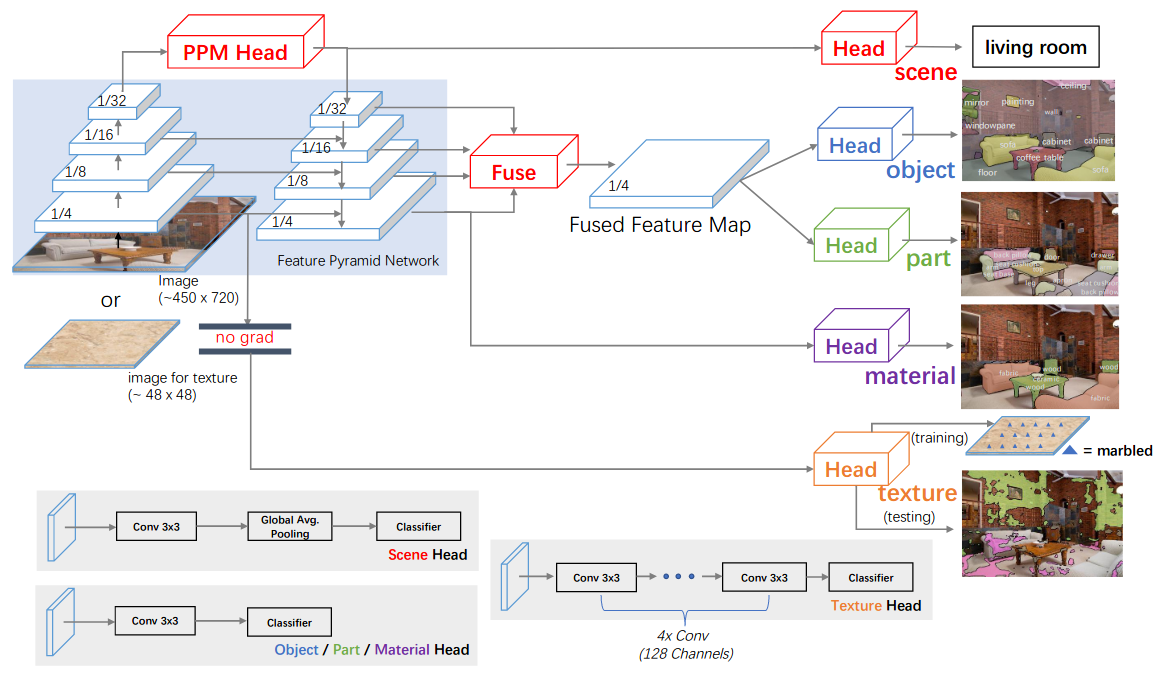
UPerNet
Unified Perceptual Parsing for Scene Understanding
Introduction
Official Repo
Code Snippet
Abstract
Humans recognize the visual world at multiple levels: we effortlessly categorize scenes and detect objects inside, while also identifying the textures and surfaces of the objects along with their different compositional parts. In this paper, we study a new task called Unified Perceptual Parsing, which requires the machine vision systems to recognize as many visual concepts as possible from a given image. A multi-task framework called UPerNet and a training strategy are developed to learn from heterogeneous image annotations. We benchmark our framework on Unified Perceptual Parsing and show that it is able to effectively segment a wide range of concepts from images. The trained networks are further applied to discover visual knowledge in natural scenes. Models are available at this https URL.
Results and models
Cityscapes
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| UPerNet |
R-50 |
512x1024 |
40000 |
6.4 |
4.25 |
V100 |
77.10 |
78.37 |
config |
model | log |
| UPerNet |
R-101 |
512x1024 |
40000 |
7.4 |
3.79 |
V100 |
78.69 |
80.11 |
config |
model | log |
| UPerNet |
R-50 |
769x769 |
40000 |
7.2 |
1.76 |
V100 |
77.98 |
79.70 |
config |
model | log |
| UPerNet |
R-101 |
769x769 |
40000 |
8.4 |
1.56 |
V100 |
79.03 |
80.77 |
config |
model | log |
| UPerNet |
R-50 |
512x1024 |
80000 |
- |
- |
V100 |
78.19 |
79.19 |
config |
model | log |
| UPerNet |
R-101 |
512x1024 |
80000 |
- |
- |
V100 |
79.40 |
80.46 |
config |
model | log |
| UPerNet |
R-50 |
769x769 |
80000 |
- |
- |
V100 |
79.39 |
80.92 |
config |
model | log |
| UPerNet |
R-101 |
769x769 |
80000 |
- |
- |
V100 |
80.10 |
81.49 |
config |
model | log |
ADE20K
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| UPerNet |
R-50 |
512x512 |
80000 |
8.1 |
23.40 |
V100 |
40.70 |
41.81 |
config |
model | log |
| UPerNet |
R-101 |
512x512 |
80000 |
9.1 |
20.34 |
V100 |
42.91 |
43.96 |
config |
model | log |
| UPerNet |
R-50 |
512x512 |
160000 |
- |
- |
V100 |
42.05 |
42.78 |
config |
model | log |
| UPerNet |
R-101 |
512x512 |
160000 |
- |
- |
V100 |
43.82 |
44.85 |
config |
model | log |
Pascal VOC 2012 + Aug
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| UPerNet |
R-50 |
512x512 |
20000 |
6.4 |
23.17 |
V100 |
74.82 |
76.35 |
config |
model | log |
| UPerNet |
R-101 |
512x512 |
20000 |
7.5 |
19.98 |
V100 |
77.10 |
78.29 |
config |
model | log |
| UPerNet |
R-50 |
512x512 |
40000 |
- |
- |
V100 |
75.92 |
77.44 |
config |
model | log |
| UPerNet |
R-101 |
512x512 |
40000 |
- |
- |
V100 |
77.43 |
78.56 |
config |
model | log |
Citation
@inproceedings{xiao2018unified,
title={Unified perceptual parsing for scene understanding},
author={Xiao, Tete and Liu, Yingcheng and Zhou, Bolei and Jiang, Yuning and Sun, Jian},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={418--434},
year={2018}
}