[Doc] Refactor runner tutorial (#657)
* refactor runner tutorial * remove watermark in picture * fix as comments * remove toc in runner tutorial * Apply suggestions from code review Co-authored-by: Zaida Zhou <58739961+zhouzaida@users.noreply.github.com> * Update docs/zh_cn/tutorials/runner.md Co-authored-by: Zaida Zhou <58739961+zhouzaida@users.noreply.github.com> Co-authored-by: Zaida Zhou <58739961+zhouzaida@users.noreply.github.com>pull/792/head
parent
11ae76ae3e
commit
6482845671
|
|
@ -1,256 +1,524 @@
|
|||
# 执行器(Runner)
|
||||
|
||||
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此 MMEngine 提供了执行器以帮助用户简化这些任务的实现流程。用户只需要准备好模型训练、验证、测试所需要的模块构建执行器,便能够通过简单调用执行器的接口来完成这些任务。用户如果需要使用这几项功能中的某一项,只需要准备好对应功能所依赖的模块即可。
|
||||
欢迎来到 MMEngine 用户界面的核心——执行器!
|
||||
|
||||
用户可以手动构建这些模块的实例,也可以通过编写[配置文件](../advanced_tutorials/config.md),由执行器自动从[注册器](../advanced_tutorials/registry.md)中构建所需要的模块,我们推荐使用后一种方式。
|
||||
作为 MMEngine 中的“集大成者”,执行器涵盖了整个框架的方方面面,肩负着串联所有组件的重要责任;因此,其中的代码和实现逻辑需要兼顾各种情景,相对庞大复杂。但是**不用担心**!在这篇教程中,我们将隐去繁杂的细节,速览执行器常用的接口、功能、示例,为你呈现一个清晰易懂的用户界面。阅读完本篇教程,你将会:
|
||||
|
||||
## 手动构建模块来使用执行器
|
||||
- 掌握执行器的常见参数与使用方式
|
||||
- 了解执行器的最佳实践——配置文件的写法
|
||||
- 了解执行器基本数据流与简要执行逻辑
|
||||
- 亲身感受使用执行器的优越性(也许)
|
||||
|
||||
### 手动构建模块进行训练
|
||||
## 执行器示例
|
||||
|
||||
如上文所说,使用执行器的某一项功能时需要准备好对应功能所依赖的模块。以使用执行器的训练功能为例,用户需要准备[模型](./model.md)、[优化器](./optim_wrapper.md)、[参数调度器](./param_scheduler.md)还有训练[数据集](../advanced_tutorials/basedataset.md)。
|
||||
使用执行器构建属于你自己的训练流程,通常有两种开始方式:
|
||||
|
||||
- 参考 [API 文档](mmengine.runner.Runner),逐项确认和配置参数
|
||||
- 在已有配置(如 [15 分钟上手](../get_started/15_minutes.md)或 [MMDet](https://github.com/open-mmlab/mmdetection) 等下游算法库)的基础上,进行定制化修改
|
||||
|
||||
两种方式各有利弊。使用前者,初学者很容易迷失在茫茫多的参数项中不知所措;而使用后者,一份过度精简或过度详细的参考配置都不利于初学者快速找到所需内容。
|
||||
|
||||
解决上述问题的关键在于,把执行器作为备忘录:掌握其中最常用的部分,并在有特殊需求时聚焦感兴趣的部分,其余部分使用缺省值。下面我们将通过一个适合初学者参考的例子,说明其中最常用的参数,并为一些不常用参数给出进阶指引。
|
||||
|
||||
### 面向初学者的示例代码
|
||||
|
||||
```{hint}
|
||||
我们希望你在本教程中更多地关注整体结构,而非具体模块的实现。这种“自顶向下”的思考方式是我们所倡导的。别担心,之后你将有充足的机会和指引,聚焦于自己想要改进的模块
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>运行下面的示例前,请先执行本段代码准备模型、数据集与评测指标;但是在本教程中,暂时无需关注它们的具体实现</summary>
|
||||
|
||||
```python
|
||||
# 准备训练任务所需要的模块
|
||||
import torch
|
||||
from torch import nn
|
||||
from torchvision import transforms
|
||||
from torchvision import datasets
|
||||
from torch.utils.data import DataLoader
|
||||
from mmengine.model import BaseModel
|
||||
from mmengine.optim.scheduler import MultiStepLR
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
# 定义一个多层感知机网络
|
||||
class Network(BaseModel):
|
||||
from mmengine.model import BaseModel
|
||||
from mmengine.evaluator import BaseMetric
|
||||
from mmengine.registry import MODELS, DATASETS, METRICS
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class MyAwesomeModel(BaseModel):
|
||||
def __init__(self, layers=4, activation='relu') -> None:
|
||||
super().__init__()
|
||||
if activation == 'relu':
|
||||
act_type = nn.ReLU
|
||||
elif activation == 'silu':
|
||||
act_type = nn.SiLU
|
||||
elif activation == 'none':
|
||||
act_type = nn.Identity
|
||||
else:
|
||||
raise NotImplementedError
|
||||
sequence = [nn.Linear(2, 64), act_type()]
|
||||
for _ in range(layers-1):
|
||||
sequence.extend([nn.Linear(64, 64), act_type()])
|
||||
self.mlp = nn.Sequential(*sequence)
|
||||
self.classifier = nn.Linear(64, 2)
|
||||
|
||||
def forward(self, data, labels, mode):
|
||||
x = self.mlp(data)
|
||||
