* [Feat] Migrate blip caption to mmpretrain. (#50) * Migrate blip caption to mmpretrain * minor fix * support train * [Feature] Support OFA caption task. (#51) * [Feature] Support OFA caption task. * Remove duplicated files. * [Feature] Support OFA vqa task. (#58) * [Feature] Support OFA vqa task. * Fix lint. * [Feat] Add BLIP retrieval to mmpretrain. (#55) * init * minor fix for train * fix according to comments * refactor * Update Blip retrieval. (#62) * [Feature] Support OFA visual grounding task. (#59) * [Feature] Support OFA visual grounding task. * minor add TODO --------- Co-authored-by: yingfhu <yingfhu@gmail.com> * [Feat] Add flamingos coco caption and vqa. (#60) * first init * init flamingo coco * add vqa * minor fix * remove unnecessary modules * Update config * Use `ApplyToList`. --------- Co-authored-by: mzr1996 <mzr1996@163.com> * [Feature]: BLIP2 coco retrieval (#53) * [Feature]: Add blip2 retriever * [Feature]: Add blip2 all modules * [Feature]: Refine model * [Feature]: x1 * [Feature]: Runnable coco ret * [Feature]: Runnable version * [Feature]: Fix lint * [Fix]: Fix lint * [Feature]: Use 364 img size * [Feature]: Refactor blip2 * [Fix]: Fix lint * refactor files * minor fix * minor fix --------- Co-authored-by: yingfhu <yingfhu@gmail.com> * Remove * fix blip caption inputs (#68) * [Feat] Add BLIP NLVR support. (#67) * first init * init flamingo coco * add vqa * add nlvr * refactor nlvr * minor fix * minor fix * Update dataset --------- Co-authored-by: mzr1996 <mzr1996@163.com> * [Feature]: BLIP2 Caption (#70) * [Feature]: Add language model * [Feature]: blip2 caption forward * [Feature]: Reproduce the results * [Feature]: Refactor caption * refine config --------- Co-authored-by: yingfhu <yingfhu@gmail.com> * [Feat] Migrate BLIP VQA to mmpretrain (#69) * reformat * change * change * change * change * change * change * change * change * change * change * change * change * change * change * change * change * change * change * change * refactor code --------- Co-authored-by: yingfhu <yingfhu@gmail.com> * Update RefCOCO dataset * [Fix] fix lint * [Feature] Implement inference APIs for multi-modal tasks. (#65) * [Feature] Implement inference APIs for multi-modal tasks. * [Project] Add gradio demo. * [Improve] Update requirements * Update flamingo * Update blip * Add NLVR inferencer * Update flamingo * Update hugging face model register * Update ofa vqa * Update BLIP-vqa (#71) * Update blip-vqa docstring (#72) * Refine flamingo docstring (#73) * [Feature]: BLIP2 VQA (#61) * [Feature]: VQA forward * [Feature]: Reproduce accuracy * [Fix]: Fix lint * [Fix]: Add blank line * minor fix --------- Co-authored-by: yingfhu <yingfhu@gmail.com> * [Feature]: BLIP2 docstring (#74) * [Feature]: Add caption docstring * [Feature]: Add docstring to blip2 vqa * [Feature]: Add docstring to retrieval * Update BLIP-2 metafile and README (#75) * [Feature]: Add readme and docstring * Update blip2 results --------- Co-authored-by: mzr1996 <mzr1996@163.com> * [Feature] BLIP Visual Grounding on MMPretrain Branch (#66) * blip grounding merge with mmpretrain * remove commit * blip grounding test and inference api * refcoco dataset * refcoco dataset refine config * rebasing * gitignore * rebasing * minor edit * minor edit * Update blip-vqa docstring (#72) * rebasing * Revert "minor edit" This reverts commit 639cec757c215e654625ed0979319e60f0be9044. * blip grounding final * precommit * refine config * refine config * Update blip visual grounding --------- Co-authored-by: Yiqin Wang 王逸钦 <wyq1217@outlook.com> Co-authored-by: mzr1996 <mzr1996@163.com> * Update visual grounding metric * Update OFA docstring, README and metafiles. (#76) * [Docs] Update installation docs and gradio demo docs. (#77) * Update OFA name * Update Visual Grounding Visualizer * Integrate accelerate support * Fix imports. * Fix timm backbone * Update imports * Update README * Update circle ci * Update flamingo config * Add gradio demo README * [Feature]: Add scienceqa (#1571) * [Feature]: Add scienceqa * [Feature]: Change param name * Update docs * Update video --------- Co-authored-by: Hubert <42952108+yingfhu@users.noreply.github.com> Co-authored-by: yingfhu <yingfhu@gmail.com> Co-authored-by: Yuan Liu <30762564+YuanLiuuuuuu@users.noreply.github.com> Co-authored-by: Yiqin Wang 王逸钦 <wyq1217@outlook.com> Co-authored-by: Rongjie Li <limo97@163.com>
CLIP
Learning Transferable Visual Models From Natural Language Supervision
Abstract
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at this https URL.
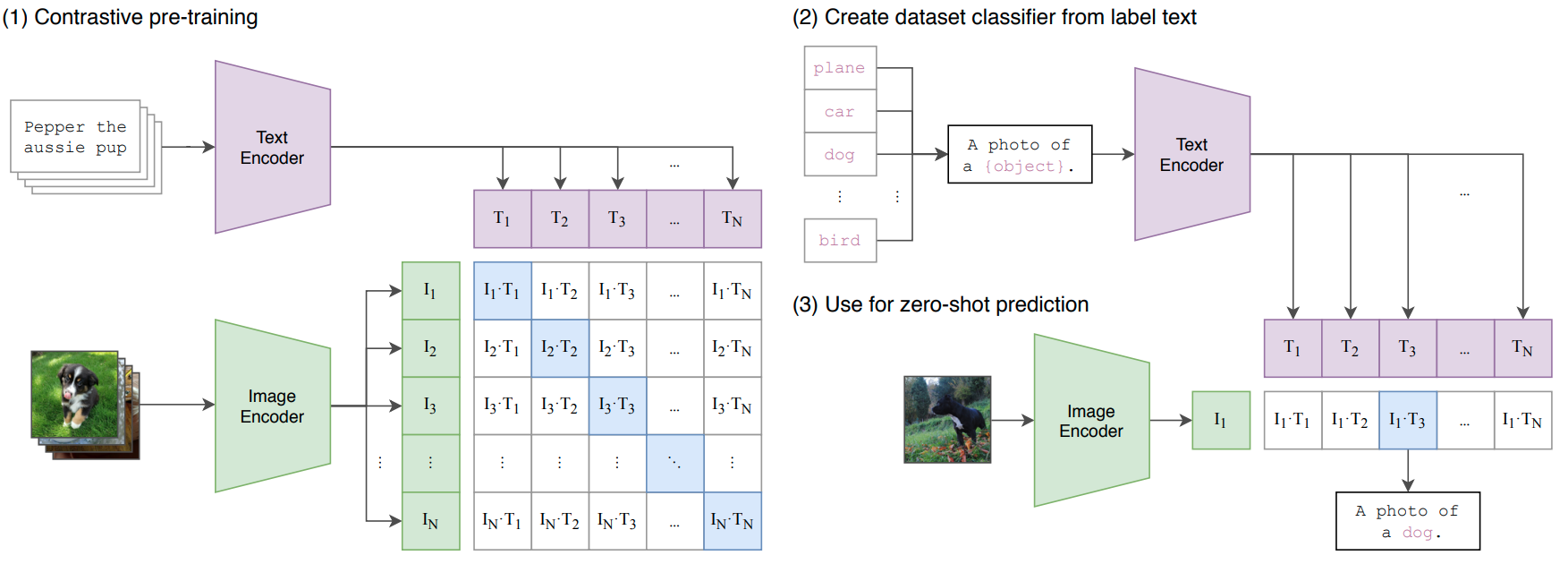
How to use it?
Predict image
from mmpretrain import inference_model
predict = inference_model('vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k', 'demo/bird.JPEG')
print(predict['pred_class'])
print(predict['pred_score'])
Use the model
import torch
from mmpretrain import get_model
model = get_model('vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k', pretrained=True)
inputs = torch.rand(1, 3, 224, 224)
out = model(inputs)
print(type(out))
# To extract features.
feats = model.extract_feat(inputs)
print(type(feats))
Test Command
Prepare your dataset according to the docs.
Test:
python tools/test.py configs/clip/vit-base-p32_pt-64xb64_in1k.py https://download.openmmlab.com/mmclassification/v0/clip/clip-vit-base-p32_laion2b-in12k-pre_3rdparty_in1k_20221220-b384e830.pth
Models and results
Image Classification on ImageNet-1k
| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
|---|---|---|---|---|---|---|---|
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k* |
CLIP LAION2B ImageNet-12k | 88.22 | 4.36 | 83.06 | 96.49 | config | model |
vit-base-p32_clip-laion2b-pre_3rdparty_in1k* |
CLIP LAION2B | 88.22 | 4.36 | 82.46 | 96.12 | config | model |
vit-base-p32_clip-openai-pre_3rdparty_in1k* |
CLIP OPENAI | 88.22 | 4.36 | 81.77 | 95.89 | config | model |
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k-384px* |
CLIP LAION2B ImageNet-12k | 88.22 | 12.66 | 85.39 | 97.67 | config | model |
vit-base-p32_clip-openai-in12k-pre_3rdparty_in1k-384px* |
CLIP OPENAI ImageNet-12k | 88.22 | 12.66 | 85.13 | 97.42 | config | model |
vit-base-p16_clip-laion2b-in12k-pre_3rdparty_in1k* |
CLIP LAION2B ImageNet-12k | 86.57 | 16.86 | 86.02 | 97.76 | config | model |
vit-base-p16_clip-laion2b-pre_3rdparty_in1k* |
CLIP LAION2B | 86.57 | 16.86 | 85.49 | 97.59 | config | model |
vit-base-p16_clip-openai-in12k-pre_3rdparty_in1k* |
CLIP OPENAI ImageNet-12k | 86.57 | 16.86 | 85.99 | 97.72 | config | model |
vit-base-p16_clip-openai-pre_3rdparty_in1k* |
CLIP OPENAI | 86.57 | 16.86 | 85.30 | 97.50 | config | model |
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k-448px* |
CLIP LAION2B ImageNet-12k | 88.22 | 17.20 | 85.76 | 97.63 | config | model |
vit-base-p16_clip-laion2b-in12k-pre_3rdparty_in1k-384px* |
CLIP LAION2B ImageNet-12k | 86.57 | 49.37 | 87.17 | 98.02 | config | model |
vit-base-p16_clip-laion2b-pre_3rdparty_in1k-384px* |
CLIP LAION2B | 86.57 | 49.37 | 86.52 | 97.97 | config | model |
vit-base-p16_clip-openai-in12k-pre_3rdparty_in1k-384px* |
CLIP OPENAI ImageNet-12k | 86.57 | 49.37 | 86.87 | 98.05 | config | model |
vit-base-p16_clip-openai-pre_3rdparty_in1k-384px* |
CLIP OPENAI | 86.57 | 49.37 | 86.25 | 97.90 | config | model |
Models with * are converted from the timm. The config files of these models are only for inference. We haven't reprodcue the training results.
Citation
@InProceedings{pmlr-v139-radford21a,
title = {Learning Transferable Visual Models From Natural Language Supervision},
author = {Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
year = {2021},
series = {Proceedings of Machine Learning Research},
publisher = {PMLR},
}