fix md lint error
parent
19ba8e89e4
commit
fab78c1153
|
|
@ -33,10 +33,10 @@ There are two methods to build the nuget package.
|
|||
|
||||
(*option 1*) Use the command.
|
||||
|
||||
If your environment is well prepared, you can just go to the `csrc\apis\csharp` folder, open a terminal and type the following command, the nupkg will be built in `csrc\apis\csharp\MMDeploy\bin\Release\MMDeployCSharp.1.0.0-rc2.nupkg`.
|
||||
If your environment is well prepared, you can just go to the `csrc\apis\csharp` folder, open a terminal and type the following command, the nupkg will be built in `csrc\apis\csharp\MMDeploy\bin\Release\MMDeployCSharp.1.0.0.nupkg`.
|
||||
|
||||
```shell
|
||||
dotnet build --configuration Release -p:Version=1.0.0-rc2
|
||||
dotnet build --configuration Release -p:Version=1.0.0
|
||||
```
|
||||
|
||||
(*option 2*) Open MMDeploy.sln && Build.
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.Extensions" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
</PropertyGroup>
|
||||
|
||||
<ItemGroup>
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0-rc2" />
|
||||
<PackageReference Include="MMDeployCSharp" Version="1.0.0" />
|
||||
<PackageReference Include="OpenCvSharp4" Version="4.5.5.20211231" />
|
||||
<PackageReference Include="OpenCvSharp4.runtime.win" Version="4.5.5.20211231" />
|
||||
</ItemGroup>
|
||||
|
|
|
|||
|
|
@ -51,7 +51,7 @@ docker run --gpus all -it mmdeploy:master-gpu
|
|||
|
||||
As described [here](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754), update the GPU driver to the latest one for your GPU.
|
||||
|
||||
2. docker: Error response from daemon: could not select device driver "" with capabilities: \[gpu\].
|
||||
2. docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
|
||||
|
||||
```
|
||||
# Add the package repositories
|
||||
|
|
|
|||
|
|
@ -83,7 +83,7 @@ python tools/onnx2pplnn.py \
|
|||
- `onnx_path`: The path of the `ONNX` model to convert.
|
||||
- `output_path`: The converted `PPLNN` algorithm path in json format.
|
||||
- `device`: The device of the model during conversion.
|
||||
- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "\[\]" or "()" and the shapes of tensors should be separated by ",".
|
||||
- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "[]" or "()" and the shapes of tensors should be separated by ",".
|
||||
- `--log-level`: To set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`.
|
||||
|
||||
## onnx2tensorrt
|
||||
|
|
|
|||
|
|
@ -308,7 +308,7 @@ Perform RoIAlign on output feature, used in bbox_head of most two-stage detector
|
|||
|
||||
#### Description
|
||||
|
||||
ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape\[-1\] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
|
||||
ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape[-1] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
|
||||
|
||||
The `output` is calculated via the following equation:
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
Fp16 mode requires a device with full-rate fp16 support.
|
||||
|
||||
- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d\[i\] \<= dimensions.d\[i\]"
|
||||
- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d[i] \<= dimensions.d[i]"
|
||||
|
||||
When building an `ICudaEngine` from an `INetworkDefinition` that has dynamically resizable inputs, users need to specify at least one optimization profile. Which can be set in deploy config:
|
||||
|
||||
|
|
@ -25,7 +25,7 @@
|
|||
|
||||
The input tensor shape should be limited between `min_shape` and `max_shape`.
|
||||
|
||||
- "error: \[TensorRT\] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
|
||||
- "error: [TensorRT] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
|
||||
|
||||
TRT 7.2.1 switches to use cuBLASLt (previously it was cuBLAS). cuBLASLt is the defaulted choice for SM version >= 7.0. You may need CUDA-10.2 Patch 1 (Released Aug 26, 2020) to resolve some cuBLASLt issues. Another option is to use the new TacticSource API and disable cuBLASLt tactics if you dont want to upgrade.
|
||||
|
||||
|
|
|
|||
|
|
@ -51,7 +51,7 @@ docker run --gpus all -it mmdeploy:master-gpu
|
|||
|
||||
如 [这里](https://forums.developer.nvidia.com/t/cuda-error-the-provided-ptx-was-compiled-with-an-unsupported-toolchain/185754)所说,更新 GPU 的驱动到您的GPU能使用的最新版本。
|
||||
|
||||
2. docker: Error response from daemon: could not select device driver "" with capabilities: \[gpu\].
|
||||
2. docker: Error response from daemon: could not select device driver "" with capabilities: [gpu].
