mirror of
https://github.com/open-mmlab/mmocr.git
synced 2025-06-03 21:54:47 +08:00
[Docs] update data prepare (#1784)
* [Docs] update data prepare * fix comment and need to update some fig * update --------- Co-authored-by: gaotongxiao <gaotongxiao@gmail.com>
This commit is contained in:
parent
231cff5da2
commit
1e696887b9
@ -44,7 +44,7 @@ python tools/dataset_converters/prepare_dataset.py icdar2015 totaltext --task te
|
||||
|
||||
### LMDB 格式
|
||||
|
||||
在文本识别任务中,我们通常使用 LMDB 格式来存储数据,以加快数据的读取速度。在使用 `prepare_dataset.py` 脚本准备数据时,可以通过 `--lmdb` 参数来指定将数据转换为 LMDB 格式。例如:
|
||||
在文本识别任务中,通常使用 LMDB 格式来存储数据,以加快数据的读取速度。在使用 `prepare_dataset.py` 脚本准备数据时,可以通过 `--lmdb` 参数来指定将数据转换为 LMDB 格式。例如:
|
||||
|
||||
```bash
|
||||
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textrecog --lmdb
|
||||
@ -52,7 +52,7 @@ python tools/dataset_converters/prepare_dataset.py icdar2015 --task textrecog --
|
||||
|
||||
数据集准备完成后,Dataset Preparer 会在 `configs/textrecog/_base_/datasets/` 中生成 `icdar2015_lmdb.py` 配置。你可以继承该配置,并将 `dataloader` 指向 LMDB 数据集。然而,LMDB 数据集的读取需要配合 [`LoadImageFromNDArray`](mmocr.datasets.transforms.LoadImageFromNDArray),因此你也同样需要修改 `pipeline`。
|
||||
|
||||
例如,我们想要将 `configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py` 的训练集改为刚刚生成的 icdar2015,则需要作如下修改:
|
||||
例如,想要将 `configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py` 的训练集改为刚刚生成的 icdar2015,则需要作如下修改:
|
||||
|
||||
1. 修改 `configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py`:
|
||||
|
||||
@ -80,30 +80,30 @@ python tools/dataset_converters/prepare_dataset.py icdar2015 --task textrecog --
|
||||
]
|
||||
```
|
||||
|
||||
### 数据集配置
|
||||
## 设计
|
||||
|
||||
数据集自动化准备脚本使用了模块化的设计,极大地增强了扩展性,用户能够很方便地配置其他公开数据集或私有数据集。数据集自动化准备脚本的配置文件被统一存储在 `dataset_zoo/` 目录下,用户可以在该目录下找到所有已由 MMOCR 官方支持的数据集准备脚本配置文件。该文件夹的目录结构如下:
|
||||
OCR 数据集数量众多,不同的数据集有着不同的语言,不同的标注格式,不同的场景等。 数据集的使用情况一般有两种,一种是快速的了解数据集的相关信息,另一种是在使用数据集训练模型。为了满足这两种使用场景MMOCR 提供数据集自动化准备脚本,数据集自动化准备脚本使用了模块化的设计,极大地增强了扩展性,用户能够很方便地配置其他公开数据集或私有数据集。数据集自动化准备脚本的配置文件被统一存储在 `dataset_zoo/` 目录下,用户可以在该目录下找到所有已由 MMOCR 官方支持的数据集准备脚本配置文件。该文件夹的目录结构如下:
|
||||
|
||||
```text
|
||||
dataset_zoo/
|
||||
├── icdar2015
|
||||
│ ├── metafile.yml
|
||||
│ ├── sample_anno.md
|
||||
│ ├── textdet.py
|
||||
│ ├── textrecog.py
|
||||
│ └── textspotting.py
|
||||
└── wildreceipt
|
||||
├── metafile.yml
|
||||
├── sample_anno.md
|
||||
├── kie.py
|
||||
├── textdet.py
|
||||
├── textrecog.py
|
||||
└── textspotting.py
|
||||
```
|
||||
|
||||
其中,`metafile.yml` 是数据集的元信息文件,其中存放了对应数据集的基本信息,包括发布年份,论文作者,以及版权等其他信息。其它以任务名命名的则是数据集准备脚本的配置文件,用于配置数据集的下载、解压、格式转换等操作。这些配置文件采用了 Python 格式,其使用方法与 MMOCR 算法库的其他配置文件完全一致,详见[配置文件文档](../config.md)。
|
||||
### 数据集相关信息
|
||||
|
||||
#### 数据集元文件
|
||||
|
||||
以数据集 ICDAR2015 为例,`metafile.yml` 中存储了基础的数据集信息:
|
||||
数据集的相关信息包括数据集的标注格式、数据集的标注示例、数据集的基本统计信息等。虽然在每个数据集的官网中都有这些信息,但是这些信息分散在各个数据集的官网中,用户需要花费大量的时间来挖掘数据集的基本信息。因此,MMOCR 设计了一些范式,它可以帮助用户快速了解数据集的基本信息。 MMOCR 将数据集的相关信息分为两个部分,一部分是数据集的基本信息包括包括发布年份,论文作者,以及版权等其他信息,另一部分是数据集的标注信息,包括数据集的标注格式、数据集的标注示例。每一部分 MMOCR 都会提供一个范式,贡献者可以根据范式来填写数据集的基本信息,使用用户就可以快速了解数据集的基本信息。 根据数据集的基本信息 MMOCR 提供了一个 `metafile.yml` 文件,其中存放了对应数据集的基本信息,包括发布年份,论文作者,以及版权等其他信息,这样用户就可以快速了解数据集的基本信息。该文件在数据集准备过程中并不是强制要求的(因此用户在使用添加自己的私有数据集时可以忽略该文件),但为了用户更好地了解各个公开数据集的信息,MMOCR 建议用户在使用数据集准备脚本前阅读对应的元文件信息,以了解该数据集的特征是否符合用户需求。MMOCR 以 ICDAR2015 作为示例, 其示例内容如下所示:
|
||||
|
||||
```yaml
|
||||
Name: 'Incidental Scene Text IC15'
|
||||
@ -136,118 +136,184 @@ Data:
|
||||
Link: https://creativecommons.org/licenses/by/4.0/
|
||||
```
|
||||
|
||||
该文件在数据集准备过程中并不是强制要求的(因此用户在使用添加自己的私有数据集时可以忽略该文件),但为了用户更好地了解各个公开数据集的信息,我们建议用户在使用数据集准备脚本前阅读对应的元文件信息,以了解该数据集的特征是否符合用户需求。
|
||||
具体地,MMOCR 在下表中列出每个字段对应的含义:
|
||||
|
||||
```{warning}
|
||||
自 MMOCR 1.0.0rc6 起,接下来的章节可能会与实际实现有所出入。
|
||||
```
|
||||
| 字段名 | 含义 |
|
||||
| :--------------- | :-------------------------------------------------------------------- |
|
||||
| Name | 数据集的名称 |
|
||||
| Paper.Title | 数据集论文的标题 |
|
||||
| Paper.URL | 数据集论文的链接 |
|
||||
| Paper.Venue | 数据集论文发表的会议/期刊名称 |
|
||||
| Paper.Year | 数据集论文发表的年份 |
|
||||
| Paper.BibTeX | 数据集论文的引用的 BibTex |
|
||||
| Data.Website | 数据集的官方网站 |
|
||||
| Data.Language | 数据集支持的语言 |
|
||||
| Data.Scene | 数据集支持的场景,如 `Natural Scene`, `Document`, `Handwritten` 等 |
|
||||
| Data.Granularity | 数据集支持的粒度,如 `Character`, `Word`, `Line` 等 |
|
||||
| Data.Tasks | 数据集支持的任务,如 `textdet`, `textrecog`, `textspotting`, `kie` 等 |
|
||||
| Data.License | 数据集的许可证信息,如果不存在许可证,则使用 `N/A` 填充 |
|
||||
| Data.Format | 数据集标注文件的格式,如 `.txt`, `.xml`, `.json` 等 |
|
||||
| Data.Keywords | 数据集的特性关键词,如 `Horizontal`, `Vertical`, `Curved` 等 |
|
||||
|
||||
#### 数据集准备脚本配置文件
|
||||
对于数据集的标注信息,MMOCR 提供了一个 `sample_anno.md` 文件,用户可以根据范式来填写数据集的标注信息,这样用户就可以快速了解数据集的标注信息。MMOCR 以 ICDAR2015 作为示例, 其示例内容如下所示:
|
||||
|
||||
下面,我们将介绍数据集准备脚本配置文件 `textXXX.py` 的默认字段与使用方法。
|
||||
````markdown
|
||||
**Text Detection**
|
||||
|
||||
我们在配置文件中提供了 `data_root` 与 `cache_path` 两个默认字段,分别用于存放转换后的 MMOCR 格式的数据集文件,以及在数据准备过程中下载的压缩包等临时文件。
|
||||
```text
|
||||
# x1,y1,x2,y2,x3,y3,x4,y4,trans
|
||||
|
||||
377,117,463,117,465,130,378,130,Genaxis Theatre
|
||||
493,115,519,115,519,131,493,131,[06]
|
||||
374,155,409,155,409,170,374,170,###
|
||||
```
|
||||
````
|
||||
|
||||
`sample_anno.md` 中包含数据集针对不同任务的标注信息,包含标注文件的格式(text 对应的是 txt 文件,标注文件的格式也可以在 meta.yml 中找到),标注的示例。
|
||||
|
||||
通过上述两个文件的信息,用户就可以快速了解数据集的基本信息,同时 MMOCR 汇总了所有数据集的基本信息,用户可以在 [Overview](.overview.md) 中查看所有数据集的基本信息。
|
||||
|
||||
### 数据集使用
|
||||
|
||||
经过数十年的发展,OCR 领域涌现出了一系列的相关数据集,这些数据集往往采用风格各异的格式来提供文本的标注文件,使得用户在使用这些数据集时不得不进行格式转换。因此,为了方便用户进行数据集准备,我们设计了 Dataset Preaprer,帮助用户快速将数据集准备为 MMOCR 支持的格式, 详见[数据格式文档](../../basic_concepts/datasets.md)。下图展示了 Dataset Preparer 的典型运行流程。
|
||||
|
||||
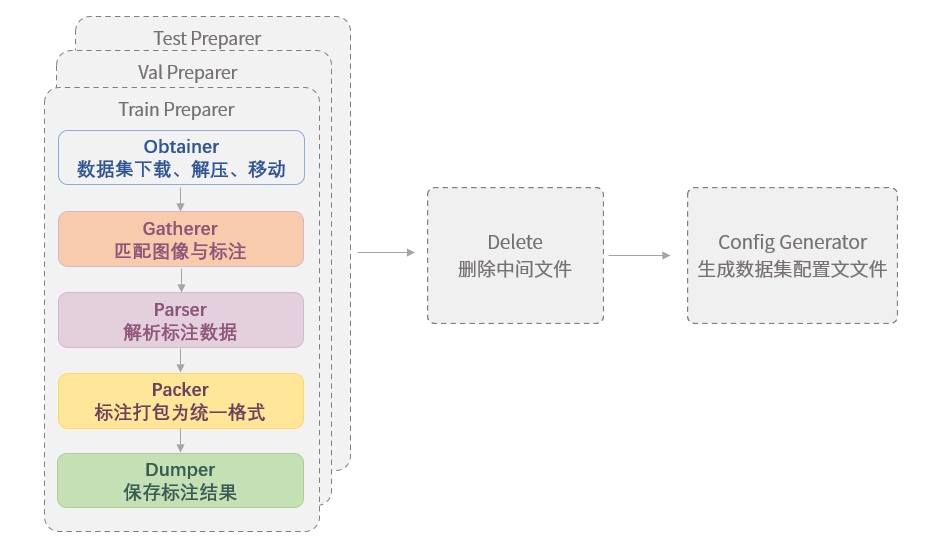
|
||||
|
||||
由图可见,Dataset Preparer 在运行时,会依次执行以下操作:
|
||||
|
||||
1. 对训练集、验证集和测试集,由各 preparer 进行:
|
||||
|
||||
1. [数据集的下载、解压、移动(Obtainer)](#数据集下载解压移动-obtainer)
|
||||
2. [匹配标注与图像(Gatherer)](#数据集收集-gatherer)
|
||||
3. [解析原标注(Parser)](#数据集解析-parser)
|
||||
4. [打包标注为统一格式(Packer)](#数据集转换-packer)
|
||||
5. [保存标注(Dumper)](#标注保存-dumper)
|
||||
|
||||
2. 删除文件(Delete)
|
||||
|
||||
3. 生成数据集的配置文件(Config Generator)
|
||||
|
||||
为了便于应对各种数据集的情况,MMOCR 将每个部分均设计为可插拔的模块,并允许用户通过 dataset_zoo/ 下的配置文件对数据集准备流程进行配置。这些配置文件采用了 Python 格式,其使用方法与 MMOCR 算法库的其他配置文件完全一致,详见[配置文件文档](../config.md)。
|
||||
|
||||
在 `dataset_zoo/` 下,每个数据集均占有一个文件夹,文件夹下会以任务名命名配置文件,以区分不同任务下的配置。以 ICDAR2015 文字检测部分为例,示例配置 `dataset_zoo/icdar2015/textdet.py` 如下所示:
|
||||
|
||||
```python
|
||||
data_root = './data/icdar2015'
|
||||
cache_path = './data/cache'
|
||||
```
|
||||
|
||||
其次,数据集的准备通常包含了“原始数据准备”、“格式转换和保存”及“生成基础配置”这三个主要步骤。因此,我们约定通过 `data_obtainer`、 `data_converter` 和 `config_generator` 参数来配置这三个步骤的行为。
|
||||
|
||||
```{note}
|
||||
如果用户需要跳过某一步骤,则可以省略配置相应参数。例如,如果数据集本身已经遵循 MMOCR 的格式,用户就可以省略掉 `data_converter` 的配置来跳过数据集格式的转换。或者,如果用户不需要自动生成基础配置,可以忽略掉 `config_generator` 的配置。
|
||||
```
|
||||
|
||||
接下来,我们将以 ICDAR2015 数据集的文本检测任务准备配置文件(`dataset_zoo/icdar2015/textdet.py`)为例,逐个模块解析 Dataset Preparer 的运行流程。
|
||||
|
||||
##### 原始数据准备 - `data_obtainer`
|
||||
|
||||
```python
|
||||
data_obtainer = dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
data_root=data_root,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
|
||||
save_name='ic15_textdet_train_img.zip',
|
||||
md5='c51cbace155dcc4d98c8dd19d378f30d',
|
||||
split=['train'],
|
||||
content=['image'],
|
||||
mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'ch4_training_localization_transcription_gt.zip',
|
||||
save_name='ic15_textdet_train_gt.zip',
|
||||
md5='3bfaf1988960909014f7987d2343060b',
|
||||
split=['train'],
|
||||
content=['annotation'],
|
||||
mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
|
||||
# ...
|
||||
])
|
||||
```
|
||||
|
||||
数据准备器 `data_obtainer` 的类型默认为 `NaiveDataObtainer`,其主要功能是依次下载压缩包并解压到指定目录。在这里,我们通过 `files` 参数来配置下载的压缩包的 URL、保存名称、MD5 值等信息。其中,`mapping` 参数用于指定该压缩包中的数据解压后的存放路径。另外 `split` 和 `content` 这两个可选参数则分别标明了该压缩包中存储的内容类型与其对应的数据集合。
|
||||
|
||||
##### 格式转换和保存 - `data_converter`
|
||||
|
||||
```python
|
||||
data_converter = dict(
|
||||
type='TextDetDataConverter',
|
||||
splits=['train', 'test'],
|
||||
data_root=data_root,
|
||||
data_root = 'data/icdar2015'
|
||||
cache_path = 'data/cache'
|
||||
train_preparer = dict(
|
||||
obtainer=dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
|
||||
save_name='ic15_textdet_train_img.zip',
|
||||
md5='c51cbace155dcc4d98c8dd19d378f30d',
|
||||
content=['image'],
|
||||
mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'ch4_training_localization_transcription_gt.zip',
|
||||
save_name='ic15_textdet_train_gt.zip',
|
||||
md5='3bfaf1988960909014f7987d2343060b',
|
||||
content=['annotation'],
|
||||
mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
|
||||
]),
|
||||
gatherer=dict(
|
||||
type='pair_gather',
|
||||
suffixes=['.jpg', '.JPG'],
|
||||
type='PairGatherer',
|
||||
img_suffixes=['.jpg', '.JPG'],
|
||||
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
|
||||
parser=dict(type='ICDARTxtTextDetAnnParser'),
|
||||
parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
|
||||
packer=dict(type='TextDetPacker'),
|
||||
dumper=dict(type='JsonDumper'),
|
||||
delete=['annotations', 'ic15_textdet_test_img', 'ic15_textdet_train_img'])
|
||||
)
|
||||
|
||||
test_preparer = dict(
|
||||
obtainer=dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/ch4_test_images.zip',
|
||||
save_name='ic15_textdet_test_img.zip',
|
||||
md5='97e4c1ddcf074ffcc75feff2b63c35dd',
|
||||
content=['image'],
|
||||
mapping=[['ic15_textdet_test_img', 'textdet_imgs/test']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge4_Test_Task4_GT.zip',
|
||||
save_name='ic15_textdet_test_gt.zip',
|
||||
md5='8bce173b06d164b98c357b0eb96ef430',
|
||||
content=['annotation'],
|
||||
mapping=[['ic15_textdet_test_gt', 'annotations/test']]),
|
||||
]),
|
||||
gatherer=dict(
|
||||
type='PairGatherer',
|
||||
img_suffixes=['.jpg', '.JPG'],
|
||||
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
|
||||
parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
|
||||
packer=dict(type='TextDetPacker'),
|
||||
dumper=dict(type='JsonDumper'),
|
||||
)
|
||||
|
||||
delete = ['annotations', 'ic15_textdet_test_img', 'ic15_textdet_train_img']
|
||||
config_generator = dict(type='TextDetConfigGenerator')
|
||||
```
|
||||
|
||||
数据转换器 `data_converter` 主要由转换器及子模块 `gatherer`、`parser` 及 `dumper` 组成,负责完成原始数据的读取与格式转换,并保存为 MMOCR 支持的格式。
|
||||
#### 数据集下载、解压、移动 (Obtainer)
|
||||
|
||||
目前,MMOCR 中支持的数据集转换器类别如下:
|
||||
Dataset Preparer 中,`obtainer` 模块负责了数据集的下载、解压和移动。如今,MMOCR 暂时只提供了 `NaiveDataObtainer`。通常来说,内置的 `NaiveDataObtainer` 即可完成绝大部分可以通过直链访问的数据集的下载,并支持解压、移动文件和重命名等操作。然而,MMOCR 暂时不支持自动下载存储在百度或谷歌网盘等需要登陆才能访问资源的数据集。 这里简要介绍一下 `NaiveDataObtainer`.
|
||||
|
||||
- 文本检测任务数据转换器 `TextDetDataConverter`
|
||||
- 文本识别任务数据转换器
|
||||
- `TextRecogDataConverter`
|
||||
- `TextRecogCropConverter`
|
||||
- 端到端文本检测识别任务转换器 `TextSpottingDataConverter`
|
||||
- 关键信息抽取任务数据转换器 `WildReceiptConverter`
|
||||
| 字段名 | 含义 |
|
||||
| ---------- | ---------------------------------------------------------- |
|
||||
| cache_path | 数据集缓存路径,用于存储数据集准备过程中下载的压缩包等文件 |
|
||||
| data_root | 数据集存储的根目录 |
|
||||
| files | 数据集文件列表,用于描述数据集的下载信息 |
|
||||
|
||||
MMOCR 中目前支持的转换器主要以任务为边界,这是因为不同任务所需的数据格式有细微的差异。
|
||||
比较特别的是,文本识别任务有两个数据转换器,这是因为不同的文本识别数据集提供文字图片的方式有所差别。有的数据集提供了仅包含文字的小图,它们天然适用于文本识别任务,可以直接使用 `TextRecogDataConverter` 处理。而有的数据集提供的是包含了周围场景的大图,因此在准备数据集时,我们需要预先根据标注信息把文字区域裁剪出来,这种情况下则要用到 `TextRecogCropConverter`。
|
||||
`files` 字段是一个列表,列表中的每个元素都是一个字典,用于描述一个数据集文件的下载信息。如下表所示:
|
||||
|
||||
简单介绍下 `TextRecogCropConverter` 数据转换器的使用方法:
|
||||
| 字段名 | 含义 |
|
||||
| ----------------- | -------------------------------------------------------------------- |
|
||||
| url | 数据集文件的下载链接 |
|
||||
| save_name | 数据集文件的保存名称 |
|
||||
| md5 (可选) | 数据集文件的 md5 值,用于校验下载的文件是否完整 |
|
||||
| split (可选) | 数据集文件所属的数据集划分,如 `train`,`test` 等,该字段可以空缺 |
|
||||
| content (可选) | 数据集文件的内容,如 `image`,`annotation` 等,该字段可以空缺 |
|
||||
| mapping (可选) | 数据集文件的解压映射,用于指定解压后的文件存储的位置,该字段可以空缺 |
|
||||
|
||||
- 由于标注文件的解析方式与 TextDet 环节一致,所以仅需继承 `dataset_zoo/xxx/textdet.py` 的 data_converter,并修改type值为 'TextRecogCropConverter',`TextRecogCropConverter` 会在执行 `pack_instance()` 方法时根据解析获得的标注信息完成文字区域的裁剪。
|
||||
- 同时,根据是否存在旋转文字区域标注内置了两种裁剪方式,默认按照水平文本框裁剪。如果存在旋转的文字区域,可以设置 `crop_with_warp=True` 切换为使用 OpenCV warpPerspective 方法进行裁剪。
|
||||
同时,Dataset Preparer 存在以下约定:
|
||||
|
||||
- 不同类型的数据集的图片统一移动到对应类别 `{taskname}_imgs/{split}/`文件夹下,如 `textdet_imgs/train/`。
|
||||
- 对于一个标注文件包含所有图像的标注信息的情况,标注移到到`annotations/{split}.*`文件中。 如 `annotations/train.json`。
|
||||
- 对于一个标注文件包含一个图像的标注信息的情况,所有的标注文件移动到`annotations/{split}/`文件中。 如 `annotations/train/`。
|
||||
- 对于一些其他的特殊情况,比如所有训练、测试、验证的图像都在一个文件夹下,可以将图像移动到自己设定的文件夹下,比如 `{taskname}_imgs/imgs/`,同时要在后续的 `gatherer` 模块中指定图像的存储位置。
|
||||
|
||||
示例配置如下:
|
||||
|
||||
```python
|
||||
_base_ = ['textdet.py']
|
||||
|
||||
data_converter = dict(
|
||||
type='TextRecogCropConverter',
|
||||
crop_with_warp=True)
|
||||
obtainer=dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
|
||||
save_name='ic15_textdet_train_img.zip',
|
||||
md5='c51cbace155dcc4d98c8dd19d378f30d',
|
||||
content=['image'],
|
||||
mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'ch4_training_localization_transcription_gt.zip',
|
||||
save_name='ic15_textdet_train_gt.zip',
|
||||
md5='3bfaf1988960909014f7987d2343060b',
|
||||
content=['annotation'],
|
||||
mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
|
||||
]),
|
||||
```
|
||||
|
||||
接下来,我们将具体解析 `data_converter` 的功能。以文本检测任务为例,`TextDetDataConverter` 与各子模块配合,主要完成以下工作:
|
||||
#### 数据集收集 (Gatherer)
|
||||
|
||||
- `gatherer` 负责收集并匹配原始数据集中的图片与标注文件,如图像 `img_1.jpg` 与标注 `gt_img_1.txt`
|
||||
- `parser` 负责读取原始标注文件,解析出文本框坐标与文本内容等必要信息
|
||||
- 转换器将解析后的数据统一转换至 MMOCR 中当前任务的格式
|
||||
- `dumper` 将转换后的数据保存为指定路径和文件格式
|
||||
- 转换器删除 `delete` 参数指定的临时文件
|
||||
|
||||
以上个步骤我们分别可以通过 `gatherer`,`parser`,`dumper`, `delete` 来进行配置。
|
||||
|
||||
###### `gatherer`
|
||||
|
||||
作为数据转换的第一步,`data_converter` 会通过 `gatherer` 遍历数据集目录下的文件,将图像与标注文件一一对应,并整理出一份文件列表供 `parser` 读取。因此,我们首先需要知道当前数据集下,图片文件与标注文件匹配的规则。
|
||||
|
||||
OCR 数据集通常有两种标注保存形式,一种为多个标注文件对应多张图片,一种则为单个标注文件对应多张图片,如:
|
||||
`gatherer` 遍历数据集目录下的文件,将图像与标注文件一一对应,并整理出一份文件列表供 `parser` 读取。因此,首先需要知道当前数据集下,图片文件与标注文件匹配的规则。OCR 数据集有两种常用标注保存形式,一种为多个标注文件对应多张图片,一种则为单个标注文件对应多张图片,如:
|
||||
|
||||
```text
|
||||
多对多
|
||||
@ -265,35 +331,142 @@ OCR 数据集通常有两种标注保存形式,一种为多个标注文件对
|
||||
├── annotations/gt.txt
|
||||
```
|
||||
|
||||
具体设计如下所示
|
||||
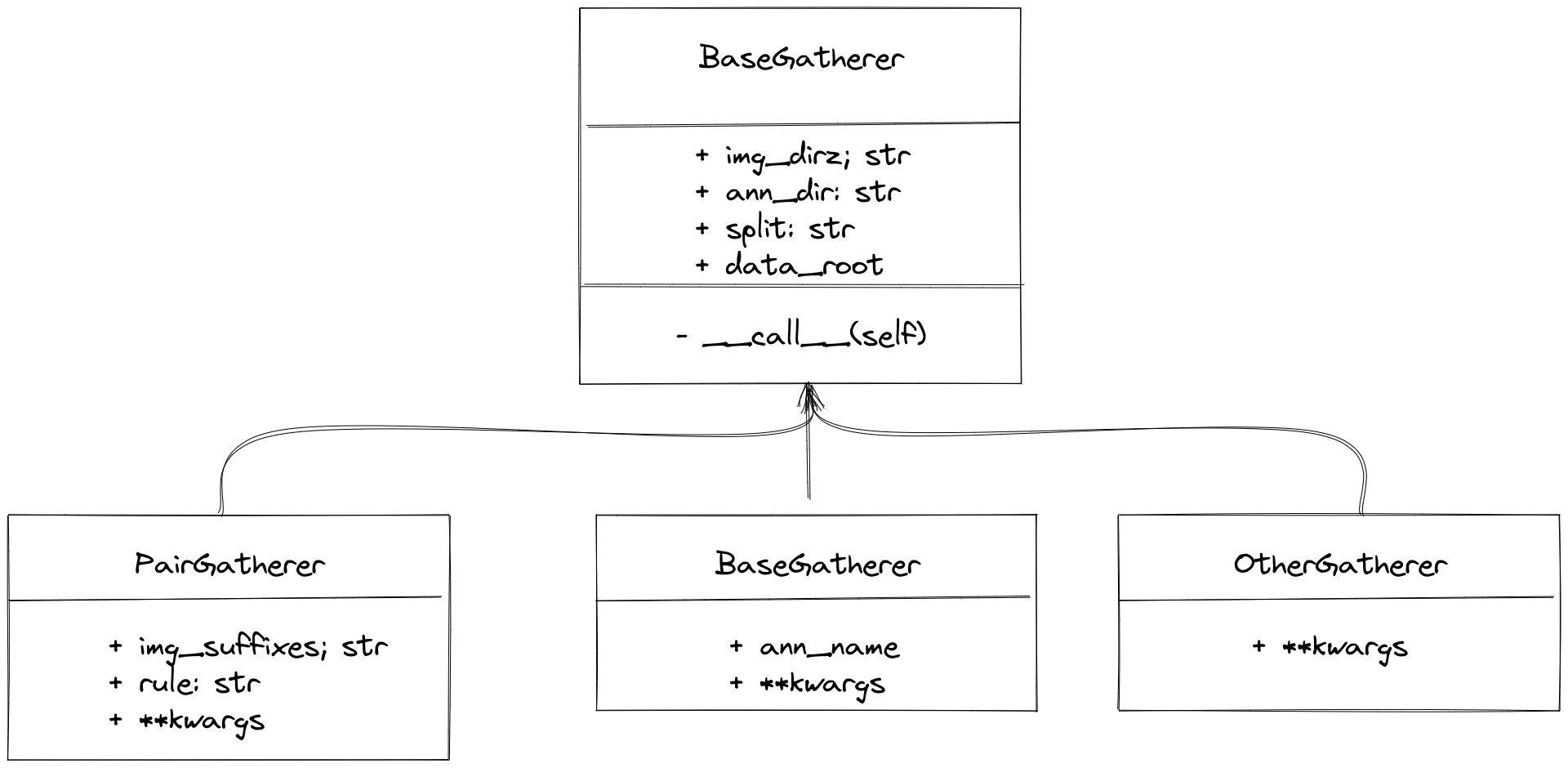
|
||||
|
||||
MMOCR 内置了 `PairGatherer` 与 `MonoGatherer` 来处理以上这两种常用情况。其中 `PairGatherer` 用于多对多的情况,`MonoGatherer` 用于单对多的情况。
|
||||
|
||||
```{note}
|
||||
为了简化处理,gatherer 约定数据集的图片和标注需要分别储存在 `{taskname}_imgs/{split}/` 和 `annotations/` 下。特别地,对于多对多的情况,标注文件需要放置于 `annotations/{split}` 下。如本例中,icdar 2015 训练集的图片就被储存在 `textdet_imgs/train/` 下,而训练的标注则被存在 `annotations/train/` 下。
|
||||
为了简化处理,gatherer 约定数据集的图片和标注需要分别储存在 `{taskname}_imgs/{split}/` 和 `annotations/` 下。特别地,对于多对多的情况,标注文件需要放置于 `annotations/{split}`。
|
||||
```
|
||||
|
||||
因此,我们内置了 `pair_gather` 与 `mono_gather` 来处理以上这两种情况。其中 `pair_gather` 用于多对多的情况,`mono_gather` 用于单对多的情况。
|
||||
- 在多对多的情况下,`PairGatherer` 需要按照一定的命名规则找到图片文件和对应的标注文件。首先,需要通过 `img_suffixes` 参数指定图片的后缀名,如上述例子中的 `img_suffixes=[.jpg,.JPG]`。此外,还需要通过[正则表达式](https://docs.python.org/3/library/re.html) `rule`, 来指定图片与标注文件的对应关系,其中,规则 `rule` 是一个**正则表达式对**,例如 `rule=[r'img_(\d+)\.([jJ][pP][gG])',r'gt_img_\1.txt']`。 第一个正则表达式用于匹配图片文件名,`\d+` 用于匹配图片的序号,`([jJ][pP][gG])` 用于匹配图片的后缀名。 第二个正则表达式用于匹配标注文件名,其中 `\1` 则将匹配到的图片序号与标注文件序号对应起来。示例配置为
|
||||
|
||||
在多对多的情况下,`pair_gather` 需要按照一定的命名规则找到图片文件和对应的标注文件。首先,我们需要通过 `suffixes` 参数指定图片的后缀名,如上述例子中的 `suffixes=[.jpg,.JPG]`。此外,还需要通过正则表达式来指定图片与标注文件的对应关系,如上述例子中的 `rule=[r'img_(\d+)\.([jJ][pP][gG])',r'gt_img_\1.txt']`。其中 `\d+` 用于匹配图片的序号,`([jJ][pP][gG])` 用于匹配图片的后缀名,`\1` 则将匹配到的图片序号与标注文件序号对应起来。
|
||||
```python
|
||||
gatherer=dict(
|
||||
type='PairGatherer',
|
||||
img_suffixes=['.jpg', '.JPG'],
|
||||
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
|
||||
```
|
||||
|
||||
单对多的情况通常比较简单,用户只需要指定每个 split 对应的标注文件即可。因此 `mono_gather` 预设了 `train_ann`、`val_ann` 和 `test_ann` 参数,供用户直接指定标注文件。
|
||||
- 单对多的情况通常比较简单,用户只需要指定标注文件名即可。对于训练集示例配置为
|
||||
|
||||
###### `parser`
|
||||
```python
|
||||
gatherer=dict(type='MonoGatherer', ann_name='train.txt'),
|
||||
```
|
||||
|
||||
当获取了图像与标注文件的对应关系后,data preparer 将解析原始标注文件。由于不同数据集的标注格式通常有很大的区别,当我们需要支持新的数据集时,**通常需要实现一个新的 `parser` 来解析原始标注文件**。parser 将任务相关的数据解析后打包成 MMOCR 的统一格式。
|
||||
MMOCR 同样对 `Gatherer` 的返回值做了约定,`Gatherer` 会返回两个元素的元组,第一个元素为图像路径列表(包含所有图像路径) 或者所有图像所在的文件夹, 第二个元素为标注文件路径列表(包含所有标注文件路径)或者标注文件的路径(该标注文件包含所有图像标注信息)。
|
||||
具体而言,`PairGatherer` 的返回值为(图像路径列表, 标注文件路径列表),示例如下:
|
||||
|
||||
###### `dumper`
|
||||
```python
|
||||
(['{taskname}_imgs/{split}/img_1.jpg', '{taskname}_imgs/{split}/img_2.jpg', '{taskname}_imgs/{split}/img_3.JPG'],
|
||||
['annotations/{split}/gt_img_1.txt', 'annotations/{split}/gt_img_2.txt', 'annotations/{split}/gt_img_3.txt'])
|
||||
```
|
||||
|
||||
之后,我们可以通过指定不同的 dumper 来决定要将数据保存为何种格式。目前,我们支持 `JsonDumper`, `WildreceiptOpensetDumper`,及 `TextRecogLMDBDumper`。他们分别用于将数据保存为标准的 MMOCR Json 格式、Wildreceipt 格式,及文本识别领域学术界常用的 LMDB 格式。
|
||||
`MonoGatherer` 的返回值为(图像文件夹路径, 标注文件路径), 示例为:
|
||||
|
||||
###### `delete`
|
||||
```python
|
||||
('{taskname}/{split}', 'annotations/gt.txt')
|
||||
```
|
||||
|
||||
#### 数据集解析 (Parser)
|
||||
|
||||
`Parser` 主要用于解析原始的标注文件,因为原始标注情况多种多样,因此 MMOCR 提供了 `BaseParser` 作为基类,用户可以继承该类来实现自己的 `Parser`。在 `BaseParser` 中,MMOCR 设计了两个接口:`parse_files` 和 `parse_file`,约定在其中进行标注的解析。而对于 `Gatherer` 的两种不同输入情况(多对多、单对多),这两个接口的实现则应有所不同。
|
||||
|
||||
- `BaseParser` 默认处理**多对多**的情况。其中,由 `parer_files` 将数据并行分发至多个 `parse_file` 进程,并由每个 `parse_file` 分别进行单个图像标注的解析。
|
||||
- 对于**单对多**的情况,用户则需要重写 `parse_files`,以实现加载标注,并返回规范的结果。
|
||||
|
||||
`BaseParser` 的接口定义如下所示:
|
||||
|
||||
```python
|
||||
class BaseParser:
|
||||
|
||||
def __call__(self, img_paths, ann_paths):
|
||||
return self.parse_files(img_paths, ann_paths)
|
||||
|
||||
def parse_files(self, img_paths: Union[List[str], str],
|
||||
ann_paths: Union[List[str], str]) -> List[Tuple]:
|
||||
samples = track_parallel_progress_multi_args(
|
||||
self.parse_file, (img_paths, ann_paths), nproc=self.nproc)
|
||||
return samples
|
||||
|
||||
@abstractmethod
|
||||
def parse_file(self, img_path: str, ann_path: str) -> Tuple:
|
||||
|
||||
raise NotImplementedError
|
||||
```
|
||||
|
||||
为了保证后续模块的统一性,MMOCR 对 `parse_files` 与 `parse_file` 的返回值做了约定。 `parse_file` 的返回值为一个元组,元组中的第一个元素为图像路径,第二个元素为标注信息。标注信息为一个列表,列表中的每个元素为一个字典,字典中的字段为`poly`, `text`, `ignore`,如下所示:
|
||||
|
||||
```python
|
||||
# An example of returned values:
|
||||
(
|
||||
'imgs/train/xxx.jpg',
|
||||
[
|
||||
dict(
|
||||
poly=[0, 1, 1, 1, 1, 0, 0, 0],
|
||||
text='hello',
|
||||
ignore=False),
|
||||
...
