465 lines
39 KiB
Plaintext
465 lines
39 KiB
Plaintext
{
|
||
"cells": [
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"# 文档分析技术\n",
|
||
"\n",
|
||
"本章主要介绍文档分析技术的理论知识,包括背景介绍、算法分类和对应思路。\n",
|
||
"\n",
|
||
"通过本章的学习,你可以掌握:\n",
|
||
"\n",
|
||
"1. 版面分析的分类和典型思想\n",
|
||
"2. 表格识别的分类和典型思想\n",
|
||
"3. 信息提取的分类和典型思想"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"\n",
|
||
"作为信息承载工具,文档的不同布局代表了各种不同的信息,如清单和身份证。文档分析是一个从文档中阅读、解释和提取信息的自动化过程。文档分析常包含以下几个研究方向:\n",
|
||
"\n",
|
||
"1. 版面分析模块: 将每个文档页面划分为不同的内容区域。该模块不仅可用于划定相关区域和不相关区域,还可用于对其识别的内容类型进行分类。\n",
|
||
"2. 光学字符识别 (OCR) 模块: 定位并识别文档中存在的所有文本。\n",
|
||
"3. 表格识别模块: 将文档里的表格信息进行识别和转换到excel文件中。\n",
|
||
"4. 信息提取模块: 借助OCR结果和图像信息来理解和识别文档中表达的特定信息或信息之间的关系。\n",
|
||
"\n",
|
||
"由于OCR模块在前面的章节中进行了详细的介绍,接下来将针对上面版面分析、表格识别和信息提取三个模块做单独的介绍。对于每一个模块,会介绍该模块的经典或常用方法以及数据集。"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"## 1. 版面分析\n",
|
||
"\n",
|
||
"### 1.1 背景介绍\n",
|
||
"\n",
|
||
"版面分析主要用于文档检索,关键信息提取,内容分类等,其任务主要是对文档图像进行内容分类,内容的类别一般可分为纯文本、标题、表格、图片和列表等。但是文档布局、格式的多样性和复杂性,文档图像质量差,大规模的带标注的数据集的缺少等问题使得版面分析仍然是一个很有挑战性的任务。\n",
|
||
"版面分析任务的可视化如下图所示:\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/2510dc76c66c49b8af079f25d08a9dcba726b2ce53d14c8ba5cd9bd57acecf19\" width=\"1000\"/></center>\n",
|
||
"<center>图 1:版面分析效果图</center>\n",
|
||
"\n",
|
||
"现有的解决办法一般是基于目标检测或语义分割的方法,这类方法基将文档中不同的板式当做不同的目标进行检测或分割。\n",
|
||
"\n",
|
||
"一些代表性论文被划分为上述两个类别中,具体如下表所示:\n",
|
||
"\n",
|
||
"| 类别 | 主要论文 |\n",
|
||
"| ---------------- | -------- |\n",
|
||
"| 基于目标检测的方法 | [Visual Detection with Context](https://aclanthology.org/D19-1348.pdf),[Object Detection](https://arxiv.org/pdf/2003.13197v1.pdf),[VSR](https://arxiv.org/pdf/2105.06220v1.pdf)|\n",
|
||
"| 基于语义分割的方法 |[Semantic Segmentation](https://arxiv.org/pdf/1911.12170v2.pdf) |\n",
|
||
"\n",
|
||
"\n",
|
||
"### 1.2 基于目标检测的方法 \n",
|
||
"\n",
|
||
"Soto Carlos[1]在目标检测算法Faster R-CNN的基础上,结合上下文信息并利用文档内容的固有位置信息来提高区域检测性能。Li Kai [2]等人也提出了一种基于目标检测的文档分析方法,通过引入了特征金字塔对齐模块,区域对齐模块,渲染层对齐模块来解决跨域的问题,这三个模块相互补充,并从一般的图像角度和特定的文档图像角度调整域,从而解决了大型标记训练数据集与目标域不同的问题。下图是一个基于目标检测Faster R-CNN算法进行版面分析的流程图。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/d396e0d6183243898c0961250ee7a49bc536677079fb4ba2ac87c653f5472f01\" width=\"800\"/></center>\n",
|
||
"<center>图 2:基于Faster R-CNN的版面分析流程图</center>\n",
|
||
"\n",
|
||
"### 1.3 基于语义分割的方法 \n",
|
||
"\n",
|
||
"Sarkar Mausoom[3]等人提出了一种基于先验的分割机制,在非常高的分辨率的图像上训练文档分割模型,解决了过度缩小原始图像导致的密集区域不同结构无法区分进而合并的问题。Zhang Peng[4]等人结合文档中的视觉、语义和关系提出了一个统一的框架VSR(Vision, Semantics and Relations)用于文档布局分析,该框架使用一个双流网络来提取特定模态的视觉和语义特征,并通过自适应聚合模块自适应地融合这些特征,解决了现有基于CV的方法不同模态融合效率低下和布局组件之间缺乏关系建模的局限性。\n",
|
||
"\n",
|
||
"### 1.4 数据集\n",
|
||
"\n",
|
||
"虽然现有的方法可以在一定程度上解决版面分析任务,但是该类方法依赖于大量有标记的训练数据。最近也有很多数据集被提出用于文档分析任务。\n",
|
||
"\n",
|
||
"1. PubLayNet[5]: 该数据集包含50万张文档图像,其中40万用于训练,5万用于验证,5万用于测试,共标记了表格,文本,图像,标题和列表五种形式\n",
|
||
"2. HJDataset[6]: 数据集包含2271张文档图像, 除了内容区域的边界框和掩码之外,它还包括布局元素的层次结构和阅读顺序。\n",
|
||
"\n",
|
||
"PubLayNet数据集样例如下图所示:\n",
|
||
