mirror of
https://github.com/open-mmlab/mmrazor.git
synced 2025-06-03 15:02:54 +08:00
Revert "[Enhancement] Add benchmark test script" (#263)
Revert "[Enhancement] Add benchmark test script (#262)" This reverts commit f60cf9c469c1365cb8e1dd62aabb6e2937e1cffa.
This commit is contained in:
parent
f60cf9c469
commit
5105489d64
@ -124,7 +124,8 @@ jobs:
|
||||
docker exec mmrazor pip install -e /mmdetection
|
||||
docker exec mmrazor pip install -e /mmclassification
|
||||
docker exec mmrazor pip install -e /mmsegmentation
|
||||
docker exec mmrazor pip install -r requirements.txt
|
||||
pip install -r requirements.txt
|
||||
python -c 'import mmcv; print(mmcv.__version__)'
|
||||
- run:
|
||||
name: Build and install
|
||||
command: |
|
||||
|
||||
@ -40,8 +40,6 @@ def parse_args():
|
||||
'--work-dir',
|
||||
default='work_dirs/benchmark_test',
|
||||
help='the dir to save metric')
|
||||
parser.add_argument(
|
||||
'--replace-ceph', action='store_true', help='load data from ceph')
|
||||
parser.add_argument(
|
||||
'--run', action='store_true', help='run script directly')
|
||||
parser.add_argument(
|
||||
@ -68,70 +66,12 @@ def parse_args():
|
||||
return args
|
||||
|
||||
|
||||
def replace_to_ceph(cfg):
|
||||
|
||||
file_client_args = dict(
|
||||
backend='petrel',
|
||||
path_mapping=dict({
|
||||
'./data/coco':
|
||||
's3://openmmlab/datasets/detection/coco',
|
||||
'data/coco':
|
||||
's3://openmmlab/datasets/detection/coco',
|
||||
'./data/cityscapes':
|
||||
's3://openmmlab/datasets/segmentation/cityscapes',
|
||||
'data/cityscapes':
|
||||
's3://openmmlab/datasets/segmentation/cityscapes',
|
||||
'./data/imagenet':
|
||||
's3://openmmlab/datasets/classification/imagenet',
|
||||
'data/imagenet':
|
||||
's3://openmmlab/datasets/classification/imagenet',
|
||||
}))
|
||||
|
||||
def _process_pipeline(dataset, name):
|
||||
|
||||
def replace_img(pipeline):
|
||||
if pipeline['type'] == 'LoadImageFromFile':
|
||||
pipeline['file_client_args'] = file_client_args
|
||||
|
||||
def replace_ann(pipeline):
|
||||
if pipeline['type'] == 'LoadAnnotations' or pipeline[
|
||||
'type'] == 'LoadPanopticAnnotations':
|
||||
pipeline['file_client_args'] = file_client_args
|
||||
|
||||
if 'pipeline' in dataset:
|
||||
replace_img(dataset.pipeline[0])
|
||||
replace_ann(dataset.pipeline[1])
|
||||
if 'dataset' in dataset:
|
||||
# dataset wrapper
|
||||
replace_img(dataset.dataset.pipeline[0])
|
||||
replace_ann(dataset.dataset.pipeline[1])
|
||||
else:
|
||||
# dataset wrapper
|
||||
replace_img(dataset.dataset.pipeline[0])
|
||||
replace_ann(dataset.dataset.pipeline[1])
|
||||
|
||||
def _process_evaluator(evaluator, name):
|
||||
if evaluator['type'] == 'CocoPanopticMetric':
|
||||
evaluator['file_client_args'] = file_client_args
|
||||
|
||||
# half ceph
|
||||
_process_pipeline(cfg.train_dataloader.dataset, cfg.filename)
|
||||
_process_pipeline(cfg.val_dataloader.dataset, cfg.filename)
|
||||
_process_pipeline(cfg.test_dataloader.dataset, cfg.filename)
|
||||
_process_evaluator(cfg.val_evaluator, cfg.filename)
|
||||
_process_evaluator(cfg.test_evaluator, cfg.filename)
|
||||
|
||||
|
||||
def create_test_job_batch(commands, model_info, args, port):
|
||||
|
||||
fname = model_info.name
|
||||
|
||||
cfg_path = Path(model_info.config)
|
||||
|
||||
cfg = mmengine.Config.fromfile(cfg_path)
|
||||
|
||||
if args.replace_ceph:
|
||||
replace_to_ceph(cfg)
|
||||
config = Path(model_info.config)
|
||||
# assert config.exists(), f'{fname}: {config} not found.'
|
||||
|
||||
http_prefix = 'https://download.openmmlab.com/mmrazor/'
|
||||
if 's3://' in args.checkpoint_root:
|
||||
@ -159,8 +99,6 @@ def create_test_job_batch(commands, model_info, args, port):
|
||||
job_name = f'{args.job_name}_{fname}'
|
||||
work_dir = Path(args.work_dir) / fname
|
||||
work_dir.mkdir(parents=True, exist_ok=True)
|
||||
test_cfg_path = work_dir / 'config.py'
|
||||
cfg.dump(test_cfg_path)
|
||||
|
||||
if args.quotatype is not None:
|
||||
quota_cfg = f'#SBATCH --quotatype {args.quotatype}\n'
|
||||
@ -172,24 +110,24 @@ def create_test_job_batch(commands, model_info, args, port):
|
||||
master_port = f'NASTER_PORT={port}'
|
||||
|
||||
script_name = osp.join('tools', 'test.py')
|
||||
job_script = (f'#!/bin/bash\n'
|
||||
f'#SBATCH --output {work_dir}/job.%j.out\n'
|
||||
f'#SBATCH --partition={args.partition}\n'
|
||||
f'#SBATCH --job-name {job_name}\n'
|
||||
f'#SBATCH --gres=gpu:{args.gpus}\n'
|
||||
f'{quota_cfg}'
|
||||
f'#SBATCH --ntasks-per-node={args.gpus}\n'
|
||||
f'#SBATCH --ntasks={args.gpus}\n'
|
||||
f'#SBATCH --cpus-per-task=5\n\n'
|
||||
f'{master_port} {runner} -u {script_name} '
|
||||
f'{test_cfg_path} {checkpoint} '
|
||||
f'--work-dir {work_dir} '
|
||||
f'--launcher={launcher}\n')
|
||||
job_script = (
|
||||
f'#!/bin/bash\n'
|
||||
f'#SBATCH --output {work_dir}/job.%j.out\n'
|
||||
f'#SBATCH --partition={args.partition}\n'
|
||||
f'#SBATCH --job-name {job_name}\n'
|
||||
f'#SBATCH --gres=gpu:{args.gpus}\n'
|
||||
f'{quota_cfg}'
|
||||
f'#SBATCH --ntasks-per-node={args.gpus}\n'
|
||||
f'#SBATCH --ntasks={args.gpus}\n'
|
||||
f'#SBATCH --cpus-per-task=5\n\n'
|
||||
f'{master_port} {runner} -u {script_name} {config} {checkpoint} '
|
||||
f'--work-dir {work_dir} '
|
||||
f'--launcher={launcher}\n')
|
||||
|
||||
with open(work_dir / 'job.sh', 'w') as f:
|
||||
f.write(job_script)
|
||||
|
||||
commands.append(f'echo "{test_cfg_path}"')
|
||||
commands.append(f'echo "{config}"')
|
||||
if args.local:
|
||||
commands.append(f'bash {work_dir}/job.sh')
|
||||
else:
|
||||
@ -238,8 +176,9 @@ def summary(args):
|
||||
expect_result = model_info.results[0].metrics
|
||||
summary_result = {
|
||||
'expect': expect_result,
|
||||
'actual': {k: v
|
||||
for k, v in latest_result.items()}
|
||||
'actual':
|
||||
{METRIC_MAPPINGS[k]: v
|
||||
for k, v in latest_result.items()}
|
||||
}
|
||||
model_results[model_name] = summary_result
|
||||
|
||||
|
||||
@ -10,6 +10,7 @@ An activation boundary for a neuron refers to a separating hyperplane that deter
|
||||
|
||||
<img width="1184" alt="pipeline" src="https://user-images.githubusercontent.com/88702197/187422794-d681ed58-293a-4d9e-9e5b-9937289136a7.png">
|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
### Classification
|
||||
|
||||
@ -8,6 +8,7 @@ Convolutional neural networks have been widely deployed in various application s
|
||||
|
||||

|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
#### Classification
|
||||
|
||||
@ -10,6 +10,7 @@ Learning portable neural networks is very essential for computer vision for the
|
||||
|
||||
<img width="910" alt="pipeline" src="https://user-images.githubusercontent.com/88702197/187423163-b34896fc-8516-403b-acd7-4c0b8e43af5b.png">
|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
### Classification
|
||||
|
||||
@ -22,6 +22,7 @@ almost 10.4 times less parameters outperforms a larger, state-of-the-art teacher
|
||||
|
||||
<img width="743" alt="pipeline" src="https://user-images.githubusercontent.com/88702197/187423686-68719140-a978-4a19-a684-42b1d793d1fb.png">
|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
### Classification
|
||||
|
||||
@ -10,6 +10,7 @@ Knowledge distillation (KD) has been proven to be a simple and effective tool fo
|
||||
|
||||

|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
### Segmentation
|
||||
|
||||
@ -10,6 +10,7 @@ Knowledge distillation, in which a student model is trained to mimic a teacher m
|
||||
|
||||
<img width="836" alt="pipeline" src="https://user-images.githubusercontent.com/88702197/187424617-6259a7fc-b610-40ae-92eb-f21450dcbaa1.png">
|
||||
|
||||
|
||||
## Results and models
|
||||
|
||||
### Detection
|
||||
|
||||
@ -11,6 +11,7 @@ Comprehensive experiments verify that our approach is flexible and effective. It
|
||||
|
||||

|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
### Supernet pre-training on ImageNet
|
||||
|
||||
@ -11,6 +11,8 @@ Notably, by setting optimized channel numbers, our AutoSlim-MobileNet-v2 at 305M
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
### Supernet pre-training on ImageNet
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
# Algorithm
|
||||
|
||||
## Introduction
|
||||
|
||||
### What is algorithm in MMRazor
|
||||
@ -11,15 +10,15 @@ MMRazor is a model compression toolkit, which includes 4 mianstream technologies
|
||||
- Knowledge Distillation (KD)
|
||||
- Quantization (come soon)
|
||||
|
||||
And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
|
||||
And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
|
||||
|
||||
[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
|
||||
[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
|
||||
|
||||
`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
|
||||
`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
|
||||
|
||||
### About base algorithm
|
||||
|
||||
In the directory of ``` models/algorith``ms ```, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
|
||||
In the directory of `models/algorith``ms`, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
|
||||
|
||||
```Python
|
||||
from typing import Dict, List, Optional, Tuple, Union
|
||||
@ -38,9 +37,9 @@ class BaseAlgorithm(BaseModel):
|
||||
architecture: Union[BaseModel, Dict],
|
||||
data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
|
||||
init_cfg: Optional[Dict] = None):
|
||||
|
||||
|
||||
......
|
||||
|
||||
|
||||
super().__init__(data_preprocessor, init_cfg)
|
||||
self.architecture = architecture
|
||||
|
||||
@ -48,7 +47,7 @@ class BaseAlgorithm(BaseModel):
|
||||
batch_inputs: torch.Tensor,
|
||||
data_samples: Optional[List[BaseDataElement]] = None,
|
||||
mode: str = 'tensor') -> ForwardResults:
|
||||
|
||||
|
||||
if mode == 'loss':
|
||||
return self.loss(batch_inputs, data_samples)
|
||||
elif mode == 'tensor':
|
||||
@ -87,10 +86,12 @@ class BaseAlgorithm(BaseModel):
|
||||
|
||||
As you can see from above, `BaseAlgorithm` is inherited from `BaseModel` of MMEngine. `BaseModel` implements the basic functions of the algorithmic model, such as weights initialize,
|
||||
|
||||
batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
|
||||
batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
|
||||
|
||||
`BaseAlgorithm`'s forward is just a wrapper of `BaseModel`'s forward. Sub-classes inherited from BaseAlgorithm only need to override the `loss` method, which implements the logic to calculate loss, thus various algorithms can be trained in the runner.
|
||||
|
||||
|
||||
|
||||
## How to use existing algorithms in MMRazor
|
||||
|
||||
1. Configure your architecture that will be slimmed
|
||||
@ -107,7 +108,7 @@ architecture = _base_.model
|
||||
|
||||
- Use your customized model as below, which is an example of defining a VGG model as our architecture.
|
||||
|
||||
> How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html).
|
||||
> How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html#).
|
||||
|
||||
```Python
|
||||
default_scope='mmcls'
|
||||
@ -122,7 +123,7 @@ architecture = dict(
|
||||
))
|
||||
```
|
||||
|
||||
2. Apply the registered algorithm to your architecture.
|
||||
2. Apply the registered algorithm to your architecture.
|
||||
|
||||
> The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
|
||||
|
||||
@ -195,8 +196,8 @@ class XXX(BaseAlgorithm):
|
||||
def __init__(self, architecture):
|
||||
super().__init__(architecture)
|
||||
......
|
||||
|
||||
def loss(self, batch_inputs):
|
||||
|
||||
def loss(self, batch_inputs):
|
||||
......
|
||||
return LossResults
|
||||
```
|
||||
@ -218,17 +219,17 @@ class XXX(BaseAlgorithm):
|
||||
def loss(self, batch_inputs):
|
||||
......
|
||||
return LossResults
|
||||
|
||||
|
||||
def aaa(self):
|
||||
......
|
||||
|
||||
|
||||
def bbb(self):
|
||||
......
|
||||
```
|
||||
|
||||
4. Import the class
|
||||
|
||||
You can add the following line to ``` mmrazor/models/algorithms/``{subdirectory}/``__init__.py ```
|
||||
You can add the following line to `mmrazor/models/algorithms/``{subdirectory}/``__init__.py`
|
||||
|
||||
```CoffeeScript
|
||||
from .xxx import XXX
|
||||
@ -254,12 +255,12 @@ Please refer to our tutorials about how to customize different algorithms for mo
|
||||
|
||||
1. NAS
|
||||
|
||||
[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html)
|
||||
[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html#)
|
||||
|
||||
2. Pruning
|
||||
|
||||
[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_5_customize_pruning_algorithms.html)
|
||||
|
||||
3. Distill
|
||||
3. Distill
|
||||
|
||||
[Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
|
||||
[Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
|
||||
@ -1,12 +1,11 @@
|
||||
# Apply existing algorithms to new tasks
|
||||
|
||||
Here we show how to apply existing algorithms to other tasks with an example of [SPOS ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmcls/spos)& [DetNAS](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmdet/detnas).
|
||||
|
||||
> SPOS: Single Path One-Shot NAS for classification
|
||||
>
|
||||
> DetNAS: Single Path One-Shot NAS for detection
|
||||
|
||||
**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet**\*\*'s\*\*
|
||||
**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet****'s**
|
||||
|
||||
You can implement a new algorithm by inheriting from the existing algorithm quickly if the new task's specificity leads to the failure of applying directly.
|
||||
|
||||
@ -80,4 +79,4 @@ model = dict(
|
||||
mutator=dict(type='mmrazor.OneShotModuleMutator'))
|
||||
|
||||
find_unused_parameters = True
|
||||
```
|
||||
```
|
||||
@ -1,12 +1,11 @@
|
||||
# Customize Architectures
|
||||
Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
|
||||
|
||||
Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
|
||||
|
||||
> Please refer to these documents as follows if you want to know about **connectors** and **dynamic ops**.
|
||||
> Please refer to these documents as follows if you want to know about **connectors** and **dynamic ops**.
|
||||
>
|
||||
> [Connector 用户文档](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
|
||||
> [Connector 用户文档](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
|
||||
>
|
||||
> [Dynamic op 用户文档](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
|
||||
> [Dynamic op 用户文档](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
|
||||
|
||||
## Develop searchable model components
|
||||
|
||||
@ -73,14 +72,14 @@ class SearchableShuffleNetV2(BaseBackbone):
|
||||
if index not in range(0, layers_nums):
|
||||
raise ValueError('the item in out_indices must in '
|
||||
f'range(0, 5). But received {index}')
|
||||
|
||||
|
||||
self.frozen_stages = frozen_stages
|
||||
if frozen_stages not in range(-1, layers_nums):
|
||||
raise ValueError('frozen_stages must be in range(-1, 5). '
|
||||
f'But received {frozen_stages}')
|
||||
|
||||
|
||||
super().__init__(init_cfg)
|
||||
|
||||
|
||||
self.arch_setting = arch_setting
|
||||
self.widen_factor = widen_factor
|
||||
self.out_indices = out_indices
|
||||
@ -89,10 +88,10 @@ class SearchableShuffleNetV2(BaseBackbone):
|
||||
self.act_cfg = act_cfg
|
||||
self.norm_eval = norm_eval
|
||||
self.with_cp = with_cp
|
||||
|
||||
|
||||
last_channels = 1024
|
||||
self.in_channels = 16 * stem_multiplier
|
||||
|
||||
|
||||
# build the first layer
|
||||
self.conv1 = ConvModule(
|
||||
in_channels=3,
|
||||
@ -103,7 +102,7 @@ class SearchableShuffleNetV2(BaseBackbone):
|
||||
conv_cfg=conv_cfg,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg)
|
||||
|
||||
|
||||
# build the middle layers
|
||||
self.layers = ModuleList()
|
||||
for channel, num_blocks, mutable_cfg in arch_setting:
|
||||
@ -111,7 +110,7 @@ class SearchableShuffleNetV2(BaseBackbone):
|
||||
layer = self._make_layer(out_channels, num_blocks,
|
||||
copy.deepcopy(mutable_cfg))
|
||||
self.layers.append(layer)
|
||||
|
||||
|
||||
# build the last layer
|
||||
if with_last_layer:
|
||||
self.layers.append(
|
||||
@ -258,4 +257,4 @@ architecture = dict(
|
||||
...
|
||||
```
|
||||
|
||||
How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
|
||||
How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
|
||||
@ -1,5 +1,4 @@
|
||||
# Customize mixed algorithms
|
||||
|
||||
Here we show how to customize mixed algorithms with our algorithm components. We take [AutoSlim ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim)as an example.
|
||||
|
||||
> **Why is AutoSlim a mixed algorithm?**
|
||||
@ -8,19 +7,19 @@ Here we show how to customize mixed algorithms with our algorithm components. We
|
||||
|
||||
1. Register a new algorithm
|
||||
|
||||
Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
|
||||
Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
|
||||
|
||||
> You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
|
||||
> You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
|
||||
|
||||
> You can choose existing algorithm components in MMRazor, such as `OneShotChannelMutator` and `ConfigurableDistiller` in AutoSlim.
|
||||
>
|
||||
> If these in MMRazor don't meet your needs, you can customize new algorithm components for your algorithm. Reference is as follows:
|
||||
>
|
||||
> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
|
||||
> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
|
||||
>
|
||||
> [Tutorials: Customize Pruning algorithms](https://aicarrier.feishu.cn/docx/doxcnzXlPv0cDdmd0wNrq0SEqsh)
|
||||
> [Tutorials: Customize Pruning algorithms](https://aicarrier.feishu.cn/docx/doxcnzXlPv0cDdmd0wNrq0SEqsh)
|
||||
>
|
||||
> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
|
||||
> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
|
||||
|
||||
```Python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
@ -53,9 +52,9 @@ class AutoSlim(BaseAlgorithm):
|
||||
self.distiller = self._build_distiller(distiller)
|
||||
self.distiller.prepare_from_teacher(self.architecture)
|
||||
self.distiller.prepare_from_student(self.architecture)
|
||||
|
||||
|
||||
......
|
||||
|
||||
|
||||
def _build_mutator(self,
|
||||
mutator: VALID_MUTATOR_TYPE) -> OneShotChannelMutator:
|
||||
"""build mutator."""
|
||||
@ -87,12 +86,12 @@ In `train_step`, both the `mutator` and the `distiller` play an important role.
|
||||
```Python
|
||||
@MODELS.register_module()
|
||||
class AutoSlim(BaseAlgorithm):
|
||||
|
||||
|
||||
......
|
||||
|
||||
|
||||
def train_step(self, data: List[dict],
|
||||
optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
|
||||
|
||||
|
||||
def distill_step(
|
||||
batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
|
||||
) -> Dict[str, torch.Tensor]:
|
||||
@ -107,12 +106,12 @@ class AutoSlim(BaseAlgorithm):
|
||||
self.set_max_subnet()
|
||||
......
|
||||
total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
|
||||
|
||||
|
||||
# update the min subnet loss.
|
||||
self.set_min_subnet()
|
||||
min_subnet_losses = distill_step(batch_inputs, data_samples)
|
||||
total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
|
||||
|
||||
|
||||
# update the random subnet loss.
|
||||
for sample_idx in range(self.num_samples):
|
||||
self.set_subnet(self.sample_subnet())
|
||||
@ -157,4 +156,4 @@ model= dict(
|
||||
type='ConfigurableDistiller',
|
||||
...),
|
||||
...)
|
||||
```
|
||||
```
|
||||
@ -1,8 +1,7 @@
|
||||
# Delivery
|
||||
|
||||
## Introduction of Delivery
|
||||
|
||||
`Delivery` is a mechanism used in **knowledge distillation**\*\*,\*\* which is to **align the intermediate results** between the teacher model and the student model by delivering and rewriting these intermediate results between them. As shown in the figure below, deliveries can be used to:
|
||||
`Delivery` is a mechanism used in **knowledge distillation****,** which is to **align the intermediate results** between the teacher model and the student model by delivering and rewriting these intermediate results between them. As shown in the figure below, deliveries can be used to:
|
||||
|
||||
- **Deliver the output of a layer of the teacher model directly to a layer of the student model.** In some knowledge distillation algorithms, we may need to deliver the output of a layer of the teacher model to the student model directly. For example, in [LAD](https://arxiv.org/abs/2108.10520) algorithm, the student model needs to obtain the label assignment of the teacher model directly.
|
||||
- **Align the inputs of the teacher model and the student model.** For example, in the MMClassification framework, some widely used data augmentations such as [mixup](https://arxiv.org/abs/1710.09412) and [CutMix](https://arxiv.org/abs/1905.04899) are not implemented in Data Pipelines but in `forward_train`, and due to the randomness of these data augmentation methods, it may lead to a gap between the input of the teacher model and the student model.
|
||||
@ -11,25 +10,28 @@
|
||||
|
||||
In general, the delivery mechanism allows us to deliver intermediate results between the teacher model and the student model **without adding additional code**, which reduces the hard coding in the source code.
|
||||
|
||||
## Usage of Delivery
|
||||
## Usage of Delivery
|
||||
|
||||
Currently, we support two deliveries: ``` FunctionOutputs``Delivery ``` and ``` MethodOutputs``Delivery ```, both of which inherit from `DistillDiliver`. And these deliveries can be managed by ``` Distill``Delivery``Manager ``` or just be used on their own.
|
||||
Currently, we support two deliveries: `FunctionOutputs``Delivery` and `MethodOutputs``Delivery`, both of which inherit from `DistillDiliver`. And these deliveries can be managed by `Distill``Delivery``Manager` or just be used on their own.
|
||||
|
||||
Their relationship is shown below.
|
||||
|
||||
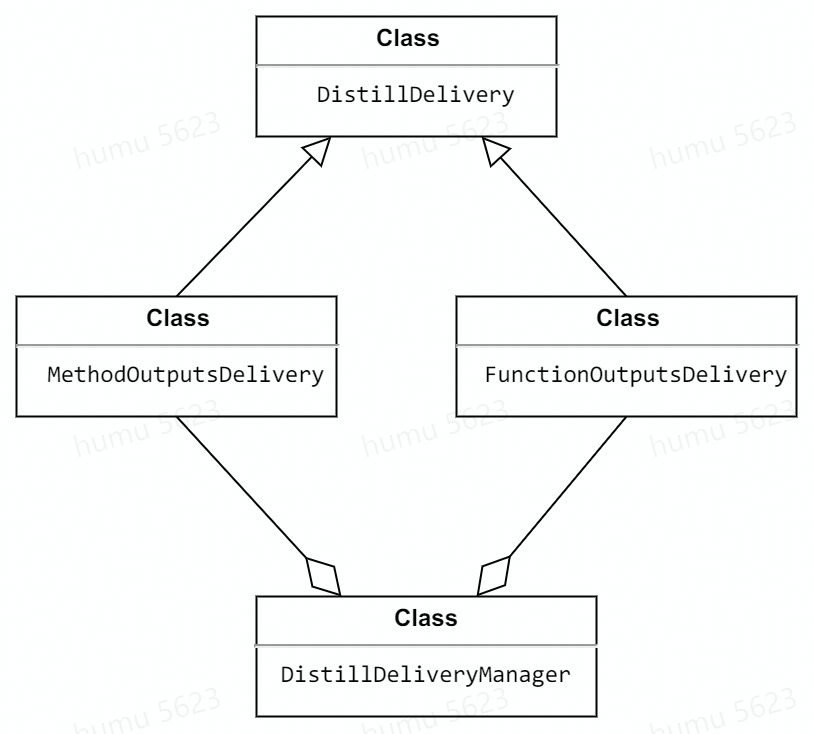
|
||||
|
||||
|
||||
|
||||
|
||||
### FunctionOutputsDelivery
|
||||
|
||||
``` FunctionOutputs``Delivery ``` is used to align the **function's** intermediate results between the teacher model and the student model.
|
||||
`FunctionOutputs``Delivery` is used to align the **function's** intermediate results between the teacher model and the student model.
|
||||
|
||||
> When initializing ``` FunctionOutputs``Delivery ```, you need to pass `func_path` argument, which requires extra attention. For example,
|
||||
> `anchor_inside_flags` is a function in mmdetection to check whether the
|
||||
> anchors are inside the border. This function is in
|
||||
> `mmdet/core/anchor/utils.py` and used in
|
||||
> `mmdet/models/dense_heads/anchor_head`. Then the `func_path` should be
|
||||
> `mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
|
||||
> `mmdet.core.anchor.utils.anchor_inside_flags`.
|
||||
> When initializing `FunctionOutputs``Delivery`, you need to pass `func_path` argument, which requires extra attention. For example,
|
||||
`anchor_inside_flags` is a function in mmdetection to check whether the
|
||||
anchors are inside the border. This function is in
|
||||
`mmdet/core/anchor/utils.py` and used in
|
||||
`mmdet/models/dense_heads/anchor_head`. Then the `func_path` should be
|
||||
`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
|
||||
`mmdet.core.anchor.utils.anchor_inside_flags`.
|
||||
|
||||
#### Case 1: Delivery single function's output from the teacher to the student.
|
||||
|
||||
@ -39,18 +41,18 @@ from mmrazor.core import FunctionOutputsDelivery
|
||||
|
||||
def toy_func() -> int:
|
||||
return random.randint(0, 1000000)
|
||||
|
||||
|
||||
delivery = FunctionOutputsDelivery(max_keep_data=1, func_path='toy_module.toy_func')
|
||||
|
||||
# override_data is False, which means that not override the data with
|
||||
# the recorded data. So it will get the original output of toy_func
|
||||
# override_data is False, which means that not override the data with
|
||||
# the recorded data. So it will get the original output of toy_func
|
||||
# in teacher model, and it is also recorded to be deliveried to the student.
|
||||
delivery.override_data = False
|
||||
with delivery:
|
||||
output_teacher = toy_module.toy_func()
|
||||
|
||||
# override_data is True, which means that override the data with
|
||||
# the recorded data, so it will get the output of toy_func
|
||||
# override_data is True, which means that override the data with
|
||||
# the recorded data, so it will get the output of toy_func
|
||||
# in teacher model rather than the student's.
|
||||
delivery.override_data = True
|
||||
with delivery:
|
||||
@ -94,9 +96,11 @@ Out:
|
||||
True
|
||||
```
|
||||
|
||||
|
||||
|
||||
### MethodOutputsDelivery
|
||||
|
||||
``` MethodOutputs``Delivery ``` is used to align the **method's** intermediate results between the teacher model and the student model.
|
||||
`MethodOutputs``Delivery` is used to align the **method's** intermediate results between the teacher model and the student model.
|
||||
|
||||
#### Case: **Align the inputs of the teacher model and the student model**
|
||||
|
||||
@ -160,11 +164,13 @@ True
|
||||
|
||||
The randomness is eliminated by using `MethodOutputsDelivery`.
|
||||
|
||||
|
||||
|
||||
### 2.3 DistillDeliveryManager
|
||||
|
||||
``` Distill``Delivery``Manager ``` is actually a context manager, used to manage delivers. When entering the ``` Distill``Delivery``Manager ```, all delivers managed will be started.
|
||||
`Distill``Delivery``Manager` is actually a context manager, used to manage delivers. When entering the `Distill``Delivery``Manager`, all delivers managed will be started.
|
||||
|
||||
With the help of ``` Distill``Delivery``Manager ```, we are able to manage several different DistillDeliveries with as little code as possible, thereby reducing the possibility of errors.
|
||||
With the help of `Distill``Delivery``Manager`, we are able to manage several different DistillDeliveries with as little code as possible, thereby reducing the possibility of errors.
|
||||
|
||||
#### Case: Manager deliveries with DistillDeliveryManager
|
||||
|
||||
@ -206,8 +212,8 @@ True
|
||||
|
||||
## Reference
|
||||
|
||||
\[1\] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." *arXiv* abs/1710.09412 (2017).
|
||||
[1] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." *arXiv* abs/1710.09412 (2017).
|
||||
|
||||
\[2\] Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." *ICCV* (2019).
|
||||
[2] Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." *ICCV* (2019).
|
||||
|
||||
\[3\] Nguyen, Chuong H., et al. "Improving object detection by label assignment distillation." *WACV* (2022).
|
||||
[3] Nguyen, Chuong H., et al. "Improving object detection by label assignment distillation." *WACV* (2022).
|
||||
@ -1,18 +1,18 @@
|
||||
# Mutable
|
||||
|
||||
## Introduction
|
||||
|
||||
### What is Mutable
|
||||
|
||||
`Mutable` is one of basic function components in NAS algorithms and some pruning algorithms, which makes supernet searchable by providing optional modules or parameters.
|
||||
`Mutable` is one of basic function components in NAS algorithms and some pruning algorithms, which makes supernet searchable by providing optional modules or parameters.
|
||||
|
||||
To understand it better, we take the mutable module as an example to explain as follows.
|
||||
|
||||

|
||||
|
||||
|
||||
As shown in the figure above, `Mutable` is a container that holds some candidate operations, thus it can sample candidates to constitute the subnet. `Supernet` usually consists of multiple `Mutable`, therefore, `Supernet` will be searchable with the help of `Mutable`. And all candidate operations in `Mutable` constitute the search space of `SuperNet`.
|
||||
|
||||
> If you want to know more about the relationship between Mutable and Mutator, please refer to [Mutator 用户文档](https://aicarrier.feishu.cn/docx/doxcnmcie75HcbqkfBGaEoemBKg)
|
||||
> If you want to know more about the relationship between Mutable and Mutator, please refer to [Mutator 用户文档](https://aicarrier.feishu.cn/docx/doxcnmcie75HcbqkfBGaEoemBKg)
|
||||
|
||||
### Features
|
||||
|
||||
@ -20,7 +20,7 @@ As shown in the figure above, `Mutable` is a container that holds some candidat
|
||||
|
||||
It is the common and basic function for NAS algorithms. We can use it to implement some classical one-shot NAS algorithms, such as [SPOS](https://arxiv.org/abs/1904.00420), [DetNAS ](https://arxiv.org/abs/1903.10979)and so on.
|
||||
|
||||
#### 2. Support parameter mutable
|
||||
#### 2. Support parameter mutable
|
||||
|
||||
To implement more complicated and funny algorithms easier, we supported making some important parameters searchable, such as input channel, output channel, kernel size and so on.
|
||||
|
||||
@ -34,7 +34,7 @@ Because of the restriction of defined architecture, there may be correlations be
|
||||
>
|
||||
> When out_channel (conv1) = 3, out_channel (conv2) = 4
|
||||
>
|
||||
> Then in_channel (conv3) must be 7 rather than mutable.
|
||||
> Then in_channel (conv3) must be 7 rather than mutable.
|
||||
>
|
||||
> So use derived mutable from conv1 and conv2 to generate in_channel (conv3)
|
||||
|
||||
@ -48,19 +48,18 @@ As shown in the figure above.
|
||||
|
||||
- **White blocks** stand the basic classes, which include `BaseMutable` and `DerivedMethodMixin`. `BaseMutable` is the base class for all mutables, which defines required properties and abstracmethods. `DerivedMethodMixin` is a mixin class to provide mutable parameters with some useful methods to derive mutable.
|
||||
|
||||
- **Gray blocks** stand different types of base mutables.
|
||||
|
||||
- **Gray blocks** stand different types of base mutables.
|
||||
> Because there are correlations between channels of some layers, we divide mutable parameters into `MutableChannel` and `MutableValue`, so you can also think `MutableChannel` is a special `MutableValue`.
|
||||
|
||||
For supporting module and parameters mutable, we provide `MutableModule`, `MutableChannel` and `MutableValue` these base classes to implement required basic functions. And we also add `OneshotMutableModule` and `DiffMutableModule` two types based on `MutableModule` to meet different types of algorithms' requirements.
|
||||
|
||||
For supporting module and parameters mutable, we provide `MutableModule`, `MutableChannel` and `MutableValue` these base classes to implement required basic functions. And we also add `OneshotMutableModule` and `DiffMutableModule` two types based on `MutableModule` to meet different types of algorithms' requirements.
|
||||
|
||||
For supporting deriving from mutable parameters, we make `MutableChannel` and `MutableValue` inherit from `BaseMutable` and `DerivedMethodMixin`, thus they can get derived functions provided by `DerivedMethodMixin`.
|
||||
|
||||
- **Red blocks** and **green blocks** stand registered classes for implementing some specific algorithms, which means that you can use them directly in configs. If they do not meet your requirements, you can also customize your mutable based on our base classes. If you are interested in their realization, please refer to their docstring.
|
||||
- **Red blocks** and **green blocks** stand registered classes for implementing some specific algorithms, which means that you can use them directly in configs. If they do not meet your requirements, you can also customize your mutable based on our base classes. If you are interested in their realization, please refer to their docstring.
|
||||
|
||||
## How to use existing mutables to configure searchable backbones
|
||||
|
||||
We will use `OneShotMutableOP` to build a `SearchableShuffleNetV2` backbone as follows.
|
||||
We will use `OneShotMutableOP` to build a `SearchableShuffleNetV2` backbone as follows.
|
||||
|
||||
1. Configure needed mutables
|
||||
|
||||
@ -106,7 +105,7 @@ Then you can use it in your architecture. If existing mutables do not meet your
|
||||
|
||||
### About base mutable
|
||||
|
||||
Before customizing mutables, we need to know what some base mutables do.
|
||||
Before customizing mutables, we need to know what some base mutables do.
|
||||
|
||||
**BaseMutable**
|
||||
|
||||
@ -153,7 +152,7 @@ class BaseMutable(BaseModule, ABC, Generic[CHOICE_TYPE, CHOSEN_TYPE]):
|
||||
@abstractmethod
|
||||
def fix_chosen(self, chosen: CHOSEN_TYPE) -> None:
|
||||
pass
|
||||
|
||||
|
||||
@abstractmethod
|
||||
def dump_chosen(self) -> CHOSEN_TYPE:
|
||||
pass
|
||||
@ -221,7 +220,7 @@ Let's use `OneShotMutableOP` as an example for customizing mutable.
|
||||
|
||||
First, you need to determine which type mutable to implement. Thus, you can implement your mutable faster by inheriting from correlative base mutable.
|
||||
|
||||
Then create a new file ``` mmrazor/models/mutables/mutable_module/``one_shot_mutable_module ```, class `OneShotMutableOP` inherits from `OneShotMutableModule`.
|
||||
Then create a new file `mmrazor/models/mutables/mutable_module/``one_shot_mutable_module`, class `OneShotMutableOP` inherits from `OneShotMutableModule`.
|
||||
|
||||
```Python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
@ -252,7 +251,7 @@ These basic abstract methods are mainly from `BaseMutable` and `MutableModule`,
|
||||
@MODELS.register_module()
|
||||
class OneShotMutableOP(OneShotMutableModule[str, str]):
|
||||
......
|
||||
|
||||
|
||||
def fix_chosen(self, chosen: str) -> None:
|
||||
"""Fix mutable with subnet config. This operation would convert
|
||||
`unfixed` mode to `fixed` mode. The :attr:`is_fixed` will be set to
|
||||
@ -295,11 +294,11 @@ In `OneShotMutableModule`, sample and forward these required abstract methods ar
|
||||
@MODELS.register_module()
|
||||
class OneShotMutableOP(OneShotMutableModule[str, str]):
|
||||
......
|
||||
|
||||
|
||||
def sample_choice(self) -> str:
|
||||
"""uniform sampling."""
|
||||
return np.random.choice(self.choices, 1)[0]
|
||||
|
||||
|
||||
def forward_fixed(self, x: Any) -> Tensor:
|
||||
"""Forward with the `fixed` mutable.
|
||||
Args:
|
||||
@ -338,13 +337,13 @@ class OneShotMutableOP(OneShotMutableModule[str, str]):
|
||||
|
||||
#### 3. Implement other methods
|
||||
|
||||
After finishing some required methods, we need to add some special methods, such as `_build_ops`, because it is needed in building candidates for sampling.
|
||||
After finishing some required methods, we need to add some special methods, such as `_build_ops`, because it is needed in building candidates for sampling.
|
||||
|
||||
```Python
|
||||
@MODELS.register_module()
|
||||
class OneShotMutableOP(OneShotMutableModule[str, str]):
|
||||
......
|
||||
|
||||
|
||||
@staticmethod
|
||||
def _build_ops(
|
||||
candidates: Union[Dict[str, Dict], nn.ModuleDict],
|
||||
@ -392,4 +391,4 @@ custom_imports = dict(
|
||||
|
||||
to the config file to avoid modifying the original code.
|
||||
|
||||
Customize `OneShotMutableOP` is over, then you can use it directly in your algorithm.
|
||||
Customize `OneShotMutableOP` is over, then you can use it directly in your algorithm.
|
||||
@ -1,5 +1,6 @@
|
||||
# Mutator
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
### What is Mutator
|
||||
@ -10,6 +11,7 @@
|
||||
|
||||

|
||||
|
||||
|
||||
In a word, Mutator is the manager of Mutable. Each different type of mutable is commonly managed by their one correlative mutator, respectively.
|
||||
|
||||
As shown in the figure, Mutable is a component of supernet, therefore Mutator can implement some functions about subnet from supernet by handling Mutable.
|
||||
@ -20,6 +22,7 @@ In MMRazor, we have implemented some mutators, their relationship is as below.
|
||||
|
||||

|
||||
|
||||
|
||||
`BaseMutator`: Base class for all mutators. It has appointed some abstract methods supported by all mutators.
|
||||
|
||||
`ModuleMuator`/ `ChannelMutator`: Two different types mutators are for handling mutable module and mutable channel respectively.
|
||||
@ -38,7 +41,7 @@ You just use them directly in configs as below
|
||||
supernet = dict(
|
||||
...
|
||||
)
|
||||
|
||||
|
||||
model = dict(
|
||||
type='mmrazor.SPOS',
|
||||
architecture=supernet,
|
||||
@ -52,14 +55,12 @@ If existing mutators do not meet your needs, you can also customize your needed
|
||||
All mutators need to implement at least two of the following interfaces
|
||||
|
||||
- `prepare_from_supernet()`
|
||||
|
||||
- Make some necessary preparations according to the given supernet. These preparations may include, but are not limited to, grouping the search space, and initializing mutator with the parameters needed for itself.
|
||||
- Make some necessary preparations according to the given supernet. These preparations may include, but are not limited to, grouping the search space, and initializing mutator with the parameters needed for itself.
|
||||
|
||||
- `search_groups`
|
||||
- Group of search space.
|
||||
|
||||
- Group of search space.
|
||||
|
||||
- Note that **search groups** and **search space** are two different concepts. The latter defines what choices can be used for searching. The former groups the search space, and searchable blocks that are grouped into the same group will share the same search space and the same sample result.
|
||||
- Note that **search groups** and **search space** are two different concepts. The latter defines what choices can be used for searching. The former groups the search space, and searchable blocks that are grouped into the same group will share the same search space and the same sample result.
|
||||
|
||||
- ```Python
|
||||
# Example
|
||||
@ -97,7 +98,6 @@ class OneShotModuleMutator(ModuleMutator):
|
||||
```
|
||||
|
||||
### 2. Implement abstract methods
|
||||
|
||||
2.1. Rewrite the `mutable_class_type` property
|
||||
|
||||
```Python
|
||||
@ -119,7 +119,7 @@ As the `prepare_from_supernet()` method and the `search_groups` property are alr
|
||||
|
||||
If you need to implement them by yourself, you can refer to these as follows.
|
||||
|
||||
2.3. **Understand** **`search_groups`\*\*\*\*(optional)**
|
||||
2.3. **Understand** **`search_groups`****(optional)**
|
||||
|
||||
Let's take an example to see what default `search_groups` do.
|
||||
|
||||
@ -133,14 +133,14 @@ class SearchableModel(nn.Module):
|
||||
self.choice_block1 = OneShotMutableModule(**one_shot_op_cfg)
|
||||
self.choice_block2 = OneShotMutableModule(**one_shot_op_cfg)
|
||||
self.choice_block3 = OneShotMutableModule(**one_shot_op_cfg)
|
||||
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
x = self.choice_block1(x)
|
||||
x = self.choice_block2(x)
|
||||
x = self.choice_block3(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
supernet = SearchableModel(one_shot_op_cfg)
|
||||
mutator1 = OneShotModuleMutator()
|
||||
# build mutator1 from supernet.
|
||||
@ -178,7 +178,7 @@ from typing import Any, Dict
|
||||
|
||||
from mmrazor.registry import MODELS
|
||||
from ...mutables import OneShotMutableModule
|
||||
from .module_mutator import
|
||||
from .module_mutator import
|
||||
|
||||
@MODELS.register_module()
|
||||
class OneShotModuleMutator(ModuleMutator):
|
||||
@ -238,4 +238,4 @@ custom_imports = dict(
|
||||
|
||||
to the config file to avoid modifying the original code.
|
||||
|
||||
Customize `OneShotModuleMutator` is over, then you can use it directly in your algorithm.
|
||||
Customize `OneShotModuleMutator` is over, then you can use it directly in your algorithm.
|
||||
@ -1,5 +1,6 @@
|
||||
# Recorder
|
||||
|
||||
|
||||
## Introduction of Recorder
|
||||
|
||||
`Recorder` is a context manager used to record various intermediate results during the model forward. It can help `Delivery` finish data delivering by recording source data in some distillation algorithms. And it can also be used to obtain some specific data for visual analysis or other functions you want.
|
||||
@ -8,10 +9,9 @@ To adapt to more requirements, we implement multiple types of recorders to obtai
|
||||
|
||||
In general, `Recorder` will help us expand more functions in implementing algorithms by recording various intermediate results.
|
||||
|
||||
## Usage of Recorder
|
||||
## Usage of Recorder
|
||||
|
||||
Currently, we support five `Recorder`, as shown in the following table
|
||||
|
||||
| FunctionOutputsRecorder | Record output results of some functions |
|
||||
| ----------------------- | ------------------------------------------- |
|
||||
| MethodOutputsRecorder | Record output results of some methods |
|
||||
@ -25,17 +25,20 @@ Their relationship is shown below.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
### FunctionOutputsRecorder
|
||||
|
||||
`FunctionOutputsRecorder` is used to record the output results of intermediate **function**.
|
||||
`FunctionOutputsRecorder` is used to record the output results of intermediate **function**.
|
||||
|
||||
> When instantiating `FunctionOutputsRecorder`, you need to pass `source` argument, which requires extra attention. For example,
|
||||
> `anchor_inside_flags` is a function in mmdetection to check whether the
|
||||
> anchors are inside the border. This function is in
|
||||
> `mmdet/core/anchor/utils.py` and used in
|
||||
> `mmdet/models/dense_heads/anchor_head`. Then the `source` argument should be
|
||||
> `mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
|
||||
> `mmdet.core.anchor.utils.anchor_inside_flags`.
|
||||
`anchor_inside_flags` is a function in mmdetection to check whether the
|
||||
anchors are inside the border. This function is in
|
||||
`mmdet/core/anchor/utils.py` and used in
|
||||
`mmdet/models/dense_heads/anchor_head`. Then the `source` argument should be
|
||||
`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
|
||||
`mmdet.core.anchor.utils.anchor_inside_flags`.
|
||||
|
||||
#### Example
|
||||
|
||||
@ -49,10 +52,10 @@ from mmrazor.structures import FunctionOutputsRecorder
|
||||
def toy_func() -> int:
|
||||
return random.randint(0, 1000000)
|
||||
|
||||
# instantiate with specifying used path
|
||||
# instantiate with specifing used path
|
||||
r1 = FunctionOutputsRecorder('toy_module.toy_func')
|
||||
|
||||
# initialize is to make specified module can be recorded by
|
||||
# initialize is to make specified module can be recorded by
|
||||
# registering customized forward hook.
|
||||
r1.initialize()
|
||||
with r1:
|
||||
@ -95,9 +98,11 @@ Out:
|
||||
119729
|
||||
```
|
||||
|
||||
|
||||
|
||||
### MethodOutputsRecorder
|
||||
|
||||
`MethodOutputsRecorder` is used to record the output results of intermediate **method**.
|
||||
`MethodOutputsRecorder` is used to record the output results of intermediate **method**.
|
||||
|
||||
#### Example
|
||||
|
||||
@ -113,9 +118,9 @@ class Toy():
|
||||
|
||||
toy = Toy()
|
||||
|
||||
# instantiate with specifying used path
|
||||
# instantiate with specifing used path
|
||||
r1 = MethodOutputsRecorder('toy_module.Toy.toy_func')
|
||||
# initialize is to make specified module can be recorded by
|
||||
# initialize is to make specified module can be recorded by
|
||||
# registering customized forward hook.
|
||||
r1.initialize()
|
||||
|
||||
@ -186,17 +191,17 @@ class ToyModel(nn.Module):
|
||||
return self.conv2(x1 + x2)
|
||||
|
||||
model = ToyModel()
|
||||
# instantiate with specifying module name.
|
||||
# instantiate with specifing module name.
|
||||
r1 = ModuleOutputsRecorder('conv1')
|
||||
|
||||
# initialize is to make specified module can be recorded by
|
||||
# initialize is to make specified module can be recorded by
|
||||
# registering customized forward hook.
|
||||
r1.initialize(model)
|
||||
|
||||
x = torch.randn(1, 1, 1, 1)
|
||||
with r1:
|
||||
out = model(x)
|
||||
|
||||
|
||||
print(r1.data_buffer)
|
||||
```
|
||||
|
||||
@ -222,7 +227,7 @@ True
|
||||
|
||||
### ParameterRecorder
|
||||
|
||||
`ParameterRecorder` is used to record the intermediate parameter of ``` nn.``Module ```. Its usage is similar to `ModuleOutputsRecorder`'s and `ModuleInputsRecorder`'s, but it instantiates with parameter name instead of module name.
|
||||
`ParameterRecorder` is used to record the intermediate parameter of `nn.``Module`. Its usage is similar to `ModuleOutputsRecorder`'s and `ModuleInputsRecorder`'s, but it instantiates with parameter name instead of module name.
|
||||
|
||||
#### Example
|
||||
|
||||
@ -242,9 +247,9 @@ class ToyModel(nn.Module):
|
||||
return self.toy_conv(x)
|
||||
|
||||
model = ToyModel()
|
||||
# instantiate with specifying parameter name.
|
||||
# instantiate with specifing parameter name.
|
||||
r1 = ParameterRecorder('toy_conv.weight')
|
||||
# initialize is to make specified module can be recorded by
|
||||
# initialize is to make specified module can be recorded by
|
||||
# registering customized forward hook.
|
||||
r1.initialize(model)
|
||||
|
||||
@ -310,14 +315,14 @@ manager = RecorderManager(
|
||||
'func_rec': func_rec})
|
||||
|
||||
model = ToyModel()
|
||||
# initialize is to make specified module can be recorded by
|
||||
# initialize is to make specified module can be recorded by
|
||||
# registering customized forward hook.
|
||||
manager.initialize(model)
|
||||
|
||||
x = torch.rand(1, 1, 1, 1)
|
||||
with manager:
|
||||
out = model(x)
|
||||
|
||||
|
||||
conv2_out = manager.get_recorder('conv2_rec').get_record_data()
|
||||
print(conv2_out)
|
||||
```
|
||||
@ -339,4 +344,4 @@ Out:
|
||||
|
||||
```Python
|
||||
313167
|
||||
```
|
||||
```
|
||||
@ -1,5 +1,4 @@
|
||||
# Overview
|
||||
|
||||
## Why MMRazor
|
||||
|
||||
MMRazor is a model compression toolkit for model slimming, which includes 4 mainstream technologies:
|
||||
@ -25,15 +24,16 @@ Different algorithms, e.g., NAS, pruning and KD, can be incorporated in a plug-n
|
||||
|
||||
With better modular design, developers can implement new model compression algorithms with only a few codes, or even by simply modifying config files.
|
||||
|
||||
## Design and Implement
|
||||
|
||||
|
||||
## Design and Implement
|
||||

|
||||
|
||||
### Design
|
||||
|
||||
There are 3 layers (**Application** / **Algorithm** / **Component**) in overview design. MMRazor mainly includes both of **Component** and **Algorithm**, while **Application** consist of some OpenMMLab upstream repos, such as MMClassification, MMDetection, MMSegmentation and so on.
|
||||
There are 3 layers (**Application** / **Algorithm** / **Component**) in overview design. MMRazor mainly includes both of **Component** and **Algorithm**, while **Application** consist of some OpenMMLab upstream repos, such as MMClassification, MMDetection, MMSegmentation and so on.
|
||||
|
||||
**Component** provides many useful functions for quickly implementing **Algorithm.** And thanks to OpenMMLab 's powerful and highly flexible config mode and registry mechanism\*\*, Algorithm\*\* can be conveniently applied to **Application.**
|
||||
**Component** provides many useful functions for quickly implementing **Algorithm.** And thanks to OpenMMLab 's powerful and highly flexible config mode and registry mechanism**, Algorithm** can be conveniently applied to **Application.**
|
||||
|
||||
How to apply our lightweight algorithms to some upstream tasks? Please refer to the below.
|
||||
|
||||
@ -41,11 +41,11 @@ How to apply our lightweight algorithms to some upstream tasks? Please refer to
|
||||
|
||||
In OpenMMLab, implementing vision tasks commonly includes 3 parts (model / dataset / schedule). And just like that, implementing lightweight model also includes 3 parts (algorithm / dataset / schedule) in MMRazor.
|
||||
|
||||
`Algorithm` consist of `architecture` and `components`.
|
||||
`Algorithm` consist of `architecture` and `components`.
|
||||
|
||||
`Architecture` is similar to `model` of the upstream repos. You can chose to directly use the original `model` or customize the new `model` as your architecture according to different tasks. For example, you can directly use ResNet-34 and ResNet-18 of MMClassification to implement some KD algorithms, but in NAS, you may need to customize a searchable model.
|
||||
`Architecture` is similar to `model` of the upstream repos. You can chose to directly use the original `model` or customize the new `model` as your architecture according to different tasks. For example, you can directly use ResNet-34 and ResNet-18 of MMClassification to implement some KD algorithms, but in NAS, you may need to customize a searchable model.
|
||||
|
||||
``` Compone``n``ts ``` consist of various special functions for supporting different lightweight algorithms. They can be directly used in config because of registered into MMEngine. Thus, you can pick some components you need to quickly implement your algorithm. For example, you may need `mutator` / `mutable` / `searchle backbone` if you want to implement a NAS algorithm, and you can pick from `distill loss` / `recorder` / `delivery` / `connector` if you need a KD algorithm.
|
||||
`Compone``n``ts` consist of various special functions for supporting different lightweight algorithms. They can be directly used in config because of registered into MMEngine. Thus, you can pick some components you need to quickly implement your algorithm. For example, you may need `mutator` / `mutable` / `searchle backbone` if you want to implement a NAS algorithm, and you can pick from `distill loss` / `recorder` / `delivery` / `connector` if you need a KD algorithm.
|
||||
|
||||
Please refer to the next section for more details about **Implement**.
|
||||
|
||||
@ -57,7 +57,7 @@ For better understanding and using MMRazor, it is highly recommended to read the
|
||||
|
||||
**Global**
|
||||
|
||||
- [Algorithm](https://aicarrier.feishu.cn/docs/doccnw4XX4zCRJ3FHhZpjkWS4gf)
|
||||
- [Algorithm](https://aicarrier.feishu.cn/docs/doccnw4XX4zCRJ3FHhZpjkWS4gf)
|
||||
|
||||
**NAS & Pruning**
|
||||
|
||||
@ -81,13 +81,13 @@ We provide more complete and systematic guide documents for different technical
|
||||
- Knowledge Distillation (to add link)
|
||||
- Quantization (to add link)
|
||||
|
||||
## Tutorials
|
||||
## Tutorials
|
||||
|
||||
We provide the following general tutorials according to some typical requirements. If you want to further use MMRazor, you can refer to our source code and API Reference.
|
||||
|
||||
**Tutorial list**
|
||||
|
||||
- [Tutorial 1: Overview](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_1_overview.html)
|
||||
- [Tutorial 1: Overview](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_1_overview.html#)
|
||||
- [Tutorial 2: Learn about Configs](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_2_learn_about_configs.html)
|
||||
- [Toturial 3: Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html)
|
||||
- [Toturial 4: Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html)
|
||||
@ -96,13 +96,16 @@ We provide the following general tutorials according to some typical requirement
|
||||
- [Tutorial 7: Customize mixed algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_7_customize_mixed_algorithms_with_out_algorithms_components.html)
|
||||
- [Tutorial 8: Apply existing algorithms to new tasks](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_8_apply_existing_algorithms_to_new_tasks.html)
|
||||
|
||||
|
||||
|
||||
## F&Q
|
||||
|
||||
If you encounter some trouble using MMRazor, you can find whether your question has existed in **F&Q(to add link)**. If not existed, welcome to open a [Github issue](https://github.com/open-mmlab/mmrazor/issues) for getting support, we will reply it as soon.
|
||||
|
||||
|
||||
## Get support and contribute back
|
||||
|
||||
MMRazor is maintained on the [MMRazor Github repository](https://github.com/open-mmlab/mmrazor). We collect feedback and new proposals/ideas on Github. You can:
|
||||
|
||||
- Open a [GitHub issue](https://github.com/open-mmlab/mmrazor/issues) for bugs and feature requests.
|
||||
- Open a [pull request](https://github.com/open-mmlab/mmrazor/pulls) to contribute code (make sure to read the [contribution guide](https://github.com/open-mmlab/mmcv/blob/master/CONTRIBUTING.md) before doing this).
|
||||
- Open a [pull request](https://github.com/open-mmlab/mmrazor/pulls) to contribute code (make sure to read the [contribution guide](https://github.com/open-mmlab/mmcv/blob/master/CONTRIBUTING.md) before doing this).
|
||||
@ -2,6 +2,7 @@
|
||||
|
||||
## Directory structure of configs in mmrazor
|
||||
|
||||
## More about config
|
||||
|
||||
Please refer to config.md in mmengine.
|
||||
|
||||
## More about config
|
||||
Please refer to config.md in mmengine.
|
||||
Loading…
x
Reference in New Issue
Block a user