Generate supported-backends markdown table (#1986)
* Generate supported-backends markdown table * Generate supported-backends markdown table * update branch * update codebase dir * update backends nargs * update args to capitals * center alignment starting from the 3rd coloumn * center alignment starting from the 3rd coloumn * fix bad urls * fix bad urls * Update codebases.txt fix circleci * Update codebases.txt --------- Co-authored-by: RunningLeon <mnsheng@yeah.net>pull/2013/head^2
parent
6c26e887d4
commit
671d626e33
|
|
@ -202,3 +202,45 @@ And the output look like this:
|
|||
| Max | 1.689 | 591.983 |
|
||||
+--------+------------+---------+
|
||||
```
|
||||
|
||||
## generate_md_table
|
||||
|
||||
This tool can be used to generate supported-backends markdown table.
|
||||
|
||||
### Usage
|
||||
|
||||
```shell
|
||||
python tools/generate_md_table.py \
|
||||
${YML_FILE} \
|
||||
${OUTPUT} \
|
||||
--backends ${BACKENDS}
|
||||
```
|
||||
|
||||
### Description of all arguments
|
||||
|
||||
- `yml_file:` input yml config path
|
||||
- `output:` output markdown file path
|
||||
- `--backends:` output backends list. If not specified, it will be set 'onnxruntime' 'tensorrt' 'torchscript' 'pplnn' 'openvino' 'ncnn'.
|
||||
|
||||
### Example:
|
||||
|
||||
Generate backends markdown table from mmocr.yml
|
||||
|
||||
```shell
|
||||
python tools/generate_md_table.py tests/regression/mmocr.yml tests/regression/mmocr.md --backends onnxruntime tensorrt torchscript pplnn openvino ncnn
|
||||
```
|
||||
|
||||
And the output look like this:
|
||||
|
||||
| model | task | onnxruntime | tensorrt | torchscript | pplnn | openvino | ncnn |
|
||||
| :----------------------------------------------------------------------------------- | :-------------- | :---------: | :------: | :---------: | :---: | :------: | :--: |
|
||||
| [DBNet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [DBNetpp](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnetpp) | TextDetection | Y | Y | N | N | Y | Y |
|
||||
| [PANet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/panet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [PSENet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/psenet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [TextSnake](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/textsnake) | TextDetection | Y | Y | Y | N | N | N |
|
||||
| [MaskRCNN](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/maskrcnn) | TextDetection | Y | Y | Y | N | N | N |
|
||||
| [CRNN](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) | TextRecognition | Y | Y | Y | Y | N | Y |
|
||||
| [SAR](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) | TextRecognition | Y | N | Y | N | N | N |
|
||||
| [SATRN](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/satrn) | TextRecognition | Y | Y | Y | N | N | N |
|
||||
| [ABINet](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/abinet) | TextRecognition | Y | Y | Y | N | N | N |
|
||||
|
|
|
|||
|
|
@ -202,3 +202,45 @@ python tools/profiler.py \
|
|||
| Max | 1.689 | 591.983 |
|
||||
+--------+------------+---------+
|
||||
```
|
||||
|
||||
## generate_md_table
|
||||
|
||||
生成mmdeploy支持的后端表。
|
||||
|
||||
### 用法
|
||||
|
||||
```shell
|
||||
python tools/generate_md_table.py \
|
||||
${YML_FILE} \
|
||||
${OUTPUT} \
|
||||
--backends ${BACKENDS}
|
||||
```
|
||||
|
||||
### 参数说明
|
||||
|
||||
- `yml_file:` 输入 yml 配置路径
|
||||
- `output:` 输出markdown文件路径
|
||||
- `--backends:` 要输出的后端,默认为 onnxruntime tensorrt torchscript pplnn openvino ncnn
|
||||
|
||||
### 使用举例
|
||||
|
||||
从 mmocr.yml 生成mmdeploy支持的后端表
|
||||
|
||||
```shell
|
||||
python tools/generate_md_table.py tests/regression/mmocr.yml tests/regression/mmocr.md --backends onnxruntime tensorrt torchscript pplnn openvino ncnn
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
| model | task | onnxruntime | tensorrt | torchscript | pplnn | openvino | ncnn |
|
||||
| :----------------------------------------------------------------------------------- | :-------------- | :---------: | :------: | :---------: | :---: | :------: | :--: |
|
||||
| [DBNet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [DBNetpp](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnetpp) | TextDetection | Y | Y | N | N | Y | Y |
|
||||
| [PANet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/panet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [PSENet](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/psenet) | TextDetection | Y | Y | Y | Y | Y | Y |
|
||||
| [TextSnake](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/textsnake) | TextDetection | Y | Y | Y | N | N | N |
|
||||
| [MaskRCNN](https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/maskrcnn) | TextDetection | Y | Y | Y | N | N | N |
|
||||
| [CRNN](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/crnn) | TextRecognition | Y | Y | Y | Y | N | Y |
|
||||
| [SAR](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/sar) | TextRecognition | Y | N | Y | N | N | N |
|
||||
| [SATRN](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/satrn) | TextRecognition | Y | Y | Y | N | N | N |
|
||||
| [ABINet](https://github.com/open-mmlab/mmocr/tree/main/configs/textrecog/abinet) | TextRecognition | Y | Y | Y | N | N | N |
|
||||
|
|
|
|||
|
|
@ -280,7 +280,7 @@ ONNX 算子的定义情况,都可以在官方的[算子文档](https://github.
|
|||
|
||||
### PyTorch 对 ONNX 算子的映射
|
||||
|
||||
在 PyTorch 中,和 ONNX 有关的定义全部放在 [torch.onnx 目录](https://github.com/pytorch/pytorch/tree/master/torch/onnx)中,如下图所示:
|
||||
在 PyTorch 中,和 ONNX 有关的定义全部放在 [torch.onnx 目录](https://github.com/pytorch/pytorch/tree/main/torch/onnx)中,如下图所示:
|
||||
|
||||
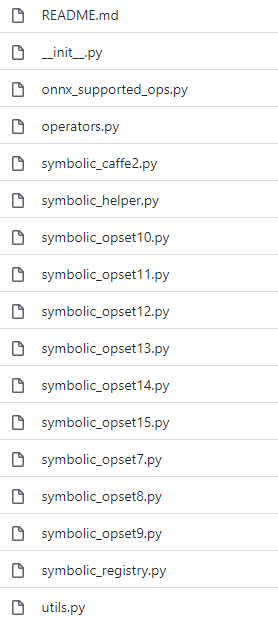
|
||||
|
||||
|
|
|
|||
|
|
@ -233,7 +233,7 @@ def symbolic(g,
|
|||
|
||||
在这个符号函数中,我们以刚刚搜索到的算子输入参数作为符号函数的输入参数,并只用 `input` 和 `offset` 来构造一个简单的 ONNX 算子。
|
||||
|
||||
这段代码中,最令人疑惑的就是装饰器 `@parse_args` 了。简单来说,TorchScript 算子的符号函数要求标注出每一个输入参数的类型。比如"v"表示 Torch 库里的 `value` 类型,一般用于标注张量,而"i"表示 int 类型,"f"表示 float 类型,"none"表示该参数为空。具体的类型含义可以在 [torch.onnx.symbolic_helper.py](https://github.com/pytorch/pytorch/blob/master/torch/onnx/symbolic_helper.py)中查看。这里输入参数中的 `input, weight, offset, mask, bias` 都是张量,所以用"v"表示。后面的其他参数同理。我们不必纠结于 `@parse_args`的原理,根据实际情况对符号函数的参数标注类型即可。
|
||||
这段代码中,最令人疑惑的就是装饰器 `@parse_args` 了。简单来说,TorchScript 算子的符号函数要求标注出每一个输入参数的类型。比如"v"表示 Torch 库里的 `value` 类型,一般用于标注张量,而"i"表示 int 类型,"f"表示 float 类型,"none"表示该参数为空。具体的类型含义可以在 [torch.onnx.symbolic_helper.py](https://github.com/pytorch/pytorch/blob/main/torch/onnx/symbolic_helper.py)中查看。这里输入参数中的 `input, weight, offset, mask, bias` 都是张量,所以用"v"表示。后面的其他参数同理。我们不必纠结于 `@parse_args`的原理,根据实际情况对符号函数的参数标注类型即可。
|
||||
|
||||
有了符号函数后,我们通过如下的方式注册符号函数:
|
||||
|
||||
|
|
|
|||
|
|
@ -5,4 +5,4 @@ mmedit>=1.0.0rc2
|
|||
mmocr>=1.0.0rc4
|
||||
mmpose>=1.0.0rc0
|
||||
mmrotate>=1.0.0rc0
|
||||
mmsegmentation @ git+https://github.com/open-mmlab/mmsegmentation.git@dev-1.x
|
||||
mmsegmentation>=1.0.0
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmaction2/tree/main
|
||||
codebase_dir: ../mmaction2
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
globals:
|
||||
codebase_dir: ../mmclassification
|
||||
repo_url: https://github.com/open-mmlab/mmpretrain/tree/main
|
||||
codebase_dir: ../mmpretrain
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
img_snake: &img_snake ../mmclassification/demo/demo.JPEG
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmdetection/tree/main
|
||||
codebase_dir: ../mmdetection
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmdetection3d/tree/main
|
||||
codebase_dir: ../mmdetection3d
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmediting/tree/main
|
||||
codebase_dir: ../mmediting
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmocr/tree/main
|
||||
codebase_dir: ../mmocr
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmpose/tree/main
|
||||
codebase_dir: ../mmpose
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmrotate/tree/main
|
||||
codebase_dir: ../mmrotate
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
globals:
|
||||
repo_url: https://github.com/open-mmlab/mmsegmentation/tree/main
|
||||
codebase_dir: ../mmsegmentation
|
||||
checkpoint_force_download: False
|
||||
images:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,81 @@
|
|||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import argparse
|
||||
import os
|
||||
import os.path as osp
|
||||
|
||||
import yaml
|
||||
from mmengine import Config
|
||||
|
||||
from mmdeploy.utils import get_backend, get_task_type, load_config
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description='from yaml export markdown table')
|
||||
parser.add_argument('yml_file', help='input yml config path')
|
||||
parser.add_argument('output', help='output markdown file path')
|
||||
parser.add_argument(
|
||||
'--backends',
|
||||
nargs='+',
|
||||
help='backends you want to generate',
|
||||
default=[
|
||||
'onnxruntime', 'tensorrt', 'torchscript', 'pplnn', 'openvino',
|
||||
'ncnn'
|
||||
])
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
assert osp.exists(args.yml_file), f'File not exists: {args.yml_file}'
|
||||
output_dir, _ = osp.split(args.output)
|
||||
if output_dir:
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
header = ['model', 'task'] + args.backends
|
||||
aligner = [':--'] * 2 + [':--:'] * len(args.backends)
|
||||
|
||||
def write_row_f(writer, row):
|
||||
writer.write('|' + '|'.join(row) + '|\n')
|
||||
|
||||
print(f'Processing{args.yml_file}')
|
||||
with open(args.yml_file, 'r') as reader, open(args.output, 'w') as writer:
|
||||
config = yaml.load(reader, Loader=yaml.FullLoader)
|
||||
config = Config(config)
|
||||
write_row_f(writer, header)
|
||||
write_row_f(writer, aligner)
|
||||
repo_url = config.globals.repo_url
|
||||
for i in range(len(config.models)):
|
||||
name = config.models[i].name
|
||||
model_configs = config.models[i].model_configs
|
||||
pipelines = config.models[i].pipelines
|
||||
config_url = osp.join(repo_url, model_configs[0])
|
||||
config_url, _ = osp.split(config_url)
|
||||
support_backends = {b: 'N' for b in args.backends}
|
||||
deploy_config = [
|
||||
pipelines[i].deploy_config for i in range(len(pipelines))
|
||||
]
|
||||
cfg = [
|
||||
load_config(deploy_config[i])
|
||||
for i in range(len(deploy_config))
|
||||
]
|
||||
task = [
|
||||
get_task_type(cfg[i][0]).value
|
||||
for i in range(len(deploy_config))
|
||||
]
|
||||
backend_type = [
|
||||
get_backend(cfg[i][0]).value
|
||||
for i in range(len(deploy_config))
|
||||
]
|
||||
for i in range(len(deploy_config)):
|
||||
support_backends[backend_type[i]] = 'Y'
|
||||
support_backends = [support_backends[i] for i in args.backends]
|
||||
model_name = f'[{name}]({config_url})'
|
||||
row = [model_name, task[i]] + support_backends
|
||||
|
||||
write_row_f(writer, row)
|
||||
print(f'Save to {args.output}')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
Loading…
Reference in New Issue