"<center class=\"two\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/4b153117c9384f98a0ce5a6c6e7c205a4b1c57e95c894ccb9688cbfc94e68a1c\" width=\"400\"/><img src=\"https://ai-studio-static-online.cdn.bcebos.com/efb9faea39554760b280f9e0e70631d2915399fa97774eecaa44ee84411c4994\" width=\"400\"/>\n",
|
||
"</center>\n",
|
||
"<center>图 3:PubLayNet样例</center>\n",
|
||
"参考文献:\n",
|
||
"\n",
|
||
"[1]:Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.\n",
|
||
"\n",
|
||
"[2]:Li K, Wigington C, Tensmeyer C, et al. Cross-domain document object detection: Benchmark suite and method[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12915-12924.\n",
|
||
"\n",
|
||
"[3]:Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.\n",
|
||
"\n",
|
||
"[4]:Zhang P, Li C, Qiao L, et al. VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations[J]. arXiv preprint arXiv:2105.06220, 2021.\n",
|
||
"\n",
|
||
"[5]:Zhong X, Tang J, Yepes A J. Publaynet: largest dataset ever for document layout analysis[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1015-1022.\n",
|
||
"\n",
|
||
"[6]:Li M, Xu Y, Cui L, et al. DocBank: A benchmark dataset for document layout analysis[J]. arXiv preprint arXiv:2006.01038, 2020.\n",
|
||
"\n",
|
||
"[7]:Shen Z, Zhang K, Dell M. A large dataset of historical japanese documents with complex layouts[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 548-549."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"## 2. 表格识别\n",
|
||
"\n",
|
||
"### 2.1 背景介绍\n",
|
||
"\n",
|
||
"表格是各类文档中常见的页面元素,随着各类文档的爆炸性增长,如何高效地从文档中找到表格并获取内容与结构信息即表格识别,成为了一个亟需解决的问题。表格识别的难点总结如下:\n",
|
||
"\n",
|
||
"1. 表格种类和样式复杂多样,例如*不同的行列合并,不同的内容文本类型*等。\n",
|
||
"2. 文档的样式本身的样式多样。\n",
|
||
"3. 拍摄时的光照环境等\n",
|
||
"\n",
|
||
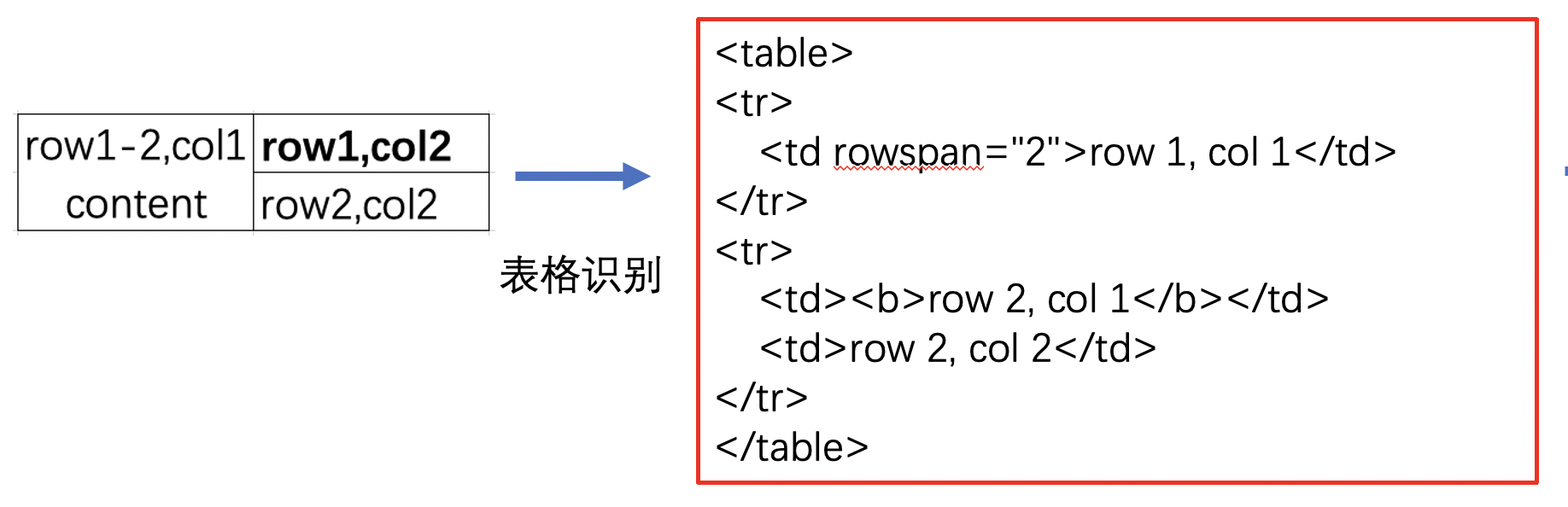
"表格识别的任务就是将文档里的表格信息转换到excel文件中,任务可视化如下:\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/99faa017e28b4928a408573406870ecaa251b626e0e84ab685e4b6f06f601a5f\" width=\"1600\"/></center>\n",
|
||
"\n",
|
||
"\n",
|
||
"<center>图 4:表格识别示例图,其中左边为原图,右边为表格识别后的结果图,以Excel形式呈现</center>\n",
|
||
"\n",
|
||
"现有的表格识别算法根据表格结构重建的原理可以分为下面四大类:\n",
|
||
"1. 基于启发式规则的方法\n",
|
||
"2. 基于CNN的方法\n",
|
||
"3. 基于GCN的方法\n",
|
||
"4. 基于End to End的方法\n",
|
||
"\n",
|
||
"一些代表性论文被划分为上述四个类别中,具体如下表所示:\n",
|
||
"| 类别 | 思路 | 主要论文 |\n",
|
||
"| ---------------- | ---- | -------- |\n",
|
||
"|基于启发式规则的方法|人工设计规则,连通域检测分析处理|[T-Rect](https://www.researchgate.net/profile/Andreas-Dengel/publication/249657389_A_Paper-to-HTML_Table_Converting_System/links/0c9605322c9a67274d000000/A-Paper-to-HTML-Table-Converting-System.pdf),[pdf2table](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.724.7272&rep=rep1&type=pdf)|\n",
|
||
"| 基于CNN的方法 | 目标检测,语义分割 | [CascadeTabNet](https://arxiv.org/pdf/2004.12629v2.pdf), [Multi-Type-TD-TSR](https://arxiv.org/pdf/2105.11021v1.pdf), [LGPMA](https://arxiv.org/pdf/2105.06224v2.pdf), [tabstruct-net](https://arxiv.org/pdf/2010.04565v1.pdf), [CDeC-Net](https://arxiv.org/pdf/2008.10831v1.pdf), [TableNet](https://arxiv.org/pdf/2001.01469v1.pdf), [TableSense](https://arxiv.org/pdf/2106.13500v1.pdf), [Deepdesrt](https://www.dfki.de/fileadmin/user_upload/import/9672_PID4966073.pdf), [Deeptabstr](https://www.dfki.de/fileadmin/user_upload/import/10649_DeepTabStR.pdf), [GTE](https://arxiv.org/pdf/2005.00589v2.pdf), [Cycle-CenterNet](https://arxiv.org/pdf/2109.02199v1.pdf), [FCN](https://www.researchgate.net/publication/339027294_Rethinking_Semantic_Segmentation_for_Table_Structure_Recognition_in_Documents)|\n",
