mirror of
https://github.com/open-mmlab/mmengine.git
synced 2025-06-03 21:54:44 +08:00
[Docs] Fix Chinese docs whitespaces (#521)
* change pre-commit-config * modify docs with pre-commit hook * change pre-commit-config-zh-cn * fallback readme.md Co-authored-by: HAOCHENYE <21724054@zju.edu.cn>
This commit is contained in:
parent
028f4e5919
commit
09a195b24c
@ -49,10 +49,11 @@ repos:
|
||||
- id: pyupgrade
|
||||
args: ["--py36-plus"]
|
||||
- repo: https://gitee.com/openmmlab/pre-commit-hooks
|
||||
rev: v0.2.0
|
||||
rev: v0.4.0
|
||||
hooks:
|
||||
- id: check-copyright
|
||||
args: ["mmengine", "tests"]
|
||||
- id: remove-improper-eol-in-cn-docs
|
||||
- repo: https://gitee.com/openmmlab/mirrors-mypy
|
||||
rev: v0.812
|
||||
hooks:
|
||||
|
||||
@ -49,10 +49,11 @@ repos:
|
||||
- id: pyupgrade
|
||||
args: ["--py36-plus"]
|
||||
- repo: https://github.com/open-mmlab/pre-commit-hooks
|
||||
rev: v0.2.0
|
||||
rev: v0.4.0
|
||||
hooks:
|
||||
- id: check-copyright
|
||||
args: ["mmengine", "tests"]
|
||||
- id: remove-improper-eol-in-cn-docs
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
rev: v0.812
|
||||
hooks:
|
||||
|
||||
@ -30,8 +30,7 @@
|
||||
|
||||
yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
|
||||
|
||||
通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
|
||||
修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
|
||||
通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
|
||||
pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
|
||||
|
||||
在克隆算法库后,你需要安装并初始化 pre-commit 钩子
|
||||
|
||||
@ -95,10 +95,7 @@ python -c 'from mmengine.utils.dl_utils import collect_env;print(collect_env())'
|
||||
<details>
|
||||
<summary>构建模型</summary>
|
||||
|
||||
首先,我们需要构建一个**模型**,在 MMEngine 中,我们约定这个模型应当继承 `BaseModel`,并且其 `forward` 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 `mode`:
|
||||
|
||||
- 对于训练,我们需要 `mode` 接受字符串 "loss",并返回一个包含 "loss" 字段的字典;
|
||||
- 对于验证,我们需要 `mode` 接受字符串 "predict",并返回同时包含预测信息和真实信息的结果。
|
||||
首先,我们需要构建一个**模型**,在 MMEngine 中,我们约定这个模型应当继承 `BaseModel`,并且其 `forward` 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 `mode`:对于训练,我们需要 `mode` 接受字符串 "loss",并返回一个包含 "loss" 字段的字典;对于验证,我们需要 `mode` 接受字符串 "predict",并返回同时包含预测信息和真实信息的结果。
|
||||
|
||||
```python
|
||||
import torch.nn.functional as F
