Glaucoma grAding from Multi-Modality imAges Task3
Description
This project support Glaucoma grAding from Multi-Modality imAges Task3, and the dataset used in this project can be downloaded from here.
Dataset Overview
This regular-challenge dataset was provided by Sun Yat-sen Ophthalmic Center, Sun Yat-sen University, Guangzhou, China. The dataset contains 200 fundus color images: 100 pairs in the training set and 100 pairs in the test set.
Original Statistic Information
| Dataset name | Anatomical region | Task type | Modality | Num. Classes | Train/Val/Test Images | Train/Val/Test Labeled | Release Date | License |
|---|---|---|---|---|---|---|---|---|
| GammaTask3 | eye | segmentation | fundus photophy | 3 | 100/-/100 | yes/-/- | 2021 | CC-BY-NC 4.0 |
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|---|---|---|---|---|---|---|
| background | 100 | 99.02 | - | - | - | - |
| optic disc | 100 | 0.67 | - | - | - | - |
| optic cup | 100 | 0.31 | - | - | - | - |
Note:
Pctmeans percentage of pixels in this category in all pixels.
Visualization
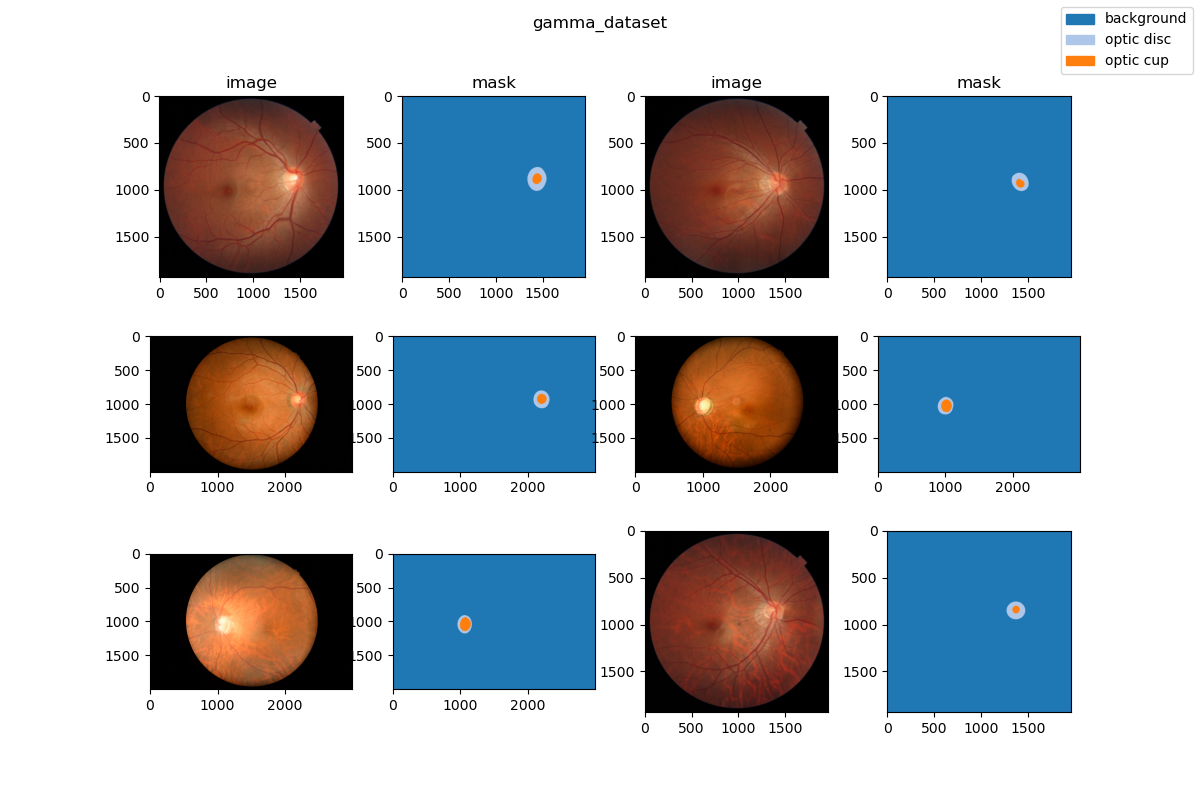
Dataset Citation
@article{fu2018joint,
title={Joint optic disc and cup segmentation based on multi-label deep network and polar transformation},
author={Fu, Huazhu and Cheng, Jun and Xu, Yanwu and Wong, Damon Wing Kee and Liu, Jiang and Cao, Xiaochun},
journal={IEEE transactions on medical imaging},
volume={37},
number={7},
pages={1597--1605},
year={2018},
publisher={IEEE}
}
@article{sevastopolsky2017optic,
title={Optic disc and cup segmentation methods for glaucoma detection with modification of U-Net convolutional neural network},
author={Sevastopolsky, Artem},
journal={Pattern Recognition and Image Analysis},
volume={27},
pages={618--624},
year={2017},
publisher={Springer}
}
Prerequisites
- Python v3.8
- PyTorch v1.10.0
- pillow(PIL) v9.3.0
- scikit-learn(sklearn) v1.2.0
- MIM v0.3.4
- MMCV v2.0.0rc4
- MMEngine v0.2.0 or higher
- MMSegmentation v1.0.0rc5
All the commands below rely on the correct configuration of PYTHONPATH, which should point to the project's directory so that Python can locate the module files. In gammm3/ root directory, run the following line to add the current directory to PYTHONPATH:
export PYTHONPATH=`pwd`:$PYTHONPATH
Dataset preparing
- download dataset from here and decompression data to path
'data/'. - run script
"python tools/prepare_dataset.py"to split dataset and change folder structure as below. - run script
"python ../../tools/split_seg_dataset.py"to split dataset and generatetrain.txt,val.txtandtest.txt. If the label of official validation set and test set can't be obtained, we generatetrain.txtandval.txtfrom the training set randomly.
mmsegmentation
├── mmseg
├── projects
│ ├── medical
│ │ ├── 2d_image
│ │ │ ├── fundus_photography
│ │ │ │ ├── gamma3
│ │ │ │ │ ├── configs
│ │ │ │ │ ├── datasets
│ │ │ │ │ ├── tools
│ │ │ │ │ ├── data
│ │ │ │ │ │ ├── train.txt
│ │ │ │ │ │ ├── val.txt
│ │ │ │ │ │ ├── images
│ │ │ │ │ │ │ ├── train
│ │ │ │ | │ │ │ ├── xxx.png
│ │ │ │ | │ │ │ ├── ...
│ │ │ │ | │ │ │ └── xxx.png
│ │ │ │ │ │ │ ├── test
│ │ │ │ | │ │ │ ├── yyy.png
│ │ │ │ | │ │ │ ├── ...
│ │ │ │ | │ │ │ └── yyy.png
│ │ │ │ │ │ ├── masks
│ │ │ │ │ │ │ ├── train
│ │ │ │ | │ │ │ ├── xxx.png
│ │ │ │ | │ │ │ ├── ...
│ │ │ │ | │ │ │ └── xxx.png
Divided Dataset Information
Note: The table information below is divided by ourselves.
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|---|---|---|---|---|---|---|
| background | 80 | 99.01 | 20 | 99.07 | - | - |
| optic disc | 80 | 0.68 | 20 | 0.63 | - | - |
| optic cup | 80 | 0.32 | 20 | 0.31 | - | - |
Training commands
To train models on a single server with one GPU. (default)
mim train mmseg ./configs/${CONFIG_PATH}
Testing commands
To test models on a single server with one GPU. (default)
mim test mmseg ./configs/${CONFIG_PATH} --checkpoint ${CHECKPOINT_PATH}
Checklist
-
Milestone 1: PR-ready, and acceptable to be one of the
projects/.-
Finish the code
-
Basic docstrings & proper citation
-
Test-time correctness
-
A full README
-
-
Milestone 2: Indicates a successful model implementation.
- Training-time correctness
-
Milestone 3: Good to be a part of our core package!
-
Type hints and docstrings
-
Unit tests
-
Code polishing
-
Metafile.yml
-
-
Move your modules into the core package following the codebase's file hierarchy structure.
-
Refactor your modules into the core package following the codebase's file hierarchy structure.