|
||
"| 基于GCN的方法 | 基于图神经网络,将表格识别看作图重建问题 | [GNN](https://arxiv.org/pdf/1905.13391v2.pdf), [TGRNet](https://arxiv.org/pdf/2106.10598v3.pdf), [GraphTSR](https://arxiv.org/pdf/1908.04729v2.pdf)|\n",
|
||
"| 基于End to End的方法 | 利用attention机制 | [Table-Master](https://arxiv.org/pdf/2105.01848v1.pdf)|\n",
|
||
"\n",
|
||
"### 2.2 基于启发式规则的传统算法\n",
|
||
"早期的表格识别研究主要是基于启发式规则的方法。例如由Kieninger[1]等人提出的T-Rect系统使用自底向上的方法对文档图像进行连通域分析,然后按照定义的规则进行合并,得到逻辑文本块。而之后由Yildiz[2]等人提出的pdf2table则是第一个在PDF文档上进行表格识别的方法,它利用了PDF文件的一些特有信息(例如文字、绘制路径等图像文档中难以获取的信息)来协助表格识别。而在最近的工作中,Koci[3]等人将页面中的布局区域表示为图(Graph)的形式,然后使用了Remove and Conquer(RAC)算法从中将表格作为一个子图识别出来。\n",
|
||
"\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/66aeedb3f0924d80aee15f185e6799cc687b51fc20b74b98b338ca2ea25be3f3\" width=\"1000\"/></center>\n",
|
||
"<center>图 5:启发式算法示意图</center>\n",
|
||
"\n",
|
||
"### 2.3 基于深度学习CNN的方法\n",
|
||
"随着深度学习技术在计算机视觉、自然语言处理、语音处理等领域的飞速发展,研究者将深度学习技术应用到表格识别领域并取得了不错的效果。\n",
|
||
"\n",
|
||
"Siddiqui Shoaib Ahmed[12]等人在DeepTabStR算法中,将表格结构识别问题表述为对象检测问题,并利用可变形卷积来进更好的进行表格单元格的检测。Raja Sachin[6]等人提出TabStruct-Net将单元格检测和结构识别在视觉上结合起来进行表格结构识别,解决了现有方法由于表格布局发生较大变化而识别错误的问题,但是该方法无法处理行列出现较多空单元格的问题。\n",
|
||
"\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/838be28836444bc1835ac30a25613d8b045a1b5aedd44b258499fe9f93dd298f\" width=\"1600\"/></center>\n",
|
||
"<center>图 6:基于深度学习CNN的算法示意图</center>\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/4c40dda737bd44b09a533e1b1dd2e4c6a90ceea083bf4238b7f3c7b21087f409\" width=\"1600\"/></center>\n",
|
||
"<center>图 7:基于深度学习CNN的算法错误示例</center>\n",
|
||
"\n",
|
||
"之前的表格结构识别方法一般是从不同粒度(行/列、文本区域)的元素开始处理问题,容易忽略空单元格合并的问题。Qiao Liang[10]等人提出了一个新框架LGPMA,通过掩码重评分策略充分利用来自局部和全局特征的信息,进而可以获得更可靠的对齐单元格区域,最后引入了包括单元格匹配、空单元格搜索和空单元格合并的表格结构复原pipeline来处理表格结构识别问题。\n",
|
||
"\n",
|
||
"除了以上单独做表格识别的算法外,也有部分方法将表格检测和表格识别在一个模型里完成,Schreiber Sebastian[11]等人提出了DeepDeSRT,通过Faster RCNN进行表格检测,通过FCN语义分割模型用于表格结构行列检测,但是该方法是用两个独立的模型来解决这两个问题。Prasad Devashish[4]等人提出了一种基于端到端深度学习的方法CascadeTabNet,使用Cascade Mask R-CNN HRNet模型同时进行表格检测和结构识别,解决了以往方法使用独立的两个方法处理表格识别问题的不足。Paliwal Shubham[8]等人提出一种新颖的端到端深度多任务架构TableNet,用于表格检测和结构识别,同时在训练期间向TableNet添加额外的空间语义特征,进一步提高了模型性能。Zheng Xinyi[13]等人提出了表格识别的系统框架GTE,利用单元格检测网络来指导表格检测网络的训练,同时提出了一种层次网络和一种新的基于聚类的单元格结构识别算法,该框架可以接入到任何目标检测模型的后面,方便训练不同的表格识别算法。之前的研究主要集中在从扫描的PDF文档中解析具有简单布局的,对齐良好的表格图像,但是现实场景中的表格一般很复杂,可能存在严重变形,弯曲或者遮挡等问题,因此Long Rujiao[14]等人同时构造了一个现实复杂场景下的表格识别数据集WTW,并提出了一种Cycle-CenterNet方法,它利用循环配对模块优化和提出的新配对损失,将离散单元精确地分组到结构化表中,提高了表格识别的性能。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/a01f714cbe1f42fc9c45c6658317d9d7da2cec9726844f6b9fa75e30cadc9f76\" width=\"1600\"/></center>\n",
|
||
"<center>图 8:端到端算法示意图</center>\n",
|
||
"\n",
|
||
"基于CNN的方法对跨行列的表格无法很好的处理,因此在后续的方法中,分为了两个研究方法来解决表格中跨行列的问题。\n",
|
||
"\n",
|
||
"### 2.4 基于深度学习GCN的方法\n",
|
||
"近些年来,随着图卷积神经网络(Graph Convolutional Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上。Qasim Shah Rukh[20]等人将表格结构识别问题转换为与图神经网络兼容的图问题,并设计了一种新颖的可微架构,该架构既可以利用卷积神经网络提取特征的优点,也可以利用图神经网络顶点之间有效交互的优点,但是该方法只使用了单元格的位置特征,没有利用语义特征。Chi Zewen[19]等人提出了一种新颖的图神经网络GraphTSR,用于PDF文件中的表格结构识别,它以表格中的单元格为输入,然后通过利用图的边和节点相连的特性来预测单元格之间的关系来识别表格结构,一定程度上解决了跨行或者跨列的单元格识别问题。Xue Wenyuan[21]等人将表格结构识别的问题重新表述为表图重建,并提出了一种用于表格结构识别的端到端方法TGRNet,该方法包含单元格检测分支和单元格逻辑位置分支,这两个分支共同预测不同单元格的空间位置和逻辑位置,解决了之前方法没有关注单元格逻辑位置的问题。\n",
|
||
"\n",
|
||
"GraphTSR表格识别算法示意图:\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/8ff89661142045a8aef54f8a7a2c69b1d243f8269034406a9e66bee2149f730f\" width=\"1600\"/></center>\n",
|
||
"<center>图 9:GraphTSR表格识别算法示意图</center>\n",
|
||
"\n",
|
||
"### 2.5 基于端到端的方法\n",
|
||
"\n",
|
||
"和其他使用后处理完成表格结构的重建不同,基于端到端的方法直接使用网络完成表格结构的HTML表示输出\n",
|
||
"\n",
|
||
" | )\n",
|
||
"---|---\n",
|
||
"图 10:端到端方法的输入输出|图 11:Image Caption示例\n",
|
||
"\n",
|
||
"端到端的方法大多采用Image Caption(看图说话)的Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/3571280a9c364d3499a062e3edc724294fb5eaef8b38440991941e87f0af0c3b\" width=\"800\"/></center>\n",
|
||
"<center>图 12:Seq2Seq示意图</center>\n",
|
||
"\n",
|
||
"Ye Jiaquan[22]在TableMaster中通过改进基于Transformer的Master文字算法来得到表格结构输出模型。此外,还添加了一个分支进行框的坐标回归,作者并没有在最后一层将模型拆分为两个分支,而是在第一个 Transformer 解码层之后就将序列预测和框回归解耦为两个分支。其网络结构和原始Master网络的对比如下图所示:\n",
|
||
"\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/f573709447a848b4ba7c73a2e297f0304caaca57c5c94588aada1f4cd893946c\" width=\"800\"/></center>\n",
|
||
"<center>图 13:左:master网络图,右:TableMaster网络图</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"### 2.6 数据集\n",
|
||
"\n",
|
||
"由于深度学习方法是数据驱动的方法,需要大量的标注数据对模型进行训练,而现有的数据集规模偏小也是一个重要的制约因素,因此也有一些数据集被提出。\n",
|
||
"\n",
|
||
"1. PubTabNet[16]: 包含568k表格图像和相应的结构化HTML表示。\n",
|
||
"2. PubMed Tables(PubTables-1M)[17]:表格结构识别数据集,包含高度详细的结构注释,460,589张pdf图像用于表格检测任务, 947,642张表格图像用于表格识别任务。\n",
|
||
"3. TableBank[18]: 表格检测和识别数据集,使用互联网上Word和Latex文档构建了包含417K高质量标注的表格数据。\n",
|
||
"4. SciTSR[19]: 表格结构识别数据集,图像大部分从论文中转换而来,其中包含来自PDF文件的15,000个表格及其相应的结构标签。\n",
|
||
"5. TabStructDB[12]: 包括1081个表格区域,这些区域用行和列信息密集标记。\n",
|
||
"6. WTW[14]: 大规模数据集场景表格检测识别数据集,该数据集包含各种变形,弯曲和遮挡等情况下的表格数据,共包含14,581 张图像。\n",
|
||
"\n",
|
||
"数据集示例\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/c9763df56e67434f97cd435100d50ded71ba66d9d4f04d7f8f896d613cdf02b0\" /></center>\n",
|
||
"<center>图 14:PubTables-1M数据集样例图</center>\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/64de203bbe584642a74f844ac4b61d1ec3c5a38cacb84443ac961fbcc54a66ce\" width=\"600\"/></center>\n",
|
||
"<center>图 15:WTW数据集样例图</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"\n",
|
||
"参考文献\n",
|
||
"\n",
|
||
"[1]:Kieninger T, Dengel A. A paper-to-HTML table converting system[C]//Proceedings of document analysis systems (DAS). 1998, 98: 356-365.\n",
|
||
"\n",
|
||
"[2]:Yildiz B, Kaiser K, Miksch S. pdf2table: A method to extract table information from pdf files[C]//IICAI. 2005: 1773-1785.\n",
|
||
"\n",
|
||
"[3]:Koci E, Thiele M, Lehner W, et al. Table recognition in spreadsheets via a graph representation[C]//2018 13th IAPR International Workshop on Document Analysis Systems (DAS). IEEE, 2018: 139-144.\n",
