diff --git a/docs/zh_cn/algorithm_descriptions/yolov5_description.md b/docs/zh_cn/algorithm_descriptions/yolov5_description.md
new file mode 100644
index 00000000..4cc629ef
--- /dev/null
+++ b/docs/zh_cn/algorithm_descriptions/yolov5_description.md
@@ -0,0 +1,672 @@
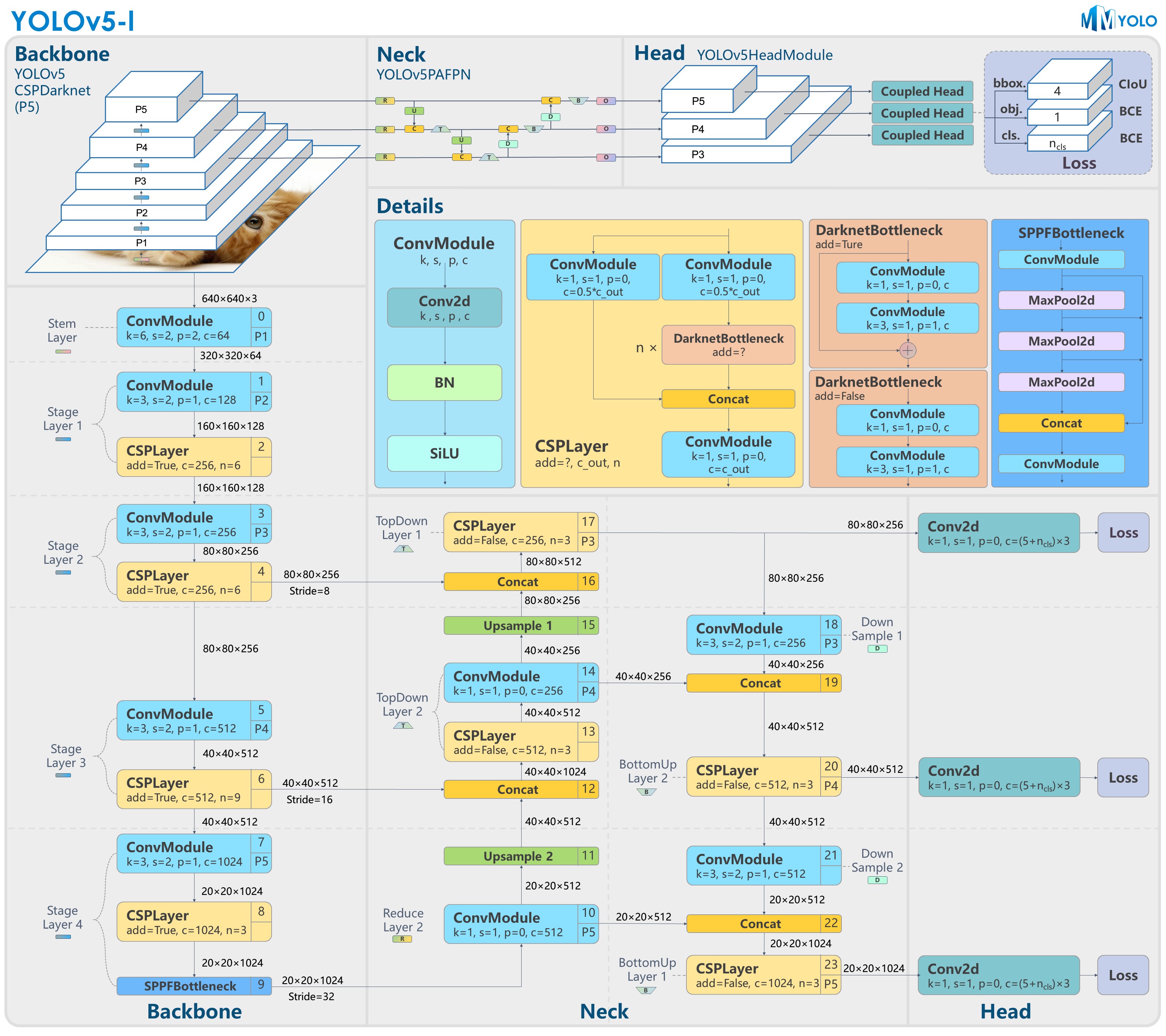
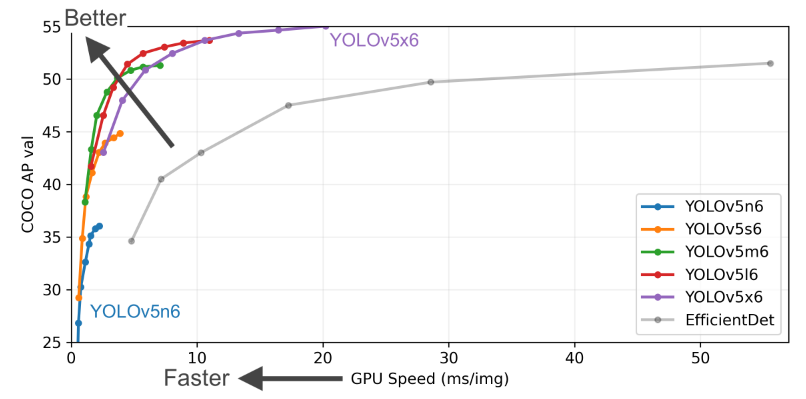
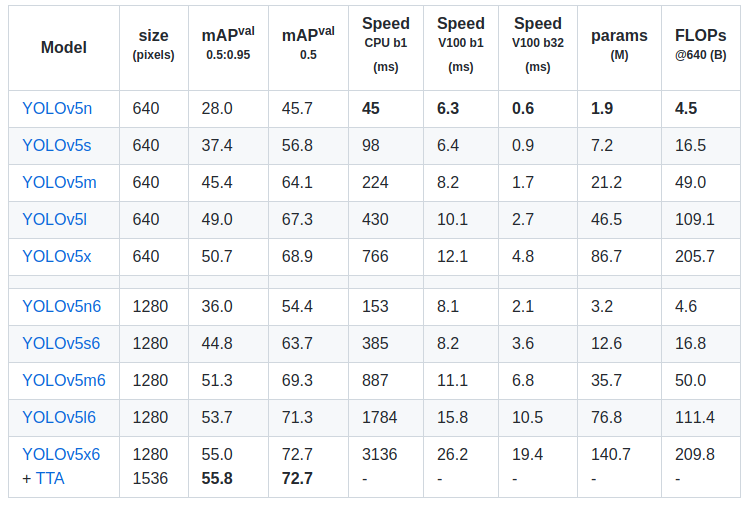
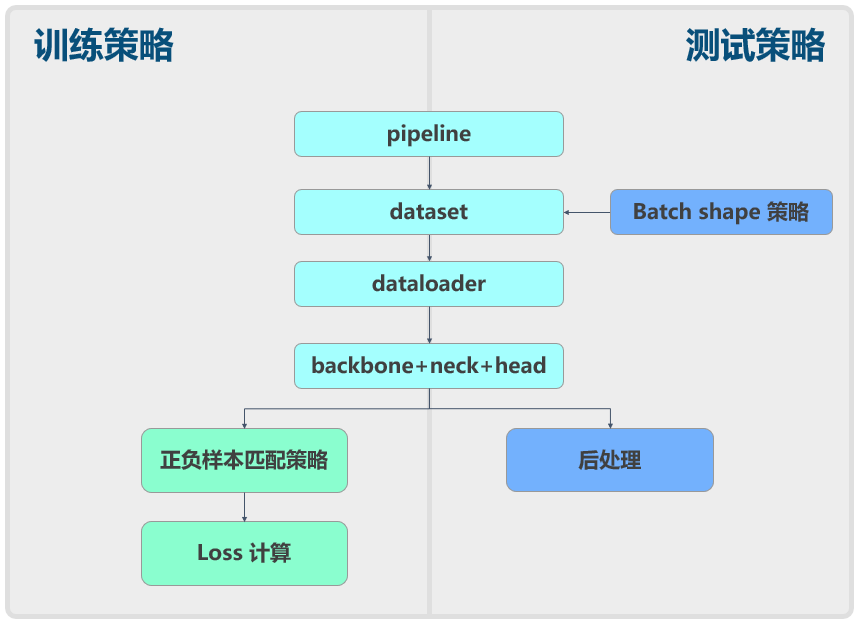
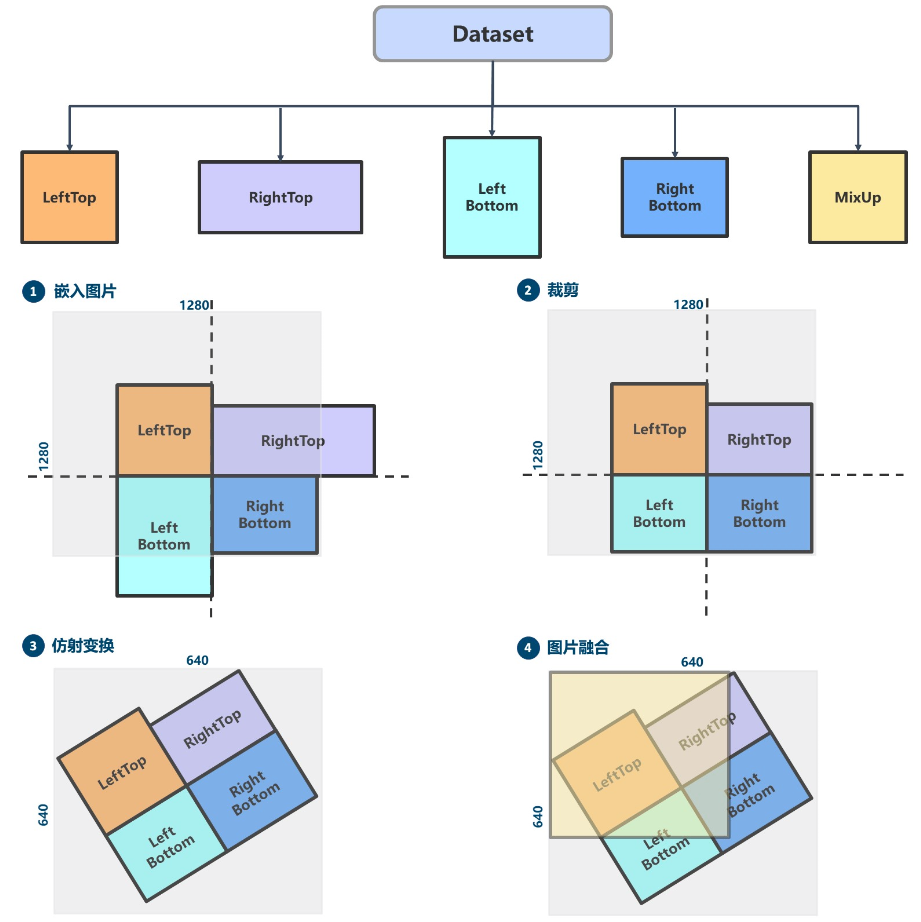
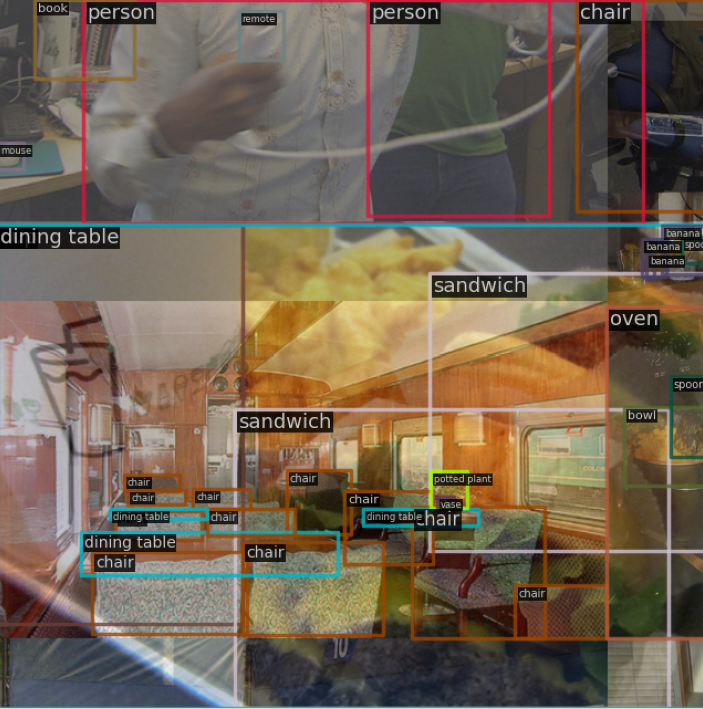
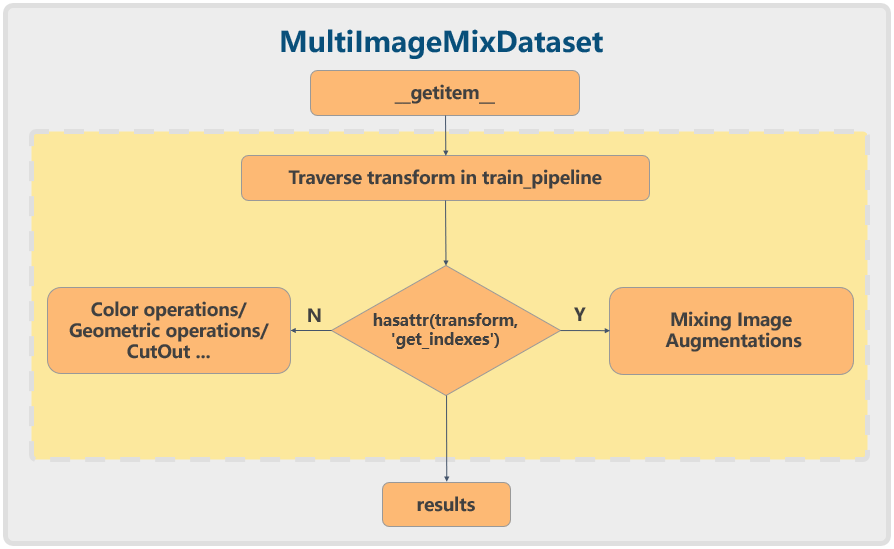
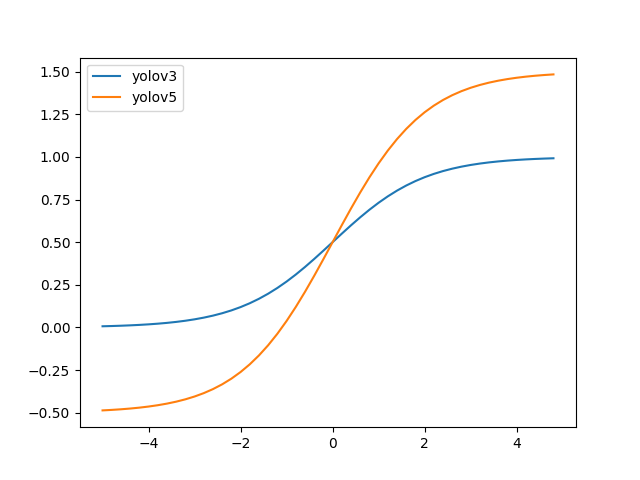
+# YOLOv5 原理和实现全解析
+
+## 0 简介
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+