| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-DocLayout_plus-L | Inference Model/Training Model | 83.2 | 34.6244 / 10.3945 | 510.57 / - | 126.01 M | A higher-precision layout area localization model trained on a self-built dataset containing Chinese and English papers, PPT, multi-layout magazines, contracts, books, exams, ancient books and research reports using RT-DETR-L |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-DocBlockLayout | Inference Model/Training Model | 95.9 | 34.6244 / 10.3945 | 510.57 / - | 123.92 M | A layout block localization model trained on a self-built dataset containing Chinese and English papers, PPT, multi-layout magazines, contracts, books, exams, ancient books and research reports using RT-DETR-L |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PP-DocLayout-L | Inference Model/Training Model | 90.4 | 34.6244 / 10.3945 | 510.57 / - | 123.76 M | A high-precision layout area localization model trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports using RT-DETR-L. |
| PP-DocLayout-M | Inference Model/Training Model | 75.2 | 13.3259 / 4.8685 | 44.0680 / 44.0680 | 22.578 | A layout area localization model with balanced precision and efficiency, trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports using PicoDet-L. |
| PP-DocLayout-S | Inference Model/Training Model | 70.9 | 8.3008 / 2.3794 | 10.0623 / 9.9296 | 4.834 | A high-efficiency layout area localization model trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports using PicoDet-S. |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x_table | Inference Model/Training Model | 97.5 | 8.02 / 3.09 | 23.70 / 20.41 | 7.4 M | A high-efficiency layout area localization model trained on a self-built dataset using PicoDet-1x, capable of detecting table regions. |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PicoDet-S_layout_3cls | Inference Model/Training Model | 88.2 | 8.99 / 2.22 | 16.11 / 8.73 | 4.8 | A high-efficiency layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using PicoDet-S. |
| PicoDet-L_layout_3cls | Inference Model/Training Model | 89.0 | 13.05 / 4.50 | 41.30 / 41.30 | 22.6 | A balanced efficiency and precision layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using PicoDet-L. |
| RT-DETR-H_layout_3cls | Inference Model/Training Model | 95.8 | 114.93 / 27.71 | 947.56 / 947.56 | 470.1 | A high-precision layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using RT-DETR-H. |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x | Inference Model/Training Model | 97.8 | 9.03 / 3.10 | 25.82 / 20.70 | 7.4 | A high-efficiency English document layout area localization model trained on the PubLayNet dataset using PicoDet-1x. |
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (M) | Introduction |
|---|---|---|---|---|---|---|
| PicoDet-S_layout_17cls | Inference Model/Training Model | 87.4 | 9.11 / 2.12 | 15.42 / 9.12 | 4.8 | A high-efficiency layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using PicoDet-S. |
| PicoDet-L_layout_17cls | Inference Model/Training Model | 89.0 | 13.50 / 4.69 | 43.32 / 43.32 | 22.6 | A balanced efficiency and precision layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using PicoDet-L. |
| RT-DETR-H_layout_17cls | Inference Model/Training Model | 98.3 | 115.29 / 104.09 | 995.27 / 995.27 | 470.2 | A high-precision layout area localization model trained on a self-built dataset of Chinese and English papers, magazines, and research reports using RT-DETR-H. |
| Mode | GPU Configuration | CPU Configuration | Acceleration Technology Combination |
|---|---|---|---|
| Normal Mode | FP32 Precision / No TRT Acceleration | FP32 Precision / 8 Threads | PaddleInference |
| High-Performance Mode | Optimal combination of pre-selected precision types and acceleration strategies | FP32 Precision / 8 Threads | Pre-selected optimal backend (Paddle/OpenVINO/TRT, etc.) |
[xmin, ymin, xmax, ymax].
The visualized image is as follows:
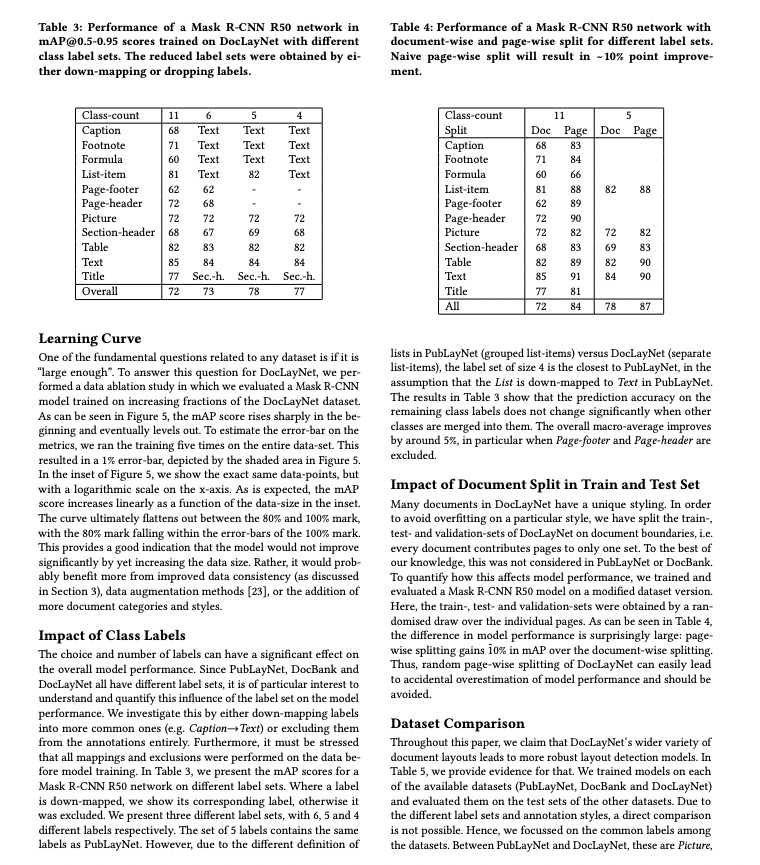
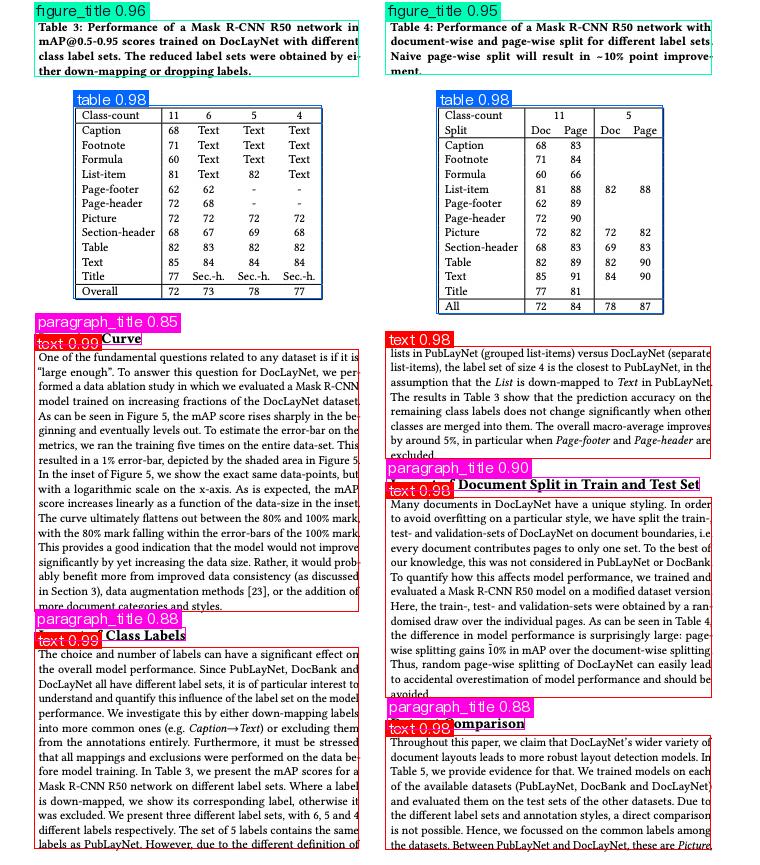 Relevant methods, parameters, and explanations are as follows:
* `LayoutDetection` instantiates a target detection model (here, `PP-DocLayout_plus-L` is used as an example). The detailed explanation is as follows:
Relevant methods, parameters, and explanations are as follows:
* `LayoutDetection` instantiates a target detection model (here, `PP-DocLayout_plus-L` is used as an example). The detailed explanation is as follows:
| Parameter | Description | Type | Options | Default Value |
|---|---|---|---|---|
model_name |
Name of the model | str |
None | None |
model_dir |
Path to store the model | str |
None | None |
device |
The device used for model inference | str |
It supports specifying specific GPU card numbers, such as "gpu:0", other hardware card numbers, such as "npu:0", or CPU, such as "cpu". | gpu:0 |
img_size |
Size of the input image; if not specified, the default 800x800 be used | int/list/None |
|
None |
threshold |
Threshold for filtering low-confidence prediction results; if not specified, the default 0.5 will be used | float/dict/None |
|
None |
layout_nms |
Whether to use NMS post-processing to filter overlapping boxes; if not specified, the default False will be used | bool/None |
|
None |
layout_unclip_ratio |
Scaling factor for the side length of the detection box; if not specified, the default 1.0 will be used | float/list/dict/None |
|
|
layout_merge_bboxes_mode |
Merging mode for the detection boxes output by the model; if not specified, the default union will be used | string/dict/None |
|
None |
use_hpip |
Whether to enable the high-performance inference plugin | bool |
None | False |
hpi_config |
High-performance inference configuration | dict | None |
None | None |
| Parameter | Description | Type | Options | Default Value |
|---|---|---|---|---|
input |
Data for prediction, supporting multiple input types | Python Var/str/list |
|
None |
batch_size |
Batch size | int |
Any integer greater than 0 | 1 |
threshold |
Threshold for filtering low-confidence prediction results | float/dict/None |
|
|
layout_nms |
Whether to use NMS post-processing to filter overlapping boxes; if not specified, the default False will be used | bool/None |
|
None |
layout_unclip_ratio |
Scaling factor for the side length of the detection box; if not specified, the default 1.0 will be used | float/list/dict/None |
|
|
layout_merge_bboxes_mode |
Merging mode for the detection boxes output by the model; if not specified, the default union will be used | string/dict/None |
|
None |
| Method | Method Description | Parameters | Parameter type | Parameter Description | Default value |
|---|---|---|---|---|---|
print() |
Print the result to the terminal | format_json |
bool |
Do you want to use JSON indentation formatting for the output content |
True |
indent |
int |
Specify the indentation level to enhance the readability of the JSON data output, only valid when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether to escape non ASCII characters to Unicode characters. When set to True, all non ASCII characters will be escaped; False preserves the original characters and is only valid when format_json is True |
False |
||
save_to_json() |
Save the result as a JSON format file | save_path |
str |
The saved file path, when it is a directory, the name of the saved file is consistent with the name of the input file type | None |
indent |
int |
Specify the indentation level to enhance the readability of the JSON data output, only valid when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether to escape non ASCII characters to Unicode characters. When set to True, all non ASCII characters will be escaped; False preserves the original characters and is only valid whenformat_json is True |
False |
||
save_to_img() |
Save the results as an image format file | save_path |
str |
The saved file path, when it is a directory, the name of the saved file is consistent with the name of the input file type | None |
| Attribute | Description |
|---|---|
json |
Get the prediction result in json format |
img |
Get the visualized image in dict format |
{kind=link}