mirror of https://github.com/open-mmlab/mmyolo.git
update RTMDet docs (#109)
parent
15f3caf033
commit
05a5b2aaa2
|
|
@ -121,6 +121,7 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
|
|||
- [模型设计相关说明](docs/zh_cn/algorithm_descriptions/model_design.md)
|
||||
- [算法原理和实现全解析](https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/index.html#算法原理和实现全解析)
|
||||
- [YOLOv5 原理和实现全解析](docs/zh_cn/algorithm_descriptions/yolov5_description.md)
|
||||
- [RTMDet 原理和实现全解析](docs/zh_cn/algorithm_descriptions/rtmdet_description.md)
|
||||
|
||||
- 进阶指南
|
||||
|
||||
|
|
|
|||
|
|
@ -14,3 +14,4 @@
|
|||
:maxdepth: 1
|
||||
|
||||
yolov5_description.md
|
||||
rtmdet_description.md
|
||||
|
|
|
|||
|
|
@ -8,10 +8,10 @@
|
|||
<img alt="RTMDet_structure_v1.0" src="https://user-images.githubusercontent.com/27466624/192815848-c2db9680-df03-40af-8051-124b9ae59d06.jpg"/>
|
||||
</div>
|
||||
|
||||
最近一段时间,开源界涌现出了大量的高精度目标检测项目,其中最突出的就是 YOLO 系列,OpenMMLab 也在与社区的合作下推出了 MMYOLO。
|
||||
在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet。
|
||||
以上结构图由 RangeKing@github 绘制。
|
||||
|
||||
**R**eal-**t**ime **M**odels for Object **Det**ection
|
||||
最近一段时间,开源界涌现出了大量的高精度目标检测项目,其中最突出的就是 YOLO 系列,OpenMMLab 也在与社区的合作下推出了 MMYOLO。
|
||||
在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet, **R**eal-**t**ime **M**odels for Object **Det**ection
|
||||
(**R**elease **t**o **M**anufacture)
|
||||
|
||||
RTMDet 由 tiny/s/m/l/x 一系列不同大小的模型组成,为不同的应用场景提供了不同的选择。
|
||||
|
|
@ -21,13 +21,18 @@ RTMDet 由 tiny/s/m/l/x 一系列不同大小的模型组成,为不同的应
|
|||
注:推理速度和精度测试(不包含 NMS)是在 1 块 NVIDIA 3090 GPU 上的 `TensorRT 8.4.3, cuDNN 8.2.0, FP16, batch size=1` 条件里测试的。
|
||||
```
|
||||
|
||||
而最轻量的模型 RTMDet-tiny,在仅有4M参数量的情况下也能够达到 40.9 mAP,且推理速度 \< 1 ms。
|
||||
而最轻量的模型 RTMDet-tiny,在仅有 4M 参数量的情况下也能够达到 40.9 mAP,且推理速度 \< 1 ms。
|
||||
|
||||
<div align=center >
|
||||
<img alt="RTMDet_精度图" src="https://user-images.githubusercontent.com/12907710/192182907-f9a671d6-89cb-4d73-abd8-c2b9dada3c66.png"/>
|
||||
</div>
|
||||
|
||||
## 数据增强模块
|
||||
- 官方开源地址: https://github.com/open-mmlab/mmdetection/blob/3.x/configs/rtmdet/README.md
|
||||
- MMYOLO 开源地址: https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/README.md
|
||||
|
||||
## 1 v1.0 算法原理和 MMYOLO 实现解析
|
||||
|
||||
### 1.1 数据增强模块
|
||||
|
||||
RTMDet 采用了多种数据增强的方式来增加模型的性能,主要包括单图数据增强:
|
||||
|
||||
|
|
@ -47,20 +52,22 @@ RTMDet 采用了多种数据增强的方式来增加模型的性能,主要包
|
|||
<img src="https://user-images.githubusercontent.com/33799979/192940322-3864fac4-cbbc-4f80-a8d3-0f84a2c40e27.png" width=800 />
|
||||
</center>
|
||||
|
||||
其中 RandomResize 这个在 大模型 M,L,X 和 小模型 s, tiny 上是不一样的,大模型由于参数较多,可以使用 large scale jitter 策略即参数为 (0.1,2.0),而小模型采用 stand scale jitter 策略即 (0.5, 2.0) 策略。
