Merge remote-tracking branch 'origin/dygraph' into dy1
commit
df783f5acf
PPOCRLabel
configs
kie
deploy
cpp_infer
slim/quantization
doc
imgs_results
ppocr
modeling
utils
e2e_metric
e2e_utils
|
|
@ -2449,13 +2449,6 @@ class MainWindow(QMainWindow):
|
|||
export PPLabel and CSV to JSON (PubTabNet)
|
||||
'''
|
||||
import pandas as pd
|
||||
from libs.dataPartitionDialog import DataPartitionDialog
|
||||
|
||||
# data partition user input
|
||||
partitionDialog = DataPartitionDialog(parent=self)
|
||||
partitionDialog.exec()
|
||||
if partitionDialog.getStatus() == False:
|
||||
return
|
||||
|
||||
# automatically save annotations
|
||||
self.saveFilestate()
|
||||
|
|
@ -2478,28 +2471,19 @@ class MainWindow(QMainWindow):
|
|||
labeldict[file] = eval(label)
|
||||
else:
|
||||
labeldict[file] = []
|
||||
|
||||
# read table recognition output
|
||||
TableRec_excel_dir = os.path.join(
|
||||
self.lastOpenDir, 'tableRec_excel_output')
|
||||
|
||||
train_split, val_split, test_split = partitionDialog.getDataPartition()
|
||||
# check validate
|
||||
if train_split + val_split + test_split > 100:
|
||||
msg = "The sum of training, validation and testing data should be less than 100%"
|
||||
QMessageBox.information(self, "Information", msg)
|
||||
return
|
||||
print(train_split, val_split, test_split)
|
||||
train_split, val_split, test_split = float(train_split) / 100., float(val_split) / 100., float(test_split) / 100.
|
||||
train_id = int(len(labeldict) * train_split)
|
||||
val_id = int(len(labeldict) * (train_split + val_split))
|
||||
print('Data partition: train:', train_id,
|
||||
'validation:', val_id - train_id,
|
||||
'test:', len(labeldict) - val_id)
|
||||
|
||||
TableRec_excel_dir = os.path.join(self.lastOpenDir, 'tableRec_excel_output')
|
||||
json_results = []
|
||||
imgid = 0
|
||||
# save txt
|
||||
fid = open(
|
||||
"{}/gt.txt".format(self.lastOpenDir), "w", encoding='utf-8')
|
||||
for image_path in labeldict.keys():
|
||||
# load csv annotations
|
||||
filename, _ = os.path.splitext(os.path.basename(image_path))
|
||||
csv_path = os.path.join(TableRec_excel_dir, filename + '.xlsx')
|
||||
csv_path = os.path.join(
|
||||
TableRec_excel_dir, filename + '.xlsx')
|
||||
if not os.path.exists(csv_path):
|
||||
continue
|
||||
|
||||
|
|
@ -2518,28 +2502,31 @@ class MainWindow(QMainWindow):
|
|||
cells = []
|
||||
for anno in labeldict[image_path]:
|
||||
tokens = list(anno['transcription'])
|
||||
obb = anno['points']
|
||||
hbb = OBB2HBB(np.array(obb)).tolist()
|
||||
cells.append({'tokens': tokens, 'bbox': hbb})
|
||||
|
||||
# data split
|
||||
if imgid < train_id:
|
||||
split = 'train'
|
||||
elif imgid < val_id:
|
||||
split = 'val'
|
||||
else:
|
||||
split = 'test'
|
||||
cells.append({
|
||||
'tokens': tokens,
|
||||
'bbox': anno['points']
|
||||
})
|
||||
|
||||
# save dict
|
||||
html = {'structure': {'tokens': token_list}, 'cell': cells}
|
||||
json_results.append({'filename': os.path.basename(image_path), 'split': split, 'imgid': imgid, 'html': html})
|
||||
imgid += 1
|
||||
|
||||
# save json
|
||||
with open("{}/annotation.json".format(self.lastOpenDir), "w", encoding='utf-8') as fid:
|
||||
fid.write(json.dumps(json_results, ensure_ascii=False))
|
||||
|
||||
msg = 'JSON sucessfully saved in {}/annotation.json'.format(self.lastOpenDir)
|
||||
# 构造标注信息
|
||||
html = {
|
||||
'structure': {
|
||||
'tokens': token_list
|
||||
},
|
||||
'cells': cells
|
||||
}
|
||||
d = {
|
||||
'filename': os.path.basename(image_path),
|
||||
'html': html
|
||||
}
|
||||
# 重构HTML
|
||||
d['gt'] = rebuild_html_from_ppstructure_label(d)
|
||||
fid.write('{}\n'.format(
|
||||
json.dumps(
|
||||
d, ensure_ascii=False)))
|
||||
|
||||
# convert to PP-Structure label format
|
||||
fid.close()
|
||||
msg = 'JSON sucessfully saved in {}/gt.txt'.format(self.lastOpenDir)
|
||||
QMessageBox.information(self, "Information", msg)
|
||||
|
||||
def autolcm(self):
|
||||
|
|
@ -2728,6 +2715,9 @@ class MainWindow(QMainWindow):
|
|||
|
||||
self._update_shape_color(shape)
|
||||
self.keyDialog.addLabelHistory(key_text)
|
||||
|
||||
# save changed shape
|
||||
self.setDirty()
|
||||
|
||||
def undoShapeEdit(self):
|
||||
self.canvas.restoreShape()
|
||||
|
|
|
|||
|
|
@ -611,8 +611,8 @@ class Canvas(QWidget):
|
|||
|
||||
if self.drawing() and not self.prevPoint.isNull() and not self.outOfPixmap(self.prevPoint):
|
||||
p.setPen(QColor(0, 0, 0))
|
||||
p.drawLine(self.prevPoint.x(), 0, self.prevPoint.x(), self.pixmap.height())
|
||||
p.drawLine(0, self.prevPoint.y(), self.pixmap.width(), self.prevPoint.y())
|
||||
p.drawLine(int(self.prevPoint.x()), 0, int(self.prevPoint.x()), self.pixmap.height())
|
||||
p.drawLine(0, int(self.prevPoint.y()), self.pixmap.width(), int(self.prevPoint.y()))
|
||||
|
||||
self.setAutoFillBackground(True)
|
||||
if self.verified:
|
||||
|
|
@ -909,4 +909,4 @@ class Canvas(QWidget):
|
|||
def updateShapeIndex(self):
|
||||
for i in range(len(self.shapes)):
|
||||
self.shapes[i].idx = i
|
||||
self.update()
|
||||
self.update()
|
||||
|
|
|
|||
|
|
@ -1,113 +0,0 @@
|
|||
try:
|
||||
from PyQt5.QtGui import *
|
||||
from PyQt5.QtCore import *
|
||||
from PyQt5.QtWidgets import *
|
||||
except ImportError:
|
||||
from PyQt4.QtGui import *
|
||||
from PyQt4.QtCore import *
|
||||
|
||||
from libs.utils import newIcon
|
||||
|
||||
import time
|
||||
import datetime
|
||||
import json
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
|
||||
BB = QDialogButtonBox
|
||||
|
||||
class DataPartitionDialog(QDialog):
|
||||
def __init__(self, parent=None):
|
||||
super().__init__()
|
||||
self.parnet = parent
|
||||
self.title = 'DATA PARTITION'
|
||||
|
||||
self.train_ratio = 70
|
||||
self.val_ratio = 15
|
||||
self.test_ratio = 15
|
||||
|
||||
self.initUI()
|
||||
|
||||
def initUI(self):
|
||||
self.setWindowTitle(self.title)
|
||||
self.setWindowModality(Qt.ApplicationModal)
|
||||
|
||||
self.flag_accept = True
|
||||
|
||||
if self.parnet.lang == 'ch':
|
||||
msg = "导出JSON前请保存所有图像的标注且关闭EXCEL!"
|
||||
else:
|
||||
msg = "Please save all the annotations and close the EXCEL before exporting JSON!"
|
||||
|
||||
info_msg = QLabel(msg, self)
|
||||
info_msg.setWordWrap(True)
|
||||
info_msg.setStyleSheet("color: red")
|
||||
info_msg.setFont(QFont('Arial', 12))
|
||||
|
||||
train_lbl = QLabel('Train split: ', self)
|
||||
train_lbl.setFont(QFont('Arial', 15))
|
||||
val_lbl = QLabel('Valid split: ', self)
|
||||
val_lbl.setFont(QFont('Arial', 15))
|
||||
test_lbl = QLabel('Test split: ', self)
|
||||
test_lbl.setFont(QFont('Arial', 15))
|
||||
|
||||
self.train_input = QLineEdit(self)
|
||||
self.train_input.setFont(QFont('Arial', 15))
|
||||
self.val_input = QLineEdit(self)
|
||||
self.val_input.setFont(QFont('Arial', 15))
|
||||
self.test_input = QLineEdit(self)
|
||||
self.test_input.setFont(QFont('Arial', 15))
|
||||
|
||||
self.train_input.setText(str(self.train_ratio))
|
||||
self.val_input.setText(str(self.val_ratio))
|
||||
self.test_input.setText(str(self.test_ratio))
|
||||
|
||||
validator = QIntValidator(0, 100)
|
||||
self.train_input.setValidator(validator)
|
||||
self.val_input.setValidator(validator)
|
||||
self.test_input.setValidator(validator)
|
||||
|
||||
gridlayout = QGridLayout()
|
||||
gridlayout.addWidget(info_msg, 0, 0, 1, 2)
|
||||
gridlayout.addWidget(train_lbl, 1, 0)
|
||||
gridlayout.addWidget(val_lbl, 2, 0)
|
||||
gridlayout.addWidget(test_lbl, 3, 0)
|
||||
gridlayout.addWidget(self.train_input, 1, 1)
|
||||
gridlayout.addWidget(self.val_input, 2, 1)
|
||||
gridlayout.addWidget(self.test_input, 3, 1)
|
||||
|
||||
bb = BB(BB.Ok | BB.Cancel, Qt.Horizontal, self)
|
||||
bb.button(BB.Ok).setIcon(newIcon('done'))
|
||||
bb.button(BB.Cancel).setIcon(newIcon('undo'))
|
||||
bb.accepted.connect(self.validate)
|
||||
bb.rejected.connect(self.cancel)
|
||||
gridlayout.addWidget(bb, 4, 0, 1, 2)
|
||||
|
||||
self.setLayout(gridlayout)
|
||||
|
||||
self.show()
|
||||
|
||||
def validate(self):
|
||||
self.flag_accept = True
|
||||
self.accept()
|
||||
|
||||
def cancel(self):
|
||||
self.flag_accept = False
|
||||
self.reject()
|
||||
|
||||
def getStatus(self):
|
||||
return self.flag_accept
|
||||
|
||||
def getDataPartition(self):
|
||||
self.train_ratio = int(self.train_input.text())
|
||||
self.val_ratio = int(self.val_input.text())
|
||||
self.test_ratio = int(self.test_input.text())
|
||||
|
||||
return self.train_ratio, self.val_ratio, self.test_ratio
|
||||
|
||||
def closeEvent(self, event):
|
||||
self.flag_accept = False
|
||||
self.reject()
|
||||
|
||||
|
||||
|
|
@ -176,18 +176,6 @@ def boxPad(box, imgShape, pad : int) -> np.array:
|
|||
return box
|
||||
|
||||
|
||||
def OBB2HBB(obb) -> np.array:
|
||||
"""
|
||||
Convert Oriented Bounding Box to Horizontal Bounding Box.
|
||||
"""
|
||||
hbb = np.zeros(4, dtype=np.int32)
|
||||
hbb[0] = min(obb[:, 0])
|
||||
hbb[1] = min(obb[:, 1])
|
||||
hbb[2] = max(obb[:, 0])
|
||||
hbb[3] = max(obb[:, 1])
|
||||
return hbb
|
||||
|
||||
|
||||
def expand_list(merged, html_list):
|
||||
'''
|
||||
Fill blanks according to merged cells
|
||||
|
|
@ -232,6 +220,26 @@ def convert_token(html_list):
|
|||
return token_list
|
||||
|
||||
|
||||
def rebuild_html_from_ppstructure_label(label_info):
|
||||
from html import escape
|
||||
html_code = label_info['html']['structure']['tokens'].copy()
|
||||
to_insert = [
|
||||
i for i, tag in enumerate(html_code) if tag in ('<td>', '>')
|
||||
]
|
||||
for i, cell in zip(to_insert[::-1], label_info['html']['cells'][::-1]):
|
||||
if cell['tokens']:
|
||||
cell = [
|
||||
escape(token) if len(token) == 1 else token
|
||||
for token in cell['tokens']
|
||||
]
|
||||
cell = ''.join(cell)
|
||||
html_code.insert(i + 1, cell)
|
||||
html_code = ''.join(html_code)
|
||||
html_code = '<html><body><table>{}</table></body></html>'.format(
|
||||
html_code)
|
||||
return html_code
|
||||
|
||||
|
||||
def stepsInfo(lang='en'):
|
||||
if lang == 'ch':
|
||||
msg = "1. 安装与运行:使用上述命令安装与运行程序。\n" \
|
||||
|
|
|
|||
|
|
@ -0,0 +1,472 @@
|
|||
# 智能运营:通用中文表格识别
|
||||
|
||||
- [1. 背景介绍](#1-背景介绍)
|
||||
- [2. 中文表格识别](#2-中文表格识别)
|
||||
- [2.1 环境准备](#21-环境准备)
|
||||
- [2.2 准备数据集](#22-准备数据集)
|
||||
- [2.2.1 划分训练测试集](#221-划分训练测试集)
|
||||
- [2.2.2 查看数据集](#222-查看数据集)
|
||||
- [2.3 训练](#23-训练)
|
||||
- [2.4 验证](#24-验证)
|
||||
- [2.5 训练引擎推理](#25-训练引擎推理)
|
||||
- [2.6 模型导出](#26-模型导出)
|
||||
- [2.7 预测引擎推理](#27-预测引擎推理)
|
||||
- [2.8 表格识别](#28-表格识别)
|
||||
- [3. 表格属性识别](#3-表格属性识别)
|
||||
- [3.1 代码、环境、数据准备](#31-代码环境数据准备)
|
||||
- [3.1.1 代码准备](#311-代码准备)
|
||||
- [3.1.2 环境准备](#312-环境准备)
|
||||
- [3.1.3 数据准备](#313-数据准备)
|
||||
- [3.2 表格属性识别训练](#32-表格属性识别训练)
|
||||
- [3.3 表格属性识别推理和部署](#33-表格属性识别推理和部署)
|
||||
- [3.3.1 模型转换](#331-模型转换)
|
||||
- [3.3.2 模型推理](#332-模型推理)
|
||||
|
||||
## 1. 背景介绍
|
||||
|
||||
中文表格识别在金融行业有着广泛的应用,如保险理赔、财报分析和信息录入等领域。当前,金融行业的表格识别主要以手动录入为主,开发一种自动表格识别成为丞待解决的问题。
|
||||
|
||||
|
||||
|
||||
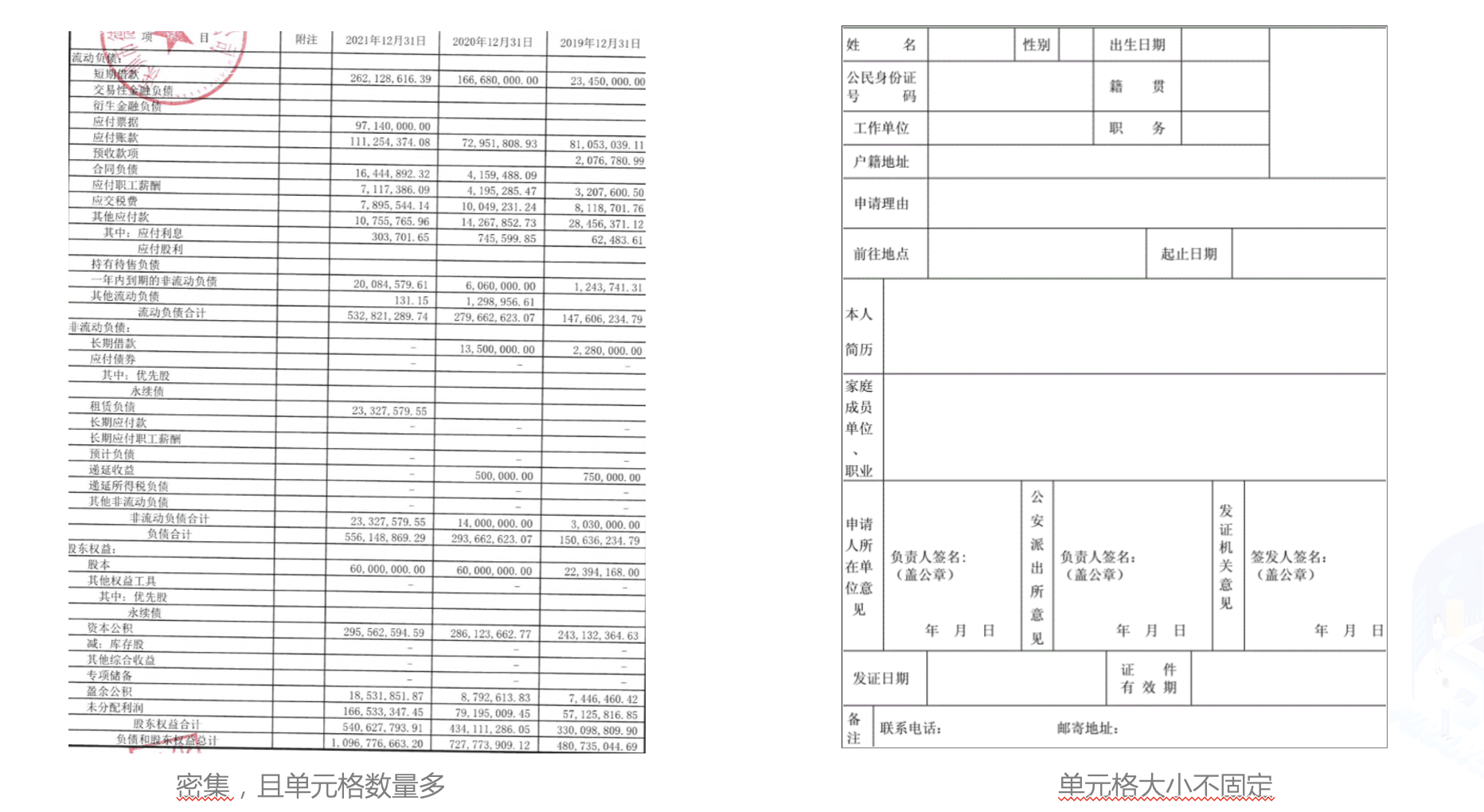
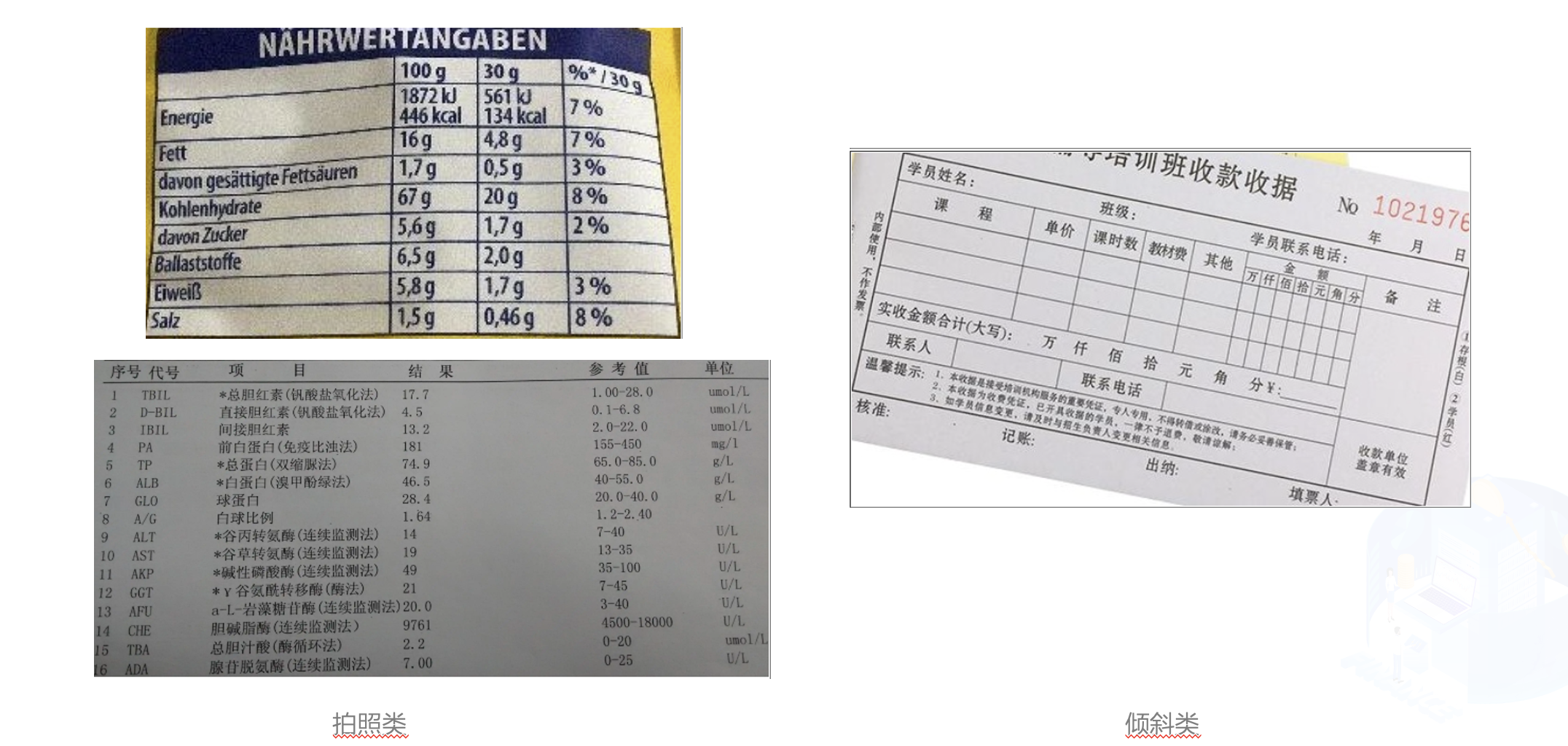
在金融行业中,表格图像主要有清单类的单元格密集型表格,申请表类的大单元格表格,拍照表格和倾斜表格四种主要形式。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
当前的表格识别算法不能很好的处理这些场景下的表格图像。在本例中,我们使用PP-Structurev2最新发布的表格识别模型SLANet来演示如何进行中文表格是识别。同时,为了方便作业流程,我们使用表格属性识别模型对表格图像的属性进行识别,对表格的难易程度进行判断,加快人工进行校对速度。
|
||||
|
||||
本项目AI Studio链接:https://aistudio.baidu.com/aistudio/projectdetail/4588067
|
||||
|
||||
## 2. 中文表格识别
|
||||
### 2.1 环境准备
|
||||
|
||||
|
||||
```python
|
||||
# 下载PaddleOCR代码
|
||||
! git clone -b dygraph https://gitee.com/paddlepaddle/PaddleOCR
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 安装PaddleOCR环境
|
||||
! pip install -r PaddleOCR/requirements.txt --force-reinstall
|
||||
! pip install protobuf==3.19
|
||||
```
|
||||
|
||||
### 2.2 准备数据集
|
||||
|
||||
本例中使用的数据集采用表格[生成工具](https://github.com/WenmuZhou/TableGeneration)制作。
|
||||
|
||||
使用如下命令对数据集进行解压,并查看数据集大小
|
||||
|
||||
|
||||
```python
|
||||
! cd data/data165849 && tar -xf table_gen_dataset.tar && cd -
|
||||
! wc -l data/data165849/table_gen_dataset/gt.txt
|
||||
```
|
||||
|
||||
#### 2.2.1 划分训练测试集
|
||||
|
||||
使用下述命令将数据集划分为训练集和测试集, 这里将90%划分为训练集,10%划分为测试集
|
||||
|
||||
|
||||
```python
|
||||
import random
|
||||
with open('/home/aistudio/data/data165849/table_gen_dataset/gt.txt') as f:
|
||||
lines = f.readlines()
|
||||
random.shuffle(lines)
|
||||
train_len = int(len(lines)*0.9)
|
||||
train_list = lines[:train_len]
|
||||
val_list = lines[train_len:]
|
||||
|
||||
# 保存结果
|
||||
with open('/home/aistudio/train.txt','w',encoding='utf-8') as f:
|
||||
f.writelines(train_list)
|
||||
with open('/home/aistudio/val.txt','w',encoding='utf-8') as f:
|
||||
f.writelines(val_list)
|
||||
```
|
||||
|
||||
划分完成后,数据集信息如下
|
||||
|
||||
|类型|数量|图片地址|标注文件路径|
|
||||
|---|---|---|---|
|
||||
|训练集|18000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/train.txt|
|
||||
|测试集|2000|/home/aistudio/data/data165849/table_gen_dataset|/home/aistudio/val.txt|
|
||||
|
||||
#### 2.2.2 查看数据集
|
||||
|
||||
|
||||
```python
|
||||
import cv2
|
||||
import os, json
|
||||
import numpy as np
|
||||
from matplotlib import pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
def parse_line(data_dir, line):
|
||||
data_line = line.strip("\n")
|
||||
info = json.loads(data_line)
|
||||
file_name = info['filename']
|
||||
cells = info['html']['cells'].copy()
|
||||
structure = info['html']['structure']['tokens'].copy()
|
||||
|
||||
img_path = os.path.join(data_dir, file_name)
|
||||
if not os.path.exists(img_path):
|
||||
print(img_path)
|
||||
return None
|
||||
data = {
|
||||
'img_path': img_path,
|
||||
'cells': cells,
|
||||
'structure': structure,
|
||||
'file_name': file_name
|
||||
}
|
||||
return data
|
||||
|
||||
def draw_bbox(img_path, points, color=(255, 0, 0), thickness=2):
|
||||
if isinstance(img_path, str):
|
||||
img_path = cv2.imread(img_path)
|
||||
img_path = img_path.copy()
|
||||
for point in points:
|
||||
cv2.polylines(img_path, [point.astype(int)], True, color, thickness)
|
||||
return img_path
|
||||
|
||||
|
||||
def rebuild_html(data):
|
||||
html_code = data['structure']
|
||||
cells = data['cells']
|
||||
to_insert = [i for i, tag in enumerate(html_code) if tag in ('<td>', '>')]
|
||||
|
||||
for i, cell in zip(to_insert[::-1], cells[::-1]):
|
||||
if cell['tokens']:
|
||||
text = ''.join(cell['tokens'])
|
||||
# skip empty text
|
||||
sp_char_list = ['<b>', '</b>', '\u2028', ' ', '<i>', '</i>']
|
||||
text_remove_style = skip_char(text, sp_char_list)
|
||||
if len(text_remove_style) == 0:
|
||||
continue
|
||||
html_code.insert(i + 1, text)
|
||||
|
||||
html_code = ''.join(html_code)
|
||||
return html_code
|
||||
|
||||
|
||||
def skip_char(text, sp_char_list):
|
||||
"""
|
||||
skip empty cell
|
||||
@param text: text in cell
|
||||
@param sp_char_list: style char and special code
|
||||
@return:
|
||||
"""
|
||||
for sp_char in sp_char_list:
|
||||
text = text.replace(sp_char, '')
|
||||
return text
|
||||
|
||||
save_dir = '/home/aistudio/vis'
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
image_dir = '/home/aistudio/data/data165849/'
|
||||
html_str = '<table border="1">'
|
||||
|
||||
# 解析标注信息并还原html表格
|
||||
data = parse_line(image_dir, val_list[0])
|
||||
|
||||
img = cv2.imread(data['img_path'])
|
||||
img_name = ''.join(os.path.basename(data['file_name']).split('.')[:-1])
|
||||
img_save_name = os.path.join(save_dir, img_name)
|
||||
boxes = [np.array(x['bbox']) for x in data['cells']]
|
||||
show_img = draw_bbox(data['img_path'], boxes)
|
||||
cv2.imwrite(img_save_name + '_show.jpg', show_img)
|
||||
|
||||
html = rebuild_html(data)
|
||||
html_str += html
|
||||
html_str += '</table>'
|
||||
|
||||
# 显示标注的html字符串
|
||||
from IPython.core.display import display, HTML
|
||||
display(HTML(html_str))
|
||||
# 显示单元格坐标
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### 2.3 训练
|
||||
|
||||
这里选用PP-Structurev2中的表格识别模型[SLANet](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/configs/table/SLANet.yml)
|
||||
|
||||
SLANet是PP-Structurev2全新推出的表格识别模型,相比PP-Structurev1中TableRec-RARE,在速度不变的情况下精度提升4.7%。TEDS提升2%
|
||||
|
||||
|
||||
|算法|Acc|[TEDS(Tree-Edit-Distance-based Similarity)](https://github.com/ibm-aur-nlp/PubTabNet/tree/master/src)|Speed|
|
||||
| --- | --- | --- | ---|
|
||||
| EDD<sup>[2]</sup> |x| 88.3% |x|
|
||||
| TableRec-RARE(ours) | 71.73%| 93.88% |779ms|
|
||||
| SLANet(ours) | 76.31%| 95.89%|766ms|
|
||||
|
||||
进行训练之前先使用如下命令下载预训练模型
|
||||
|
||||
|
||||
```python
|
||||
# 进入PaddleOCR工作目录
|
||||
os.chdir('/home/aistudio/PaddleOCR')
|
||||
# 下载英文预训练模型
|
||||
! wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_train.tar --no-check-certificate
|
||||
! cd ./pretrain_models/ && tar xf en_ppstructure_mobile_v2.0_SLANet_train.tar && cd ../
|
||||
```
|
||||
|
||||
使用如下命令即可启动训练,需要修改的配置有
|
||||
|
||||
|字段|修改值|含义|
|
||||
|---|---|---|
|
||||
|Global.pretrained_model|./pretrain_models/en_ppstructure_mobile_v2.0_SLANet_train/best_accuracy.pdparams|指向英文表格预训练模型地址|
|
||||
|Global.eval_batch_step|562|模型多少step评估一次,一般设置为一个epoch总的step数|
|
||||
|Optimizer.lr.name|Const|学习率衰减器 |
|
||||
|Optimizer.lr.learning_rate|0.0005|学习率设为之前的0.05倍 |
|
||||
|Train.dataset.data_dir|/home/aistudio/data/data165849|指向训练集图片存放目录 |
|
||||
|Train.dataset.label_file_list|/home/aistudio/data/data165849/table_gen_dataset/train.txt|指向训练集标注文件 |
|
||||
|Train.loader.batch_size_per_card|32|训练时每张卡的batch_size |
|
||||
|Train.loader.num_workers|1|训练集多进程数据读取的进程数,在aistudio中需要设为1 |
|
||||
|Eval.dataset.data_dir|/home/aistudio/data/data165849|指向测试集图片存放目录 |
|
||||
|Eval.dataset.label_file_list|/home/aistudio/data/data165849/table_gen_dataset/val.txt|指向测试集标注文件 |
|
||||
|Eval.loader.batch_size_per_card|32|测试时每张卡的batch_size |
|
||||
|Eval.loader.num_workers|1|测试集多进程数据读取的进程数,在aistudio中需要设为1 |
|
||||
|
||||
|
||||
已经修改好的配置存储在 `/home/aistudio/SLANet_ch.yml`
|
||||
|
||||
|
||||
```python
|
||||
import os
|
||||
os.chdir('/home/aistudio/PaddleOCR')
|
||||
! python3 tools/train.py -c /home/aistudio/SLANet_ch.yml
|
||||
```
|
||||
|
||||
大约在7个epoch后达到最高精度 97.49%
|
||||
|
||||
### 2.4 验证
|
||||
|
||||
训练完成后,可使用如下命令在测试集上评估最优模型的精度
|
||||
|
||||
|
||||
```python
|
||||
! python3 tools/eval.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams
|
||||
```
|
||||
|
||||
### 2.5 训练引擎推理
|
||||
使用如下命令可使用训练引擎对单张图片进行推理
|
||||
|
||||
|
||||
```python
|
||||
import os;os.chdir('/home/aistudio/PaddleOCR')
|
||||
! python3 tools/infer_table.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.infer_img=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from matplotlib import pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
# 显示原图
|
||||
show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
|
||||
# 显示预测的单元格
|
||||
show_img = cv2.imread('/home/aistudio/PaddleOCR/output/infer/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### 2.6 模型导出
|
||||
|
||||
使用如下命令可将模型导出为inference模型
|
||||
|
||||
|
||||
```python
|
||||
! python3 tools/export_model.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.save_inference_dir=/home/aistudio/SLANet_ch/infer
|
||||
```
|
||||
|
||||
### 2.7 预测引擎推理
|
||||
使用如下命令可使用预测引擎对单张图片进行推理
|
||||
|
||||
|
||||
|
||||
```python
|
||||
os.chdir('/home/aistudio/PaddleOCR/ppstructure')
|
||||
! python3 table/predict_structure.py \
|
||||
--table_model_dir=/home/aistudio/SLANet_ch/infer \
|
||||
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
|
||||
--image_dir=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg \
|
||||
--output=../output/inference
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 显示原图
|
||||
show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
|
||||
# 显示预测的单元格
|
||||
show_img = cv2.imread('/home/aistudio/PaddleOCR/output/inference/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
### 2.8 表格识别
|
||||
|
||||
在表格结构模型训练完成后,可结合OCR检测识别模型,对表格内容进行识别。
|
||||
|
||||
首先下载PP-OCRv3文字检测识别模型
|
||||
|
||||
|
||||
```python
|
||||
# 下载PP-OCRv3文本检测识别模型并解压
|
||||
! wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar --no-check-certificate
|
||||
! wget -nc -P ./inference/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar --no-check-certificate
|
||||
! cd ./inference/ && tar xf ch_PP-OCRv3_det_slim_infer.tar && tar xf ch_PP-OCRv3_rec_slim_infer.tar && cd ../
|
||||
```
|
||||
|
||||
模型下载完成后,使用如下命令进行表格识别
|
||||
|
||||
|
||||
```python
|
||||
import os;os.chdir('/home/aistudio/PaddleOCR/ppstructure')
|
||||
! python3 table/predict_table.py \
|
||||
--det_model_dir=inference/ch_PP-OCRv3_det_slim_infer \
|
||||
--rec_model_dir=inference/ch_PP-OCRv3_rec_slim_infer \
|
||||
--table_model_dir=/home/aistudio/SLANet_ch/infer \
|
||||
--rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
|
||||
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
|
||||
--image_dir=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg \
|
||||
--output=../output/table
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
# 显示原图
|
||||
show_img = cv2.imread('/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg')
|
||||
plt.figure(figsize=(15,15))
|
||||
plt.imshow(show_img)
|
||||
plt.show()
|
||||
|
||||
# 显示预测结果
|
||||
from IPython.core.display import display, HTML
|
||||
display(HTML('<html><body><table><tr><td colspan="5">alleadersh</td><td rowspan="2">不贰过,推</td><td rowspan="2">从自己参与浙江数</td><td rowspan="2">。另一方</td></tr><tr><td>AnSha</td><td>自己越</td><td>共商共建工作协商</td><td>w.east </td><td>抓好改革试点任务</td></tr><tr><td>Edime</td><td>ImisesElec</td><td>怀天下”。</td><td></td><td>22.26 </td><td>31.61</td><td>4.30 </td><td>794.94</td></tr><tr><td rowspan="2">ip</td><td> Profundi</td><td>:2019年12月1</td><td>Horspro</td><td>444.48</td><td>2.41 </td><td>87</td><td>679.98</td></tr><tr><td> iehaiTrain</td><td>组长蒋蕊</td><td>Toafterdec</td><td>203.43</td><td>23.54 </td><td>4</td><td>4266.62</td></tr><tr><td>Tyint </td><td> roudlyRol</td><td>谢您的好意,我知道</td><td>ErChows</td><td></td><td>48.90</td><td>1031</td><td>6</td></tr><tr><td>NaFlint</td><td></td><td>一辈的</td><td>aterreclam</td><td>7823.86</td><td>9829.23</td><td>7.96 </td><td> 3068</td></tr><tr><td>家上下游企业,5</td><td>Tr</td><td>景象。当地球上的我们</td><td>Urelaw</td><td>799.62</td><td>354.96</td><td>12.98</td><td>33 </td></tr><tr><td>赛事(</td><td> uestCh</td><td>复制的业务模式并</td><td>Listicjust</td><td>9.23</td><td></td><td>92</td><td>53.22</td></tr><tr><td> Ca</td><td> Iskole</td><td>扶贫"之名引导</td><td> Papua </td><td>7191.90</td><td>1.65</td><td>3.62</td><td>48</td></tr><tr><td rowspan="2">避讳</td><td>ir</td><td>但由于</td><td>Fficeof</td><td>0.22</td><td>6.37</td><td>7.17</td><td>3397.75</td></tr><tr><td>ndaTurk</td><td>百处遗址</td><td>gMa</td><td>1288.34</td><td>2053.66</td><td>2.29</td><td>885.45</td></tr></table></body></html>'))
|
||||
```
|
||||
|
||||
## 3. 表格属性识别
|
||||
### 3.1 代码、环境、数据准备
|
||||
#### 3.1.1 代码准备
|
||||
首先,我们需要准备训练表格属性的代码,PaddleClas集成了PULC方案,该方案可以快速获得一个在CPU上用时2ms的属性识别模型。PaddleClas代码可以clone下载得到。获取方式如下:
|
||||
|
||||
|
||||
|
||||
```python
|
||||
! git clone -b develop https://gitee.com/paddlepaddle/PaddleClas
|
||||
```
|
||||
|
||||
#### 3.1.2 环境准备
|
||||
其次,我们需要安装训练PaddleClas相关的依赖包
|
||||
|
||||
|
||||
```python
|
||||
! pip install -r PaddleClas/requirements.txt --force-reinstall
|
||||
! pip install protobuf==3.20.0
|
||||
```
|
||||
|
||||
|
||||
#### 3.1.3 数据准备
|
||||
|
||||
最后,准备训练数据。在这里,我们一共定义了表格的6个属性,分别是表格来源、表格数量、表格颜色、表格清晰度、表格有无干扰、表格角度。其可视化如下:
|
||||
|
||||

|
||||
|
||||
这里,我们提供了一个表格属性的demo子集,可以快速迭代体验。下载方式如下:
|
||||
|
||||
|
||||
```python
|
||||
%cd PaddleClas/dataset
|
||||
!wget https://paddleclas.bj.bcebos.com/data/PULC/table_attribute.tar
|
||||
!tar -xf table_attribute.tar
|
||||
%cd ../PaddleClas/dataset
|
||||
%cd ../
|
||||
```
|
||||
|
||||
### 3.2 表格属性识别训练
|
||||
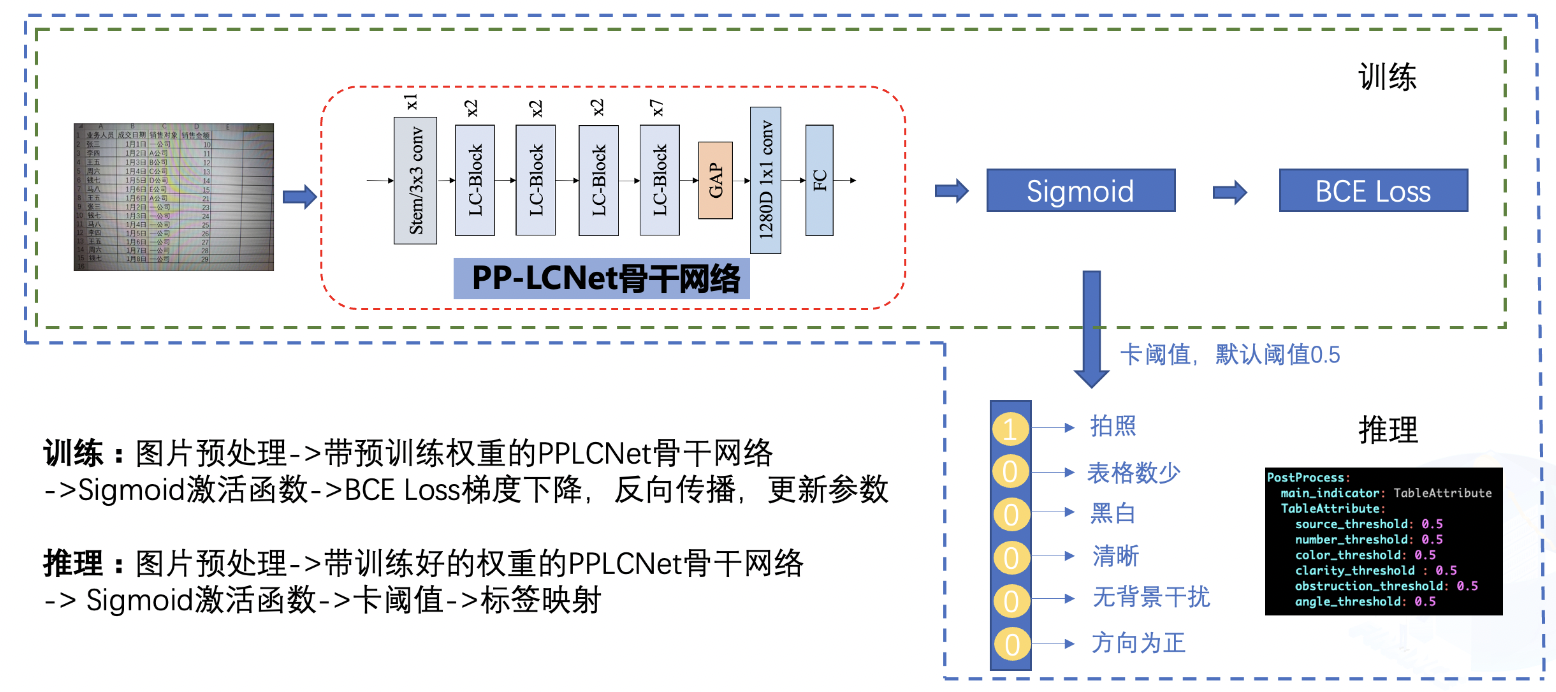
表格属性训练整体pipelinie如下:
|
||||
|
||||
|
||||
|
||||
1.训练过程中,图片经过预处理之后,送入到骨干网络之中,骨干网络将抽取表格图片的特征,最终该特征连接输出的FC层,FC层经过Sigmoid激活函数后和真实标签做交叉熵损失函数,优化器通过对该损失函数做梯度下降来更新骨干网络的参数,经过多轮训练后,骨干网络的参数可以对为止图片做很好的预测;
|
||||
|
||||
2.推理过程中,图片经过预处理之后,送入到骨干网络之中,骨干网络加载学习好的权重后对该表格图片做出预测,预测的结果为一个6维向量,该向量中的每个元素反映了每个属性对应的概率值,通过对该值进一步卡阈值之后,得到最终的输出,最终的输出描述了该表格的6个属性。
|
||||
|
||||
当准备好相关的数据之后,可以一键启动表格属性的训练,训练代码如下:
|
||||
|
||||
|
||||
```python
|
||||
|
||||
!python tools/train.py -c ./ppcls/configs/PULC/table_attribute/PPLCNet_x1_0.yaml -o Global.device=cpu -o Global.epochs=10
|
||||
```
|
||||
|
||||
### 3.3 表格属性识别推理和部署
|
||||
#### 3.3.1 模型转换
|
||||
当训练好模型之后,需要将模型转换为推理模型进行部署。转换脚本如下:
|
||||
|
||||
|
||||
```python
|
||||
!python tools/export_model.py -c ppcls/configs/PULC/table_attribute/PPLCNet_x1_0.yaml -o Global.pretrained_model=output/PPLCNet_x1_0/best_model
|
||||
```
|
||||
|
||||
执行以上命令之后,会在当前目录上生成`inference`文件夹,该文件夹中保存了当前精度最高的推理模型。
|
||||
|
||||
#### 3.3.2 模型推理
|
||||
安装推理需要的paddleclas包, 此时需要通过下载安装paddleclas的develop的whl包
|
||||
|
||||
|
||||
|
||||
```python
|
||||
!pip install https://paddleclas.bj.bcebos.com/whl/paddleclas-0.0.0-py3-none-any.whl
|
||||
```
|
||||
|
||||
进入`deploy`目录下即可对模型进行推理
|
||||
|
||||
|
||||
```python
|
||||
%cd deploy/
|
||||
```
|
||||
|
||||
推理命令如下:
|
||||
|
||||
|
||||
```python
|
||||
!python python/predict_cls.py -c configs/PULC/table_attribute/inference_table_attribute.yaml -o Global.inference_model_dir="../inference" -o Global.infer_imgs="../dataset/table_attribute/Table_val/val_9.jpg"
|
||||
!python python/predict_cls.py -c configs/PULC/table_attribute/inference_table_attribute.yaml -o Global.inference_model_dir="../inference" -o Global.infer_imgs="../dataset/table_attribute/Table_val/val_3253.jpg"
|
||||
```
|
||||
|
||||
推理的表格图片:
|
||||
|
||||
|
||||
|
||||
预测结果如下:
|
||||
```
|
||||
val_9.jpg: {'attributes': ['Scanned', 'Little', 'Black-and-White', 'Clear', 'Without-Obstacles', 'Horizontal'], 'output': [1, 1, 1, 1, 1, 1]}
|
||||
```
|
||||
|
||||
|
||||
推理的表格图片:
|
||||
|
||||

|
||||
|
||||
预测结果如下:
|
||||
```
|
||||
val_3253.jpg: {'attributes': ['Photo', 'Little', 'Black-and-White', 'Blurry', 'Without-Obstacles', 'Tilted'], 'output': [0, 1, 1, 0, 1, 0]}
|
||||
```
|
||||
|
||||
对比两张图片可以发现,第一张图片比较清晰,表格属性的结果也偏向于比较容易识别,我们可以更相信表格识别的结果,第二张图片比较模糊,且存在倾斜现象,表格识别可能存在错误,需要我们人工进一步校验。通过表格的属性识别能力,可以进一步将“人工”和“智能”很好的结合起来,为表格识别能力的落地的精度提供保障。
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -30,7 +30,7 @@ cd PaddleOCR
|
|||
# 安装PaddleOCR的依赖
|
||||
pip install -r requirements.txt
|
||||
# 安装关键信息抽取任务的依赖
|
||||
pip install -r ./ppstructure/vqa/requirements.txt
|
||||
pip install -r ./ppstructure/kie/requirements.txt
|
||||
```
|
||||
|
||||
## 4. 关键信息抽取
|
||||
|
|
@ -94,7 +94,7 @@ VI-LayoutXLM的配置为[ser_vi_layoutxlm_xfund_zh_udml.yml](../configs/kie/vi_l
|
|||
|
||||
```yml
|
||||
Architecture:
|
||||
model_type: &model_type "vqa"
|
||||
model_type: &model_type "kie"
|
||||
name: DistillationModel
|
||||
algorithm: Distillation
|
||||
Models:
|
||||
|
|
@ -177,7 +177,7 @@ python3 tools/eval.py -c ./fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.