x = self.classifier(x)
|
||||
if mode == 'tensor':
|
||||
return x
|
||||
elif mode == 'predict':
|
||||
return F.softmax(x, dim=1), labels
|
||||
elif mode == 'loss':
|
||||
return {'loss': F.cross_entropy(x, labels)}
|
||||
|
||||
|
||||
@DATASETS.register_module()
|
||||
class MyDataset(Dataset):
|
||||
def __init__(self, is_train, size):
|
||||
self.is_train = is_train
|
||||
if self.is_train:
|
||||
torch.manual_seed(0)
|
||||
self.labels = torch.randint(0, 2, (size,))
|
||||
else:
|
||||
torch.manual_seed(3407)
|
||||
self.labels = torch.randint(0, 2, (size,))
|
||||
r = 3 * (self.labels+1) + torch.randn(self.labels.shape)
|
||||
theta = torch.rand(self.labels.shape) * 2 * torch.pi
|
||||
self.data = torch.vstack([r*torch.cos(theta), r*torch.sin(theta)]).T
|
||||
|
||||
def __getitem__(self, index):
|
||||
return self.data[index], self.labels[index]
|
||||
|
||||
def __len__(self):
|
||||
return len(self.data)
|
||||
|
||||
|
||||
@METRICS.register_module()
|
||||
class Accuracy(BaseMetric):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.mlp = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10))
|
||||
self.loss = nn.CrossEntropyLoss()
|
||||
|
||||
def forward(self, batch_inputs: torch.Tensor, data_samples = None, mode: str = 'tensor'):
|
||||
x = batch_inputs.flatten(1)
|
||||
x = self.mlp(x)
|
||||
if mode == 'loss':
|
||||
return {'loss': self.loss(x, data_samples)}
|
||||
elif mode == 'predict':
|
||||
return x.argmax(1)
|
||||
else:
|
||||
return x
|
||||
def process(self, data_batch, data_samples):
|
||||
score, gt = data_samples
|
||||
self.results.append({
|
||||
'batch_size': len(gt),
|
||||
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
|
||||
})
|
||||
|
||||
model = Network()
|
||||
|
||||
# 构建优化器
|
||||
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
# 构建参数调度器用于调整学习率
|
||||
lr_scheduler = MultiStepLR(optimizer, milestones=[2], by_epoch=True)
|
||||
# 构建手写数字识别 (MNIST) 数据集
|
||||
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
|
||||
# 构建数据加载器
|
||||
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
|
||||
```
|
||||
|
||||
在创建完符合上述文档规范的模块的对象后,就可以使用这些模块初始化执行器:
|
||||
|
||||
```python
|
||||
from mmengine.runner import Runner
|
||||
|
||||
|
||||
# 训练相关参数设置,按轮次训练,训练 3 轮
|
||||
train_cfg = dict(by_epoch=True, max_epochs=3)
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model,
|
||||
work_dir='./train_mnist', # 工作目录,用于保存模型和日志
|
||||
train_cfg=train_cfg,
|
||||
train_dataloader=train_dataloader,
|
||||
optim_wrapper=dict(optimizer=optimizer),
|
||||
param_scheduler=lr_scheduler)
|
||||
# 执行训练
|
||||
runner.train()
|
||||
```
|
||||
|
||||
上面的例子中,我们手动构建了一个多层感知机网络和手写数字识别 (MNIST) 数据集,以及训练所需要的优化器和学习率调度器,使用这些模块初始化了执行器,并且设置了训练配置 `train_cfg`,让执行器将模型训练 3 个轮次,最后通过调用执行器的 `train` 方法进行模型训练。
|
||||
|
||||
用户也可以修改 `train_cfg` 使执行器按迭代次数控制训练:
|
||||
|
||||
```python
|
||||
# 训练相关参数设置,按迭代次数训练,训练 9000 次迭代
|
||||
train_cfg = dict(by_epoch=False, max_iters=9000)
|
||||
```
|
||||
|
||||
### 手动构建模块进行测试
|
||||
|
||||
再举一个模型测试的例子,模型的测试需要用户准备模型和训练好的权重路径、测试数据集以及[评测器](./evaluation.md):
|
||||
|
||||
```python
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
|
||||
class MnistAccuracy(BaseMetric):
|
||||
def process(self, data, preds) -> None:
|
||||
self.results.append(((data[1] == preds.cpu()).sum(), len(preds)))
|
||||
def compute_metrics(self, results):
|
||||
correct, batch_size = zip(*results)
|
||||
acc = sum(correct) / sum(batch_size)
|
||||
return dict(accuracy=acc)
|
||||
|
||||
model = Network()
|
||||
test_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
|
||||
test_dataloader = DataLoader(dataset=test_dataset)
|
||||
metric = MnistAccuracy()
|
||||
test_evaluator = Evaluator(metric)
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
|
||||
load_from='./train_mnist/epoch_3.pth', work_dir='./test_mnist')
|
||||
|
||||
# 执行测试
|
||||
runner.test()
|
||||
total_correct = sum(r['correct'] for r in results)
|
||||
total_size = sum(r['batch_size'] for r in results)
|
||||
return dict(accuracy=100*total_correct/total_size)
|
||||
```
|
||||
|
||||
这个例子中我们重新手动构建了一个多层感知机网络,以及测试用的手写数字识别数据集和使用 Accuracy 指标的评测器,并使用这些模块初始化执行器,最后通过调用执行器的 `test` 函数进行模型测试。
|
||||
</details>
|
||||
|
||||
### 手动构建模块在训练过程中进行验证
|
||||
|
||||
在模型训练过程中,通常会按一定的间隔在验证集上对模型进行验证。在使用 MMEngine 时,只需要构建训练和验证的模块,并在训练配置中设置验证间隔即可:
|
||||
<details>
|
||||
<summary>点击展开一段长长的示例代码。做好准备</summary>
|
||||
|
||||
```python
|
||||
# 准备训练任务所需要的模块
|
||||
optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
|
||||
lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
|
||||
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
|
||||
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
|
||||
|
||||
# 准备验证需要的模块
|
||||
val_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
|
||||
val_dataloader = Dataloader(dataset=val_dataset)
|
||||
metric = MnistAccuracy()
|
||||
val_evaluator = Evaluator(metric)
|
||||
|
||||
# 训练相关参数设置
|
||||
train_cfg = dict(by_epoch=True, # 按轮次训练
|
||||
max_epochs=5, # 训练 5 轮
|
||||
val_begin=2, # 从第 2 个 epoch 开始验证
|
||||
val_interval=1) # 每隔1轮进行 1 次验证
|
||||
|
||||
# 初始化执行器
|
||||
runner = Runner(model=model, optim_wrapper=dict(optimizer=optimzier), param_scheduler=lr_scheduler,
|
||||
train_dataloader=train_dataloader, val_dataloader=val_dataloader, val_evaluator=val_evaluator,
|
||||
train_cfg=train_cfg, work_dir='./train_val_mnist')
|
||||
# 执行训练
|
||||
runner.train()
|
||||
```
|
||||
|
||||
## 通过配置文件使用执行器
|
||||
|
||||
OpenMMLab 的开源项目普遍使用注册器 + 配置文件的方式来管理和构建模块,MMEngine 中的执行器也推荐使用配置文件进行构建。下面是一个通过配置文件使用执行器的例子:
|
||||
|
||||
```python
|
||||
from mmengine import Config
|
||||
from torch.utils.data import DataLoader, default_collate
|
||||
from torch.optim import Adam
|
||||
from mmengine.runner import Runner
|
||||
|
||||
# 加载配置文件
|
||||
config = Config.fromfile('configs/resnet/resnet50_8xb32_in1k.py')
|
||||
|
||||
# 通过配置文件初始化执行器
|
||||
runner = Runner.build_from_cfg(config)
|
||||
runner = Runner(
|
||||
# 你的模型
|
||||
model=MyAwesomeModel(
|
||||
layers=2,
|
||||
activation='relu'),
|
||||
# 模型检查点、日志等都将存储在工作路径中
|
||||
work_dir='exp/my_awesome_model',
|
||||
|
||||
# 执行训练
|
||||
# 训练所用数据
|
||||
train_dataloader=DataLoader(
|
||||
dataset=MyDataset(
|
||||
is_train=True,
|
||||
size=10000),
|
||||
shuffle=True,
|
||||
collate_fn=default_collate,
|
||||
batch_size=64,
|
||||
pin_memory=True,
|
||||
num_workers=2),
|
||||
# 训练相关配置
|
||||
train_cfg=dict(
|
||||
by_epoch=True, # 根据 epoch 计数而非 iteration
|
||||
max_epochs=10,
|
||||
val_begin=2, # 从第 2 个 epoch 开始验证
|
||||
val_interval=1), # 每隔 1 个 epoch 进行一次验证
|
||||
|
||||
# 优化器封装,MMEngine 中的新概念,提供更丰富的优化选择。
|
||||
# 通常使用默认即可,可缺省。有特殊需求可查阅文档更换,如
|
||||
# 'AmpOptimWrapper' 开启混合精度训练
|
||||
optim_wrapper=dict(
|
||||
optimizer=dict(
|
||||
type=Adam,
|
||||
lr=0.001)),
|
||||
# 参数调度器,用于在训练中调整学习率/动量等参数
|
||||
param_scheduler=dict(
|
||||
type='MultiStepLR',
|
||||
by_epoch=True,
|
||||
milestones=[4, 8],
|
||||
gamma=0.1),
|
||||
|
||||
# 验证所用数据
|
||||
val_dataloader=DataLoader(
|
||||
dataset=MyDataset(
|
||||
is_train=False,
|
||||
size=1000),
|
||||
shuffle=False,
|
||||
collate_fn=default_collate,
|
||||
batch_size=1000,
|
||||
pin_memory=True,
|
||||
num_workers=2),
|
||||
# 验证相关配置,通常为空即可
|
||||
val_cfg=dict(),
|
||||
# 验证指标与验证器封装,可自由实现与配置,也可缺省
|
||||
val_evaluator=dict(type=Accuracy),
|
||||
|
||||
# 以下为其他进阶配置,无特殊需要时尽量缺省
|
||||
# 钩子属于进阶用法,如无特殊需要,尽量缺省
|
||||
default_hooks=dict(
|
||||
# 最常用的默认钩子,可修改保存 checkpoint 的间隔
|
||||
checkpoint=dict(type='CheckpointHook', interval=1)),
|
||||
|
||||
# `luancher` 与 `env_cfg` 共同构成分布式训练环境配置
|
||||
launcher='none',
|
||||
env_cfg=dict(
|
||||
cudnn_benchmark=False, # 是否使用 cudnn_benchmark
|
||||
backend='nccl', # 分布式通信后端
|
||||
mp_cfg=dict(mp_start_method='fork')), # 多进程设置
|
||||
log_level='INFO',
|
||||
|
||||
# 加载权重的路径 (None 表示不加载)
|
||||
load_from=None
|
||||
# 从加载的权重文件中恢复训练
|
||||
resume=False
|
||||
)
|
||||
|
||||
# 开始训练你的模型吧
|
||||
runner.train()
|
||||
|
||||
# 执行测试
|
||||
runner.test()
|
||||
```
|
||||
|
||||
与手动构建模块来使用执行器不同的是,通过调用 Runner 类的 `build_from_cfg` 方法,执行器能够自动读取配置文件中的模块配置,从相应的注册器中构建所需要的模块,用户不再需要考虑训练和测试分别依赖哪些模块,也不需要为了切换训练的模型和数据而大量改动代码。
|
||||
</details>
|
||||
|
||||
下面是一个典型的使用配置文件调用 MMClassification 中的模块训练分类器的简单例子:
|
||||
### 示例代码讲解
|
||||
|
||||
真是一段长长的代码!但是如果你通读了上述样例,即使不了解实现细节,你也一定大体理解了这个训练流程,并感叹于执行器代码的紧凑与可读性(也许)。这也是 MMEngine 所期望的:结构化、模块化、标准化的训练流程,使得复现更加可靠、对比更加清晰。
|
||||
|
||||
上述例子可能会让你产生如下问题:
|
||||
|
||||
<details>
|
||||
<summary>参数项实在是太多了!</summary>
|
||||
|
||||
不用担心,正如我们前面所说,**把执行器作为备忘录**。执行器涵盖了方方面面,防止你漏掉重要内容,但是这并不意味着你需要配置所有参数。如[15分钟上手](../get_started/15_minutes.md)中的极简例子(甚至,舍去 `val_evaluator` `val_dataloader` 和 `val_cfg`)也可以正常运行。所有的参数由你的需求驱动,不关注的内容往往缺省值也可以工作得很好。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>为什么有些传入参数是 dict?</summary>
|
||||
|
||||
是的,这与 MMEngine 的风格相关。在 MMEngine 中我们提供了两种不同风格的执行器构建方式:a)基于手动构建的,以及 b)基于注册机制的。如果你感到迷惑,下面的例子将给出一个对比:
|
||||
|
||||
```python
|
||||
# 工作目录,保存权重和日志
|
||||
work_dir = './train_resnet'
|
||||
# 默认注册器域
|
||||
default_scope = 'mmcls' # 默认使用 `mmcls` (MMClassification) 注册器中的模块
|
||||
# 模型配置
|
||||
model = dict(type='ImageClassifier',
|
||||
backbone=dict(type='ResNet', depth=50),
|
||||
neck=dict(type='GlobalAveragePooling'),
|
||||
head=dict(type='LinearClsHead',num_classes=1000))
|
||||
# 数据配置
|
||||
train_dataloader = dict(dataset=dict(type='ImageNet', pipeline=[...]),
|
||||
sampler=dict(type='DefaultSampler', shuffle=True),
|
||||
batch_size=32,
|
||||
num_workers=4)
|
||||
val_dataloader = ...
|
||||
test_dataloader = ...
|
||||
from mmengine.model import BaseModel
|
||||
from mmengine.runner import Runner
|
||||
from mmengine.registry import MODELS # 模型根注册器,你的自定义模型需要注册到这个根注册器中
|
||||
|
||||
# 优化器配置
|
||||
optim_wrapper = dict(
|
||||
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
|
||||
# 参数调度器配置
|
||||
param_scheduler = dict(
|
||||
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
|
||||
# 验证和测试的评测器配置
|
||||
val_evaluator = dict(type='Accuracy')
|
||||
test_evaluator = dict(type='Accuracy')
|
||||
@MODELS.register_module() # 用于注册的装饰器
|
||||
class MyAwesomeModel(BaseModel): # 你的自定义模型
|
||||
def __init__(self, layers=18, activation='silu'):
|
||||
...
|
||||
|
||||
# 训练、验证、测试流程配置
|
||||
# 基于注册机制的例子
|
||||
runner = Runner(
|
||||
model=dict(
|
||||
type='MyAwesomeModel',
|
||||
layers=50,
|
||||
activation='relu'),
|
||||
...
|
||||
)
|
||||
|
||||
# 基于手动构建的例子
|
||||
model = MyAwesomeModel(layers=18, activation='relu')
|
||||
runner = Runner(
|
||||
model=model,
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
类似上述例子,执行器中的参数大多同时支持两种输入类型。以上两种写法基本是等价的,区别在于:前者以 `dict` 作为输入时,该模块会在**需要时在执行器内部**被构建;而后者是构建完成后传递给执行器。如果你对于注册机制并不了解,下面的示意图展示了它的核心思想:注册器维护着**模块的构建方式**和它的**名字**之间的映射。如果你在使用中发现问题,或者想要进一步了解完整用法,我们推荐阅读[注册器(Registry)](../advanced_tutorials/registry.md)文档。
|
||||
|
||||
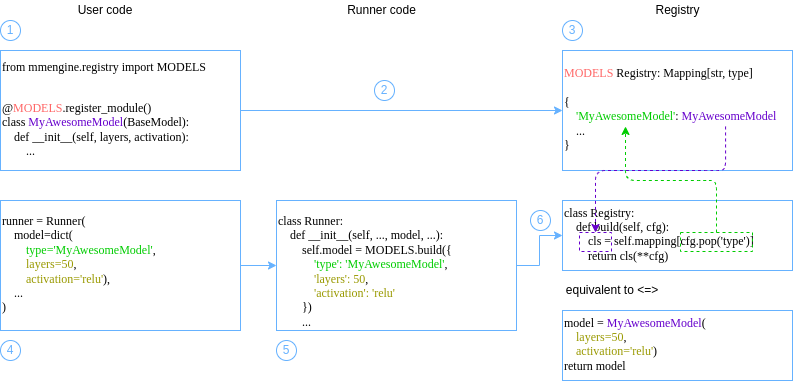
|
||||
|
||||
看到这你可能仍然很疑惑,为什么我要传入字典让 Runner 来构建实例,这样又有什么好处?如果你有产生这样的疑问,那我们就会很自豪的回答:“当然!(没有好处)”。事实上,基于注册机制的构建方式只有在结合配置文件时才会发挥它的最大优势。这里直接传入字典的写法也并非使用执行器的最佳实践。在这里,我们希望你能够通过这个例子读懂并习惯这种写法,方便理解我们马上将要讲到的执行器最佳实践——配置文件。敬请期待!
|
||||
|
||||
如果你作为初学者无法立刻理解,使用*手动构建的方式*依然不失为一种好选择,甚至在小规模使用、试错和调试时是一种更加推荐的方式,因为对于 IDE 更加友好。但我们也希望你能够读懂并习惯基于注册机制的写法,并且在后续教程中不会因此而产生不必要的混淆和疑惑。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>我应该去哪里找到 xxx 参数的可能配置选项?</summary>
|
||||
|
||||
你可以在对应模块的教程中找到丰富的说明和示例,你也可以在 [API 文档](mmengine.runner.Runner) 中找到 `Runner` 的所有参数。如果上述两种方式都无法解决你的疑问,你随时可以在我们的[讨论区](https://github.com/open-mmlab/mmengine/discussions)中发起话题,帮助我们更好地改进文档。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>我来自 MMDet/MMCls...下游库,为什么例子写法与我接触的不同?</summary>
|
||||
|
||||
OpenMMLab 下游库广泛采用了配置文件的方式。我们将在下个章节,基于上述示例稍微变换,从而展示配置文件——MMEngine 中执行器的最佳实践——的用法。
|
||||
|
||||
</details>
|
||||
|
||||
## 执行器最佳实践——配置文件
|
||||
|
||||
MMEngine 提供了一套支持 `Python` 语法的、功能强大的配置文件系统。你可以从之前的示例代码中**近乎**(我们将在下面说明)无缝地转换到配置文件。下面给出一段示例代码:
|
||||
|
||||
```python
|
||||
# 以下代码存放在 example_config.py 文件中
|
||||
# 基本拷贝自上面的示例,并将每项结尾的逗号删去
|
||||
model = dict(type='MyAwesomeModel',
|
||||
layers=2,
|
||||
activation='relu')
|
||||
work_dir = 'exp/my_awesome_model'
|
||||
|
||||
train_dataloader = dict(
|
||||
dataset=dict(type='MyDataset',
|
||||
is_train=True,
|
||||
size=10000),
|
||||
sampler=dict(
|
||||
type='DefaultSampler',
|
||||
shuffle=True),
|
||||
collate_fn=dict(type='default_collate'),
|
||||
batch_size=64,
|
||||
pin_memory=True,
|
||||
num_workers=2)
|
||||
train_cfg = dict(
|
||||
by_epoch=True,
|
||||
max_epochs=100,
|
||||
val_begin=20, # 从第 20 个 epoch 开始验证
|
||||
val_interval=1 # 每隔一个 epoch 进行一次验证
|
||||
)
|
||||
max_epochs=10,
|
||||
val_begin=2,
|
||||
val_interval=1)
|
||||
optim_wrapper = dict(
|
||||
optimizer=dict(
|
||||
type='Adam',
|
||||
lr=0.001))
|
||||
param_scheduler = dict(
|
||||
type='MultiStepLR',
|
||||
by_epoch=True,
|
||||
milestones=[4, 8],
|
||||
gamma=0.1)
|
||||
|
||||
val_dataloader = dict(
|
||||
dataset=dict(type='MyDataset',
|
||||
is_train=False,
|
||||
size=1000),
|
||||
sampler=dict(
|
||||
type='DefaultSampler',
|
||||
shuffle=False),
|
||||
collate_fn=dict(type='default_collate'),
|
||||
batch_size=1000,
|
||||
pin_memory=True,
|
||||
num_workers=2)
|
||||
val_cfg = dict()
|
||||
test_cfg = dict()
|
||||
val_evaluator = dict(type='Accuracy')
|
||||
|
||||
# 自定义钩子(可选)
|
||||
custom_hooks = [...]
|
||||
|
||||
# 默认钩子(可选,未在配置文件中写明时将使用默认配置)
|
||||
default_hooks = dict(
|
||||
runtime_info=dict(type='RuntimeInfoHook'), # 运行时信息钩子
|
||||
timer=dict(type='IterTimerHook'), # 计时器钩子
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'), # 为每轮次的数据采样设置随机种子的钩子
|
||||
logger=dict(type='TextLoggerHook'), # 训练日志钩子
|
||||
param_scheduler=dict(type='ParamSchedulerHook'), # 参数调度器执行钩子
|
||||
checkpoint=dict(type='CheckpointHook', interval=1), # 模型保存钩子
|
||||
)
|
||||
|
||||
# 环境配置(可选,未在配置文件中写明时将使用默认配置)
|
||||
checkpoint=dict(type='CheckpointHook', interval=1))
|
||||
launcher = 'none'
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=False, # 是否使用 cudnn_benchmark
|
||||
dist_cfg=dict(backend='nccl'), # 分布式通信后端
|
||||
mp_cfg=dict(mp_start_method='fork') # 多进程设置
|
||||
)
|
||||
# 日志处理器(可选,未在配置文件中写明时将使用默认配置)
|
||||
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
|
||||
# 日志等级配置
|
||||
cudnn_benchmark=False,
|
||||
backend='nccl',
|
||||
mp_cfg=dict(mp_start_method='fork'))
|
||||
log_level = 'INFO'
|
||||
|
||||
# 加载权重的路径(None 表示不加载)
|
||||
load_from = None
|
||||
# 从加载的权重文件中恢复训练
|
||||
resume = False
|
||||
```
|
||||
|
||||
一个完整的配置文件主要由模型、数据、优化器、参数调度器、评测器等模块的配置,训练、验证、测试等流程的配置,还有执行流程过程中的各种钩子模块的配置,以及环境和日志等其他配置的字段组成。通过配置文件构建的执行器采用了懒初始化 (lazy initialization),只有当调用到训练或测试等执行函数时,才会根据配置文件去完整初始化所需要的模块。
|
||||
|
||||
关于配置文件的更详细的使用方式,请参考[配置文件教程](../advanced_tutorials/config.md)
|
||||
|
||||
## 加载权重或恢复训练
|
||||
|
||||
执行器可以通过 `load_from` 参数加载检查点(checkpoint)文件中的模型权重,只需要将 `load_from` 参数设置为检查点文件的路径即可。
|
||||
此时,我们只需要在训练代码中加载配置,然后运行即可
|
||||
|
||||
```python
|
||||
runner = Runner(model=model, test_dataloader=test_dataloader, test_evaluator=test_evaluator,
|
||||
load_from='./resnet50.pth')
|
||||
from mmengine.config import Config
|
||||
from mmengine.runner import Runner
|
||||
config = Config.fromfile('example_config.py')
|
||||
runner = Runner.from_cfg(config)
|
||||
runner.train()
|
||||
```
|
||||
|
||||
如果是通过配置文件使用执行器,只需修改配置文件中的 `load_from` 字段即可。
|
||||
```{note}
|
||||
虽然是 `Python` 语法,但合法的配置文件需要满足以下条件:所有的变量必须是**基本类型**(例如 `str` `dict` `int`等)。因此,配置文件系统高度依赖于注册机制,以实现从基本类型到其他类型(如 `nn.Module`)的构建。
|
||||
```
|
||||
|
||||
用户也可通过设置 `resume=True` 来,加载检查点中的训练状态信息来恢复训练。当 `load_from` 和 `resume=True` 同时被设置时,执行器将加载 `load_from` 路径对应的检查点文件中的训练状态。
|
||||
```{note}
|
||||
使用配置文件时,你通常不需要手动注册所有模块。例如,`torch.optim` 中的所有优化器(如 `Adam` `SGD`等)都已经在 `mmengine.optim` 中注册完成。使用时的经验法则是:尝试直接使用 `PyTorch` 中的组件,只有当出现报错时再手动注册。
|
||||
```
|
||||
|
||||
如果仅设置 `resume=True`,执行器将会尝试从 `work_dir` 文件夹中寻找并读取最新的检查点文件。
|
||||
```{note}
|
||||
当使用配置文件写法时,你的自定义模块的实现代码通常存放在独立文件中,可能并未被正确注册,进而导致构建失败。我们推荐你阅读[注册器](./registry.md)文档中 `custom_imports` 相关的内容以更好地使用配置文件系统。
|
||||
```
|
||||
|
||||
你可能还想阅读[执行器的设计](../design/runner.md)或者[执行器的 API 文档](mmengine.runner.Runner)。
|
||||
```{warning}
|
||||
虽然与示例中的写法一致,但 `from_cfg` 与 `__init__` 的缺省值处理可能存在些微不同,例如 `env_cfg` 参数。
|
||||
```
|
||||
|
||||
执行器配置文件已经在 OpenMMLab 的众多下游库(MMCls,MMDet...)中被广泛使用,并成为事实标准与最佳实践。配置文件的功能远不止如此,如果你对于继承、覆写等进阶功能感兴趣,请参考[配置(Config)](../advanced_tutorials/config.md)文档。
|
||||
|
||||
## 基本数据流
|
||||
|
||||
```{hint}
|
||||
在本章节中,我们将会介绍执行器内部各模块之间的数据传递流向与格式约定。如果你还没有基于 MMEngine 构建一个训练流程,本章节的部分内容可能会比较抽象、枯燥;你也可以暂时跳过,并在将来有需要时结合实践进行阅读。
|
||||
```
|
||||
|
||||
接下来,我们将**稍微**深入执行器的内部,结合图示来理清其中数据的流向与格式约定。
|
||||
|
||||
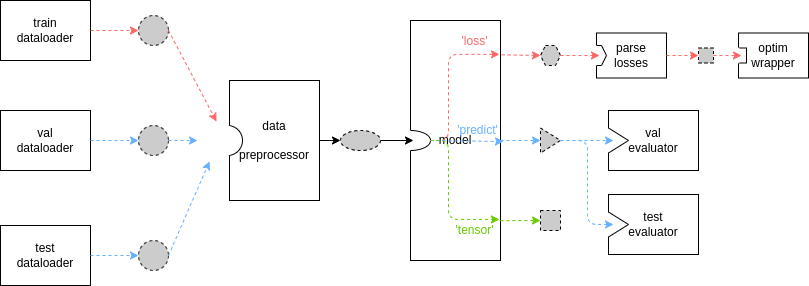
|
||||
|
||||
上图是执行器的**基本**数据流,其中虚线边框、灰色填充的不同形状代表不同的数据格式,实线方框代表模块或方法。由于 MMEngine 强大的灵活性与可扩展性,你总可以继承某些关键基类并重载其中的方法,因此上图并不总是成立。只有当你没有自定义 `Runner` 或 `TrainLoop` ,并且你的自定义模型没有重载 `train_step`、`val_step` 与 `test_step` 方法时上图才会成立(而这在检测、分割等任务上是常见的,参考[模型](./model.md)教程)。
|
||||
|
||||
<details>
|
||||
<summary>可以确切地说明图中传递的每项数据的具体类型吗?</summary>
|
||||
|
||||
很遗憾,这一点无法做到。虽然 MMEngine 做了大量类型注释,但 `Python` 是一门高度动态化的编程语言,同时以数据为核心的深度学习系统也需要足够的灵活性来处理纷繁复杂的数据源,你有充分的自由决定何时需要(有时是必须)打破类型约定。因此,在你自定义某一或某几个模块(如 `val_evaluator` )时,你需要确保它的输入与上游(如 `model` 的输出)兼容,同时输出可以被下游解析。MMEngine 将处理数据的灵活性交给了用户,因而也需要用户保证数据流的兼容性——当然,实际上手后会发现,这一点并不十分困难。
|
||||
|
||||
数据一致性的考验一直存在于深度学习领域,MMEngine 也在尝试用自己的方式改进。如果你有兴趣,可以参考[数据集基类](../advanced_tutorials/basedataset.md)与[抽象数据接口](../advanced_tutorials/data_element.md)文档——但是**请注意,它们主要面向进阶用户**。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>dataloader、model 和 evaluator 之间的数据格式是如何约定的?</summary>
|
||||
|
||||
针对图中所展示的基本数据流,上述三个模块之间的数据传递可以用如下伪代码表示
|
||||
|
||||
```python
|
||||
# 训练过程
|
||||
for data_batch in train_dataloader:
|
||||
data_batch = data_preprocessor(data_batch)
|
||||
if isinstance(data_batch, dict):
|
||||
losses = model.forward(**data_batch, mode='loss')
|
||||
elif isinstance(data_batch, (list, tuple)):
|
||||
losses = model.forward(*data_batch, mode='loss')
|
||||
else:
|
||||
raise TypeError()
|
||||
|
||||
# 验证过程
|
||||
for data_batch in val_dataloader:
|
||||
data_batch = data_preprocessor(data_batch)
|
||||
if isinstance(data_batch, dict):
|
||||
outputs = model.forward(**data_batch, mode='predict')
|
||||
elif isinstance(data_batch, (list, tuple)):
|
||||
outputs = model.forward(**data_batch, mode='predict')
|
||||
else:
|
||||
raise TypeError()
|
||||
evaluator.process(data_samples=outputs, data_batch=data_batch)
|
||||
metrics = evaluator.evaluate(len(val_dataloader.dataset))
|
||||
```
|
||||
|
||||
上述伪代码的关键点在于:
|
||||
|
||||
- data_preprocessor 的输出需要经过解包后传递给 model
|
||||
- evaluator 的 `data_samples` 参数接收模型的预测结果,而 `data_batch` 参数接收 dataloader 的原始数据
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>什么是 data preprocessor?我可以用它做裁减缩放等图像预处理吗?</summary>
|
||||
|
||||
虽然图中的 data preprocessor 与 model 是分离的,但在实际中前者是后者的一部分,因此可以在[模型](./model.md)文档中的数据处理器章节找到。
|
||||
|
||||
通常来说,数据处理器不需要额外关注和指定,默认的数据处理器只会自动将数据搬运到 GPU 中。但是,如果你的模型与数据加载器的数据格式不匹配,你也可以自定义一个数据处理器来进行格式转换。
|
||||
|
||||
裁减缩放等图像预处理更推荐在[数据变换](./data_transform.md)中进行,但如果是 batch 相关的数据处理(如 batch-resize 等),可以在这里实现。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>为什么 model 产生了 3 个不同的输出? loss、predict、tensor 是什么含义?</summary>
|
||||
|
||||
[15 分钟上手](../get_started/15_minutes.md)对此有一定的描述,你需要在自定义模型的 `forward` 函数中实现 3 条数据通路,适配训练、验证等不同需求。[模型](./model.md)文档中对此有详细解释。
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>我可以看出红线是训练流程,蓝线是验证/测试流程,但绿线是什么?</summary>
|
||||
|
||||
在目前的执行器流程中,`'tensor'` 模式的输出并未被使用,大多数情况下用户无需实现。但一些情况下输出中间结果可以方便地进行 debug
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>如果我重载了 train_step 等方法,上图会完全失效吗?</summary>
|
||||
|
||||
默认的 `train_step`、`val_step`、`test_step` 的行为,覆盖了从数据进入 `data preprocessor` 到 `model` 输出 `loss`、`predict` 结果的这一段流程,不影响其余部分。
|
||||
|
||||
</details>
|
||||
|
||||
## 为什么使用执行器(可选)
|
||||
|
||||
```{hint}
|
||||
这一部分内容并不能教会你如何使用执行器乃至整个 MMEngine,如果你正在被雇主/教授/DDL催促着几个小时内拿出成果,那这部分可能无法帮助到你,请随意跳过。但我们仍强烈推荐抽出时间阅读本章节,这可以帮助你更好地理解并使用 MMEngine
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>放轻松,接下来是闲聊时间</summary>
|
||||
|
||||
恭喜你通关了执行器!这真是一篇长长的、但还算有趣(希望如此)的教程。无论如何,请相信这些都是为了让你更加**轻松**——不论是本篇教程、执行器,还是 MMEngine。
|
||||
|
||||
执行器是 MMEngine 中所有模块的“管理者”。所有的独立模块——不论是模型、数据集这些看得见摸的着的,还是日志记录、分布式训练、随机种子等相对隐晦的——都在执行器中被统一调度、产生关联。事物之间的关系是复杂的,但执行器为你处理了一切,并提供了一个清晰易懂的配置式接口。这样做的好处主要有:
|
||||
|
||||
1. 你可以轻易地在已搭建流程上修改/添加所需配置,而不会搅乱整个代码。也许你起初只有单卡训练,但你随时可以添加1、2行的分布式配置,切换到多卡甚至多机训练
|
||||
2. 你可以享受 MMEngine 不断引入的新特性,而不必担心后向兼容性。混合精度训练、可视化、崭新的分布式训练方式、多种设备后端……我们会在保证后向兼容性的前提下不断吸收社区的优秀建议与前沿技术,并以简洁明了的方式提供给你
|
||||
3. 你可以集中关注并实现自己的惊人想法,而不必受限于其他恼人的、不相关的细节。执行器的缺省值会为你处理绝大多数的情况
|
||||
|
||||
所以,MMEngine 与执行器会确实地让你更加轻松。只要花费一点点努力完成迁移,你的代码与实验会随着 MMEngine 的发展而与时俱进;如果再花费一点努力,MMEngine 的配置系统可以让你更加高效地管理数据、模型、实验。便利性与可靠性,这些正是我们努力的目标。
|
||||
|
||||
蓝色药丸,还是红色药丸——你准备好加入吗?
|
||||
|
||||
</details>
|
||||
|
||||
## 下一步的建议
|
||||
|
||||
如果你想要进一步地:
|
||||
|
||||
<details>
|
||||
<summary>实现自己的模型结构</summary>
|
||||
|
||||
参考[模型(Model)](./model.md)
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>使用自己的数据集</summary>
|
||||
|
||||
MMEngine 使用和 pytorch 一致的 `dataloader` ,请参考 pytorch 相关文档进行构建
|
||||
|
||||
同时 MMEngine 提供了一个进阶的[数据集基类](../advanced_tutorials/basedataset.md)供下游库与用户使用,如有兴趣也可以阅读文档了解
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>更换模型评测/验证指标</summary>
|
||||
|
||||
参考[模型精度评测(Evaluation)](./evaluation.md)
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>调整优化器封装(如开启混合精度训练、梯度累积等)与更换优化器</summary>
|
||||
|
||||
参考[优化器封装(OptimWrapper)](./optim_wrapper.md)
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>动态调整学习率等参数(如 warmup )</summary>
|
||||
|
||||
参考[优化器参数调整策略(Parameter Scheduler)](./param_scheduler.md)
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>其他</summary>
|
||||
|
||||
- 左侧的“常用功能”中包含更多常用的与新特性的示例代码可供参考
|
||||
- “进阶教程”中有更多面向资深开发者的内容,可以更加灵活地配置训练流程、日志、可视化等
|
||||
- 如果以上所有内容都无法实现你的新想法,那么[钩子(Hook)](./hook.md)值得一试
|
||||
- 欢迎在我们的 [讨论版](https://github.com/open-mmlab/mmengine/discussions) 中发起话题求助!
|
||||
|
||||
</details>
|
||||
|
|
|
|||
Loading…
Reference in New Issue