* segmenter: add model * update * readme: update * config: update * segmenter: update readme * segmenter: update * segmenter: update * segmenter: update * configs: set checkpoint path to pretrain folder * segmenter: modify vit-s/lin, remove data config * rreadme: update * configs: transfer from _base_ to segmenter * configs: add 8x1 suffix * configs: remove redundant lines * configs: cleanup * first attempt * swipe CI error * Update mmseg/models/decode_heads/__init__.py Co-authored-by: Junjun2016 <hejunjun@sjtu.edu.cn> * segmenter_linear: use fcn backbone * segmenter_mask: update * models: add segmenter vit * decoders: yapf+remove unused imports * apply precommit * segmenter/linear_head: fix * segmenter/linear_header: fix * segmenter: fix mask transformer * fix error * segmenter/mask_head: use trunc_normal init * refactor segmenter head * Fetch upstream (#1) * [Feature] Change options to cfg-option (#1129) * [Feature] Change option to cfg-option * add expire date and fix the docs * modify docstring * [Fix] Add <!-- [ABSTRACT] --> in metafile #1127 * [Fix] Fix correct num_classes of HRNet in LoveDA dataset #1136 * Bump to v0.20.1 (#1138) * bump version 0.20.1 * bump version 0.20.1 * [Fix] revise --option to --options #1140 Co-authored-by: Rockey <41846794+RockeyCoss@users.noreply.github.com> Co-authored-by: MengzhangLI <mcmong@pku.edu.cn> * decode_head: switch from linear to fcn * fix init list formatting * configs: remove variants, keep only vit-s on ade * align inference metric of vit-s-mask * configs: add vit t/b/l * Update mmseg/models/decode_heads/segmenter_mask_head.py Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> * Update mmseg/models/decode_heads/segmenter_mask_head.py Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> * Update mmseg/models/decode_heads/segmenter_mask_head.py Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> * Update mmseg/models/decode_heads/segmenter_mask_head.py Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> * Update mmseg/models/decode_heads/segmenter_mask_head.py Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> * model_converters: use torch instead of einops * setup: remove einops * segmenter_mask: fix missing imports * add necessary imported init funtion * segmenter/seg-l: set resolution to 640 * segmenter/seg-l: fix test size * fix vitjax2mmseg * add README and unittest * fix unittest * add docstring * refactor config and add pretrained link * fix typo * add paper name in readme * change segmenter config names * fix typo in readme * fix typos in readme * fix segmenter typo * fix segmenter typo * delete redundant comma in config files * delete redundant comma in config files * fix convert script * update lateset master version Co-authored-by: MengzhangLI <mcmong@pku.edu.cn> Co-authored-by: Junjun2016 <hejunjun@sjtu.edu.cn> Co-authored-by: Rockey <41846794+RockeyCoss@users.noreply.github.com> Co-authored-by: Miao Zheng <76149310+MeowZheng@users.noreply.github.com> |
||
|---|---|---|
| .. | ||
| README.md | ||
| segmenter.yml | ||
| segmenter_vit-b_mask_8x1_512x512_160k_ade20k.py | ||
| segmenter_vit-l_mask_8x1_512x512_160k_ade20k.py | ||
| segmenter_vit-s_linear_8x1_512x512_160k_ade20k.py | ||
| segmenter_vit-s_mask_8x1_512x512_160k_ade20k.py | ||
| segmenter_vit-t_mask_8x1_512x512_160k_ade20k.py | ||
README.md
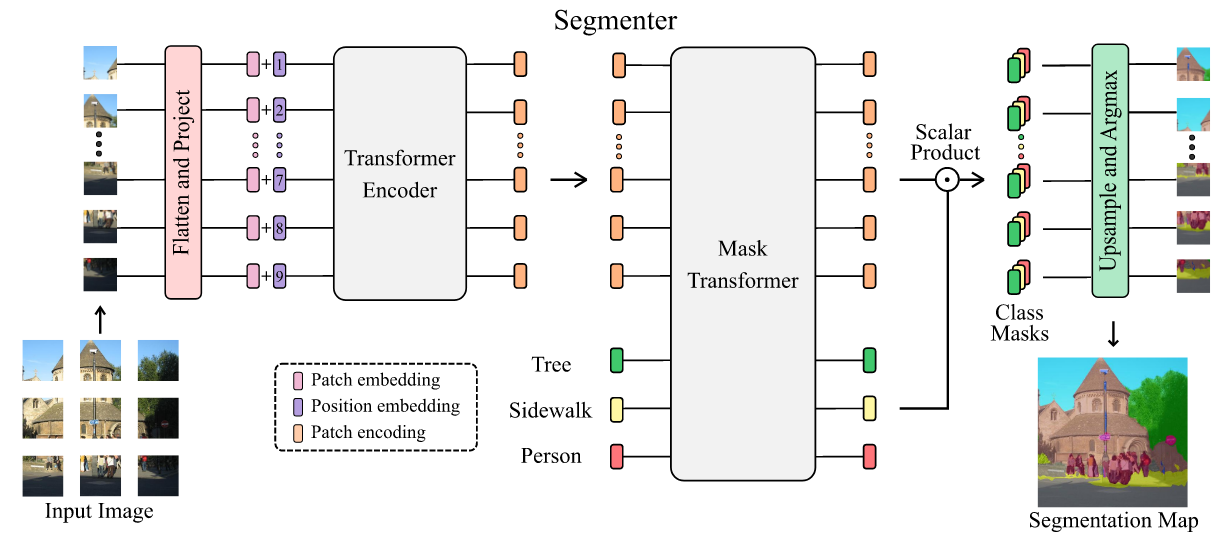
Segmenter
Segmenter: Transformer for Semantic Segmentation
Introduction
Abstract
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution-based methods, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation. To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks. We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on both ADE20K and Pascal Context datasets and is competitive on Cityscapes.
@article{strudel2021Segmenter,
title={Segmenter: Transformer for Semantic Segmentation},
author={Strudel, Robin and Ricardo, Garcia, and Laptev, Ivan and Schmid, Cordelia},
journal={arXiv preprint arXiv:2105.05633},
year={2021}
}
Usage
To use the pre-trained ViT model from Segmenter, it is necessary to convert keys.
We provide a script vitjax2mmseg.py in the tools directory to convert the key of models from ViT-AugReg to MMSegmentation style.
python tools/model_converters/vitjax2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}
E.g.
python tools/model_converters/vitjax2mmseg.py \
Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz \
pretrain/vit_tiny_p16_384.pth
This script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
In our default setting, pretrained models and their corresponding ViT-AugReg models could be defined below:
| pretrained models | original models |
|---|---|
| vit_tiny_p16_384.pth | 'vit_tiny_patch16_384' |
| vit_small_p16_384.pth | 'vit_small_patch16_384' |
| vit_base_p16_384.pth | 'vit_base_patch16_384' |
| vit_large_p16_384.pth | 'vit_large_patch16_384' |
Results and models
ADE20K
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| Segmenter-Mask | ViT-T_16 | 512x512 | 160000 | 1.21 | 27.98 | 39.99 | 40.83 | config | model | log |
| Segmenter-Linear | ViT-S_16 | 512x512 | 160000 | 1.78 | 28.07 | 45.75 | 46.82 | config | model | log |
| Segmenter-Mask | ViT-S_16 | 512x512 | 160000 | 2.03 | 24.80 | 46.19 | 47.85 | config | model | log |
| Segmenter-Mask | ViT-B_16 | 512x512 | 160000 | 4.20 | 13.20 | 49.60 | 51.07 | config | model | log |
| Segmenter-Mask | ViT-L_16 | 640x640 | 160000 | 16.56 | 2.62 | 52.16 | 53.65 | config | model | log |