|
||
"\n",
|
||
"[4]:Prasad D, Gadpal A, Kapadni K, et al. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 572-573.\n",
|
||
"\n",
|
||
"[5]:Fischer P, Smajic A, Abrami G, et al. Multi-Type-TD-TSR–Extracting Tables from Document Images Using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: From OCR to Structured Table Representations[C]//German Conference on Artificial Intelligence (Künstliche Intelligenz). Springer, Cham, 2021: 95-108.\n",
|
||
"\n",
|
||
"[6]:Raja S, Mondal A, Jawahar C V. Table structure recognition using top-down and bottom-up cues[C]//European Conference on Computer Vision. Springer, Cham, 2020: 70-86.\n",
|
||
"\n",
|
||
"[7]:Agarwal M, Mondal A, Jawahar C V. Cdec-net: Composite deformable cascade network for table detection in document images[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 9491-9498.\n",
|
||
"\n",
|
||
"[8]:Paliwal S S, Vishwanath D, Rahul R, et al. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 128-133.\n",
|
||
"\n",
|
||
"[9]:Dong H, Liu S, Han S, et al. Tablesense: Spreadsheet table detection with convolutional neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 69-76.\n",
|
||
"\n",
|
||
"[10]:Qiao L, Li Z, Cheng Z, et al. LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment[J]. arXiv preprint arXiv:2105.06224, 2021.\n",
|
||
"\n",
|
||
"[11]:Schreiber S, Agne S, Wolf I, et al. Deepdesrt: Deep learning for detection and structure recognition of tables in document images[C]//2017 14th IAPR international conference on document analysis and recognition (ICDAR). IEEE, 2017, 1: 1162-1167.\n",
|
||
"\n",
|
||
"[12]:Siddiqui S A, Fateh I A, Rizvi S T R, et al. Deeptabstr: Deep learning based table structure recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1403-1409.\n",
|
||
"\n",
|
||
"[13]:Zheng X, Burdick D, Popa L, et al. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 697-706.\n",
|
||
"\n",
|
||
"[14]:Long R, Wang W, Xue N, et al. Parsing Table Structures in the Wild[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 944-952.\n",
|
||
"\n",
|
||
"[15]:Siddiqui S A, Khan P I, Dengel A, et al. Rethinking semantic segmentation for table structure recognition in documents[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1397-1402.\n",
|
||
"\n",
|
||
"[16]:Zhong X, ShafieiBavani E, Jimeno Yepes A. Image-based table recognition: data, model, and evaluation[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer International Publishing, 2020: 564-580.\n",
|
||
"\n",
|
||
"[17]:Smock B, Pesala R, Abraham R. PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models[J]. arXiv preprint arXiv:2110.00061, 2021.\n",
|
||
"\n",
|
||
"[18]:Li M, Cui L, Huang S, et al. Tablebank: Table benchmark for image-based table detection and recognition[C]//Proceedings of the 12th Language Resources and Evaluation Conference. 2020: 1918-1925.\n",
|
||
"\n",
|
||
"[19]:Chi Z, Huang H, Xu H D, et al. Complicated table structure recognition[J]. arXiv preprint arXiv:1908.04729, 2019.\n",
|
||
"\n",
|
||
"[20]:Qasim S R, Mahmood H, Shafait F. Rethinking table recognition using graph neural networks[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 142-147.\n",
|
||
"\n",
|
||
"[21]:Xue W, Yu B, Wang W, et al. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition[J]. arXiv preprint arXiv:2106.10598, 2021.\n",
|
||
"\n",
|
||
"[22]:Ye J, Qi X, He Y, et al. PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML[J]. arXiv preprint arXiv:2105.01848, 2021.\n"
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"## 3. Document VQA\n",
|
||
"\n",
|
||
"老板派任务:开发一个身份证识别系统\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/63bbe893465e4f98b3aec80a042758b520d43e1a993a47e39bce1123c2d29b3f\" width=\"1600\"/></center>\n",
|
||
"\n",
|
||
"\n",
|
||
"> 如何选择方案 \n",
|
||
"> 1. 文字检测之后用规则来进行信息提取\n",
|
||
"> 2. 文字检测之后用规模型来进行信息提取\n",
|
||
"> 3. 外包出去\n",
|
||
"\n",
|
||
"\n",
|
||
"### 3.1 背景介绍\n",
|
||
"在VQA(Visual Question Answering)任务中,主要针对图像内容进行提问和回答,但是对于文本图像来说,关注的内容是图像中的文字信息,因此这类方法可以分为自然场景的Text-VQA和扫描文档场景的DocVQA,三者的关系如下图所示。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/a91cfd5152284152b020ca8a396db7a21fd982e3661540d5998cc19c17d84861\" width=\"600\"/></center>\n",
|
||
"<center>图 16: VQA层级</center>\n",
|
||
"\n",
|
||
"VQA,Text-VQA和DocVQA的示例图如下图所示。\n",
|
||
"\n",
|
||
"|任务类型|VQA | Text-VQA | DocVQA| \n",
|
||
"|---|---|---|---|\n",
|
||
"|任务描述|针对**图片内容**提出问题|针对**图片上的文字内容**提出问题|针对**文档图像的文字内容**提出问题|\n",
|
||
"|示例图片||||\n",
|
||
"\n",
|
||
"DocVQA由于其更加贴近实际应用场景,涌现出了大批学术界和工业界的工作。在常用的场景中,DocVQA里提问的问题都是固定的,比如身份证场景下的问题一般为\n",
|
||
"1. 公民身份号码是什么?\n",
|
||
"2. 姓名是什么?\n",
|
||
"3. 名族是什么?\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/2d2b86468daf47c98be01f44b8d6efa64bc09e43cd764298afb127f19b07aede\" width=\"800\"/></center>\n",
|
||
"<center>图 17: 身份证示例</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"基于这样的先验知识,DocVQA的 研究开始偏向Key Information Extraction(KIE)任务,本次我们也主要讨论KIE相关的研究,KIE任务主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息。\n",
|
||
"\n",
|
||
"KIE通常分为两个子任务进行研究\n",
|
||
"1. SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。\n",
|
||
"2. RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。\n",
|
||
"\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/899470ba601349fbbc402a4c83e6cdaee08aaa10b5004977b1f684f346ebe31f\" width=\"800\"/></center>\n",
|
||
"<center>图 18: SER,RE任务示例</center>\n",
|
||
"\n",
|
||
"一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)[4]来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的的原理可以将这些方法分为下面三种:\n",
|
||
"\n",
|
||
"1. 基于Grid的方法\n",
|
||
"1. 基于Token的方法\n",
|
||
"2. 基于GCN的方法\n",
|
||
"3. 基于End to End 的方法\n",
|
||
"\n",
|
||
"一些代表性论文被划分为上述三个类别中,具体如下表所示:\n",
|
||
"| 类别 | 思路 | 主要论文 |\n",
|
||
"| ---------------- | ---- | -------- |\n",
|
||
"| 基于Grid的方法 |在图像上多模态信息的融合(文本,布局,图像)| [Chargrid](https://arxiv.org/pdf/1809.08799) |\n",
|
||
"| 基于Token的方法 |利用Bert这类方法进行多模态信息的融合|[LayoutLM](https://arxiv.org/pdf/1912.13318), [LayoutLMv2](https://arxiv.org/pdf/2012.14740), [StrucText](https://arxiv.org/pdf/2108.02923), |\n",
|
||
"| 基于GCN的方法 |利用图网络结构进行多模态信息的融合 |[GCN](https://arxiv.org/pdf/1903.11279), [PICK](https://arxiv.org/pdf/2004.07464), [SDMG-R](https://arxiv.org/pdf/2103.14470),[SERA](https://arxiv.org/pdf/2110.09915) |\n",
|
||
"| 基于End to End的方法 |将OCR和关键信息提取统一到一个网络 |[Trie](https://arxiv.org/pdf/2005.13118) |\n",
|
||
"\n",
|
||
"### 3.2 基于Grid的方法\n",
|
||
"\n",
|
||
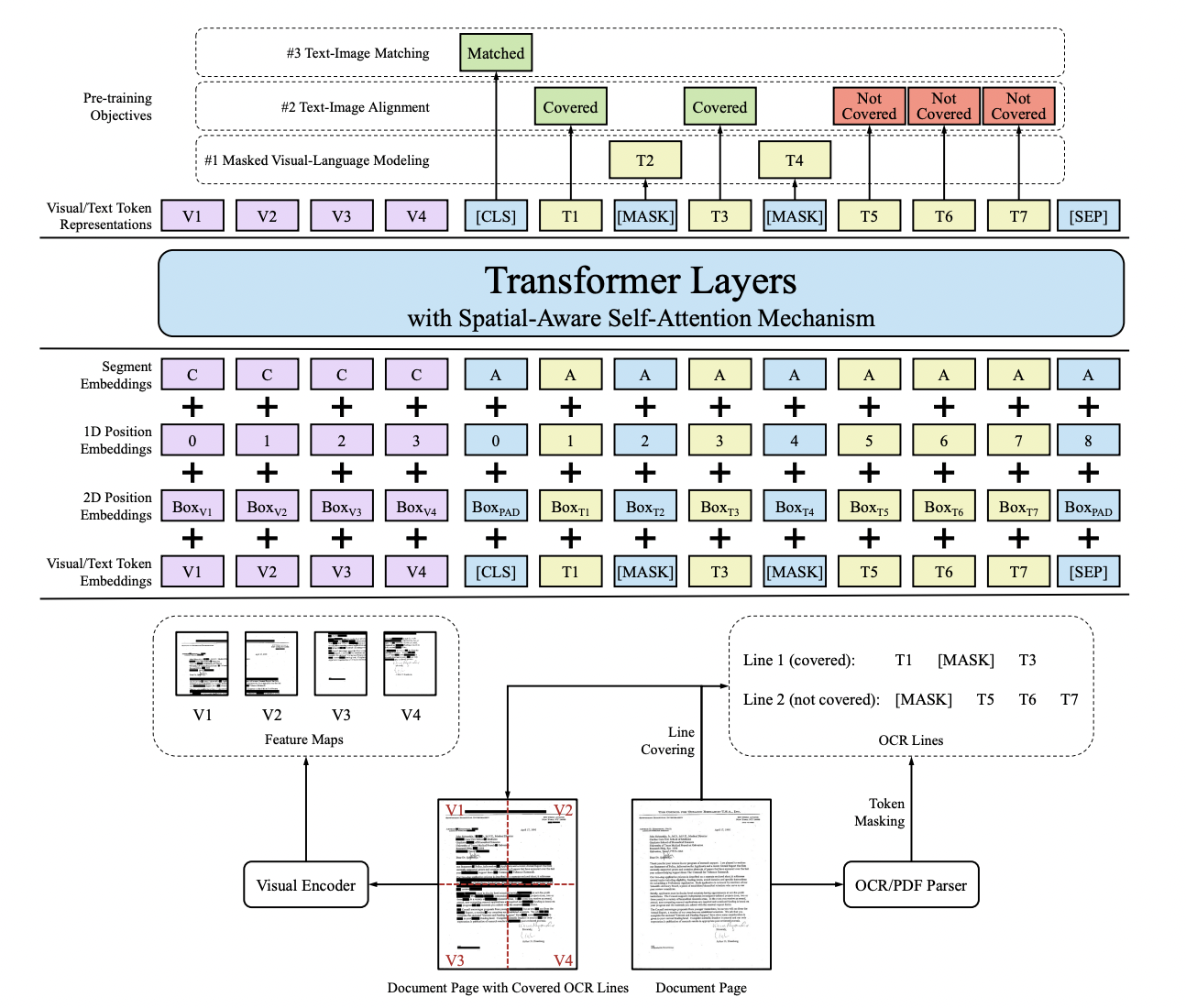
"基于Grid的方法在图像层面进行多模态信息的融合。Chargrid[5]首先对图像进行字符级的文字检测和识别,然后通过将类别的one-hot编码填充到对应的字符区域(下图中右图的非黑色部分)内来完成对网络输入的构建,输入最后通过encoder-decoder结构的CNN网络来进行关键信息的坐标检测和类别分类。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/f248841769ec4312a9015b4befda37bf29db66226431420ca1faad517783875e\" width=\"800\"/></center>\n",
|
||
"<center>图 19: Chargrid数据示例</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/0682e52e275b4187a0e74f54961a50091fd3a0cdff734e17bedcbc993f6e29f9\" width=\"800\"/></center>\n",
|
||
"<center>图 20: Chargrid网络</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"相比于传统的仅基于文本的方法,该方法能够同时利用文本信息和结构信息,因此能够取得一定的精度提升,但是该方法对文本和结构信息的融合只是做了简单的嵌入,并没有很好的将二者进行融合\n",
|
||
"\n",
|
||
"### 3.3 基于Token的方法\n",
|
||
"LayoutLM[6]将2D位置信息和文本信息一起编码到BERT模型中,并且借鉴NLP中Bert的预训练思想,在大规模的数据集上进行预训练,在下游任务中,LayoutLM还加入了图像信息来进一步提升模型性能。LayoutLM虽然将文本,位置和图像信息做了融合,但是图像信息是在下游任务的训练中进行融合,这样对三种信息的多模态融合并不充分。LayoutLMv2[7]在LayoutLM的基础上,通过transformers在预训练阶段将图像信息和文本,layout信息进行融合,还在Transformer中加入空间感知自注意力机制辅助模型更好地融合视觉和文本特征。LayoutLMv2虽然在预训练阶段对文本,位置和图像信息做了融合,但是由于预训练任务的限制,模型学到的视觉特征不够精细。StrucTexT[8]在以往多模态方法的基础上,在预训练任务提出Sentence Length Prediction (SLP) 和Paired Boxes Direction (PBD)两个新任务来帮助网络学习精细的视觉特征,其中SLP任务让模型学习文本段的长度,PDB任务让模型学习Box方向之间的匹配关系。通过这两个新的预训练任务,能够加速文本、视觉和布局信息之间的深度跨模态融合。\n",
|
||
"\n",
|
||
" | )\n",
|
||
"---|---\n",
|
||
"图 21:transformer算法流程图|图 22:LayoutLMv2算法流程图\n",
|
||
"\n",
|
||
"### 3.4 基于GCN的方法\n",
|
||
"\n",
|
||
"现有的基于GCN的方法[10]虽然利用了文字和结构信息,但是没有对图像信息进行很好的利用。PICK[11]在GCN网络中加入了图像信息并且提出graph learning module来自动学习edge的类型。SDMG-R [12]将图像编码为双模态图,图的节点为文字区域的视觉和文本信息,边表示相邻文本直接的空间关系,通过迭代地沿边传播信息和推理图节点类别,SDMG-R解决了现有的方法对没见过的模板无能为力的问题。\n",
|
||
"\n",
|
||
"\n",
|
||
"PICK流程图如下图所示:\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/d3282959e6b2448c89b762b3b9bbf6197a0364b101214a1f83cf01a28623c01c\" width=\"800\"/></center>\n",
|
||
"<center>图 23:PICK算法流程图</center>\n",
|
||
"\n",
|
||
"SERA[10]将依存句法分析里的biaffine parser引入到文档关系抽取中,并且使用GCN来融合文本和视觉信息。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/a97b7647968a4fa59e7b14b384dd7ffe812f158db8f741459b6e6bb0e8b657c7\" width=\"800\"/></center>\n",
|
||
"<center>图 24:SERA算法流程图</center>\n",
|
||
"\n",
|
||
"### 3.5 基于End to End 的方法\n",
|
||
"\n",
|
||
"现有的方法将KIE分为两个独立的任务:文本读取和信息提取,然而他们主要关注于改进信息提取任务,而忽略了文本读取和信息提取是相互关联的,因此,Trie[9]提出了一个统一的端到端网络,可以同时学习这两个任务,并且在学习过程中相互加强。\n",
|
||
"\n",
|
||
"<center class=\"img\">\n",
|
||
"<img src=\"https://ai-studio-static-online.cdn.bcebos.com/6e4a3b0f65254f6b9d40cea0875854d4f47e1dca6b1e408cad435b3629600608\" width=\"1300\"/></center>\n",
|
||
"<center>图 25: Trie算法流程图</center>\n",
|
||
"\n",
|
||
"\n",
|
||
"### 3.6 数据集\n",
|
||
"用于KIE的数据集主要有下面两个:\n",
|
||
"1. SROIE: SROIE数据集[2]的任务3旨在从扫描收据中提取四个预定义的信息:公司、日期、地址或总数。数据集中有626个样本用于训练,347个样本用于测试。\n",
|
||
"2. FUNSD: FUNSD数据集[3]是一个用于从扫描文档中提取表单信息的数据集。它包含199个标注好的真实扫描表单。199个样本中149个用于训练,50个用于测试。FUNSD数据集为每个单词分配一个语义实体标签:问题、答案、标题或其他。\n",
|
||
"3. XFUN: XFUN数据集是微软提出的一个多语言数据集,包含7种语言,每种语言包含149张训练集,50张测试集。\n",
|
||
"\n",
|
||
"\n",
|
||
" | )\n",
|
||
"---|---\n",
|
||
"图 26: sroie示例图|图 27: xfun示例图\n",
|
||
"\n",
|
||
"参考文献:\n",
|
||
"\n",
|
||
"[1]:Mathew M, Karatzas D, Jawahar C V. Docvqa: A dataset for vqa on document images[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2021: 2200-2209.\n",
|
||
"\n",
|
||
"[2]:Huang Z, Chen K, He J, et al. Icdar2019 competition on scanned receipt ocr and information extraction[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1516-1520.\n",
|
||
"\n",
|
||
"[3]:Jaume G, Ekenel H K, Thiran J P. Funsd: A dataset for form understanding in noisy scanned documents[C]//2019 International Conference on Document Analysis and Recognition Workshops (ICDARW). IEEE, 2019, 2: 1-6.\n",
|
||
"\n",
|
||
"[4]:Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.\n",
|
||
"\n",
|
||
"[5]:Katti A R, Reisswig C, Guder C, et al. Chargrid: Towards understanding 2d documents[J]. arXiv preprint arXiv:1809.08799, 2018.\n",
|
||
"\n",
|
||
"[6]:Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.\n",
|
||
"\n",
|
||
"[7]:Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding[J]. arXiv preprint arXiv:2012.14740, 2020.\n",
|
||
"\n",
|
||
"[8]:Li Y, Qian Y, Yu Y, et al. StrucTexT: Structured Text Understanding with Multi-Modal Transformers[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 1912-1920.\n",
|
||
"\n",
|
||
"[9]:Zhang P, Xu Y, Cheng Z, et al. Trie: End-to-end text reading and information extraction for document understanding[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1413-1422.\n",
|
||
"\n",
|
||
"[10]:Liu X, Gao F, Zhang Q, et al. Graph convolution for multimodal information extraction from visually rich documents[J]. arXiv preprint arXiv:1903.11279, 2019.\n",
|
||
"\n",
|
||
"[11]:Yu W, Lu N, Qi X, et al. Pick: Processing key information extraction from documents using improved graph learning-convolutional networks[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 4363-4370.\n",
|
||
"\n",
|
||
"[12]:Sun H, Kuang Z, Yue X, et al. Spatial Dual-Modality Graph Reasoning for Key Information Extraction[J]. arXiv preprint arXiv:2103.14470, 2021."
|
||
]
|
||
},
|
||
{
|
||
"cell_type": "markdown",
|
||
"metadata": {
|
||
"collapsed": false
|
||
},
|
||
"source": [
|
||
"## 4. 总结\n",
|
||
"本节我们主要介绍了文档分析技术相关的三个子模块的理论知识:版面分析、表格识别和信息提取。下面我们会基于PaddleOCR框架对这表格识别和DOC-VQA进行实战教程的讲解。"
|
||
]
|
||
}
|
||
],
|
||
"metadata": {
|
||
"kernelspec": {
|
||
"display_name": "Python 3",
|
||
"language": "python",
|
||
"name": "py35-paddle1.2.0"
|
||
},
|
||
"language_info": {
|
||
"codemirror_mode": {
|
||
"name": "ipython",
|
||
"version": 3
|
||
},
|
||
"file_extension": ".py",
|
||
"mimetype": "text/x-python",
|
||
"name": "python",
|
||
"nbconvert_exporter": "python",
|
||
"pygments_lexer": "ipython3",
|
||
"version": "3.7.4"
|
||
}
|
||
},
|
||
"nbformat": 4,
|
||
"nbformat_minor": 1
|
||
}
|