|
||||
其中 RandomResize 超参在大模型 M,L,X 和小模型 S, Tiny 上是不一样的,大模型由于参数较多,可以使用 large scale jitter 策略即参数为 (0.1,2.0),而小模型采用 stand scale jitter 策略即 (0.5, 2.0) 策略。
|
||||
MMDetection 开源库中已经对单图数据增强进行了封装,用户通过简单的修改配置即可使用库中提供的任何数据增强功能,且都是属于比较常规的数据增强,不需要特殊介绍。下面将具体介绍混合类数据增强的具体实现。
|
||||
|
||||
与 YOLOv5 不同的是,YOLOv5认为在 s 和 nano 模型上使用 MixUp 是过剩的,小模型不需要这么强的数据增强。而 RTMDet 在 s 和 tiny 上也使用了 MixUp,这是因为 RTMDet 在最后 20 epoch 会切换为正常的 aug, 并通过训练证明这个操作是有效的。 并且 RTMDet 为混合类数据增强引入了 Cache 方案,有效地减少了图像处理的时间,和引入了可调超参 max_cached_images ,当使用较小的 cache 时,其效果类似 repeated augmentation。具体介绍如下:
|
||||
与 YOLOv5 不同的是,YOLOv5 认为在 S 和 Nano 模型上使用 MixUp 是过剩的,小模型不需要这么强的数据增强。而 RTMDet 在 S 和 Tiny 上也使用了 MixUp,这是因为 RTMDet 在最后 20 epoch 会切换为正常的 aug, 并通过训练证明这个操作是有效的。 并且 RTMDet 为混合类数据增强引入了 Cache 方案,有效地减少了图像处理的时间, 和引入了可调超参 `max_cached_images` ,当使用较小的 cache 时,其效果类似 `repeated augmentation`。具体介绍如下:
|
||||
|
||||
### 为图像混合数据增强引入Cache
|
||||
#### 1.1.1 为图像混合数据增强引入 Cache
|
||||
|
||||
Mosaic&MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的K倍(K为混入图片的数量)。 如在YOLOv5中,每次做 Mosaic 时, 4张图片的信息都需要从硬盘中重新加载。 而 RTMDet 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。 另外,通过调整 cache 的大小以及 pop 的方式,也可以调整增强的强度。
|
||||
Mosaic&MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 K 倍(K 为混入图片的数量)。 如在 YOLOv5 中,每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而 RTMDet 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。 另外通过调整 cache 的大小以及 pop 的方式,也可以调整增强的强度。
|
||||
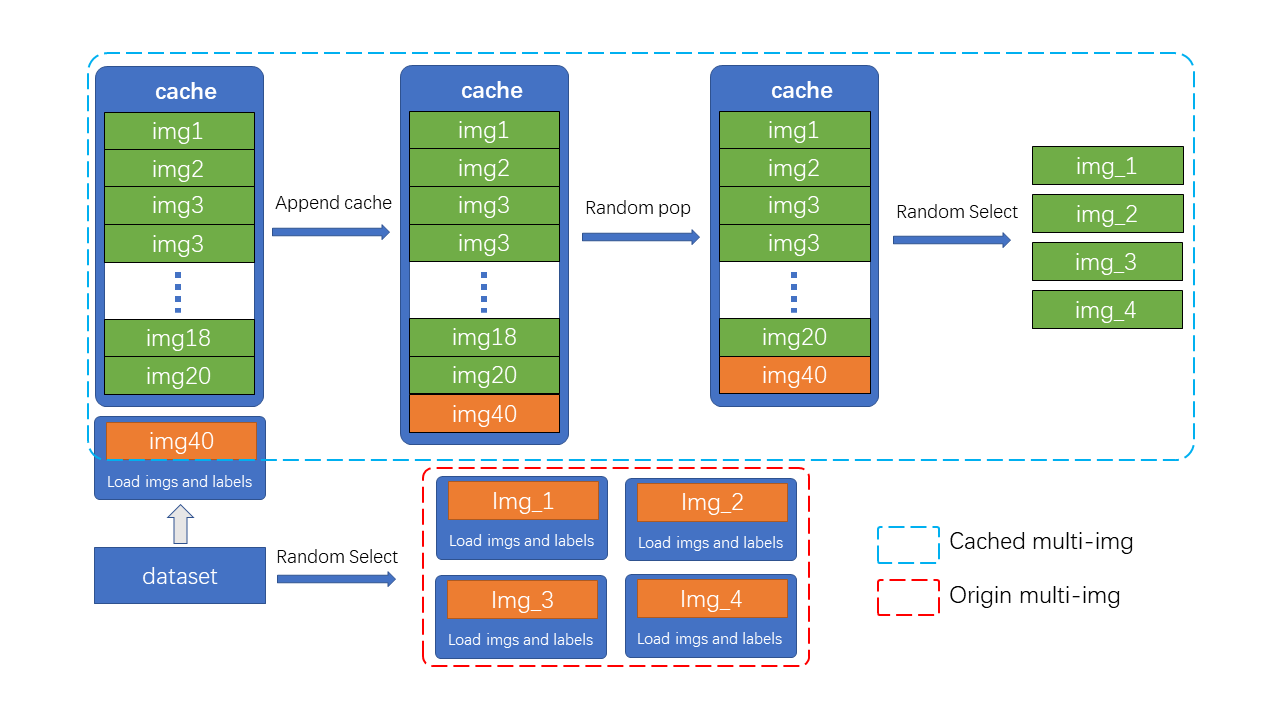
|
||||
如图所示,cache 队列中预先储存了N张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图(为了 tiny 模型训练更稳定,在 tiny 模型中不采用随机 pop 的方式, 而是移除最先加入的图片。),当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
|
||||
如图所示,cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图(为了 Tiny 模型训练更稳定,在 Tiny 模型中不采用随机 pop 的方式, 而是移除最先加入的图片),当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
|
||||
|
||||
> cache 队列的最大长度 N 为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而 Mosaic 增强是四张图混合,因此 cache 数量默认 N=40, 同理 MixUp 的 cache 数量默认为20, tiny 模型需要更稳定的训练条件,因此其 cache 数量也为其余规格模型的一半( MixUp 为10,Mosaic 为20)
|
||||
```{note}
|
||||
cache 队列的最大长度 N 为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而 Mosaic 增强是四张图混合,因此 cache 数量默认 N=40, 同理 MixUp 的 cache 数量默认为20, tiny 模型需要更稳定的训练条件,因此其 cache 数量也为其余规格模型的一半( MixUp 为10,Mosaic 为20)
|
||||
```
|
||||
|
||||
在具体实现中,MMYOLO 设计了`BaseMiximageTransform`类来支持多张图像混合数据增强:
|
||||
在具体实现中,MMYOLO 设计了 `BaseMiximageTransform` 类来支持多张图像混合数据增强:
|
||||
|
||||
```python
|
||||
if self.use_cached:
|
||||
|
|
@ -84,7 +91,7 @@ else:
|
|||
dataset = results.pop('dataset', None)
|
||||
```
|
||||
|
||||
### Mosaic
|
||||
#### 1.1.2 Mosaic
|
||||
|
||||
Mosaic 是将 4 张图拼接为 1 张大图,相当于变相的增加了 batch size,具体步骤为:
|
||||
|
||||
|
|
@ -115,7 +122,7 @@ center_y = int(
|
|||
center_position = (center_x, center_y)
|
||||
```
|
||||
|
||||
3. 根据采样的 index 读取图片并拼接, 拼接前会先进行 keep-ratio 的 resize 图片(即为最大边一定是 640)。
|
||||
3. 根据采样的 index 读取图片并拼接, 拼接前会先进行 `keep-ratio` 的 resize 图片(即为最大边一定是 640)。
|
||||
|
||||
```python
|
||||
# keep_ratio resize
|
||||
|
|
@ -133,35 +140,38 @@ mosaic_bboxes.clip_([2 * self.img_scale[0], 2 * self.img_scale[1]])
|
|||
|
||||
更多的关于 Mosaic 原理的详情可以参考 [YOLOv5 原理和实现全解析](./yolov5_description.md) 中的 Mosaic 原理分析。
|
||||
|
||||
### MixUp
|
||||
#### 1.1.3 MixUp
|
||||
|
||||
RTMDet 的 MixUp 实现方式与 YOLOX 中一样,只不过增加了类似上文中提到的 [cache](#31-为图像混合数据增强引入cache) 功能。
|
||||
RTMDet 的 MixUp 实现方式与 YOLOX 中一样,只不过增加了类似上文中提到的 cache 功能。
|
||||
|
||||
更多的关于 MixUp 原理的详情也可以参考 [YOLOv5 原理和实现全解析](./yolov5_description.md) 中的 MixUp 原理分析。
|
||||
|
||||
### 强弱两阶段训练
|
||||
#### 1.1.4 强弱两阶段训练
|
||||
|
||||
Mosaic+MixUp 失真度比较高,持续用太强的数据增强对模型并不一定有益。YOLOX 中率先使用了强弱两阶段的训川练方式,但由于引入了旋转,切片导致box标注产生误差,需要在第二阶段引入额外的L1oss来纠正回归分支的性能。
|
||||
Mosaic+MixUp 失真度比较高,持续用太强的数据增强对模型并不一定有益。YOLOX 中率先使用了强弱两阶段的训川练方式,但由于引入了旋转,切片导致 box 标注产生误差,需要在第二阶段引入额外的 L1oss 来纠正回归分支的性能。
|
||||
|
||||
为了使数据增强的方式更为通用,RTMDet 在前 280 epoch 使用不带旋转的 Mosaic+MixUp, 且通过混入8张图片来提升强度以及正样本数。后 20 epoch 使用比较小的学习率在比较弱的 Random Crop 下进行微调,同时在EMA的作用下将参数缓慢更新至模型,能够得到比较大的提升。
|
||||
为了使数据增强的方式更为通用,RTMDet 在前 280 epoch 使用不带旋转的 Mosaic+MixUp, 且通过混入 8 张图片来提升强度以及正样本数。后 20 epoch 使用比较小的学习率在比较弱的增强下进行微调,同时在 EMA 的作用下将参数缓慢更新至模型,能够得到比较大的提升。
|
||||
|
||||
## 模型结构
|
||||
### 1.2 模型结构
|
||||
|
||||
RTMDet 模型整体结构和 [YOLOX](https://arxiv.org/abs/2107.08430) 几乎一致,由 `CSPNeXt` + `CSPNeXtPAFPN` + `共享卷积权重但分别计算 BN 的 SepBNHead` 构成。内部核心模块也是 `CSPLayer`,但对其中的 `Basic Block` 进行了改进,提出了 `CSPNeXt Block`。
|
||||
|
||||
### Backbone
|
||||
#### 1.2.1 Backbone
|
||||
|
||||
`CSPNeXt` 整体以 `CSPDarknet` 为基础,共 5 层结构,包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`:
|
||||
|
||||
- `Stem Layer` 是 3 层 3x3 kernel 的 `ConvModule` ,不同于之前的 `Focus` 模块或者 1 层 6x6 kernel 的 `ConvModule` 。
|
||||
|
||||
- `Stage Layer` 总体结构与已有模型类似,前 3 个 `Stage Layer` 由 1 个 `ConvModule` 和 1 个 `CSPLayer` 组成。第 4 个 `Stage Layer` 在 `ConvModule` 和 `CSPLayer` 中间增加了 `SPPF` 模块(MMDetection 版本为 `SPP` 模块)。
|
||||
|
||||
- 如模型图 Details 部分所示,`CSPLayer` 由 3 个 `ConvModule` + n 个 `CSPNeXt Block`(带残差连接) + 1 个 `Channel Attention` 模块组成。`ConvModule` 为 1 层 3x3 `Conv2d` + `BatchNorm` + `SiLU` 激活函数。`Channel Attention` 模块为 1 层 `AdaptiveAvgPool2d` + 1 层 1x1 `Conv2d` + `Hardsigmoid` 激活函数。`CSPNeXt Block` 模块在下节详细讲述。
|
||||
- 如果想阅读 Backbone - `CSPNeXt` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L16-L171)跳转。
|
||||
|
||||
#### CSPNeXt Block
|
||||
- 如果想阅读 Backbone - `CSPNeXt` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L16-L171) 跳转。
|
||||
|
||||
Darknet (图 a)使用 1x1 与 3x3 卷积的 `Basic Block`。[YOLOv6](https://arxiv.org/abs/2209.02976)、[YOLOv7](https://arxiv.org/abs/2207.02696)、[PPYOLO-E](https://arxiv.org/abs/2203.16250)(图 b & c)使用了重参数化 Block。但重参数化的训练代价高,且不易量化,需要其他方式来弥补量化误差。
|
||||
RTMDet 则借鉴了最近比较热门的 [ConvNeXt](https://arxiv.org/abs/2201.03545)、[RepLKNet](https://arxiv.org/abs/2203.06717) 的做法,为 `Basic Block` 加入了大 kernel 的 `depth-wise` 卷积(图 d),并将其命名为 `CSPNeXt Block`。
|
||||
#### 1.2.2 CSPNeXt Block
|
||||
|
||||
Darknet (图 a)使用 1x1 与 3x3 卷积的 `Basic Block`。[YOLOv6](https://arxiv.org/abs/2209.02976) 、[YOLOv7](https://arxiv.org/abs/2207.02696) 、[PPYOLO-E](https://arxiv.org/abs/2203.16250) (图 b & c)使用了重参数化 Block。但重参数化的训练代价高,且不易量化,需要其他方式来弥补量化误差。
|
||||
RTMDet 则借鉴了最近比较热门的 [ConvNeXt](https://arxiv.org/abs/2201.03545) 、[RepLKNet](https://arxiv.org/abs/2203.06717) 的做法,为 `Basic Block` 加入了大 kernel 的 `depth-wise` 卷积(图 d),并将其命名为 `CSPNeXt Block`。
|
||||
|
||||
<div align=center >
|
||||
<img alt="BasicBlock" src="https://user-images.githubusercontent.com/27466624/192752976-4c20f944-1ef0-4746-892e-ba814cdcda20.png"/>
|
||||
|
|
@ -175,9 +185,9 @@ RTMDet 则借鉴了最近比较热门的 [ConvNeXt](https://arxiv.org/abs/2201.0
|
|||
| **5x5** | **50.92M** | **79.7G** | **2.11** | **50.9** |
|
||||
| 7x7 | 51.1 | 80.34G | 2.73 | 51.1 |
|
||||
|
||||
如果想阅读 `Basic Block` - `CSPNeXt Block` 源码,可以[**点此**](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/layers/csp_layer.py#L79-L146)跳转。
|
||||
如果想阅读 `Basic Block` 和 `CSPNeXt Block` 源码,可以[**点此**](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/layers/csp_layer.py#L79-L146)跳转。
|
||||
|
||||
#### 调整检测器不同 stage 间的 block 数
|
||||
#### 1.2.3 调整检测器不同 stage 间的 block 数
|
||||
|
||||
由于 `CSPNeXt Block` 内使用了 `depth-wise` 卷积,单个 block 内的层数增多。如果保持原有的 stage 内的 block 数,则会导致模型的推理速度大幅降低。
|
||||
|
||||
|
|
@ -191,14 +201,15 @@ RTMDet 重新调整了不同 stage 间的 block 数,并调整了通道的超
|
|||
| L+3-6-6-3 | 50.92M | 79.7G | 2.11 | 50.9 |
|
||||
| **L+3-6-6-3 + channel attention** | **52.3M** | **79.9G** | **2.4** | **51.3** |
|
||||
|
||||
最后不同大小模型的 block 数设置,可以参见[源码](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L50-L56)。
|
||||
最后不同大小模型的 block 数设置,可以参见[源码](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L50-L56) 。
|
||||
|
||||
### Neck
|
||||
#### 1.2.4 Neck
|
||||
|
||||
#### Backbone 与 Neck 之间的参数量和计算量的均衡
|
||||
Neck 模型结构和 YOLOX 几乎一样,只不过内部的 block 进行了替换。
|
||||
|
||||
[EfficientDet](https://arxiv.org/abs/1911.09070)、[NASFPN](https://arxiv.org/abs/1904.07392) 等工作在改进 Neck 时往往聚焦于如何修改特征融合的方式。
|
||||
但引入过多的连接会增加检测器的延时,并增加内存开销。
|
||||
#### 1.2.5 Backbone 与 Neck 之间的参数量和计算量的均衡
|
||||
|
||||
