
|
||||

|
||||
|
||||
- 端侧部署
|
||||
|
||||
端侧部署我们采用基于 PaddleLite 的 cpp 推理。Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。具体可参考 [PaddleOCR lite教程](../deploy/lite/readme_ch.md)
|
||||
|
||||
|
||||
### 4.5 实验总结
|
||||
|
||||
我们分别使用PP-OCRv3中英文超轻量预训练模型在车牌数据集上进行了直接评估和 fine-tune 和 fine-tune +量化3种方案的实验,并基于[PaddleOCR lite教程](../deploy/lite/readme_ch.md)进行了速度测试,指标对比如下:
|
||||
|
||||
- 检测
|
||||
|
||||
|方案|hmeans| 模型大小 | 预测速度(lite) |
|
||||
|---|---|------|------------|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型直接预测|76.12%|2.5M| 233ms |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 fine-tune|99%| 2.5M | 233ms |
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 fine-tune + 量化|98.91%| 1M | 189ms |fine-tune
|
||||
|
||||
- 识别
|
||||
|
||||
|方案| acc | 模型大小 | 预测速度(lite) |
|
||||
|---|--------|-------|------------|
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测| 0% |10.3M| 4.2ms |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型直接预测+后处理去掉多识别的`·`| 90.97% |10.3M| 4.2ms |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型 fine-tune| 94.54% | 10.3M | 4,2ms |
|
||||
|PP-OCRv3中英文超轻量识别预训练模型 fine-tune + 量化| 93.4% | 4.8M | 1.8ms |
|
||||
|
||||
|
||||
- 端到端指标如下:
|
||||
|
||||
|方案|fmeasure|模型大小|预测速度(lite) |
|
||||
|---|---|---|---|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型|0.08%|12.8M|298ms|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型 <br> PP-OCRv3中英文超轻量识别预训练模型 + 后处理去掉多识别的`·`|91.66%|12.8M|298ms|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune|92.5%|12.8M|298ms|
|
||||
|PP-OCRv3中英文超轻量检测预训练模型+fine-tune+量化 <br> PP-OCRv3中英文超轻量识别预训练模型+fine-tune+量化|92.02%|5.8M|224ms|
|
||||
|
||||
|
||||
**结论**
|
||||
|
||||
PP-OCRv3的检测模型在未经过fine-tune的情况下,在车牌数据集上也有一定的精度,经过 fine-tune 后能够极大的提升检测效果,精度达到99%。在使用量化训练后检测模型的精度几乎无损,并且模型大小压缩60%。
|
||||
|
||||
PP-OCRv3的识别模型在未经过fine-tune的情况下,在车牌数据集上精度为0,但是经过分析可以知道,模型大部分字符都预测正确,但是会多预测一个特殊字符,去掉这个特殊字符后,精度达到90%。PP-OCRv3识别模型在经过 fine-tune 后识别精度进一步提升,达到94.4%。在使用量化训练后识别模型大小压缩53%,但是由于数据量多少,带来了1%的精度损失。
|
||||
|
||||
从端到端结果中可以看到对预训练模型不做修改,只根据场景下的具体情况进行后处理的修改就能大幅提升端到端指标到91.66%,在CCPD数据集上进行 fine-tune 后指标进一步提升到92.5%, 在经过量化训练之后,指标轻微下降到92.02%但模型大小降低54%。
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
# 高精度中文场景文本识别模型SVTR
|
||||
|
||||
## 1. 简介
|
||||
|
||||
PP-OCRv3是百度开源的超轻量级场景文本检测识别模型库,其中超轻量的场景中文识别模型SVTR_LCNet使用了SVTR算法结构。为了保证速度,SVTR_LCNet将SVTR模型的Local Blocks替换为LCNet,使用两层Global Blocks。在中文场景中,PP-OCRv3识别主要使用如下优化策略:
|
||||
- GTC:Attention指导CTC训练策略;
|
||||
- TextConAug:挖掘文字上下文信息的数据增广策略;
|
||||
- TextRotNet:自监督的预训练模型;
|
||||
- UDML:联合互学习策略;
|
||||
- UIM:无标注数据挖掘方案。
|
||||
|
||||
其中 *UIM:无标注数据挖掘方案* 使用了高精度的SVTR中文模型进行无标注文件的刷库,该模型在PP-OCRv3识别的数据集上训练,精度对比如下表。
|
||||
|
||||
|中文识别算法|模型|UIM|精度|
|
||||
| --- | --- | --- |--- |
|
||||
|PP-OCRv3|SVTR_LCNet| w/o |78.4%|
|
||||
|PP-OCRv3|SVTR_LCNet| w |79.4%|
|
||||
|SVTR|SVTR-Tiny|-|82.5%|
|
||||
|
||||
