From 5a96fcdec069b746a4677e17e8cb093c37a4761f Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Haian=20Huang=28=E6=B7=B1=E5=BA=A6=E7=9C=B8=29?=
<1286304229@qq.com>
Date: Mon, 20 Mar 2023 19:03:24 +0800
Subject: [PATCH] [Docs] Add training and testing tricks (#659)
* Add training_testing_tricks.md
* update
* update
* update
* update
* update
* update
* update
---
README.md | 1 +
README_zh-CN.md | 1 +
docs/en/index.rst | 1 +
.../training_testing_tricks.md | 1 +
docs/zh_cn/index.rst | 1 +
.../training_testing_tricks.md | 303 ++++++++++++++++++
6 files changed, 308 insertions(+)
create mode 100644 docs/en/recommended_topics/training_testing_tricks.md
create mode 100644 docs/zh_cn/recommended_topics/training_testing_tricks.md
diff --git a/README.md b/README.md
index 0960efd7..910c052f 100644
--- a/README.md
+++ b/README.md
@@ -184,6 +184,7 @@ For different parts from MMDetection, we have also prepared user guides and adva
Recommended Topics
- [How to contribute code to MMYOLO](docs/en/recommended_topics/contributing.md)
+- [Training testing tricks](docs/en/recommended_topics/training_testing_tricks.md)
- [MMYOLO model design](docs/en/recommended_topics/model_design.md)
- [Algorithm principles and implementation](docs/en/recommended_topics/algorithm_descriptions/)
- [Replace the backbone network](docs/en/recommended_topics/replace_backbone.md)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 5db71314..16838c22 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -205,6 +205,7 @@ MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也
推荐专题
- [如何给 MMYOLO 贡献代码](docs/zh_cn/recommended_topics/contributing.md)
+- [训练和测试技巧](docs/zh_cn/recommended_topics/training_testing_tricks.md)
- [MMYOLO 模型结构设计](docs/zh_cn/recommended_topics/model_design.md)
- [原理和实现全解析](docs/zh_cn/recommended_topics/algorithm_descriptions/)
- [轻松更换主干网络](docs/zh_cn/recommended_topics/replace_backbone.md)
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 1878c4e8..1a0ab6c3 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -19,6 +19,7 @@ You can switch between Chinese and English documents in the top-right corner of
:caption: Recommended Topics
recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
recommended_topics/model_design.md
recommended_topics/algorithm_descriptions/index.rst
recommended_topics/application_examples/index.rst
diff --git a/docs/en/recommended_topics/training_testing_tricks.md b/docs/en/recommended_topics/training_testing_tricks.md
new file mode 100644
index 00000000..5a3fb77b
--- /dev/null
+++ b/docs/en/recommended_topics/training_testing_tricks.md
@@ -0,0 +1 @@
+# Training testing tricks
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index 9fc716c8..9f150ac6 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -19,6 +19,7 @@
:caption: 推荐专题
recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
recommended_topics/model_design.md
recommended_topics/algorithm_descriptions/index.rst
recommended_topics/application_examples/index.rst
diff --git a/docs/zh_cn/recommended_topics/training_testing_tricks.md b/docs/zh_cn/recommended_topics/training_testing_tricks.md
new file mode 100644
index 00000000..6d9c57f4
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/training_testing_tricks.md
@@ -0,0 +1,303 @@
+# 训练和测试技巧
+
+MMYOLO 中已经支持了大部分 YOLO 系列目标检测相关算法。不同算法可能涉及到一些实用技巧。本章节将基于所实现的目标检测算法,详细描述 MMYOLO 中已经支持的常用的训练和测试技巧。
+
+## 训练技巧
+
+### 提升检测性能
+
+#### 1 开启多尺度训练
+
+在目标检测领域,多尺度训练是一个非常常用的技巧,但是在 YOLO 中大部分模型的训练输入都是单尺度的 640x640,原因有两个方面:
+
+1. 单尺度训练速度快。当训练 epoch 在 300 或者 500 的时候训练效率是用户非常关注的,多尺度训练会比较慢
+2. 训练 pipeline 中隐含了多尺度增强,等价于应用了多尺度训练,典型的如 `Mosaic`、`RandomAffine` 和 `Resize` 等,故没有必要再次引入模型输入的多尺度训练
+
+在 COCO 数据集上进行了简单实验,如果直接在 YOLOv5 的 DataLoader 输出后再次引入多尺度训练增强实际性能提升非常小,但是这不代表用户自定义数据集微调模式下没有明显增益。如果想在 MMYOLO 中对 YOLO 系列算法开启多尺度训练,可以参考 [多尺度训练文档](../common_usage/ms_training_testing.md)
+
+#### 2 使用 Mask 标注优化目标检测性能
+
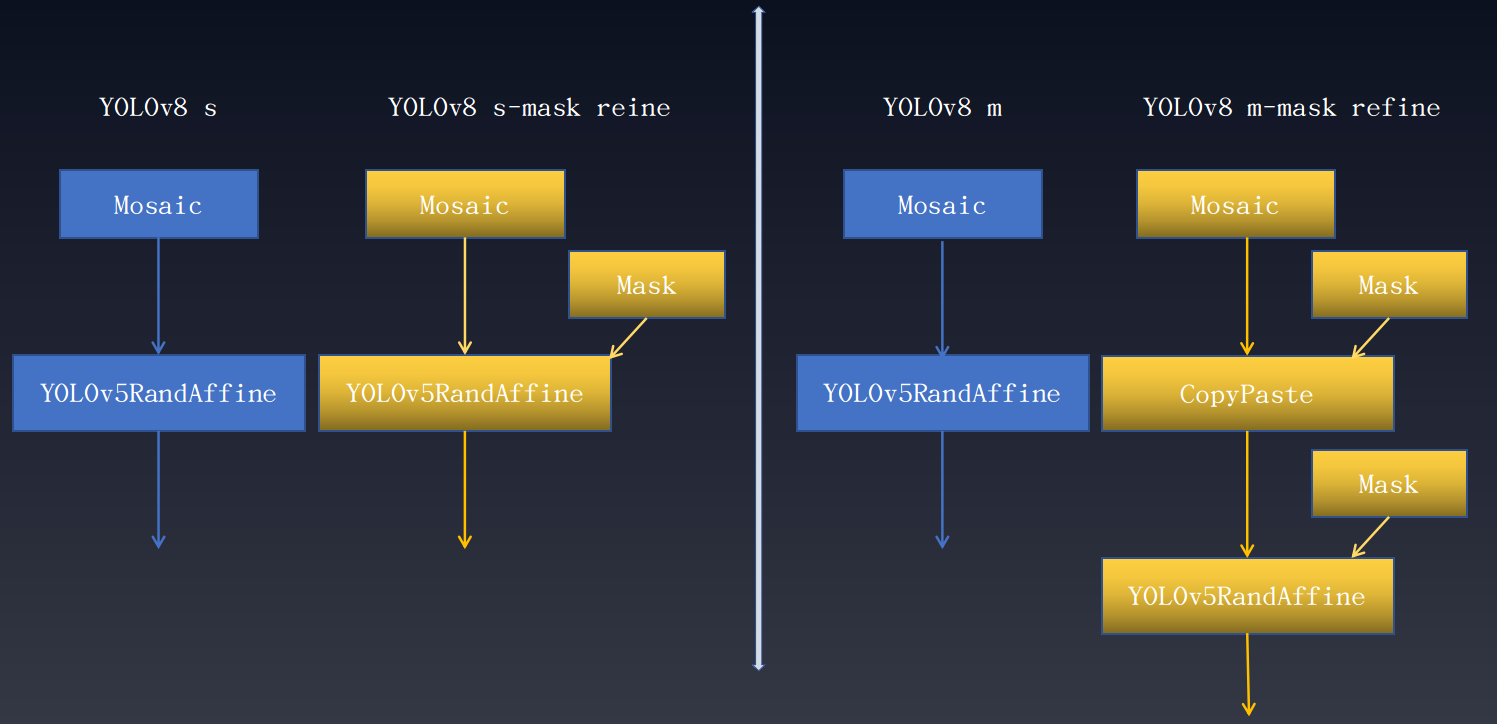
+在数据集标注完备例如同时存在边界框和实例分割标注但任务只需要其中部分标注情况下,可以借助完备的数据标注训练单一任务从而提升性能。在目标检测中同样可以借鉴实例分割标注来提升目标检测性能。 以下是 YOLOv8 额外引入实例分割标注优化目标检测结果。 性能增益如下所示:
+
+
+

+
+
+
+

+
+

+
+

+
+
+
+

+