|
|||
使用下面的命令进行预测。
|
||||
|
||||
```bash
|
||||
python3 tools/infer_vqa_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/XFUND/zh_val/val.json Global.infer_mode=False
|
||||
python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/XFUND/zh_val/val.json Global.infer_mode=False
|
||||
```
|
||||
|
||||
预测结果会保存在配置文件中的`Global.save_res_path`目录中。
|
||||
|
|
@ -195,7 +195,7 @@ python3 tools/infer_vqa_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architect
|
|||
|
||||
|
||||
```bash
|
||||
python3 tools/infer_vqa_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True
|
||||
python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True
|
||||
```
|
||||
|
||||
结果如下所示。
|
||||
|
|
@ -211,7 +211,7 @@ python3 tools/infer_vqa_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architect
|
|||
如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入检测与识别的inference 模型路径,即可完成OCR文本检测与识别以及SER的串联过程。
|
||||
|
||||
```bash
|
||||
python3 tools/infer_vqa_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
|
||||
python3 tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/imgs/b25.jpg Global.infer_mode=True Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
|
||||
```
|
||||
|
||||
### 4.4 关系抽取(Relation Extraction)
|
||||
|
|
@ -316,7 +316,7 @@ python3 tools/eval.py -c ./fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.c
|
|||
# -o 后面的字段是RE任务的配置
|
||||
# -c_ser 后面的是SER任务的配置文件
|
||||
# -c_ser 后面的字段是SER任务的配置
|
||||
python3 tools/infer_vqa_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=False -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
|
||||
python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_trained/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=False -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_trained/best_accuracy
|
||||
```
|
||||
|
||||
预测结果会保存在配置文件中的`Global.save_res_path`目录中。
|
||||
|
|
@ -333,11 +333,11 @@ python3 tools/infer_vqa_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Archite
|
|||
如果希望使用OCR引擎结果得到的结果进行推理,则可以使用下面的命令进行推理。
|
||||
|
||||
```bash
|
||||
python3 tools/infer_vqa_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
|
||||
python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
|
||||
```
|
||||
|
||||
如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入,即可完成SER + RE的串联过程。
|
||||
|
||||
```bash
|
||||
python3 tools/infer_vqa_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
|
||||
python3 tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints=fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img=./train_data/zzsfp/val.json Global.infer_mode=True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints=fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.kie_rec_model_dir="your_rec_model" Global.kie_det_model_dir="your_det_model"
|
||||
```
|
||||
|
|
|
|||
|
|
@ -0,0 +1,782 @@
|
|||
# 快速构建卡证类OCR
|
||||
|
||||
|
||||
- [快速构建卡证类OCR](#快速构建卡证类ocr)
|
||||
- [1. 金融行业卡证识别应用](#1-金融行业卡证识别应用)
|
||||
- [1.1 金融行业中的OCR相关技术](#11-金融行业中的ocr相关技术)
|
||||
- [1.2 金融行业中的卡证识别场景介绍](#12-金融行业中的卡证识别场景介绍)
|
||||
- [1.3 OCR落地挑战](#13-ocr落地挑战)
|
||||
- [2. 卡证识别技术解析](#2-卡证识别技术解析)
|
||||
- [2.1 卡证分类模型](#21-卡证分类模型)
|
||||
- [2.2 卡证识别模型](#22-卡证识别模型)
|
||||
- [3. OCR技术拆解](#3-ocr技术拆解)
|
||||
- [3.1技术流程](#31技术流程)
|
||||
- [3.2 OCR技术拆解---卡证分类](#32-ocr技术拆解---卡证分类)
|
||||
- [卡证分类:数据、模型准备](#卡证分类数据模型准备)
|
||||
- [卡证分类---修改配置文件](#卡证分类---修改配置文件)
|
||||
- [卡证分类---训练](#卡证分类---训练)
|
||||
- [3.2 OCR技术拆解---卡证识别](#32-ocr技术拆解---卡证识别)
|
||||
- [身份证识别:检测+分类](#身份证识别检测分类)
|
||||
- [数据标注](#数据标注)
|
||||
- [4 . 项目实践](#4--项目实践)
|
||||
- [4.1 环境准备](#41-环境准备)
|
||||
- [4.2 配置文件修改](#42-配置文件修改)
|
||||
- [4.3 代码修改](#43-代码修改)
|
||||
- [4.3.1 数据读取](#431-数据读取)
|
||||
- [4.3.2 head修改](#432--head修改)
|
||||
- [4.3.3 修改loss](#433-修改loss)
|
||||
- [4.3.4 后处理](#434-后处理)
|
||||
- [4.4. 模型启动](#44-模型启动)
|
||||
- [5 总结](#5-总结)
|
||||
- [References](#references)
|
||||
|
||||
## 1. 金融行业卡证识别应用
|
||||
|
||||
### 1.1 金融行业中的OCR相关技术
|
||||
|
||||
* 《“十四五”数字经济发展规划》指出,2020年我国数字经济核心产业增加值占GDP比重达7.8%,随着数字经济迈向全面扩展,到2025年该比例将提升至10%。
|
||||
|
||||
* 在过去数年的跨越发展与积累沉淀中,数字金融、金融科技已在对金融业的重塑与再造中充分印证了其自身价值。
|
||||
|
||||
* 以智能为目标,提升金融数字化水平,实现业务流程自动化,降低人力成本。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 1.2 金融行业中的卡证识别场景介绍
|
||||
|
||||
应用场景:身份证、银行卡、营业执照、驾驶证等。
|
||||
|
||||
应用难点:由于数据的采集来源多样,以及实际采集数据各种噪声:反光、褶皱、模糊、倾斜等各种问题干扰。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
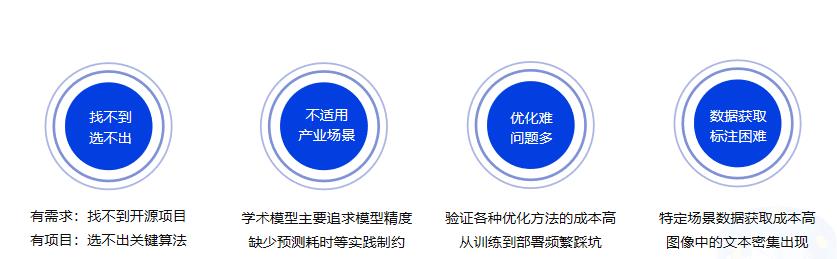
### 1.3 OCR落地挑战
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 2. 卡证识别技术解析
|
||||
|
||||
|
||||
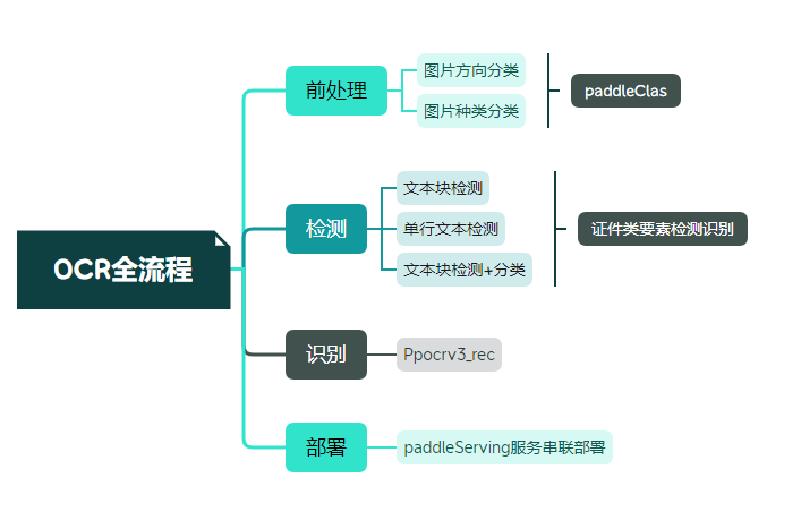
|
||||
|
||||
|
||||
### 2.1 卡证分类模型
|
||||
|
||||
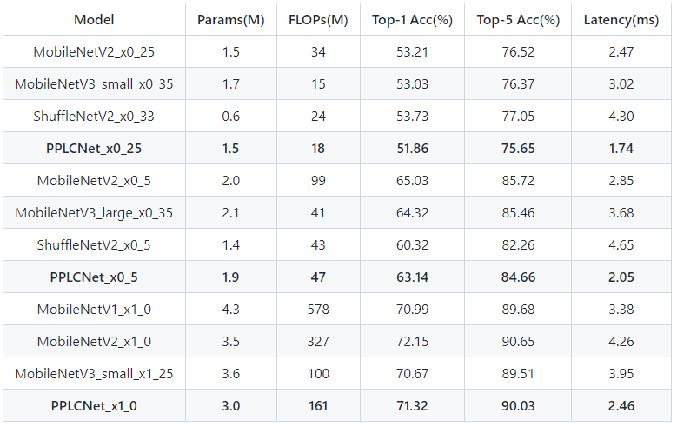
卡证分类:基于PPLCNet
|
||||
|
||||
与其他轻量级模型相比在CPU环境下ImageNet数据集上的表现
|
||||
|
||||
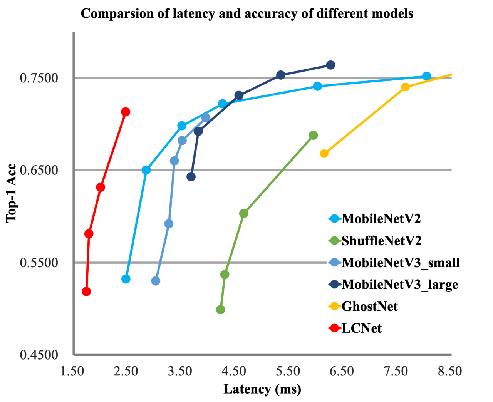
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* 模型来自模型库PaddleClas,它是一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 2.2 卡证识别模型
|
||||
|
||||
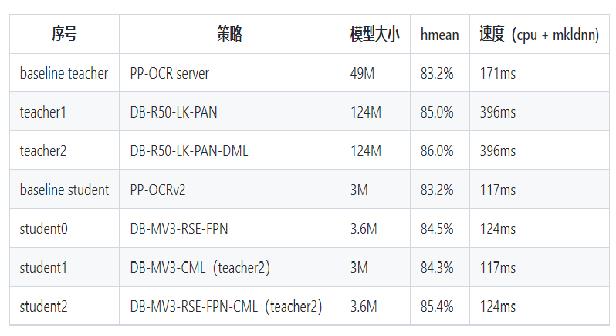
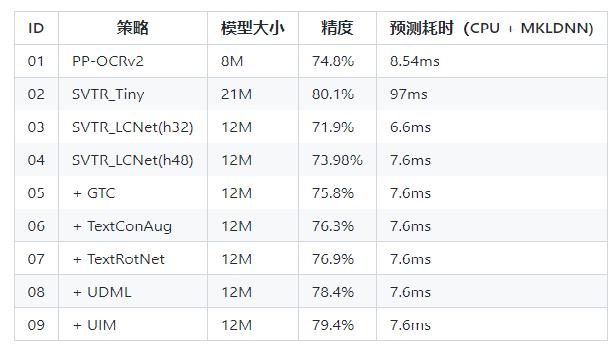
* 检测:DBNet 识别:SVRT
|
||||
|
||||

|
||||
|
||||
|
||||
* PPOCRv3在文本检测、识别进行了一系列改进优化,在保证精度的同时提升预测效率
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 3. OCR技术拆解
|
||||
|
||||
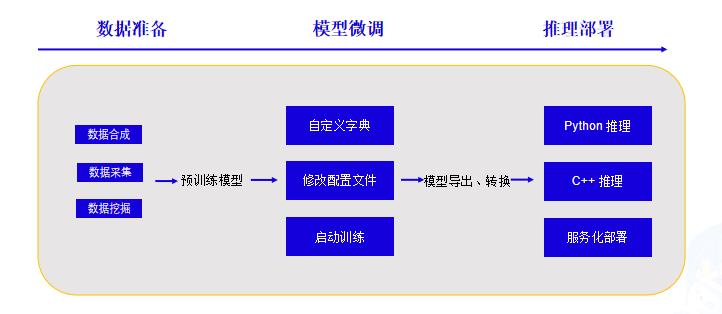
### 3.1技术流程
|
||||
|
||||
|
||||
|
||||
|
||||
### 3.2 OCR技术拆解---卡证分类
|
||||
|
||||
#### 卡证分类:数据、模型准备
|
||||
|
||||
|
||||
A 使用爬虫获取无标注数据,将相同类别的放在同一文件夹下,文件名从0开始命名。具体格式如下图所示。
|
||||
|
||||
注:卡证类数据,建议每个类别数据量在500张以上
|
||||

|
||||
|
||||
|
||||
B 一行命令生成标签文件
|
||||
|
||||
```
|
||||
tree -r -i -f | grep -E "jpg|JPG|jpeg|JPEG|png|PNG|webp" | awk -F "/" '{print $0" "$2}' > train_list.txt
|
||||
```
|
||||
|
||||
C [下载预训练模型 ](https://github.com/PaddlePaddle/PaddleClas/blob/release/2.4/docs/zh_CN/models/PP-LCNet.md)
|
||||
|
||||
|
||||
|
||||
#### 卡证分类---修改配置文件
|
||||
|
||||
|
||||
配置文件主要修改三个部分:
|
||||
|
||||
全局参数:预训练模型路径/训练轮次/图像尺寸
|
||||
|
||||
模型结构:分类数
|
||||
|
||||
数据处理:训练/评估数据路径
|
||||
|
||||
|
||||

|
||||
|
||||
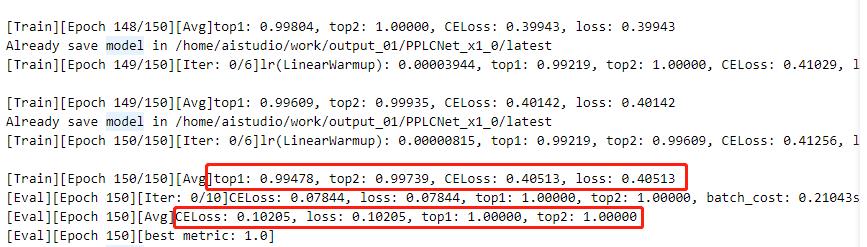
#### 卡证分类---训练
|
||||
|
||||
|
||||
指定配置文件启动训练:
|
||||
|
||||
```
|
||||
!python /home/aistudio/work/PaddleClas/tools/train.py -c /home/aistudio/work/PaddleClas/ppcls/configs/PULC/text_image_orientation/PPLCNet_x1_0.yaml
|
||||
```
|
||||
|
||||
|
||||
注:日志中显示了训练结果和评估结果(训练时可以设置固定轮数评估一次)
|
||||
|
||||
|
||||
### 3.2 OCR技术拆解---卡证识别
|
||||
|
||||
卡证识别(以身份证检测为例)
|
||||
存在的困难及问题:
|
||||
|
||||
* 在自然场景下,由于各种拍摄设备以及光线、角度不同等影响导致实际得到的证件影像千差万别。
|
||||
|
||||
* 如何快速提取需要的关键信息
|
||||
|
||||
* 多行的文本信息,检测结果如何正确拼接
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
* OCR技术拆解---OCR工具库
|
||||
|
||||
PaddleOCR是一个丰富、领先且实用的OCR工具库,助力开发者训练出更好的模型并应用落地
|
||||
|
||||
|
||||
|
||||
|
||||
身份证识别:用现有的方法识别
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
#### 身份证识别:检测+分类
|
||||
|
||||
> 方法:基于现有的dbnet检测模型,加入分类方法。检测同时进行分类,从一定程度上优化识别流程
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
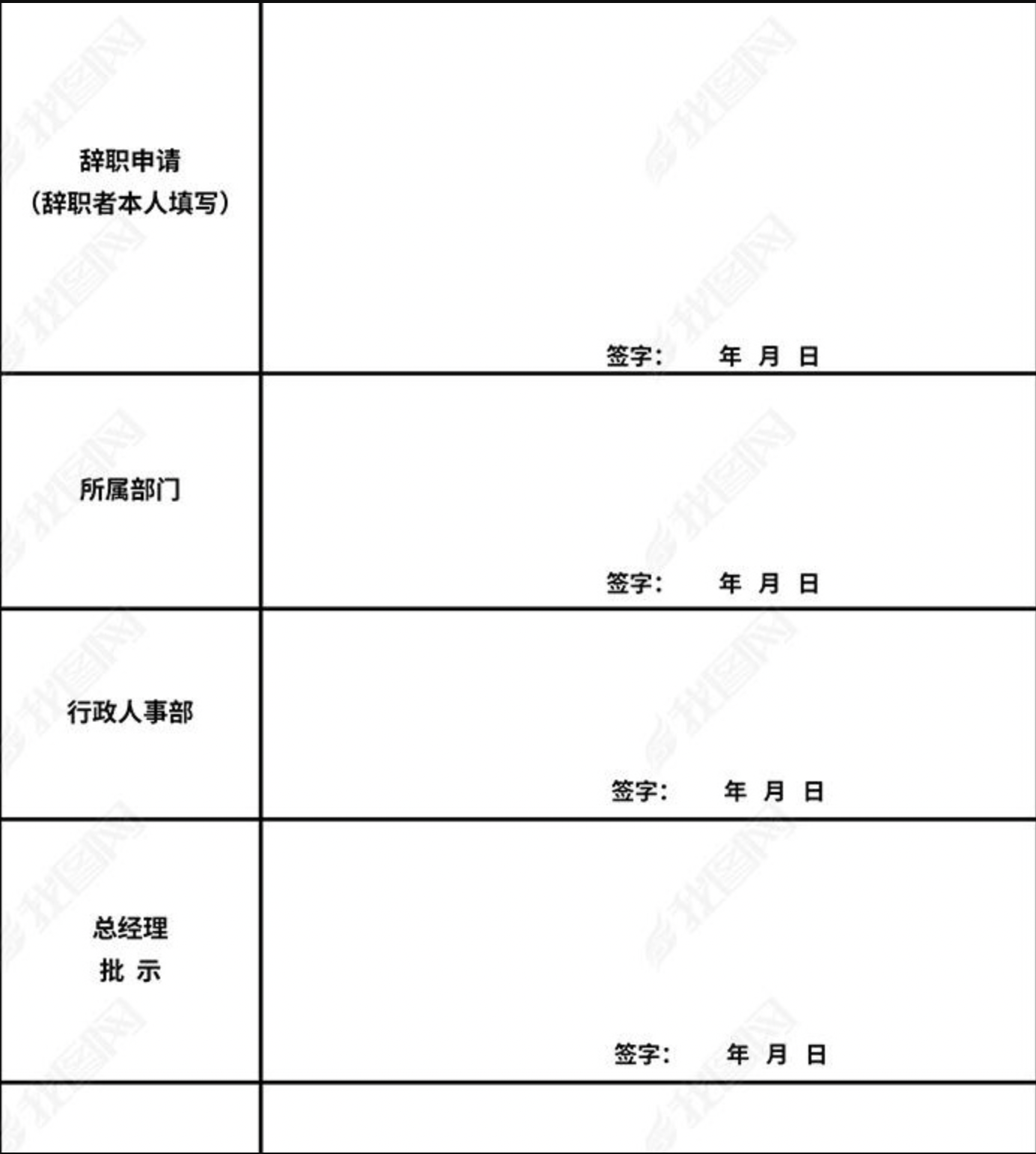
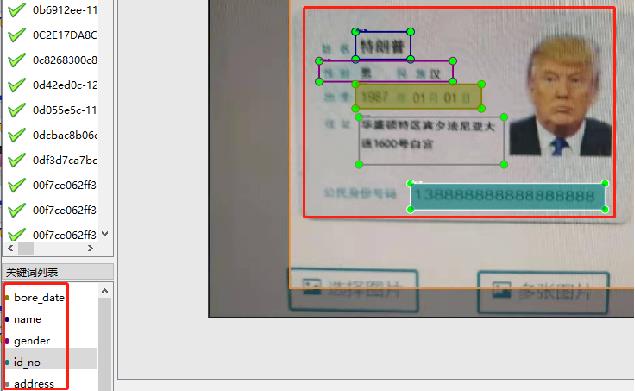
#### 数据标注
|
||||
|
||||
使用PaddleOCRLable进行快速标注
|
||||
|
||||
|
||||
|
||||
|
||||
* 修改PPOCRLabel.py,将下图中的kie参数设置为True
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
* 数据标注踩坑分享
|
||||
|
||||

|
||||
|
||||
注:两者只有标注有差别,训练参数数据集都相同
|
||||
|
||||
## 4 . 项目实践
|
||||
|
||||
AIStudio项目链接:[快速构建卡证类OCR](https://aistudio.baidu.com/aistudio/projectdetail/4459116)
|
||||
|
||||
### 4.1 环境准备
|
||||
|
||||
1)拉取[paddleocr](https://github.com/PaddlePaddle/PaddleOCR)项目,如果从github上拉取速度慢可以选择从gitee上获取。
|
||||
```
|
||||
!git clone https://github.com/PaddlePaddle/PaddleOCR.git -b release/2.6 /home/aistudio/work/
|
||||
```
|
||||
|
||||
2)获取并解压预训练模型,如果要使用其他模型可以从模型库里自主选择合适模型。
|
||||
```
|
||||
!wget -P work/pre_trained/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
|
||||
!tar -vxf /home/aistudio/work/pre_trained/ch_PP-OCRv3_det_distill_train.tar -C /home/aistudio/work/pre_trained
|
||||
```
|
||||
3) 安装必要依赖
|
||||
```
|
||||
!pip install -r /home/aistudio/work/requirements.txt
|
||||
```
|
||||
|
||||
### 4.2 配置文件修改
|
||||
|
||||
修改配置文件 *work/configs/det/detmv3db.yml*
|
||||
|
||||
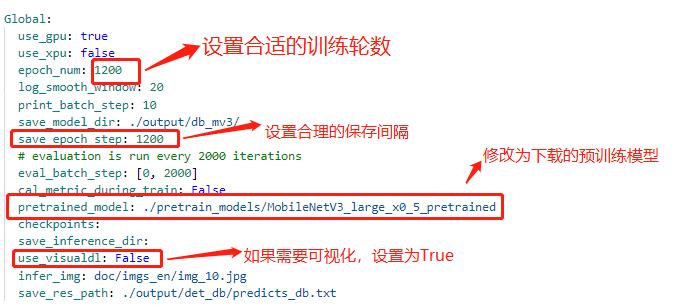
具体修改说明如下:
|
||||
|
||||
|
||||
|
||||
注:在上述的配置文件的Global变量中需要添加以下两个参数:
|
||||
|
||||
label_list 为标签表
|
||||
num_classes 为分类数
|
||||
上述两个参数根据实际的情况配置即可
|
||||
|
||||
|
||||

|
||||
|
||||
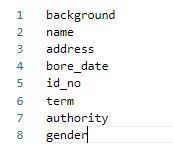
其中lable_list内容如下例所示,***建议第一个参数设置为 background,不要设置为实际要提取的关键信息种类***:
|
||||
|
||||
|
||||
|
||||
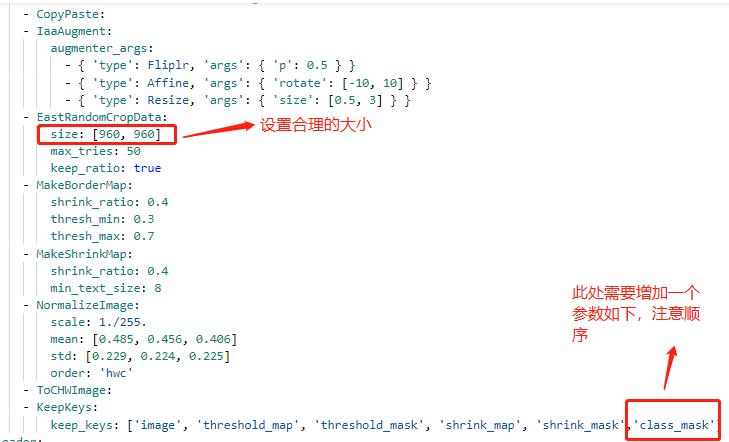
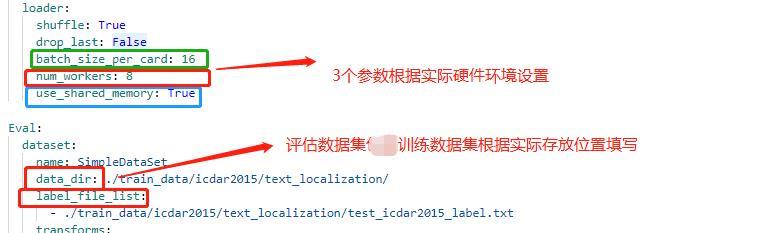
配置文件中的其他设置说明
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 4.3 代码修改
|
||||
|
||||
|
||||
#### 4.3.1 数据读取
|
||||
|
||||
|
||||
|
||||
* 修改 PaddleOCR/ppocr/data/imaug/label_ops.py中的DetLabelEncode
|
||||
|
||||
|
||||
```python
|
||||
class DetLabelEncode(object):
|
||||
|
||||
# 修改检测标签的编码处,新增了参数分类数:num_classes,重写初始化方法,以及分类标签的读取
|
||||
|
||||
def __init__(self, label_list, num_classes=8, **kwargs):
|
||||
self.num_classes = num_classes
|
||||
self.label_list = []
|
||||
if label_list:
|
||||
if isinstance(label_list, str):
|
||||
with open(label_list, 'r+', encoding='utf-8') as f:
|
||||
for line in f.readlines():
|
||||
self.label_list.append(line.replace("\n", ""))
|
||||
else:
|
||||
self.label_list = label_list
|
||||
else:
|
||||
assert ' please check label_list whether it is none or config is right'
|
||||
|
||||
if num_classes != len(self.label_list): # 校验分类数和标签的一致性
|
||||
assert 'label_list length is not equal to the num_classes'
|
||||
|
||||
def __call__(self, data):
|
||||
label = data['label']
|
||||
label = json.loads(label)
|
||||
nBox = len(label)
|
||||
boxes, txts, txt_tags, classes = [], [], [], []
|
||||
for bno in range(0, nBox):
|
||||
box = label[bno]['points']
|
||||
txt = label[bno]['key_cls'] # 此处将kie中的参数作为分类读取
|
||||
boxes.append(box)
|
||||
txts.append(txt)
|
||||
|
||||
if txt in ['*', '###']:
|
||||
txt_tags.append(True)
|
||||
if self.num_classes > 1:
|
||||
classes.append(-2)
|
||||
else:
|
||||
txt_tags.append(False)
|
||||
if self.num_classes > 1: # 将KIE内容的key标签作为分类标签使用
|
||||
classes.append(int(self.label_list.index(txt)))
|
||||
|
||||
if len(boxes) == 0:
|
||||
|
||||
return None
|
||||
boxes = self.expand_points_num(boxes)
|
||||
boxes = np.array(boxes, dtype=np.float32)
|
||||
txt_tags = np.array(txt_tags, dtype=np.bool)
|
||||
classes = classes
|
||||
data['polys'] = boxes
|
||||
data['texts'] = txts
|
||||
data['ignore_tags'] = txt_tags
|
||||
if self.num_classes > 1:
|
||||
data['classes'] = classes
|
||||
return data
|
||||
```
|
||||
|
||||
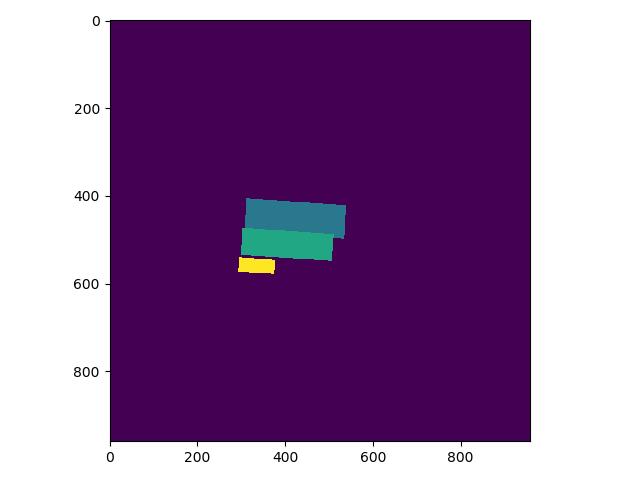
* 修改 PaddleOCR/ppocr/data/imaug/make_shrink_map.py中的MakeShrinkMap类。这里需要注意的是,如果我们设置的label_list中的第一个参数为要检测的信息那么会得到如下的mask,
|
||||
|
||||
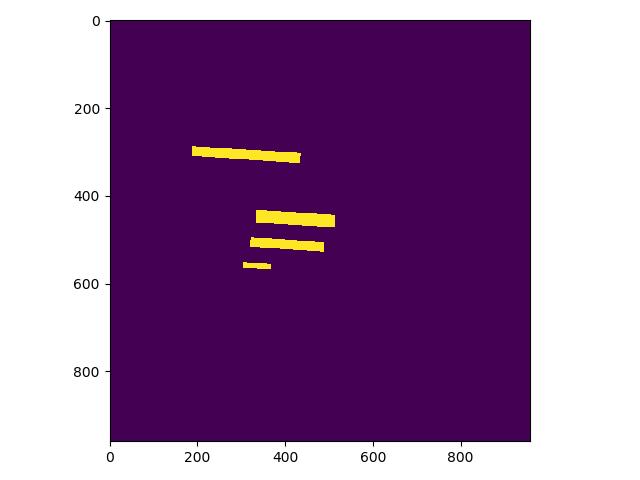
举例说明:
|
||||
这是检测的mask图,图中有四个mask那么实际对应的分类应该是4类
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
label_list中第一个为关键分类,则得到的分类Mask实际如下,与上图相比,少了一个box:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
class MakeShrinkMap(object):
|
||||
r'''
|
||||
Making binary mask from detection data with ICDAR format.
|
||||
Typically following the process of class `MakeICDARData`.
|
||||
'''
|
||||
|
||||
def __init__(self, min_text_size=8, shrink_ratio=0.4, num_classes=8, **kwargs):
|
||||
self.min_text_size = min_text_size
|
||||
self.shrink_ratio = shrink_ratio
|
||||
self.num_classes = num_classes # 添加了分类
|
||||
|
||||
def __call__(self, data):
|
||||
image = data['image']
|
||||
text_polys = data['polys']
|
||||
ignore_tags = data['ignore_tags']
|
||||
if self.num_classes > 1:
|
||||
classes = data['classes']
|
||||
|
||||
h, w = image.shape[:2]
|
||||
text_polys, ignore_tags = self.validate_polygons(text_polys,
|
||||
ignore_tags, h, w)
|
||||
gt = np.zeros((h, w), dtype=np.float32)
|
||||
mask = np.ones((h, w), dtype=np.float32)
|
||||
gt_class = np.zeros((h, w), dtype=np.float32) # 新增分类
|
||||
for i in range(len(text_polys)):
|
||||
polygon = text_polys[i]
|
||||
height = max(polygon[:, 1]) - min(polygon[:, 1])
|
||||
width = max(polygon[:, 0]) - min(polygon[:, 0])
|
||||
if ignore_tags[i] or min(height, width) < self.min_text_size:
|
||||
cv2.fillPoly(mask,
|
||||
polygon.astype(np.int32)[np.newaxis, :, :], 0)
|
||||
ignore_tags[i] = True
|
||||
else:
|
||||
polygon_shape = Polygon(polygon)
|
||||
subject = [tuple(l) for l in polygon]
|
||||
padding = pyclipper.PyclipperOffset()
|
||||
padding.AddPath(subject, pyclipper.JT_ROUND,
|
||||
pyclipper.ET_CLOSEDPOLYGON)
|
||||
shrinked = []
|
||||
|
||||
# Increase the shrink ratio every time we get multiple polygon returned back
|
||||
possible_ratios = np.arange(self.shrink_ratio, 1,
|
||||
self.shrink_ratio)
|
||||
np.append(possible_ratios, 1)
|
||||
for ratio in possible_ratios:
|
||||
distance = polygon_shape.area * (
|
||||
1 - np.power(ratio, 2)) / polygon_shape.length
|
||||
shrinked = padding.Execute(-distance)
|
||||
if len(shrinked) == 1:
|
||||
break
|
||||
|
||||
if shrinked == []:
|
||||
cv2.fillPoly(mask,
|
||||
polygon.astype(np.int32)[np.newaxis, :, :], 0)
|
||||
ignore_tags[i] = True
|
||||
continue
|
||||
|
||||
for each_shirnk in shrinked:
|
||||
shirnk = np.array(each_shirnk).reshape(-1, 2)
|
||||
cv2.fillPoly(gt, [shirnk.astype(np.int32)], 1)
|
||||
if self.num_classes > 1: # 绘制分类的mask
|
||||
cv2.fillPoly(gt_class, polygon.astype(np.int32)[np.newaxis, :, :], classes[i])
|
||||
|
||||
|
||||
data['shrink_map'] = gt
|
||||
|
||||
if self.num_classes > 1:
|
||||
data['class_mask'] = gt_class
|
||||
|
||||
data['shrink_mask'] = mask
|
||||
return data
|
||||
```
|
||||
|
||||
由于在训练数据中会对数据进行resize设置,yml中的操作为:EastRandomCropData,所以需要修改PaddleOCR/ppocr/data/imaug/random_crop_data.py中的EastRandomCropData
|
||||
|
||||
|
||||
```python
|
||||
class EastRandomCropData(object):
|
||||
def __init__(self,
|
||||
size=(640, 640),
|
||||
max_tries=10,
|
||||
min_crop_side_ratio=0.1,
|
||||
keep_ratio=True,
|
||||
num_classes=8,
|
||||
**kwargs):
|
||||
self.size = size
|
||||
self.max_tries = max_tries
|
||||
self.min_crop_side_ratio = min_crop_side_ratio
|
||||
self.keep_ratio = keep_ratio
|
||||
self.num_classes = num_classes
|
||||
|
||||
def __call__(self, data):
|
||||
img = data['image']
|
||||
text_polys = data['polys']
|
||||
ignore_tags = data['ignore_tags']
|
||||
texts = data['texts']
|
||||
if self.num_classes > 1:
|
||||
classes = data['classes']
|
||||
all_care_polys = [
|
||||
text_polys[i] for i, tag in enumerate(ignore_tags) if not tag
|
||||
]
|
||||
# 计算crop区域
|
||||
crop_x, crop_y, crop_w, crop_h = crop_area(
|
||||
img, all_care_polys, self.min_crop_side_ratio, self.max_tries)
|
||||
# crop 图片 保持比例填充
|
||||
scale_w = self.size[0] / crop_w
|
||||
scale_h = self.size[1] / crop_h
|
||||
scale = min(scale_w, scale_h)
|
||||
h = int(crop_h * scale)
|
||||
w = int(crop_w * scale)
|
||||
if self.keep_ratio:
|
||||
padimg = np.zeros((self.size[1], self.size[0], img.shape[2]),
|
||||
img.dtype)
|
||||
padimg[:h, :w] = cv2.resize(
|
||||
img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w], (w, h))
|
||||
img = padimg
|
||||
else:
|
||||
img = cv2.resize(
|
||||
img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w],
|
||||
tuple(self.size))
|
||||
# crop 文本框
|
||||
text_polys_crop = []
|
||||
ignore_tags_crop = []
|
||||
texts_crop = []
|
||||
classes_crop = []
|
||||
for poly, text, tag,class_index in zip(text_polys, texts, ignore_tags,classes):
|
||||
poly = ((poly - (crop_x, crop_y)) * scale).tolist()
|
||||
if not is_poly_outside_rect(poly, 0, 0, w, h):
|
||||
text_polys_crop.append(poly)
|
||||
ignore_tags_crop.append(tag)
|
||||
texts_crop.append(text)
|
||||
if self.num_classes > 1:
|
||||
classes_crop.append(class_index)
|
||||
data['image'] = img
|
||||
data['polys'] = np.array(text_polys_crop)
|
||||
data['ignore_tags'] = ignore_tags_crop
|
||||
data['texts'] = texts_crop
|
||||
if self.num_classes > 1:
|
||||
data['classes'] = classes_crop
|
||||
return data
|
||||
```
|
||||
|
||||
#### 4.3.2 head修改
|
||||
|
||||
|
||||
|
||||
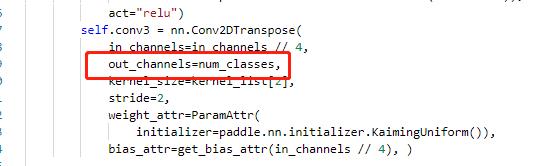
主要修改 ppocr/modeling/heads/det_db_head.py,将Head类中的最后一层的输出修改为实际的分类数,同时在DBHead中新增分类的head。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### 4.3.3 修改loss
|
||||
|
||||
|
||||
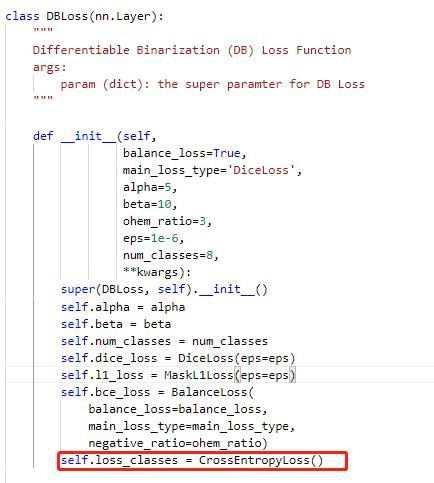
修改PaddleOCR/ppocr/losses/det_db_loss.py中的DBLoss类,分类采用交叉熵损失函数进行计算。
|
||||
|
||||
|
||||
|
||||
|
||||
#### 4.3.4 后处理
|
||||
|
||||
|
||||
|
||||
由于涉及到eval以及后续推理能否正常使用,我们需要修改后处理的相关代码,修改位置 PaddleOCR/ppocr/postprocess/db_postprocess.py中的DBPostProcess类
|
||||
|
||||
|
||||
```python
|
||||
class DBPostProcess(object):
|
||||
"""
|
||||
The post process for Differentiable Binarization (DB).
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
thresh=0.3,
|
||||
box_thresh=0.7,
|
||||
max_candidates=1000,
|
||||
unclip_ratio=2.0,
|
||||
use_dilation=False,
|
||||
score_mode="fast",
|
||||
**kwargs):
|
||||
self.thresh = thresh
|
||||
self.box_thresh = box_thresh
|
||||
self.max_candidates = max_candidates
|
||||
self.unclip_ratio = unclip_ratio
|
||||
self.min_size = 3
|
||||
self.score_mode = score_mode
|
||||
assert score_mode in [
|
||||
"slow", "fast"
|
||||
], "Score mode must be in [slow, fast] but got: {}".format(score_mode)
|
||||
|
||||
self.dilation_kernel = None if not use_dilation else np.array(
|
||||
[[1, 1], [1, 1]])
|
||||
|
||||
def boxes_from_bitmap(self, pred, _bitmap, classes, dest_width, dest_height):
|
||||
"""
|
||||
_bitmap: single map with shape (1, H, W),
|
||||
whose values are binarized as {0, 1}
|
||||
"""
|
||||
|
||||
bitmap = _bitmap
|
||||
height, width = bitmap.shape
|
||||
|
||||
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
|
||||
cv2.CHAIN_APPROX_SIMPLE)
|
||||
if len(outs) == 3:
|
||||
img, contours, _ = outs[0], outs[1], outs[2]
|
||||
elif len(outs) == 2:
|
||||
contours, _ = outs[0], outs[1]
|
||||
|
||||
num_contours = min(len(contours), self.max_candidates)
|
||||
|
||||
boxes = []
|
||||
scores = []
|
||||
class_indexes = []
|
||||
class_scores = []
|
||||
for index in range(num_contours):
|
||||
contour = contours[index]
|
||||
points, sside = self.get_mini_boxes(contour)
|
||||
if sside < self.min_size:
|
||||
continue
|
||||
points = np.array(points)
|
||||
if self.score_mode == "fast":
|
||||
score, class_index, class_score = self.box_score_fast(pred, points.reshape(-1, 2), classes)
|
||||
else:
|
||||
score, class_index, class_score = self.box_score_slow(pred, contour, classes)
|
||||
if self.box_thresh > score:
|
||||
continue
|
||||
|
||||
box = self.unclip(points).reshape(-1, 1, 2)
|
||||
box, sside = self.get_mini_boxes(box)
|
||||
if sside < self.min_size + 2:
|
||||
continue
|
||||
box = np.array(box)
|
||||
|
||||
box[:, 0] = np.clip(
|
||||
np.round(box[:, 0] / width * dest_width), 0, dest_width)
|
||||
box[:, 1] = np.clip(
|
||||
np.round(box[:, 1] / height * dest_height), 0, dest_height)
|
||||
|
||||
boxes.append(box.astype(np.int16))
|
||||
scores.append(score)
|
||||
|
||||
class_indexes.append(class_index)
|
||||
class_scores.append(class_score)
|
||||
|
||||
if classes is None:
|
||||
return np.array(boxes, dtype=np.int16), scores
|
||||
else:
|
||||
return np.array(boxes, dtype=np.int16), scores, class_indexes, class_scores
|
||||
|
||||
def unclip(self, box):
|
||||
unclip_ratio = self.unclip_ratio
|
||||
poly = Polygon(box)
|
||||
distance = poly.area * unclip_ratio / poly.length
|
||||
offset = pyclipper.PyclipperOffset()
|
||||
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
|
||||
expanded = np.array(offset.Execute(distance))
|
||||
return expanded
|
||||
|
||||
def get_mini_boxes(self, contour):
|
||||
bounding_box = cv2.minAreaRect(contour)
|
||||
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
|
||||
|
||||
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
|
||||
if points[1][1] > points[0][1]:
|
||||
index_1 = 0
|
||||
index_4 = 1
|
||||
else:
|
||||
index_1 = 1
|
||||
index_4 = 0
|
||||
if points[3][1] > points[2][1]:
|
||||
index_2 = 2
|
||||
index_3 = 3
|
||||
else:
|
||||
index_2 = 3
|
||||
index_3 = 2
|
||||
|
||||
box = [
|
||||
points[index_1], points[index_2], points[index_3], points[index_4]
|
||||
]
|
||||
return box, min(bounding_box[1])
|
||||
|
||||
def box_score_fast(self, bitmap, _box, classes):
|
||||
'''
|
||||
box_score_fast: use bbox mean score as the mean score
|
||||
'''
|
||||
h, w = bitmap.shape[:2]
|
||||
box = _box.copy()
|
||||
xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
|
||||
xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
|
||||
ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
|
||||
ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
|
||||
|
||||
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
|
||||
box[:, 0] = box[:, 0] - xmin
|
||||
box[:, 1] = box[:, 1] - ymin
|
||||
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
|
||||
|
||||
if classes is None:
|
||||
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
|
||||
else:
|
||||
k = 999
|
||||
class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
|
||||
|
||||
cv2.fillPoly(class_mask, box.reshape(1, -1, 2).astype(np.int32), 0)
|
||||
classes = classes[ymin:ymax + 1, xmin:xmax + 1]
|
||||
|
||||
new_classes = classes + class_mask
|
||||
a = new_classes.reshape(-1)
|
||||
b = np.where(a >= k)
|
||||
classes = np.delete(a, b[0].tolist())
|
||||
|
||||
class_index = np.argmax(np.bincount(classes))
|
||||
class_score = np.sum(classes == class_index) / len(classes)
|
||||
|
||||
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
|
||||
|
||||
def box_score_slow(self, bitmap, contour, classes):
|
||||
"""
|
||||
box_score_slow: use polyon mean score as the mean score
|
||||
"""
|
||||
h, w = bitmap.shape[:2]
|
||||
contour = contour.copy()
|
||||
contour = np.reshape(contour, (-1, 2))
|
||||
|
||||
xmin = np.clip(np.min(contour[:, 0]), 0, w - 1)
|
||||
xmax = np.clip(np.max(contour[:, 0]), 0, w - 1)
|
||||
ymin = np.clip(np.min(contour[:, 1]), 0, h - 1)
|
||||
ymax = np.clip(np.max(contour[:, 1]), 0, h - 1)
|
||||
|
||||
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
|
||||
|
||||
contour[:, 0] = contour[:, 0] - xmin
|
||||
contour[:, 1] = contour[:, 1] - ymin
|
||||
|
||||
cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
|
||||
|
||||
if classes is None:
|
||||
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], None, None
|
||||
else:
|
||||
k = 999
|
||||
class_mask = np.full((ymax - ymin + 1, xmax - xmin + 1), k, dtype=np.int32)
|
||||
|
||||
cv2.fillPoly(class_mask, contour.reshape(1, -1, 2).astype(np.int32), 0)
|
||||
classes = classes[ymin:ymax + 1, xmin:xmax + 1]
|
||||
|
||||
new_classes = classes + class_mask
|
||||
a = new_classes.reshape(-1)
|
||||
b = np.where(a >= k)
|
||||
classes = np.delete(a, b[0].tolist())
|
||||
|
||||
class_index = np.argmax(np.bincount(classes))
|
||||
class_score = np.sum(classes == class_index) / len(classes)
|
||||
|
||||
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0], class_index, class_score
|
||||
|
||||
def __call__(self, outs_dict, shape_list):
|
||||
pred = outs_dict['maps']
|
||||
if isinstance(pred, paddle.Tensor):
|
||||
pred = pred.numpy()
|
||||
pred = pred[:, 0, :, :]
|
||||
segmentation = pred > self.thresh
|
||||
|
||||
if "classes" in outs_dict:
|
||||
classes = outs_dict['classes']
|
||||
if isinstance(classes, paddle.Tensor):
|
||||
classes = classes.numpy()
|
||||
classes = classes[:, 0, :, :]
|
||||
|
||||
else:
|
||||
classes = None
|
||||
|
||||
boxes_batch = []
|
||||
for batch_index in range(pred.shape[0]):
|
||||
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
|
||||
if self.dilation_kernel is not None:
|
||||
mask = cv2.dilate(
|
||||
np.array(segmentation[batch_index]).astype(np.uint8),
|
||||
self.dilation_kernel)
|
||||
else:
|
||||
mask = segmentation[batch_index]
|
||||
|
||||
if classes is None:
|
||||
boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask, None,
|
||||
src_w, src_h)
|
||||
boxes_batch.append({'points': boxes})
|
||||
else:
|
||||
boxes, scores, class_indexes, class_scores = self.boxes_from_bitmap(pred[batch_index], mask,
|
||||
classes[batch_index],
|
||||
src_w, src_h)
|
||||
boxes_batch.append({'points': boxes, "classes": class_indexes, "class_scores": class_scores})
|
||||
|
||||
return boxes_batch
|
||||
```
|
||||
|
||||
### 4.4. 模型启动
|
||||
|
||||
在完成上述步骤后我们就可以正常启动训练
|
||||
|
||||
```
|
||||
!python /home/aistudio/work/PaddleOCR/tools/train.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
|
||||
```
|
||||
|
||||
其他命令:
|
||||
```
|
||||
!python /home/aistudio/work/PaddleOCR/tools/eval.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
|
||||
!python /home/aistudio/work/PaddleOCR/tools/infer_det.py -c /home/aistudio/work/PaddleOCR/configs/det/det_mv3_db.yml
|
||||
```
|
||||
模型推理
|
||||
```
|
||||
!python /home/aistudio/work/PaddleOCR/tools/infer/predict_det.py --image_dir="/home/aistudio/work/test_img/" --det_model_dir="/home/aistudio/work/PaddleOCR/output/infer"
|
||||
```
|
||||
|
||||
## 5 总结
|
||||
|
||||
1. 分类+检测在一定程度上能够缩短用时,具体的模型选取要根据业务场景恰当选择。
|
||||
2. 数据标注需要多次进行测试调整标注方法,一般进行检测模型微调,需要标注至少上百张。
|
||||
3. 设置合理的batch_size以及resize大小,同时注意lr设置。
|
||||
|
||||
|
||||
## References
|
||||
|
||||
1 https://github.com/PaddlePaddle/PaddleOCR
|
||||
|
||||
2 https://github.com/PaddlePaddle/PaddleClas
|
||||
|
||||
3 https://blog.csdn.net/YY007H/article/details/124491217
|
||||
|
|
@ -0,0 +1,284 @@
|
|||
# 金融智能核验:扫描合同关键信息抽取
|
||||
|
||||
本案例将使用OCR技术和通用信息抽取技术,实现合同关键信息审核和比对。通过本章的学习,你可以快速掌握:
|
||||
|
||||
1. 使用PaddleOCR提取扫描文本内容
|
||||
2. 使用PaddleNLP抽取自定义信息
|
||||
|
||||
点击进入 [AI Studio 项目](https://aistudio.baidu.com/aistudio/projectdetail/4545772)
|
||||
|
||||
## 1. 项目背景
|
||||
合同审核广泛应用于大中型企业、上市公司、证券、基金公司中,是规避风险的重要任务。
|
||||
- 合同内容对比:合同审核场景中,快速找出不同版本合同修改区域、版本差异;如合同盖章归档场景中有效识别实际签署的纸质合同、电子版合同差异。
|
||||
|
||||
- 合规性检查:法务人员进行合同审核,如合同完备性检查、大小写金额检查、签约主体一致性检查、双方权利和义务对等性分析等。
|
||||
|
||||
- 风险点识别:通过合同审核可识别事实倾向型风险点和数值计算型风险点等,例如交付地点约定不明、合同总价款不一致、重要条款缺失等风险点。
|
||||
|
||||
|
||||

|
||||
|
||||
传统业务中大多使用人工进行纸质版合同审核,存在成本高,工作量大,效率低的问题,且一旦出错将造成巨额损失。
|
||||
|
||||
|
||||
本项目针对以上场景,使用PaddleOCR+PaddleNLP快速提取文本内容,经过少量数据微调即可准确抽取关键信息,**高效完成合同内容对比、合规性检查、风险点识别等任务,提高效率,降低风险**。
|
||||
|
||||
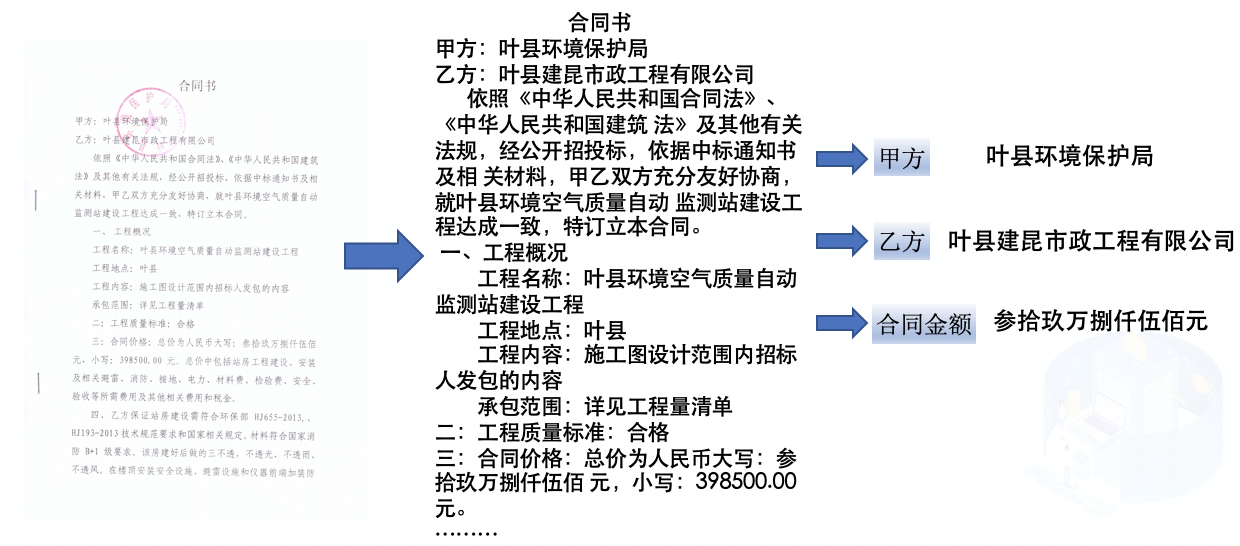
|
||||
|
||||
|
||||
## 2. 解决方案
|
||||
|
||||
### 2.1 扫描合同文本内容提取
|
||||
|
||||
使用PaddleOCR开源的模型可以快速完成扫描文档的文本内容提取,在清晰文档上识别准确率可达到95%+。下面来快速体验一下:
|
||||
|
||||
#### 2.1.1 环境准备
|
||||
|
||||
[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)提供了适用于通用场景的高精轻量模型,提供数据预处理-模型推理-后处理全流程,支持pip安装:
|
||||
|
||||
```
|
||||
python -m pip install paddleocr
|
||||
```
|
||||
|
||||
#### 2.1.2 效果测试
|
||||
|
||||
使用一张合同图片作为测试样本,感受ppocrv3模型效果:
|
||||
|
||||
<img src=https://ai-studio-static-online.cdn.bcebos.com/46258d0dc9dc40bab3ea0e70434e4a905646df8a647f4c49921e217de5142def width=300>
|
||||
|
||||
使用中文检测+识别模型提取文本,实例化PaddleOCR类:
|
||||
|
||||
```
|
||||
from paddleocr import PaddleOCR, draw_ocr
|
||||
|
||||
# paddleocr目前支持中英文、英文、法语、德语、韩语、日语等80个语种,可以通过修改lang参数进行切换
|
||||
ocr = PaddleOCR(use_angle_cls=False, lang="ch") # need to run only once to download and load model into memory
|
||||
```
|
||||
|
||||
一行命令启动预测,预测结果包括`检测框`和`文本识别内容`:
|
||||
|
||||
```
|
||||
img_path = "./test_img/hetong2.jpg"
|
||||
result = ocr.ocr(img_path, cls=False)
|
||||
for line in result:
|
||||
print(line)
|
||||
|
||||
# 可视化结果
|
||||
from PIL import Image
|
||||
|
||||
image = Image.open(img_path).convert('RGB')
|
||||
boxes = [line[0] for line in result]
|
||||
txts = [line[1][0] for line in result]
|
||||
scores = [line[1][1] for line in result]
|
||||
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
|
||||
im_show = Image.fromarray(im_show)
|
||||
im_show.show()
|
||||
```
|
||||
|
||||
#### 2.1.3 图片预处理
|
||||
|
||||
通过上图可视化结果可以看到,印章部分造成的文本遮盖,影响了文本识别结果,因此可以考虑通道提取,去除图片中的红色印章:
|
||||
|
||||
```
|
||||
import cv2
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
#读入图像,三通道
|
||||
image=cv2.imread("./test_img/hetong2.jpg",cv2.IMREAD_COLOR) #timg.jpeg
|
||||
|
||||
#获得三个通道
|
||||
Bch,Gch,Rch=cv2.split(image)
|
||||
|
||||
#保存三通道图片
|
||||
cv2.imwrite('blue_channel.jpg',Bch)
|
||||
cv2.imwrite('green_channel.jpg',Gch)
|
||||
cv2.imwrite('red_channel.jpg',Rch)
|
||||
```
|
||||
#### 2.1.4 合同文本信息提取
|
||||
|
||||
经过2.1.3的预处理后,合同照片的红色通道被分离,获得了一张相对更干净的图片,此时可以再次使用ppocr模型提取文本内容:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
import cv2
|
||||
|
||||
|
||||
img_path = './red_channel.jpg'
|
||||
result = ocr.ocr(img_path, cls=False)
|
||||
|
||||
# 可视化结果
|
||||
from PIL import Image
|
||||
|
||||
image = Image.open(img_path).convert('RGB')
|
||||
boxes = [line[0] for line in result]
|
||||
txts = [line[1][0] for line in result]
|
||||
scores = [line[1][1] for line in result]
|
||||
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
|
||||
im_show = Image.fromarray(im_show)
|
||||
vis = np.array(im_show)
|
||||
im_show.show()
|
||||
```
|
||||
|
||||
忽略检测框内容,提取完整的合同文本:
|
||||
|
||||
```
|
||||
txts = [line[1][0] for line in result]
|
||||
all_context = "\n".join(txts)
|
||||
print(all_context)
|
||||
```
|
||||
|
||||
通过以上环节就完成了扫描合同关键信息抽取的第一步:文本内容提取,接下来可以基于识别出的文本内容抽取关键信息
|
||||
|
||||
### 2.2 合同关键信息抽取
|
||||
|
||||
#### 2.2.1 环境准备
|
||||
|
||||
安装PaddleNLP
|
||||
|
||||
|
||||
```
|
||||
pip install --upgrade pip
|
||||
pip install --upgrade paddlenlp
|
||||
```
|
||||
|
||||
#### 2.2.2 合同关键信息抽取
|
||||
|
||||
PaddleNLP 使用 Taskflow 统一管理多场景任务的预测功能,其中`information_extraction` 通过大量的有标签样本进行训练,在通用的场景中一般可以直接使用,只需更换关键字即可。例如在合同信息抽取中,我们重新定义抽取关键字:
|
||||
|
||||
甲方、乙方、币种、金额、付款方式
|
||||
|
||||
|
||||
将使用OCR提取好的文本作为输入,使用三行命令可以对上文中提取到的合同文本进行关键信息抽取:
|
||||
|
||||
```
|
||||
from paddlenlp import Taskflow
|
||||
schema = ["甲方","乙方","总价"]
|
||||
ie = Taskflow('information_extraction', schema=schema)
|
||||
ie.set_schema(schema)
|
||||
ie(all_context)
|
||||
```
|
||||
|
||||
可以看到UIE模型可以准确的提取出关键信息,用于后续的信息比对或审核。
|
||||
|
||||
## 3.效果优化
|
||||
|
||||
### 3.1 文本识别后处理调优
|
||||
|
||||
实际图片采集过程中,可能出现部分图片弯曲等问题,导致使用默认参数识别文本时存在漏检,影响关键信息获取。
|
||||
|
||||
例如下图:
|
||||
|
||||
<img src="https://ai-studio-static-online.cdn.bcebos.com/fe350481be0241c58736d487d1bf06c2e65911bf01254a79944be629c4c10091" height="300" width="300">
|
||||
|
||||
|
||||
直接进行预测:
|
||||
|
||||
```
|
||||
img_path = "./test_img/hetong3.jpg"
|
||||
# 预测结果
|
||||
result = ocr.ocr(img_path, cls=False)
|
||||
# 可视化结果
|
||||
from PIL import Image
|
||||
|
||||
image = Image.open(img_path).convert('RGB')
|
||||
boxes = [line[0] for line in result]
|
||||
txts = [line[1][0] for line in result]
|
||||
scores = [line[1][1] for line in result]
|
||||
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
|
||||
im_show = Image.fromarray(im_show)
|
||||
im_show.show()
|
||||
```
|
||||
|
||||
可视化结果可以看到,弯曲图片存在漏检,一般来说可以通过调整后处理参数解决,无需重新训练模型。漏检问题往往是因为检测模型获得的分割图太小,生成框的得分过低被过滤掉了,通常有两种方式调整参数:
|
||||
- 开启`use_dilatiion=True` 膨胀分割区域
|
||||
- 调小`det_db_box_thresh`阈值
|
||||
|
||||
```
|
||||
# 重新实例化 PaddleOCR
|
||||
ocr = PaddleOCR(use_angle_cls=False, lang="ch", det_db_box_thresh=0.3, use_dilation=True)
|
||||
|
||||
# 预测并可视化
|
||||
img_path = "./test_img/hetong3.jpg"
|
||||
# 预测结果
|
||||
result = ocr.ocr(img_path, cls=False)
|
||||
# 可视化结果
|
||||
image = Image.open(img_path).convert('RGB')
|
||||
boxes = [line[0] for line in result]
|
||||
txts = [line[1][0] for line in result]
|
||||
scores = [line[1][1] for line in result]
|
||||
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
|
||||
im_show = Image.fromarray(im_show)
|
||||
im_show.show()
|
||||
```
|
||||
|
||||
可以看到漏检问题被很好的解决,提取完整的文本内容:
|
||||
|
||||
```
|
||||
txts = [line[1][0] for line in result]
|
||||
context = "\n".join(txts)
|
||||
print(context)
|
||||
```
|
||||
|
||||
### 3.2 关键信息提取调优
|
||||
|
||||
UIE通过大量有标签样本进行训练,得到了一个开箱即用的高精模型。 然而针对不同场景,可能会出现部分实体无法被抽取的情况。通常来说有以下几个方法进行效果调优:
|
||||
|
||||
|
||||
- 修改 schema
|
||||
- 添加正则方法
|
||||
- 标注小样本微调模型
|
||||
|
||||
**修改schema**
|
||||
|
||||
Prompt和原文描述越像,抽取效果越好,例如
|
||||
```
|
||||
三:合同价格:总价为人民币大写:参拾玖万捌仟伍佰
|
||||
元,小写:398500.00元。总价中包括站房工程建设、安装
|
||||
及相关避雷、消防、接地、电力、材料费、检验费、安全、
|
||||
验收等所需费用及其他相关费用和税金。
|
||||
```
|
||||
schema = ["总金额"] 时无法准确抽取,与原文描述差异较大。 修改 schema = ["总价"] 再次尝试:
|
||||
|
||||
```
|
||||
from paddlenlp import Taskflow
|
||||
# schema = ["总金额"]
|
||||
schema = ["总价"]
|
||||
ie = Taskflow('information_extraction', schema=schema)
|
||||
ie.set_schema(schema)
|
||||
ie(all_context)
|
||||
```
|
||||
|
||||
|
||||
**模型微调**
|
||||
|
||||
UIE的建模方式主要是通过 `Prompt` 方式来建模, `Prompt` 在小样本上进行微调效果非常有效。详细的数据标注+模型微调步骤可以参考项目:
|
||||
|
||||
[PaddleNLP信息抽取技术重磅升级!](https://aistudio.baidu.com/aistudio/projectdetail/3914778?channelType=0&channel=0)
|
||||
|
||||
[工单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/3914778?contributionType=1)
|
||||
|
||||
[快递单信息抽取](https://aistudio.baidu.com/aistudio/projectdetail/4038499?contributionType=1)
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
扫描合同的关键信息提取可以使用 PaddleOCR + PaddleNLP 组合实现,两个工具均有以下优势:
|
||||
|
||||
* 使用简单:whl包一键安装,3行命令调用
|
||||
* 效果领先:优秀的模型效果可覆盖几乎全部的应用场景
|
||||
* 调优成本低:OCR模型可通过后处理参数的调整适配略有偏差的扫描文本, UIE模型可以通过极少的标注样本微调,成本很低。
|
||||
|
||||
## 作业
|
||||
|
||||
尝试自己解析出 `test_img/homework.png` 扫描合同中的 [甲方、乙方] 关键词:
|
||||
|
||||
|
||||
|
||||
<img src=https://ai-studio-static-online.cdn.bcebos.com/50a49a3c9f8348bfa04e8c8b97d3cce0d0dd6b14040f43939268d120688ef7ca width=300 hight=400>
|
||||
|
||||
|
||||
|
||||
更多场景下的垂类模型获取,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
|
||||
|
||||
<img src=https://ai-studio-static-online.cdn.bcebos.com/606538b59ea845cb99943b1dec6efe724e78f75c1e9c49228c7bf7da9f8837f5 width=300 hight=300>
|
||||
|
|
@ -0,0 +1,107 @@
|
|||
Global:
|
||||
use_gpu: true
|
||||
epoch_num: 600
|
||||
log_smooth_window: 20
|
||||
print_batch_step: 10
|
||||
save_model_dir: ./output/det_ct/
|
||||
save_epoch_step: 10
|
||||
# evaluation is run every 2000 iterations
|
||||
eval_batch_step: [0,1000]
|
||||
cal_metric_during_train: False
|
||||
pretrained_model: ./pretrain_models/ResNet18_vd_pretrained.pdparams
|
||||
checkpoints:
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
infer_img: doc/imgs_en/img623.jpg
|
||||
save_res_path: ./output/det_ct/predicts_ct.txt
|
||||
|
||||
Architecture:
|
||||
model_type: det
|
||||
algorithm: CT
|
||||
Transform:
|
||||
Backbone:
|
||||
name: ResNet_vd
|
||||
layers: 18
|
||||
Neck:
|
||||
name: CTFPN
|
||||
Head:
|
||||
name: CT_Head
|
||||
in_channels: 512
|
||||
hidden_dim: 128
|
||||
num_classes: 3
|
||||
|
||||
Loss:
|
||||
name: CTLoss
|
||||
|
||||
Optimizer:
|
||||
name: Adam
|
||||
lr: #PolynomialDecay
|
||||
name: Linear
|
||||
learning_rate: 0.001
|
||||
end_lr: 0.
