diff --git a/.circleci/test.yml b/.circleci/test.yml
index 76f9f70d8..c8acb4829 100644
--- a/.circleci/test.yml
+++ b/.circleci/test.yml
@@ -61,8 +61,9 @@ jobs:
command: |
pip install git+https://github.com/open-mmlab/mmengine.git@main
pip install -U openmim
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
pip install -r requirements/tests.txt -r requirements/optional.txt
- run:
name: Build and install
@@ -96,18 +97,20 @@ jobs:
command: |
git clone -b main --depth 1 https://github.com/open-mmlab/mmengine.git /home/circleci/mmengine
git clone -b dev-1.x --depth 1 https://github.com/open-mmlab/mmclassification.git /home/circleci/mmclassification
+ git clone -b dev-3.x --depth 1 https://github.com/open-mmlab/mmdetection.git /home/circleci/mmdetection
- run:
name: Build Docker image
command: |
docker build .circleci/docker -t mmseg:gpu --build-arg PYTORCH=<< parameters.torch >> --build-arg CUDA=<< parameters.cuda >> --build-arg CUDNN=<< parameters.cudnn >>
- docker run --gpus all -t -d -v /home/circleci/project:/mmseg -v /home/circleci/mmengine:/mmengine -v /home/circleci/mmclassification:/mmclassification -w /mmseg --name mmseg mmseg:gpu
+ docker run --gpus all -t -d -v /home/circleci/project:/mmseg -v /home/circleci/mmengine:/mmengine -v /home/circleci/mmclassification:/mmclassification -v /home/circleci/mmdetection:/mmdetection -w /mmseg --name mmseg mmseg:gpu
- run:
name: Install mmseg dependencies
command: |
docker exec mmseg pip install -e /mmengine
docker exec mmseg pip install -U openmim
- docker exec mmseg mim install 'mmcv>=2.0.0rc1'
+ docker exec mmseg mim install 'mmcv>=2.0.0rc3'
docker exec mmseg pip install -e /mmclassification
+ docker exec mmseg pip install -e /mmdetection
docker exec mmseg pip install -r requirements/tests.txt -r requirements/optional.txt
- run:
name: Build and install
diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
index 644eaf651..97cfda589 100644
--- a/.github/workflows/lint.yml
+++ b/.github/workflows/lint.yml
@@ -20,11 +20,7 @@ jobs:
python -m pip install pre-commit
pre-commit install
- name: Linting
- run: |
- sudo apt-add-repository ppa:brightbox/ruby-ng -y
- sudo apt-get update
- sudo apt-get install -y ruby2.7
- pre-commit run --all-files
+ run: pre-commit run --all-files
- name: Check docstring coverage
run: |
python -m pip install interrogate
diff --git a/.github/workflows/merge_stage_test.yml b/.github/workflows/merge_stage_test.yml
index 42a9dc0c4..b4a4a4424 100644
--- a/.github/workflows/merge_stage_test.yml
+++ b/.github/workflows/merge_stage_test.yml
@@ -44,8 +44,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
@@ -92,8 +93,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
@@ -155,8 +157,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
@@ -187,8 +190,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
diff --git a/.github/workflows/pr_stage_test.yml b/.github/workflows/pr_stage_test.yml
index 30e50a962..302c4689f 100644
--- a/.github/workflows/pr_stage_test.yml
+++ b/.github/workflows/pr_stage_test.yml
@@ -40,8 +40,9 @@ jobs:
run: |
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
@@ -92,8 +93,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
@@ -124,8 +126,9 @@ jobs:
python -V
pip install -U openmim
pip install git+https://github.com/open-mmlab/mmengine.git
- mim install 'mmcv>=2.0.0rc1'
+ mim install 'mmcv>=2.0.0rc3'
pip install git+https://github.com/open-mmlab/mmclassification.git@dev-1.x
+ pip install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
- name: Install unittest dependencies
run: pip install -r requirements/tests.txt -r requirements/optional.txt
- name: Build and install
diff --git a/.gitignore b/.gitignore
index f5841a1be..787d13ec6 100644
--- a/.gitignore
+++ b/.gitignore
@@ -105,6 +105,7 @@ venv.bak/
# mypy
.mypy_cache/
+data
.vscode
.idea
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 34b120968..03b537683 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -1,5 +1,5 @@
repos:
- - repo: https://gitlab.com/pycqa/flake8.git
+ - repo: https://github.com/PyCQA/flake8
rev: 5.0.4
hooks:
- id: flake8
diff --git a/README.md b/README.md
index 8a0bc52ec..056f9029b 100644
--- a/README.md
+++ b/README.md
@@ -62,11 +62,10 @@ The 1.x branch works with **PyTorch 1.6+**.
## What's New
-v1.0.0rc1 was released in 2/11/2022.
+v1.0.0rc2 was released in 6/12/2022.
Please refer to [changelog.md](docs/en/notes/changelog.md) for details and release history.
-- Support PoolFormer ([#2191](https://github.com/open-mmlab/mmsegmentation/pull/2191))
-- Add Decathlon dataset ([#2227](https://github.com/open-mmlab/mmsegmentation/pull/2227))
+- Support MaskFormer and Mask2Former ([#2215](https://github.com/open-mmlab/mmsegmentation/pull/2215), [2255](https://github.com/open-mmlab/mmsegmentation/pull/2255))
## Installation
@@ -139,6 +138,8 @@ Supported methods:
- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
- [x] [K-Net (NeurIPS'2021)](configs/knet)
+- [x] [MaskFormer (NeurIPS'2021)](configs/maskformer)
+- [x] [Mask2Former (CVPR'2022)](configs/mask2former)
Supported datasets:
@@ -194,6 +195,7 @@ This project is released under the [Apache 2.0 license](LICENSE).
- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab foundational library for training deep learning models
- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
+- [MMEval](https://github.com/open-mmlab/mmeval): A unified evaluation library for multiple machine learning libraries.
- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab image classification toolbox and benchmark.
- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 975fca4ee..72abc867a 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -61,7 +61,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
## 更新日志
-最新版本 v1.0.0rc1 在 2022.11.2 发布。
+最新版本 v1.0.0rc2 在 2022.12.6 发布。
如果想了解更多版本更新细节和历史信息,请阅读[更新日志](docs/en/notes/changelog.md)。
## 安装
@@ -134,6 +134,8 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
- [x] [K-Net (NeurIPS'2021)](configs/knet)
+- [x] [MaskFormer (NeurIPS'2021)](configs/maskformer)
+- [x] [Mask2Former (CVPR'2022)](configs/mask2former)
已支持的数据集:
@@ -186,6 +188,7 @@ MMSegmentation 是一个由来自不同高校和企业的研发人员共同参
- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab 深度学习模型训练库
- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab 计算机视觉基础库
- [MIM](https://github.com/open-mmlab/mim): MIM 是 OpenMMlab 项目、算法、模型的统一入口
+- [MMEval](https://github.com/open-mmlab/mmeval): 统一开放的跨框架算法评测库
- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab 图像分类工具箱
- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab 目标检测工具箱
- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab 新一代通用 3D 目标检测平台
diff --git a/configs/mask2former/README.md b/configs/mask2former/README.md
new file mode 100644
index 000000000..8881b0d66
--- /dev/null
+++ b/configs/mask2former/README.md
@@ -0,0 +1,72 @@
+# Mask2Former
+
+[Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+Image segmentation is about grouping pixels with different semantics, e.g., category or instance membership, where each choice of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
+
+```bibtex
+@inproceedings{cheng2021mask2former,
+ title={Masked-attention Mask Transformer for Universal Image Segmentation},
+ author={Bowen Cheng and Ishan Misra and Alexander G. Schwing and Alexander Kirillov and Rohit Girdhar},
+ journal={CVPR},
+ year={2022}
+}
+@inproceedings{cheng2021maskformer,
+ title={Per-Pixel Classification is Not All You Need for Semantic Segmentation},
+ author={Bowen Cheng and Alexander G. Schwing and Alexander Kirillov},
+ journal={NeurIPS},
+ year={2021}
+}
+```
+
+### Usage
+
+- Mask2Former model needs to install [MMDetection](https://github.com/open-mmlab/mmdetection) first.
+
+```shell
+pip install "mmdet>=3.0.0rc4"
+```
+
+## Results and models
+
+### Cityscapes
+
+| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
+| ----------- | -------------- | --------- | ------- | -------: | -------------- | ----- | ------------: | -----------------------------------------------------------------------------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Mask2Former | R-50-D32 | 512x1024 | 90000 | 5806 | 9.17 | 80.44 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024/mask2former_r50_8xb2-90k_cityscapes-512x1024_20221202_140802-2ff5ffa0.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024/mask2former_r50_8xb2-90k_cityscapes-512x1024_20221202_140802.json) |
+| Mask2Former | R-101-D32 | 512x1024 | 90000 | 6971 | 7.11 | 80.80 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024/mask2former_r101_8xb2-90k_cityscapes-512x1024_20221130_031628-8ad528ea.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024/mask2former_r101_8xb2-90k_cityscapes-512x1024_20221130_031628.json)) |
+| Mask2Former | Swin-T | 512x1024 | 90000 | 6511 | 7.18 | 81.71 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024/mask2former_swin-t_8xb2-90k_cityscapes-512x1024_20221127_144501-290b34af.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024/mask2former_swin-t_8xb2-90k_cityscapes-512x1024_20221127_144501.json)) |
+| Mask2Former | Swin-S | 512x1024 | 90000 | 8282 | 5.57 | 82.57 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024/mask2former_swin-s_8xb2-90k_cityscapes-512x1024_20221127_143802-7c98854a.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024/mask2former_swin-s_8xb2-90k_cityscapes-512x1024_20221127_143802.json)) |
+| Mask2Former | Swin-B (in22k) | 512x1024 | 90000 | 11152 | 4.32 | 83.52 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221203_045030-59a4379a.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221203_045030.json)) |
+| Mask2Former | Swin-L (in22k) | 512x1024 | 90000 | 16207 | 2.86 | 83.65 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-dc2c2ddd.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901.json)) |
+
+### ADE20K
+
+| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
+| ----------- | -------------- | --------- | ------- | -------: | -------------- | ----- | ------------: | -------------------------------------------------------------------------------------------------------------------------------------------------------: | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Mask2Former | R-50-D32 | 512x512 | 160000 | 3385 | 26.59 | 47.87 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512/mask2former_r50_8xb2-160k_ade20k-512x512_20221204_000055-4c62652d.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512/mask2former_r50_8xb2-160k_ade20k-512x512_20221204_000055.json)) |
+| Mask2Former | R-101-D32 | 512x512 | 160000 | 4190 | 22.97 | 48.60 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512/mask2former_r101_8xb2-160k_ade20k-512x512_20221203_233905-b1169bc0.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512/mask2former_r101_8xb2-160k_ade20k-512x512_20221203_233905.json)) |
+| Mask2Former | Swin-T | 512x512 | 160000 | 3826 | 23.82 | 48.66 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512/mask2former_swin-t_8xb2-160k_ade20k-512x512_20221203_234230-4341520b.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512/mask2former_swin-t_8xb2-160k_ade20k-512x512_20221203_234230.json)) |
+| Mask2Former | Swin-S | 512x512 | 160000 | 5034 | 19.69 | 51.24 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512/mask2former_swin-s_8xb2-160k_ade20k-512x512_20221204_143905-ab263c11.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512/mask2former_swin-s_8xb2-160k_ade20k-512x512_20221204_143905.json)) |
+| Mask2Former | Swin-B | 640x640 | 160000 | 5795 | 12.48 | 52.44 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640_20221129_125118-35e3a2c7.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640_20221129_125118.json)) |
+| Mask2Former | Swin-B (in22k) | 640x640 | 160000 | 5795 | 12.43 | 53.90 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235230-622e093b.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235230.json)) |
+| Mask2Former | Swin-L (in22k) | 640x640 | 160000 | 9077 | 8.81 | 56.01 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235933-5cc76a78.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235933.json)) |
+
+Note:
+
+- All experiments of Mask2Former are implemented with 8 A100 GPUs with 2 samplers per GPU.
+- As mentioned at [the official repo](https://github.com/facebookresearch/Mask2Former/issues/5), the results of Mask2Former are relatively not stable, the result of Mask2Former(swin-s) on ADE20K dataset in the table is the medium result obtained by training 5 times following the suggestion of the author.
+- The ResNet backbones utilized in MaskFormer models are standard `ResNet` rather than `ResNetV1c`.
+- Test time augmentation is not supported in MMSegmentation 1.x version yet, we would add "ms+flip" results as soon as possible.
diff --git a/configs/mask2former/mask2former.yml b/configs/mask2former/mask2former.yml
new file mode 100644
index 000000000..78655fc52
--- /dev/null
+++ b/configs/mask2former/mask2former.yml
@@ -0,0 +1,290 @@
+Collections:
+- Name: Mask2Former
+ Metadata:
+ Training Data:
+ - Usage
+ - Cityscapes
+ - ADE20K
+ Paper:
+ URL: https://arxiv.org/abs/2112.01527
+ Title: Masked-attention Mask Transformer for Universal Image Segmentation
+ README: configs/mask2former/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/dense_heads/mask2former_head.py
+ Version: 3.x
+ Converted From:
+ Code: https://github.com/facebookresearch/Mask2Former
+Models:
+- Name: mask2former_r50_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: R-50-D32
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 109.05
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 5806.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 80.44
+ Config: configs/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024/mask2former_r50_8xb2-90k_cityscapes-512x1024_20221202_140802-2ff5ffa0.pth
+- Name: mask2former_r101_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: R-101-D32
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 140.65
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 6971.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 80.8
+ Config: configs/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024/mask2former_r101_8xb2-90k_cityscapes-512x1024_20221130_031628-8ad528ea.pth
+- Name: mask2former_swin-t_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-T
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 139.28
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 6511.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 81.71
+ Config: configs/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024/mask2former_swin-t_8xb2-90k_cityscapes-512x1024_20221127_144501-290b34af.pth
+- Name: mask2former_swin-s_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-S
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 179.53
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 8282.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 82.57
+ Config: configs/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024/mask2former_swin-s_8xb2-90k_cityscapes-512x1024_20221127_143802-7c98854a.pth
+- Name: mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-B (in22k)
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 231.48
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 11152.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 83.52
+ Config: configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221203_045030-59a4379a.pth
+- Name: mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-L (in22k)
+ crop size: (512,1024)
+ lr schd: 90000
+ inference time (ms/im):
+ - value: 349.65
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,1024)
+ Training Memory (GB): 16207.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: Cityscapes
+ Metrics:
+ mIoU: 83.65
+ Config: configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024_20221202_141901-dc2c2ddd.pth
+- Name: mask2former_r50_8xb2-160k_ade20k-512x512
+ In Collection: Mask2Former
+ Metadata:
+ backbone: R-50-D32
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 37.61
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 3385.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 47.87
+ Config: configs/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512/mask2former_r50_8xb2-160k_ade20k-512x512_20221204_000055-4c62652d.pth
+- Name: mask2former_r101_8xb2-160k_ade20k-512x512
+ In Collection: Mask2Former
+ Metadata:
+ backbone: R-101-D32
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 43.54
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 4190.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 48.6
+ Config: configs/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512/mask2former_r101_8xb2-160k_ade20k-512x512_20221203_233905-b1169bc0.pth
+- Name: mask2former_swin-t_8xb2-160k_ade20k-512x512
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-T
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 41.98
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 3826.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 48.66
+ Config: configs/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512/mask2former_swin-t_8xb2-160k_ade20k-512x512_20221203_234230-4341520b.pth
+- Name: mask2former_swin-s_8xb2-160k_ade20k-512x512
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-S
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 50.79
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 5034.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 51.24
+ Config: configs/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512/mask2former_swin-s_8xb2-160k_ade20k-512x512_20221204_143905-ab263c11.pth
+- Name: mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-B
+ crop size: (640,640)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 80.13
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (640,640)
+ Training Memory (GB): 5795.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 52.44
+ Config: configs/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640_20221129_125118-35e3a2c7.pth
+- Name: mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-B (in22k)
+ crop size: (640,640)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 80.45
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (640,640)
+ Training Memory (GB): 5795.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 53.9
+ Config: configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235230-622e093b.pth
+- Name: mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640
+ In Collection: Mask2Former
+ Metadata:
+ backbone: Swin-L (in22k)
+ crop size: (640,640)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 113.51
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (640,640)
+ Training Memory (GB): 9077.0
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 56.01
+ Config: configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640_20221203_235933-5cc76a78.pth
diff --git a/configs/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512.py b/configs/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512.py
new file mode 100644
index 000000000..48f6c12d1
--- /dev/null
+++ b/configs/mask2former/mask2former_r101_8xb2-160k_ade20k-512x512.py
@@ -0,0 +1,7 @@
+_base_ = ['./mask2former_r50_8xb2-160k_ade20k-512x512.py']
+
+model = dict(
+ backbone=dict(
+ depth=101,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet101')))
diff --git a/configs/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..275a7dab5
--- /dev/null
+++ b/configs/mask2former/mask2former_r101_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,7 @@
+_base_ = ['./mask2former_r50_8xb2-90k_cityscapes-512x1024.py']
+
+model = dict(
+ backbone=dict(
+ depth=101,
+ init_cfg=dict(type='Pretrained',
+ checkpoint='torchvision://resnet101')))
diff --git a/configs/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512.py b/configs/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512.py
new file mode 100644
index 000000000..598cabfb6
--- /dev/null
+++ b/configs/mask2former/mask2former_r50_8xb2-160k_ade20k-512x512.py
@@ -0,0 +1,207 @@
+_base_ = ['../_base_/default_runtime.py', '../_base_/datasets/ade20k.py']
+
+custom_imports = dict(imports='mmdet.models', allow_failed_imports=False)
+
+crop_size = (512, 512)
+data_preprocessor = dict(
+ type='SegDataPreProcessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_val=0,
+ seg_pad_val=255,
+ size=crop_size,
+ test_cfg=dict(size_divisor=32))
+num_classes = 150
+model = dict(
+ type='EncoderDecoder',
+ data_preprocessor=data_preprocessor,
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ deep_stem=False,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=-1,
+ norm_cfg=dict(type='SyncBN', requires_grad=False),
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ decode_head=dict(
+ type='Mask2FormerHead',
+ in_channels=[256, 512, 1024, 2048],
+ strides=[4, 8, 16, 32],
+ feat_channels=256,
+ out_channels=256,
+ num_classes=num_classes,
+ num_queries=100,
+ num_transformer_feat_level=3,
+ align_corners=False,
+ pixel_decoder=dict(
+ type='mmdet.MSDeformAttnPixelDecoder',
+ num_outs=3,
+ norm_cfg=dict(type='GN', num_groups=32),
+ act_cfg=dict(type='ReLU'),
+ encoder=dict(
+ type='mmdet.DetrTransformerEncoder',
+ num_layers=6,
+ transformerlayers=dict(
+ type='mmdet.BaseTransformerLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiScaleDeformableAttention',
+ embed_dims=256,
+ num_heads=8,
+ num_levels=3,
+ num_points=4,
+ im2col_step=64,
+ dropout=0.0,
+ batch_first=False,
+ norm_cfg=None,
+ init_cfg=None),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.0,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ operation_order=('self_attn', 'norm', 'ffn', 'norm')),
+ init_cfg=None),
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding',
+ num_feats=128,
+ normalize=True),
+ init_cfg=None),
+ enforce_decoder_input_project=False,
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding', num_feats=128,
+ normalize=True),
+ transformer_decoder=dict(
+ type='mmdet.DetrTransformerDecoder',
+ return_intermediate=True,
+ num_layers=9,
+ transformerlayers=dict(
+ type='mmdet.DetrTransformerDecoderLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiheadAttention',
+ embed_dims=256,
+ num_heads=8,
+ attn_drop=0.0,
+ proj_drop=0.0,
+ dropout_layer=None,
+ batch_first=False),
+ ffn_cfgs=dict(
+ embed_dims=256,
+ feedforward_channels=2048,
+ num_fcs=2,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ffn_drop=0.0,
+ dropout_layer=None,
+ add_identity=True),
+ feedforward_channels=2048,
+ operation_order=('cross_attn', 'norm', 'self_attn', 'norm',
+ 'ffn', 'norm')),
+ init_cfg=None),
+ loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=2.0,
+ reduction='mean',
+ class_weight=[1.0] * num_classes + [0.1]),
+ loss_mask=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=5.0),
+ loss_dice=dict(
+ type='mmdet.DiceLoss',
+ use_sigmoid=True,
+ activate=True,
+ reduction='mean',
+ naive_dice=True,
+ eps=1.0,
+ loss_weight=5.0),
+ train_cfg=dict(
+ num_points=12544,
+ oversample_ratio=3.0,
+ importance_sample_ratio=0.75,
+ assigner=dict(
+ type='mmdet.HungarianAssigner',
+ match_costs=[
+ dict(type='mmdet.ClassificationCost', weight=2.0),
+ dict(
+ type='mmdet.CrossEntropyLossCost',
+ weight=5.0,
+ use_sigmoid=True),
+ dict(
+ type='mmdet.DiceCost',
+ weight=5.0,
+ pred_act=True,
+ eps=1.0)
+ ]),
+ sampler=dict(type='mmdet.MaskPseudoSampler'))),
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
+
+# dataset config
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(
+ type='RandomChoiceResize',
+ scales=[int(512 * x * 0.1) for x in range(5, 21)],
+ resize_type='ResizeShortestEdge',
+ max_size=2048),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='PackSegInputs')
+]
+train_dataloader = dict(batch_size=2, dataset=dict(pipeline=train_pipeline))
+
+# optimizer
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+optimizer = dict(
+ type='AdamW', lr=0.0001, weight_decay=0.05, eps=1e-8, betas=(0.9, 0.999))
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=optimizer,
+ clip_grad=dict(max_norm=0.01, norm_type=2),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi,
+ },
+ norm_decay_mult=0.0))
+# learning policy
+param_scheduler = [
+ dict(
+ type='PolyLR',
+ eta_min=0,
+ power=0.9,
+ begin=0,
+ end=160000,
+ by_epoch=False)
+]
+
+# training schedule for 160k
+train_cfg = dict(
+ type='IterBasedTrainLoop', max_iters=160000, val_interval=5000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(
+ type='CheckpointHook', by_epoch=False, interval=5000,
+ save_best='mIoU'),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='SegVisualizationHook'))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..f92dda98a
--- /dev/null
+++ b/configs/mask2former/mask2former_r50_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,206 @@
+_base_ = ['../_base_/default_runtime.py', '../_base_/datasets/cityscapes.py']
+
+custom_imports = dict(imports='mmdet.models', allow_failed_imports=False)
+
+crop_size = (512, 1024)
+data_preprocessor = dict(
+ type='SegDataPreProcessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_val=0,
+ seg_pad_val=255,
+ size=crop_size,
+ test_cfg=dict(size_divisor=32))
+num_classes = 19
+model = dict(
+ type='EncoderDecoder',
+ data_preprocessor=data_preprocessor,
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ deep_stem=False,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=-1,
+ norm_cfg=dict(type='SyncBN', requires_grad=False),
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ decode_head=dict(
+ type='Mask2FormerHead',
+ in_channels=[256, 512, 1024, 2048],
+ strides=[4, 8, 16, 32],
+ feat_channels=256,
+ out_channels=256,
+ num_classes=num_classes,
+ num_queries=100,
+ num_transformer_feat_level=3,
+ align_corners=False,
+ pixel_decoder=dict(
+ type='mmdet.MSDeformAttnPixelDecoder',
+ num_outs=3,
+ norm_cfg=dict(type='GN', num_groups=32),
+ act_cfg=dict(type='ReLU'),
+ encoder=dict(
+ type='mmdet.DetrTransformerEncoder',
+ num_layers=6,
+ transformerlayers=dict(
+ type='mmdet.BaseTransformerLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiScaleDeformableAttention',
+ embed_dims=256,
+ num_heads=8,
+ num_levels=3,
+ num_points=4,
+ im2col_step=64,
+ dropout=0.0,
+ batch_first=False,
+ norm_cfg=None,
+ init_cfg=None),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.0,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ operation_order=('self_attn', 'norm', 'ffn', 'norm')),
+ init_cfg=None),
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding',
+ num_feats=128,
+ normalize=True),
+ init_cfg=None),
+ enforce_decoder_input_project=False,
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding', num_feats=128,
+ normalize=True),
+ transformer_decoder=dict(
+ type='mmdet.DetrTransformerDecoder',
+ return_intermediate=True,
+ num_layers=9,
+ transformerlayers=dict(
+ type='mmdet.DetrTransformerDecoderLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiheadAttention',
+ embed_dims=256,
+ num_heads=8,
+ attn_drop=0.0,
+ proj_drop=0.0,
+ dropout_layer=None,
+ batch_first=False),
+ ffn_cfgs=dict(
+ embed_dims=256,
+ feedforward_channels=2048,
+ num_fcs=2,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ffn_drop=0.0,
+ dropout_layer=None,
+ add_identity=True),
+ feedforward_channels=2048,
+ operation_order=('cross_attn', 'norm', 'self_attn', 'norm',
+ 'ffn', 'norm')),
+ init_cfg=None),
+ loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=2.0,
+ reduction='mean',
+ class_weight=[1.0] * num_classes + [0.1]),
+ loss_mask=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=5.0),
+ loss_dice=dict(
+ type='mmdet.DiceLoss',
+ use_sigmoid=True,
+ activate=True,
+ reduction='mean',
+ naive_dice=True,
+ eps=1.0,
+ loss_weight=5.0),
+ train_cfg=dict(
+ num_points=12544,
+ oversample_ratio=3.0,
+ importance_sample_ratio=0.75,
+ assigner=dict(
+ type='mmdet.HungarianAssigner',
+ match_costs=[
+ dict(type='mmdet.ClassificationCost', weight=2.0),
+ dict(
+ type='mmdet.CrossEntropyLossCost',
+ weight=5.0,
+ use_sigmoid=True),
+ dict(
+ type='mmdet.DiceCost',
+ weight=5.0,
+ pred_act=True,
+ eps=1.0)
+ ]),
+ sampler=dict(type='mmdet.MaskPseudoSampler'))),
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
+
+# dataset config
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(
+ type='RandomChoiceResize',
+ scales=[int(1024 * x * 0.1) for x in range(5, 21)],
+ resize_type='ResizeShortestEdge',
+ max_size=4096),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='PackSegInputs')
+]
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+
+# optimizer
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+optimizer = dict(
+ type='AdamW', lr=0.0001, weight_decay=0.05, eps=1e-8, betas=(0.9, 0.999))
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=optimizer,
+ clip_grad=dict(max_norm=0.01, norm_type=2),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi,
+ },
+ norm_decay_mult=0.0))
+# learning policy
+param_scheduler = [
+ dict(
+ type='PolyLR',
+ eta_min=0,
+ power=0.9,
+ begin=0,
+ end=90000,
+ by_epoch=False)
+]
+
+# training schedule for 90k
+train_cfg = dict(type='IterBasedTrainLoop', max_iters=90000, val_interval=5000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(
+ type='CheckpointHook', by_epoch=False, interval=5000,
+ save_best='mIoU'),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='SegVisualizationHook'))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py b/configs/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py
new file mode 100644
index 000000000..56112dfa3
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py
@@ -0,0 +1,237 @@
+_base_ = [
+ '../_base_/default_runtime.py', '../_base_/datasets/ade20k_640x640.py'
+]
+
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_base_patch4_window12_384_20220317-55b0104a.pth' # noqa
+custom_imports = dict(imports='mmdet.models', allow_failed_imports=False)
+
+crop_size = (640, 640)
+data_preprocessor = dict(
+ type='SegDataPreProcessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True,
+ pad_val=0,
+ seg_pad_val=255,
+ size=crop_size)
+num_classes = 150
+
+depths = [2, 2, 18, 2]
+model = dict(
+ type='EncoderDecoder',
+ data_preprocessor=data_preprocessor,
+ backbone=dict(
+ type='SwinTransformer',
+ pretrain_img_size=384,
+ embed_dims=128,
+ depths=depths,
+ num_heads=[4, 8, 16, 32],
+ window_size=12,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3,
+ patch_norm=True,
+ out_indices=(0, 1, 2, 3),
+ with_cp=False,
+ frozen_stages=-1,
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(
+ type='Mask2FormerHead',
+ in_channels=[128, 256, 512, 1024],
+ strides=[4, 8, 16, 32],
+ feat_channels=256,
+ out_channels=256,
+ num_classes=num_classes,
+ num_queries=100,
+ num_transformer_feat_level=3,
+ align_corners=False,
+ pixel_decoder=dict(
+ type='mmdet.MSDeformAttnPixelDecoder',
+ num_outs=3,
+ norm_cfg=dict(type='GN', num_groups=32),
+ act_cfg=dict(type='ReLU'),
+ encoder=dict(
+ type='mmdet.DetrTransformerEncoder',
+ num_layers=6,
+ transformerlayers=dict(
+ type='mmdet.BaseTransformerLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiScaleDeformableAttention',
+ embed_dims=256,
+ num_heads=8,
+ num_levels=3,
+ num_points=4,
+ im2col_step=64,
+ dropout=0.0,
+ batch_first=False,
+ norm_cfg=None,
+ init_cfg=None),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=256,
+ feedforward_channels=1024,
+ num_fcs=2,
+ ffn_drop=0.0,
+ act_cfg=dict(type='ReLU', inplace=True)),
+ operation_order=('self_attn', 'norm', 'ffn', 'norm')),
+ init_cfg=None),
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding',
+ num_feats=128,
+ normalize=True),
+ init_cfg=None),
+ enforce_decoder_input_project=False,
+ positional_encoding=dict(
+ type='mmdet.SinePositionalEncoding', num_feats=128,
+ normalize=True),
+ transformer_decoder=dict(
+ type='mmdet.DetrTransformerDecoder',
+ return_intermediate=True,
+ num_layers=9,
+ transformerlayers=dict(
+ type='mmdet.DetrTransformerDecoderLayer',
+ attn_cfgs=dict(
+ type='mmdet.MultiheadAttention',
+ embed_dims=256,
+ num_heads=8,
+ attn_drop=0.0,
+ proj_drop=0.0,
+ dropout_layer=None,
+ batch_first=False),
+ ffn_cfgs=dict(
+ embed_dims=256,
+ feedforward_channels=2048,
+ num_fcs=2,
+ act_cfg=dict(type='ReLU', inplace=True),
+ ffn_drop=0.0,
+ dropout_layer=None,
+ add_identity=True),
+ feedforward_channels=2048,
+ operation_order=('cross_attn', 'norm', 'self_attn', 'norm',
+ 'ffn', 'norm')),
+ init_cfg=None),
+ loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=2.0,
+ reduction='mean',
+ class_weight=[1.0] * num_classes + [0.1]),
+ loss_mask=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=5.0),
+ loss_dice=dict(
+ type='mmdet.DiceLoss',
+ use_sigmoid=True,
+ activate=True,
+ reduction='mean',
+ naive_dice=True,
+ eps=1.0,
+ loss_weight=5.0),
+ train_cfg=dict(
+ num_points=12544,
+ oversample_ratio=3.0,
+ importance_sample_ratio=0.75,
+ assigner=dict(
+ type='mmdet.HungarianAssigner',
+ match_costs=[
+ dict(type='mmdet.ClassificationCost', weight=2.0),
+ dict(
+ type='mmdet.CrossEntropyLossCost',
+ weight=5.0,
+ use_sigmoid=True),
+ dict(
+ type='mmdet.DiceCost',
+ weight=5.0,
+ pred_act=True,
+ eps=1.0)
+ ]),
+ sampler=dict(type='mmdet.MaskPseudoSampler'))),
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
+
+# dataset config
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(
+ type='RandomChoiceResize',
+ scales=[int(x * 0.1 * 640) for x in range(5, 21)],
+ resize_type='ResizeShortestEdge',
+ max_size=2560),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='PackSegInputs')
+]
+train_dataloader = dict(batch_size=2, dataset=dict(pipeline=train_pipeline))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optimizer = dict(
+ type='AdamW', lr=0.0001, weight_decay=0.05, eps=1e-8, betas=(0.9, 0.999))
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=optimizer,
+ clip_grad=dict(max_norm=0.01, norm_type=2),
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
+
+# learning policy
+param_scheduler = [
+ dict(
+ type='PolyLR',
+ eta_min=0,
+ power=0.9,
+ begin=0,
+ end=160000,
+ by_epoch=False)
+]
+
+# training schedule for 160k
+train_cfg = dict(
+ type='IterBasedTrainLoop', max_iters=160000, val_interval=5000)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(
+ type='CheckpointHook', by_epoch=False, interval=5000,
+ save_best='mIoU'),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='SegVisualizationHook'))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py b/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
new file mode 100644
index 000000000..f39a3c590
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
@@ -0,0 +1,5 @@
+_base_ = ['./mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py']
+
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_base_patch4_window12_384_22k_20220317-e5c09f74.pth' # noqa
+model = dict(
+ backbone=dict(init_cfg=dict(type='Pretrained', checkpoint=pretrained)))
diff --git a/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..0c229c145
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-b-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,42 @@
+_base_ = ['./mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_base_patch4_window12_384_22k_20220317-e5c09f74.pth' # noqa
+
+depths = [2, 2, 18, 2]
+model = dict(
+ backbone=dict(
+ pretrain_img_size=384,
+ embed_dims=128,
+ depths=depths,
+ num_heads=[4, 8, 16, 32],
+ window_size=12,
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(in_channels=[128, 256, 512, 1024]))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py b/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
new file mode 100644
index 000000000..f2657e884
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-160k_ade20k-640x640.py
@@ -0,0 +1,9 @@
+_base_ = ['./mask2former_swin-b-in1k-384x384-pre_8xb2-160k_ade20k-640x640.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_large_patch4_window12_384_22k_20220412-6580f57d.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ embed_dims=192,
+ num_heads=[6, 12, 24, 48],
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(num_queries=100, in_channels=[192, 384, 768, 1536]))
diff --git a/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..01a7b9988
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-l-in22k-384x384-pre_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,42 @@
+_base_ = ['./mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_large_patch4_window12_384_22k_20220412-6580f57d.pth' # noqa
+
+depths = [2, 2, 18, 2]
+model = dict(
+ backbone=dict(
+ pretrain_img_size=384,
+ embed_dims=192,
+ depths=depths,
+ num_heads=[6, 12, 24, 48],
+ window_size=12,
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(in_channels=[192, 384, 768, 1536]))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512.py b/configs/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512.py
new file mode 100644
index 000000000..a7796d569
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-s_8xb2-160k_ade20k-512x512.py
@@ -0,0 +1,37 @@
+_base_ = ['./mask2former_swin-t_8xb2-160k_ade20k-512x512.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_small_patch4_window7_224_20220317-7ba6d6dd.pth' # noqa
+
+depths = [2, 2, 18, 2]
+model = dict(
+ backbone=dict(
+ depths=depths, init_cfg=dict(type='Pretrained',
+ checkpoint=pretrained)))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..5f75544b1
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-s_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,37 @@
+_base_ = ['./mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_small_patch4_window7_224_20220317-7ba6d6dd.pth' # noqa
+
+depths = [2, 2, 18, 2]
+model = dict(
+ backbone=dict(
+ depths=depths, init_cfg=dict(type='Pretrained',
+ checkpoint=pretrained)))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512.py b/configs/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512.py
new file mode 100644
index 000000000..9de3d242e
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-t_8xb2-160k_ade20k-512x512.py
@@ -0,0 +1,52 @@
+_base_ = ['./mask2former_r50_8xb2-160k_ade20k-512x512.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_tiny_patch4_window7_224_20220317-1cdeb081.pth' # noqa
+depths = [2, 2, 6, 2]
+model = dict(
+ backbone=dict(
+ _delete_=True,
+ type='SwinTransformer',
+ embed_dims=96,
+ depths=depths,
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3,
+ patch_norm=True,
+ out_indices=(0, 1, 2, 3),
+ with_cp=False,
+ frozen_stages=-1,
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(in_channels=[96, 192, 384, 768]))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py b/configs/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py
new file mode 100644
index 000000000..0abda6430
--- /dev/null
+++ b/configs/mask2former/mask2former_swin-t_8xb2-90k_cityscapes-512x1024.py
@@ -0,0 +1,52 @@
+_base_ = ['./mask2former_r50_8xb2-90k_cityscapes-512x1024.py']
+pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_tiny_patch4_window7_224_20220317-1cdeb081.pth' # noqa
+depths = [2, 2, 6, 2]
+model = dict(
+ backbone=dict(
+ _delete_=True,
+ type='SwinTransformer',
+ embed_dims=96,
+ depths=depths,
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3,
+ patch_norm=True,
+ out_indices=(0, 1, 2, 3),
+ with_cp=False,
+ frozen_stages=-1,
+ init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
+ decode_head=dict(in_channels=[96, 192, 384, 768]))
+
+# set all layers in backbone to lr_mult=0.1
+# set all norm layers, position_embeding,
+# query_embeding, level_embeding to decay_multi=0.0
+backbone_norm_multi = dict(lr_mult=0.1, decay_mult=0.0)
+backbone_embed_multi = dict(lr_mult=0.1, decay_mult=0.0)
+embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
+custom_keys = {
+ 'backbone': dict(lr_mult=0.1, decay_mult=1.0),
+ 'backbone.patch_embed.norm': backbone_norm_multi,
+ 'backbone.norm': backbone_norm_multi,
+ 'absolute_pos_embed': backbone_embed_multi,
+ 'relative_position_bias_table': backbone_embed_multi,
+ 'query_embed': embed_multi,
+ 'query_feat': embed_multi,
+ 'level_embed': embed_multi
+}
+custom_keys.update({
+ f'backbone.stages.{stage_id}.blocks.{block_id}.norm': backbone_norm_multi
+ for stage_id, num_blocks in enumerate(depths)
+ for block_id in range(num_blocks)
+})
+custom_keys.update({
+ f'backbone.stages.{stage_id}.downsample.norm': backbone_norm_multi
+ for stage_id in range(len(depths) - 1)
+})
+# optimizer
+optim_wrapper = dict(
+ paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
diff --git a/configs/maskformer/README.md b/configs/maskformer/README.md
new file mode 100644
index 000000000..5e33d17af
--- /dev/null
+++ b/configs/maskformer/README.md
@@ -0,0 +1,60 @@
+# MaskFormer
+
+[MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.
+
+
+
+
+
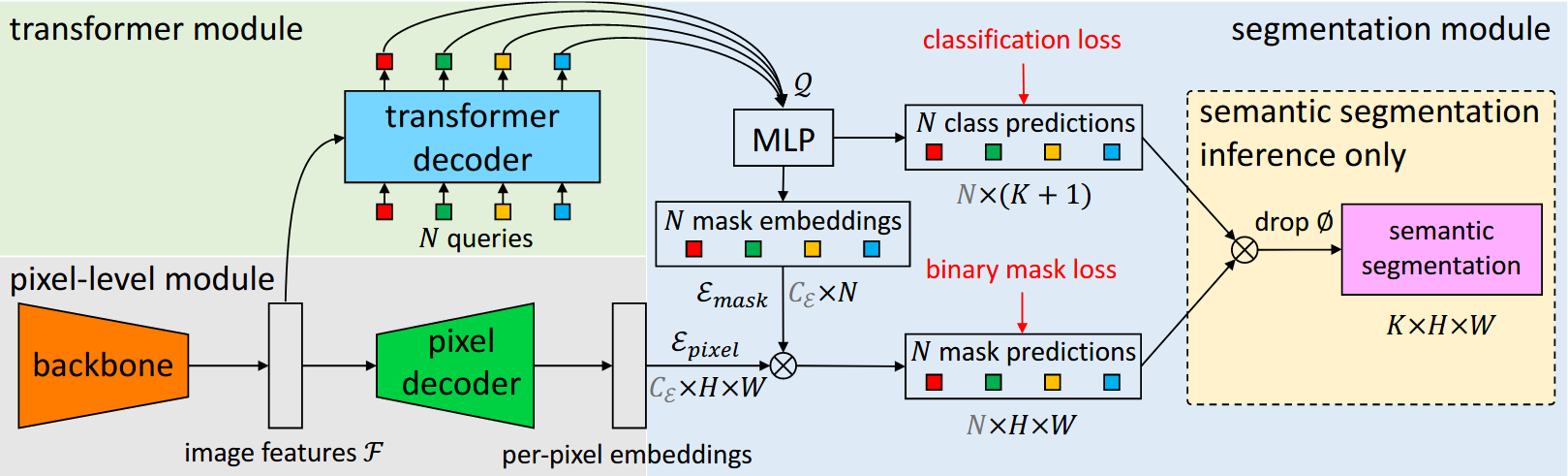
+
+

+
+

+