aistudio项目链接: [高精度中文场景文本识别模型SVTR](https://aistudio.baidu.com/aistudio/projectdetail/4263032)
|
||||
|
||||
## 2. SVTR中文模型使用
|
||||
|
||||
### 环境准备
|
||||
|
||||
|
||||
本任务基于Aistudio完成, 具体环境如下:
|
||||
|
||||
- 操作系统: Linux
|
||||
- PaddlePaddle: 2.3
|
||||
- PaddleOCR: dygraph
|
||||
|
||||
下载 PaddleOCR代码
|
||||
|
||||
```bash
|
||||
git clone -b dygraph https://github.com/PaddlePaddle/PaddleOCR
|
||||
```
|
||||
|
||||
安装依赖库
|
||||
|
||||
```bash
|
||||
pip install -r PaddleOCR/requirements.txt -i https://mirror.baidu.com/pypi/simple
|
||||
```
|
||||
|
||||
### 快速使用
|
||||
|
||||
获取SVTR中文模型文件,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
<div align="center">
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e" width = "150" height = "150" />
|
||||
</div>
|
||||
|
||||
```bash
|
||||
# 解压模型文件
|
||||
tar xf svtr_ch_high_accuracy.tar
|
||||
```
|
||||
|
||||
预测中文文本,以下图为例:
|
||||

|
||||
|
||||
预测命令:
|
||||
|
||||
```bash
|
||||
# CPU预测
|
||||
python tools/infer_rec.py -c configs/rec/rec_svtrnet_ch.yml -o Global.pretrained_model=./svtr_ch_high_accuracy/best_accuracy Global.infer_img=./doc/imgs_words/ch/word_1.jpg Global.use_gpu=False
|
||||
|
||||
# GPU预测
|
||||
#python tools/infer_rec.py -c configs/rec/rec_svtrnet_ch.yml -o Global.pretrained_model=./svtr_ch_high_accuracy/best_accuracy Global.infer_img=./doc/imgs_words/ch/word_1.jpg Global.use_gpu=True
|
||||
```
|
||||
|
||||
可以看到最后打印结果为
|
||||
- result: 韩国小馆 0.9853458404541016
|
||||
|
||||
0.9853458404541016为预测置信度。
|
||||
|
||||
### 推理模型导出与预测
|
||||
|
||||
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
|
||||
|
||||
运行识别模型转inference模型命令,如下:
|
||||
|
||||
```bash
|
||||
python tools/export_model.py -c configs/rec/rec_svtrnet_ch.yml -o Global.pretrained_model=./svtr_ch_high_accuracy/best_accuracy Global.save_inference_dir=./inference/svtr_ch
|
||||
```
|
||||
|
||||
转换成功后,在目录下有三个文件:
|
||||
```shell
|
||||
inference/svtr_ch/
|
||||
├── inference.pdiparams # 识别inference模型的参数文件
|
||||
├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
|
||||
└── inference.pdmodel # 识别inference模型的program文件
|
||||
```
|
||||
|
||||
inference模型预测,命令如下:
|
||||
|
||||
```bash
|
||||
# CPU预测
|
||||
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/ch/word_1.jpg" --rec_algorithm='SVTR' --rec_model_dir=./inference/svtr_ch/ --rec_image_shape='3, 32, 320' --rec_char_dict_path=ppocr/utils/ppocr_keys_v1.txt --use_gpu=False
|
||||
|
||||
# GPU预测
|
||||
#python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/ch/word_1.jpg" --rec_algorithm='SVTR' --rec_model_dir=./inference/svtr_ch/ --rec_image_shape='3, 32, 320' --rec_char_dict_path=ppocr/utils/ppocr_keys_v1.txt --use_gpu=True
|
||||
```
|
||||
|
||||
**注意**
|
||||
|
||||
- 使用SVTR算法时,需要指定--rec_algorithm='SVTR'
|
||||
- 如果使用自定义字典训练的模型,需要将--rec_char_dict_path=ppocr/utils/ppocr_keys_v1.txt修改为自定义的字典
|
||||
- --rec_image_shape='3, 32, 320' 该参数不能去掉
|
||||
Loading…
Reference in New Issue