|
|
||
|---|---|---|
| assets | ||
| .DS_Store | ||
| README.md | ||
README.md
👀SEEM: Segment Everything Everywhere All at Once

We introduce SEEM, a Segment Everything Everywhere all at Once Model. SEEM allows users to easily segment an image using prompts of different types including visual prompts (points, marks, boxes, scribbles and image segments) and language prompts (text and audio), etc. It can also work with any combination of prompts or generalize to custom prompts!
🔥 Read our Paper! 🔥 Try the Demo!
🎯 Highlights
Inspired by the appealing universal interface in LLM, we are advocating a universal multi-modal interface for visual understanding, in particular segmentation with a SINGLE MODEL! We emphasize 4 important features of SEEM here.
- Versatility: work with various types of prompts, for example, clicks, boxes, polygon, scribble, text, and referring image;
- Compositionaliy: deal with any compositions of prompts;
- Interactivity: interact with user multi-rounds because SEEM has a memory prompt to store the session history;
- Semantic awareness: give a semantic label to any predicted mask;
💡 Model
A breif overview of our model design:

🔥Click, scribble to mask
With a simple click or stoke from the user, we can generate the masks and the corresponding category labels for it.

🔥Text to mask
SEEM can generate the mask with text input from the user, providing multi-modality interaction with human.

🔥Referring image to mask
With a simple click or stroke on the referring image, the model is able to segment the objects with similar semantics on the target images.

SEEM seems understand the spatial relationshio very well. Look at the three zebras!

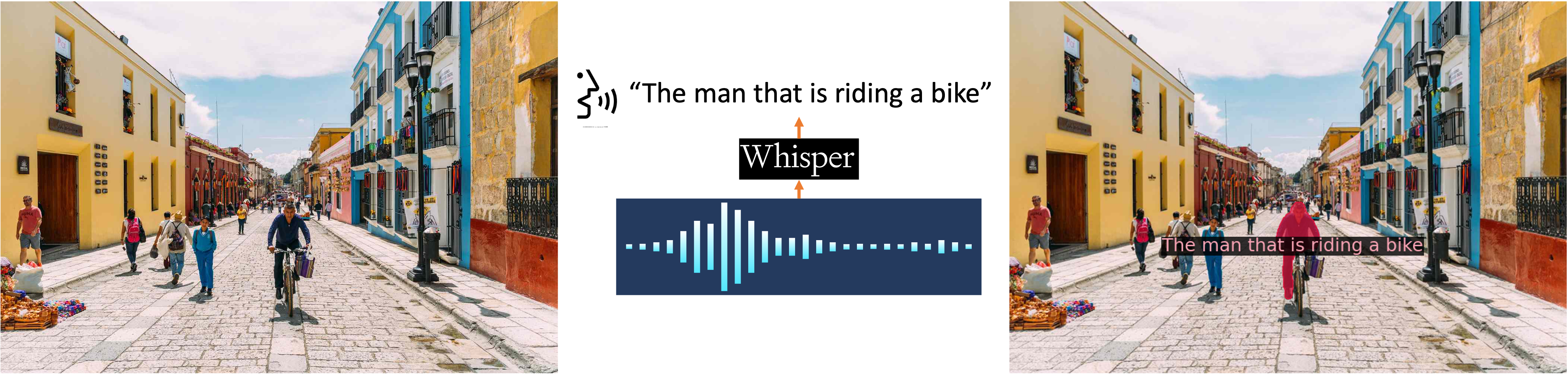
🔥Audio to mask
We use Whiper to turn audio into text prompt to segment the object. Try it in our demo!
🔥Examples of different styles
An example of segmenting an emoji.

An example of segmenting a minecraft image.


Comparison with SAM
Compared with SAM, SEEM has the following strengths. First, SEEM has a Unified prompt encoder that encode all visual and language prompts into a joint representation space. In consequence, SEEM has more general usage. It has potential to extend to custom prompts. Second, SEEM do very well on text to mask (grounding segmentation) and output semantic-aware predictions.

📑 Catelog
- SEEM + Whisper Demo
- SEEM + Whisper + Stable Diffusion Demo
- Inference and installation code
- Hugging Face Demo
💘 Acknowledgements
We thank these wonderful projects: