diff --git a/README.md b/README.md
index a7bd9ad7d..112ed40de 100644
--- a/README.md
+++ b/README.md
@@ -65,7 +65,8 @@ Supported backbones:
- [x] [MobileNetV2 (CVPR'2018)](configs/mobilenet_v2)
- [x] [MobileNetV3 (ICCV'2019)](configs/mobilenet_v3)
- [x] [Vision Transformer (ICLR'2021)](configs/vit)
-- [x] [Swin Transformer (ArXiv'2021)](configs/swin)
+- [x] [Swin Transformer (ICCV'2021)](configs/swin)
+- [x] [Twins (NeurIPS'2021)](configs/twins)
Supported methods:
@@ -99,7 +100,7 @@ Supported methods:
- [x] [BiSeNetV2 (IJCV'2021)](configs/bisenetv2)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
-- [x] [SegFormer (ArXiv'2021)](configs/segformer)
+- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
Supported datasets:
diff --git a/README_zh-CN.md b/README_zh-CN.md
index abe641444..8be4a56a7 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -64,7 +64,8 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [MobileNetV2 (CVPR'2018)](configs/mobilenet_v2)
- [x] [MobileNetV3 (ICCV'2019)](configs/mobilenet_v3)
- [x] [Vision Transformer (ICLR'2021)](configs/vit)
-- [x] [Swin Transformer (ArXiv'2021)](configs/swin)
+- [x] [Swin Transformer (ICCV'2021)](configs/swin)
+- [x] [Twins (NeurIPS'2021)](configs/twins)
已支持的算法:
@@ -98,7 +99,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [BiSeNetV2 (IJCV'2021)](configs/bisenetv2)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
-- [x] [SegFormer (ArXiv'2021)](configs/segformer)
+- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
已支持的数据集:
diff --git a/configs/_base_/models/twins_pcpvt-s_fpn.py b/configs/_base_/models/twins_pcpvt-s_fpn.py
new file mode 100644
index 000000000..e7722759b
--- /dev/null
+++ b/configs/_base_/models/twins_pcpvt-s_fpn.py
@@ -0,0 +1,44 @@
+# model settings
+backbone_norm_cfg = dict(type='LN')
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='PCPVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_small.pth'),
+ in_channels=3,
+ embed_dims=[64, 128, 320, 512],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ mlp_ratios=[8, 8, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ norm_cfg=backbone_norm_cfg,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2),
+ neck=dict(
+ type='FPN',
+ in_channels=[64, 128, 320, 512],
+ out_channels=256,
+ num_outs=4),
+ decode_head=dict(
+ type='FPNHead',
+ in_channels=[256, 256, 256, 256],
+ in_index=[0, 1, 2, 3],
+ feature_strides=[4, 8, 16, 32],
+ channels=128,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/_base_/models/twins_pcpvt-s_upernet.py b/configs/_base_/models/twins_pcpvt-s_upernet.py
new file mode 100644
index 000000000..a48e1a953
--- /dev/null
+++ b/configs/_base_/models/twins_pcpvt-s_upernet.py
@@ -0,0 +1,52 @@
+# model settings
+backbone_norm_cfg = dict(type='LN')
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ backbone=dict(
+ type='PCPVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_small.pth'),
+ in_channels=3,
+ embed_dims=[64, 128, 320, 512],
+ num_heads=[1, 2, 5, 8],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ mlp_ratios=[8, 8, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=True,
+ norm_cfg=backbone_norm_cfg,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2),
+ decode_head=dict(
+ type='UPerHead',
+ in_channels=[64, 128, 320, 512],
+ in_index=[0, 1, 2, 3],
+ pool_scales=(1, 2, 3, 6),
+ channels=512,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=dict(
+ type='FCNHead',
+ in_channels=320,
+ in_index=2,
+ channels=256,
+ num_convs=1,
+ concat_input=False,
+ dropout_ratio=0.1,
+ num_classes=150,
+ norm_cfg=norm_cfg,
+ align_corners=False,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole'))
diff --git a/configs/twins/README.md b/configs/twins/README.md
new file mode 100644
index 000000000..00a52cd80
--- /dev/null
+++ b/configs/twins/README.md
@@ -0,0 +1,75 @@
+# Twins: Revisiting the Design of Spatial Attention in Vision Transformers
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks, including image level classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code is released at [this https URL](https://github.com/Meituan-AutoML/Twins).
+
+
+
+
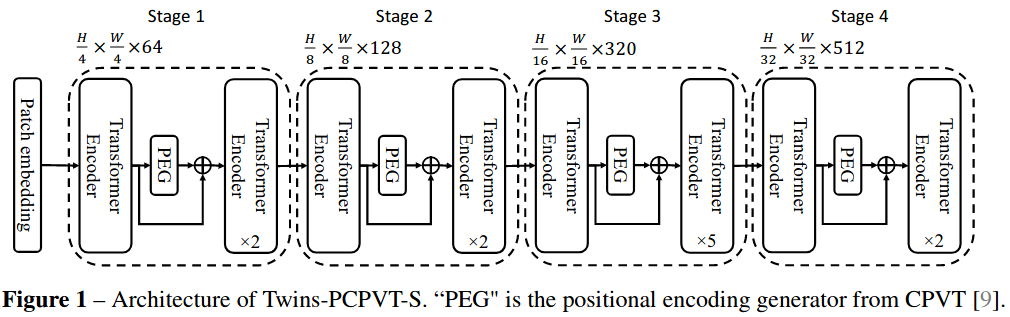
+
+ Twins (NeurIPS'2021)
+
+```latex
+@article{chu2021twins,
+ title={Twins: Revisiting spatial attention design in vision transformers},
+ author={Chu, Xiangxiang and Tian, Zhi and Wang, Yuqing and Zhang, Bo and Ren, Haibing and Wei, Xiaolin and Xia, Huaxia and Shen, Chunhua},
+ journal={arXiv preprint arXiv:2104.13840},
+ year={2021}altgvt
+}
+```
+
+
+
+## Usage
+
+To use other repositories' pre-trained models, it is necessary to convert keys.
+
+We provide a script [`twins2mmseg.py`](../../tools/model_converters/twins2mmseg.py) in the tools directory to convert the key of models from [the official repo](https://github.com/Meituan-AutoML/Twins) to MMSegmentation style.
+
+```shell
+python tools/model_converters/twins2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH} ${MODEL_TYPE}
+```
+
+This script convert `pcpvt` or `svt` pretrained model from `PRETRAIN_PATH` and store the converted model in `STORE_PATH`.
+
+For example,
+
+```shell
+python tools/model_converters/twins2mmseg.py ./alt_gvt_base.pth ./pretrained/alt_gvt_base.pth svt
+```
+
+## Results and models
+
+### ADE20K
+
+| Method| Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
+| ----- | ------- | --------- | ------| ------ | -------------- | ----- | ------------- | ------ |------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| Twins-FPN | PCPVT-S | 512x512 | 80000| 6.60 | 27.15 | 43.26 | 44.11 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_204132-41acd132.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_204132.log.json) |
+| Twins-UPerNet | PCPVT-S | 512x512 | 160000| 9.67 | 14.24 | 46.04 | 46.92 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k_20211201_233537-8e99c07a.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k_20211201_233537.log.json) |
+| Twins-FPN | PCPVT-B | 512x512 | 80000| 8.41 | 19.67 | 45.66 | 46.48 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141019-d396db72.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141019.log.json) |
+| Twins-UPerNet (8x2) | PCPVT-B | 512x512 | 160000| 6.46 | 12.04 | 47.91 | 48.64 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k_20211130_141020-02094ea5.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k_20211130_141020.log.json) |
+| Twins-FPN | PCPVT-L | 512x512 | 80000| 10.78 | 14.32 | 45.94 | 46.70 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_105226-bc6d61dc.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_105226.log.json) |
+| Twins-UPerNet (8x2) | PCPVT-L | 512x512 | 160000| 7.82 | 10.70 | 49.35 | 50.08 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k_20211201_075053-c6095c07.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k_20211201_075053.log.json)|
+| Twins-FPN | SVT-S| 512x512 | 80000| 5.80 | 29.79 | 44.47 | 45.42 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141006-0a0d3317.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141006.log.json)|
+| Twins-UPerNet (8x2) | SVT-S| 512x512 | 160000| 4.93 | 15.09 | 46.08 | 46.96 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k/twins_svt-s_uperhead_8x2_512x512_160k_ade20k_20211130_141005-e48a2d94.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k/twins_svt-s_uperhead_8x2_512x512_160k_ade20k_20211130_141005.log.json)|
+| Twins-FPN | SVT-B| 512x512 | 80000| 8.75 | 21.10 | 46.77 | 47.47 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_113849-88b2907c.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_113849.log.json)|
+| Twins-UPerNet (8x2) | SVT-B| 512x512 | 160000| 6.77 | 12.66 | 48.04 | 48.87 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k/twins_svt-b_uperhead_8x2_512x512_160k_ade20k_20211202_040826-0943a1f1.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k/twins_svt-b_uperhead_8x2_512x512_160k_ade20k_20211202_040826.log.json)|
+| Twins-FPN | SVT-L| 512x512 | 80000| 11.20 | 17.80 | 46.55 | 47.74 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141005-1d59bee2.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141005.log.json)|
+| Twins-UPerNet (8x2) | SVT-L| 512x512 | 160000| 8.41 | 10.73 | 49.65 | 50.63 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k.py) |[model](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k/twins_svt-l_uperhead_8x2_512x512_160k_ade20k_20211130_141005-3e2cae61.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k/twins_svt-l_uperhead_8x2_512x512_160k_ade20k_20211130_141005.log.json)|
+
+
+Note:
+
+- `8x2` means 8 GPUs with 2 samples per GPU in training. Default setting of Twins on ADE20K is 8 GPUs with 4 samples per GPU in training.
+- `UPerNet` and `FPN` are decoder heads utilized in corresponding Twins model, which is `UPerHead` and `FPNHead`, respectively. Specifically, models in [official repo](https://github.com/Meituan-AutoML/Twins) all use `UPerHead`.
diff --git a/configs/twins/twins.yml b/configs/twins/twins.yml
new file mode 100644
index 000000000..98c840174
--- /dev/null
+++ b/configs/twins/twins.yml
@@ -0,0 +1,279 @@
+Collections:
+- Name: twins
+ Metadata:
+ Training Data:
+ - ADE20K
+ Paper:
+ URL: https://arxiv.org/pdf/2104.13840.pdf
+ Title: 'Twins: Revisiting the Design of Spatial Attention in Vision Transformers'
+ README: configs/twins/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmsegmentation/blob/v0.20.0/mmseg/models/backbones/twins.py#L352
+ Version: v0.20.0
+ Converted From:
+ Code: https://github.com/Meituan-AutoML/Twins
+Models:
+- Name: twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-S
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 36.83
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 6.6
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 43.26
+ mIoU(ms+flip): 44.11
+ Config: configs/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_204132-41acd132.pth
+- Name: twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-S
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 70.22
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 9.67
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 46.04
+ mIoU(ms+flip): 46.92
+ Config: configs/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k_20211201_233537-8e99c07a.pth
+- Name: twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-B
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 50.84
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 8.41
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 45.66
+ mIoU(ms+flip): 46.48
+ Config: configs/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141019-d396db72.pth
+- Name: twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-B
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 83.06
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 6.46
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 47.91
+ mIoU(ms+flip): 48.64
+ Config: configs/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k_20211130_141020-02094ea5.pth
+- Name: twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-L
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 69.83
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 10.78
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 45.94
+ mIoU(ms+flip): 46.7
+ Config: configs/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_105226-bc6d61dc.pth
+- Name: twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: PCPVT-L
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 93.46
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 7.82
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 49.35
+ mIoU(ms+flip): 50.08
+ Config: configs/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k_20211201_075053-c6095c07.pth
+- Name: twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-S
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 33.57
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 5.8
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 44.47
+ mIoU(ms+flip): 45.42
+ Config: configs/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141006-0a0d3317.pth
+- Name: twins_svt-s_uperhead_8x2_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-S
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 66.27
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 4.93
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 46.08
+ mIoU(ms+flip): 46.96
+ Config: configs/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k/twins_svt-s_uperhead_8x2_512x512_160k_ade20k_20211130_141005-e48a2d94.pth
+- Name: twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-B
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 47.39
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 8.75
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 46.77
+ mIoU(ms+flip): 47.47
+ Config: configs/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k_20211201_113849-88b2907c.pth
+- Name: twins_svt-b_uperhead_8x2_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-B
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 78.99
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 6.77
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 48.04
+ mIoU(ms+flip): 48.87
+ Config: configs/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k/twins_svt-b_uperhead_8x2_512x512_160k_ade20k_20211202_040826-0943a1f1.pth
+- Name: twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-L
+ crop size: (512,512)
+ lr schd: 80000
+ inference time (ms/im):
+ - value: 56.18
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 11.2
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 46.55
+ mIoU(ms+flip): 47.74
+ Config: configs/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k_20211130_141005-1d59bee2.pth
+- Name: twins_svt-l_uperhead_8x2_512x512_160k_ade20k
+ In Collection: twins
+ Metadata:
+ backbone: SVT-L
+ crop size: (512,512)
+ lr schd: 160000
+ inference time (ms/im):
+ - value: 93.2
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (512,512)
+ Training Memory (GB): 8.41
+ Results:
+ - Task: Semantic Segmentation
+ Dataset: ADE20K
+ Metrics:
+ mIoU: 49.65
+ mIoU(ms+flip): 50.63
+ Config: configs/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k.py
+ Weights: https://download.openmmlab.com/mmsegmentation/v0.5/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k/twins_svt-l_uperhead_8x2_512x512_160k_ade20k_20211130_141005-3e2cae61.pth
diff --git a/configs/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..1da668a99
--- /dev/null
+++ b/configs/twins/twins_pcpvt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,7 @@
+_base_ = ['./twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py']
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_base.pth'),
+ depths=[3, 4, 18, 3]), )
diff --git a/configs/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k.py b/configs/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k.py
new file mode 100644
index 000000000..95f0bd410
--- /dev/null
+++ b/configs/twins/twins_pcpvt-b_uperhead_8x2_512x512_160k_ade20k.py
@@ -0,0 +1,10 @@
+_base_ = ['./twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py']
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_base.pth'),
+ depths=[3, 4, 18, 3],
+ drop_path_rate=0.3))
+
+data = dict(samples_per_gpu=2, workers_per_gpu=2)
diff --git a/configs/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..e8fcd9326
--- /dev/null
+++ b/configs/twins/twins_pcpvt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,7 @@
+_base_ = ['./twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py']
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_large.pth'),
+ depths=[3, 8, 27, 3]))
diff --git a/configs/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k.py b/configs/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k.py
new file mode 100644
index 000000000..90307ee3a
--- /dev/null
+++ b/configs/twins/twins_pcpvt-l_uperhead_8x2_512x512_160k_ade20k.py
@@ -0,0 +1,9 @@
+_base_ = ['./twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py']
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/pcpvt_large.pth'),
+ depths=[3, 8, 27, 3],
+ drop_path_rate=0.3))
+
+data = dict(samples_per_gpu=2, workers_per_gpu=2)
diff --git a/configs/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..3d7be96e8
--- /dev/null
+++ b/configs/twins/twins_pcpvt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/twins_pcpvt-s_fpn.py', '../_base_/datasets/ade20k.py',
+ '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py'
+]
+
+optimizer = dict(_delete_=True, type='AdamW', lr=0.0001, weight_decay=0.0001)
diff --git a/configs/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py b/configs/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py
new file mode 100644
index 000000000..c888b921c
--- /dev/null
+++ b/configs/twins/twins_pcpvt-s_uperhead_8x4_512x512_160k_ade20k.py
@@ -0,0 +1,26 @@
+_base_ = [
+ '../_base_/models/twins_pcpvt-s_upernet.py',
+ '../_base_/datasets/ade20k.py', '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_160k.py'
+]
+
+optimizer = dict(
+ _delete_=True,
+ type='AdamW',
+ lr=0.00006,
+ betas=(0.9, 0.999),
+ weight_decay=0.01,
+ paramwise_cfg=dict(custom_keys={
+ 'pos_block': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }))
+
+lr_config = dict(
+ _delete_=True,
+ policy='poly',
+ warmup='linear',
+ warmup_iters=1500,
+ warmup_ratio=1e-6,
+ power=1.0,
+ min_lr=0.0,
+ by_epoch=False)
diff --git a/configs/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..a6484cf7f
--- /dev/null
+++ b/configs/twins/twins_svt-b_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,11 @@
+_base_ = ['./twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py']
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_base.pth'),
+ embed_dims=[96, 192, 384, 768],
+ num_heads=[3, 6, 12, 24],
+ depths=[2, 2, 18, 2]),
+ neck=dict(in_channels=[96, 192, 384, 768]),
+)
diff --git a/configs/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k.py b/configs/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k.py
new file mode 100644
index 000000000..7c2ffce95
--- /dev/null
+++ b/configs/twins/twins_svt-b_uperhead_8x2_512x512_160k_ade20k.py
@@ -0,0 +1,10 @@
+_base_ = ['./twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py']
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_base.pth'),
+ embed_dims=[96, 192, 384, 768],
+ num_heads=[3, 6, 12, 24],
+ depths=[2, 2, 18, 2]),
+ decode_head=dict(in_channels=[96, 192, 384, 768]),
+ auxiliary_head=dict(in_channels=384))
diff --git a/configs/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..8ec0ed3ff
--- /dev/null
+++ b/configs/twins/twins_svt-l_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,12 @@
+_base_ = ['./twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py']
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_large.pth'),
+ embed_dims=[128, 256, 512, 1024],
+ num_heads=[4, 8, 16, 32],
+ depths=[2, 2, 18, 2],
+ drop_path_rate=0.3),
+ neck=dict(in_channels=[128, 256, 512, 1024]),
+)
diff --git a/configs/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k.py b/configs/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k.py
new file mode 100644
index 000000000..aba31532d
--- /dev/null
+++ b/configs/twins/twins_svt-l_uperhead_8x2_512x512_160k_ade20k.py
@@ -0,0 +1,11 @@
+_base_ = ['./twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py']
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_large.pth'),
+ embed_dims=[128, 256, 512, 1024],
+ num_heads=[4, 8, 16, 32],
+ depths=[2, 2, 18, 2],
+ drop_path_rate=0.3),
+ decode_head=dict(in_channels=[128, 256, 512, 1024]),
+ auxiliary_head=dict(in_channels=512))
diff --git a/configs/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py b/configs/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
new file mode 100644
index 000000000..dd4ef7765
--- /dev/null
+++ b/configs/twins/twins_svt-s_fpn_fpnhead_8x4_512x512_80k_ade20k.py
@@ -0,0 +1,20 @@
+_base_ = [
+ '../_base_/models/twins_pcpvt-s_fpn.py', '../_base_/datasets/ade20k.py',
+ '../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py'
+]
+model = dict(
+ backbone=dict(
+ type='SVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_small.pth'),
+ embed_dims=[64, 128, 256, 512],
+ num_heads=[2, 4, 8, 16],
+ mlp_ratios=[4, 4, 4, 4],
+ depths=[2, 2, 10, 4],
+ windiow_sizes=[7, 7, 7, 7],
+ norm_after_stage=True),
+ neck=dict(in_channels=[64, 128, 256, 512], out_channels=256, num_outs=4),
+ decode_head=dict(num_classes=150),
+)
+
+optimizer = dict(_delete_=True, type='AdamW', lr=0.0001, weight_decay=0.0001)
diff --git a/configs/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py b/configs/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py
new file mode 100644
index 000000000..05948391e
--- /dev/null
+++ b/configs/twins/twins_svt-s_uperhead_8x2_512x512_160k_ade20k.py
@@ -0,0 +1,41 @@
+_base_ = [
+ '../_base_/models/twins_pcpvt-s_upernet.py',
+ '../_base_/datasets/ade20k.py', '../_base_/default_runtime.py',
+ '../_base_/schedules/schedule_160k.py'
+]
+model = dict(
+ backbone=dict(
+ type='SVT',
+ init_cfg=dict(
+ type='Pretrained', checkpoint='pretrained/alt_gvt_small.pth'),
+ embed_dims=[64, 128, 256, 512],
+ num_heads=[2, 4, 8, 16],
+ mlp_ratios=[4, 4, 4, 4],
+ depths=[2, 2, 10, 4],
+ windiow_sizes=[7, 7, 7, 7],
+ norm_after_stage=True),
+ decode_head=dict(in_channels=[64, 128, 256, 512]),
+ auxiliary_head=dict(in_channels=256))
+
+optimizer = dict(
+ _delete_=True,
+ type='AdamW',
+ lr=0.00006,
+ betas=(0.9, 0.999),
+ weight_decay=0.01,
+ paramwise_cfg=dict(custom_keys={
+ 'pos_block': dict(decay_mult=0.),
+ 'norm': dict(decay_mult=0.)
+ }))
+
+lr_config = dict(
+ _delete_=True,
+ policy='poly',
+ warmup='linear',
+ warmup_iters=1500,
+ warmup_ratio=1e-6,
+ power=1.0,
+ min_lr=0.0,
+ by_epoch=False)
+
+data = dict(samples_per_gpu=2, workers_per_gpu=2)
diff --git a/mmseg/models/backbones/__init__.py b/mmseg/models/backbones/__init__.py
index 6fe6d3caa..cdd171d6a 100644
--- a/mmseg/models/backbones/__init__.py
+++ b/mmseg/models/backbones/__init__.py
@@ -14,6 +14,7 @@ from .resnet import ResNet, ResNetV1c, ResNetV1d
from .resnext import ResNeXt
from .swin import SwinTransformer
from .timm_backbone import TIMMBackbone
+from .twins import PCPVT, SVT
from .unet import UNet
from .vit import VisionTransformer
@@ -21,5 +22,5 @@ __all__ = [
'ResNet', 'ResNetV1c', 'ResNetV1d', 'ResNeXt', 'HRNet', 'FastSCNN',
'ResNeSt', 'MobileNetV2', 'UNet', 'CGNet', 'MobileNetV3',
'VisionTransformer', 'SwinTransformer', 'MixVisionTransformer',
- 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet'
+ 'BiSeNetV1', 'BiSeNetV2', 'ICNet', 'TIMMBackbone', 'ERFNet', 'PCPVT', 'SVT'
]
diff --git a/mmseg/models/backbones/twins.py b/mmseg/models/backbones/twins.py
new file mode 100644
index 000000000..b41325b88
--- /dev/null
+++ b/mmseg/models/backbones/twins.py
@@ -0,0 +1,587 @@
+import math
+import warnings
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import build_norm_layer
+from mmcv.cnn.bricks.drop import build_dropout
+from mmcv.cnn.bricks.transformer import FFN
+from mmcv.cnn.utils.weight_init import (constant_init, normal_init,
+ trunc_normal_init)
+from mmcv.runner import BaseModule, ModuleList
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmseg.models.backbones.mit import EfficientMultiheadAttention
+from mmseg.models.builder import BACKBONES
+from ..utils.embed import PatchEmbed
+
+
+class GlobalSubsampledAttention(EfficientMultiheadAttention):
+ """Global Sub-sampled Attention (Spatial Reduction Attention)
+
+ This module is modified from EfficientMultiheadAttention,
+ which is a module from mmseg.models.backbones.mit.py.
+ Specifically, there is no difference between
+ `GlobalSubsampledAttention` and `EfficientMultiheadAttention`,
+ `GlobalSubsampledAttention` is built as a brand new class
+ because it is renamed as `Global sub-sampled attention (GSA)`
+ in paper.
+
+
+ Args:
+ embed_dims (int): The embedding dimension.
+ num_heads (int): Parallel attention heads.
+ attn_drop (float): A Dropout layer on attn_output_weights.
+ Default: 0.0.
+ proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
+ Default: 0.0.
+ dropout_layer (obj:`ConfigDict`): The dropout_layer used
+ when adding the shortcut. Default: None.
+ batch_first (bool): Key, Query and Value are shape of
+ (batch, n, embed_dims)
+ or (n, batch, embed_dims). Default: False.
+ qkv_bias (bool): enable bias for qkv if True. Default: True.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (int): The ratio of spatial reduction of GSA of PCPVT.
+ Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ attn_drop=0.,
+ proj_drop=0.,
+ dropout_layer=None,
+ batch_first=True,
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1,
+ init_cfg=None):
+ super(GlobalSubsampledAttention, self).__init__(
+ embed_dims,
+ num_heads,
+ attn_drop=attn_drop,
+ proj_drop=proj_drop,
+ dropout_layer=dropout_layer,
+ batch_first=batch_first,
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio,
+ init_cfg=init_cfg)
+
+
+class GSAEncoderLayer(BaseModule):
+ """Implements one encoder layer with GSA.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default: 0.0.
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ sr_ratio (float): Kernel_size of conv in Attention modules. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=1.,
+ init_cfg=None):
+ super(GSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = GlobalSubsampledAttention(
+ embed_dims=embed_dims,
+ num_heads=num_heads,
+ attn_drop=attn_drop_rate,
+ proj_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ qkv_bias=qkv_bias,
+ norm_cfg=norm_cfg,
+ sr_ratio=sr_ratio)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape, identity=0.))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class LocallyGroupedSelfAttention(BaseModule):
+ """Locally-grouped Self Attention (LSA) module.
+
+ Args:
+ embed_dims (int): Number of input channels.
+ num_heads (int): Number of attention heads. Default: 8
+ qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
+ Default: False.
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
+ window_size(int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads=8,
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop_rate=0.,
+ proj_drop_rate=0.,
+ window_size=1,
+ init_cfg=None):
+ super(LocallyGroupedSelfAttention, self).__init__(init_cfg=init_cfg)
+
+ assert embed_dims % num_heads == 0, f'dim {embed_dims} should be ' \
+ f'divided by num_heads ' \
+ f'{num_heads}.'
+ self.embed_dims = embed_dims
+ self.num_heads = num_heads
+ head_dim = embed_dims // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(embed_dims, embed_dims * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop_rate)
+ self.proj = nn.Linear(embed_dims, embed_dims)
+ self.proj_drop = nn.Dropout(proj_drop_rate)
+ self.window_size = window_size
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ x = x.view(b, h, w, c)
+
+ # pad feature maps to multiples of Local-groups
+ pad_l = pad_t = 0
+ pad_r = (self.window_size - w % self.window_size) % self.window_size
+ pad_b = (self.window_size - h % self.window_size) % self.window_size
+ x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
+
+ # calculate attention mask for LSA
+ Hp, Wp = x.shape[1:-1]
+ _h, _w = Hp // self.window_size, Wp // self.window_size
+ mask = torch.zeros((1, Hp, Wp), device=x.device)
+ mask[:, -pad_b:, :].fill_(1)
+ mask[:, :, -pad_r:].fill_(1)
+
+ # [B, _h, _w, window_size, window_size, C]
+ x = x.reshape(b, _h, self.window_size, _w, self.window_size,
+ c).transpose(2, 3)
+ mask = mask.reshape(1, _h, self.window_size, _w,
+ self.window_size).transpose(2, 3).reshape(
+ 1, _h * _w,
+ self.window_size * self.window_size)
+ # [1, _h*_w, window_size*window_size, window_size*window_size]
+ attn_mask = mask.unsqueeze(2) - mask.unsqueeze(3)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0,
+ float(-1000.0)).masked_fill(
+ attn_mask == 0, float(0.0))
+
+ # [3, B, _w*_h, nhead, window_size*window_size, dim]
+ qkv = self.qkv(x).reshape(b, _h * _w,
+ self.window_size * self.window_size, 3,
+ self.num_heads, c // self.num_heads).permute(
+ 3, 0, 1, 4, 2, 5)
+ q, k, v = qkv[0], qkv[1], qkv[2]
+ # [B, _h*_w, n_head, window_size*window_size, window_size*window_size]
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn + attn_mask.unsqueeze(2)
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ attn = (attn @ v).transpose(2, 3).reshape(b, _h, _w, self.window_size,
+ self.window_size, c)
+ x = attn.transpose(2, 3).reshape(b, _h * self.window_size,
+ _w * self.window_size, c)
+ if pad_r > 0 or pad_b > 0:
+ x = x[:, :h, :w, :].contiguous()
+
+ x = x.reshape(b, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class LSAEncoderLayer(BaseModule):
+ """Implements one encoder layer in Twins-SVT.
+
+ Args:
+ embed_dims (int): The feature dimension.
+ num_heads (int): Parallel attention heads.
+ feedforward_channels (int): The hidden dimension for FFNs.
+ drop_rate (float): Probability of an element to be zeroed
+ after the feed forward layer. Default: 0.0.
+ attn_drop_rate (float, optional): Dropout ratio of attention weight.
+ Default: 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0.
+ num_fcs (int): The number of fully-connected layers for FFNs.
+ Default: 2.
+ qkv_bias (bool): Enable bias for qkv if True. Default: True
+ qk_scale (float | None, optional): Override default qk scale of
+ head_dim ** -0.5 if set. Default: None.
+ act_cfg (dict): The activation config for FFNs.
+ Default: dict(type='GELU').
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN').
+ window_size (int): Window size of LSA. Default: 1.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dims,
+ num_heads,
+ feedforward_channels,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ num_fcs=2,
+ qkv_bias=True,
+ qk_scale=None,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ window_size=1,
+ init_cfg=None):
+
+ super(LSAEncoderLayer, self).__init__(init_cfg=init_cfg)
+
+ self.norm1 = build_norm_layer(norm_cfg, embed_dims, postfix=1)[1]
+ self.attn = LocallyGroupedSelfAttention(embed_dims, num_heads,
+ qkv_bias, qk_scale,
+ attn_drop_rate, drop_rate,
+ window_size)
+
+ self.norm2 = build_norm_layer(norm_cfg, embed_dims, postfix=2)[1]
+ self.ffn = FFN(
+ embed_dims=embed_dims,
+ feedforward_channels=feedforward_channels,
+ num_fcs=num_fcs,
+ ffn_drop=drop_rate,
+ dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
+ act_cfg=act_cfg,
+ add_identity=False)
+
+ self.drop_path = build_dropout(
+ dict(type='DropPath', drop_prob=drop_path_rate)
+ ) if drop_path_rate > 0. else nn.Identity()
+
+ def forward(self, x, hw_shape):
+ x = x + self.drop_path(self.attn(self.norm1(x), hw_shape))
+ x = x + self.drop_path(self.ffn(self.norm2(x)))
+ return x
+
+
+class ConditionalPositionEncoding(BaseModule):
+ """The Conditional Position Encoding (CPE) module.
+
+ The CPE is the implementation of 'Conditional Positional Encodings
+ for Vision Transformers '_.
+
+ Args:
+ in_channels (int): Number of input channels.
+ embed_dims (int): The feature dimension. Default: 768.
+ stride (int): Stride of conv layer. Default: 1.
+ """
+
+ def __init__(self, in_channels, embed_dims=768, stride=1, init_cfg=None):
+ super(ConditionalPositionEncoding, self).__init__(init_cfg=init_cfg)
+ self.proj = nn.Conv2d(
+ in_channels,
+ embed_dims,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=True,
+ groups=embed_dims)
+ self.stride = stride
+
+ def forward(self, x, hw_shape):
+ b, n, c = x.shape
+ h, w = hw_shape
+ feat_token = x
+ cnn_feat = feat_token.transpose(1, 2).view(b, c, h, w)
+ if self.stride == 1:
+ x = self.proj(cnn_feat) + cnn_feat
+ else:
+ x = self.proj(cnn_feat)
+ x = x.flatten(2).transpose(1, 2)
+ return x
+
+
+@BACKBONES.register_module()
+class PCPVT(BaseModule):
+ """The backbone of Twins-PCPVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4, 8].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Probability of an element to be zeroed.
+ Default 0.
+ attn_drop_rate (float): The drop out rate for attention layer.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.0
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [3, 4, 6, 3]
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [8, 4, 2, 1].
+ norm_after_stage(bool): Add extra norm. Default False.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256, 512],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4, 8],
+ mlp_ratios=[4, 4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.,
+ norm_cfg=dict(type='LN'),
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False,
+ pretrained=None,
+ init_cfg=None):
+ super(PCPVT, self).__init__(init_cfg=init_cfg)
+ assert not (init_cfg and pretrained), \
+ 'init_cfg and pretrained cannot be set at the same time'
+ if isinstance(pretrained, str):
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+ elif pretrained is not None:
+ raise TypeError('pretrained must be a str or None')
+ self.depths = depths
+
+ # patch_embed
+ self.patch_embeds = ModuleList()
+ self.position_encoding_drops = ModuleList()
+ self.layers = ModuleList()
+
+ for i in range(len(depths)):
+ self.patch_embeds.append(
+ PatchEmbed(
+ in_channels=in_channels if i == 0 else embed_dims[i - 1],
+ embed_dims=embed_dims[i],
+ conv_type='Conv2d',
+ kernel_size=patch_sizes[i],
+ stride=strides[i],
+ padding='corner',
+ norm_cfg=norm_cfg))
+
+ self.position_encoding_drops.append(nn.Dropout(p=drop_rate))
+
+ self.position_encodings = ModuleList([
+ ConditionalPositionEncoding(embed_dim, embed_dim)
+ for embed_dim in embed_dims
+ ])
+
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+ cur = 0
+
+ for k in range(len(depths)):
+ _block = ModuleList([
+ GSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ attn_drop_rate=attn_drop_rate,
+ drop_rate=drop_rate,
+ drop_path_rate=dpr[cur + i],
+ num_fcs=2,
+ qkv_bias=qkv_bias,
+ act_cfg=dict(type='GELU'),
+ norm_cfg=dict(type='LN'),
+ sr_ratio=sr_ratios[k]) for i in range(depths[k])
+ ])
+ self.layers.append(_block)
+ cur += depths[k]
+
+ self.norm_name, norm = build_norm_layer(
+ norm_cfg, embed_dims[-1], postfix=1)
+
+ self.out_indices = out_indices
+ self.norm_after_stage = norm_after_stage
+ if self.norm_after_stage:
+ self.norm_list = ModuleList()
+ for dim in embed_dims:
+ self.norm_list.append(build_norm_layer(norm_cfg, dim)[1])
+
+ def init_weights(self):
+ if self.init_cfg is not None:
+ super(PCPVT, self).init_weights()
+ else:
+ for m in self.modules():
+ if isinstance(m, nn.Linear):
+ trunc_normal_init(m, std=.02, bias=0.)
+ elif isinstance(m, (_BatchNorm, nn.GroupNorm, nn.LayerNorm)):
+ constant_init(m, val=1.0, bias=0.)
+ elif isinstance(m, nn.Conv2d):
+ fan_out = m.kernel_size[0] * m.kernel_size[
+ 1] * m.out_channels
+ fan_out //= m.groups
+ normal_init(
+ m, mean=0, std=math.sqrt(2.0 / fan_out), bias=0)
+
+ def forward(self, x):
+ outputs = list()
+
+ b = x.shape[0]
+
+ for i in range(len(self.depths)):
+ x, hw_shape = self.patch_embeds[i](x)
+ h, w = hw_shape
+ x = self.position_encoding_drops[i](x)
+ for j, blk in enumerate(self.layers[i]):
+ x = blk(x, hw_shape)
+ if j == 0:
+ x = self.position_encodings[i](x, hw_shape)
+ if self.norm_after_stage:
+ x = self.norm_list[i](x)
+ x = x.reshape(b, h, w, -1).permute(0, 3, 1, 2).contiguous()
+
+ if i in self.out_indices:
+ outputs.append(x)
+
+ return tuple(outputs)
+
+
+@BACKBONES.register_module()
+class SVT(PCPVT):
+ """The backbone of Twins-SVT.
+
+ This backbone is the implementation of `Twins: Revisiting the Design
+ of Spatial Attention in Vision Transformers
+ `_.
+
+ Args:
+ in_channels (int): Number of input channels. Default: 3.
+ embed_dims (list): Embedding dimension. Default: [64, 128, 256, 512].
+ patch_sizes (list): The patch sizes. Default: [4, 2, 2, 2].
+ strides (list): The strides. Default: [4, 2, 2, 2].
+ num_heads (int): Number of attention heads. Default: [1, 2, 4].
+ mlp_ratios (int): Ratio of mlp hidden dim to embedding dim.
+ Default: [4, 4, 4].
+ out_indices (tuple[int]): Output from which stages.
+ Default: (0, 1, 2, 3).
+ qkv_bias (bool): Enable bias for qkv if True. Default: False.
+ drop_rate (float): Dropout rate. Default 0.
+ attn_drop_rate (float): Dropout ratio of attention weight.
+ Default 0.0
+ drop_path_rate (float): Stochastic depth rate. Default 0.2.
+ norm_cfg (dict): Config dict for normalization layer.
+ Default: dict(type='LN')
+ depths (list): Depths of each stage. Default [4, 4, 4].
+ sr_ratios (list): Kernel_size of conv in each Attn module in
+ Transformer encoder layer. Default: [4, 2, 1].
+ windiow_sizes (list): Window size of LSA. Default: [7, 7, 7],
+ input_features_slice(bool): Input features need slice. Default: False.
+ norm_after_stage(bool): Add extra norm. Default False.
+ strides (list): Strides in patch-Embedding modules. Default: (2, 2, 2)
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ embed_dims=[64, 128, 256],
+ patch_sizes=[4, 2, 2, 2],
+ strides=[4, 2, 2, 2],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ out_indices=(0, 1, 2, 3),
+ qkv_bias=False,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ norm_cfg=dict(type='LN'),
+ depths=[4, 4, 4],
+ sr_ratios=[4, 2, 1],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True,
+ pretrained=None,
+ init_cfg=None):
+ super(SVT, self).__init__(in_channels, embed_dims, patch_sizes,
+ strides, num_heads, mlp_ratios, out_indices,
+ qkv_bias, drop_rate, attn_drop_rate,
+ drop_path_rate, norm_cfg, depths, sr_ratios,
+ norm_after_stage, pretrained, init_cfg)
+ # transformer encoder
+ dpr = [
+ x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
+ ] # stochastic depth decay rule
+
+ for k in range(len(depths)):
+ for i in range(depths[k]):
+ if i % 2 == 0:
+ self.layers[k][i] = \
+ LSAEncoderLayer(
+ embed_dims=embed_dims[k],
+ num_heads=num_heads[k],
+ feedforward_channels=mlp_ratios[k] * embed_dims[k],
+ drop_rate=drop_rate,
+ attn_drop_rate=attn_drop_rate,
+ drop_path_rate=dpr[sum(depths[:k])+i],
+ qkv_bias=qkv_bias,
+ window_size=windiow_sizes[k])
diff --git a/model-index.yml b/model-index.yml
index 1d77a78b8..6ff11b80a 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -33,6 +33,7 @@ Import:
- configs/sem_fpn/sem_fpn.yml
- configs/setr/setr.yml
- configs/swin/swin.yml
+- configs/twins/twins.yml
- configs/unet/unet.yml
- configs/upernet/upernet.yml
- configs/vit/vit.yml
diff --git a/tests/test_models/test_backbones/test_twins.py b/tests/test_models/test_backbones/test_twins.py
new file mode 100644
index 000000000..c7d4a8eb5
--- /dev/null
+++ b/tests/test_models/test_backbones/test_twins.py
@@ -0,0 +1,170 @@
+import pytest
+import torch
+
+from mmseg.models.backbones.twins import (PCPVT, SVT,
+ ConditionalPositionEncoding,
+ LocallyGroupedSelfAttention)
+
+
+def test_pcpvt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = PCPVT(
+ embed_dims=[32, 64, 160, 256],
+ num_heads=[1, 2, 5, 8],
+ mlp_ratios=[8, 8, 4, 4],
+ qkv_bias=True,
+ depths=[3, 4, 6, 3],
+ sr_ratios=[8, 4, 2, 1],
+ norm_after_stage=False)
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 160, H // 16, W // 16)
+ assert outs[3].shape == (1, 256, H // 32, W // 32)
+
+
+def test_svt():
+ # Test normal input
+ H, W = (224, 224)
+ temp = torch.randn((1, 3, H, W))
+ model = SVT(
+ embed_dims=[32, 64, 128],
+ num_heads=[1, 2, 4],
+ mlp_ratios=[4, 4, 4],
+ qkv_bias=False,
+ depths=[4, 4, 4],
+ windiow_sizes=[7, 7, 7],
+ norm_after_stage=True)
+
+ model.init_weights()
+ outs = model(temp)
+ assert outs[0].shape == (1, 32, H // 4, W // 4)
+ assert outs[1].shape == (1, 64, H // 8, W // 8)
+ assert outs[2].shape == (1, 128, H // 16, W // 16)
+
+
+def test_svt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = SVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = SVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = SVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = SVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = SVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = SVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = SVT(pretrained=123, init_cfg=123)
+
+
+def test_pcpvt_init():
+ path = 'PATH_THAT_DO_NOT_EXIST'
+ # Test all combinations of pretrained and init_cfg
+ # pretrained=None, init_cfg=None
+ model = PCPVT(pretrained=None, init_cfg=None)
+ assert model.init_cfg is None
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg loads pretrain from an non-existent file
+ model = PCPVT(
+ pretrained=None, init_cfg=dict(type='Pretrained', checkpoint=path))
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained=None
+ # init_cfg=123, whose type is unsupported
+ model = PCPVT(pretrained=None, init_cfg=123)
+ with pytest.raises(TypeError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg=None
+ model = PCPVT(pretrained=path, init_cfg=None)
+ assert model.init_cfg == dict(type='Pretrained', checkpoint=path)
+ # Test loading a checkpoint from an non-existent file
+ with pytest.raises(OSError):
+ model.init_weights()
+
+ # pretrained loads pretrain from an non-existent file
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=path, init_cfg=dict(type='Pretrained', checkpoint=path))
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=path, init_cfg=123)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=None
+ with pytest.raises(TypeError):
+ model = PCPVT(pretrained=123, init_cfg=None)
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg loads pretrain from an non-existent file
+ with pytest.raises(AssertionError):
+ model = PCPVT(
+ pretrained=123, init_cfg=dict(type='Pretrained', checkpoint=path))
+
+ # pretrain=123, whose type is unsupported
+ # init_cfg=123, whose type is unsupported
+ with pytest.raises(AssertionError):
+ model = PCPVT(pretrained=123, init_cfg=123)
+
+
+def test_locallygrouped_self_attention_module():
+ LSA = LocallyGroupedSelfAttention(embed_dims=32, window_size=3)
+ outs = LSA(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 3136, 32])
+
+
+def test_conditional_position_encoding_module():
+ CPE = ConditionalPositionEncoding(in_channels=32, embed_dims=32, stride=2)
+ outs = CPE(torch.randn(1, 3136, 32), (56, 56))
+ assert outs.shape == torch.Size([1, 784, 32])
diff --git a/tools/model_converters/twins2mmseg.py b/tools/model_converters/twins2mmseg.py
new file mode 100644
index 000000000..ab64aa526
--- /dev/null
+++ b/tools/model_converters/twins2mmseg.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from collections import OrderedDict
+
+import mmcv
+import torch
+from mmcv.runner import CheckpointLoader
+
+
+def convert_twins(args, ckpt):
+
+ new_ckpt = OrderedDict()
+
+ for k, v in list(ckpt.items()):
+ new_v = v
+ if k.startswith('head'):
+ continue
+ elif k.startswith('patch_embeds'):
+ if 'proj.' in k:
+ new_k = k.replace('proj.', 'projection.')
+ else:
+ new_k = k
+ elif k.startswith('blocks'):
+ # Union
+ if 'attn.q.' in k:
+ new_k = k.replace('q.', 'attn.in_proj_')
+ new_v = torch.cat([v, ckpt[k.replace('attn.q.', 'attn.kv.')]],
+ dim=0)
+ elif 'mlp.fc1' in k:
+ new_k = k.replace('mlp.fc1', 'ffn.layers.0.0')
+ elif 'mlp.fc2' in k:
+ new_k = k.replace('mlp.fc2', 'ffn.layers.1')
+ # Only pcpvt
+ elif args.model == 'pcpvt':
+ if 'attn.proj.' in k:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+
+ # Only svt
+ else:
+ if 'attn.proj.' in k:
+ k_lst = k.split('.')
+ if int(k_lst[2]) % 2 == 1:
+ new_k = k.replace('proj.', 'attn.out_proj.')
+ else:
+ new_k = k
+ else:
+ new_k = k
+ new_k = new_k.replace('blocks.', 'layers.')
+ elif k.startswith('pos_block'):
+ new_k = k.replace('pos_block', 'position_encodings')
+ if 'proj.0.' in new_k:
+ new_k = new_k.replace('proj.0.', 'proj.')
+ else:
+ new_k = k
+ if 'attn.kv.' not in k:
+ new_ckpt[new_k] = new_v
+ return new_ckpt
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Convert keys in timm pretrained vit models to '
+ 'MMSegmentation style.')
+ parser.add_argument('src', help='src model path or url')
+ # The dst path must be a full path of the new checkpoint.
+ parser.add_argument('dst', help='save path')
+ parser.add_argument('model', help='model: pcpvt or svt')
+ args = parser.parse_args()
+
+ checkpoint = CheckpointLoader.load_checkpoint(args.src, map_location='cpu')
+
+ if 'state_dict' in checkpoint:
+ # timm checkpoint
+ state_dict = checkpoint['state_dict']
+ else:
+ state_dict = checkpoint
+
+ weight = convert_twins(args, state_dict)
+ mmcv.mkdir_or_exist(osp.dirname(args.dst))
+ torch.save(weight, args.dst)
+
+
+if __name__ == '__main__':
+ main()