|
||||
epochs: 600
|
||||
step_each_epoch: 1254
|
||||
power: 0.9
|
||||
|
||||
PostProcess:
|
||||
name: CTPostProcess
|
||||
box_type: poly
|
||||
|
||||
Metric:
|
||||
name: CTMetric
|
||||
main_indicator: f_score
|
||||
|
||||
Train:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/total_text/train
|
||||
label_file_list:
|
||||
- ./train_data/total_text/train/train.txt
|
||||
ratio_list: [1.0]
|
||||
transforms:
|
||||
- DecodeImage:
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- CTLabelEncode: # Class handling label
|
||||
- RandomScale:
|
||||
- MakeShrink:
|
||||
- GroupRandomHorizontalFlip:
|
||||
- GroupRandomRotate:
|
||||
- GroupRandomCropPadding:
|
||||
- MakeCentripetalShift:
|
||||
- ColorJitter:
|
||||
brightness: 0.125
|
||||
saturation: 0.5
|
||||
- ToCHWImage:
|
||||
- NormalizeImage:
|
||||
- KeepKeys:
|
||||
keep_keys: ['image', 'gt_kernel', 'training_mask', 'gt_instance', 'gt_kernel_instance', 'training_mask_distance', 'gt_distance'] # the order of the dataloader list
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: True
|
||||
batch_size_per_card: 4
|
||||
num_workers: 8
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
name: SimpleDataSet
|
||||
data_dir: ./train_data/total_text/test
|
||||
label_file_list:
|
||||
- ./train_data/total_text/test/test.txt
|
||||
ratio_list: [1.0]
|
||||
transforms:
|
||||
- DecodeImage:
|
||||
img_mode: RGB
|
||||
channel_first: False
|
||||
- CTLabelEncode: # Class handling label
|
||||
- ScaleAlignedShort:
|
||||
- NormalizeImage:
|
||||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: ['image', 'shape', 'polys', 'texts'] # the order of the dataloader list
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 1
|
||||
num_workers: 2
|
||||
|
|
@ -13,6 +13,7 @@ Global:
|
|||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
infer_img:
|
||||
infer_visual_type: EN # two mode: EN is for english datasets, CN is for chinese datasets
|
||||
valid_set: totaltext # two mode: totaltext valid curved words, partvgg valid non-curved words
|
||||
save_res_path: ./output/pgnet_r50_vd_totaltext/predicts_pgnet.txt
|
||||
character_dict_path: ppocr/utils/ic15_dict.txt
|
||||
|
|
@ -32,6 +33,7 @@ Architecture:
|
|||
name: PGFPN
|
||||
Head:
|
||||
name: PGHead
|
||||
character_dict_path: ppocr/utils/ic15_dict.txt # the same as Global:character_dict_path
|
||||
|
||||
Loss:
|
||||
name: PGLoss
|
||||
|
|
@ -45,16 +47,18 @@ Optimizer:
|
|||
beta1: 0.9
|
||||
beta2: 0.999
|
||||
lr:
|
||||
name: Cosine
|
||||
learning_rate: 0.001
|
||||
warmup_epoch: 50
|
||||
regularizer:
|
||||
name: 'L2'
|
||||
factor: 0
|
||||
|
||||
factor: 0.0001
|
||||
|
||||
PostProcess:
|
||||
name: PGPostProcess
|
||||
score_thresh: 0.5
|
||||
mode: fast # fast or slow two ways
|
||||
point_gather_mode: align # same as PGProcessTrain: point_gather_mode
|
||||
|
||||
Metric:
|
||||
name: E2EMetric
|
||||
|
|
@ -76,9 +80,12 @@ Train:
|
|||
- E2ELabelEncodeTrain:
|
||||
- PGProcessTrain:
|
||||
batch_size: 14 # same as loader: batch_size_per_card
|
||||
use_resize: True
|
||||
use_random_crop: False
|
||||
min_crop_size: 24
|
||||
min_text_size: 4
|
||||
max_text_size: 512
|
||||
point_gather_mode: align # two mode: align and none, align mode is better than none mode
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'images', 'tcl_maps', 'tcl_label_maps', 'border_maps','direction_maps', 'training_masks', 'label_list', 'pos_list', 'pos_mask' ] # dataloader will return list in this order
|
||||
loader:
|
||||
|
|
|
|||
|
|
@ -68,6 +68,7 @@ Train:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -83,7 +84,6 @@ Train:
|
|||
drop_last: False
|
||||
batch_size_per_card: 2
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
|
|
@ -105,6 +105,7 @@ Eval:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -120,4 +121,3 @@ Eval:
|
|||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
|
|
|||
|
|
@ -73,6 +73,7 @@ Train:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -82,13 +83,12 @@ Train:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 2
|
||||
num_workers: 4
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
|
|
@ -112,6 +112,7 @@ Eval:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -121,11 +122,9 @@ Eval:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
|
|
|
|||
|
|
@ -57,14 +57,16 @@ Loss:
|
|||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_5
|
||||
key: hidden_states
|
||||
index: 5
|
||||
name: "loss_5"
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_8
|
||||
key: hidden_states
|
||||
index: 8
|
||||
name: "loss_8"
|
||||
|
||||
|
||||
|
|
@ -116,6 +118,7 @@ Train:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -125,13 +128,12 @@ Train:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox','attention_mask', 'token_type_ids', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: True
|
||||
drop_last: False
|
||||
batch_size_per_card: 2
|
||||
num_workers: 4
|
||||
collate_fn: ListCollator
|
||||
|
||||
Eval:
|
||||
dataset:
|
||||
|
|
@ -155,6 +157,7 @@ Eval:
|
|||
- VQAReTokenRelation:
|
||||
- VQAReTokenChunk:
|
||||
max_seq_len: *max_seq_len
|
||||
- TensorizeEntitiesRelations:
|
||||
- Resize:
|
||||
size: [224,224]
|
||||
- NormalizeImage:
|
||||
|
|
@ -164,12 +167,11 @@ Eval:
|
|||
order: 'hwc'
|
||||
- ToCHWImage:
|
||||
- KeepKeys:
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'image', 'entities', 'relations'] # dataloader will return list in this order
|
||||
keep_keys: [ 'input_ids', 'bbox', 'attention_mask', 'token_type_ids', 'entities', 'relations'] # dataloader will return list in this order
|
||||
loader:
|
||||
shuffle: False
|
||||
drop_last: False
|
||||
batch_size_per_card: 8
|
||||
num_workers: 8
|
||||
collate_fn: ListCollator
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -70,14 +70,16 @@ Loss:
|
|||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_5
|
||||
key: hidden_states
|
||||
index: 5
|
||||
name: "loss_5"
|
||||
- DistillationVQADistanceLoss:
|
||||
weight: 0.5
|
||||
mode: "l2"
|
||||
model_name_pairs:
|
||||
- ["Student", "Teacher"]
|
||||
key: hidden_states_8
|
||||
key: hidden_states
|
||||
index: 8
|
||||
name: "loss_8"
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -88,6 +88,7 @@ Train:
|
|||
prob: 0.5
|
||||
ext_data_num: 2
|
||||
image_shape: [48, 320, 3]
|
||||
max_text_length: *max_text_length
|
||||
- RecAug:
|
||||
- MultiLabelEncode:
|
||||
- RecResizeImg:
|
||||
|
|
|
|||
|
|
@ -162,6 +162,7 @@ Train:
|
|||
prob: 0.5
|
||||
ext_data_num: 2
|
||||
image_shape: [48, 320, 3]
|
||||
max_text_length: *max_text_length
|
||||
- RecAug:
|
||||
- MultiLabelEncode:
|
||||
- RecResizeImg:
|
||||
|
|
|
|||
|
|
@ -88,6 +88,7 @@ Train:
|
|||
prob: 0.5
|
||||
ext_data_num: 2
|
||||
image_shape: [48, 320, 3]
|
||||
max_text_length: *max_text_length
|
||||
- RecAug:
|
||||
- MultiLabelEncode:
|
||||
- RecResizeImg:
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Global:
|
|||
checkpoints:
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
infer_img: ./inference/rec_inference
|
||||
infer_img: doc/imgs_words_en/word_10.png
|
||||
# for data or label process
|
||||
character_dict_path: ppocr/utils/dict90.txt
|
||||
max_text_length: &max_text_length 40
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Global:
|
|||
checkpoints:
|
||||
save_inference_dir:
|
||||
use_visualdl: False
|
||||
infer_img: doc/imgs_words/ch/word_1.jpg
|
||||
infer_img: doc/imgs_words_en/word_10.png
|
||||
# for data or label process
|
||||
character_dict_path: ./ppocr/utils/dict/spin_dict.txt
|
||||
max_text_length: 25
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Global:
|
|||
checkpoints:
|
||||
save_inference_dir: ./output/SLANet/infer
|
||||
use_visualdl: False
|
||||
infer_img: doc/table/table.jpg
|
||||
infer_img: ppstructure/docs/table/table.jpg
|
||||
# for data or label process
|
||||
character_dict_path: ppocr/utils/dict/table_structure_dict.txt
|
||||
character_type: en
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Global:
|
|||
checkpoints:
|
||||
save_inference_dir: ./output/SLANet_ch/infer
|
||||
use_visualdl: False
|
||||
infer_img: doc/table/table.jpg
|
||||
infer_img: ppstructure/docs/table/table.jpg
|
||||
# for data or label process
|
||||
character_dict_path: ppocr/utils/dict/table_structure_dict_ch.txt
|
||||
character_type: en
|
||||
|
|
@ -107,7 +107,7 @@ Train:
|
|||
Eval:
|
||||
dataset:
|
||||
name: PubTabDataSet
|
||||
data_dir: train_data/table/val/
|
||||
data_dir: train_data/table/val/
|
||||
label_file_list: [train_data/table/val.txt]
|
||||
transforms:
|
||||
- DecodeImage:
|
||||
|
|
|
|||
|
|
@ -43,7 +43,6 @@ Architecture:
|
|||
Head:
|
||||
name: TableAttentionHead
|
||||
hidden_size: 256
|
||||
loc_type: 2
|
||||
max_text_length: *max_text_length
|
||||
loc_reg_num: &loc_reg_num 4
|
||||
|
||||
|
|
|
|||
|
|
@ -49,13 +49,20 @@ DECLARE_int32(rec_batch_num);
|
|||
DECLARE_string(rec_char_dict_path);
|
||||
DECLARE_int32(rec_img_h);
|
||||
DECLARE_int32(rec_img_w);
|
||||
// layout model related
|
||||
DECLARE_string(layout_model_dir);
|
||||
DECLARE_string(layout_dict_path);
|
||||
DECLARE_double(layout_score_threshold);
|
||||
DECLARE_double(layout_nms_threshold);
|
||||
// structure model related
|
||||
DECLARE_string(table_model_dir);
|
||||
DECLARE_int32(table_max_len);
|
||||
DECLARE_int32(table_batch_num);
|
||||
DECLARE_string(table_char_dict_path);
|
||||
DECLARE_bool(merge_no_span_structure);
|
||||
// forward related
|
||||
DECLARE_bool(det);
|
||||
DECLARE_bool(rec);
|
||||
DECLARE_bool(cls);
|
||||
DECLARE_bool(table);
|
||||
DECLARE_bool(table);
|
||||
DECLARE_bool(layout);
|
||||
|
|
@ -14,26 +14,12 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/preprocess_op.h>
|
||||
#include <include/utility.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
class Classifier {
|
||||
|
|
@ -66,7 +52,7 @@ public:
|
|||
std::vector<float> &cls_scores, std::vector<double> ×);
|
||||
|
||||
private:
|
||||
std::shared_ptr<Predictor> predictor_;
|
||||
std::shared_ptr<paddle_infer::Predictor> predictor_;
|
||||
|
||||
bool use_gpu_ = false;
|
||||
int gpu_id_ = 0;
|
||||
|
|
|
|||
|
|
@ -14,26 +14,12 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/postprocess_op.h>
|
||||
#include <include/preprocess_op.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
class DBDetector {
|
||||
|
|
@ -41,7 +27,7 @@ public:
|
|||
explicit DBDetector(const std::string &model_dir, const bool &use_gpu,
|
||||
const int &gpu_id, const int &gpu_mem,
|
||||
const int &cpu_math_library_num_threads,
|
||||
const bool &use_mkldnn, const string &limit_type,
|
||||
const bool &use_mkldnn, const std::string &limit_type,
|
||||
const int &limit_side_len, const double &det_db_thresh,
|
||||
const double &det_db_box_thresh,
|
||||
const double &det_db_unclip_ratio,
|
||||
|
|
@ -77,7 +63,7 @@ public:
|
|||
std::vector<double> ×);
|
||||
|
||||
private:
|
||||
std::shared_ptr<Predictor> predictor_;
|
||||
std::shared_ptr<paddle_infer::Predictor> predictor_;
|
||||
|
||||
bool use_gpu_ = false;
|
||||
int gpu_id_ = 0;
|
||||
|
|
@ -85,7 +71,7 @@ private:
|
|||
int cpu_math_library_num_threads_ = 4;
|
||||
bool use_mkldnn_ = false;
|
||||
|
||||
string limit_type_ = "max";
|
||||
std::string limit_type_ = "max";
|
||||
int limit_side_len_ = 960;
|
||||
|
||||
double det_db_thresh_ = 0.3;
|
||||
|
|
|
|||
|
|
@ -14,27 +14,12 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/ocr_cls.h>
|
||||
#include <include/preprocess_op.h>
|
||||
#include <include/utility.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
class CRNNRecognizer {
|
||||
|
|
@ -42,7 +27,7 @@ public:
|
|||
explicit CRNNRecognizer(const std::string &model_dir, const bool &use_gpu,
|
||||
const int &gpu_id, const int &gpu_mem,
|
||||
const int &cpu_math_library_num_threads,
|
||||
const bool &use_mkldnn, const string &label_path,
|
||||
const bool &use_mkldnn, const std::string &label_path,
|
||||
const bool &use_tensorrt,
|
||||
const std::string &precision,
|
||||
const int &rec_batch_num, const int &rec_img_h,
|
||||
|
|
@ -75,7 +60,7 @@ public:
|
|||
std::vector<float> &rec_text_scores, std::vector<double> ×);
|
||||
|
||||
private:
|
||||
std::shared_ptr<Predictor> predictor_;
|
||||
std::shared_ptr<paddle_infer::Predictor> predictor_;
|
||||
|
||||
bool use_gpu_ = false;
|
||||
int gpu_id_ = 0;
|
||||
|
|
|
|||
|
|
@ -14,28 +14,9 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/ocr_cls.h>
|
||||
#include <include/ocr_det.h>
|
||||
#include <include/ocr_rec.h>
|
||||
#include <include/preprocess_op.h>
|
||||
#include <include/utility.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
|
|
@ -43,21 +24,27 @@ class PPOCR {
|
|||
public:
|
||||
explicit PPOCR();
|
||||
~PPOCR();
|
||||
std::vector<std::vector<OCRPredictResult>>
|
||||
ocr(std::vector<cv::String> cv_all_img_names, bool det = true,
|
||||
bool rec = true, bool cls = true);
|
||||
|
||||
std::vector<std::vector<OCRPredictResult>> ocr(std::vector<cv::Mat> img_list,
|
||||
bool det = true,
|
||||
bool rec = true,
|
||||
bool cls = true);
|
||||
std::vector<OCRPredictResult> ocr(cv::Mat img, bool det = true,
|
||||
bool rec = true, bool cls = true);
|
||||
|
||||
void reset_timer();
|
||||
void benchmark_log(int img_num);
|
||||
|
||||
protected:
|
||||
void det(cv::Mat img, std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×);
|
||||
std::vector<double> time_info_det = {0, 0, 0};
|
||||
std::vector<double> time_info_rec = {0, 0, 0};
|
||||
std::vector<double> time_info_cls = {0, 0, 0};
|
||||
|
||||
void det(cv::Mat img, std::vector<OCRPredictResult> &ocr_results);
|
||||
void rec(std::vector<cv::Mat> img_list,
|
||||
std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×);
|
||||
std::vector<OCRPredictResult> &ocr_results);
|
||||
void cls(std::vector<cv::Mat> img_list,
|
||||
std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×);
|
||||
void log(std::vector<double> &det_times, std::vector<double> &rec_times,
|
||||
std::vector<double> &cls_times, int img_num);
|
||||
std::vector<OCRPredictResult> &ocr_results);
|
||||
|
||||
private:
|
||||
DBDetector *detector_ = nullptr;
|
||||
|
|
|
|||
|
|
@ -14,27 +14,9 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/paddleocr.h>
|
||||
#include <include/preprocess_op.h>
|
||||
#include <include/structure_layout.h>
|
||||
#include <include/structure_table.h>
|
||||
#include <include/utility.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
|
|
@ -42,27 +24,32 @@ class PaddleStructure : public PPOCR {
|
|||
public:
|
||||
explicit PaddleStructure();
|
||||
~PaddleStructure();
|
||||
std::vector<std::vector<StructurePredictResult>>
|
||||
structure(std::vector<cv::String> cv_all_img_names, bool layout = false,
|
||||
bool table = true);
|
||||
|
||||
std::vector<StructurePredictResult> structure(cv::Mat img,
|
||||
bool layout = false,
|
||||
bool table = true,
|
||||
bool ocr = false);
|
||||
|
||||
void reset_timer();
|
||||
void benchmark_log(int img_num);
|
||||
|
||||
private:
|
||||
StructureTableRecognizer *recognizer_ = nullptr;
|
||||
std::vector<double> time_info_table = {0, 0, 0};
|
||||
std::vector<double> time_info_layout = {0, 0, 0};
|
||||
|
||||
void table(cv::Mat img, StructurePredictResult &structure_result,
|
||||
std::vector<double> &time_info_table,
|
||||
std::vector<double> &time_info_det,
|
||||
std::vector<double> &time_info_rec,
|
||||
std::vector<double> &time_info_cls);
|
||||
std::string
|
||||
rebuild_table(std::vector<std::string> rec_html_tags,
|
||||
std::vector<std::vector<std::vector<int>>> rec_boxes,
|
||||
std::vector<OCRPredictResult> &ocr_result);
|
||||
StructureTableRecognizer *table_model_ = nullptr;
|
||||
StructureLayoutRecognizer *layout_model_ = nullptr;
|
||||
|
||||
float iou(std::vector<std::vector<int>> &box1,
|
||||
std::vector<std::vector<int>> &box2);
|
||||
float dis(std::vector<std::vector<int>> &box1,
|
||||
std::vector<std::vector<int>> &box2);
|
||||
void layout(cv::Mat img,
|
||||
std::vector<StructurePredictResult> &structure_result);
|
||||
|
||||
void table(cv::Mat img, StructurePredictResult &structure_result);
|
||||
|
||||
std::string rebuild_table(std::vector<std::string> rec_html_tags,
|
||||
std::vector<std::vector<int>> rec_boxes,
|
||||
std::vector<OCRPredictResult> &ocr_result);
|
||||
|
||||
float dis(std::vector<int> &box1, std::vector<int> &box2);
|
||||
|
||||
static bool comparison_dis(const std::vector<float> &dis1,
|
||||
const std::vector<float> &dis2) {
|
||||
|
|
|
|||
|
|
@ -14,24 +14,9 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include "include/clipper.h"
|
||||
#include "include/utility.h"
|
||||
|
||||
using namespace std;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
class DBPostProcessor {
|
||||
|
|
@ -92,14 +77,13 @@ private:
|
|||
|
||||
class TablePostProcessor {
|
||||
public:
|
||||
void init(std::string label_path);
|
||||
void
|
||||
Run(std::vector<float> &loc_preds, std::vector<float> &structure_probs,
|
||||
std::vector<float> &rec_scores, std::vector<int> &loc_preds_shape,
|
||||
std::vector<int> &structure_probs_shape,
|
||||
std::vector<std::vector<std::string>> &rec_html_tag_batch,
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>> &rec_boxes_batch,
|
||||
std::vector<int> &width_list, std::vector<int> &height_list);
|
||||
void init(std::string label_path, bool merge_no_span_structure = true);
|
||||
void Run(std::vector<float> &loc_preds, std::vector<float> &structure_probs,
|
||||
std::vector<float> &rec_scores, std::vector<int> &loc_preds_shape,
|
||||
std::vector<int> &structure_probs_shape,
|
||||
std::vector<std::vector<std::string>> &rec_html_tag_batch,
|
||||
std::vector<std::vector<std::vector<int>>> &rec_boxes_batch,
|
||||
std::vector<int> &width_list, std::vector<int> &height_list);
|
||||
|
||||
private:
|
||||
std::vector<std::string> label_list_;
|
||||
|
|
@ -107,4 +91,27 @@ private:
|
|||
std::string beg = "sos";
|
||||
};
|
||||
|
||||
class PicodetPostProcessor {
|
||||
public:
|
||||
void init(std::string label_path, const double score_threshold = 0.4,
|
||||
const double nms_threshold = 0.5,
|
||||
const std::vector<int> &fpn_stride = {8, 16, 32, 64});
|
||||
void Run(std::vector<StructurePredictResult> &results,
|
||||
std::vector<std::vector<float>> outs, std::vector<int> ori_shape,
|
||||
std::vector<int> resize_shape, int eg_max);
|
||||
std::vector<int> fpn_stride_ = {8, 16, 32, 64};
|
||||
|
||||
private:
|
||||
StructurePredictResult disPred2Bbox(std::vector<float> bbox_pred, int label,
|
||||
float score, int x, int y, int stride,
|
||||
std::vector<int> im_shape, int reg_max);
|
||||
void nms(std::vector<StructurePredictResult> &input_boxes,
|
||||
float nms_threshold);
|
||||
|
||||
std::vector<std::string> label_list_;
|
||||
double score_threshold_ = 0.4;
|
||||
double nms_threshold_ = 0.5;
|
||||
int num_class_ = 5;
|
||||
};
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -14,21 +14,12 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
using namespace std;
|
||||
using namespace paddle;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
|
|
@ -51,9 +42,9 @@ public:
|
|||
|
||||
class ResizeImgType0 {
|
||||
public:
|
||||
virtual void Run(const cv::Mat &img, cv::Mat &resize_img, string limit_type,
|
||||
int limit_side_len, float &ratio_h, float &ratio_w,
|
||||
bool use_tensorrt);
|
||||
virtual void Run(const cv::Mat &img, cv::Mat &resize_img,
|
||||
std::string limit_type, int limit_side_len, float &ratio_h,
|
||||
float &ratio_w, bool use_tensorrt);
|
||||
};
|
||||
|
||||
class CrnnResizeImg {
|
||||
|
|
@ -82,4 +73,10 @@ public:
|
|||
const int max_len = 488);
|
||||
};
|
||||
|
||||
class Resize {
|
||||
public:
|
||||
virtual void Run(const cv::Mat &img, cv::Mat &resize_img, const int h,
|
||||
const int w);
|
||||
};
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
@ -0,0 +1,78 @@
|
|||
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#pragma once
|
||||
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
|
||||
#include <include/postprocess_op.h>
|
||||
#include <include/preprocess_op.h>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
class StructureLayoutRecognizer {
|
||||
public:
|
||||
explicit StructureLayoutRecognizer(
|
||||
const std::string &model_dir, const bool &use_gpu, const int &gpu_id,
|
||||
const int &gpu_mem, const int &cpu_math_library_num_threads,
|
||||
const bool &use_mkldnn, const std::string &label_path,
|
||||
const bool &use_tensorrt, const std::string &precision,
|
||||
const double &layout_score_threshold,
|
||||
const double &layout_nms_threshold) {
|
||||
this->use_gpu_ = use_gpu;
|
||||
this->gpu_id_ = gpu_id;
|
||||
this->gpu_mem_ = gpu_mem;
|
||||
this->cpu_math_library_num_threads_ = cpu_math_library_num_threads;
|
||||
this->use_mkldnn_ = use_mkldnn;
|
||||
this->use_tensorrt_ = use_tensorrt;
|
||||
this->precision_ = precision;
|
||||
|
||||
this->post_processor_.init(label_path, layout_score_threshold,
|
||||
layout_nms_threshold);
|
||||
LoadModel(model_dir);
|
||||
}
|
||||
|
||||
// Load Paddle inference model
|
||||
void LoadModel(const std::string &model_dir);
|
||||
|
||||
void Run(cv::Mat img, std::vector<StructurePredictResult> &result,
|
||||
std::vector<double> ×);
|
||||
|
||||
private:
|
||||
std::shared_ptr<paddle_infer::Predictor> predictor_;
|
||||
|
||||
bool use_gpu_ = false;
|
||||
int gpu_id_ = 0;
|
||||
int gpu_mem_ = 4000;
|
||||
int cpu_math_library_num_threads_ = 4;
|
||||
bool use_mkldnn_ = false;
|
||||
|
||||
std::vector<float> mean_ = {0.485f, 0.456f, 0.406f};
|
||||
std::vector<float> scale_ = {1 / 0.229f, 1 / 0.224f, 1 / 0.225f};
|
||||
bool is_scale_ = true;
|
||||
|
||||
bool use_tensorrt_ = false;
|
||||
std::string precision_ = "fp32";
|
||||
|
||||
// pre-process
|
||||
Resize resize_op_;
|
||||
Normalize normalize_op_;
|
||||
Permute permute_op_;
|
||||
|
||||
// post-process
|
||||
PicodetPostProcessor post_processor_;
|
||||
};
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
@ -14,26 +14,11 @@
|
|||
|
||||
#pragma once
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/postprocess_op.h>
|
||||
#include <include/preprocess_op.h>
|
||||
#include <include/utility.h>
|
||||
|
||||
using namespace paddle_infer;
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
|
|
@ -42,9 +27,10 @@ public:
|
|||
explicit StructureTableRecognizer(
|
||||
const std::string &model_dir, const bool &use_gpu, const int &gpu_id,
|
||||
const int &gpu_mem, const int &cpu_math_library_num_threads,
|
||||
const bool &use_mkldnn, const string &label_path,
|
||||
const bool &use_mkldnn, const std::string &label_path,
|
||||
const bool &use_tensorrt, const std::string &precision,
|
||||
const int &table_batch_num, const int &table_max_len) {
|
||||
const int &table_batch_num, const int &table_max_len,
|
||||
const bool &merge_no_span_structure) {
|
||||
this->use_gpu_ = use_gpu;
|
||||
this->gpu_id_ = gpu_id;
|
||||
this->gpu_mem_ = gpu_mem;
|
||||
|
|
@ -55,7 +41,7 @@ public:
|
|||
this->table_batch_num_ = table_batch_num;
|
||||
this->table_max_len_ = table_max_len;
|
||||
|
||||
this->post_processor_.init(label_path);
|
||||
this->post_processor_.init(label_path, merge_no_span_structure);
|
||||
LoadModel(model_dir);
|
||||
}
|
||||
|
||||
|
|
@ -65,11 +51,11 @@ public:
|
|||
void Run(std::vector<cv::Mat> img_list,
|
||||
std::vector<std::vector<std::string>> &rec_html_tags,
|
||||
std::vector<float> &rec_scores,
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>> &rec_boxes,
|
||||
std::vector<std::vector<std::vector<int>>> &rec_boxes,
|
||||
std::vector<double> ×);
|
||||
|
||||
private:
|
||||
std::shared_ptr<Predictor> predictor_;
|
||||
std::shared_ptr<paddle_infer::Predictor> predictor_;
|
||||
|
||||
bool use_gpu_ = false;
|
||||
int gpu_id_ = 0;
|
||||
|
|
|
|||
|
|
@ -41,11 +41,13 @@ struct OCRPredictResult {
|
|||
};
|
||||
|
||||
struct StructurePredictResult {
|
||||
std::vector<int> box;
|
||||
std::vector<float> box;
|
||||
std::vector<std::vector<int>> cell_box;
|
||||
std::string type;
|
||||
std::vector<OCRPredictResult> text_res;
|
||||
std::string html;
|
||||
float html_score = -1;
|
||||
float confidence;
|
||||
};
|
||||
|
||||
class Utility {
|
||||
|
|
@ -56,6 +58,10 @@ public:
|
|||
const std::vector<OCRPredictResult> &ocr_result,
|
||||
const std::string &save_path);
|
||||
|
||||
static void VisualizeBboxes(const cv::Mat &srcimg,
|
||||
const StructurePredictResult &structure_result,
|
||||
const std::string &save_path);
|
||||
|
||||
template <class ForwardIterator>
|
||||
inline static size_t argmax(ForwardIterator first, ForwardIterator last) {
|
||||
return std::distance(first, std::max_element(first, last));
|
||||
|
|
@ -77,10 +83,20 @@ public:
|
|||
|
||||
static void print_result(const std::vector<OCRPredictResult> &ocr_result);
|
||||
|
||||
static cv::Mat crop_image(cv::Mat &img, std::vector<int> &area);
|
||||
static cv::Mat crop_image(cv::Mat &img, const std::vector<int> &area);
|
||||
static cv::Mat crop_image(cv::Mat &img, const std::vector<float> &area);
|
||||
|
||||
static void sorted_boxes(std::vector<OCRPredictResult> &ocr_result);
|
||||
|
||||
static std::vector<int> xyxyxyxy2xyxy(std::vector<std::vector<int>> &box);
|
||||
static std::vector<int> xyxyxyxy2xyxy(std::vector<int> &box);
|
||||
|
||||
static float fast_exp(float x);
|
||||
static std::vector<float>
|
||||
activation_function_softmax(std::vector<float> &src);
|
||||
static float iou(std::vector<int> &box1, std::vector<int> &box2);
|
||||
static float iou(std::vector<float> &box1, std::vector<float> &box2);
|
||||
|
||||
private:
|
||||
static bool comparison_box(const OCRPredictResult &result1,
|
||||
const OCRPredictResult &result2) {
|
||||
|
|
|
|||
|
|
@ -174,6 +174,9 @@ inference/
|
|||
|-- table
|
||||
| |--inference.pdiparams
|
||||
| |--inference.pdmodel
|
||||
|-- layout
|
||||
| |--inference.pdiparams
|
||||
| |--inference.pdmodel
|
||||
```
|
||||
|
||||
|
||||
|
|
@ -278,8 +281,30 @@ Specifically,
|
|||
--cls=true \
|
||||
```
|
||||
|
||||
##### 7. layout+table
|
||||
```shell
|
||||
./build/ppocr --det_model_dir=inference/det_db \
|
||||
--rec_model_dir=inference/rec_rcnn \
|
||||
--table_model_dir=inference/table \
|
||||
--image_dir=../../ppstructure/docs/table/table.jpg \
|
||||
--layout_model_dir=inference/layout \
|
||||
--type=structure \
|
||||
--table=true \
|
||||
--layout=true
|
||||
```
|
||||
|
||||
##### 7. table
|
||||
##### 8. layout
|
||||
```shell
|
||||
./build/ppocr --layout_model_dir=inference/layout \
|
||||
--image_dir=../../ppstructure/docs/table/1.png \
|
||||
--type=structure \
|
||||
--table=false \
|
||||
--layout=true \
|
||||
--det=false \
|
||||
--rec=false
|
||||
```
|
||||
|
||||
##### 9. table
|
||||
```shell
|
||||
./build/ppocr --det_model_dir=inference/det_db \
|
||||
--rec_model_dir=inference/rec_rcnn \
|
||||
|
|
@ -343,6 +368,16 @@ More parameters are as follows,
|
|||
|rec_img_h|int|48|image height of recognition|
|
||||
|rec_img_w|int|320|image width of recognition|
|
||||
|
||||
- Layout related parameters
|
||||
|
||||
|parameter|data type|default|meaning|
|
||||
| :---: | :---: | :---: | :---: |
|
||||
|layout_model_dir|string|-| Address of layout inference model|
|
||||
|layout_dict_path|string|../../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt|dictionary file|
|
||||
|layout_score_threshold|float|0.5|Threshold of score.|
|
||||
|layout_nms_threshold|float|0.5|Threshold of nms.|
|
||||
|
||||
|
||||
- Table recognition related parameters
|
||||
|
||||
|parameter|data type|default|meaning|
|
||||
|
|
@ -350,6 +385,7 @@ More parameters are as follows,
|
|||
|table_model_dir|string|-|Address of table recognition inference model|
|
||||
|table_char_dict_path|string|../../ppocr/utils/dict/table_structure_dict.txt|dictionary file|
|
||||
|table_max_len|int|488|The size of the long side of the input image of the table recognition model, the final input image size of the network is(table_max_len,table_max_len)|
|
||||
|merge_no_span_structure|bool|true|Whether to merge <td> and </td> to <td></td|
|
||||
|
||||
|
||||
* Multi-language inference is also supported in PaddleOCR, you can refer to [recognition tutorial](../../doc/doc_en/recognition_en.md) for more supported languages and models in PaddleOCR. Specifically, if you want to infer using multi-language models, you just need to modify values of `rec_char_dict_path` and `rec_model_dir`.
|
||||
|
|
@ -367,11 +403,51 @@ predict img: ../../doc/imgs/12.jpg
|
|||
The detection visualized image saved in ./output//12.jpg
|
||||
```
|
||||
|
||||
- table
|
||||
- layout+table
|
||||
|
||||
```bash
|
||||
predict img: ../../ppstructure/docs/table/table.jpg
|
||||
0 type: table, region: [0,0,371,293], res: <html><body><table><thead><tr><td>Methods</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>SegLink [26]</td><td>70.0</td><td>86.0</td><td>77.0</td><td>8.9</td></tr><tr><td>PixelLink [4]</td><td>73.2</td><td>83.0</td><td>77.8</td><td>-</td></tr><tr><td>TextSnake [18]</td><td>73.9</td><td>83.2</td><td>78.3</td><td>1.1</td></tr><tr><td>TextField [37]</td><td>75.9</td><td>87.4</td><td>81.3</td><td>5.2 </td></tr><tr><td>MSR[38]</td><td>76.7</td><td>87.4</td><td>81.7</td><td>-</td></tr><tr><td>FTSN [3]</td><td>77.1</td><td>87.6</td><td>82.0</td><td>-</td></tr><tr><td>LSE[30]</td><td>81.7</td><td>84.2</td><td>82.9</td><td>-</td></tr><tr><td>CRAFT [2]</td><td>78.2</td><td>88.2</td><td>82.9</td><td>8.6</td></tr><tr><td>MCN [16]</td><td>79</td><td>88</td><td>83</td><td>-</td></tr><tr><td>ATRR[35]</td><td>82.1</td><td>85.2</td><td>83.6</td><td>-</td></tr><tr><td>PAN [34]</td><td>83.8</td><td>84.4</td><td>84.1</td><td>30.2</td></tr><tr><td>DB[12]</td><td>79.2</td><td>91.5</td><td>84.9</td><td>32.0</td></tr><tr><td>DRRG [41]</td><td>82.30</td><td>88.05</td><td>85.08</td><td>-</td></tr><tr><td>Ours (SynText)</td><td>80.68</td><td>85.40</td><td>82.97</td><td>12.68</td></tr><tr><td>Ours (MLT-17)</td><td>84.54</td><td>86.62</td><td>85.57</td><td>12.31</td></tr></tbody></table></body></html>
|
||||
predict img: ../../ppstructure/docs/table/1.png
|
||||
0 type: text, region: [12,729,410,848], score: 0.781044, res: count of ocr result is : 7
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[4,1],[79,1],[79,12],[4,12]] rec text: CTW1500. rec score: 0.769472
|
||||
...
|
||||
6 det boxes: [[4,99],[391,99],[391,112],[4,112]] rec text: sate-of-the-artmethods[12.34.36l.ourapproachachieves rec score: 0.90414
|
||||
********** end print ocr result **********
|
||||
1 type: text, region: [69,342,342,359], score: 0.703666, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[8,2],[269,2],[269,13],[8,13]] rec text: Table6.Experimentalresults on CTW-1500 rec score: 0.890454
|
||||
********** end print ocr result **********
|
||||
2 type: text, region: [70,316,706,332], score: 0.659738, res: count of ocr result is : 2
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[373,2],[630,2],[630,11],[373,11]] rec text: oroposals.andthegreencontoursarefinal rec score: 0.919729
|
||||
1 det boxes: [[8,3],[357,3],[357,11],[8,11]] rec text: Visualexperimentalresultshebluecontoursareboundar rec score: 0.915963
|
||||
********** end print ocr result **********
|
||||
3 type: text, region: [489,342,789,359], score: 0.630538, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[8,2],[294,2],[294,14],[8,14]] rec text: Table7.Experimentalresults onMSRA-TD500 rec score: 0.942251
|
||||
********** end print ocr result **********
|
||||
4 type: text, region: [444,751,841,848], score: 0.607345, res: count of ocr result is : 5
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[19,3],[389,3],[389,17],[19,17]] rec text: Inthispaper,weproposeanovel adaptivebound rec score: 0.941031
|
||||
1 det boxes: [[4,22],[390,22],[390,36],[4,36]] rec text: aryproposalnetworkforarbitraryshapetextdetection rec score: 0.960172
|
||||
2 det boxes: [[4,42],[392,42],[392,56],[4,56]] rec text: whichadoptanboundaryproposalmodeltogeneratecoarse rec score: 0.934647
|
||||
3 det boxes: [[4,61],[389,61],[389,75],[4,75]] rec text: ooundaryproposals,andthenadoptanadaptiveboundary rec score: 0.946296
|
||||
4 det boxes: [[5,80],[387,80],[387,93],[5,93]] rec text: leformationmodelcombinedwithGCNandRNNtoper rec score: 0.952401
|
||||
********** end print ocr result **********
|
||||
5 type: title, region: [444,705,564,724], score: 0.785429, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[6,2],[113,2],[113,14],[6,14]] rec text: 5.Conclusion rec score: 0.856903
|
||||
********** end print ocr result **********
|
||||
6 type: table, region: [14,360,402,711], score: 0.963643, res: <html><body><table><thead><tr><td>Methods</td><td>Ext</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>TextSnake [18]</td><td>Syn</td><td>85.3</td><td>67.9</td><td>75.6</td><td></td></tr><tr><td>CSE [17]</td><td>MiLT</td><td>76.1</td><td>78.7</td><td>77.4</td><td>0.38</td></tr><tr><td>LOMO[40]</td><td>Syn</td><td>76.5</td><td>85.7</td><td>80.8</td><td>4.4</td></tr><tr><td>ATRR[35]</td><td>Sy-</td><td>80.2</td><td>80.1</td><td>80.1</td><td>-</td></tr><tr><td>SegLink++ [28]</td><td>Syn</td><td>79.8</td><td>82.8</td><td>81.3</td><td>-</td></tr><tr><td>TextField [37]</td><td>Syn</td><td>79.8</td><td>83.0</td><td>81.4</td><td>6.0</td></tr><tr><td>MSR[38]</td><td>Syn</td><td>79.0</td><td>84.1</td><td>81.5</td><td>4.3</td></tr><tr><td>PSENet-1s [33]</td><td>MLT</td><td>79.7</td><td>84.8</td><td>82.2</td><td>3.9</td></tr><tr><td>DB [12]</td><td>Syn</td><td>80.2</td><td>86.9</td><td>83.4</td><td>22.0</td></tr><tr><td>CRAFT [2]</td><td>Syn</td><td>81.1</td><td>86.0</td><td>83.5</td><td>-</td></tr><tr><td>TextDragon [5]</td><td>MLT+</td><td>82.8</td><td>84.5</td><td>83.6</td><td></td></tr><tr><td>PAN [34]</td><td>Syn</td><td>81.2</td><td>86.4</td><td>83.7</td><td>39.8</td></tr><tr><td>ContourNet [36]</td><td></td><td>84.1</td><td>83.7</td><td>83.9</td><td>4.5</td></tr><tr><td>DRRG [41]</td><td>MLT</td><td>83.02</td><td>85.93</td><td>84.45</td><td>-</td></tr><tr><td>TextPerception[23]</td><td>Syn</td><td>81.9</td><td>87.5</td><td>84.6</td><td></td></tr><tr><td>Ours</td><td> Syn</td><td>80.57</td><td>87.66</td><td>83.97</td><td>12.08</td></tr><tr><td>Ours</td><td></td><td>81.45</td><td>87.81</td><td>84.51</td><td>12.15</td></tr><tr><td>Ours</td><td>MLT</td><td>83.60</td><td>86.45</td><td>85.00</td><td>12.21</td></tr></tbody></table></body></html>
|
||||
The table visualized image saved in ./output//6_1.png
|
||||
7 type: table, region: [462,359,820,657], score: 0.953917, res: <html><body><table><thead><tr><td>Methods</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>SegLink [26]</td><td>70.0</td><td>86.0</td><td>77.0</td><td>8.9</td></tr><tr><td>PixelLink [4]</td><td>73.2</td><td>83.0</td><td>77.8</td><td>-</td></tr><tr><td>TextSnake [18]</td><td>73.9</td><td>83.2</td><td>78.3</td><td>1.1</td></tr><tr><td>TextField [37]</td><td>75.9</td><td>87.4</td><td>81.3</td><td>5.2 </td></tr><tr><td>MSR[38]</td><td>76.7</td><td>87.4</td><td>81.7</td><td>-</td></tr><tr><td>FTSN[3]</td><td>77.1</td><td>87.6</td><td>82.0</td><td>:</td></tr><tr><td>LSE[30]</td><td>81.7</td><td>84.2</td><td>82.9</td><td></td></tr><tr><td>CRAFT [2]</td><td>78.2</td><td>88.2</td><td>82.9</td><td>8.6</td></tr><tr><td>MCN [16]</td><td>79</td><td>88</td><td>83</td><td>-</td></tr><tr><td>ATRR[35]</td><td>82.1</td><td>85.2</td><td>83.6</td><td>-</td></tr><tr><td>PAN [34]</td><td>83.8</td><td>84.4</td><td>84.1</td><td>30.2</td></tr><tr><td>DB[12]</td><td>79.2</td><td>91.5</td><td>84.9</td><td>32.0</td></tr><tr><td>DRRG [41]</td><td>82.30</td><td>88.05</td><td>85.08</td><td>-</td></tr><tr><td>Ours (SynText)</td><td>80.68</td><td>85.40</td><td>82.97</td><td>12.68</td></tr><tr><td>Ours (MLT-17)</td><td>84.54</td><td>86.62</td><td>85.57</td><td>12.31</td></tr></tbody></table></body></html>
|
||||
The table visualized image saved in ./output//7_1.png
|
||||
8 type: figure, region: [14,3,836,310], score: 0.969443, res: count of ocr result is : 26
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[506,14],[539,15],[539,22],[506,21]] rec text: E rec score: 0.318073
|
||||
...
|
||||
25 det boxes: [[680,290],[759,288],[759,303],[680,305]] rec text: (d) CTW1500 rec score: 0.95911
|
||||
********** end print ocr result **********
|
||||
```
|
||||
|
||||
<a name="3"></a>
|
||||
|
|
|
|||
|
|
@ -184,6 +184,9 @@ inference/
|
|||
|-- table
|
||||
| |--inference.pdiparams
|
||||
| |--inference.pdmodel
|
||||
|-- layout
|
||||
| |--inference.pdiparams
|
||||
| |--inference.pdmodel
|
||||
```
|
||||
|
||||
<a name="22"></a>
|
||||
|
|
@ -288,7 +291,30 @@ CUDNN_LIB_DIR=/your_cudnn_lib_dir
|
|||
--cls=true \
|
||||
```
|
||||
|
||||
##### 7. 表格识别
|
||||
##### 7. 版面分析+表格识别
|
||||
```shell
|
||||
./build/ppocr --det_model_dir=inference/det_db \
|
||||
--rec_model_dir=inference/rec_rcnn \
|
||||
--table_model_dir=inference/table \
|
||||
--image_dir=../../ppstructure/docs/table/table.jpg \
|
||||
--layout_model_dir=inference/layout \
|
||||
--type=structure \
|
||||
--table=true \
|
||||
--layout=true
|
||||
```
|
||||
|
||||
##### 8. 版面分析
|
||||
```shell
|
||||
./build/ppocr --layout_model_dir=inference/layout \
|
||||
--image_dir=../../ppstructure/docs/table/1.png \
|
||||
--type=structure \
|
||||
--table=false \
|
||||
--layout=true \
|
||||
--det=false \
|
||||
--rec=false
|
||||
```
|
||||
|
||||
##### 9. 表格识别
|
||||
```shell
|
||||
./build/ppocr --det_model_dir=inference/det_db \
|
||||
--rec_model_dir=inference/rec_rcnn \
|
||||
|
|
@ -352,13 +378,24 @@ CUDNN_LIB_DIR=/your_cudnn_lib_dir
|
|||
|rec_img_w|int|320|文字识别模型输入图像宽度|
|
||||
|
||||
|
||||
- 版面分析模型相关
|
||||
|
||||
|参数名称|类型|默认参数|意义|
|
||||
| :---: | :---: | :---: | :---: |
|
||||
|layout_model_dir|string|-|版面分析模型inference model地址|
|
||||
|layout_dict_path|string|../../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt|字典文件|
|
||||
|layout_score_threshold|float|0.5|检测框的分数阈值|
|
||||
|layout_nms_threshold|float|0.5|nms的阈值|
|
||||
|
||||
|
||||
- 表格识别模型相关
|
||||
|
||||
|参数名称|类型|默认参数|意义|
|
||||
| :---: | :---: | :---: | :---: |
|
||||
|table_model_dir|string|-|表格识别模型inference model地址|
|
||||
|table_char_dict_path|string|../../ppocr/utils/dict/table_structure_dict.txt|字典文件|
|
||||
|table_char_dict_path|string|../../ppocr/utils/dict/table_structure_dict_ch.txt|字典文件|
|
||||
|table_max_len|int|488|表格识别模型输入图像长边大小,最终网络输入图像大小为(table_max_len,table_max_len)|
|
||||
|merge_no_span_structure|bool|true|是否合并<td> 和 </td> 为<td></td>|
|
||||
|
||||
|
||||
* PaddleOCR也支持多语言的预测,更多支持的语言和模型可以参考[识别文档](../../doc/doc_ch/recognition.md)中的多语言字典与模型部分,如果希望进行多语言预测,只需将修改`rec_char_dict_path`(字典文件路径)以及`rec_model_dir`(inference模型路径)字段即可。
|
||||
|
|
@ -377,11 +414,51 @@ predict img: ../../doc/imgs/12.jpg
|
|||
The detection visualized image saved in ./output//12.jpg
|
||||
```
|
||||
|
||||
- table
|
||||
- layout+table
|
||||
|
||||
```bash
|
||||
predict img: ../../ppstructure/docs/table/table.jpg
|
||||
0 type: table, region: [0,0,371,293], res: <html><body><table><thead><tr><td>Methods</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>SegLink [26]</td><td>70.0</td><td>86.0</td><td>77.0</td><td>8.9</td></tr><tr><td>PixelLink [4]</td><td>73.2</td><td>83.0</td><td>77.8</td><td>-</td></tr><tr><td>TextSnake [18]</td><td>73.9</td><td>83.2</td><td>78.3</td><td>1.1</td></tr><tr><td>TextField [37]</td><td>75.9</td><td>87.4</td><td>81.3</td><td>5.2 </td></tr><tr><td>MSR[38]</td><td>76.7</td><td>87.4</td><td>81.7</td><td>-</td></tr><tr><td>FTSN [3]</td><td>77.1</td><td>87.6</td><td>82.0</td><td>-</td></tr><tr><td>LSE[30]</td><td>81.7</td><td>84.2</td><td>82.9</td><td>-</td></tr><tr><td>CRAFT [2]</td><td>78.2</td><td>88.2</td><td>82.9</td><td>8.6</td></tr><tr><td>MCN [16]</td><td>79</td><td>88</td><td>83</td><td>-</td></tr><tr><td>ATRR[35]</td><td>82.1</td><td>85.2</td><td>83.6</td><td>-</td></tr><tr><td>PAN [34]</td><td>83.8</td><td>84.4</td><td>84.1</td><td>30.2</td></tr><tr><td>DB[12]</td><td>79.2</td><td>91.5</td><td>84.9</td><td>32.0</td></tr><tr><td>DRRG [41]</td><td>82.30</td><td>88.05</td><td>85.08</td><td>-</td></tr><tr><td>Ours (SynText)</td><td>80.68</td><td>85.40</td><td>82.97</td><td>12.68</td></tr><tr><td>Ours (MLT-17)</td><td>84.54</td><td>86.62</td><td>85.57</td><td>12.31</td></tr></tbody></table></body></html>
|
||||
predict img: ../../ppstructure/docs/table/1.png
|
||||
0 type: text, region: [12,729,410,848], score: 0.781044, res: count of ocr result is : 7
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[4,1],[79,1],[79,12],[4,12]] rec text: CTW1500. rec score: 0.769472
|
||||
...
|
||||
6 det boxes: [[4,99],[391,99],[391,112],[4,112]] rec text: sate-of-the-artmethods[12.34.36l.ourapproachachieves rec score: 0.90414
|
||||
********** end print ocr result **********
|
||||
1 type: text, region: [69,342,342,359], score: 0.703666, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[8,2],[269,2],[269,13],[8,13]] rec text: Table6.Experimentalresults on CTW-1500 rec score: 0.890454
|
||||
********** end print ocr result **********
|
||||
2 type: text, region: [70,316,706,332], score: 0.659738, res: count of ocr result is : 2
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[373,2],[630,2],[630,11],[373,11]] rec text: oroposals.andthegreencontoursarefinal rec score: 0.919729
|
||||
1 det boxes: [[8,3],[357,3],[357,11],[8,11]] rec text: Visualexperimentalresultshebluecontoursareboundar rec score: 0.915963
|
||||
********** end print ocr result **********
|
||||
3 type: text, region: [489,342,789,359], score: 0.630538, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[8,2],[294,2],[294,14],[8,14]] rec text: Table7.Experimentalresults onMSRA-TD500 rec score: 0.942251
|
||||
********** end print ocr result **********
|
||||
4 type: text, region: [444,751,841,848], score: 0.607345, res: count of ocr result is : 5
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[19,3],[389,3],[389,17],[19,17]] rec text: Inthispaper,weproposeanovel adaptivebound rec score: 0.941031
|
||||
1 det boxes: [[4,22],[390,22],[390,36],[4,36]] rec text: aryproposalnetworkforarbitraryshapetextdetection rec score: 0.960172
|
||||
2 det boxes: [[4,42],[392,42],[392,56],[4,56]] rec text: whichadoptanboundaryproposalmodeltogeneratecoarse rec score: 0.934647
|
||||
3 det boxes: [[4,61],[389,61],[389,75],[4,75]] rec text: ooundaryproposals,andthenadoptanadaptiveboundary rec score: 0.946296
|
||||
4 det boxes: [[5,80],[387,80],[387,93],[5,93]] rec text: leformationmodelcombinedwithGCNandRNNtoper rec score: 0.952401
|
||||
********** end print ocr result **********
|
||||
5 type: title, region: [444,705,564,724], score: 0.785429, res: count of ocr result is : 1
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[6,2],[113,2],[113,14],[6,14]] rec text: 5.Conclusion rec score: 0.856903
|
||||
********** end print ocr result **********
|
||||
6 type: table, region: [14,360,402,711], score: 0.963643, res: <html><body><table><thead><tr><td>Methods</td><td>Ext</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>TextSnake [18]</td><td>Syn</td><td>85.3</td><td>67.9</td><td>75.6</td><td></td></tr><tr><td>CSE [17]</td><td>MiLT</td><td>76.1</td><td>78.7</td><td>77.4</td><td>0.38</td></tr><tr><td>LOMO[40]</td><td>Syn</td><td>76.5</td><td>85.7</td><td>80.8</td><td>4.4</td></tr><tr><td>ATRR[35]</td><td>Sy-</td><td>80.2</td><td>80.1</td><td>80.1</td><td>-</td></tr><tr><td>SegLink++ [28]</td><td>Syn</td><td>79.8</td><td>82.8</td><td>81.3</td><td>-</td></tr><tr><td>TextField [37]</td><td>Syn</td><td>79.8</td><td>83.0</td><td>81.4</td><td>6.0</td></tr><tr><td>MSR[38]</td><td>Syn</td><td>79.0</td><td>84.1</td><td>81.5</td><td>4.3</td></tr><tr><td>PSENet-1s [33]</td><td>MLT</td><td>79.7</td><td>84.8</td><td>82.2</td><td>3.9</td></tr><tr><td>DB [12]</td><td>Syn</td><td>80.2</td><td>86.9</td><td>83.4</td><td>22.0</td></tr><tr><td>CRAFT [2]</td><td>Syn</td><td>81.1</td><td>86.0</td><td>83.5</td><td>-</td></tr><tr><td>TextDragon [5]</td><td>MLT+</td><td>82.8</td><td>84.5</td><td>83.6</td><td></td></tr><tr><td>PAN [34]</td><td>Syn</td><td>81.2</td><td>86.4</td><td>83.7</td><td>39.8</td></tr><tr><td>ContourNet [36]</td><td></td><td>84.1</td><td>83.7</td><td>83.9</td><td>4.5</td></tr><tr><td>DRRG [41]</td><td>MLT</td><td>83.02</td><td>85.93</td><td>84.45</td><td>-</td></tr><tr><td>TextPerception[23]</td><td>Syn</td><td>81.9</td><td>87.5</td><td>84.6</td><td></td></tr><tr><td>Ours</td><td> Syn</td><td>80.57</td><td>87.66</td><td>83.97</td><td>12.08</td></tr><tr><td>Ours</td><td></td><td>81.45</td><td>87.81</td><td>84.51</td><td>12.15</td></tr><tr><td>Ours</td><td>MLT</td><td>83.60</td><td>86.45</td><td>85.00</td><td>12.21</td></tr></tbody></table></body></html>
|
||||
The table visualized image saved in ./output//6_1.png
|
||||
7 type: table, region: [462,359,820,657], score: 0.953917, res: <html><body><table><thead><tr><td>Methods</td><td>R</td><td>P</td><td>F</td><td>FPS</td></tr></thead><tbody><tr><td>SegLink [26]</td><td>70.0</td><td>86.0</td><td>77.0</td><td>8.9</td></tr><tr><td>PixelLink [4]</td><td>73.2</td><td>83.0</td><td>77.8</td><td>-</td></tr><tr><td>TextSnake [18]</td><td>73.9</td><td>83.2</td><td>78.3</td><td>1.1</td></tr><tr><td>TextField [37]</td><td>75.9</td><td>87.4</td><td>81.3</td><td>5.2 </td></tr><tr><td>MSR[38]</td><td>76.7</td><td>87.4</td><td>81.7</td><td>-</td></tr><tr><td>FTSN[3]</td><td>77.1</td><td>87.6</td><td>82.0</td><td>:</td></tr><tr><td>LSE[30]</td><td>81.7</td><td>84.2</td><td>82.9</td><td></td></tr><tr><td>CRAFT [2]</td><td>78.2</td><td>88.2</td><td>82.9</td><td>8.6</td></tr><tr><td>MCN [16]</td><td>79</td><td>88</td><td>83</td><td>-</td></tr><tr><td>ATRR[35]</td><td>82.1</td><td>85.2</td><td>83.6</td><td>-</td></tr><tr><td>PAN [34]</td><td>83.8</td><td>84.4</td><td>84.1</td><td>30.2</td></tr><tr><td>DB[12]</td><td>79.2</td><td>91.5</td><td>84.9</td><td>32.0</td></tr><tr><td>DRRG [41]</td><td>82.30</td><td>88.05</td><td>85.08</td><td>-</td></tr><tr><td>Ours (SynText)</td><td>80.68</td><td>85.40</td><td>82.97</td><td>12.68</td></tr><tr><td>Ours (MLT-17)</td><td>84.54</td><td>86.62</td><td>85.57</td><td>12.31</td></tr></tbody></table></body></html>
|
||||
The table visualized image saved in ./output//7_1.png
|
||||
8 type: figure, region: [14,3,836,310], score: 0.969443, res: count of ocr result is : 26
|
||||
********** print ocr result **********
|
||||
0 det boxes: [[506,14],[539,15],[539,22],[506,21]] rec text: E rec score: 0.318073
|
||||
...
|
||||
25 det boxes: [[680,290],[759,288],[759,303],[680,305]] rec text: (d) CTW1500 rec score: 0.95911
|
||||
********** end print ocr result **********
|
||||
```
|
||||
|
||||
<a name="3"></a>
|
||||
|
|
|
|||
|
|
@ -51,16 +51,26 @@ DEFINE_string(rec_char_dict_path, "../../ppocr/utils/ppocr_keys_v1.txt",
|
|||
DEFINE_int32(rec_img_h, 48, "rec image height");
|
||||
DEFINE_int32(rec_img_w, 320, "rec image width");
|
||||
|
||||
// layout model related
|
||||
DEFINE_string(layout_model_dir, "", "Path of table layout inference model.");
|
||||
DEFINE_string(layout_dict_path,
|
||||
"../../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt",
|
||||
"Path of dictionary.");
|
||||
DEFINE_double(layout_score_threshold, 0.5, "Threshold of score.");
|
||||
DEFINE_double(layout_nms_threshold, 0.5, "Threshold of nms.");
|
||||
// structure model related
|
||||
DEFINE_string(table_model_dir, "", "Path of table struture inference model.");
|
||||
DEFINE_int32(table_max_len, 488, "max len size of input image.");
|
||||
DEFINE_int32(table_batch_num, 1, "table_batch_num.");
|
||||
DEFINE_bool(merge_no_span_structure, true,
|
||||
"Whether merge <td> and </td> to <td></td>");
|
||||
DEFINE_string(table_char_dict_path,
|
||||
"../../ppocr/utils/dict/table_structure_dict.txt",
|
||||
"../../ppocr/utils/dict/table_structure_dict_ch.txt",
|
||||
"Path of dictionary.");
|
||||
|
||||
// ocr forward related
|
||||
DEFINE_bool(det, true, "Whether use det in forward.");
|
||||
DEFINE_bool(rec, true, "Whether use rec in forward.");
|
||||
DEFINE_bool(cls, false, "Whether use cls in forward.");
|
||||
DEFINE_bool(table, false, "Whether use table structure in forward.");
|
||||
DEFINE_bool(table, false, "Whether use table structure in forward.");
|
||||
DEFINE_bool(layout, false, "Whether use layout analysis in forward.");
|
||||
|
|
@ -65,9 +65,18 @@ void check_params() {
|
|||
exit(1);
|
||||
}
|
||||
}
|
||||
if (FLAGS_layout) {
|
||||
if (FLAGS_layout_model_dir.empty() || FLAGS_image_dir.empty()) {
|
||||
std::cout << "Usage[layout]: ./ppocr "
|
||||
<< "--layout_model_dir=/PATH/TO/LAYOUT_INFERENCE_MODEL/ "
|
||||
<< "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
if (FLAGS_precision != "fp32" && FLAGS_precision != "fp16" &&
|
||||
FLAGS_precision != "int8") {
|
||||
cout << "precison should be 'fp32'(default), 'fp16' or 'int8'. " << endl;
|
||||
std::cout << "precison should be 'fp32'(default), 'fp16' or 'int8'. "
|
||||
<< std::endl;
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
|
|
@ -75,65 +84,94 @@ void check_params() {
|
|||
void ocr(std::vector<cv::String> &cv_all_img_names) {
|
||||
PPOCR ocr = PPOCR();
|
||||
|
||||
std::vector<std::vector<OCRPredictResult>> ocr_results =
|
||||
ocr.ocr(cv_all_img_names, FLAGS_det, FLAGS_rec, FLAGS_cls);
|
||||
if (FLAGS_benchmark) {
|
||||
ocr.reset_timer();
|
||||
}
|
||||
|
||||
std::vector<cv::Mat> img_list;
|
||||
std::vector<cv::String> img_names;
|
||||
for (int i = 0; i < cv_all_img_names.size(); ++i) {
|
||||
if (FLAGS_benchmark) {
|
||||
cout << cv_all_img_names[i] << '\t';
|
||||
if (FLAGS_rec && FLAGS_det) {
|
||||
Utility::print_result(ocr_results[i]);
|
||||
} else if (FLAGS_det) {
|
||||
for (int n = 0; n < ocr_results[i].size(); n++) {
|
||||
for (int m = 0; m < ocr_results[i][n].box.size(); m++) {
|
||||
cout << ocr_results[i][n].box[m][0] << ' '
|
||||
<< ocr_results[i][n].box[m][1] << ' ';
|
||||
}
|
||||
}
|
||||
cout << endl;
|
||||
} else {
|
||||
Utility::print_result(ocr_results[i]);
|
||||
}
|
||||
} else {
|
||||
cout << cv_all_img_names[i] << "\n";
|
||||
Utility::print_result(ocr_results[i]);
|
||||
if (FLAGS_visualize && FLAGS_det) {
|
||||
cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!srcimg.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << endl;
|
||||
exit(1);
|
||||
}
|
||||
std::string file_name = Utility::basename(cv_all_img_names[i]);
|
||||
|
||||
Utility::VisualizeBboxes(srcimg, ocr_results[i],
|
||||
FLAGS_output + "/" + file_name);
|
||||
}
|
||||
cout << "***************************" << endl;
|
||||
cv::Mat img = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!img.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << std::endl;
|
||||
continue;
|
||||
}
|
||||
img_list.push_back(img);
|
||||
img_names.push_back(cv_all_img_names[i]);
|
||||
}
|
||||
|
||||
std::vector<std::vector<OCRPredictResult>> ocr_results =
|
||||
ocr.ocr(img_list, FLAGS_det, FLAGS_rec, FLAGS_cls);
|
||||
|
||||
for (int i = 0; i < img_names.size(); ++i) {
|
||||
std::cout << "predict img: " << cv_all_img_names[i] << std::endl;
|
||||
Utility::print_result(ocr_results[i]);
|
||||
if (FLAGS_visualize && FLAGS_det) {
|
||||
std::string file_name = Utility::basename(img_names[i]);
|
||||
cv::Mat srcimg = img_list[i];
|
||||
Utility::VisualizeBboxes(srcimg, ocr_results[i],
|
||||
FLAGS_output + "/" + file_name);
|
||||
}
|
||||
}
|
||||
if (FLAGS_benchmark) {
|
||||
ocr.benchmark_log(cv_all_img_names.size());
|
||||
}
|
||||
}
|
||||
|
||||
void structure(std::vector<cv::String> &cv_all_img_names) {
|
||||
PaddleOCR::PaddleStructure engine = PaddleOCR::PaddleStructure();
|
||||
std::vector<std::vector<StructurePredictResult>> structure_results =
|
||||
engine.structure(cv_all_img_names, false, FLAGS_table);
|
||||
|
||||
if (FLAGS_benchmark) {
|
||||
engine.reset_timer();
|
||||
}
|
||||
|
||||
for (int i = 0; i < cv_all_img_names.size(); i++) {
|
||||
cout << "predict img: " << cv_all_img_names[i] << endl;
|
||||
for (int j = 0; j < structure_results[i].size(); j++) {
|
||||
std::cout << j << "\ttype: " << structure_results[i][j].type
|
||||
std::cout << "predict img: " << cv_all_img_names[i] << std::endl;
|
||||
cv::Mat img = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!img.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << std::endl;
|
||||
continue;
|
||||
}
|
||||
|
||||
std::vector<StructurePredictResult> structure_results = engine.structure(
|
||||
img, FLAGS_layout, FLAGS_table, FLAGS_det && FLAGS_rec);
|
||||
|
||||
for (int j = 0; j < structure_results.size(); j++) {
|
||||
std::cout << j << "\ttype: " << structure_results[j].type
|
||||
<< ", region: [";
|
||||
std::cout << structure_results[i][j].box[0] << ","
|
||||
<< structure_results[i][j].box[1] << ","
|
||||
<< structure_results[i][j].box[2] << ","
|
||||
<< structure_results[i][j].box[3] << "], res: ";
|
||||
if (structure_results[i][j].type == "table") {
|
||||
std::cout << structure_results[i][j].html << std::endl;
|
||||
std::cout << structure_results[j].box[0] << ","
|
||||
<< structure_results[j].box[1] << ","
|
||||
<< structure_results[j].box[2] << ","
|
||||
<< structure_results[j].box[3] << "], score: ";
|
||||
std::cout << structure_results[j].confidence << ", res: ";
|
||||
|
||||
if (structure_results[j].type == "table") {
|
||||
std::cout << structure_results[j].html << std::endl;
|
||||
if (structure_results[j].cell_box.size() > 0 && FLAGS_visualize) {
|
||||
std::string file_name = Utility::basename(cv_all_img_names[i]);
|
||||
|
||||
Utility::VisualizeBboxes(img, structure_results[j],
|
||||
FLAGS_output + "/" + std::to_string(j) +
|
||||
"_" + file_name);
|
||||
}
|
||||
} else {
|
||||
Utility::print_result(structure_results[i][j].text_res);
|
||||
std::cout << "count of ocr result is : "
|
||||
<< structure_results[j].text_res.size() << std::endl;
|
||||
if (structure_results[j].text_res.size() > 0) {
|
||||
std::cout << "********** print ocr result "
|
||||
<< "**********" << std::endl;
|
||||
Utility::print_result(structure_results[j].text_res);
|
||||
std::cout << "********** end print ocr result "
|
||||
<< "**********" << std::endl;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
if (FLAGS_benchmark) {
|
||||
engine.benchmark_log(cv_all_img_names.size());
|
||||
}
|
||||
}
|
||||
|
||||
int main(int argc, char **argv) {
|
||||
|
|
@ -143,19 +181,22 @@ int main(int argc, char **argv) {
|
|||
|
||||
if (!Utility::PathExists(FLAGS_image_dir)) {
|
||||
std::cerr << "[ERROR] image path not exist! image_dir: " << FLAGS_image_dir
|
||||
<< endl;
|
||||
<< std::endl;
|
||||
exit(1);
|
||||
}
|
||||
|
||||
std::vector<cv::String> cv_all_img_names;
|
||||
cv::glob(FLAGS_image_dir, cv_all_img_names);
|
||||
std::cout << "total images num: " << cv_all_img_names.size() << endl;
|
||||
std::cout << "total images num: " << cv_all_img_names.size() << std::endl;
|
||||
|
||||
if (!Utility::PathExists(FLAGS_output)) {
|
||||
Utility::CreateDir(FLAGS_output);
|
||||
}
|
||||
if (FLAGS_type == "ocr") {
|
||||
ocr(cv_all_img_names);
|
||||
} else if (FLAGS_type == "structure") {
|
||||
structure(cv_all_img_names);
|
||||
} else {
|
||||
std::cout << "only value in ['ocr','structure'] is supported" << endl;
|
||||
std::cout << "only value in ['ocr','structure'] is supported" << std::endl;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ void Classifier::Run(std::vector<cv::Mat> img_list,
|
|||
for (int beg_img_no = 0; beg_img_no < img_num;
|
||||
beg_img_no += this->cls_batch_num_) {
|
||||
auto preprocess_start = std::chrono::steady_clock::now();
|
||||
int end_img_no = min(img_num, beg_img_no + this->cls_batch_num_);
|
||||
int end_img_no = std::min(img_num, beg_img_no + this->cls_batch_num_);
|
||||
int batch_num = end_img_no - beg_img_no;
|
||||
// preprocess
|
||||
std::vector<cv::Mat> norm_img_batch;
|
||||
|
|
@ -97,7 +97,7 @@ void Classifier::Run(std::vector<cv::Mat> img_list,
|
|||
}
|
||||
|
||||
void Classifier::LoadModel(const std::string &model_dir) {
|
||||
AnalysisConfig config;
|
||||
paddle_infer::Config config;
|
||||
config.SetModel(model_dir + "/inference.pdmodel",
|
||||
model_dir + "/inference.pdiparams");
|
||||
|
||||
|
|
@ -112,6 +112,11 @@ void Classifier::LoadModel(const std::string &model_dir) {
|
|||
precision = paddle_infer::Config::Precision::kInt8;
|
||||
}
|
||||
config.EnableTensorRtEngine(1 << 20, 10, 3, precision, false, false);
|
||||
if (!Utility::PathExists("./trt_cls_shape.txt")) {
|
||||
config.CollectShapeRangeInfo("./trt_cls_shape.txt");
|
||||
} else {
|
||||
config.EnableTunedTensorRtDynamicShape("./trt_cls_shape.txt", true);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
config.DisableGpu();
|
||||
|
|
@ -131,6 +136,6 @@ void Classifier::LoadModel(const std::string &model_dir) {
|
|||
config.EnableMemoryOptim();
|
||||
config.DisableGlogInfo();
|
||||
|
||||
this->predictor_ = CreatePredictor(config);
|
||||
this->predictor_ = paddle_infer::CreatePredictor(config);
|
||||
}
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -32,49 +32,12 @@ void DBDetector::LoadModel(const std::string &model_dir) {
|
|||
if (this->precision_ == "int8") {
|
||||
precision = paddle_infer::Config::Precision::kInt8;
|
||||
}
|
||||
config.EnableTensorRtEngine(1 << 20, 1, 20, precision, false, false);
|
||||
std::map<std::string, std::vector<int>> min_input_shape = {
|
||||
{"x", {1, 3, 50, 50}},
|
||||
{"conv2d_92.tmp_0", {1, 120, 20, 20}},
|
||||
{"conv2d_91.tmp_0", {1, 24, 10, 10}},
|
||||
{"conv2d_59.tmp_0", {1, 96, 20, 20}},
|
||||
{"nearest_interp_v2_1.tmp_0", {1, 256, 10, 10}},
|
||||
{"nearest_interp_v2_2.tmp_0", {1, 256, 20, 20}},
|
||||
{"conv2d_124.tmp_0", {1, 256, 20, 20}},
|
||||
{"nearest_interp_v2_3.tmp_0", {1, 64, 20, 20}},
|
||||
{"nearest_interp_v2_4.tmp_0", {1, 64, 20, 20}},
|
||||
{"nearest_interp_v2_5.tmp_0", {1, 64, 20, 20}},
|
||||
{"elementwise_add_7", {1, 56, 2, 2}},
|
||||
{"nearest_interp_v2_0.tmp_0", {1, 256, 2, 2}}};
|
||||
std::map<std::string, std::vector<int>> max_input_shape = {
|
||||
{"x", {1, 3, 1536, 1536}},
|
||||
{"conv2d_92.tmp_0", {1, 120, 400, 400}},
|
||||
{"conv2d_91.tmp_0", {1, 24, 200, 200}},
|
||||
{"conv2d_59.tmp_0", {1, 96, 400, 400}},
|
||||
{"nearest_interp_v2_1.tmp_0", {1, 256, 200, 200}},
|
||||
{"nearest_interp_v2_2.tmp_0", {1, 256, 400, 400}},
|
||||
{"conv2d_124.tmp_0", {1, 256, 400, 400}},
|
||||
{"nearest_interp_v2_3.tmp_0", {1, 64, 400, 400}},
|
||||
{"nearest_interp_v2_4.tmp_0", {1, 64, 400, 400}},
|
||||
{"nearest_interp_v2_5.tmp_0", {1, 64, 400, 400}},
|
||||
{"elementwise_add_7", {1, 56, 400, 400}},
|
||||
{"nearest_interp_v2_0.tmp_0", {1, 256, 400, 400}}};
|
||||
std::map<std::string, std::vector<int>> opt_input_shape = {
|
||||
{"x", {1, 3, 640, 640}},
|
||||
{"conv2d_92.tmp_0", {1, 120, 160, 160}},
|
||||
{"conv2d_91.tmp_0", {1, 24, 80, 80}},
|
||||
{"conv2d_59.tmp_0", {1, 96, 160, 160}},
|
||||
{"nearest_interp_v2_1.tmp_0", {1, 256, 80, 80}},
|
||||
{"nearest_interp_v2_2.tmp_0", {1, 256, 160, 160}},
|
||||
{"conv2d_124.tmp_0", {1, 256, 160, 160}},
|
||||
{"nearest_interp_v2_3.tmp_0", {1, 64, 160, 160}},
|
||||
{"nearest_interp_v2_4.tmp_0", {1, 64, 160, 160}},
|
||||
{"nearest_interp_v2_5.tmp_0", {1, 64, 160, 160}},
|
||||
{"elementwise_add_7", {1, 56, 40, 40}},
|
||||
{"nearest_interp_v2_0.tmp_0", {1, 256, 40, 40}}};
|
||||
|
||||
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
|
||||
opt_input_shape);
|
||||
config.EnableTensorRtEngine(1 << 30, 1, 20, precision, false, false);
|
||||
if (!Utility::PathExists("./trt_det_shape.txt")) {
|
||||
config.CollectShapeRangeInfo("./trt_det_shape.txt");
|
||||
} else {
|
||||
config.EnableTunedTensorRtDynamicShape("./trt_det_shape.txt", true);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
config.DisableGpu();
|
||||
|
|
@ -95,7 +58,7 @@ void DBDetector::LoadModel(const std::string &model_dir) {
|
|||
config.EnableMemoryOptim();
|
||||
// config.DisableGlogInfo();
|
||||
|
||||
this->predictor_ = CreatePredictor(config);
|
||||
this->predictor_ = paddle_infer::CreatePredictor(config);
|
||||
}
|
||||
|
||||
void DBDetector::Run(cv::Mat &img,
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ void CRNNRecognizer::Run(std::vector<cv::Mat> img_list,
|
|||
for (int beg_img_no = 0; beg_img_no < img_num;
|
||||
beg_img_no += this->rec_batch_num_) {
|
||||
auto preprocess_start = std::chrono::steady_clock::now();
|
||||
int end_img_no = min(img_num, beg_img_no + this->rec_batch_num_);
|
||||
int end_img_no = std::min(img_num, beg_img_no + this->rec_batch_num_);
|
||||
int batch_num = end_img_no - beg_img_no;
|
||||
int imgH = this->rec_image_shape_[1];
|
||||
int imgW = this->rec_image_shape_[2];
|
||||
|
|
@ -46,7 +46,7 @@ void CRNNRecognizer::Run(std::vector<cv::Mat> img_list,
|
|||
int h = img_list[indices[ino]].rows;
|
||||
int w = img_list[indices[ino]].cols;
|
||||
float wh_ratio = w * 1.0 / h;
|
||||
max_wh_ratio = max(max_wh_ratio, wh_ratio);
|
||||
max_wh_ratio = std::max(max_wh_ratio, wh_ratio);
|
||||
}
|
||||
|
||||
int batch_width = imgW;
|
||||
|
|
@ -60,7 +60,7 @@ void CRNNRecognizer::Run(std::vector<cv::Mat> img_list,
|
|||
this->normalize_op_.Run(&resize_img, this->mean_, this->scale_,
|
||||
this->is_scale_);
|
||||
norm_img_batch.push_back(resize_img);
|
||||
batch_width = max(resize_img.cols, batch_width);
|
||||
batch_width = std::max(resize_img.cols, batch_width);
|
||||
}
|
||||
|
||||
std::vector<float> input(batch_num * 3 * imgH * batch_width, 0.0f);
|
||||
|
|
@ -115,7 +115,7 @@ void CRNNRecognizer::Run(std::vector<cv::Mat> img_list,
|
|||
last_index = argmax_idx;
|
||||
}
|
||||
score /= count;
|
||||
if (isnan(score)) {
|
||||
if (std::isnan(score)) {
|
||||
continue;
|
||||
}
|
||||
rec_texts[indices[beg_img_no + m]] = str_res;
|
||||
|
|
@ -130,7 +130,6 @@ void CRNNRecognizer::Run(std::vector<cv::Mat> img_list,
|
|||
}
|
||||
|
||||
void CRNNRecognizer::LoadModel(const std::string &model_dir) {
|
||||
// AnalysisConfig config;
|
||||
paddle_infer::Config config;
|
||||
config.SetModel(model_dir + "/inference.pdmodel",
|
||||
model_dir + "/inference.pdiparams");
|
||||
|
|
@ -147,20 +146,11 @@ void CRNNRecognizer::LoadModel(const std::string &model_dir) {
|
|||
if (this->precision_ == "int8") {
|
||||
precision = paddle_infer::Config::Precision::kInt8;
|
||||
}
|
||||
config.EnableTensorRtEngine(1 << 20, 10, 15, precision, false, false);
|
||||
int imgH = this->rec_image_shape_[1];
|
||||
int imgW = this->rec_image_shape_[2];
|
||||
std::map<std::string, std::vector<int>> min_input_shape = {
|
||||
{"x", {1, 3, imgH, 10}}, {"lstm_0.tmp_0", {10, 1, 96}}};
|
||||
std::map<std::string, std::vector<int>> max_input_shape = {
|
||||
{"x", {this->rec_batch_num_, 3, imgH, 2500}},
|
||||
{"lstm_0.tmp_0", {1000, 1, 96}}};
|
||||
std::map<std::string, std::vector<int>> opt_input_shape = {
|
||||
{"x", {this->rec_batch_num_, 3, imgH, imgW}},
|
||||
{"lstm_0.tmp_0", {25, 1, 96}}};
|
||||
|
||||
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
|
||||
opt_input_shape);
|
||||
if (!Utility::PathExists("./trt_rec_shape.txt")) {
|
||||
config.CollectShapeRangeInfo("./trt_rec_shape.txt");
|
||||
} else {
|
||||
config.EnableTunedTensorRtDynamicShape("./trt_rec_shape.txt", true);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
config.DisableGpu();
|
||||
|
|
@ -185,7 +175,7 @@ void CRNNRecognizer::LoadModel(const std::string &model_dir) {
|
|||
config.EnableMemoryOptim();
|
||||
// config.DisableGlogInfo();
|
||||
|
||||
this->predictor_ = CreatePredictor(config);
|
||||
this->predictor_ = paddle_infer::CreatePredictor(config);
|
||||
}
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@
|
|||
#include <include/paddleocr.h>
|
||||
|
||||
#include "auto_log/autolog.h"
|
||||
#include <numeric>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
PPOCR::PPOCR() {
|
||||
|
|
@ -44,8 +44,71 @@ PPOCR::PPOCR() {
|
|||
}
|
||||
};
|
||||
|
||||
void PPOCR::det(cv::Mat img, std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×) {
|
||||
std::vector<std::vector<OCRPredictResult>>
|
||||
PPOCR::ocr(std::vector<cv::Mat> img_list, bool det, bool rec, bool cls) {
|
||||
std::vector<std::vector<OCRPredictResult>> ocr_results;
|
||||
|
||||
if (!det) {
|
||||
std::vector<OCRPredictResult> ocr_result;
|
||||
ocr_result.resize(img_list.size());
|
||||
if (cls && this->classifier_ != nullptr) {
|
||||
this->cls(img_list, ocr_result);
|
||||
for (int i = 0; i < img_list.size(); i++) {
|
||||
if (ocr_result[i].cls_label % 2 == 1 &&
|
||||
ocr_result[i].cls_score > this->classifier_->cls_thresh) {
|
||||
cv::rotate(img_list[i], img_list[i], 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
if (rec) {
|
||||
this->rec(img_list, ocr_result);
|
||||
}
|
||||
for (int i = 0; i < ocr_result.size(); ++i) {
|
||||
std::vector<OCRPredictResult> ocr_result_tmp;
|
||||
ocr_result_tmp.push_back(ocr_result[i]);
|
||||
ocr_results.push_back(ocr_result_tmp);
|
||||
}
|
||||
} else {
|
||||
for (int i = 0; i < img_list.size(); ++i) {
|
||||
std::vector<OCRPredictResult> ocr_result =
|
||||
this->ocr(img_list[i], true, rec, cls);
|
||||
ocr_results.push_back(ocr_result);
|
||||
}
|
||||
}
|
||||
return ocr_results;
|
||||
}
|
||||
|
||||
std::vector<OCRPredictResult> PPOCR::ocr(cv::Mat img, bool det, bool rec,
|
||||
bool cls) {
|
||||
|
||||
std::vector<OCRPredictResult> ocr_result;
|
||||
// det
|
||||
this->det(img, ocr_result);
|
||||
// crop image
|
||||
std::vector<cv::Mat> img_list;
|
||||
for (int j = 0; j < ocr_result.size(); j++) {
|
||||
cv::Mat crop_img;
|
||||
crop_img = Utility::GetRotateCropImage(img, ocr_result[j].box);
|
||||
img_list.push_back(crop_img);
|
||||
}
|
||||
// cls
|
||||
if (cls && this->classifier_ != nullptr) {
|
||||
this->cls(img_list, ocr_result);
|
||||
for (int i = 0; i < img_list.size(); i++) {
|
||||
if (ocr_result[i].cls_label % 2 == 1 &&
|
||||
ocr_result[i].cls_score > this->classifier_->cls_thresh) {
|
||||
cv::rotate(img_list[i], img_list[i], 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
// rec
|
||||
if (rec) {
|
||||
this->rec(img_list, ocr_result);
|
||||
}
|
||||
return ocr_result;
|
||||
}
|
||||
|
||||
void PPOCR::det(cv::Mat img, std::vector<OCRPredictResult> &ocr_results) {
|
||||
std::vector<std::vector<std::vector<int>>> boxes;
|
||||
std::vector<double> det_times;
|
||||
|
||||
|
|
@ -58,14 +121,13 @@ void PPOCR::det(cv::Mat img, std::vector<OCRPredictResult> &ocr_results,
|
|||
}
|
||||
// sort boex from top to bottom, from left to right
|
||||
Utility::sorted_boxes(ocr_results);
|
||||
times[0] += det_times[0];
|
||||
times[1] += det_times[1];
|
||||
times[2] += det_times[2];
|
||||
this->time_info_det[0] += det_times[0];
|
||||
this->time_info_det[1] += det_times[1];
|
||||
this->time_info_det[2] += det_times[2];
|
||||
}
|
||||
|
||||
void PPOCR::rec(std::vector<cv::Mat> img_list,
|
||||
std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×) {
|
||||
std::vector<OCRPredictResult> &ocr_results) {
|
||||
std::vector<std::string> rec_texts(img_list.size(), "");
|
||||
std::vector<float> rec_text_scores(img_list.size(), 0);
|
||||
std::vector<double> rec_times;
|
||||
|
|
@ -75,14 +137,13 @@ void PPOCR::rec(std::vector<cv::Mat> img_list,
|
|||
ocr_results[i].text = rec_texts[i];
|
||||
ocr_results[i].score = rec_text_scores[i];
|
||||
}
|
||||
times[0] += rec_times[0];
|
||||
times[1] += rec_times[1];
|
||||
times[2] += rec_times[2];
|
||||
this->time_info_rec[0] += rec_times[0];
|
||||
this->time_info_rec[1] += rec_times[1];
|
||||
this->time_info_rec[2] += rec_times[2];
|
||||
}
|
||||
|
||||
void PPOCR::cls(std::vector<cv::Mat> img_list,
|
||||
std::vector<OCRPredictResult> &ocr_results,
|
||||
std::vector<double> ×) {
|
||||
std::vector<OCRPredictResult> &ocr_results) {
|
||||
std::vector<int> cls_labels(img_list.size(), 0);
|
||||
std::vector<float> cls_scores(img_list.size(), 0);
|
||||
std::vector<double> cls_times;
|
||||
|
|
@ -92,125 +153,43 @@ void PPOCR::cls(std::vector<cv::Mat> img_list,
|
|||
ocr_results[i].cls_label = cls_labels[i];
|
||||
ocr_results[i].cls_score = cls_scores[i];
|
||||
}
|
||||
times[0] += cls_times[0];
|
||||
times[1] += cls_times[1];
|
||||
times[2] += cls_times[2];
|
||||
this->time_info_cls[0] += cls_times[0];
|
||||
this->time_info_cls[1] += cls_times[1];
|
||||
this->time_info_cls[2] += cls_times[2];
|
||||
}
|
||||
|
||||
std::vector<std::vector<OCRPredictResult>>
|
||||
PPOCR::ocr(std::vector<cv::String> cv_all_img_names, bool det, bool rec,
|
||||
bool cls) {
|
||||
std::vector<double> time_info_det = {0, 0, 0};
|
||||
std::vector<double> time_info_rec = {0, 0, 0};
|
||||
std::vector<double> time_info_cls = {0, 0, 0};
|
||||
std::vector<std::vector<OCRPredictResult>> ocr_results;
|
||||
void PPOCR::reset_timer() {
|
||||
this->time_info_det = {0, 0, 0};
|
||||
this->time_info_rec = {0, 0, 0};
|
||||
this->time_info_cls = {0, 0, 0};
|
||||
}
|
||||
|
||||
if (!det) {
|
||||
std::vector<OCRPredictResult> ocr_result;
|
||||
// read image
|
||||
std::vector<cv::Mat> img_list;
|
||||
for (int i = 0; i < cv_all_img_names.size(); ++i) {
|
||||
cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!srcimg.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << endl;
|
||||
exit(1);
|
||||
}
|
||||
img_list.push_back(srcimg);
|
||||
OCRPredictResult res;
|
||||
ocr_result.push_back(res);
|
||||
}
|
||||
if (cls && this->classifier_ != nullptr) {
|
||||
this->cls(img_list, ocr_result, time_info_cls);
|
||||
for (int i = 0; i < img_list.size(); i++) {
|
||||
if (ocr_result[i].cls_label % 2 == 1 &&
|
||||
ocr_result[i].cls_score > this->classifier_->cls_thresh) {
|
||||
cv::rotate(img_list[i], img_list[i], 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
if (rec) {
|
||||
this->rec(img_list, ocr_result, time_info_rec);
|
||||
}
|
||||
for (int i = 0; i < cv_all_img_names.size(); ++i) {
|
||||
std::vector<OCRPredictResult> ocr_result_tmp;
|
||||
ocr_result_tmp.push_back(ocr_result[i]);
|
||||
ocr_results.push_back(ocr_result_tmp);
|
||||
}
|
||||
} else {
|
||||
if (!Utility::PathExists(FLAGS_output) && FLAGS_det) {
|
||||
Utility::CreateDir(FLAGS_output);
|
||||
}
|
||||
|
||||
for (int i = 0; i < cv_all_img_names.size(); ++i) {
|
||||
std::vector<OCRPredictResult> ocr_result;
|
||||
if (!FLAGS_benchmark) {
|
||||
cout << "predict img: " << cv_all_img_names[i] << endl;
|
||||
}
|
||||
|
||||
cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!srcimg.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << endl;
|
||||
exit(1);
|
||||
}
|
||||
// det
|
||||
this->det(srcimg, ocr_result, time_info_det);
|
||||
// crop image
|
||||
std::vector<cv::Mat> img_list;
|
||||
for (int j = 0; j < ocr_result.size(); j++) {
|
||||
cv::Mat crop_img;
|
||||
crop_img = Utility::GetRotateCropImage(srcimg, ocr_result[j].box);
|
||||
img_list.push_back(crop_img);
|
||||
}
|
||||
|
||||
// cls
|
||||
if (cls && this->classifier_ != nullptr) {
|
||||
this->cls(img_list, ocr_result, time_info_cls);
|
||||
for (int i = 0; i < img_list.size(); i++) {
|
||||
if (ocr_result[i].cls_label % 2 == 1 &&
|
||||
ocr_result[i].cls_score > this->classifier_->cls_thresh) {
|
||||
cv::rotate(img_list[i], img_list[i], 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
// rec
|
||||
if (rec) {
|
||||
this->rec(img_list, ocr_result, time_info_rec);
|
||||
}
|
||||
ocr_results.push_back(ocr_result);
|
||||
}
|
||||
}
|
||||
if (FLAGS_benchmark) {
|
||||
this->log(time_info_det, time_info_rec, time_info_cls,
|
||||
cv_all_img_names.size());
|
||||
}
|
||||
return ocr_results;
|
||||
} // namespace PaddleOCR
|
||||
|
||||
void PPOCR::log(std::vector<double> &det_times, std::vector<double> &rec_times,
|
||||
std::vector<double> &cls_times, int img_num) {
|
||||
if (det_times[0] + det_times[1] + det_times[2] > 0) {
|
||||
void PPOCR::benchmark_log(int img_num) {
|
||||
if (this->time_info_det[0] + this->time_info_det[1] + this->time_info_det[2] >
|
||||
0) {
|
||||
AutoLogger autolog_det("ocr_det", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads, 1, "dynamic",
|
||||
FLAGS_precision, det_times, img_num);
|
||||
FLAGS_precision, this->time_info_det, img_num);
|
||||
autolog_det.report();
|
||||
}
|
||||
if (rec_times[0] + rec_times[1] + rec_times[2] > 0) {
|
||||
if (this->time_info_rec[0] + this->time_info_rec[1] + this->time_info_rec[2] >
|
||||
0) {
|
||||
AutoLogger autolog_rec("ocr_rec", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_rec_batch_num, "dynamic", FLAGS_precision,
|
||||
rec_times, img_num);
|
||||
this->time_info_rec, img_num);
|
||||
autolog_rec.report();
|
||||
}
|
||||
if (cls_times[0] + cls_times[1] + cls_times[2] > 0) {
|
||||
if (this->time_info_cls[0] + this->time_info_cls[1] + this->time_info_cls[2] >
|
||||
0) {
|
||||
AutoLogger autolog_cls("ocr_cls", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_cls_batch_num, "dynamic", FLAGS_precision,
|
||||
cls_times, img_num);
|
||||
this->time_info_cls, img_num);
|
||||
autolog_cls.report();
|
||||
}
|
||||
}
|
||||
|
||||
PPOCR::~PPOCR() {
|
||||
if (this->detector_ != nullptr) {
|
||||
delete this->detector_;
|
||||
|
|
|
|||
|
|
@ -16,83 +16,83 @@
|
|||
#include <include/paddlestructure.h>
|
||||
|
||||
#include "auto_log/autolog.h"
|
||||
#include <numeric>
|
||||
#include <sys/stat.h>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
PaddleStructure::PaddleStructure() {
|
||||
if (FLAGS_layout) {
|
||||
this->layout_model_ = new StructureLayoutRecognizer(
|
||||
FLAGS_layout_model_dir, FLAGS_use_gpu, FLAGS_gpu_id, FLAGS_gpu_mem,
|
||||
FLAGS_cpu_threads, FLAGS_enable_mkldnn, FLAGS_layout_dict_path,
|
||||
FLAGS_use_tensorrt, FLAGS_precision, FLAGS_layout_score_threshold,
|
||||
FLAGS_layout_nms_threshold);
|
||||
}
|
||||
if (FLAGS_table) {
|
||||
this->recognizer_ = new StructureTableRecognizer(
|
||||
this->table_model_ = new StructureTableRecognizer(
|
||||
FLAGS_table_model_dir, FLAGS_use_gpu, FLAGS_gpu_id, FLAGS_gpu_mem,
|
||||
FLAGS_cpu_threads, FLAGS_enable_mkldnn, FLAGS_table_char_dict_path,
|
||||
FLAGS_use_tensorrt, FLAGS_precision, FLAGS_table_batch_num,
|
||||
FLAGS_table_max_len);
|
||||
FLAGS_table_max_len, FLAGS_merge_no_span_structure);
|
||||
}
|
||||
};
|
||||
|
||||
std::vector<std::vector<StructurePredictResult>>
|
||||
PaddleStructure::structure(std::vector<cv::String> cv_all_img_names,
|
||||
bool layout, bool table) {
|
||||
std::vector<double> time_info_det = {0, 0, 0};
|
||||
std::vector<double> time_info_rec = {0, 0, 0};
|
||||
std::vector<double> time_info_cls = {0, 0, 0};
|
||||
std::vector<double> time_info_table = {0, 0, 0};
|
||||
std::vector<StructurePredictResult>
|
||||
PaddleStructure::structure(cv::Mat srcimg, bool layout, bool table, bool ocr) {
|
||||
cv::Mat img;
|
||||
srcimg.copyTo(img);
|
||||
|
||||
std::vector<std::vector<StructurePredictResult>> structure_results;
|
||||
std::vector<StructurePredictResult> structure_results;
|
||||
|
||||
if (!Utility::PathExists(FLAGS_output) && FLAGS_det) {
|
||||
mkdir(FLAGS_output.c_str(), 0777);
|
||||
if (layout) {
|
||||
this->layout(img, structure_results);
|
||||
} else {
|
||||
StructurePredictResult res;
|
||||
res.type = "table";
|
||||
res.box = std::vector<float>(4, 0.0);
|
||||
res.box[2] = img.cols;
|
||||
res.box[3] = img.rows;
|
||||
structure_results.push_back(res);
|
||||
}
|
||||
for (int i = 0; i < cv_all_img_names.size(); ++i) {
|
||||
std::vector<StructurePredictResult> structure_result;
|
||||
cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
|
||||
if (!srcimg.data) {
|
||||
std::cerr << "[ERROR] image read failed! image path: "
|
||||
<< cv_all_img_names[i] << endl;
|
||||
exit(1);
|
||||
cv::Mat roi_img;
|
||||
for (int i = 0; i < structure_results.size(); i++) {
|
||||
// crop image
|
||||
roi_img = Utility::crop_image(img, structure_results[i].box);
|
||||
if (structure_results[i].type == "table" && table) {
|
||||
this->table(roi_img, structure_results[i]);
|
||||
} else if (ocr) {
|
||||
structure_results[i].text_res = this->ocr(roi_img, true, true, false);
|
||||
}
|
||||
if (layout) {
|
||||
} else {
|
||||
StructurePredictResult res;
|
||||
res.type = "table";
|
||||
res.box = std::vector<int>(4, 0);
|
||||
res.box[2] = srcimg.cols;
|
||||
res.box[3] = srcimg.rows;
|
||||
structure_result.push_back(res);
|
||||
}
|
||||
cv::Mat roi_img;
|
||||
for (int i = 0; i < structure_result.size(); i++) {
|
||||
// crop image
|
||||
roi_img = Utility::crop_image(srcimg, structure_result[i].box);
|
||||
if (structure_result[i].type == "table") {
|
||||
this->table(roi_img, structure_result[i], time_info_table,
|
||||
time_info_det, time_info_rec, time_info_cls);
|
||||
}
|
||||
}
|
||||
structure_results.push_back(structure_result);
|
||||
}
|
||||
|
||||
return structure_results;
|
||||
};
|
||||
|
||||
void PaddleStructure::layout(
|
||||
cv::Mat img, std::vector<StructurePredictResult> &structure_result) {
|
||||
std::vector<double> layout_times;
|
||||
this->layout_model_->Run(img, structure_result, layout_times);
|
||||
|
||||
this->time_info_layout[0] += layout_times[0];
|
||||
this->time_info_layout[1] += layout_times[1];
|
||||
this->time_info_layout[2] += layout_times[2];
|
||||
}
|
||||
|
||||
void PaddleStructure::table(cv::Mat img,
|
||||
StructurePredictResult &structure_result,
|
||||
std::vector<double> &time_info_table,
|
||||
std::vector<double> &time_info_det,
|
||||
std::vector<double> &time_info_rec,
|
||||
std::vector<double> &time_info_cls) {
|
||||
StructurePredictResult &structure_result) {
|
||||
// predict structure
|
||||
std::vector<std::vector<std::string>> structure_html_tags;
|
||||
std::vector<float> structure_scores(1, 0);
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>> structure_boxes;
|
||||
std::vector<double> structure_imes;
|
||||
std::vector<std::vector<std::vector<int>>> structure_boxes;
|
||||
std::vector<double> structure_times;
|
||||
std::vector<cv::Mat> img_list;
|
||||
img_list.push_back(img);
|
||||
this->recognizer_->Run(img_list, structure_html_tags, structure_scores,
|
||||
structure_boxes, structure_imes);
|
||||
time_info_table[0] += structure_imes[0];
|
||||
time_info_table[1] += structure_imes[1];
|
||||
time_info_table[2] += structure_imes[2];
|
||||
|
||||
this->table_model_->Run(img_list, structure_html_tags, structure_scores,
|
||||
structure_boxes, structure_times);
|
||||
|
||||
this->time_info_table[0] += structure_times[0];
|
||||
this->time_info_table[1] += structure_times[1];
|
||||
this->time_info_table[2] += structure_times[2];
|
||||
|
||||
std::vector<OCRPredictResult> ocr_result;
|
||||
std::string html;
|
||||
|
|
@ -100,63 +100,57 @@ void PaddleStructure::table(cv::Mat img,
|
|||
|
||||
for (int i = 0; i < img_list.size(); i++) {
|
||||
// det
|
||||
this->det(img_list[i], ocr_result, time_info_det);
|
||||
this->det(img_list[i], ocr_result);
|
||||
// crop image
|
||||
std::vector<cv::Mat> rec_img_list;
|
||||
std::vector<int> ocr_box;
|
||||
for (int j = 0; j < ocr_result.size(); j++) {
|
||||
int x_collect[4] = {ocr_result[j].box[0][0], ocr_result[j].box[1][0],
|
||||
ocr_result[j].box[2][0], ocr_result[j].box[3][0]};
|
||||
int y_collect[4] = {ocr_result[j].box[0][1], ocr_result[j].box[1][1],
|
||||
ocr_result[j].box[2][1], ocr_result[j].box[3][1]};
|
||||
int left = int(*std::min_element(x_collect, x_collect + 4));
|
||||
int right = int(*std::max_element(x_collect, x_collect + 4));
|
||||
int top = int(*std::min_element(y_collect, y_collect + 4));
|
||||
int bottom = int(*std::max_element(y_collect, y_collect + 4));
|
||||
std::vector<int> box{max(0, left - expand_pixel),
|
||||
max(0, top - expand_pixel),
|
||||
min(img_list[i].cols, right + expand_pixel),
|
||||
min(img_list[i].rows, bottom + expand_pixel)};
|
||||
cv::Mat crop_img = Utility::crop_image(img_list[i], box);
|
||||
ocr_box = Utility::xyxyxyxy2xyxy(ocr_result[j].box);
|
||||
ocr_box[0] = std::max(0, ocr_box[0] - expand_pixel);
|
||||
ocr_box[1] = std::max(0, ocr_box[1] - expand_pixel),
|
||||
ocr_box[2] = std::min(img_list[i].cols, ocr_box[2] + expand_pixel);
|
||||
ocr_box[3] = std::min(img_list[i].rows, ocr_box[3] + expand_pixel);
|
||||
|
||||
cv::Mat crop_img = Utility::crop_image(img_list[i], ocr_box);
|
||||
rec_img_list.push_back(crop_img);
|
||||
}
|
||||
// rec
|
||||
this->rec(rec_img_list, ocr_result, time_info_rec);
|
||||
this->rec(rec_img_list, ocr_result);
|
||||
// rebuild table
|
||||
html = this->rebuild_table(structure_html_tags[i], structure_boxes[i],
|
||||
ocr_result);
|
||||
structure_result.html = html;
|
||||
structure_result.cell_box = structure_boxes[i];
|
||||
structure_result.html_score = structure_scores[i];
|
||||
}
|
||||
};
|
||||
|
||||
std::string PaddleStructure::rebuild_table(
|
||||
std::vector<std::string> structure_html_tags,
|
||||
std::vector<std::vector<std::vector<int>>> structure_boxes,
|
||||
std::vector<OCRPredictResult> &ocr_result) {
|
||||
std::string
|
||||
PaddleStructure::rebuild_table(std::vector<std::string> structure_html_tags,
|
||||
std::vector<std::vector<int>> structure_boxes,
|
||||
std::vector<OCRPredictResult> &ocr_result) {
|
||||
// match text in same cell
|
||||
std::vector<std::vector<string>> matched(structure_boxes.size(),
|
||||
std::vector<std::string>());
|
||||
std::vector<std::vector<std::string>> matched(structure_boxes.size(),
|
||||
std::vector<std::string>());
|
||||
|
||||
std::vector<int> ocr_box;
|
||||
std::vector<int> structure_box;
|
||||
for (int i = 0; i < ocr_result.size(); i++) {
|
||||
ocr_box = Utility::xyxyxyxy2xyxy(ocr_result[i].box);
|
||||
ocr_box[0] -= 1;
|
||||
ocr_box[1] -= 1;
|
||||
ocr_box[2] += 1;
|
||||
ocr_box[3] += 1;
|
||||
std::vector<std::vector<float>> dis_list(structure_boxes.size(),
|
||||
std::vector<float>(3, 100000.0));
|
||||
for (int j = 0; j < structure_boxes.size(); j++) {
|
||||
int x_collect[4] = {ocr_result[i].box[0][0], ocr_result[i].box[1][0],
|
||||
ocr_result[i].box[2][0], ocr_result[i].box[3][0]};
|
||||
int y_collect[4] = {ocr_result[i].box[0][1], ocr_result[i].box[1][1],
|
||||
ocr_result[i].box[2][1], ocr_result[i].box[3][1]};
|
||||
int left = int(*std::min_element(x_collect, x_collect + 4));
|
||||
int right = int(*std::max_element(x_collect, x_collect + 4));
|
||||
int top = int(*std::min_element(y_collect, y_collect + 4));
|
||||
int bottom = int(*std::max_element(y_collect, y_collect + 4));
|
||||
std::vector<std::vector<int>> box(2, std::vector<int>(2, 0));
|
||||
box[0][0] = left - 1;
|
||||
box[0][1] = top - 1;
|
||||
box[1][0] = right + 1;
|
||||
box[1][1] = bottom + 1;
|
||||
|
||||
dis_list[j][0] = this->dis(box, structure_boxes[j]);
|
||||
dis_list[j][1] = 1 - this->iou(box, structure_boxes[j]);
|
||||
if (structure_boxes[i].size() == 8) {
|
||||
structure_box = Utility::xyxyxyxy2xyxy(structure_boxes[j]);
|
||||
} else {
|
||||
structure_box = structure_boxes[j];
|
||||
}
|
||||
dis_list[j][0] = this->dis(ocr_box, structure_box);
|
||||
dis_list[j][1] = 1 - Utility::iou(ocr_box, structure_box);
|
||||
dis_list[j][2] = j;
|
||||
}
|
||||
// find min dis idx
|
||||
|
|
@ -164,6 +158,7 @@ std::string PaddleStructure::rebuild_table(
|
|||
PaddleStructure::comparison_dis);
|
||||
matched[dis_list[0][2]].push_back(ocr_result[i].text);
|
||||
}
|
||||
|
||||
// get pred html
|
||||
std::string html_str = "";
|
||||
int td_tag_idx = 0;
|
||||
|
|
@ -221,51 +216,79 @@ std::string PaddleStructure::rebuild_table(
|
|||
return html_str;
|
||||
}
|
||||
|
||||
float PaddleStructure::iou(std::vector<std::vector<int>> &box1,
|
||||
std::vector<std::vector<int>> &box2) {
|
||||
int area1 = max(0, box1[1][0] - box1[0][0]) * max(0, box1[1][1] - box1[0][1]);
|
||||
int area2 = max(0, box2[1][0] - box2[0][0]) * max(0, box2[1][1] - box2[0][1]);
|
||||
float PaddleStructure::dis(std::vector<int> &box1, std::vector<int> &box2) {
|
||||
int x1_1 = box1[0];
|
||||
int y1_1 = box1[1];
|
||||
int x2_1 = box1[2];
|
||||
int y2_1 = box1[3];
|
||||
|
||||
// computing the sum_area
|
||||
int sum_area = area1 + area2;
|
||||
|
||||
// find the each point of intersect rectangle
|
||||
int x1 = max(box1[0][0], box2[0][0]);
|
||||
int y1 = max(box1[0][1], box2[0][1]);
|
||||
int x2 = min(box1[1][0], box2[1][0]);
|
||||
int y2 = min(box1[1][1], box2[1][1]);
|
||||
|
||||
// judge if there is an intersect
|
||||
if (y1 >= y2 || x1 >= x2) {
|
||||
return 0.0;
|
||||
} else {
|
||||
int intersect = (x2 - x1) * (y2 - y1);
|
||||
return intersect / (sum_area - intersect + 0.00000001);
|
||||
}
|
||||
}
|
||||
|
||||
float PaddleStructure::dis(std::vector<std::vector<int>> &box1,
|
||||
std::vector<std::vector<int>> &box2) {
|
||||
int x1_1 = box1[0][0];
|
||||
int y1_1 = box1[0][1];
|
||||
int x2_1 = box1[1][0];
|
||||
int y2_1 = box1[1][1];
|
||||
|
||||
int x1_2 = box2[0][0];
|
||||
int y1_2 = box2[0][1];
|
||||
int x2_2 = box2[1][0];
|
||||
int y2_2 = box2[1][1];
|
||||
int x1_2 = box2[0];
|
||||
int y1_2 = box2[1];
|
||||
int x2_2 = box2[2];
|
||||
int y2_2 = box2[3];
|
||||
|
||||
float dis =
|
||||
abs(x1_2 - x1_1) + abs(y1_2 - y1_1) + abs(x2_2 - x2_1) + abs(y2_2 - y2_1);
|
||||
float dis_2 = abs(x1_2 - x1_1) + abs(y1_2 - y1_1);
|
||||
float dis_3 = abs(x2_2 - x2_1) + abs(y2_2 - y2_1);
|
||||
return dis + min(dis_2, dis_3);
|
||||
return dis + std::min(dis_2, dis_3);
|
||||
}
|
||||
|
||||
void PaddleStructure::reset_timer() {
|
||||
this->time_info_det = {0, 0, 0};
|
||||
this->time_info_rec = {0, 0, 0};
|
||||
this->time_info_cls = {0, 0, 0};
|
||||
this->time_info_table = {0, 0, 0};
|
||||
this->time_info_layout = {0, 0, 0};
|
||||
}
|
||||
|
||||
void PaddleStructure::benchmark_log(int img_num) {
|
||||
if (this->time_info_det[0] + this->time_info_det[1] + this->time_info_det[2] >
|
||||
0) {
|
||||
AutoLogger autolog_det("ocr_det", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads, 1, "dynamic",
|
||||
FLAGS_precision, this->time_info_det, img_num);
|
||||
autolog_det.report();
|
||||
}
|
||||
if (this->time_info_rec[0] + this->time_info_rec[1] + this->time_info_rec[2] >
|
||||
0) {
|
||||
AutoLogger autolog_rec("ocr_rec", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_rec_batch_num, "dynamic", FLAGS_precision,
|
||||
this->time_info_rec, img_num);
|
||||
autolog_rec.report();
|
||||
}
|
||||
if (this->time_info_cls[0] + this->time_info_cls[1] + this->time_info_cls[2] >
|
||||
0) {
|
||||
AutoLogger autolog_cls("ocr_cls", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_cls_batch_num, "dynamic", FLAGS_precision,
|
||||
this->time_info_cls, img_num);
|
||||
autolog_cls.report();
|
||||
}
|
||||
if (this->time_info_table[0] + this->time_info_table[1] +
|
||||
this->time_info_table[2] >
|
||||
0) {
|
||||
AutoLogger autolog_table("table", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_cls_batch_num, "dynamic", FLAGS_precision,
|
||||
this->time_info_table, img_num);
|
||||
autolog_table.report();
|
||||
}
|
||||
if (this->time_info_layout[0] + this->time_info_layout[1] +
|
||||
this->time_info_layout[2] >
|
||||
0) {
|
||||
AutoLogger autolog_layout("layout", FLAGS_use_gpu, FLAGS_use_tensorrt,
|
||||
FLAGS_enable_mkldnn, FLAGS_cpu_threads,
|
||||
FLAGS_cls_batch_num, "dynamic", FLAGS_precision,
|
||||
this->time_info_layout, img_num);
|
||||
autolog_layout.report();
|
||||
}
|
||||
}
|
||||
|
||||
PaddleStructure::~PaddleStructure() {
|
||||
if (this->recognizer_ != nullptr) {
|
||||
delete this->recognizer_;
|
||||
if (this->table_model_ != nullptr) {
|
||||
delete this->table_model_;
|
||||
}
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,6 @@
|
|||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#include <include/clipper.h>
|
||||
#include <include/postprocess_op.h>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
|
@ -352,8 +351,21 @@ std::vector<std::vector<std::vector<int>>> DBPostProcessor::FilterTagDetRes(
|
|||
return root_points;
|
||||
}
|
||||
|
||||
void TablePostProcessor::init(std::string label_path) {
|
||||
void TablePostProcessor::init(std::string label_path,
|
||||
bool merge_no_span_structure) {
|
||||
this->label_list_ = Utility::ReadDict(label_path);
|
||||
if (merge_no_span_structure) {
|
||||
this->label_list_.push_back("<td></td>");
|
||||
std::vector<std::string>::iterator it;
|
||||
for (it = this->label_list_.begin(); it != this->label_list_.end();) {
|
||||
if (*it == "<td>") {
|
||||
it = this->label_list_.erase(it);
|
||||
} else {
|
||||
++it;
|
||||
}
|
||||
}
|
||||
}
|
||||
// add_special_char
|
||||
this->label_list_.insert(this->label_list_.begin(), this->beg);
|
||||
this->label_list_.push_back(this->end);
|
||||
}
|
||||
|
|
@ -363,12 +375,12 @@ void TablePostProcessor::Run(
|
|||
std::vector<float> &rec_scores, std::vector<int> &loc_preds_shape,
|
||||
std::vector<int> &structure_probs_shape,
|
||||
std::vector<std::vector<std::string>> &rec_html_tag_batch,
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>> &rec_boxes_batch,
|
||||
std::vector<std::vector<std::vector<int>>> &rec_boxes_batch,
|
||||
std::vector<int> &width_list, std::vector<int> &height_list) {
|
||||
for (int batch_idx = 0; batch_idx < structure_probs_shape[0]; batch_idx++) {
|
||||
// image tags and boxs
|
||||
std::vector<std::string> rec_html_tags;
|
||||
std::vector<std::vector<std::vector<int>>> rec_boxes;
|
||||
std::vector<std::vector<int>> rec_boxes;
|
||||
|
||||
float score = 0.f;
|
||||
int count = 0;
|
||||
|
|
@ -378,7 +390,7 @@ void TablePostProcessor::Run(
|
|||
// step
|
||||
for (int step_idx = 0; step_idx < structure_probs_shape[1]; step_idx++) {
|
||||
std::string html_tag;
|
||||
std::vector<std::vector<int>> rec_box;
|
||||
std::vector<int> rec_box;
|
||||
// html tag
|
||||
int step_start_idx = (batch_idx * structure_probs_shape[1] + step_idx) *
|
||||
structure_probs_shape[2];
|
||||
|
|
@ -399,24 +411,26 @@ void TablePostProcessor::Run(
|
|||
count += 1;
|
||||
score += char_score;
|
||||
rec_html_tags.push_back(html_tag);
|
||||
|
||||
// box
|
||||
if (html_tag == "<td>" || html_tag == "<td" || html_tag == "<td></td>") {
|
||||
for (int point_idx = 0; point_idx < loc_preds_shape[2];
|
||||
point_idx += 2) {
|
||||
std::vector<int> point(2, 0);
|
||||
for (int point_idx = 0; point_idx < loc_preds_shape[2]; point_idx++) {
|
||||
step_start_idx = (batch_idx * structure_probs_shape[1] + step_idx) *
|
||||
loc_preds_shape[2] +
|
||||
point_idx;
|
||||
point[0] = int(loc_preds[step_start_idx] * width_list[batch_idx]);
|
||||
point[1] =
|
||||
int(loc_preds[step_start_idx + 1] * height_list[batch_idx]);
|
||||
float point = loc_preds[step_start_idx];
|
||||
if (point_idx % 2 == 0) {
|
||||
point = int(point * width_list[batch_idx]);
|
||||
} else {
|
||||
point = int(point * height_list[batch_idx]);
|
||||
}
|
||||
rec_box.push_back(point);
|
||||
}
|
||||
rec_boxes.push_back(rec_box);
|
||||
}
|
||||
}
|
||||
score /= count;
|
||||
if (isnan(score) || rec_boxes.size() == 0) {
|
||||
if (std::isnan(score) || rec_boxes.size() == 0) {
|
||||
score = -1;
|
||||
}
|
||||
rec_scores.push_back(score);
|
||||
|
|
@ -425,4 +439,137 @@ void TablePostProcessor::Run(
|
|||
}
|
||||
}
|
||||
|
||||
void PicodetPostProcessor::init(std::string label_path,
|
||||
const double score_threshold,
|
||||
const double nms_threshold,
|
||||
const std::vector<int> &fpn_stride) {
|
||||
this->label_list_ = Utility::ReadDict(label_path);
|
||||
this->score_threshold_ = score_threshold;
|
||||
this->nms_threshold_ = nms_threshold;
|
||||
this->num_class_ = label_list_.size();
|
||||
this->fpn_stride_ = fpn_stride;
|
||||
}
|
||||
|
||||
void PicodetPostProcessor::Run(std::vector<StructurePredictResult> &results,
|
||||
std::vector<std::vector<float>> outs,
|
||||
std::vector<int> ori_shape,
|
||||
std::vector<int> resize_shape, int reg_max) {
|
||||
int in_h = resize_shape[0];
|
||||
int in_w = resize_shape[1];
|
||||
float scale_factor_h = resize_shape[0] / float(ori_shape[0]);
|
||||
float scale_factor_w = resize_shape[1] / float(ori_shape[1]);
|
||||
|
||||
std::vector<std::vector<StructurePredictResult>> bbox_results;
|
||||
bbox_results.resize(this->num_class_);
|
||||
for (int i = 0; i < this->fpn_stride_.size(); ++i) {
|
||||
int feature_h = std::ceil((float)in_h / this->fpn_stride_[i]);
|
||||
int feature_w = std::ceil((float)in_w / this->fpn_stride_[i]);
|
||||
for (int idx = 0; idx < feature_h * feature_w; idx++) {
|
||||
// score and label
|
||||
float score = 0;
|
||||
int cur_label = 0;
|
||||
for (int label = 0; label < this->num_class_; label++) {
|
||||
if (outs[i][idx * this->num_class_ + label] > score) {
|
||||
score = outs[i][idx * this->num_class_ + label];
|
||||
cur_label = label;
|
||||
}
|
||||
}
|
||||
// bbox
|
||||
if (score > this->score_threshold_) {
|
||||
int row = idx / feature_w;
|
||||
int col = idx % feature_w;
|
||||
std::vector<float> bbox_pred(
|
||||
outs[i + this->fpn_stride_.size()].begin() + idx * 4 * reg_max,
|
||||
outs[i + this->fpn_stride_.size()].begin() +
|
||||
(idx + 1) * 4 * reg_max);
|
||||
bbox_results[cur_label].push_back(
|
||||
this->disPred2Bbox(bbox_pred, cur_label, score, col, row,
|
||||
this->fpn_stride_[i], resize_shape, reg_max));
|
||||
}
|
||||
}
|
||||
}
|
||||
for (int i = 0; i < bbox_results.size(); i++) {
|
||||
bool flag = bbox_results[i].size() <= 0;
|
||||
}
|
||||
for (int i = 0; i < bbox_results.size(); i++) {
|
||||
bool flag = bbox_results[i].size() <= 0;
|
||||
if (bbox_results[i].size() <= 0) {
|
||||
continue;
|
||||
}
|
||||
this->nms(bbox_results[i], this->nms_threshold_);
|
||||
for (auto box : bbox_results[i]) {
|
||||
box.box[0] = box.box[0] / scale_factor_w;
|
||||
box.box[2] = box.box[2] / scale_factor_w;
|
||||
box.box[1] = box.box[1] / scale_factor_h;
|
||||
box.box[3] = box.box[3] / scale_factor_h;
|
||||
results.push_back(box);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
StructurePredictResult
|
||||
PicodetPostProcessor::disPred2Bbox(std::vector<float> bbox_pred, int label,
|
||||
float score, int x, int y, int stride,
|
||||
std::vector<int> im_shape, int reg_max) {
|
||||
float ct_x = (x + 0.5) * stride;
|
||||
float ct_y = (y + 0.5) * stride;
|
||||
std::vector<float> dis_pred;
|
||||
dis_pred.resize(4);
|
||||
for (int i = 0; i < 4; i++) {
|
||||
float dis = 0;
|
||||
std::vector<float> bbox_pred_i(bbox_pred.begin() + i * reg_max,
|
||||
bbox_pred.begin() + (i + 1) * reg_max);
|
||||
std::vector<float> dis_after_sm =
|
||||
Utility::activation_function_softmax(bbox_pred_i);
|
||||
for (int j = 0; j < reg_max; j++) {
|
||||
dis += j * dis_after_sm[j];
|
||||
}
|
||||
dis *= stride;
|
||||
dis_pred[i] = dis;
|
||||
}
|
||||
|
||||
float xmin = (std::max)(ct_x - dis_pred[0], .0f);
|
||||
float ymin = (std::max)(ct_y - dis_pred[1], .0f);
|
||||
float xmax = (std::min)(ct_x + dis_pred[2], (float)im_shape[1]);
|
||||
float ymax = (std::min)(ct_y + dis_pred[3], (float)im_shape[0]);
|
||||
|
||||
StructurePredictResult result_item;
|
||||
result_item.box = {xmin, ymin, xmax, ymax};
|
||||
result_item.type = this->label_list_[label];
|
||||
result_item.confidence = score;
|
||||
|
||||
return result_item;
|
||||
}
|
||||
|
||||
void PicodetPostProcessor::nms(std::vector<StructurePredictResult> &input_boxes,
|
||||
float nms_threshold) {
|
||||
std::sort(input_boxes.begin(), input_boxes.end(),
|
||||
[](StructurePredictResult a, StructurePredictResult b) {
|
||||
return a.confidence > b.confidence;
|
||||
});
|
||||
std::vector<int> picked(input_boxes.size(), 1);
|
||||
|
||||
for (int i = 0; i < input_boxes.size(); ++i) {
|
||||
if (picked[i] == 0) {
|
||||
continue;
|
||||
}
|
||||
for (int j = i + 1; j < input_boxes.size(); ++j) {
|
||||
if (picked[j] == 0) {
|
||||
continue;
|
||||
}
|
||||
float iou = Utility::iou(input_boxes[i].box, input_boxes[j].box);
|
||||
if (iou > nms_threshold) {
|
||||
picked[j] = 0;
|
||||
}
|
||||
}
|
||||
}
|
||||
std::vector<StructurePredictResult> input_boxes_nms;
|
||||
for (int i = 0; i < input_boxes.size(); ++i) {
|
||||
if (picked[i] == 1) {
|
||||
input_boxes_nms.push_back(input_boxes[i]);
|
||||
}
|
||||
}
|
||||
input_boxes = input_boxes_nms;
|
||||
}
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -12,21 +12,6 @@
|
|||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#include "opencv2/core.hpp"
|
||||
#include "opencv2/imgcodecs.hpp"
|
||||
#include "opencv2/imgproc.hpp"
|
||||
#include "paddle_api.h"
|
||||
#include "paddle_inference_api.h"
|
||||
#include <chrono>
|
||||
#include <iomanip>
|
||||
#include <iostream>
|
||||
#include <ostream>
|
||||
#include <vector>
|
||||
|
||||
#include <cstring>
|
||||
#include <fstream>
|
||||
#include <numeric>
|
||||
|
||||
#include <include/preprocess_op.h>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
|
@ -69,13 +54,13 @@ void Normalize::Run(cv::Mat *im, const std::vector<float> &mean,
|
|||
}
|
||||
|
||||
void ResizeImgType0::Run(const cv::Mat &img, cv::Mat &resize_img,
|
||||
string limit_type, int limit_side_len, float &ratio_h,
|
||||
float &ratio_w, bool use_tensorrt) {
|
||||
std::string limit_type, int limit_side_len,
|
||||
float &ratio_h, float &ratio_w, bool use_tensorrt) {
|
||||
int w = img.cols;
|
||||
int h = img.rows;
|
||||
float ratio = 1.f;
|
||||
if (limit_type == "min") {
|
||||
int min_wh = min(h, w);
|
||||
int min_wh = std::min(h, w);
|
||||
if (min_wh < limit_side_len) {
|
||||
if (h < w) {
|
||||
ratio = float(limit_side_len) / float(h);
|
||||
|
|
@ -84,7 +69,7 @@ void ResizeImgType0::Run(const cv::Mat &img, cv::Mat &resize_img,
|
|||
}
|
||||
}
|
||||
} else {
|
||||
int max_wh = max(h, w);
|
||||
int max_wh = std::max(h, w);
|
||||
if (max_wh > limit_side_len) {
|
||||
if (h > w) {
|
||||
ratio = float(limit_side_len) / float(h);
|
||||
|
|
@ -97,8 +82,8 @@ void ResizeImgType0::Run(const cv::Mat &img, cv::Mat &resize_img,
|
|||
int resize_h = int(float(h) * ratio);
|
||||
int resize_w = int(float(w) * ratio);
|
||||
|
||||
resize_h = max(int(round(float(resize_h) / 32) * 32), 32);
|
||||
resize_w = max(int(round(float(resize_w) / 32) * 32), 32);
|
||||
resize_h = std::max(int(round(float(resize_h) / 32) * 32), 32);
|
||||
resize_w = std::max(int(round(float(resize_w) / 32) * 32), 32);
|
||||
|
||||
cv::resize(img, resize_img, cv::Size(resize_w, resize_h));
|
||||
ratio_h = float(resize_h) / float(h);
|
||||
|
|
@ -175,4 +160,9 @@ void TablePadImg::Run(const cv::Mat &img, cv::Mat &resize_img,
|
|||
cv::BORDER_CONSTANT, cv::Scalar(0, 0, 0));
|
||||
}
|
||||
|
||||
void Resize::Run(const cv::Mat &img, cv::Mat &resize_img, const int h,
|
||||
const int w) {
|
||||
cv::resize(img, resize_img, cv::Size(w, h));
|
||||
}
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -0,0 +1,149 @@
|
|||
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#include <include/structure_layout.h>
|
||||
|
||||
namespace PaddleOCR {
|
||||
|
||||
void StructureLayoutRecognizer::Run(cv::Mat img,
|
||||
std::vector<StructurePredictResult> &result,
|
||||
std::vector<double> ×) {
|
||||
std::chrono::duration<float> preprocess_diff =
|
||||
std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
|
||||
std::chrono::duration<float> inference_diff =
|
||||
std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
|
||||
std::chrono::duration<float> postprocess_diff =
|
||||
std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
|
||||
|
||||
// preprocess
|
||||
auto preprocess_start = std::chrono::steady_clock::now();
|
||||
|
||||
cv::Mat srcimg;
|
||||
img.copyTo(srcimg);
|
||||
cv::Mat resize_img;
|
||||
this->resize_op_.Run(srcimg, resize_img, 800, 608);
|
||||
this->normalize_op_.Run(&resize_img, this->mean_, this->scale_,
|
||||
this->is_scale_);
|
||||
|
||||
std::vector<float> input(1 * 3 * resize_img.rows * resize_img.cols, 0.0f);
|
||||
this->permute_op_.Run(&resize_img, input.data());
|
||||
auto preprocess_end = std::chrono::steady_clock::now();
|
||||
preprocess_diff += preprocess_end - preprocess_start;
|
||||
|
||||
// inference.
|
||||
auto input_names = this->predictor_->GetInputNames();
|
||||
auto input_t = this->predictor_->GetInputHandle(input_names[0]);
|
||||
input_t->Reshape({1, 3, resize_img.rows, resize_img.cols});
|
||||
auto inference_start = std::chrono::steady_clock::now();
|
||||
input_t->CopyFromCpu(input.data());
|
||||
|
||||
this->predictor_->Run();
|
||||
|
||||
// Get output tensor
|
||||
std::vector<std::vector<float>> out_tensor_list;
|
||||
std::vector<std::vector<int>> output_shape_list;
|
||||
auto output_names = this->predictor_->GetOutputNames();
|
||||
for (int j = 0; j < output_names.size(); j++) {
|
||||
auto output_tensor = this->predictor_->GetOutputHandle(output_names[j]);
|
||||
std::vector<int> output_shape = output_tensor->shape();
|
||||
int out_num = std::accumulate(output_shape.begin(), output_shape.end(), 1,
|
||||
std::multiplies<int>());
|
||||
output_shape_list.push_back(output_shape);
|
||||
|
||||
std::vector<float> out_data;
|
||||
out_data.resize(out_num);
|
||||
output_tensor->CopyToCpu(out_data.data());
|
||||
out_tensor_list.push_back(out_data);
|
||||
}
|
||||
auto inference_end = std::chrono::steady_clock::now();
|
||||
inference_diff += inference_end - inference_start;
|
||||
|
||||
// postprocess
|
||||
auto postprocess_start = std::chrono::steady_clock::now();
|
||||
|
||||
std::vector<int> bbox_num;
|
||||
int reg_max = 0;
|
||||
for (int i = 0; i < out_tensor_list.size(); i++) {
|
||||
if (i == this->post_processor_.fpn_stride_.size()) {
|
||||
reg_max = output_shape_list[i][2] / 4;
|
||||
break;
|
||||
}
|
||||
}
|
||||
std::vector<int> ori_shape = {srcimg.rows, srcimg.cols};
|
||||
std::vector<int> resize_shape = {resize_img.rows, resize_img.cols};
|
||||
this->post_processor_.Run(result, out_tensor_list, ori_shape, resize_shape,
|
||||
reg_max);
|
||||
bbox_num.push_back(result.size());
|
||||
|
||||
auto postprocess_end = std::chrono::steady_clock::now();
|
||||
postprocess_diff += postprocess_end - postprocess_start;
|
||||
times.push_back(double(preprocess_diff.count() * 1000));
|
||||
times.push_back(double(inference_diff.count() * 1000));
|
||||
times.push_back(double(postprocess_diff.count() * 1000));
|
||||
}
|
||||
|
||||
void StructureLayoutRecognizer::LoadModel(const std::string &model_dir) {
|
||||
paddle_infer::Config config;
|
||||
if (Utility::PathExists(model_dir + "/inference.pdmodel") &&
|
||||
Utility::PathExists(model_dir + "/inference.pdiparams")) {
|
||||
config.SetModel(model_dir + "/inference.pdmodel",
|
||||
model_dir + "/inference.pdiparams");
|
||||
} else if (Utility::PathExists(model_dir + "/model.pdmodel") &&
|
||||
Utility::PathExists(model_dir + "/model.pdiparams")) {
|
||||
config.SetModel(model_dir + "/model.pdmodel",
|
||||
model_dir + "/model.pdiparams");
|
||||
} else {
|
||||
std::cerr << "[ERROR] not find model.pdiparams or inference.pdiparams in "
|
||||
<< model_dir << std::endl;
|
||||
exit(1);
|
||||
}
|
||||
|
||||
if (this->use_gpu_) {
|
||||
config.EnableUseGpu(this->gpu_mem_, this->gpu_id_);
|
||||
if (this->use_tensorrt_) {
|
||||
auto precision = paddle_infer::Config::Precision::kFloat32;
|
||||
if (this->precision_ == "fp16") {
|
||||
precision = paddle_infer::Config::Precision::kHalf;
|
||||
}
|
||||
if (this->precision_ == "int8") {
|
||||
precision = paddle_infer::Config::Precision::kInt8;
|
||||
}
|
||||
config.EnableTensorRtEngine(1 << 20, 10, 3, precision, false, false);
|
||||
if (!Utility::PathExists("./trt_layout_shape.txt")) {
|
||||
config.CollectShapeRangeInfo("./trt_layout_shape.txt");
|
||||
} else {
|
||||
config.EnableTunedTensorRtDynamicShape("./trt_layout_shape.txt", true);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
config.DisableGpu();
|
||||
if (this->use_mkldnn_) {
|
||||
config.EnableMKLDNN();
|
||||
}
|
||||
config.SetCpuMathLibraryNumThreads(this->cpu_math_library_num_threads_);
|
||||
}
|
||||
|
||||
// false for zero copy tensor
|
||||
config.SwitchUseFeedFetchOps(false);
|
||||
// true for multiple input
|
||||
config.SwitchSpecifyInputNames(true);
|
||||
|
||||
config.SwitchIrOptim(true);
|
||||
|
||||
config.EnableMemoryOptim();
|
||||
config.DisableGlogInfo();
|
||||
|
||||
this->predictor_ = paddle_infer::CreatePredictor(config);
|
||||
}
|
||||
} // namespace PaddleOCR
|
||||
|
|
@ -20,7 +20,7 @@ void StructureTableRecognizer::Run(
|
|||
std::vector<cv::Mat> img_list,
|
||||
std::vector<std::vector<std::string>> &structure_html_tags,
|
||||
std::vector<float> &structure_scores,
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>> &structure_boxes,
|
||||
std::vector<std::vector<std::vector<int>>> &structure_boxes,
|
||||
std::vector<double> ×) {
|
||||
std::chrono::duration<float> preprocess_diff =
|
||||
std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
|
||||
|
|
@ -34,7 +34,7 @@ void StructureTableRecognizer::Run(
|
|||
beg_img_no += this->table_batch_num_) {
|
||||
// preprocess
|
||||
auto preprocess_start = std::chrono::steady_clock::now();
|
||||
int end_img_no = min(img_num, beg_img_no + this->table_batch_num_);
|
||||
int end_img_no = std::min(img_num, beg_img_no + this->table_batch_num_);
|
||||
int batch_num = end_img_no - beg_img_no;
|
||||
std::vector<cv::Mat> norm_img_batch;
|
||||
std::vector<int> width_list;
|
||||
|
|
@ -89,8 +89,7 @@ void StructureTableRecognizer::Run(
|
|||
auto postprocess_start = std::chrono::steady_clock::now();
|
||||
std::vector<std::vector<std::string>> structure_html_tag_batch;
|
||||
std::vector<float> structure_score_batch;
|
||||
std::vector<std::vector<std::vector<std::vector<int>>>>
|
||||
structure_boxes_batch;
|
||||
std::vector<std::vector<std::vector<int>>> structure_boxes_batch;
|
||||
this->post_processor_.Run(loc_preds, structure_probs, structure_score_batch,
|
||||
predict_shape0, predict_shape1,
|
||||
structure_html_tag_batch, structure_boxes_batch,
|
||||
|
|
@ -119,7 +118,7 @@ void StructureTableRecognizer::Run(
|
|||
}
|
||||
|
||||
void StructureTableRecognizer::LoadModel(const std::string &model_dir) {
|
||||
AnalysisConfig config;
|
||||
paddle_infer::Config config;
|
||||
config.SetModel(model_dir + "/inference.pdmodel",
|
||||
model_dir + "/inference.pdiparams");
|
||||
|
||||
|
|
@ -134,6 +133,11 @@ void StructureTableRecognizer::LoadModel(const std::string &model_dir) {
|
|||
precision = paddle_infer::Config::Precision::kInt8;
|
||||
}
|
||||
config.EnableTensorRtEngine(1 << 20, 10, 3, precision, false, false);
|
||||
if (!Utility::PathExists("./trt_table_shape.txt")) {
|
||||
config.CollectShapeRangeInfo("./trt_table_shape.txt");
|
||||
} else {
|
||||
config.EnableTunedTensorRtDynamicShape("./trt_table_shape.txt", true);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
config.DisableGpu();
|
||||
|
|
@ -153,6 +157,6 @@ void StructureTableRecognizer::LoadModel(const std::string &model_dir) {
|
|||
config.EnableMemoryOptim();
|
||||
config.DisableGlogInfo();
|
||||
|
||||
this->predictor_ = CreatePredictor(config);
|
||||
this->predictor_ = paddle_infer::CreatePredictor(config);
|
||||
}
|
||||
} // namespace PaddleOCR
|
||||
|
|
|
|||
|
|
@ -65,6 +65,38 @@ void Utility::VisualizeBboxes(const cv::Mat &srcimg,
|
|||
<< std::endl;
|
||||
}
|
||||
|
||||
void Utility::VisualizeBboxes(const cv::Mat &srcimg,
|
||||
const StructurePredictResult &structure_result,
|
||||
const std::string &save_path) {
|
||||
cv::Mat img_vis;
|
||||
srcimg.copyTo(img_vis);
|
||||
img_vis = crop_image(img_vis, structure_result.box);
|
||||
for (int n = 0; n < structure_result.cell_box.size(); n++) {
|
||||
if (structure_result.cell_box[n].size() == 8) {
|
||||
cv::Point rook_points[4];
|
||||
for (int m = 0; m < structure_result.cell_box[n].size(); m += 2) {
|
||||
rook_points[m / 2] =
|
||||
cv::Point(int(structure_result.cell_box[n][m]),
|
||||
int(structure_result.cell_box[n][m + 1]));
|
||||
}
|
||||
const cv::Point *ppt[1] = {rook_points};
|
||||
int npt[] = {4};
|
||||
cv::polylines(img_vis, ppt, npt, 1, 1, CV_RGB(0, 255, 0), 2, 8, 0);
|
||||
} else if (structure_result.cell_box[n].size() == 4) {
|
||||
cv::Point rook_points[2];
|
||||
rook_points[0] = cv::Point(int(structure_result.cell_box[n][0]),
|
||||
int(structure_result.cell_box[n][1]));
|
||||
rook_points[1] = cv::Point(int(structure_result.cell_box[n][2]),
|
||||
int(structure_result.cell_box[n][3]));
|
||||
cv::rectangle(img_vis, rook_points[0], rook_points[1], CV_RGB(0, 255, 0),
|
||||
2, 8, 0);
|
||||
}
|
||||
}
|
||||
|
||||
cv::imwrite(save_path, img_vis);
|
||||
std::cout << "The table visualized image saved in " + save_path << std::endl;
|
||||
}
|
||||
|
||||
// list all files under a directory
|
||||
void Utility::GetAllFiles(const char *dir_name,
|
||||
std::vector<std::string> &all_inputs) {
|
||||
|
|
@ -249,32 +281,145 @@ void Utility::print_result(const std::vector<OCRPredictResult> &ocr_result) {
|
|||
}
|
||||
}
|
||||
|
||||
cv::Mat Utility::crop_image(cv::Mat &img, std::vector<int> &area) {
|
||||
cv::Mat Utility::crop_image(cv::Mat &img, const std::vector<int> &box) {
|
||||
cv::Mat crop_im;
|
||||
int crop_x1 = std::max(0, area[0]);
|
||||
int crop_y1 = std::max(0, area[1]);
|
||||
int crop_x2 = std::min(img.cols - 1, area[2] - 1);
|
||||
int crop_y2 = std::min(img.rows - 1, area[3] - 1);
|
||||
int crop_x1 = std::max(0, box[0]);
|
||||
int crop_y1 = std::max(0, box[1]);
|
||||
int crop_x2 = std::min(img.cols - 1, box[2] - 1);
|
||||
int crop_y2 = std::min(img.rows - 1, box[3] - 1);
|
||||
|
||||
crop_im = cv::Mat::zeros(area[3] - area[1], area[2] - area[0], 16);
|
||||
crop_im = cv::Mat::zeros(box[3] - box[1], box[2] - box[0], 16);
|
||||
cv::Mat crop_im_window =
|
||||
crop_im(cv::Range(crop_y1 - area[1], crop_y2 + 1 - area[1]),
|
||||
cv::Range(crop_x1 - area[0], crop_x2 + 1 - area[0]));
|
||||
crop_im(cv::Range(crop_y1 - box[1], crop_y2 + 1 - box[1]),
|
||||
cv::Range(crop_x1 - box[0], crop_x2 + 1 - box[0]));
|
||||
cv::Mat roi_img =
|
||||
img(cv::Range(crop_y1, crop_y2 + 1), cv::Range(crop_x1, crop_x2 + 1));
|
||||
crop_im_window += roi_img;
|
||||
return crop_im;
|
||||
}
|
||||
|
||||
cv::Mat Utility::crop_image(cv::Mat &img, const std::vector<float> &box) {
|
||||
std::vector<int> box_int = {(int)box[0], (int)box[1], (int)box[2],
|
||||
(int)box[3]};
|
||||
return crop_image(img, box_int);
|
||||
}
|
||||
|
||||
void Utility::sorted_boxes(std::vector<OCRPredictResult> &ocr_result) {
|
||||
std::sort(ocr_result.begin(), ocr_result.end(), Utility::comparison_box);
|
||||
|
||||
for (int i = 0; i < ocr_result.size() - 1; i++) {
|
||||
if (abs(ocr_result[i + 1].box[0][1] - ocr_result[i].box[0][1]) < 10 &&
|
||||
(ocr_result[i + 1].box[0][0] < ocr_result[i].box[0][0])) {
|
||||
std::swap(ocr_result[i], ocr_result[i + 1]);
|
||||
if (ocr_result.size() > 0) {
|
||||
for (int i = 0; i < ocr_result.size() - 1; i++) {
|
||||
for (int j = i; j > 0; j--) {
|
||||
if (abs(ocr_result[j + 1].box[0][1] - ocr_result[j].box[0][1]) < 10 &&
|
||||
(ocr_result[j + 1].box[0][0] < ocr_result[j].box[0][0])) {
|
||||
std::swap(ocr_result[i], ocr_result[i + 1]);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
std::vector<int> Utility::xyxyxyxy2xyxy(std::vector<std::vector<int>> &box) {
|
||||
int x_collect[4] = {box[0][0], box[1][0], box[2][0], box[3][0]};
|
||||
int y_collect[4] = {box[0][1], box[1][1], box[2][1], box[3][1]};
|
||||
int left = int(*std::min_element(x_collect, x_collect + 4));
|
||||
int right = int(*std::max_element(x_collect, x_collect + 4));
|
||||
int top = int(*std::min_element(y_collect, y_collect + 4));
|
||||
int bottom = int(*std::max_element(y_collect, y_collect + 4));
|
||||
std::vector<int> box1(4, 0);
|
||||
box1[0] = left;
|
||||
box1[1] = top;
|
||||
box1[2] = right;
|
||||
box1[3] = bottom;
|
||||
return box1;
|
||||
}
|
||||
|
||||
std::vector<int> Utility::xyxyxyxy2xyxy(std::vector<int> &box) {
|
||||
int x_collect[4] = {box[0], box[2], box[4], box[6]};
|
||||
int y_collect[4] = {box[1], box[3], box[5], box[7]};
|
||||
int left = int(*std::min_element(x_collect, x_collect + 4));
|
||||
int right = int(*std::max_element(x_collect, x_collect + 4));
|
||||
int top = int(*std::min_element(y_collect, y_collect + 4));
|
||||
int bottom = int(*std::max_element(y_collect, y_collect + 4));
|
||||
std::vector<int> box1(4, 0);
|
||||
box1[0] = left;
|
||||
box1[1] = top;
|
||||
box1[2] = right;
|
||||
box1[3] = bottom;
|
||||
return box1;
|
||||
}
|
||||
|
||||
float Utility::fast_exp(float x) {
|
||||
union {
|
||||
uint32_t i;
|
||||
float f;
|
||||
} v{};
|
||||
v.i = (1 << 23) * (1.4426950409 * x + 126.93490512f);
|
||||
return v.f;
|
||||
}
|
||||
|
||||
std::vector<float>
|
||||
Utility::activation_function_softmax(std::vector<float> &src) {
|
||||
int length = src.size();
|
||||
std::vector<float> dst;
|
||||
dst.resize(length);
|
||||
const float alpha = float(*std::max_element(&src[0], &src[0 + length]));
|
||||
float denominator{0};
|
||||
|
||||
for (int i = 0; i < length; ++i) {
|
||||
dst[i] = fast_exp(src[i] - alpha);
|
||||
denominator += dst[i];
|
||||
}
|
||||
|
||||
for (int i = 0; i < length; ++i) {
|
||||
dst[i] /= denominator;
|
||||
}
|
||||
return dst;
|
||||
}
|
||||
|
||||
float Utility::iou(std::vector<int> &box1, std::vector<int> &box2) {
|
||||
int area1 = std::max(0, box1[2] - box1[0]) * std::max(0, box1[3] - box1[1]);
|
||||
int area2 = std::max(0, box2[2] - box2[0]) * std::max(0, box2[3] - box2[1]);
|
||||
|
||||
// computing the sum_area
|
||||
int sum_area = area1 + area2;
|
||||
|
||||
// find the each point of intersect rectangle
|
||||
int x1 = std::max(box1[0], box2[0]);
|
||||
int y1 = std::max(box1[1], box2[1]);
|
||||
int x2 = std::min(box1[2], box2[2]);
|
||||
int y2 = std::min(box1[3], box2[3]);
|
||||
|
||||
// judge if there is an intersect
|
||||
if (y1 >= y2 || x1 >= x2) {
|
||||
return 0.0;
|
||||
} else {
|
||||
int intersect = (x2 - x1) * (y2 - y1);
|
||||
return intersect / (sum_area - intersect + 0.00000001);
|
||||
}
|
||||
}
|
||||
|
||||
float Utility::iou(std::vector<float> &box1, std::vector<float> &box2) {
|
||||
float area1 = std::max((float)0.0, box1[2] - box1[0]) *
|
||||
std::max((float)0.0, box1[3] - box1[1]);
|
||||
float area2 = std::max((float)0.0, box2[2] - box2[0]) *
|
||||
std::max((float)0.0, box2[3] - box2[1]);
|
||||
|
||||
// computing the sum_area
|
||||
float sum_area = area1 + area2;
|
||||
|
||||
// find the each point of intersect rectangle
|
||||
float x1 = std::max(box1[0], box2[0]);
|
||||
float y1 = std::max(box1[1], box2[1]);
|
||||
float x2 = std::min(box1[2], box2[2]);
|
||||
float y2 = std::min(box1[3], box2[3]);
|
||||
|
||||
// judge if there is an intersect
|
||||
if (y1 >= y2 || x1 >= x2) {
|
||||
return 0.0;
|
||||
} else {
|
||||
float intersect = (x2 - x1) * (y2 - y1);
|
||||
return intersect / (sum_area - intersect + 0.00000001);
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace PaddleOCR
|
||||
|
|
@ -5,4 +5,4 @@ det_db_unclip_ratio 1.6
|
|||
det_db_use_dilate 0
|
||||
det_use_polygon_score 1
|
||||
use_direction_classify 1
|
||||
rec_image_height 32
|
||||
rec_image_height 48
|
||||
|
|
@ -99,6 +99,8 @@ The following table also provides a series of models that can be deployed on mob
|
|||
|
||||
|Version|Introduction|Model size|Detection model|Text Direction model|Recognition model|Paddle-Lite branch|
|
||||
|---|---|---|---|---|---|---|
|
||||
|PP-OCRv3|extra-lightweight chinese OCR optimized model|16.2M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.nb)|v2.10|
|
||||
|PP-OCRv3(slim)|extra-lightweight chinese OCR optimized model|5.9M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.nb)|v2.10|
|
||||
|PP-OCRv2|extra-lightweight chinese OCR optimized model|11M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_infer_opt.nb)|v2.10|
|
||||
|PP-OCRv2(slim)|extra-lightweight chinese OCR optimized model|4.6M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_slim_opt.nb)|v2.10|
|
||||
|
||||
|
|
@ -134,17 +136,16 @@ Introduction to paddle_lite_opt parameters:
|
|||
The following takes the ultra-lightweight Chinese model of PaddleOCR as an example to introduce the use of the compiled opt file to complete the conversion of the inference model to the Paddle-Lite optimized model
|
||||
|
||||
```
|
||||
# 【[Recommendation] Download the Chinese and English inference model of PP-OCRv2
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
|
||||
# 【[Recommendation] Download the Chinese and English inference model of PP-OCRv3
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar && tar xf ch_PP-OCRv3_det_slim_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_slim_infer.tar
|
||||
# Convert detection model
|
||||
./opt --model_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
paddle_lite_opt --model_file=./ch_PP-OCRv3_det_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_det_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
# Convert recognition model
|
||||
./opt --model_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
paddle_lite_opt --model_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
# Convert angle classifier model
|
||||
./opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
|
||||
paddle_lite_opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
```
|
||||
|
||||
After the conversion is successful, there will be more files ending with `.nb` in the inference model directory, which is the successfully converted model file.
|
||||
|
|
@ -197,15 +198,15 @@ Some preparatory work is required first.
|
|||
cp ../../../cxx/lib/libpaddle_light_api_shared.so ./debug/
|
||||
```
|
||||
|
||||
Prepare the test image, taking PaddleOCR/doc/imgs/11.jpg as an example, copy the image file to the demo/cxx/ocr/debug/ folder. Prepare the model files optimized by the lite opt tool, ch_det_mv3_db_opt.nb, ch_rec_mv3_crnn_opt.nb, and place them under the demo/cxx/ocr/debug/ folder.
|
||||
Prepare the test image, taking PaddleOCR/doc/imgs/11.jpg as an example, copy the image file to the demo/cxx/ocr/debug/ folder. Prepare the model files optimized by the lite opt tool, ch_PP-OCRv3_det_slim_opt.nb , ch_PP-OCRv3_rec_slim_opt.nb , and place them under the demo/cxx/ocr/debug/ folder.
|
||||
|
||||
The structure of the OCR demo is as follows after the above command is executed:
|
||||
|
||||
```
|
||||
demo/cxx/ocr/
|
||||
|-- debug/
|
||||
| |--ch_PP-OCRv2_det_slim_opt.nb Detection model
|
||||
| |--ch_PP-OCRv2_rec_slim_opt.nb Recognition model
|
||||
| |--ch_PP-OCRv3_det_slim_opt.nb Detection model
|
||||
| |--ch_PP-OCRv3_rec_slim_opt.nb Recognition model
|
||||
| |--ch_ppocr_mobile_v2.0_cls_slim_opt.nb Text direction classification model
|
||||
| |--11.jpg Image for OCR
|
||||
| |--ppocr_keys_v1.txt Dictionary file
|
||||
|
|
@ -240,7 +241,7 @@ det_db_thresh 0.3 # Used to filter the binarized image of DB prediction,
|
|||
det_db_box_thresh 0.5 # DDB post-processing filter box threshold, if there is a missing box detected, it can be reduced as appropriate
|
||||
det_db_unclip_ratio 1.6 # Indicates the compactness of the text box, the smaller the value, the closer the text box to the text
|
||||
use_direction_classify 0 # Whether to use the direction classifier, 0 means not to use, 1 means to use
|
||||
rec_image_height 32 # The height of the input image of the recognition model, the PP-OCRv3 model needs to be set to 48, and the PP-OCRv2 model needs to be set to 32
|
||||
rec_image_height 48 # The height of the input image of the recognition model, the PP-OCRv3 model needs to be set to 48, and the PP-OCRv2 model needs to be set to 32
|
||||
```
|
||||
|
||||
5. Run Model on phone
|
||||
|
|
@ -260,14 +261,14 @@ After the above steps are completed, you can use adb to push the file to the pho
|
|||
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
|
||||
# The use of ocr_db_crnn is:
|
||||
# ./ocr_db_crnn Mode Detection model file Orientation classifier model file Recognition model file Hardware Precision Threads Batchsize Test image path Dictionary file path
|
||||
./ocr_db_crnn system ch_PP-OCRv2_det_slim_opt.nb ch_PP-OCRv2_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt ppocr_keys_v1.txt True
|
||||
./ocr_db_crnn system ch_PP-OCRv3_det_slim_opt.nb ch_PP-OCRv3_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt ppocr_keys_v1.txt True
|
||||
# precision can be INT8 for quantitative model or FP32 for normal model.
|
||||
|
||||
# Only using detection model
|
||||
./ocr_db_crnn det ch_PP-OCRv2_det_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt
|
||||
./ocr_db_crnn det ch_PP-OCRv3_det_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt
|
||||
|
||||
# Only using recognition model
|
||||
./ocr_db_crnn rec ch_PP-OCRv2_rec_slim_opt.nb arm8 INT8 10 1 word_1.jpg ppocr_keys_v1.txt config.txt
|
||||
./ocr_db_crnn rec ch_PP-OCRv3_rec_slim_opt.nb arm8 INT8 10 1 word_1.jpg ppocr_keys_v1.txt config.txt
|
||||
```
|
||||
|
||||
If you modify the code, you need to recompile and push to the phone.
|
||||
|
|
|
|||
|
|
@ -97,6 +97,8 @@ Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括
|
|||
|
||||
|模型版本|模型简介|模型大小|检测模型|文本方向分类模型|识别模型|Paddle-Lite版本|
|
||||
|---|---|---|---|---|---|---|
|
||||
|PP-OCRv3|蒸馏版超轻量中文OCR移动端模型|16.2M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.nb)|v2.10|
|
||||
|PP-OCRv3(slim)|蒸馏版超轻量中文OCR移动端模型|5.9M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.nb)|v2.10|
|
||||
|PP-OCRv2|蒸馏版超轻量中文OCR移动端模型|11M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_infer_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_infer_opt.nb)|v2.10|
|
||||
|PP-OCRv2(slim)|蒸馏版超轻量中文OCR移动端模型|4.6M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_slim_opt.nb)|v2.10|
|
||||
|
||||
|
|
@ -131,16 +133,16 @@ paddle_lite_opt 参数介绍:
|
|||
下面以PaddleOCR的超轻量中文模型为例,介绍使用编译好的opt文件完成inference模型到Paddle-Lite优化模型的转换。
|
||||
|
||||
```
|
||||
# 【推荐】 下载 PP-OCRv2版本的中英文 inference模型
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
|
||||
# 【推荐】 下载 PP-OCRv3版本的中英文 inference模型
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar && tar xf ch_PP-OCRv3_det_slim_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_slim_infer.tar
|
||||
# 转换检测模型
|
||||
./opt --model_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
paddle_lite_opt --model_file=./ch_PP-OCRv3_det_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_det_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
# 转换识别模型
|
||||
./opt --model_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
paddle_lite_opt --model_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdmodel --param_file=./ch_PP-OCRv3_rec_slim_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv3_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
# 转换方向分类器模型
|
||||
./opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
paddle_lite_opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
|
||||
|
||||
```
|
||||
|
||||
|
|
@ -194,15 +196,15 @@ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls
|
|||
```
|
||||
|
||||
准备测试图像,以`PaddleOCR/doc/imgs/11.jpg`为例,将测试的图像复制到`demo/cxx/ocr/debug/`文件夹下。
|
||||
准备lite opt工具优化后的模型文件,比如使用`ch_PP-OCRv2_det_slim_opt.ch_PP-OCRv2_rec_slim_rec.nb, ch_ppocr_mobile_v2.0_cls_slim_opt.nb`,模型文件放置在`demo/cxx/ocr/debug/`文件夹下。
|
||||
准备lite opt工具优化后的模型文件,比如使用`ch_PP-OCRv3_det_slim_opt.ch_PP-OCRv3_rec_slim_rec.nb, ch_ppocr_mobile_v2.0_cls_slim_opt.nb`,模型文件放置在`demo/cxx/ocr/debug/`文件夹下。
|
||||
|
||||
执行完成后,ocr文件夹下将有如下文件格式:
|
||||
|
||||
```
|
||||
demo/cxx/ocr/
|
||||
|-- debug/
|
||||
| |--ch_PP-OCRv2_det_slim_opt.nb 优化后的检测模型文件
|
||||
| |--ch_PP-OCRv2_rec_slim_opt.nb 优化后的识别模型文件
|
||||
| |--ch_PP-OCRv3_det_slim_opt.nb 优化后的检测模型文件
|
||||
| |--ch_PP-OCRv3_rec_slim_opt.nb 优化后的识别模型文件
|
||||
| |--ch_ppocr_mobile_v2.0_cls_slim_opt.nb 优化后的文字方向分类器模型文件
|
||||
| |--11.jpg 待测试图像
|
||||
| |--ppocr_keys_v1.txt 中文字典文件
|
||||
|
|
@ -239,7 +241,7 @@ det_db_thresh 0.3 # 用于过滤DB预测的二值化图像,设置为0.
|
|||
det_db_box_thresh 0.5 # 检测器后处理过滤box的阈值,如果检测存在漏框情况,可酌情减小
|
||||
det_db_unclip_ratio 1.6 # 表示文本框的紧致程度,越小则文本框更靠近文本
|
||||
use_direction_classify 0 # 是否使用方向分类器,0表示不使用,1表示使用
|
||||
rec_image_height 32 # 识别模型输入图像的高度,PP-OCRv3模型设置为48,PP-OCRv2模型需要设置为32
|
||||
rec_image_height 48 # 识别模型输入图像的高度,PP-OCRv3模型设置为48,PP-OCRv2模型需要设置为32
|
||||
```
|
||||
|
||||
5. 启动调试
|
||||
|
|
@ -259,13 +261,13 @@ rec_image_height 32 # 识别模型输入图像的高度,PP-OCRv3模型
|
|||
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
|
||||
# 开始使用,ocr_db_crnn可执行文件的使用方式为:
|
||||
# ./ocr_db_crnn 预测模式 检测模型文件 方向分类器模型文件 识别模型文件 运行硬件 运行精度 线程数 batchsize 测试图像路径 参数配置路径 字典文件路径 是否使用benchmark参数
|
||||
./ocr_db_crnn system ch_PP-OCRv2_det_slim_opt.nb ch_PP-OCRv2_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt ppocr_keys_v1.txt True
|
||||
./ocr_db_crnn system ch_PP-OCRv3_det_slim_opt.nb ch_PP-OCRv3_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt ppocr_keys_v1.txt True
|
||||
|
||||
# 仅使用文本检测模型,使用方式如下:
|
||||
./ocr_db_crnn det ch_PP-OCRv2_det_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt
|
||||
./ocr_db_crnn det ch_PP-OCRv3_det_slim_opt.nb arm8 INT8 10 1 ./11.jpg config.txt
|
||||
|
||||
# 仅使用文本识别模型,使用方式如下:
|
||||
./ocr_db_crnn rec ch_PP-OCRv2_rec_slim_opt.nb arm8 INT8 10 1 word_1.jpg ppocr_keys_v1.txt config.txt
|
||||
./ocr_db_crnn rec ch_PP-OCRv3_rec_slim_opt.nb arm8 INT8 10 1 word_1.jpg ppocr_keys_v1.txt config.txt
|
||||
```
|
||||
|
||||
如果对代码做了修改,则需要重新编译并push到手机上。
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@
|
|||
### 1. 安装PaddleSlim
|
||||
|
||||
```bash
|
||||
pip3 install paddleslim==2.2.2
|
||||
pip3 install paddleslim==2.3.2
|
||||
```
|
||||
|
||||
### 2. 准备训练好的模型
|
||||
|
|
@ -33,17 +33,7 @@ PaddleOCR提供了一系列训练好的[模型](../../../doc/doc_ch/models_list.
|
|||
量化训练包括离线量化训练和在线量化训练,在线量化训练效果更好,需加载预训练模型,在定义好量化策略后即可对模型进行量化。
|
||||
|
||||
|
||||
量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,训练指令如下:
|
||||
```bash
|
||||
python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model='your trained model' Global.save_model_dir=./output/quant_model
|
||||
|
||||
# 比如下载提供的训练模型
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
|
||||
tar -xf ch_ppocr_mobile_v2.0_det_train.tar
|
||||
python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./ch_ppocr_mobile_v2.0_det_train/best_accuracy Global.save_model_dir=./output/quant_model
|
||||
```
|
||||
|
||||
模型蒸馏和模型量化可以同时使用,以PPOCRv3检测模型为例:
|
||||
量化训练的代码位于slim/quantization/quant.py 中,比如训练检测模型,以PPOCRv3检测模型为例,训练指令如下:
|
||||
```
|
||||
# 下载检测预训练模型:
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
|
||||
|
|
@ -58,7 +48,7 @@ python deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_
|
|||
在得到量化训练保存的模型后,我们可以将其导出为inference_model,用于预测部署:
|
||||
|
||||
```bash
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
|
||||
```
|
||||
|
||||
### 5. 量化模型部署
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ After training, if you want to further compress the model size and accelerate th
|
|||
### 1. Install PaddleSlim
|
||||
|
||||
```bash
|
||||
pip3 install paddleslim==2.2.2
|
||||
pip3 install paddleslim==2.3.2
|
||||
```
|
||||
|
||||
|
||||
|
|
@ -39,18 +39,7 @@ Quantization training includes offline quantization training and online quantiza
|
|||
Online quantization training is more effective. It is necessary to load the pre-trained model.
|
||||
After the quantization strategy is defined, the model can be quantified.
|
||||
|
||||
The code for quantization training is located in `slim/quantization/quant.py`. For example, to train a detection model, the training instructions are as follows:
|
||||
```bash
|
||||
python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model='your trained model' Global.save_model_dir=./output/quant_model
|
||||
|
||||
# download provided model
|
||||
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
|
||||
tar -xf ch_ppocr_mobile_v2.0_det_train.tar
|
||||
python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./ch_ppocr_mobile_v2.0_det_train/best_accuracy Global.save_model_dir=./output/quant_model
|
||||
```
|
||||
|
||||
|
||||
Model distillation and model quantization can be used at the same time, taking the PPOCRv3 detection model as an example:
|
||||
The code for quantization training is located in `slim/quantization/quant.py`. For example, the training instructions of slim PPOCRv3 detection model are as follows:
|
||||
```
|
||||
# download provided model
|
||||
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
|
||||
|
|
@ -66,7 +55,7 @@ If you want to quantify the text recognition model, you can modify the configura
|
|||
Once we got the model after pruning and fine-tuning, we can export it as an inference model for the deployment of predictive tasks:
|
||||
|
||||
```bash
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
|
||||
python deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.checkpoints=output/quant_model/best_accuracy Global.save_inference_dir=./output/quant_inference_model
|
||||
```
|
||||
|
||||
### 5. Deploy
|
||||
|
|
|
|||
|
|
@ -151,17 +151,24 @@ def main():
|
|||
|
||||
arch_config = config["Architecture"]
|
||||
|
||||
arch_config = config["Architecture"]
|
||||
if arch_config["algorithm"] == "SVTR" and arch_config["Head"][
|
||||
"name"] != 'MultiHead':
|
||||
input_shape = config["Eval"]["dataset"]["transforms"][-2][
|
||||
'SVTRRecResizeImg']['image_shape']
|
||||
else:
|
||||
input_shape = None
|
||||
|
||||
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
|
||||
archs = list(arch_config["Models"].values())
|
||||
for idx, name in enumerate(model.model_name_list):
|
||||
sub_model_save_path = os.path.join(save_path, name, "inference")
|
||||
export_single_model(model.model_list[idx], archs[idx],
|
||||
sub_model_save_path, logger, quanter)
|
||||
sub_model_save_path, logger, input_shape,
|
||||
quanter)
|
||||
else:
|
||||
save_path = os.path.join(save_path, "inference")
|
||||
export_single_model(model, arch_config, save_path, logger, quanter)
|
||||
export_single_model(model, arch_config, save_path, logger, input_shape,
|
||||
quanter)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
|
|
|||
|
|
@ -158,8 +158,7 @@ def main(config, device, logger, vdl_writer):
|
|||
|
||||
pre_best_model_dict = dict()
|
||||
# load fp32 model to begin quantization
|
||||
if config["Global"]["pretrained_model"] is not None:
|
||||
pre_best_model_dict = load_model(config, model)
|
||||
pre_best_model_dict = load_model(config, model, None, config['Architecture']["model_type"])
|
||||
|
||||
freeze_params = False
|
||||
if config['Architecture']["algorithm"] in ["Distillation"]:
|
||||
|
|
@ -184,8 +183,7 @@ def main(config, device, logger, vdl_writer):
|
|||
model=model)
|
||||
|
||||
# resume PACT training process
|
||||
if config["Global"]["checkpoints"] is not None:
|
||||
pre_best_model_dict = load_model(config, model, optimizer)
|
||||
pre_best_model_dict = load_model(config, model, optimizer, config['Architecture']["model_type"])
|
||||
|
||||
# build metric
|
||||
eval_class = build_metric(config['Metric'])
|
||||
|
|
|
|||
|
|
@ -97,6 +97,17 @@ def sample_generator(loader):
|
|||
|
||||
return __reader__
|
||||
|
||||
def sample_generator_layoutxlm_ser(loader):
|
||||
def __reader__():
|
||||
for indx, data in enumerate(loader):
|
||||
input_ids = np.array(data[0])
|
||||
bbox = np.array(data[1])
|
||||
attention_mask = np.array(data[2])
|
||||
token_type_ids = np.array(data[3])
|
||||
images = np.array(data[4])
|
||||
yield [input_ids, bbox, attention_mask, token_type_ids, images]
|
||||
|
||||
return __reader__
|
||||
|
||||
def main(config, device, logger, vdl_writer):
|
||||
# init dist environment
|
||||
|
|
@ -107,16 +118,18 @@ def main(config, device, logger, vdl_writer):
|
|||
|
||||
# build dataloader
|
||||
config['Train']['loader']['num_workers'] = 0
|
||||
is_layoutxlm_ser = config['Architecture']['model_type'] =='kie' and config['Architecture']['Backbone']['name'] == 'LayoutXLMForSer'
|
||||
train_dataloader = build_dataloader(config, 'Train', device, logger)
|
||||
if config['Eval']:
|
||||
config['Eval']['loader']['num_workers'] = 0
|
||||
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
|
||||
if is_layoutxlm_ser:
|
||||
train_dataloader = valid_dataloader
|
||||
else:
|
||||
valid_dataloader = None
|
||||
|
||||
paddle.enable_static()
|
||||
place = paddle.CPUPlace()
|
||||
exe = paddle.static.Executor(place)
|
||||
exe = paddle.static.Executor(device)
|
||||
|
||||
if 'inference_model' in global_config.keys(): # , 'inference_model'):
|
||||
inference_model_dir = global_config['inference_model']
|
||||
|
|
@ -127,6 +140,11 @@ def main(config, device, logger, vdl_writer):
|
|||
raise ValueError(
|
||||
"Please set inference model dir in Global.inference_model or Global.pretrained_model for post-quantazition"
|
||||
)
|
||||
|
||||
if is_layoutxlm_ser:
|
||||
generator = sample_generator_layoutxlm_ser(train_dataloader)
|
||||
else:
|
||||
generator = sample_generator(train_dataloader)
|
||||
|
||||
paddleslim.quant.quant_post_static(
|
||||
executor=exe,
|
||||
|
|
@ -134,7 +152,7 @@ def main(config, device, logger, vdl_writer):
|
|||
model_filename='inference.pdmodel',
|
||||
params_filename='inference.pdiparams',
|
||||
quantize_model_path=global_config['save_inference_dir'],
|
||||
sample_generator=sample_generator(train_dataloader),
|
||||
sample_generator=generator,
|
||||
save_model_filename='inference.pdmodel',
|
||||
save_params_filename='inference.pdiparams',
|
||||
batch_size=1,
|
||||
|
|
|
|||
|
|
@ -0,0 +1,95 @@
|
|||
# CT
|
||||
|
||||
- [1. 算法简介](#1)
|
||||
- [2. 环境配置](#2)
|
||||
- [3. 模型训练、评估、预测](#3)
|
||||
- [3.1 训练](#3-1)
|
||||
- [3.2 评估](#3-2)
|
||||
- [3.3 预测](#3-3)
|
||||
- [4. 推理部署](#4)
|
||||
- [4.1 Python推理](#4-1)
|
||||
- [4.2 C++推理](#4-2)
|
||||
- [4.3 Serving服务化部署](#4-3)
|
||||
- [4.4 更多推理部署](#4-4)
|
||||
- [5. FAQ](#5)
|
||||
|
||||
<a name="1"></a>
|
||||
## 1. 算法简介
|
||||
|
||||
论文信息:
|
||||
> [CentripetalText: An Efficient Text Instance Representation for Scene Text Detection](https://arxiv.org/abs/2107.05945)
|
||||
> Tao Sheng, Jie Chen, Zhouhui Lian
|
||||
> NeurIPS, 2021
|
||||
|
||||
|
||||
在Total-Text文本检测公开数据集上,算法复现效果如下:
|
||||
|
||||
|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
|
||||
| --- | --- | --- | --- | --- | --- | --- |
|
||||
|CT|ResNet18_vd|[configs/det/det_r18_vd_ct.yml](../../configs/det/det_r18_vd_ct.yml)|88.68%|81.70%|85.05%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r18_ct_train.tar)|
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
## 2. 环境配置
|
||||
请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
|
||||
|
||||
|
||||
<a name="3"></a>
|
||||
## 3. 模型训练、评估、预测
|
||||
|
||||
CT模型使用Total-Text文本检测公开数据集训练得到,数据集下载可参考 [Total-Text-Dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset), 我们将标签文件转成了paddleocr格式,转换好的标签文件下载参考[train.txt](https://paddleocr.bj.bcebos.com/dataset/ct_tipc/train.txt), [text.txt](https://paddleocr.bj.bcebos.com/dataset/ct_tipc/test.txt)。
|
||||
|
||||
请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
|
||||
|
||||
|
||||
<a name="4"></a>
|
||||
## 4. 推理部署
|
||||
|
||||
<a name="4-1"></a>
|
||||
### 4.1 Python推理
|
||||
首先将CT文本检测训练过程中保存的模型,转换成inference model。以基于Resnet18_vd骨干网络,在Total-Text英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r18_ct_train.tar) ),可以使用如下命令进行转换:
|
||||
|
||||
```shell
|
||||
python3 tools/export_model.py -c configs/det/det_r18_vd_ct.yml -o Global.pretrained_model=./det_r18_ct_train/best_accuracy Global.save_inference_dir=./inference/det_ct
|
||||
```
|
||||
|
||||
CT文本检测模型推理,可以执行如下命令:
|
||||
|
||||
```shell
|
||||
python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_ct/" --det_algorithm="CT"
|
||||
```
|
||||
|
||||
可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
|
||||
|
||||

|
||||
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++推理
|
||||
|
||||
暂不支持
|
||||
|
||||
<a name="4-3"></a>
|
||||
### 4.3 Serving服务化部署
|
||||
|
||||
暂不支持
|
||||
|
||||
<a name="4-4"></a>
|
||||
### 4.4 更多推理部署
|
||||
|
||||
暂不支持
|
||||
|
||||
<a name="5"></a>
|
||||
## 5. FAQ
|
||||
|
||||
|
||||
## 引用
|
||||
|
||||
```bibtex
|
||||
@inproceedings{sheng2021centripetaltext,
|
||||
title={CentripetalText: An Efficient Text Instance Representation for Scene Text Detection},
|
||||
author={Tao Sheng and Jie Chen and Zhouhui Lian},
|
||||
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
|
||||
year={2021}
|
||||
}
|
||||
```
|
||||
|
|
@ -30,7 +30,7 @@
|
|||
|模型|骨干网络|任务|配置文件|hmean|下载链接|
|
||||
| --- | --- |--|--- | --- | --- |
|
||||
|LayoutXLM|LayoutXLM-base|SER |[ser_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml)|90.38%|[训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar)/[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh_infer.tar)|
|
||||
|LayoutXLM|LayoutXLM-base|RE | [re_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml)|74.83%|[训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)/[推理模型(coming soon)]()|
|
||||
|LayoutXLM|LayoutXLM-base|RE | [re_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml)|74.83%|[训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)/[推理模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh_infer.tar)|
|
||||
|
||||
<a name="2"></a>
|
||||
|
||||
|
|
@ -52,14 +52,14 @@
|
|||
|
||||
### 4.1 Python推理
|
||||
|
||||
**注:** 目前RE任务推理过程仍在适配中,下面以SER任务为例,介绍基于LayoutXLM模型的关键信息抽取过程。
|
||||
- SER
|
||||
|
||||
首先将训练得到的模型转换成inference model。LayoutXLM模型在XFUND_zh数据集上训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar)),可以使用下面的命令进行转换。
|
||||
|
||||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar
|
||||
tar -xf ser_LayoutXLM_xfun_zh.tar
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./ser_LayoutXLM_xfun_zh/best_accuracy Global.save_inference_dir=./inference/ser_layoutxlm
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./ser_LayoutXLM_xfun_zh Global.save_inference_dir=./inference/ser_layoutxlm_infer
|
||||
```
|
||||
|
||||
LayoutXLM模型基于SER任务进行推理,可以执行如下命令:
|
||||
|
|
@ -80,6 +80,34 @@ SER可视化结果默认保存到`./output`文件夹里面,结果示例如下
|
|||
<img src="../../ppstructure/docs/kie/result_ser/zh_val_42_ser.jpg" width="800">
|
||||
</div>
|
||||
|
||||
- RE
|
||||
|
||||
首先将训练得到的模型转换成inference model。LayoutXLM模型在XFUND_zh数据集上训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)),可以使用下面的命令进行转换。
|
||||
|
||||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar
|
||||
tar -xf re_LayoutXLM_xfun_zh.tar
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./re_LayoutXLM_xfun_zh Global.save_inference_dir=./inference/ser_layoutxlm_infer
|
||||
```
|
||||
|
||||
LayoutXLM模型基于RE任务进行推理,可以执行如下命令:
|
||||
|
||||
```bash
|
||||
cd ppstructure
|
||||
python3 kie/predict_kie_token_ser_re.py \
|
||||
--kie_algorithm=LayoutXLM \
|
||||
--re_model_dir=../inference/re_layoutxlm_infer \
|
||||
--ser_model_dir=../inference/ser_layoutxlm_infer \
|
||||
--image_dir=./docs/kie/input/zh_val_42.jpg \
|
||||
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
|
||||
--vis_font_path=../doc/fonts/simfang.ttf
|
||||
```
|
||||
|
||||
RE可视化结果默认保存到`./output`文件夹里面,结果示例如下:
|
||||
|
||||
<div align="center">
|
||||
<img src="../../ppstructure/docs/kie/result_re/zh_val_42_re.jpg" width="800">
|
||||
</div>
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++推理部署
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ VI-LayoutXLM基于LayoutXLM进行改进,在下游任务训练过程中,去
|
|||
|模型|骨干网络|任务|配置文件|hmean|下载链接|
|
||||
| --- | --- |---| --- | --- | --- |
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base | SER |[ser_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml)|93.19%|[训练模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar)/[推理模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar)|
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base |RE | [re_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml)|83.92%|[训练模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)/[推理模型(coming soon)]()|
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base |RE | [re_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml)|83.92%|[训练模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)/[推理模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar)|
|
||||
|
||||
<a name="2"></a>
|
||||
|
||||
|
|
@ -45,7 +45,7 @@ VI-LayoutXLM基于LayoutXLM进行改进,在下游任务训练过程中,去
|
|||
|
||||
### 4.1 Python推理
|
||||
|
||||
**注:** 目前RE任务推理过程仍在适配中,下面以SER任务为例,介绍基于VI-LayoutXLM模型的关键信息抽取过程。
|
||||
- SER
|
||||
|
||||
首先将训练得到的模型转换成inference model。以VI-LayoutXLM模型在XFUND_zh数据集上训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar)),可以使用下面的命令进行转换。
|
||||
|
||||
|
|
@ -74,6 +74,36 @@ SER可视化结果默认保存到`./output`文件夹里面,结果示例如下
|
|||
<img src="../../ppstructure/docs/kie/result_ser/zh_val_42_ser.jpg" width="800">
|
||||
</div>
|
||||
|
||||
- RE
|
||||
|
||||
首先将训练得到的模型转换成inference model。以VI-LayoutXLM模型在XFUND_zh数据集上训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)),可以使用下面的命令进行转换。
|
||||
|
||||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar
|
||||
tar -xf re_vi_layoutxlm_xfund_pretrained.tar
|
||||
python3 tools/export_model.py -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./re_vi_layoutxlm_xfund_pretrained/best_accuracy Global.save_inference_dir=./inference/re_vi_layoutxlm_infer
|
||||
```
|
||||
|
||||
VI-LayoutXLM模型基于RE任务进行推理,可以执行如下命令:
|
||||
|
||||
```bash
|
||||
cd ppstructure
|
||||
python3 kie/predict_kie_token_ser_re.py \
|
||||
--kie_algorithm=LayoutXLM \
|
||||
--re_model_dir=../inference/re_vi_layoutxlm_infer \
|
||||
--ser_model_dir=../inference/ser_vi_layoutxlm_infer \
|
||||
--use_visual_backbone=False \
|
||||
--image_dir=./docs/kie/input/zh_val_42.jpg \
|
||||
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
|
||||
--vis_font_path=../doc/fonts/simfang.ttf \
|
||||
--ocr_order_method="tb-yx"
|
||||
```
|
||||
|
||||
RE可视化结果默认保存到`./output`文件夹里面,结果示例如下:
|
||||
|
||||
<div align="center">
|
||||
<img src="../../ppstructure/docs/kie/result_re/zh_val_42_re.jpg" width="800">
|
||||
</div>
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++推理部署
|
||||
|
|
|
|||
|
|
@ -100,8 +100,8 @@ PaddleOCR将**持续新增**支持OCR领域前沿算法与模型,**欢迎广
|
|||
|ViTSTR|ViTSTR| 79.82% | rec_vitstr_none_ce | [训练模型](https://paddleocr.bj.bcebos.com/rec_vitstr_none_ce_train.tar) |
|
||||
|ABINet|Resnet45| 90.75% | rec_r45_abinet | [训练模型](https://paddleocr.bj.bcebos.com/rec_r45_abinet_train.tar) |
|
||||
|VisionLAN|Resnet45| 90.30% | rec_r45_visionlan | [训练模型](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar) |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | coming soon |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | coming soon |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | [训练模型](https://paddleocr.bj.bcebos.com/contribution/rec_r32_gaspin_bilstm_att.tar) |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | [训练模型](https://paddleocr.bj.bcebos.com/contribution/rec_r31_robustscanner.tar)|
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ Zhang
|
|||
|
||||
|模型|骨干网络|配置文件|Acc|下载链接|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|RobustScanner|ResNet31|[rec_r31_robustscanner.yml](../../configs/rec/rec_r31_robustscanner.yml)|87.77%|coming soon|
|
||||
|RobustScanner|ResNet31|[rec_r31_robustscanner.yml](../../configs/rec/rec_r31_robustscanner.yml)|87.77%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/rec_r31_robustscanner.tar)|
|
||||
|
||||
注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
|
||||
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ SPIN收录于AAAI2020。主要用于OCR识别任务。在任意形状文本识
|
|||
|
||||
|模型|骨干网络|配置文件|Acc|下载链接|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|SPIN|ResNet32|[rec_r32_gaspin_bilstm_att.yml](../../configs/rec/rec_r32_gaspin_bilstm_att.yml)|90.0%|coming soon|
|
||||
|SPIN|ResNet32|[rec_r32_gaspin_bilstm_att.yml](../../configs/rec/rec_r32_gaspin_bilstm_att.yml)|90.0%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/rec_r32_gaspin_bilstm_att.tar)|
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@
|
|||
| 参数名称 | 类型 | 默认值 | 含义 |
|
||||
| :--: | :--: | :--: | :--: |
|
||||
| image_dir | str | 无,必须显式指定 | 图像或者文件夹路径 |
|
||||
| page_num | int | 0 | 当输入类型为pdf文件时有效,指定预测前面page_num页,默认预测所有页 |
|
||||
| vis_font_path | str | "./doc/fonts/simfang.ttf" | 用于可视化的字体路径 |
|
||||
| drop_score | float | 0.5 | 识别得分小于该值的结果会被丢弃,不会作为返回结果 |
|
||||
| use_pdserving | bool | False | 是否使用Paddle Serving进行预测 |
|
||||
|
|
|
|||
|
|
@ -0,0 +1,96 @@
|
|||
# CT
|
||||
|
||||
- [1. Introduction](#1)
|
||||
- [2. Environment](#2)
|
||||
- [3. Model Training / Evaluation / Prediction](#3)
|
||||
- [3.1 Training](#3-1)
|
||||
- [3.2 Evaluation](#3-2)
|
||||
- [3.3 Prediction](#3-3)
|
||||
- [4. Inference and Deployment](#4)
|
||||
- [4.1 Python Inference](#4-1)
|
||||
- [4.2 C++ Inference](#4-2)
|
||||
- [4.3 Serving](#4-3)
|
||||
- [4.4 More](#4-4)
|
||||
- [5. FAQ](#5)
|
||||
|
||||
<a name="1"></a>
|
||||
## 1. Introduction
|
||||
|
||||
Paper:
|
||||
> [CentripetalText: An Efficient Text Instance Representation for Scene Text Detection](https://arxiv.org/abs/2107.05945)
|
||||
> Tao Sheng, Jie Chen, Zhouhui Lian
|
||||
> NeurIPS, 2021
|
||||
|
||||
|
||||
On the Total-Text dataset, the text detection result is as follows:
|
||||
|
||||
|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
|
||||
| --- | --- | --- | --- | --- | --- | --- |
|
||||
|CT|ResNet18_vd|[configs/det/det_r18_vd_ct.yml](../../configs/det/det_r18_vd_ct.yml)|88.68%|81.70%|85.05%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r18_ct_train.tar)|
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
## 2. Environment
|
||||
Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
|
||||
|
||||
|
||||
<a name="3"></a>
|
||||
## 3. Model Training / Evaluation / Prediction
|
||||
|
||||
|
||||
The above CT model is trained using the Total-Text text detection public dataset. For the download of the dataset, please refer to [Total-Text-Dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset). PaddleOCR format annotation download link [train.txt](https://paddleocr.bj.bcebos.com/dataset/ct_tipc/train.txt), [test.txt](https://paddleocr.bj.bcebos.com/dataset/ct_tipc/test.txt).
|
||||
|
||||
|
||||
Please refer to [text detection training tutorial](./detection_en.md). PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
|
||||
|
||||
<a name="4"></a>
|
||||
## 4. Inference and Deployment
|
||||
|
||||
<a name="4-1"></a>
|
||||
### 4.1 Python Inference
|
||||
First, convert the model saved in the CT text detection training process into an inference model. Taking the model based on the Resnet18_vd backbone network and trained on the Total Text English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r18_ct_train.tar)), you can use the following command to convert:
|
||||
|
||||
```shell
|
||||
python3 tools/export_model.py -c configs/det/det_r18_vd_ct.yml -o Global.pretrained_model=./det_r18_ct_train/best_accuracy Global.save_inference_dir=./inference/det_ct
|
||||
```
|
||||
|
||||
CT text detection model inference, you can execute the following command:
|
||||
|
||||
```shell
|
||||
python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_ct/" --det_algorithm="CT"
|
||||
```
|
||||
|
||||
The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
|
||||
|
||||

|
||||
|
||||
|
||||
<a name="4-2"></a>
|
||||
### 4.2 C++ Inference
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="4-3"></a>
|
||||
### 4.3 Serving
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="4-4"></a>
|
||||
### 4.4 More
|
||||
|
||||
Not supported
|
||||
|
||||
<a name="5"></a>
|
||||
## 5. FAQ
|
||||
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@inproceedings{sheng2021centripetaltext,
|
||||
title={CentripetalText: An Efficient Text Instance Representation for Scene Text Detection},
|
||||
author={Tao Sheng and Jie Chen and Zhouhui Lian},
|
||||
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
|
||||
year={2021}
|
||||
}
|
||||
```
|
||||
|
|
@ -28,7 +28,7 @@ On XFUND_zh dataset, the algorithm reproduction Hmean is as follows.
|
|||
|Model|Backbone|Task |Cnnfig|Hmean|Download link|
|
||||
| --- | --- |--|--- | --- | --- |
|
||||
|LayoutXLM|LayoutXLM-base|SER |[ser_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml)|90.38%|[trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar)/[inference model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh_infer.tar)|
|
||||
|LayoutXLM|LayoutXLM-base|RE | [re_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml)|74.83%|[trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)/[inference model(coming soon)]()|
|
||||
|LayoutXLM|LayoutXLM-base|RE | [re_layoutxlm_xfund_zh.yml](../../configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml)|74.83%|[trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)/[inference model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh_infer.tar)|
|
||||
|
||||
|
||||
## 2. Environment
|
||||
|
|
@ -46,7 +46,7 @@ Please refer to [KIE tutorial](./kie_en.md)。PaddleOCR has modularized the code
|
|||
|
||||
### 4.1 Python Inference
|
||||
|
||||
**Note:** Currently, the RE model inference process is still in the process of adaptation. We take SER model as an example to introduce the KIE process based on LayoutXLM model.
|
||||
- SER
|
||||
|
||||
First, we need to export the trained model into inference model. Take LayoutXLM model trained on XFUND_zh as an example ([trained model download link](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar)). Use the following command to export.
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ First, we need to export the trained model into inference model. Take LayoutXLM
|
|||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar
|
||||
tar -xf ser_LayoutXLM_xfun_zh.tar
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./ser_LayoutXLM_xfun_zh/best_accuracy Global.save_inference_dir=./inference/ser_layoutxlm
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/ser_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./ser_LayoutXLM_xfun_zh Global.save_inference_dir=./inference/ser_layoutxlm_infer
|
||||
```
|
||||
|
||||
Use the following command to infer using LayoutXLM SER model.
|
||||
|
|
@ -77,6 +77,38 @@ The SER visualization results are saved in the `./output` directory by default.
|
|||
</div>
|
||||
|
||||
|
||||
- RE
|
||||
|
||||
First, we need to export the trained model into inference model. Take LayoutXLM model trained on XFUND_zh as an example ([trained model download link](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar)). Use the following command to export.
|
||||
|
||||
|
||||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar
|
||||
tar -xf re_LayoutXLM_xfun_zh.tar
|
||||
python3 tools/export_model.py -c configs/kie/layoutlm_series/re_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./re_LayoutXLM_xfun_zh Global.save_inference_dir=./inference/re_layoutxlm_infer
|
||||
```
|
||||
|
||||
Use the following command to infer using LayoutXLM RE model.
|
||||
|
||||
|
||||
```bash
|
||||
cd ppstructure
|
||||
python3 kie/predict_kie_token_ser_re.py \
|
||||
--kie_algorithm=LayoutXLM \
|
||||
--re_model_dir=../inference/re_layoutxlm_infer \
|
||||
--ser_model_dir=../inference/ser_layoutxlm_infer \
|
||||
--image_dir=./docs/kie/input/zh_val_42.jpg \
|
||||
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
|
||||
--vis_font_path=../doc/fonts/simfang.ttf
|
||||
```
|
||||
The RE visualization results are saved in the `./output` directory by default. The results are as follows.
|
||||
|
||||
|
||||
<div align="center">
|
||||
<img src="../../ppstructure/docs/kie/result_re/zh_val_42_re.jpg" width="800">
|
||||
</div>
|
||||
|
||||
|
||||
### 4.2 C++ Inference
|
||||
|
||||
Not supported
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@ On XFUND_zh dataset, the algorithm reproduction Hmean is as follows.
|
|||
|Model|Backbone|Task |Cnnfig|Hmean|Download link|
|
||||
| --- | --- |---| --- | --- | --- |
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base | SER |[ser_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh_udml.yml)|93.19%|[trained model](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar)/[inference model](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar)|
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base |RE | [re_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml)|83.92%|[trained model](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)/[inference model(coming soon)]()|
|
||||
|VI-LayoutXLM |VI-LayoutXLM-base |RE | [re_vi_layoutxlm_xfund_zh_udml.yml](../../configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh_udml.yml)|83.92%|[trained model](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)/[inference model](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar)|
|
||||
|
||||
|
||||
Please refer to ["Environment Preparation"](./environment_en.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone_en.md) to clone the project code.
|
||||
|
|
@ -37,7 +37,7 @@ Please refer to [KIE tutorial](./kie_en.md)。PaddleOCR has modularized the code
|
|||
|
||||
### 4.1 Python Inference
|
||||
|
||||
**Note:** Currently, the RE model inference process is still in the process of adaptation. We take SER model as an example to introduce the KIE process based on VI-LayoutXLM model.
|
||||
- SER
|
||||
|
||||
First, we need to export the trained model into inference model. Take VI-LayoutXLM model trained on XFUND_zh as an example ([trained model download link](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar)). Use the following command to export.
|
||||
|
||||
|
|
@ -70,6 +70,41 @@ The SER visualization results are saved in the `./output` folder by default. The
|
|||
</div>
|
||||
|
||||
|
||||
- RE
|
||||
|
||||
First, we need to export the trained model into inference model. Take VI-LayoutXLM model trained on XFUND_zh as an example ([trained model download link](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar)). Use the following command to export.
|
||||
|
||||
|
||||
``` bash
|
||||
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar
|
||||
tar -xf re_vi_layoutxlm_xfund_pretrained.tar
|
||||
python3 tools/export_model.py -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./re_vi_layoutxlm_xfund_pretrained/best_accuracy Global.save_inference_dir=./inference/re_vi_layoutxlm_infer
|
||||
```
|
||||
|
||||
Use the following command to infer using VI-LayoutXLM RE model.
|
||||
|
||||
|
||||
```bash
|
||||
cd ppstructure
|
||||
python3 kie/predict_kie_token_ser_re.py \
|
||||
--kie_algorithm=LayoutXLM \
|
||||
--re_model_dir=../inference/re_vi_layoutxlm_infer \
|
||||
--ser_model_dir=../inference/ser_vi_layoutxlm_infer \
|
||||
--use_visual_backbone=False \
|
||||
--image_dir=./docs/kie/input/zh_val_42.jpg \
|
||||
--ser_dict_path=../train_data/XFUND/class_list_xfun.txt \
|
||||
--vis_font_path=../doc/fonts/simfang.ttf \
|
||||
--ocr_order_method="tb-yx"
|
||||
```
|
||||
|
||||
The RE visualization results are saved in the `./output` folder by default. The results are as follows.
|
||||
|
||||
|
||||
<div align="center">
|
||||
<img src="../../ppstructure/docs/kie/result_re/zh_val_42_re.jpg" width="800">
|
||||
</div>
|
||||
|
||||
|
||||
### 4.2 C++ Inference
|
||||
|
||||
Not supported
|
||||
|
|
|
|||
|
|
@ -97,8 +97,8 @@ Refer to [DTRB](https://arxiv.org/abs/1904.01906), the training and evaluation r
|
|||
|ViTSTR|ViTSTR| 79.82% | rec_vitstr_none_ce | [trained model](https://paddleocr.bj.bcebos.com/rec_vitstr_none_none_train.tar) |
|
||||
|ABINet|Resnet45| 90.75% | rec_r45_abinet | [trained model](https://paddleocr.bj.bcebos.com/rec_r45_abinet_train.tar) |
|
||||
|VisionLAN|Resnet45| 90.30% | rec_r45_visionlan | [trained model](https://paddleocr.bj.bcebos.com/rec_r45_visionlan_train.tar) |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | coming soon |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | coming soon |
|
||||
|SPIN|ResNet32| 90.00% | rec_r32_gaspin_bilstm_att | [trained model](https://paddleocr.bj.bcebos.com/contribution/rec_r32_gaspin_bilstm_att.tar) |
|
||||
|RobustScanner|ResNet31| 87.77% | rec_r31_robustscanner | [trained model](https://paddleocr.bj.bcebos.com/contribution/rec_r31_robustscanner.tar)|
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ Using MJSynth and SynthText two text recognition datasets for training, and eval
|
|||
|
||||
|Model|Backbone|config|Acc|Download link|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|RobustScanner|ResNet31|[rec_r31_robustscanner.yml](../../configs/rec/rec_r31_robustscanner.yml)|87.77%|coming soon|
|
||||
|RobustScanner|ResNet31|[rec_r31_robustscanner.yml](../../configs/rec/rec_r31_robustscanner.yml)|87.77%|[trained model](https://paddleocr.bj.bcebos.com/contribution/rec_r31_robustscanner.tar)|
|
||||
|
||||
Note:In addition to using the two text recognition datasets MJSynth and SynthText, [SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg) data (extraction code: 627x), and some real data are used in training, the specific data details can refer to the paper.
|
||||
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ Using MJSynth and SynthText two text recognition datasets for training, and eval
|
|||
|
||||
|Model|Backbone|config|Acc|Download link|
|
||||
| --- | --- | --- | --- | --- |
|
||||
|SPIN|ResNet32|[rec_r32_gaspin_bilstm_att.yml](../../configs/rec/rec_r32_gaspin_bilstm_att.yml)|90.0%|coming soon|
|
||||
|SPIN|ResNet32|[rec_r32_gaspin_bilstm_att.yml](../../configs/rec/rec_r32_gaspin_bilstm_att.yml)|90.0%|[trained model](https://paddleocr.bj.bcebos.com/contribution/rec_r32_gaspin_bilstm_att.tar) |
|
||||
|
||||
|
||||
<a name="2"></a>
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@ When using PaddleOCR for model inference, you can customize the modification par
|
|||
| parameters | type | default | implication |
|
||||
| :--: | :--: | :--: | :--: |
|
||||
| image_dir | str | None, must be specified explicitly | Image or folder path |
|
||||
| page_num | int | 0 | Valid when the input type is pdf file, specify to predict the previous page_num pages, all pages are predicted by default |
|
||||
| vis_font_path | str | "./doc/fonts/simfang.ttf" | font path for visualization |
|
||||
| drop_score | float | 0.5 | Results with a recognition score less than this value will be discarded and will not be returned as results |
|
||||
| use_pdserving | bool | False | Whether to use Paddle Serving for prediction |
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 138 KiB |
76
paddleocr.py
76
paddleocr.py
|
|
@ -414,6 +414,33 @@ def get_model_config(type, version, model_type, lang):
|
|||
return model_urls[version][model_type][lang]
|
||||
|
||||
|
||||
def img_decode(content: bytes):
|
||||
np_arr = np.frombuffer(content, dtype=np.uint8)
|
||||
return cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
|
||||
|
||||
|
||||
def check_img(img):
|
||||
if isinstance(img, bytes):
|
||||
img = img_decode(img)
|
||||
if isinstance(img, str):
|
||||
# download net image
|
||||
if is_link(img):
|
||||
download_with_progressbar(img, 'tmp.jpg')
|
||||
img = 'tmp.jpg'
|
||||
image_file = img
|
||||
img, flag, _ = check_and_read(image_file)
|
||||
if not flag:
|
||||
with open(image_file, 'rb') as f:
|
||||
img = img_decode(f.read())
|
||||
if img is None:
|
||||
logger.error("error in loading image:{}".format(image_file))
|
||||
return None
|
||||
if isinstance(img, np.ndarray) and len(img.shape) == 2:
|
||||
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||
|
||||
return img
|
||||
|
||||
|
||||
class PaddleOCR(predict_system.TextSystem):
|
||||
def __init__(self, **kwargs):
|
||||
"""
|
||||
|
|
@ -453,10 +480,11 @@ class PaddleOCR(predict_system.TextSystem):
|
|||
params.rec_image_shape = "3, 48, 320"
|
||||
else:
|
||||
params.rec_image_shape = "3, 32, 320"
|
||||
# download model
|
||||
maybe_download(params.det_model_dir, det_url)
|
||||
maybe_download(params.rec_model_dir, rec_url)
|
||||
maybe_download(params.cls_model_dir, cls_url)
|
||||
# download model if using paddle infer
|
||||
if not params.use_onnx:
|
||||
maybe_download(params.det_model_dir, det_url)
|
||||
maybe_download(params.rec_model_dir, rec_url)
|
||||
maybe_download(params.cls_model_dir, cls_url)
|
||||
|
||||
if params.det_algorithm not in SUPPORT_DET_MODEL:
|
||||
logger.error('det_algorithm must in {}'.format(SUPPORT_DET_MODEL))
|
||||
|
|
@ -482,7 +510,7 @@ class PaddleOCR(predict_system.TextSystem):
|
|||
rec: use text recognition or not. If false, only det will be exec. Default is True
|
||||
cls: use angle classifier or not. Default is True. If true, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
|
||||
"""
|
||||
assert isinstance(img, (np.ndarray, list, str))
|
||||
assert isinstance(img, (np.ndarray, list, str, bytes))
|
||||
if isinstance(img, list) and det == True:
|
||||
logger.error('When input a list of images, det must be false')
|
||||
exit(0)
|
||||
|
|
@ -491,22 +519,8 @@ class PaddleOCR(predict_system.TextSystem):
|
|||
'Since the angle classifier is not initialized, the angle classifier will not be uesd during the forward process'
|
||||
)
|
||||
|
||||
if isinstance(img, str):
|
||||
# download net image
|
||||
if img.startswith('http'):
|
||||
download_with_progressbar(img, 'tmp.jpg')
|
||||
img = 'tmp.jpg'
|
||||
image_file = img
|
||||
img, flag, _ = check_and_read(image_file)
|
||||
if not flag:
|
||||
with open(image_file, 'rb') as f:
|
||||
np_arr = np.frombuffer(f.read(), dtype=np.uint8)
|
||||
img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
|
||||
if img is None:
|
||||
logger.error("error in loading image:{}".format(image_file))
|
||||
return None
|
||||
if isinstance(img, np.ndarray) and len(img.shape) == 2:
|
||||
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||
img = check_img(img)
|
||||
|
||||
if det and rec:
|
||||
dt_boxes, rec_res, _ = self.__call__(img, cls)
|
||||
return [[box.tolist(), res] for box, res in zip(dt_boxes, rec_res)]
|
||||
|
|
@ -585,23 +599,7 @@ class PPStructure(StructureSystem):
|
|||
super().__init__(params)
|
||||
|
||||
def __call__(self, img, return_ocr_result_in_table=False, img_idx=0):
|
||||
if isinstance(img, str):
|
||||
# download net image
|
||||
if img.startswith('http'):
|
||||
download_with_progressbar(img, 'tmp.jpg')
|
||||
img = 'tmp.jpg'
|
||||
image_file = img
|
||||
img, flag, _ = check_and_read(image_file)
|
||||
if not flag:
|
||||
with open(image_file, 'rb') as f:
|
||||
np_arr = np.frombuffer(f.read(), dtype=np.uint8)
|
||||
img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
|
||||
if img is None:
|
||||
logger.error("error in loading image:{}".format(image_file))
|
||||
return None
|
||||
if isinstance(img, np.ndarray) and len(img.shape) == 2:
|
||||
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||
|
||||
img = check_img(img)
|
||||
res, _ = super().__call__(
|
||||
img, return_ocr_result_in_table, img_idx=img_idx)
|
||||
return res
|
||||
|
|
@ -644,7 +642,7 @@ def main():
|
|||
|
||||
if not flag_pdf:
|
||||
if img is None:
|
||||
logger.error("error in loading image:{}".format(image_file))
|
||||
logger.error("error in loading image:{}".format(img_path))
|
||||
continue
|
||||
img_paths = [[img_path, img]]
|
||||
else:
|
||||
|
|
|
|||
|
|
@ -43,6 +43,7 @@ from .vqa import *
|
|||
|
||||
from .fce_aug import *
|
||||
from .fce_targets import FCENetTargets
|
||||
from .ct_process import *
|
||||
|
||||
|
||||
def transform(data, ops=None):
|
||||
|
|
|
|||
|
|
@ -0,0 +1,355 @@
|
|||
# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
import cv2
|
||||
import random
|
||||
import pyclipper
|
||||
import paddle
|
||||
|
||||
import numpy as np
|
||||
import Polygon as plg
|
||||
import scipy.io as scio
|
||||
|
||||
from PIL import Image
|
||||
import paddle.vision.transforms as transforms
|
||||
|
||||
|
||||
class RandomScale():
|
||||
def __init__(self, short_size=640, **kwargs):
|
||||
self.short_size = short_size
|
||||
|
||||
def scale_aligned(self, img, scale):
|
||||
oh, ow = img.shape[0:2]
|
||||
h = int(oh * scale + 0.5)
|
||||
w = int(ow * scale + 0.5)
|
||||
if h % 32 != 0:
|
||||
h = h + (32 - h % 32)
|
||||
if w % 32 != 0:
|
||||
w = w + (32 - w % 32)
|
||||
img = cv2.resize(img, dsize=(w, h))
|
||||
factor_h = h / oh
|
||||
factor_w = w / ow
|
||||
return img, factor_h, factor_w
|
||||
|
||||
def __call__(self, data):
|
||||
img = data['image']
|
||||
|
||||
h, w = img.shape[0:2]
|
||||
random_scale = np.array([0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3])
|
||||
scale = (np.random.choice(random_scale) * self.short_size) / min(h, w)
|
||||
img, factor_h, factor_w = self.scale_aligned(img, scale)
|
||||
|
||||
data['scale_factor'] = (factor_w, factor_h)
|
||||
data['image'] = img
|
||||
return data
|
||||
|
||||
|
||||
class MakeShrink():
|
||||
def __init__(self, kernel_scale=0.7, **kwargs):
|
||||
self.kernel_scale = kernel_scale
|
||||
|
||||
def dist(self, a, b):
|
||||
return np.linalg.norm((a - b), ord=2, axis=0)
|
||||
|
||||
def perimeter(self, bbox):
|
||||
peri = 0.0
|
||||
for i in range(bbox.shape[0]):
|
||||
peri += self.dist(bbox[i], bbox[(i + 1) % bbox.shape[0]])
|
||||
return peri
|
||||
|
||||
def shrink(self, bboxes, rate, max_shr=20):
|
||||
rate = rate * rate
|
||||
shrinked_bboxes = []
|
||||
for bbox in bboxes:
|
||||
area = plg.Polygon(bbox).area()
|
||||
peri = self.perimeter(bbox)
|
||||
|
||||
try:
|
||||
pco = pyclipper.PyclipperOffset()
|
||||
pco.AddPath(bbox, pyclipper.JT_ROUND,
|
||||
pyclipper.ET_CLOSEDPOLYGON)
|
||||
offset = min(
|
||||
int(area * (1 - rate) / (peri + 0.001) + 0.5), max_shr)
|
||||
|
||||
shrinked_bbox = pco.Execute(-offset)
|
||||
if len(shrinked_bbox) == 0:
|
||||
shrinked_bboxes.append(bbox)
|
||||
continue
|
||||
|
||||
shrinked_bbox = np.array(shrinked_bbox[0])
|
||||
if shrinked_bbox.shape[0] <= 2:
|
||||
shrinked_bboxes.append(bbox)
|
||||
continue
|
||||
|
||||
shrinked_bboxes.append(shrinked_bbox)
|
||||
except Exception as e:
|
||||
shrinked_bboxes.append(bbox)
|
||||
|
||||
return shrinked_bboxes
|
||||
|
||||
def __call__(self, data):
|
||||
img = data['image']
|
||||
bboxes = data['polys']
|
||||
words = data['texts']
|
||||
scale_factor = data['scale_factor']
|
||||
|
||||
gt_instance = np.zeros(img.shape[0:2], dtype='uint8') # h,w
|
||||
training_mask = np.ones(img.shape[0:2], dtype='uint8')
|
||||
training_mask_distance = np.ones(img.shape[0:2], dtype='uint8')
|
||||
|
||||
for i in range(len(bboxes)):
|
||||
bboxes[i] = np.reshape(bboxes[i] * (
|
||||
[scale_factor[0], scale_factor[1]] * (bboxes[i].shape[0] // 2)),
|
||||
(bboxes[i].shape[0] // 2, 2)).astype('int32')
|
||||
|
||||
for i in range(len(bboxes)):
|
||||
#different value for different bbox
|
||||
cv2.drawContours(gt_instance, [bboxes[i]], -1, i + 1, -1)
|
||||
|
||||
# set training mask to 0
|
||||
cv2.drawContours(training_mask, [bboxes[i]], -1, 0, -1)
|
||||
|
||||
# for not accurate annotation, use training_mask_distance
|
||||
if words[i] == '###' or words[i] == '???':
|
||||
cv2.drawContours(training_mask_distance, [bboxes[i]], -1, 0, -1)
|
||||
|
||||
# make shrink
|
||||
gt_kernel_instance = np.zeros(img.shape[0:2], dtype='uint8')
|
||||
kernel_bboxes = self.shrink(bboxes, self.kernel_scale)
|
||||
for i in range(len(bboxes)):
|
||||
cv2.drawContours(gt_kernel_instance, [kernel_bboxes[i]], -1, i + 1,
|
||||
-1)
|
||||
|
||||
# for training mask, kernel and background= 1, box region=0
|
||||
if words[i] != '###' and words[i] != '???':
|
||||
cv2.drawContours(training_mask, [kernel_bboxes[i]], -1, 1, -1)
|
||||
|
||||
gt_kernel = gt_kernel_instance.copy()
|
||||
# for gt_kernel, kernel = 1
|
||||
gt_kernel[gt_kernel > 0] = 1
|
||||
|
||||
# shrink 2 times
|
||||
tmp1 = gt_kernel_instance.copy()
|
||||
erode_kernel = np.ones((3, 3), np.uint8)
|
||||
tmp1 = cv2.erode(tmp1, erode_kernel, iterations=1)
|
||||
tmp2 = tmp1.copy()
|
||||
tmp2 = cv2.erode(tmp2, erode_kernel, iterations=1)
|
||||
|
||||
# compute text region
|
||||
gt_kernel_inner = tmp1 - tmp2
|
||||
|
||||
# gt_instance: text instance, bg=0, diff word use diff value
|
||||
# training_mask: text instance mask, word=0,kernel and bg=1
|
||||
# gt_kernel_instance: text kernel instance, bg=0, diff word use diff value
|
||||
# gt_kernel: text_kernel, bg=0,diff word use same value
|
||||
# gt_kernel_inner: text kernel reference
|
||||
# training_mask_distance: word without anno = 0, else 1
|
||||
|
||||
data['image'] = [
|
||||
img, gt_instance, training_mask, gt_kernel_instance, gt_kernel,
|
||||
gt_kernel_inner, training_mask_distance
|
||||
]
|
||||
return data
|
||||
|
||||
|
||||
class GroupRandomHorizontalFlip():
|
||||
def __init__(self, p=0.5, **kwargs):
|
||||
self.p = p
|
||||
|
||||
def __call__(self, data):
|
||||
imgs = data['image']
|
||||
|
||||
if random.random() < self.p:
|
||||
for i in range(len(imgs)):
|
||||
imgs[i] = np.flip(imgs[i], axis=1).copy()
|
||||
data['image'] = imgs
|
||||
return data
|
||||
|
||||
|
||||
class GroupRandomRotate():
|
||||
def __init__(self, **kwargs):
|
||||
pass
|
||||
|
||||
def __call__(self, data):
|
||||
imgs = data['image']
|
||||
|
||||
max_angle = 10
|
||||
angle = random.random() * 2 * max_angle - max_angle
|
||||
for i in range(len(imgs)):
|
||||
img = imgs[i]
|
||||
w, h = img.shape[:2]
|
||||
rotation_matrix = cv2.getRotationMatrix2D((h / 2, w / 2), angle, 1)
|
||||
img_rotation = cv2.warpAffine(
|
||||
img, rotation_matrix, (h, w), flags=cv2.INTER_NEAREST)
|
||||
imgs[i] = img_rotation
|
||||
|
||||
data['image'] = imgs
|
||||
return data
|
||||
|
||||
|
||||
class GroupRandomCropPadding():
|
||||
def __init__(self, target_size=(640, 640), **kwargs):
|
||||
self.target_size = target_size
|
||||
|
||||
def __call__(self, data):
|
||||
imgs = data['image']
|
||||
|
||||
h, w = imgs[0].shape[0:2]
|
||||
t_w, t_h = self.target_size
|
||||
p_w, p_h = self.target_size
|
||||
if w == t_w and h == t_h:
|
||||
return data
|
||||
|
||||
t_h = t_h if t_h < h else h
|
||||
t_w = t_w if t_w < w else w
|
||||
|
||||
if random.random() > 3.0 / 8.0 and np.max(imgs[1]) > 0:
|
||||
# make sure to crop the text region
|
||||
tl = np.min(np.where(imgs[1] > 0), axis=1) - (t_h, t_w)
|
||||
tl[tl < 0] = 0
|
||||
br = np.max(np.where(imgs[1] > 0), axis=1) - (t_h, t_w)
|
||||
br[br < 0] = 0
|
||||
br[0] = min(br[0], h - t_h)
|
||||
br[1] = min(br[1], w - t_w)
|
||||
|
||||
i = random.randint(tl[0], br[0]) if tl[0] < br[0] else 0
|
||||
j = random.randint(tl[1], br[1]) if tl[1] < br[1] else 0
|
||||
else:
|
||||
i = random.randint(0, h - t_h) if h - t_h > 0 else 0
|
||||
j = random.randint(0, w - t_w) if w - t_w > 0 else 0
|
||||
|
||||
n_imgs = []
|
||||
for idx in range(len(imgs)):
|
||||
if len(imgs[idx].shape) == 3:
|
||||
s3_length = int(imgs[idx].shape[-1])
|
||||
img = imgs[idx][i:i + t_h, j:j + t_w, :]
|
||||
img_p = cv2.copyMakeBorder(
|
||||
img,
|
||||
0,
|
||||
p_h - t_h,
|
||||
0,
|
||||
p_w - t_w,
|
||||
borderType=cv2.BORDER_CONSTANT,
|
||||
value=tuple(0 for i in range(s3_length)))
|
||||
else:
|
||||
img = imgs[idx][i:i + t_h, j:j + t_w]
|
||||
img_p = cv2.copyMakeBorder(
|
||||
img,
|
||||
0,
|
||||
p_h - t_h,
|
||||
0,
|
||||
p_w - t_w,
|
||||
borderType=cv2.BORDER_CONSTANT,
|
||||
value=(0, ))
|
||||
n_imgs.append(img_p)
|
||||
|
||||
data['image'] = n_imgs
|
||||
return data
|
||||
|
||||
|
||||
class MakeCentripetalShift():
|
||||
def __init__(self, **kwargs):
|
||||
pass
|
||||
|
||||
def jaccard(self, As, Bs):
|
||||
A = As.shape[0] # small
|
||||
B = Bs.shape[0] # large
|
||||
|
||||
dis = np.sqrt(
|
||||
np.sum((As[:, np.newaxis, :].repeat(
|
||||
B, axis=1) - Bs[np.newaxis, :, :].repeat(
|
||||
A, axis=0))**2,
|
||||
axis=-1))
|
||||
|
||||
ind = np.argmin(dis, axis=-1)
|
||||
|
||||
return ind
|
||||
|
||||
def __call__(self, data):
|
||||
imgs = data['image']
|
||||
|
||||
img, gt_instance, training_mask, gt_kernel_instance, gt_kernel, gt_kernel_inner, training_mask_distance = \
|
||||
imgs[0], imgs[1], imgs[2], imgs[3], imgs[4], imgs[5], imgs[6]
|
||||
|
||||
max_instance = np.max(gt_instance) # num bbox
|
||||
|
||||
# make centripetal shift
|
||||
gt_distance = np.zeros((2, *img.shape[0:2]), dtype=np.float32)
|
||||
for i in range(1, max_instance + 1):
|
||||
# kernel_reference
|
||||
ind = (gt_kernel_inner == i)
|
||||
|
||||
if np.sum(ind) == 0:
|
||||
training_mask[gt_instance == i] = 0
|
||||
training_mask_distance[gt_instance == i] = 0
|
||||
continue
|
||||
|
||||
kpoints = np.array(np.where(ind)).transpose(
|
||||
(1, 0))[:, ::-1].astype('float32')
|
||||
|
||||
ind = (gt_instance == i) * (gt_kernel_instance == 0)
|
||||
if np.sum(ind) == 0:
|
||||
continue
|
||||
pixels = np.where(ind)
|
||||
|
||||
points = np.array(pixels).transpose(
|
||||
(1, 0))[:, ::-1].astype('float32')
|
||||
|
||||
bbox_ind = self.jaccard(points, kpoints)
|
||||
|
||||
offset_gt = kpoints[bbox_ind] - points
|
||||
|
||||
gt_distance[:, pixels[0], pixels[1]] = offset_gt.T * 0.1
|
||||
|
||||
img = Image.fromarray(img)
|
||||
img = img.convert('RGB')
|
||||
|
||||
data["image"] = img
|
||||
data["gt_kernel"] = gt_kernel.astype("int64")
|
||||
data["training_mask"] = training_mask.astype("int64")
|
||||
data["gt_instance"] = gt_instance.astype("int64")
|
||||
data["gt_kernel_instance"] = gt_kernel_instance.astype("int64")
|
||||
data["training_mask_distance"] = training_mask_distance.astype("int64")
|
||||
data["gt_distance"] = gt_distance.astype("float32")
|
||||
|
||||
return data
|
||||
|
||||
|
||||
class ScaleAlignedShort():
|
||||
def __init__(self, short_size=640, **kwargs):
|
||||
self.short_size = short_size
|
||||
|
||||
def __call__(self, data):
|
||||
img = data['image']
|
||||
|
||||
org_img_shape = img.shape
|
||||
|
||||
h, w = img.shape[0:2]
|
||||
scale = self.short_size * 1.0 / min(h, w)
|
||||
h = int(h * scale + 0.5)
|
||||
w = int(w * scale + 0.5)
|
||||
if h % 32 != 0:
|
||||
h = h + (32 - h % 32)
|
||||
if w % 32 != 0:
|
||||
w = w + (32 - w % 32)
|
||||
img = cv2.resize(img, dsize=(w, h))
|
||||
|
||||
new_img_shape = img.shape
|
||||
img_shape = np.array(org_img_shape + new_img_shape)
|
||||
|
||||
data['shape'] = img_shape
|
||||
data['image'] = img
|
||||
|
||||
return data
|
||||
|
|
@ -1395,3 +1395,29 @@ class VLLabelEncode(BaseRecLabelEncode):
|
|||
data['label_res'] = np.array(label_res)
|
||||
data['label_sub'] = np.array(label_sub)
|
||||
return data
|
||||
|
||||
|
||||
class CTLabelEncode(object):
|
||||
def __init__(self, **kwargs):
|
||||
pass
|
||||
|
||||
def __call__(self, data):
|
||||
label = data['label']
|
||||
|
||||
label = json.loads(label)
|
||||
nBox = len(label)
|
||||
boxes, txts = [], []
|
||||
for bno in range(0, nBox):
|
||||
box = label[bno]['points']
|
||||
box = np.array(box)
|
||||
|
||||
boxes.append(box)
|
||||
txt = label[bno]['transcription']
|
||||
txts.append(txt)
|
||||
|
||||
if len(boxes) == 0:
|
||||
return None
|
||||
|
||||
data['polys'] = boxes
|
||||
data['texts'] = txts
|
||||
return data
|
||||
|
|
@ -225,6 +225,8 @@ class DetResizeForTest(object):
|
|||
def __call__(self, data):
|
||||
img = data['image']
|
||||
src_h, src_w, _ = img.shape
|
||||
if sum([src_h, src_w]) < 64:
|
||||
img = self.image_padding(img)
|
||||
|
||||
if self.resize_type == 0:
|
||||
# img, shape = self.resize_image_type0(img)
|
||||
|
|
@ -238,6 +240,12 @@ class DetResizeForTest(object):
|
|||
data['shape'] = np.array([src_h, src_w, ratio_h, ratio_w])
|
||||
return data
|
||||
|
||||
def image_padding(self, im, value=0):
|
||||
h, w, c = im.shape
|
||||
im_pad = np.zeros((max(32, h), max(32, w), c), np.uint8) + value
|
||||
im_pad[:h, :w, :] = im
|
||||
return im_pad
|
||||
|
||||
def resize_image_type1(self, img):
|
||||
resize_h, resize_w = self.image_shape
|
||||
ori_h, ori_w = img.shape[:2] # (h, w, c)
|
||||
|
|
|
|||
|
|
@ -15,6 +15,8 @@
|
|||
import math
|
||||
import cv2
|
||||
import numpy as np
|
||||
from skimage.morphology._skeletonize import thin
|
||||
from ppocr.utils.e2e_utils.extract_textpoint_fast import sort_and_expand_with_direction_v2
|
||||
|
||||
__all__ = ['PGProcessTrain']
|
||||
|
||||
|
|
@ -26,17 +28,24 @@ class PGProcessTrain(object):
|
|||
max_text_nums,
|
||||
tcl_len,
|
||||
batch_size=14,
|
||||
use_resize=True,
|
||||
use_random_crop=False,
|
||||
min_crop_size=24,
|
||||
min_text_size=4,
|
||||
max_text_size=512,
|
||||
point_gather_mode=None,
|
||||
**kwargs):
|
||||
self.tcl_len = tcl_len
|
||||
self.max_text_length = max_text_length
|
||||
self.max_text_nums = max_text_nums
|
||||
self.batch_size = batch_size
|
||||
self.min_crop_size = min_crop_size
|
||||
if use_random_crop is True:
|
||||
self.min_crop_size = min_crop_size
|
||||
self.use_random_crop = use_random_crop
|
||||
self.min_text_size = min_text_size
|
||||
self.max_text_size = max_text_size
|
||||
self.use_resize = use_resize
|
||||
self.point_gather_mode = point_gather_mode
|
||||
self.Lexicon_Table = self.get_dict(character_dict_path)
|
||||
self.pad_num = len(self.Lexicon_Table)
|
||||
self.img_id = 0
|
||||
|
|
@ -282,6 +291,95 @@ class PGProcessTrain(object):
|
|||
pos_m[:keep] = 1.0
|
||||
return pos_l, pos_m
|
||||
|
||||
def fit_and_gather_tcl_points_v3(self,
|
||||
min_area_quad,
|
||||
poly,
|
||||
max_h,
|
||||
max_w,
|
||||
fixed_point_num=64,
|
||||
img_id=0,
|
||||
reference_height=3):
|
||||
"""
|
||||
Find the center point of poly as key_points, then fit and gather.
|
||||
"""
|
||||
det_mask = np.zeros((int(max_h / self.ds_ratio),
|
||||
int(max_w / self.ds_ratio))).astype(np.float32)
|
||||
|
||||
# score_big_map
|
||||
cv2.fillPoly(det_mask,
|
||||
np.round(poly / self.ds_ratio).astype(np.int32), 1.0)
|
||||
det_mask = cv2.resize(
|
||||
det_mask, dsize=None, fx=self.ds_ratio, fy=self.ds_ratio)
|
||||
det_mask = np.array(det_mask > 1e-3, dtype='float32')
|
||||
|
||||
f_direction = self.f_direction
|
||||
skeleton_map = thin(det_mask.astype(np.uint8))
|
||||
instance_count, instance_label_map = cv2.connectedComponents(
|
||||
skeleton_map.astype(np.uint8), connectivity=8)
|
||||
|
||||
ys, xs = np.where(instance_label_map == 1)
|
||||
pos_list = list(zip(ys, xs))
|
||||
if len(pos_list) < 3:
|
||||
return None
|
||||
pos_list_sorted = sort_and_expand_with_direction_v2(
|
||||
pos_list, f_direction, det_mask)
|
||||
|
||||
pos_list_sorted = np.array(pos_list_sorted)
|
||||
length = len(pos_list_sorted) - 1
|
||||
insert_num = 0
|
||||
for index in range(length):
|
||||
stride_y = np.abs(pos_list_sorted[index + insert_num][0] -
|
||||
pos_list_sorted[index + 1 + insert_num][0])
|
||||
stride_x = np.abs(pos_list_sorted[index + insert_num][1] -
|
||||
pos_list_sorted[index + 1 + insert_num][1])
|
||||
max_points = int(max(stride_x, stride_y))
|
||||
|
||||
stride = (pos_list_sorted[index + insert_num] -
|
||||
pos_list_sorted[index + 1 + insert_num]) / (max_points)
|
||||
insert_num_temp = max_points - 1
|
||||
|
||||
for i in range(int(insert_num_temp)):
|
||||
insert_value = pos_list_sorted[index + insert_num] - (i + 1
|
||||
) * stride
|
||||
insert_index = index + i + 1 + insert_num
|
||||
pos_list_sorted = np.insert(
|
||||
pos_list_sorted, insert_index, insert_value, axis=0)
|
||||
insert_num += insert_num_temp
|
||||
|
||||
pos_info = np.array(pos_list_sorted).reshape(-1, 2).astype(
|
||||
np.float32) # xy-> yx
|
||||
|
||||
point_num = len(pos_info)
|
||||
if point_num > fixed_point_num:
|
||||
keep_ids = [
|
||||
int((point_num * 1.0 / fixed_point_num) * x)
|
||||
for x in range(fixed_point_num)
|
||||
]
|
||||
pos_info = pos_info[keep_ids, :]
|
||||
|
||||
keep = int(min(len(pos_info), fixed_point_num))
|
||||
reference_width = (np.abs(poly[0, 0, 0] - poly[-1, 1, 0]) +
|
||||
np.abs(poly[0, 3, 0] - poly[-1, 2, 0])) // 2
|
||||
if np.random.rand() < 1:
|
||||
dh = (np.random.rand(keep) - 0.5) * reference_height
|
||||
offset = np.random.rand() - 0.5
|
||||
dw = np.array([[0, offset * reference_width * 0.2]])
|
||||
random_float_h = np.array([1, 0]).reshape([1, 2]) * dh.reshape(
|
||||
[keep, 1])
|
||||
random_float_w = dw.repeat(keep, axis=0)
|
||||
pos_info += random_float_h
|
||||
pos_info += random_float_w
|
||||
pos_info[:, 0] = np.clip(pos_info[:, 0], 0, max_h - 1)
|
||||
pos_info[:, 1] = np.clip(pos_info[:, 1], 0, max_w - 1)
|
||||
|
||||
# padding to fixed length
|
||||
pos_l = np.zeros((self.tcl_len, 3), dtype=np.int32)
|
||||
pos_l[:, 0] = np.ones((self.tcl_len, )) * img_id
|
||||
pos_m = np.zeros((self.tcl_len, 1), dtype=np.float32)
|
||||
pos_l[:keep, 1:] = np.round(pos_info).astype(np.int32)
|
||||
pos_m[:keep] = 1.0
|
||||
return pos_l, pos_m
|
||||
|
||||
def generate_direction_map(self, poly_quads, n_char, direction_map):
|
||||
"""
|
||||
"""
|
||||
|
|
@ -334,6 +432,7 @@ class PGProcessTrain(object):
|
|||
"""
|
||||
Generate polygon.
|
||||
"""
|
||||
self.ds_ratio = ds_ratio
|
||||
score_map_big = np.zeros(
|
||||
(
|
||||
h,
|
||||
|
|
@ -384,7 +483,6 @@ class PGProcessTrain(object):
|
|||
text_label = text_strs[poly_idx]
|
||||
text_label = self.prepare_text_label(text_label,
|
||||
self.Lexicon_Table)
|
||||
|
||||
text_label_index_list = [[self.Lexicon_Table.index(c_)]
|
||||
for c_ in text_label
|
||||
if c_ in self.Lexicon_Table]
|
||||
|
|
@ -432,14 +530,30 @@ class PGProcessTrain(object):
|
|||
# pos info
|
||||
average_shrink_height = self.calculate_average_height(
|
||||
stcl_quads)
|
||||
pos_l, pos_m = self.fit_and_gather_tcl_points_v2(
|
||||
min_area_quad,
|
||||
poly,
|
||||
max_h=h,
|
||||
max_w=w,
|
||||
fixed_point_num=64,
|
||||
img_id=self.img_id,
|
||||
reference_height=average_shrink_height)
|
||||
|
||||
if self.point_gather_mode == 'align':
|
||||
self.f_direction = direction_map[:, :, :-1].copy()
|
||||
pos_res = self.fit_and_gather_tcl_points_v3(
|
||||
min_area_quad,
|
||||
stcl_quads,
|
||||
max_h=h,
|
||||
max_w=w,
|
||||
fixed_point_num=64,
|
||||
img_id=self.img_id,
|
||||
reference_height=average_shrink_height)
|
||||
if pos_res is None:
|
||||
continue
|
||||
pos_l, pos_m = pos_res[0], pos_res[1]
|
||||
|
||||
else:
|
||||
pos_l, pos_m = self.fit_and_gather_tcl_points_v2(
|
||||
min_area_quad,
|
||||
poly,
|
||||
max_h=h,
|
||||
max_w=w,
|
||||
fixed_point_num=64,
|
||||
img_id=self.img_id,
|
||||
reference_height=average_shrink_height)
|
||||
|
||||
label_l = text_label_index_list
|
||||
if len(text_label_index_list) < 2:
|
||||
|
|
@ -770,27 +884,41 @@ class PGProcessTrain(object):
|
|||
text_polys[:, :, 0] *= asp_wx
|
||||
text_polys[:, :, 1] *= asp_hy
|
||||
|
||||
h, w, _ = im.shape
|
||||
if max(h, w) > 2048:
|
||||
rd_scale = 2048.0 / max(h, w)
|
||||
im = cv2.resize(im, dsize=None, fx=rd_scale, fy=rd_scale)
|
||||
text_polys *= rd_scale
|
||||
h, w, _ = im.shape
|
||||
if min(h, w) < 16:
|
||||
return None
|
||||
if self.use_resize is True:
|
||||
ori_h, ori_w, _ = im.shape
|
||||
if max(ori_h, ori_w) < 200:
|
||||
ratio = 200 / max(ori_h, ori_w)
|
||||
im = cv2.resize(im, (int(ori_w * ratio), int(ori_h * ratio)))
|
||||
text_polys[:, :, 0] *= ratio
|
||||
text_polys[:, :, 1] *= ratio
|
||||
|
||||
# no background
|
||||
im, text_polys, text_tags, hv_tags, text_strs = self.crop_area(
|
||||
im,
|
||||
text_polys,
|
||||
text_tags,
|
||||
hv_tags,
|
||||
text_strs,
|
||||
crop_background=False)
|
||||
if max(ori_h, ori_w) > 512:
|
||||
ratio = 512 / max(ori_h, ori_w)
|
||||
im = cv2.resize(im, (int(ori_w * ratio), int(ori_h * ratio)))
|
||||
text_polys[:, :, 0] *= ratio
|
||||
text_polys[:, :, 1] *= ratio
|
||||
elif self.use_random_crop is True:
|
||||
h, w, _ = im.shape
|
||||
if max(h, w) > 2048:
|
||||
rd_scale = 2048.0 / max(h, w)
|
||||
im = cv2.resize(im, dsize=None, fx=rd_scale, fy=rd_scale)
|
||||
text_polys *= rd_scale
|
||||
h, w, _ = im.shape
|
||||
if min(h, w) < 16:
|
||||
return None
|
||||
|
||||
# no background
|
||||
im, text_polys, text_tags, hv_tags, text_strs = self.crop_area(
|
||||
im,
|
||||
text_polys,
|
||||
text_tags,
|
||||
hv_tags,
|
||||
text_strs,
|
||||
crop_background=False)
|
||||
|
||||
if text_polys.shape[0] == 0:
|
||||
return None
|
||||
# # continue for all ignore case
|
||||
# continue for all ignore case
|
||||
if np.sum((text_tags * 1.0)) >= text_tags.size:
|
||||
return None
|
||||
new_h, new_w, _ = im.shape
|
||||
|
|
|
|||
|
|
@ -12,11 +12,9 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .token import VQATokenPad, VQASerTokenChunk, VQAReTokenChunk, VQAReTokenRelation
|
||||
from .token import VQATokenPad, VQASerTokenChunk, VQAReTokenChunk, VQAReTokenRelation, TensorizeEntitiesRelations
|
||||
|
||||
__all__ = [
|
||||
'VQATokenPad',
|
||||
'VQASerTokenChunk',
|
||||
'VQAReTokenChunk',
|
||||
'VQAReTokenRelation',
|
||||
'VQATokenPad', 'VQASerTokenChunk', 'VQAReTokenChunk', 'VQAReTokenRelation',
|
||||
'TensorizeEntitiesRelations'
|
||||
]
|
||||
|
|
|
|||
|
|
@ -15,3 +15,4 @@
|
|||
from .vqa_token_chunk import VQASerTokenChunk, VQAReTokenChunk
|
||||
from .vqa_token_pad import VQATokenPad
|
||||
from .vqa_token_relation import VQAReTokenRelation
|
||||
from .vqa_re_convert import TensorizeEntitiesRelations
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import numpy as np
|
||||
|
||||
|
||||
class TensorizeEntitiesRelations(object):
|
||||
def __init__(self, max_seq_len=512, infer_mode=False, **kwargs):
|
||||
self.max_seq_len = max_seq_len
|
||||
self.infer_mode = infer_mode
|
||||
|
||||
def __call__(self, data):
|
||||
entities = data['entities']
|
||||
relations = data['relations']
|
||||
|
||||
entities_new = np.full(
|
||||
shape=[self.max_seq_len + 1, 3], fill_value=-1, dtype='int64')
|
||||
entities_new[0, 0] = len(entities['start'])
|
||||
entities_new[0, 1] = len(entities['end'])
|
||||
entities_new[0, 2] = len(entities['label'])
|
||||
entities_new[1:len(entities['start']) + 1, 0] = np.array(entities[
|
||||
'start'])
|
||||
entities_new[1:len(entities['end']) + 1, 1] = np.array(entities['end'])
|
||||
entities_new[1:len(entities['label']) + 1, 2] = np.array(entities[
|
||||
'label'])
|
||||
|
||||
relations_new = np.full(
|
||||
shape=[self.max_seq_len * self.max_seq_len + 1, 2],
|
||||
fill_value=-1,
|
||||
dtype='int64')
|
||||
relations_new[0, 0] = len(relations['head'])
|
||||
relations_new[0, 1] = len(relations['tail'])
|
||||
relations_new[1:len(relations['head']) + 1, 0] = np.array(relations[
|
||||
'head'])
|
||||
relations_new[1:len(relations['tail']) + 1, 1] = np.array(relations[
|
||||
'tail'])
|
||||
|
||||
data['entities'] = entities_new
|
||||
data['relations'] = relations_new
|
||||
return data
|
||||
|
|
@ -25,6 +25,7 @@ from .det_east_loss import EASTLoss
|
|||
from .det_sast_loss import SASTLoss
|
||||
from .det_pse_loss import PSELoss
|
||||
from .det_fce_loss import FCELoss
|
||||
from .det_ct_loss import CTLoss
|
||||
|
||||
# rec loss
|
||||
from .rec_ctc_loss import CTCLoss
|
||||
|
|
@ -68,7 +69,7 @@ def build_loss(config):
|
|||
'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
|
||||
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss',
|
||||
'TableMasterLoss', 'SPINAttentionLoss', 'VLLoss', 'StrokeFocusLoss',
|
||||
'SLALoss'
|
||||
'SLALoss', 'CTLoss'
|
||||
]
|
||||
config = copy.deepcopy(config)
|
||||
module_name = config.pop('name')
|
||||
|
|
|
|||
|
|
@ -0,0 +1,276 @@
|
|||
# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
This code is refer from:
|
||||
https://github.com/shengtao96/CentripetalText/tree/main/models/loss
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import paddle
|
||||
from paddle import nn
|
||||
import paddle.nn.functional as F
|
||||
import numpy as np
|
||||
|
||||
|
||||
def ohem_single(score, gt_text, training_mask):
|
||||
# online hard example mining
|
||||
|
||||
pos_num = int(paddle.sum(gt_text > 0.5)) - int(
|
||||
paddle.sum((gt_text > 0.5) & (training_mask <= 0.5)))
|
||||
|
||||
if pos_num == 0:
|
||||
# selected_mask = gt_text.copy() * 0 # may be not good
|
||||
selected_mask = training_mask
|
||||
selected_mask = paddle.cast(
|
||||
selected_mask.reshape(
|
||||
(1, selected_mask.shape[0], selected_mask.shape[1])), "float32")
|
||||
return selected_mask
|
||||
|
||||
neg_num = int(paddle.sum((gt_text <= 0.5) & (training_mask > 0.5)))
|
||||
neg_num = int(min(pos_num * 3, neg_num))
|
||||
|
||||
if neg_num == 0:
|
||||
selected_mask = training_mask
|
||||
selected_mask = paddle.cast(
|
||||
selected_mask.reshape(
|
||||
(1, selected_mask.shape[0], selected_mask.shape[1])), "float32")
|
||||
return selected_mask
|
||||
|
||||
# hard example
|
||||
neg_score = score[(gt_text <= 0.5) & (training_mask > 0.5)]
|
||||
neg_score_sorted = paddle.sort(-neg_score)
|
||||
threshold = -neg_score_sorted[neg_num - 1]
|
||||
|
||||
selected_mask = ((score >= threshold) |
|
||||
(gt_text > 0.5)) & (training_mask > 0.5)
|
||||
selected_mask = paddle.cast(
|
||||
selected_mask.reshape(
|
||||
(1, selected_mask.shape[0], selected_mask.shape[1])), "float32")
|
||||
return selected_mask
|
||||
|
||||
|
||||
def ohem_batch(scores, gt_texts, training_masks):
|
||||
selected_masks = []
|
||||
for i in range(scores.shape[0]):
|
||||
selected_masks.append(
|
||||
ohem_single(scores[i, :, :], gt_texts[i, :, :], training_masks[
|
||||
i, :, :]))
|
||||
|
||||
selected_masks = paddle.cast(paddle.concat(selected_masks, 0), "float32")
|
||||
return selected_masks
|
||||
|
||||
|
||||
def iou_single(a, b, mask, n_class):
|
||||
EPS = 1e-6
|
||||
valid = mask == 1
|
||||
a = a[valid]
|
||||
b = b[valid]
|
||||
miou = []
|
||||
|
||||
# iou of each class
|
||||
for i in range(n_class):
|
||||
inter = paddle.cast(((a == i) & (b == i)), "float32")
|
||||
union = paddle.cast(((a == i) | (b == i)), "float32")
|
||||
|
||||
miou.append(paddle.sum(inter) / (paddle.sum(union) + EPS))
|
||||
miou = sum(miou) / len(miou)
|
||||
return miou
|
||||
|
||||
|
||||
def iou(a, b, mask, n_class=2, reduce=True):
|
||||
batch_size = a.shape[0]
|
||||
|
||||
a = a.reshape((batch_size, -1))
|
||||
b = b.reshape((batch_size, -1))
|
||||
mask = mask.reshape((batch_size, -1))
|
||||
|
||||
iou = paddle.zeros((batch_size, ), dtype="float32")
|
||||
for i in range(batch_size):
|
||||
iou[i] = iou_single(a[i], b[i], mask[i], n_class)
|
||||
|
||||
if reduce:
|
||||
iou = paddle.mean(iou)
|
||||
return iou
|
||||
|
||||
|
||||
class DiceLoss(nn.Layer):
|
||||
def __init__(self, loss_weight=1.0):
|
||||
super(DiceLoss, self).__init__()
|
||||
self.loss_weight = loss_weight
|
||||
|
||||
def forward(self, input, target, mask, reduce=True):
|
||||
batch_size = input.shape[0]
|
||||
input = F.sigmoid(input) # scale to 0-1
|
||||
|
||||
input = input.reshape((batch_size, -1))
|
||||
target = paddle.cast(target.reshape((batch_size, -1)), "float32")
|
||||
mask = paddle.cast(mask.reshape((batch_size, -1)), "float32")
|
||||
|
||||
input = input * mask
|
||||
target = target * mask
|
||||
|
||||
a = paddle.sum(input * target, axis=1)
|
||||
b = paddle.sum(input * input, axis=1) + 0.001
|
||||
c = paddle.sum(target * target, axis=1) + 0.001
|
||||
d = (2 * a) / (b + c)
|
||||
loss = 1 - d
|
||||
|
||||
loss = self.loss_weight * loss
|
||||
|
||||
if reduce:
|
||||
loss = paddle.mean(loss)
|
||||
|
||||
return loss
|
||||
|
||||
|
||||
class SmoothL1Loss(nn.Layer):
|
||||
def __init__(self, beta=1.0, loss_weight=1.0):
|
||||
super(SmoothL1Loss, self).__init__()
|
||||
self.beta = beta
|
||||
self.loss_weight = loss_weight
|
||||
|
||||
np_coord = np.zeros(shape=[640, 640, 2], dtype=np.int64)
|
||||
for i in range(640):
|
||||
for j in range(640):
|
||||
np_coord[i, j, 0] = j
|
||||
np_coord[i, j, 1] = i
|
||||
np_coord = np_coord.reshape((-1, 2))
|
||||
|
||||
self.coord = self.create_parameter(
|
||||
shape=[640 * 640, 2],
|
||||
dtype="int32", # NOTE: not support "int64" before paddle 2.3.1
|
||||
default_initializer=nn.initializer.Assign(value=np_coord))
|
||||
self.coord.stop_gradient = True
|
||||
|
||||
def forward_single(self, input, target, mask, beta=1.0, eps=1e-6):
|
||||
batch_size = input.shape[0]
|
||||
|
||||
diff = paddle.abs(input - target) * mask.unsqueeze(1)
|
||||
loss = paddle.where(diff < beta, 0.5 * diff * diff / beta,
|
||||
diff - 0.5 * beta)
|
||||
loss = paddle.cast(loss.reshape((batch_size, -1)), "float32")
|
||||
mask = paddle.cast(mask.reshape((batch_size, -1)), "float32")
|
||||
loss = paddle.sum(loss, axis=-1)
|
||||
loss = loss / (mask.sum(axis=-1) + eps)
|
||||
|
||||
return loss
|
||||
|
||||
def select_single(self, distance, gt_instance, gt_kernel_instance,
|
||||
training_mask):
|
||||
|
||||
with paddle.no_grad():
|
||||
# paddle 2.3.1, paddle.slice not support:
|
||||
# distance[:, self.coord[:, 1], self.coord[:, 0]]
|
||||
select_distance_list = []
|
||||
for i in range(2):
|
||||
tmp1 = distance[i, :]
|
||||
tmp2 = tmp1[self.coord[:, 1], self.coord[:, 0]]
|
||||
select_distance_list.append(tmp2.unsqueeze(0))
|
||||
select_distance = paddle.concat(select_distance_list, axis=0)
|
||||
|
||||
off_points = paddle.cast(
|
||||
self.coord, "float32") + 10 * select_distance.transpose((1, 0))
|
||||
|
||||
off_points = paddle.cast(off_points, "int64")
|
||||
off_points = paddle.clip(off_points, 0, distance.shape[-1] - 1)
|
||||
|
||||
selected_mask = (
|
||||
gt_instance[self.coord[:, 1], self.coord[:, 0]] !=
|
||||
gt_kernel_instance[off_points[:, 1], off_points[:, 0]])
|
||||
selected_mask = paddle.cast(
|
||||
selected_mask.reshape((1, -1, distance.shape[-1])), "int64")
|
||||
selected_training_mask = selected_mask * training_mask
|
||||
|
||||
return selected_training_mask
|
||||
|
||||
def forward(self,
|
||||
distances,
|
||||
gt_instances,
|
||||
gt_kernel_instances,
|
||||
training_masks,
|
||||
gt_distances,
|
||||
reduce=True):
|
||||
|
||||
selected_training_masks = []
|
||||
for i in range(distances.shape[0]):
|
||||
selected_training_masks.append(
|
||||
self.select_single(distances[i, :, :, :], gt_instances[i, :, :],
|
||||
gt_kernel_instances[i, :, :], training_masks[
|
||||
i, :, :]))
|
||||
selected_training_masks = paddle.cast(
|
||||
paddle.concat(selected_training_masks, 0), "float32")
|
||||
|
||||
loss = self.forward_single(distances, gt_distances,
|
||||
selected_training_masks, self.beta)
|
||||
loss = self.loss_weight * loss
|
||||
|
||||
with paddle.no_grad():
|
||||
batch_size = distances.shape[0]
|
||||
false_num = selected_training_masks.reshape((batch_size, -1))
|
||||
false_num = false_num.sum(axis=-1)
|
||||
total_num = paddle.cast(
|
||||
training_masks.reshape((batch_size, -1)), "float32")
|
||||
total_num = total_num.sum(axis=-1)
|
||||
iou_text = (total_num - false_num) / (total_num + 1e-6)
|
||||
|
||||
if reduce:
|
||||
loss = paddle.mean(loss)
|
||||
|
||||
return loss, iou_text
|
||||
|
||||
|
||||
class CTLoss(nn.Layer):
|
||||
def __init__(self):
|
||||
super(CTLoss, self).__init__()
|
||||
self.kernel_loss = DiceLoss()
|
||||
self.loc_loss = SmoothL1Loss(beta=0.1, loss_weight=0.05)
|
||||
|
||||
def forward(self, preds, batch):
|
||||
imgs = batch[0]
|
||||
out = preds['maps']
|
||||
gt_kernels, training_masks, gt_instances, gt_kernel_instances, training_mask_distances, gt_distances = batch[
|
||||
1:]
|
||||
|
||||
kernels = out[:, 0, :, :]
|
||||
distances = out[:, 1:, :, :]
|
||||
|
||||
# kernel loss
|
||||
selected_masks = ohem_batch(kernels, gt_kernels, training_masks)
|
||||
|
||||
loss_kernel = self.kernel_loss(
|
||||
kernels, gt_kernels, selected_masks, reduce=False)
|
||||
|
||||
iou_kernel = iou(paddle.cast((kernels > 0), "int64"),
|
||||
gt_kernels,
|
||||
training_masks,
|
||||
reduce=False)
|
||||
losses = dict(loss_kernels=loss_kernel, )
|
||||
|
||||
# loc loss
|
||||
loss_loc, iou_text = self.loc_loss(
|
||||
distances,
|
||||
gt_instances,
|
||||
gt_kernel_instances,
|
||||
training_mask_distances,
|
||||
gt_distances,
|
||||
reduce=False)
|
||||
losses.update(dict(loss_loc=loss_loc, ))
|
||||
|
||||
loss_all = loss_kernel + loss_loc
|
||||
losses = {'loss': loss_all}
|
||||
|
||||
return losses
|
||||
|
|
@ -417,11 +417,13 @@ class DistillationVQADistanceLoss(DistanceLoss):
|
|||
mode="l2",
|
||||
model_name_pairs=[],
|
||||
key=None,
|
||||
index=None,
|
||||
name="loss_distance",
|
||||
**kargs):
|
||||
super().__init__(mode=mode, **kargs)
|
||||
assert isinstance(model_name_pairs, list)
|
||||
self.key = key
|
||||
self.index = index
|
||||
self.model_name_pairs = model_name_pairs
|
||||
self.name = name + "_l2"
|
||||
|
||||
|
|
@ -434,6 +436,9 @@ class DistillationVQADistanceLoss(DistanceLoss):
|
|||
if self.key is not None:
|
||||
out1 = out1[self.key]
|
||||
out2 = out2[self.key]
|
||||
if self.index is not None:
|
||||
out1 = out1[:, self.index, :, :]
|
||||
out2 = out2[:, self.index, :, :]
|
||||
if attention_mask is not None:
|
||||
max_len = attention_mask.shape[-1]
|
||||
out1 = out1[:, :max_len]
|
||||
|
|
|
|||
|
|
@ -89,12 +89,13 @@ class PGLoss(nn.Layer):
|
|||
tcl_pos = paddle.reshape(tcl_pos, [-1, 3])
|
||||
tcl_pos = paddle.cast(tcl_pos, dtype=int)
|
||||
f_tcl_char = paddle.gather_nd(f_char, tcl_pos)
|
||||
f_tcl_char = paddle.reshape(f_tcl_char,
|
||||
[-1, 64, 37]) # len(Lexicon_Table)+1
|
||||
f_tcl_char_fg, f_tcl_char_bg = paddle.split(f_tcl_char, [36, 1], axis=2)
|
||||
f_tcl_char = paddle.reshape(
|
||||
f_tcl_char, [-1, 64, self.pad_num + 1]) # len(Lexicon_Table)+1
|
||||
f_tcl_char_fg, f_tcl_char_bg = paddle.split(
|
||||
f_tcl_char, [self.pad_num, 1], axis=2)
|
||||
f_tcl_char_bg = f_tcl_char_bg * tcl_mask + (1.0 - tcl_mask) * 20.0
|
||||
b, c, l = tcl_mask.shape
|
||||
tcl_mask_fg = paddle.expand(x=tcl_mask, shape=[b, c, 36 * l])
|
||||
tcl_mask_fg = paddle.expand(x=tcl_mask, shape=[b, c, self.pad_num * l])
|
||||
tcl_mask_fg.stop_gradient = True
|
||||
f_tcl_char_fg = f_tcl_char_fg * tcl_mask_fg + (1.0 - tcl_mask_fg) * (
|
||||
-20.0)
|
||||
|
|
|
|||
|
|
@ -31,12 +31,14 @@ from .kie_metric import KIEMetric
|
|||
from .vqa_token_ser_metric import VQASerTokenMetric
|
||||
from .vqa_token_re_metric import VQAReTokenMetric
|
||||
from .sr_metric import SRMetric
|
||||
from .ct_metric import CTMetric
|
||||
|
||||
|
||||
def build_metric(config):
|
||||
support_dict = [
|
||||
"DetMetric", "DetFCEMetric", "RecMetric", "ClsMetric", "E2EMetric",
|
||||
"DistillationMetric", "TableMetric", 'KIEMetric', 'VQASerTokenMetric',
|
||||
'VQAReTokenMetric', 'SRMetric'
|
||||
'VQAReTokenMetric', 'SRMetric', 'CTMetric'
|
||||
]
|
||||
|
||||
config = copy.deepcopy(config)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,52 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
from scipy import io
|
||||
import numpy as np
|
||||
|
||||
from ppocr.utils.e2e_metric.Deteval import combine_results, get_score_C
|
||||
|
||||
|
||||
class CTMetric(object):
|
||||
def __init__(self, main_indicator, delimiter='\t', **kwargs):
|
||||
self.delimiter = delimiter
|
||||
self.main_indicator = main_indicator
|
||||
self.reset()
|
||||
|
||||
def reset(self):
|
||||
self.results = [] # clear results
|
||||
|
||||
def __call__(self, preds, batch, **kwargs):
|
||||
# NOTE: only support bs=1 now, as the label length of different sample is Unequal
|
||||
assert len(
|
||||
preds) == 1, "CentripetalText test now only suuport batch_size=1."
|
||||
label = batch[2]
|
||||
text = batch[3]
|
||||
pred = preds[0]['points']
|
||||
result = get_score_C(label, text, pred)
|
||||
|
||||
self.results.append(result)
|
||||
|
||||
def get_metric(self):
|
||||
"""
|
||||
Input format: y0,x0, ..... yn,xn. Each detection is separated by the end of line token ('\n')'
|
||||
"""
|
||||
metrics = combine_results(self.results, rec_flag=False)
|
||||
self.reset()
|
||||
return metrics
|
||||
|
|
@ -37,23 +37,25 @@ class VQAReTokenMetric(object):
|
|||
gt_relations = []
|
||||
for b in range(len(self.relations_list)):
|
||||
rel_sent = []
|
||||
if "head" in self.relations_list[b]:
|
||||
for head, tail in zip(self.relations_list[b]["head"],
|
||||
self.relations_list[b]["tail"]):
|
||||
relation_list = self.relations_list[b]
|
||||
entitie_list = self.entities_list[b]
|
||||
head_len = relation_list[0, 0]
|
||||
if head_len > 0:
|
||||
entitie_start_list = entitie_list[1:entitie_list[0, 0] + 1, 0]
|
||||
entitie_end_list = entitie_list[1:entitie_list[0, 1] + 1, 1]
|
||||
entitie_label_list = entitie_list[1:entitie_list[0, 2] + 1, 2]
|
||||
for head, tail in zip(relation_list[1:head_len + 1, 0],
|
||||
relation_list[1:head_len + 1, 1]):
|
||||
rel = {}
|
||||
rel["head_id"] = head
|
||||
rel["head"] = (
|
||||
self.entities_list[b]["start"][rel["head_id"]],
|
||||
self.entities_list[b]["end"][rel["head_id"]])
|
||||
rel["head_type"] = self.entities_list[b]["label"][rel[
|
||||
"head_id"]]
|
||||
rel["head"] = (entitie_start_list[head],
|
||||
entitie_end_list[head])
|
||||
rel["head_type"] = entitie_label_list[head]
|
||||
|
||||
rel["tail_id"] = tail
|
||||
rel["tail"] = (
|
||||
self.entities_list[b]["start"][rel["tail_id"]],
|
||||
self.entities_list[b]["end"][rel["tail_id"]])
|
||||
rel["tail_type"] = self.entities_list[b]["label"][rel[
|
||||
"tail_id"]]
|
||||
rel["tail"] = (entitie_start_list[tail],
|
||||
entitie_end_list[tail])
|
||||
rel["tail_type"] = entitie_label_list[tail]
|
||||
|
||||
rel["type"] = 1
|
||||
rel_sent.append(rel)
|
||||
|
|
|
|||
|
|
@ -218,8 +218,12 @@ class LayoutXLMForRe(NLPBaseModel):
|
|||
def forward(self, x):
|
||||
if self.use_visual_backbone is True:
|
||||
image = x[4]
|
||||
entities = x[5]
|
||||
relations = x[6]
|
||||
else:
|
||||
image = None
|
||||
entities = x[4]
|
||||
relations = x[5]
|
||||
x = self.model(
|
||||
input_ids=x[0],
|
||||
bbox=x[1],
|
||||
|
|
@ -229,6 +233,6 @@ class LayoutXLMForRe(NLPBaseModel):
|
|||
position_ids=None,
|
||||
head_mask=None,
|
||||
labels=None,
|
||||
entities=x[5],
|
||||
relations=x[6])
|
||||
entities=entities,
|
||||
relations=relations)
|
||||
return x
|
||||
|
|
|
|||
|
|
@ -23,6 +23,7 @@ def build_head(config):
|
|||
from .det_pse_head import PSEHead
|
||||
from .det_fce_head import FCEHead
|
||||
from .e2e_pg_head import PGHead
|
||||
from .det_ct_head import CT_Head
|
||||
|
||||
# rec head
|
||||
from .rec_ctc_head import CTCHead
|
||||
|
|
@ -52,7 +53,7 @@ def build_head(config):
|
|||
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
|
||||
'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
|
||||
'MultiHead', 'ABINetHead', 'TableMasterHead', 'SPINAttentionHead',
|
||||
'VLHead', 'SLAHead', 'RobustScannerHead'
|
||||
'VLHead', 'SLAHead', 'RobustScannerHead', 'CT_Head'
|
||||
]
|
||||
|
||||
#table head
|
||||
|
|
|
|||
|
|
@ -0,0 +1,69 @@
|
|||
# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import math
|
||||
import paddle
|
||||
from paddle import nn
|
||||
import paddle.nn.functional as F
|
||||
from paddle import ParamAttr
|
||||
|
||||
import math
|
||||
from paddle.nn.initializer import TruncatedNormal, Constant, Normal
|
||||
ones_ = Constant(value=1.)
|
||||
zeros_ = Constant(value=0.)
|
||||
|
||||
|
||||
class CT_Head(nn.Layer):
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
hidden_dim,
|
||||
num_classes,
|
||||
loss_kernel=None,
|
||||
loss_loc=None):
|
||||
super(CT_Head, self).__init__()
|
||||
self.conv1 = nn.Conv2D(
|
||||
in_channels, hidden_dim, kernel_size=3, stride=1, padding=1)
|
||||
self.bn1 = nn.BatchNorm2D(hidden_dim)
|
||||
self.relu1 = nn.ReLU()
|
||||
|
||||
self.conv2 = nn.Conv2D(
|
||||
hidden_dim, num_classes, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
for m in self.sublayers():
|
||||
if isinstance(m, nn.Conv2D):
|
||||
n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
|
||||
normal_ = Normal(mean=0.0, std=math.sqrt(2. / n))
|
||||
normal_(m.weight)
|
||||
elif isinstance(m, nn.BatchNorm2D):
|
||||
zeros_(m.bias)
|
||||
ones_(m.weight)
|
||||
|
||||
def _upsample(self, x, scale=1):
|
||||
return F.upsample(x, scale_factor=scale, mode='bilinear')
|
||||
|
||||
def forward(self, f, targets=None):
|
||||
out = self.conv1(f)
|
||||
out = self.relu1(self.bn1(out))
|
||||
out = self.conv2(out)
|
||||
|
||||
if self.training:
|
||||
out = self._upsample(out, scale=4)
|
||||
return {'maps': out}
|
||||
else:
|
||||
score = F.sigmoid(out[:, 0, :, :])
|
||||
return {'maps': out, 'score': score}
|
||||
|
|
@ -66,8 +66,17 @@ class PGHead(nn.Layer):
|
|||
"""
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels, **kwargs):
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
character_dict_path='ppocr/utils/ic15_dict.txt',
|
||||
**kwargs):
|
||||
super(PGHead, self).__init__()
|
||||
|
||||
# get character_length
|
||||
with open(character_dict_path, "rb") as fin:
|
||||
lines = fin.readlines()
|
||||
character_length = len(lines) + 1
|
||||
|
||||
self.conv_f_score1 = ConvBNLayer(
|
||||
in_channels=in_channels,
|
||||
out_channels=64,
|
||||
|
|
@ -178,7 +187,7 @@ class PGHead(nn.Layer):
|
|||
name="conv_f_char{}".format(5))
|
||||
self.conv3 = nn.Conv2D(
|
||||
in_channels=256,
|
||||
out_channels=37,
|
||||
out_channels=character_length,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
|
|
|
|||
|
|
@ -16,6 +16,7 @@ from __future__ import absolute_import
|
|||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import math
|
||||
import paddle
|
||||
import paddle.nn as nn
|
||||
from paddle import ParamAttr
|
||||
|
|
@ -42,7 +43,6 @@ class TableAttentionHead(nn.Layer):
|
|||
def __init__(self,
|
||||
in_channels,
|
||||
hidden_size,
|
||||
loc_type,
|
||||
in_max_len=488,
|
||||
max_text_length=800,
|
||||
out_channels=30,
|
||||
|
|
@ -57,20 +57,16 @@ class TableAttentionHead(nn.Layer):
|
|||
self.structure_attention_cell = AttentionGRUCell(
|
||||
self.input_size, hidden_size, self.out_channels, use_gru=False)
|
||||
self.structure_generator = nn.Linear(hidden_size, self.out_channels)
|
||||
self.loc_type = loc_type
|
||||
self.in_max_len = in_max_len
|
||||
|
||||
if self.loc_type == 1:
|
||||
self.loc_generator = nn.Linear(hidden_size, 4)
|
||||
if self.in_max_len == 640:
|
||||
self.loc_fea_trans = nn.Linear(400, self.max_text_length + 1)
|
||||
elif self.in_max_len == 800:
|
||||
self.loc_fea_trans = nn.Linear(625, self.max_text_length + 1)
|
||||
else:
|
||||
if self.in_max_len == 640:
|
||||
self.loc_fea_trans = nn.Linear(400, self.max_text_length + 1)
|
||||
elif self.in_max_len == 800:
|
||||
self.loc_fea_trans = nn.Linear(625, self.max_text_length + 1)
|
||||
else:
|
||||
self.loc_fea_trans = nn.Linear(256, self.max_text_length + 1)
|
||||
self.loc_generator = nn.Linear(self.input_size + hidden_size,
|
||||
loc_reg_num)
|
||||
self.loc_fea_trans = nn.Linear(256, self.max_text_length + 1)
|
||||
self.loc_generator = nn.Linear(self.input_size + hidden_size,
|
||||
loc_reg_num)
|
||||
|
||||
def _char_to_onehot(self, input_char, onehot_dim):
|
||||
input_ont_hot = F.one_hot(input_char, onehot_dim)
|
||||
|
|
@ -80,16 +76,13 @@ class TableAttentionHead(nn.Layer):
|
|||
# if and else branch are both needed when you want to assign a variable
|
||||
# if you modify the var in just one branch, then the modification will not work.
|
||||
fea = inputs[-1]
|
||||
if len(fea.shape) == 3:
|
||||
pass
|
||||
else:
|
||||
last_shape = int(np.prod(fea.shape[2:])) # gry added
|
||||
fea = paddle.reshape(fea, [fea.shape[0], fea.shape[1], last_shape])
|
||||
fea = fea.transpose([0, 2, 1]) # (NTC)(batch, width, channels)
|
||||
last_shape = int(np.prod(fea.shape[2:])) # gry added
|
||||
fea = paddle.reshape(fea, [fea.shape[0], fea.shape[1], last_shape])
|
||||
fea = fea.transpose([0, 2, 1]) # (NTC)(batch, width, channels)
|
||||
batch_size = fea.shape[0]
|
||||
|
||||
hidden = paddle.zeros((batch_size, self.hidden_size))
|
||||
output_hiddens = []
|
||||
output_hiddens = paddle.zeros((batch_size, self.max_text_length + 1, self.hidden_size))
|
||||
if self.training and targets is not None:
|
||||
structure = targets[0]
|
||||
for i in range(self.max_text_length + 1):
|
||||
|
|
@ -97,7 +90,8 @@ class TableAttentionHead(nn.Layer):
|
|||
structure[:, i], onehot_dim=self.out_channels)
|
||||
(outputs, hidden), alpha = self.structure_attention_cell(
|
||||
hidden, fea, elem_onehots)
|
||||
output_hiddens.append(paddle.unsqueeze(outputs, axis=1))
|
||||
output_hiddens[:, i, :] = outputs
|
||||
# output_hiddens.append(paddle.unsqueeze(outputs, axis=1))
|
||||
output = paddle.concat(output_hiddens, axis=1)
|
||||
structure_probs = self.structure_generator(output)
|
||||
if self.loc_type == 1:
|
||||
|
|
@ -118,30 +112,25 @@ class TableAttentionHead(nn.Layer):
|
|||
outputs = None
|
||||
alpha = None
|
||||
max_text_length = paddle.to_tensor(self.max_text_length)
|
||||
i = 0
|
||||
while i < max_text_length + 1:
|
||||
for i in range(max_text_length + 1):
|
||||
elem_onehots = self._char_to_onehot(
|
||||
temp_elem, onehot_dim=self.out_channels)
|
||||
(outputs, hidden), alpha = self.structure_attention_cell(
|
||||
hidden, fea, elem_onehots)
|
||||
output_hiddens.append(paddle.unsqueeze(outputs, axis=1))
|
||||
output_hiddens[:, i, :] = outputs
|
||||
# output_hiddens.append(paddle.unsqueeze(outputs, axis=1))
|
||||
structure_probs_step = self.structure_generator(outputs)
|
||||
temp_elem = structure_probs_step.argmax(axis=1, dtype="int32")
|
||||
i += 1
|
||||
|
||||
output = paddle.concat(output_hiddens, axis=1)
|
||||
output = output_hiddens
|
||||
structure_probs = self.structure_generator(output)
|
||||
structure_probs = F.softmax(structure_probs)
|
||||
if self.loc_type == 1:
|
||||
loc_preds = self.loc_generator(output)
|
||||
loc_preds = F.sigmoid(loc_preds)
|
||||
else:
|
||||
loc_fea = fea.transpose([0, 2, 1])
|
||||
loc_fea = self.loc_fea_trans(loc_fea)
|
||||
loc_fea = loc_fea.transpose([0, 2, 1])
|
||||
loc_concat = paddle.concat([output, loc_fea], axis=2)
|
||||
loc_preds = self.loc_generator(loc_concat)
|
||||
loc_preds = F.sigmoid(loc_preds)
|
||||
loc_fea = fea.transpose([0, 2, 1])
|
||||
loc_fea = self.loc_fea_trans(loc_fea)
|
||||
loc_fea = loc_fea.transpose([0, 2, 1])
|
||||
loc_concat = paddle.concat([output, loc_fea], axis=2)
|
||||
loc_preds = self.loc_generator(loc_concat)
|
||||
loc_preds = F.sigmoid(loc_preds)
|
||||
return {'structure_probs': structure_probs, 'loc_preds': loc_preds}
|
||||
|
||||
|
||||
|
|
@ -166,6 +155,7 @@ class SLAHead(nn.Layer):
|
|||
self.max_text_length = max_text_length
|
||||
self.emb = self._char_to_onehot
|
||||
self.num_embeddings = out_channels
|
||||
self.loc_reg_num = loc_reg_num
|
||||
|
||||
# structure
|
||||
self.structure_attention_cell = AttentionGRUCell(
|
||||
|
|
@ -213,15 +203,17 @@ class SLAHead(nn.Layer):
|
|||
fea = fea.transpose([0, 2, 1]) # (NTC)(batch, width, channels)
|
||||
|
||||
hidden = paddle.zeros((batch_size, self.hidden_size))
|
||||
structure_preds = []
|
||||
loc_preds = []
|
||||
structure_preds = paddle.zeros((batch_size, self.max_text_length + 1, self.num_embeddings))
|
||||
loc_preds = paddle.zeros((batch_size, self.max_text_length + 1, self.loc_reg_num))
|
||||
structure_preds.stop_gradient = True
|
||||
loc_preds.stop_gradient = True
|
||||
if self.training and targets is not None:
|
||||
structure = targets[0]
|
||||
for i in range(self.max_text_length + 1):
|
||||
hidden, structure_step, loc_step = self._decode(structure[:, i],
|
||||
fea, hidden)
|
||||
structure_preds.append(structure_step)
|
||||
loc_preds.append(loc_step)
|
||||
structure_preds[:, i, :] = structure_step
|
||||
loc_preds[:, i, :] = loc_step
|
||||
else:
|
||||
pre_chars = paddle.zeros(shape=[batch_size], dtype="int32")
|
||||
max_text_length = paddle.to_tensor(self.max_text_length)
|
||||
|
|
@ -231,10 +223,8 @@ class SLAHead(nn.Layer):
|
|||
hidden, structure_step, loc_step = self._decode(pre_chars, fea,
|
||||
hidden)
|
||||
pre_chars = structure_step.argmax(axis=1, dtype="int32")
|
||||
structure_preds.append(structure_step)
|
||||
loc_preds.append(loc_step)
|
||||
structure_preds = paddle.stack(structure_preds, axis=1)
|
||||
loc_preds = paddle.stack(loc_preds, axis=1)
|
||||
structure_preds[:, i, :] = structure_step
|
||||
loc_preds[:, i, :] = loc_step
|
||||
if not self.training:
|
||||
structure_preds = F.softmax(structure_preds)
|
||||
return {'structure_probs': structure_preds, 'loc_preds': loc_preds}
|
||||
|
|
|
|||
|
|
@ -26,13 +26,15 @@ def build_neck(config):
|
|||
from .fce_fpn import FCEFPN
|
||||
from .pren_fpn import PRENFPN
|
||||
from .csp_pan import CSPPAN
|
||||
from .ct_fpn import CTFPN
|
||||
support_dict = [
|
||||
'FPN', 'FCEFPN', 'LKPAN', 'DBFPN', 'RSEFPN', 'EASTFPN', 'SASTFPN',
|
||||
'SequenceEncoder', 'PGFPN', 'TableFPN', 'PRENFPN', 'CSPPAN'
|
||||
'SequenceEncoder', 'PGFPN', 'TableFPN', 'PRENFPN', 'CSPPAN', 'CTFPN'
|
||||
]
|
||||
|
||||
module_name = config.pop('name')
|
||||
assert module_name in support_dict, Exception('neck only support {}'.format(
|
||||
support_dict))
|
||||
|
||||
module_class = eval(module_name)(**config)
|
||||
return module_class
|
||||
|
|
|
|||
|
|
@ -0,0 +1,185 @@
|
|||
# copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import paddle
|
||||
from paddle import nn
|
||||
import paddle.nn.functional as F
|
||||
from paddle import ParamAttr
|
||||
import os
|
||||
import sys
|
||||
|
||||
import math
|
||||
from paddle.nn.initializer import TruncatedNormal, Constant, Normal
|
||||
ones_ = Constant(value=1.)
|
||||
zeros_ = Constant(value=0.)
|
||||
|
||||
__dir__ = os.path.dirname(os.path.abspath(__file__))
|
||||
sys.path.append(__dir__)
|
||||
sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '../../..')))
|
||||
|
||||
|
||||
class Conv_BN_ReLU(nn.Layer):
|
||||
def __init__(self,
|
||||
in_planes,
|
||||
out_planes,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0):
|
||||
super(Conv_BN_ReLU, self).__init__()
|
||||
self.conv = nn.Conv2D(
|
||||
in_planes,
|
||||
out_planes,
|
||||
kernel_size=kernel_size,
|
||||
stride=stride,
|
||||
padding=padding,
|
||||
bias_attr=False)
|
||||
self.bn = nn.BatchNorm2D(out_planes)
|
||||
self.relu = nn.ReLU()
|
||||
|
||||
for m in self.sublayers():
|
||||
if isinstance(m, nn.Conv2D):
|
||||
n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
|
||||
normal_ = Normal(mean=0.0, std=math.sqrt(2. / n))
|
||||
normal_(m.weight)
|
||||
elif isinstance(m, nn.BatchNorm2D):
|
||||
zeros_(m.bias)
|
||||
ones_(m.weight)
|
||||
|
||||
def forward(self, x):
|
||||
return self.relu(self.bn(self.conv(x)))
|
||||
|
||||
|
||||
class FPEM(nn.Layer):
|
||||
def __init__(self, in_channels, out_channels):
|
||||
super(FPEM, self).__init__()
|
||||
planes = out_channels
|
||||
self.dwconv3_1 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer3_1 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
self.dwconv2_1 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer2_1 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
self.dwconv1_1 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer1_1 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
self.dwconv2_2 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=2,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer2_2 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
self.dwconv3_2 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=2,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer3_2 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
self.dwconv4_2 = nn.Conv2D(
|
||||
planes,
|
||||
planes,
|
||||
kernel_size=3,
|
||||
stride=2,
|
||||
padding=1,
|
||||
groups=planes,
|
||||
bias_attr=False)
|
||||
self.smooth_layer4_2 = Conv_BN_ReLU(planes, planes)
|
||||
|
||||
def _upsample_add(self, x, y):
|
||||
return F.upsample(x, scale_factor=2, mode='bilinear') + y
|
||||
|
||||
def forward(self, f1, f2, f3, f4):
|
||||
# up-down
|
||||
f3 = self.smooth_layer3_1(self.dwconv3_1(self._upsample_add(f4, f3)))
|
||||
f2 = self.smooth_layer2_1(self.dwconv2_1(self._upsample_add(f3, f2)))
|
||||
f1 = self.smooth_layer1_1(self.dwconv1_1(self._upsample_add(f2, f1)))
|
||||
|
||||
# down-up
|
||||
f2 = self.smooth_layer2_2(self.dwconv2_2(self._upsample_add(f2, f1)))
|
||||
f3 = self.smooth_layer3_2(self.dwconv3_2(self._upsample_add(f3, f2)))
|
||||
f4 = self.smooth_layer4_2(self.dwconv4_2(self._upsample_add(f4, f3)))
|
||||
|
||||
return f1, f2, f3, f4
|
||||
|
||||
|
||||
class CTFPN(nn.Layer):
|
||||
def __init__(self, in_channels, out_channel=128):
|
||||
super(CTFPN, self).__init__()
|
||||
self.out_channels = out_channel * 4
|
||||
|
||||
self.reduce_layer1 = Conv_BN_ReLU(in_channels[0], 128)
|
||||
self.reduce_layer2 = Conv_BN_ReLU(in_channels[1], 128)
|
||||
self.reduce_layer3 = Conv_BN_ReLU(in_channels[2], 128)
|
||||
self.reduce_layer4 = Conv_BN_ReLU(in_channels[3], 128)
|
||||
|
||||
self.fpem1 = FPEM(in_channels=(64, 128, 256, 512), out_channels=128)
|
||||
self.fpem2 = FPEM(in_channels=(64, 128, 256, 512), out_channels=128)
|
||||
|
||||
def _upsample(self, x, scale=1):
|
||||
return F.upsample(x, scale_factor=scale, mode='bilinear')
|
||||
|
||||
def forward(self, f):
|
||||
# # reduce channel
|
||||
f1 = self.reduce_layer1(f[0]) # N,64,160,160 --> N, 128, 160, 160
|
||||
f2 = self.reduce_layer2(f[1]) # N, 128, 80, 80 --> N, 128, 80, 80
|
||||
f3 = self.reduce_layer3(f[2]) # N, 256, 40, 40 --> N, 128, 40, 40
|
||||
f4 = self.reduce_layer4(f[3]) # N, 512, 20, 20 --> N, 128, 20, 20
|
||||
|
||||
# FPEM
|
||||
f1_1, f2_1, f3_1, f4_1 = self.fpem1(f1, f2, f3, f4)
|
||||
f1_2, f2_2, f3_2, f4_2 = self.fpem2(f1_1, f2_1, f3_1, f4_1)
|
||||
|
||||
# FFM
|
||||
f1 = f1_1 + f1_2
|
||||
f2 = f2_1 + f2_2
|
||||
f3 = f3_1 + f3_2
|
||||
f4 = f4_1 + f4_2
|
||||
|
||||
f2 = self._upsample(f2, scale=2)
|
||||
f3 = self._upsample(f3, scale=4)
|
||||
f4 = self._upsample(f4, scale=8)
|
||||
ff = paddle.concat((f1, f2, f3, f4), 1) # N,512, 160,160
|
||||
return ff
|
||||
|
|
@ -35,6 +35,7 @@ from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess,
|
|||
from .vqa_token_re_layoutlm_postprocess import VQAReTokenLayoutLMPostProcess, DistillationRePostProcess
|
||||
from .table_postprocess import TableMasterLabelDecode, TableLabelDecode
|
||||
from .picodet_postprocess import PicoDetPostProcess
|
||||
from .ct_postprocess import CTPostProcess
|
||||
|
||||
|
||||
def build_post_process(config, global_config=None):
|
||||
|
|
@ -48,7 +49,7 @@ def build_post_process(config, global_config=None):
|
|||
'DistillationSARLabelDecode', 'ViTSTRLabelDecode', 'ABINetLabelDecode',
|
||||
'TableMasterLabelDecode', 'SPINLabelDecode',
|
||||
'DistillationSerPostProcess', 'DistillationRePostProcess',
|
||||
'VLLabelDecode', 'PicoDetPostProcess'
|
||||
'VLLabelDecode', 'PicoDetPostProcess', 'CTPostProcess'
|
||||
]
|
||||
|
||||
if config['name'] == 'PSEPostProcess':
|
||||
|
|
|
|||
|
|
@ -0,0 +1,154 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
This code is refered from:
|
||||
https://github.com/shengtao96/CentripetalText/blob/main/test.py
|
||||
"""
|
||||
|
||||
from __future__ import absolute_import
|
||||
from __future__ import division
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import os.path as osp
|
||||
import numpy as np
|
||||
import cv2
|
||||
import paddle
|
||||
import pyclipper
|
||||
|
||||
|
||||
class CTPostProcess(object):
|
||||
"""
|
||||
The post process for Centripetal Text (CT).
|
||||
"""
|
||||
|
||||
def __init__(self, min_score=0.88, min_area=16, box_type='poly', **kwargs):
|
||||
self.min_score = min_score
|
||||
self.min_area = min_area
|
||||
self.box_type = box_type
|
||||
|
||||
self.coord = np.zeros((2, 300, 300), dtype=np.int32)
|
||||
for i in range(300):
|
||||
for j in range(300):
|
||||
self.coord[0, i, j] = j
|
||||
self.coord[1, i, j] = i
|
||||
|
||||
def __call__(self, preds, batch):
|
||||
outs = preds['maps']
|
||||
out_scores = preds['score']
|
||||
|
||||
if isinstance(outs, paddle.Tensor):
|
||||
outs = outs.numpy()
|
||||
if isinstance(out_scores, paddle.Tensor):
|
||||
out_scores = out_scores.numpy()
|
||||
|
||||
batch_size = outs.shape[0]
|
||||
boxes_batch = []
|
||||
for idx in range(batch_size):
|
||||
bboxes = []
|
||||
scores = []
|
||||
|
||||
img_shape = batch[idx]
|
||||
|
||||
org_img_size = img_shape[:3]
|
||||
img_shape = img_shape[3:]
|
||||
img_size = img_shape[:2]
|
||||
|
||||
out = np.expand_dims(outs[idx], axis=0)
|
||||
outputs = dict()
|
||||
|
||||
score = np.expand_dims(out_scores[idx], axis=0)
|
||||
|
||||
kernel = out[:, 0, :, :] > 0.2
|
||||
loc = out[:, 1:, :, :].astype("float32")
|
||||
|
||||
score = score[0].astype(np.float32)
|
||||
kernel = kernel[0].astype(np.uint8)
|
||||
loc = loc[0].astype(np.float32)
|
||||
|
||||
label_num, label_kernel = cv2.connectedComponents(
|
||||
kernel, connectivity=4)
|
||||
|
||||
for i in range(1, label_num):
|
||||
ind = (label_kernel == i)
|
||||
if ind.sum(
|
||||
) < 10: # pixel number less than 10, treated as background
|
||||
label_kernel[ind] = 0
|
||||
|
||||
label = np.zeros_like(label_kernel)
|
||||
h, w = label_kernel.shape
|
||||
pixels = self.coord[:, :h, :w].reshape(2, -1)
|
||||
points = pixels.transpose([1, 0]).astype(np.float32)
|
||||
|
||||
off_points = (points + 10. / 4. * loc[:, pixels[1], pixels[0]].T
|
||||
).astype(np.int32)
|
||||
off_points[:, 0] = np.clip(off_points[:, 0], 0, label.shape[1] - 1)
|
||||
off_points[:, 1] = np.clip(off_points[:, 1], 0, label.shape[0] - 1)
|
||||
|
||||
label[pixels[1], pixels[0]] = label_kernel[off_points[:, 1],
|
||||
off_points[:, 0]]
|
||||
label[label_kernel > 0] = label_kernel[label_kernel > 0]
|
||||
|
||||
score_pocket = [0.0]
|
||||
for i in range(1, label_num):
|
||||
ind = (label_kernel == i)
|
||||
if ind.sum() == 0:
|
||||
score_pocket.append(0.0)
|
||||
continue
|
||||
score_i = np.mean(score[ind])
|
||||
score_pocket.append(score_i)
|
||||
|
||||
label_num = np.max(label) + 1
|
||||
label = cv2.resize(
|
||||
label, (img_size[1], img_size[0]),
|
||||
interpolation=cv2.INTER_NEAREST)
|
||||
|
||||
scale = (float(org_img_size[1]) / float(img_size[1]),
|
||||
float(org_img_size[0]) / float(img_size[0]))
|
||||
|
||||
for i in range(1, label_num):
|
||||
ind = (label == i)
|
||||
points = np.array(np.where(ind)).transpose((1, 0))
|
||||
|
||||
if points.shape[0] < self.min_area:
|
||||
continue
|
||||
|
||||
score_i = score_pocket[i]
|
||||
if score_i < self.min_score:
|
||||
continue
|
||||
|
||||
if self.box_type == 'rect':
|
||||
rect = cv2.minAreaRect(points[:, ::-1])
|
||||
bbox = cv2.boxPoints(rect) * scale
|
||||
z = bbox.mean(0)
|
||||
bbox = z + (bbox - z) * 0.85
|
||||
elif self.box_type == 'poly':
|
||||
binary = np.zeros(label.shape, dtype='uint8')
|
||||
binary[ind] = 1
|
||||
try:
|
||||
_, contours, _ = cv2.findContours(
|
||||
binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
except BaseException:
|
||||
contours, _ = cv2.findContours(
|
||||
binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
|
||||
bbox = contours[0] * scale
|
||||
|
||||
bbox = bbox.astype('int32')
|
||||
bboxes.append(bbox.reshape(-1, 2))
|
||||
scores.append(score_i)
|
||||
|
||||
boxes_batch.append({'points': bboxes})
|
||||
|
||||
return boxes_batch
|
||||
|
|
@ -30,12 +30,18 @@ class PGPostProcess(object):
|
|||
The post process for PGNet.
|
||||
"""
|
||||
|
||||
def __init__(self, character_dict_path, valid_set, score_thresh, mode,
|
||||
def __init__(self,
|
||||
character_dict_path,
|
||||
valid_set,
|
||||
score_thresh,
|
||||
mode,
|
||||
point_gather_mode=None,
|
||||
**kwargs):
|
||||
self.character_dict_path = character_dict_path
|
||||
self.valid_set = valid_set
|
||||
self.score_thresh = score_thresh
|
||||
self.mode = mode
|
||||
self.point_gather_mode = point_gather_mode
|
||||
|
||||
# c++ la-nms is faster, but only support python 3.5
|
||||
self.is_python35 = False
|
||||
|
|
@ -43,8 +49,13 @@ class PGPostProcess(object):
|
|||
self.is_python35 = True
|
||||
|
||||
def __call__(self, outs_dict, shape_list):
|
||||
post = PGNet_PostProcess(self.character_dict_path, self.valid_set,
|
||||
self.score_thresh, outs_dict, shape_list)
|
||||
post = PGNet_PostProcess(
|
||||
self.character_dict_path,
|
||||
self.valid_set,
|
||||
self.score_thresh,
|
||||
outs_dict,
|
||||
shape_list,
|
||||
point_gather_mode=self.point_gather_mode)
|
||||
if self.mode == 'fast':
|
||||
data = post.pg_postprocess_fast()
|
||||
else:
|
||||
|
|
|
|||
|
|
@ -21,18 +21,22 @@ class VQAReTokenLayoutLMPostProcess(object):
|
|||
super(VQAReTokenLayoutLMPostProcess, self).__init__()
|
||||
|
||||
def __call__(self, preds, label=None, *args, **kwargs):
|
||||
pred_relations = preds['pred_relations']
|
||||
if isinstance(preds['pred_relations'], paddle.Tensor):
|
||||
pred_relations = pred_relations.numpy()
|
||||
pred_relations = self.decode_pred(pred_relations)
|
||||
|
||||
if label is not None:
|
||||
return self._metric(preds, label)
|
||||
return self._metric(pred_relations, label)
|
||||
else:
|
||||
return self._infer(preds, *args, **kwargs)
|
||||
return self._infer(pred_relations, *args, **kwargs)
|
||||
|
||||
def _metric(self, preds, label):
|
||||
return preds['pred_relations'], label[6], label[5]
|
||||
def _metric(self, pred_relations, label):
|
||||
return pred_relations, label[-1], label[-2]
|
||||
|
||||
def _infer(self, preds, *args, **kwargs):
|
||||
def _infer(self, pred_relations, *args, **kwargs):
|
||||
ser_results = kwargs['ser_results']
|
||||
entity_idx_dict_batch = kwargs['entity_idx_dict_batch']
|
||||
pred_relations = preds['pred_relations']
|
||||
|
||||
# merge relations and ocr info
|
||||
results = []
|
||||
|
|
@ -50,6 +54,24 @@ class VQAReTokenLayoutLMPostProcess(object):
|
|||
results.append(result)
|
||||
return results
|
||||
|
||||
def decode_pred(self, pred_relations):
|
||||
pred_relations_new = []
|
||||
for pred_relation in pred_relations:
|
||||
pred_relation_new = []
|
||||
pred_relation = pred_relation[1:pred_relation[0, 0, 0] + 1]
|
||||
for relation in pred_relation:
|
||||
relation_new = dict()
|
||||
relation_new['head_id'] = relation[0, 0]
|
||||
relation_new['head'] = tuple(relation[1])
|
||||
relation_new['head_type'] = relation[2, 0]
|
||||
relation_new['tail_id'] = relation[3, 0]
|
||||
relation_new['tail'] = tuple(relation[4])
|
||||
relation_new['tail_type'] = relation[5, 0]
|
||||
relation_new['type'] = relation[6, 0]
|
||||
pred_relation_new.append(relation_new)
|
||||
pred_relations_new.append(pred_relation_new)
|
||||
return pred_relations_new
|
||||
|
||||
|
||||
class DistillationRePostProcess(VQAReTokenLayoutLMPostProcess):
|
||||
"""
|
||||
|
|
|
|||
|
|
@ -12,8 +12,10 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import json
|
||||
import numpy as np
|
||||
import scipy.io as io
|
||||
import Polygon as plg
|
||||
from ppocr.utils.e2e_metric.polygon_fast import iod, area_of_intersection, area
|
||||
|
||||
|
||||
|
|
@ -269,7 +271,124 @@ def get_socre_B(gt_dir, img_id, pred_dict):
|
|||
return single_data
|
||||
|
||||
|
||||
def combine_results(all_data):
|
||||
def get_score_C(gt_label, text, pred_bboxes):
|
||||
"""
|
||||
get score for CentripetalText (CT) prediction.
|
||||
"""
|
||||
|
||||
def gt_reading_mod(gt_label, text):
|
||||
"""This helper reads groundtruths from mat files"""
|
||||
groundtruths = []
|
||||
nbox = len(gt_label)
|
||||
for i in range(nbox):
|
||||
label = {"transcription": text[i][0], "points": gt_label[i].numpy()}
|
||||
groundtruths.append(label)
|
||||
|
||||
return groundtruths
|
||||
|
||||
def get_union(pD, pG):
|
||||
areaA = pD.area()
|
||||
areaB = pG.area()
|
||||
return areaA + areaB - get_intersection(pD, pG)
|
||||
|
||||
def get_intersection(pD, pG):
|
||||
pInt = pD & pG
|
||||
if len(pInt) == 0:
|
||||
return 0
|
||||
return pInt.area()
|
||||
|
||||
def detection_filtering(detections, groundtruths, threshold=0.5):
|
||||
for gt in groundtruths:
|
||||
point_num = gt['points'].shape[1] // 2
|
||||
if gt['transcription'] == '###' and (point_num > 1):
|
||||
gt_p = np.array(gt['points']).reshape(point_num,
|
||||
2).astype('int32')
|
||||
gt_p = plg.Polygon(gt_p)
|
||||
|
||||
for det_id, detection in enumerate(detections):
|
||||
det_y = detection[0::2]
|
||||
det_x = detection[1::2]
|
||||
|
||||
det_p = np.concatenate((np.array(det_x), np.array(det_y)))
|
||||
det_p = det_p.reshape(2, -1).transpose()
|
||||
det_p = plg.Polygon(det_p)
|
||||
|
||||
try:
|
||||
det_gt_iou = get_intersection(det_p,
|
||||
gt_p) / det_p.area()
|
||||
except:
|
||||
print(det_x, det_y, gt_p)
|
||||
if det_gt_iou > threshold:
|
||||
detections[det_id] = []
|
||||
|
||||
detections[:] = [item for item in detections if item != []]
|
||||
return detections
|
||||
|
||||
def sigma_calculation(det_p, gt_p):
|
||||
"""
|
||||
sigma = inter_area / gt_area
|
||||
"""
|
||||
if gt_p.area() == 0.:
|
||||
return 0
|
||||
return get_intersection(det_p, gt_p) / gt_p.area()
|
||||
|
||||
def tau_calculation(det_p, gt_p):
|
||||
"""
|
||||
tau = inter_area / det_area
|
||||
"""
|
||||
if det_p.area() == 0.:
|
||||
return 0
|
||||
return get_intersection(det_p, gt_p) / det_p.area()
|
||||
|
||||
detections = []
|
||||
|
||||
for item in pred_bboxes:
|
||||
detections.append(item[:, ::-1].reshape(-1))
|
||||
|
||||
groundtruths = gt_reading_mod(gt_label, text)
|
||||
|
||||
detections = detection_filtering(
|
||||
detections, groundtruths) # filters detections overlapping with DC area
|
||||
|
||||
for idx in range(len(groundtruths) - 1, -1, -1):
|
||||
#NOTE: source code use 'orin' to indicate '#', here we use 'anno',
|
||||
# which may cause slight drop in fscore, about 0.12
|
||||
if groundtruths[idx]['transcription'] == '###':
|
||||
groundtruths.pop(idx)
|
||||
|
||||
local_sigma_table = np.zeros((len(groundtruths), len(detections)))
|
||||
local_tau_table = np.zeros((len(groundtruths), len(detections)))
|
||||
|
||||
for gt_id, gt in enumerate(groundtruths):
|
||||
if len(detections) > 0:
|
||||
for det_id, detection in enumerate(detections):
|
||||
point_num = gt['points'].shape[1] // 2
|
||||
|
||||
gt_p = np.array(gt['points']).reshape(point_num,
|
||||
2).astype('int32')
|
||||
gt_p = plg.Polygon(gt_p)
|
||||
|
||||
det_y = detection[0::2]
|
||||
det_x = detection[1::2]
|
||||
|
||||
det_p = np.concatenate((np.array(det_x), np.array(det_y)))
|
||||
|
||||
det_p = det_p.reshape(2, -1).transpose()
|
||||
det_p = plg.Polygon(det_p)
|
||||
|
||||
local_sigma_table[gt_id, det_id] = sigma_calculation(det_p,
|
||||
gt_p)
|
||||
local_tau_table[gt_id, det_id] = tau_calculation(det_p, gt_p)
|
||||
|
||||
data = {}
|
||||
data['sigma'] = local_sigma_table
|
||||
data['global_tau'] = local_tau_table
|
||||
data['global_pred_str'] = ''
|
||||
data['global_gt_str'] = ''
|
||||
return data
|
||||
|
||||
|
||||
def combine_results(all_data, rec_flag=True):
|
||||
tr = 0.7
|
||||
tp = 0.6
|
||||
fsc_k = 0.8
|
||||
|
|
@ -278,6 +397,7 @@ def combine_results(all_data):
|
|||
global_tau = []
|
||||
global_pred_str = []
|
||||
global_gt_str = []
|
||||
|
||||
for data in all_data:
|
||||
global_sigma.append(data['sigma'])
|
||||
global_tau.append(data['global_tau'])
|
||||
|
|
@ -294,7 +414,7 @@ def combine_results(all_data):
|
|||
def one_to_one(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idy):
|
||||
gt_flag, det_flag, idy, rec_flag):
|
||||
hit_str_num = 0
|
||||
for gt_id in range(num_gt):
|
||||
gt_matching_qualified_sigma_candidates = np.where(
|
||||
|
|
@ -328,14 +448,15 @@ def combine_results(all_data):
|
|||
gt_flag[0, gt_id] = 1
|
||||
matched_det_id = np.where(local_sigma_table[gt_id, :] > tr)
|
||||
# recg start
|
||||
gt_str_cur = global_gt_str[idy][gt_id]
|
||||
pred_str_cur = global_pred_str[idy][matched_det_id[0].tolist()[
|
||||
0]]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
if rec_flag:
|
||||
gt_str_cur = global_gt_str[idy][gt_id]
|
||||
pred_str_cur = global_pred_str[idy][matched_det_id[0]
|
||||
.tolist()[0]]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
# recg end
|
||||
det_flag[0, matched_det_id] = 1
|
||||
return local_accumulative_recall, local_accumulative_precision, global_accumulative_recall, global_accumulative_precision, gt_flag, det_flag, hit_str_num
|
||||
|
|
@ -343,7 +464,7 @@ def combine_results(all_data):
|
|||
def one_to_many(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idy):
|
||||
gt_flag, det_flag, idy, rec_flag):
|
||||
hit_str_num = 0
|
||||
for gt_id in range(num_gt):
|
||||
# skip the following if the groundtruth was matched
|
||||
|
|
@ -374,6 +495,22 @@ def combine_results(all_data):
|
|||
gt_flag[0, gt_id] = 1
|
||||
det_flag[0, qualified_tau_candidates] = 1
|
||||
# recg start
|
||||
if rec_flag:
|
||||
gt_str_cur = global_gt_str[idy][gt_id]
|
||||
pred_str_cur = global_pred_str[idy][
|
||||
qualified_tau_candidates[0].tolist()[0]]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
# recg end
|
||||
elif (np.sum(local_sigma_table[gt_id, qualified_tau_candidates])
|
||||
>= tr):
|
||||
gt_flag[0, gt_id] = 1
|
||||
det_flag[0, qualified_tau_candidates] = 1
|
||||
# recg start
|
||||
if rec_flag:
|
||||
gt_str_cur = global_gt_str[idy][gt_id]
|
||||
pred_str_cur = global_pred_str[idy][
|
||||
qualified_tau_candidates[0].tolist()[0]]
|
||||
|
|
@ -382,20 +519,6 @@ def combine_results(all_data):
|
|||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
# recg end
|
||||
elif (np.sum(local_sigma_table[gt_id, qualified_tau_candidates])
|
||||
>= tr):
|
||||
gt_flag[0, gt_id] = 1
|
||||
det_flag[0, qualified_tau_candidates] = 1
|
||||
# recg start
|
||||
gt_str_cur = global_gt_str[idy][gt_id]
|
||||
pred_str_cur = global_pred_str[idy][
|
||||
qualified_tau_candidates[0].tolist()[0]]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
# recg end
|
||||
|
||||
global_accumulative_recall = global_accumulative_recall + fsc_k
|
||||
|
|
@ -409,7 +532,7 @@ def combine_results(all_data):
|
|||
def many_to_one(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idy):
|
||||
gt_flag, det_flag, idy, rec_flag):
|
||||
hit_str_num = 0
|
||||
for det_id in range(num_det):
|
||||
# skip the following if the detection was matched
|
||||
|
|
@ -440,6 +563,30 @@ def combine_results(all_data):
|
|||
gt_flag[0, qualified_sigma_candidates] = 1
|
||||
det_flag[0, det_id] = 1
|
||||
# recg start
|
||||
if rec_flag:
|
||||
pred_str_cur = global_pred_str[idy][det_id]
|
||||
gt_len = len(qualified_sigma_candidates[0])
|
||||
for idx in range(gt_len):
|
||||
ele_gt_id = qualified_sigma_candidates[
|
||||
0].tolist()[idx]
|
||||
if ele_gt_id not in global_gt_str[idy]:
|
||||
continue
|
||||
gt_str_cur = global_gt_str[idy][ele_gt_id]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
break
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower(
|
||||
):
|
||||
hit_str_num += 1
|
||||
break
|
||||
# recg end
|
||||
elif (np.sum(local_tau_table[qualified_sigma_candidates,
|
||||
det_id]) >= tp):
|
||||
det_flag[0, det_id] = 1
|
||||
gt_flag[0, qualified_sigma_candidates] = 1
|
||||
# recg start
|
||||
if rec_flag:
|
||||
pred_str_cur = global_pred_str[idy][det_id]
|
||||
gt_len = len(qualified_sigma_candidates[0])
|
||||
for idx in range(gt_len):
|
||||
|
|
@ -454,27 +601,7 @@ def combine_results(all_data):
|
|||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
break
|
||||
# recg end
|
||||
elif (np.sum(local_tau_table[qualified_sigma_candidates,
|
||||
det_id]) >= tp):
|
||||
det_flag[0, det_id] = 1
|
||||
gt_flag[0, qualified_sigma_candidates] = 1
|
||||
# recg start
|
||||
pred_str_cur = global_pred_str[idy][det_id]
|
||||
gt_len = len(qualified_sigma_candidates[0])
|
||||
for idx in range(gt_len):
|
||||
ele_gt_id = qualified_sigma_candidates[0].tolist()[idx]
|
||||
if ele_gt_id not in global_gt_str[idy]:
|
||||
continue
|
||||
gt_str_cur = global_gt_str[idy][ele_gt_id]
|
||||
if pred_str_cur == gt_str_cur:
|
||||
hit_str_num += 1
|
||||
break
|
||||
else:
|
||||
if pred_str_cur.lower() == gt_str_cur.lower():
|
||||
hit_str_num += 1
|
||||
break
|
||||
break
|
||||
# recg end
|
||||
|
||||
global_accumulative_recall = global_accumulative_recall + num_qualified_sigma_candidates * fsc_k
|
||||
|
|
@ -504,7 +631,7 @@ def combine_results(all_data):
|
|||
gt_flag, det_flag, hit_str_num = one_to_one(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idx)
|
||||
gt_flag, det_flag, idx, rec_flag)
|
||||
|
||||
hit_str_count += hit_str_num
|
||||
#######then check for one-to-many case##########
|
||||
|
|
@ -512,14 +639,14 @@ def combine_results(all_data):
|
|||
gt_flag, det_flag, hit_str_num = one_to_many(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idx)
|
||||
gt_flag, det_flag, idx, rec_flag)
|
||||
hit_str_count += hit_str_num
|
||||
#######then check for many-to-one case##########
|
||||
local_accumulative_recall, local_accumulative_precision, global_accumulative_recall, global_accumulative_precision, \
|
||||
gt_flag, det_flag, hit_str_num = many_to_one(local_sigma_table, local_tau_table,
|
||||
local_accumulative_recall, local_accumulative_precision,
|
||||
global_accumulative_recall, global_accumulative_precision,
|
||||
gt_flag, det_flag, idx)
|
||||
gt_flag, det_flag, idx, rec_flag)
|
||||
hit_str_count += hit_str_num
|
||||
|
||||
try:
|
||||
|
|
|
|||
|
|
@ -88,8 +88,35 @@ def ctc_greedy_decoder(probs_seq, blank=95, keep_blank_in_idxs=True):
|
|||
return dst_str, keep_idx_list
|
||||
|
||||
|
||||
def instance_ctc_greedy_decoder(gather_info, logits_map, pts_num=4):
|
||||
def instance_ctc_greedy_decoder(gather_info,
|
||||
logits_map,
|
||||
pts_num=4,
|
||||
point_gather_mode=None):
|
||||
_, _, C = logits_map.shape
|
||||
if point_gather_mode == 'align':
|
||||
insert_num = 0
|
||||
gather_info = np.array(gather_info)
|
||||
length = len(gather_info) - 1
|
||||
for index in range(length):
|
||||
stride_y = np.abs(gather_info[index + insert_num][0] - gather_info[
|
||||
index + 1 + insert_num][0])
|
||||
stride_x = np.abs(gather_info[index + insert_num][1] - gather_info[
|
||||
index + 1 + insert_num][1])
|
||||
max_points = int(max(stride_x, stride_y))
|
||||
stride = (gather_info[index + insert_num] -
|
||||
gather_info[index + 1 + insert_num]) / (max_points)
|
||||
insert_num_temp = max_points - 1
|
||||
|
||||
for i in range(int(insert_num_temp)):
|
||||
insert_value = gather_info[index + insert_num] - (i + 1
|
||||
) * stride
|
||||
insert_index = index + i + 1 + insert_num
|
||||
gather_info = np.insert(
|
||||
gather_info, insert_index, insert_value, axis=0)
|
||||
insert_num += insert_num_temp
|
||||
gather_info = gather_info.tolist()
|
||||
else:
|
||||
pass
|
||||
ys, xs = zip(*gather_info)
|
||||
logits_seq = logits_map[list(ys), list(xs)]
|
||||
probs_seq = logits_seq
|
||||
|
|
@ -104,7 +131,8 @@ def instance_ctc_greedy_decoder(gather_info, logits_map, pts_num=4):
|
|||
def ctc_decoder_for_image(gather_info_list,
|
||||
logits_map,
|
||||
Lexicon_Table,
|
||||
pts_num=6):
|
||||
pts_num=6,
|
||||
point_gather_mode=None):
|
||||
"""
|
||||
CTC decoder using multiple processes.
|
||||
"""
|
||||
|
|
@ -114,7 +142,10 @@ def ctc_decoder_for_image(gather_info_list,
|
|||
if len(gather_info) < pts_num:
|
||||
continue
|
||||
dst_str, xys_list = instance_ctc_greedy_decoder(
|
||||
gather_info, logits_map, pts_num=pts_num)
|
||||
gather_info,
|
||||
logits_map,
|
||||
pts_num=pts_num,
|
||||
point_gather_mode=point_gather_mode)
|
||||
dst_str_readable = ''.join([Lexicon_Table[idx] for idx in dst_str])
|
||||
if len(dst_str_readable) < 2:
|
||||
continue
|
||||
|
|
@ -356,7 +387,8 @@ def generate_pivot_list_fast(p_score,
|
|||
p_char_maps,
|
||||
f_direction,
|
||||
Lexicon_Table,
|
||||
score_thresh=0.5):
|
||||
score_thresh=0.5,
|
||||
point_gather_mode=None):
|
||||
"""
|
||||
return center point and end point of TCL instance; filter with the char maps;
|
||||
"""
|
||||
|
|
@ -384,7 +416,10 @@ def generate_pivot_list_fast(p_score,
|
|||
|
||||
p_char_maps = p_char_maps.transpose([1, 2, 0])
|
||||
decoded_str, keep_yxs_list = ctc_decoder_for_image(
|
||||
all_pos_yxs, logits_map=p_char_maps, Lexicon_Table=Lexicon_Table)
|
||||
all_pos_yxs,
|
||||
logits_map=p_char_maps,
|
||||
Lexicon_Table=Lexicon_Table,
|
||||
point_gather_mode=point_gather_mode)
|
||||
return keep_yxs_list, decoded_str
|
||||
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue