From 3167c469693b5812cb6e49aa456bdd83dadb24e0 Mon Sep 17 00:00:00 2001
From: Nioolek <40284075+Nioolek@users.noreply.github.com>
Date: Sun, 18 Sep 2022 12:17:29 +0800
Subject: [PATCH] Add yolov5 head and doc (#14)
* add yolov5_description.md
* add yolov5_head.py
---
.../yolov5_description.md | 672 ++++++++++++++++++
mmyolo/models/dense_heads/__init__.py | 9 +
mmyolo/models/dense_heads/yolov5_head.py | 643 +++++++++++++++++
3 files changed, 1324 insertions(+)
create mode 100644 docs/zh_cn/algorithm_descriptions/yolov5_description.md
create mode 100644 mmyolo/models/dense_heads/__init__.py
create mode 100644 mmyolo/models/dense_heads/yolov5_head.py
diff --git a/docs/zh_cn/algorithm_descriptions/yolov5_description.md b/docs/zh_cn/algorithm_descriptions/yolov5_description.md
new file mode 100644
index 00000000..4cc629ef
--- /dev/null
+++ b/docs/zh_cn/algorithm_descriptions/yolov5_description.md
@@ -0,0 +1,672 @@
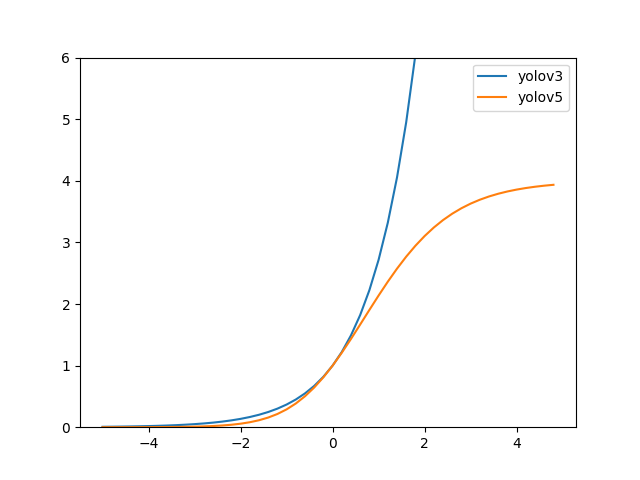
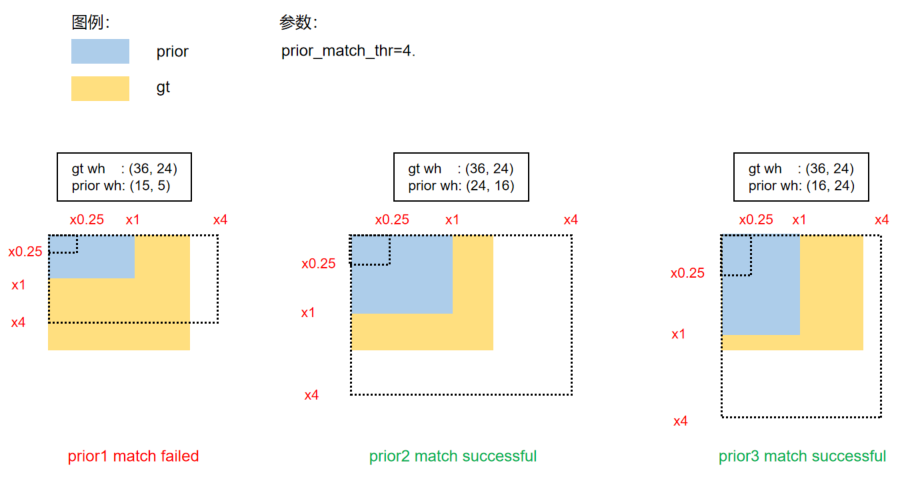
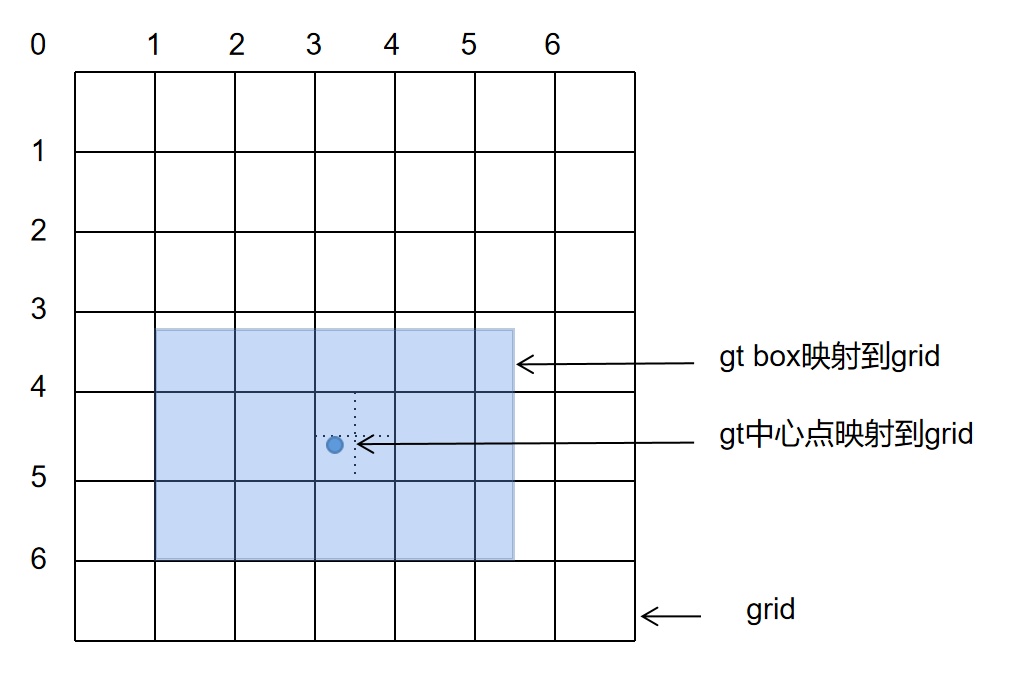
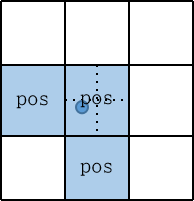
+# YOLOv5 原理和实现全解析
+
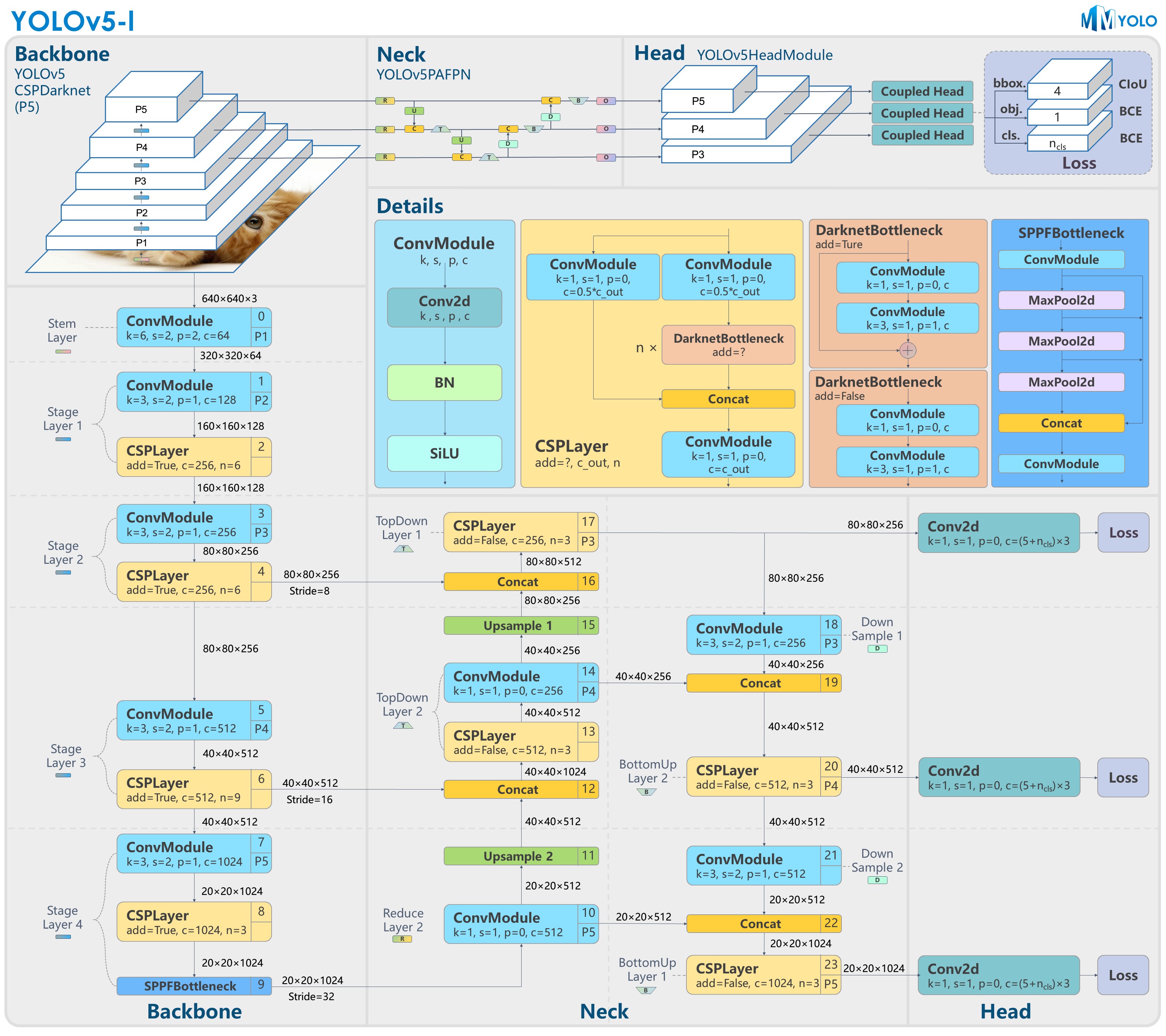
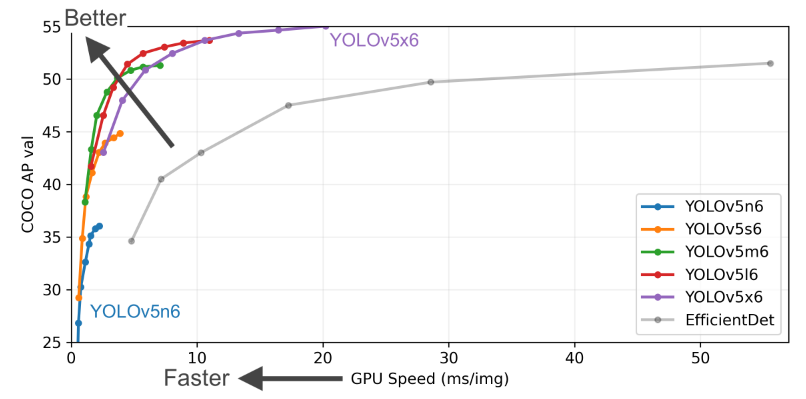
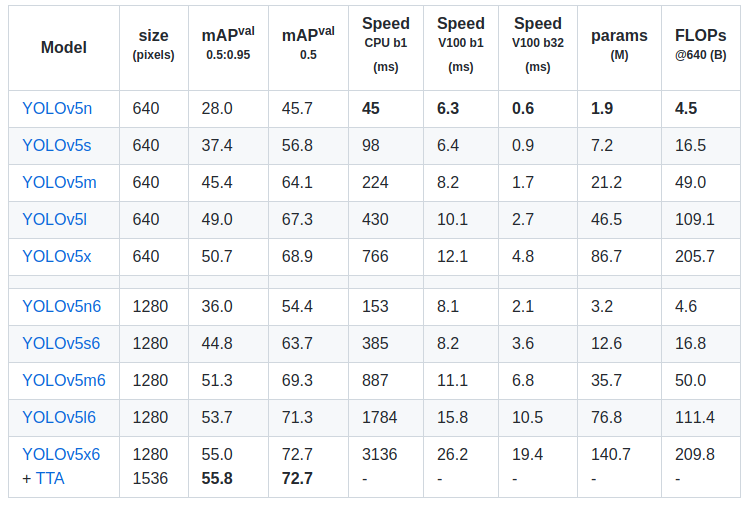
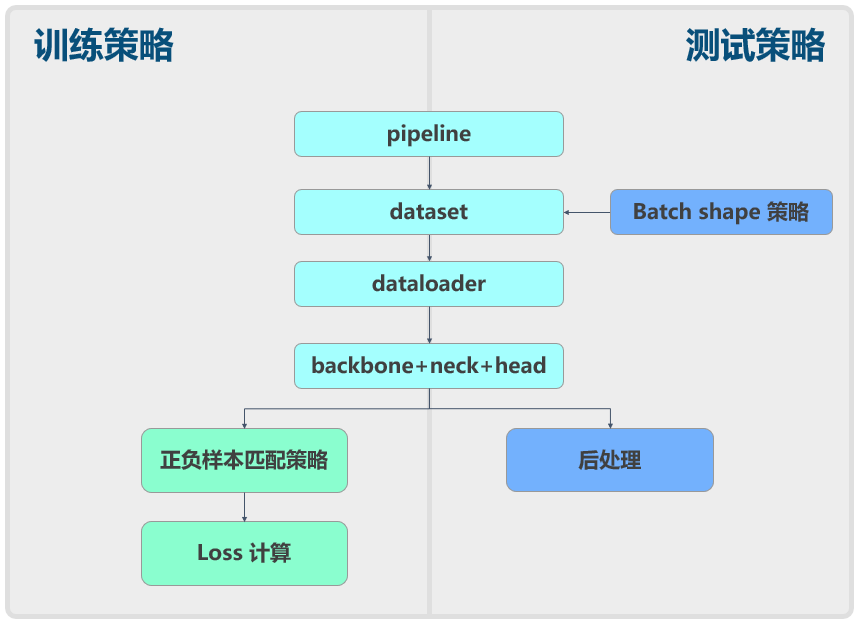
+## 0 简介
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+