* make -install -> make install (#621) change `make -install` to `make install` https://github.com/open-mmlab/mmdeploy/issues/618 * [Fix] fix csharp api detector release result (#620) * fix csharp api detector release result * fix wrong count arg of xxx_release_result in c# api * [Enhancement] Support two-stage rotated detector TensorRT. (#530) * upload * add fake_multiclass_nms_rotated * delete unused code * align with pytorch * Update delta_midpointoffset_rbbox_coder.py * add trt rotated roi align * add index feature in nms * not good * fix index * add ut * add benchmark * move to csrc/mmdeploy * update unit test Co-authored-by: zytx121 <592267829@qq.com> * Reduce mmcls version dependency (#635) * fix shufflenetv2 with trt (#645) * fix shufflenetv2 and pspnet * fix ci * remove print * ' -> " (#654) If there is a variable in the string, single quotes will ignored it, while double quotes will bring the variable into the string after parsing * ' -> " (#655) same with https://github.com/open-mmlab/mmdeploy/pull/654 * Support deployment of Segmenter (#587) * support segmentor with ncnn * update regression yml * replace chunk with split to support ts * update regression yml * update docs * fix segmenter ncnn inference failure brought by #477 * add test * fix test for ncnn and trt * fix lint * export nn.linear to Gemm op in onnx for ncnn * fix ci * simplify `Expand` (#617) * Fix typo (#625) * Add make install in en docs * Add make install in zh docs * Fix typo * Merge and add windows build Co-authored-by: tripleMu <865626@163.com> * [Enhancement] Fix ncnn unittest (#626) * optmize-csp-darknet * replace floordiv to torch.div * update csp_darknet default implement * fix test * [Enhancement] TensorRT Anchor generator plugin (#646) * custom trt anchor generator * add ut * add docstring, update doc * Add partition doc and sample code (#599) * update torch2onnx tool to support onnx partition * add model partition of yolov3 * add cn doc * update torch2onnx tool to support onnx partition * add model partition of yolov3 * add cn doc * add to index.rst * resolve comment * resolve comments * fix lint * change caption level in docs * update docs (#624) * Add java apis and demos (#563) * add java classifier detector * add segmentor * fix lint * add ImageRestorer java apis and demo * remove useless count parameter for Segmentor and Restorer, add PoseDetector * add RotatedDetection java api and demo * add Ocr java demo and apis * remove mmrotate ncnn java api and demo * fix lint * sync java api folder after rebase to master * fix include * remove record * fix java apis dir path in cmake * add java demo readme * fix lint mdformat * add test javaapi ci * fix lint * fix flake8 * fix test javaapi ci * refactor readme.md * fix install opencv for ci * fix install opencv : add permission * add all codebases and mmcv install * add torch * install mmdeploy * fix image path * fix picture path * fix import ncnn * fix import ncnn * add submodule of pybind * fix pybind submodule * change download to git clone for submodule * fix ncnn dir * fix README error * simplify the github ci * fix ci * fix yapf * add JNI as required * fix Capitalize * fix Capitalize * fix copyright * ignore .class changed * add OpenJDK installation docs * install target of javaapi * simplify ci * add jar * fix ci * fix ci * fix test java command * debugging what failed * debugging what failed * debugging what failed * add java version info * install openjdk * add java env var * fix export * fix export * fix export * fix export * fix picture path * fix picture path * fix file name * fix file name * fix README * remove java_api strategy * fix python version * format task name * move args position * extract common utils code * show image class result * add detector result * segmentation result format * add ImageRestorer result * add PoseDetection java result format * fix ci * stage ocr * add visualize * move utils * fix lint * fix ocr bugs * fix ci demo * fix java classpath for ci * fix popd * fix ocr demo text garbled * fix ci * fix ci * fix ci * fix path of utils ci * update the circleci config file by adding workflows both for linux, windows and linux-gpu (#368) * update circleci by adding more workflows * fix test workflow failure on windows platform * fix docker exec command for SDK unittests * Fixed tensorrt plugin not found in Windows (#672) * update introduction.png (#674) * [Enhancement] Add fuse select assign pass (#589) * Add fuse select assign pass * move code to csrc * add config flag * remove bool cast * fix export sdk info of input shape (#667) * Update get_started.md (#675) Fix backend model assignment * Update get_started.md (#676) Fix backend model assignment * [Fix] fix clang build (#677) * fix clang build * fix ndk build * fix ndk build * switch to `std::filesystem` for clang-7 and later * Deploy the Swin Transformer on TensorRT. (#652) * resolve conflicts * update ut and docs * fix ut * refine docstring * add comments and refine UT * resolve comments * resolve comments * update doc * add roll export * check backend * update regression test * bump version to 0.6.0 (#680) * bump vertion to 0.6.0 * update version * pass img_metas while exporting to onnx (#681) * pass img_metas while exporting to onnx * remove try-catch in tools for beter debugging * use get * fix typo * [Fix] fix ssd ncnn ut (#692) * fix ssd ncnn ut * fix yapf * fix passing img_metas to pytorch2onnx for mmedit (#700) * fix passing img_metas for mmdet3d (#707) * [Fix] Fix android build (#698) * fix android build * fix cmake * fix url link * fix wrong exit code in pipeline_manager (#715) * fix exit * change to general exit errorcode=1 * fix passing wrong backend type (#719) * Rename onnx2ncnn to mmdeploy_onnx2ncnn (#694) * improvement(tools/onnx2ncnn.py): rename to mmdeploy_onnx2ncnn * format(tools/deploy.py): clean code * fix(init_plugins.py): improve if condition * fix(CI): update target * fix(test_onnx2ncnn.py): update desc * Update init_plugins.py * [Fix] Fix mmdet ort static shape bug (#687) * fix shape * add device * fix yapf * fix rewriter for transforms * reverse image shape * fix ut of distance2bbox * fix rewriter name * fix c4 for torchscript (#724) * [Enhancement] Standardize C API (#634) * unify C API naming * fix demo and move apis/c/* -> apis/c/mmdeploy/* * fix lint * fix C# project * fix Java API * [Enhancement] Support Slide Vertex TRT (#650) * reorgnize mmrotate * fix * add hbb2obb * add ut * fix rotated nms * update docs * update benchmark * update test * remove ort regression test, remove comment * Fix get-started rendering issues in readthedocs (#740) * fix mermaid markdown rendering issue in readthedocs * fix error in C++ example * fix error in c++ example in zh_cn get_started doc * [Fix] set default topk for dump info (#702) * set default topk for dump info * remove redundant docstrings * add ci densenet * fix classification warnings * fix mmcls version * fix logger.warnings * add version control (#754) * fix satrn for ORT (#753) * fix satrn for ORT * move rewrite into pytorch * Add inference latency test tool (#665) * add profile tool * remove print envs in profile tool * set cudnn_benchmark to True * add doc * update tests * fix typo * support test with images from a directory * update doc * resolve comments * [Enhancement] Add CSE ONNX pass (#647) * Add fuse select assign pass * move code to csrc * add config flag * Add fuse select assign pass * Add CSE for ONNX * remove useless code * Test robot Just test robot * Update README.md Revert * [Fix] fix yolox point_generator (#758) * fix yolox point_generator * add a UT * resolve comments * fix comment lines * limit markdown version (#773) * [Enhancement] Better index put ONNX export. (#704) * Add rewriter for tensor setitem * add version check * Upgrade Dockerfile to use TensorRT==8.2.4.2 (#706) * Upgrade TensorRT to 8.2.4.2 * upgrade pytorch&mmcv in CPU Dockerfile * Delete redundant port example in Docker * change 160x160-608x608 to 64x64-608x608 for yolov3 * [Fix] reduce log verbosity & improve error reporting (#755) * reduce log verbosity & improve error reporting * improve error reporting * [Enhancement] Support latest ppl.nn & ppl.cv (#564) * support latest ppl.nn * fix pplnn for model convertor * fix lint * update memory policy * import algo from buffer * update ppl.cv * use `ppl.cv==0.7.0` * document supported ppl.nn version * skip pplnn dependency when building shared libs * [Fix][P0] Fix for torch1.12 (#751) * fix for torch1.12 * add comment * fix check env (#785) * [Fix] fix cascade mask rcnn (#787) * fix cascade mask rcnn * fix lint * add regression * [Feature] Support RoITransRoIHead (#713) * [Feature] Support RoITransRoIHead * Add docs * Add mmrotate models regression test * Add a draft for test code * change the argument name * fix test code * fix minor change for not class agnostic case * fix sample for test code * fix sample for test code * Add mmrotate in requirements * Revert "Add mmrotate in requirements" This reverts commit 043490075e6dbe4a8fb98e94b2b583b91fc5038d. * [Fix] fix triu (#792) * fix triu * triu -> triu_default * [Enhancement] Install Optimizer by setuptools (#690) * Add fuse select assign pass * move code to csrc * add config flag * Add fuse select assign pass * Add CSE for ONNX * remove useless code * Install optimizer by setup tools * fix comment * [Feature] support MMRotate model with le135 (#788) * support MMRotate model with le135 * cse before fuse select assign * remove unused import * [Fix] Support macOS build (#762) * fix macOS build * fix missing * add option to build & install examples (#822) * [Fix] Fix setup on non-linux-x64 (#811) * fix setup * replace long to int64_t * [Feature] support build single sdk library (#806) * build single lib for c api * update csharp doc & project * update test build * fix test build * fix * update document for building android sdk (#817) Co-authored-by: dwSun <dwsunny@icloud.com> * [Enhancement] support kwargs in SDK python bindings (#794) * support-kwargs * make '__call__' as single image inference and add 'batch' API to deal with batch images inference * fix linting error and typo * fix lint * improvement(sdk): add sdk code coverage (#808) * feat(doc): add CI * CI(sdk): add sdk coverage * style(test): code format * fix(CI): update coverage.info path * improvement(CI): use internal image * improvement(CI): push coverage info once * [Feature] Add C++ API for SDK (#831) * add C++ API * unify result type & add examples * minor fix * install cxx API headers * fix Mat, add more examples * fix monolithic build & fix lint * install examples correctly * fix lint * feat(tools/deploy.py): support snpe (#789) * fix(tools/deploy.py): support snpe * improvement(backend/snpe): review advices * docs(backend/snpe): update build * docs(backend/snpe): server support specify port * docs(backend/snpe): update path * fix(backend/snpe): time counter missing argument * docs(backend/snpe): add missing argument * docs(backend/snpe): update download and using * improvement(snpe_net.cpp): load model with modeldata * Support setup on environment with no PyTorch (#843) * support test with multi batch (#829) * support test with multi batch * resolve comment * import algorithm from buffer (#793) * [Enhancement] build sdk python api in standard-alone manner (#810) * build sdk python api in standard-alone manner * enable MMDEPLOY_BUILD_SDK_MONOLITHIC and MMDEPLOY_BUILD_EXAMPLES in prebuild config * link mmdeploy to python target when monolithic option is on * checkin README to describe precompiled package build procedure * use packaging.version.parse(python_version) instead of list(python_version) * fix according to review results * rebase master * rollback cmake.in and apis/python/CMakeLists.txt * reorganize files in install/example * let cmake detect visual studio instead of specifying 2019 * rename whl name of precompiled package * fix according to review results * Fix SDK backend (#844) * fix mmpose python api (#852) * add prebuild package usage docs on windows (#816) * add prebuild package usage docs on windows * fix lint * update * try fix lint * add en docs * update * update * udpate faq * fix typo (#862) * [Enhancement] Improve get_started documents and bump version to 0.7.0 (#813) * simplify commands in get_started * add installation commands for Windows * fix typo * limit markdown and sphinx_markdown_tables version * adopt html <details open> tag * bump mmdeploy version * bump mmdeploy version * update get_started * update get_started * use python3.8 instead of python3.7 * remove duplicate section * resolve issue #856 * update according to review results * add reference to prebuilt_package_windows.md * fix error when build sdk demos * improvement(dockerfile): use make -j$(nporc) when build ncnn (#840) * use make -j$(nporc) when build ncnn * improve cpu dockerfile * fix error when set device cpu && fix docs error (#866) * [Feature]support pointpillar nus version (#391) * support pointpillar nus version * support pointpillar nus version * add regression test config for mmdet3d * fix exit with no error code * fix cfg * fix worksize * fix worksize * fix cfg * support nus pp * fix yaml * fix yaml * fix yaml * add ut * fix ut Co-authored-by: RunningLeon <mnsheng@yeah.net> * Fix doc error of building C examples (#879) * fix doc error of building C demo examples Path error in cmake compilation of C demo examples * fix en doc error of building C demo examples Path error in cmake compilation of C demo examples * fix adaptive_avg_pool exporting to onnx (#857) * fix adaptive_avg_pool exporting to onnx * remove debug codes * fix ci * resolve comment * docs(project): sync en and zh docs (#842) * docs(en): update file structure * docs(zh_cn): update * docs(structure): update * docs(snpe): update * docs(README): update * fix(CI): update * fix(CI): index.rst error * fix(docs): update * fix(docs): remove mermaid * fix(docs): remove useless * fix(docs): update link * docs(en): update * docs(en): update * docs(zh_cn): remove \[ * docs(zh_cn): format * docs(en): remove blank * fix(CI): doc link error * docs(project): remove "./" prefix * docs(zh_cn): fix mdformat * docs(en): update title * fix(CI): update docs * fix mmdeploy_pplnn_net build error when target device is cpu (#896) * docs(zh_cn): add architect (#882) * docs(zh_cn): add architect docs(en): add architect fix(docs): readthedocs index * docs(en): update architect.md * docs(README.md): update * docs(architecture): fix review advices * add device backend check (#886) * add device backend check * safe check * only activated for tensorrt and openvino * resolve comments * support multi-batch test in profile tool (#868) * test batch profile with resnet pspnet yolov3 srcnn * update doc * update docs * fix ut * fix mmdet * support batch mmorc and mmrotate * fix mmcls export to sdk * resolve comments * rename to fix #819 * fix conflicts with master * [Fix] fix device error in dump-info (#912) * fix device error in dump-info * fix UT * improvement(cmake): simplify build option and doc (#832) * improvement(cmake): simplify build option improvement(cmake): convert target_backends with directory * fix(dockerfile): build error * fix(CI): circle CI * fix(docs): snpe and cmake option * fix(docs): revert update cmake * fix(docs): revert * update(docs): remove useless * set test_mode for mmdet (#920) * fix * update * [Doc] How to write a customized TensorRT plugin (#290) * first edition * fix lint * add 06, 07 * resolve comments * update index.rst * update title * update img * [Feature] add swin for cls (#911) * add swin for cls * add ut and doc * reduce trt batch size * add regression test * resolve comments * remove useless rewriting logic * docs(mmdet3d): give detail model path (#940) * add cflags explicitly in ci (#945) * improvement(installation): add script install mmdeploy (#919) * feat(tools): add build ubuntu x64 ncnn * ci(tools): add ncnn auto install * fix(ci): auto install ncnn * fix(tools): no interactive * docs(build): add script build * CI(ncnn): script install ncnn * docs(zh_cn): fix error os * fix * CI(tools/script): test ort install passed * update * CI(tools): support pplnn * CI(build): add pplnn * docs(tools): update * fix * CI(tools): script install torchscript * docs(build): add torchscript * fix(tools): clean code and doc * update * fix(CI): requirements install failed * debug CI * update * update * update * feat(tools/script): support user specify make jobs * fix(tools/script): fix build pplnn with cuda * fix(tools/script): torchscript add tips and simplify install mmcv * fix(tools/script): check nvcc version first * fix(tools/scripts): pplnn checkout * fix(CI): add simple check install succcess * fix * debug CI * fix * fix(CI): pplnn install mis wheel * fix(CI): build error * fix(CI): remove misleading message * Support risc-v platform (#910) * add ppl.nn riscv engine * update ppl.nn riscv engine * udpate riscv service (ncnn backend) * update _build_wrapper for ncnn * fix build * fix lint * update default uri * update file structure & add cn doc * remove copy input data * update docs * remove ncnn server * fix docs * update zh doc * update toolchain * remove unused * update doc * update doc * update doc * rename cross build dirname * add riscv.md to build_from_source.md * update cls model * test ci * test ci * test ci * test ci * test ci * update ci * update ci * [Feature] TorchScript SDK backend (#890) * WIP SDK torchscript support * support detection task * make torchvision optional * force link torchvision if enabled * support torch-1.12 * fix export & sync cuda stream * hide internal classes * handle error * set `MMDEPLOY_USE_CUDA` when CUDA is enabled * [Bug] fix setitem with scalar or single element tensor (#941) * fix setitem * add copy symbolic * docs(convert_model): update description (#956) * [Enhancement] Support DETR (#924) * add detr support * fix softmax * add reg test, update document * fix ut failed (#951) * [Enhancement] Rewriter support pre-import function (#899) * support preimport * update rewriter * fix batched nms ort * add_multi_label_postprocess (#950) * 'add_multi_label_postprocess' * fix pre-commit * delete partial_sort * delete idx * delete num_classes and num_classes_ * Fix right brackets and spelling errors in lines 19 and 20 Co-authored-by: gaoying <gaoying@xiaobaishiji.com> * fix ci (#964) * [Fix] Close onnx optimizer for ncnn (#961) * close onnx optimizer for ncnn * fix docformatter * fix lint * remove Release dir in mmdeploy package (#960) * CI(tools/scripts): add submodule init and update (#977) * fix mmroate (#976) * Fix mmseg pointrend (#903) * support mmseg:pointrend * update docs * update docs for torchscript * resolve comments * Add CI to test full pipeline (#966) * add mmcls full pipeline test ci * update * update * add mmcv * install torch * install mmdeploy * change clone with https * install mmcls * update * change mmcls version * add mmcv version * update mmcls version * test sdk * tast with imagnet * sed pipeline * print env * update * move to backend-ort ci * install mim * fix regression test (#958) * fix reg * set sdk wrapper device id * resolve comment * fix(CI): typo (#983) * fix(CI): ort test all pipeline (#985) * add missing sqrt for PAAHead's score calculation (#984) Co-authored-by: xianghongyi1 <xianghongyi1@sensetime.com> * Fix: skip tests for uninstalled codebases (#987) * skip tests if codebase not installed * skip ort run test * fix mmseg * [Feature] Ascend backend (#747) * add acl backend * support dynamic batch size and dynamic image size * add preliminary ascend backend * support dtypes other than float * support dynamic_dims in SDK * fix dynamic batch size * better error handling * remove debug info * [WIP] dynamic shape support * fix static shape * fix dynamic batch size * add retinanet support * fix dynamic image size * fix dynamic image size * fix dynamic dims * fix dynamic dims * simplify config files * fix yolox support * fix negative index * support faster rcnn * add seg config * update benchmark * fix onnx2ascend dynamic shape * update docstring and benchmark * add unit test, update documents * fix wrapper * fix ut * fix for vit * error handling * context handling & multi-device support * build with stub libraries * add ci * fix lint * fix lint * update doc ref * fix typo * down with `target_link_directories` * setup python * makedir * fix ci * fix ci * remove verbose logs * fix UBs * export Error * fix lint * update checkenv Co-authored-by: grimoire <yaoqian@sensetime.com> * fix(backend): disable cublaslt for cu102 (#947) * fix(backend): disable cublaslt for cu102 * fix * fix(backend): update * fix(tensorrt/util.py): add find cuda version * fix * fix(CI): first use cmd to get cuda version * docs(tensorrt/utils.py): update docstring * TensorRT dot product attention ops (#949) * add detr support * fix softmax * add placeholder * add implement * add docs and ut * update testcase * update docs * update docs * fix mmdet showresult (#999) * fix mmdet showresult * Consider compatibility * mmdet showresult add *args * Revert "mmdet showresult add *args" This reverts commit 82265a31cf910618a1dff4aab65e9dc793a623c4. Co-authored-by: whhuang <whhuang@hitotek.com> * support coreml (#760) * sdk inference * fix typo * fix typo * add convert things * fix missling name * add cls support * add more pytorch rewriter * add det support * support det wip * make Model export model_path * fix nms * add output back * add docstring * fix lint * add coreml build action * add zh docs * add coreml backend check * update ci * update * update * update * update * update * fix lint * update configs * add return value when error occured * update docs * update docs * update docs * fix lint * udpate docs * udpate docs * update Co-authored-by: grimoire <streetyao@live.com> * fix mmdet ut (#1001) * [Feature] Add option to fuse transform. (#741) * add collect_impl.cpp to cuda device * add dummy compute node wich device elena * add compiler & dynamic library loader * add code to compile with gen code(elena) * move folder * fix lint * add tracer module * add license * update type id * add fuse kernel registry * remove compilier & dynamic_library * update fuse kernel interface * Add elena-mmdeploy project in 3rd-party * Fix README.md * fix cmake file * Support cuda device and clang format all file * Add cudaStreamSynchronize for cudafree * fix cudaStreamSynchronize * rename to __tracer__ * remove unused code * update kernel * update extract elena script * update gitignore * fix ci * Change the crop_size to crop_h and crop_w in arglist * update Tracer * remove cond * avoid allocate memory * add build.sh for elena * remove code * update test * Support bilinear resize with float input * Rename elena-mmdeploy to delete * Introduce public submodule * use get_ref * update elena * update tools * update tools * update fuse transform docs * add fuse transform doc link to get_started * fix shape in crop * remove fuse_transform_ == true check * remove fuse_transform_ member * remove elena_int.h * doesn't dump transform_static.json * update tracer * update CVFusion to remove compile warning * remove mmcv version > 1.5.1 dep * fix tests * update docs * add elena use option * remove submodule of CVFusion * update doc * use auto * use throw_exception(eEntryNotFound); * update Co-authored-by: cx <cx@ubuntu20.04> Co-authored-by: miraclezqc <969226879@qq.com> * Add RKNN support. (#865) * save codes * support resnet and yolov3 * support yolox * fix lint * add mmseg support and a doc * add UT * update supported model list * fix ci * refine docstring * resolve comments * remote output_tensor_type * resolve comments * update readme * [Fix] Add isolated option for TorchScript SDK backend (#1002) * add option for TorchScript SDK backend * add doc * format * bump version to v0.8.0 (#1009) * fix(CI): update link checker (#1008) * New issue template (#1007) * update bug report * update issue template * update bug-report * fix mmdeploy builder on windows (#1018) * fix mmdeploy builder on windows * add pyyaml * fix lint * BUG P0 (#1044) * update api in doc (#1021) * fix two stage batch dynamic (#1046) * docs(scripts): update auto install desc (#1036) * Fix `RoIAlignFunction` error for CoreML backend (#1029) * Fixed typo for install commands for TensorRT runtime (#1025) * Fixed typo for install commands for TensorRT runtime * Apply typo-fix on 'cn' documentation Co-authored-by: Tümer Tosik <tumer_t@hotmail.de> * merge master@a1a19f0 documents to dev-1.x * missed ubuntu_utils.py * change benchmark reference in readme_zh-CN Co-authored-by: Ryan_Huang <44900829+DrRyanHuang@users.noreply.github.com> Co-authored-by: Chen Xin <xinchen.tju@gmail.com> Co-authored-by: q.yao <yaoqian@sensetime.com> Co-authored-by: zytx121 <592267829@qq.com> Co-authored-by: RunningLeon <mnsheng@yeah.net> Co-authored-by: Li Zhang <lzhang329@gmail.com> Co-authored-by: tripleMu <gpu@163.com> Co-authored-by: tripleMu <865626@163.com> Co-authored-by: hanrui1sensetime <83800577+hanrui1sensetime@users.noreply.github.com> Co-authored-by: Bryan Glen Suello <11388006+bgsuello@users.noreply.github.com> Co-authored-by: zambranohally <63218980+zambranohally@users.noreply.github.com> Co-authored-by: AllentDan <41138331+AllentDan@users.noreply.github.com> Co-authored-by: tpoisonooo <khj.application@aliyun.com> Co-authored-by: Hakjin Lee <nijkah@gmail.com> Co-authored-by: 孙德伟 <5899962+dwSun@users.noreply.github.com> Co-authored-by: dwSun <dwsunny@icloud.com> Co-authored-by: Chen Xin <irexyc@gmail.com> Co-authored-by: OldDreamInWind <108687632+OldDreamInWind@users.noreply.github.com> Co-authored-by: VVsssssk <88368822+VVsssssk@users.noreply.github.com> Co-authored-by: 梦阳 <49838178+liu-mengyang@users.noreply.github.com> Co-authored-by: gy77 <64619863+gy-7@users.noreply.github.com> Co-authored-by: gaoying <gaoying@xiaobaishiji.com> Co-authored-by: Hongyi Xiang <Groexhy@users.noreply.github.com> Co-authored-by: xianghongyi1 <xianghongyi1@sensetime.com> Co-authored-by: munhou <51435578+munhou@users.noreply.github.com> Co-authored-by: whhuang <whhuang@hitotek.com> Co-authored-by: grimoire <streetyao@live.com> Co-authored-by: cx <cx@ubuntu20.04> Co-authored-by: miraclezqc <969226879@qq.com> Co-authored-by: Jelle Maas <typiqally@gmail.com> Co-authored-by: ichitaka <tuemerffm@hotmail.com> Co-authored-by: Tümer Tosik <tumer_t@hotmail.de>
19 KiB
第二章:解决模型部署中的难题
在第一章中,我们部署了一个简单的超分辨率模型,一切都十分顺利。但是,上一个模型还有一些缺陷——图片的放大倍数固定是 4,我们无法让图片放大任意的倍数。现在,我们来尝试部署一个支持动态放大倍数的模型,体验一下在模型部署中可能会碰到的困难。
模型部署中常见的难题
在之前的学习中,我们在模型部署上顺风顺水,没有碰到任何问题。这是因为 SRCNN 模型只包含几个简单的算子,而这些卷积、插值算子已经在各个中间表示和推理引擎上得到了完美支持。如果模型的操作稍微复杂一点,我们可能就要为兼容模型而付出大量的功夫了。实际上,模型部署时一般会碰到以下几类困难:
- 模型的动态化。出于性能的考虑,各推理框架都默认模型的输入形状、输出形状、结构是静态的。而为了让模型的泛用性更强,部署时需要在尽可能不影响原有逻辑的前提下,让模型的输入输出或是结构动态化。
- 新算子的实现。深度学习技术日新月异,提出新算子的速度往往快于 ONNX 维护者支持的速度。为了部署最新的模型,部署工程师往往需要自己在 ONNX 和推理引擎中支持新算子。
- 中间表示与推理引擎的兼容问题。由于各推理引擎的实现不同,对 ONNX 难以形成统一的支持。为了确保模型在不同的推理引擎中有同样的运行效果,部署工程师往往得为某个推理引擎定制模型代码,这为模型部署引入了许多工作量。
我们会在后续教程详细讲述解决这些问题的方法。如果对前文中 ONNX、推理引擎、中间表示、算子等名词感觉陌生,不用担心,可以阅读第一章,了解有关概念。
现在,让我们对原来的 SRCNN 模型做一些小的修改,体验一下模型动态化对模型部署造成的困难,并学习解决该问题的一种方法。
问题:实现动态放大的超分辨率模型
在原来的 SRCNN 中,图片的放大比例是写死在模型里的:
class SuperResolutionNet(nn.Module):
def __init__(self, upscale_factor):
super().__init__()
self.upscale_factor = upscale_factor
self.img_upsampler = nn.Upsample(
scale_factor=self.upscale_factor,
mode='bicubic',
align_corners=False)
...
def init_torch_model():
torch_model = SuperResolutionNet(upscale_factor=3)
我们使用 upscale_factor 来控制模型的放大比例。初始化模型的时候,我们默认令 upscale_factor 为 3,生成了一个放大 3 倍的 PyTorch 模型。这个 PyTorch 模型最终被转换成了 ONNX 格式的模型。如果我们需要一个放大 4 倍的模型,需要重新生成一遍模型,再做一次到 ONNX 的转换。
现在,假设我们要做一个超分辨率的应用。我们的用户希望图片的放大倍数能够自由设置。而我们交给用户的,只有一个 .onnx 文件和运行超分辨率模型的应用程序。我们在不修改 .onnx 文件的前提下改变放大倍数。
因此,我们必须修改原来的模型,令模型的放大倍数变成推理时的输入。在第一章中的 Python 脚本的基础上,我们做一些修改,得到这样的脚本:
import torch
from torch import nn
from torch.nn.functional import interpolate
import torch.onnx
import cv2
import numpy as np
class SuperResolutionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x, upscale_factor):
x = interpolate(x,
scale_factor=upscale_factor,
mode='bicubic',
align_corners=False)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
def init_torch_model():
torch_model = SuperResolutionNet()
# Please read the code about downloading 'srcnn.pth' and 'face.png' in
# https://mmdeploy.readthedocs.io/zh_CN/latest/tutorials/chapter_01_introduction_to_model_deployment.html#pytorch
state_dict = torch.load('srcnn.pth')['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
input_img = cv2.imread('face.png').astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img), 3).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch_2.png", torch_output)
SuperResolutionNet 未修改之前,nn.Upsample 在初始化阶段固化了放大倍数,而 PyTorch 的 interpolate 插值算子可以在运行阶段选择放大倍数。因此,我们在新脚本中使用 interpolate 代替 nn.Upsample,从而让模型支持动态放大倍数的超分。 在第 55 行使用模型推理时,我们把放大倍数设置为 3。最后,图片保存在文件 "face_torch_2.png" 中。一切正常的话,"face_torch_2.png" 和 "face_torch.png" 的内容一模一样。
通过简单的修改,PyTorch 模型已经支持了动态分辨率。现在我们来一下尝试导出模型:
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(model, (x, 3),
"srcnn2.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output'])
运行这些脚本时,会报一长串错误。没办法,我们碰到了模型部署中的兼容性问题。
解决方法:自定义算子
直接使用 PyTorch 模型的话,我们修改几行代码就能实现模型输入的动态化。但在模型部署中,我们要花数倍的时间来设法解决这一问题。现在,让我们顺着解决问题的思路,体验一下模型部署的困难,并学习使用自定义算子的方式,解决超分辨率模型的动态化问题。
刚刚的报错是因为 PyTorch 模型在导出到 ONNX 模型时,模型的输入参数的类型必须全部是 torch.Tensor。而实际上我们传入的第二个参数" 3 "是一个整形变量。这不符合 PyTorch 转 ONNX 的规定。我们必须要修改一下原来的模型的输入。为了保证输入的所有参数都是 torch.Tensor 类型的,我们做如下修改:
...
class SuperResolutionNet(nn.Module):
def forward(self, x, upscale_factor):
x = interpolate(x,
scale_factor=upscale_factor.item(),
mode='bicubic',
align_corners=False)
...
# Inference
# Note that the second input is torch.tensor(3)
torch_output = model(torch.from_numpy(input_img), torch.tensor(3)).detach().numpy()
...
with torch.no_grad():
torch.onnx.export(model, (x, torch.tensor(3)),
"srcnn2.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output'])
由于 PyTorch 中 interpolate 的 scale_factor 参数必须是一个数值,我们使用 torch.Tensor.item() 来把只有一个元素的 torch.Tensor 转换成数值。之后,在模型推理时,我们使用 torch.tensor(3) 代替 3,以使得我们的所有输入都满足要求。现在运行脚本的话,无论是直接运行模型,还是导出 ONNX 模型,都不会报错了。
但是,导出 ONNX 时却报了一条 TraceWarning 的警告。这条警告说有一些量可能会追踪失败。这是怎么回事呢?让我们把生成的 srcnn2.onnx 用 Netron 可视化一下:

可以发现,虽然我们把模型推理的输入设置为了两个,但 ONNX 模型还是长得和原来一模一样,只有一个叫 " input " 的输入。这是由于我们使用了 torch.Tensor.item() 把数据从 Tensor 里取出来,而导出 ONNX 模型时这个操作是无法被记录的,只好报了一条 TraceWarning。这导致 interpolate 插值函数的放大倍数还是被设置成了" 3 "这个固定值,我们导出的" srcnn2.onnx "和最开始的" srcnn.onnx "完全相同。
直接修改原来的模型似乎行不通,我们得从 PyTorch 转 ONNX 的原理入手,强行令 ONNX 模型明白我们的想法了。
仔细观察 Netron 上可视化出的 ONNX 模型,可以发现在 PyTorch 中无论是使用最早的 nn.Upsample,还是后来的 interpolate,PyTorch 里的插值操作最后都会转换成 ONNX 定义的 Resize 操作。也就是说,所谓 PyTorch 转 ONNX,实际上就是把每个 PyTorch 的操作映射成了 ONNX 定义的算子。
点击该算子,可以看到它的详细参数如下:
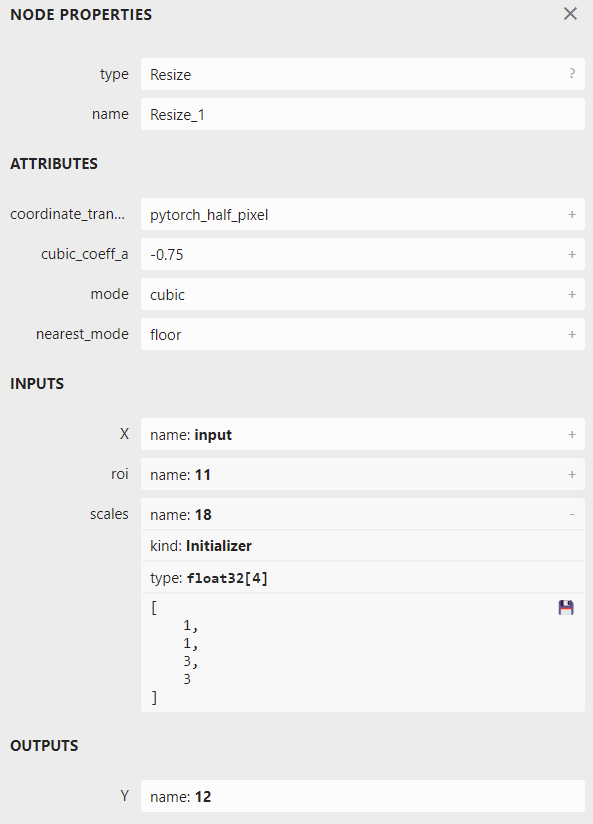
其中,展开 scales,可以看到 scales 是一个长度为 4 的一维张量,其内容为 [1, 1, 3, 3], 表示 Resize 操作每一个维度的缩放系数;其类型为 Initializer,表示这个值是根据常量直接初始化出来的。如果我们能够自己生成一个 ONNX 的 Resize 算子,让 scales 成为一个可变量而不是常量,就像它上面的 X 一样,那这个超分辨率模型就能动态缩放了。
现有实现插值的 PyTorch 算子有一套规定好的映射到 ONNX Resize 算子的方法,这些映射出的 Resize 算子的 scales 只能是常量,无法满足我们的需求。我们得自己定义一个实现插值的 PyTorch 算子,然后让它映射到一个我们期望的 ONNX Resize 算子上。
下面的脚本定义了一个 PyTorch 插值算子,并在模型里使用了它。我们先通过运行模型来验证该算子的正确性:
import torch
from torch import nn
from torch.nn.functional import interpolate
import torch.onnx
import cv2
import numpy as np
class NewInterpolate(torch.autograd.Function):
@staticmethod
def symbolic(g, input, scales):
return g.op("Resize",
input,
g.op("Constant",
value_t=torch.tensor([], dtype=torch.float32)),
scales,
coordinate_transformation_mode_s="pytorch_half_pixel",
cubic_coeff_a_f=-0.75,
mode_s='cubic',
nearest_mode_s="floor")
@staticmethod
def forward(ctx, input, scales):
scales = scales.tolist()[-2:]
return interpolate(input,
scale_factor=scales,
mode='bicubic',
align_corners=False)
class StrangeSuperResolutionNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.conv2 = nn.Conv2d(64, 32, kernel_size=1, padding=0)
self.conv3 = nn.Conv2d(32, 3, kernel_size=5, padding=2)
self.relu = nn.ReLU()
def forward(self, x, upscale_factor):
x = NewInterpolate.apply(x, upscale_factor)
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.conv3(out)
return out
def init_torch_model():
torch_model = StrangeSuperResolutionNet()
state_dict = torch.load('srcnn.pth')['state_dict']
# Adapt the checkpoint
for old_key in list(state_dict.keys()):
new_key = '.'.join(old_key.split('.')[1:])
state_dict[new_key] = state_dict.pop(old_key)
torch_model.load_state_dict(state_dict)
torch_model.eval()
return torch_model
model = init_torch_model()
factor = torch.tensor([1, 1, 3, 3], dtype=torch.float)
input_img = cv2.imread('face.png').astype(np.float32)
# HWC to NCHW
input_img = np.transpose(input_img, [2, 0, 1])
input_img = np.expand_dims(input_img, 0)
# Inference
torch_output = model(torch.from_numpy(input_img), factor).detach().numpy()
# NCHW to HWC
torch_output = np.squeeze(torch_output, 0)
torch_output = np.clip(torch_output, 0, 255)
torch_output = np.transpose(torch_output, [1, 2, 0]).astype(np.uint8)
# Show image
cv2.imwrite("face_torch_3.png", torch_output)
模型运行正常的话,一幅放大3倍的超分辨率图片会保存在"face_torch_3.png"中,其内容和"face_torch.png"完全相同。
在刚刚那个脚本中,我们定义 PyTorch 插值算子的代码如下:
class NewInterpolate(torch.autograd.Function):
@staticmethod
def symbolic(g, input, scales):
return g.op("Resize",
input,
g.op("Constant",
value_t=torch.tensor([], dtype=torch.float32)),
scales,
coordinate_transformation_mode_s="pytorch_half_pixel",
cubic_coeff_a_f=-0.75,
mode_s='cubic',
nearest_mode_s="floor")
@staticmethod
def forward(ctx, input, scales):
scales = scales.tolist()[-2:]
return interpolate(input,
scale_factor=scales,
mode='bicubic',
align_corners=False)
在具体介绍这个算子的实现前,让我们先理清一下思路。我们希望新的插值算子有两个输入,一个是被用于操作的图像,一个是图像的放缩比例。前面讲到,为了对接 ONNX 中 Resize 算子的 scales 参数,这个放缩比例是一个 [1, 1, x, x] 的张量,其中 x 为放大倍数。在之前放大3倍的模型中,这个参数被固定成了[1, 1, 3, 3]。因此,在插值算子中,我们希望模型的第二个输入是一个 [1, 1, w, h] 的张量,其中 w 和 h 分别是图片宽和高的放大倍数。
搞清楚了插值算子的输入,再看一看算子的具体实现。算子的推理行为由算子的 forward 方法决定。该方法的第一个参数必须为 ctx,后面的参数为算子的自定义输入,我们设置两个输入,分别为被操作的图像和放缩比例。为保证推理正确,需要把 [1, 1, w, h] 格式的输入对接到原来的 interpolate 函数上。我们的做法是截取输入张量的后两个元素,把这两个元素以 list 的格式传入 interpolate 的 scale_factor 参数。
接下来,我们要决定新算子映射到 ONNX 算子的方法。映射到 ONNX 的方法由一个算子的 symbolic 方法决定。symbolic 方法第一个参数必须是g,之后的参数是算子的自定义输入,和 forward 函数一样。ONNX 算子的具体定义由 g.op 实现。g.op 的每个参数都可以映射到 ONNX 中的算子属性:
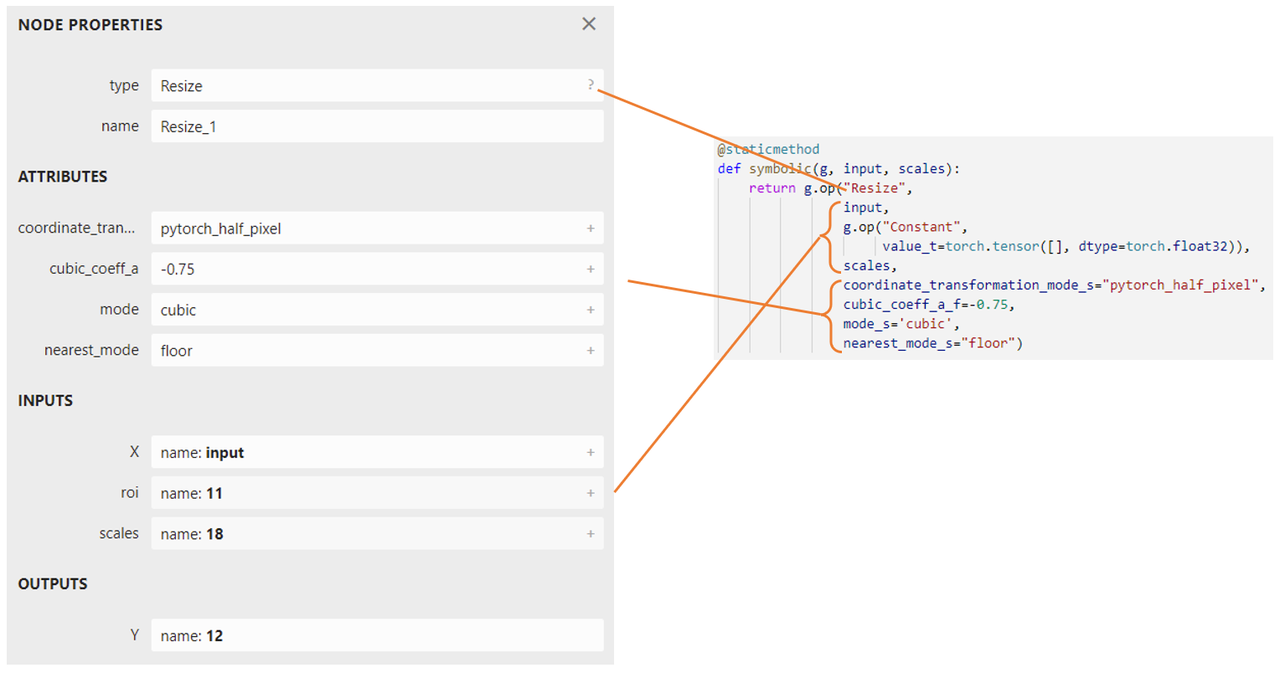
对于其他参数,我们可以照着现在的 Resize 算子填。而要注意的是,我们现在希望 scales 参数是由输入动态决定的。因此,在填入 ONNX 的 scales 时,我们要把 symbolic 方法的输入参数中的 scales 填入。
接着,让我们把新模型导出成 ONNX 模型:
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(model, (x, factor),
"srcnn3.onnx",
opset_version=11,
input_names=['input', 'factor'],
output_names=['output'])
把导出的 " srcnn3.onnx " 进行可视化:
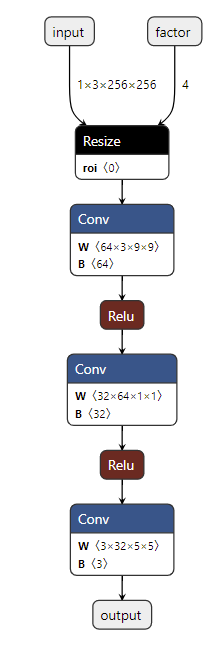
可以看到,正如我们所期望的,导出的 ONNX 模型有了两个输入!第二个输入表示图像的放缩比例。
之前在验证 PyTorch 模型和导出 ONNX 模型时,我们宽高的缩放比例设置成了 3x3。现在,在用 ONNX Runtime 推理时,我们尝试使用 4x4 的缩放比例:
import onnxruntime
input_factor = np.array([1, 1, 4, 4], dtype=np.float32)
ort_session = onnxruntime.InferenceSession("srcnn3.onnx")
ort_inputs = {'input': input_img, 'factor': input_factor}
ort_output = ort_session.run(None, ort_inputs)[0]
ort_output = np.squeeze(ort_output, 0)
ort_output = np.clip(ort_output, 0, 255)
ort_output = np.transpose(ort_output, [1, 2, 0]).astype(np.uint8)
cv2.imwrite("face_ort_3.png", ort_output)
运行上面的代码,可以得到一个边长放大4倍的超分辨率图片 "face_ort_3.png"。动态的超分辨率模型生成成功了!只要修改 input_factor,我们就可以自由地控制图片的缩放比例。
我们刚刚的工作,实际上是绕过 PyTorch 本身的限制,凭空“捏”出了一个 ONNX 算子。事实上,我们不仅可以创建现有的 ONNX 算子,还可以定义新的 ONNX 算子以拓展 ONNX 的表达能力。后续教程中我们将介绍自定义新 ONNX 算子的方法。
总结
通过学习前两篇教程,我们走完了整个部署流水线,成功部署了支持动态放大倍数的超分辨率模型。在这个过程中,我们既学会了如何简单地调用各框架的API实现模型部署,又学到了如何分析并尝试解决模型部署时碰到的难题。
同样,让我们总结一下本篇教程的知识点:
- 模型部署中常见的几类困难有:模型的动态化;新算子的实现;框架间的兼容。
- PyTorch 转 ONNX,实际上就是把每一个操作转化成 ONNX 定义的某一个算子。比如对于 PyTorch 中的 Upsample 和 interpolate,在转 ONNX 后最终都会成为 ONNX 的 Resize 算子。
- 通过修改继承自 torch.autograd.Function 的算子的 symbolic 方法,可以改变该算子映射到 ONNX 算子的行为。
至此,"部署第一个模型“的教程算是告一段落了。是不是觉得学到的知识还不够多?没关系,在接下来的几篇教程中,我们将结合 MMDeploy ,重点介绍 ONNX 中间表示和 ONNX Runtime/TensorRT 推理引擎的知识,让大家学会如何部署更复杂的模型。