* [CodeCamp2023-584]Support DINO self-supervised learning in project (#1756) * feat: impelemt DINO * chore: delete debug code * chore: impplement pre-commit * fix: fix imported package * chore: pre-commit check * [CodeCamp2023-340] New Version of config Adapting MobileNet Algorithm (#1774) * add new config adapting MobileNetV2,V3 * add base model config for mobile net v3, modified all training configs of mobile net v3 inherit from the base model config * removed directory _base_/models/mobilenet_v3 * [Feature] Implement of Zero-Shot CLIP Classifier (#1737) * zero-shot CLIP * modify zero-shot clip config * add in1k_sub_prompt(8 prompts) for improvement * add some annotations doc * clip base class & clip_zs sub-class * some modifications of details after review * convert into and use mmpretrain-vit * modify names of some files and directories * ram init commit * [Fix] Fix pipeline bug in image retrieval inferencer * [CodeCamp2023-341] 多模态数据集文档补充-COCO Retrieval * Update OFA to compat with latest huggingface. * Update train.py to compat with new config * Bump version to v1.1.0 * Update __init__.py --------- Co-authored-by: LALBJ <40877073+LALBJ@users.noreply.github.com> Co-authored-by: DE009 <57087096+DE009@users.noreply.github.com> Co-authored-by: mzr1996 <mzr1996@163.com> Co-authored-by: 飞飞 <102729089+ASHORE1225@users.noreply.github.com> |
||
|---|---|---|
| .. | ||
| README.md | ||
| clip_vit-base-p16_zeroshot-cls_cifar100.py | ||
| clip_vit-base-p16_zeroshot-cls_in1k.py | ||
| clip_vit-large-p14_zeroshot-cls_cifar100.py | ||
| clip_vit-large-p14_zeroshot-cls_in1k.py | ||
| metafile.yml | ||
| vit-base-p16_pt-64xb64_in1k-384px.py | ||
| vit-base-p16_pt-64xb64_in1k-448px.py | ||
| vit-base-p16_pt-64xb64_in1k.py | ||
| vit-base-p32_pt-64xb64_in1k-384px.py | ||
| vit-base-p32_pt-64xb64_in1k-448px.py | ||
| vit-base-p32_pt-64xb64_in1k.py | ||
| vit-large-p14_headless.py | ||
README.md
CLIP
Learning Transferable Visual Models From Natural Language Supervision
Abstract
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at this https URL.
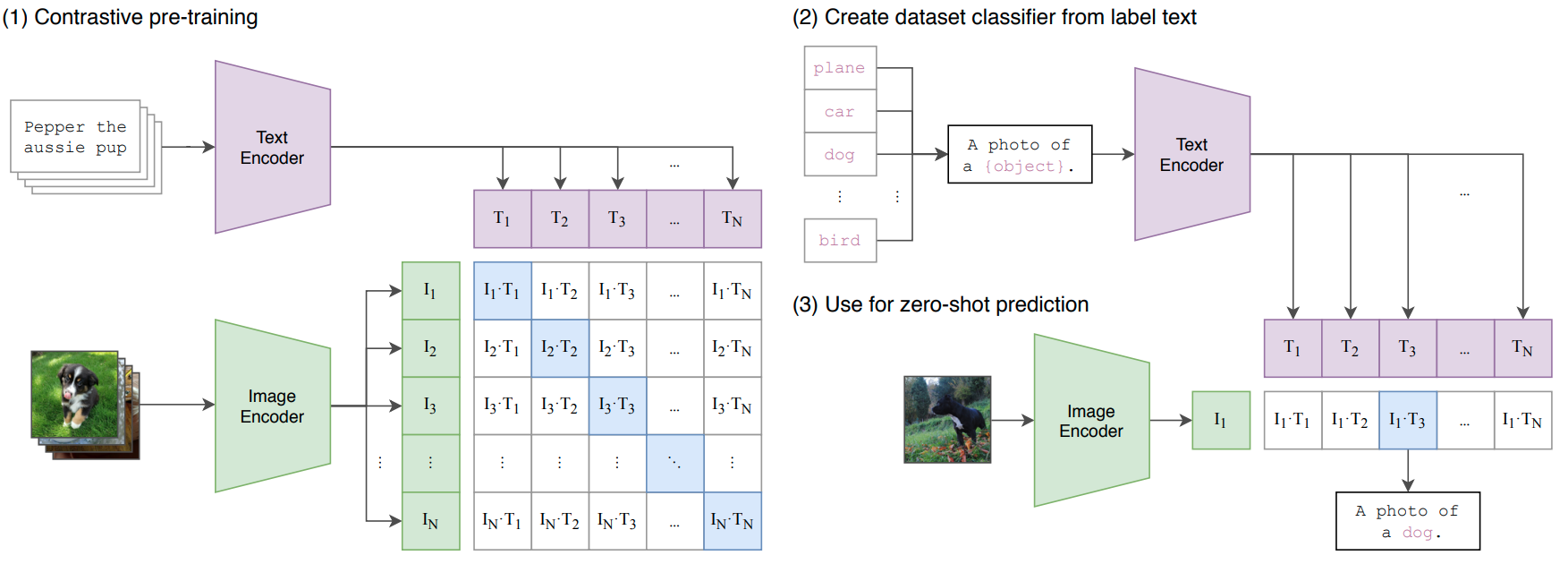
How to use it?
Predict image
from mmpretrain import inference_model
predict = inference_model('vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k', 'demo/bird.JPEG')
print(predict['pred_class'])
print(predict['pred_score'])
Use the model
import torch
from mmpretrain import get_model
model = get_model('vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k', pretrained=True)
inputs = torch.rand(1, 3, 224, 224)
out = model(inputs)
print(type(out))
# To extract features.
feats = model.extract_feat(inputs)
print(type(feats))
Test Command
Prepare your dataset according to the docs.
Test:
python tools/test.py configs/clip/vit-base-p32_pt-64xb64_in1k.py https://download.openmmlab.com/mmclassification/v0/clip/clip-vit-base-p32_laion2b-in12k-pre_3rdparty_in1k_20221220-b384e830.pth
Models and results
Image Classification on ImageNet-1k
| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
|---|---|---|---|---|---|---|---|
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k* |
CLIP LAION2B ImageNet-12k | 88.22 | 4.36 | 83.06 | 96.49 | config | model |
vit-base-p32_clip-laion2b-pre_3rdparty_in1k* |
CLIP LAION2B | 88.22 | 4.36 | 82.46 | 96.12 | config | model |
vit-base-p32_clip-openai-pre_3rdparty_in1k* |
CLIP OPENAI | 88.22 | 4.36 | 81.77 | 95.89 | config | model |
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k-384px* |
CLIP LAION2B ImageNet-12k | 88.22 | 12.66 | 85.39 | 97.67 | config | model |
vit-base-p32_clip-openai-in12k-pre_3rdparty_in1k-384px* |
CLIP OPENAI ImageNet-12k | 88.22 | 12.66 | 85.13 | 97.42 | config | model |
vit-base-p16_clip-laion2b-in12k-pre_3rdparty_in1k* |
CLIP LAION2B ImageNet-12k | 86.57 | 16.86 | 86.02 | 97.76 | config | model |
vit-base-p16_clip-laion2b-pre_3rdparty_in1k* |
CLIP LAION2B | 86.57 | 16.86 | 85.49 | 97.59 | config | model |
vit-base-p16_clip-openai-in12k-pre_3rdparty_in1k* |
CLIP OPENAI ImageNet-12k | 86.57 | 16.86 | 85.99 | 97.72 | config | model |
vit-base-p16_clip-openai-pre_3rdparty_in1k* |
CLIP OPENAI | 86.57 | 16.86 | 85.30 | 97.50 | config | model |
vit-base-p32_clip-laion2b-in12k-pre_3rdparty_in1k-448px* |
CLIP LAION2B ImageNet-12k | 88.22 | 17.20 | 85.76 | 97.63 | config | model |
vit-base-p16_clip-laion2b-in12k-pre_3rdparty_in1k-384px* |
CLIP LAION2B ImageNet-12k | 86.57 | 49.37 | 87.17 | 98.02 | config | model |
vit-base-p16_clip-laion2b-pre_3rdparty_in1k-384px* |
CLIP LAION2B | 86.57 | 49.37 | 86.52 | 97.97 | config | model |
vit-base-p16_clip-openai-in12k-pre_3rdparty_in1k-384px* |
CLIP OPENAI ImageNet-12k | 86.57 | 49.37 | 86.87 | 98.05 | config | model |
vit-base-p16_clip-openai-pre_3rdparty_in1k-384px* |
CLIP OPENAI | 86.57 | 49.37 | 86.25 | 97.90 | config | model |
Models with * are converted from the timm. The config files of these models are only for inference. We haven't reproduce the training results.
Citation
@InProceedings{pmlr-v139-radford21a,
title = {Learning Transferable Visual Models From Natural Language Supervision},
author = {Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya},
booktitle = {Proceedings of the 38th International Conference on Machine Learning},
year = {2021},
series = {Proceedings of Machine Learning Research},
publisher = {PMLR},
}