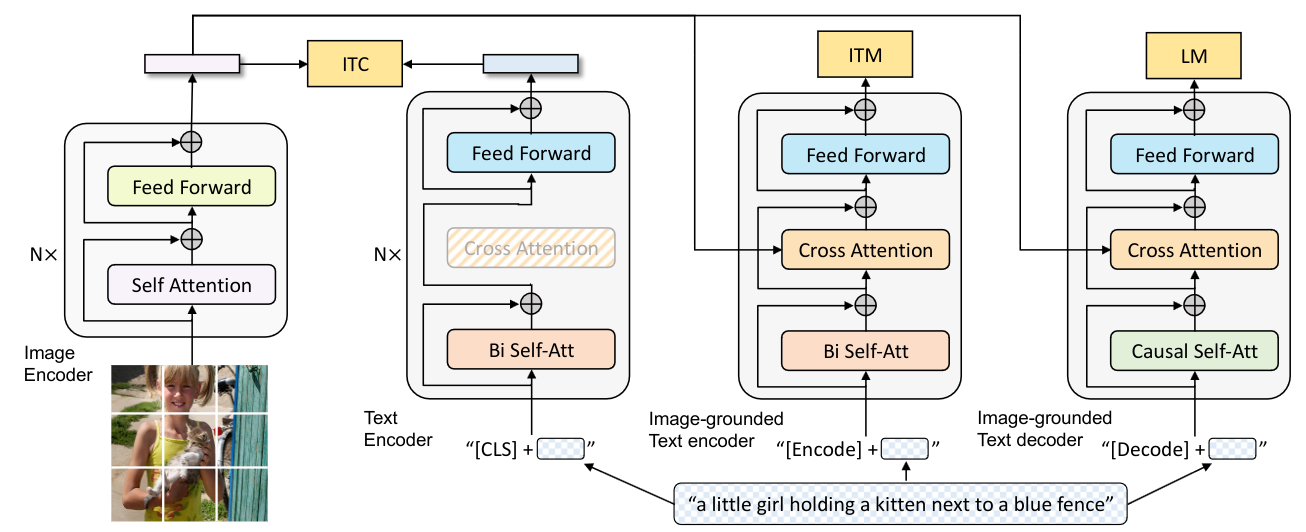
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner.
How to use it?
Use the model
frommmpretrainimportinference_modelresult=inference_model('blip-base_3rdparty_caption','demo/cat-dog.png')print(result)# {'pred_caption': 'a puppy and a cat sitting on a blanket'}
Models with * are converted from the official repo. The config files of these models are only for inference. We haven't reproduce the training results.
Results with # denote zero-shot evaluation. The corresponding model hasn't been finetuned on that dataset.
Citation
@inproceedings{li2022blip,title={BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation},author={Junnan Li and Dongxu Li and Caiming Xiong and Steven Hoi},year={2022},booktitle={ICML},}