[Docs] Update runner documents. (#430)
* [Doc] Update runner documents. * update * fix link * update * update * Update import manner of Runner Co-authored-by: Wenwei Zhang <40779233+ZwwWayne@users.noreply.github.com>pull/440/head
parent
d6bf587d68
commit
5e1ef1dd6c
|
|
@ -0,0 +1,160 @@
|
|||
# 执行器的设计
|
||||
|
||||
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此, MMEngine 抽象出了执行器来负责通用的算法模型的训练、测试、推理任务。用户一般可以直接使用 MMEngine 中的默认执行器,也可以对执行器进行修改以满足定制化需求。
|
||||
|
||||
在介绍执行器的设计之前,我们先举几个例子来帮助用户理解为什么需要执行器。下面是一段使用 PyTorch 进行模型训练的伪代码:
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
train_dataset = ImageNetDataset(...)
|
||||
train_dataloader = DataLoader(train_dataset, ...)
|
||||
|
||||
for i in range(max_epochs):
|
||||
for data_batch in train_dataloader:
|
||||
optimizer.zero_grad()
|
||||
outputs = model(data_batch)
|
||||
loss = loss_func(outputs, data_batch)
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
```
|
||||
|
||||
下面是一段使用 PyTorch 进行模型测试的伪代码:
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
model.load_state_dict(torch.load(CKPT_PATH))
|
||||
model.eval()
|
||||
|
||||
test_dataset = ImageNetDataset(...)
|
||||
test_dataloader = DataLoader(test_dataset, ...)
|
||||
|
||||
for data_batch in test_dataloader:
|
||||
outputs = model(data_batch)
|
||||
acc = calculate_acc(outputs, data_batch)
|
||||
```
|
||||
|
||||
下面是一段使用 PyTorch 进行模型推理的伪代码:
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
model.load_state_dict(torch.load(CKPT_PATH))
|
||||
model.eval()
|
||||
|
||||
for img in imgs:
|
||||
prediction = model(img)
|
||||
```
|
||||
|
||||
可以从上面的三段代码看出,这三个任务的执行流程都可以归纳为构建模型、读取数据、循环迭代等步骤。上述代码都是以图像分类为例,但不论是图像分类还是目标检测或是图像分割,都脱离不了这套范式。
|
||||
因此,我们将模型的训练、验证、测试的流程整合起来,形成了执行器。在执行器中,我们只需要准备好模型、数据等任务必须的模块或是这些模块的配置文件,执行器会自动完成任务流程的准备和执行。
|
||||
通过使用执行器以及 MMEngine 中丰富的功能模块,用户不再需要手动搭建训练测试的流程,也不再需要去处理分布式与非分布式训练的区别,可以专注于算法和模型本身。
|
||||
|
||||
|
||||
|
||||
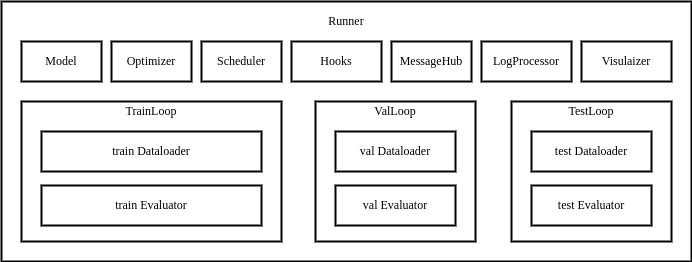
MMEngine 的执行器内包含训练、测试、验证所需的各个模块,以及循环控制器(Loop)和[钩子(Hook)](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html)。用户通过提供配置文件或已构建完成的模块,执行器将自动完成运行环境的配置,模块的构建和组合,最终通过循环控制器执行任务循环。执行器对外提供三个接口:`train`, `val`, `test`,当调用这三个接口时,便会运行对应的循环控制器,并在循环的运行过程中调用钩子模块各个位点的钩子函数。
|
||||
|
||||
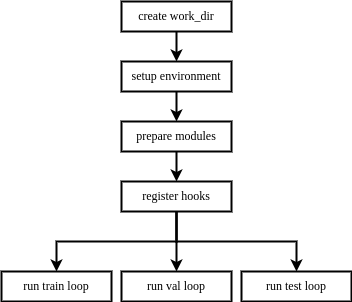
当用户构建一个执行器并调用训练、验证、测试的接口时,执行器的执行流程如下:
|
||||
创建工作目录 -> 配置运行环境 -> 准备任务所需模块 -> 注册钩子 -> 运行循环
|
||||
|
||||
|
||||
|
||||
执行器具有延迟初始化(Lazy Initialization)的特性,在初始化执行器时,并不需要依赖训练、验证和测试的全量模块,只有当运行某个循环控制器时,才会检查所需模块是否构建。因此,若用户只需要执行训练、验证或测试中的某一项功能,只需提供对应的模块或模块的配置即可。
|
||||
|
||||
## 循环控制器
|
||||
|
||||
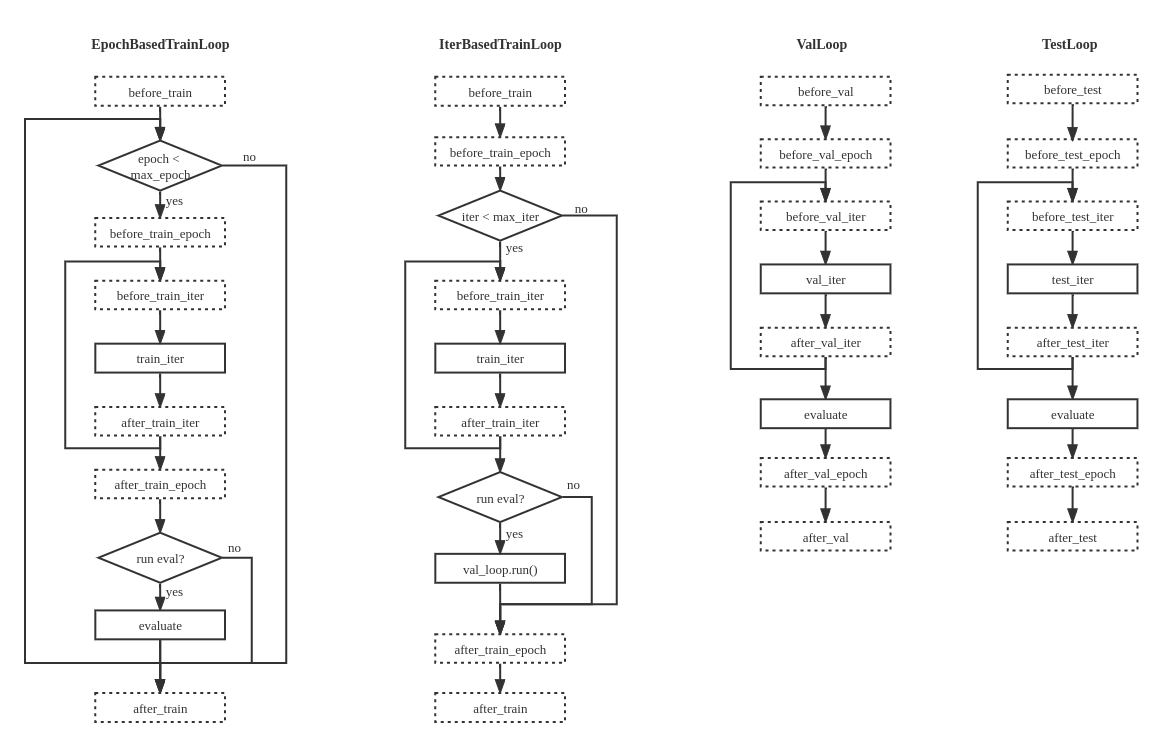
在 MMEngine 中,我们将任务的执行流程抽象成循环控制器(Loop),因为大部分的深度学习任务执行流程都可以归纳为模型在一组或多组数据上进行循环迭代。
|
||||
MMEngine 内提供了四种默认的循环控制器:
|
||||
|
||||
- EpochBasedTrainLoop 基于轮次的训练循环
|
||||
- IterBasedTrainLoop 基于迭代次数的训练循环
|
||||
- ValLoop 标准的验证循环
|
||||
- TestLoop 标准的测试循环
|
||||
|
||||
|
||||
|
||||
MMEngine 中的默认执行器和循环控制器能够完成大部分的深度学习任务,但不可避免会存在无法满足的情况。有的用户希望能够对执行器进行更多自定义修改,因此,MMEngine 支持自定义模型的训练、验证以及测试的流程。
|
||||
|
||||
用户可以通过继承循环基类来实现自己的训练流程。循环基类需要提供两个输入:`runner` 执行器的实例和 `loader` 循环所需要迭代的迭代器。
|
||||
用户如果有自定义的需求,也可以增加更多的输入参数。MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,
|
||||
然后在配置文件的 `train_cfg`、`val_cfg`、`test_cfg` 中增加 `type` 字段来指定使用何种循环。
|
||||
用户可以在自定义的循环中实现任意的执行逻辑,也可以增加或删减钩子(hook)点位,但需要注意的是一旦钩子点位被修改,默认的钩子函数可能不会被执行,导致一些训练过程中默认发生的行为发生变化。
|
||||
因此,我们强烈建议用户按照本文档中定义的循环执行流程图以及[钩子设计](https://mmengine.readthedocs.io/zh_CN/latest/design/hook.html) 去重载循环基类。
|
||||
|
||||
```python
|
||||
from mmengine.registry import LOOPS, HOOKS
|
||||
from mmengine.runner import BaseLoop
|
||||
from mmengine.hooks import Hook
|
||||
|
||||
|
||||
# 自定义验证循环
|
||||
@LOOPS.register_module()
|
||||
class CustomValLoop(BaseLoop):
|
||||
def __init__(self, runner, dataloader, evaluator, dataloader2):
|
||||
super().__init__(runner, dataloader, evaluator)
|
||||
self.dataloader2 = runner.build_dataloader(dataloader2)
|
||||
|
||||
def run(self):
|
||||
self.runner.call_hooks('before_val_epoch')
|
||||
for idx, data_batch in enumerate(self.dataloader):
|
||||
self.runner.call_hooks(
|
||||
'before_val_iter', batch_idx=idx, data_batch=data_batch)
|
||||
outputs = self.run_iter(idx, data_batch)
|
||||
self.runner.call_hooks(
|
||||
'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
|
||||
metric = self.evaluator.evaluate()
|
||||
|
||||
# 增加额外的验证循环
|
||||
for idx, data_batch in enumerate(self.dataloader2):
|
||||
# 增加额外的钩子点位
|
||||
self.runner.call_hooks(
|
||||
'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
|
||||
self.run_iter(idx, data_batch)
|
||||
# 增加额外的钩子点位
|
||||
self.runner.call_hooks(
|
||||
'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
|
||||
metric2 = self.evaluator.evaluate()
|
||||
|
||||
...
|
||||
|
||||
self.runner.call_hooks('after_val_epoch')
|
||||
|
||||
|
||||
# 定义额外点位的钩子类
|
||||
@HOOKS.register_module()
|
||||
class CustomValHook(Hook):
|
||||
def before_valloader2_iter(self, batch_idx, data_batch):
|
||||
...
|
||||
|
||||
def after_valloader2_iter(self, batch_idx, data_batch, outputs):
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,
|
||||
只需要在配置文件的 `val_cfg` 内设置 `type='CustomValLoop'`,并添加额外的配置即可。
|
||||
|
||||
```python
|
||||
# 自定义验证循环
|
||||
val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
|
||||
# 额外点位的钩子
|
||||
custom_hooks = [dict(type='CustomValHook')]
|
||||
```
|
||||
|
||||
## 自定义执行器
|
||||
|
||||
更进一步,如果默认执行器中依然有其他无法满足需求的部分,用户可以像自定义其他模块一样,通过继承重写的方式,实现自定义的执行器。执行器同样也可以通过注册器进行管理。具体实现流程与其他模块无异:继承 MMEngine 中的 Runner,重写需要修改的函数,添加进 RUNNERS 注册器中,最后在配置文件中指定 `runner_type` 即可。
|
||||
|
||||
```python
|
||||
from mmengine.registry import RUNNERS
|
||||
from mmengine.runner import Runner
|
||||
|
||||
@RUNNERS.register_module()
|
||||
class CustomRunner(Runner):
|
||||
|
||||
def setup_env(self):
|
||||
...
|
||||
```
|
||||
|
||||
上述例子实现了一个自定义的执行器,并重写了 `setup_env` 函数,然后添加进了 RUNNERS 注册器中,完成了这些步骤之后,便可以在配置文件中设置 `runner_type='CustomRunner'` 来构建自定义的执行器。
|
||||
|
||||
你可能还想阅读[执行器的教程](../tutorials/runner.md)或者[执行器的 API 文档](https://mmengine.readthedocs.io/zh_CN/latest/api/runner.html)。
|
||||
|
|
@ -1,119 +1,160 @@
|
|||
# 执行器(Runner)
|
||||
|
||||
OpenMMLab 的算法库中提供了各种算法模型的训练、测试、推理功能,这些功能在不同算法方向上都有着相似的接口。
|
||||
因此, MMEngine 抽象出了执行器来负责通用的算法模型的训练、测试、推理任务。
|
||||
用户一般可以直接使用 MMEngine 中的默认执行器,也可以对执行器进行修改以满足定制化需求。
|
||||
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此 MMEngine 提供了执行器以帮助用户简化这些任务的实现流程。 用户只需要准备好模型训练、验证、测试所需要的模块构建执行器,便能够通过简单调用执行器的接口来完成这些任务。用户如果需要使用这几项功能中的某一项,只需要准备好对应功能所依赖的模块即可。
|
||||
|
||||
在介绍如何使用执行器之前,我们先举几个例子来帮助用户理解为什么需要执行器。
|
||||
用户可以手动构建这些模块的实例,也可以通过编写[配置文件](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html),
|
||||
由执行器自动从[注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html)中构建所需要的模块,我们推荐使用后一种方式。
|
||||
|
||||
下面是一段使用 PyTorch 进行模型训练的伪代码:
|
||||
## 手动构建模块来使用执行器
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
train_dataset = ImageNetDataset(...)
|
||||
train_dataloader = DataLoader(train_dataset, ...)
|
||||
|
||||
for i in range(max_epochs):
|
||||
for data_batch in train_dataloader:
|
||||
optimizer.zero_grad()
|
||||
outputs = model(data_batch)
|
||||
loss = loss_func(outputs, data_batch)
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
```
|
||||
|
||||
下面是一段使用 PyTorch 进行模型测试的伪代码:
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
model.load_state_dict(torch.load(CKPT_PATH))
|
||||
model.eval()
|
||||
|
||||
test_dataset = ImageNetDataset(...)
|
||||
test_dataloader = DataLoader(test_dataset, ...)
|
||||
|
||||
for data_batch in test_dataloader:
|
||||
outputs = model(data_batch)
|
||||
acc = calculate_acc(outputs, data_batch)
|
||||
```
|
||||
|
||||
下面是一段使用 PyTorch 进行模型推理的伪代码:
|
||||
|
||||
```python
|
||||
model = ResNet()
|
||||
model.load_state_dict(torch.load(CKPT_PATH))
|
||||
model.eval()
|
||||
|
||||
for img in imgs:
|
||||
prediction = model(img)
|
||||
```
|
||||
|
||||
可以从上面的三段代码看出,这三个任务的执行流程都可以归纳为构建模型、读取数据、循环迭代等步骤。上述代码都是以图像分类为例,但不论是图像分类还是目标检测或是图像分割,都脱离不了这套范式。
|
||||
因此,我们将模型的训练、验证、测试的流程整合起来,形成了执行器。在执行器中,我们只需要准备好模型、数据等任务必须的模块或是这些模块的配置文件,执行器会自动完成任务流程的准备和执行。
|
||||
通过使用执行器以及 MMEngine 中丰富的功能模块,用户不再需要手动搭建训练测试的流程,也不再需要去处理分布式与非分布式训练的区别,可以专注于算法和模型本身。
|
||||
|
||||
## 如何使用执行器
|
||||
|
||||
MMEngine 中默认的执行器支持执行模型的训练、测试以及推理。用户如果需要使用这几项功能中的某一项,就需要准备好对应功能所依赖的模块。
|
||||
用户可以手动构建这些模块的实例,也可以通过编写[配置文件](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html) ,
|
||||
由执行器自动从[注册器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/registry.html) 中构建所需要的模块。这两种使用方式中,我们更推荐后者。
|
||||
|
||||
### 手动构建模块来使用执行器
|
||||
### 手动构建模块进行训练
|
||||
|
||||
如上文所说,使用执行器的某一项功能时需要准备好对应功能所依赖的模块。以使用执行器的训练功能为例,用户需要准备[模型](TODO) 、[优化器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optimizer.html) 、
|
||||
[参数调度器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/param_scheduler.html) 还有训练[数据集](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/basedataset.html) 。
|
||||
在创建完符合上述文档规范的模块的对象后,就可以使用这些模块初始化执行器:
|
||||
|
||||
```python
|
||||
# 准备训练任务所需要的模块
|
||||
model = ResNet()
|
||||
optimzier = SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
lr_scheduler = MultiStepLR(milestones=[80, 90], by_epoch=True)
|
||||
train_dataset = ImageNetDataset()
|
||||
train_dataloader = Dataloader(dataset=train_dataset, batch_size=32, num_workers=4)
|
||||
import torch
|
||||
from torch import nn
|
||||
from torchvision import transforms
|
||||
from torchvision import datasets
|
||||
from torch.utils.data import DataLoader
|
||||
from mmengine.model import BaseModel
|
||||
from mmengine.optim.scheduler import MultiStepLR
|
||||
|
||||
# 训练相关参数设置
|
||||
train_cfg = dict(by_epoch=True, max_epoch=100)
|
||||
# 定义一个多层感知机网络
|
||||
class Network(BaseModel):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.mlp = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10))
|
||||
self.loss = nn.CrossEntropyLoss()
|
||||
|
||||
def forward(self, batch_inputs: torch.Tensor, data_samples = None, mode: str = 'tensor'):
|
||||
x = batch_inputs.flatten(1)
|
||||
x = self.mlp(x)
|
||||
if mode == 'loss':
|
||||
return {'loss': self.loss(x, data_samples)}
|
||||
elif mode == 'predict':
|
||||
return x.argmax(1)
|
||||
else:
|
||||
return x
|
||||
|
||||
model = Network()
|
||||
|
||||
# 构建优化器
|
||||
optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
# 构建参数调度器用于调整学习率
|
||||
lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
|
||||
# 构建手写数字识别 (MNIST) 数据集
|
||||
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
|
||||
# 构建数据加载器
|
||||
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
|
||||
```
|
||||
|
||||
在创建完符合上述文档规范的模块的对象后,就可以使用这些模块初始化执行器:
|
||||
|
||||
```python
|
||||
from mmengine.runner import Runner
|
||||
|
||||
|
||||
# 训练相关参数设置,按轮次训练,训练3轮
|
||||
train_cfg = dict(by_epoch=True, max_epoch=3)
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model=model, optimizer=optimzier, param_scheduler=lr_scheduler,
|
||||
train_dataloader=train_dataloader, train_cfg=train_cfg)
|
||||
runner = Runner(model,
|
||||
work_dir='./train_mnist', # 工作目录,用于保存模型和日志
|
||||
train_cfg=train_cfg,
|
||||
train_dataloader=train_dataloader,
|
||||
optim_wrapper=dict(optimizer=optimizer),
|
||||
param_scheduler=lr_scheduler)
|
||||
# 执行训练
|
||||
runner.train()
|
||||
```
|
||||
|
||||
上面的例子中,我们手动构建了 ResNet 分类模型和 ImageNet 数据集,以及训练所需要的优化器和学习率调度器,使用这些模块初始化了执行器,最后通过调用执行器的 `train` 函数进行模型训练。
|
||||
上面的例子中,我们手动构建了一个多层感知机网络和手写数字识别 (MNIST) 数据集,以及训练所需要的优化器和学习率调度器,使用这些模块初始化了执行器,并且设置了训练配置 `train_cfg`,让执行器将模型训练3个轮次,最后通过调用执行器的 `train` 方法进行模型训练。
|
||||
|
||||
用户也可以修改 `train_cfg` 使执行器按迭代次数控制训练:
|
||||
|
||||
```python
|
||||
# 训练相关参数设置,按迭代次数训练,训练9000次迭代
|
||||
train_cfg = dict(by_epoch=False, max_epoch=9000)
|
||||
```
|
||||
|
||||
### 手动构建模块进行测试
|
||||
|
||||
再举一个模型测试的例子,模型的测试需要用户准备模型和训练好的权重路径、测试数据集以及[评测器](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluator.html) :
|
||||
|
||||
```python
|
||||
model = FasterRCNN()
|
||||
test_dataset = CocoDataset()
|
||||
test_dataloader = Dataloader(dataset=test_dataset, batch_size=2, num_workers=2)
|
||||
metric = CocoMetric()
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
|
||||
class MnistAccuracy(BaseMetric):
|
||||
def process(self, data, preds) -> None:
|
||||
self.results.append(((data[1] == preds.cpu()).sum(), len(preds)))
|
||||
def compute_metrics(self, results):
|
||||
correct, batch_size = zip(*results)
|
||||
acc = sum(correct) / sum(batch_size)
|
||||
return dict(accuracy=acc)
|
||||
|
||||
model = Network()
|
||||
test_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
|
||||
test_dataloader = DataLoader(dataset=test_dataset)
|
||||
metric = MnistAccuracy()
|
||||
test_evaluator = Evaluator(metric)
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
|
||||
load_from='./faster_rcnn.pth')
|
||||
load_from='./train_mnist/epoch_3.pth', work_dir='./test_mnist')
|
||||
|
||||
# 执行测试
|
||||
runner.test()
|
||||
```
|
||||
|
||||
这个例子中我们手动构建了一个 Faster R-CNN 检测模型,以及测试用的 COCO 数据集和使用 COCO 指标的评测器,并使用这些模块初始化执行器,最后通过调用执行器的 `test` 函数进行模型测试。
|
||||
这个例子中我们重新手动构建了一个多层感知机网络,以及测试用的手写数字识别数据集和使用 (Accuracy) 指标的评测器,并使用这些模块初始化执行器,最后通过调用执行器的 `test` 函数进行模型测试。
|
||||
|
||||
### 通过配置文件使用执行器
|
||||
### 手动构建模块在训练过程中进行验证
|
||||
|
||||
在模型训练过程中,通常会按一定的间隔在验证集上对模型的进行进行验证。在使用 MMEngine 时,只需要构建训练和验证的模块,并在训练配置中设置验证间隔即可
|
||||
|
||||
```python
|
||||
# 准备训练任务所需要的模块
|
||||
optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
|
||||
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
|
||||
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
|
||||
|
||||
# 准备验证需要的模块
|
||||
val_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
|
||||
val_dataloader = Dataloader(dataset=val_dataset)
|
||||
metric = MnistAccuracy()
|
||||
val_evaluator = Evaluator(metric)
|
||||
|
||||
|
||||
# 训练相关参数设置
|
||||
train_cfg = dict(by_epoch=True, # 按轮次训练
|
||||
max_epochs=5, # 训练5轮
|
||||
val_begin=2, # 从第 2 个 epoch 开始验证
|
||||
val_interval=1) # 每隔1轮进行1次验证
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model=model, optim_wrapper=dict(optimizer=optimzier), param_scheduler=lr_scheduler,
|
||||
train_dataloader=train_dataloader, val_dataloader=val_dataloader, val_evaluator=val_evaluator,
|
||||
train_cfg=train_cfg, work_dir='./train_val_mnist')
|
||||
# 执行训练
|
||||
runner.train()
|
||||
```
|
||||
|
||||
## 通过配置文件使用执行器
|
||||
|
||||
OpenMMLab 的开源项目普遍使用注册器 + 配置文件的方式来管理和构建模块,MMEngine 中的执行器也推荐使用配置文件进行构建。
|
||||
下面是一个通过配置文件使用执行器的例子:
|
||||
|
||||
```python
|
||||
from mmengine import Config, Runner
|
||||
from mmengine import Config
|
||||
from mmengine.runner import Runner
|
||||
|
||||
# 加载配置文件
|
||||
config = Config.fromfile('configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py/')
|
||||
config = Config.fromfile('configs/resnet/resnet50_8xb32_in1k.py')
|
||||
|
||||
# 通过配置文件初始化执行器
|
||||
runner = Runner.build_from_cfg(config)
|
||||
|
|
@ -127,9 +168,13 @@ runner.test()
|
|||
|
||||
与手动构建模块来使用执行器不同的是,通过调用 Runner 类的 `build_from_cfg` 方法,执行器能够自动读取配置文件中的模块配置,从相应的注册器中构建所需要的模块,用户不再需要考虑训练和测试分别依赖哪些模块,也不需要为了切换训练的模型和数据而大量改动代码。
|
||||
|
||||
下面是一个典型的配置简单例子:
|
||||
下面是一个典型的使用配置文件调用 MMClassification 中的模块训练分类器的简单例子:
|
||||
|
||||
```python
|
||||
# 工作目录,保存权重和日志
|
||||
work_dir = './train_resnet'
|
||||
# 默认注册器域
|
||||
default_scope = 'mmcls' # 默认使用 `mmcls` (MMClassification) 注册器中的模块
|
||||
# 模型配置
|
||||
model = dict(type='ImageClassifier',
|
||||
backbone=dict(type='ResNet', depth=50),
|
||||
|
|
@ -144,9 +189,11 @@ val_dataloader = ...
|
|||
test_dataloader = ...
|
||||
|
||||
# 优化器配置
|
||||
optimizer = dict(type='SGD', lr=0.01)
|
||||
optim_wrapper = dict(
|
||||
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
|
||||
# 参数调度器配置
|
||||
param_scheduler = dict(type='MultiStepLR', milestones=[80, 90])
|
||||
param_scheduler = dict(
|
||||
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
|
||||
#验证和测试的评测器配置
|
||||
val_evaluator = dict(type='Accuracy')
|
||||
test_evaluator = dict(type='Accuracy')
|
||||
|
|
@ -161,145 +208,54 @@ train_cfg = dict(
|
|||
val_cfg = dict()
|
||||
test_cfg = dict()
|
||||
|
||||
# 自定义钩子
|
||||
# 自定义钩子 (可选)
|
||||
custom_hooks = [...]
|
||||
|
||||
# 默认钩子
|
||||
# 默认钩子 (可选,未在配置文件中写明时将使用默认配置)
|
||||
default_hooks = dict(
|
||||
runtime_info=dict(type='RuntimeInfoHook'), # 运行时信息钩子
|
||||
timer=dict(type='IterTimerHook'), # 计时器钩子
|
||||
checkpoint=dict(type='CheckpointHook', interval=1), # 模型保存钩子
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'), # 为每轮次的数据采样设置随机种子的钩子
|
||||
logger=dict(type='TextLoggerHook'), # 训练日志钩子
|
||||
optimizer=dict(type='OptimzierHook', grad_clip=False), # 优化器钩子
|
||||
param_scheduler=dict(type='ParamSchedulerHook'), # 参数调度器执行钩子
|
||||
sampler_seed=dict(type='DistSamplerSeedHook')) # 为每轮次的数据采样设置随机种子的钩子
|
||||
|
||||
# 环境配置
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=False,
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
mp_cfg=dict(mp_start_method='fork')
|
||||
checkpoint=dict(type='CheckpointHook', interval=1), # 模型保存钩子
|
||||
)
|
||||
|
||||
# 环境配置 (可选,未在配置文件中写明时将使用默认配置)
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=False, # 是否使用 cudnn_benchmark
|
||||
dist_cfg=dict(backend='nccl'), # 分布式通信后端
|
||||
mp_cfg=dict(mp_start_method='fork') # 多进程设置
|
||||
)
|
||||
# 日志处理器 (可选,未在配置文件中写明时将使用默认配置)
|
||||
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
|
||||
# 日志等级配置
|
||||
log_level = 'INFO'
|
||||
|
||||
# 加载权重
|
||||
# 加载权重的路径 (None 表示不加载)
|
||||
load_from = None
|
||||
# 恢复训练
|
||||
# 从加载的权重文件中恢复训练
|
||||
resume = False
|
||||
```
|
||||
|
||||
一个完整的配置文件主要由模型、数据、优化器、参数调度器、评测器等模块的配置,训练、验证、测试等流程的配置,还有执行流程过程中的各种钩子模块的配置,以及环境和日志等其他配置的字段组成。
|
||||
通过配置文件构建的执行器采用了懒初始化 (lazy initialization),只有当调用到训练或测试等执行函数时,才会根据配置文件去完整初始化所需要的模块。
|
||||
|
||||
关于配置文件的更详细的使用方式,请参考[配置文件教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.md)
|
||||
|
||||
## 加载权重或恢复训练
|
||||
|
||||
执行器可以通过 `load_from` 参数加载检查点(checkpoint)文件中的模型权重,只需要将 `load_from` 参数设置为检查点文件的路径即可。
|
||||
|
||||
```python
|
||||
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
|
||||
load_from='./faster_rcnn.pth')
|
||||
load_from='./resnet50.pth')
|
||||
```
|
||||
|
||||
如果是通过配置文件使用执行器,只需修改配置文件中的 `load_from` 字段即可。
|
||||
|
||||
用户也可通过设置 `resume=True` 来,加载检查点中的训练状态信息来恢复训练。当 `load_from` 和 `resume=True` 同时被设置时,执行器将加载 `load_from` 路径对应的检查点文件中的训练状态。如果仅设置 `resume=True`,执行器将会尝试从 `work_dir` 文件夹中寻找并读取最新的检查点文件。
|
||||
用户也可通过设置 `resume=True` 来,加载检查点中的训练状态信息来恢复训练。当 `load_from` 和 `resume=True` 同时被设置时,执行器将加载 `load_from` 路径对应的检查点文件中的训练状态。
|
||||
|
||||
## 进阶使用
|
||||
如果仅设置 `resume=True`,执行器将会尝试从 `work_dir` 文件夹中寻找并读取最新的检查点文件。
|
||||
|
||||
MMEngine 中的默认执行器能够完成大部分的深度学习任务,但不可避免会存在无法满足的情况。有的用户希望能够对执行器进行更多自定义修改,因此,MMEngine 支持自定义模型的训练、验证以及测试的流程。
|
||||
更进一步,如果默认执行器中依然有其他无法满足需求的部分,用户可以像自定义其他模块一样,通过继承重写的方式,实现自定义的执行器。执行器同样也可以通过注册器进行管理。
|
||||
|
||||
### 自定义执行流程
|
||||
|
||||
在 MMEngine 中,我们将任务的执行流程抽象成循环(Loop),因为大部分的深度学习任务执行流程都可以归纳为模型在一组或多组数据上进行循环迭代。
|
||||
MMEngine 内提供了四种默认的循环:
|
||||
|
||||
- EpochBasedTrainLoop 基于轮次的训练循环
|
||||
- IterBasedTrainLoop 基于迭代次数的训练循环
|
||||
- ValLoop 标准的验证循环
|
||||
- TestLoop 标准的测试循环
|
||||
|
||||

|
||||
|
||||
用户可以通过继承循环基类来实现自己的训练流程。循环基类需要提供两个输入:`runner` 执行器的实例和 `loader` 循环所需要迭代的迭代器。
|
||||
用户如果有自定义的需求,也可以增加更多的输入参数。MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,
|
||||
然后在配置文件的 `train_cfg`、`val_cfg`、`test_cfg` 中增加 `type` 字段来指定使用何种循环。
|
||||
用户可以在自定义的循环中实现任意的执行逻辑,也可以增加或删减钩子(hook)点位,但需要注意的是一旦钩子点位被修改,默认的钩子函数可能不会被执行,导致一些训练过程中默认发生的行为发生变化。
|
||||
因此,我们强烈建议用户按照本文档中定义的循环执行流程图以及[钩子规范](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html) 去重载循环基类。
|
||||
|
||||
```python
|
||||
from mmengine.registry import LOOPS, HOOKS
|
||||
from mmengine.runner.loop import BaseLoop
|
||||
from mmengine.hooks import Hook
|
||||
|
||||
|
||||
# 自定义验证循环
|
||||
@LOOPS.register_module()
|
||||
class CustomValLoop(BaseLoop):
|
||||
def __init__(self, runner, dataloader, evaluator, dataloader2):
|
||||
super().__init__(runner, dataloader, evaluator)
|
||||
self.dataloader2 = runner.build_dataloader(dataloader2)
|
||||
|
||||
def run(self):
|
||||
self.runner.call_hooks('before_val_epoch')
|
||||
for idx, data_batch in enumerate(self.dataloader):
|
||||
self.runner.call_hooks(
|
||||
'before_val_iter', batch_idx=idx, data_batch=data_batch)
|
||||
outputs = self.run_iter(idx, data_batch)
|
||||
self.runner.call_hooks(
|
||||
'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
|
||||
metric = self.evaluator.evaluate()
|
||||
|
||||
# 增加额外的验证循环
|
||||
for idx, data_batch in enumerate(self.dataloader2):
|
||||
# 增加额外的钩子点位
|
||||
self.runner.call_hooks(
|
||||
'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
|
||||
self.run_iter(idx, data_batch)
|
||||
# 增加额外的钩子点位
|
||||
self.runner.call_hooks(
|
||||
'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
|
||||
metric2 = self.evaluator.evaluate()
|
||||
|
||||
...
|
||||
|
||||
self.runner.call_hooks('after_val_epoch')
|
||||
|
||||
|
||||
# 定义额外点位的钩子类
|
||||
@HOOKS.register_module()
|
||||
class CustomValHook(Hook):
|
||||
def before_valloader2_iter(self, batch_idx, data_batch):
|
||||
...
|
||||
|
||||
def after_valloader2_iter(self, batch_idx, data_batch, outputs):
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,
|
||||
只需要在配置文件的 `val_cfg` 内设置 `type='CustomValLoop'`,并添加额外的配置即可。
|
||||
|
||||
```python
|
||||
# 自定义验证循环
|
||||
val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
|
||||
# 额外点位的钩子
|
||||
custom_hooks = [dict(type='CustomValHook')]
|
||||
```
|
||||
|
||||
### 自定义执行器
|
||||
|
||||
如果自定义执行流程依然无法满足需求,用户同样可以实现自己的执行器。具体实现流程与其他模块无异:继承 MMEngine 中的 Runner,重写需要修改的函数,添加进 RUNNERS 注册器中,最后在配置文件中指定 `runner_type` 即可。
|
||||
|
||||
```python
|
||||
from mmengine.registry import RUNNERS
|
||||
from mmengine.runner import Runner
|
||||
|
||||
@RUNNERS.register_module()
|
||||
class CustomRunner(Runner):
|
||||
|
||||
def setup_env(self):
|
||||
...
|
||||
```
|
||||
|
||||
上述例子实现了一个自定义的执行器,并重写了 `setup_env` 函数,然后添加进了 RUNNERS 注册器中,完成了这些步骤之后,便可以在配置文件中设置 `runner_type='CustomRunner'` 来构建自定义的执行器。
|
||||
你可能还想阅读[执行器的设计](../design/runner.md)或者[执行器的 API 文档](https://mmengine.readthedocs.io/zh_CN/latest/api/runner.html)。
|
||||
|
|
|
|||
Loading…
Reference in New Issue