diff --git a/configs/_base_/models/upernet_mae.py b/configs/_base_/models/upernet_mae.py
new file mode 100644
index 000000000..1e0da7082
--- /dev/null
+++ b/configs/_base_/models/upernet_mae.py
@@ -0,0 +1,49 @@
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained=None,
+ backbone=dict(
+ type='MAE',
+ img_size=(640, 640),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ mlp_ratio=4,
+ out_indices=(3, 5, 7, 11),
+ attn_drop_rate=0.0,
+ drop_path_rate=0.1,
+ norm_cfg=dict(type='LN', eps=1e-6),
+ act_cfg=dict(type='GELU'),
+ norm_eval=False,
+ init_values=0.1),
+ neck=dict(type='Feature2Pyramid', embed_dim=768, rescales=[4, 2, 1, 0.5]),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[384, 384, 384, 384],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=384,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=19,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/mae/README.md b/configs/mae/README.md
new file mode 100644
index 000000000..f42ff0a71
--- /dev/null
+++ b/configs/mae/README.md
@@ -0,0 +1,81 @@
+# MAE
+
+[Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
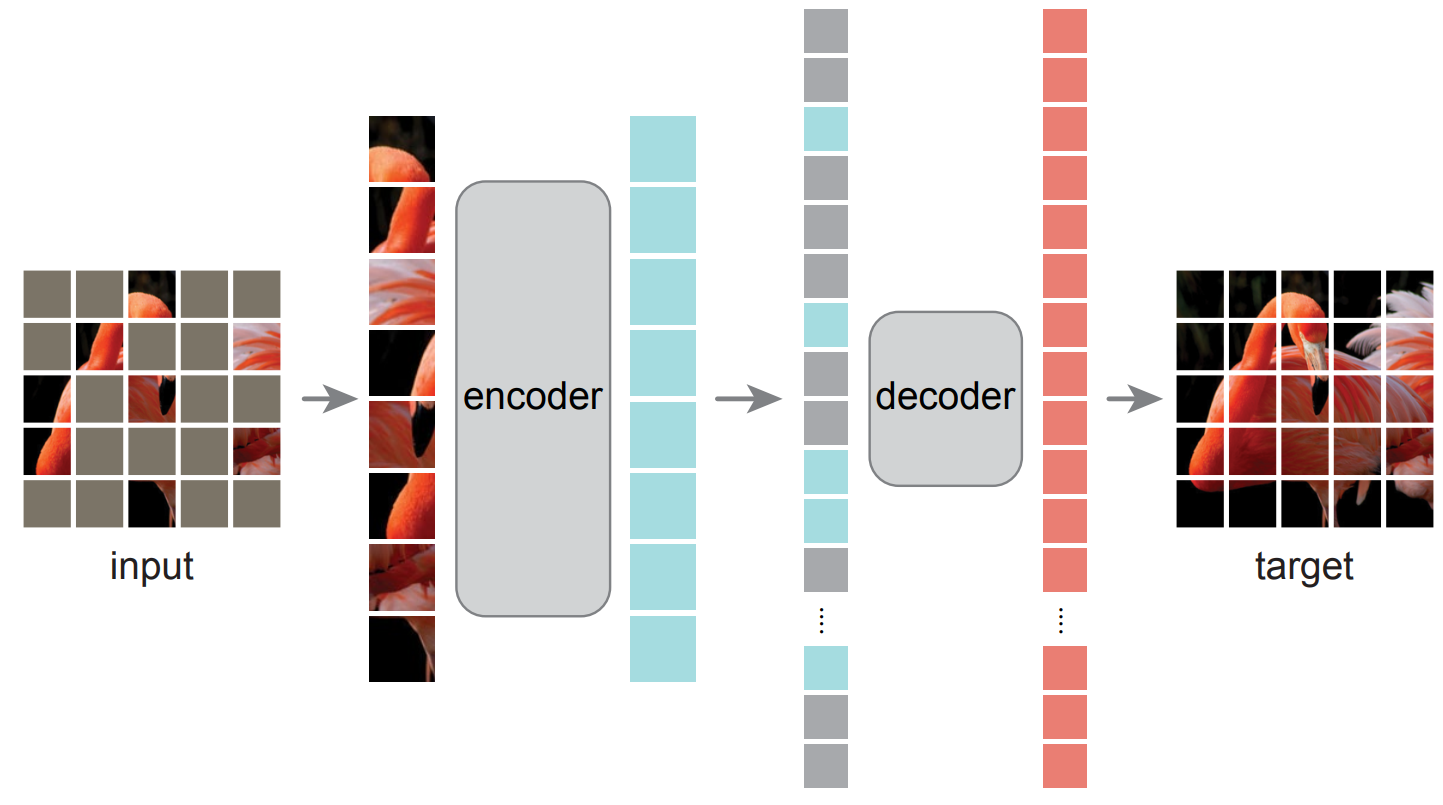
+This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
+
+
+
+
+