[EfficientDet](https://arxiv.org/abs/1911.09070) 、[NASFPN](https://arxiv.org/abs/1904.07392) 等工作在改进 Neck 时往往聚焦于如何修改特征融合的方式。 但引入过多的连接会增加检测器的延时,并增加内存开销。
|
||||
|
||||
所以 RTMDet 选择不引入额外的连接,而是改变 Backbone 与 Neck 间参数量的配比。该配比是通过手动调整 Backbone 和 Neck 的 `expand_ratio` 参数来实现的,其数值在 Backbone 和 Neck 中都为 0.5。`expand_ratio` 实际上是改变 `CSPLayer` 中各层通道数的参数(具体可见模型图 `CSPLayer` 部分)。如果想进行不同配比的实验,可以通过调整配置文件中的 [backbone {expand_ratio}](https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py#L32) 和 [neck {expand_ratio}](https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py#L45) 参数完成。
|
||||
|
||||
|
|
@ -213,9 +224,9 @@ RTMDet 重新调整了不同 stage 间的 block 数,并调整了通道的超
|
|||
| **L** | **47%** | **45%** | **50.92M** | **79.7G** | **2.11** | **50.9** |
|
||||
| L | 63% | 29% | 57.43M | 93.73 | 2.57 | 51.0 |
|
||||
|
||||
如果想阅读 Neck - `CSPNeXtPAFPN` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/necks/cspnext_pafpn.py#L15-L201)跳转。
|
||||
如果想阅读 Neck - `CSPNeXtPAFPN` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/necks/cspnext_pafpn.py#L15-L201) 跳转。
|
||||
|
||||
### Head
|
||||
#### 1.2.6 Head
|
||||
|
||||
传统的 YOLO 系列都使用同一 Head 进行分类和回归。YOLOX 则将分类和回归分支解耦,PPYOLO-E 和 YOLOv6 则引入了 [TOOD](https://arxiv.org/abs/2108.07755) 中的结构。它们在不同特征层级之间都使用独立的 Head,因此 Head 在模型中也占有较多的参数量。
|
||||
|
||||
|
|
@ -229,9 +240,9 @@ RTMDet 参考了 [NAS-FPN](https://arxiv.org/abs/1904.07392) 中的做法,使
|
|||
| Separated head | 57.03 | 80.23 | 2.44 | 51.2 |
|
||||
| **SepBN** **head** | **52.32** | **80.23** | **2.44** | **51.3** |
|
||||
|
||||
同时,RTMDet 也延续了作者之前在 [NanoDet](https://zhuanlan.zhihu.com/p/306530300) 中的思想,使用 [Quality Focal Loss](https://arxiv.org/abs/2011.12885),并去掉 Objectness 分支,进一步将 Head 轻量化。
|
||||
同时,RTMDet 也延续了作者之前在 [NanoDet](https://zhuanlan.zhihu.com/p/306530300) 中的思想,使用 [Quality Focal Loss](https://arxiv.org/abs/2011.12885) ,并去掉 Objectness 分支,进一步将 Head 轻量化。
|
||||
|
||||
如果想阅读 Head - `RTMDetSepBNHeadModule` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/dense_heads/rtmdet_head.py#L24-L189)跳转。
|
||||
如果想阅读 Head 中 `RTMDetSepBNHeadModule` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/dense_heads/rtmdet_head.py#L24-L189) 跳转。
|
||||
|
||||
```{note}
|
||||
注:MMYOLO 和 MMDetection 中 Neck 和 Head 的具体实现稍有不同。
|
||||
|
|
@ -257,7 +268,59 @@ RTMDet 参考了 [NAS-FPN](https://arxiv.org/abs/1904.07392) 中的做法,使
|
|||
|
||||
`RTMDet` 作者也是采用了动态的 `SimOTA` 做法,不过其对动态的正负样本分配策略进行了改进。 之前的动态匹配策略( `HungarianAssigner` 、`OTA` )往往使用与 `Loss` 完全一致的代价函数作为匹配的依据,但我们经过实验发现这并不一定时最优的。 使用更多 `Soften` 的 `Cost` 以及先验,能够提升性能。
|
||||
|
||||
综上, `RTMDet` 提出了 `Dynamic Soft Label Assigner` 来实现标签的动态匹配策略, 该方法主要包括使用 **位置先验信息损失** , **样本回归损失** , **样本分类损失** , 同时对三个损失进行了 `Soft` 处理进行参数调优, 以达到最佳的动态匹配效果。
|
||||
#### 1.3.1 Bbox 编解码过程
|
||||
|
||||
RTMDet 的 BBox Coder 采用的是 `mmdet.DistancePointBBoxCoder`。
|
||||
|
||||
该类的 docstring 为 `This coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left, right) and decode it back to the original.`
|
||||
|
||||
编码器将 gt bboxes (x1, y1, x2, y2) 编码为 (top, bottom, left, right),并且解码至原图像上。
|
||||
|
||||
MMDet 编码的核心源码:
|
||||
|
||||
```python
|
||||
def bbox2distance(points: Tensor, bbox: Tensor, ...) -> Tensor:
|
||||
"""
|
||||
points (Tensor): 相当于 scale 值 stride ,且每个预测点仅为一个正方形 anchor 的 anchor point [x, y],Shape (n, 2) or (b, n, 2).
|
||||
bbox (Tensor): Bbox 为乘上 stride 的网络预测值,格式为 xyxy,Shape (n, 4) or (b, n, 4).
|
||||
"""
|
||||
# 计算点距离四边的距离
|
||||
left = points[..., 0] - bbox[..., 0]
|
||||
top = points[..., 1] - bbox[..., 1]
|
||||
right = bbox[..., 2] - points[..., 0]
|
||||
bottom = bbox[..., 3] - points[..., 1]
|
||||
|
||||
...
|
||||
|
||||
return torch.stack([left, top, right, bottom], -1)
|
||||
```
|
||||
|
||||
MMDetection 解码的核心源码:
|
||||
|
||||
```python
|
||||
def distance2bbox(points: Tensor, distance: Tensor, ...) -> Tensor:
|
||||
"""
|
||||
通过距离反算 bbox 的 xyxy
|
||||
points (Tensor): 正方形的预测 anchor 的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
|
||||
distance (Tensor): 距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
|
||||
"""
|
||||
|
||||
# 反算 bbox xyxy
|
||||
x1 = points[..., 0] - distance[..., 0]
|
||||
y1 = points[..., 1] - distance[..., 1]
|
||||
x2 = points[..., 0] + distance[..., 2]
|
||||
y2 = points[..., 1] + distance[..., 3]
|
||||
|
||||
bboxes = torch.stack([x1, y1, x2, y2], -1)
|
||||
|
||||
...
|
||||
|
||||
return bboxes
|
||||
```
|
||||
|
||||
#### 1.3.2 匹配策略
|
||||
|
||||
`RTMDet` 提出了 `Dynamic Soft Label Assigner` 来实现标签的动态匹配策略, 该方法主要包括使用 **位置先验信息损失** , **样本回归损失** , **样本分类损失** , 同时对三个损失进行了 `Soft` 处理进行参数调优, 以达到最佳的动态匹配效果。
|
||||
|
||||
该方法 Matching Cost 矩阵由如下损失构成:
|
||||
|
||||
|
|
@ -355,59 +418,7 @@ soft_cls_cost = soft_cls_cost.sum(dim=-1)
|
|||
| RTMDet-s + SimOTA | 43.2 |
|
||||
| RTMDet-s + DSLA | 44.5 |
|
||||
|
||||
## BBox Coder
|
||||
|
||||
RTMDet 的 BBox Coder 采用的是 `mmdet.DistancePointBBoxCoder`。
|
||||
|
||||
该类的 docstring 是这样的:
|
||||
|
||||
> This coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left, right) and decode it back to the original.
|
||||
>
|
||||
> 这个编码器将 gt bboxes (x1, y1, x2, y2) 编码为 (top, bottom, left, right),并且解码至原图像上
|
||||
|
||||
MMDet 编码的核心源码:
|
||||
|
||||
```python
|
||||
def bbox2distance(points: Tensor, bbox: Tensor, ...) -> Tensor:
|
||||
"""
|
||||
points (Tensor): 相当于 scale 值 stride ,且每个预测点仅为一个正方形 anchor 的 anchor point [x, y],Shape (n, 2) or (b, n, 2).
|
||||
bbox (Tensor): Bbox 为乘上 stride 的网络预测值,格式为 xyxy,Shape (n, 4) or (b, n, 4).
|
||||
"""
|
||||
# 计算点距离四边的距离
|
||||
left = points[..., 0] - bbox[..., 0]
|
||||
top = points[..., 1] - bbox[..., 1]
|
||||
right = bbox[..., 2] - points[..., 0]
|
||||
bottom = bbox[..., 3] - points[..., 1]
|
||||
|
||||
...
|
||||
|
||||
return torch.stack([left, top, right, bottom], -1)
|
||||
```
|
||||
|
||||
MMDet 解码的核心源码:
|
||||
|
||||
```python
|
||||
def distance2bbox(points: Tensor, distance: Tensor, ...) -> Tensor:
|
||||
"""
|
||||
通过距离反算 bbox 的 xyxy
|
||||
points (Tensor): 正方形的预测 anchor 的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
|
||||
distance (Tensor): 距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
|
||||
"""
|
||||
|
||||
# 反算 bbox xyxy
|
||||
x1 = points[..., 0] - distance[..., 0]
|
||||
y1 = points[..., 1] - distance[..., 1]
|
||||
x2 = points[..., 0] + distance[..., 2]
|
||||
y2 = points[..., 1] + distance[..., 3]
|
||||
|
||||
bboxes = torch.stack([x1, y1, x2, y2], -1)
|
||||
|
||||
...
|
||||
|
||||
return bboxes
|
||||
```
|
||||
|
||||
## Loss
|
||||
### 1.4 Loss 设计
|
||||
|
||||
参与 Loss 计算的共有两个值:`loss_cls` 和 `loss_bbox`,其各自使用的 Loss 方法如下:
|
||||
|
||||
|
|
@ -416,7 +427,7 @@ def distance2bbox(points: Tensor, distance: Tensor, ...) -> Tensor:
|
|||
|
||||
权重比例是:`loss_cls` : `loss_bbox` = `1 : 2`
|
||||
|
||||
### QualityFocalLoss
|
||||
#### QualityFocalLoss
|
||||
|
||||
Quality Focal Loss (QFL) 是 [Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection](https://arxiv.org/abs/2006.04388) 的一部分。
|
||||
|
||||
|
|
@ -438,18 +449,18 @@ p, & \bold{when} \ y = 1 \\
|
|||
|
||||
首先 $y = 0$ 表示质量得分为 0 的负样本,$0 \< y \\leq1$ 表示目标 IoU 得分为 y 的正样本。为了针对连续的标签,扩展 FL 的两个部分:
|
||||
|
||||
1. 交叉熵部分 $-\\log(p_t)$ 扩展为完整版本 $-((1-y)\\log(1-\\sigma)+y\\log(\\sigma))$;
|
||||
1. 交叉熵部分 $-\\log(p_t)$ 扩展为完整版本 `{math} $-((1-y)\\log(1-\\sigma)+y\\log(\\sigma))$ `
|
||||
2. 比例因子部分 $-(1-p_t)^\\gamma$ 被泛化为估计 $\\gamma$ 与其连续标签 $y$ 的绝对距离,即 $|y-\\sigma|^\\beta (\\beta \\geq 0)$。
|
||||
|
||||
结合上面两个部分之后,我们得出 QFL 的公式:
|
||||
|
||||
```{math}
|
||||
\bold{QFL}(\sigma) = -|y-\sigma|^\beta((1-y)\log(1-\sigma)+y\log(\sigma))
|
||||
{QFL}(\sigma) = -|y-\sigma|^\beta((1-y)\log(1-\sigma)+y\log(\sigma))
|
||||
```
|
||||
|
||||
具体作用是:可以将离散标签的 `focal loss` 泛化到连续标签上,将 bboxes 与 gt 的 IoU 的作为分类分数的标签,使得分类分数为表征回归质量的分数。
|
||||
|
||||
MMDet 实现源码的核心部分:
|
||||
MMDetection 实现源码的核心部分:
|
||||
|
||||
```python
|
||||
@weighted_loss
|
||||
|
|
@ -493,7 +504,7 @@ def quality_focal_loss(pred, target, beta=2.0):
|
|||
return loss
|
||||
```
|
||||
|
||||
### GIoULoss
|
||||
#### GIoULoss
|
||||
|
||||
论文:[Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression](https://arxiv.org/abs/1902.09630)
|
||||
|
||||
|
|
@ -505,7 +516,7 @@ GIoU Loss 用于计算两个框重叠区域的关系,重叠区域越大,损
|
|||
<img src="https://user-images.githubusercontent.com/25873202/192568784-3884b677-d8e1-439c-8bd2-20943fcedd93.png" alt="image"/>
|
||||
</div>
|
||||
|
||||
MMDet 实现源码的核心部分:
|
||||
MMDetection 实现源码的核心部分:
|
||||
|
||||
```python
|
||||
def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):
|
||||
|
|
@ -560,12 +571,14 @@ def giou_loss(pred, target, eps=1e-7):
|
|||
return loss
|
||||
```
|
||||
|
||||
### 训练策略
|
||||
### 1.5 优化策略和训练过程
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/89863442/192943607-74952731-4eb7-45f5-b86d-2dad46732614.png" width="800"/>
|
||||
</div>
|
||||
|
||||
### 推理和后处理过程
|
||||
### 1.6 推理和后处理过程
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/89863442/192943600-98c3a8f9-e42c-47ea-8e12-d20f686e9318.png" width="800"/>
|
||||
</div>
|
||||
|
|
@ -576,23 +589,25 @@ def giou_loss(pred, target, eps=1e-7):
|
|||
|
||||
**(2) 初始化网格**
|
||||
|
||||
根据特征图尺寸初始化三个网格,大小分别为 6400 (80 x 80)、1600 (40 x 40)、400 (20 x 20),如第一个层,shape 为 torch.Size([ 6400, 2 ]),最后一个维度是 2,为网格点的横纵坐标,而 6400 表示当前特征层的网格点数量。
|
||||
根据特征图尺寸初始化三个网格,大小分别为 6400 (80 x 80)、1600 (40 x 40)、400 (20 x 20),如第一个层 shape 为 torch.Size(\[ 6400, 2 \]),最后一个维度是 2,为网格点的横纵坐标,而 6400 表示当前特征层的网格点数量。
|
||||
|
||||
**(3) 维度变换**
|
||||
|
||||
经过 `_predict_by_feat_single` 函数,将从 head 提取的单一图像的特征转换为 bbox 结果输入,得到三个列表 `cls_score_list`,`bbox_pred_list`,`mlvl_priors`,详细大小如图所示。之后分别遍历三个特征层,分别对 class 类别预测分支、bbox 回归分支进行处理。以第一层为例,对 bbox 预测分支 [ 4,80,80 ] 维度变换为 [ 6400,4 ],对类别预测分支 [ 80,80,80 ] 变化为 [ 6400,80 ],并对其做归一化,确保类别置信度在 0 - 1 之间。
|
||||
经过 `_predict_by_feat_single` 函数,将从 head 提取的单一图像的特征转换为 bbox 结果输入,得到三个列表 `cls_score_list`,`bbox_pred_list`,`mlvl_priors`,详细大小如图所示。之后分别遍历三个特征层,分别对 class 类别预测分支、bbox 回归分支进行处理。以第一层为例,对 bbox 预测分支 \[ 4,80,80 \] 维度变换为 \[ 6400,4 \],对类别预测分支 \[ 80,80,80 \] 变化为 \[ 6400,80 \],并对其做归一化,确保类别置信度在 0 - 1 之间。
|
||||
|
||||
**(4) 阈值过滤**
|
||||
|
||||
先使用一个 `nms_pre` 操作,先过滤大部分置信度比较低的预测结果(比如 `score_thr` 阈值设置为 0.05,则去除当前预测置信度低于 0.05 的结果),然后得到 bbox 坐标、所在网格的坐标、置信度、标签的信息。经过三个特征层遍历之后,分别整合这三个层得到的的四个信息放入 results 列表中。
|
||||
|
||||
|
||||
**(5) 还原到原图尺度**
|
||||
|
||||
最后将网络的预测结果映射到整图当中,得到 bbox 在整图中的坐标值
|
||||
|
||||
|
||||
**(6) NMS**
|
||||
|
||||
进行 nms 操作,最终预测得到的返回值为经过后处理的每张图片的检测结果,包含分类置信度,框的 labels,框的四个坐标
|
||||
|
||||
## 2 总结
|
||||
|
||||
本文对 RTMDet 原理和在 MMYOLO 实现进行了详细解析,希望能帮助用户理解算法实现过程。同时请注意:由于 RTMDet 本身也在不断更新,
|
||||
本开源库也会不断迭代,请及时阅读和同步最新版本。
|
||||
|
|
|
|||
|
|
@ -119,7 +119,7 @@ MixUp 和 Mosaic 类似,也是属于混合图片类增强,其是随机从另
|
|||
需要特别注意的是:
|
||||
**YOLOv5 实现的 MixUp 中,随机出来的另一张图也需要经过 Mosaic 马赛克 + RandomAffine 随机仿射变换 增强后才能混合。这个和其他开源库实现可能不太一样**。
|
||||
|
||||
### 1.1.4 图像模糊和其他数据增强
|
||||
#### 1.1.4 图像模糊和其他数据增强
|
||||
|
||||
<div align=center >
|
||||
<img alt="image" src="https://user-images.githubusercontent.com/40284075/190543533-8b9ece51-676b-4a7d-a7d0-597e2dd1d42e.png"/>
|
||||
|
|
@ -483,7 +483,7 @@ GT_y^{center_grid}=37/8=4.625
|
|||
<img alt="image" src="https://user-images.githubusercontent.com/40284075/190549696-3da08c06-753a-4108-be47-64495ea480f2.png"/>
|
||||
</div>
|
||||
|
||||
### 1.4 Loss设计
|
||||
### 1.4 Loss 设计
|
||||
|
||||
YOLOv5 中总共包含 3 个 Loss,分别为:
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue