merge master and fix the conflicts
commit
594c835b6b
|
|
@ -39,7 +39,7 @@ repos:
|
|||
rev: v2.1.0
|
||||
hooks:
|
||||
- id: codespell
|
||||
args: ["--skip=third_party/*,*.proto"]
|
||||
args: ["--skip=third_party/*,*.ipynb,*.proto"]
|
||||
|
||||
- repo: https://github.com/myint/docformatter
|
||||
rev: v1.4
|
||||
|
|
|
|||
|
|
@ -205,6 +205,18 @@ pluginStatus_t allClassNMS_gpu(cudaStream_t stream, const int num, const int num
|
|||
(T_BBOX *)bbox_data, (T_SCORE *)beforeNMS_scores, (int *)beforeNMS_index_array,
|
||||
(T_SCORE *)afterNMS_scores, (int *)afterNMS_index_array, flipXY);
|
||||
|
||||
cudaError_t code = cudaGetLastError();
|
||||
if (code != cudaSuccess) {
|
||||
// Verify if cuda dev0 requires top_k to be reduced;
|
||||
// sm_53 (Jetson Nano) and sm_62 (Jetson TX2) requires reduced top_k < 1000
|
||||
auto __cuda_arch__ = get_cuda_arch(0);
|
||||
if ((__cuda_arch__ == 530 || __cuda_arch__ == 620) && top_k >= 1000) {
|
||||
printf(
|
||||
"Warning: pre_top_k need to be reduced for devices with arch 5.3, 6.2, got "
|
||||
"pre_top_k=%d\n",
|
||||
top_k);
|
||||
}
|
||||
}
|
||||
CSC(cudaGetLastError(), STATUS_FAILURE);
|
||||
return STATUS_SUCCESS;
|
||||
}
|
||||
|
|
@ -243,13 +255,7 @@ pluginStatus_t allClassNMS(cudaStream_t stream, const int num, const int num_cla
|
|||
const bool isNormalized, const DataType DT_SCORE, const DataType DT_BBOX,
|
||||
void *bbox_data, void *beforeNMS_scores, void *beforeNMS_index_array,
|
||||
void *afterNMS_scores, void *afterNMS_index_array, bool flipXY) {
|
||||
auto __cuda_arch__ = get_cuda_arch(0); // assume there is only one arch 7.2 device
|
||||
if (__cuda_arch__ == 720 && top_k >= 1000) {
|
||||
printf("Warning: pre_top_k need to be reduced for devices with arch 7.2, got pre_top_k=%d\n",
|
||||
top_k);
|
||||
}
|
||||
nmsLaunchConfigSSD lc(DT_SCORE, DT_BBOX);
|
||||
|
||||
for (unsigned i = 0; i < nmsFuncVec.size(); ++i) {
|
||||
if (lc == nmsFuncVec[i]) {
|
||||
DEBUG_PRINTF("all class nms kernel %d\n", i);
|
||||
|
|
|
|||
File diff suppressed because one or more lines are too long
|
|
@ -82,9 +82,10 @@ RUN cd /root/workspace/mmdeploy &&\
|
|||
-DCMAKE_CXX_COMPILER=g++ \
|
||||
-Dpplcv_DIR=/root/workspace/ppl.cv/cuda-build/install/lib/cmake/ppl \
|
||||
-DTENSORRT_DIR=${TENSORRT_DIR} \
|
||||
-DONNXRUNTIME_DIR=${ONNXRUNTIME_DIR} \
|
||||
-DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
|
||||
-DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
|
||||
-DMMDEPLOY_TARGET_BACKENDS="trt" \
|
||||
-DMMDEPLOY_TARGET_BACKENDS="ort;trt" \
|
||||
-DMMDEPLOY_CODEBASES=all &&\
|
||||
make -j$(nproc) && make install &&\
|
||||
cd install/example && mkdir -p build && cd build &&\
|
||||
|
|
|
|||
|
|
@ -76,9 +76,9 @@ export OPENCV_ANDROID_SDK_DIR=${PWD}/OpenCV-android-sdk
|
|||
<tr>
|
||||
<td>ncnn </td>
|
||||
<td>A high-performance neural network inference computing framework supporting for android.</br>
|
||||
<b> Now, MMDeploy supports v20211208 and has to use <code>git clone</code> to download it.</b><br>
|
||||
<b> Now, MMDeploy supports v20220216 and has to use <code>git clone</code> to download it.</b><br>
|
||||
<pre><code>
|
||||
git clone -b 20211208 https://github.com/Tencent/ncnn.git
|
||||
git clone -b 20220216 https://github.com/Tencent/ncnn.git
|
||||
cd ncnn
|
||||
git submodule update --init
|
||||
export NCNN_DIR=${PWD}
|
||||
|
|
|
|||
|
|
@ -1,127 +1,345 @@
|
|||
## Build for Jetson
|
||||
# Build for Jetson
|
||||
|
||||
In this chapter, we introduce how to install MMDeploy on NVIDIA Jetson platforms, which we have verified on the following modules:
|
||||
|
||||
This tutorial introduces how to install mmdeploy on Nvidia Jetson systems. It mainly introduces the installation of mmdeploy on three Jetson series boards:
|
||||
- Jetson Nano
|
||||
- Jetson AGX Xavier
|
||||
- Jetson Xavier NX
|
||||
- Jetson TX2
|
||||
- Jetson AGX Xavier
|
||||
|
||||
For Jetson Nano, we use Jetson Nano 2GB and install [JetPack SDK](https://developer.nvidia.com/embedded/jetpack) through SD card image method.
|
||||
Hardware recommendation:
|
||||
|
||||
### Install JetPack SDK
|
||||
- [Seeed reComputer built with Jetson Nano module](https://www.seeedstudio.com/Jetson-10-1-A0-p-5336.html)
|
||||
- [Seeed reComputer built with Jetson Xavier NX module](https://www.seeedstudio.com/Jetson-20-1-H1-p-5328.html)
|
||||
|
||||
There are mainly two ways to install the JetPack:
|
||||
1. Write the image to the SD card directly.
|
||||
2. Use the SDK Manager to do this.
|
||||
## Prerequisites
|
||||
|
||||
The first method does not need two separated machines and their display equipment or cables. We just follow the instruction to write the image. This is pretty convenient. Click [here](https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-2gb-devkit#intro) for Jetson Nano 2GB to start. And click [here](https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit) for Jetson Nano 4GB to start the journey.
|
||||
- To equip a Jetson device, JetPack SDK is a must.
|
||||
- The Model Converter of MMDeploy requires an environment with PyTorch for converting PyTorch models to ONNX models.
|
||||
- Regarding the toolchain, CMake and GCC has to be upgraded to no less than 3.14 and 7.0 respectively.
|
||||
|
||||
The second method, however, requires we set up another display tool and cable to the jetson hardware. This method is safer than the previous one as the first method may sometimes cannot write the image in and throws a warning during validation. Click [here](https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html) to start.
|
||||
### JetPack SDK
|
||||
|
||||
For the first method, if it always throws `Attention something went wrong...` even the file already get re-downloaded, just try `wget` to download the file and change the tail name instead.
|
||||
JetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development.
|
||||
All Jetson modules and developer kits are supported by JetPack SDK.
|
||||
|
||||
### Launch the system
|
||||
There are two major installation methods including,
|
||||
1. SD Card Image Method
|
||||
2. NVIDIA SDK Manager Method
|
||||
|
||||
Sometimes we just need to reboot the jetson device when it gets stuck in initializing the system.
|
||||
You can find a very detailed installation guide from NVIDIA [official website](https://developer.nvidia.com/jetpack-sdk-461).
|
||||
|
||||
### Cuda
|
||||
|
||||
The Cuda is installed by default while the cudnn is not if we use the first method. We have to write the cuda path and lib to `$PATH` and `$LD_LIBRARY_PATH`:
|
||||
```
|
||||
export PATH=$PATH:/usr/local/cuda/bin
|
||||
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
|
||||
```
|
||||
Then we can use `nvcc -V` the get the version of cuda we use.
|
||||
|
||||
### Anaconda
|
||||
|
||||
We have to install [Archiconda](https://github.com/Archiconda/build-tools/releases) instead as the Anaconda does not provide the wheel built for jetson.
|
||||
|
||||
After we installed the Archiconda successfully and created the virtual env correctly. If the pip in the env does not work properly or throw `Illegal instruction (core dumped)`, we may consider re-install the pip manually, reinstalling the whole JetPack SDK is the last method we can try.
|
||||
|
||||
### Move tensorrt to conda env
|
||||
After we installed the Archiconda, we can use it to create a virtual env like `mmdeploy`. Then we have to move the pre-installed tensorrt package in Jetpack to the virtual env.
|
||||
|
||||
First we use `find` to get where the tensorrt is
|
||||
```
|
||||
sudo find / -name tensorrt
|
||||
```
|
||||
Then copy the tensorrt to our destination like:
|
||||
```
|
||||
cp -r /usr/lib/python3.6/dist-packages/tensorrt* /home/archiconda3/env/mmdeploy/lib/python3.6/site-packages/
|
||||
```
|
||||
Meanwhle, tensorrt libs like `libnvinfer.so` can be found in `LD_LIBRARY_PATH`, which is done by Jetpack as well.
|
||||
|
||||
### Install torch
|
||||
|
||||
Install the PyTorch for Jetsons **specifically**. Click [here](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048) to get the wheel. Before we use `pip install`, we have to install `libopenblas-base`, `libopenmpi-dev` first:
|
||||
```
|
||||
sudo apt-get install libopenblas-base libopenmpi-dev
|
||||
```
|
||||
Or, it will throw the following error when we import torch in python:
|
||||
```
|
||||
libmpi_cxx.so.20: cannot open shared object file: No such file or directory
|
||||
```{note}
|
||||
Please select the option to install "Jetson SDK Components" when using NVIDIA SDK Manager as this includes CUDA and TensorRT which are needed for this guide.
|
||||
```
|
||||
|
||||
### Install torchvision
|
||||
We can't directly use `pip install torchvision` to install torchvision for Jetson Nano. But we can clone the repository from Github and build it locally. First we have to install some dependencies:
|
||||
Here we have chosen [JetPack 4.6.1](https://developer.nvidia.com/jetpack-sdk-461) as our best practice on setting up Jetson platforms. MMDeploy has been tested on JetPack 4.6 (rev.3) and above and TensorRT 8.0.1.6 and above. Earlier JetPack versions has incompatibilities with TensorRT 7.x
|
||||
|
||||
### Conda
|
||||
|
||||
Install [Archiconda](https://github.com/Archiconda/build-tools/releases) instead of Anaconda because the latter does not provide the wheel built for Jetson.
|
||||
|
||||
```shell
|
||||
wget https://github.com/Archiconda/build-tools/releases/download/0.2.3/Archiconda3-0.2.3-Linux-aarch64.sh
|
||||
bash Archiconda3-0.2.3-Linux-aarch64.sh -b
|
||||
|
||||
echo -e '\n# set environment variable for conda' >> ~/.bashrc
|
||||
echo ". ~/archiconda3/etc/profile.d/conda.sh" >> ~/.bashrc
|
||||
echo 'export PATH=$PATH:~/archiconda3/bin' >> ~/.bashrc
|
||||
|
||||
echo -e '\n# set environment variable for pip' >> ~/.bashrc
|
||||
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
conda --version
|
||||
```
|
||||
sudo apt-get install libjpeg-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
|
||||
|
||||
After the installation, create a conda environment and activate it.
|
||||
|
||||
```shell
|
||||
# get the version of python3 installed by default
|
||||
export PYTHON_VERSION=`python3 --version | cut -d' ' -f 2 | cut -d'.' -f1,2`
|
||||
conda create -y -n mmdeploy python=${PYTHON_VERSION}
|
||||
conda activate mmdeploy
|
||||
```
|
||||
Then just clone and compile the project:
|
||||
|
||||
```{note}
|
||||
JetPack SDK 4+ provides Python 3.6. We strongly recommend using the default Python. Trying to upgrade it will probably ruin the JetPack environment.
|
||||
|
||||
If a higher-version of Python is necessary, you can install JetPack 5+, in which the Python version is 3.8.
|
||||
```
|
||||
git clone git@github.com:pytorch/vision.git
|
||||
cd vision
|
||||
git co tags/v0.7.0 -b vision07
|
||||
|
||||
### PyTorch
|
||||
|
||||
Download the PyTorch wheel for Jetson from [here](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-11-now-available/72048) and save it to the `/home/username` directory. Build torchvision from source as there is no prebuilt torchvision for Jetson platforms.
|
||||
|
||||
Take `torch 1.10.0` and `torchvision 0.11.1` for example. You can install them as below:
|
||||
|
||||
```shell
|
||||
# pytorch
|
||||
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||
|
||||
# torchvision
|
||||
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev libopenblas-base libopenmpi-dev -y
|
||||
git clone --branch v0.11.1 https://github.com/pytorch/vision torchvision
|
||||
cd torchvision
|
||||
export BUILD_VERSION=0.11.1
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### Install mmcv
|
||||
```{note}
|
||||
It takes about 30 minutes to install torchvision on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
Install openssl first:
|
||||
```
|
||||
sudo apt-get install libssl-dev
|
||||
```
|
||||
Then install it from source like `MMCV_WITH_OPS=1 pip install -e .`
|
||||
If you install other versions of PyTorch and torchvision, make sure the versions are compatible. Refer to the compatibility chart listed [here](https://pypi.org/project/torchvision/).
|
||||
|
||||
### Update cmake
|
||||
### CMake
|
||||
|
||||
We choose cmake version 20 as an example.
|
||||
```
|
||||
sudo apt-get install -y libssl-dev
|
||||
wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0.tar.gz
|
||||
tar -zxvf cmake-3.20.0.tar.gz
|
||||
cd cmake-3.20.0
|
||||
./bootstrap
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
Then we can check the cmake version through:
|
||||
```
|
||||
source ~/.bashrc
|
||||
We use the latest cmake v3.23.1 released in April 2022.
|
||||
|
||||
```shell
|
||||
# purge existing
|
||||
sudo apt-get purge cmake -y
|
||||
|
||||
# install prebuilt binary
|
||||
export CMAKE_VER=3.23.1
|
||||
export ARCH=aarch64
|
||||
wget https://github.com/Kitware/CMake/releases/download/v${CMAKE_VER}/cmake-${CMAKE_VER}-linux-${ARCH}.sh
|
||||
chmod +x cmake-${CMAKE_VER}-linux-${ARCH}.sh
|
||||
sudo ./cmake-${CMAKE_VER}-linux-${ARCH}.sh --prefix=/usr --skip-license
|
||||
cmake --version
|
||||
```
|
||||
|
||||
### Install mmdeploy
|
||||
Just follow the instruction [here](../01-how-to-build/build_from_source.md). If it throws `failed building wheel for numpy...ERROR: Failed to build one or more wheels` when installing `h5py`, try install `h5py` manually.
|
||||
```
|
||||
sudo apt-get install pkg-config libhdf5-100 libhdf5-dev
|
||||
pip install versioned-hdf5 --no-cache-dir
|
||||
## Install Dependencies
|
||||
|
||||
The Model Converter of MMDeploy on Jetson platforms depends on [MMCV](https://github.com/open-mmlab/mmcv) and the inference engine [TensorRT](https://developer.nvidia.com/tensorrt).
|
||||
While MMDeploy C/C++ Inference SDK relies on [spdlog](https://github.com/gabime/spdlog), OpenCV and [ppl.cv](https://github.com/openppl-public/ppl.cv) and so on, as well as TensorRT.
|
||||
Thus, in the following sections, we will describe how to prepare TensorRT.
|
||||
And then, we will present the way to install dependencies of Model Converter and C/C++ Inference SDK respectively.
|
||||
|
||||
### Prepare TensorRT
|
||||
|
||||
TensorRT is already packed into JetPack SDK. But In order to import it successfully in conda environment, we need to copy the tensorrt package to the conda environment created before.
|
||||
|
||||
```shell
|
||||
cp -r /usr/lib/python${PYTHON_VERSION}/dist-packages/tensorrt* ~/archiconda3/envs/mmdeploy/lib/python${PYTHON_VERSION}/site-packages/
|
||||
conda deactivate
|
||||
conda activate mmdeploy
|
||||
python -c "import tensorrt; print(tensorrt.__version__)" # Will print the version of TensorRT
|
||||
|
||||
# set environment variable for building mmdeploy later on
|
||||
export TENSORRT_DIR=/usr/include/aarch64-linux-gnu
|
||||
|
||||
# append cuda path and libraries to PATH and LD_LIBRARY_PATH, which is also used for building mmdeploy later on.
|
||||
# this is not needed if you use NVIDIA SDK Manager with "Jetson SDK Components" for installing JetPack.
|
||||
# this is only needed if you install JetPack using SD Card Image Method.
|
||||
export PATH=$PATH:/usr/local/cuda/bin
|
||||
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
|
||||
```
|
||||
|
||||
Then install onnx manually. First, we have to install protobuf compiler:
|
||||
You can also make the above environment variables permanent by adding them to `~/.bashrc`.
|
||||
|
||||
```shell
|
||||
echo -e '\n# set environment variable for TensorRT' >> ~/.bashrc
|
||||
echo 'export TENSORRT_DIR=/usr/include/aarch64-linux-gnu' >> ~/.bashrc
|
||||
|
||||
# this is not needed if you use NVIDIA SDK Manager with "Jetson SDK Components" for installing JetPack.
|
||||
# this is only needed if you install JetPack using SD Card Image Method.
|
||||
echo -e '\n# set environment variable for CUDA' >> ~/.bashrc
|
||||
echo 'export PATH=$PATH:/usr/local/cuda/bin' >> ~/.bashrc
|
||||
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64' >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
conda activate mmdeploy
|
||||
```
|
||||
sudo apt-get install libprotobuf-dev protobuf-compiler
|
||||
|
||||
### Install Dependencies for Model Converter
|
||||
|
||||
#### Install MMCV
|
||||
|
||||
[MMCV](https://github.com/open-mmlab/mmcv) has not provided prebuilt package for Jetson platforms, so we have to build it from source.
|
||||
|
||||
```shell
|
||||
sudo apt-get install -y libssl-dev
|
||||
git clone --branch v1.4.0 https://github.com/open-mmlab/mmcv.git
|
||||
cd mmcv
|
||||
MMCV_WITH_OPS=1 pip install -e .
|
||||
```
|
||||
Then install onnx through:
|
||||
|
||||
```{note}
|
||||
It takes about 1 hour 40 minutes to install MMCV on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
#### Install ONNX
|
||||
|
||||
```shell
|
||||
pip install onnx
|
||||
```
|
||||
Then reinstall mmdeploy.
|
||||
|
||||
#### Install h5py
|
||||
|
||||
### FAQs
|
||||
Model Converter employs HDF5 to save the calibration data for TensorRT INT8 quantization.
|
||||
|
||||
- For Jetson TX2 and Jetson Nano, `#assertion/root/workspace/mmdeploy/csrc/backend_ops/tensorrt/batched_nms/trt_batched_nms.cpp,98` or `pre_top_k need to be reduced for devices with arch 7.2`
|
||||
```shell
|
||||
sudo apt-get install -y pkg-config libhdf5-100 libhdf5-dev
|
||||
pip install versioned-hdf5
|
||||
```
|
||||
|
||||
Set MAX N mode and `sudo nvpmodel -m 0 && sudo jetson_clocks`.
|
||||
Reducing the number of [pre_top_k](https://github.com/open-mmlab/mmdeploy/blob/34879e638cc2db511e798a376b9a4b9932660fe1/configs/mmdet/_base_/base_static.py#L13) to reduce the number of proposals may resolve the problem.
|
||||
```{note}
|
||||
It takes about 6 minutes to install versioned-hdf5 on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
### Install Dependencies for C/C++ Inference SDK
|
||||
|
||||
#### Install spdlog
|
||||
|
||||
[spdlog](https://github.com/gabime/spdlog) is a very fast, header-only/compiled, C++ logging library
|
||||
|
||||
```shell
|
||||
sudo apt-get install -y libspdlog-dev
|
||||
```
|
||||
|
||||
#### Install ppl.cv
|
||||
|
||||
[ppl.cv](https://github.com/openppl-public/ppl.cv) is a high-performance image processing library of [openPPL](https://openppl.ai/home)
|
||||
|
||||
```shell
|
||||
git clone https://github.com/openppl-public/ppl.cv.git
|
||||
cd ppl.cv
|
||||
export PPLCV_DIR=$(pwd)
|
||||
echo -e '\n# set environment variable for ppl.cv' >> ~/.bashrc
|
||||
echo "export PPLCV_DIR=$(pwd)" >> ~/.bashrc
|
||||
./build.sh cuda
|
||||
```
|
||||
|
||||
```{note}
|
||||
It takes about 15 minutes to install ppl.cv on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
## Install MMDeploy
|
||||
|
||||
```shell
|
||||
git clone --recursive https://github.com/open-mmlab/mmdeploy.git
|
||||
cd mmdeploy
|
||||
export MMDEPLOY_DIR=$(pwd)
|
||||
```
|
||||
|
||||
### Install Model Converter
|
||||
|
||||
Since some operators adopted by OpenMMLab codebases are not supported by TensorRT, we build the custom TensorRT plugins to make it up, such as `roi_align`, `scatternd`, etc.
|
||||
You can find a full list of custom plugins from [here](../ops/tensorrt.md).
|
||||
|
||||
```shell
|
||||
# build TensorRT custom operators
|
||||
mkdir -p build && cd build
|
||||
cmake .. -DMMDEPLOY_TARGET_BACKENDS="trt"
|
||||
make -j$(nproc)
|
||||
|
||||
# install model converter
|
||||
cd ${MMDEPLOY_DIR}
|
||||
pip install -v -e .
|
||||
# "-v" means verbose, or more output
|
||||
# "-e" means installing a project in editable mode,
|
||||
# thus any local modifications made to the code will take effect without re-installation.
|
||||
```
|
||||
|
||||
```{note}
|
||||
It takes about 5 minutes to install model converter on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
### Install C/C++ Inference SDK
|
||||
|
||||
1. Build SDK Libraries
|
||||
|
||||
```shell
|
||||
mkdir -p build && cd build
|
||||
cmake .. \
|
||||
-DMMDEPLOY_BUILD_SDK=ON \
|
||||
-DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
|
||||
-DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
|
||||
-DMMDEPLOY_TARGET_BACKENDS="trt" \
|
||||
-DMMDEPLOY_CODEBASES=all \
|
||||
-Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl
|
||||
make -j$(nproc) && make install
|
||||
```
|
||||
|
||||
```{note}
|
||||
It takes about 9 minutes to build SDK libraries on a Jetson Nano. So, please be patient until the installation is complete.
|
||||
```
|
||||
|
||||
2. Build SDK demos
|
||||
|
||||
```shell
|
||||
cd ${MMDEPLOY_DIR}/build/install/example
|
||||
mkdir -p build && cd build
|
||||
cmake .. -DMMDeploy_DIR=${MMDEPLOY_DIR}/buildinstall/lib/cmake/MMDeploy
|
||||
make -j$(nproc)
|
||||
```
|
||||
|
||||
### Run a Demo
|
||||
|
||||
#### Object Detection demo
|
||||
|
||||
Before running this demo, you need to convert model files to be able to use with this SDK.
|
||||
|
||||
1. Install [MMDetection](https://github.com/open-mmlab/mmdetection) which is needed for model conversion
|
||||
|
||||
MMDetection is an open source object detection toolbox based on PyTorch
|
||||
|
||||
```shell
|
||||
git clone https://github.com/open-mmlab/mmdetection.git
|
||||
cd mmdetection
|
||||
pip install -r requirements/build.txt
|
||||
pip install -v -e . # or "python setup.py develop"
|
||||
```
|
||||
|
||||
2. Follow [this document](https://github.com/open-mmlab/mmdeploy/blob/master/docs/en/tutorials/how_to_convert_model.md) on how to convert model files.
|
||||
|
||||
For this example, we have used [retinanet_r18_fpn_1x_coco.py](https://github.com/open-mmlab/mmdetection/blob/master/configs/retinanet/retinanet_r18_fpn_1x_coco.py) as the model config, and [this file](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r18_fpn_1x_coco/retinanet_r18_fpn_1x_coco_20220407_171055-614fd399.pth) as the corresponding checkpoint file. Also for deploy config, we have used [detection_tensorrt_dynamic-320x320-1344x1344.py](https://github.com/open-mmlab/mmdeploy/blob/master/configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py)
|
||||
|
||||
```shell
|
||||
python ./tools/deploy.py \
|
||||
configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
|
||||
$PATH_TO_MMDET/configs/retinanet/retinanet_r18_fpn_1x_coco.py \
|
||||
retinanet_r18_fpn_1x_coco_20220407_171055-614fd399.pth \
|
||||
$PATH_TO_MMDET/demo/demo.jpg \
|
||||
--work-dir work_dir \
|
||||
--show \
|
||||
--device cuda:0 \
|
||||
--dump-info
|
||||
```
|
||||
|
||||
3. Finally run inference on an image
|
||||
|
||||
<div align=center><img width=650 src="https://files.seeedstudio.com/wiki/open-mmlab/source_image.jpg"/></div>
|
||||
|
||||
```shell
|
||||
./object_detection cuda ${directory/to/the/converted/models} ${path/to/an/image}
|
||||
```
|
||||
|
||||
<div align=center><img width=650 src="https://files.seeedstudio.com/wiki/open-mmlab/output_detection.png"/></div>
|
||||
|
||||
The above inference is done on a [Seeed reComputer built with Jetson Nano module](https://www.seeedstudio.com/Jetson-10-1-A0-p-5336.html)
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Installation
|
||||
|
||||
- `pip install` throws an error like `Illegal instruction (core dumped)`
|
||||
|
||||
Check if you are using any mirror, if you did, try this:
|
||||
|
||||
```shell
|
||||
rm .condarc
|
||||
conda clean -i
|
||||
conda create -n xxx python=${PYTHON_VERSION}
|
||||
```
|
||||
|
||||
### Runtime
|
||||
|
||||
- `#assertion/root/workspace/mmdeploy/csrc/backend_ops/tensorrt/batched_nms/trt_batched_nms.cpp,98` or `pre_top_k need to be reduced for devices with arch 7.2`
|
||||
|
||||
1. Set `MAX N` mode and perform `sudo nvpmodel -m 0 && sudo jetson_clocks`.
|
||||
2. Reduce the number of `pre_top_k` in deploy config file like [mmdet pre_top_k](https://github.com/open-mmlab/mmdeploy/blob/34879e638cc2db511e798a376b9a4b9932660fe1/configs/mmdet/_base_/base_static.py#L13) does, e.g., `1000`.
|
||||
3. Convert the model again and try SDK demo again.
|
||||
|
|
|
|||
|
|
@ -308,7 +308,7 @@ export MMDEPLOY_DIR=$(pwd)
|
|||
3. <b>pplnn</b>: PPL.NN. <code>pplnn_DIR</code> is needed.
|
||||
<pre><code>-Dpplnn_DIR=${PPLNN_DIR}</code></pre>
|
||||
4. <b>ncnn</b>: ncnn. <code>ncnn_DIR</code> is needed.
|
||||
<pre><code>-Dncnn_DIR=${NCNN_DIR}</code></pre>
|
||||
<pre><code>-Dncnn_DIR=${NCNN_DIR}/build/install/lib/cmake/ncnn</code></pre>
|
||||
5. <b>openvino</b>: OpenVINO. <code>InferenceEngine_DIR</code> is needed.
|
||||
<pre><code>-DInferenceEngine_DIR=${INTEL_OPENVINO_DIR}/deployment_tools/inference_engine/share</code></pre>
|
||||
6. <b>torchscript</b>: TorchScript. <code>Torch_DIR</code> is needed.
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# ncnn Support
|
||||
|
||||
MMDeploy now supports ncnn version == 1.0.20211208
|
||||
MMDeploy now supports ncnn version == 1.0.20220216
|
||||
|
||||
## Installation
|
||||
|
||||
|
|
@ -27,7 +27,7 @@ You should ensure your gcc satisfies `gcc >= 6`.
|
|||
|
||||
- Download ncnn source code
|
||||
```bash
|
||||
git clone -b 20211208 git@github.com:Tencent/ncnn.git
|
||||
git clone -b 20220216 git@github.com:Tencent/ncnn.git
|
||||
```
|
||||
|
||||
- <font color=red>Make install</font> ncnn library
|
||||
|
|
@ -72,7 +72,7 @@ If you haven't installed ncnn in the default path, please add `-Dncnn_DIR` flag
|
|||
|
||||
## Reminder
|
||||
|
||||
- In ncnn version >= 1.0.20201208, the dimension of ncnn.Mat should be no more than 4.
|
||||
- In ncnn version >= 1.0.20220216, the dimension of ncnn.Mat should be no more than 4.
|
||||
|
||||
## FAQs
|
||||
|
||||
|
|
|
|||
|
|
@ -229,3 +229,20 @@ Although the backend engines are usually implemented in C/C++, it is convenient
|
|||
```
|
||||
|
||||
5. Add docstring and unit tests for new code :).
|
||||
|
||||
|
||||
### Support new backends using MMDeploy as a third party
|
||||
Previous parts show how to add a new backend in MMDeploy, which requires changing its source codes. However, if we treat MMDeploy as a third party, the methods above are no longer efficient. To this end, adding a new backend requires us pre-install another package named `aenum`. We can install it directly through `pip install aenum`.
|
||||
|
||||
After installing `aenum` successfully, we can use it to add a new backend through:
|
||||
```python
|
||||
from mmdeploy.utils.constants import Backend
|
||||
from aenum import extend_enum
|
||||
|
||||
try:
|
||||
Backend.get('backend_name')
|
||||
except Exception:
|
||||
extend_enum(Backend, 'BACKEND', 'backend_name')
|
||||
```
|
||||
|
||||
We can run the codes above before we use the rewrite logic of MMDeploy.
|
||||
|
|
|
|||
|
|
@ -57,6 +57,8 @@ extensions = [
|
|||
'sphinx_copybutton',
|
||||
] # yapf: disable
|
||||
|
||||
autodoc_mock_imports = ['tensorrt']
|
||||
|
||||
autosectionlabel_prefix_document = True
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
|
|
|
|||
|
|
@ -76,9 +76,9 @@ export OPENCV_ANDROID_SDK_DIR=${PWD}/OpenCV-android-sdk
|
|||
<tr>
|
||||
<td>ncnn </td>
|
||||
<td>ncnn 是支持 android 平台的高效神经网络推理计算框架</br>
|
||||
<b> 目前, MMDeploy 支持 ncnn 的 20211208 版本, 且必须使用<code>git clone</code> 下载源码的方式安装</b><br>
|
||||
<b> 目前, MMDeploy 支持 ncnn 的 20220216 版本, 且必须使用<code>git clone</code> 下载源码的方式安装</b><br>
|
||||
<pre><code>
|
||||
git clone -b 20211208 https://github.com/Tencent/ncnn.git
|
||||
git clone -b 20220216 https://github.com/Tencent/ncnn.git
|
||||
cd ncnn
|
||||
git submodule update --init
|
||||
export NCNN_DIR=${PWD}
|
||||
|
|
|
|||
|
|
@ -37,4 +37,4 @@ git clone -b master git@github.com:open-mmlab/mmdeploy.git --recursive
|
|||
- [Linux-x86_64](linux-x86_64.md)
|
||||
- [Windows](windows.md)
|
||||
- [Android-aarch64](android.md)
|
||||
- [NVIDIA Jetson](https://mmdeploy.readthedocs.io/en/latest/01-how-to-build/jetsons.html)
|
||||
- [NVIDIA Jetson](jetsons.md)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,282 @@
|
|||
# 如何在 Jetson 模组上安装 MMDeploy
|
||||
|
||||
本教程将介绍如何在 NVIDIA Jetson 平台上安装 MMDeploy。该方法已经在以下 3 种 Jetson 模组上进行了验证:
|
||||
- Jetson Nano
|
||||
- Jetson TX2
|
||||
- Jetson AGX Xavier
|
||||
|
||||
## 预备
|
||||
|
||||
首先需要在 Jetson 模组上安装 JetPack SDK。
|
||||
此外,在利用 MMDeploy 的 Model Converter 转换 PyTorch 模型为 ONNX 模型时,需要创建一个装有 PyTorch 的环境。
|
||||
最后,关于编译工具链,要求 CMake 和 GCC 的版本分别不低于 3.14 和 7.0。
|
||||
|
||||
### JetPack SDK
|
||||
|
||||
JetPack SDK 为构建硬件加速的边缘 AI 应用提供了一个全面的开发环境。
|
||||
其支持所有的 Jetson 模组及开发套件。
|
||||
|
||||
主要有两种安装 JetPack SDK 的方式:
|
||||
1. 使用 SD 卡镜像方式,直接将镜像刻录到 SD 卡上
|
||||
2. 使用 NVIDIA SDK Manager 进行安装
|
||||
|
||||
你可以在 NVIDIA [官网](https://developer.nvidia.com/jetpack-sdk-50dp)上找到详细的安装指南。
|
||||
|
||||
这里我们选择 [JetPack 4.6.1](https://developer.nvidia.com/jetpack-sdk-461) 作为装配 Jetson 模组的首选。MMDeploy 已经在 JetPack 4.6 rev3 及以上版本,TensorRT 8.0.1.6 及以上版本进行了测试。更早的 JetPack 版本与 TensorRT 7.x 存在不兼容的情况。
|
||||
|
||||
### Conda
|
||||
|
||||
安装 [Archiconda](https://github.com/Archiconda/build-tools/releases) 而不是 Anaconda,因为后者不提供针对 Jetson 的 wheel 文件。
|
||||
|
||||
```shell
|
||||
wget https://github.com/Archiconda/build-tools/releases/download/0.2.3/Archiconda3-0.2.3-Linux-aarch64.sh
|
||||
bash Archiconda3-0.2.3-Linux-aarch64.sh -b
|
||||
|
||||
echo -e '\n# set environment variable for conda' >> ~/.bashrc
|
||||
echo ". ~/archiconda3/etc/profile.d/conda.sh" >> ~/.bashrc
|
||||
echo 'export PATH=$PATH:~/archiconda3/bin' >> ~/.bashrc
|
||||
|
||||
echo -e '\n# set environment variable for pip' >> ~/.bashrc
|
||||
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
conda --version
|
||||
```
|
||||
|
||||
完成安装后需创建并启动一个 conda 环境。
|
||||
|
||||
```shell
|
||||
# 得到默认安装的 python3 版本
|
||||
export PYTHON_VERSION=`python3 --version | cut -d' ' -f 2 | cut -d'.' -f1,2`
|
||||
conda create -y -n mmdeploy python=${PYTHON_VERSION}
|
||||
conda activate mmdeploy
|
||||
```
|
||||
|
||||
```{note}
|
||||
JetPack SDK 4+ 自带 python 3.6。我们强烈建议使用默认的 python 版本。尝试升级 python 可能会破坏 JetPack 环境。
|
||||
|
||||
如果必须安装更高版本的 python, 可以选择安装 JetPack 5+,其提供 python 3.8。
|
||||
```
|
||||
### PyTorch
|
||||
|
||||
从[这里](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-10-now-available/72048)下载 Jetson 的 PyTorch wheel 文件并保存在本地目录 `/opt` 中。
|
||||
此外,由于 torchvision 不提供针对 Jetson 平台的预编译包,因此需要从源码进行编译。
|
||||
|
||||
以 `torch 1.10.0` 和 `torchvision 0.11.1` 为例,可按以下方式进行安装:
|
||||
|
||||
```shell
|
||||
# pytorch
|
||||
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
|
||||
# torchvision
|
||||
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev -y
|
||||
sudo rm -r torchvision
|
||||
git clone https://github.com/pytorch/vision torchvision
|
||||
cd torchvision
|
||||
git checkout tags/v0.11.1 -b v0.11.1
|
||||
export BUILD_VERSION=0.11.1
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
如果安装其他版本的 PyTorch 和 torchvision,需参考[这里](https://pypi.org/project/torchvision/)的表格以保证版本兼容性。
|
||||
|
||||
### CMake
|
||||
|
||||
这里我们使用 CMake 截至2022年4月的最新版本 v3.23.1。
|
||||
|
||||
```shell
|
||||
# purge existing
|
||||
sudo apt-get purge cmake
|
||||
sudo snap remove cmake
|
||||
|
||||
# install prebuilt binary
|
||||
export CMAKE_VER=3.23.1
|
||||
export ARCH=aarch64
|
||||
wget https://github.com/Kitware/CMake/releases/download/v${CMAKE_VER}/cmake-${CMAKE_VER}-linux-${ARCH}.sh
|
||||
chmod +x cmake-${CMAKE_VER}-linux-${ARCH}.sh
|
||||
sudo ./cmake-${CMAKE_VER}-linux-${ARCH}.sh --prefix=/usr --skip-license
|
||||
cmake --version
|
||||
```
|
||||
|
||||
## 安装依赖项
|
||||
|
||||
MMDeploy 中的 Model Converter 依赖于 [MMCV](https://github.com/open-mmlab/mmcv) 和推理引擎 [TensorRT](https://developer.nvidia.com/tensorrt)。
|
||||
同时, MMDeploy 的 C/C++ Inference SDK 依赖于 [spdlog](https://github.com/gabime/spdlog), OpenCV, [ppl.cv](https://github.com/openppl-public/ppl.cv) 和 TensorRT 等。
|
||||
因此,接下来我们将先介绍如何配置 TensorRT。
|
||||
之后再分别展示安装 Model Converter 和 C/C++ Inference SDK 的步骤。
|
||||
|
||||
### 配置 TensorRT
|
||||
|
||||
JetPack SDK 自带 TensorRT。
|
||||
但是为了能够在 Conda 环境中成功导入,我们需要将 TensorRT 拷贝进先前创建的 Conda 环境中。
|
||||
|
||||
```shell
|
||||
cp -r /usr/lib/python${PYTHON_VERSION}/dist-packages/tensorrt* ~/archiconda3/envs/mmdeploy/lib/python${PYTHON_VERSION}/site-packages/
|
||||
conda deactivate
|
||||
conda activate mmdeploy
|
||||
python -c "import tensorrt; print(tensorrt.__version__)" # 将会打印出 TensorRT 版本
|
||||
|
||||
# 为之后编译 MMDeploy 设置环境变量
|
||||
export TENSORRT_DIR=/usr/include/aarch64-linux-gnu
|
||||
|
||||
# 将 cuda 路径和 lib 路径写入到环境变量 `$PATH` 和 `$LD_LIBRARY_PATH` 中, 为之后编译 MMDeploy 做准备
|
||||
export PATH=$PATH:/usr/local/cuda/bin
|
||||
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
|
||||
```
|
||||
|
||||
你也可以通过添加以上环境变量至 `~/.bashrc` 使得它们永久化。
|
||||
|
||||
```shell
|
||||
echo -e '\n# set environment variable for TensorRT' >> ~/.bashrc
|
||||
echo 'export TENSORRT_DIR=/usr/include/aarch64-linux-gnu' >> ~/.bashrc
|
||||
|
||||
echo -e '\n# set environment variable for CUDA' >> ~/.bashrc
|
||||
echo 'export PATH=$PATH:/usr/local/cuda/bin' >> ~/.bashrc
|
||||
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64' >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
conda activate mmdeploy
|
||||
```
|
||||
|
||||
### 安装 Model Converter 的依赖项
|
||||
|
||||
- 安装 [MMCV](https://github.com/open-mmlab/mmcv)
|
||||
|
||||
MMCV 还未提供针对 Jetson 平台的预编译包,因此我们需要从源对其进行编译。
|
||||
|
||||
```shell
|
||||
sudo apt-get install -y libssl-dev
|
||||
git clone https://github.com/open-mmlab/mmcv.git
|
||||
cd mmcv
|
||||
git checkout v1.4.0
|
||||
MMCV_WITH_OPS=1 pip install -e .
|
||||
```
|
||||
|
||||
- 安装 ONNX
|
||||
|
||||
```shell
|
||||
pip install onnx
|
||||
```
|
||||
|
||||
- 安装 h5py
|
||||
|
||||
Model Converter 使用 HDF5 存储 TensorRT INT8 量化的校准数据。
|
||||
|
||||
```shell
|
||||
sudo apt-get install -y pkg-config libhdf5-100 libhdf5-dev
|
||||
pip install versioned-hdf5
|
||||
```
|
||||
|
||||
### 安装 SDK 的依赖项
|
||||
|
||||
如果你不需要使用 MMDeploy C/C++ Inference SDK 则可以跳过本步骤。
|
||||
|
||||
- 安装 [spdlog](https://github.com/gabime/spdlog)
|
||||
|
||||
“`spdlog` 是一个快速的,仅有头文件的 C++ 日志库。”
|
||||
|
||||
```shell
|
||||
sudo apt-get install -y libspdlog-dev
|
||||
```
|
||||
|
||||
- 安装 [ppl.cv](https://github.com/openppl-public/ppl.cv)
|
||||
|
||||
“`ppl.cv` 是 [OpenPPL](https://openppl.ai/home) 的高性能图像处理库。”
|
||||
|
||||
```shell
|
||||
git clone https://github.com/openppl-public/ppl.cv.git
|
||||
cd ppl.cv
|
||||
export PPLCV_DIR=$(pwd)
|
||||
echo -e '\n# set environment variable for ppl.cv' >> ~/.bashrc
|
||||
echo "export PPLCV_DIR=$(pwd)" >> ~/.bashrc
|
||||
./build.sh cuda
|
||||
```
|
||||
|
||||
## 安装 MMDeploy
|
||||
|
||||
```shell
|
||||
git clone --recursive https://github.com/open-mmlab/mmdeploy.git
|
||||
cd mmdeploy
|
||||
export MMDEPLOY_DIR=$(pwd)
|
||||
```
|
||||
|
||||
### 安装 Model Converter
|
||||
|
||||
由于一些算子采用的是 OpenMMLab 代码库中的实现,并不被 TenorRT 支持,
|
||||
因此我们需要自定义 TensorRT 插件,例如 `roi_align`, `scatternd` 等。
|
||||
你可以从[这里](../../en/ops/tensorrt.md)找到完整的自定义插件列表。
|
||||
|
||||
```shell
|
||||
# 编译 TensorRT 自定义算子
|
||||
mkdir -p build && cd build
|
||||
cmake .. -DMMDEPLOY_TARGET_BACKENDS="trt"
|
||||
make -j$(nproc)
|
||||
|
||||
# 安装 model converter
|
||||
cd ${MMDEPLOY_DIR}
|
||||
pip install -v -e .
|
||||
# "-v" 表示显示详细安装信息
|
||||
# "-e" 表示在可编辑模式下安装
|
||||
# 因此任何针对代码的本地修改都可以在无需重装的情况下生效。
|
||||
```
|
||||
|
||||
### 安装 C/C++ Inference SDK
|
||||
|
||||
如果你不需要使用 MMDeploy C/C++ Inference SDK 则可以跳过本步骤。
|
||||
|
||||
1. 编译 SDK Libraries
|
||||
|
||||
```shell
|
||||
mkdir -p build && cd build
|
||||
cmake .. \
|
||||
-DMMDEPLOY_BUILD_SDK=ON \
|
||||
-DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
|
||||
-DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
|
||||
-DMMDEPLOY_TARGET_BACKENDS="trt" \
|
||||
-DMMDEPLOY_CODEBASES=all \
|
||||
-Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl
|
||||
make -j$(nproc) && make install
|
||||
```
|
||||
|
||||
2. 编译 SDK demos
|
||||
|
||||
```shell
|
||||
cd ${MMDEPLOY_DIR}/build/install/example
|
||||
mkdir -p build && cd build
|
||||
cmake .. -DMMDeploy_DIR=${MMDEPLOY_DIR}/build/install/lib/cmake/MMDeploy
|
||||
make -j$(nproc)
|
||||
```
|
||||
|
||||
3. 运行 demo
|
||||
|
||||
以目标检测为例:
|
||||
```shell
|
||||
./object_detection cuda ${directory/to/the/converted/models} ${path/to/an/image}
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### 安装
|
||||
|
||||
- `pip install` 报错 `Illegal instruction (core dumped)`
|
||||
|
||||
```shell
|
||||
echo '# set env for pip' >> ~/.bashrc
|
||||
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
如果上述方法仍无法解决问题,检查是否正在使用镜像文件。如果是的,可尝试:
|
||||
```shell
|
||||
rm .condarc
|
||||
conda clean -i
|
||||
conda create -n xxx python=${PYTHON_VERSION}
|
||||
```
|
||||
|
||||
### 执行
|
||||
|
||||
- `#assertion/root/workspace/mmdeploy/csrc/backend_ops/tensorrt/batched_nms/trt_batched_nms.cpp,98` or `pre_top_k need to be reduced for devices with arch 7.2`
|
||||
|
||||
1. 设置为 `MAX N` 模式并执行 `sudo nvpmodel -m 0 && sudo jetson_clocks`。
|
||||
2. 效仿 [mmdet pre_top_k](https://github.com/open-mmlab/mmdeploy/blob/34879e638cc2db511e798a376b9a4b9932660fe1/configs/mmdet/_base_/base_static.py#L13),减少配置文件中 `pre_top_k` 的个数,例如 `1000`。
|
||||
3. 重新进行模型转换并重新运行 demo。
|
||||
|
|
@ -301,7 +301,7 @@ export MMDEPLOY_DIR=$(pwd)
|
|||
3. <b>pplnn</b>: 表示 PPL.NN。需要设置 <code>pplnn_DIR</code>
|
||||
<pre><code>-Dpplnn_DIR=${PPLNN_DIR}</code></pre>
|
||||
4. <b>ncnn</b>: 表示 ncnn。需要设置 <code>ncnn_DIR</code>
|
||||
<pre><code>-Dncnn_DIR=${NCNN_DIR}</code></pre>
|
||||
<pre><code>-Dncnn_DIR=${NCNN_DIR}/build/install/lib/cmake/ncnn</code></pre>
|
||||
5. <b>openvino</b>: 表示 OpenVINO。需要设置 <code>InferenceEngine_DIR</code>
|
||||
<pre><code>-DInferenceEngine_DIR=${INTEL_OPENVINO_DIR}/deployment_tools/inference_engine/share</code></pre>
|
||||
6. <b>torchscript</b>: TorchScript. 需要设置<code>Torch_DIR</code>
|
||||
|
|
|
|||
|
|
@ -229,3 +229,19 @@ MMDeploy 中的后端必须支持 ONNX,因此后端能直接加载“.onnx”
|
|||
```
|
||||
|
||||
5. 为新后端引擎代码添加相关注释和单元测试 :).
|
||||
|
||||
|
||||
### 将MMDeploy作为第三方库时添加新后端
|
||||
前面的部分展示了如何在 MMDeploy 中添加新的后端,这需要更改其源代码。但是,如果我们将 MMDeploy 视为第三方,则上述方法不再有效。为此,添加一个新的后端需要我们预先安装另一个名为 `aenum` 的包。我们可以直接通过`pip install aenum`进行安装。
|
||||
|
||||
成功安装 `aenum` 后,我们可以通过以下方式使用它来添加新的后端:
|
||||
```python
|
||||
from mmdeploy.utils.constants import Backend
|
||||
from aenum import extend_enum
|
||||
|
||||
try:
|
||||
Backend.get('backend_name')
|
||||
except Exception:
|
||||
extend_enum(Backend, 'BACKEND', 'backend_name')
|
||||
```
|
||||
我们可以在使用 MMDeploy 的重写逻辑之前运行上面的代码,这就完成了新后端的添加。
|
||||
|
|
|
|||
|
|
@ -351,4 +351,4 @@ cv2.imwrite("face_ort_3.png", ort_output)
|
|||
- 通过修改继承自 torch.autograd.Function 的算子的 symbolic 方法,可以改变该算子映射到 ONNX 算子的行为。
|
||||
|
||||
|
||||
至此,"部署第一个模型“的教程算是告一段落了。是不是觉得学到的知识还不够多?没关系,在接下来的几篇教程中,我们将结合 MMDeploy ,重点介绍 ONNX 中间表示和 ONNX Runtime/TensorRT 推理引擎的知识,让大家学会如何部署更复杂的模型。敬请期待!
|
||||
至此,"部署第一个模型“的教程算是告一段落了。是不是觉得学到的知识还不够多?没关系,在接下来的几篇教程中,我们将结合 MMDeploy ,重点介绍 ONNX 中间表示和 ONNX Runtime/TensorRT 推理引擎的知识,让大家学会如何部署更复杂的模型。
|
||||
|
|
|
|||
|
|
@ -0,0 +1,294 @@
|
|||
ONNX 是目前模型部署中最重要的中间表示之一。学懂了 ONNX 的技术细节,就能规避大量的模型部署问题。从这篇文章开始,在接下来的三篇文章里,我们将由浅入深地介绍 ONNX 相关的知识。在第一篇文章里,我们会介绍更多 PyTorch 转 ONNX 的细节,让大家完全掌握把简单的 PyTorch 模型转成 ONNX 模型的方法;在第二篇文章里,我们将介绍如何在 PyTorch 中支持更多的 ONNX 算子,让大家能彻底走通 PyTorch 到 ONNX 这条部署路线;第三篇文章里,我们讲介绍 ONNX 本身的知识,以及修改、调试 ONNX 模型的常用方法,使大家能自行解决大部分和 ONNX 有关的部署问题。
|
||||
|
||||
在把 PyTorch 模型转换成 ONNX 模型时,我们往往只需要轻松地调用一句`torch.onnx.export`就行了。这个函数的接口看上去简单,但它在使用上还有着诸多的“潜规则”。在这篇教程中,我们会详细介绍 PyTorch 模型转 ONNX 模型的原理及注意事项。除此之外,我们还会介绍 PyTorch 与 ONNX 的算子对应关系,以教会大家如何处理 PyTorch 模型转换时可能会遇到的算子支持问题。
|
||||
|
||||
## `torch.onnx.export` 细解
|
||||
在这一节里,我们将详细介绍 PyTorch 到 ONNX 的转换函数—— torch.onnx.export。我们希望大家能够更加灵活地使用这个模型转换接口,并通过了解它的实现原理来更好地应对该函数的报错(由于模型部署的兼容性问题,部署复杂模型时该函数时常会报错)。
|
||||
### 计算图导出方法
|
||||
[TorchScript](https://pytorch.org/docs/stable/jit.html) 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个`torch.nn.Module`模型会被转换成 TorchScript 的`torch.jit.ScriptModule`模型。现在, TorchScript 也被常当成一种中间表示使用。我们在[其他文章](https://zhuanlan.zhihu.com/p/486914187)中对 TorchScript 有详细的介绍,这里介绍 TorchScript 仅用于说明 PyTorch 模型转 ONNX的原理。
|
||||
`torch.onnx.export`中需要的模型实际上是一个`torch.jit.ScriptModule`。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。如果给`torch.onnx.export`传入了一个普通 PyTorch 模型(`torch.nn.Module`),那么这个模型会默认使用跟踪的方法导出。这一过程如下图所示:
|
||||
|
||||

|
||||
|
||||
回忆一下我们[第一篇教程](./01_introduction_to_model_deployment.md)知识:跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);脚本化则能通过解析模型来正确记录所有的控制流。我们以下面这段代码为例来看一看这两种转换方法的区别:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self, n):
|
||||
super().__init__()
|
||||
self.n = n
|
||||
self.conv = torch.nn.Conv2d(3, 3, 3)
|
||||
|
||||
def forward(self, x):
|
||||
for i in range(self.n):
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
models = [Model(2), Model(3)]
|
||||
model_names = ['model_2', 'model_3']
|
||||
|
||||
for model, model_name in zip(models, model_names):
|
||||
dummy_input = torch.rand(1, 3, 10, 10)
|
||||
dummy_output = model(dummy_input)
|
||||
model_trace = torch.jit.trace(model, dummy_input)
|
||||
model_script = torch.jit.script(model)
|
||||
|
||||
# 跟踪法与直接 torch.onnx.export(model, ...)等价
|
||||
torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)
|
||||
# 脚本化必须先调用 torch.jit.sciprt
|
||||
torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
|
||||
```
|
||||
|
||||
在这段代码里,我们定义了一个带循环的模型,模型通过参数`n`来控制输入张量被卷积的次数。之后,我们各创建了一个`n=2`和`n=3`的模型。我们把这两个模型分别用跟踪和脚本化的方法进行导出。
|
||||
值得一提的是,由于这里的两个模型(`model_trace`, `model_script`)是 TorchScript 模型,`export`函数已经不需要再运行一遍模型了。(如果模型是用跟踪法得到的,那么在执行`torch.jit.trace`的时候就运行过一遍了;而用脚本化导出时,模型不需要实际运行)参数中的`dummy_input`和`dummy_output`仅仅是为了获取输入和输出张量的类型和形状。
|
||||
运行上面的代码,我们把得到的4个 onnx 文件用 Netron 可视化:
|
||||
|
||||
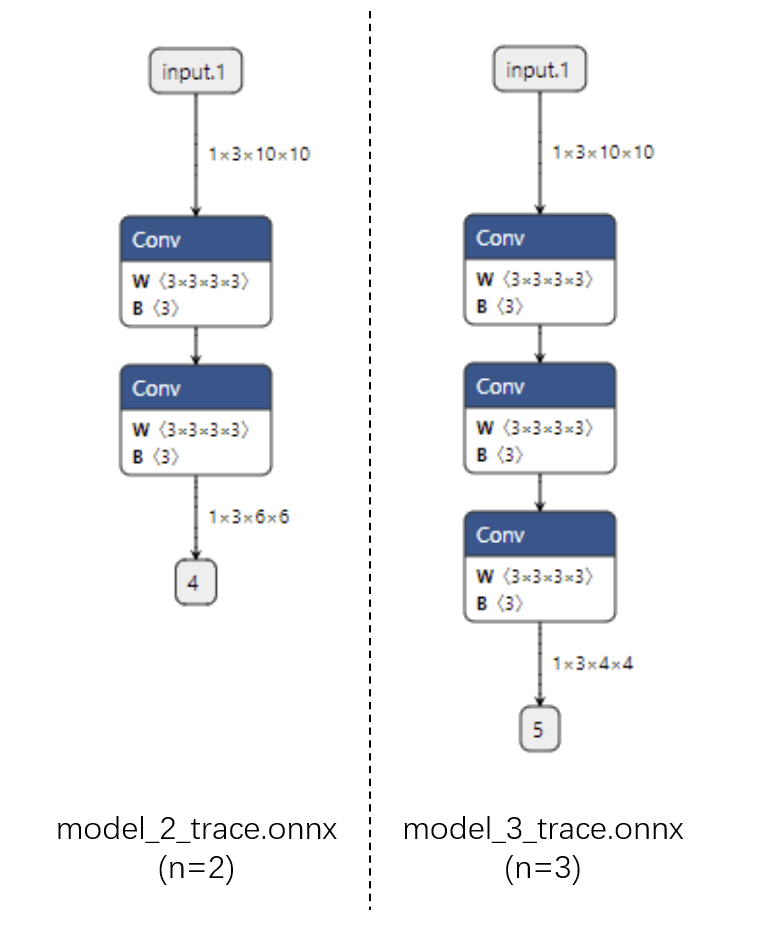
|
||||
|
||||
首先看跟踪法得到的 ONNX 模型结构。可以看出来,对于不同的 `n`,ONNX 模型的结构是不一样的。
|
||||
|
||||
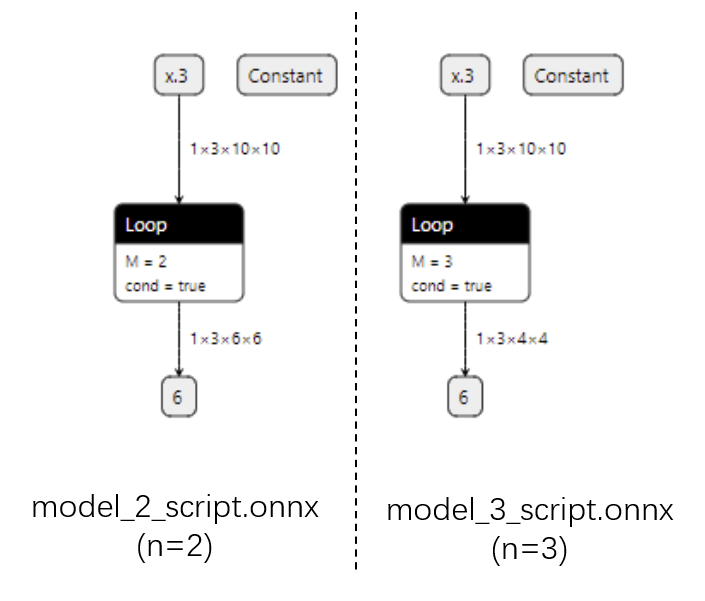
|
||||
|
||||
而用脚本化的话,最终的 ONNX 模型用 `Loop` 节点来表示循环。这样哪怕对于不同的 `n`,ONNX 模型也有同样的结构。
|
||||
由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用 `torch.onnx.export` 跟踪导出即可。了解这部分的知识主要是为了在模型转换报错时能够更好地定位问题是否发生在 PyTorch 转 TorchScript 阶段。
|
||||
### 参数讲解
|
||||
了解完转换函数的原理后,我们来详细介绍一下该函数的主要参数的作用。我们主要会从应用的角度来介绍每个参数在不同的模型部署场景中应该如何设置,而不会去列出每个参数的所有设置方法。该函数详细的 API 文档可参考 [torch.onnx ‒ PyTorch 1.11.0 documentation](https://pytorch.org/docs/stable/onnx.html#functions)
|
||||
|
||||
`torch.onnx.export` 在 `torch.onnx.__init__.py`文件中的定义如下:
|
||||
```python
|
||||
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
|
||||
input_names=None, output_names=None, aten=False, export_raw_ir=False,
|
||||
operator_export_type=None, opset_version=None, _retain_param_name=True,
|
||||
do_constant_folding=True, example_outputs=None, strip_doc_string=True,
|
||||
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
|
||||
enable_onnx_checker=True, use_external_data_format=False):
|
||||
```
|
||||
前三个必选参数为模型、模型输入、导出的 onnx 文件名,我们对这几个参数已经很熟悉了。我们来着重看一下后面的一些常用可选参数。
|
||||
#### export_params
|
||||
模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。
|
||||
我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
|
||||
#### input_names, output_names
|
||||
设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。
|
||||
ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。
|
||||
在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
|
||||
#### opset_version
|
||||
转换时参考哪个 ONNX 算子集版本,默认为9。后文会详细介绍 PyTorch 与 ONNX 的算子对应关系。
|
||||
#### dynamic_axes
|
||||
指定输入输出张量的哪些维度是动态的。
|
||||
为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。
|
||||
我们来看一个`dynamic_axes`的设置例子:
|
||||
```python
|
||||
import torch
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.conv = torch.nn.Conv2d(3, 3, 3)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
model = Model()
|
||||
dummy_input = torch.rand(1, 3, 10, 10)
|
||||
model_names = ['model_static.onnx',
|
||||
'model_dynamic_0.onnx',
|
||||
'model_dynamic_23.onnx']
|
||||
|
||||
dynamic_axes_0 = {
|
||||
'in' : [0],
|
||||
'out' : [0]
|
||||
}
|
||||
dynamic_axes_23 = {
|
||||
'in' : [2, 3],
|
||||
'out' : [2, 3]
|
||||
}
|
||||
|
||||
torch.onnx.export(model, dummy_input, model_names[0],
|
||||
input_names=['in'], output_names=['out'])
|
||||
torch.onnx.export(model, dummy_input, model_names[1],
|
||||
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
|
||||
torch.onnx.export(model, dummy_input, model_names[2],
|
||||
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
|
||||
```
|
||||
首先,我们导出3个 ONNX 模型,分别为没有动态维度、第0维动态、第2第3维动态的模型。
|
||||
在这份代码里,我们是用列表的方式表示动态维度,例如:
|
||||
```python
|
||||
dynamic_axes_0 = {
|
||||
'in' : [0],
|
||||
'out' : [0]
|
||||
}
|
||||
``
|
||||
由于 ONNX 要求每个动态维度都有一个名字,这样写的话会引出一条 UserWarning,警告我们通过列表的方式设置动态维度的话系统会自动为它们分配名字。一种显式添加动态维度名字的方法如下:
|
||||
```python
|
||||
dynamic_axes_0 = {
|
||||
'in' : {0: 'batch'},
|
||||
'out' : {0: 'batch'}
|
||||
}
|
||||
```
|
||||
|
||||
由于在这份代码里我们没有更多的对动态维度的操作,因此简单地用列表指定动态维度即可。
|
||||
之后,我们用下面的代码来看一看动态维度的作用:
|
||||
```python
|
||||
import onnxruntime
|
||||
import numpy as np
|
||||
|
||||
origin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)
|
||||
mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)
|
||||
big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32)
|
||||
|
||||
inputs = [origin_tensor, mult_batch_tensor, big_tensor]
|
||||
exceptions = dict()
|
||||
|
||||
for model_name in model_names:
|
||||
for i, input in enumerate(inputs):
|
||||
try:
|
||||
ort_session = onnxruntime.InferenceSession(model_name)
|
||||
ort_inputs = {'in': input}
|
||||
ort_session.run(['out'], ort_inputs)
|
||||
except Exception as e:
|
||||
exceptions[(i, model_name)] = e
|
||||
print(f'Input[{i}] on model {model_name} error.')
|
||||
else:
|
||||
print(f'Input[{i}] on model {model_name} succeed.')
|
||||
```
|
||||
我们在模型导出计算图时用的是一个形状为`(1, 3, 10, 10)`的张量。现在,我们来尝试以形状分别是`(1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20)`为输入,用ONNX Runtime运行一下这几个模型,看看哪些情况下会报错,并保存对应的报错信息。得到的输出信息应该如下:
|
||||
```python
|
||||
Input[0] on model model_static.onnx succeed.
|
||||
Input[1] on model model_static.onnx error.
|
||||
Input[2] on model model_static.onnx error.
|
||||
Input[0] on model model_dynamic_0.onnx succeed.
|
||||
Input[1] on model model_dynamic_0.onnx succeed.
|
||||
Input[2] on model model_dynamic_0.onnx error.
|
||||
Input[0] on model model_dynamic_23.onnx succeed.
|
||||
Input[1] on model model_dynamic_23.onnx error.
|
||||
Input[2] on model model_dynamic_23.onnx succeed.
|
||||
```
|
||||
可以看出,形状相同的`(1, 3, 10, 10)`的输入在所有模型上都没有出错。而对于batch(第0维)或者长宽(第2、3维)不同的输入,只有在设置了对应的动态维度后才不会出错。我们可以错误信息中找出是哪些维度出了问题。比如我们可以用以下代码查看`input[1]`在`model_static.onnx`中的报错信息:
|
||||
```python
|
||||
print(exceptions[(1, 'model_static.onnx')])
|
||||
|
||||
# output
|
||||
# [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
|
||||
```
|
||||
|
||||
这段报错告诉我们名字叫`in`的输入的第0维不匹配。本来该维的长度应该为1,但我们的输入是2。实际部署中,如果我们碰到了类似的报错,就可以通过设置动态维度来解决问题。
|
||||
### 使用技巧
|
||||
通过学习之前的知识,我们基本掌握了 `torch.onnx.export` 函数的部分实现原理和参数设置方法,足以完成简单模型的转换了。但在实际应用中,使用该函数还会踩很多坑。这里我们模型部署团队把在实战中积累的一些经验分享给大家。
|
||||
#### 使模型在 ONNX 转换时有不同的行为
|
||||
有些时候,我们希望模型在直接用 PyTorch 推理时有一套逻辑,而在导出的ONNX模型中有另一套逻辑。比如,我们可以把一些后处理的逻辑放在模型里,以简化除运行模型之外的其他代码。`torch.onnx.is_in_onnx_export()`可以实现这一任务,该函数仅在执行 `torch.onnx.export()`时为真。以下是一个例子:
|
||||
```python
|
||||
import torch
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.conv = torch.nn.Conv2d(3, 3, 3)
|
||||
|
||||
def forward(self, x):
|
||||
x = self.conv(x)
|
||||
if torch.onnx.is_in_onnx_export():
|
||||
x = torch.clip(x, 0, 1)
|
||||
return x
|
||||
```
|
||||
|
||||
这里,我们仅在模型导出时把输出张量的数值限制在[0, 1]之间。使用 `is_in_onnx_export` 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,`is_in_onnx_export` 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
|
||||
#### 利用中断张量跟踪的操作
|
||||
PyTorch 转 ONNX 的跟踪导出法是不是万能的。如果我们在模型中做了一些很“出格”的操作,跟踪法会把某些取决于输入的中间结果变成常量,从而使导出的ONNX模型和原来的模型有出入。以下是一个会造成这种“跟踪中断”的例子:
|
||||
```python
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x):
|
||||
x = x * x[0].item()
|
||||
return x, torch.Tensor([i for i in x])
|
||||
|
||||
model = Model()
|
||||
dummy_input = torch.rand(10)
|
||||
torch.onnx.export(model, dummy_input, 'a.onnx')
|
||||
```
|
||||
|
||||
如果你尝试去导出这个模型,会得到一大堆 warning,告诉你转换出来的模型可能不正确。这也难怪,我们在这个模型里使用了`.item()`把 torch 中的张量转换成了普通的 Python 变量,还尝试遍历 torch 张量,并用一个列表新建一个 torch 张量。这些涉及张量与普通变量转换的逻辑都会导致最终的 ONNX 模型不太正确。
|
||||
另一方面,我们也可以利用这个性质,在保证正确性的前提下令模型的中间结果变成常量。这个技巧常常用于模型的静态化上,即令模型中所有的张量形状都变成常量。在未来的教程中,我们会在部署实例中详细介绍这些“高级”操作。
|
||||
#### 使用张量为输入(PyTorch版本 < 1.9.0)
|
||||
正如我们第一篇教程所展示的,在较旧(< 1.9.0)的 PyTorch 中把 Python 数值作为 `torch.onnx.export()`的模型输入时会报错。出于兼容性的考虑,我们还是推荐以张量为模型转换时的模型输入。
|
||||
## PyTorch 对 ONNX 的算子支持
|
||||
在确保`torch.onnx.export()`的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。而具体添加算子的方法我们会在之后的文章里介绍。
|
||||
在转换普通的`torch.nn.Module`模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
|
||||
- 该算子可以一对一地翻译成一个 ONNX 算子。
|
||||
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
|
||||
- 该算子没有定义翻译成 ONNX 的规则,报错。
|
||||
|
||||
那么,该如何查看 PyTorch 算子与 ONNX 算子的对应情况呢?由于 PyTorch 算子是向 ONNX 对齐的,这里我们先看一下 ONNX 算子的定义情况,再看一下 PyTorch 定义的算子映射关系。
|
||||
### ONNX 算子文档
|
||||
ONNX 算子的定义情况,都可以在官方的[算子文档](https://github.com/onnx/onnx/blob/main/docs/Operators.md)中查看。这份文档十分重要,我们碰到任何和 ONNX 算子有关的问题都得来”请教“这份文档。
|
||||
|
||||
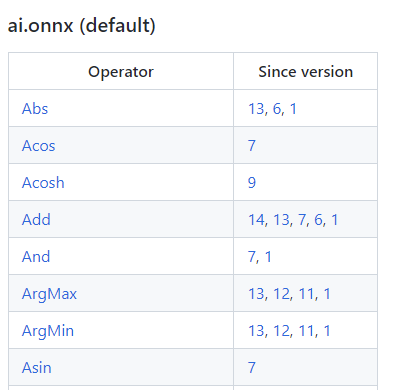
|
||||
|
||||
这份文档中最重要的开头的这个算子变更表格。表格的第一列是算子名,第二列是该算子发生变动的算子集版本号,也就是我们之前在`torch.onnx.export`中提到的`opset_version`表示的算子集版本号。通过查看算子第一次发生变动的版本号,我们可以知道某个算子是从哪个版本开始支持的;通过查看某算子小于等于`opset_version`的第一个改动记录,我们可以知道当前算子集版本中该算子的定义规则。
|
||||
|
||||
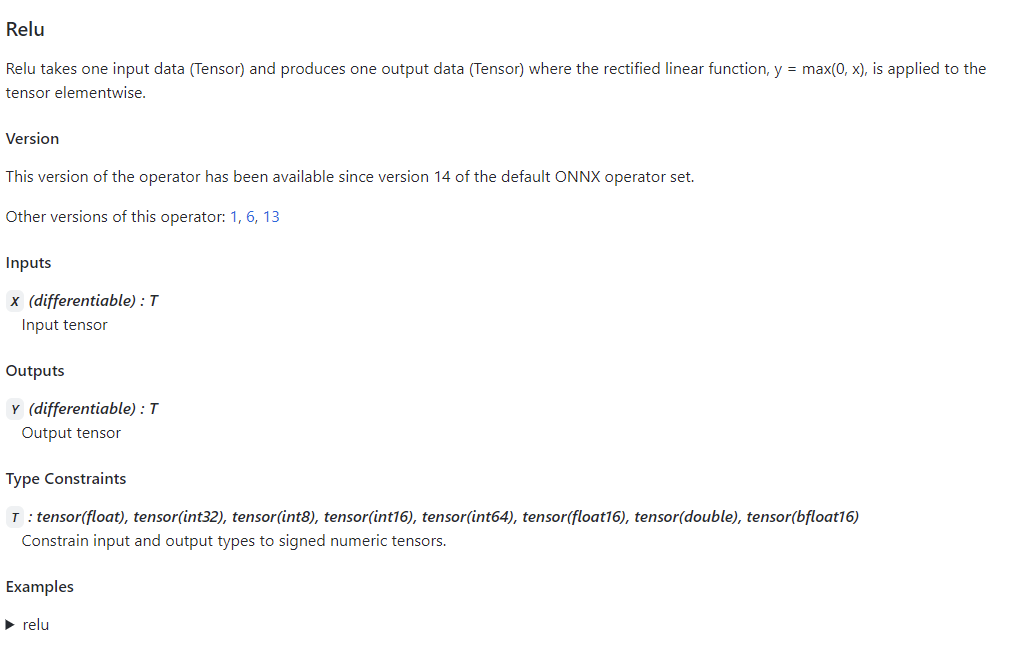
|
||||
|
||||
通过点击表格中的链接,我们可以查看某个算子的输入、输出参数规定及使用示例。比如上图是Relu在 ONNX 中的定义规则,这份定义表明 Relu 应该有一个输入和一个输入,输入输出的类型相同,均为 tensor。
|
||||
### PyTorch 对 ONNX 算子的映射
|
||||
在 PyTorch 中,和 ONNX 有关的定义全部放在 [torch.onnx 目录](https://github.com/pytorch/pytorch/tree/master/torch/onnx)中,如下图所示:
|
||||
|
||||
|
||||
|
||||
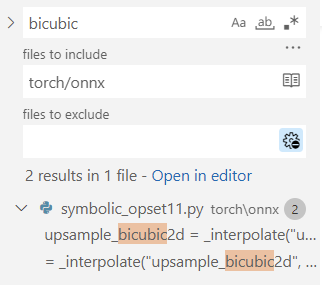
其中,`symbloic_opset{n}.py`(符号表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容。我们之前讲过, bicubic 插值是在第 11 个版本开始支持的。我们以它为例来看看如何查找算子的映射情况。
|
||||
首先,使用搜索功能,在`torch/onnx`文件夹搜索"bicubic",可以发现这个这个插值在第 11 个版本的定义文件中:
|
||||
|
||||
|
||||
|
||||
之后,我们按照代码的调用逻辑,逐步跳转直到最底层的 ONNX 映射函数:
|
||||
```python
|
||||
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
|
||||
|
||||
->
|
||||
|
||||
def _interpolate(name, dim, interpolate_mode):
|
||||
return sym_help._interpolate_helper(name, dim, interpolate_mode)
|
||||
|
||||
->
|
||||
|
||||
def _interpolate_helper(name, dim, interpolate_mode):
|
||||
def symbolic_fn(g, input, output_size, *args):
|
||||
...
|
||||
|
||||
return symbolic_fn
|
||||
```
|
||||
最后,在`symbolic_fn`中,我们可以看到插值算子是怎么样被映射成多个 ONNX 算子的。其中,每一个`g.op`就是一个 ONNX 的定义。比如其中的 `Resize` 算子就是这样写的:
|
||||
```python
|
||||
return g.op("Resize",
|
||||
input,
|
||||
empty_roi,
|
||||
empty_scales,
|
||||
output_size,
|
||||
coordinate_transformation_mode_s=coordinate_transformation_mode,
|
||||
cubic_coeff_a_f=-0.75, # only valid when mode="cubic"
|
||||
mode_s=interpolate_mode, # nearest, linear, or cubic
|
||||
nearest_mode_s="floor") # only valid when mode="nearest"
|
||||
```
|
||||
通过在前面提到的 ONNX 算子文档中查找 [Resize 算子的定义](https://github.com/onnx/onnx/blob/main/docs/Operators.md#resize),我们就可以知道这每一个参数的含义了。用类似的方法,我们可以去查询其他 ONNX 算子的参数含义,进而知道 PyTorch 中的参数是怎样一步一步传入到每个 ONNX 算子中的。
|
||||
掌握了如何查询 PyTorch 映射到 ONNX 的关系后,我们在实际应用时就可以在 `torch.onnx.export()`的`opset_version`中先预设一个版本号,碰到了问题就去对应的 PyTorch 符号表文件里去查。如果某算子确实不存在,或者算子的映射关系不满足我们的要求,我们就可能得用其他的算子绕过去,或者自定义算子了。
|
||||
## 总结
|
||||
在这篇教程中,我们系统地介绍了 PyTorch 转 ONNX 的原理。我们先是着重讲解了使用最频繁的 `torch.onnx.export`函数,又给出了查询 PyTorch 对 ONNX 算子支持情况的方法。通过本文,我们希望大家能够成功转换出大部分不需要添加新算子的 ONNX 模型,并在碰到算子问题时能够有效定位问题原因。具体而言,大家读完本文后应该了解以下的知识:
|
||||
- 跟踪法和脚本化在导出带控制语句的计算图时有什么区别。
|
||||
- `torch.onnx.export()`中该如何设置 `input_names, output_names, dynamic_axes`。
|
||||
- 使用 `torch.onnx.is_in_onnx_export()`来使模型在转换到 ONNX 时有不同的行为。
|
||||
- 如何查询 [ONNX 算子文档](https://github.com/onnx/onnx/blob/main/docs/Operators.md)。
|
||||
- 如何查询 PyTorch 对某个 ONNX 版本的新特性支持情况。
|
||||
- 如何判断 PyTorch 对某个 ONNX 算子是否支持,支持的方法是怎样的。
|
||||
|
||||
这期介绍的知识比较抽象,大家会不会觉得有点“水”?没关系,下一篇教程中,我们将以给出代码实例的形式,介绍多种为 PyTorch 转 ONNX 添加算子支持的方法,为大家在 PyTorch 转 ONNX 这条路上扫除更多的障碍。
|
||||
## 练习
|
||||
1. Asinh 算子出现于第 9 个 ONNX 算子集。PyTorch 在 9 号版本的符号表文件中是怎样支持这个算子的?
|
||||
2. BitShift 算子出现于第11个 ONNX 算子集。PyTorch 在 11 号版本的符号表文件中是怎样支持这个算子的?
|
||||
3. 在[第一篇教程](./chapter_01_introduction_to_model_deployment.md)中,我们讲过 PyTorch (截至第 11 号算子集)不支持在插值中设置动态的放缩系数。这个系数对应 `torch.onnx.symbolic_helper._interpolate_helper`的symbolic_fn的Resize算子映射关系中的哪个参数?我们是如何修改这一参数的?
|
||||
|
||||
练习的答案会在下期教程中揭晓。
|
||||
|
|
@ -0,0 +1,464 @@
|
|||
# 模型部署入门教程(四):在 PyTorch 中支持更多 ONNX 算子
|
||||
|
||||
在[上一篇教程](03_pytorch2onnx.md)中,我们系统地学习了 PyTorch 转 ONNX 的方法,可以发现 PyTorch 对 ONNX 的支持还不错。但在实际的部署过程中,难免碰到模型无法用原生 PyTorch 算子表示的情况。这个时候,我们就得考虑扩充 PyTorch,即在 PyTorch 中支持更多 ONNX 算子。
|
||||
|
||||
而要使 PyTorch 算子顺利转换到 ONNX ,我们需要保证以下三个环节都不出错:
|
||||
|
||||
* 算子在 PyTorch 中有实现
|
||||
* 有把该 PyTorch 算子映射成一个或多个 ONNX 算子的方法
|
||||
* ONNX 有相应的算子
|
||||
|
||||
可在实际部署中,这三部分的内容都可能有所缺失。其中最坏的情况是:我们定义了一个全新的算子,它不仅缺少 PyTorch 实现,还缺少 PyTorch 到 ONNX 的映射关系。但所谓车到山前必有路,对于这三个环节,我们也分别都有以下的添加支持的方法:
|
||||
|
||||
* PyTorch 算子
|
||||
* 组合现有算子
|
||||
* 添加 TorchScript 算子
|
||||
* 添加普通 C++ 拓展算子
|
||||
* 映射方法
|
||||
* 为 ATen 算子添加符号函数
|
||||
* 为 TorchScript 算子添加符号函数
|
||||
* 封装成 torch.autograd.Function 并添加符号函数
|
||||
* ONNX 算子
|
||||
* 使用现有 ONNX 算子
|
||||
* 定义新 ONNX 算子
|
||||
|
||||
那么,面对不同的情况时,就需要我们灵活地选用和组合这些方法。听起来是不是很复杂?别担心,本篇文章中,我们将围绕着三种算子映射方法,学习三个添加算子支持的实例,来理清如何为 PyTorch 算子转 ONNX 算子的三个环节添加支持。
|
||||
|
||||
## 支持 ATen 算子
|
||||
实际的部署过程中,我们都有可能会碰到一个最简单的算子缺失问题: 算子在 ATen 中已经实现了,ONNX 中也有相关算子的定义,但是相关算子映射成 ONNX 的规则没有写。在这种情况下,我们只需要**为 ATen 算子补充描述映射规则的符号函数**就行了。
|
||||
|
||||
> [ATen](https://pytorch.org/cppdocs/#aten) 是 PyTorch 内置的 C++ 张量计算库,PyTorch 算子在底层绝大多数计算都是用 ATen 实现的。
|
||||
|
||||
上期习题中,我们曾经提到了 ONNX 的 `Asinh` 算子。这个算子在 ATen 中有实现,却缺少了映射到 ONNX 算子的符号函数。在这里,我们来尝试为它补充符号函数,并导出一个包含这个算子的 ONNX 模型。
|
||||
|
||||
### 获取 ATen 中算子接口定义
|
||||
为了编写符号函数,我们需要获得 `asinh` 推理接口的输入参数定义。这时,我们要去 `torch/_C/_VariableFunctions.pyi` 和 `torch/nn/functional.pyi` 这两个文件中搜索我们刚刚得到的这个算子名。这两个文件是编译 PyTorch 时本地自动生成的文件,里面包含了 ATen 算子的 PyTorch 调用接口。通过搜索,我们可以知道 `asinh` 在文件 `torch/_C/_VariableFunctions.pyi` 中,其接口定义为:
|
||||
|
||||
```python
|
||||
def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
|
||||
```
|
||||
|
||||
经过这些步骤,我们确认了缺失的算子名为 `asinh`,它是一个有实现的 ATen 算子。我们还记下了 `asinh` 的调用接口。接下来,我们要为它补充符号函数,使它在转换成 ONNX 模型时不再报错。
|
||||
|
||||
### 添加符号函数
|
||||
到目前为止,我们已经多次接触了定义 PyTorch 到 ONNX 映射规则的符号函数了。现在,我们向大家正式介绍一下符号函数。
|
||||
|
||||
符号函数,可以看成是 PyTorch 算子类的一个静态方法。在把 PyTorch 模型转换成 ONNX 模型时,各个 PyTorch 算子的符号函数会被依次调用,以完成 PyTorch 算子到 ONNX 算子的转换。符号函数的定义一般如下:
|
||||
|
||||
```python
|
||||
def symbolic(g: torch._C.Graph, input_0: torch._C.Value, input_1: torch._C.Value, ...):
|
||||
```
|
||||
|
||||
其中,`torch._C.Graph` 和 `torch._C.Value` 都对应 PyTorch 的 C++ 实现里的一些类。我们在这篇文章不深究它们的细节,只需要知道第一个参数就固定叫 `g`,它表示和计算图相关的内容;后面的每个参数都表示算子的输入,需要和算子的前向推理接口的输入相同。对于 ATen 算子来说,它们的前向推理接口就是上述两个 `.pyi` 文件里的函数接口。
|
||||
|
||||
`g` 有一个方法 `op`。在把 PyTorch 算子转换成 ONNX 算子时,需要在符号函数中调用此方法来为最终的计算图添加一个 ONNX 算子。其定义如下:
|
||||
|
||||
```python
|
||||
def op(name: str, input_0: torch._C.Value, input_1: torch._C.Value, ...)
|
||||
```
|
||||
|
||||
其中,第一个参数是算子名称。如果该算子是普通的 ONNX 算子,只需要把它在 ONNX 官方文档里的名称填进去即可(我们稍后再讲其他情况)。
|
||||
|
||||
在最简单的情况下,我们只要把 PyTorch 算子的输入用`g.op()`一一对应到 ONNX 算子上即可,并把`g.op()`的返回值作为符号函数的返回值。在情况更复杂时,我们转换一个 PyTorch 算子可能要新建若干个 ONNX 算子。
|
||||
|
||||
补充完了背景知识,让我们回到 `asinh` 算子上,来为它编写符号函数。我们先去翻阅一下 ONNX 算子文档,学习一下我们在符号函数里的映射关系 `g.op()` 里应该怎么写。[`Asinh` 的文档](https://github.com/onnx/onnx/blob/main/docs/Operators.md#asinh)写道:该算子有一个输入 `input`,一个输出 `output`,二者的类型都为张量。
|
||||
|
||||
到这里,我们已经完成了信息收集环节。我们在上一小节得知了 `asinh` 的推理接口定义,在这一小节里收集了 ONNX 算子 `Asinh` 的定义。现在,我们可以用代码来补充这二者的映射关系了。在刚刚导出 `asinh` 算子的代码中,我们添加以下内容:
|
||||
|
||||
```python
|
||||
from torch.onnx.symbolic_registry import register_op
|
||||
|
||||
def asinh_symbolic(g, input, *, out=None):
|
||||
return g.op("Asinh", input)
|
||||
|
||||
register_op('asinh', asinh_symbolic, '', 9)
|
||||
```
|
||||
|
||||
这里的`asinh_symbolic`就是`asinh`的符号函数。从除`g`以外的第二个输入参数开始,其输入参数应该严格对应它在 ATen 中的定义:
|
||||
|
||||
```python
|
||||
def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
|
||||
```
|
||||
|
||||
在符号函数的函数体中,`g.op("Asinh", input)`则完成了 ONNX 算子的定义。其中,第一个参数`"Asinh"`是算子在 ONNX 中的名称。至于第二个参数 `input`,如我们刚刚在文档里所见,这个算子只有一个输入,因此我们只要把符号函数的输入参数 `input` 对应过去就行。ONNX 的 `Asinh` 的输出和 ATen 的 `asinh` 的输出是一致的,因此我们直接把 `g.op()` 的结果返回即可。
|
||||
|
||||
定义完符号函数后,我们要把这个符号函数和原来的 ATen 算子“绑定”起来。这里,我们要用到 `register_op` 这个 PyTorch API 来完成绑定。如示例所示,只需要一行简单的代码即可把符号函数 `asinh_symbolic` 绑定到算子 `asinh` 上:
|
||||
|
||||
```python
|
||||
register_op('asinh', asinh_symbolic, '', 9)
|
||||
```
|
||||
|
||||
`register_op`的第一个参数是目标 ATen 算子名,第二个是要注册的符号函数,这两个参数很好理解。第三个参数是算子的“域”,对于普通 ONNX 算子,直接填空字符串即可。第四个参数表示向哪个算子集版本注册。我们遵照 ONNX 标准,向第 9 号算子集注册。值得注意的是,这里向第 9 号算子集注册,不代表较新的算子集(第 10 号、第 11 号……)都得到了注册。在示例中,我们先只向第 9 号算子集注册。
|
||||
|
||||
整理一下,我们最终的代码如下:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x):
|
||||
return torch.asinh(x)
|
||||
|
||||
from torch.onnx.symbolic_registry import register_op
|
||||
|
||||
def asinh_symbolic(g, input, *, out=None):
|
||||
return g.op("Asinh", input)
|
||||
|
||||
register_op('asinh', asinh_symbolic, '', 9)
|
||||
|
||||
model = Model()
|
||||
input = torch.rand(1, 3, 10, 10)
|
||||
torch.onnx.export(model, input, 'asinh.onnx')
|
||||
```
|
||||
|
||||
成功导出的话,`asinh.onnx` 应该长这个样子:
|
||||
|
||||
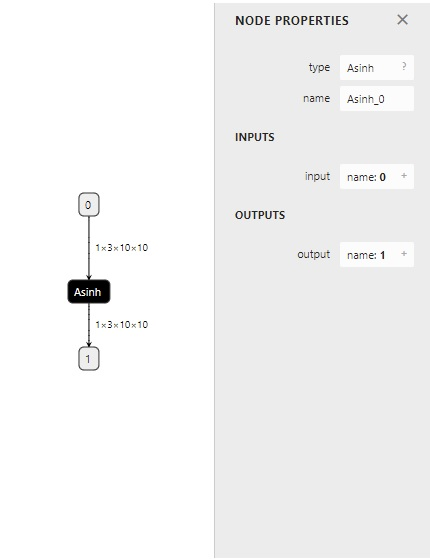
|
||||
|
||||
### 测试算子
|
||||
在完成了一份自定义算子后,我们一定要测试一下算子的正确性。一般我们要用 PyTorch 运行一遍原算子,再用推理引擎(比如 ONNX Runtime)运行一下 ONNX 算子,最后比对两次的运行结果。对于我们刚刚得到的 `asinh.onnx`,可以用如下代码来验证:
|
||||
|
||||
```python
|
||||
import onnxruntime
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x):
|
||||
return torch.asinh(x)
|
||||
|
||||
model = Model()
|
||||
input = torch.rand(1, 3, 10, 10)
|
||||
torch_output = model(input).detach().numpy()
|
||||
|
||||
sess = onnxruntime.InferenceSession('asinh.onnx')
|
||||
ort_output = sess.run(None, {'0': input.numpy()})[0]
|
||||
|
||||
assert np.allclose(torch_output, ort_output)
|
||||
```
|
||||
|
||||
在这份代码里,我们用 PyTorch 做了一遍推理,并把结果转成了 numpy 格式。之后,我们又用 ONNX Runtime 对 onnx 文件做了一次推理。最后,我们使用 `np.allclose` 来保证两个结果张量的误差在一个可以允许的范围内。一切正常的话,运行这段代码后,`assert` 所在行不会报错,程序应该没有任何输出。
|
||||
|
||||
## 支持 TorchScript 算子
|
||||
对于一些比较复杂的运算,仅使用 PyTorch 原生算子是无法实现的。这个时候,就要考虑自定义一个 PyTorch 算子,再把它转换到 ONNX 中了。新增 PyTorch 算子的方法有很多,PyTorch 官方比较推荐的一种做法是[添加 TorchScript 算子](https://pytorch.org/tutorials/advanced/torch_script_custom_ops.html) 。
|
||||
|
||||
由于添加算子的方法较繁琐,我们今天跳过新增 TorchScript 算子的内容,以可变形卷积(Deformable Convolution)算子为例,介绍为现有 TorchScript 算子添加 ONNX 支持的方法。
|
||||
|
||||
> 可变形卷积(Deformable Convolution)是在 Torchvision 中实现的 TorchScript 算子,虽然尚未得到广泛支持,但是出现在许多模型中。
|
||||
|
||||
有了支持 ATen 算子的经验之后,我们可以知道为算子添加符号函数一般要经过以下几步:
|
||||
|
||||
1. 获取原算子的前向推理接口。
|
||||
2. 获取目标 ONNX 算子的定义。
|
||||
3. 编写符号函数并绑定。
|
||||
|
||||
在为可变形卷积添加符号函数时,我们也可以尝试走一遍这个流程。
|
||||
|
||||
### 使用 TorchScript 算子
|
||||
和之前一样,我们首先定义一个包含了算子的模型,为之后转换 ONNX 模型做准备。
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torchvision
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.conv1 = torch.nn.Conv2d(3, 18, 3)
|
||||
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv2(x, self.conv1(x))
|
||||
```
|
||||
|
||||
其中,`torchvision.ops.DeformConv2d` 就是 Torchvision 中的可变形卷积层。相比于普通卷积,可变形卷积的其他参数都大致相同,唯一的区别就是在推理时需要多输入一个表示偏移量的张量。
|
||||
|
||||
然后,我们查询算子的前向推理接口。`DeformConv2d` 层最终会调用 `deform_conv2d` 这个算子。我们可以在 `torchvision/csrc/ops/deform_conv2d.cpp` 中查到该算子的调用接口:
|
||||
|
||||
```python
|
||||
m.def(TORCH_SELECTIVE_SCHEMA(
|
||||
"torchvision::deform_conv2d(Tensor input,
|
||||
Tensor weight,
|
||||
Tensor offset,
|
||||
......
|
||||
bool use_mask) -> Tensor"));
|
||||
```
|
||||
|
||||
那么接下来,根据之前的经验,我们就是要去 ONNX 官方文档中查找算子的定义了。
|
||||
|
||||
### 自定义 ONNX 算子
|
||||
很遗憾的是,如果我们去 ONNX 的官方算子页面搜索 "deform",将搜不出任何内容。目前,ONNX 还没有提供可变形卷积的算子,我们要自己定义一个 ONNX 算子了。
|
||||
|
||||
我们在前面讲过,`g.op()` 是用来定义 ONNX 算子的函数。对于 ONNX 官方定义的算子,`g.op()` 的第一个参数就是该算子的名称。而对于一个自定义算子,`g.op()` 的第一个参数是一个带命名空间的算子名,比如:
|
||||
|
||||
```python
|
||||
g.op("custom::deform_conv2d, ...)
|
||||
```
|
||||
|
||||
其中,"::"前面的内容就是我们的命名空间。该概念和 C++ 的命名空间类似,是为了防止命名冲突而设定的。如果在 `g.op()` 里不加前面的命名空间,则算子会被默认成 ONNX 的官方算子。
|
||||
|
||||
PyTorch 在运行 `g.op()` 时会对官方的算子做检查,如果算子名有误,或者算子的输入类型不正确, `g.op()` 就会报错。为了让我们随心所欲地定义新 ONNX 算子,我们必须设定一个命名空间,给算子取个名,再定义自己的算子。
|
||||
|
||||
我们在[第一篇教程](01_introduction_to_model_deployment.md)学过:ONNX 是一套标准,本身并不包括实现。在这里,我们就简略地定义一个 ONNX 可变形卷积算子,而不去写它在某个推理引擎上的实现。在之后的教程中,我们再学习在各个推理引擎中添加新 ONNX 算子支持的方法。此处,我们只关心如何导出一个包含新 ONNX 算子节点的 onnx 文件。因此,我们可以为新算子编写如下简单的符号函数:
|
||||
|
||||
```python
|
||||
@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
|
||||
def symbolic(g,
|
||||
input,
|
||||
weight,
|
||||
offset,
|
||||
mask,
|
||||
bias,
|
||||
stride_h, stride_w,
|
||||
pad_h, pad_w,
|
||||
dil_h, dil_w,
|
||||
n_weight_grps,
|
||||
n_offset_grps,
|
||||
use_mask):
|
||||
return g.op("custom::deform_conv2d", input, offset)
|
||||
```
|
||||
|
||||
在这个符号函数中,我们以刚刚搜索到的算子输入参数作为符号函数的输入参数,并只用 `input` 和 `offset` 来构造一个简单的 ONNX 算子。
|
||||
|
||||
这段代码中,最令人疑惑的就是装饰器 `@parse_args` 了。简单来说,TorchScript 算子的符号函数要求标注出每一个输入参数的类型。比如"v"表示 Torch 库里的 `value` 类型,一般用于标注张量,而"i"表示 int 类型,"f"表示 float 类型,"none"表示该参数为空。具体的类型含义可以在 [torch.onnx.symbolic_helper.py](https://github.com/pytorch/pytorch/blob/master/torch/onnx/symbolic_helper.py)中查看。这里输入参数中的 `input, weight, offset, mask, bias` 都是张量,所以用"v"表示。后面的其他参数同理。我们不必纠结于 `@parse_args`的原理,根据实际情况对符号函数的参数标注类型即可。
|
||||
|
||||
有了符号函数后,我们通过如下的方式注册符号函数:
|
||||
|
||||
```python
|
||||
register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
|
||||
```
|
||||
|
||||
和前面的 `register_op` 类似,注册符号函数时,我们要输入算子名、符号函数、算子集版本。与前面不同的是,这里的算子集版本是最早生效版本,在这里设定版本 9,意味着之后的第 10 号、第 11 号……版本集都能使用这个新算子。
|
||||
|
||||
最后,我们完整的模型导出代码如下:
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torchvision
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.conv1 = torch.nn.Conv2d(3, 18, 3)
|
||||
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv2(x, self.conv1(x))
|
||||
|
||||
from torch.onnx import register_custom_op_symbolic
|
||||
from torch.onnx.symbolic_helper import parse_args
|
||||
|
||||
@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
|
||||
def symbolic(g,
|
||||
input,
|
||||
weight,
|
||||
offset,
|
||||
mask,
|
||||
bias,
|
||||
stride_h, stride_w,
|
||||
pad_h, pad_w,
|
||||
dil_h, dil_w,
|
||||
n_weight_grps,
|
||||
n_offset_grps,
|
||||
use_mask):
|
||||
return g.op("custom::deform_conv2d", input, offset)
|
||||
|
||||
register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
|
||||
|
||||
model = Model()
|
||||
input = torch.rand(1, 3, 10, 10)
|
||||
torch.onnx.export(model, input, 'dcn.onnx')
|
||||
```
|
||||
|
||||
代码成功运行的话,我们应该能得到如下的 ONNX 模型:
|
||||
|
||||
|
||||
|
||||
|
||||
可以看到,我们自定义的 ONNX 算子 `deform_conv2d` 包含了两个输入,一个输出,和我们预想得一样。
|
||||
|
||||
## 使用 torch.autograd.Function
|
||||
最后,我们来学习一种简单的为 PyTorch 添加 C++ 算子实现的方法,来代替较为复杂的新增 TorchScript 算子。同时,我们会用 torch.autograd.Function 封装这个新算子。torch.autograd.Function 能完成算子实现和算子调用的隔离。不管算子是怎么实现的,它封装后的使用体验以及 ONNX 导出方法会和原生的 PyTorch 算子一样。这是我们比较推荐的为算子添加 ONNX 支持的方法。
|
||||
|
||||
为了应对更复杂的情况,我们来自定义一个奇怪的 `my_add` 算子。这个算子的输入张量 a, b ,输出 `2a + b` 的值。我们会先把它在 PyTorch 中实现,再把它导出到 ONNX 中。
|
||||
|
||||
### 为 PyTorch 添加 C++ 拓展
|
||||
为 PyTorch 添加简单的 C++ 拓展还是很方便的。对于我们定义的 my_add 算子,可以用以下的 C++ 源文件来实现。我们把该文件命名为 "my_add.cpp":
|
||||
|
||||
```C++
|
||||
// my_add.cpp
|
||||
|
||||
#include <torch/torch.h>
|
||||
|
||||
torch::Tensor my_add(torch::Tensor a, torch::Tensor b)
|
||||
{
|
||||
return 2 * a + b;
|
||||
}
|
||||
|
||||
PYBIND11_MODULE(my_lib, m)
|
||||
{
|
||||
m.def("my_add", my_add);
|
||||
}
|
||||
```
|
||||
|
||||
由于在 PyTorch 中添加 C++ 拓展和模型部署关系不大,这里我们仅给出这个简单的示例,并不对其原理做过多讲解。
|
||||
|
||||
在这段代码中,torch::Tensor 就是 C++ 中 torch 的张量类型,它的加法和乘法等运算符均已重载。因此,我们可以像对普通标量一样对张量做加法和乘法。
|
||||
|
||||
轻松地完成了算子的实现后,我们用 `PYBIND11_MODULE` 来为 C++ 函数提供 Python 调用接口。这里的 `my_lib` 是我们未来要在 Python 里导入的模块名。双引号中的 `my_add` 是 Python 调用接口的名称,这里我们对齐 C++ 函数的名称,依然用 "my_add"这个名字。
|
||||
|
||||
之后,我们可以编写如下的 Python 代码并命名为 "setup.py",来编译刚刚的 C++ 文件:
|
||||
|
||||
```python
|
||||
from setuptools import setup
|
||||
from torch.utils import cpp_extension
|
||||
|
||||
setup(name='my_add',
|
||||
ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],
|
||||
cmdclass={'build_ext': cpp_extension.BuildExtension})
|
||||
```
|
||||
|
||||
这段代码使用了 Python 的 setuptools 编译功能和 PyTorch 的 C++ 拓展工具函数,可以编译包含了 torch 库的 C++ 源文件。这里我们需要填写的只有模块名和模块中的源文件名。我们刚刚把模块命名为 `my_lib`,而源文件只有一个 `my_add.cpp`,因此拓展模块那一行要写成 `ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],`。
|
||||
|
||||
之后,像处理普通的 Python 包一样执行安装命令,我们的 C++ 代码就会自动编译了。
|
||||
|
||||
```shell
|
||||
python setup.py develop
|
||||
```
|
||||
|
||||
### 用 `torch.autograd.Function` 封装
|
||||
|
||||
直接用 Python 接口调用 C++ 函数不太“美观”,一种比较优雅的做法是把这个调用接口封装起来。这里我们用 `torch.autograd.Function` 来封装算子的底层调用:
|
||||
|
||||
```python
|
||||
import torch
|
||||
import my_lib
|
||||
class MyAddFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, a, b):
|
||||
return my_lib.my_add(a, b)
|
||||
|
||||
@staticmethod
|
||||
def symbolic(g, a, b):
|
||||
two = g.op("Constant", value_t=torch.tensor([2]))
|
||||
a = g.op('Mul', a, two)
|
||||
return g.op('Add', a, b)
|
||||
```
|
||||
|
||||
我们在前面的教程中已经见过 `torch.autograd.Function`,这里我们正式地对其做一个介绍。`Function` 类本身表示 PyTorch 的一个可导函数,只要为其定义了前向推理和反向传播的实现,我们就可以把它当成一个普通 PyTorch 函数来使用。
|
||||
|
||||
PyTorch 会自动调度该函数,合适地执行前向和反向计算。对模型部署来说,`Function` 类有一个很好的性质:如果它定义了 `symbolic` 静态方法,该 `Function` 在执行 `torch.onnx.export()` 时就可以根据 `symbolic` 中定义的规则转换成 ONNX 算子。这个 `symbolic` 就是前面提到的符号函数,只是它的名称必须是 `symbolic` 而已。
|
||||
|
||||
在 `forward `函数中,我们用 `my_lib.my_add(a, b)` 就可以调用之前写的C++函数了。这里 `my_lib` 是库名,`my_add` 是函数名,这两个名字是在前面C++的 `PYBIND11_MODULE` 中定义的。
|
||||
|
||||
在 `symbolic` 函数中,我们用 `g.op()` 定义了三个算子:常量、乘法、加法。这里乘法和加法的用法和前面提到的 `asinh` 一样,只需要根据 ONNX 算子定义规则把输入参数填入即可。而在定义常量算子时,我们要把 PyTorch 张量的值传入 `value_t` 参数中。
|
||||
|
||||
在 ONNX 中,我们需要把新建常量当成一个算子来看待,尽管这个算子并不会以节点的形式出现在 ONNX 模型的可视化结果里。
|
||||
|
||||
把算子封装成 Function 后,我们可以把 `my_add` 算子用起来了。
|
||||
|
||||
```python
|
||||
my_add = MyAddFunction.apply
|
||||
|
||||
class MyAdd(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, a, b):
|
||||
return my_add(a, b)
|
||||
```
|
||||
|
||||
在这份代码里,我们先用 `my_add = MyAddFunction.apply` 获取了一个奇怪的变量。这个变量是用来做什么的呢?其实,`apply`是`torch.autograd.Function` 的一个方法,这个方法完成了 `Function` 在前向推理或者反向传播时的调度。我们在使用 `Function` 的派生类做推理时,不应该显式地调用 `forward`,而应该调用其 `apply` 方法。
|
||||
|
||||
这里我们使用 `my_add = MyAddFunction.apply` 把这个调用方法取了一个更简短的别名 `my_add`。以后在使用 `my_add` 算子时,我们应该忽略 `MyAddFunction` 的实现细节,而只通过 `my_add` 这个接口来访问算子。这里 `my_add` 的地位,和 PyTorch 的 `asinh, interpolate, conv2d`等原生函数是类似的。
|
||||
|
||||
有了访问新算子的接口后,我们可以进一步把算子封装成一个神经网络中的计算层。我们定义一个叫做的 `MyAdd` 的 `torch.nn.Module`,它封装了`my_add`,就和封装了`conv2d` 的 `torch.nn.Conv2d` 一样。
|
||||
|
||||
### 测试算子
|
||||
费了好大的功夫来“包装”我们的新算子后,我们终于可以来使用它了。和之前的测试流程一样,让我们用下面的代码来导出一个包含新算子的 ONNX 模型,并验证一下它是否正确。
|
||||
|
||||
```python
|
||||
model = MyAdd()
|
||||
input = torch.rand(1, 3, 10, 10)
|
||||
torch.onnx.export(model, (input, input), 'my_add.onnx')
|
||||
torch_output = model(input, input).detach().numpy()
|
||||
|
||||
import onnxruntime
|
||||
import numpy as np
|
||||
sess = onnxruntime.InferenceSession('my_add.onnx')
|
||||
ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0]
|
||||
|
||||
assert np.allclose(torch_output, ort_output)
|
||||
```
|
||||
|
||||
在这份代码中,我们直接把 `MyAdd` 作为要导出的模型。我们计算了一个 PyTorch 模型的运行结果,又导出 ONNX 模型,计算了 ONNX 模型在 ONNX Runtime 上的运算结果。如果一切正常的话,这两个结果是一样的,这份代码不会报任何错误,没有任何输出。
|
||||
|
||||
|
||||
|
||||
可视化一下 `my_add.onnx`,可以看出,和我们设计得一样,`my_add` 算子被翻译成了两个 ONNX 算子节点(其中常量算子被放入了 `Mul` 的参数中)。
|
||||
|
||||
整理一下,整个流程的 Python 代码如下:
|
||||
|
||||
```python
|
||||
import torch
|
||||
import my_lib
|
||||
class MyAddFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, a, b):
|
||||
return my_lib.my_add(a, b)
|
||||
|
||||
@staticmethod
|
||||
def symbolic(g, a, b):
|
||||
two = g.op("Constant", value_t=torch.tensor([2]))
|
||||
a = g.op('Mul', a, two)
|
||||
return g.op('Add', a, b)
|
||||
|
||||
my_add = MyAddFunction.apply
|
||||
|
||||
class MyAdd(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, a, b):
|
||||
return my_add(a, b)
|
||||
|
||||
model = MyAdd()
|
||||
input = torch.rand(1, 3, 10, 10)
|
||||
torch.onnx.export(model, (input, input), 'my_add.onnx')
|
||||
torch_output = model(input, input).detach().numpy()
|
||||
|
||||
import onnxruntime
|
||||
import numpy as np
|
||||
sess = onnxruntime.InferenceSession('my_add.onnx')
|
||||
ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0]
|
||||
|
||||
assert np.allclose(torch_output, ort_output)
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
在这篇教程中,我们围绕“为 ATen 算子添加符号函数”、“为 TorchScript 算子添加符号函数”、“封装成 `torch.autograd.Function` 并添加符号函数”这三种添加映射关系的方法,讲解了 3 个为 PyTorch 和 ONNX 添加支持的实例。在这个过程中,我们学到了很多零散的知识,来总结一下吧。
|
||||
|
||||
* ATen 是 PyTorch 的 C++ 张量运算库。通过查询 torch/_C/_VariableFunctions.pyi 和 torch/nn/functional.pyi,我们可以知道 ATen 算子的 Python 接口定义。
|
||||
* 用 register_op 可以为 ATen 算子补充注册符号函数
|
||||
* 用 register_custom_op_symbolic 可以为 TorchScript 算子补充注册符号函数
|
||||
* 如何在 PyTorch 里添加 C++ 拓展
|
||||
* 如何用 torch.autograd.Function 封装一个自定义 PyTorch 算子
|
||||
* 如何编写符号函数 symbolic(g, ...)。
|
||||
* 如何用 g.op() 把一个 PyTorch 算子映射成一个或多个 ONNX 算子,或者是自定义的 ONNX 算子。
|
||||
|
||||
这篇教程涉及的代码比较多。如果大家在阅读时碰到了问题,最好去跑一跑代码,改一改代码里的内容,实际感受一下每行代码的意义。
|
||||
|
||||
## 上期习题解答
|
||||
|
||||
1. PyTorch 目前没有支持 ONNX 的 `Asinh` 算子。我们在 `torch.onnx.symbolic_opset9.py` 中搜索不到 Asinh 的相关内容。
|
||||
2. 通过在 `torch.onnx.symbolic_opset11.py` 搜索 `BitShift`,我们可以发现 PyTorch 在 `__lshift_` 和 `__rshift_` 里用到了ONNX的 `BitShift` 算子。当输入类型为 `Byte` 时,PyTorch会把算子直接翻译翻译 `BitShift`,以代替乘除 2 的次幂的操作。
|
||||
3. 对应 `Resize` 算子的第3个参数(`g.op()` 的第4个参数)`scales`。原来的 `scales` 传入 `g.op() `前会经过 `_interpolate_get_scales_if_available()` 函数,一定会被转换成一个常量。为了让 `scales` 由输入决定,我们直接把输入参数中的 `scales` 传入 `g.op()`。
|
||||
|
|
@ -0,0 +1,463 @@
|
|||
# 模型部署入门教程(五):ONNX 模型的修改与调试
|
||||
|
||||
在前两期教程中,我们学习了 PyTorch 模型转 ONNX 模型的方法,了解了如何在原生算子表达能力不足时,为 PyTorch 或 ONNX 自定义算子。一直以来,我们都是通过 PyTorch 来导出 ONNX 模型的,基本没有单独探究过 ONNX 模型的构造知识。
|
||||
|
||||
不知道大家会不会有这样一些疑问:ONNX 模型在底层是用什么格式存储的?如何不依赖深度学习框架,只用 ONNX 的 API 来构造一个 ONNX 模型?如果没有源代码,只有一个 ONNX 模型,该如何对这个模型进行调试?这篇教程可以解答大家的这些问题。
|
||||
|
||||
在这期教程里,我们将围绕 ONNX 这一套神经网络定义标准本身,探究 ONNX 模型的构造、读取、子模型提取、调试。首先,我们会学习 ONNX 的底层表示方式。之后,我们会用 ONNX API 构造和读取模型。最后,我们会利用 ONNX 提供的子模型提取功能,学习如何调试 ONNX 模型。
|
||||
|
||||
## ONNX 的底层实现
|
||||
### ONNX 的存储格式
|
||||
ONNX 在底层是用 **Protobuf** 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文件把数据存储进一份二进制文件。可以说,数据定义文件就是数据类,二进制文件就是数据类的实例。
|
||||
这里给出一个 Protobuf 数据定义文件的例子:
|
||||
|
||||
```protobuf
|
||||
message Person {
|
||||
required string name = 1;
|
||||
required int32 id = 2;
|
||||
optional string email = 3;
|
||||
}
|
||||
```
|
||||
|
||||
这段定义表示在 `Person` 这种数据类型中,必须包含 `name`、`id` 这两个字段,选择性包含 `email` 字段。根据这份定义文件,用户就可以选择一种编程语言,定义一个含有成员变量 `name`、`id`、`email` 的 `Person` 类,把这个类的某个实例用 Protobuf 存储成二进制文件;反之,用户也可以用二进制文件和对应的数据定义文件,读取出一个 `Person` 类的实例。
|
||||
|
||||
而对于 ONNX ,它的 Protobuf 数据定义文件在其[开源库](https://github.com/onnx/onnx/tree/main/onnx)中,这些文件定义了神经网络中模型、节点、张量的数据类型规范;而数据定义文件对应的二进制文件就是我们熟悉的“.onnx"文件,每一个 ".onnx" 文件按照数据定义规范,存储了一个神经网络的所有相关数据。直接用 Protobuf 生成 ONNX 模型还是比较麻烦的。幸运的是,ONNX 提供了很多实用 API,我们可以在完全不了解 Protobuf 的前提下,构造和读取 ONNX 模型。
|
||||
|
||||
|
||||
### ONNX 的结构定义
|
||||
|
||||
在用 API 对 ONNX 模型进行操作之前,我们还需要先了解一下 ONNX 的结构定义规则,学习一下 ONNX 在 Protobuf 定义文件里是怎样描述一个神经网络的。
|
||||
|
||||
回想一下,神经网络本质上是一个计算图。计算图的节点是算子,边是参与运算的张量。而通过可视化 ONNX 模型,我们知道 ONNX 记录了所有算子节点的属性信息,并把参与运算的张量信息存储在算子节点的输入输出信息中。事实上,ONNX 模型的结构可以用类图大致表示如下:
|
||||
|
||||

|
||||
|
||||
如图所示,一个 ONNX 模型可以用 `ModelProto` 类表示。`ModelProto` 包含了版本、创建者等日志信息,还包含了存储计算图结构的 `graph`。`GraphProto` 类则由输入张量信息、输出张量信息、节点信息组成。张量信息 `ValueInfoProto` 类包括张量名、基本数据类型、形状。节点信息 `NodeProto` 类包含了算子名、算子输入张量名、算子输出张量名。
|
||||
让我们来看一个具体的例子。假如我们有一个描述 `output=a*x+b` 的 ONNX 模型 `model`,用 `print(model)` 可以输出以下内容:
|
||||
|
||||
```python
|
||||
ir_version: 8
|
||||
graph {
|
||||
node {
|
||||
input: "a"
|
||||
input: "x"
|
||||
output: "c"
|
||||
op_type: "Mul"
|
||||
}
|
||||
node {
|
||||
input: "c"
|
||||
input: "b"
|
||||
output: "output"
|
||||
op_type: "Add"
|
||||
}
|
||||
name: "linear_func"
|
||||
input {
|
||||
name: "a"
|
||||
type {
|
||||
tensor_type {
|
||||
elem_type: 1
|
||||
shape {
|
||||
dim {dim_value: 10}
|
||||
dim {dim_value: 10}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
input {
|
||||
name: "x"
|
||||
type {
|
||||
tensor_type {
|
||||
elem_type: 1
|
||||
shape {
|
||||
dim {dim_value: 10}
|
||||
dim {dim_value: 10}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
input {
|
||||
name: "b"
|
||||
type {
|
||||
tensor_type {
|
||||
elem_type: 1
|
||||
shape {
|
||||
dim {dim_value: 10}
|
||||
dim {dim_value: 10}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
output {
|
||||
name: "output"
|
||||
type {
|
||||
tensor_type {
|
||||
elem_type: 1
|
||||
shape {
|
||||
dim { dim_value: 10}
|
||||
dim { dim_value: 10}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
opset_import {version: 15}
|
||||
```
|
||||
|
||||
对应上文中的类图,这个模型的信息由 `ir_version`,`opset_import` 等全局信息和 `graph` 图信息组成。而 `graph` 包含一个乘法节点、一个加法节点、三个输入张量 `a, x, b` 以及一个输出张量 `output`。在下一节里,我们会用 API 构造出这个模型,并输出这段结果。
|
||||
|
||||
## 读写 ONNX 模型
|
||||
|
||||
### 构造 ONNX 模型
|
||||
|
||||
在上一小节中,我们知道了 ONNX 模型是按以下的结构组织起来的:
|
||||
|
||||
* ModelProto
|
||||
* GraphProto
|
||||
* NodeProto
|
||||
* ValueInfoProto
|
||||
|
||||
现在,让我们抛开 PyTorch,尝试完全用 ONNX 的 Python API 构造一个描述线性函数 `output=a*x+b` 的 ONNX 模型。我们将根据上面的结构,自底向上地构造这个模型。
|
||||
|
||||
首先,我们可以用 `helper.make_tensor_value_info` 构造出一个描述张量信息的 `ValueInfoProto` 对象。如前面的类图所示,我们要传入张量名、张量的基本数据类型、张量形状这三个信息。在 ONNX 中,不管是输入张量还是输出张量,它们的表示方式都是一样的。因此,这里我们用类似的方式为三个输入 `a, x, b` 和一个输出 `output` 构造 `ValueInfoProto` 对象。如下面的代码所示:
|
||||
|
||||
```python
|
||||
import onnx
|
||||
from onnx import helper
|
||||
from onnx import TensorProto
|
||||
|
||||
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
|
||||
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
|
||||
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
|
||||
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])
|
||||
```
|
||||
|
||||
之后,我们要构造算子节点信息 `NodeProto`,这可以通过在 `helper.make_node` 中传入算子类型、输入张量名、输出张量名这三个信息来实现。我们这里先构造了描述 `c=a*x` 的乘法节点,再构造了 `output=c+b` 的加法节点。如下面的代码所示:
|
||||
|
||||
```python
|
||||
mul = helper.make_node('Mul', ['a', 'x'], ['c'])
|
||||
add = helper.make_node('Add', ['c', 'b'], ['output'])
|
||||
```
|
||||
|
||||
在计算机中,图一般是用一个节点集和一个边集表示的。而 ONNX 巧妙地把边的信息保存在了节点信息里,省去了保存边集的步骤。在 ONNX 中,如果某节点的输入名和之前某节点的输出名相同,就默认这两个节点是相连的。如上面的例子所示:`Mul` 节点定义了输出 `c`,`Add` 节点定义了输入 `c`,则 `Mul` 节点和 `Add` 节点是相连的。
|
||||
|
||||
正是因为有这种边的隐式定义规则,所以 ONNX 对节点的输入有一定的要求:一个节点的输入,要么是整个模型的输入,要么是之前某个节点的输出。如果我们把 `a, x, b` 中的某个输入节点从计算图中拿出(这个操作会在之后的代码中介绍),或者把 `Mul` 的输出从 `c` 改成 `d`,则最终的 ONNX 模型都是不满足标准的。
|
||||
|
||||
> 一个不满足标准的 ONNX 模型可能无法被推理引擎正确识别。ONNX 提供了 API `onnx.checker.check_model` 来判断一个 ONNX 模型是否满足标准。
|
||||
|
||||
接下来,我们用 `helper.make_graph` 来构造计算图 `GraphProto`。`helper.make_graph` 函数需要传入节点、图名称、输入张量信息、输出张量信息这 4 个参数。如下面的代码所示,我们把之前构造出来的 `NodeProto` 对象和 `ValueInfoProto` 对象按照顺序传入即可。
|
||||
|
||||
```python
|
||||
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
|
||||
```
|
||||
|
||||
这里 `make_graph` 的节点参数有一个要求:计算图的节点必须以拓扑序给出。
|
||||
|
||||
> 拓扑序是与有向图的相关的数学概念。如果按拓扑序遍历所有节点的话,能保证每个节点的输入都能在之前节点的输出里找到(对于 ONNX 模型,我们把计算图的输入张量也看成“之前的输出”)。
|
||||
|
||||
如果对这个概念不熟也没有关系,我们以刚刚构造出来的这个计算图为研究对象,通过下图展示的两个例子来直观理解拓扑序。
|
||||
|
||||

|
||||
|
||||
这里我们只关注 `Mul` 和 `Add` 节点以及它们之间的边 `c`。在情况 1 中:如果我们的节点以 `[Mul, Add]` 顺序给出,那么遍历到 `Add` 时,它的输入 `c` 可以在之前的 `Mul` 的输出中找到。但是,如情况 2 所示:如果我们的节点以 `[Add, Mul]` 的顺序给出,那么 `Add` 就找不到输入边,计算图也无法成功构造出来了。这里的 `[Mul, Add]` 就是符合有向图的拓扑序的,而 `[Add, Mul]` 则不满足。
|
||||
|
||||
最后,我们用 `helper.make_model` 把计算图 `GraphProto` 封装进模型 `ModelProto` 里,一个 ONNX 模型就构造完成了。`make_model` 函数中还可以添加模型制作者、版本等信息,为了简单起见,我们没有添加额外的信息。如下面的代码所示:
|
||||
|
||||
```python
|
||||
model = helper.make_model(graph)
|
||||
```
|
||||
|
||||
构造完模型之后,我们用下面这三行代码来检查模型正确性、把模型以文本形式输出、存储到一个 ".onnx" 文件里。这里用 `onnx.checker.check_model` 来检查模型是否满足 ONNX 标准是必要的,因为无论模型是否满足标准,ONNX 都允许我们用 onnx.save 存储模型。我们肯定不希望生成一个不满足标准的模型。
|
||||
|
||||
```python
|
||||
onnx.checker.check_model(model)
|
||||
print(model)
|
||||
onnx.save(model, 'linear_func.onnx')
|
||||
```
|
||||
|
||||
成功执行这些代码的话,程序会以文本格式输出模型的信息,其内容应该和我们在上一节展示的输出一样。
|
||||
|
||||
整理一下,用 ONNX Python API 构造模型的代码如下:
|
||||
|
||||
```python
|
||||
import onnx
|
||||
from onnx import helper
|
||||
from onnx import TensorProto
|
||||
|
||||
# input and output
|
||||
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
|
||||
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
|
||||
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
|
||||
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10])
|
||||
|
||||
# Mul
|
||||
mul = helper.make_node('Mul', ['a', 'x'], ['c'])
|
||||
|
||||
# Add
|
||||
add = helper.make_node('Add', ['c', 'b'], ['output'])
|
||||
|
||||
# graph and model
|
||||
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
|
||||
model = helper.make_model(graph)
|
||||
|
||||
# save model
|
||||
onnx.checker.check_model(model)
|
||||
print(model)
|
||||
onnx.save(model, 'linear_func.onnx')
|
||||
```
|
||||
|
||||
老规矩,我们可以用 ONNX Runtime 运行模型,来看看模型是否正确:
|
||||
|
||||
```python
|
||||
import onnxruntime
|
||||
import numpy as np
|
||||
|
||||
sess = onnxruntime.InferenceSession('linear_func.onnx')
|
||||
a = np.random.rand(10, 10).astype(np.float32)
|
||||
b = np.random.rand(10, 10).astype(np.float32)
|
||||
x = np.random.rand(10, 10).astype(np.float32)
|
||||
|
||||
output = sess.run(['output'], {'a': a, 'b': b, 'x': x})[0]
|
||||
|
||||
assert np.allclose(output, a * x + b)
|
||||
```
|
||||
|
||||
一切顺利的话,这段代码不会有任何报错信息。这说明我们的模型等价于执行 a * x + b 这个计算。
|
||||
|
||||
|
||||
### 读取并修改 ONNX 模型
|
||||
通过用 API 构造 ONNX 模型,我们已经彻底搞懂了 ONNX 由哪些模块组成。现在,让我们看看该如何读取现有的".onnx"文件并从中提取模型信息。
|
||||
|
||||
首先,我们可以用下面的代码读取一个 ONNX 模型:
|
||||
|
||||
```python
|
||||
import onnx
|
||||
model = onnx.load('linear_func.onnx')
|
||||
print(model)
|
||||
```
|
||||
|
||||
之前在输出模型时,我们传给 `onnx.save` 的是一个 `ModelProto` 的对象。同理,用上面的 `onnx.load` 读取 ONNX 模型时,我们收获的也是一个 `ModelProto` 的对象。输出这个对象后,我们应该得到和之前完全相同的输出。
|
||||
接下来,我们来看看怎么把图 `GraphProto`、节点 `NodeProto`、张量信息 `ValueInfoProto` 读取出来:
|
||||
|
||||
```python
|
||||
graph = model.graph
|
||||
node = graph.node
|
||||
input = graph.input
|
||||
output = graph.output
|
||||
print(node)
|
||||
print(input)
|
||||
print(output)
|
||||
```
|
||||
|
||||
使用如上这些代码,我们可以分别访问模型的图、节点、张量信息。这里大家或许会有疑问:该怎样找出 `graph.node,graph.input` 中 `node, input` 这些属性名称呢?其实,属性的名称就写在每个对象的输出里。我们以 `print(node)` 的输出为例:
|
||||
|
||||
```python
|
||||
[input: "a"
|
||||
input: "x"
|
||||
output: "c"
|
||||
op_type: "Mul"
|
||||
, input: "c"
|
||||
input: "b"
|
||||
output: "output"
|
||||
op_type: "Add"
|
||||
]
|
||||
```
|
||||
|
||||
在这段输出中,我们能看出 `node` 其实就是一个列表,列表中的对象有属性 `input, output, op_type`(这里 `input` 也是一个列表,它包含的两个元素都显示出来了)。我们可以用下面的代码来获取 `node` 里第一个节点 `Mul` 的属性:
|
||||
|
||||
```python
|
||||
node_0 = node[0]
|
||||
node_0_inputs = node_0.input
|
||||
node_0_outputs = node_0.output
|
||||
input_0 = node_0_inputs[0]
|
||||
input_1 = node_0_inputs[1]
|
||||
output = node_0_outputs[0]
|
||||
op_type = node_0.op_type
|
||||
|
||||
print(input_0)
|
||||
print(input_1)
|
||||
print(output)
|
||||
print(op_type)
|
||||
|
||||
# Output
|
||||
"""
|
||||
a
|
||||
x
|
||||
c
|
||||
Mul
|
||||
"""
|
||||
```
|
||||
|
||||
当我们想知道 ONNX 模型某数据对象有哪些属性时,我们不必去翻 ONNX 文档,只需要先把数据对象输出一下,然后在输出结果找出属性名即可。
|
||||
|
||||
读取完 ONNX 模型的信息后,修改 ONNX 模型就是一件很轻松的事了。我们既可以按照上一小节的模型构造方法,新建节点和张量信息,与原有模型组合成一个新的模型,也可以在不违反 ONNX 规范的前提下直接修改某个数据对象的属性。
|
||||
|
||||
这里我们来看一个直接修改模型属性的例子:
|
||||
|
||||
```python
|
||||
import onnx
|
||||
model = onnx.load('linear_func.onnx')
|
||||
|
||||
node = model.graph.node
|
||||
node[1].op_type = 'Sub'
|
||||
|
||||
onnx.checker.check_model(model)
|
||||
onnx.save(model, 'linear_func_2.onnx')
|
||||
```
|
||||
|
||||
在读入之前的 `linear_func.onnx` 模型后,我们可以直接修改第二个节点的类型 `node[1].op_type`,把加法变成减法。这样,我们的模型描述的是 `a * x - b` 这个线性函数。大家感兴趣的话,可以用 ONNX Runtime 运行新模型 `linear_func_2.onnx`,来验证一下它和 `a * x - b` 是否等价。
|
||||
|
||||
## 调试 ONNX 模型
|
||||
在实际部署中,如果用深度学习框架导出的 ONNX 模型出了问题,一般要通过修改框架的代码来解决,而不会从 ONNX 入手,我们把 ONNX 模型当成一个不可修改的黑盒看待。
|
||||
现在,我们已经深入学习了 ONNX 的原理,可以尝试对 ONNX 模型本身进行调试了。在这一节里,让我们看看该如何巧妙利用 ONNX 提供的子模型提取功能,对 ONNX 模型进行调试。
|
||||
|
||||
### 子模型提取
|
||||
ONNX 官方为开发者提供了子模型提取(extract)的功能。子模型提取,顾名思义,就是从一个给定的 ONNX 模型中,拿出一个子模型。这个子模型的节点集、边集都是原模型中对应集合的子集。让我们来用 PyTorch 导出一个复杂一点的 ONNX 模型,并在它的基础上执行提取操作:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
class Model(torch.nn.Module):
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.convs1 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3))
|
||||
self.convs2 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3))
|
||||
self.convs3 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3))
|
||||
self.convs4 = torch.nn.Sequential(torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3),
|
||||
torch.nn.Conv2d(3, 3, 3))
|
||||
def forward(self, x):
|
||||
x = self.convs1(x)
|
||||
x1 = self.convs2(x)
|
||||
x2 = self.convs3(x)
|
||||
x = x1 + x2
|
||||
x = self.convs4(x)
|
||||
return x
|
||||
|
||||
model = Model()
|
||||
input = torch.randn(1, 3, 20, 20)
|
||||
|
||||
torch.onnx.export(model, input, 'whole_model.onnx')
|
||||
```
|
||||
|
||||
这个模型的可视化结果如下图所示(提取子模型需要输入边的序号,为了大家方面阅读,这幅图标出了之后要用到的边的序号):
|
||||
|
||||

|
||||
|
||||
|
||||
> 在前面的章节中,我们学过,ONNX 的边用同名张量表示的。也就是说,这里的边序号,实际上是前一个节点的输出张量序号和后一个节点的输入张量序号。由于这个模型是用 PyTorch 导出的,这些张量序号都是 PyTorch 自动生成的。
|
||||
|
||||
接着,我们可以下面的代码提取出一个子模型:
|
||||
|
||||
```python
|
||||
import onnx
|
||||
|
||||
onnx.utils.extract_model('whole_model.onnx', 'partial_model.onnx', ['22'], ['28'])
|
||||
```
|
||||
|
||||
子模型的可视化结果如下图所示:
|
||||
|
||||

|
||||
|
||||
通过观察代码和输出图,应该不难猜出这段代码的作用是把原计算图从边 22 到边 28 的子图提取出来,并组成一个子模型。`onnx.utils.extract_model` 就是完成子模型提取的函数,它的参数分别是原模型路径、输出模型路径、子模型的输入边(输入张量)、子模型的输出边(输出张量)。
|
||||
|
||||
直观地来看,子模型提取就是把输入边到输出边之间的全部节点都取出来。那么,这个功能在使用上有什么限制呢?基于 `whole_model.onnx`, 我们来看一看三个子模型提取的示例。
|
||||
|
||||
#### 添加额外输出
|
||||
|
||||
我们在提取时新设定了一个输出张量,如下面的代码所示:
|
||||
|
||||
```python
|
||||
onnx.utils.extract_model('whole_model.onnx', 'submodel_1.onnx', ['22'], ['27', '31'])
|
||||
```
|
||||
|
||||
我们可以看到子模型会添加一条把张量输出的新边,如下图所示:
|
||||
|
||||

|
||||
|
||||
#### 添加冗余输入
|
||||
|
||||
如果我们还是像开始一样提取边 22 到边 28 之间的子模型,但是多添加了一个输入 input.1,那么提取出的子模型会有一个冗余的输入 input.1,如下面的代码所示:
|
||||
|
||||
```python
|
||||
onnx.utils.extract_model('whole_model.onnx', 'submodel_2.onnx', ['22', 'input.1'], ['28'])
|
||||
```
|
||||
|
||||
从下图中可以看出:无论给这个输入传入什么值,都不会影响子模型的输出。可以认为如果只用子模型的部分输入就能得到输出,那么那些”较早“的多出来的输入就是冗余的。
|
||||
|
||||

|
||||
|
||||
#### 输入信息不足
|
||||
|
||||
这次,我们尝试提取的子模型输入是边 24,输出是边 28。如下面的代码和图所示:
|
||||
|
||||
```python
|
||||
# Error
|
||||
onnx.utils.extract_model('whole_model.onnx', 'submodel_3.onnx', ['24'], ['28'])
|
||||
```
|
||||
|
||||

|
||||
|
||||
从图中可以看出,想通过边 24 计算边 28 的结果,至少还需要输入边 26,或者更上面的边。仅凭借边 24 是无法计算出边 28 的结果的,因此这样提取子模型会报错。
|
||||
|
||||
通过上面几个使用示例,我们可以整理出子模型提取的实现原理:新建一个模型,把给定的输入和输出填入。之后把图的所有有向边反向,从输出边开始遍历节点,碰到输入边则停止,把这样遍历得到的节点做为子模型的节点。
|
||||
|
||||
如果还没有彻底弄懂这个提取原理,没关系,我们只要尽量保证在填写子模型的输入输出时,让输出恰好可以由输入决定即可。
|
||||
|
||||
### 输出 ONNX 中间节点的值
|
||||
|
||||
在使用 ONNX 模型时,最常见的一个需求是能够用推理引擎输出中间节点的值。这多见于深度学习框架模型和 ONNX 模型的精度对齐中,因为只要能够输出中间节点的值,就能定位到精度出现偏差的算子。我们来看看如何用子模型提取实现这一任务。
|
||||
|
||||
在刚刚的第一个子模型提取示例中,我们添加了一条原来模型中不存在的输出边。用同样的原理,我们可以在保持原有输入输出不变的同时,新增加一些输出,提取出一个能输出中间节点的”子模型“。例如:
|
||||
|
||||
```python
|
||||
onnx.utils.extract_model('whole_model.onnx', 'more_output_model.onnx', ['input.1'], ['31', '23', '25', '27'])
|
||||
```
|
||||
|
||||
在这个子模型中,我们在保持原有的输入 `input.1`,输出 `31` 的同时,把其他几个边加入了输出中。如下图所示:
|
||||
|
||||

|
||||
|
||||
这样,用 ONNX Runtime 运行 `more_output_model.onnx` 这个模型时,我们就能得到更多的输出了。
|
||||
为了方便调试,我们还可以把原模型拆分成多个互不相交的子模型。这样,在每次调试时,可以只对原模型的部分子模块调试。比如:
|
||||
|
||||
```python
|
||||
onnx.utils.extract_model('whole_model.onnx', 'debug_model_1.onnx', ['input.1'], ['23'])
|
||||
onnx.utils.extract_model('whole_model.onnx', 'debug_model_2.onnx', ['23'], ['25'])
|
||||
onnx.utils.extract_model('whole_model.onnx', 'debug_model_3.onnx', ['23'], ['27'])
|
||||
onnx.utils.extract_model('whole_model.onnx', 'debug_model_4.onnx', ['25', '27'], ['31'])
|
||||
```
|
||||
|
||||
在这个例子中,我们把原来较为复杂的模型拆成了四个较为简单的子模型,如下图所示。在调试时,我们可以先调试顶层的子模型,确认顶层子模型无误后,把它的输出做为后面子模型的输入。
|
||||
|
||||
比如对于这些子模型,我们可以先调试第一个子模型,并存储输出 23。之后把张量 23 做为第二个和第三个子模型的输入,调试这两个模型。最后用同样方法调试第四个子模型。可以说,有了子模型提取功能,哪怕是面对一个庞大的模型,我们也能够从中提取出有问题的子模块,细致地只对这个子模块调试。
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
子模型提取固然是一个便利的 ONNX 调试工具。但是,在实际的情况中,我们一般是用 PyTorch 等框架导出 ONNX 模型。这里有两个问题:
|
||||
|
||||
1. 一旦 PyTorch 模型改变,ONNX 模型的边序号也会改变。这样每次提取同样的子模块时都要重新去 ONNX 模型里查序号,如此繁琐的调试方法是不会在实践中采用的。
|
||||
2. 即使我们能保证 ONNX 的边序号不发生改变,我们也难以把 PyTorch 代码和 ONNX 节点对应起来——当模型结构变得十分复杂时,要识别 ONNX 中每个节点的含义是不可能的。
|
||||
|
||||
MMDeploy 为 PyTorch 模型添加了模型分块功能。使用这个功能,我们可以通过只修改 PyTorch 模型的实现代码来把原模型导出成多个互不相交的子 ONNX 模型。我们会在后续教程中对其介绍。
|
||||
|
||||
## 总结
|
||||
|
||||
在这篇教程中,我们抛开了 PyTorch,学习了 ONNX 模型本身的知识。老规矩,我们来总结一下这篇教程的知识点:
|
||||
|
||||
* ONNX 使用 Protobuf 定义规范和序列化模型。
|
||||
* 一个 ONNX 模型主要由 `ModelProto`,`GraphProto`,`NodeProto`,`ValueInfoProto` 这几个数据类的对象组成。
|
||||
* 使用 `onnx.helper.make_xxx`,我们可以构造 ONNX 模型的数据对象。
|
||||
* `onnx.save()` 可以保存模型,`onnx.load()` 可以读取模型,`onnx.checker.check_model()` 可以检查模型是否符合规范。
|
||||
* `onnx.utils.extract_model()` 可以从原模型中取出部分节点,和新定义的输入、输出边构成一个新的子模型。
|
||||
* 利用子模型提取功能,我们可以输出原 ONNX 模型的中间结果,实现对 ONNX 模型的调试。
|
||||
|
||||
至此,我们对 ONNX 相关知识的学习就告一段落了。回顾一下,我们先学习了 PyTorch 转 ONNX 有关 API 的用法;接着,我们学习了如何用自定义算子解决 PyTorch 和 ONNX 表达能力不足的问题;最后我们单独学习了 ONNX 模型的调试方法。通过对 ONNX 由浅入深的学习,我们基本可以应对模型部署中和 ONNX 有关的绝大多数问题了。
|
||||
|
||||
如果大家想了解更多有关 ONNX API 的知识,可以去阅读 ONNX 的[官方 Python API 文档](https://github.com/onnx/onnx/blob/main/docs/PythonAPIOverview.md)。
|
||||
|
|
@ -58,6 +58,8 @@ extensions = [
|
|||
'sphinx_copybutton',
|
||||
] # yapf: disable
|
||||
|
||||
autodoc_mock_imports = ['tensorrt']
|
||||
|
||||
autosectionlabel_prefix_document = True
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
|
|
|
|||
|
|
@ -42,6 +42,9 @@
|
|||
get_started.md
|
||||
05-tutorial/01_introduction_to_model_deployment.md
|
||||
05-tutorial/02_challenges.md
|
||||
05-tutorial/03_pytorch2onnx.md
|
||||
05-tutorial/04_onnx_custom_op.md
|
||||
05-tutorial/05_onnx_model_editing.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
|
|
|||
|
|
@ -16,15 +16,15 @@ def inference_model(model_cfg: Union[str, mmcv.Config],
|
|||
|
||||
Examples:
|
||||
>>> from mmdeploy.apis import inference_model
|
||||
>>> model_cfg = 'mmdetection/configs/fcos/' \
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py'
|
||||
>>> deploy_cfg = 'configs/mmdet/detection/' \
|
||||
'detection_onnxruntime_dynamic.py'
|
||||
>>> model_cfg = ('mmdetection/configs/fcos/'
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py')
|
||||
>>> deploy_cfg = ('configs/mmdet/detection/'
|
||||
'detection_onnxruntime_dynamic.py')
|
||||
>>> backend_files = ['work_dir/fcos.onnx']
|
||||
>>> img = 'demo.jpg'
|
||||
>>> device = 'cpu'
|
||||
>>> model_output = inference_model(model_cfg, deploy_cfg, \
|
||||
backend_files, img, device)
|
||||
>>> model_output = inference_model(model_cfg, deploy_cfg,
|
||||
backend_files, img, device)
|
||||
|
||||
Args:
|
||||
model_cfg (str | mmcv.Config): Model config file or Config object.
|
||||
|
|
|
|||
|
|
@ -27,12 +27,12 @@ def torch2onnx(img: Any,
|
|||
>>> img = 'demo.jpg'
|
||||
>>> work_dir = 'work_dir'
|
||||
>>> save_file = 'fcos.onnx'
|
||||
>>> deploy_cfg = 'configs/mmdet/detection/' \
|
||||
'detection_onnxruntime_dynamic.py'
|
||||
>>> model_cfg = 'mmdetection/configs/fcos/' \
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py'
|
||||
>>> model_checkpoint = 'checkpoints/' \
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco-821213aa.pth'
|
||||
>>> deploy_cfg = ('configs/mmdet/detection/'
|
||||
'detection_onnxruntime_dynamic.py')
|
||||
>>> model_cfg = ('mmdetection/configs/fcos/'
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py')
|
||||
>>> model_checkpoint = ('checkpoints/'
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco-821213aa.pth')
|
||||
>>> device = 'cpu'
|
||||
>>> torch2onnx(img, work_dir, save_file, deploy_cfg, \
|
||||
model_cfg, model_checkpoint, device)
|
||||
|
|
|
|||
|
|
@ -21,10 +21,10 @@ def visualize_model(model_cfg: Union[str, mmcv.Config],
|
|||
|
||||
Examples:
|
||||
>>> from mmdeploy.apis import visualize_model
|
||||
>>> model_cfg = 'mmdetection/configs/fcos/' \
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py'
|
||||
>>> deploy_cfg = 'configs/mmdet/detection/' \
|
||||
'detection_onnxruntime_dynamic.py'
|
||||
>>> model_cfg = ('mmdetection/configs/fcos/'
|
||||
'fcos_r50_caffe_fpn_gn-head_1x_coco.py')
|
||||
>>> deploy_cfg = ('configs/mmdet/detection/'
|
||||
'detection_onnxruntime_dynamic.py')
|
||||
>>> model = 'work_dir/fcos.onnx'
|
||||
>>> img = 'demo.jpg'
|
||||
>>> device = 'cpu'
|
||||
|
|
|
|||
|
|
@ -50,9 +50,9 @@ class ORTWrapper(BaseWrapper):
|
|||
logger.warning(f'The library of onnxruntime custom ops does \
|
||||
not exist: {ort_custom_op_path}')
|
||||
device_id = parse_device_id(device)
|
||||
is_cuda_available = ort.get_device() == 'GPU'
|
||||
providers = [('CUDAExecutionProvider', {'device_id': device_id})] \
|
||||
if is_cuda_available else ['CPUExecutionProvider']
|
||||
providers = ['CPUExecutionProvider'] \
|
||||
if device == 'cpu' else \
|
||||
[('CUDAExecutionProvider', {'device_id': device_id})]
|
||||
sess = ort.InferenceSession(
|
||||
onnx_file, session_options, providers=providers)
|
||||
if output_names is None:
|
||||
|
|
@ -60,8 +60,7 @@ class ORTWrapper(BaseWrapper):
|
|||
self.sess = sess
|
||||
self.io_binding = sess.io_binding()
|
||||
self.device_id = device_id
|
||||
self.is_cuda_available = is_cuda_available
|
||||
self.device_type = 'cuda' if is_cuda_available else 'cpu'
|
||||
self.device_type = 'cpu' if device == 'cpu' else 'cuda'
|
||||
super().__init__(output_names)
|
||||
|
||||
def forward(self, inputs: Dict[str,
|
||||
|
|
@ -77,7 +76,7 @@ class ORTWrapper(BaseWrapper):
|
|||
for name, input_tensor in inputs.items():
|
||||
# set io binding for inputs/outputs
|
||||
input_tensor = input_tensor.contiguous()
|
||||
if not self.is_cuda_available:
|
||||
if self.device_type == 'cpu':
|
||||
input_tensor = input_tensor.cpu()
|
||||
# Avoid unnecessary data transfer between host and device
|
||||
element_type = input_tensor.new_zeros(
|
||||
|
|
|
|||
|
|
@ -26,10 +26,10 @@ def onnx2tensorrt(work_dir: str,
|
|||
>>> work_dir = 'work_dir'
|
||||
>>> save_file = 'end2end.engine'
|
||||
>>> model_id = 0
|
||||
>>> deploy_cfg = 'configs/mmdet/detection/' \
|
||||
'detection_tensorrt_dynamic-320x320-1344x1344.py'
|
||||
>>> deploy_cfg = ('configs/mmdet/detection/'
|
||||
'detection_tensorrt_dynamic-320x320-1344x1344.py')
|
||||
>>> onnx_model = 'work_dir/end2end.onnx'
|
||||
>>> onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg, \
|
||||
>>> onnx2tensorrt(work_dir, save_file, model_id, deploy_cfg,
|
||||
onnx_model, 'cuda:0')
|
||||
|
||||
Args:
|
||||
|
|
|
|||
|
|
@ -201,7 +201,7 @@ def multiclass_nms__default(ctx,
|
|||
"""
|
||||
deploy_cfg = ctx.cfg
|
||||
batch_size = boxes.size(0)
|
||||
if not is_dynamic_batch(deploy_cfg) and batch_size != 1:
|
||||
if not is_dynamic_batch(deploy_cfg) and batch_size == 1:
|
||||
return _multiclass_nms_single(
|
||||
boxes,
|
||||
scores,
|
||||
|
|
|
|||
|
|
@ -111,37 +111,40 @@ class End2EndModel(BaseBackendModel):
|
|||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def postprocessing_masks(det_bboxes: np.ndarray,
|
||||
det_masks: np.ndarray,
|
||||
def postprocessing_masks(det_bboxes: Union[np.ndarray, torch.Tensor],
|
||||
det_masks: Union[np.ndarray, torch.Tensor],
|
||||
img_w: int,
|
||||
img_h: int,
|
||||
device: str = 'cpu',
|
||||
mask_thr_binary: float = 0.5) -> np.ndarray:
|
||||
device: str = 'cpu') -> torch.Tensor:
|
||||
"""Additional processing of masks. Resizes masks from [num_det, 28, 28]
|
||||
to [num_det, img_w, img_h]. Analog of the 'mmdeploy.codebase.mmdet.
|
||||
models.roi_heads.fcn_mask_head._do_paste_mask' function.
|
||||
|
||||
Args:
|
||||
det_bboxes (np.ndarray): Bbox of shape [num_det, 4]
|
||||
det_masks (np.ndarray): Masks of shape [num_det, 28, 28].
|
||||
det_bboxes (np.ndarray | Tensor): Bbox of shape [num_det, 4]
|
||||
det_masks (np.ndarray | Tensor): Masks of shape [num_det, 28, 28].
|
||||
img_w (int): Width of the original image.
|
||||
img_h (int): Height of the original image.
|
||||
mask_thr_binary (float): The threshold for the mask.
|
||||
device :(str): The device type.
|
||||
|
||||
Returns:
|
||||
np.ndarray: masks of shape [N, num_det, img_h, img_w].
|
||||
torch.Tensor: masks of shape [N, num_det, img_h, img_w].
|
||||
"""
|
||||
masks = det_masks
|
||||
bboxes = det_bboxes
|
||||
|
||||
device = torch.device(device)
|
||||
num_det = bboxes.shape[0]
|
||||
# Skip postprocessing if no detections are found.
|
||||
if num_det == 0:
|
||||
return np.zeros((0, img_h, img_w))
|
||||
return torch.zeros(
|
||||
0, img_h, img_w, dtype=torch.float32, device=device)
|
||||
|
||||
if isinstance(masks, np.ndarray):
|
||||
masks = torch.tensor(masks, device=torch.device(device))
|
||||
bboxes = torch.tensor(bboxes, device=torch.device(device))
|
||||
masks = torch.tensor(masks, device=device)
|
||||
bboxes = torch.tensor(bboxes, device=device)
|
||||
|
||||
masks = masks.to(device)
|
||||
bboxes = bboxes.to(device)
|
||||
|
||||
result_masks = []
|
||||
for bbox, mask in zip(bboxes, masks):
|
||||
|
|
@ -150,15 +153,9 @@ class End2EndModel(BaseBackendModel):
|
|||
x1_int, y1_int = img_w, img_h
|
||||
|
||||
img_y = torch.arange(
|
||||
y0_int,
|
||||
y1_int,
|
||||
dtype=torch.float32,
|
||||
device=torch.device(device)) + 0.5
|
||||
y0_int, y1_int, dtype=torch.float32, device=device) + 0.5
|
||||
img_x = torch.arange(
|
||||
x0_int,
|
||||
x1_int,
|
||||
dtype=torch.float32,
|
||||
device=torch.device(device)) + 0.5
|
||||
x0_int, x1_int, dtype=torch.float32, device=device) + 0.5
|
||||
x0, y0, x1, y1 = bbox
|
||||
|
||||
img_y = (img_y - y0) / (y1 - y0) * 2 - 1
|
||||
|
|
@ -214,8 +211,7 @@ class End2EndModel(BaseBackendModel):
|
|||
if isinstance(scale_factor, (list, tuple, np.ndarray)):
|
||||
assert len(scale_factor) == 4
|
||||
scale_factor = np.array(scale_factor)[None, :] # [1,4]
|
||||
scale_factor = torch.from_numpy(scale_factor).to(
|
||||
device=torch.device(self.device))
|
||||
scale_factor = torch.from_numpy(scale_factor).to(dets)
|
||||
dets[:, :4] /= scale_factor
|
||||
|
||||
if 'border' in img_metas[i]:
|
||||
|
|
@ -254,6 +250,8 @@ class End2EndModel(BaseBackendModel):
|
|||
masks = masks.squeeze(0)
|
||||
if masks.dtype != bool:
|
||||
masks = masks >= 0.5
|
||||
# aligned with mmdet to easily convert to numpy
|
||||
masks = masks.cpu()
|
||||
segms_results = [[] for _ in range(len(self.CLASSES))]
|
||||
for j in range(len(dets)):
|
||||
segms_results[labels[j]].append(masks[j])
|
||||
|
|
@ -599,23 +597,21 @@ class NCNNEnd2EndModel(End2EndModel):
|
|||
imgs (torch.Tensor): Input image(s) in [N x C x H x W] format.
|
||||
|
||||
Returns:
|
||||
list[np.ndarray]: dets of shape [N, num_det, 5] and
|
||||
list[torch.Tensor]: dets of shape [N, num_det, 5] and
|
||||
class labels of shape [N, num_det].
|
||||
"""
|
||||
_, _, H, W = imgs.shape
|
||||
outputs = self.wrapper({self.input_name: imgs})
|
||||
for key, item in outputs.items():
|
||||
if item is None:
|
||||
return [np.zeros((1, 0, 5)), np.zeros((1, 0))]
|
||||
return torch.zeros(1, 0, 5), torch.zeros(1, 0)
|
||||
out = self.wrapper.output_to_list(outputs)[0]
|
||||
labels = out[:, :, 0] - 1
|
||||
scales = torch.tensor([W, H, W, H]).reshape(1, 1, 4)
|
||||
scales = torch.tensor([W, H, W, H]).reshape(1, 1, 4).to(out)
|
||||
scores = out[:, :, 1:2]
|
||||
boxes = out[:, :, 2:6] * scales
|
||||
dets = torch.cat([boxes, scores], dim=2)
|
||||
dets = dets.detach().cpu().numpy()
|
||||
labels = labels.detach().cpu().numpy()
|
||||
return [dets, labels]
|
||||
return dets, labels
|
||||
|
||||
|
||||
@__BACKEND_MODEL.register_module('sdk')
|
||||
|
|
|
|||
|
|
@ -174,7 +174,7 @@ class VoxelDetectionModel(BaseBackendModel):
|
|||
@staticmethod
|
||||
def post_process(model_cfg: Union[str, mmcv.Config],
|
||||
deploy_cfg: Union[str, mmcv.Config],
|
||||
outs: torch.Tensor,
|
||||
outs: Dict,
|
||||
img_metas: Dict,
|
||||
device: str,
|
||||
rescale=False):
|
||||
|
|
@ -184,7 +184,7 @@ class VoxelDetectionModel(BaseBackendModel):
|
|||
model_cfg (str | mmcv.Config): The model config.
|
||||
deploy_cfg (str|mmcv.Config): Deployment config file or loaded
|
||||
Config object.
|
||||
outs (torch.Tensor): Output of model's head.
|
||||
outs (Dict): Output of model's head.
|
||||
img_metas(Dict): Meta info for pcd.
|
||||
device (str): A string specifying device type.
|
||||
rescale (list[torch.Tensor]): whether th rescale bbox.
|
||||
|
|
|
|||
|
|
@ -30,19 +30,18 @@ def pillar_encoder__forward(ctx, self, features, num_points, coors):
|
|||
|
||||
# Find distance of x, y, and z from pillar center
|
||||
device = features.device
|
||||
|
||||
if self._with_voxel_center:
|
||||
if not self.legacy:
|
||||
f_center = features[..., :3] - (
|
||||
coors * torch.tensor([1, self.vz, self.vy, self.vx]).to(device)
|
||||
+
|
||||
torch.tensor([1, self.z_offset, self.y_offset, self.x_offset
|
||||
]).to(device)).unsqueeze(1).flip(2)[..., :3]
|
||||
f_center = features[..., :3] - (coors[..., 1:] * torch.tensor(
|
||||
[self.vz, self.vy, self.vx]).to(device) + torch.tensor([
|
||||
self.z_offset, self.y_offset, self.x_offset
|
||||
]).to(device)).unsqueeze(1).flip(2)
|
||||
else:
|
||||
f_center = features[..., :3] - (
|
||||
coors * torch.tensor([1, self.vz, self.vy, self.vx]).to(device)
|
||||
+
|
||||
torch.tensor([1, self.z_offset, self.y_offset, self.x_offset
|
||||
]).to(device)).unsqueeze(1).flip(2)[..., :3]
|
||||
f_center = features[..., :3] - (coors[..., 1:] * torch.tensor(
|
||||
[self.vz, self.vy, self.vx]).to(device) + torch.tensor([
|
||||
self.z_offset, self.y_offset, self.x_offset
|
||||
]).to(device)).unsqueeze(1).flip(2)
|
||||
features_ls[0] = torch.cat((f_center, features[..., 3:]), dim=-1)
|
||||
features_ls.append(f_center)
|
||||
|
||||
|
|
|
|||
|
|
@ -137,7 +137,6 @@ class PoseDetection(BaseTask):
|
|||
Returns:
|
||||
tuple: (data, img), meta information for the input image and input.
|
||||
"""
|
||||
from mmpose.apis.inference import _box2cs
|
||||
from mmpose.datasets.dataset_info import DatasetInfo
|
||||
from mmpose.datasets.pipelines import Compose
|
||||
|
||||
|
|
@ -162,17 +161,12 @@ class PoseDetection(BaseTask):
|
|||
image_size = input_shape
|
||||
else:
|
||||
image_size = np.array(cfg.data_cfg['image_size'])
|
||||
for bbox in bboxes:
|
||||
center, scale = _box2cs(cfg, bbox)
|
||||
|
||||
for bbox in bboxes:
|
||||
# prepare data
|
||||
data = {
|
||||
'img':
|
||||
imgs,
|
||||
'center':
|
||||
center,
|
||||
'scale':
|
||||
scale,
|
||||
'bbox_score':
|
||||
bbox[4] if len(bbox) == 5 else 1,
|
||||
'bbox_id':
|
||||
|
|
@ -192,6 +186,17 @@ class PoseDetection(BaseTask):
|
|||
}
|
||||
}
|
||||
|
||||
# for compatibility of mmpose
|
||||
try:
|
||||
# for mmpose<=v0.25.1
|
||||
from mmpose.apis.inference import _box2cs
|
||||
center, scale = _box2cs(cfg, bbox)
|
||||
data['center'] = center
|
||||
data['scale'] = scale
|
||||
except ImportError:
|
||||
# for mmpose>=v0.26.0
|
||||
data['bbox'] = bbox
|
||||
|
||||
data = test_pipeline(data)
|
||||
batch_data.append(data)
|
||||
|
||||
|
|
|
|||
|
|
@ -214,7 +214,7 @@ class SDKEnd2EndModel(End2EndModel):
|
|||
bbox_ids.append(img_meta['bbox_id'])
|
||||
|
||||
pred = self.wrapper.handle(
|
||||
[img[0].contiguous().detach().cpu().numpy()], sdk_boxes)[0]
|
||||
[img[0].contiguous().detach().cpu().numpy()], [sdk_boxes])[0]
|
||||
|
||||
result = dict(
|
||||
preds=pred,
|
||||
|
|
|
|||
|
|
@ -272,5 +272,10 @@ class Segmentation(BaseTask):
|
|||
"""
|
||||
assert 'decode_head' in self.model_cfg.model, 'model config contains'
|
||||
' no decode_head'
|
||||
name = self.model_cfg.model.decode_head.type[:-4].lower()
|
||||
if isinstance(self.model_cfg.model.decode_head, list):
|
||||
name = self.model_cfg.model.decode_head[-1].type[:-4].lower()
|
||||
elif 'type' in self.model_cfg.model.decode_head:
|
||||
name = self.model_cfg.model.decode_head.type[:-4].lower()
|
||||
else:
|
||||
name = 'mmseg_model'
|
||||
return name
|
||||
|
|
|
|||
|
|
@ -4,11 +4,11 @@ import torch.nn as nn
|
|||
from mmseg.ops import resize
|
||||
|
||||
from mmdeploy.core import FUNCTION_REWRITER
|
||||
from mmdeploy.utils import is_dynamic_shape
|
||||
from mmdeploy.utils import IR, get_root_logger, is_dynamic_shape
|
||||
|
||||
|
||||
@FUNCTION_REWRITER.register_rewriter(
|
||||
func_name='mmseg.models.decode_heads.psp_head.PPM.forward')
|
||||
func_name='mmseg.models.decode_heads.psp_head.PPM.forward', ir=IR.ONNX)
|
||||
def ppm__forward(ctx, self, x):
|
||||
"""Rewrite `forward` for default backend.
|
||||
|
||||
|
|
@ -34,9 +34,10 @@ def ppm__forward(ctx, self, x):
|
|||
for ppm in self:
|
||||
if isinstance(ppm[0], nn.AdaptiveAvgPool2d) and \
|
||||
ppm[0].output_size != 1:
|
||||
assert not is_dynamic_flag, 'AdaptiveAvgPool2d is not \
|
||||
supported with dynamic shape in backends'
|
||||
|
||||
if is_dynamic_flag:
|
||||
logger = get_root_logger()
|
||||
logger.warning('`AdaptiveAvgPool2d` would be '
|
||||
'replaced to `AvgPool2d` explicitly')
|
||||
# replace AdaptiveAvgPool2d with AvgPool2d explicitly
|
||||
output_size = 2 * [ppm[0].output_size]
|
||||
k = [int(size[i] / output_size[i]) for i in range(0, len(size))]
|
||||
|
|
|
|||
|
|
@ -1,9 +1,7 @@
|
|||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import torch.nn.functional as F
|
||||
from mmseg.ops import resize
|
||||
|
||||
from mmdeploy.core import FUNCTION_REWRITER
|
||||
from mmdeploy.utils import is_dynamic_shape
|
||||
|
||||
|
||||
@FUNCTION_REWRITER.register_rewriter(
|
||||
|
|
@ -25,16 +23,6 @@ def encoder_decoder__simple_test(ctx, self, img, img_meta, **kwargs):
|
|||
torch.Tensor: Output segmentation map pf shape [N, 1, H, W].
|
||||
"""
|
||||
seg_logit = self.encode_decode(img, img_meta)
|
||||
seg_logit = resize(
|
||||
input=seg_logit,
|
||||
size=img_meta['img_shape'],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
seg_logit = F.softmax(seg_logit, dim=1)
|
||||
seg_pred = seg_logit.argmax(dim=1)
|
||||
# our inference backend only support 4D output
|
||||
shape = seg_pred.shape
|
||||
if not is_dynamic_shape(ctx.cfg):
|
||||
shape = [int(_) for _ in shape]
|
||||
seg_pred = seg_pred.view(shape[0], 1, shape[1], shape[2])
|
||||
seg_pred = seg_logit.argmax(dim=1, keepdim=True)
|
||||
return seg_pred
|
||||
|
|
|
|||
|
|
@ -154,7 +154,7 @@ def mark_tensors(xs: Any, func: str, func_id: int, io_type: str, ctx: Any,
|
|||
if ys not in visit:
|
||||
visit.add(ys)
|
||||
root = ctx.names[ctx.index]
|
||||
name = '/'.join(str(x) for x in (root, *prefix))
|
||||
name = '.'.join(str(x) for x in (root, *prefix))
|
||||
ys_shape = tuple(int(s) for s in ys.shape)
|
||||
ret = Mark.apply(ys, ys.dtype, ys_shape, func, func_id,
|
||||
io_type, name, index, attrs)
|
||||
|
|
|
|||
|
|
@ -1,2 +1,4 @@
|
|||
h5py
|
||||
mmcv
|
||||
onnx>=1.8.0
|
||||
torch
|
||||
|
|
|
|||
|
|
@ -1,5 +1,8 @@
|
|||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
# model settings
|
||||
import mmpose
|
||||
from packaging import version
|
||||
|
||||
channel_cfg = dict(
|
||||
num_output_channels=17,
|
||||
dataset_joints=17,
|
||||
|
|
@ -47,6 +50,7 @@ data_cfg = dict(
|
|||
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
# dict(type='TopDownGetBboxCenterScale'),
|
||||
dict(type='TopDownAffine'),
|
||||
dict(type='ToTensor'),
|
||||
dict(
|
||||
|
|
@ -61,6 +65,9 @@ test_pipeline = [
|
|||
'flip_pairs'
|
||||
]),
|
||||
]
|
||||
# compatible with mmpose >=v0.26.0
|
||||
if version.parse(mmpose.__version__) >= version.parse('0.26.0'):
|
||||
test_pipeline.insert(1, dict(type='TopDownGetBboxCenterScale'))
|
||||
|
||||
dataset_info = dict(
|
||||
dataset_name='coco',
|
||||
|
|
|
|||
|
|
@ -46,7 +46,6 @@ num_output_channels = model_cfg['data_cfg']['num_output_channels']
|
|||
|
||||
|
||||
def test_create_input():
|
||||
model_cfg = load_config(model_cfg_path)[0]
|
||||
deploy_cfg = mmcv.Config(
|
||||
dict(
|
||||
backend_config=dict(type=Backend.ONNXRUNTIME.value),
|
||||
|
|
|
|||
|
|
@ -93,7 +93,8 @@ def _demo_mm_inputs(input_shape=(1, 3, 8, 16), num_classes=10):
|
|||
return mm_inputs
|
||||
|
||||
|
||||
@pytest.mark.parametrize('backend', [Backend.ONNXRUNTIME, Backend.OPENVINO])
|
||||
@pytest.mark.parametrize('backend',
|
||||
[Backend.ONNXRUNTIME, Backend.OPENVINO, Backend.NCNN])
|
||||
def test_encoderdecoder_simple_test(backend):
|
||||
check_backend(backend)
|
||||
segmentor = get_model()
|
||||
|
|
@ -109,7 +110,8 @@ def test_encoderdecoder_simple_test(backend):
|
|||
num_classes = segmentor.decode_head[-1].num_classes
|
||||
else:
|
||||
num_classes = segmentor.decode_head.num_classes
|
||||
mm_inputs = _demo_mm_inputs(num_classes=num_classes)
|
||||
mm_inputs = _demo_mm_inputs(
|
||||
input_shape=(1, 3, 32, 32), num_classes=num_classes)
|
||||
imgs = mm_inputs.pop('imgs')
|
||||
img_metas = mm_inputs.pop('img_metas')
|
||||
model_inputs = {'img': imgs, 'img_meta': img_metas}
|
||||
|
|
|
|||
|
|
@ -1,6 +1,7 @@
|
|||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import argparse
|
||||
import logging
|
||||
import os
|
||||
import os.path as osp
|
||||
from functools import partial
|
||||
|
||||
|
|
@ -27,7 +28,10 @@ def parse_args():
|
|||
parser.add_argument('img', help='image used to convert model model')
|
||||
parser.add_argument(
|
||||
'--test-img', default=None, help='image used to test model')
|
||||
parser.add_argument('--work-dir', help='the dir to save logs and models')
|
||||
parser.add_argument(
|
||||
'--work-dir',
|
||||
default=os.getcwd(),
|
||||
help='the dir to save logs and models')
|
||||
parser.add_argument(
|
||||
'--calib-dataset-cfg',
|
||||
help='dataset config path used to calibrate in int8 mode. If not \
|
||||
|
|
@ -314,10 +318,17 @@ def main():
|
|||
|
||||
if args.test_img is None:
|
||||
args.test_img = args.img
|
||||
import os
|
||||
is_display = os.getenv('DISPLAY')
|
||||
|
||||
headless = False
|
||||
# check headless or not for all platforms.
|
||||
import tkinter
|
||||
try:
|
||||
tkinter.Tk()
|
||||
except Exception:
|
||||
headless = True
|
||||
|
||||
# for headless installation.
|
||||
if is_display is not None:
|
||||
if not headless:
|
||||
# visualize model of the backend
|
||||
create_process(
|
||||
f'visualize {backend.value} model',
|
||||
|
|
|
|||
Loading…
Reference in New Issue