 -
-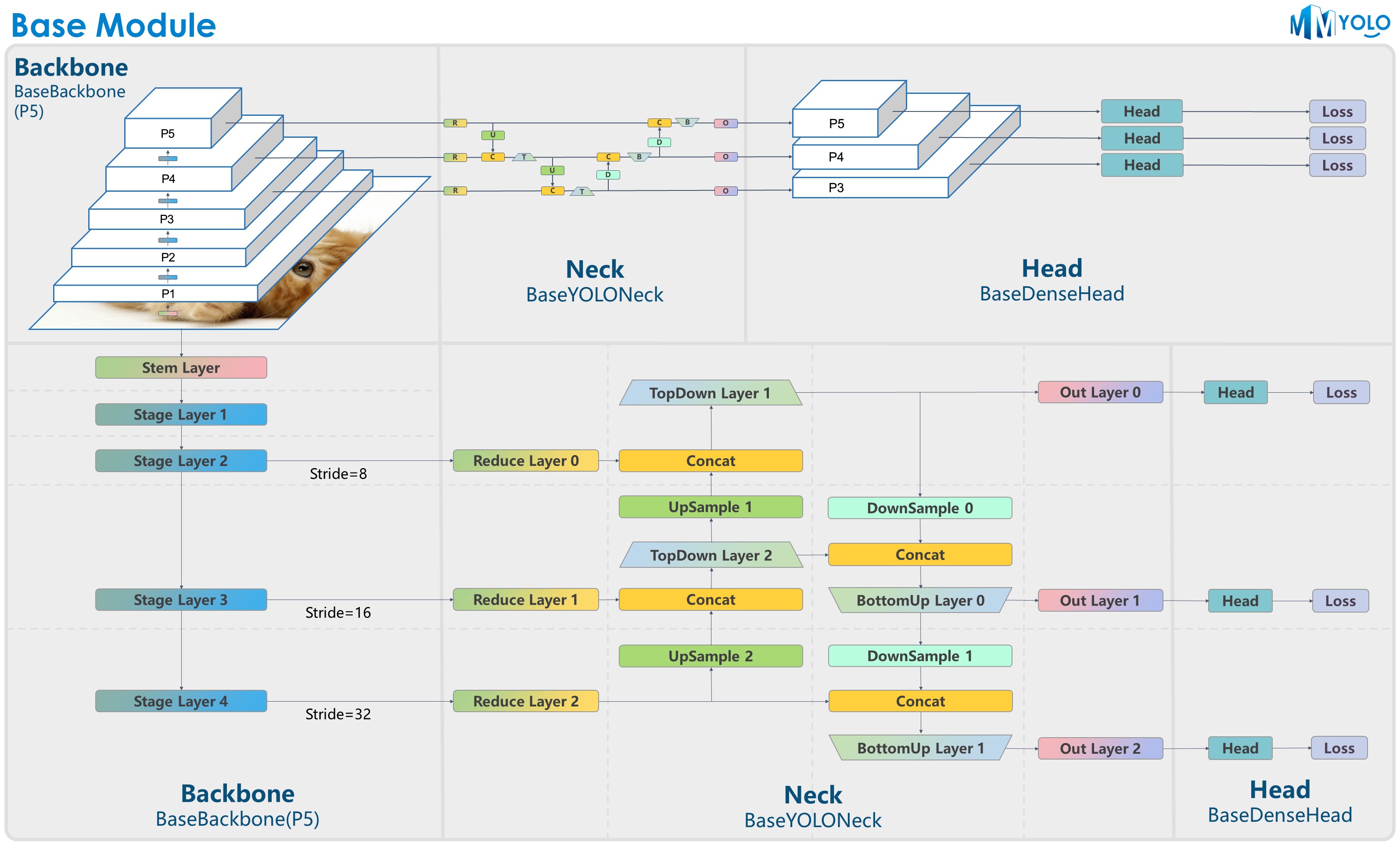 The figure above is contributed by RangeKing@GitHub, thank you very much!
-And the figure of P6 model is in [model_design.md](docs/en/algorithm_descriptions/model_design.md).
+And the figure of P6 model is in [model_design.md](docs/en/recommended_topics/model_design.md).
## 🛠️ Installation [🔝](#-table-of-contents)
-MMYOLO relies on PyTorch, MMCV, MMEngine, and MMDetection. Below are quick steps for installation. Please refer to the [Install Guide](docs/en/get_started.md) for more detailed instructions.
+MMYOLO relies on PyTorch, MMCV, MMEngine, and MMDetection. Below are quick steps for installation. Please refer to the [Install Guide](docs/en/get_started/installation.md) for more detailed instructions.
```shell
conda create -n open-mmlab python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
@@ -160,38 +160,96 @@ The usage of MMYOLO is almost identical to MMDetection and all tutorials are str
For different parts from MMDetection, we have also prepared user guides and advanced guides, please read our [documentation](https://mmyolo.readthedocs.io/zenh_CN/latest/).
-- User Guides
+
图为 RangeKing@GitHub 提供,非常感谢!
-P6 模型图详见 [model_design.md](docs/zh_cn/featured_topics/model_design.md)。
+P6 模型图详见 [model_design.md](docs/zh_cn/recommended_topics/model_design.md)。
@@ -197,16 +197,17 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
The figure above is contributed by RangeKing@GitHub, thank you very much!
-And the figure of P6 model is in [model_design.md](docs/en/algorithm_descriptions/model_design.md).
+And the figure of P6 model is in [model_design.md](docs/en/recommended_topics/model_design.md).
## 🛠️ Installation [🔝](#-table-of-contents)
-MMYOLO relies on PyTorch, MMCV, MMEngine, and MMDetection. Below are quick steps for installation. Please refer to the [Install Guide](docs/en/get_started.md) for more detailed instructions.
+MMYOLO relies on PyTorch, MMCV, MMEngine, and MMDetection. Below are quick steps for installation. Please refer to the [Install Guide](docs/en/get_started/installation.md) for more detailed instructions.
```shell
conda create -n open-mmlab python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
@@ -160,38 +160,96 @@ The usage of MMYOLO is almost identical to MMDetection and all tutorials are str
For different parts from MMDetection, we have also prepared user guides and advanced guides, please read our [documentation](https://mmyolo.readthedocs.io/zenh_CN/latest/).
-- User Guides
+
图为 RangeKing@GitHub 提供,非常感谢!
-P6 模型图详见 [model_design.md](docs/zh_cn/featured_topics/model_design.md)。
+P6 模型图详见 [model_design.md](docs/zh_cn/recommended_topics/model_design.md)。
@@ -197,16 +197,17 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
 -
-- Plot the classification and regression loss of some run, and save the figure to a pdf.
-
- ```shell
- mim run mmdet analyze_logs plot_curve \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
- --keys loss_cls loss_bbox \
- --legend loss_cls loss_bbox \
- --out losses_yolov5_s.pdf
- ```
-
-
-
-- Plot the classification and regression loss of some run, and save the figure to a pdf.
-
- ```shell
- mim run mmdet analyze_logs plot_curve \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
- --keys loss_cls loss_bbox \
- --legend loss_cls loss_bbox \
- --out losses_yolov5_s.pdf
- ```
-
-  -
-- Compare the bbox mAP of two runs in the same figure.
-
- ```shell
- mim run mmdet analyze_logs plot_curve \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
- yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
- --keys bbox_mAP \
- --legend yolov5_s yolov5_n \
- --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
- ```
-
-
-
-- Compare the bbox mAP of two runs in the same figure.
-
- ```shell
- mim run mmdet analyze_logs plot_curve \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
- yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
- --keys bbox_mAP \
- --legend yolov5_s yolov5_n \
- --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
- ```
-
- -
-#### Compute the average training speed
-
-```shell
-mim run mmdet analyze_logs cal_train_time \
- ${LOG} \ # path of train log in json format
- [--include-outliers] # include the first value of every epoch when computing the average time
-```
-
-Examples:
-
-```shell
-mim run mmdet analyze_logs cal_train_time \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
-```
-
-The output is expected to be like the following.
-
-```text
------Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
-slowest epoch 278, average time is 0.1705 s/iter
-fastest epoch 300, average time is 0.1510 s/iter
-time std over epochs is 0.0026
-average iter time: 0.1556 s/iter
-```
-
-### Print the whole config
-
-`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
-
-```shell
-mim run mmdet print_config \
- ${CONFIG} \ # path of the config file
- [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
- [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
-```
-
-Examples:
-
-```shell
-mim run mmdet print_config \
- configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
- --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
-```
-
-Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
-
-## Set the random seed
-
-If you want to set the random seed during training, you can use the following command.
-
-```shell
-python ./tools/train.py \
- ${CONFIG} \ # path of the config file
- --cfg-options randomness.seed=2023 \ # set seed to 2023
- [randomness.diff_rank_seed=True] \ # set different seeds according to global rank
- [randomness.deterministic=True] # set the deterministic option for CUDNN backend
-# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
-```
-
-`randomness` has three parameters that can be set, with the following meanings.
-
-- `randomness.seed=2023`, set the random seed to 2023.
-- `randomness.diff_rank_seed=True`, set different seeds according to global rank. Defaults to False.
-- `randomness.deterministic=True`, set the deterministic option for cuDNN backend, i.e., set `torch.backends.cudnn.deterministic` to True and `torch.backends.cudnn.benchmark` to False. Defaults to False. See https://pytorch.org/docs/stable/notes/randomness.html for more details.
-
-## Specify specific GPUs during training or inference
-
-If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
-
-```shell
-CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
-CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
-```
-
-If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
-
-If you want to use several of these GPUs to train in parallel, you can use the following command:
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
-```
-
-Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
-CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
-```
diff --git a/docs/en/advanced_guides/index.rst b/docs/en/advanced_guides/index.rst
deleted file mode 100644
index bd72cd2e..00000000
--- a/docs/en/advanced_guides/index.rst
+++ /dev/null
@@ -1,25 +0,0 @@
-Data flow
-************************
-
-.. toctree::
- :maxdepth: 1
-
- data_flow.md
-
-
-How to
-************************
-
-.. toctree::
- :maxdepth: 1
-
- how_to.md
-
-
-Plugins
-************************
-
-.. toctree::
- :maxdepth: 1
-
- plugins.md
diff --git a/docs/en/common_usage/amp_training.md b/docs/en/common_usage/amp_training.md
new file mode 100644
index 00000000..3767114a
--- /dev/null
+++ b/docs/en/common_usage/amp_training.md
@@ -0,0 +1 @@
+# Automatic mixed precision(AMP)training
diff --git a/docs/en/common_usage/freeze_layers.md b/docs/en/common_usage/freeze_layers.md
new file mode 100644
index 00000000..4614f324
--- /dev/null
+++ b/docs/en/common_usage/freeze_layers.md
@@ -0,0 +1,28 @@
+# Freeze layers
+
+## Freeze the weight of backbone
+
+In MMYOLO, we can freeze some `stages` of the backbone network by setting `frozen_stages` parameters, so that these `stage` parameters do not participate in model updating.
+It should be noted that `frozen_stages = i` means that all parameters from the initial `stage` to the `i`th `stage` will be frozen. The following is an example of `YOLOv5`. Other algorithms are the same logic.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ frozen_stages=1 # Indicates that the parameters in the first stage and all stages before it are frozen
+ ))
+```
+
+## Freeze the weight of neck
+
+In addition, it's able to freeze the whole `neck` with the parameter `freeze_all` in MMYOLO. The following is an example of `YOLOv5`. Other algorithms are the same logic.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck=dict(
+ freeze_all=True # If freeze_all=True, all parameters of the neck will be frozen
+ ))
+```
diff --git a/docs/en/common_usage/mim_usage.md b/docs/en/common_usage/mim_usage.md
new file mode 100644
index 00000000..2752ea5f
--- /dev/null
+++ b/docs/en/common_usage/mim_usage.md
@@ -0,0 +1,89 @@
+# Use mim to run scripts from other OpenMMLab repositories
+
+```{note}
+1. All script calls across libraries are currently not supported and are being fixed. More examples will be added to this document when the fix is complete. 2.
+2. mAP plotting and average training speed calculation are fixed in the MMDetection dev-3.x branch, which currently needs to be installed via the source code to be run successfully.
+```
+
+## Log Analysis
+
+### Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/docs/en/common_usage/module_combination.md b/docs/en/common_usage/module_combination.md
new file mode 100644
index 00000000..3f9ffa4c
--- /dev/null
+++ b/docs/en/common_usage/module_combination.md
@@ -0,0 +1 @@
+# Module combination
diff --git a/docs/en/common_usage/multi_necks.md b/docs/en/common_usage/multi_necks.md
new file mode 100644
index 00000000..b6f2bc25
--- /dev/null
+++ b/docs/en/common_usage/multi_necks.md
@@ -0,0 +1,37 @@
+# Apply multiple Necks
+
+If you want to stack multiple Necks, you can directly set the Neck parameters in the config. MMYOLO supports concatenating multiple Necks in the form of `List`. You need to ensure that the output channel of the previous Neck matches the input channel of the next Neck. If you need to adjust the number of channels, you can insert the `mmdet.ChannelMapper` module to align the number of channels between multiple Necks. The specific configuration is as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024], # The out_channels is controlled by widen_factor,so the YOLOv5PAFPN's out_channels equls to out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ]
+ bbox_head=dict(head_module=dict(in_channels=[512,512,512])) # The out_channels is controlled by widen_factor,so the YOLOv5HeadModuled in_channels * widen_factor equals to the last neck's out_channels
+)
+```
diff --git a/docs/en/common_usage/output_predictions.md b/docs/en/common_usage/output_predictions.md
new file mode 100644
index 00000000..57192990
--- /dev/null
+++ b/docs/en/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# Output prediction results
+
+If you want to save the prediction results as a specific file for offline evaluation, MMYOLO currently supports both json and pkl formats.
+
+```{note}
+The json file only save `image_id`, `bbox`, `score` and `category_id`. The json file can be read using the json library.
+The pkl file holds more content than the json file, and also holds information such as the file name and size of the predicted image; the pkl file can be read using the pickle library. The pkl file can be read using the pickle library.
+```
+
+## Output into json file
+
+If you want to output the prediction results as a json file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --json-prefix {json_prefix}
+```
+
+The argument after `--json-prefix` should be a filename prefix (no need to enter the `.json` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+Running the above command will output the `json_demo.bbox.json` file in the `work_dirs/demo` folder.
+
+## Output into pkl file
+
+If you want to output the prediction results as a pkl file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --out {path_to_output_file}
+```
+
+The argument after `--out` should be a full filename (**must be** with a `.pkl` or `.pickle` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+Running the above command will output the `pkl_demo.pkl` file in the `work_dirs/demo` folder.
diff --git a/docs/en/advanced_guides/plugins.md b/docs/en/common_usage/plugins.md
similarity index 100%
rename from docs/en/advanced_guides/plugins.md
rename to docs/en/common_usage/plugins.md
diff --git a/docs/en/common_usage/resume_training.md b/docs/en/common_usage/resume_training.md
new file mode 100644
index 00000000..d33f1d28
--- /dev/null
+++ b/docs/en/common_usage/resume_training.md
@@ -0,0 +1 @@
+# Resume training
diff --git a/docs/en/common_usage/set_random_seed.md b/docs/en/common_usage/set_random_seed.md
new file mode 100644
index 00000000..c45c165f
--- /dev/null
+++ b/docs/en/common_usage/set_random_seed.md
@@ -0,0 +1,18 @@
+# Set the random seed
+
+If you want to set the random seed during training, you can use the following command.
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # path of the config file
+ --cfg-options randomness.seed=2023 \ # set seed to 2023
+ [randomness.diff_rank_seed=True] \ # set different seeds according to global rank
+ [randomness.deterministic=True] # set the deterministic option for CUDNN backend
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+`randomness` has three parameters that can be set, with the following meanings.
+
+- `randomness.seed=2023`, set the random seed to 2023.
+- `randomness.diff_rank_seed=True`, set different seeds according to global rank. Defaults to False.
+- `randomness.deterministic=True`, set the deterministic option for cuDNN backend, i.e., set `torch.backends.cudnn.deterministic` to True and `torch.backends.cudnn.benchmark` to False. Defaults to False. See https://pytorch.org/docs/stable/notes/randomness.html for more details.
diff --git a/docs/en/common_usage/set_syncbn.md b/docs/en/common_usage/set_syncbn.md
new file mode 100644
index 00000000..dba33be6
--- /dev/null
+++ b/docs/en/common_usage/set_syncbn.md
@@ -0,0 +1 @@
+# Enabling and disabling SyncBatchNorm
diff --git a/docs/en/common_usage/specify_device.md b/docs/en/common_usage/specify_device.md
new file mode 100644
index 00000000..72c8017e
--- /dev/null
+++ b/docs/en/common_usage/specify_device.md
@@ -0,0 +1,23 @@
+# Specify specific GPUs during training or inference
+
+If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
+CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
+```
+
+If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
+
+If you want to use several of these GPUs to train in parallel, you can use the following command:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
+```
+
+Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
+```
diff --git a/docs/en/deploy/index.rst b/docs/en/deploy/index.rst
deleted file mode 100644
index 6fcfb241..00000000
--- a/docs/en/deploy/index.rst
+++ /dev/null
@@ -1,16 +0,0 @@
-Basic Deployment Guide
-************************
-
-.. toctree::
- :maxdepth: 1
-
- basic_deployment_guide.md
-
-
-Deployment tutorial
-************************
-
-.. toctree::
- :maxdepth: 1
-
- yolov5_deployment.md
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
deleted file mode 100644
index 01c1a716..00000000
--- a/docs/en/get_started.md
+++ /dev/null
@@ -1,280 +0,0 @@
-# Get Started
-
-## Prerequisites
-
-Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please install the correct version to avoid installation issues.
-
-| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
-| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.0 | mmdet==3.0.0rc0 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-
-In this section, we demonstrate how to prepare an environment with PyTorch.
-
-MMDetection works on Linux, Windows, and macOS. It requires Python 3.7+, CUDA 9.2+, and PyTorch 1.7+.
-
-```{note}
-If you are experienced with PyTorch and have already installed it, just skip this part and jump to the [next section](#installation). Otherwise, you can follow these steps for the preparation.
-```
-
-**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
-
-**Step 1.** Create a conda environment and activate it.
-
-```shell
-conda create --name openmmlab python=3.8 -y
-conda activate openmmlab
-```
-
-**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
-
-On GPU platforms:
-
-```shell
-conda install pytorch torchvision -c pytorch
-```
-
-On CPU platforms:
-
-```shell
-conda install pytorch torchvision cpuonly -c pytorch
-```
-
-## Installation
-
-### Best Practices
-
-**Step 0.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-pip install -U openmim
-mim install "mmengine>=0.3.1"
-mim install "mmcv>=2.0.0rc1,<2.1.0"
-mim install "mmdet>=3.0.0rc5,<3.1.0"
-```
-
-**Note:**
-
-a. In MMCV-v2.x, `mmcv-full` is rename to `mmcv`, if you want to install `mmcv` without CUDA ops, you can use `mim install "mmcv-lite>=2.0.0rc1"` to install the lite version.
-
-b. If you would like to use albumentations, we suggest using pip install -r requirements/albu.txt or pip install -U albumentations --no-binary qudida,albumentations. If you simply use pip install albumentations==1.0.1, it will install opencv-python-headless simultaneously (even though you have already installed opencv-python). We recommended checking the environment after installing albumentation to ensure that opencv-python and opencv-python-headless are not installed at the same time, because it might cause unexpected issues if they both installed. Please refer to [official documentation](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies) for more details.
-
-**Step 1.** Install MMYOLO.
-
-Case a: If you develop and run mmdet directly, install it from source:
-
-```shell
-git clone https://github.com/open-mmlab/mmyolo.git
-cd mmyolo
-# Install albumentations
-pip install -r requirements/albu.txt
-# Install MMYOLO
-mim install -v -e .
-# "-v" means verbose, or more output
-# "-e" means installing a project in editable mode,
-# thus any local modifications made to the code will take effect without reinstallation.
-```
-
-Case b: If you use MMYOLO as a dependency or third-party package, install it with MIM:
-
-```shell
-mim install "mmyolo"
-```
-
-## Verify the installation
-
-To verify whether MMYOLO is installed correctly, we provide some sample codes to run an inference demo.
-
-**Step 1.** We need to download config and checkpoint files.
-
-```shell
-mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
-```
-
-The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py` and `yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth` in your current folder.
-
-**Step 2.** Verify the inference demo.
-
-Option (a). If you install MMYOLO from source, just run the following command.
-
-```shell
-python demo/image_demo.py demo/demo.jpg \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
-
-# Optional parameters
-# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
-# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
-# --show *Display the results on the screen. Default: False
-# --score-thr 0.3 *Confidence threshold. Default: 0.3
-```
-
-You will see a new image on your `output` folder, where bounding boxes are plotted.
-
-Supported input types:
-
-- Single image, include `jpg`, `jpeg`, `png`, `ppm`, `bmp`, `pgm`, `tif`, `tiff`, `webp`.
-- Folder, all image files in the folder will be traversed and the corresponding results will be output.
-- URL, will automatically download from the URL and the corresponding results will be output.
-
-Option (b). If you install MMYOLO with MIM, open your python interpreter and copy&paste the following codes.
-
-```python
-from mmdet.apis import init_detector, inference_detector
-from mmyolo.utils import register_all_modules
-
-register_all_modules()
-config_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
-checkpoint_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
-model = init_detector(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
-inference_detector(model, 'demo/demo.jpg')
-```
-
-You will see a list of `DetDataSample`, and the predictions are in the `pred_instance`, indicating the detected bounding boxes, labels, and scores.
-
-### Customize Installation
-
-#### CUDA versions
-
-When installing PyTorch, you need to specify the version of CUDA. If you are not clear on which to choose, follow our recommendations:
-
-- For Ampere-based NVIDIA GPUs, such as GeForce 30 series and NVIDIA A100, CUDA 11 is a must.
-- For older NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 offers better compatibility and is more lightweight.
-
-Please make sure the GPU driver satisfies the minimum version requirements. See [this table](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) for more information.
-
-```{note}
-Installing CUDA runtime libraries is enough if you follow our best practices, because no CUDA code will be compiled locally. However, if you hope to compile MMCV from source or develop other CUDA operators, you need to install the complete CUDA toolkit from NVIDIA's [website](https://developer.nvidia.com/cuda-downloads), and its version should match the CUDA version of PyTorch. i.e., the specified version of cudatoolkit in `conda install` command.
-```
-
-#### Install MMEngine without MIM
-
-To install MMEngine with pip instead of MIM, please follow \[MMEngine installation guides\](https://mmengine.readthedocs.io/en/latest/get_started/installation.html).
-
-For example, you can install MMEngine by the following command.
-
-```shell
-pip install "mmengine>=0.3.1"
-```
-
-#### Install MMCV without MIM
-
-MMCV contains C++ and CUDA extensions, thus depending on PyTorch in a complex way. MIM solves such dependencies automatically and makes the installation easier. However, it is not a must.
-
-To install MMCV with pip instead of MIM, please follow [MMCV installation guides](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html). This requires manually specifying a find-url based on the PyTorch version and its CUDA version.
-
-For example, the following command installs MMCV built for PyTorch 1.12.x and CUDA 11.6.
-
-```shell
-pip install "mmcv>=2.0.0rc1" -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12.0/index.html
-```
-
-#### Install on CPU-only platforms
-
-MMDetection can be built for the CPU-only environment. In CPU mode you can train (requires MMCV version >= `2.0.0rc1`), test, or infer a model.
-
-However, some functionalities are gone in this mode:
-
-- Deformable Convolution
-- Modulated Deformable Convolution
-- ROI pooling
-- Deformable ROI pooling
-- CARAFE
-- SyncBatchNorm
-- CrissCrossAttention
-- MaskedConv2d
-- Temporal Interlace Shift
-- nms_cuda
-- sigmoid_focal_loss_cuda
-- bbox_overlaps
-
-If you try to train/test/infer a model containing the above ops, an error will be raised.
-The following table lists affected algorithms.
-
-| Operator | Model |
-| :-----------------------------------------------------: | :--------------------------------------------------------------------------------------: |
-| Deformable Convolution/Modulated Deformable Convolution | DCN、Guided Anchoring、RepPoints、CentripetalNet、VFNet、CascadeRPN、NAS-FCOS、DetectoRS |
-| MaskedConv2d | Guided Anchoring |
-| CARAFE | CARAFE |
-| SyncBatchNorm | ResNeSt |
-
-#### Install on Google Colab
-
-[Google Colab](https://research.google.com/) usually has PyTorch installed,
-thus we only need to install MMEngine, MMCV, MMDetection, and MMYOLO with the following commands.
-
-**Step 1.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-!pip3 install openmim
-!mim install "mmengine>=0.3.1"
-!mim install "mmcv>=2.0.0rc1,<2.1.0"
-!mim install "mmdet>=3.0.0rc5,<3.1.0"
-```
-
-**Step 2.** Install MMYOLO from the source.
-
-```shell
-!git clone https://github.com/open-mmlab/mmyolo.git
-%cd mmyolo
-!pip install -e .
-```
-
-**Step 3.** Verification.
-
-```python
-import mmyolo
-print(mmyolo.__version__)
-# Example output: 0.1.0, or an another version.
-```
-
-```{note}
-Within Jupyter, the exclamation mark `!` is used to call external executables and `%cd` is a [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) to change the current working directory of Python.
-```
-
-#### Using MMYOLO with Docker
-
-We provide a [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
-
-Reminder: If you find out that your download speed is very slow, we suggest that you can canceling the comments in the last two lines of `Optional` in the [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile#L19-L20) to obtain a rocket like download speed:
-
-```dockerfile
-# (Optional)
-RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
- pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
-```
-
-Build Command:
-
-```shell
-# build an image with PyTorch 1.9, CUDA 11.1
-# If you prefer other versions, just modified the Dockerfile
-docker build -t mmyolo docker/
-```
-
-Run it with:
-
-```shell
-export DATA_DIR=/path/to/your/dataset
-docker run --gpus all --shm-size=8g -it -v ${DATA_DIR}:/mmyolo/data mmyolo
-```
-
-### Troubleshooting
-
-If you have some issues during the installation, please first view the [FAQ](notes/faq.md) page.
-You may [open an issue](https://github.com/open-mmlab/mmyolo/issues/new/choose) on GitHub if no solution is found.
-
-### Develop using multiple MMYOLO versions
-
-The training and testing scripts have been modified in `PYTHONPATH` to ensure that the scripts use MMYOLO in the current directory.
-
-To have the default MMYOLO installed in your environment instead of what is currently in use, you can remove the code that appears in the relevant script:
-
-```shell
-PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
-```
diff --git a/docs/en/get_started/15_minutes_instance_segmentation.md b/docs/en/get_started/15_minutes_instance_segmentation.md
new file mode 100644
index 00000000..c66a2f28
--- /dev/null
+++ b/docs/en/get_started/15_minutes_instance_segmentation.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO instance segmentation
+
+TODO
diff --git a/docs/en/get_started/15_minutes_object_detection.md b/docs/en/get_started/15_minutes_object_detection.md
new file mode 100644
index 00000000..37409e5a
--- /dev/null
+++ b/docs/en/get_started/15_minutes_object_detection.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO object detection
+
+TODO
diff --git a/docs/en/get_started/15_minutes_rotated_object_detection.md b/docs/en/get_started/15_minutes_rotated_object_detection.md
new file mode 100644
index 00000000..6e04c8c0
--- /dev/null
+++ b/docs/en/get_started/15_minutes_rotated_object_detection.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO rotated object detection
+
+TODO
diff --git a/docs/en/get_started/article.md b/docs/en/get_started/article.md
new file mode 100644
index 00000000..ea28d491
--- /dev/null
+++ b/docs/en/get_started/article.md
@@ -0,0 +1 @@
+# Resources summary
diff --git a/docs/en/get_started/dependencies.md b/docs/en/get_started/dependencies.md
new file mode 100644
index 00000000..d75275f1
--- /dev/null
+++ b/docs/en/get_started/dependencies.md
@@ -0,0 +1,44 @@
+# Prerequisites
+
+Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please install the correct version to avoid installation issues.
+
+| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
+| :------------: | :----------------------: | :----------------------: | :---------------------: |
+| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.0 | mmdet==3.0.0rc0 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+
+In this section, we demonstrate how to prepare an environment with PyTorch.
+
+MMDetection works on Linux, Windows, and macOS. It requires Python 3.7+, CUDA 9.2+, and PyTorch 1.7+.
+
+```{note}
+If you are experienced with PyTorch and have already installed it, just skip this part and jump to the [next section](#installation). Otherwise, you can follow these steps for the preparation.
+```
+
+**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
+
+**Step 1.** Create a conda environment and activate it.
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
+
+On GPU platforms:
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+On CPU platforms:
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
diff --git a/docs/en/get_started/installation.md b/docs/en/get_started/installation.md
new file mode 100644
index 00000000..d73bede7
--- /dev/null
+++ b/docs/en/get_started/installation.md
@@ -0,0 +1,123 @@
+# Installation
+
+## Best Practices
+
+**Step 0.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
+
+```shell
+pip install -U openmim
+mim install "mmengine>=0.3.1"
+mim install "mmcv>=2.0.0rc1,<2.1.0"
+mim install "mmdet>=3.0.0rc5,<3.1.0"
+```
+
+**Note:**
+
+a. In MMCV-v2.x, `mmcv-full` is rename to `mmcv`, if you want to install `mmcv` without CUDA ops, you can use `mim install "mmcv-lite>=2.0.0rc1"` to install the lite version.
+
+b. If you would like to use albumentations, we suggest using pip install -r requirements/albu.txt or pip install -U albumentations --no-binary qudida,albumentations. If you simply use pip install albumentations==1.0.1, it will install opencv-python-headless simultaneously (even though you have already installed opencv-python). We recommended checking the environment after installing albumentation to ensure that opencv-python and opencv-python-headless are not installed at the same time, because it might cause unexpected issues if they both installed. Please refer to [official documentation](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies) for more details.
+
+**Step 1.** Install MMYOLO.
+
+Case a: If you develop and run mmdet directly, install it from source:
+
+```shell
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+# Install albumentations
+pip install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+# "-v" means verbose, or more output
+# "-e" means installing a project in editable mode,
+# thus any local modifications made to the code will take effect without reinstallation.
+```
+
+Case b: If you use MMYOLO as a dependency or third-party package, install it with MIM:
+
+```shell
+mim install "mmyolo"
+```
+
+## Verify the installation
+
+To verify whether MMYOLO is installed correctly, we provide some sample codes to run an inference demo.
+
+**Step 1.** We need to download config and checkpoint files.
+
+```shell
+mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
+```
+
+The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py` and `yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth` in your current folder.
+
+**Step 2.** Verify the inference demo.
+
+Option (a). If you install MMYOLO from source, just run the following command.
+
+```shell
+python demo/image_demo.py demo/demo.jpg \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
+
+# Optional parameters
+# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
+# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
+# --show *Display the results on the screen. Default: False
+# --score-thr 0.3 *Confidence threshold. Default: 0.3
+```
+
+You will see a new image on your `output` folder, where bounding boxes are plotted.
+
+Supported input types:
+
+- Single image, include `jpg`, `jpeg`, `png`, `ppm`, `bmp`, `pgm`, `tif`, `tiff`, `webp`.
+- Folder, all image files in the folder will be traversed and the corresponding results will be output.
+- URL, will automatically download from the URL and the corresponding results will be output.
+
+Option (b). If you install MMYOLO with MIM, open your python interpreter and copy&paste the following codes.
+
+```python
+from mmdet.apis import init_detector, inference_detector
+from mmyolo.utils import register_all_modules
+
+register_all_modules()
+config_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
+checkpoint_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+model = init_detector(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
+inference_detector(model, 'demo/demo.jpg')
+```
+
+You will see a list of `DetDataSample`, and the predictions are in the `pred_instance`, indicating the detected bounding boxes, labels, and scores.
+
+## Using MMYOLO with Docker
+
+We provide a [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
+
+Reminder: If you find out that your download speed is very slow, we suggest that you can canceling the comments in the last two lines of `Optional` in the [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile#L19-L20) to obtain a rocket like download speed:
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+Build Command:
+
+```shell
+# build an image with PyTorch 1.9, CUDA 11.1
+# If you prefer other versions, just modified the Dockerfile
+docker build -t mmyolo docker/
+```
+
+Run it with:
+
+```shell
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it -v ${DATA_DIR}:/mmyolo/data mmyolo
+```
+
+## Troubleshooting
+
+If you have some issues during the installation, please first view the [FAQ](../tutorials/faq.md) page.
+You may [open an issue](https://github.com/open-mmlab/mmyolo/issues/new/choose) on GitHub if no solution is found.
diff --git a/docs/en/get_started/overview.md b/docs/en/get_started/overview.md
new file mode 100644
index 00000000..07dd0c5c
--- /dev/null
+++ b/docs/en/get_started/overview.md
@@ -0,0 +1 @@
+# Overview
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 123680de..5516b619 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -1,36 +1,83 @@
Welcome to MMYOLO's documentation!
=======================================
+You can switch between Chinese and English documents in the top-right corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/overview.md
+ get_started/dependencies.md
+ get_started/installation.md
+ get_started/15_minutes_object_detection.md
+ get_started/15_minutes_rotated_object_detection.md
+ get_started/15_minutes_instance_segmentation.md
+ get_started/article.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Recommended Topics
+
+ recommended_topics/contributing.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/industry_examples.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Common Usage
+
+ common_usage/resume_training.md
+ common_usage/syncbn.md
+ common_usage/amp_training.md
+ common_usage/plugins.md
+ common_usage/freeze_layers.md
+ common_usage/output_predictions.md
+ common_usage/set_random_seed.md
+ common_usage/module_combination.md
+ common_usage/mim_usage.md
+ common_usage/multi_necks.md
+ common_usage/specify_device.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Useful Tools
+
+ useful_tools/browse_coco_json.md
+ useful_tools/browse_dataset.md
+ useful_tools/print_config.md
+ useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
+ useful_tools/dataset_converters.md
+ useful_tools/download_dataset.md
+ useful_tools/log_analysis.md
+ useful_tools/model_converters.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Basic Tutorials
+
+ tutorials/config.md
+ tutorials/data_flow.md
+ tutorials/custom_installation.md
+ tutorials/faq.md
+
.. toctree::
:maxdepth: 1
- :caption: Get Started
+ :caption: Advanced Tutorials
- overview.md
- get_started.md
-
-.. toctree::
- :maxdepth: 2
- :caption: User Guides
-
- user_guides/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Algorithm Descriptions
-
- algorithm_descriptions/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Advanced Guides
-
- advanced_guides/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Deployment Guides
-
- deploy/index.rst
+ advanced_guides/cross-library_application.md
.. toctree::
:maxdepth: 1
@@ -49,24 +96,17 @@ Welcome to MMYOLO's documentation!
:caption: Notes
notes/changelog.md
- notes/faq.md
notes/compatibility.md
notes/conventions.md
+ notes/code_style.md
+
.. toctree::
- :maxdepth: 2
- :caption: Community
-
- community/contributing.md
- community/code_style.md
-
-.. toctree::
- :caption: Switch Languag
+ :caption: Switch Language
switch_language.md
-
Indices and tables
==================
diff --git a/docs/en/community/code_style.md b/docs/en/notes/code_style.md
similarity index 89%
rename from docs/en/community/code_style.md
rename to docs/en/notes/code_style.md
index 08c534ea..3bc8291e 100644
--- a/docs/en/community/code_style.md
+++ b/docs/en/notes/code_style.md
@@ -1,3 +1,3 @@
-## Code Style
+# Code Style
Coming soon. Please refer to [chinese documentation](https://mmyolo.readthedocs.io/zh_CN/latest/community/code_style.html).
diff --git a/docs/en/overview.md b/docs/en/overview.md
deleted file mode 100644
index 339bcfa3..00000000
--- a/docs/en/overview.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Overview
-
-This chapter introduces you to the overall framework of MMYOLO and provides links to detailed tutorials.
-
-## What is MMYOLO
-
-
-
-
-#### Compute the average training speed
-
-```shell
-mim run mmdet analyze_logs cal_train_time \
- ${LOG} \ # path of train log in json format
- [--include-outliers] # include the first value of every epoch when computing the average time
-```
-
-Examples:
-
-```shell
-mim run mmdet analyze_logs cal_train_time \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
-```
-
-The output is expected to be like the following.
-
-```text
------Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
-slowest epoch 278, average time is 0.1705 s/iter
-fastest epoch 300, average time is 0.1510 s/iter
-time std over epochs is 0.0026
-average iter time: 0.1556 s/iter
-```
-
-### Print the whole config
-
-`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
-
-```shell
-mim run mmdet print_config \
- ${CONFIG} \ # path of the config file
- [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
- [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
-```
-
-Examples:
-
-```shell
-mim run mmdet print_config \
- configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
- --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
-```
-
-Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
-
-## Set the random seed
-
-If you want to set the random seed during training, you can use the following command.
-
-```shell
-python ./tools/train.py \
- ${CONFIG} \ # path of the config file
- --cfg-options randomness.seed=2023 \ # set seed to 2023
- [randomness.diff_rank_seed=True] \ # set different seeds according to global rank
- [randomness.deterministic=True] # set the deterministic option for CUDNN backend
-# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
-```
-
-`randomness` has three parameters that can be set, with the following meanings.
-
-- `randomness.seed=2023`, set the random seed to 2023.
-- `randomness.diff_rank_seed=True`, set different seeds according to global rank. Defaults to False.
-- `randomness.deterministic=True`, set the deterministic option for cuDNN backend, i.e., set `torch.backends.cudnn.deterministic` to True and `torch.backends.cudnn.benchmark` to False. Defaults to False. See https://pytorch.org/docs/stable/notes/randomness.html for more details.
-
-## Specify specific GPUs during training or inference
-
-If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
-
-```shell
-CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
-CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
-```
-
-If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
-
-If you want to use several of these GPUs to train in parallel, you can use the following command:
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
-```
-
-Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
-
-```shell
-CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
-CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
-```
diff --git a/docs/en/advanced_guides/index.rst b/docs/en/advanced_guides/index.rst
deleted file mode 100644
index bd72cd2e..00000000
--- a/docs/en/advanced_guides/index.rst
+++ /dev/null
@@ -1,25 +0,0 @@
-Data flow
-************************
-
-.. toctree::
- :maxdepth: 1
-
- data_flow.md
-
-
-How to
-************************
-
-.. toctree::
- :maxdepth: 1
-
- how_to.md
-
-
-Plugins
-************************
-
-.. toctree::
- :maxdepth: 1
-
- plugins.md
diff --git a/docs/en/common_usage/amp_training.md b/docs/en/common_usage/amp_training.md
new file mode 100644
index 00000000..3767114a
--- /dev/null
+++ b/docs/en/common_usage/amp_training.md
@@ -0,0 +1 @@
+# Automatic mixed precision(AMP)training
diff --git a/docs/en/common_usage/freeze_layers.md b/docs/en/common_usage/freeze_layers.md
new file mode 100644
index 00000000..4614f324
--- /dev/null
+++ b/docs/en/common_usage/freeze_layers.md
@@ -0,0 +1,28 @@
+# Freeze layers
+
+## Freeze the weight of backbone
+
+In MMYOLO, we can freeze some `stages` of the backbone network by setting `frozen_stages` parameters, so that these `stage` parameters do not participate in model updating.
+It should be noted that `frozen_stages = i` means that all parameters from the initial `stage` to the `i`th `stage` will be frozen. The following is an example of `YOLOv5`. Other algorithms are the same logic.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ frozen_stages=1 # Indicates that the parameters in the first stage and all stages before it are frozen
+ ))
+```
+
+## Freeze the weight of neck
+
+In addition, it's able to freeze the whole `neck` with the parameter `freeze_all` in MMYOLO. The following is an example of `YOLOv5`. Other algorithms are the same logic.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck=dict(
+ freeze_all=True # If freeze_all=True, all parameters of the neck will be frozen
+ ))
+```
diff --git a/docs/en/common_usage/mim_usage.md b/docs/en/common_usage/mim_usage.md
new file mode 100644
index 00000000..2752ea5f
--- /dev/null
+++ b/docs/en/common_usage/mim_usage.md
@@ -0,0 +1,89 @@
+# Use mim to run scripts from other OpenMMLab repositories
+
+```{note}
+1. All script calls across libraries are currently not supported and are being fixed. More examples will be added to this document when the fix is complete. 2.
+2. mAP plotting and average training speed calculation are fixed in the MMDetection dev-3.x branch, which currently needs to be installed via the source code to be run successfully.
+```
+
+## Log Analysis
+
+### Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/docs/en/common_usage/module_combination.md b/docs/en/common_usage/module_combination.md
new file mode 100644
index 00000000..3f9ffa4c
--- /dev/null
+++ b/docs/en/common_usage/module_combination.md
@@ -0,0 +1 @@
+# Module combination
diff --git a/docs/en/common_usage/multi_necks.md b/docs/en/common_usage/multi_necks.md
new file mode 100644
index 00000000..b6f2bc25
--- /dev/null
+++ b/docs/en/common_usage/multi_necks.md
@@ -0,0 +1,37 @@
+# Apply multiple Necks
+
+If you want to stack multiple Necks, you can directly set the Neck parameters in the config. MMYOLO supports concatenating multiple Necks in the form of `List`. You need to ensure that the output channel of the previous Neck matches the input channel of the next Neck. If you need to adjust the number of channels, you can insert the `mmdet.ChannelMapper` module to align the number of channels between multiple Necks. The specific configuration is as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024], # The out_channels is controlled by widen_factor,so the YOLOv5PAFPN's out_channels equls to out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ]
+ bbox_head=dict(head_module=dict(in_channels=[512,512,512])) # The out_channels is controlled by widen_factor,so the YOLOv5HeadModuled in_channels * widen_factor equals to the last neck's out_channels
+)
+```
diff --git a/docs/en/common_usage/output_predictions.md b/docs/en/common_usage/output_predictions.md
new file mode 100644
index 00000000..57192990
--- /dev/null
+++ b/docs/en/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# Output prediction results
+
+If you want to save the prediction results as a specific file for offline evaluation, MMYOLO currently supports both json and pkl formats.
+
+```{note}
+The json file only save `image_id`, `bbox`, `score` and `category_id`. The json file can be read using the json library.
+The pkl file holds more content than the json file, and also holds information such as the file name and size of the predicted image; the pkl file can be read using the pickle library. The pkl file can be read using the pickle library.
+```
+
+## Output into json file
+
+If you want to output the prediction results as a json file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --json-prefix {json_prefix}
+```
+
+The argument after `--json-prefix` should be a filename prefix (no need to enter the `.json` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+Running the above command will output the `json_demo.bbox.json` file in the `work_dirs/demo` folder.
+
+## Output into pkl file
+
+If you want to output the prediction results as a pkl file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --out {path_to_output_file}
+```
+
+The argument after `--out` should be a full filename (**must be** with a `.pkl` or `.pickle` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+Running the above command will output the `pkl_demo.pkl` file in the `work_dirs/demo` folder.
diff --git a/docs/en/advanced_guides/plugins.md b/docs/en/common_usage/plugins.md
similarity index 100%
rename from docs/en/advanced_guides/plugins.md
rename to docs/en/common_usage/plugins.md
diff --git a/docs/en/common_usage/resume_training.md b/docs/en/common_usage/resume_training.md
new file mode 100644
index 00000000..d33f1d28
--- /dev/null
+++ b/docs/en/common_usage/resume_training.md
@@ -0,0 +1 @@
+# Resume training
diff --git a/docs/en/common_usage/set_random_seed.md b/docs/en/common_usage/set_random_seed.md
new file mode 100644
index 00000000..c45c165f
--- /dev/null
+++ b/docs/en/common_usage/set_random_seed.md
@@ -0,0 +1,18 @@
+# Set the random seed
+
+If you want to set the random seed during training, you can use the following command.
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # path of the config file
+ --cfg-options randomness.seed=2023 \ # set seed to 2023
+ [randomness.diff_rank_seed=True] \ # set different seeds according to global rank
+ [randomness.deterministic=True] # set the deterministic option for CUDNN backend
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+`randomness` has three parameters that can be set, with the following meanings.
+
+- `randomness.seed=2023`, set the random seed to 2023.
+- `randomness.diff_rank_seed=True`, set different seeds according to global rank. Defaults to False.
+- `randomness.deterministic=True`, set the deterministic option for cuDNN backend, i.e., set `torch.backends.cudnn.deterministic` to True and `torch.backends.cudnn.benchmark` to False. Defaults to False. See https://pytorch.org/docs/stable/notes/randomness.html for more details.
diff --git a/docs/en/common_usage/set_syncbn.md b/docs/en/common_usage/set_syncbn.md
new file mode 100644
index 00000000..dba33be6
--- /dev/null
+++ b/docs/en/common_usage/set_syncbn.md
@@ -0,0 +1 @@
+# Enabling and disabling SyncBatchNorm
diff --git a/docs/en/common_usage/specify_device.md b/docs/en/common_usage/specify_device.md
new file mode 100644
index 00000000..72c8017e
--- /dev/null
+++ b/docs/en/common_usage/specify_device.md
@@ -0,0 +1,23 @@
+# Specify specific GPUs during training or inference
+
+If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
+CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
+```
+
+If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
+
+If you want to use several of these GPUs to train in parallel, you can use the following command:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
+```
+
+Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
+```
diff --git a/docs/en/deploy/index.rst b/docs/en/deploy/index.rst
deleted file mode 100644
index 6fcfb241..00000000
--- a/docs/en/deploy/index.rst
+++ /dev/null
@@ -1,16 +0,0 @@
-Basic Deployment Guide
-************************
-
-.. toctree::
- :maxdepth: 1
-
- basic_deployment_guide.md
-
-
-Deployment tutorial
-************************
-
-.. toctree::
- :maxdepth: 1
-
- yolov5_deployment.md
diff --git a/docs/en/get_started.md b/docs/en/get_started.md
deleted file mode 100644
index 01c1a716..00000000
--- a/docs/en/get_started.md
+++ /dev/null
@@ -1,280 +0,0 @@
-# Get Started
-
-## Prerequisites
-
-Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please install the correct version to avoid installation issues.
-
-| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
-| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-| 0.1.0 | mmdet==3.0.0rc0 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
-
-In this section, we demonstrate how to prepare an environment with PyTorch.
-
-MMDetection works on Linux, Windows, and macOS. It requires Python 3.7+, CUDA 9.2+, and PyTorch 1.7+.
-
-```{note}
-If you are experienced with PyTorch and have already installed it, just skip this part and jump to the [next section](#installation). Otherwise, you can follow these steps for the preparation.
-```
-
-**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
-
-**Step 1.** Create a conda environment and activate it.
-
-```shell
-conda create --name openmmlab python=3.8 -y
-conda activate openmmlab
-```
-
-**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
-
-On GPU platforms:
-
-```shell
-conda install pytorch torchvision -c pytorch
-```
-
-On CPU platforms:
-
-```shell
-conda install pytorch torchvision cpuonly -c pytorch
-```
-
-## Installation
-
-### Best Practices
-
-**Step 0.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-pip install -U openmim
-mim install "mmengine>=0.3.1"
-mim install "mmcv>=2.0.0rc1,<2.1.0"
-mim install "mmdet>=3.0.0rc5,<3.1.0"
-```
-
-**Note:**
-
-a. In MMCV-v2.x, `mmcv-full` is rename to `mmcv`, if you want to install `mmcv` without CUDA ops, you can use `mim install "mmcv-lite>=2.0.0rc1"` to install the lite version.
-
-b. If you would like to use albumentations, we suggest using pip install -r requirements/albu.txt or pip install -U albumentations --no-binary qudida,albumentations. If you simply use pip install albumentations==1.0.1, it will install opencv-python-headless simultaneously (even though you have already installed opencv-python). We recommended checking the environment after installing albumentation to ensure that opencv-python and opencv-python-headless are not installed at the same time, because it might cause unexpected issues if they both installed. Please refer to [official documentation](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies) for more details.
-
-**Step 1.** Install MMYOLO.
-
-Case a: If you develop and run mmdet directly, install it from source:
-
-```shell
-git clone https://github.com/open-mmlab/mmyolo.git
-cd mmyolo
-# Install albumentations
-pip install -r requirements/albu.txt
-# Install MMYOLO
-mim install -v -e .
-# "-v" means verbose, or more output
-# "-e" means installing a project in editable mode,
-# thus any local modifications made to the code will take effect without reinstallation.
-```
-
-Case b: If you use MMYOLO as a dependency or third-party package, install it with MIM:
-
-```shell
-mim install "mmyolo"
-```
-
-## Verify the installation
-
-To verify whether MMYOLO is installed correctly, we provide some sample codes to run an inference demo.
-
-**Step 1.** We need to download config and checkpoint files.
-
-```shell
-mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
-```
-
-The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py` and `yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth` in your current folder.
-
-**Step 2.** Verify the inference demo.
-
-Option (a). If you install MMYOLO from source, just run the following command.
-
-```shell
-python demo/image_demo.py demo/demo.jpg \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
- yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
-
-# Optional parameters
-# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
-# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
-# --show *Display the results on the screen. Default: False
-# --score-thr 0.3 *Confidence threshold. Default: 0.3
-```
-
-You will see a new image on your `output` folder, where bounding boxes are plotted.
-
-Supported input types:
-
-- Single image, include `jpg`, `jpeg`, `png`, `ppm`, `bmp`, `pgm`, `tif`, `tiff`, `webp`.
-- Folder, all image files in the folder will be traversed and the corresponding results will be output.
-- URL, will automatically download from the URL and the corresponding results will be output.
-
-Option (b). If you install MMYOLO with MIM, open your python interpreter and copy&paste the following codes.
-
-```python
-from mmdet.apis import init_detector, inference_detector
-from mmyolo.utils import register_all_modules
-
-register_all_modules()
-config_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
-checkpoint_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
-model = init_detector(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
-inference_detector(model, 'demo/demo.jpg')
-```
-
-You will see a list of `DetDataSample`, and the predictions are in the `pred_instance`, indicating the detected bounding boxes, labels, and scores.
-
-### Customize Installation
-
-#### CUDA versions
-
-When installing PyTorch, you need to specify the version of CUDA. If you are not clear on which to choose, follow our recommendations:
-
-- For Ampere-based NVIDIA GPUs, such as GeForce 30 series and NVIDIA A100, CUDA 11 is a must.
-- For older NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 offers better compatibility and is more lightweight.
-
-Please make sure the GPU driver satisfies the minimum version requirements. See [this table](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) for more information.
-
-```{note}
-Installing CUDA runtime libraries is enough if you follow our best practices, because no CUDA code will be compiled locally. However, if you hope to compile MMCV from source or develop other CUDA operators, you need to install the complete CUDA toolkit from NVIDIA's [website](https://developer.nvidia.com/cuda-downloads), and its version should match the CUDA version of PyTorch. i.e., the specified version of cudatoolkit in `conda install` command.
-```
-
-#### Install MMEngine without MIM
-
-To install MMEngine with pip instead of MIM, please follow \[MMEngine installation guides\](https://mmengine.readthedocs.io/en/latest/get_started/installation.html).
-
-For example, you can install MMEngine by the following command.
-
-```shell
-pip install "mmengine>=0.3.1"
-```
-
-#### Install MMCV without MIM
-
-MMCV contains C++ and CUDA extensions, thus depending on PyTorch in a complex way. MIM solves such dependencies automatically and makes the installation easier. However, it is not a must.
-
-To install MMCV with pip instead of MIM, please follow [MMCV installation guides](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html). This requires manually specifying a find-url based on the PyTorch version and its CUDA version.
-
-For example, the following command installs MMCV built for PyTorch 1.12.x and CUDA 11.6.
-
-```shell
-pip install "mmcv>=2.0.0rc1" -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.12.0/index.html
-```
-
-#### Install on CPU-only platforms
-
-MMDetection can be built for the CPU-only environment. In CPU mode you can train (requires MMCV version >= `2.0.0rc1`), test, or infer a model.
-
-However, some functionalities are gone in this mode:
-
-- Deformable Convolution
-- Modulated Deformable Convolution
-- ROI pooling
-- Deformable ROI pooling
-- CARAFE
-- SyncBatchNorm
-- CrissCrossAttention
-- MaskedConv2d
-- Temporal Interlace Shift
-- nms_cuda
-- sigmoid_focal_loss_cuda
-- bbox_overlaps
-
-If you try to train/test/infer a model containing the above ops, an error will be raised.
-The following table lists affected algorithms.
-
-| Operator | Model |
-| :-----------------------------------------------------: | :--------------------------------------------------------------------------------------: |
-| Deformable Convolution/Modulated Deformable Convolution | DCN、Guided Anchoring、RepPoints、CentripetalNet、VFNet、CascadeRPN、NAS-FCOS、DetectoRS |
-| MaskedConv2d | Guided Anchoring |
-| CARAFE | CARAFE |
-| SyncBatchNorm | ResNeSt |
-
-#### Install on Google Colab
-
-[Google Colab](https://research.google.com/) usually has PyTorch installed,
-thus we only need to install MMEngine, MMCV, MMDetection, and MMYOLO with the following commands.
-
-**Step 1.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
-
-```shell
-!pip3 install openmim
-!mim install "mmengine>=0.3.1"
-!mim install "mmcv>=2.0.0rc1,<2.1.0"
-!mim install "mmdet>=3.0.0rc5,<3.1.0"
-```
-
-**Step 2.** Install MMYOLO from the source.
-
-```shell
-!git clone https://github.com/open-mmlab/mmyolo.git
-%cd mmyolo
-!pip install -e .
-```
-
-**Step 3.** Verification.
-
-```python
-import mmyolo
-print(mmyolo.__version__)
-# Example output: 0.1.0, or an another version.
-```
-
-```{note}
-Within Jupyter, the exclamation mark `!` is used to call external executables and `%cd` is a [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) to change the current working directory of Python.
-```
-
-#### Using MMYOLO with Docker
-
-We provide a [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
-
-Reminder: If you find out that your download speed is very slow, we suggest that you can canceling the comments in the last two lines of `Optional` in the [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile#L19-L20) to obtain a rocket like download speed:
-
-```dockerfile
-# (Optional)
-RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
- pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
-```
-
-Build Command:
-
-```shell
-# build an image with PyTorch 1.9, CUDA 11.1
-# If you prefer other versions, just modified the Dockerfile
-docker build -t mmyolo docker/
-```
-
-Run it with:
-
-```shell
-export DATA_DIR=/path/to/your/dataset
-docker run --gpus all --shm-size=8g -it -v ${DATA_DIR}:/mmyolo/data mmyolo
-```
-
-### Troubleshooting
-
-If you have some issues during the installation, please first view the [FAQ](notes/faq.md) page.
-You may [open an issue](https://github.com/open-mmlab/mmyolo/issues/new/choose) on GitHub if no solution is found.
-
-### Develop using multiple MMYOLO versions
-
-The training and testing scripts have been modified in `PYTHONPATH` to ensure that the scripts use MMYOLO in the current directory.
-
-To have the default MMYOLO installed in your environment instead of what is currently in use, you can remove the code that appears in the relevant script:
-
-```shell
-PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
-```
diff --git a/docs/en/get_started/15_minutes_instance_segmentation.md b/docs/en/get_started/15_minutes_instance_segmentation.md
new file mode 100644
index 00000000..c66a2f28
--- /dev/null
+++ b/docs/en/get_started/15_minutes_instance_segmentation.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO instance segmentation
+
+TODO
diff --git a/docs/en/get_started/15_minutes_object_detection.md b/docs/en/get_started/15_minutes_object_detection.md
new file mode 100644
index 00000000..37409e5a
--- /dev/null
+++ b/docs/en/get_started/15_minutes_object_detection.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO object detection
+
+TODO
diff --git a/docs/en/get_started/15_minutes_rotated_object_detection.md b/docs/en/get_started/15_minutes_rotated_object_detection.md
new file mode 100644
index 00000000..6e04c8c0
--- /dev/null
+++ b/docs/en/get_started/15_minutes_rotated_object_detection.md
@@ -0,0 +1,3 @@
+# 15 minutes to get started with MMYOLO rotated object detection
+
+TODO
diff --git a/docs/en/get_started/article.md b/docs/en/get_started/article.md
new file mode 100644
index 00000000..ea28d491
--- /dev/null
+++ b/docs/en/get_started/article.md
@@ -0,0 +1 @@
+# Resources summary
diff --git a/docs/en/get_started/dependencies.md b/docs/en/get_started/dependencies.md
new file mode 100644
index 00000000..d75275f1
--- /dev/null
+++ b/docs/en/get_started/dependencies.md
@@ -0,0 +1,44 @@
+# Prerequisites
+
+Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please install the correct version to avoid installation issues.
+
+| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
+| :------------: | :----------------------: | :----------------------: | :---------------------: |
+| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.0 | mmdet==3.0.0rc0 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+
+In this section, we demonstrate how to prepare an environment with PyTorch.
+
+MMDetection works on Linux, Windows, and macOS. It requires Python 3.7+, CUDA 9.2+, and PyTorch 1.7+.
+
+```{note}
+If you are experienced with PyTorch and have already installed it, just skip this part and jump to the [next section](#installation). Otherwise, you can follow these steps for the preparation.
+```
+
+**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
+
+**Step 1.** Create a conda environment and activate it.
+
+```shell
+conda create --name openmmlab python=3.8 -y
+conda activate openmmlab
+```
+
+**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
+
+On GPU platforms:
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+On CPU platforms:
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
diff --git a/docs/en/get_started/installation.md b/docs/en/get_started/installation.md
new file mode 100644
index 00000000..d73bede7
--- /dev/null
+++ b/docs/en/get_started/installation.md
@@ -0,0 +1,123 @@
+# Installation
+
+## Best Practices
+
+**Step 0.** Install [MMEngine](https://github.com/open-mmlab/mmengine) and [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
+
+```shell
+pip install -U openmim
+mim install "mmengine>=0.3.1"
+mim install "mmcv>=2.0.0rc1,<2.1.0"
+mim install "mmdet>=3.0.0rc5,<3.1.0"
+```
+
+**Note:**
+
+a. In MMCV-v2.x, `mmcv-full` is rename to `mmcv`, if you want to install `mmcv` without CUDA ops, you can use `mim install "mmcv-lite>=2.0.0rc1"` to install the lite version.
+
+b. If you would like to use albumentations, we suggest using pip install -r requirements/albu.txt or pip install -U albumentations --no-binary qudida,albumentations. If you simply use pip install albumentations==1.0.1, it will install opencv-python-headless simultaneously (even though you have already installed opencv-python). We recommended checking the environment after installing albumentation to ensure that opencv-python and opencv-python-headless are not installed at the same time, because it might cause unexpected issues if they both installed. Please refer to [official documentation](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies) for more details.
+
+**Step 1.** Install MMYOLO.
+
+Case a: If you develop and run mmdet directly, install it from source:
+
+```shell
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+# Install albumentations
+pip install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+# "-v" means verbose, or more output
+# "-e" means installing a project in editable mode,
+# thus any local modifications made to the code will take effect without reinstallation.
+```
+
+Case b: If you use MMYOLO as a dependency or third-party package, install it with MIM:
+
+```shell
+mim install "mmyolo"
+```
+
+## Verify the installation
+
+To verify whether MMYOLO is installed correctly, we provide some sample codes to run an inference demo.
+
+**Step 1.** We need to download config and checkpoint files.
+
+```shell
+mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
+```
+
+The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py` and `yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth` in your current folder.
+
+**Step 2.** Verify the inference demo.
+
+Option (a). If you install MMYOLO from source, just run the following command.
+
+```shell
+python demo/image_demo.py demo/demo.jpg \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
+
+# Optional parameters
+# --out-dir ./output *The detection results are output to the specified directory. When args have action --show, the script do not save results. Default: ./output
+# --device cuda:0 *The computing resources used, including cuda and cpu. Default: cuda:0
+# --show *Display the results on the screen. Default: False
+# --score-thr 0.3 *Confidence threshold. Default: 0.3
+```
+
+You will see a new image on your `output` folder, where bounding boxes are plotted.
+
+Supported input types:
+
+- Single image, include `jpg`, `jpeg`, `png`, `ppm`, `bmp`, `pgm`, `tif`, `tiff`, `webp`.
+- Folder, all image files in the folder will be traversed and the corresponding results will be output.
+- URL, will automatically download from the URL and the corresponding results will be output.
+
+Option (b). If you install MMYOLO with MIM, open your python interpreter and copy&paste the following codes.
+
+```python
+from mmdet.apis import init_detector, inference_detector
+from mmyolo.utils import register_all_modules
+
+register_all_modules()
+config_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
+checkpoint_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+model = init_detector(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
+inference_detector(model, 'demo/demo.jpg')
+```
+
+You will see a list of `DetDataSample`, and the predictions are in the `pred_instance`, indicating the detected bounding boxes, labels, and scores.
+
+## Using MMYOLO with Docker
+
+We provide a [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
+
+Reminder: If you find out that your download speed is very slow, we suggest that you can canceling the comments in the last two lines of `Optional` in the [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile#L19-L20) to obtain a rocket like download speed:
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+Build Command:
+
+```shell
+# build an image with PyTorch 1.9, CUDA 11.1
+# If you prefer other versions, just modified the Dockerfile
+docker build -t mmyolo docker/
+```
+
+Run it with:
+
+```shell
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it -v ${DATA_DIR}:/mmyolo/data mmyolo
+```
+
+## Troubleshooting
+
+If you have some issues during the installation, please first view the [FAQ](../tutorials/faq.md) page.
+You may [open an issue](https://github.com/open-mmlab/mmyolo/issues/new/choose) on GitHub if no solution is found.
diff --git a/docs/en/get_started/overview.md b/docs/en/get_started/overview.md
new file mode 100644
index 00000000..07dd0c5c
--- /dev/null
+++ b/docs/en/get_started/overview.md
@@ -0,0 +1 @@
+# Overview
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 123680de..5516b619 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -1,36 +1,83 @@
Welcome to MMYOLO's documentation!
=======================================
+You can switch between Chinese and English documents in the top-right corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/overview.md
+ get_started/dependencies.md
+ get_started/installation.md
+ get_started/15_minutes_object_detection.md
+ get_started/15_minutes_rotated_object_detection.md
+ get_started/15_minutes_instance_segmentation.md
+ get_started/article.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Recommended Topics
+
+ recommended_topics/contributing.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/industry_examples.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Common Usage
+
+ common_usage/resume_training.md
+ common_usage/syncbn.md
+ common_usage/amp_training.md
+ common_usage/plugins.md
+ common_usage/freeze_layers.md
+ common_usage/output_predictions.md
+ common_usage/set_random_seed.md
+ common_usage/module_combination.md
+ common_usage/mim_usage.md
+ common_usage/multi_necks.md
+ common_usage/specify_device.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Useful Tools
+
+ useful_tools/browse_coco_json.md
+ useful_tools/browse_dataset.md
+ useful_tools/print_config.md
+ useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
+ useful_tools/dataset_converters.md
+ useful_tools/download_dataset.md
+ useful_tools/log_analysis.md
+ useful_tools/model_converters.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Basic Tutorials
+
+ tutorials/config.md
+ tutorials/data_flow.md
+ tutorials/custom_installation.md
+ tutorials/faq.md
+
.. toctree::
:maxdepth: 1
- :caption: Get Started
+ :caption: Advanced Tutorials
- overview.md
- get_started.md
-
-.. toctree::
- :maxdepth: 2
- :caption: User Guides
-
- user_guides/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Algorithm Descriptions
-
- algorithm_descriptions/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Advanced Guides
-
- advanced_guides/index.rst
-
-.. toctree::
- :maxdepth: 2
- :caption: Deployment Guides
-
- deploy/index.rst
+ advanced_guides/cross-library_application.md
.. toctree::
:maxdepth: 1
@@ -49,24 +96,17 @@ Welcome to MMYOLO's documentation!
:caption: Notes
notes/changelog.md
- notes/faq.md
notes/compatibility.md
notes/conventions.md
+ notes/code_style.md
+
.. toctree::
- :maxdepth: 2
- :caption: Community
-
- community/contributing.md
- community/code_style.md
-
-.. toctree::
- :caption: Switch Languag
+ :caption: Switch Language
switch_language.md
-
Indices and tables
==================
diff --git a/docs/en/community/code_style.md b/docs/en/notes/code_style.md
similarity index 89%
rename from docs/en/community/code_style.md
rename to docs/en/notes/code_style.md
index 08c534ea..3bc8291e 100644
--- a/docs/en/community/code_style.md
+++ b/docs/en/notes/code_style.md
@@ -1,3 +1,3 @@
-## Code Style
+# Code Style
Coming soon. Please refer to [chinese documentation](https://mmyolo.readthedocs.io/zh_CN/latest/community/code_style.html).
diff --git a/docs/en/overview.md b/docs/en/overview.md
deleted file mode 100644
index 339bcfa3..00000000
--- a/docs/en/overview.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Overview
-
-This chapter introduces you to the overall framework of MMYOLO and provides links to detailed tutorials.
-
-## What is MMYOLO
-
-
- -#### 7. Resolve conflicts
+### 7. Resolve conflicts
If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
@@ -189,9 +189,9 @@ git merge upstream/dev
If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
-### Guidance
+## Guidance
-#### Unit test
+### Unit test
We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
@@ -201,7 +201,7 @@ python -m coverage html
# check file in htmlcov/index.html
```
-#### Document rendering
+### Document rendering
If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
@@ -213,9 +213,9 @@ make html
# check file in ./docs/zh_cn/_build/html/index.html
```
-### Code style
+## Code style
-#### Python
+### Python
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
@@ -228,17 +228,17 @@ We use the following tools for linting and formatting:
- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
-Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
-The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
-#### C++ and CUDA
+### C++ and CUDA
We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
-### PR Specs
+## PR Specs
1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
diff --git a/docs/en/recommended_topics/dataset_preparation.md b/docs/en/recommended_topics/dataset_preparation.md
new file mode 100644
index 00000000..5c573910
--- /dev/null
+++ b/docs/en/recommended_topics/dataset_preparation.md
@@ -0,0 +1 @@
+# Dataset preparation and description
diff --git a/docs/en/recommended_topics/deploy/easydeploy_guide.md b/docs/en/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 00000000..46fab865
--- /dev/null
+++ b/docs/en/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1 @@
+# EasyDeploy Deployment
diff --git a/docs/en/recommended_topics/deploy/index.rst b/docs/en/recommended_topics/deploy/index.rst
new file mode 100644
index 00000000..f21f353c
--- /dev/null
+++ b/docs/en/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy deployment tutorial
+********************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy deployment tutorial
+************************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/docs/en/deploy/basic_deployment_guide.md b/docs/en/recommended_topics/deploy/mmdeploy_guide.md
similarity index 100%
rename from docs/en/deploy/basic_deployment_guide.md
rename to docs/en/recommended_topics/deploy/mmdeploy_guide.md
diff --git a/docs/en/deploy/yolov5_deployment.md b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
similarity index 97%
rename from docs/en/deploy/yolov5_deployment.md
rename to docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
index f0e31967..7eb85b24 100644
--- a/docs/en/deploy/yolov5_deployment.md
+++ b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -1,10 +1,10 @@
# YOLOv5 Deployment
-Please check the [basic_deployment_guide](basic_deployment_guide.md) to get familiar with the configurations.
+Please check the [basic_deployment_guide](mmdeploy_guide.md) to get familiar with the configurations.
## Model Training and Validation
-The details of training and validation can be found at [yolov5_tutorial](../user_guides/yolov5_tutorial.md).
+TODO
## MMDeploy Environment Setup
@@ -75,7 +75,7 @@ codebase_config = dict(
backend_config = dict(type='onnxruntime')
```
-The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](basic_deployment_guide.md).
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](mmdeploy_guide.md).
To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
@@ -283,7 +283,7 @@ After exporting to `TensorRT`, you will get the four files as shown in Figure 2,
After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
-#### ONNXRuntime
+### ONNXRuntime
```shell
python3 ${MMDEPLOY_DIR}/tools/test.py \
@@ -298,7 +298,7 @@ Once the process is done, you can get the output results as this:
-#### TensorRT
+### TensorRT
Note: `TensorRT` must run on `CUDA` devices!
diff --git a/docs/en/recommended_topics/industry_examples.md b/docs/en/recommended_topics/industry_examples.md
new file mode 100644
index 00000000..2380143b
--- /dev/null
+++ b/docs/en/recommended_topics/industry_examples.md
@@ -0,0 +1 @@
+# MMYOLO industry examples
diff --git a/docs/en/user_guides/custom_dataset.md b/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
similarity index 100%
rename from docs/en/user_guides/custom_dataset.md
rename to docs/en/recommended_topics/labeling_to_deployment_tutorials.md
diff --git a/docs/en/recommended_topics/mm_basics.md b/docs/en/recommended_topics/mm_basics.md
new file mode 100644
index 00000000..9f23cfe6
--- /dev/null
+++ b/docs/en/recommended_topics/mm_basics.md
@@ -0,0 +1 @@
+# MM series repo essential basics
diff --git a/docs/en/algorithm_descriptions/model_design.md b/docs/en/recommended_topics/model_design.md
similarity index 100%
rename from docs/en/algorithm_descriptions/model_design.md
rename to docs/en/recommended_topics/model_design.md
diff --git a/docs/en/recommended_topics/replace_backbone.md b/docs/en/recommended_topics/replace_backbone.md
new file mode 100644
index 00000000..82d2046b
--- /dev/null
+++ b/docs/en/recommended_topics/replace_backbone.md
@@ -0,0 +1,306 @@
+# Replace the backbone network
+
+```{note}
+1. When using other backbone networks, you need to ensure that the output channels of the backbone network match the input channels of the neck network.
+2. The configuration files given below only ensure that the training will work correctly, and their training performance may not be optimal. Because some backbones require specific learning rates, optimizers, and other hyperparameters. Related contents will be added in the "Training Tips" section later.
+```
+
+## Use backbone network implemented in MMYOLO
+
+Suppose you want to use `YOLOv6EfficientRep` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ type='YOLOv6EfficientRep',
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='ReLU', inplace=True))
+)
+```
+
+## Use backbone network implemented in other OpenMMLab repositories
+
+The model registry in MMYOLO, MMDetection, MMClassification, and MMSegmentation all inherit from the root registry in MMEngine in the OpenMMLab 2.0 system, allowing these repositories to directly use modules already implemented by each other. Therefore, in MMYOLO, users can use backbone networks from MMDetection and MMClassification without reimplementation.
+
+### Use backbone network implemented in MMDetection
+
+1. Suppose you want to use `ResNet-50` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.ResNet', # Using ResNet from mmdet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+2. Suppose you want to use `SwinTransformer-Tiny` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.SwinTransformer', # Using SwinTransformer from mmdet
+ embed_dims=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ patch_norm=True,
+ out_indices=(1, 2, 3),
+ with_cp=False,
+ convert_weights=True,
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of SwinTransformer-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network implemented in MMClassification
+
+1. Suppose you want to use `ConvNeXt-Tiny` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.ConvNeXt', # Using ConvNeXt from mmcls
+ arch='tiny',
+ out_indices=(1, 2, 3),
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained', checkpoint=checkpoint_file,
+ prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ConvNeXt-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+2. Suppose you want to use `MobileNetV3-small` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [24, 48, 96]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.MobileNetV3', # Using MobileNetV3 from mmcls
+ arch='small',
+ out_indices=(3, 8, 11), # Modify out_indices
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=checkpoint_file,
+ prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of MobileNetV3 output are [24, 48, 96], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network in `timm` through MMClassification
+
+MMClassification also provides a wrapper for the Py**T**orch **Im**age **M**odels (`timm`) backbone network, users can directly use the backbone network in `timm` through MMClassification. Suppose you want to use `EfficientNet-B1` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# and the command, pip install timm, to install timm
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [40, 112, 320]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.TIMMBackbone', # Using timm from mmcls
+ model_name='efficientnet_b1', # Using efficientnet_b1 in timm
+ features_only=True,
+ pretrained=True,
+ out_indices=(2, 3, 4)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of EfficientNet-B1 output are [40, 112, 320], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network implemented in MMSelfSup
+
+Suppose you want to use `ResNet-50` which is self-supervised trained by `MoCo v3` in MMSelfSup as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmselfsup>=1.0.0rc3", to install mmselfsup
+# import mmselfsup.models to trigger register_module in mmselfsup
+custom_imports = dict(imports=['mmselfsup.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmselfsup/1.x/mocov3/mocov3_resnet50_8xb512-amp-coslr-800e_in1k/mocov3_resnet50_8xb512-amp-coslr-800e_in1k_20220927-e043f51a.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmselfsup.ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(2, 3, 4), # Note: out_indices of ResNet in MMSelfSup are 1 larger than those in MMdet and MMCls
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Don't used pre-training weights
+
+When we replace the backbone network, the model initialization is trained by default loading the pre-training weight of the backbone network. Instead of using the pre-training weights of the backbone network, if you want to train the time model from scratch,
+You can set `init_cfg` in 'backbone' to 'None'. In this case, the backbone network will be initialized with the default initialization method, instead of using the trained pre-training weight.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.ResNet', # Using ResNet from mmdet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=None # If init_cfg is set to None, backbone will not be initialized with pre-trained weights
+ ),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
diff --git a/docs/en/recommended_topics/troubleshooting_steps.md b/docs/en/recommended_topics/troubleshooting_steps.md
new file mode 100644
index 00000000..60cc1143
--- /dev/null
+++ b/docs/en/recommended_topics/troubleshooting_steps.md
@@ -0,0 +1 @@
+# Troubleshooting steps for common errors
diff --git a/docs/en/user_guides/visualization.md b/docs/en/recommended_topics/visualization.md
similarity index 90%
rename from docs/en/user_guides/visualization.md
rename to docs/en/recommended_topics/visualization.md
index 7835a434..30caa9e1 100644
--- a/docs/en/user_guides/visualization.md
+++ b/docs/en/recommended_topics/visualization.md
@@ -291,3 +291,56 @@ python demo/boxam_vis_demo.py \
-#### 7. Resolve conflicts
+### 7. Resolve conflicts
If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
@@ -189,9 +189,9 @@ git merge upstream/dev
If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
-### Guidance
+## Guidance
-#### Unit test
+### Unit test
We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
@@ -201,7 +201,7 @@ python -m coverage html
# check file in htmlcov/index.html
```
-#### Document rendering
+### Document rendering
If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
@@ -213,9 +213,9 @@ make html
# check file in ./docs/zh_cn/_build/html/index.html
```
-### Code style
+## Code style
-#### Python
+### Python
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
@@ -228,17 +228,17 @@ We use the following tools for linting and formatting:
- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
-Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
-The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
-#### C++ and CUDA
+### C++ and CUDA
We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
-### PR Specs
+## PR Specs
1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
diff --git a/docs/en/recommended_topics/dataset_preparation.md b/docs/en/recommended_topics/dataset_preparation.md
new file mode 100644
index 00000000..5c573910
--- /dev/null
+++ b/docs/en/recommended_topics/dataset_preparation.md
@@ -0,0 +1 @@
+# Dataset preparation and description
diff --git a/docs/en/recommended_topics/deploy/easydeploy_guide.md b/docs/en/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 00000000..46fab865
--- /dev/null
+++ b/docs/en/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1 @@
+# EasyDeploy Deployment
diff --git a/docs/en/recommended_topics/deploy/index.rst b/docs/en/recommended_topics/deploy/index.rst
new file mode 100644
index 00000000..f21f353c
--- /dev/null
+++ b/docs/en/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy deployment tutorial
+********************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy deployment tutorial
+************************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/docs/en/deploy/basic_deployment_guide.md b/docs/en/recommended_topics/deploy/mmdeploy_guide.md
similarity index 100%
rename from docs/en/deploy/basic_deployment_guide.md
rename to docs/en/recommended_topics/deploy/mmdeploy_guide.md
diff --git a/docs/en/deploy/yolov5_deployment.md b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
similarity index 97%
rename from docs/en/deploy/yolov5_deployment.md
rename to docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
index f0e31967..7eb85b24 100644
--- a/docs/en/deploy/yolov5_deployment.md
+++ b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -1,10 +1,10 @@
# YOLOv5 Deployment
-Please check the [basic_deployment_guide](basic_deployment_guide.md) to get familiar with the configurations.
+Please check the [basic_deployment_guide](mmdeploy_guide.md) to get familiar with the configurations.
## Model Training and Validation
-The details of training and validation can be found at [yolov5_tutorial](../user_guides/yolov5_tutorial.md).
+TODO
## MMDeploy Environment Setup
@@ -75,7 +75,7 @@ codebase_config = dict(
backend_config = dict(type='onnxruntime')
```
-The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](basic_deployment_guide.md).
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](mmdeploy_guide.md).
To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
@@ -283,7 +283,7 @@ After exporting to `TensorRT`, you will get the four files as shown in Figure 2,
After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
-#### ONNXRuntime
+### ONNXRuntime
```shell
python3 ${MMDEPLOY_DIR}/tools/test.py \
@@ -298,7 +298,7 @@ Once the process is done, you can get the output results as this:

-#### TensorRT
+### TensorRT
Note: `TensorRT` must run on `CUDA` devices!
diff --git a/docs/en/recommended_topics/industry_examples.md b/docs/en/recommended_topics/industry_examples.md
new file mode 100644
index 00000000..2380143b
--- /dev/null
+++ b/docs/en/recommended_topics/industry_examples.md
@@ -0,0 +1 @@
+# MMYOLO industry examples
diff --git a/docs/en/user_guides/custom_dataset.md b/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
similarity index 100%
rename from docs/en/user_guides/custom_dataset.md
rename to docs/en/recommended_topics/labeling_to_deployment_tutorials.md
diff --git a/docs/en/recommended_topics/mm_basics.md b/docs/en/recommended_topics/mm_basics.md
new file mode 100644
index 00000000..9f23cfe6
--- /dev/null
+++ b/docs/en/recommended_topics/mm_basics.md
@@ -0,0 +1 @@
+# MM series repo essential basics
diff --git a/docs/en/algorithm_descriptions/model_design.md b/docs/en/recommended_topics/model_design.md
similarity index 100%
rename from docs/en/algorithm_descriptions/model_design.md
rename to docs/en/recommended_topics/model_design.md
diff --git a/docs/en/recommended_topics/replace_backbone.md b/docs/en/recommended_topics/replace_backbone.md
new file mode 100644
index 00000000..82d2046b
--- /dev/null
+++ b/docs/en/recommended_topics/replace_backbone.md
@@ -0,0 +1,306 @@
+# Replace the backbone network
+
+```{note}
+1. When using other backbone networks, you need to ensure that the output channels of the backbone network match the input channels of the neck network.
+2. The configuration files given below only ensure that the training will work correctly, and their training performance may not be optimal. Because some backbones require specific learning rates, optimizers, and other hyperparameters. Related contents will be added in the "Training Tips" section later.
+```
+
+## Use backbone network implemented in MMYOLO
+
+Suppose you want to use `YOLOv6EfficientRep` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ type='YOLOv6EfficientRep',
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='ReLU', inplace=True))
+)
+```
+
+## Use backbone network implemented in other OpenMMLab repositories
+
+The model registry in MMYOLO, MMDetection, MMClassification, and MMSegmentation all inherit from the root registry in MMEngine in the OpenMMLab 2.0 system, allowing these repositories to directly use modules already implemented by each other. Therefore, in MMYOLO, users can use backbone networks from MMDetection and MMClassification without reimplementation.
+
+### Use backbone network implemented in MMDetection
+
+1. Suppose you want to use `ResNet-50` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.ResNet', # Using ResNet from mmdet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+2. Suppose you want to use `SwinTransformer-Tiny` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.SwinTransformer', # Using SwinTransformer from mmdet
+ embed_dims=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ patch_norm=True,
+ out_indices=(1, 2, 3),
+ with_cp=False,
+ convert_weights=True,
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of SwinTransformer-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network implemented in MMClassification
+
+1. Suppose you want to use `ConvNeXt-Tiny` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.ConvNeXt', # Using ConvNeXt from mmcls
+ arch='tiny',
+ out_indices=(1, 2, 3),
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained', checkpoint=checkpoint_file,
+ prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ConvNeXt-Tiny output are [192, 384, 768], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+2. Suppose you want to use `MobileNetV3-small` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [24, 48, 96]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.MobileNetV3', # Using MobileNetV3 from mmcls
+ arch='small',
+ out_indices=(3, 8, 11), # Modify out_indices
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=checkpoint_file,
+ prefix='backbone.')), # The pre-trained weights of backbone network in MMCls have prefix='backbone.'. The prefix in the keys will be removed so that these weights can be normally loaded.
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of MobileNetV3 output are [24, 48, 96], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network in `timm` through MMClassification
+
+MMClassification also provides a wrapper for the Py**T**orch **Im**age **M**odels (`timm`) backbone network, users can directly use the backbone network in `timm` through MMClassification. Suppose you want to use `EfficientNet-B1` as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmcls>=1.0.0rc2", to install mmcls
+# and the command, pip install timm, to install timm
+# import mmcls.models to trigger register_module in mmcls
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [40, 112, 320]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmcls.TIMMBackbone', # Using timm from mmcls
+ model_name='efficientnet_b1', # Using efficientnet_b1 in timm
+ features_only=True,
+ pretrained=True,
+ out_indices=(2, 3, 4)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of EfficientNet-B1 output are [40, 112, 320], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Use backbone network implemented in MMSelfSup
+
+Suppose you want to use `ResNet-50` which is self-supervised trained by `MoCo v3` in MMSelfSup as the backbone network of `YOLOv5`, the example config is as the following:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+# please run the command, mim install "mmselfsup>=1.0.0rc3", to install mmselfsup
+# import mmselfsup.models to trigger register_module in mmselfsup
+custom_imports = dict(imports=['mmselfsup.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmselfsup/1.x/mocov3/mocov3_resnet50_8xb512-amp-coslr-800e_in1k/mocov3_resnet50_8xb512-amp-coslr-800e_in1k_20220927-e043f51a.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmselfsup.ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(2, 3, 4), # Note: out_indices of ResNet in MMSelfSup are 1 larger than those in MMdet and MMCls
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
+
+### Don't used pre-training weights
+
+When we replace the backbone network, the model initialization is trained by default loading the pre-training weight of the backbone network. Instead of using the pre-training weights of the backbone network, if you want to train the time model from scratch,
+You can set `init_cfg` in 'backbone' to 'None'. In this case, the backbone network will be initialized with the default initialization method, instead of using the trained pre-training weight.
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
+
+model = dict(
+ backbone=dict(
+ _delete_=True, # Delete the backbone field in _base_
+ type='mmdet.ResNet', # Using ResNet from mmdet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=None # If init_cfg is set to None, backbone will not be initialized with pre-trained weights
+ ),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # Note: The 3 channels of ResNet-50 output are [512, 1024, 2048], which do not match the original yolov5-s neck and need to be changed.
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # input channels of head need to be changed accordingly
+ widen_factor=widen_factor))
+)
+```
diff --git a/docs/en/recommended_topics/troubleshooting_steps.md b/docs/en/recommended_topics/troubleshooting_steps.md
new file mode 100644
index 00000000..60cc1143
--- /dev/null
+++ b/docs/en/recommended_topics/troubleshooting_steps.md
@@ -0,0 +1 @@
+# Troubleshooting steps for common errors
diff --git a/docs/en/user_guides/visualization.md b/docs/en/recommended_topics/visualization.md
similarity index 90%
rename from docs/en/user_guides/visualization.md
rename to docs/en/recommended_topics/visualization.md
index 7835a434..30caa9e1 100644
--- a/docs/en/user_guides/visualization.md
+++ b/docs/en/recommended_topics/visualization.md
@@ -291,3 +291,56 @@ python demo/boxam_vis_demo.py \
 +
+Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
+
+
+
+Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
+
+ +
+Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
+
+
+
+Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
+
+ +
+Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
+
+
+
+Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
+
+ +
+Print List: Generated by the sub function `show_class_list` and `show_data_list`.
+
+
+
+Print List: Generated by the sub function `show_class_list` and `show_data_list`.
+
+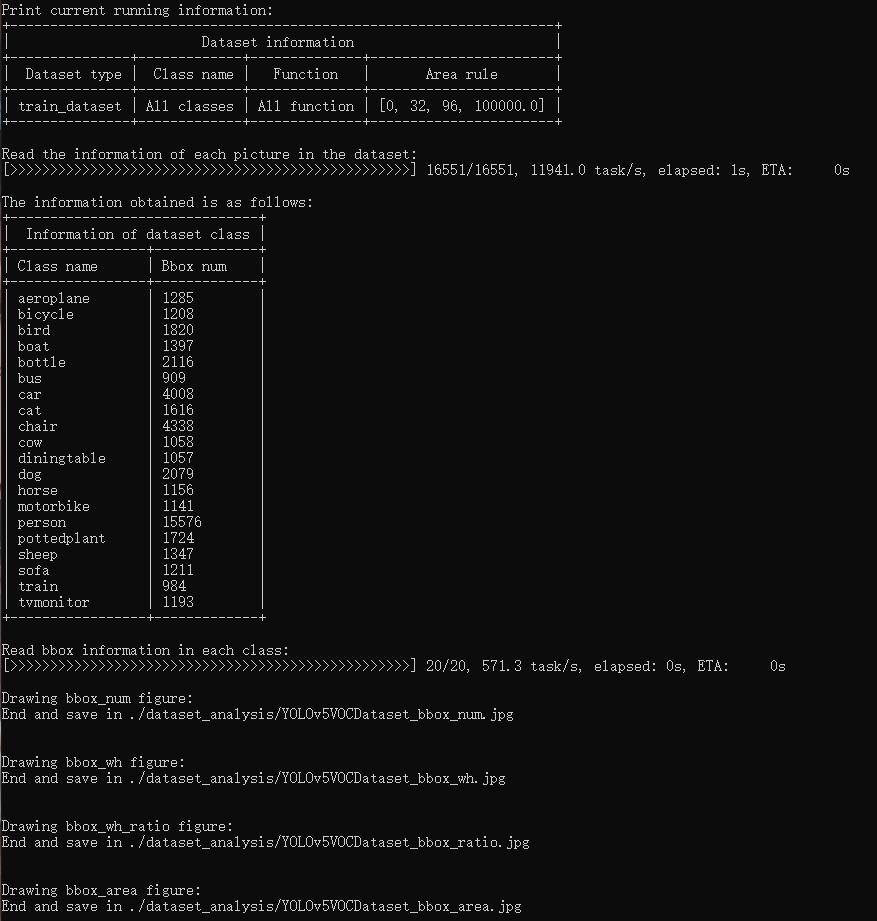 +
+```shell
+python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
+ [--type ${TYPE}] \
+ [--class-name ${CLASS_NAME}] \
+ [--area-rule ${AREA_RULE}] \
+ [--func ${FUNC}] \
+ [--out-dir ${OUT_DIR}]
+```
+
+E,g:
+
+1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
+```
+
+2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --val-dataset
+```
+
+3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --class-name person
+```
+
+4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --area-rule 30 70 125
+```
+
+5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --func show_bbox_num
+```
+
+6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --out-dir work_dirs/dataset_analysis
+```
diff --git a/docs/en/useful_tools/dataset_converters.md b/docs/en/useful_tools/dataset_converters.md
new file mode 100644
index 00000000..72ad968c
--- /dev/null
+++ b/docs/en/useful_tools/dataset_converters.md
@@ -0,0 +1,55 @@
+# Dataset Conversion
+
+The folder `tools/data_converters` currently contains `ballon2coco.py`, `yolo2coco.py`, and `labelme2coco.py` - three dataset conversion tools.
+
+- `ballon2coco.py` converts the `balloon` dataset (this small dataset is for starters only) to COCO format.
+
+```shell
+python tools/dataset_converters/balloon2coco.py
+```
+
+- `yolo2coco.py` converts a dataset from `yolo-style` **.txt** format to COCO format, please use it as follows:
+
+```shell
+python tools/dataset_converters/yolo2coco.py /path/to/the/root/dir/of/your_dataset
+```
+
+Instructions:
+
+1. `image_dir` is the root directory of the yolo-style dataset you need to pass to the script, which should contain `images`, `labels`, and `classes.txt`. `classes.txt` is the class declaration corresponding to the current dataset. One class a line. The structure of the root directory should be formatted as this example shows:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
+
+2. The script will automatically check if `train.txt`, `val.txt`, and `test.txt` have already existed under `image_dir`. If these files are located, the script will organize the dataset accordingly. Otherwise, the script will convert the dataset into one file. The image paths in these files must be **ABSOLUTE** paths.
+3. By default, the script will create a folder called `annotations` in the `image_dir` directory which stores the converted JSON file. If `train.txt`, `val.txt`, and `test.txt` are not found, the output file is `result.json`. Otherwise, the corresponding JSON file will be generated, named as `train.json`, `val.json`, and `test.json`. The `annotations` folder may look similar to this:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── annotations
+ │ ├── result.json
+ │ └── ...
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
diff --git a/docs/en/useful_tools/download_dataset.md b/docs/en/useful_tools/download_dataset.md
new file mode 100644
index 00000000..8a3e57ec
--- /dev/null
+++ b/docs/en/useful_tools/download_dataset.md
@@ -0,0 +1,11 @@
+# Download Dataset
+
+`tools/misc/download_dataset.py` supports downloading datasets such as `COCO`, `VOC`, `LVIS` and `Balloon`.
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name voc2012
+python tools/misc/download_dataset.py --dataset-name lvis
+python tools/misc/download_dataset.py --dataset-name balloon [--save-dir ${SAVE_DIR}] [--unzip]
+```
diff --git a/docs/en/useful_tools/extract_subcoco.md b/docs/en/useful_tools/extract_subcoco.md
new file mode 100644
index 00000000..b2c7e06c
--- /dev/null
+++ b/docs/en/useful_tools/extract_subcoco.md
@@ -0,0 +1,60 @@
+# Extracts a subset of COCO
+
+The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
+
+Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
+
+The root path folder format is as follows:
+
+```text
+├── root
+│ ├── annotations
+│ ├── train2017
+│ ├── val2017
+│ ├── test2017
+```
+
+1. Extract 10 training images and 10 validation images using only 5K validation sets.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 10
+```
+
+2. Extract 20 training images using the training set and 20 validation images using the validation set.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set
+```
+
+3. Set the global seed to 1. The default is no setting.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
+```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/docs/en/useful_tools/log_analysis.md b/docs/en/useful_tools/log_analysis.md
new file mode 100644
index 00000000..6b3e6040
--- /dev/null
+++ b/docs/en/useful_tools/log_analysis.md
@@ -0,0 +1,82 @@
+# Log Analysis
+
+## Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+## Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/docs/en/useful_tools/model_converters.md b/docs/en/useful_tools/model_converters.md
new file mode 100644
index 00000000..09fb52df
--- /dev/null
+++ b/docs/en/useful_tools/model_converters.md
@@ -0,0 +1,54 @@
+# Convert Model
+
+The six scripts under the `tools/model_converters` directory can help users convert the keys in the official pre-trained model of YOLO to the format of MMYOLO, and use MMYOLO to fine-tune the model.
+
+## YOLOv5
+
+Take conversion `yolov5s.pt` as an example:
+
+1. Clone the official YOLOv5 code to the local (currently the maximum supported version is `v6.1`):
+
+```shell
+git clone -b v6.1 https://github.com/ultralytics/yolov5.git
+cd yolov5
+```
+
+2. Download official weight file:
+
+```shell
+wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
+```
+
+3. Copy file `tools/model_converters/yolov5_to_mmyolo.py` to the path of YOLOv5 official code clone:
+
+```shell
+cp ${MMDET_YOLO_PATH}/tools/model_converters/yolov5_to_mmyolo.py yolov5_to_mmyolo.py
+```
+
+4. Conversion
+
+```shell
+python yolov5_to_mmyolo.py --src ${WEIGHT_FILE_PATH} --dst mmyolov5.pt
+```
+
+The converted `mmyolov5.pt` can be used by MMYOLO. The official weight conversion of YOLOv6 is also used in the same way.
+
+## YOLOX
+
+The conversion of YOLOX model **does not need** to download the official YOLOX code, just download the weight.
+
+Take conversion `yolox_s.pth` as an example:
+
+1. Download official weight file:
+
+```shell
+wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
+```
+
+2. Conversion
+
+```shell
+python tools/model_converters/yolox_to_mmyolo.py --src yolox_s.pth --dst mmyolox.pt
+```
+
+The converted `mmyolox.pt` can be used by MMYOLO.
diff --git a/docs/en/useful_tools/optimize_anchors.md b/docs/en/useful_tools/optimize_anchors.md
new file mode 100644
index 00000000..460bc6e2
--- /dev/null
+++ b/docs/en/useful_tools/optimize_anchors.md
@@ -0,0 +1,38 @@
+# Optimize anchors size
+
+Script `tools/analysis_tools/optimize_anchors.py` supports three methods to optimize YOLO anchors including `k-means`
+anchor cluster, `Differential Evolution` and `v5-k-means`.
+
+## k-means
+
+In k-means method, the distance criteria is based IoU, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## Differential Evolution
+
+In differential_evolution method, based differential evolution algorithm, use `avg_iou_cost` as minimum target function, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm DE \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## v5-k-means
+
+In v5-k-means method, clustering standard as same with YOLOv5 which use shape-match, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm v5-k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --prior_match_thr ${PRIOR_MATCH_THR} \
+ --out-dir ${OUT_DIR}
+```
diff --git a/docs/en/useful_tools/print_config.md b/docs/en/useful_tools/print_config.md
new file mode 100644
index 00000000..2a6ee79f
--- /dev/null
+++ b/docs/en/useful_tools/print_config.md
@@ -0,0 +1,20 @@
+# Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/docs/en/useful_tools/vis_scheduler.md b/docs/en/useful_tools/vis_scheduler.md
new file mode 100644
index 00000000..f1526342
--- /dev/null
+++ b/docs/en/useful_tools/vis_scheduler.md
@@ -0,0 +1,44 @@
+# Hyper-parameter Scheduler Visualization
+
+`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
+
+```bash
+python tools/analysis_tools/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-o, --out-dir ${OUT_DIR}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**Description of all arguments**:
+
+- `config`: The path of a model config file.
+- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
+- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
+- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
+- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
+- `--title`: Title of figure. If not set, default to be config file name.
+- `--style`: Style of plt. If not set, default to be `whitegrid`.
+- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
+- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../tutorials/config.md).
+
+```{note}
+Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
+```
+
+You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
+
+```shell
+python tools/analysis_tools/vis_scheduler.py \
+ configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
+ --dataset-size 118287 \
+ --ngpus 8 \
+ --out-dir ./output
+```
+
+
+
+```shell
+python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
+ [--type ${TYPE}] \
+ [--class-name ${CLASS_NAME}] \
+ [--area-rule ${AREA_RULE}] \
+ [--func ${FUNC}] \
+ [--out-dir ${OUT_DIR}]
+```
+
+E,g:
+
+1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
+```
+
+2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --val-dataset
+```
+
+3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --class-name person
+```
+
+4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --area-rule 30 70 125
+```
+
+5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --func show_bbox_num
+```
+
+6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --out-dir work_dirs/dataset_analysis
+```
diff --git a/docs/en/useful_tools/dataset_converters.md b/docs/en/useful_tools/dataset_converters.md
new file mode 100644
index 00000000..72ad968c
--- /dev/null
+++ b/docs/en/useful_tools/dataset_converters.md
@@ -0,0 +1,55 @@
+# Dataset Conversion
+
+The folder `tools/data_converters` currently contains `ballon2coco.py`, `yolo2coco.py`, and `labelme2coco.py` - three dataset conversion tools.
+
+- `ballon2coco.py` converts the `balloon` dataset (this small dataset is for starters only) to COCO format.
+
+```shell
+python tools/dataset_converters/balloon2coco.py
+```
+
+- `yolo2coco.py` converts a dataset from `yolo-style` **.txt** format to COCO format, please use it as follows:
+
+```shell
+python tools/dataset_converters/yolo2coco.py /path/to/the/root/dir/of/your_dataset
+```
+
+Instructions:
+
+1. `image_dir` is the root directory of the yolo-style dataset you need to pass to the script, which should contain `images`, `labels`, and `classes.txt`. `classes.txt` is the class declaration corresponding to the current dataset. One class a line. The structure of the root directory should be formatted as this example shows:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
+
+2. The script will automatically check if `train.txt`, `val.txt`, and `test.txt` have already existed under `image_dir`. If these files are located, the script will organize the dataset accordingly. Otherwise, the script will convert the dataset into one file. The image paths in these files must be **ABSOLUTE** paths.
+3. By default, the script will create a folder called `annotations` in the `image_dir` directory which stores the converted JSON file. If `train.txt`, `val.txt`, and `test.txt` are not found, the output file is `result.json`. Otherwise, the corresponding JSON file will be generated, named as `train.json`, `val.json`, and `test.json`. The `annotations` folder may look similar to this:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── annotations
+ │ ├── result.json
+ │ └── ...
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
diff --git a/docs/en/useful_tools/download_dataset.md b/docs/en/useful_tools/download_dataset.md
new file mode 100644
index 00000000..8a3e57ec
--- /dev/null
+++ b/docs/en/useful_tools/download_dataset.md
@@ -0,0 +1,11 @@
+# Download Dataset
+
+`tools/misc/download_dataset.py` supports downloading datasets such as `COCO`, `VOC`, `LVIS` and `Balloon`.
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name voc2012
+python tools/misc/download_dataset.py --dataset-name lvis
+python tools/misc/download_dataset.py --dataset-name balloon [--save-dir ${SAVE_DIR}] [--unzip]
+```
diff --git a/docs/en/useful_tools/extract_subcoco.md b/docs/en/useful_tools/extract_subcoco.md
new file mode 100644
index 00000000..b2c7e06c
--- /dev/null
+++ b/docs/en/useful_tools/extract_subcoco.md
@@ -0,0 +1,60 @@
+# Extracts a subset of COCO
+
+The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
+
+Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
+
+The root path folder format is as follows:
+
+```text
+├── root
+│ ├── annotations
+│ ├── train2017
+│ ├── val2017
+│ ├── test2017
+```
+
+1. Extract 10 training images and 10 validation images using only 5K validation sets.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 10
+```
+
+2. Extract 20 training images using the training set and 20 validation images using the validation set.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set
+```
+
+3. Set the global seed to 1. The default is no setting.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
+```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/docs/en/useful_tools/log_analysis.md b/docs/en/useful_tools/log_analysis.md
new file mode 100644
index 00000000..6b3e6040
--- /dev/null
+++ b/docs/en/useful_tools/log_analysis.md
@@ -0,0 +1,82 @@
+# Log Analysis
+
+## Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+## Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/docs/en/useful_tools/model_converters.md b/docs/en/useful_tools/model_converters.md
new file mode 100644
index 00000000..09fb52df
--- /dev/null
+++ b/docs/en/useful_tools/model_converters.md
@@ -0,0 +1,54 @@
+# Convert Model
+
+The six scripts under the `tools/model_converters` directory can help users convert the keys in the official pre-trained model of YOLO to the format of MMYOLO, and use MMYOLO to fine-tune the model.
+
+## YOLOv5
+
+Take conversion `yolov5s.pt` as an example:
+
+1. Clone the official YOLOv5 code to the local (currently the maximum supported version is `v6.1`):
+
+```shell
+git clone -b v6.1 https://github.com/ultralytics/yolov5.git
+cd yolov5
+```
+
+2. Download official weight file:
+
+```shell
+wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
+```
+
+3. Copy file `tools/model_converters/yolov5_to_mmyolo.py` to the path of YOLOv5 official code clone:
+
+```shell
+cp ${MMDET_YOLO_PATH}/tools/model_converters/yolov5_to_mmyolo.py yolov5_to_mmyolo.py
+```
+
+4. Conversion
+
+```shell
+python yolov5_to_mmyolo.py --src ${WEIGHT_FILE_PATH} --dst mmyolov5.pt
+```
+
+The converted `mmyolov5.pt` can be used by MMYOLO. The official weight conversion of YOLOv6 is also used in the same way.
+
+## YOLOX
+
+The conversion of YOLOX model **does not need** to download the official YOLOX code, just download the weight.
+
+Take conversion `yolox_s.pth` as an example:
+
+1. Download official weight file:
+
+```shell
+wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
+```
+
+2. Conversion
+
+```shell
+python tools/model_converters/yolox_to_mmyolo.py --src yolox_s.pth --dst mmyolox.pt
+```
+
+The converted `mmyolox.pt` can be used by MMYOLO.
diff --git a/docs/en/useful_tools/optimize_anchors.md b/docs/en/useful_tools/optimize_anchors.md
new file mode 100644
index 00000000..460bc6e2
--- /dev/null
+++ b/docs/en/useful_tools/optimize_anchors.md
@@ -0,0 +1,38 @@
+# Optimize anchors size
+
+Script `tools/analysis_tools/optimize_anchors.py` supports three methods to optimize YOLO anchors including `k-means`
+anchor cluster, `Differential Evolution` and `v5-k-means`.
+
+## k-means
+
+In k-means method, the distance criteria is based IoU, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## Differential Evolution
+
+In differential_evolution method, based differential evolution algorithm, use `avg_iou_cost` as minimum target function, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm DE \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## v5-k-means
+
+In v5-k-means method, clustering standard as same with YOLOv5 which use shape-match, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm v5-k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --prior_match_thr ${PRIOR_MATCH_THR} \
+ --out-dir ${OUT_DIR}
+```
diff --git a/docs/en/useful_tools/print_config.md b/docs/en/useful_tools/print_config.md
new file mode 100644
index 00000000..2a6ee79f
--- /dev/null
+++ b/docs/en/useful_tools/print_config.md
@@ -0,0 +1,20 @@
+# Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/docs/en/useful_tools/vis_scheduler.md b/docs/en/useful_tools/vis_scheduler.md
new file mode 100644
index 00000000..f1526342
--- /dev/null
+++ b/docs/en/useful_tools/vis_scheduler.md
@@ -0,0 +1,44 @@
+# Hyper-parameter Scheduler Visualization
+
+`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
+
+```bash
+python tools/analysis_tools/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-o, --out-dir ${OUT_DIR}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**Description of all arguments**:
+
+- `config`: The path of a model config file.
+- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
+- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
+- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
+- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
+- `--title`: Title of figure. If not set, default to be config file name.
+- `--style`: Style of plt. If not set, default to be `whitegrid`.
+- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
+- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../tutorials/config.md).
+
+```{note}
+Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
+```
+
+You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
+
+```shell
+python tools/analysis_tools/vis_scheduler.py \
+ configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
+ --dataset-size 118287 \
+ --ngpus 8 \
+ --out-dir ./output
+```
+
+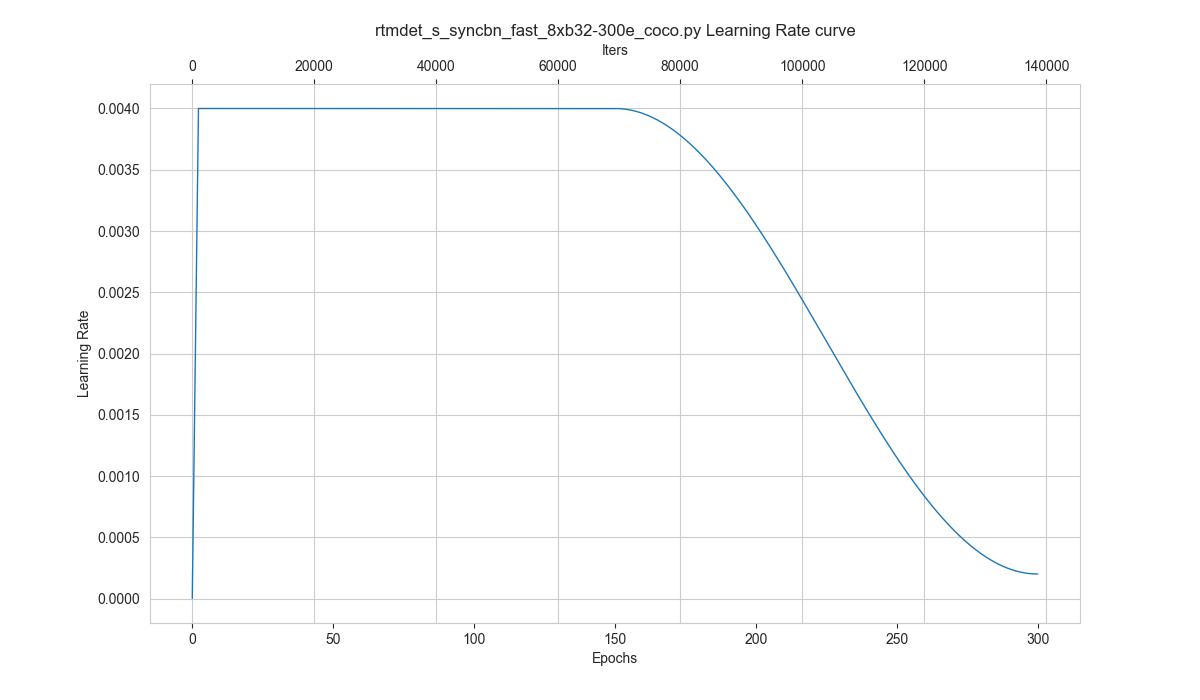 -
-Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
-
-
-
-Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
-
-
-
-Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
-
-
-
-Print List: Generated by the sub function `show_class_list` and `show_data_list`.
-
-
-
-```shell
-python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
- [--type ${TYPE}] \
- [--class-name ${CLASS_NAME}] \
- [--area-rule ${AREA_RULE}] \
- [--func ${FUNC}] \
- [--out-dir ${OUT_DIR}]
-```
-
-E,g:
-
-1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
-```
-
-2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --val-dataset
-```
-
-3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --class-name person
-```
-
-4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --area-rule 30 70 125
-```
-
-5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --func show_bbox_num
-```
-
-6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --out-dir work_dirs/dataset_analysis
-```
-
-### Hyper-parameter Scheduler Visualization
-
-`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
-
-```bash
-python tools/analysis_tools/vis_scheduler.py \
- ${CONFIG_FILE} \
- [-p, --parameter ${PARAMETER_NAME}] \
- [-d, --dataset-size ${DATASET_SIZE}] \
- [-n, --ngpus ${NUM_GPUs}] \
- [-o, --out-dir ${OUT_DIR}] \
- [--title ${TITLE}] \
- [--style ${STYLE}] \
- [--window-size ${WINDOW_SIZE}] \
- [--cfg-options]
-```
-
-**Description of all arguments**:
-
-- `config`: The path of a model config file.
-- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
-- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
-- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
-- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
-- `--title`: Title of figure. If not set, default to be config file name.
-- `--style`: Style of plt. If not set, default to be `whitegrid`.
-- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
-- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../user_guides/config.md).
-
-```{note}
-Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
-```
-
-You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
-
-```shell
-python tools/analysis_tools/vis_scheduler.py \
- configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
- --dataset-size 118287 \
- --ngpus 8 \
- --out-dir ./output
-```
-
-
-
-Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
-
-
-
-Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
-
-
-
-Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
-
-
-
-Print List: Generated by the sub function `show_class_list` and `show_data_list`.
-
-
-
-```shell
-python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
- [--type ${TYPE}] \
- [--class-name ${CLASS_NAME}] \
- [--area-rule ${AREA_RULE}] \
- [--func ${FUNC}] \
- [--out-dir ${OUT_DIR}]
-```
-
-E,g:
-
-1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
-```
-
-2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --val-dataset
-```
-
-3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --class-name person
-```
-
-4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --area-rule 30 70 125
-```
-
-5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --func show_bbox_num
-```
-
-6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
-
-```shell
-python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
- --out-dir work_dirs/dataset_analysis
-```
-
-### Hyper-parameter Scheduler Visualization
-
-`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
-
-```bash
-python tools/analysis_tools/vis_scheduler.py \
- ${CONFIG_FILE} \
- [-p, --parameter ${PARAMETER_NAME}] \
- [-d, --dataset-size ${DATASET_SIZE}] \
- [-n, --ngpus ${NUM_GPUs}] \
- [-o, --out-dir ${OUT_DIR}] \
- [--title ${TITLE}] \
- [--style ${STYLE}] \
- [--window-size ${WINDOW_SIZE}] \
- [--cfg-options]
-```
-
-**Description of all arguments**:
-
-- `config`: The path of a model config file.
-- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
-- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
-- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
-- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
-- `--title`: Title of figure. If not set, default to be config file name.
-- `--style`: Style of plt. If not set, default to be `whitegrid`.
-- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
-- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../user_guides/config.md).
-
-```{note}
-Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
-```
-
-You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
-
-```shell
-python tools/analysis_tools/vis_scheduler.py \
- configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
- --dataset-size 118287 \
- --ngpus 8 \
- --out-dir ./output
-```
-
- -
- -
- -
- -
-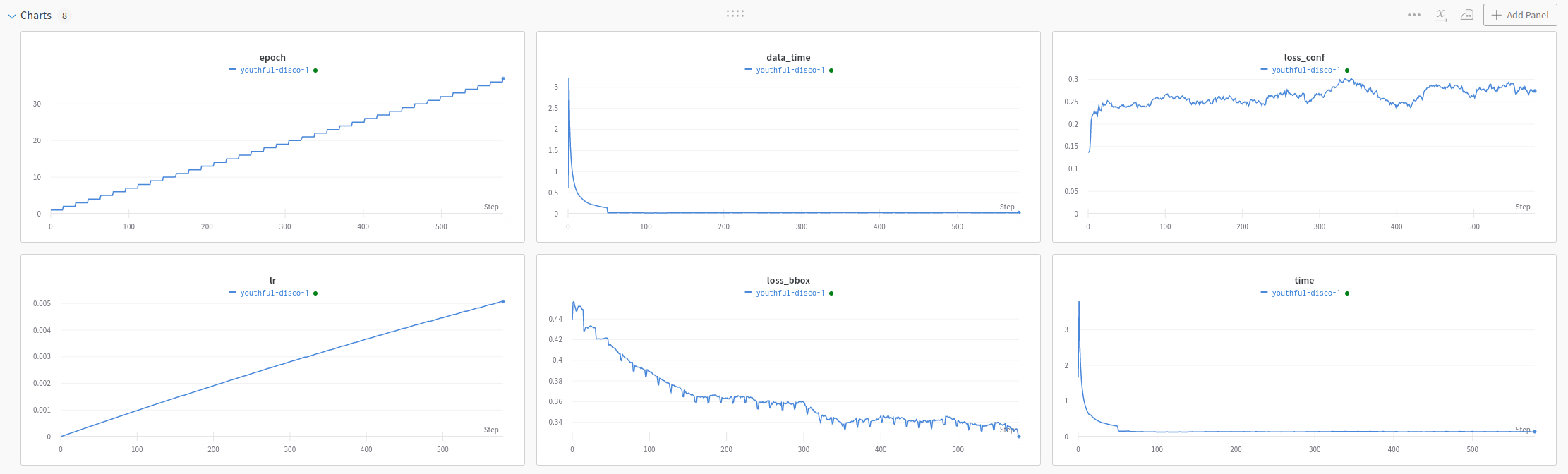 -
- -
- +
+
+
+
 +
+
+
+ -
@@ -180,7 +230,7 @@ pip install wandb
wandb login
```
-在 `configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` 添加 wandb 配置
+在 `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` 配置文件最后添加 WandB 配置
```python
visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
@@ -189,14 +239,17 @@ visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='Wandb
重新运行训练命令便可以在命令行中提示的网页链接中看到 loss、学习率和 coco/bbox_mAP 等数据可视化了。
```shell
-python tools/train.py configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py
```
+
-
@@ -180,7 +230,7 @@ pip install wandb
wandb login
```
-在 `configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` 添加 wandb 配置
+在 `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` 配置文件最后添加 WandB 配置
```python
visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
@@ -189,14 +239,17 @@ visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='Wandb
重新运行训练命令便可以在命令行中提示的网页链接中看到 loss、学习率和 coco/bbox_mAP 等数据可视化了。
```shell
-python tools/train.py configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py
```
+ +
+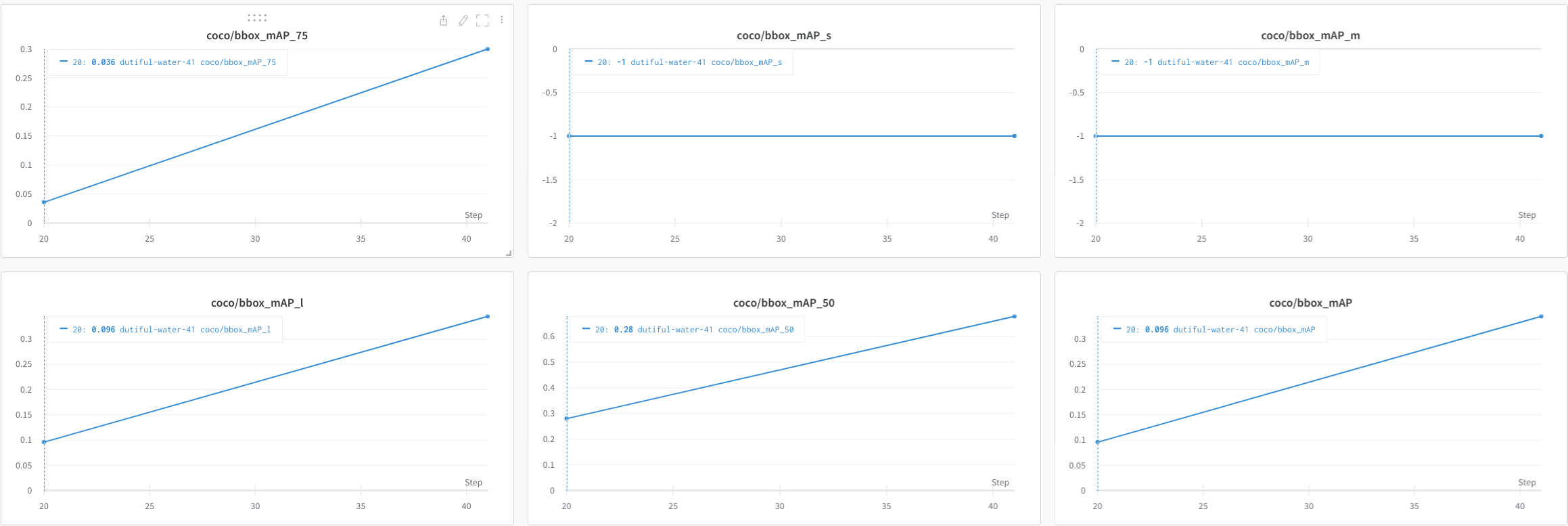 +
+
 +
+ +
+ +
+ +
+ +
+
 +
+ 图为 RangeKing@GitHub 提供,非常感谢!
+
+## 本文档使用指南
MMYOLO 中将文档结构分成 6 个部分,对应不同需求的用户。
@@ -35,7 +62,7 @@ MMYOLO 中将文档结构分成 6 个部分,对应不同需求的用户。
- **推荐专题**。本部分是 MMYOLO 中提供的以主题形式的精华文档,包括了 MMYOLO 中大量的特性等。强烈推荐使用 MMYOLO 的所有用户阅读
- **常用功能**。本部分提供了训练测试过程中用户经常会用到的各类常用功能,用户可以在用到时候再次查阅
- **实用工具**。本部分是 tools 下使用工具的汇总文档,便于大家能够快速的愉快使用 MMYOLO 中提供的各类脚本
-- **基础和进阶教程**。本部分设计到 MMYOLO 中的一些基本概念和进阶教程等,适合想详细了解 MMYOLO 设计思想和结构设计的用户
-- **其他**。其余部分包括 模型仓库、说明和接口文档等等
+- **基础和进阶教程**。本部分涉及到 MMYOLO 中的一些基本概念和进阶教程等,适合想详细了解 MMYOLO 设计思想和结构设计的用户
+- **其他**。其余部分包括模型仓库、说明和接口文档等等
-不同需求的用户可以按需选择你心怡的内容阅读。如果你对本文档有不同异议或者更好的优化办法,欢迎给 MMYOLO 提 PR ~
+不同需求的用户可以按需选择你心怡的内容阅读。如果你对本文档有异议或者更好的优化办法,欢迎给 MMYOLO 提 PR ~, 请参考 [如何给 MMYOLO 贡献代码](../recommended_topics/contributing.md)
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index d3473e70..1138e9c3 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -1,6 +1,6 @@
欢迎来到 MMYOLO 中文文档!
=======================================
-您可以在页面左下角切换中英文文档。
+您可以在页面右上角切换中英文文档。
.. toctree::
:maxdepth: 2
@@ -18,16 +18,17 @@
:maxdepth: 2
:caption: 推荐专题
- featured_topics/contributing.md
- featured_topics/model_design.md
- featured_topics/industry_examples.md
- featured_topics/dataset_preparation.md
- featured_topics/algorithm_descriptions/index.rst
- featured_topics/replace_backbone.md
- featured_topics/labeling_to_deployment_tutorials.md
- featured_topics/visualization.md
- featured_topics/deploy/index.rst
- featured_topics/troubleshooting_steps.md
+ recommended_topics/contributing.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/industry_examples.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
.. toctree::
:maxdepth: 2
@@ -40,10 +41,11 @@
common_usage/freeze_layers.md
common_usage/output_predictions.md
common_usage/set_random_seed.md
+ common_usage/module_combination.md
common_usage/mim_usage.md
common_usage/multi_necks.md
common_usage/specify_device.md
- common_usage/module_combination.md
+
.. toctree::
:maxdepth: 2
@@ -51,15 +53,15 @@
useful_tools/browse_coco_json.md
useful_tools/browse_dataset.md
+ useful_tools/print_config.md
useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
useful_tools/dataset_converters.md
useful_tools/download_dataset.md
- useful_tools/extract_subcoco.md
useful_tools/log_analysis.md
useful_tools/model_converters.md
- useful_tools/optimize_anchors.md
- useful_tools/print_config.md
- useful_tools/vis_scheduler.md
.. toctree::
:maxdepth: 2
@@ -67,8 +69,10 @@
tutorials/config.md
tutorials/data_flow.md
+ tutorials/custom_installation.md
tutorials/faq.md
+
.. toctree::
:maxdepth: 1
:caption: 进阶教程
diff --git a/docs/zh_cn/notes/code_style.md b/docs/zh_cn/notes/code_style.md
index 4634016d..fc6120cc 100644
--- a/docs/zh_cn/notes/code_style.md
+++ b/docs/zh_cn/notes/code_style.md
@@ -1,8 +1,8 @@
-## 代码规范
+# 代码规范
-### 代码规范标准
+## 代码规范标准
-#### PEP 8 —— Python 官方代码规范
+### PEP 8 —— Python 官方代码规范
[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
@@ -46,7 +46,7 @@ hypot2 = x * x + y * y
这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
:::
-#### Google 开源项目风格指南
+### Google 开源项目风格指南
[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
@@ -70,15 +70,15 @@ from mmcv.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
```
-OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](../featured_topics/contributing.md#代码风格)。
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](../recommended_topics/contributing.md#代码风格)。
-### 命名规范
+## 命名规范
-#### 命名规范的重要性
+### 命名规范的重要性
优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
-#### 基础命名规范
+### 基础命名规范
| 类型 | 公有 | 私有 |
| --------------- | ---------------- | ------------------ |
@@ -99,7 +99,7 @@ OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献
- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
-#### 命名技巧
+### 命名技巧
良好的变量命名需要保证三点:
@@ -136,13 +136,13 @@ def __init__(self, in_channels, out_channels):
注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
-### docstring 规范
+## docstring 规范
-#### 为什么要写 docstring
+### 为什么要写 docstring
docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
-#### 如何写 docstring
+### 如何写 docstring
与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
@@ -372,13 +372,13 @@ docstring 是对一个类、一个函数功能与 API 接口的详细描述,
- [Example Google Style Python Docstrings ‒ napoleon 0.7 documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html#example-google)
```
-### 注释规范
+## 注释规范
-#### 为什么要写注释
+### 为什么要写注释
对于一个开源项目,团队合作以及社区之间的合作是必不可少的,因而尤其要重视合理的注释。不写注释的代码,很有可能过几个月自己也难以理解,造成额外的阅读和修改成本。
-#### 如何写注释
+### 如何写注释
最需要写注释的是代码中那些技巧性的部分。如果你在下次代码审查的时候必须解释一下,那么你应该现在就给它写注释。对于复杂的操作,应该在其操作开始前写上若干行注释。对于不是一目了然的代码,应在其行尾添加注释。
—— Google 开源项目风格指南
@@ -414,7 +414,7 @@ if i & (i-1) == 0: # True if i bitwise and i-1 is 0.
self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
```
-#### 注释示例
+### 注释示例
1. 出自 `mmcv/utils/registry.py`,对于较为复杂的逻辑结构,通过注释,明确了优先级关系。
@@ -447,9 +447,9 @@ self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
torch.save(checkpoint, file)
```
-### 类型注解
+## 类型注解
-#### 为什么要写类型注解
+### 为什么要写类型注解
类型注解是对函数中变量的类型做限定或提示,为代码的安全性提供保障、增强代码的可读性、避免出现类型相关的错误。
Python 没有对类型做强制限制,类型注解只起到一个提示作用,通常你的 IDE 会解析这些类型注解,然后在你调用相关代码时对类型做提示。另外也有类型注解检查工具,这些工具会根据类型注解,对代码中可能出现的问题进行检查,减少 bug 的出现。
@@ -461,7 +461,7 @@ Python 没有对类型做强制限制,类型注解只起到一个提示作用
4. 难以理解的代码请进行注释
5. 若代码中的类型已经稳定,可以进行注释. 对于一份成熟的代码,多数情况下,即使注释了所有的函数,也不会丧失太多的灵活性.
-#### 如何写类型注解
+### 如何写类型注解
1. 函数 / 方法类型注解,通常不对 self 和 cls 注释。
@@ -586,7 +586,7 @@ Python 没有对类型做强制限制,类型注解只起到一个提示作用
更多关于类型注解的写法请参考 [typing](https://docs.python.org/3/library/typing.html)。
-#### 类型注解检查工具
+### 类型注解检查工具
[mypy](https://mypy.readthedocs.io/en/stable/) 是一个 Python 静态类型检查工具。根据你的类型注解,mypy 会检查传参、赋值等操作是否符合类型注解,从而避免可能出现的 bug。
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/index.rst b/docs/zh_cn/recommended_topics/algorithm_descriptions/index.rst
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/index.rst
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/index.rst
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/rtmdet_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/rtmdet_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/rtmdet_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/rtmdet_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov5_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov5_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov5_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov5_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov6_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov6_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov6_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov6_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov8_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov8_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
diff --git a/docs/zh_cn/featured_topics/contributing.md b/docs/zh_cn/recommended_topics/contributing.md
similarity index 95%
rename from docs/zh_cn/featured_topics/contributing.md
rename to docs/zh_cn/recommended_topics/contributing.md
index 16c76b0a..ff3b2ca3 100644
--- a/docs/zh_cn/featured_topics/contributing.md
+++ b/docs/zh_cn/recommended_topics/contributing.md
@@ -1,4 +1,4 @@
-## 如何给 MMYOLO 贡献代码
+# 如何给 MMYOLO 贡献代码
欢迎加入 MMYOLO 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
@@ -23,11 +23,11 @@
1. 提交 issue,确认添加文档的必要性。
2. 添加文档,提交拉取请求。
-### 拉取请求工作流
+## 拉取请求工作流
如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
-#### 1. 复刻仓库
+### 1. 复刻仓库
当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
@@ -59,7 +59,7 @@ upstream git@github.com:open-mmlab/mmyolo (push)
这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
```
-#### 2. 配置 pre-commit
+### 2. 配置 pre-commit
在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMYOLO 目录下执行):
@@ -98,7 +98,7 @@ pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
git commit -m "xxx" --no-verify
```
-#### 3. 创建开发分支
+### 3. 创建开发分支
安装完 pre-commit 之后,我们需要基于 dev 创建开发分支,建议的分支命名规则为 `username/pr_name`。
@@ -112,7 +112,7 @@ git checkout -b yhc/refactor_contributing_doc
git pull upstream dev
```
-#### 4. 提交代码并在本地通过单元测试
+### 4. 提交代码并在本地通过单元测试
- MMYOLO 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
@@ -130,7 +130,7 @@ git pull upstream dev
- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
-#### 5. 推送代码到远程
+### 5. 推送代码到远程
代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
@@ -140,7 +140,7 @@ git push -u origin {branch_name}
这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
-#### 6. 提交拉取请求(PR)
+### 6. 提交拉取请求(PR)
(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+ 图为 RangeKing@GitHub 提供,非常感谢!
+
+## 本文档使用指南
MMYOLO 中将文档结构分成 6 个部分,对应不同需求的用户。
@@ -35,7 +62,7 @@ MMYOLO 中将文档结构分成 6 个部分,对应不同需求的用户。
- **推荐专题**。本部分是 MMYOLO 中提供的以主题形式的精华文档,包括了 MMYOLO 中大量的特性等。强烈推荐使用 MMYOLO 的所有用户阅读
- **常用功能**。本部分提供了训练测试过程中用户经常会用到的各类常用功能,用户可以在用到时候再次查阅
- **实用工具**。本部分是 tools 下使用工具的汇总文档,便于大家能够快速的愉快使用 MMYOLO 中提供的各类脚本
-- **基础和进阶教程**。本部分设计到 MMYOLO 中的一些基本概念和进阶教程等,适合想详细了解 MMYOLO 设计思想和结构设计的用户
-- **其他**。其余部分包括 模型仓库、说明和接口文档等等
+- **基础和进阶教程**。本部分涉及到 MMYOLO 中的一些基本概念和进阶教程等,适合想详细了解 MMYOLO 设计思想和结构设计的用户
+- **其他**。其余部分包括模型仓库、说明和接口文档等等
-不同需求的用户可以按需选择你心怡的内容阅读。如果你对本文档有不同异议或者更好的优化办法,欢迎给 MMYOLO 提 PR ~
+不同需求的用户可以按需选择你心怡的内容阅读。如果你对本文档有异议或者更好的优化办法,欢迎给 MMYOLO 提 PR ~, 请参考 [如何给 MMYOLO 贡献代码](../recommended_topics/contributing.md)
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index d3473e70..1138e9c3 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -1,6 +1,6 @@
欢迎来到 MMYOLO 中文文档!
=======================================
-您可以在页面左下角切换中英文文档。
+您可以在页面右上角切换中英文文档。
.. toctree::
:maxdepth: 2
@@ -18,16 +18,17 @@
:maxdepth: 2
:caption: 推荐专题
- featured_topics/contributing.md
- featured_topics/model_design.md
- featured_topics/industry_examples.md
- featured_topics/dataset_preparation.md
- featured_topics/algorithm_descriptions/index.rst
- featured_topics/replace_backbone.md
- featured_topics/labeling_to_deployment_tutorials.md
- featured_topics/visualization.md
- featured_topics/deploy/index.rst
- featured_topics/troubleshooting_steps.md
+ recommended_topics/contributing.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/industry_examples.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
.. toctree::
:maxdepth: 2
@@ -40,10 +41,11 @@
common_usage/freeze_layers.md
common_usage/output_predictions.md
common_usage/set_random_seed.md
+ common_usage/module_combination.md
common_usage/mim_usage.md
common_usage/multi_necks.md
common_usage/specify_device.md
- common_usage/module_combination.md
+
.. toctree::
:maxdepth: 2
@@ -51,15 +53,15 @@
useful_tools/browse_coco_json.md
useful_tools/browse_dataset.md
+ useful_tools/print_config.md
useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
useful_tools/dataset_converters.md
useful_tools/download_dataset.md
- useful_tools/extract_subcoco.md
useful_tools/log_analysis.md
useful_tools/model_converters.md
- useful_tools/optimize_anchors.md
- useful_tools/print_config.md
- useful_tools/vis_scheduler.md
.. toctree::
:maxdepth: 2
@@ -67,8 +69,10 @@
tutorials/config.md
tutorials/data_flow.md
+ tutorials/custom_installation.md
tutorials/faq.md
+
.. toctree::
:maxdepth: 1
:caption: 进阶教程
diff --git a/docs/zh_cn/notes/code_style.md b/docs/zh_cn/notes/code_style.md
index 4634016d..fc6120cc 100644
--- a/docs/zh_cn/notes/code_style.md
+++ b/docs/zh_cn/notes/code_style.md
@@ -1,8 +1,8 @@
-## 代码规范
+# 代码规范
-### 代码规范标准
+## 代码规范标准
-#### PEP 8 —— Python 官方代码规范
+### PEP 8 —— Python 官方代码规范
[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
@@ -46,7 +46,7 @@ hypot2 = x * x + y * y
这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
:::
-#### Google 开源项目风格指南
+### Google 开源项目风格指南
[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
@@ -70,15 +70,15 @@ from mmcv.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
```
-OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](../featured_topics/contributing.md#代码风格)。
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](../recommended_topics/contributing.md#代码风格)。
-### 命名规范
+## 命名规范
-#### 命名规范的重要性
+### 命名规范的重要性
优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
-#### 基础命名规范
+### 基础命名规范
| 类型 | 公有 | 私有 |
| --------------- | ---------------- | ------------------ |
@@ -99,7 +99,7 @@ OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献
- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
-#### 命名技巧
+### 命名技巧
良好的变量命名需要保证三点:
@@ -136,13 +136,13 @@ def __init__(self, in_channels, out_channels):
注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
-### docstring 规范
+## docstring 规范
-#### 为什么要写 docstring
+### 为什么要写 docstring
docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
-#### 如何写 docstring
+### 如何写 docstring
与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
@@ -372,13 +372,13 @@ docstring 是对一个类、一个函数功能与 API 接口的详细描述,
- [Example Google Style Python Docstrings ‒ napoleon 0.7 documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html#example-google)
```
-### 注释规范
+## 注释规范
-#### 为什么要写注释
+### 为什么要写注释
对于一个开源项目,团队合作以及社区之间的合作是必不可少的,因而尤其要重视合理的注释。不写注释的代码,很有可能过几个月自己也难以理解,造成额外的阅读和修改成本。
-#### 如何写注释
+### 如何写注释
最需要写注释的是代码中那些技巧性的部分。如果你在下次代码审查的时候必须解释一下,那么你应该现在就给它写注释。对于复杂的操作,应该在其操作开始前写上若干行注释。对于不是一目了然的代码,应在其行尾添加注释。
—— Google 开源项目风格指南
@@ -414,7 +414,7 @@ if i & (i-1) == 0: # True if i bitwise and i-1 is 0.
self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
```
-#### 注释示例
+### 注释示例
1. 出自 `mmcv/utils/registry.py`,对于较为复杂的逻辑结构,通过注释,明确了优先级关系。
@@ -447,9 +447,9 @@ self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
torch.save(checkpoint, file)
```
-### 类型注解
+## 类型注解
-#### 为什么要写类型注解
+### 为什么要写类型注解
类型注解是对函数中变量的类型做限定或提示,为代码的安全性提供保障、增强代码的可读性、避免出现类型相关的错误。
Python 没有对类型做强制限制,类型注解只起到一个提示作用,通常你的 IDE 会解析这些类型注解,然后在你调用相关代码时对类型做提示。另外也有类型注解检查工具,这些工具会根据类型注解,对代码中可能出现的问题进行检查,减少 bug 的出现。
@@ -461,7 +461,7 @@ Python 没有对类型做强制限制,类型注解只起到一个提示作用
4. 难以理解的代码请进行注释
5. 若代码中的类型已经稳定,可以进行注释. 对于一份成熟的代码,多数情况下,即使注释了所有的函数,也不会丧失太多的灵活性.
-#### 如何写类型注解
+### 如何写类型注解
1. 函数 / 方法类型注解,通常不对 self 和 cls 注释。
@@ -586,7 +586,7 @@ Python 没有对类型做强制限制,类型注解只起到一个提示作用
更多关于类型注解的写法请参考 [typing](https://docs.python.org/3/library/typing.html)。
-#### 类型注解检查工具
+### 类型注解检查工具
[mypy](https://mypy.readthedocs.io/en/stable/) 是一个 Python 静态类型检查工具。根据你的类型注解,mypy 会检查传参、赋值等操作是否符合类型注解,从而避免可能出现的 bug。
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/index.rst b/docs/zh_cn/recommended_topics/algorithm_descriptions/index.rst
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/index.rst
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/index.rst
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/rtmdet_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/rtmdet_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/rtmdet_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/rtmdet_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov5_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov5_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov5_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov5_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov6_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov6_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov6_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov6_description.md
diff --git a/docs/zh_cn/featured_topics/algorithm_descriptions/yolov8_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
similarity index 100%
rename from docs/zh_cn/featured_topics/algorithm_descriptions/yolov8_description.md
rename to docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
diff --git a/docs/zh_cn/featured_topics/contributing.md b/docs/zh_cn/recommended_topics/contributing.md
similarity index 95%
rename from docs/zh_cn/featured_topics/contributing.md
rename to docs/zh_cn/recommended_topics/contributing.md
index 16c76b0a..ff3b2ca3 100644
--- a/docs/zh_cn/featured_topics/contributing.md
+++ b/docs/zh_cn/recommended_topics/contributing.md
@@ -1,4 +1,4 @@
-## 如何给 MMYOLO 贡献代码
+# 如何给 MMYOLO 贡献代码
欢迎加入 MMYOLO 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
@@ -23,11 +23,11 @@
1. 提交 issue,确认添加文档的必要性。
2. 添加文档,提交拉取请求。
-### 拉取请求工作流
+## 拉取请求工作流
如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
-#### 1. 复刻仓库
+### 1. 复刻仓库
当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
@@ -59,7 +59,7 @@ upstream git@github.com:open-mmlab/mmyolo (push)
这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
```
-#### 2. 配置 pre-commit
+### 2. 配置 pre-commit
在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMYOLO 目录下执行):
@@ -98,7 +98,7 @@ pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
git commit -m "xxx" --no-verify
```
-#### 3. 创建开发分支
+### 3. 创建开发分支
安装完 pre-commit 之后,我们需要基于 dev 创建开发分支,建议的分支命名规则为 `username/pr_name`。
@@ -112,7 +112,7 @@ git checkout -b yhc/refactor_contributing_doc
git pull upstream dev
```
-#### 4. 提交代码并在本地通过单元测试
+### 4. 提交代码并在本地通过单元测试
- MMYOLO 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
@@ -130,7 +130,7 @@ git pull upstream dev
- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
-#### 5. 推送代码到远程
+### 5. 推送代码到远程
代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
@@ -140,7 +140,7 @@ git push -u origin {branch_name}
这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
-#### 6. 提交拉取请求(PR)
+### 6. 提交拉取请求(PR)
(1) 在 GitHub 的 Pull request 界面创建拉取请求
 @@ -177,7 +177,7 @@ MMYOLO 会在 Linux 上,基于不同版本的 Python、PyTorch 对提交的代
所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到 dev 分支。
-#### 7. 解决冲突
+### 7. 解决冲突
随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与 dev 分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
@@ -195,9 +195,9 @@ git merge upstream/dev
如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
-### 指引
+## 指引
-#### 单元测试
+### 单元测试
在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
@@ -207,7 +207,7 @@ python -m coverage html
# check file in htmlcov/index.html
```
-#### 文档渲染
+### 文档渲染
在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
本地生成渲染后的文档的方法如下
@@ -220,9 +220,9 @@ make html
# check file in ./docs/zh_cn/_build/html/index.html
```
-### 代码风格
+## 代码风格
-#### Python
+### Python
[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
@@ -233,21 +233,21 @@ make html
- [mdformat](https://github.com/executablebooks/mdformat):检查 markdown 文件的工具
- [docformatter](https://github.com/myint/docformatter):格式化 docstring 的工具
-yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+yapf 和 isort 的配置可以在 [setup.cfg](../../../setup.cfg) 找到
通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
-pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../../.pre-commit-config.yaml) 找到。
pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
更具体的规范请参考 [OpenMMLab 代码规范](../notes/code_style.md)。
-#### C++ and CUDA
+### C++ and CUDA
C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
-### 拉取请求规范
+## 拉取请求规范
1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
diff --git a/docs/zh_cn/featured_topics/dataset_preparation.md b/docs/zh_cn/recommended_topics/dataset_preparation.md
similarity index 100%
rename from docs/zh_cn/featured_topics/dataset_preparation.md
rename to docs/zh_cn/recommended_topics/dataset_preparation.md
diff --git a/docs/zh_cn/featured_topics/deploy/easydeploy_guide.md b/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
similarity index 90%
rename from docs/zh_cn/featured_topics/deploy/easydeploy_guide.md
rename to docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
index 80a69d25..8f337e6c 100644
--- a/docs/zh_cn/featured_topics/deploy/easydeploy_guide.md
+++ b/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
@@ -1,4 +1,4 @@
-# EasyDeploy 部署必备教程
+# EasyDeploy 部署
本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
diff --git a/docs/zh_cn/featured_topics/deploy/index.rst b/docs/zh_cn/recommended_topics/deploy/index.rst
similarity index 70%
rename from docs/zh_cn/featured_topics/deploy/index.rst
rename to docs/zh_cn/recommended_topics/deploy/index.rst
index 3c545466..3d5f08bc 100644
--- a/docs/zh_cn/featured_topics/deploy/index.rst
+++ b/docs/zh_cn/recommended_topics/deploy/index.rst
@@ -5,17 +5,8 @@ MMDeploy 部署必备教程
:maxdepth: 1
mmdeploy_guide.md
-
-
-MMDeploy 部署 YOLOv5 全流程说明
-************************
-
-.. toctree::
- :maxdepth: 1
-
mmdeploy_yolov5.md
-
EasyDeploy 部署必备教程
************************
diff --git a/docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
similarity index 98%
rename from docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md
rename to docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
index e0181d54..a6a98d3d 100644
--- a/docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
@@ -1,4 +1,4 @@
-# 部署必备教程
+# MMDeploy 部署
## MMDeploy 介绍
@@ -83,7 +83,7 @@ test_dataloader = dict(
`test_pipeline` 为部署时对输入图像进行处理的流程,`LetterResize` 控制了输入图像的尺寸,同时限制了导出模型所能接受的输入尺寸。
-`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/user_guides/config.md) 。
+`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](../../tutorials/config.md) 。
#### (2) 部署配置文件介绍
diff --git a/docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
similarity index 99%
rename from docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md
rename to docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
index 99c0895d..c48a6406 100644
--- a/docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -4,7 +4,7 @@
## 模型训练和测试
-模型训练和测试请参考 [YOLOv5 从入门到部署全流程](../get_started/15_minutes.md) 。
+模型训练和测试请参考 [YOLOv5 从入门到部署全流程](./mmdeploy_yolov5.md) 。
## 准备 MMDeploy 运行环境
diff --git a/docs/zh_cn/featured_topics/industry_examples.md b/docs/zh_cn/recommended_topics/industry_examples.md
similarity index 100%
rename from docs/zh_cn/featured_topics/industry_examples.md
rename to docs/zh_cn/recommended_topics/industry_examples.md
diff --git a/docs/zh_cn/featured_topics/labeling_to_deployment_tutorials.md b/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
similarity index 100%
rename from docs/zh_cn/featured_topics/labeling_to_deployment_tutorials.md
rename to docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
diff --git a/docs/zh_cn/recommended_topics/mm_basics.md b/docs/zh_cn/recommended_topics/mm_basics.md
new file mode 100644
index 00000000..2d8098b1
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/mm_basics.md
@@ -0,0 +1 @@
+# MM 系列仓库必备基础
diff --git a/docs/zh_cn/featured_topics/model_design.md b/docs/zh_cn/recommended_topics/model_design.md
similarity index 100%
rename from docs/zh_cn/featured_topics/model_design.md
rename to docs/zh_cn/recommended_topics/model_design.md
diff --git a/docs/zh_cn/featured_topics/replace_backbone.md b/docs/zh_cn/recommended_topics/replace_backbone.md
similarity index 52%
rename from docs/zh_cn/featured_topics/replace_backbone.md
rename to docs/zh_cn/recommended_topics/replace_backbone.md
index 4514fefe..d78a2520 100644
--- a/docs/zh_cn/featured_topics/replace_backbone.md
+++ b/docs/zh_cn/recommended_topics/replace_backbone.md
@@ -28,162 +28,162 @@ OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification、MMSelfsup 中
1. 假设想将 `ResNet-50` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [512, 1024, 2048]
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmdet.ResNet', # 使用 mmdet 中的 ResNet
- depth=50,
- num_stages=4,
- out_indices=(1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=True,
- style='pytorch',
- init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
- neck=dict(
- type='YOLOv5PAFPN',
- widen_factor=widen_factor,
- in_channels=channels, # 注意:ResNet-50 输出的3个通道是 [512, 1024, 2048],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmdet.ResNet', # 使用 mmdet 中的 ResNet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:ResNet-50 输出的3个通道是 [512, 1024, 2048],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
2. 假设想将 `SwinTransformer-Tiny` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [192, 384, 768]
- checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmdet.SwinTransformer', # 使用 mmdet 中的 SwinTransformer
- embed_dims=96,
- depths=[2, 2, 6, 2],
- num_heads=[3, 6, 12, 24],
- window_size=7,
- mlp_ratio=4,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.2,
- patch_norm=True,
- out_indices=(1, 2, 3),
- with_cp=False,
- convert_weights=True,
- init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:SwinTransformer-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmdet.SwinTransformer', # 使用 mmdet 中的 SwinTransformer
+ embed_dims=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ patch_norm=True,
+ out_indices=(1, 2, 3),
+ with_cp=False,
+ convert_weights=True,
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:SwinTransformer-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
### 使用在 MMClassification 中实现的主干网络
1. 假设想将 `ConvNeXt-Tiny` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- # 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
- # 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
- custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
- checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [192, 384, 768]
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+# 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmcls.ConvNeXt', # 使用 mmcls 中的 ConvNeXt
- arch='tiny',
- out_indices=(1, 2, 3),
- drop_path_rate=0.4,
- layer_scale_init_value=1.0,
- gap_before_final_norm=False,
- init_cfg=dict(
- type='Pretrained', checkpoint=checkpoint_file,
- prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:ConvNeXt-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmcls.ConvNeXt', # 使用 mmcls 中的 ConvNeXt
+ arch='tiny',
+ out_indices=(1, 2, 3),
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained', checkpoint=checkpoint_file,
+ prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:ConvNeXt-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
2. 假设想将 `MobileNetV3-small` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- # 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
- # 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
- custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
- checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [24, 48, 96]
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+# 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [24, 48, 96]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmcls.MobileNetV3', # 使用 mmcls 中的 MobileNetV3
- arch='small',
- out_indices=(3, 8, 11), # 修改 out_indices
- init_cfg=dict(
- type='Pretrained',
- checkpoint=checkpoint_file,
- prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:MobileNetV3-small 输出的3个通道是 [24, 48, 96],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmcls.MobileNetV3', # 使用 mmcls 中的 MobileNetV3
+ arch='small',
+ out_indices=(3, 8, 11), # 修改 out_indices
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=checkpoint_file,
+ prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:MobileNetV3-small 输出的3个通道是 [24, 48, 96],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
### 通过 MMClassification 使用 `timm` 中实现的主干网络
diff --git a/docs/zh_cn/featured_topics/troubleshooting_steps.md b/docs/zh_cn/recommended_topics/troubleshooting_steps.md
similarity index 100%
rename from docs/zh_cn/featured_topics/troubleshooting_steps.md
rename to docs/zh_cn/recommended_topics/troubleshooting_steps.md
diff --git a/docs/zh_cn/featured_topics/visualization.md b/docs/zh_cn/recommended_topics/visualization.md
similarity index 99%
rename from docs/zh_cn/featured_topics/visualization.md
rename to docs/zh_cn/recommended_topics/visualization.md
index 52e8c579..8a1b8c6f 100644
--- a/docs/zh_cn/featured_topics/visualization.md
+++ b/docs/zh_cn/recommended_topics/visualization.md
@@ -376,7 +376,7 @@ python tools/analysis_tools/browse_dataset.py \
- **`-p, --phase`**: 可视化数据集的阶段,只能为 `['train', 'val', 'test']` 之一,默认为 `'train'`。
- **`-n, --show-number`**: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。
- **`-m, --mode`**: 可视化的模式,只能为 `['original', 'transformed', 'pipeline']` 之一。 默认为 `'transformed'`。
-- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](./config.md)。
+- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](../../tutorials/config.md)。
```shell
`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
@@ -539,3 +539,5 @@ python tools/analysis_tools/vis_scheduler.py \
```
@@ -177,7 +177,7 @@ MMYOLO 会在 Linux 上,基于不同版本的 Python、PyTorch 对提交的代
所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到 dev 分支。
-#### 7. 解决冲突
+### 7. 解决冲突
随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与 dev 分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
@@ -195,9 +195,9 @@ git merge upstream/dev
如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
-### 指引
+## 指引
-#### 单元测试
+### 单元测试
在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
@@ -207,7 +207,7 @@ python -m coverage html
# check file in htmlcov/index.html
```
-#### 文档渲染
+### 文档渲染
在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
本地生成渲染后的文档的方法如下
@@ -220,9 +220,9 @@ make html
# check file in ./docs/zh_cn/_build/html/index.html
```
-### 代码风格
+## 代码风格
-#### Python
+### Python
[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
@@ -233,21 +233,21 @@ make html
- [mdformat](https://github.com/executablebooks/mdformat):检查 markdown 文件的工具
- [docformatter](https://github.com/myint/docformatter):格式化 docstring 的工具
-yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+yapf 和 isort 的配置可以在 [setup.cfg](../../../setup.cfg) 找到
通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
-pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../../.pre-commit-config.yaml) 找到。
pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
更具体的规范请参考 [OpenMMLab 代码规范](../notes/code_style.md)。
-#### C++ and CUDA
+### C++ and CUDA
C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
-### 拉取请求规范
+## 拉取请求规范
1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
diff --git a/docs/zh_cn/featured_topics/dataset_preparation.md b/docs/zh_cn/recommended_topics/dataset_preparation.md
similarity index 100%
rename from docs/zh_cn/featured_topics/dataset_preparation.md
rename to docs/zh_cn/recommended_topics/dataset_preparation.md
diff --git a/docs/zh_cn/featured_topics/deploy/easydeploy_guide.md b/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
similarity index 90%
rename from docs/zh_cn/featured_topics/deploy/easydeploy_guide.md
rename to docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
index 80a69d25..8f337e6c 100644
--- a/docs/zh_cn/featured_topics/deploy/easydeploy_guide.md
+++ b/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
@@ -1,4 +1,4 @@
-# EasyDeploy 部署必备教程
+# EasyDeploy 部署
本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
diff --git a/docs/zh_cn/featured_topics/deploy/index.rst b/docs/zh_cn/recommended_topics/deploy/index.rst
similarity index 70%
rename from docs/zh_cn/featured_topics/deploy/index.rst
rename to docs/zh_cn/recommended_topics/deploy/index.rst
index 3c545466..3d5f08bc 100644
--- a/docs/zh_cn/featured_topics/deploy/index.rst
+++ b/docs/zh_cn/recommended_topics/deploy/index.rst
@@ -5,17 +5,8 @@ MMDeploy 部署必备教程
:maxdepth: 1
mmdeploy_guide.md
-
-
-MMDeploy 部署 YOLOv5 全流程说明
-************************
-
-.. toctree::
- :maxdepth: 1
-
mmdeploy_yolov5.md
-
EasyDeploy 部署必备教程
************************
diff --git a/docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
similarity index 98%
rename from docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md
rename to docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
index e0181d54..a6a98d3d 100644
--- a/docs/zh_cn/featured_topics/deploy/mmdeploy_guide.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
@@ -1,4 +1,4 @@
-# 部署必备教程
+# MMDeploy 部署
## MMDeploy 介绍
@@ -83,7 +83,7 @@ test_dataloader = dict(
`test_pipeline` 为部署时对输入图像进行处理的流程,`LetterResize` 控制了输入图像的尺寸,同时限制了导出模型所能接受的输入尺寸。
-`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/user_guides/config.md) 。
+`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](../../tutorials/config.md) 。
#### (2) 部署配置文件介绍
diff --git a/docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
similarity index 99%
rename from docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md
rename to docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
index 99c0895d..c48a6406 100644
--- a/docs/zh_cn/featured_topics/deploy/mmdeploy_yolov5.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -4,7 +4,7 @@
## 模型训练和测试
-模型训练和测试请参考 [YOLOv5 从入门到部署全流程](../get_started/15_minutes.md) 。
+模型训练和测试请参考 [YOLOv5 从入门到部署全流程](./mmdeploy_yolov5.md) 。
## 准备 MMDeploy 运行环境
diff --git a/docs/zh_cn/featured_topics/industry_examples.md b/docs/zh_cn/recommended_topics/industry_examples.md
similarity index 100%
rename from docs/zh_cn/featured_topics/industry_examples.md
rename to docs/zh_cn/recommended_topics/industry_examples.md
diff --git a/docs/zh_cn/featured_topics/labeling_to_deployment_tutorials.md b/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
similarity index 100%
rename from docs/zh_cn/featured_topics/labeling_to_deployment_tutorials.md
rename to docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
diff --git a/docs/zh_cn/recommended_topics/mm_basics.md b/docs/zh_cn/recommended_topics/mm_basics.md
new file mode 100644
index 00000000..2d8098b1
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/mm_basics.md
@@ -0,0 +1 @@
+# MM 系列仓库必备基础
diff --git a/docs/zh_cn/featured_topics/model_design.md b/docs/zh_cn/recommended_topics/model_design.md
similarity index 100%
rename from docs/zh_cn/featured_topics/model_design.md
rename to docs/zh_cn/recommended_topics/model_design.md
diff --git a/docs/zh_cn/featured_topics/replace_backbone.md b/docs/zh_cn/recommended_topics/replace_backbone.md
similarity index 52%
rename from docs/zh_cn/featured_topics/replace_backbone.md
rename to docs/zh_cn/recommended_topics/replace_backbone.md
index 4514fefe..d78a2520 100644
--- a/docs/zh_cn/featured_topics/replace_backbone.md
+++ b/docs/zh_cn/recommended_topics/replace_backbone.md
@@ -28,162 +28,162 @@ OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification、MMSelfsup 中
1. 假设想将 `ResNet-50` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [512, 1024, 2048]
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [512, 1024, 2048]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmdet.ResNet', # 使用 mmdet 中的 ResNet
- depth=50,
- num_stages=4,
- out_indices=(1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=True,
- style='pytorch',
- init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
- neck=dict(
- type='YOLOv5PAFPN',
- widen_factor=widen_factor,
- in_channels=channels, # 注意:ResNet-50 输出的3个通道是 [512, 1024, 2048],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmdet.ResNet', # 使用 mmdet 中的 ResNet
+ depth=50,
+ num_stages=4,
+ out_indices=(1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:ResNet-50 输出的3个通道是 [512, 1024, 2048],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
2. 假设想将 `SwinTransformer-Tiny` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [192, 384, 768]
- checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
+checkpoint_file = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth' # noqa
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmdet.SwinTransformer', # 使用 mmdet 中的 SwinTransformer
- embed_dims=96,
- depths=[2, 2, 6, 2],
- num_heads=[3, 6, 12, 24],
- window_size=7,
- mlp_ratio=4,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.,
- attn_drop_rate=0.,
- drop_path_rate=0.2,
- patch_norm=True,
- out_indices=(1, 2, 3),
- with_cp=False,
- convert_weights=True,
- init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:SwinTransformer-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmdet.SwinTransformer', # 使用 mmdet 中的 SwinTransformer
+ embed_dims=96,
+ depths=[2, 2, 6, 2],
+ num_heads=[3, 6, 12, 24],
+ window_size=7,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.2,
+ patch_norm=True,
+ out_indices=(1, 2, 3),
+ with_cp=False,
+ convert_weights=True,
+ init_cfg=dict(type='Pretrained', checkpoint=checkpoint_file)),
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:SwinTransformer-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
### 使用在 MMClassification 中实现的主干网络
1. 假设想将 `ConvNeXt-Tiny` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- # 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
- # 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
- custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
- checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [192, 384, 768]
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+# 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [192, 384, 768]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmcls.ConvNeXt', # 使用 mmcls 中的 ConvNeXt
- arch='tiny',
- out_indices=(1, 2, 3),
- drop_path_rate=0.4,
- layer_scale_init_value=1.0,
- gap_before_final_norm=False,
- init_cfg=dict(
- type='Pretrained', checkpoint=checkpoint_file,
- prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:ConvNeXt-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmcls.ConvNeXt', # 使用 mmcls 中的 ConvNeXt
+ arch='tiny',
+ out_indices=(1, 2, 3),
+ drop_path_rate=0.4,
+ layer_scale_init_value=1.0,
+ gap_before_final_norm=False,
+ init_cfg=dict(
+ type='Pretrained', checkpoint=checkpoint_file,
+ prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:ConvNeXt-Tiny 输出的3个通道是 [192, 384, 768],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
2. 假设想将 `MobileNetV3-small` 作为 `YOLOv5` 的主干网络,则配置文件如下:
- ```python
- _base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
- # 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
- # 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
- custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
- checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
- deepen_factor = _base_.deepen_factor
- widen_factor = 1.0
- channels = [24, 48, 96]
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+# 导入 mmcls.models 使得可以调用 mmcls 中注册的模块
+custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
+checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth' # noqa
+deepen_factor = _base_.deepen_factor
+widen_factor = 1.0
+channels = [24, 48, 96]
- model = dict(
- backbone=dict(
- _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
- type='mmcls.MobileNetV3', # 使用 mmcls 中的 MobileNetV3
- arch='small',
- out_indices=(3, 8, 11), # 修改 out_indices
- init_cfg=dict(
- type='Pretrained',
- checkpoint=checkpoint_file,
- prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
- neck=dict(
- type='YOLOv5PAFPN',
- deepen_factor=deepen_factor,
- widen_factor=widen_factor,
- in_channels=channels, # 注意:MobileNetV3-small 输出的3个通道是 [24, 48, 96],和原先的 yolov5-s neck 不匹配,需要更改
- out_channels=channels),
- bbox_head=dict(
- type='YOLOv5Head',
- head_module=dict(
- type='YOLOv5HeadModule',
- in_channels=channels, # head 部分输入通道也要做相应更改
- widen_factor=widen_factor))
- )
- ```
+model = dict(
+ backbone=dict(
+ _delete_=True, # 将 _base_ 中关于 backbone 的字段删除
+ type='mmcls.MobileNetV3', # 使用 mmcls 中的 MobileNetV3
+ arch='small',
+ out_indices=(3, 8, 11), # 修改 out_indices
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=checkpoint_file,
+ prefix='backbone.')), # MMCls 中主干网络的预训练权重含义 prefix='backbone.',为了正常加载权重,需要把这个 prefix 去掉。
+ neck=dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=channels, # 注意:MobileNetV3-small 输出的3个通道是 [24, 48, 96],和原先的 yolov5-s neck 不匹配,需要更改
+ out_channels=channels),
+ bbox_head=dict(
+ type='YOLOv5Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ in_channels=channels, # head 部分输入通道也要做相应更改
+ widen_factor=widen_factor))
+)
+```
### 通过 MMClassification 使用 `timm` 中实现的主干网络
diff --git a/docs/zh_cn/featured_topics/troubleshooting_steps.md b/docs/zh_cn/recommended_topics/troubleshooting_steps.md
similarity index 100%
rename from docs/zh_cn/featured_topics/troubleshooting_steps.md
rename to docs/zh_cn/recommended_topics/troubleshooting_steps.md
diff --git a/docs/zh_cn/featured_topics/visualization.md b/docs/zh_cn/recommended_topics/visualization.md
similarity index 99%
rename from docs/zh_cn/featured_topics/visualization.md
rename to docs/zh_cn/recommended_topics/visualization.md
index 52e8c579..8a1b8c6f 100644
--- a/docs/zh_cn/featured_topics/visualization.md
+++ b/docs/zh_cn/recommended_topics/visualization.md
@@ -376,7 +376,7 @@ python tools/analysis_tools/browse_dataset.py \
- **`-p, --phase`**: 可视化数据集的阶段,只能为 `['train', 'val', 'test']` 之一,默认为 `'train'`。
- **`-n, --show-number`**: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。
- **`-m, --mode`**: 可视化的模式,只能为 `['original', 'transformed', 'pipeline']` 之一。 默认为 `'transformed'`。
-- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](./config.md)。
+- `--cfg-options` : 对配置文件的修改,参考[学习配置文件](../../tutorials/config.md)。
```shell
`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
@@ -539,3 +539,5 @@ python tools/analysis_tools/vis_scheduler.py \
```