11 KiB
DeiT III: Revenge of the ViT
This repository contains PyTorch evaluation code, training code and pretrained models for the following projects:
- DeiT (Data-Efficient Image Transformers), ICML 2021
- CaiT (Going deeper with Image Transformers), ICCV 2021 (Oral)
- ResMLP (ResMLP: Feedforward networks for image classification with data-efficient training)
- PatchConvnet (Augmenting Convolutional networks with attention-based aggregation)
- 3Things (Three things everyone should know about Vision Transformers)
- DeiT III (DeiT III: Revenge of the ViT)
This new training recipes improve previous training strategy for ViT architectures:
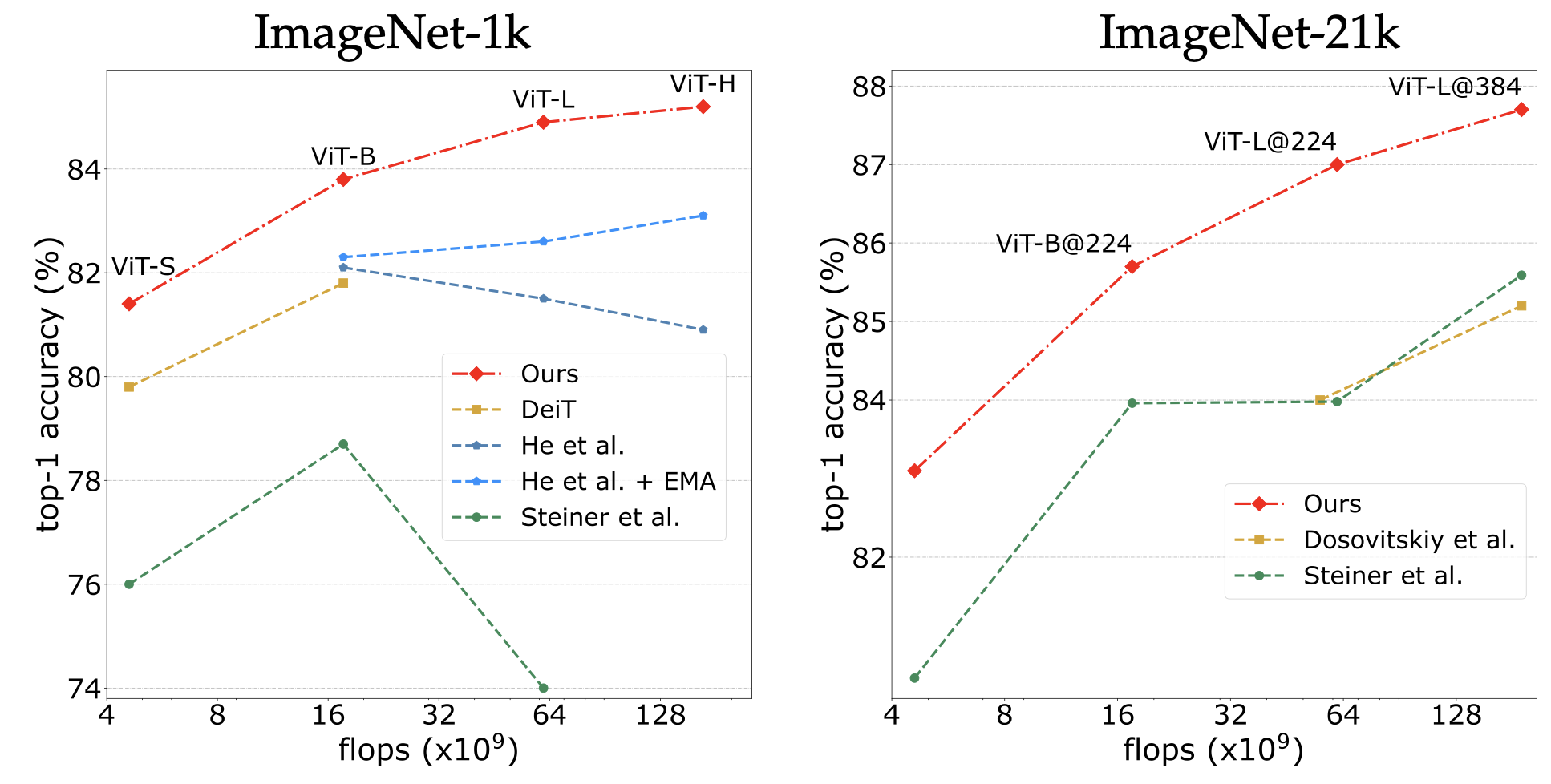
For details see DeiT III: Revenge of the ViT by Hugo Touvron, Matthieu Cord and Hervé Jégou.
If you use this code for a paper please cite:
@article{Touvron2022DeiTIR,
title={DeiT III: Revenge of the ViT},
author={Hugo Touvron and Matthieu Cord and Herve Jegou},
journal={arXiv preprint arXiv:2204.07118},
year={2022},
}
Model Zoo
We provide baseline ViT models pretrained on ImageNet-1k and ImageNet-21k.
ImageNet-1k pre-training
| name | #params | GFLOPs | throughput (im/s) | Peak Mem (MB) | Resolution | acc@1 (INet-1k) | acc@1 (v2) | url |
|---|---|---|---|---|---|---|---|---|
| ViT-S | 22.0 | 4.6 | 1891 | 987 | 224x224 | 81.4 | 70.5 | model |
| ViT-S | 22.0 | 15.5 | 424 | 4569 | 384x384 | 83.4 | 73.1 | model |
| ViT-B | 86.6 | 17.5 | 831 | 2078 | 224x224 | 83.8 | 73.6 | model |
| ViT-B | 86.9 | 55.5 | 190 | 8956 | 384x384 | 85.0 | 74.8 | model |
| ViT-L | 304.4 | 61.6 | 277 | 3789 | 224x224 | 84.9 | 75.1 | model |
| ViT-L | 304.8 | 191.2 | 67 | 12866 | 384x384 | 85.8 | 76.7 | model |
| ViT-H | 632.1 | 167.4 | 112 | 6984 | 224x224 | 85.2 | 75.9 | model |
ImageNet-21k pre-training
| name | #params | GFLOPs | throughput (im/s) | Peak Mem (MB) | Resolution | acc@1 (INet-1k) | acc@1 (v2) | url |
|---|---|---|---|---|---|---|---|---|
| ViT-S | 22.0 | 4.6 | 1891 | 987 | 224x224 | 83.1 | 73.8 | model |
| ViT-S | 22.0 | 15.5 | 424 | 4569 | 384x384 | 84.8 | 75.1 | model |
| ViT-B | 86.6 | 17.5 | 831 | 2078 | 224x224 | 85.7 | 76.5 | model |
| ViT-B | 86.9 | 55.5 | 190 | 8956 | 384x384 | 86.7 | 77.9 | model |
| ViT-L | 304.4 | 61.6 | 277 | 3789 | 224x224 | 87.0 | 78.6 | model |
| ViT-L | 304.8 | 191.2 | 67 | 12866 | 384x384 | 87.7 | 79.1 | model |
| ViT-H | 632.1 | 167.4 | 112 | 6984 | 224x224 | 87.2 | 79.2 | model |
3-Augment
We use a simple data-augmentation (3-Augment) strategy.

Training command
Multinode training
Distributed training is available via Slurm and submitit:
pip install submitit
Training on ImageNet-1k:
python run_with_submitit.py --model deit_small_patch16_LS --data-path /path/to/imagenet --batch 256 --lr 4e-3 --epochs 800 --weight-decay 0.05 --sched cosine --input-size 224 --reprob 0.0 --node 1 --gpu 8 --smoothing 0.0 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup .8 --drop-path 0.05 --cutmix 1.0 --unscale-lr --repeated-aug--bce-loss --color-jitter 0.3 --ThreeAugment
python run_with_submitit.py --model deit_base_patch16_LS --data-path /path/to/imagenet --batch 256 --lr 3e-3 --epochs 800 --weight-decay 0.05 --sched cosine --input-size 192 --reprob 0.0 --node 1 --gpu 8 --smoothing 0.0 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup .8 --drop-path 0.2 --cutmix 1.0 --unscale-lr --repeated-aug --bce-loss --color-jitter 0.3 --ThreeAugment
python run_with_submitit.py --model deit_large_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 3e-3 --epochs 800 --weight-decay 0.05 --sched cosine --input-size 192 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.0 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup .8 --drop-path 0.45 --cutmix 1.0 --unscale-lr --repeated-aug --bce-loss --color-jitter 0.3 --ThreeAugment
python run_with_submitit.py --model deit_huge_patch14_LS --data-path /path/to/imagenet --batch 64 --lr 3e-3 --epochs 800 --weight-decay 0.05 --sched cosine --input-size 160 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.0 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup .8 --drop-path 0.6 --cutmix 1.0 --unscale-lr --repeated-aug --bce-loss --color-jitter 0.3 --ThreeAugment
finetuning for ViT-B, L and H at resolution 224x224:
python run_with_submitit.py --model deit_base_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 1e-5 --epochs 20 --weight-decay 0.1 --sched cosine --input-size 224 --reprob 0.0 --node 1 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt adamw --warmup-lr 1e-6 --mixup .8 --drop-path 0.2 --cutmix 1.0 --unscale-lr --aa rand-m9-mstd0.5-inc1 --no-repeated-aug --finetune model_path
python run_with_submitit.py --model deit_large_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 1e-5 --epochs 20 --weight-decay 0.1 --sched cosine --input-size 224 --reprob 0.0 --node 1 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt adamw --warmup-lr 1e-6 --mixup .8 --drop-path 0.45 --cutmix 1.0 --unscale-lr --aa rand-m9-mstd0.5-inc1 --no-repeated-aug --finetune model_path
python run_with_submitit.py --model deit_huge_patch14_LS --data-path /path/to/imagenet --batch 32 --lr 1e-5 --epochs 20 --weight-decay 0.1 --sched cosine --input-size 224 --reprob 0.0 --node 2 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt adamw --warmup-lr 1e-6 --mixup .8 --drop-path 0.55 --cutmix 1.0 --unscale-lr --aa rand-m9-mstd0.5-inc1 --no-repeated-aug --finetune model_path
finetuning for ViT-S at resolution 384x384:
python run_with_submitit.py --model deit_small_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 1e-5 --epochs 20 --weight-decay 0.1 --sched cosine --input-size 384 --reprob 0.0 --node 1 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt adamw --warmup-lr 1e-6 --mixup .8 --drop-path 0.0 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --aa rand-m9-mstd0.5-inc1 --finetune model_path
Training on ImageNet-21k:
It is possible to train with a batch size of 4096 with a learning rate of 0.0015 instead of 0.001.
python run_with_submitit.py --model deit_small_patch16_LS --data-path /path/to/imagenet --batch 128 --lr 0.001 --epochs 240 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 2 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.05 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_base_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 0.001 --epochs 240 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.1 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_large_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 0.001 --epochs 240 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.3 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_huge_patch14_LS --data-path /path/to/imagenet --batch 64 --lr 0.001 --epochs 90 --weight-decay 0.02 --sched cosine --input-size 128 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.5 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
finetuning on ImageNet-1k:
python run_with_submitit.py --model deit_small_patch16_LS --data-path /path/to/imagenet --batch 128 --lr 0.0003 --epochs 50 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 2 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.05 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_base_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 0.0003 --epochs 50 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.15 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_large_patch16_LS --data-path /path/to/imagenet --batch 64 --lr 0.0003 --epochs 50 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.4 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
python run_with_submitit.py --model deit_huge_patch14_LS --data-path /path/to/imagenet --batch 64 --lr 0.0003 --epochs 50 --weight-decay 0.02 --sched cosine --input-size 224 --reprob 0.0 --node 4 --gpu 8 --smoothing 0.1 --warmup-epochs 5 --drop 0.0 --nb-classes 1000 --seed 0 --opt fusedlamb --warmup-lr 1e-6 --mixup 0 --drop-path 0.45 --cutmix 1.0 --unscale-lr --no-repeated-aug --color-jitter 0.3 --ThreeAugment --src
License
This repository is released under the Apache 2.0 license as found in the LICENSE file.
Contributing
We actively welcome your pull requests! Please see CONTRIBUTING.md and CODE_OF_CONDUCT.md for more info.