|
||||
|
||||
```
|
||||
# Add the package repositories
|
||||
|
|
|
|||
|
|
@ -83,7 +83,7 @@ python tools/onnx2pplnn.py \
|
|||
- `onnx_path`: The path of the `ONNX` model to convert.
|
||||
- `output_path`: The converted `PPLNN` algorithm path in json format.
|
||||
- `device`: The device of the model during conversion.
|
||||
- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "\[\]" or "()" and the shapes of tensors should be separated by ",".
|
||||
- `opt-shapes`: Optimal shapes for PPLNN optimization. The shape of each tensor should be wrap with "[]" or "()" and the shapes of tensors should be separated by ",".
|
||||
- `--log-level`: To set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`.
|
||||
|
||||
## onnx2tensorrt
|
||||
|
|
|
|||
|
|
@ -302,7 +302,7 @@ Perform RoIAlign on output feature, used in bbox_head of most two-stage detector
|
|||
|
||||
#### Description
|
||||
|
||||
ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape\[-1\] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
|
||||
ScatterND takes three inputs `data` tensor of rank r >= 1, `indices` tensor of rank q >= 1, and `updates` tensor of rank q + r - indices.shape[-1] - 1. The output of the operation is produced by creating a copy of the input `data`, and then updating its value to values specified by updates at specific index positions specified by `indices`. Its output shape is the same as the shape of `data`. Note that `indices` should not have duplicate entries. That is, two or more updates for the same index-location is not supported.
|
||||
|
||||
The `output` is calculated via the following equation:
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
Fp16 mode requires a device with full-rate fp16 support.
|
||||
|
||||
- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d\[i\] \<= dimensions.d\[i\]"
|
||||
- "error: parameter check failed at: engine.cpp::setBindingDimensions::1046, condition: profileMinDims.d[i] \<= dimensions.d[i]"
|
||||
|
||||
When building an `ICudaEngine` from an `INetworkDefinition` that has dynamically resizable inputs, users need to specify at least one optimization profile. Which can be set in deploy config:
|
||||
|
||||
|
|
@ -25,7 +25,7 @@
|
|||
|
||||
The input tensor shape should be limited between `min_shape` and `max_shape`.
|
||||
|
||||
- "error: \[TensorRT\] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
|
||||
- "error: [TensorRT] INTERNAL ERROR: Assertion failed: cublasStatus == CUBLAS_STATUS_SUCCESS"
|
||||
|
||||
TRT 7.2.1 switches to use cuBLASLt (previously it was cuBLAS). cuBLASLt is the defaulted choice for SM version >= 7.0. You may need CUDA-10.2 Patch 1 (Released Aug 26, 2020) to resolve some cuBLASLt issues. Another option is to use the new TacticSource API and disable cuBLASLt tactics if you dont want to upgrade.
|
||||
|
||||
|
|
|
|||
|
|
@ -173,7 +173,7 @@ with torch.no_grad():
|
|||
|
||||
|
||||
|
||||
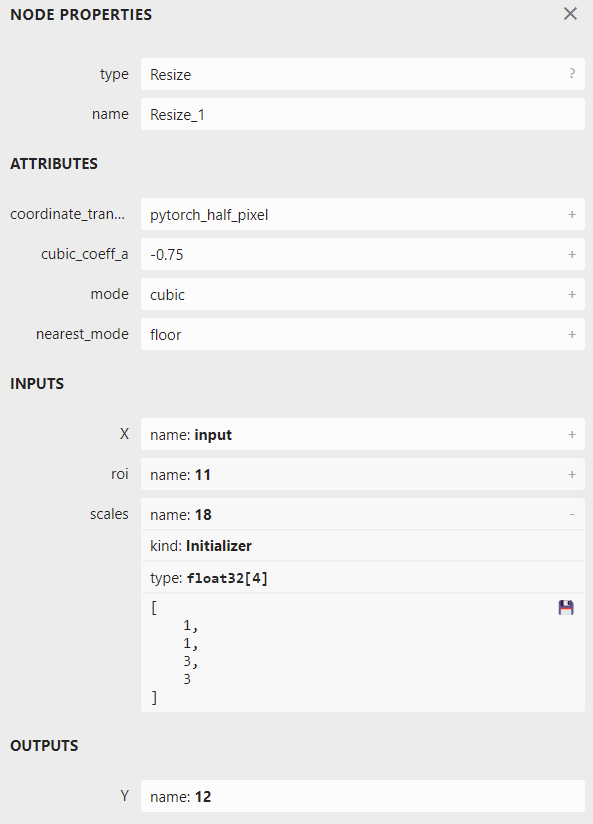
其中,展开 scales,可以看到 scales 是一个长度为 4 的一维张量,其内容为 \[1, 1, 3, 3\], 表示 Resize 操作每一个维度的缩放系数;其类型为 Initializer,表示这个值是根据常量直接初始化出来的。如果我们能够自己生成一个 ONNX 的 Resize 算子,让 scales 成为一个可变量而不是常量,就像它上面的 X 一样,那这个超分辨率模型就能动态缩放了。
|
||||
其中,展开 scales,可以看到 scales 是一个长度为 4 的一维张量,其内容为 [1, 1, 3, 3], 表示 Resize 操作每一个维度的缩放系数;其类型为 Initializer,表示这个值是根据常量直接初始化出来的。如果我们能够自己生成一个 ONNX 的 Resize 算子,让 scales 成为一个可变量而不是常量,就像它上面的 X 一样,那这个超分辨率模型就能动态缩放了。
|
||||
|
||||
现有实现插值的 PyTorch 算子有一套规定好的映射到 ONNX Resize 算子的方法,这些映射出的 Resize 算子的 scales 只能是常量,无法满足我们的需求。我们得自己定义一个实现插值的 PyTorch 算子,然后让它映射到一个我们期望的 ONNX Resize 算子上。
|
||||
|
||||
|
|
@ -294,9 +294,9 @@ class NewInterpolate(torch.autograd.Function):
|
|||
align_corners=False)
|
||||
```
|
||||
|
||||
在具体介绍这个算子的实现前,让我们先理清一下思路。我们希望新的插值算子有两个输入,一个是被用于操作的图像,一个是图像的放缩比例。前面讲到,为了对接 ONNX 中 Resize 算子的 scales 参数,这个放缩比例是一个 \[1, 1, x, x\] 的张量,其中 x 为放大倍数。在之前放大3倍的模型中,这个参数被固定成了\[1, 1, 3, 3\]。因此,在插值算子中,我们希望模型的第二个输入是一个 \[1, 1, w, h\] 的张量,其中 w 和 h 分别是图片宽和高的放大倍数。
|
||||
在具体介绍这个算子的实现前,让我们先理清一下思路。我们希望新的插值算子有两个输入,一个是被用于操作的图像,一个是图像的放缩比例。前面讲到,为了对接 ONNX 中 Resize 算子的 scales 参数,这个放缩比例是一个 [1, 1, x, x] 的张量,其中 x 为放大倍数。在之前放大3倍的模型中,这个参数被固定成了[1, 1, 3, 3]。因此,在插值算子中,我们希望模型的第二个输入是一个 [1, 1, w, h] 的张量,其中 w 和 h 分别是图片宽和高的放大倍数。
|
||||
|
||||
搞清楚了插值算子的输入,再看一看算子的具体实现。算子的推理行为由算子的 forward 方法决定。该方法的第一个参数必须为 ctx,后面的参数为算子的自定义输入,我们设置两个输入,分别为被操作的图像和放缩比例。为保证推理正确,需要把 \[1, 1, w, h\] 格式的输入对接到原来的 interpolate 函数上。我们的做法是截取输入张量的后两个元素,把这两个元素以 list 的格式传入 interpolate 的 scale_factor 参数。
|
||||
搞清楚了插值算子的输入,再看一看算子的具体实现。算子的推理行为由算子的 forward 方法决定。该方法的第一个参数必须为 ctx,后面的参数为算子的自定义输入,我们设置两个输入,分别为被操作的图像和放缩比例。为保证推理正确,需要把 [1, 1, w, h] 格式的输入对接到原来的 interpolate 函数上。我们的做法是截取输入张量的后两个元素,把这两个元素以 list 的格式传入 interpolate 的 scale_factor 参数。
|
||||
|
||||
接下来,我们要决定新算子映射到 ONNX 算子的方法。映射到 ONNX 的方法由一个算子的 symbolic 方法决定。symbolic 方法第一个参数必须是g,之后的参数是算子的自定义输入,和 forward 函数一样。ONNX 算子的具体定义由 g.op 实现。g.op 的每个参数都可以映射到 ONNX 中的算子属性:
|
||||
|
||||
|
|
|
|||
|
|
@ -228,7 +228,7 @@ class Model(torch.nn.Module):
|
|||
return x
|
||||
```
|
||||
|
||||
这里,我们仅在模型导出时把输出张量的数值限制在\[0, 1\]之间。使用 `is_in_onnx_export` 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,`is_in_onnx_export` 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
|
||||
这里,我们仅在模型导出时把输出张量的数值限制在[0, 1]之间。使用 `is_in_onnx_export` 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,`is_in_onnx_export` 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
|
||||
|
||||
#### 利用中断张量跟踪的操作
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue