252 lines
10 KiB
Markdown
252 lines
10 KiB
Markdown
# 基于PP-OCRv3的手写文字识别
|
||
|
||
- [1. 项目背景及意义](#1-项目背景及意义)
|
||
- [2. 项目内容](#2-项目内容)
|
||
- [3. PP-OCRv3识别算法介绍](#3-PP-OCRv3识别算法介绍)
|
||
- [4. 安装环境](#4-安装环境)
|
||
- [5. 数据准备](#5-数据准备)
|
||
- [6. 模型训练](#6-模型训练)
|
||
- [6.1 下载预训练模型](#61-下载预训练模型)
|
||
- [6.2 修改配置文件](#62-修改配置文件)
|
||
- [6.3 开始训练](#63-开始训练)
|
||
- [7. 模型评估](#7-模型评估)
|
||
- [8. 模型导出推理](#8-模型导出推理)
|
||
- [8.1 模型导出](#81-模型导出)
|
||
- [8.2 模型推理](#82-模型推理)
|
||
|
||
|
||
## 1. 项目背景及意义
|
||
目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高。针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。手写体在日常生活中较为常见,然而手写体的识别却存在着很大的挑战,因为每个人的手写字体风格不一样,这对于视觉模型来说还是相当有挑战的。因此训练一个手写体识别模型具有很好的现实意义。下面给出一些手写体的示例图:
|
||
|
||

|
||
|
||
## 2. 项目内容
|
||
本项目基于PaddleOCR套件,以PP-OCRv3识别模型为基础,针对手写文字识别场景进行优化。
|
||
|
||
Aistudio项目链接:[OCR手写文字识别](https://aistudio.baidu.com/aistudio/projectdetail/4330587)
|
||
|
||
## 3. PP-OCRv3识别算法介绍
|
||
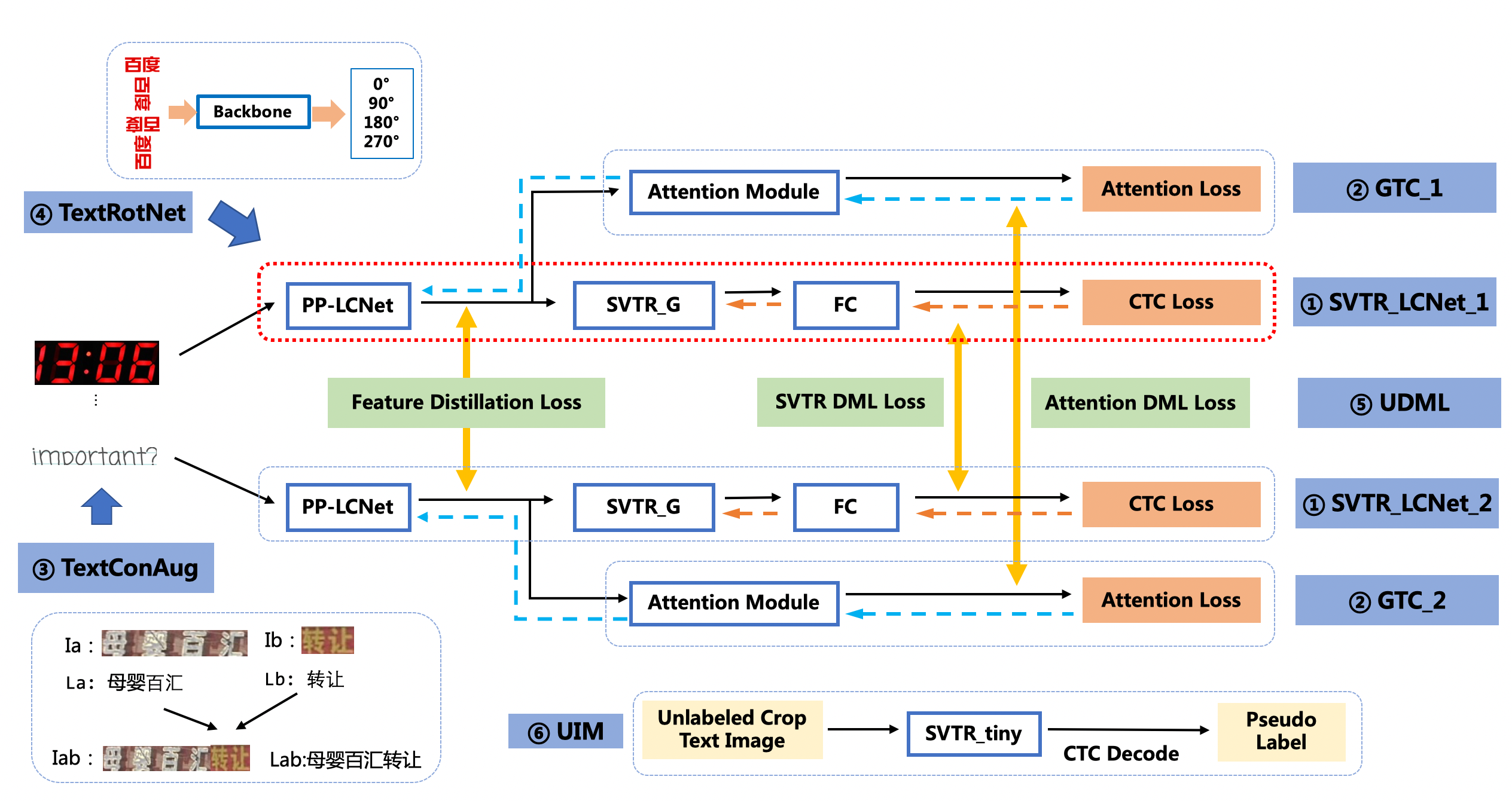
PP-OCRv3的识别模块是基于文本识别算法[SVTR](https://arxiv.org/abs/2205.00159)优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。如下图所示,PP-OCRv3采用了6个优化策略。
|
||
|
||
|
||
|
||
优化策略汇总如下:
|
||
|
||
* SVTR_LCNet:轻量级文本识别网络
|
||
* GTC:Attention指导CTC训练策略
|
||
* TextConAug:挖掘文字上下文信息的数据增广策略
|
||
* TextRotNet:自监督的预训练模型
|
||
* UDML:联合互学习策略
|
||
* UIM:无标注数据挖掘方案
|
||
|
||
详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#3-%E8%AF%86%E5%88%AB%E4%BC%98%E5%8C%96)
|
||
|
||
## 4. 安装环境
|
||
|
||
|
||
```python
|
||
# 首先git官方的PaddleOCR项目,安装需要的依赖
|
||
git clone https://github.com/PaddlePaddle/PaddleOCR.git
|
||
cd PaddleOCR
|
||
pip install -r requirements.txt
|
||
```
|
||
|
||
## 5. 数据准备
|
||
本项目使用公开的手写文本识别数据集,包含Chinese OCR, 中科院自动化研究所-手写中文数据集[CASIA-HWDB2.x](http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html),以及由中科院手写数据和网上开源数据合并组合的[数据集](https://aistudio.baidu.com/aistudio/datasetdetail/102884/0)等,该项目已经挂载处理好的数据集,可直接下载使用进行训练。
|
||
|
||
|
||
```python
|
||
下载并解压数据
|
||
tar -xf hw_data.tar
|
||
```
|
||
|
||
## 6. 模型训练
|
||
### 6.1 下载预训练模型
|
||
首先需要下载我们需要的PP-OCRv3识别预训练模型,更多选择请自行选择其他的[文字识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B)
|
||
|
||
|
||
```python
|
||
# 使用该指令下载需要的预训练模型
|
||
wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
|
||
# 解压预训练模型文件
|
||
tar -xf ./pretrained_models/ch_PP-OCRv3_rec_train.tar -C pretrained_models
|
||
```
|
||
|
||
### 6.2 修改配置文件
|
||
我们使用`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
|
||
|
||
```
|
||
epoch_num: 100 # 训练epoch数
|
||
save_model_dir: ./output/ch_PP-OCR_v3_rec
|
||
save_epoch_step: 10
|
||
eval_batch_step: [0, 100] # 评估间隔,每隔100step评估一次
|
||
pretrained_model: ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy # 预训练模型路径
|
||
|
||
|
||
lr:
|
||
name: Cosine # 修改学习率衰减策略为Cosine
|
||
learning_rate: 0.0001 # 修改fine-tune的学习率
|
||
warmup_epoch: 2 # 修改warmup轮数
|
||
|
||
Train:
|
||
dataset:
|
||
name: SimpleDataSet
|
||
data_dir: ./train_data # 训练集图片路径
|
||
ext_op_transform_idx: 1
|
||
label_file_list:
|
||
- ./train_data/chineseocr-data/rec_hand_line_all_label_train.txt # 训练集标签
|
||
- ./train_data/handwrite/HWDB2.0Train_label.txt
|
||
- ./train_data/handwrite/HWDB2.1Train_label.txt
|
||
- ./train_data/handwrite/HWDB2.2Train_label.txt
|
||
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_train_labels.txt
|
||
- ./train_data/handwrite/HW_Chinese/train_hw.txt
|
||
ratio_list:
|
||
- 0.1
|
||
- 1.0
|
||
- 1.0
|
||
- 1.0
|
||
- 0.02
|
||
- 1.0
|
||
loader:
|
||
shuffle: true
|
||
batch_size_per_card: 64
|
||
drop_last: true
|
||
num_workers: 4
|
||
Eval:
|
||
dataset:
|
||
name: SimpleDataSet
|
||
data_dir: ./train_data # 测试集图片路径
|
||
label_file_list:
|
||
- ./train_data/chineseocr-data/rec_hand_line_all_label_val.txt # 测试集标签
|
||
- ./train_data/handwrite/HWDB2.0Test_label.txt
|
||
- ./train_data/handwrite/HWDB2.1Test_label.txt
|
||
- ./train_data/handwrite/HWDB2.2Test_label.txt
|
||
- ./train_data/handwrite/hwdb_ic13/handwriting_hwdb_val_labels.txt
|
||
- ./train_data/handwrite/HW_Chinese/test_hw.txt
|
||
loader:
|
||
shuffle: false
|
||
drop_last: false
|
||
batch_size_per_card: 64
|
||
num_workers: 4
|
||
```
|
||
由于数据集大多是长文本,因此需要**注释**掉下面的数据增广策略,以便训练出更好的模型。
|
||
```
|
||
- RecConAug:
|
||
prob: 0.5
|
||
ext_data_num: 2
|
||
image_shape: [48, 320, 3]
|
||
```
|
||
|
||
|
||
### 6.3 开始训练
|
||
我们使用上面修改好的配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml`,预训练模型,数据集路径,学习率,训练轮数等都已经设置完毕后,可以使用下面命令开始训练。
|
||
|
||
|
||
```python
|
||
# 开始训练识别模型
|
||
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
|
||
|
||
```
|
||
|
||
## 7. 模型评估
|
||
在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
|
||
|
||
|
||
|
||
```python
|
||
# 评估预训练模型
|
||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy"
|
||
```
|
||
```
|
||
[2022/07/14 10:46:22] ppocr INFO: load pretrain successful from ./pretrained_models/ch_PP-OCRv3_rec_train/best_accuracy
|
||
eval model:: 100%|████████████████████████████| 687/687 [03:29<00:00, 3.27it/s]
|
||
[2022/07/14 10:49:52] ppocr INFO: metric eval ***************
|
||
[2022/07/14 10:49:52] ppocr INFO: acc:0.03724954461811258
|
||
[2022/07/14 10:49:52] ppocr INFO: norm_edit_dis:0.4859541065843199
|
||
[2022/07/14 10:49:52] ppocr INFO: Teacher_acc:0.0371584699368947
|
||
[2022/07/14 10:49:52] ppocr INFO: Teacher_norm_edit_dis:0.48718814890536477
|
||
[2022/07/14 10:49:52] ppocr INFO: fps:947.8562684823883
|
||
```
|
||
|
||
可以看出,直接加载预训练模型进行评估,效果较差,因为预训练模型并不是基于手写文字进行单独训练的,所以我们需要基于预训练模型进行finetune。
|
||
训练完成后,可以进行测试评估,评估命令如下:
|
||
|
||
|
||
|
||
```python
|
||
# 评估finetune效果
|
||
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy"
|
||
|
||
```
|
||
|
||
评估结果如下,可以看出识别准确率为54.3%。
|
||
```
|
||
[2022/07/14 10:54:06] ppocr INFO: metric eval ***************
|
||
[2022/07/14 10:54:06] ppocr INFO: acc:0.5430100180913
|
||
[2022/07/14 10:54:06] ppocr INFO: norm_edit_dis:0.9203322593158589
|
||
[2022/07/14 10:54:06] ppocr INFO: Teacher_acc:0.5401183969626324
|
||
[2022/07/14 10:54:06] ppocr INFO: Teacher_norm_edit_dis:0.919827504507755
|
||
[2022/07/14 10:54:06] ppocr INFO: fps:928.948733797251
|
||
```
|
||
|
||
如需获取已训练模型,请加入PaddleX官方交流频道,获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
|
||
|
||
- PaddleX官方交流频道:https://aistudio.baidu.com/community/channel/610
|
||
|
||
将下载或训练完成的模型放置在对应目录下即可完成模型推理
|
||
|
||
## 8. 模型导出推理
|
||
训练完成后,可以将训练模型转换成inference模型。inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
|
||
|
||
|
||
### 8.1 模型导出
|
||
导出命令如下:
|
||
|
||
|
||
|
||
```python
|
||
# 转化为推理模型
|
||
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_rec/best_accuracy" Global.save_inference_dir="./inference/rec_ppocrv3/"
|
||
|
||
```
|
||
|
||
### 8.2 模型推理
|
||
导出模型后,可以使用如下命令进行推理预测:
|
||
|
||
|
||
|
||
```python
|
||
# 推理预测
|
||
python tools/infer/predict_rec.py --image_dir="train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg" --rec_model_dir="./inference/rec_ppocrv3/Student"
|
||
```
|
||
|
||
```
|
||
[2022/07/14 10:55:56] ppocr INFO: In PP-OCRv3, rec_image_shape parameter defaults to '3, 48, 320', if you are using recognition model with PP-OCRv2 or an older version, please set --rec_image_shape='3,32,320
|
||
[2022/07/14 10:55:58] ppocr INFO: Predicts of train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg:('品结构,差异化的多品牌渗透使欧莱雅确立了其在中国化妆', 0.9904912114143372)
|
||
```
|
||
|
||
|
||
```python
|
||
# 可视化文字识别图片
|
||
from PIL import Image
|
||
import matplotlib.pyplot as plt
|
||
import numpy as np
|
||
import os
|
||
|
||
|
||
img_path = 'train_data/handwrite/HWDB2.0Test_images/104-P16_4.jpg'
|
||
|
||
def vis(img_path):
|
||
plt.figure()
|
||
image = Image.open(img_path)
|
||
plt.imshow(image)
|
||
plt.show()
|
||
# image = image.resize([208, 208])
|
||
|
||
|
||
vis(img_path)
|
||
```
|
||
|
||
|
||

|