mirror of https://github.com/open-mmlab/mmocr.git
18 lines
1.8 KiB
Markdown
18 lines
1.8 KiB
Markdown
# 概览
|
||
|
||
伴随着 OpenMMLab 2.0 的发布,MMOCR 1.0 本身也作出了许多突破性的改变,使得代码的冗余度降低,代码效率提高,整体设计上也变得更为一致。然而,这些改变使得完美的后向兼容不再可能。我们也深知在这样巨大的变动之下,老用户想第一时间适应新版本也绝非易事。因此,我们推出了详细的迁移指南,旨在让老用户们尽可能平滑地过渡到全新的框架,最终能享受到全新的 MMOCR 和整个OpenMMLab 2.0 生态系统为生产力带来的巨大优势。
|
||
|
||
```{warning}
|
||
MMOCR 1.0 依赖于新的基础训练框架 [MMEngine](https://github.com/open-mmlab/mmengine),因而有着与 MMOCR 0.x 完全不同的依赖链。尽管你可能已经拥有了一个可以正常运行 MMOCR 0.x 的环境,但你仍然需要创建一个新的 python 环境来安装 MMOCR 1.0 版本所需要的依赖库。我们提供了详细的[安装文档](../get_started/install.md)以供参考。
|
||
```
|
||
|
||
接下来,请根据你的实际需求,阅读需要的章节:
|
||
|
||
- 如果你需要把 0.x 版本中训练的模型直接迁移到 1.0 版本中使用,请阅读 [预训练模型迁移](./model.md)
|
||
- 如果你需要训练模型,请阅读 [数据集迁移](./dataset.md) 和 [数据增强迁移](./transforms.md)
|
||
- 如果你需要在 MMOCR 上进行开发,请阅读 [代码迁移](code.md) 和 [上游依赖库变更](https://github.com/open-mmlab/mmengine/tree/main/docs/zh_cn/migration)
|
||
|
||
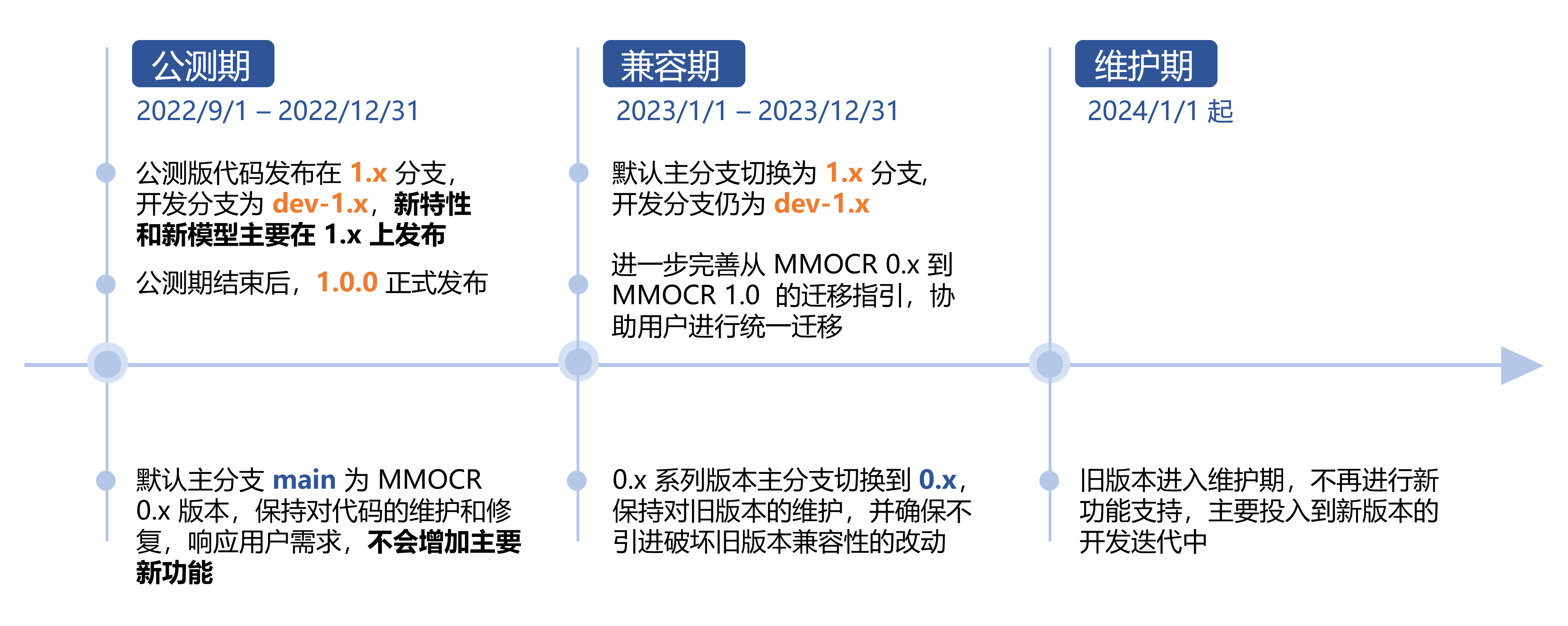
如下图所示,MMOCR 1.x 版本的维护计划主要分为三个阶段,即“公测期”,“兼容期”以及“维护期”。对于旧版本,我们将不再增加主要新功能。因此,我们强烈建议用户尽早迁移至 MMOCR 1.x 版本。
|
||
|
||
|