* 网络搭建完成、能正常推理 * 网络搭建完成、能正常推理 * 网络搭建完成、能正常推理 * 添加了模型转换未验证,配置文件 但有无法运行 * 模型转换、结构验证完成,可以推理出正确答案 * 推理精度与原论文一致 已完成转化 * 三个方法改为class 暂存 * 完成推理精度对齐 误差0.04 * 暂时使用的levit2mmcls * 训练跑通,训练相关参数未对齐 * '训练相关参数对齐'参数' * '修复训练时验证导致模型结构改变无法复原问题' * '修复训练时验证导致模型结构改变无法复原问题' * '添加mixup和labelsmooth' * '配置文件补齐' * 添加模型转换 * 添加meta文件 * 添加meta文件 * 删除demo.py测试文件 * 添加模型README文件 * docs文件回滚 * model-index删除末行空格 * 更新模型metafile * 更新metafile * 更新metafile * 更新README和metafile * 更新模型README * 更新模型metafile * Delete the model class and get_LeViT_model methods in the mmcls.models.backone.levit file * Change the class name to Google Code Style * use arch to provide default architectures * use nn.Conv2d * mmcv.cnn.fuse_conv_bn * modify some details * remove down_ops from the architectures. * remove init_weight function * Modify ambiguous variable names * Change the drop_path in config to drop_path_rate * Add unit test * remove train function * add unit test * modify nn.norm1d to build_norm_layer * update metafile and readme * Update configs and LeViT implementations. * Update README. * Add docstring and update unit tests. * Revert irrelative modification. * Fix unit tests * minor fix Co-authored-by: mzr1996 <mzr1996@163.com> |
||
|---|---|---|
| .. | ||
| deploy | ||
| README.md | ||
| levit-128_8xb256_in1k.py | ||
| levit-128s_8xb256_in1k.py | ||
| levit-192_8xb256_in1k.py | ||
| levit-256_8xb256_in1k.py | ||
| levit-384_8xb256_in1k.py | ||
| metafile.yml | ||
README.md
LeViT
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
Abstract
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We revisit principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU.
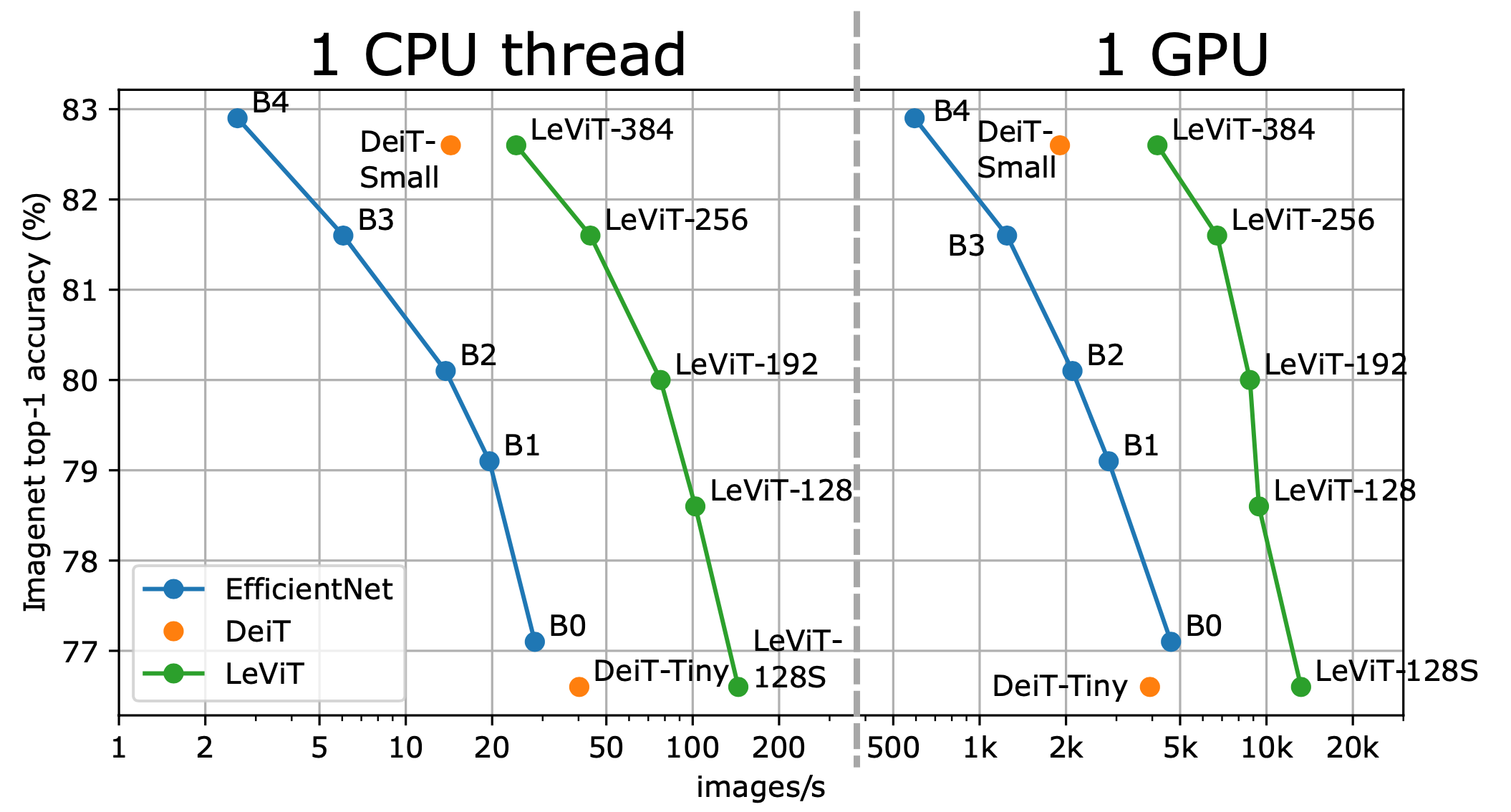
Results and models
ImageNet-1k
| Model | Pretrain | Params(M) | Flops(G) | Top-1 (%) | Top-5 (%) | Config | Download |
|---|---|---|---|---|---|---|---|
| levit-128s_3rdparty_in1k* | From scratch | 7.39 | 0.31 | 76.51 | 92.90 | config | deploy | model |
| levit-128_3rdparty_in1k* | From scratch | 8.83 | 0.41 | 78.58 | 93.95 | config | deploy | model |
| levit-192_3rdparty_in1k* | From scratch | 10.56 | 0.67 | 79.86 | 94.75 | config | deploy | model |
| levit-256_3rdparty_in1k* | From scratch | 18.38 | 1.14 | 81.59 | 95.46 | config | deploy | model |
| levit-384_3rdparty_in1k* | From scratch | 38.36 | 2.37 | 82.59 | 95.95 | config | deploy | model |
Models with * are converted from the official repo. The config files of these models are only for inference. All these models are trained by distillation on RegNet, and MMClassification doesn't support distillation by now. See MMRazor for model distillation.
Citation
@InProceedings{Graham_2021_ICCV,
author = {Graham, Benjamin and El-Nouby, Alaaeldin and Touvron, Hugo and Stock, Pierre and Joulin, Armand and Jegou, Herve and Douze, Matthijs},
title = {LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {12259-12269}
}