diff --git a/configs/ddrnet/README.md b/configs/ddrnet/README.md
new file mode 100644
index 000000000..882198866
--- /dev/null
+++ b/configs/ddrnet/README.md
@@ -0,0 +1,47 @@
+# DDRNet
+
+> [Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes](http://arxiv.org/abs/2101.06085)
+
+## Introduction
+
+
+
+Official Repo
+
+## Abstract
+
+
+
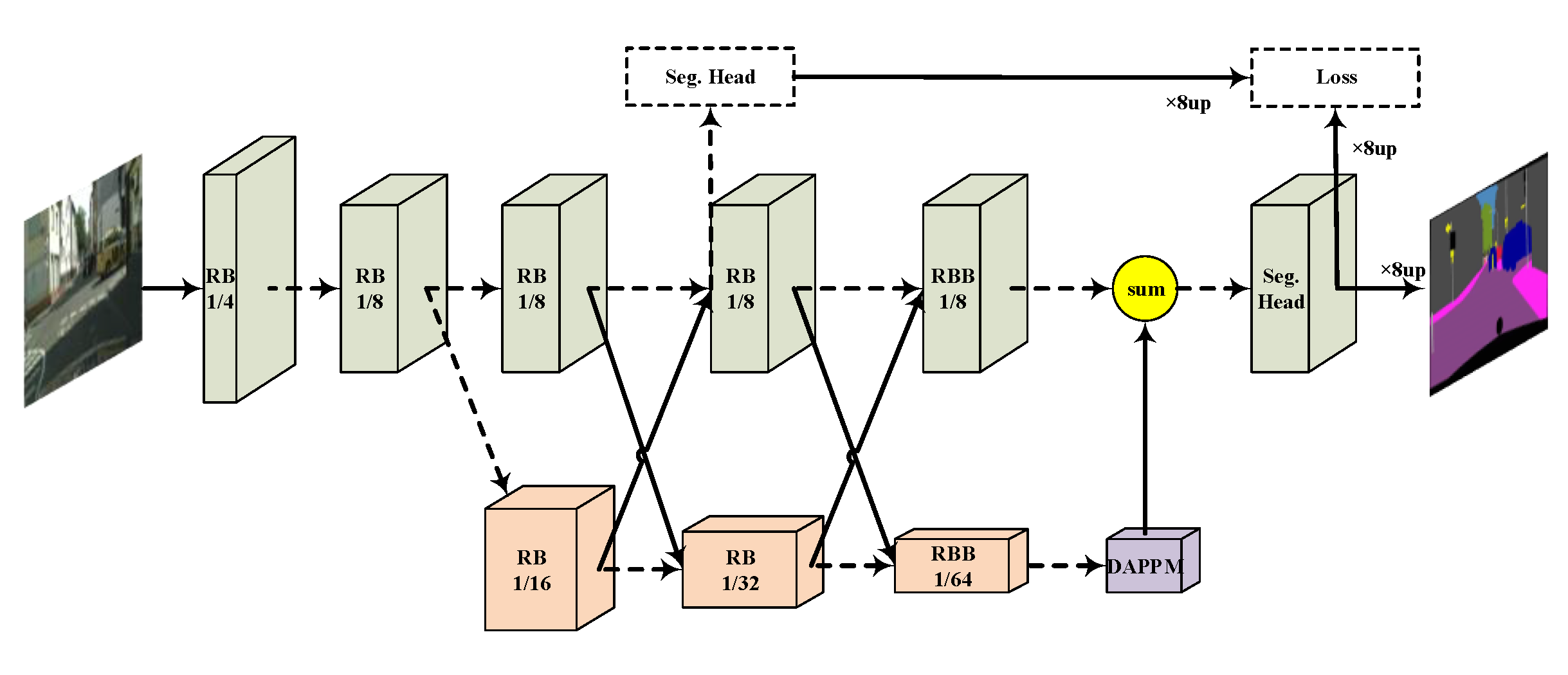
+Semantic segmentation is a key technology for autonomous vehicles to understand the surrounding scenes. The appealing performances of contemporary models usually come at the expense of heavy computations and lengthy inference time, which is intolerable for self-driving. Using light-weight architectures (encoder-decoder or two-pathway) or reasoning on low-resolution images, recent methods realize very fast scene parsing, even running at more than 100 FPS on a single 1080Ti GPU. However, there is still a significant gap in performance between these real-time methods and the models based on dilation backbones. To tackle this problem, we proposed a family of efficient backbones specially designed for real-time semantic segmentation. The proposed deep dual-resolution networks (DDRNets) are composed of two deep branches between which multiple bilateral fusions are performed. Additionally, we design a new contextual information extractor named Deep Aggregation Pyramid Pooling Module (DAPPM) to enlarge effective receptive fields and fuse multi-scale context based on low-resolution feature maps. Our method achieves a new state-of-the-art trade-off between accuracy and speed on both Cityscapes and CamVid dataset. In particular, on a single 2080Ti GPU, DDRNet-23-slim yields 77.4% mIoU at 102 FPS on Cityscapes test set and 74.7% mIoU at 230 FPS on CamVid test set. With widely used test augmentation, our method is superior to most state-of-the-art models and requires much less computation. Codes and trained models are available online.
+
+
+
+
+
+