|
||||
@ -160,8 +157,7 @@ val_dataloader = DataLoader(batch_size=32,
|
||||
<details>
|
||||
<summary>构建评测指标</summary>
|
||||
|
||||
为了进行验证和测试,我们需要定义模型推理结果的**评测指标**。我们约定这一评测指标需要继承 `BaseMetric`,
|
||||
并实现 `process` 和 `compute_metrics` 方法。
|
||||
为了进行验证和测试,我们需要定义模型推理结果的**评测指标**。我们约定这一评测指标需要继承 `BaseMetric`,并实现 `process` 和 `compute_metrics` 方法。
|
||||
|
||||
```python
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
# 抽象数据接口
|
||||
|
||||
在模型的训练/测试过程中,组件之间往往有大量的数据需要传递,不同的算法需要传递的数据经常是不一样的,
|
||||
例如,训练单阶段检测器需要获得数据集的标注框(ground truth bounding boxes)和标签(ground truth box labels),训练 Mask R-CNN 时还需要实例掩码(instance masks)。
|
||||
在模型的训练/测试过程中,组件之间往往有大量的数据需要传递,不同的算法需要传递的数据经常是不一样的,例如,训练单阶段检测器需要获得数据集的标注框(ground truth bounding boxes)和标签(ground truth box labels),训练 Mask R-CNN 时还需要实例掩码(instance masks)。
|
||||
训练这些模型时的代码如下所示
|
||||
|
||||
```python
|
||||
|
||||
@ -1,8 +1,7 @@
|
||||
# 文件读写
|
||||
|
||||
`MMEngine` 实现了一套统一的文件读写接口,可以用同一个函数来处理不同的文件格式,如 `json`、
|
||||
`yaml` 和 `pickle`,并且可以方便地拓展其它的文件格式。除此之外,文件读写模块还支持从多种文件
|
||||
存储后端读写文件,包括本地磁盘、Petrel(内部使用)、Memcached、LMDB 和 HTTP。
|
||||
`yaml` 和 `pickle`,并且可以方便地拓展其它的文件格式。除此之外,文件读写模块还支持从多种文件存储后端读写文件,包括本地磁盘、Petrel(内部使用)、Memcached、LMDB 和 HTTP。
|
||||
|
||||
## 读取和保存数据
|
||||
|
||||
@ -47,9 +46,7 @@ data = load('s3://bucket-name/test.pkl')
|
||||
dump(data, 's3://bucket-name/out.pkl')
|
||||
```
|
||||
|
||||
我们提供了易于拓展的方式以支持更多的文件格式,我们只需要创建一个继承自 `BaseFileHandler` 的
|
||||
文件句柄类,句柄类至少需要重写三个方法。然后使用使用 `register_handler` 装饰器将句柄类注册
|
||||
为对应文件格式的读写句柄。
|
||||
我们提供了易于拓展的方式以支持更多的文件格式,我们只需要创建一个继承自 `BaseFileHandler` 的文件句柄类,句柄类至少需要重写三个方法。然后使用使用 `register_handler` 装饰器将句柄类注册为对应文件格式的读写句柄。
|
||||
|
||||
```python
|
||||
from mmengine import register_handler, BaseFileHandler
|
||||
|
||||
@ -179,8 +179,7 @@ KaimingInit: a=0, mode=fan_out, nonlinearity=relu, distribution =normal, bias=0
|
||||
|
||||
`override` 可以理解成一个嵌套的 `init_cfg`, 他同样可以是 `list` 或者 `dict`,也需要通过 `type`
|
||||
字段指定初始化方式。不同的是 `override` 必须指定 `name`,`name` 相当于 `override`
|
||||
的作用域,如上例中,`override` 的作用域为 `toy_net.conv2`,
|
||||
我们会以 `Xavier` 初始化方式初始化 `toy_net.conv2` 下的所有参数,而不会影响作用域以外的模块。
|
||||
的作用域,如上例中,`override` 的作用域为 `toy_net.conv2`,我们会以 `Xavier` 初始化方式初始化 `toy_net.conv2` 下的所有参数,而不会影响作用域以外的模块。
|
||||
|
||||
### 自定义的初始化方式
|
||||
|
||||
|
||||
@ -106,8 +106,7 @@ def draw_featmap(featmap: torch.Tensor, # 输入格式要求为 CHW
|
||||
|
||||
- 考虑到输入的特征图通常非常小,函数支持输入 `resize_shape` 参数,方便将特征图进行上采样后进行可视化。
|
||||
|
||||
常见用法如下:
|
||||
以预训练好的 ResNet18 模型为例,通过提取 layer4 层输出进行特征图可视化
|
||||
常见用法如下:以预训练好的 ResNet18 模型为例,通过提取 layer4 层输出进行特征图可视化
|
||||
|
||||
(1) 将多通道特征图采用 `select_max` 参数压缩为单通道并显示
|
||||
|
||||
|
||||
@ -53,8 +53,7 @@ for img in imgs:
|
||||
|
||||
MMEngine 的执行器内包含训练、测试、验证所需的各个模块,以及循环控制器(Loop)和[钩子(Hook)](../tutorials/hook.md)。用户通过提供配置文件或已构建完成的模块,执行器将自动完成运行环境的配置,模块的构建和组合,最终通过循环控制器执行任务循环。执行器对外提供三个接口:`train`, `val`, `test`,当调用这三个接口时,便会运行对应的循环控制器,并在循环的运行过程中调用钩子模块各个位点的钩子函数。
|
||||
|
||||
当用户构建一个执行器并调用训练、验证、测试的接口时,执行器的执行流程如下:
|
||||
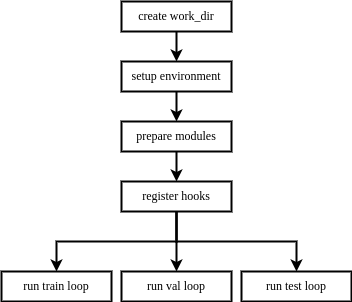
创建工作目录 -> 配置运行环境 -> 准备任务所需模块 -> 注册钩子 -> 运行循环
|
||||
当用户构建一个执行器并调用训练、验证、测试的接口时,执行器的执行流程如下:创建工作目录 -> 配置运行环境 -> 准备任务所需模块 -> 注册钩子 -> 运行循环
|
||||
|
||||
|
||||
|
||||
@ -75,8 +74,7 @@ MMEngine 内提供了四种默认的循环控制器:
|
||||
MMEngine 中的默认执行器和循环控制器能够完成大部分的深度学习任务,但不可避免会存在无法满足的情况。有的用户希望能够对执行器进行更多自定义修改,因此,MMEngine 支持自定义模型的训练、验证以及测试的流程。
|
||||
|
||||
用户可以通过继承循环基类来实现自己的训练流程。循环基类需要提供两个输入:`runner` 执行器的实例和 `loader` 循环所需要迭代的迭代器。
|
||||
用户如果有自定义的需求,也可以增加更多的输入参数。MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,
|
||||
然后在配置文件的 `train_cfg`、`val_cfg`、`test_cfg` 中增加 `type` 字段来指定使用何种循环。
|
||||
用户如果有自定义的需求,也可以增加更多的输入参数。MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,然后在配置文件的 `train_cfg`、`val_cfg`、`test_cfg` 中增加 `type` 字段来指定使用何种循环。
|
||||
用户可以在自定义的循环中实现任意的执行逻辑,也可以增加或删减钩子(hook)点位,但需要注意的是一旦钩子点位被修改,默认的钩子函数可能不会被执行,导致一些训练过程中默认发生的行为发生变化。
|
||||
因此,我们强烈建议用户按照本文档中定义的循环执行流程图以及[钩子设计](../tutorials/hook.md) 去重载循环基类。
|
||||
|
||||
@ -130,8 +128,7 @@ class CustomValHook(Hook):
|
||||
|
||||
```
|
||||
|
||||
上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,
|
||||
只需要在配置文件的 `val_cfg` 内设置 `type='CustomValLoop'`,并添加额外的配置即可。
|
||||
上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,只需要在配置文件的 `val_cfg` 内设置 `type='CustomValLoop'`,并添加额外的配置即可。
|
||||
|
||||
```python
|
||||
# 自定义验证循环
|
||||
|
||||
@ -1,9 +1,7 @@
|
||||
# 跨库调用模块
|
||||
|
||||
通过使用 MMEngine 的[注册器(Registry)](../tutorials/registry.md)和[配置文件(Config)](../tutorials/config.md),用户可以实现跨软件包的模块构建。
|
||||
例如,在 [MMDetection](https://github.com/open-mmlab/mmdetection) 中使用 [MMClassification](https://github.com/open-mmlab/mmclassification) 的 Backbone,
|
||||
或者在 [MMRotate](https://github.com/open-mmlab/mmrotate) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Transform,
|
||||
或者在 [MMTracking](https://github.com/open-mmlab/mmtracking) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Detector。
|
||||
例如,在 [MMDetection](https://github.com/open-mmlab/mmdetection) 中使用 [MMClassification](https://github.com/open-mmlab/mmclassification) 的 Backbone,或者在 [MMRotate](https://github.com/open-mmlab/mmrotate) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Transform,或者在 [MMTracking](https://github.com/open-mmlab/mmtracking) 中使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 的 Detector。
|
||||
一般来说,同类模块都可以进行跨库调用,只需要在配置文件的模块类型前加上软件包名的前缀即可。下面举几个常见的例子:
|
||||
|
||||
## 跨库调用 Backbone:
|
||||
|
||||
@ -147,8 +147,7 @@ from mmengine.model import ImgDataPreprocessor
|
||||
data_preprocessor = ImgDataPreprocessor(mean=([127.5]), std=([127.5]))
|
||||
```
|
||||
|
||||
下面的代码实现了基础 GAN 的算法。使用 MMEngine 实现算法类,需要继承 [BaseModel](mmengine.model.BaseModel) 基类,
|
||||
在 train_step 中实现训练过程。GAN 需要交替训练生成器和判别器,分别由 train_discriminator 和 train_generator 实现,并实现 disc_loss 和 gen_loss 计算判别器损失函数和生成器损失函数。
|
||||
下面的代码实现了基础 GAN 的算法。使用 MMEngine 实现算法类,需要继承 [BaseModel](mmengine.model.BaseModel) 基类,在 train_step 中实现训练过程。GAN 需要交替训练生成器和判别器,分别由 train_discriminator 和 train_generator 实现,并实现 disc_loss 和 gen_loss 计算判别器损失函数和生成器损失函数。
|
||||
关于 BaseModel 的更多信息,请参考[模型教程](../tutorials/model.md).
|
||||
|
||||
```python
|
||||
|
||||
@ -10,9 +10,7 @@
|
||||
|
||||
## 构建模型
|
||||
|
||||
首先,我们需要构建一个**模型**,在 MMEngine 中,我们约定这个模型应当继承 `BaseModel`,并且其 `forward` 方法除了接受来自数据集的若干参数外,
|
||||
还需要接受额外的参数 `mode`:对于训练,我们需要 `mode` 接受字符串 "loss",并返回一个包含 "loss" 字段的字典;
|
||||
对于验证,我们需要 `mode` 接受字符串 "predict",并返回同时包含预测信息和真实信息的结果。
|
||||
首先,我们需要构建一个**模型**,在 MMEngine 中,我们约定这个模型应当继承 `BaseModel`,并且其 `forward` 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 `mode`:对于训练,我们需要 `mode` 接受字符串 "loss",并返回一个包含 "loss" 字段的字典;对于验证,我们需要 `mode` 接受字符串 "predict",并返回同时包含预测信息和真实信息的结果。
|
||||
|
||||
```python
|
||||
import torch.nn.functional as F
|
||||
@ -70,12 +68,10 @@ val_dataloader = DataLoader(batch_size=32,
|
||||
|
||||
## 构建评测指标
|
||||
|
||||
为了进行验证和测试,我们需要定义模型推理结果的**评测指标**。我们约定这一评测指标需要继承 `BaseMetric`,
|
||||
并实现 `process` 和 `compute_metrics` 方法。其中 `process` 方法接受数据集的输出和模型 `mode="predict"`
|
||||
为了进行验证和测试,我们需要定义模型推理结果的**评测指标**。我们约定这一评测指标需要继承 `BaseMetric`,并实现 `process` 和 `compute_metrics` 方法。其中 `process` 方法接受数据集的输出和模型 `mode="predict"`
|
||||
时的输出,此时的数据为一个批次的数据,对这一批次的数据进行处理后,保存信息至 `self.results` 属性。
|
||||
而 `compute_metrics` 接受 `results` 参数,这一参数的输入为 `process` 中保存的所有信息
|
||||
(如果是分布式环境,`results` 中为已收集的,包括各个进程 `process` 保存信息的结果),
|
||||
利用这些信息计算并返回保存有评测指标结果的字典。
|
||||
(如果是分布式环境,`results` 中为已收集的,包括各个进程 `process` 保存信息的结果),利用这些信息计算并返回保存有评测指标结果的字典。
|
||||
|
||||
```python
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
@ -520,8 +520,7 @@ param_scheduler = [
|
||||
|
||||
## 参数更新频率相关配置迁移
|
||||
|
||||
如果在使用 epoch-based 训练循环且配置文件中按 epoch 设置生效区间(`begin`,`end`)或周期(`T_max`)等变量的同时希望参数率按 iteration 更新,在 MMCV 中需要将 `by_epoch` 设置为 False。而在 MMEngine 中需要注意,配置中的 `by_epoch` 仍需设置为 True,通过在配置中添加 `convert_to_iter_based=True` 来构建按 iteration 更新的参数调度器,
|
||||
关于此配置详见[参数调度器教程](../tutorials/param_scheduler.md)。
|
||||
如果在使用 epoch-based 训练循环且配置文件中按 epoch 设置生效区间(`begin`,`end`)或周期(`T_max`)等变量的同时希望参数率按 iteration 更新,在 MMCV 中需要将 `by_epoch` 设置为 False。而在 MMEngine 中需要注意,配置中的 `by_epoch` 仍需设置为 True,通过在配置中添加 `convert_to_iter_based=True` 来构建按 iteration 更新的参数调度器,关于此配置详见[参数调度器教程](../tutorials/param_scheduler.md)。
|
||||
以迁移CosineAnnealing为例:
|
||||
|
||||
<table class="docutils">
|
||||
|
||||
@ -3,10 +3,8 @@
|
||||
## 简介
|
||||
|
||||
在 TorchVision 的数据变换类接口约定中,数据变换类需要实现 `__call__` 方法,而在 OpenMMLab 1.0 的接口约定中,进一步要求
|
||||
`__call__` 方法的输出应当是一个字典,在各种数据变换中对这个字典进行增删查改。在 OpenMMLab 2.0 中,为了提升后续的
|
||||
可扩展性,我们将原先的 `__call__` 方法迁移为 `transform` 方法,并要求数据变换类应当继承
|
||||
[`mmcv.transforms.BaseTransfrom`](https://mmcv.readthedocs.io/en/dev-2.x/api.html#TODO)。具体如何实现一个数据
|
||||
变换类,可以参见[文档](../tutorials/data_transform.md)。
|
||||
`__call__` 方法的输出应当是一个字典,在各种数据变换中对这个字典进行增删查改。在 OpenMMLab 2.0 中,为了提升后续的可扩展性,我们将原先的 `__call__` 方法迁移为 `transform` 方法,并要求数据变换类应当继承
|
||||
[`mmcv.transforms.BaseTransfrom`](https://mmcv.readthedocs.io/en/dev-2.x/api.html#TODO)。具体如何实现一个数据变换类,可以参见[文档](../tutorials/data_transform.md)。
|
||||
|
||||
由于在此次更新中,我们将部分共用的数据变换类统一迁移至 MMCV 中,因此本文的将会以 [MMClassification v0.23.2](https://github.com/open-mmlab/mmclassification/tree/v0.23.2)、[MMDetection v2.25.1](https://github.com/open-mmlab/mmdetection/tree/v2.25.1) 和 [MMCV v2.0.0rc0](https://github.com/open-mmlab/mmcv/tree/dev-2.x) 为例,对比这些数据变换类在新旧版本中功能、用法和实现上的差异。
|
||||
|
||||
|
||||
@ -500,8 +500,7 @@ class CustomOptim:
|
||||
optimizer = dict(type='CustomOptim')
|
||||
```
|
||||
|
||||
那么就需要在读取配置文件和构造优化器之前,增加一行 `import my_module` 来保证将自定义的类 `CustomOptim` 注册到 OPTIMIZERS 注册器中:
|
||||
为了解决这个问题,我们给配置文件定义了一个保留字段 `custom_imports`,用于将需要提前导入的 Python 模块,直接写在配置文件中。对于上述例子,就可以将配置文件写成如下:
|
||||
那么就需要在读取配置文件和构造优化器之前,增加一行 `import my_module` 来保证将自定义的类 `CustomOptim` 注册到 OPTIMIZERS 注册器中:为了解决这个问题,我们给配置文件定义了一个保留字段 `custom_imports`,用于将需要提前导入的 Python 模块,直接写在配置文件中。对于上述例子,就可以将配置文件写成如下:
|
||||
|
||||
`custom_imports.py`
|
||||
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
# 数据变换 (Data Transform)
|
||||
|
||||
在 OpenMMLab 算法库中,数据集的构建和数据的准备是相互解耦的。通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息;
|
||||
而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
|
||||
在 OpenMMLab 算法库中,数据集的构建和数据的准备是相互解耦的。通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息;而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
|
||||
|
||||
## 使用数据变换类
|
||||
|
||||
@ -9,8 +8,7 @@
|
||||
同时,我们约定所有数据变换都接受一个字典作为输入,并将处理后的数据输出为一个字典。一个简单的例子如下:
|
||||
|
||||
```{note}
|
||||
MMEngine 中仅约定了数据变换类的规范,常用的数据变换类实现及基类都在 MMCV 中,因此在本篇教程需要提前安装好 MMCV,
|
||||
参见 MMCV 的[安装教程](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html)。
|
||||
MMEngine 中仅约定了数据变换类的规范,常用的数据变换类实现及基类都在 MMCV 中,因此在本篇教程需要提前安装好 MMCV,参见 MMCV 的[安装教程](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html)。
|
||||
```
|
||||
|
||||
```python
|
||||
|
||||
@ -150,8 +150,7 @@ default_hooks = dict(logger=dict(type='LoggerHook', interval=20))
|
||||
|
||||
### RuntimeInfoHook
|
||||
|
||||
[RuntimeInfoHook](mmengine.hooks.RuntimeInfoHook) 会在执行器的不同钩子位点将当前的运行时信息(如 epoch、iter、max_epochs、max_iters、lr、metrics等)更新至 message hub 中,
|
||||
以便其他无法访问执行器的模块能够获取到这些信息。`RuntimeInfoHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
|
||||
[RuntimeInfoHook](mmengine.hooks.RuntimeInfoHook) 会在执行器的不同钩子位点将当前的运行时信息(如 epoch、iter、max_epochs、max_iters、lr、metrics等)更新至 message hub 中,以便其他无法访问执行器的模块能够获取到这些信息。`RuntimeInfoHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
|
||||
|
||||
### EMAHook
|
||||
|
||||
|
||||
@ -278,8 +278,7 @@ optimizer = SGD([{'params': model.backbone.parameters()},
|
||||
#### 为不同类型的参数设置不同的超参系数
|
||||
|
||||
MMEngine 提供的默认优化器封装构造器支持对模型中不同类型的参数设置不同的超参系数。
|
||||
例如,我们可以在 `paramwise_cfg` 中设置 `norm_decay_mult=0` ,从而将正则化层(normalization layer)的权重(weight)和偏置(bias)的权值衰减系数(weight decay)设置为 0,
|
||||
来实现 [Bag of Tricks](https://arxiv.org/abs/1812.01187) 论文中提到的不对正则化层进行权值衰减的技巧。
|
||||
例如,我们可以在 `paramwise_cfg` 中设置 `norm_decay_mult=0` ,从而将正则化层(normalization layer)的权重(weight)和偏置(bias)的权值衰减系数(weight decay)设置为 0,来实现 [Bag of Tricks](https://arxiv.org/abs/1812.01187) 论文中提到的不对正则化层进行权值衰减的技巧。
|
||||
|
||||
具体示例如下,我们将 `ToyModel` 中所有正则化层(`head.bn`)的的权重衰减系数设置为 0:
|
||||
|
||||
|
||||
@ -6,8 +6,7 @@ OpenMMLab 大多数算法库均使用注册器来管理它们的代码模块,
|
||||
|
||||
## 什么是注册器
|
||||
|
||||
MMEngine 实现的[注册器](mmengine.registry.Registry)可以看作一个映射表和模块构建方法(build function)的组合。映射表维护了一个字符串到**类或者函数的映射**,使得用户可以借助字符串查找到相应的类或函数,例如维护字符串 `"ResNet"` 到 `ResNet` 类或函数的映射,使得用户可以通过 `"ResNet"` 找到 `ResNet` 类;
|
||||
而模块构建方法则定义了如何根据字符串查找到对应的类或函数以及如何实例化这个类或者调用这个函数,例如,通过字符串 `"bn"` 找到 `nn.BatchNorm2d` 并实例化 `BatchNorm2d` 模块;又或者通过字符串 `"build_batchnorm2d"` 找到 `build_batchnorm2d` 函数并返回该函数的调用结果。
|
||||
MMEngine 实现的[注册器](mmengine.registry.Registry)可以看作一个映射表和模块构建方法(build function)的组合。映射表维护了一个字符串到**类或者函数的映射**,使得用户可以借助字符串查找到相应的类或函数,例如维护字符串 `"ResNet"` 到 `ResNet` 类或函数的映射,使得用户可以通过 `"ResNet"` 找到 `ResNet` 类;而模块构建方法则定义了如何根据字符串查找到对应的类或函数以及如何实例化这个类或者调用这个函数,例如,通过字符串 `"bn"` 找到 `nn.BatchNorm2d` 并实例化 `BatchNorm2d` 模块;又或者通过字符串 `"build_batchnorm2d"` 找到 `build_batchnorm2d` 函数并返回该函数的调用结果。
|
||||
MMEngine 中的注册器默认使用 [build_from_cfg](mmengine.registry.build_from_cfg) 函数来查找并实例化字符串对应的类或者函数。
|
||||
|
||||
一个注册器管理的类或函数通常有相似的接口和功能,因此该注册器可以被视作这些类或函数的抽象。例如注册器 `MODELS` 可以被视作所有模型的抽象,管理了 `ResNet`, `SEResNet` 和 `RegNetX` 等分类网络的类以及 `build_ResNet`, `build_SEResNet` 和 `build_RegNetX` 等分类网络的构建函数。
|
||||
|
||||
@ -2,8 +2,7 @@
|
||||
|
||||
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此 MMEngine 提供了执行器以帮助用户简化这些任务的实现流程。 用户只需要准备好模型训练、验证、测试所需要的模块构建执行器,便能够通过简单调用执行器的接口来完成这些任务。用户如果需要使用这几项功能中的某一项,只需要准备好对应功能所依赖的模块即可。
|
||||
|
||||
用户可以手动构建这些模块的实例,也可以通过编写[配置文件](./config.md),
|
||||
由执行器自动从[注册器](./registry.md)中构建所需要的模块,我们推荐使用后一种方式。
|
||||
用户可以手动构建这些模块的实例,也可以通过编写[配置文件](./config.md),由执行器自动从[注册器](./registry.md)中构建所需要的模块,我们推荐使用后一种方式。
|
||||
|
||||
## 手动构建模块来使用执行器
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user