|
|
||
|---|---|---|
| .. | ||
| configs | ||
| datasets | ||
| tools | ||
| README.md | ||
| conic2022_seg_dataset.png | ||
{kind=link}
README.md
CoNIC: Colon Nuclei Identification and Counting Challenge
Description
This project supports CoNIC: Colon Nuclei Identification and Counting Challenge, which can be downloaded from here.
Dataset Overview
Nuclear segmentation, classification and quantification within Haematoxylin & Eosin stained histology images enables the extraction of interpretable cell-based features that can be used in downstream explainable models in computational pathology (CPath). To help drive forward research and innovation for automatic nuclei recognition in CPath, we organise the Colon Nuclei Identification and Counting (CoNIC) Challenge. The challenge requires researchers to develop algorithms that perform segmentation, classification and counting of 6 different types of nuclei within the current largest known publicly available nuclei-level dataset in CPath, containing around half a million labelled nuclei.
Task Information
The CONIC challenge has 2 tasks:
- Task 1: Nuclear segmentation and classification.
The first task requires participants to segment nuclei within the tissue, while also classifying each nucleus into one of the following categories: epithelial, lymphocyte, plasma, eosinophil, neutrophil or connective tissue.
- Task 2: Prediction of cellular composition.
For the second task, we ask participants to predict how many nuclei of each class are present in each input image.
The output of Task 1 can be directly used to perform Task 2, but these can be treated as independent tasks. Therefore, if it is preferred, prediction of cellular composition can be treated as a stand alone regression task.
NOTE:We only consider Task 1 in the following sections.
Original Statistic Information
| Dataset name | Anatomical region | Task type | Modality | Num. Classes | Train/Val/Test Images | Train/Val/Test Labeled | Release Date | License |
|---|---|---|---|---|---|---|---|---|
| CoNIC202 | abdomen | segmentation | histopathology | 7 | 4981/-/- | yes/-/- | 2022 | Attribution-NonCommercial-ShareAlike 4.0 International |
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|---|---|---|---|---|---|---|
| background | 4981 | 83.97 | - | - | - | - |
| neutrophil | 1218 | 0.13 | - | - | - | - |
| epithelial | 4256 | 10.31 | - | - | - | - |
| lymphocyte | 4473 | 1.85 | - | - | - | - |
| plasma | 3316 | 0.55 | - | - | - | - |
| eosinophil | 1456 | 0.1 | - | - | - | - |
| connective | 4613 | 3.08 | - | - | - | - |
Note:
Pctmeans percentage of pixels in this category in all pixels.
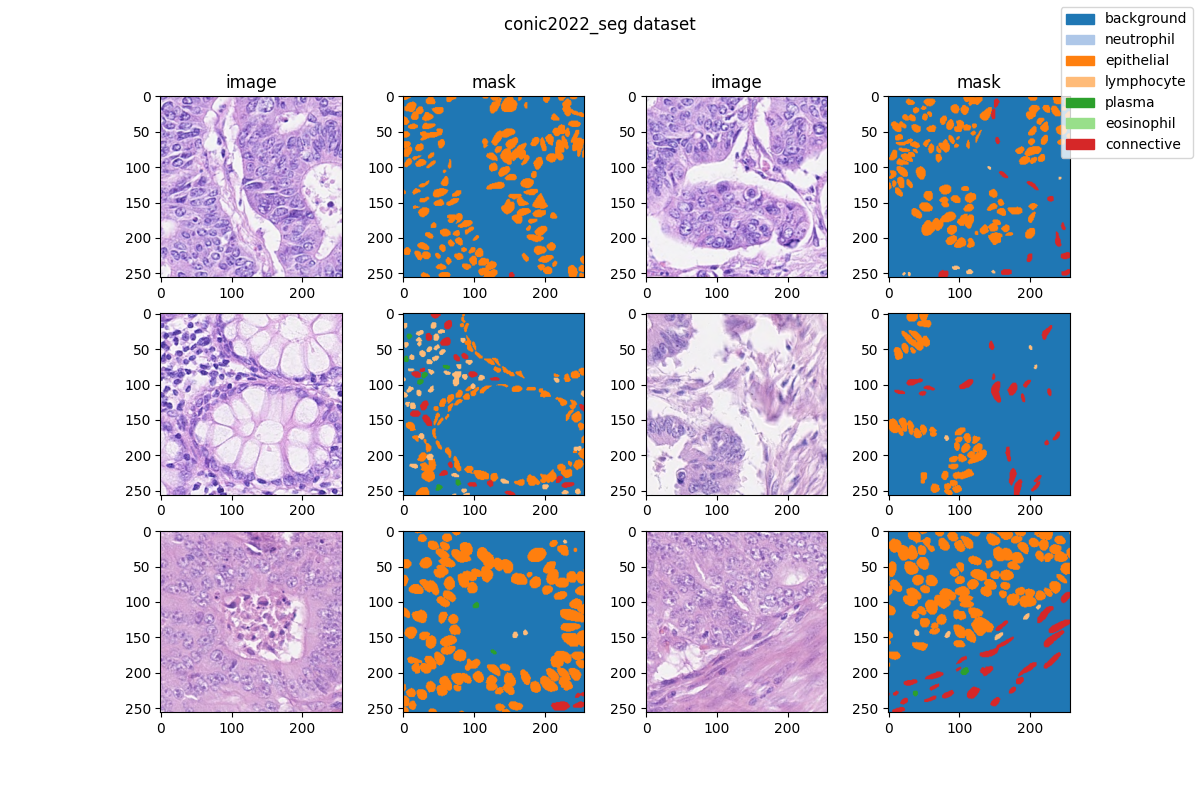
Visualization
Prerequisites
- Python v3.8
- PyTorch v1.10.0
- pillow(PIL) v9.3.0
- scikit-learn(sklearn) v1.2.0
- MIM v0.3.4
- MMCV v2.0.0rc4
- MMEngine v0.2.0 or higher
- MMSegmentation v1.0.0rc5
All the commands below rely on the correct configuration of PYTHONPATH, which should point to the project's directory so that Python can locate the module files. In conic2022_seg/ root directory, run the following line to add the current directory to PYTHONPATH:
export PYTHONPATH=`pwd`:$PYTHONPATH
Dataset preparing
- download dataset from here and move data to path
'data/CoNIC_Challenge'. The directory should be like:data/CoNIC_Challenge ├── README.txt ├── by-nc-sa.md ├── counts.csv ├── images.npy ├── labels.npy └── patch_info.csv - run script
"python tools/prepare_dataset.py"to format data and change folder structure as below. - run script
"python ../../tools/split_seg_dataset.py"to split dataset and generatetrain.txt,val.txtandtest.txt. If the label of official validation set and test set can't be obtained, we generatetrain.txtandval.txtfrom the training set randomly.
mmsegmentation
├── mmseg
├── projects
│ ├── medical
│ │ ├── 2d_image
│ │ │ ├── histopathology
│ │ │ │ ├── conic2022_seg
│ │ │ │ │ ├── configs
│ │ │ │ │ ├── datasets
│ │ │ │ │ ├── tools
│ │ │ │ │ ├── data
│ │ │ │ │ │ ├── train.txt
│ │ │ │ │ │ ├── val.txt
│ │ │ │ │ │ ├── images
│ │ │ │ │ │ │ ├── train
│ │ │ │ | │ │ │ ├── xxx.png
│ │ │ │ | │ │ │ ├── ...
│ │ │ │ | │ │ │ └── xxx.png
│ │ │ │ │ │ ├── masks
│ │ │ │ │ │ │ ├── train
│ │ │ │ | │ │ │ ├── xxx.png
│ │ │ │ | │ │ │ ├── ...
│ │ │ │ | │ │ │ └── xxx.png
Divided Dataset Information
Note: The table information below is divided by ourselves.
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|---|---|---|---|---|---|---|
| background | 3984 | 84.06 | 997 | 83.65 | - | - |
| neutrophil | 956 | 0.12 | 262 | 0.13 | - | - |
| epithelial | 3400 | 10.26 | 856 | 10.52 | - | - |
| lymphocyte | 3567 | 1.83 | 906 | 1.96 | - | - |
| plasma | 2645 | 0.55 | 671 | 0.56 | - | - |
| eosinophil | 1154 | 0.1 | 302 | 0.1 | - | - |
| connective | 3680 | 3.08 | 933 | 3.08 | - | - |
Training commands
Train models on a single server with one GPU.
mim train mmseg ./configs/${CONFIG_FILE}
Testing commands
Test models on a single server with one GPU.
mim test mmseg ./configs/${CONFIG_FILE} --checkpoint ${CHECKPOINT_PATH}
Organizers
- Simon Graham (TIA, PathLAKE)
- Mostafa Jahanifar (TIA, PathLAKE)
- Dang Vu (TIA)
- Giorgos Hadjigeorghiou (TIA, PathLAKE)
- Thomas Leech (TIA, PathLAKE)
- David Snead (UHCW, PathLAKE)
- Shan Raza (TIA, PathLAKE)
- Fayyaz Minhas (TIA, PathLAKE)
- Nasir Rajpoot (TIA, PathLAKE)
TIA: Tissue Image Analytics Centre, Department of Computer Science, University of Warwick, United Kingdom
UHCW: Department of Pathology, University Hospitals Coventry and Warwickshire, United Kingdom
PathLAKE: Pathology Image Data Lake for Analytics Knowledge & Education, , University Hospitals Coventry and Warwickshire, United Kingdom
Dataset Citation
If this work is helpful for your research, please consider citing the below paper.
@inproceedings{graham2021lizard,
title={Lizard: A large-scale dataset for colonic nuclear instance segmentation and classification},
author={Graham, Simon and Jahanifar, Mostafa and Azam, Ayesha and Nimir, Mohammed and Tsang, Yee-Wah and Dodd, Katherine and Hero, Emily and Sahota, Harvir and Tank, Atisha and Benes, Ksenija and others},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={684--693},
year={2021}
}
@article{graham2021conic,
title={Conic: Colon nuclei identification and counting challenge 2022},
author={Graham, Simon and Jahanifar, Mostafa and Vu, Quoc Dang and Hadjigeorghiou, Giorgos and Leech, Thomas and Snead, David and Raza, Shan E Ahmed and Minhas, Fayyaz and Rajpoot, Nasir},
journal={arXiv preprint arXiv:2111.14485},
year={2021}
}
Checklist
-
Milestone 1: PR-ready, and acceptable to be one of the
projects/.-
Finish the code
-
Basic docstrings & proper citation
-
A full README
-
-
Milestone 2: Indicates a successful model implementation.
- Training-time correctness
-
Milestone 3: Good to be a part of our core package!
-
Type hints and docstrings
-
Unit tests
-
Code polishing
-
Metafile.yml
-
-
Move your modules into the core package following the codebase's file hierarchy structure.
-
Refactor your modules into the core package following the codebase's file hierarchy structure.