|
|
||
|---|---|---|
| assets | ||
| README.md | ||
README.md
👀SEEM: Segment Everything Everywhere All at Once
🍎[Demo Route 1] 🍊[Demo Route 2] 🥝[Demo Route 3] 🍎[Demo Route 4] 🍊[Demo Route 5] 🥝[Demo Route 6] 🍇[ArXiv]
If you find any of these demo link cannot run successfully multiple times (not beacause of your illegal prompt), please try another route. You are also welcome to post interesting demos in issues or giving a PR. Thanks!
We introduce SEEM that can Segment Everything Everywhere with Multi-modal prompts all at once. SEEM allows users to easily segment an image using prompts of different types including visual prompts (points, marks, boxes, scribbles and image segments) and language prompts (text and audio), etc. It can also work with any combinations of prompts or generalize to custom prompts!
💡 Highlights
Inspired by the appealing universal interface in LLMs, we are advocating universal, interactive multi-modal interface for any types of segmentation with ONE SINGLE MODEL. We emphasize 4 important features of SEEM below.
- Versatility: work with various types of prompts, for example, clicks, boxes, polygons, scribbles, texts, and referring image;
- Compositionaliy: deal with any compositions of prompts;
- Interactivity: interact with user in multi-rounds, thanks to the memory prompt of SEEM to store the session history;
- Semantic awareness: give a semantic label to any predicted mask;
 A breif introduction of all the generic and interactive segmentation tasks we can do. Try our demo at
[Demo Route 1] [Demo Route 2] [Demo Route 3].
A breif introduction of all the generic and interactive segmentation tasks we can do. Try our demo at
[Demo Route 1] [Demo Route 2] [Demo Route 3].
🔥How to use the demo
- Try our default examples first.
- Upload an image;
- Select at least one type of prompt you want (If you want to use referred region of another image please check "Example" and upload another image in referring image panel);
- Remember to give prompt for each promt type you select or there will be an error (Rember to draw on referred image if you use it);
- Our model by defualt has a vocabulary of COCO 80 categories, others will be classified to 'others' or misclassifed. If you wanna segment using open-vocabulary labels, put the text label in 'text' button after drawing sribbles.
- Click "Submit" and wait for a few seconds.
🔥An interesting example
An example of Transformers. The referred image is the truck form of Optimus Prime. Our model can always segment Optimus Prime in target images no matter which form it is in. Thanks Hongyang Li for this fun example.

🔥Click, scribble to mask
With a simple click or stoke from the user, we can generate the masks and the corresponding category labels for it.

🔥Text to mask
SEEM can generate the mask with text input from the user, providing multi-modality interaction with human.

🔥Referring image to mask
With a simple click or stroke on the referring image, the model is able to segment the objects with similar semantics on the target images.

SEEM understands the spatial relationship very well. Look at the three zebras! The segmented zebras have similar positions with the referred zeras. For example, when the left most zebra is referred on the upper row, the left most zebra on the bottom row is segmented.

SEEM understands the oil pastel paintings painted by 🐿️

🔥Referring image to video mask
No training on video data needed, SEEM works perfectly for you to segment videos with whatever queries you specify!

🔥Audio to mask
We use Whiper to turn audio into text prompt to segment the object. Try it in our demo!

🔥Examples of different styles
An example of segmenting a emoji.

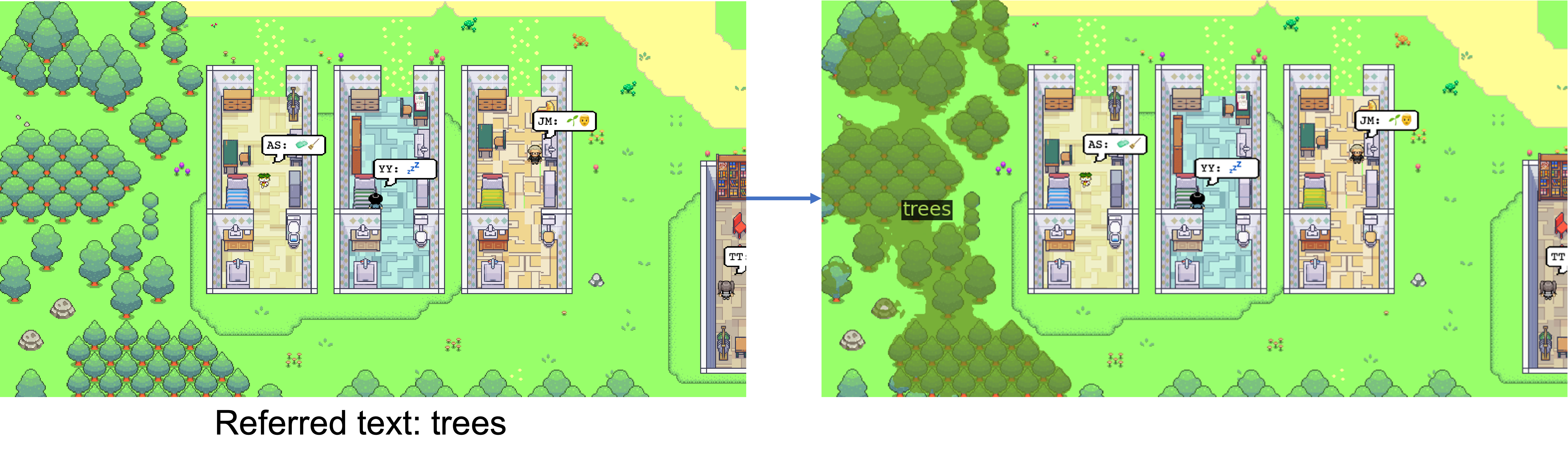
An example of segmenting trees in cartoon style.
An example of segmenting a minecraft image.


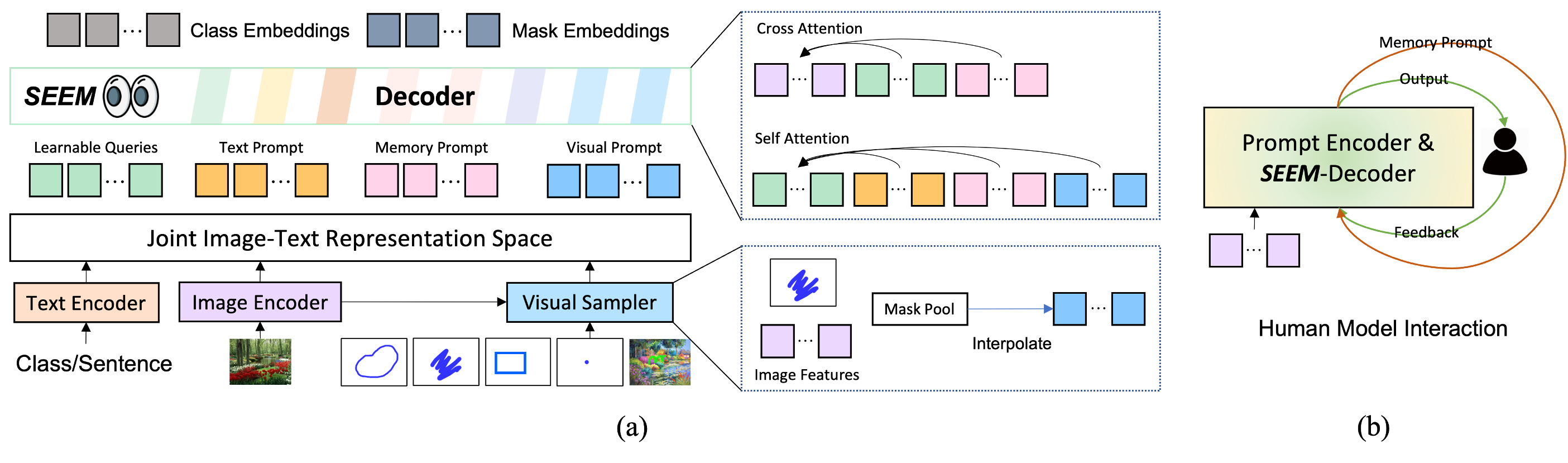
Model
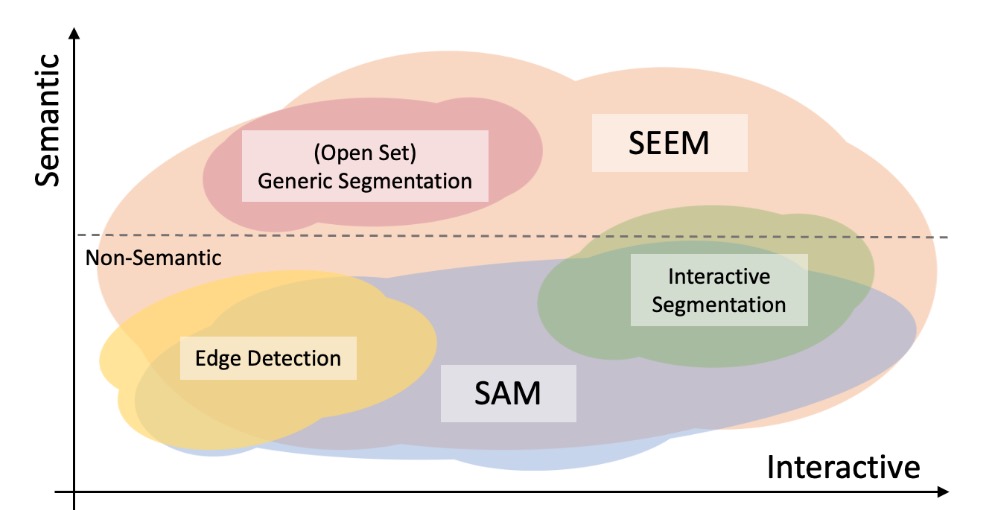
Comparison with SAM
In the following figure, we compare the levels of interaction and semantics of three segmentation tasks (edge detection, open-set, and interactive segmentation). Open-set Segmentation usually requires a high level of semantics and does not require interaction. Compared with SAM, SEEM covers a larger range in both interaction and semantics levels. For example, SAM only supports limited interaction types like points and boxes, while misses high-semantic tasks since it does not output semantic labels itself. The reasons are: First, SEEM has a unified prompt encoder that encodes all visual and language prompts into a joint representation space. In consequence, SEEM can support more general usages. It has potential to extend to custom prompts. Second, SEEM works very well on text to mask (grounding segmentation) and outputs semantic-aware predictions.
📑 Catelog
- SEEM + Whisper Demo
- SEEM + Whisper + Stable Diffusion Demo
- Inference and installation code
- Hugging Face Demo
💘 Acknowledgements
We thank these wonderful projects: