diff --git a/docs/zh_cn/algorithm_descriptions/rtmdet_description.md b/docs/zh_cn/algorithm_descriptions/rtmdet_description.md
index 094a2d6b..c55f16a4 100644
--- a/docs/zh_cn/algorithm_descriptions/rtmdet_description.md
+++ b/docs/zh_cn/algorithm_descriptions/rtmdet_description.md
@@ -559,3 +559,40 @@ def giou_loss(pred, target, eps=1e-7):
loss = 1 - gious
return loss
```
+
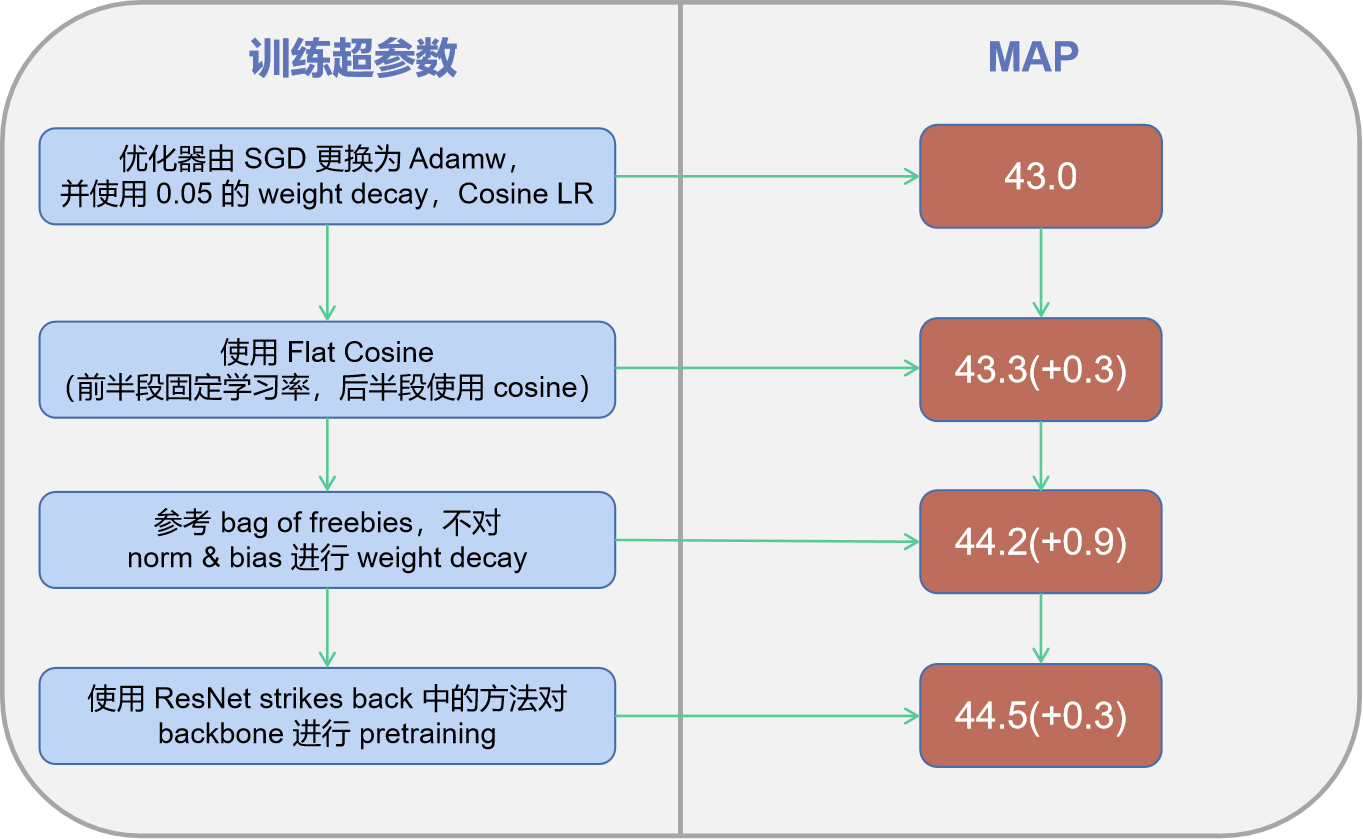
+### 训练策略
+
+
+
+

+