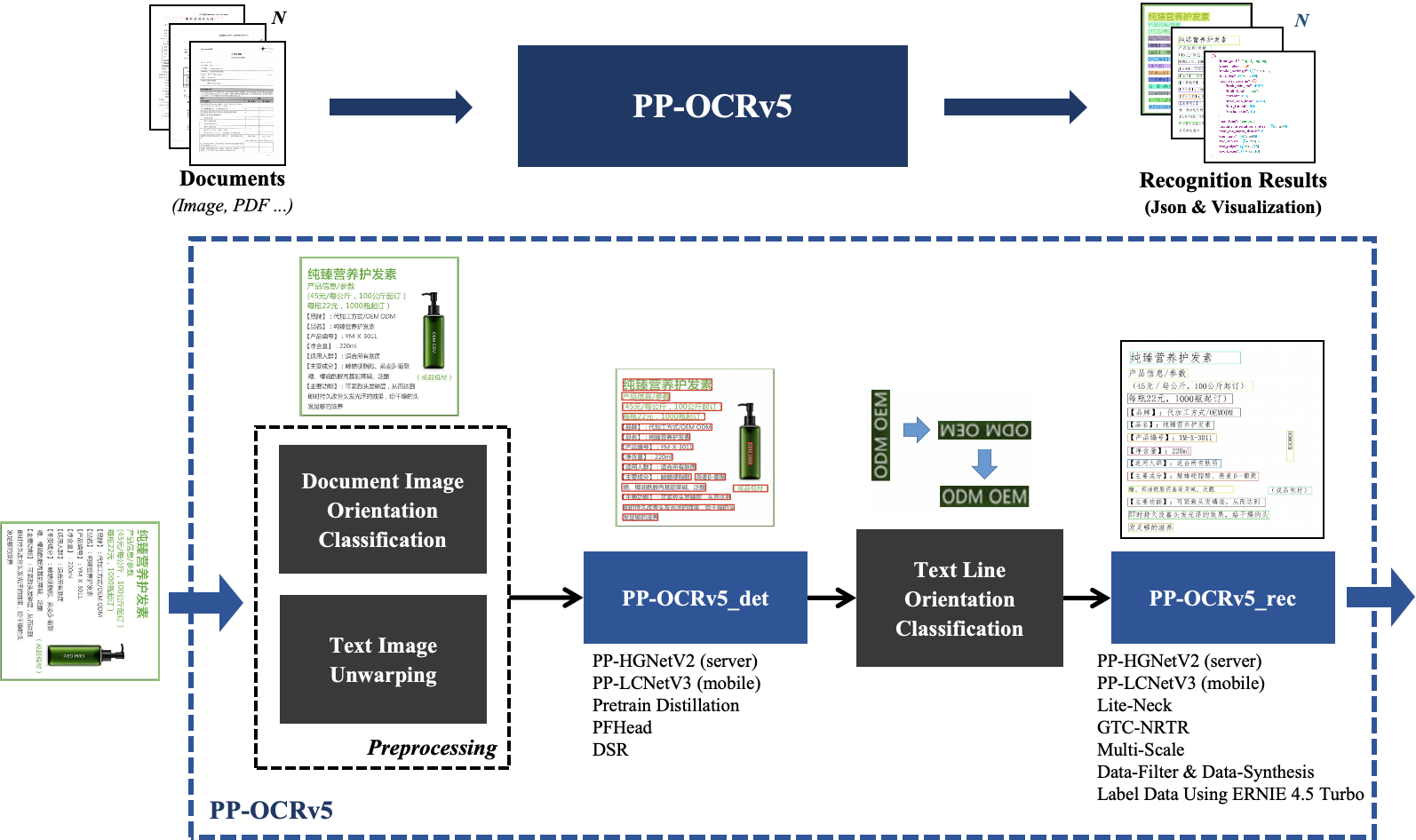
# Introduction to PP-OCRv5
**PP-OCRv5** is the new generation text recognition solution of PP-OCR, focusing on multi-scenario and multi-text type recognition. In terms of text types, PP-OCRv5 supports 5 major mainstream text types: Simplified Chinese, Chinese Pinyin, Traditional Chinese, English, and Japanese. For scenarios, PP-OCRv5 has upgraded recognition capabilities for challenging scenarios such as complex Chinese and English handwriting, vertical text, and uncommon characters. On internal complex evaluation sets across multiple scenarios, PP-OCRv5 achieved a 13 percentage point end-to-end improvement over PP-OCRv4.
# Key Metrics
### 1. Text Detection Metrics
| Model |
Handwritten Chinese |
Handwritten English |
Printed Chinese |
Printed English |
Traditional Chinese |
Ancient Text |
Japanese |
General Scenario |
Pinyin |
Rotation |
Distortion |
Artistic Text |
Average |
| PP-OCRv5_server_det |
0.803 |
0.841 |
0.945 |
0.917 |
0.815 |
0.676 |
0.772 |
0.797 |
0.671 |
0.8 |
0.876 |
0.673 |
0.827 |
| PP-OCRv4_server_det |
0.706 |
0.249 |
0.888 |
0.690 |
0.759 |
0.473 |
0.685 |
0.715 |
0.542 |
0.366 |
0.775 |
0.583 |
0.662 |
| PP-OCRv5_mobile_det |
0.744 |
0.777 |
0.905 |
0.910 |
0.823 |
0.581 |
0.727 |
0.721 |
0.575 |
0.647 |
0.827 |
0.525 |
0.770 |
| PP-OCRv4_mobile_det |
0.583 |
0.369 |
0.872 |
0.773 |
0.663 |
0.231 |
0.634 |
0.710 |
0.430 |
0.299 |
0.715 |
0.549 |
0.624 |
Compared to PP-OCRv4, PP-OCRv5 shows significant improvement in all detection scenarios, especially in handwriting, ancient texts, and Japanese detection capabilities.
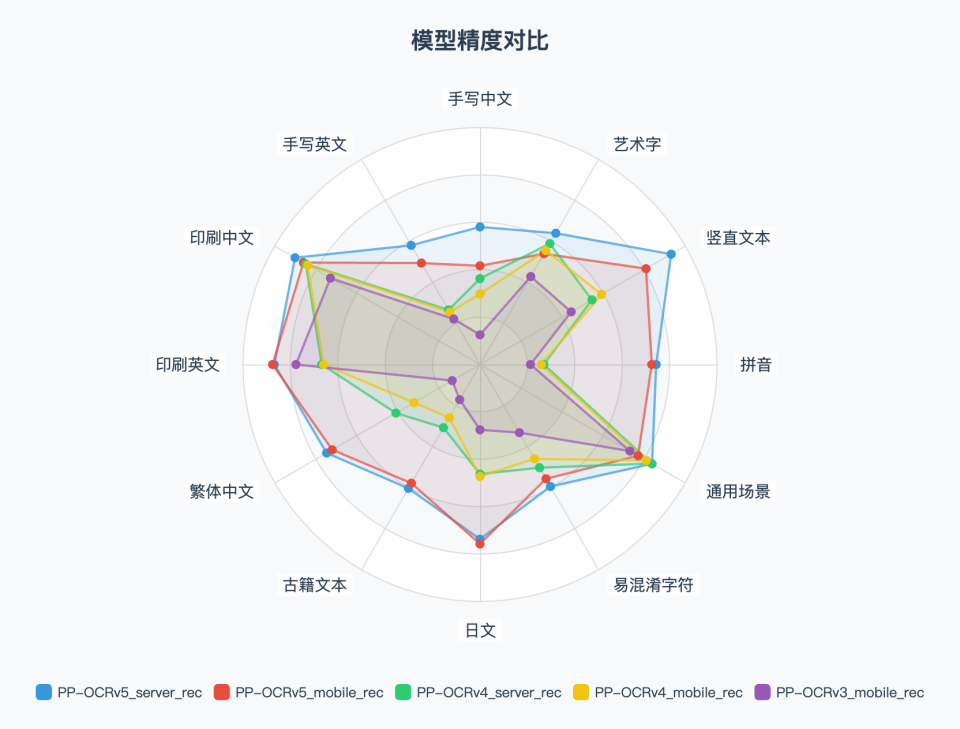
### 2. Text Recognition Metrics
| Evaluation Set Category |
Handwritten Chinese |
Handwritten English |
Printed Chinese |
Printed English |
Traditional Chinese |
Ancient Text |
Japanese |
Confusable Characters |
General Scenario |
Pinyin |
Vertical Text |
Artistic Text |
Weighted Average |
| PP-OCRv5_server_rec |
0.5807 |
0.5806 |
0.9013 |
0.8679 |
0.7472 |
0.6039 |
0.7372 |
0.5946 |
0.8384 |
0.7435 |
0.9314 |
0.6397 |
0.8401 |
| PP-OCRv4_server_rec |
0.3626 |
0.2661 |
0.8486 |
0.6677 |
0.4097 |
0.3080 |
0.4623 |
0.5028 |
0.8362 |
0.2694 |
0.5455 |
0.5892 |
0.5735 |
| PP-OCRv5_mobile_rec |
0.4166 |
0.4944 |
0.8605 |
0.8753 |
0.7199 |
0.5786 |
0.7577 |
0.5570 |
0.7703 |
0.7248 |
0.8089 |
0.5398 |
0.8015 |
| PP-OCRv4_mobile_rec |
0.2980 |
0.2550 |
0.8398 |
0.6598 |
0.3218 |
0.2593 |
0.4724 |
0.4599 |
0.8106 |
0.2593 |
0.5924 |
0.5555 |
0.5301 |
A single model can cover multiple languages and text types, with recognition accuracy significantly ahead of previous generation products and mainstream open-source solutions.
# PP-OCRv5 Demo Examples
More Demos
# Deployment and Secondary Development
* **Multiple System Support**: Compatible with mainstream operating systems including Windows, Linux, and Mac.
* **Multiple Hardware Support**: Besides NVIDIA GPUs, it also supports inference and deployment on Intel CPU, Kunlun chips, Ascend, and other new hardware.
* **High-Performance Inference Plugin**: Recommended to combine with high-performance inference plugins to further improve inference speed. See [High-Performance Inference Guide](../../deployment/high_performance_inference.md) for details.
* **Service Deployment**: Supports highly stable service deployment solutions. See [Service Deployment Guide](../../deployment/serving.md) for details.
* **Secondary Development Capability**: Supports custom dataset training, dictionary extension, and model fine-tuning. Example: To add Korean recognition, you can extend the dictionary and fine-tune the model, seamlessly integrating into existing production lines. See [Text Detection Module Usage Tutorial](../../module_usage/text_detection.en.md) and [Text Recognition Module Usage Tutorial](../../module_usage/text_recognition.en.md) for details.