12 KiB
12 KiB
English | 简体中文

![]()

![]()
![]()



简介
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
近期更新
- 2022.3 OCR算法新增1种文本检测算法(PSENet),3种文本识别算法(NRTR、SEED、SAR);文档结构化算法新增1种关键信息提取算法(SDMGR,文档),3种DocVQA算法(LayoutLM、LayoutLMv2,LayoutXLM,文档)。
- 2021.12.21 发布PaddleOCR v2.4,《动手学OCR · 十讲》课程开讲,12月21日起每晚八点半线上授课!免费报名地址。
- PaddleOCR研发团队对最新发版内容技术深入解读,9月8日晚上20:15,课程回放。
- 2021.9.7 发布PaddleOCR v2.3与PP-OCRv2,CPU推理速度相比于PP-OCR server提升220%;效果相比于PP-OCR mobile 提升7%。
- 2021.8.3 发布PaddleOCR v2.2,新增文档结构分析PP-Structure工具包,支持版面分析与表格识别(含Excel导出)。
特性
- PP-OCR系列高质量预训练模型,准确的识别效果
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
- PP-Structure文档结构化系统
- 支持版面分析与表格识别(含Excel导出)
- 支持关键信息提取任务
- 支持DocVQA任务
- 丰富易用的OCR相关工具组件
- 半自动数据标注工具PPOCRLabel:支持快速高效的数据标注
- 数据合成工具Style-Text:批量合成大量与目标场景类似的图像
- 支持用户自定义训练,提供丰富的预测推理部署方案
- 支持PIP快速安装使用
- 可运行于Linux、Windows、MacOS等多种系统
上述内容的使用方法建议从文档教程中的快速开始体验
社区、社区贡献与社区常规赛
- 加入社区:微信扫描下方二维码加入官方交流群,与各行各业开发者充分交流,期待您的加入。
- 社区贡献:社区贡献文档中包含了社区用户使用PaddleOCR开发的各种工具、应用以及为PaddleOCR贡献的功能、优化的文档与代码等,是官方为社区开发者打造的荣誉墙、也是帮助优质项目宣传的广播站。如果您的OCR项目未被收集在文档中,可根据文档说明与我们联系。
- 社区常规赛:社区常规赛是面向OCR开发者的积分赛事,覆盖文档、代码、模型和应用四大类型,以季度为单位评选并发放奖励,赛题详情与报名方法可参考链接。

零代码体验
- 在线网站体验:超轻量PP-OCR mobile模型体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
- 移动端:安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)
PP-OCR系列模型列表(更新中)
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 预训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
更多模型下载(包括多语言),可以参考PP-OCR 系列模型下载
文档教程
- 运行环境准备
- 快速开始(中英文/多语言/版面分析)
- PaddleOCR全景图与项目克隆
- PP-OCR产业落地:从训练到部署
- PP-OCR模型库
- PP-OCR模型训练
- PP-OCR模型压缩
- PP-OCR模型推理部署
- PP-Structure信息提取
- OCR学术前沿模型介绍与下载
- 数据标注与合成
- 数据集
- 效果展示
- FAQ
- 参考文献
- 许可证书
- 代码组织结构
PP-OCRv2 Pipeline
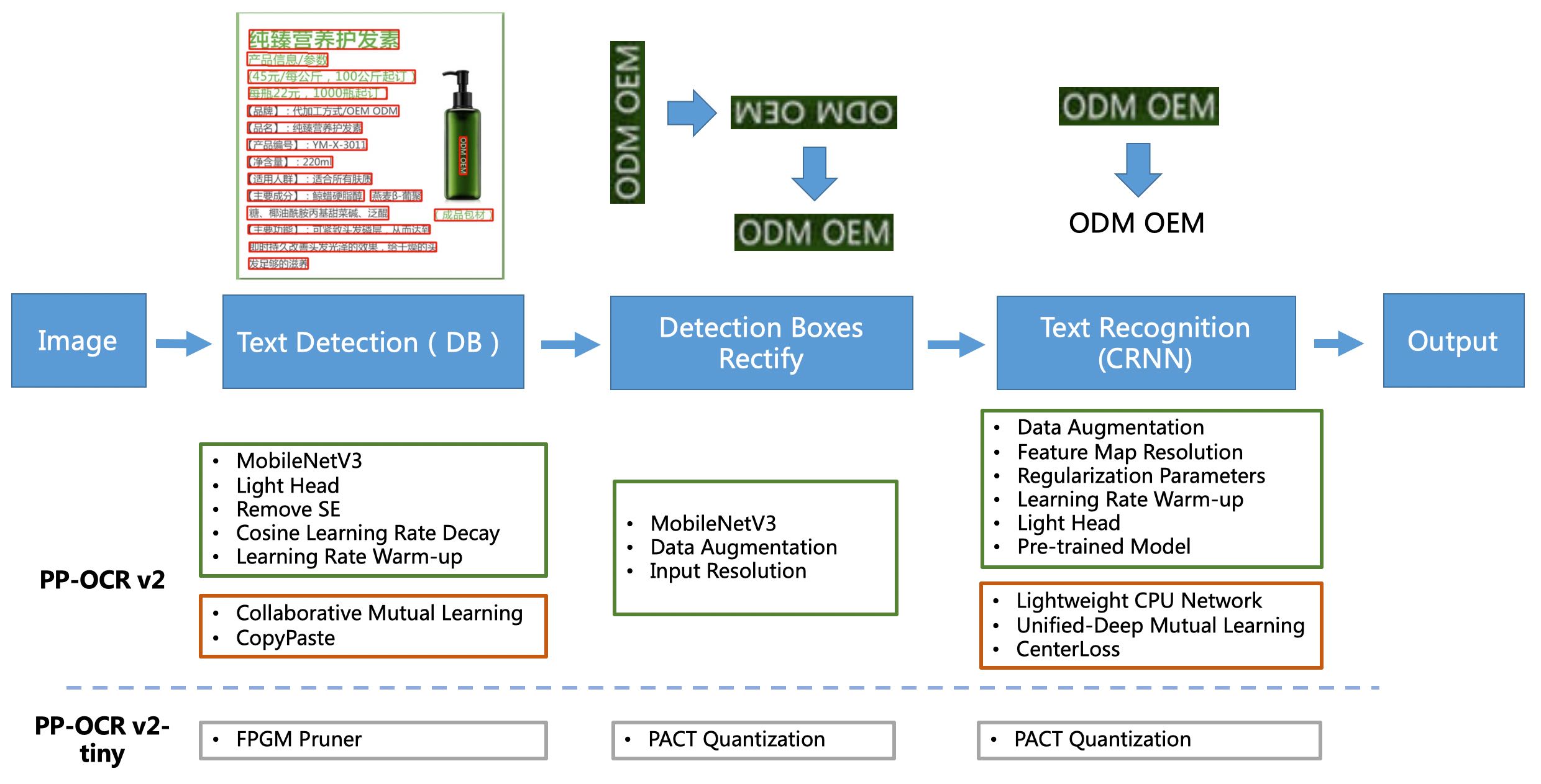
[2] PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2技术报告。
效果展示 more
- 中文模型



- 英文模型

- 其他语言模型


许可证书
本项目的发布受Apache 2.0 license许可认证。