* make -install -> make install (#621) change `make -install` to `make install` https://github.com/open-mmlab/mmdeploy/issues/618 * [Fix] fix csharp api detector release result (#620) * fix csharp api detector release result * fix wrong count arg of xxx_release_result in c# api * [Enhancement] Support two-stage rotated detector TensorRT. (#530) * upload * add fake_multiclass_nms_rotated * delete unused code * align with pytorch * Update delta_midpointoffset_rbbox_coder.py * add trt rotated roi align * add index feature in nms * not good * fix index * add ut * add benchmark * move to csrc/mmdeploy * update unit test Co-authored-by: zytx121 <592267829@qq.com> * Reduce mmcls version dependency (#635) * fix shufflenetv2 with trt (#645) * fix shufflenetv2 and pspnet * fix ci * remove print * ' -> " (#654) If there is a variable in the string, single quotes will ignored it, while double quotes will bring the variable into the string after parsing * ' -> " (#655) same with https://github.com/open-mmlab/mmdeploy/pull/654 * Support deployment of Segmenter (#587) * support segmentor with ncnn * update regression yml * replace chunk with split to support ts * update regression yml * update docs * fix segmenter ncnn inference failure brought by #477 * add test * fix test for ncnn and trt * fix lint * export nn.linear to Gemm op in onnx for ncnn * fix ci * simplify `Expand` (#617) * Fix typo (#625) * Add make install in en docs * Add make install in zh docs * Fix typo * Merge and add windows build Co-authored-by: tripleMu <865626@163.com> * [Enhancement] Fix ncnn unittest (#626) * optmize-csp-darknet * replace floordiv to torch.div * update csp_darknet default implement * fix test * [Enhancement] TensorRT Anchor generator plugin (#646) * custom trt anchor generator * add ut * add docstring, update doc * Add partition doc and sample code (#599) * update torch2onnx tool to support onnx partition * add model partition of yolov3 * add cn doc * update torch2onnx tool to support onnx partition * add model partition of yolov3 * add cn doc * add to index.rst * resolve comment * resolve comments * fix lint * change caption level in docs * update docs (#624) * Add java apis and demos (#563) * add java classifier detector * add segmentor * fix lint * add ImageRestorer java apis and demo * remove useless count parameter for Segmentor and Restorer, add PoseDetector * add RotatedDetection java api and demo * add Ocr java demo and apis * remove mmrotate ncnn java api and demo * fix lint * sync java api folder after rebase to master * fix include * remove record * fix java apis dir path in cmake * add java demo readme * fix lint mdformat * add test javaapi ci * fix lint * fix flake8 * fix test javaapi ci * refactor readme.md * fix install opencv for ci * fix install opencv : add permission * add all codebases and mmcv install * add torch * install mmdeploy * fix image path * fix picture path * fix import ncnn * fix import ncnn * add submodule of pybind * fix pybind submodule * change download to git clone for submodule * fix ncnn dir * fix README error * simplify the github ci * fix ci * fix yapf * add JNI as required * fix Capitalize * fix Capitalize * fix copyright * ignore .class changed * add OpenJDK installation docs * install target of javaapi * simplify ci * add jar * fix ci * fix ci * fix test java command * debugging what failed * debugging what failed * debugging what failed * add java version info * install openjdk * add java env var * fix export * fix export * fix export * fix export * fix picture path * fix picture path * fix file name * fix file name * fix README * remove java_api strategy * fix python version * format task name * move args position * extract common utils code * show image class result * add detector result * segmentation result format * add ImageRestorer result * add PoseDetection java result format * fix ci * stage ocr * add visualize * move utils * fix lint * fix ocr bugs * fix ci demo * fix java classpath for ci * fix popd * fix ocr demo text garbled * fix ci * fix ci * fix ci * fix path of utils ci * update the circleci config file by adding workflows both for linux, windows and linux-gpu (#368) * update circleci by adding more workflows * fix test workflow failure on windows platform * fix docker exec command for SDK unittests * Fixed tensorrt plugin not found in Windows (#672) * update introduction.png (#674) * [Enhancement] Add fuse select assign pass (#589) * Add fuse select assign pass * move code to csrc * add config flag * remove bool cast * fix export sdk info of input shape (#667) * Update get_started.md (#675) Fix backend model assignment * Update get_started.md (#676) Fix backend model assignment * [Fix] fix clang build (#677) * fix clang build * fix ndk build * fix ndk build * switch to `std::filesystem` for clang-7 and later * Deploy the Swin Transformer on TensorRT. (#652) * resolve conflicts * update ut and docs * fix ut * refine docstring * add comments and refine UT * resolve comments * resolve comments * update doc * add roll export * check backend * update regression test * bump version to 0.6.0 (#680) * bump vertion to 0.6.0 * update version * pass img_metas while exporting to onnx (#681) * pass img_metas while exporting to onnx * remove try-catch in tools for beter debugging * use get * fix typo * [Fix] fix ssd ncnn ut (#692) * fix ssd ncnn ut * fix yapf * fix passing img_metas to pytorch2onnx for mmedit (#700) * fix passing img_metas for mmdet3d (#707) * [Fix] Fix android build (#698) * fix android build * fix cmake * fix url link * fix wrong exit code in pipeline_manager (#715) * fix exit * change to general exit errorcode=1 * fix passing wrong backend type (#719) * Rename onnx2ncnn to mmdeploy_onnx2ncnn (#694) * improvement(tools/onnx2ncnn.py): rename to mmdeploy_onnx2ncnn * format(tools/deploy.py): clean code * fix(init_plugins.py): improve if condition * fix(CI): update target * fix(test_onnx2ncnn.py): update desc * Update init_plugins.py * [Fix] Fix mmdet ort static shape bug (#687) * fix shape * add device * fix yapf * fix rewriter for transforms * reverse image shape * fix ut of distance2bbox * fix rewriter name * fix c4 for torchscript (#724) * [Enhancement] Standardize C API (#634) * unify C API naming * fix demo and move apis/c/* -> apis/c/mmdeploy/* * fix lint * fix C# project * fix Java API * [Enhancement] Support Slide Vertex TRT (#650) * reorgnize mmrotate * fix * add hbb2obb * add ut * fix rotated nms * update docs * update benchmark * update test * remove ort regression test, remove comment * Fix get-started rendering issues in readthedocs (#740) * fix mermaid markdown rendering issue in readthedocs * fix error in C++ example * fix error in c++ example in zh_cn get_started doc * [Fix] set default topk for dump info (#702) * set default topk for dump info * remove redundant docstrings * add ci densenet * fix classification warnings * fix mmcls version * fix logger.warnings * add version control (#754) * fix satrn for ORT (#753) * fix satrn for ORT * move rewrite into pytorch * Add inference latency test tool (#665) * add profile tool * remove print envs in profile tool * set cudnn_benchmark to True * add doc * update tests * fix typo * support test with images from a directory * update doc * resolve comments * [Enhancement] Add CSE ONNX pass (#647) * Add fuse select assign pass * move code to csrc * add config flag * Add fuse select assign pass * Add CSE for ONNX * remove useless code * Test robot Just test robot * Update README.md Revert * [Fix] fix yolox point_generator (#758) * fix yolox point_generator * add a UT * resolve comments * fix comment lines * limit markdown version (#773) * [Enhancement] Better index put ONNX export. (#704) * Add rewriter for tensor setitem * add version check * Upgrade Dockerfile to use TensorRT==8.2.4.2 (#706) * Upgrade TensorRT to 8.2.4.2 * upgrade pytorch&mmcv in CPU Dockerfile * Delete redundant port example in Docker * change 160x160-608x608 to 64x64-608x608 for yolov3 * [Fix] reduce log verbosity & improve error reporting (#755) * reduce log verbosity & improve error reporting * improve error reporting * [Enhancement] Support latest ppl.nn & ppl.cv (#564) * support latest ppl.nn * fix pplnn for model convertor * fix lint * update memory policy * import algo from buffer * update ppl.cv * use `ppl.cv==0.7.0` * document supported ppl.nn version * skip pplnn dependency when building shared libs * [Fix][P0] Fix for torch1.12 (#751) * fix for torch1.12 * add comment * fix check env (#785) * [Fix] fix cascade mask rcnn (#787) * fix cascade mask rcnn * fix lint * add regression * [Feature] Support RoITransRoIHead (#713) * [Feature] Support RoITransRoIHead * Add docs * Add mmrotate models regression test * Add a draft for test code * change the argument name * fix test code * fix minor change for not class agnostic case * fix sample for test code * fix sample for test code * Add mmrotate in requirements * Revert "Add mmrotate in requirements" This reverts commit 043490075e6dbe4a8fb98e94b2b583b91fc5038d. * [Fix] fix triu (#792) * fix triu * triu -> triu_default * [Enhancement] Install Optimizer by setuptools (#690) * Add fuse select assign pass * move code to csrc * add config flag * Add fuse select assign pass * Add CSE for ONNX * remove useless code * Install optimizer by setup tools * fix comment * [Feature] support MMRotate model with le135 (#788) * support MMRotate model with le135 * cse before fuse select assign * remove unused import * [Fix] Support macOS build (#762) * fix macOS build * fix missing * add option to build & install examples (#822) * [Fix] Fix setup on non-linux-x64 (#811) * fix setup * replace long to int64_t * [Feature] support build single sdk library (#806) * build single lib for c api * update csharp doc & project * update test build * fix test build * fix * update document for building android sdk (#817) Co-authored-by: dwSun <dwsunny@icloud.com> * [Enhancement] support kwargs in SDK python bindings (#794) * support-kwargs * make '__call__' as single image inference and add 'batch' API to deal with batch images inference * fix linting error and typo * fix lint * improvement(sdk): add sdk code coverage (#808) * feat(doc): add CI * CI(sdk): add sdk coverage * style(test): code format * fix(CI): update coverage.info path * improvement(CI): use internal image * improvement(CI): push coverage info once * [Feature] Add C++ API for SDK (#831) * add C++ API * unify result type & add examples * minor fix * install cxx API headers * fix Mat, add more examples * fix monolithic build & fix lint * install examples correctly * fix lint * feat(tools/deploy.py): support snpe (#789) * fix(tools/deploy.py): support snpe * improvement(backend/snpe): review advices * docs(backend/snpe): update build * docs(backend/snpe): server support specify port * docs(backend/snpe): update path * fix(backend/snpe): time counter missing argument * docs(backend/snpe): add missing argument * docs(backend/snpe): update download and using * improvement(snpe_net.cpp): load model with modeldata * Support setup on environment with no PyTorch (#843) * support test with multi batch (#829) * support test with multi batch * resolve comment * import algorithm from buffer (#793) * [Enhancement] build sdk python api in standard-alone manner (#810) * build sdk python api in standard-alone manner * enable MMDEPLOY_BUILD_SDK_MONOLITHIC and MMDEPLOY_BUILD_EXAMPLES in prebuild config * link mmdeploy to python target when monolithic option is on * checkin README to describe precompiled package build procedure * use packaging.version.parse(python_version) instead of list(python_version) * fix according to review results * rebase master * rollback cmake.in and apis/python/CMakeLists.txt * reorganize files in install/example * let cmake detect visual studio instead of specifying 2019 * rename whl name of precompiled package * fix according to review results * Fix SDK backend (#844) * fix mmpose python api (#852) * add prebuild package usage docs on windows (#816) * add prebuild package usage docs on windows * fix lint * update * try fix lint * add en docs * update * update * udpate faq * fix typo (#862) * [Enhancement] Improve get_started documents and bump version to 0.7.0 (#813) * simplify commands in get_started * add installation commands for Windows * fix typo * limit markdown and sphinx_markdown_tables version * adopt html <details open> tag * bump mmdeploy version * bump mmdeploy version * update get_started * update get_started * use python3.8 instead of python3.7 * remove duplicate section * resolve issue #856 * update according to review results * add reference to prebuilt_package_windows.md * fix error when build sdk demos * improvement(dockerfile): use make -j$(nporc) when build ncnn (#840) * use make -j$(nporc) when build ncnn * improve cpu dockerfile * fix error when set device cpu && fix docs error (#866) * [Feature]support pointpillar nus version (#391) * support pointpillar nus version * support pointpillar nus version * add regression test config for mmdet3d * fix exit with no error code * fix cfg * fix worksize * fix worksize * fix cfg * support nus pp * fix yaml * fix yaml * fix yaml * add ut * fix ut Co-authored-by: RunningLeon <mnsheng@yeah.net> * Fix doc error of building C examples (#879) * fix doc error of building C demo examples Path error in cmake compilation of C demo examples * fix en doc error of building C demo examples Path error in cmake compilation of C demo examples * fix adaptive_avg_pool exporting to onnx (#857) * fix adaptive_avg_pool exporting to onnx * remove debug codes * fix ci * resolve comment * docs(project): sync en and zh docs (#842) * docs(en): update file structure * docs(zh_cn): update * docs(structure): update * docs(snpe): update * docs(README): update * fix(CI): update * fix(CI): index.rst error * fix(docs): update * fix(docs): remove mermaid * fix(docs): remove useless * fix(docs): update link * docs(en): update * docs(en): update * docs(zh_cn): remove \[ * docs(zh_cn): format * docs(en): remove blank * fix(CI): doc link error * docs(project): remove "./" prefix * docs(zh_cn): fix mdformat * docs(en): update title * fix(CI): update docs * fix mmdeploy_pplnn_net build error when target device is cpu (#896) * docs(zh_cn): add architect (#882) * docs(zh_cn): add architect docs(en): add architect fix(docs): readthedocs index * docs(en): update architect.md * docs(README.md): update * docs(architecture): fix review advices * add device backend check (#886) * add device backend check * safe check * only activated for tensorrt and openvino * resolve comments * support multi-batch test in profile tool (#868) * test batch profile with resnet pspnet yolov3 srcnn * update doc * update docs * fix ut * fix mmdet * support batch mmorc and mmrotate * fix mmcls export to sdk * resolve comments * rename to fix #819 * fix conflicts with master * [Fix] fix device error in dump-info (#912) * fix device error in dump-info * fix UT * improvement(cmake): simplify build option and doc (#832) * improvement(cmake): simplify build option improvement(cmake): convert target_backends with directory * fix(dockerfile): build error * fix(CI): circle CI * fix(docs): snpe and cmake option * fix(docs): revert update cmake * fix(docs): revert * update(docs): remove useless * set test_mode for mmdet (#920) * fix * update * [Doc] How to write a customized TensorRT plugin (#290) * first edition * fix lint * add 06, 07 * resolve comments * update index.rst * update title * update img * [Feature] add swin for cls (#911) * add swin for cls * add ut and doc * reduce trt batch size * add regression test * resolve comments * remove useless rewriting logic * docs(mmdet3d): give detail model path (#940) * add cflags explicitly in ci (#945) * improvement(installation): add script install mmdeploy (#919) * feat(tools): add build ubuntu x64 ncnn * ci(tools): add ncnn auto install * fix(ci): auto install ncnn * fix(tools): no interactive * docs(build): add script build * CI(ncnn): script install ncnn * docs(zh_cn): fix error os * fix * CI(tools/script): test ort install passed * update * CI(tools): support pplnn * CI(build): add pplnn * docs(tools): update * fix * CI(tools): script install torchscript * docs(build): add torchscript * fix(tools): clean code and doc * update * fix(CI): requirements install failed * debug CI * update * update * update * feat(tools/script): support user specify make jobs * fix(tools/script): fix build pplnn with cuda * fix(tools/script): torchscript add tips and simplify install mmcv * fix(tools/script): check nvcc version first * fix(tools/scripts): pplnn checkout * fix(CI): add simple check install succcess * fix * debug CI * fix * fix(CI): pplnn install mis wheel * fix(CI): build error * fix(CI): remove misleading message * Support risc-v platform (#910) * add ppl.nn riscv engine * update ppl.nn riscv engine * udpate riscv service (ncnn backend) * update _build_wrapper for ncnn * fix build * fix lint * update default uri * update file structure & add cn doc * remove copy input data * update docs * remove ncnn server * fix docs * update zh doc * update toolchain * remove unused * update doc * update doc * update doc * rename cross build dirname * add riscv.md to build_from_source.md * update cls model * test ci * test ci * test ci * test ci * test ci * update ci * update ci * [Feature] TorchScript SDK backend (#890) * WIP SDK torchscript support * support detection task * make torchvision optional * force link torchvision if enabled * support torch-1.12 * fix export & sync cuda stream * hide internal classes * handle error * set `MMDEPLOY_USE_CUDA` when CUDA is enabled * [Bug] fix setitem with scalar or single element tensor (#941) * fix setitem * add copy symbolic * docs(convert_model): update description (#956) * [Enhancement] Support DETR (#924) * add detr support * fix softmax * add reg test, update document * fix ut failed (#951) * [Enhancement] Rewriter support pre-import function (#899) * support preimport * update rewriter * fix batched nms ort * add_multi_label_postprocess (#950) * 'add_multi_label_postprocess' * fix pre-commit * delete partial_sort * delete idx * delete num_classes and num_classes_ * Fix right brackets and spelling errors in lines 19 and 20 Co-authored-by: gaoying <gaoying@xiaobaishiji.com> * fix ci (#964) * [Fix] Close onnx optimizer for ncnn (#961) * close onnx optimizer for ncnn * fix docformatter * fix lint * remove Release dir in mmdeploy package (#960) * CI(tools/scripts): add submodule init and update (#977) * fix mmroate (#976) * Fix mmseg pointrend (#903) * support mmseg:pointrend * update docs * update docs for torchscript * resolve comments * Add CI to test full pipeline (#966) * add mmcls full pipeline test ci * update * update * add mmcv * install torch * install mmdeploy * change clone with https * install mmcls * update * change mmcls version * add mmcv version * update mmcls version * test sdk * tast with imagnet * sed pipeline * print env * update * move to backend-ort ci * install mim * fix regression test (#958) * fix reg * set sdk wrapper device id * resolve comment * fix(CI): typo (#983) * fix(CI): ort test all pipeline (#985) * add missing sqrt for PAAHead's score calculation (#984) Co-authored-by: xianghongyi1 <xianghongyi1@sensetime.com> * Fix: skip tests for uninstalled codebases (#987) * skip tests if codebase not installed * skip ort run test * fix mmseg * [Feature] Ascend backend (#747) * add acl backend * support dynamic batch size and dynamic image size * add preliminary ascend backend * support dtypes other than float * support dynamic_dims in SDK * fix dynamic batch size * better error handling * remove debug info * [WIP] dynamic shape support * fix static shape * fix dynamic batch size * add retinanet support * fix dynamic image size * fix dynamic image size * fix dynamic dims * fix dynamic dims * simplify config files * fix yolox support * fix negative index * support faster rcnn * add seg config * update benchmark * fix onnx2ascend dynamic shape * update docstring and benchmark * add unit test, update documents * fix wrapper * fix ut * fix for vit * error handling * context handling & multi-device support * build with stub libraries * add ci * fix lint * fix lint * update doc ref * fix typo * down with `target_link_directories` * setup python * makedir * fix ci * fix ci * remove verbose logs * fix UBs * export Error * fix lint * update checkenv Co-authored-by: grimoire <yaoqian@sensetime.com> * fix(backend): disable cublaslt for cu102 (#947) * fix(backend): disable cublaslt for cu102 * fix * fix(backend): update * fix(tensorrt/util.py): add find cuda version * fix * fix(CI): first use cmd to get cuda version * docs(tensorrt/utils.py): update docstring * TensorRT dot product attention ops (#949) * add detr support * fix softmax * add placeholder * add implement * add docs and ut * update testcase * update docs * update docs * fix mmdet showresult (#999) * fix mmdet showresult * Consider compatibility * mmdet showresult add *args * Revert "mmdet showresult add *args" This reverts commit 82265a31cf910618a1dff4aab65e9dc793a623c4. Co-authored-by: whhuang <whhuang@hitotek.com> * support coreml (#760) * sdk inference * fix typo * fix typo * add convert things * fix missling name * add cls support * add more pytorch rewriter * add det support * support det wip * make Model export model_path * fix nms * add output back * add docstring * fix lint * add coreml build action * add zh docs * add coreml backend check * update ci * update * update * update * update * update * fix lint * update configs * add return value when error occured * update docs * update docs * update docs * fix lint * udpate docs * udpate docs * update Co-authored-by: grimoire <streetyao@live.com> * fix mmdet ut (#1001) * [Feature] Add option to fuse transform. (#741) * add collect_impl.cpp to cuda device * add dummy compute node wich device elena * add compiler & dynamic library loader * add code to compile with gen code(elena) * move folder * fix lint * add tracer module * add license * update type id * add fuse kernel registry * remove compilier & dynamic_library * update fuse kernel interface * Add elena-mmdeploy project in 3rd-party * Fix README.md * fix cmake file * Support cuda device and clang format all file * Add cudaStreamSynchronize for cudafree * fix cudaStreamSynchronize * rename to __tracer__ * remove unused code * update kernel * update extract elena script * update gitignore * fix ci * Change the crop_size to crop_h and crop_w in arglist * update Tracer * remove cond * avoid allocate memory * add build.sh for elena * remove code * update test * Support bilinear resize with float input * Rename elena-mmdeploy to delete * Introduce public submodule * use get_ref * update elena * update tools * update tools * update fuse transform docs * add fuse transform doc link to get_started * fix shape in crop * remove fuse_transform_ == true check * remove fuse_transform_ member * remove elena_int.h * doesn't dump transform_static.json * update tracer * update CVFusion to remove compile warning * remove mmcv version > 1.5.1 dep * fix tests * update docs * add elena use option * remove submodule of CVFusion * update doc * use auto * use throw_exception(eEntryNotFound); * update Co-authored-by: cx <cx@ubuntu20.04> Co-authored-by: miraclezqc <969226879@qq.com> * Add RKNN support. (#865) * save codes * support resnet and yolov3 * support yolox * fix lint * add mmseg support and a doc * add UT * update supported model list * fix ci * refine docstring * resolve comments * remote output_tensor_type * resolve comments * update readme * [Fix] Add isolated option for TorchScript SDK backend (#1002) * add option for TorchScript SDK backend * add doc * format * bump version to v0.8.0 (#1009) * fix(CI): update link checker (#1008) * New issue template (#1007) * update bug report * update issue template * update bug-report * fix mmdeploy builder on windows (#1018) * fix mmdeploy builder on windows * add pyyaml * fix lint * BUG P0 (#1044) * update api in doc (#1021) * fix two stage batch dynamic (#1046) * docs(scripts): update auto install desc (#1036) * Fix `RoIAlignFunction` error for CoreML backend (#1029) * Fixed typo for install commands for TensorRT runtime (#1025) * Fixed typo for install commands for TensorRT runtime * Apply typo-fix on 'cn' documentation Co-authored-by: Tümer Tosik <tumer_t@hotmail.de> * merge master@a1a19f0 documents to dev-1.x * missed ubuntu_utils.py * change benchmark reference in readme_zh-CN Co-authored-by: Ryan_Huang <44900829+DrRyanHuang@users.noreply.github.com> Co-authored-by: Chen Xin <xinchen.tju@gmail.com> Co-authored-by: q.yao <yaoqian@sensetime.com> Co-authored-by: zytx121 <592267829@qq.com> Co-authored-by: RunningLeon <mnsheng@yeah.net> Co-authored-by: Li Zhang <lzhang329@gmail.com> Co-authored-by: tripleMu <gpu@163.com> Co-authored-by: tripleMu <865626@163.com> Co-authored-by: hanrui1sensetime <83800577+hanrui1sensetime@users.noreply.github.com> Co-authored-by: Bryan Glen Suello <11388006+bgsuello@users.noreply.github.com> Co-authored-by: zambranohally <63218980+zambranohally@users.noreply.github.com> Co-authored-by: AllentDan <41138331+AllentDan@users.noreply.github.com> Co-authored-by: tpoisonooo <khj.application@aliyun.com> Co-authored-by: Hakjin Lee <nijkah@gmail.com> Co-authored-by: 孙德伟 <5899962+dwSun@users.noreply.github.com> Co-authored-by: dwSun <dwsunny@icloud.com> Co-authored-by: Chen Xin <irexyc@gmail.com> Co-authored-by: OldDreamInWind <108687632+OldDreamInWind@users.noreply.github.com> Co-authored-by: VVsssssk <88368822+VVsssssk@users.noreply.github.com> Co-authored-by: 梦阳 <49838178+liu-mengyang@users.noreply.github.com> Co-authored-by: gy77 <64619863+gy-7@users.noreply.github.com> Co-authored-by: gaoying <gaoying@xiaobaishiji.com> Co-authored-by: Hongyi Xiang <Groexhy@users.noreply.github.com> Co-authored-by: xianghongyi1 <xianghongyi1@sensetime.com> Co-authored-by: munhou <51435578+munhou@users.noreply.github.com> Co-authored-by: whhuang <whhuang@hitotek.com> Co-authored-by: grimoire <streetyao@live.com> Co-authored-by: cx <cx@ubuntu20.04> Co-authored-by: miraclezqc <969226879@qq.com> Co-authored-by: Jelle Maas <typiqally@gmail.com> Co-authored-by: ichitaka <tuemerffm@hotmail.com> Co-authored-by: Tümer Tosik <tumer_t@hotmail.de>
22 KiB
第三章:PyTorch 转 ONNX 详解
ONNX 是目前模型部署中最重要的中间表示之一。学懂了 ONNX 的技术细节,就能规避大量的模型部署问题。从这篇文章开始,在接下来的三篇文章里,我们将由浅入深地介绍 ONNX 相关的知识。在第一篇文章里,我们会介绍更多 PyTorch 转 ONNX 的细节,让大家完全掌握把简单的 PyTorch 模型转成 ONNX 模型的方法;在第二篇文章里,我们将介绍如何在 PyTorch 中支持更多的 ONNX 算子,让大家能彻底走通 PyTorch 到 ONNX 这条部署路线;第三篇文章里,我们讲介绍 ONNX 本身的知识,以及修改、调试 ONNX 模型的常用方法,使大家能自行解决大部分和 ONNX 有关的部署问题。
在把 PyTorch 模型转换成 ONNX 模型时,我们往往只需要轻松地调用一句torch.onnx.export就行了。这个函数的接口看上去简单,但它在使用上还有着诸多的“潜规则”。在这篇教程中,我们会详细介绍 PyTorch 模型转 ONNX 模型的原理及注意事项。除此之外,我们还会介绍 PyTorch 与 ONNX 的算子对应关系,以教会大家如何处理 PyTorch 模型转换时可能会遇到的算子支持问题。
torch.onnx.export 细解
在这一节里,我们将详细介绍 PyTorch 到 ONNX 的转换函数—— torch.onnx.export。我们希望大家能够更加灵活地使用这个模型转换接口,并通过了解它的实现原理来更好地应对该函数的报错(由于模型部署的兼容性问题,部署复杂模型时该函数时常会报错)。
计算图导出方法
TorchScript 是一种序列化和优化 PyTorch 模型的格式,在优化过程中,一个torch.nn.Module模型会被转换成 TorchScript 的torch.jit.ScriptModule模型。现在, TorchScript 也被常当成一种中间表示使用。我们在其他文章中对 TorchScript 有详细的介绍,这里介绍 TorchScript 仅用于说明 PyTorch 模型转 ONNX的原理。
torch.onnx.export中需要的模型实际上是一个torch.jit.ScriptModule。而要把普通 PyTorch 模型转一个这样的 TorchScript 模型,有跟踪(trace)和脚本化(script)两种导出计算图的方法。如果给torch.onnx.export传入了一个普通 PyTorch 模型(torch.nn.Module),那么这个模型会默认使用跟踪的方法导出。这一过程如下图所示:

回忆一下我们第一篇教程 知识:跟踪法只能通过实际运行一遍模型的方法导出模型的静态图,即无法识别出模型中的控制流(如循环);脚本化则能通过解析模型来正确记录所有的控制流。我们以下面这段代码为例来看一看这两种转换方法的区别:
import torch
class Model(torch.nn.Module):
def __init__(self, n):
super().__init__()
self.n = n
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
for i in range(self.n):
x = self.conv(x)
return x
models = [Model(2), Model(3)]
model_names = ['model_2', 'model_3']
for model, model_name in zip(models, model_names):
dummy_input = torch.rand(1, 3, 10, 10)
dummy_output = model(dummy_input)
model_trace = torch.jit.trace(model, dummy_input)
model_script = torch.jit.script(model)
# 跟踪法与直接 torch.onnx.export(model, ...)等价
torch.onnx.export(model_trace, dummy_input, f'{model_name}_trace.onnx', example_outputs=dummy_output)
# 脚本化必须先调用 torch.jit.sciprt
torch.onnx.export(model_script, dummy_input, f'{model_name}_script.onnx', example_outputs=dummy_output)
在这段代码里,我们定义了一个带循环的模型,模型通过参数n来控制输入张量被卷积的次数。之后,我们各创建了一个n=2和n=3的模型。我们把这两个模型分别用跟踪和脚本化的方法进行导出。
值得一提的是,由于这里的两个模型(model_trace, model_script)是 TorchScript 模型,export函数已经不需要再运行一遍模型了。(如果模型是用跟踪法得到的,那么在执行torch.jit.trace的时候就运行过一遍了;而用脚本化导出时,模型不需要实际运行)参数中的dummy_input和dummy_output仅仅是为了获取输入和输出张量的类型和形状。
运行上面的代码,我们把得到的4个 onnx 文件用 Netron 可视化:
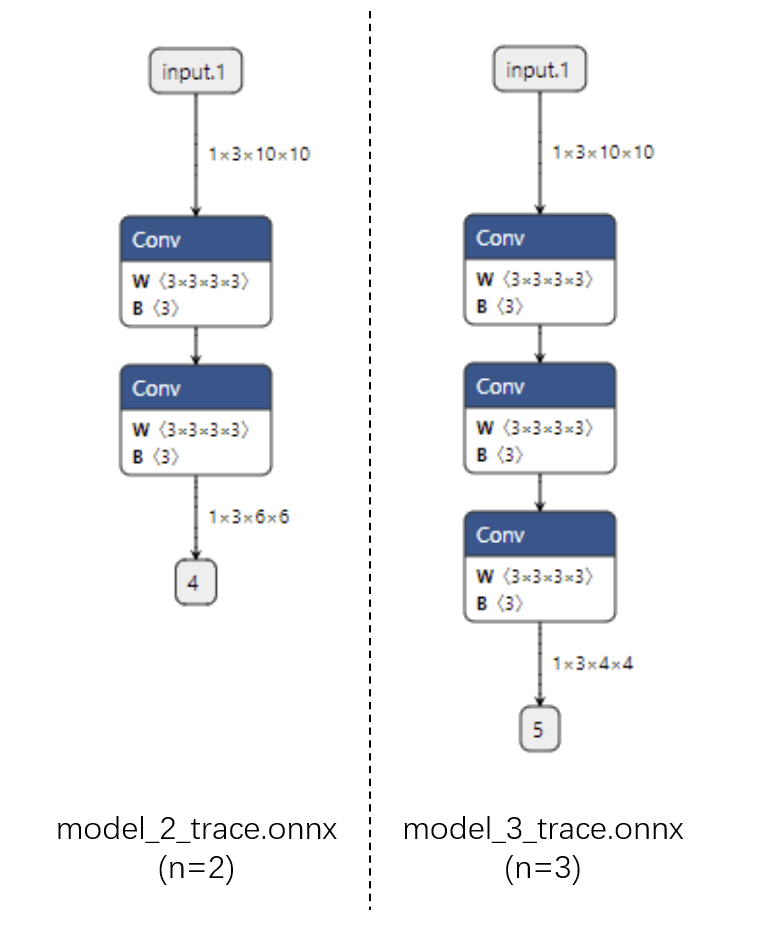
首先看跟踪法得到的 ONNX 模型结构。可以看出来,对于不同的 n,ONNX 模型的结构是不一样的。
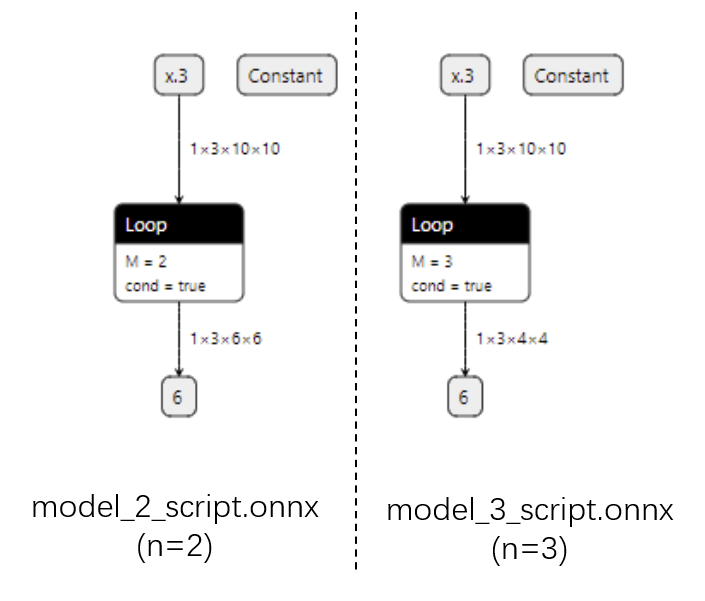
而用脚本化的话,最终的 ONNX 模型用 Loop 节点来表示循环。这样哪怕对于不同的 n,ONNX 模型也有同样的结构。
由于推理引擎对静态图的支持更好,通常我们在模型部署时不需要显式地把 PyTorch 模型转成 TorchScript 模型,直接把 PyTorch 模型用 torch.onnx.export 跟踪导出即可。了解这部分的知识主要是为了在模型转换报错时能够更好地定位问题是否发生在 PyTorch 转 TorchScript 阶段。
参数讲解
了解完转换函数的原理后,我们来详细介绍一下该函数的主要参数的作用。我们主要会从应用的角度来介绍每个参数在不同的模型部署场景中应该如何设置,而不会去列出每个参数的所有设置方法。该函数详细的 API 文档可参考 torch.onnx ‒ PyTorch 1.11.0 documentation
torch.onnx.export 在 torch.onnx.__init__.py文件中的定义如下:
def export(model, args, f, export_params=True, verbose=False, training=TrainingMode.EVAL,
input_names=None, output_names=None, aten=False, export_raw_ir=False,
operator_export_type=None, opset_version=None, _retain_param_name=True,
do_constant_folding=True, example_outputs=None, strip_doc_string=True,
dynamic_axes=None, keep_initializers_as_inputs=None, custom_opsets=None,
enable_onnx_checker=True, use_external_data_format=False):
前三个必选参数为模型、模型输入、导出的 onnx 文件名,我们对这几个参数已经很熟悉了。我们来着重看一下后面的一些常用可选参数。
export_params
模型中是否存储模型权重。一般中间表示包含两大类信息:模型结构和模型权重,这两类信息可以在同一个文件里存储,也可以分文件存储。ONNX 是用同一个文件表示记录模型的结构和权重的。 我们部署时一般都默认这个参数为 True。如果 onnx 文件是用来在不同框架间传递模型(比如 PyTorch 到 Tensorflow)而不是用于部署,则可以令这个参数为 False。
input_names, output_names
设置输入和输出张量的名称。如果不设置的话,会自动分配一些简单的名字(如数字)。 ONNX 模型的每个输入和输出张量都有一个名字。很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。 在实际的部署流水线中,我们都需要设置输入和输出张量的名称,并保证 ONNX 和推理引擎中使用同一套名称。
opset_version
转换时参考哪个 ONNX 算子集版本,默认为9。后文会详细介绍 PyTorch 与 ONNX 的算子对应关系。
dynamic_axes
指定输入输出张量的哪些维度是动态的。
为了追求效率,ONNX 默认所有参与运算的张量都是静态的(张量的形状不发生改变)。但在实际应用中,我们又希望模型的输入张量是动态的,尤其是本来就没有形状限制的全卷积模型。因此,我们需要显式地指明输入输出张量的哪几个维度的大小是可变的。
我们来看一个dynamic_axes的设置例子:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
x = self.conv(x)
return x
model = Model()
dummy_input = torch.rand(1, 3, 10, 10)
model_names = ['model_static.onnx',
'model_dynamic_0.onnx',
'model_dynamic_23.onnx']
dynamic_axes_0 = {
'in' : [0],
'out' : [0]
}
dynamic_axes_23 = {
'in' : [2, 3],
'out' : [2, 3]
}
torch.onnx.export(model, dummy_input, model_names[0],
input_names=['in'], output_names=['out'])
torch.onnx.export(model, dummy_input, model_names[1],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_0)
torch.onnx.export(model, dummy_input, model_names[2],
input_names=['in'], output_names=['out'], dynamic_axes=dynamic_axes_23)
首先,我们导出3个 ONNX 模型,分别为没有动态维度、第0维动态、第2第3维动态的模型。 在这份代码里,我们是用列表的方式表示动态维度,例如:
dynamic_axes_0 = {
'in' : [0],
'out' : [0]
}
```
由于 ONNX 要求每个动态维度都有一个名字,这样写的话会引出一条 UserWarning,警告我们通过列表的方式设置动态维度的话系统会自动为它们分配名字。一种显式添加动态维度名字的方法如下:
```python
dynamic_axes_0 = {
'in' : {0: 'batch'},
'out' : {0: 'batch'}
}
由于在这份代码里我们没有更多的对动态维度的操作,因此简单地用列表指定动态维度即可。 之后,我们用下面的代码来看一看动态维度的作用:
import onnxruntime
import numpy as np
origin_tensor = np.random.rand(1, 3, 10, 10).astype(np.float32)
mult_batch_tensor = np.random.rand(2, 3, 10, 10).astype(np.float32)
big_tensor = np.random.rand(1, 3, 20, 20).astype(np.float32)
inputs = [origin_tensor, mult_batch_tensor, big_tensor]
exceptions = dict()
for model_name in model_names:
for i, input in enumerate(inputs):
try:
ort_session = onnxruntime.InferenceSession(model_name)
ort_inputs = {'in': input}
ort_session.run(['out'], ort_inputs)
except Exception as e:
exceptions[(i, model_name)] = e
print(f'Input[{i}] on model {model_name} error.')
else:
print(f'Input[{i}] on model {model_name} succeed.')
我们在模型导出计算图时用的是一个形状为(1, 3, 10, 10)的张量。现在,我们来尝试以形状分别是(1, 3, 10, 10), (2, 3, 10, 10), (1, 3, 20, 20)为输入,用ONNX Runtime运行一下这几个模型,看看哪些情况下会报错,并保存对应的报错信息。得到的输出信息应该如下:
Input[0] on model model_static.onnx succeed.
Input[1] on model model_static.onnx error.
Input[2] on model model_static.onnx error.
Input[0] on model model_dynamic_0.onnx succeed.
Input[1] on model model_dynamic_0.onnx succeed.
Input[2] on model model_dynamic_0.onnx error.
Input[0] on model model_dynamic_23.onnx succeed.
Input[1] on model model_dynamic_23.onnx error.
Input[2] on model model_dynamic_23.onnx succeed.
可以看出,形状相同的(1, 3, 10, 10)的输入在所有模型上都没有出错。而对于batch(第0维)或者长宽(第2、3维)不同的输入,只有在设置了对应的动态维度后才不会出错。我们可以错误信息中找出是哪些维度出了问题。比如我们可以用以下代码查看input[1]在model_static.onnx中的报错信息:
print(exceptions[(1, 'model_static.onnx')])
# output
# [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: in for the following indices index: 0 Got: 2 Expected: 1 Please fix either the inputs or the model.
这段报错告诉我们名字叫in的输入的第0维不匹配。本来该维的长度应该为1,但我们的输入是2。实际部署中,如果我们碰到了类似的报错,就可以通过设置动态维度来解决问题。
使用技巧
通过学习之前的知识,我们基本掌握了 torch.onnx.export 函数的部分实现原理和参数设置方法,足以完成简单模型的转换了。但在实际应用中,使用该函数还会踩很多坑。这里我们模型部署团队把在实战中积累的一些经验分享给大家。
使模型在 ONNX 转换时有不同的行为
有些时候,我们希望模型在直接用 PyTorch 推理时有一套逻辑,而在导出的ONNX模型中有另一套逻辑。比如,我们可以把一些后处理的逻辑放在模型里,以简化除运行模型之外的其他代码。torch.onnx.is_in_onnx_export()可以实现这一任务,该函数仅在执行 torch.onnx.export()时为真。以下是一个例子:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(3, 3, 3)
def forward(self, x):
x = self.conv(x)
if torch.onnx.is_in_onnx_export():
x = torch.clip(x, 0, 1)
return x
这里,我们仅在模型导出时把输出张量的数值限制在[0, 1]之间。使用 is_in_onnx_export 确实能让我们方便地在代码中添加和模型部署相关的逻辑。但是,这些代码对只关心模型训练的开发者和用户来说很不友好,突兀的部署逻辑会降低代码整体的可读性。同时,is_in_onnx_export 只能在每个需要添加部署逻辑的地方都“打补丁”,难以进行统一的管理。我们之后会介绍如何使用 MMDeploy 的重写机制来规避这些问题。
利用中断张量跟踪的操作
PyTorch 转 ONNX 的跟踪导出法是不是万能的。如果我们在模型中做了一些很“出格”的操作,跟踪法会把某些取决于输入的中间结果变成常量,从而使导出的ONNX模型和原来的模型有出入。以下是一个会造成这种“跟踪中断”的例子:
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
x = x * x[0].item()
return x, torch.Tensor([i for i in x])
model = Model()
dummy_input = torch.rand(10)
torch.onnx.export(model, dummy_input, 'a.onnx')
如果你尝试去导出这个模型,会得到一大堆 warning,告诉你转换出来的模型可能不正确。这也难怪,我们在这个模型里使用了.item()把 torch 中的张量转换成了普通的 Python 变量,还尝试遍历 torch 张量,并用一个列表新建一个 torch 张量。这些涉及张量与普通变量转换的逻辑都会导致最终的 ONNX 模型不太正确。
另一方面,我们也可以利用这个性质,在保证正确性的前提下令模型的中间结果变成常量。这个技巧常常用于模型的静态化上,即令模型中所有的张量形状都变成常量。在未来的教程中,我们会在部署实例中详细介绍这些“高级”操作。
使用张量为输入(PyTorch版本 < 1.9.0)
正如我们第一篇教程所展示的,在较旧(< 1.9.0)的 PyTorch 中把 Python 数值作为 torch.onnx.export()的模型输入时会报错。出于兼容性的考虑,我们还是推荐以张量为模型转换时的模型输入。
PyTorch 对 ONNX 的算子支持
在确保torch.onnx.export()的调用方法无误后,PyTorch 转 ONNX 时最容易出现的问题就是算子不兼容了。这里我们会介绍如何判断某个 PyTorch 算子在 ONNX 中是否兼容,以助大家在碰到报错时能更好地把错误归类。而具体添加算子的方法我们会在之后的文章里介绍。
在转换普通的torch.nn.Module模型时,PyTorch 一方面会用跟踪法执行前向推理,把遇到的算子整合成计算图;另一方面,PyTorch 还会把遇到的每个算子翻译成 ONNX 中定义的算子。在这个翻译过程中,可能会碰到以下情况:
- 该算子可以一对一地翻译成一个 ONNX 算子。
- 该算子在 ONNX 中没有直接对应的算子,会翻译成一至多个 ONNX 算子。
- 该算子没有定义翻译成 ONNX 的规则,报错。
那么,该如何查看 PyTorch 算子与 ONNX 算子的对应情况呢?由于 PyTorch 算子是向 ONNX 对齐的,这里我们先看一下 ONNX 算子的定义情况,再看一下 PyTorch 定义的算子映射关系。
ONNX 算子文档
ONNX 算子的定义情况,都可以在官方的算子文档中查看。这份文档十分重要,我们碰到任何和 ONNX 算子有关的问题都得来”请教“这份文档。
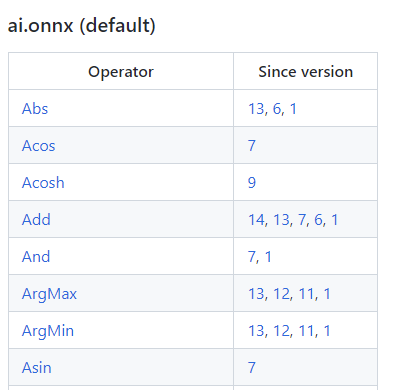
这份文档中最重要的开头的这个算子变更表格。表格的第一列是算子名,第二列是该算子发生变动的算子集版本号,也就是我们之前在torch.onnx.export中提到的opset_version表示的算子集版本号。通过查看算子第一次发生变动的版本号,我们可以知道某个算子是从哪个版本开始支持的;通过查看某算子小于等于opset_version的第一个改动记录,我们可以知道当前算子集版本中该算子的定义规则。
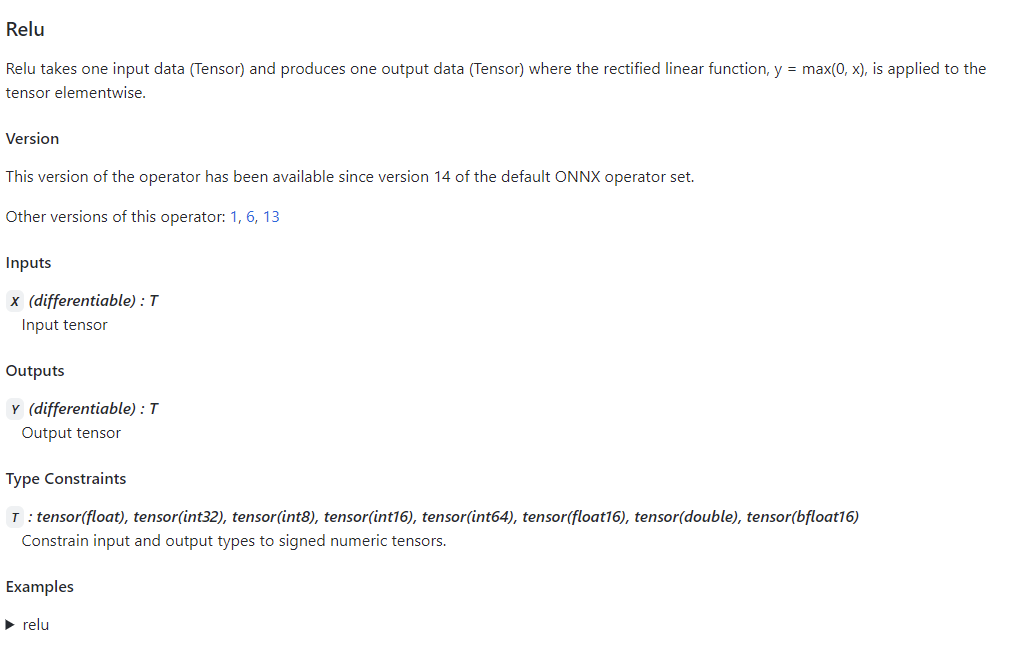
通过点击表格中的链接,我们可以查看某个算子的输入、输出参数规定及使用示例。比如上图是Relu在 ONNX 中的定义规则,这份定义表明 Relu 应该有一个输入和一个输入,输入输出的类型相同,均为 tensor。
PyTorch 对 ONNX 算子的映射
在 PyTorch 中,和 ONNX 有关的定义全部放在 torch.onnx 目录中,如下图所示:
其中,symbloic_opset{n}.py(符号表文件)即表示 PyTorch 在支持第 n 版 ONNX 算子集时新加入的内容。我们之前讲过, bicubic 插值是在第 11 个版本开始支持的。我们以它为例来看看如何查找算子的映射情况。
首先,使用搜索功能,在torch/onnx文件夹搜索"bicubic",可以发现这个这个插值在第 11 个版本的定义文件中:
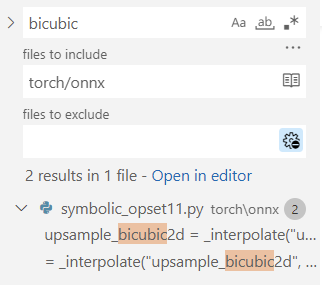
之后,我们按照代码的调用逻辑,逐步跳转直到最底层的 ONNX 映射函数:
upsample_bicubic2d = _interpolate("upsample_bicubic2d", 4, "cubic")
->
def _interpolate(name, dim, interpolate_mode):
return sym_help._interpolate_helper(name, dim, interpolate_mode)
->
def _interpolate_helper(name, dim, interpolate_mode):
def symbolic_fn(g, input, output_size, *args):
...
return symbolic_fn
最后,在symbolic_fn中,我们可以看到插值算子是怎么样被映射成多个 ONNX 算子的。其中,每一个g.op就是一个 ONNX 的定义。比如其中的 Resize 算子就是这样写的:
return g.op("Resize",
input,
empty_roi,
empty_scales,
output_size,
coordinate_transformation_mode_s=coordinate_transformation_mode,
cubic_coeff_a_f=-0.75, # only valid when mode="cubic"
mode_s=interpolate_mode, # nearest, linear, or cubic
nearest_mode_s="floor") # only valid when mode="nearest"
通过在前面提到的 ONNX 算子文档中查找 Resize 算子的定义,我们就可以知道这每一个参数的含义了。用类似的方法,我们可以去查询其他 ONNX 算子的参数含义,进而知道 PyTorch 中的参数是怎样一步一步传入到每个 ONNX 算子中的。
掌握了如何查询 PyTorch 映射到 ONNX 的关系后,我们在实际应用时就可以在 torch.onnx.export()的opset_version中先预设一个版本号,碰到了问题就去对应的 PyTorch 符号表文件里去查。如果某算子确实不存在,或者算子的映射关系不满足我们的要求,我们就可能得用其他的算子绕过去,或者自定义算子了。
总结
在这篇教程中,我们系统地介绍了 PyTorch 转 ONNX 的原理。我们先是着重讲解了使用最频繁的 torch.onnx.export函数,又给出了查询 PyTorch 对 ONNX 算子支持情况的方法。通过本文,我们希望大家能够成功转换出大部分不需要添加新算子的 ONNX 模型,并在碰到算子问题时能够有效定位问题原因。具体而言,大家读完本文后应该了解以下的知识:
- 跟踪法和脚本化在导出带控制语句的计算图时有什么区别。
torch.onnx.export()中该如何设置input_names, output_names, dynamic_axes。- 使用
torch.onnx.is_in_onnx_export()来使模型在转换到 ONNX 时有不同的行为。 - 如何查询 ONNX 算子文档。
- 如何查询 PyTorch 对某个 ONNX 版本的新特性支持情况。
- 如何判断 PyTorch 对某个 ONNX 算子是否支持,支持的方法是怎样的。
这期介绍的知识比较抽象,大家会不会觉得有点“水”?没关系,下一篇教程中,我们将以给出代码实例的形式,介绍多种为 PyTorch 转 ONNX 添加算子支持的方法,为大家在 PyTorch 转 ONNX 这条路上扫除更多的障碍。
练习
- Asinh 算子出现于第 9 个 ONNX 算子集。PyTorch 在 9 号版本的符号表文件中是怎样支持这个算子的?
- BitShift 算子出现于第11个 ONNX 算子集。PyTorch 在 11 号版本的符号表文件中是怎样支持这个算子的?
- 在 第一篇教程 中,我们讲过 PyTorch (截至第 11 号算子集)不支持在插值中设置动态的放缩系数。这个系数对应
torch.onnx.symbolic_helper._interpolate_helper的symbolic_fn的Resize算子映射关系中的哪个参数?我们是如何修改这一参数的?
练习的答案会在下期教程中揭晓。