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
`parse_files` 的输出为一个列表,列表中的每个元素为 `parse_file` 的返回值。 示例为:
|
||||
|
||||
```python
|
||||
[
|
||||
(
|
||||
'imgs/train/xxx.jpg',
|
||||
[
|
||||
dict(
|
||||
poly=[0, 1, 1, 1, 1, 0, 0, 0],
|
||||
text='hello',
|
||||
ignore=False),
|
||||
...
|
||||
]
|
||||
),
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
#### 数据集转换 (Packer)
|
||||
|
||||
`packer` 主要是将数据转化到统一的标注格式, 因为输入的数据为 Parsers 的输出,格式已经固定, 因此 Packer 只需要将输入的格式转化为每种任务统一的标注格式即可。如今 MMOCR 支持的任务有文本检测、文本识别、端对端OCR 以及关键信息提取,MMOCR 针对每个任务均有对应的 Packer,如下所示:
|
||||
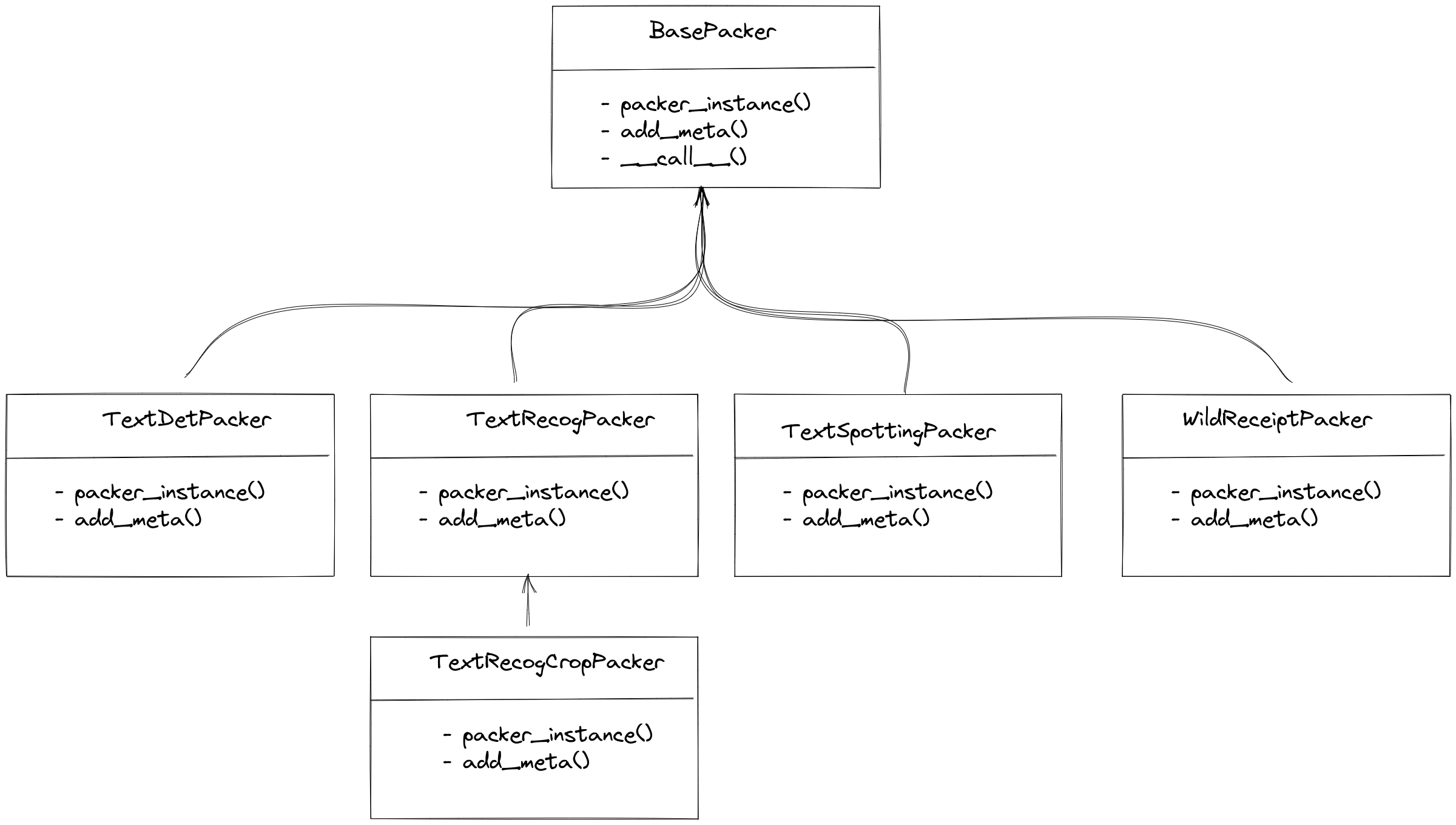
|
||||
|
||||
对于文字检测、端对端OCR及关键信息提取,MMOCR 均有唯一对应的 `Packer`。而在文字识别领域, MMOCR 则提供了两种 `Packer`,分别为 `TextRecogPacker` 和 `TextRecogCropPacker`,其原因在与文字识别的数据集存在两种情况:
|
||||
|
||||
- 每个图像均为一个识别样本,`parser` 返回的标注信息仅为一个`dict(text='xxx')`,此时使用 `TextRecogPacker` 即可。
|
||||
- 数据集没有将文字从图像中裁剪出来,本质是一个端对端OCR的标注,包含了文字的位置信息以及对应的文本信息,`TextRecogCropPacker` 会将文字从图像中裁剪出来,然后再转化成文字识别的统一格式。
|
||||
|
||||
#### 标注保存 (Dumper)
|
||||
|
||||
`dumper` 来决定要将数据保存为何种格式。目前,MMOCR 支持 `JsonDumper`, `WildreceiptOpensetDumper`,及 `TextRecogLMDBDumper`。他们分别用于将数据保存为标准的 MMOCR Json 格式、Wildreceipt 格式,及文本识别领域学术界常用的 LMDB 格式。
|
||||
|
||||
#### 临时文件清理 (Delete)
|
||||
|
||||
在处理数据集时,往往会产生一些不需要的临时文件。这里可以以列表的形式传入这些文件或文件夹,在结束转换时即会删除。
|
||||
|
||||
##### 生成基础配置 - `config_generator`
|
||||
#### 生成基础配置 (ConfigGenerator)
|
||||
|
||||
为了在数据集准备完毕后可以自动生成基础配置,目前,MMOCR 按任务实现了 `TextDetConfigGenerator`、`TextRecogConfigGenerator` 和 `TextSpottingConfigGenerator`。它们支持的主要参数如下:
|
||||
|
||||
| 字段名 | 含义 |
|
||||
| ----------- | --------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| data_root | 数据集存储的根目录 |
|
||||
| train_anns | 配置文件内训练集标注的路径。若不指定,则默认为 `[dict(ann_file='{taskname}_train.json', dataset_postfix='']`。 |
|
||||
| val_anns | 配置文件内验证集标注的路径。若不指定,则默认为空。 |
|
||||
| test_anns | 配置文件内测试集标注的路径。若不指定,则默认指向 `[dict(ann_file='{taskname}_test.json', dataset_postfix='']`。 |
|
||||
| config_path | 算法库存放配置文件的路径,配置生成器会将默认配置写入 `{config_path}/{taskname}/_base_/datasets/{dataset_name}.py` 下。若不指定,则默认为 `configs/` |
|
||||
|
||||
在准备好数据集的所有文件后,配置生成器就会自动生成调用该数据集所需要的基础配置文件。下面给出了一个最小化的 `TextDetConfigGenerator` 配置示例:
|
||||
|
||||
```python
|
||||
config_generator = dict(type='TextDetConfigGenerator', data_root=data_root)
|
||||
config_generator = dict(type='TextDetConfigGenerator')
|
||||
```
|
||||
|
||||
在准备好数据集的所有文件后,配置生成器 `TextDetConfigGenerator` 就会自动为 MMOCR 生成调用该数据集所需要的基础配置文件。生成后的文件默认会被置于 `configs/{task}/_base_/datasets/` 下。例如,本例中,icdar 2015 的基础配置文件就会被生成在 `configs/textdet/_base_/datasets/icdar2015.py` 下:
|
||||
生成后的文件默认会被置于 `configs/{task}/_base_/datasets/` 下。例如,本例中,icdar 2015 的基础配置文件就会被生成在 `configs/textdet/_base_/datasets/icdar2015.py` 下:
|
||||
|
||||
```python
|
||||
icdar2015_textdet_data_root = 'data/icdar2015'
|
||||
@ -313,7 +486,44 @@ icdar2015_textdet_test = dict(
|
||||
pipeline=None)
|
||||
```
|
||||
|
||||
有了该文件后,我们就能从模型的配置文件中直接导入该数据集到 `dataloader` 中使用(以下样例节选自 [`configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`](/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py)):
|
||||
假如数据集比较特殊,标注存在着几个变体,配置生成器也支持在基础配置中生成指向各自变体的变量,但这需要用户在设置时用不同的 `dataset_postfix` 区分。例如,ICDAR 2015 文字识别数据的测试集就存在着原版和 1811 两种标注版本,可以在 `test_anns` 中指定它们,如下所示:
|
||||
|
||||
```python
|
||||
config_generator = dict(
|
||||
type='TextRecogConfigGenerator',
|
||||
test_anns=[
|
||||
dict(ann_file='textrecog_test.json'),
|
||||
dict(dataset_postfix='857', ann_file='textrecog_test_857.json')
|
||||
])
|
||||
```
|
||||
|
||||
配置生成器会生成以下配置:
|
||||
|
||||
```python
|
||||
icdar2015_textrecog_data_root = 'data/icdar2015'
|
||||
|
||||
icdar2015_textrecog_train = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_train.json',
|
||||
pipeline=None)
|
||||
|
||||
icdar2015_textrecog_test = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_test.json',
|
||||
test_mode=True,
|
||||
pipeline=None)
|
||||
|
||||
icdar2015_1811_textrecog_test = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_test_1811.json',
|
||||
test_mode=True,
|
||||
pipeline=None)
|
||||
```
|
||||
|
||||
有了该文件后,MMOCR 就能从模型的配置文件中直接导入该数据集到 `dataloader` 中使用(以下样例节选自 [`configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py`](/configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py)):
|
||||
|
||||
```python
|
||||
_base_ = [
|
||||
@ -339,19 +549,17 @@ test_dataloader = val_dataloader
|
||||
除非用户在运行脚本的时候手动指定了 `overwrite-cfg`,配置生成器默认不会自动覆盖已经存在的基础配置文件。
|
||||
```
|
||||
|
||||
由于每个任务所需的基本数据集配置格式不一,我们也针对各个任务推出了 `TextRecogConfigGenerator` 及 `TextSpottingConfigGenerator` 等生成器。
|
||||
|
||||
## 向 Dataset Preparer 添加新的数据集
|
||||
|
||||
### 添加公开数据集
|
||||
|
||||
MMOCR 已经支持了许多[常用的公开数据集](./datasetzoo.md)。如果你想用的数据集还没有被支持,并且你也愿意为 MMOCR 开源社区[贡献代码](../../notes/contribution_guide.md),你可以按照以下步骤来添加一个新的数据集。
|
||||
|
||||
接下来我们以添加 **ICDAR2013** 数据集为例,展示如何一步一步地添加一个新的公开数据集。
|
||||
接下来以添加 **ICDAR2013** 数据集为例,展示如何一步一步地添加一个新的公开数据集。
|
||||
|
||||
#### 添加 `metafile.yml`
|
||||
|
||||
首先,我们确认 `dataset_zoo/` 中不存在我们准备添加的数据集。然后我们先新建以待添加数据集命名的文件夹,如 `icdar2013/`(通常,我们使用不包含符号的小写英文字母及数字来命名数据集)。在 `icdar2013/` 文件夹中,我们新建 `metafile.yml` 文件,并按照以下模板来填充数据集的基本信息:
|
||||
首先,确认 `dataset_zoo/` 中不存在准备添加的数据集。然后我们先新建以待添加数据集命名的文件夹,如 `icdar2013/`(通常,使用不包含符号的小写英文字母及数字来命名数据集)。在 `icdar2013/` 文件夹中,新建 `metafile.yml` 文件,并按照以下模板来填充数据集的基本信息:
|
||||
|
||||
```yaml
|
||||
Name: 'Incidental Scene Text IC13'
|
||||
@ -387,281 +595,9 @@ Data:
|
||||
- Horizontal
|
||||
```
|
||||
|
||||
`metafile.yml` 存储了数据集的基本信息,这些信息一方面可以帮助用户了解数据集的基本情况,另一方面也会被用于自动化脚本来生成相应的数据集文档。因此,当你向 MMOCR Dataset Preparer 添加新的数据集支持时,请按照以上模板来填充 `metafile.yml` 文件。具体地,我们在下表中列出每个字段对应的含义:
|
||||
|
||||
| 字段名 | 含义 |
|
||||
| :--------------- | :-------------------------------------------------------------------- |
|
||||
| Name | 数据集的名称 |
|
||||
| Paper.Title | 数据集论文的标题 |
|
||||
| Paper.URL | 数据集论文的链接 |
|
||||
| Paper.Venue | 数据集论文发表的会议/期刊名称 |
|
||||
| Paper.Year | 数据集论文发表的年份 |
|
||||
| Paper.BibTeX | 数据集论文的引用的 BibTex |
|
||||
| Data.Website | 数据集的官方网站 |
|
||||
| Data.Language | 数据集支持的语言 |
|
||||
| Data.Scene | 数据集支持的场景,如 `Natural Scene`, `Document`, `Handwritten` 等 |
|
||||
| Data.Granularity | 数据集支持的粒度,如 `Character`, `Word`, `Line` 等 |
|
||||
| Data.Tasks | 数据集支持的任务,如 `textdet`, `textrecog`, `textspotting`, `kie` 等 |
|
||||
| Data.License | 数据集的许可证信息,如果不存在许可证,则使用 `N/A` 填充 |
|
||||
| Data.Format | 数据集标注文件的格式,如 `.txt`, `.xml`, `.json` 等 |
|
||||
| Data.Keywords | 数据集的特性关键词,如 `Horizontal`, `Vertical`, `Curved` 等 |
|
||||
|
||||
#### 添加对应任务的配置文件
|
||||
|
||||
在 `dataset_zoo/icdar2013` 中,我们接着添加以任务名称命名的 `.py` 配置文件。如 `textdet.py`,`textrecog.py`,`textspotting.py`,`kie.py` 等。在该文件中,我们需要对数据获取方式和转换方式进行配置。
|
||||
|
||||
##### 配置数据集获取方法 `data_obtainer`
|
||||
|
||||
以文本检测任务为例:
|
||||
|
||||
```python
|
||||
data_obtainer = dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
data_root=data_root,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Training_Task12_Images.zip',
|
||||
save_name='ic13_textdet_train_img.zip',
|
||||
md5='a443b9649fda4229c9bc52751bad08fb',
|
||||
split=['train'],
|
||||
content=['image'],
|
||||
mapping=[['ic13_textdet_train_img', 'textdet_imgs/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Training_Task1_GT.zip',
|
||||
save_name='ic13_textdet_test_img.zip',
|
||||
md5='af2e9f070c4c6a1c7bdb7b36bacf23e3',
|
||||
split=['test'],
|
||||
content=['image'],
|
||||
mapping=[['ic13_textdet_test_img', 'textdet_imgs/test']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Test_Task12_Images.zip',
|
||||
save_name='ic13_textdet_train_gt.zip',
|
||||
md5='f3a425284a66cd67f455d389c972cce4',
|
||||
split=['train'],
|
||||
content=['annotation'],
|
||||
mapping=[['ic13_textdet_train_gt', 'annotations/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Test_Task1_GT.zip',
|
||||
save_name='ic13_textdet_test_gt.zip',
|
||||
md5='3191c34cd6ac28b60f5a7db7030190fb',
|
||||
split=['test'],
|
||||
content=['annotation'],
|
||||
mapping=[['ic13_textdet_test_gt', 'annotations/test']]),
|
||||
])
|
||||
```
|
||||
|
||||
我们首先需要配置数据集获取方法,即 `data_obtainer`,通常来说,内置的 `NaiveDataObtainer` 即可完成绝大部分可以通过直链访问的数据集的下载。`NaiveDataObtainer` 将完成下载、解压、移动文件和重命名等操作。目前,我们暂时不支持自动下载存储在百度或谷歌网盘等需要登陆才能访问资源的数据集。
|
||||
|
||||
如下表所示,`data_obtainer` 主要由四个字段构成:
|
||||
|
||||
| 字段名 | 含义 |
|
||||
| ---------- | ---------------------------------------------------------- |
|
||||
| type | 数据集获取方法,目前仅支持 `NaiveDataObtainer` |
|
||||
| cache_path | 数据集缓存路径,用于存储数据集准备过程中下载的压缩包等文件 |
|
||||
| data_root | 数据集存储的根目录 |
|
||||
| files | 数据集文件列表,用于描述数据集的下载信息 |
|
||||
|
||||
`files` 字段是一个列表,列表中的每个元素都是一个字典,用于描述一个数据集文件的下载信息。如下表所示:
|
||||
|
||||
| 字段名 | 含义 |
|
||||
| ----------------- | -------------------------------------------------------------------- |
|
||||
| url | 数据集文件的下载链接 |
|
||||
| save_name | 数据集文件的保存名称 |
|
||||
| md5 (可选) | 数据集文件的 md5 值,用于校验下载的文件是否完整 |
|
||||
| split (可选) | 数据集文件所属的数据集划分,如 `train`,`test` 等,该字段可以空缺 |
|
||||
| content (可选) | 数据集文件的内容,如 `image`,`annotation` 等,该字段可以空缺 |
|
||||
| mapping (可选) | 数据集文件的解压映射,用于指定解压后的文件存储的位置,该字段可以空缺 |
|
||||
|
||||
```{note}
|
||||
为了让 `data_converter.gatherer` 正常运行,我们约定数据集的图片和标注分别储存在 `{taskname}_imgs/{split}/` 和 `annotations/` 下。特别地,对于[多对多的情况](#gatherer),标注文件需要放置于 `annotations/{split}` 下。
|
||||
```
|
||||
|
||||
##### 配置数据集转换器 `data_converter`
|
||||
|
||||
数据集转换器 `data_converter` 主要由标注文件获取器 `gatherer`,原始标注解析器 `parser`,以及数据存储器 `dumper` 组成。其中 `gatherer` 负责将图片与标注文件进行匹配,`parser` 负责将原始标注文件解析为标准格式,`dumper` 负责将标准格式的标注文件存储为 MMOCR 支持的格式。
|
||||
|
||||
一般来说,用户无需重新实现新的 `gatherer` 或 `dumper`,但是通常需要根据数据集的标注格式实现新的 `parser`。
|
||||
|
||||
我们通过观察获取的 ICDAR2013 数据集文件发现,其每一张图片都有一个对应的 `.txt` 格式的标注文件:
|
||||
|
||||
```text
|
||||
data_root
|
||||
├── textdet_imgs/train/
|
||||
│ ├── img_1.jpg
|
||||
│ ├── img_2.jpg
|
||||
│ └── ...
|
||||
├── annotations/train/
|
||||
│ ├── gt_img_1.txt
|
||||
│ ├── gt_img_2.txt
|
||||
│ └── ...
|
||||
```
|
||||
|
||||
且每个标注文件名与图片的对应关系为:`gt_img_1.txt` 对应 `img_1.jpg`,以此类推。因此,我们可以使用 `pair_gather` 来进行匹配。
|
||||
|
||||
```python
|
||||
gatherer=dict(
|
||||
type='pair_gather',
|
||||
suffixes=['.jpg'],
|
||||
rule=[r'(\w+)\.jpg', r'gt_\1.txt'])
|
||||
```
|
||||
|
||||
其中,规则 `rule` 是一个[正则表达式对](https://docs.python.org/3/library/re.html),第一个正则表达式用于匹配图片文件名,第二个正则表达式用于匹配标注文件名。在这里,我们使用 `(\w+)` 来匹配图片文件名,使用 `gt_\1.txt` 来匹配标注文件名,其中 `\1` 表示第一个正则表达式匹配到的内容。即,实现了将 `img_xx.jpg` 替换为 `gt_img_xx.txt` 的功能。
|
||||
|
||||
接下来,我们需要实现 `parser`,即将原始标注文件解析为标准格式。通常来说,用户在添加新的数据集前,可以浏览已支持数据集的[详情页](./datasetzoo.md),并查看是否已有相同格式的数据集。如果已有相同格式的数据集,则可以直接使用该数据集的 `parser`。否则,则需要实现新的格式解析器。
|
||||
|
||||
数据格式解析器被统一存储在 `mmocr/datasets/preparers/parsers` 目录下。所有的 `parser` 都需要继承 `BaseParser`,并实现 `parse_file` 或 `parse_files` 方法。
|
||||
|
||||
其中,`parse_file()` 方法用于解析单个标注文件,如下代码块所示,`parse_file()` 接受两个参数,`file` 是一个 `Tuple` 类型的变量,包含了由 `gatherer` 获取的图片文件路径和标注文件路径,而 `split` 则会传入当前处理的数据集划分,如 `train` 或 `test`。
|
||||
|
||||
```python
|
||||
def parse_file(self, file: Tuple, split: str) -> Tuple:
|
||||
"""Convert annotation for a single image.
|
||||
|
||||
Args:
|
||||
file (Tuple): A tuple of path to image and annotation
|
||||
split (str): Current split.
|
||||
|
||||
Returns:
|
||||
Tuple: A tuple of (img_path, instance). Instance is a dict
|
||||
containing parsed annotations, which should contain the
|
||||
following keys:
|
||||
- 'poly' or 'box' (textdet or textspotting)
|
||||
- 'text' (textspotting or textrecog)
|
||||
- 'ignore' (all task)
|
||||
"""
|
||||
```
|
||||
|
||||
`parse_file()` 方法的输出是一个 `Tuple` 类型的变量,包含了图片文件路径和标注信息 `instance`。其中,`instance` 是一个字典列表,包含了解析后的标注信息,依据不同的任务类型,该列表中的每一个字典必须包含以下键:
|
||||
|
||||
| 键名 | 任务类型 | 说明 |
|
||||
| :------- | :--------------------- | :------------------------------------- |
|
||||
| box/poly | textdet/textspotting | 矩形框坐标 `box` 或多边形框坐标 `poly` |
|
||||
| text | textrecog/textspotting | 文本内容 `text` |
|
||||
| ignore | all task | 是否忽略该样本 |
|
||||
|
||||
以下代码块反映了一个 `parse_file()` 方法返回的数据示例:
|
||||
|
||||
```python
|
||||
('imgs/train/xxx.jpg',
|
||||
dict(
|
||||
poly=[[[0, 1], [1, 1], [1, 0], [0, 0]]],
|
||||
text='hello',
|
||||
ignore=False)
|
||||
)
|
||||
```
|
||||
|
||||
需要注意的是,`parse_file()` 方法解析单个标注文件,并返回单张图片的标注信息,**仅能在标注图像与标注文件满足“多对多”关系时使用**。当仅存在单个标注文件时,可以通过重写 `parse_files()` 方法的方式,直接返回所有样本的数据信息。用户可以参见 `mmocr/datasets/preparers/parsers/totaltext_parser.py` 中的实现。
|
||||
|
||||
通过观察 ICDAR2013 数据集的标注文件:
|
||||
|
||||
```text
|
||||
158 128 411 181 "Footpath"
|
||||
443 128 501 169 "To"
|
||||
64 200 363 243 "Colchester"
|
||||
542, 710, 938, 841, "break"
|
||||
87, 884, 457, 1021, "could"
|
||||
517, 919, 831, 1024, "save"
|
||||
```
|
||||
|
||||
我们发现内置的 `ICDARTxtTextDetAnnParser` 已经可以满足我们的需求,因此我们可以直接使用该 `parser`,并将其配置到 `preparer` 中。
|
||||
|
||||
```python
|
||||
parser=dict(
|
||||
type='ICDARTxtTextDetAnnParser',
|
||||
remove_strs=[',', '"'],
|
||||
encoding='utf-8',
|
||||
format='x1 y1 x2 y2 trans',
|
||||
separator=' ',
|
||||
mode='xyxy')
|
||||
```
|
||||
|
||||
其中,由于标注文件中混杂了多余的引号 `“”` 和逗号 `,`,我们通过指定 `remove_strs=[',', '"']` 来进行移除。另外,我们在 `format` 中指定了标注文件的格式,其中 `x1 y1 x2 y2 trans` 表示标注文件中的每一行包含了四个坐标和一个文本内容,且坐标和文本内容之间使用空格分隔(`separator`=' ')。另外,我们需要指定 `mode` 为 `xyxy`,表示标注文件中的坐标是左上角和右下角的坐标,这样以来,`ICDARTxtTextDetAnnParser` 即可将该格式的标注解析为 MMOCR 统一格式。
|
||||
|
||||
最后,数据格式转换器 `data_converter` 的完整配置如下:
|
||||
|
||||
```python
|
||||
data_converter = dict(
|
||||
type='TextDetDataConverter',
|
||||
splits=['train', 'test'],
|
||||
data_root=data_root,
|
||||
gatherer=dict(
|
||||
type='pair_gather',
|
||||
suffixes=['.jpg'],
|
||||
rule=[r'(\w+)\.jpg', r'gt_\1.txt']),
|
||||
parser=dict(
|
||||
type='ICDARTxtTextDetAnnParser',
|
||||
remove_strs=[',', '"'],
|
||||
encoding='utf-8',
|
||||
format='x1 y1 x2 y2 trans',
|
||||
separator=' ',
|
||||
mode='xyxy'),
|
||||
dumper=dict(type='JsonDumper'))
|
||||
```
|
||||
|
||||
##### 配置基础配置生成器 `config_generator`
|
||||
|
||||
为了在数据集准备完毕后可以自动生成基础配置,我们还需要配置一下对应任务的 `config_generator`。目前,MMOCR 按任务实现了 `TextDetConfigGenerator`、`TextRecogConfigGenerator` 和 `TextSpottingConfigGenerator`。它们支持的主要参数如下:
|
||||
|
||||
| 字段名 | 含义 |
|
||||
| ----------- | --------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| data_root | 数据集存储的根目录 |
|
||||
| train_anns | 配置文件内训练集标注的路径。若不指定,则默认为 `[dict(ann_file='{taskname}_train.json', dataset_postfix='']`。 |
|
||||
| val_anns | 配置文件内验证集标注的路径。若不指定,则默认为空。 |
|
||||
| test_anns | 配置文件内测试集标注的路径。若不指定,则默认指向 `[dict(ann_file='{taskname}_test.json', dataset_postfix='']`。 |
|
||||
| config_path | 算法库存放配置文件的路径,配置生成器会将默认配置写入 `{config_path}/{taskname}/_base_/datasets/{dataset_name}.py` 下。若不指定,则默认为 `configs/` |
|
||||
|
||||
在本例中,我们只需要设置一下 `TextDetConfigGenerator` 的 `data_root` 字段,其它字段保持默认即可。
|
||||
|
||||
```python
|
||||
config_generator = dict(type='TextDetConfigGenerator', data_root=data_root)
|
||||
```
|
||||
|
||||
假如数据集比较特殊,标注存在着几个变体,配置生成器也支持在基础配置中生成指向各自变体的变量,但这需要用户在设置时用不同的 `dataset_postfix` 区分。例如,ICDAR 2015 文字识别数据的测试集就存在着原版和 1811 两种标注版本,我们可以在 `test_anns` 中指定它们,如下所示:
|
||||
|
||||
```python
|
||||
config_generator = dict(
|
||||
type='TextRecogConfigGenerator',
|
||||
data_root=data_root,
|
||||
test_anns=[
|
||||
dict(ann_file='textrecog_test.json'),
|
||||
dict(dataset_postfix='857', ann_file='textrecog_test_857.json')
|
||||
])
|
||||
```
|
||||
|
||||
配置生成器会生成以下配置:
|
||||
|
||||
```python
|
||||
icdar2015_textrecog_data_root = 'data/icdar2015'
|
||||
|
||||
icdar2015_textrecog_train = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_train.json',
|
||||
pipeline=None)
|
||||
|
||||
icdar2015_textrecog_test = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_test.json',
|
||||
test_mode=True,
|
||||
pipeline=None)
|
||||
|
||||
icdar2015_1811_textrecog_test = dict(
|
||||
type='OCRDataset',
|
||||
data_root=icdar2015_textrecog_data_root,
|
||||
ann_file='textrecog_test_1811.json',
|
||||
test_mode=True,
|
||||
pipeline=None)
|
||||
```
|
||||
|
||||
#### 添加标注示例
|
||||
|
||||
最后,我们可以在 `dataset_zoo/icdar2013/` 目录下添加标注示例文件 `sample_anno.md` 以帮助文档脚本在生成文档时添加标注示例,标注示例文件是一个 Markdown 文件,其内容通常包含了单个样本的原始数据格式。例如,以下代码块展示了 ICDAR2013 数据集的数据样例文件:
|
||||
最后,可以在 `dataset_zoo/icdar2013/` 目录下添加标注示例文件 `sample_anno.md` 以帮助文档脚本在生成文档时添加标注示例,标注示例文件是一个 Markdown 文件,其内容通常包含了单个样本的原始数据格式。例如,以下代码块展示了 ICDAR2013 数据集的数据样例文件:
|
||||
|
||||
````markdown
|
||||
**Text Detection**
|
||||
@ -683,6 +619,162 @@ icdar2015_1811_textrecog_test = dict(
|
||||
```
|
||||
````
|
||||
|
||||
#### 添加对应任务的配置文件
|
||||
|
||||
在 `dataset_zoo/icdar2013` 中,接着添加以任务名称命名的 `.py` 配置文件。如 `textdet.py`,`textrecog.py`,`textspotting.py`,`kie.py` 等。配置模板如下所示:
|
||||
|
||||
```python
|
||||
data_root = ''
|
||||
data_cache = 'data/cache'
|
||||
train_prepare = dict(
|
||||
obtainer=dict(
|
||||
type='NaiveObtainer',
|
||||
data_cache=data_cache,
|
||||
files=[
|
||||
dict(
|
||||
url='xx',
|
||||
md5='',
|
||||
save_name='xxx',
|
||||
mapping=list())
|
||||
]),
|
||||
gatherer=dict(type='xxxGatherer', **kwargs),
|
||||
parser=dict(type='xxxParser', **kwargs),
|
||||
packer=dict(type='TextxxxPacker'), # 对应任务的 Packer
|
||||
dumper=dict(type='JsonDumper'),
|
||||
)
|
||||
test_prepare = dict(
|
||||
obtainer=dict(
|
||||
type='NaiveObtainer',
|
||||
data_cache=data_cache,
|
||||
files=[
|
||||
dict(
|
||||
url='xx',
|
||||
md5='',
|
||||
save_name='xxx',
|
||||
mapping=list())
|
||||
]),
|
||||
gatherer=dict(type='xxxGatherer', **kwargs),
|
||||
parser=dict(type='xxxParser', **kwargs),
|
||||
packer=dict(type='TextxxxPacker'), # 对应任务的 Packer
|
||||
dumper=dict(type='JsonDumper'),
|
||||
)
|
||||
```
|
||||
|
||||
以文件检测任务为例,来介绍配置文件的具体内容。
|
||||
一般情况下用户无需重新实现新的 `obtainer`, `gatherer`, `packer` 或 `dumper`,但是通常需要根据数据集的标注格式实现新的 `parser`。
|
||||
对于 `obtainer` 的配置这里不在做过的介绍,可以参考 [数据集下载、解压、移动](#数据集下载解压移动-obtainer)。
|
||||
针对 `gatherer`,通过观察获取的 ICDAR2013 数据集文件发现,其每一张图片都有一个对应的 `.txt` 格式的标注文件:
|
||||
|
||||
```text
|
||||
data_root
|
||||
├── textdet_imgs/train/
|
||||
│ ├── img_1.jpg
|
||||
│ ├── img_2.jpg
|
||||
│ └── ...
|
||||
├── annotations/train/
|
||||
│ ├── gt_img_1.txt
|
||||
│ ├── gt_img_2.txt
|
||||
│ └── ...
|
||||
```
|
||||
|
||||
且每个标注文件名与图片的对应关系为:`gt_img_1.txt` 对应 `img_1.jpg`,以此类推。因此可以使用 `PairGatherer` 来进行匹配。
|
||||
|
||||
```python
|
||||
gatherer=dict(
|
||||
type='PairGatherer',
|
||||
img_suffixes=['.jpg'],
|
||||
rule=[r'(\w+)\.jpg', r'gt_\1.txt'])
|
||||
```
|
||||
|
||||
规则 `rule` 第一个正则表达式用于匹配图片文件名,第二个正则表达式用于匹配标注文件名。在这里,使用 `(\w+)` 来匹配图片文件名,使用 `gt_\1.txt` 来匹配标注文件名,其中 `\1` 表示第一个正则表达式匹配到的内容。即,实现了将 `img_xx.jpg` 替换为 `gt_img_xx.txt` 的功能。
|
||||
|
||||
接下来,需要实现 `parser`,即将原始标注文件解析为标准格式。通常来说,用户在添加新的数据集前,可以浏览已支持数据集的[详情页](./datasetzoo.md),并查看是否已有相同格式的数据集。如果已有相同格式的数据集,则可以直接使用该数据集的 `parser`。否则,则需要实现新的格式解析器。
|
||||
|
||||
数据格式解析器被统一存储在 `mmocr/datasets/preparers/parsers` 目录下。所有的 `parser` 都需要继承 `BaseParser`,并实现 `parse_file` 或 `parse_files` 方法。具体可以参考[数据集解析](#数据集解析)
|
||||
|
||||
通过观察 ICDAR2013 数据集的标注文件:
|
||||
|
||||
```text
|
||||
158 128 411 181 "Footpath"
|
||||
443 128 501 169 "To"
|
||||
64 200 363 243 "Colchester"
|
||||
542, 710, 938, 841, "break"
|
||||
87, 884, 457, 1021, "could"
|
||||
517, 919, 831, 1024, "save"
|
||||
```
|
||||
|
||||
我们发现内置的 `ICDARTxtTextDetAnnParser` 已经可以满足需求,因此可以直接使用该 `parser`,并将其配置到 `preparer` 中。
|
||||
|
||||
```python
|
||||
parser=dict(
|
||||
type='ICDARTxtTextDetAnnParser',
|
||||
remove_strs=[',', '"'],
|
||||
encoding='utf-8',
|
||||
format='x1 y1 x2 y2 trans',
|
||||
separator=' ',
|
||||
mode='xyxy')
|
||||
```
|
||||
|
||||
其中,由于标注文件中混杂了多余的引号 `“”` 和逗号 `,`,可以通过指定 `remove_strs=[',', '"']` 来进行移除。另外在 `format` 中指定了标注文件的格式,其中 `x1 y1 x2 y2 trans` 表示标注文件中的每一行包含了四个坐标和一个文本内容,且坐标和文本内容之间使用空格分隔(`separator`=' ')。另外,需要指定 `mode` 为 `xyxy`,表示标注文件中的坐标是左上角和右下角的坐标,这样以来,`ICDARTxtTextDetAnnParser` 即可将该格式的标注解析为统一格式。
|
||||
|
||||
对于 `packer`,以文件检测任务为例,其 `packer` 为 `TextDetPacker`,其配置如下:
|
||||
|
||||
```python
|
||||
packer=dict(type='TextDetPacker')
|
||||
```
|
||||
|
||||
最后,指定 `dumper`,这里一般情况下保存为json格式,其配置如下:
|
||||
|
||||
```python
|
||||
dumper=dict(type='JsonDumper')
|
||||
```
|
||||
|
||||
经过上述配置后,针对 ICDAR2013 训练集的配置文件如下:
|
||||
|
||||
```python
|
||||
train_preparer = dict(
|
||||
obtainer=dict(
|
||||
type='NaiveDataObtainer',
|
||||
cache_path=cache_path,
|
||||
files=[
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Training_Task12_Images.zip',
|
||||
save_name='ic13_textdet_train_img.zip',
|
||||
md5='a443b9649fda4229c9bc52751bad08fb',
|
||||
content=['image'],
|
||||
mapping=[['ic13_textdet_train_img', 'textdet_imgs/train']]),
|
||||
dict(
|
||||
url='https://rrc.cvc.uab.es/downloads/'
|
||||
'Challenge2_Training_Task1_GT.zip',
|
||||
save_name='ic13_textdet_train_gt.zip',
|
||||
md5='f3a425284a66cd67f455d389c972cce4',
|
||||
content=['annotation'],
|
||||
mapping=[['ic13_textdet_train_gt', 'annotations/train']]),
|
||||
]),
|
||||
gatherer=dict(
|
||||
type='PairGatherer',
|
||||
img_suffixes=['.jpg'],
|
||||
rule=[r'(\w+)\.jpg', r'gt_\1.txt']),
|
||||
parser=dict(
|
||||
type='ICDARTxtTextDetAnnParser',
|
||||
remove_strs=[',', '"'],
|
||||
format='x1 y1 x2 y2 trans',
|
||||
separator=' ',
|
||||
mode='xyxy'),
|
||||
packer=dict(type='TextDetPacker'),
|
||||
dumper=dict(type='JsonDumper'),
|
||||
)
|
||||
```
|
||||
|
||||
为了在数据集准备完毕后可以自动生成基础配置, 还需要配置一下对应任务的 `config_generator`。
|
||||
|
||||
在本例中,因为为文字检测任务,仅需要设置 Generator 为 `TextDetConfigGenerator`即可
|
||||
|
||||
```python
|
||||
config_generator = dict(type='TextDetConfigGenerator', )
|
||||
```
|
||||
|
||||
### 添加私有数据集
|
||||
|
||||
待更新...
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user