# RTMDet 原理和实现全解析
## 0 简介
高性能,低延时的单阶段目标检测器
以上结构图由 RangeKing@github 绘制。
最近一段时间,开源界涌现出了大量的高精度目标检测项目,其中最突出的就是 YOLO 系列,OpenMMLab 也在与社区的合作下推出了 MMYOLO。
在调研了当前 YOLO 系列的诸多改进模型后,MMDetection 核心开发者针对这些设计以及训练方式进行了经验性的总结,并进行了优化,推出了高精度、低延时的单阶段目标检测器 RTMDet, **R**eal-**t**ime **M**odels for Object **Det**ection
(**R**elease **t**o **M**anufacture)
RTMDet 由 tiny/s/m/l/x 一系列不同大小的模型组成,为不同的应用场景提供了不同的选择。
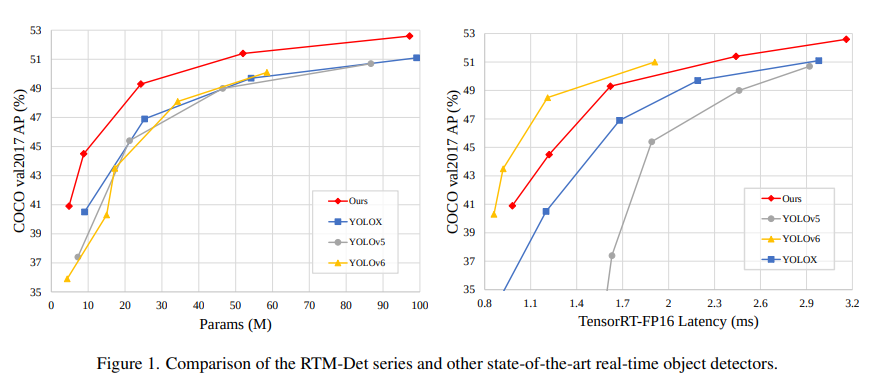
其中,RTMDet-x 在 52.6 mAP 的精度下达到了 300+ FPS 的推理速度。
```{note}
注:推理速度和精度测试(不包含 NMS)是在 1 块 NVIDIA 3090 GPU 上的 `TensorRT 8.4.3, cuDNN 8.2.0, FP16, batch size=1` 条件里测试的。
```
而最轻量的模型 RTMDet-tiny,在仅有 4M 参数量的情况下也能够达到 40.9 mAP,且推理速度 \< 1 ms。
上图中的精度是和 300 epoch 训练下的公平对比,为不使用蒸馏的结果。
| | mAP | Params | Flops | Inference speed |
| -------------------------- | --------------- | -------------- | ------------ | --------------- |
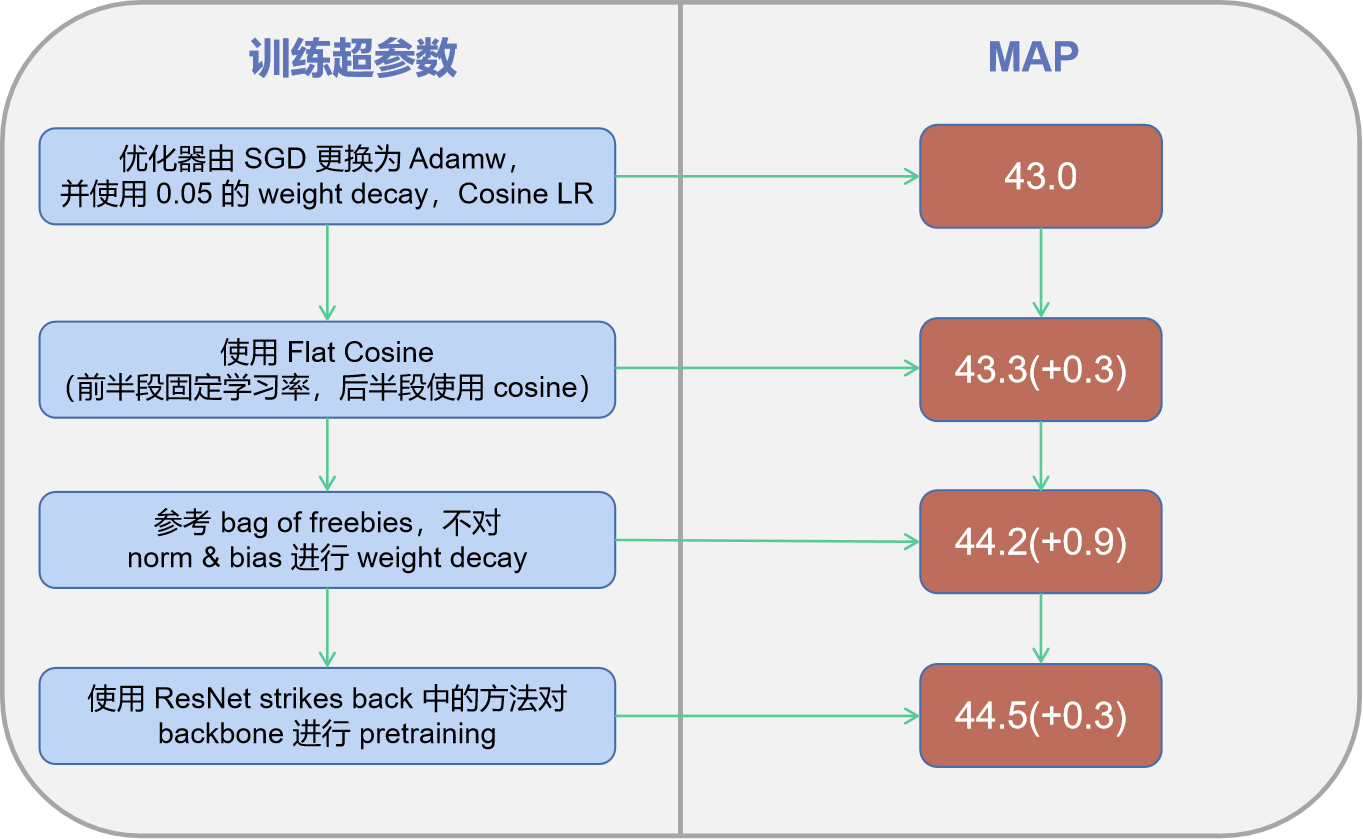
| Baseline(YOLOX) | 40.2 | 9M | 13.4G | 1.2ms |
| + AdamW + Flat Cosine | 40.6 (+0.4) | 9M | 13.4G | 1.2ms |
| + CSPNeXt backbone & PAFPN | 41.8 (+1.2) | 10.07M (+1.07) | 14.8G (+1.4) | 1.22ms (+0.02) |
| + SepBNHead | 41.8 (+0) | 8.89M (-1.18) | 14.8G | 1.22ms |
| + Label Assign & Loss | 42.9 (+1.1) | 8.89M | 14.8G | 1.22ms |
| + Cached Mosaic & MixUp | 44.2 (+1.3) | 8.89M | 14.8G | 1.22ms |
| + RSB-pretrained backbone | **44.5 (+0.3)** | 8.89M | 14.8G | 1.22ms |
- 官方开源地址: https://github.com/open-mmlab/mmdetection/blob/3.x/configs/rtmdet/README.md
- MMYOLO 开源地址: https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/README.md
## 1 v1.0 算法原理和 MMYOLO 实现解析
### 1.1 数据增强模块
RTMDet 采用了多种数据增强的方式来增加模型的性能,主要包括单图数据增强:
- **RandomResize 随机尺度变换**
- **RandomCrop 随机裁剪**
- **HSVRandomAug 颜色空间增强**
- **RandomFlip 随机水平翻转**
以及混合类数据增强:
- **Mosaic 马赛克**
- **MixUp 图像混合**
数据增强流程如下:
其中 RandomResize 超参在大模型 M,L,X 和小模型 S, Tiny 上是不一样的,大模型由于参数较多,可以使用 large scale jitter 策略即参数为 (0.1,2.0),而小模型采用 stand scale jitter 策略即 (0.5, 2.0) 策略。
MMDetection 开源库中已经对单图数据增强进行了封装,用户通过简单的修改配置即可使用库中提供的任何数据增强功能,且都是属于比较常规的数据增强,不需要特殊介绍。下面将具体介绍混合类数据增强的具体实现。
与 YOLOv5 不同的是,YOLOv5 认为在 S 和 Nano 模型上使用 MixUp 是过剩的,小模型不需要这么强的数据增强。而 RTMDet 在 S 和 Tiny 上也使用了 MixUp,这是因为 RTMDet 在最后 20 epoch 会切换为正常的 aug, 并通过训练证明这个操作是有效的。 并且 RTMDet 为混合类数据增强引入了 Cache 方案,有效地减少了图像处理的时间, 和引入了可调超参 `max_cached_images` ,当使用较小的 cache 时,其效果类似 `repeated augmentation`。具体介绍如下:
| | Use cache | ms / 100 imgs |
| ------ | --------- | ------------- |
| Mosaic | | 87.1 |
| Mosaic | √ | **24.0** |
| MixUp | | 19.3 |
| MixUp | √ | **12.4** |
| | RTMDet-s | RTMDet-l |
| ----------------------------- | -------- | -------- |
| Mosaic + MixUp + 20e finetune | 43.9 | **51.3** |
#### 1.1.1 为图像混合数据增强引入 Cache
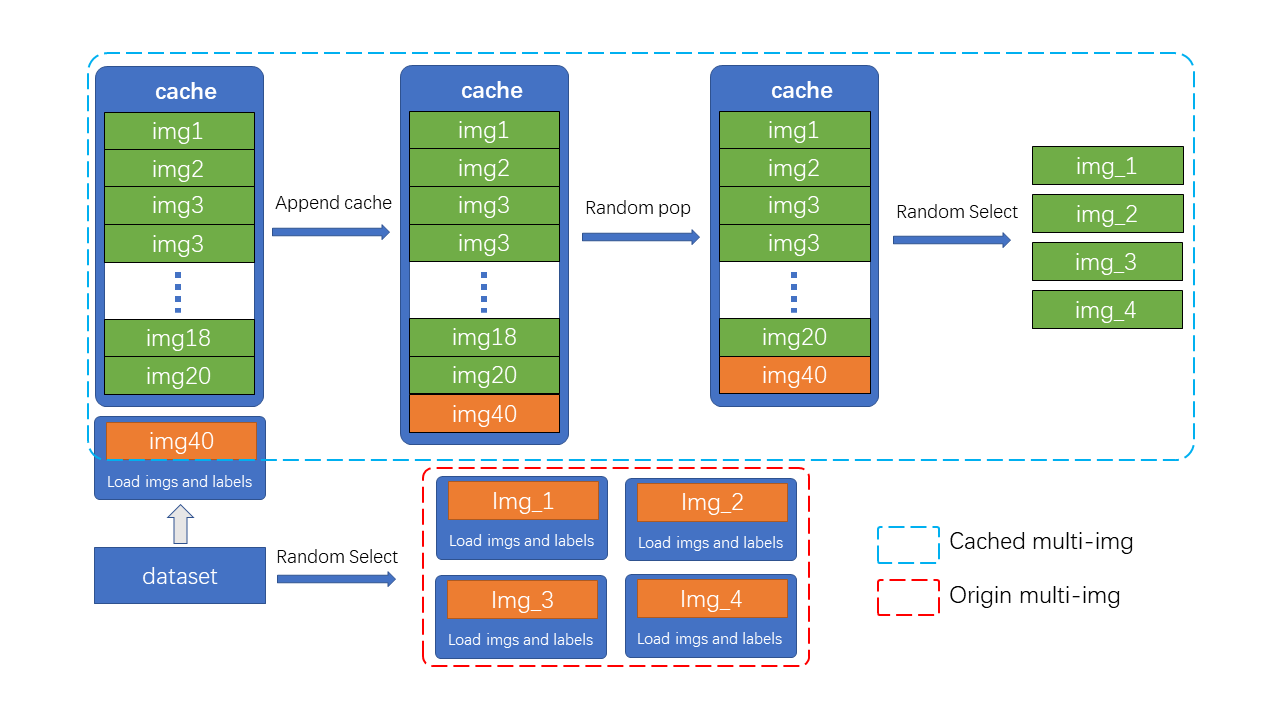
Mosaic&MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 K 倍(K 为混入图片的数量)。 如在 YOLOv5 中,每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而 RTMDet 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。 另外通过调整 cache 的大小以及 pop 的方式,也可以调整增强的强度。
如图所示,cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图(为了 Tiny 模型训练更稳定,在 Tiny 模型中不采用随机 pop 的方式, 而是移除最先加入的图片),当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
```{note}
cache 队列的最大长度 N 为可调整参数,根据经验性的原则,当为每一张需要混合的图片提供十个缓存时,可以认为提供了足够的随机性,而 Mosaic 增强是四张图混合,因此 cache 数量默认 N=40, 同理 MixUp 的 cache 数量默认为20, tiny 模型需要更稳定的训练条件,因此其 cache 数量也为其余规格模型的一半( MixUp 为10,Mosaic 为20)
```
在具体实现中,MMYOLO 设计了 `BaseMiximageTransform` 类来支持多张图像混合数据增强:
```python
if self.use_cached:
# Be careful: deep copying can be very time-consuming
# if results includes dataset.
dataset = results.pop('dataset', None)
self.results_cache.append(copy.deepcopy(results)) # 将当前加载的图片数据缓存到 cache 中
if len(self.results_cache) > self.max_cached_images:
if self.random_pop: # 除了tiny模型,self.random_pop=True
index = random.randint(0, len(self.results_cache) - 1)
else:
index = 0
self.results_cache.pop(index)
if len(self.results_cache) <= 4:
return results
else:
assert 'dataset' in results
# Be careful: deep copying can be very time-consuming
# if results includes dataset.
dataset = results.pop('dataset', None)
```
#### 1.1.2 Mosaic
Mosaic 是将 4 张图拼接为 1 张大图,相当于变相的增加了 batch size,具体步骤为:
1. 根据索引随机从自定义数据集中再采样3个图像,可能重复
```python
def get_indexes(self, dataset: Union[BaseDataset, list]) -> list:
"""Call function to collect indexes.
Args:
dataset (:obj:`Dataset` or list): The dataset or cached list.
Returns:
list: indexes.
"""
indexes = [random.randint(0, len(dataset)) for _ in range(3)]
return indexes
```
2. 随机选出 4 幅图像相交的中点。
```python
# mosaic center x, y
center_x = int(
random.uniform(*self.center_ratio_range) * self.img_scale[1])
center_y = int(
random.uniform(*self.center_ratio_range) * self.img_scale[0])
center_position = (center_x, center_y)
```
3. 根据采样的 index 读取图片并拼接, 拼接前会先进行 `keep-ratio` 的 resize 图片(即为最大边一定是 640)。
```python
# keep_ratio resize
scale_ratio_i = min(self.img_scale[0] / h_i,
self.img_scale[1] / w_i)
img_i = mmcv.imresize(
img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
```
4. 拼接后,把 bbox 和 label 全部拼接起来,然后对 bbox 进行裁剪但是不过滤(可能出现一些无效框)
```python
mosaic_bboxes.clip_([2 * self.img_scale[0], 2 * self.img_scale[1]])
```
更多的关于 Mosaic 原理的详情可以参考 [YOLOv5 原理和实现全解析](./yolov5_description.md) 中的 Mosaic 原理分析。
#### 1.1.3 MixUp
RTMDet 的 MixUp 实现方式与 YOLOX 中一样,只不过增加了类似上文中提到的 cache 功能。
更多的关于 MixUp 原理的详情也可以参考 [YOLOv5 原理和实现全解析](./yolov5_description.md) 中的 MixUp 原理分析。
#### 1.1.4 强弱两阶段训练
Mosaic+MixUp 失真度比较高,持续用太强的数据增强对模型并不一定有益。YOLOX 中率先使用了强弱两阶段的训川练方式,但由于引入了旋转,切片导致 box 标注产生误差,需要在第二阶段引入额外的 L1oss 来纠正回归分支的性能。
为了使数据增强的方式更为通用,RTMDet 在前 280 epoch 使用不带旋转的 Mosaic+MixUp, 且通过混入 8 张图片来提升强度以及正样本数。后 20 epoch 使用比较小的学习率在比较弱的增强下进行微调,同时在 EMA 的作用下将参数缓慢更新至模型,能够得到比较大的提升。
| | RTMDet-s | RTMDet-l |
| ----------------------------- | -------- | -------- |
| LSJ + rand crop | 42.3 | 46.7 |
| Mosaic+MixUp | 41.9 | 49.8 |
| Mosaic + MixUp + 20e finetune | 43.9 | **51.3** |
### 1.2 模型结构
RTMDet 模型整体结构和 [YOLOX](https://arxiv.org/abs/2107.08430) 几乎一致,由 `CSPNeXt` + `CSPNeXtPAFPN` + `共享卷积权重但分别计算 BN 的 SepBNHead` 构成。内部核心模块也是 `CSPLayer`,但对其中的 `Basic Block` 进行了改进,提出了 `CSPNeXt Block`。
#### 1.2.1 Backbone
`CSPNeXt` 整体以 `CSPDarknet` 为基础,共 5 层结构,包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`:
- `Stem Layer` 是 3 层 3x3 kernel 的 `ConvModule` ,不同于之前的 `Focus` 模块或者 1 层 6x6 kernel 的 `ConvModule` 。
- `Stage Layer` 总体结构与已有模型类似,前 3 个 `Stage Layer` 由 1 个 `ConvModule` 和 1 个 `CSPLayer` 组成。第 4 个 `Stage Layer` 在 `ConvModule` 和 `CSPLayer` 中间增加了 `SPPF` 模块(MMDetection 版本为 `SPP` 模块)。
- 如模型图 Details 部分所示,`CSPLayer` 由 3 个 `ConvModule` + n 个 `CSPNeXt Block`(带残差连接) + 1 个 `Channel Attention` 模块组成。`ConvModule` 为 1 层 3x3 `Conv2d` + `BatchNorm` + `SiLU` 激活函数。`Channel Attention` 模块为 1 层 `AdaptiveAvgPool2d` + 1 层 1x1 `Conv2d` + `Hardsigmoid` 激活函数。`CSPNeXt Block` 模块在下节详细讲述。
- 如果想阅读 Backbone - `CSPNeXt` 的源码,可以 [**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L16-L171) 跳转。
#### 1.2.2 CSPNeXt Block
Darknet (图 a)使用 1x1 与 3x3 卷积的 `Basic Block`。[YOLOv6](https://arxiv.org/abs/2209.02976) 、[YOLOv7](https://arxiv.org/abs/2207.02696) 、[PPYOLO-E](https://arxiv.org/abs/2203.16250) (图 b & c)使用了重参数化 Block。但重参数化的训练代价高,且不易量化,需要其他方式来弥补量化误差。
RTMDet 则借鉴了最近比较热门的 [ConvNeXt](https://arxiv.org/abs/2201.03545) 、[RepLKNet](https://arxiv.org/abs/2203.06717) 的做法,为 `Basic Block` 加入了大 kernel 的 `depth-wise` 卷积(图 d),并将其命名为 `CSPNeXt Block`。
关于不同 kernel 大小的实验结果,如下表所示。
| Kernel size | params | flops | latency-bs1-TRT-FP16 / ms | mAP |
| ------------ | ---------- | --------- | ------------------------- | -------- |
| 3x3 | 50.8 | 79.61G | 2.1 | 50.0 |
| **5x5** | **50.92M** | **79.7G** | **2.11** | **50.9** |
| 7x7 | 51.1 | 80.34G | 2.73 | 51.1 |
如果想阅读 `Basic Block` 和 `CSPNeXt Block` 源码,可以[**点此**](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/layers/csp_layer.py#L79-L146)跳转。
#### 1.2.3 调整检测器不同 stage 间的 block 数
由于 `CSPNeXt Block` 内使用了 `depth-wise` 卷积,单个 block 内的层数增多。如果保持原有的 stage 内的 block 数,则会导致模型的推理速度大幅降低。
RTMDet 重新调整了不同 stage 间的 block 数,并调整了通道的超参,在保证了精度的情况下提升了推理速度。
关于不同 block 数的实验结果,如下表所示。
| Num blocks | params | flops | latency-bs1-TRT-FP16 / ms | mAP |
| ---------------------------------- | --------- | --------- | ------------------------- | -------- |
| L+3-9-9-3 | 53.4 | 86.28 | 2.6 | 51.4 |
| L+3-6-6-3 | 50.92M | 79.7G | 2.11 | 50.9 |
| **L+3-6-6-3 + channel attention** | **52.3M** | **79.9G** | **2.4** | **51.3** |
最后不同大小模型的 block 数设置,可以参见[源码](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/backbones/cspnext.py#L50-L56) 。
#### 1.2.4 Neck
Neck 模型结构和 YOLOX 几乎一样,只不过内部的 block 进行了替换。
#### 1.2.5 Backbone 与 Neck 之间的参数量和计算量的均衡
[EfficientDet](https://arxiv.org/abs/1911.09070) 、[NASFPN](https://arxiv.org/abs/1904.07392) 等工作在改进 Neck 时往往聚焦于如何修改特征融合的方式。 但引入过多的连接会增加检测器的延时,并增加内存开销。
所以 RTMDet 选择不引入额外的连接,而是改变 Backbone 与 Neck 间参数量的配比。该配比是通过手动调整 Backbone 和 Neck 的 `expand_ratio` 参数来实现的,其数值在 Backbone 和 Neck 中都为 0.5。`expand_ratio` 实际上是改变 `CSPLayer` 中各层通道数的参数(具体可见模型图 `CSPLayer` 部分)。如果想进行不同配比的实验,可以通过调整配置文件中的 [backbone {expand_ratio}](https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py#L32) 和 [neck {expand_ratio}](https://github.com/open-mmlab/mmyolo/blob/main/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py#L45) 参数完成。
实验发现,当 Neck 在整个模型中的参数量占比更高时,延时更低,且对精度的影响很小。作者在直播答疑时回复,RTMDet 在 Neck 这一部分的实验参考了 [GiraffeDet](https://arxiv.org/abs/2202.04256) 的做法,但没有像 GiraffeDet 一样引入额外连接(详细可参见 [RTMDet 发布视频](https://www.bilibili.com/video/BV1e841147GD) 31分40秒左右的内容)。
关于不同参数量配比的实验结果,如下表所示。
| Model size | Backbone | Neck | params | flops | latency / ms | mAP |
| ----------- | -------- | ------- | ---------- | ---------- | ------------- | -------- |
| **S** | **47%** | **45%** | **8.54M** | **15.76G** | **1.21** | **43.9** |
| S | 63% | 29% | 9.01M | 15.85G | 1.37 | 43.7 |
| **L** | **47%** | **45%** | **50.92M** | **79.7G** | **2.11** | **50.9** |
| L | 63% | 29% | 57.43M | 93.73 | 2.57 | 51.0 |
如果想阅读 Neck - `CSPNeXtPAFPN` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/necks/cspnext_pafpn.py#L15-L201) 跳转。
#### 1.2.6 Head
传统的 YOLO 系列都使用同一 Head 进行分类和回归。YOLOX 则将分类和回归分支解耦,PPYOLO-E 和 YOLOv6 则引入了 [TOOD](https://arxiv.org/abs/2108.07755) 中的结构。它们在不同特征层级之间都使用独立的 Head,因此 Head 在模型中也占有较多的参数量。
RTMDet 参考了 [NAS-FPN](https://arxiv.org/abs/1904.07392) 中的做法,使用了 `SepBNHead`,在不同层之间共享卷积权重,但是独立计算 BN(BatchNorm) 的统计量。
关于不同结构 Head 的实验结果,如下表所示。
| Head type | params | flops | latency / ms | mAP |
| ------------------ | --------- | --------- | ------------- | -------- |
| Fully-shared head | 52.32 | 80.23 | 2.44 | 48.0 |
| Separated head | 57.03 | 80.23 | 2.44 | 51.2 |
| **SepBN** **head** | **52.32** | **80.23** | **2.44** | **51.3** |
同时,RTMDet 也延续了作者之前在 [NanoDet](https://zhuanlan.zhihu.com/p/306530300) 中的思想,使用 [Quality Focal Loss](https://arxiv.org/abs/2011.12885) ,并去掉 Objectness 分支,进一步将 Head 轻量化。
如果想阅读 Head 中 `RTMDetSepBNHeadModule` 的源码,可以[**点此**](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/dense_heads/rtmdet_head.py#L24-L189) 跳转。
```{note}
注:MMYOLO 和 MMDetection 中 Neck 和 Head 的具体实现稍有不同。
```
### 1.3 正负样本匹配策略
正负样本匹配策略或者称为标签匹配策略 `Label Assignment` 是目标检测模型训练中最核心的问题之一, 更好的标签匹配策略往往能够使得网络更好学习到物体的特征以提高检测能力。
早期的样本标签匹配策略一般都是基于 `空间以及尺度信息的先验` 来决定样本的选取。 典型案例如下:
- `FCOS` 中先限定网格中心点在 `GT` 内筛选后然后再通过不同特征层限制尺寸来决定正负样本
- `RetinaNet` 则是通过 `Anchor` 与 `GT` 的最大 `IOU` 匹配来划分正负样本
- `YOLOV5` 的正负样本则是通过样本的宽高比先筛选一部分, 然后通过位置信息选取 `GT` 中心落在的 `Grid` 以及临近的两个作为正样本
但是上述方法都是属于基于 `先验` 的静态匹配策略, 就是样本的选取方式是根据人的经验规定的。 不会随着网络的优化而进行自动优化选取到更好的样本, 近些年涌现了许多优秀的动态标签匹配策略:
- `OTA` 提出使用 `Sinkhorn` 迭代求解匹配中的最优传输问题
- `YOLOX` 中使用 `OTA` 的近似算法 `SimOTA` , `TOOD` 将分类分数以及 `IOU` 相乘计算 `Cost` 矩阵进行标签匹配等等
这些算法将 `预测的 Bboxes 与 GT 的 IOU ` 和 `分类分数` 或者是对应 `分类 Loss` 和 `回归 Loss` 拿来计算 `Matching Cost` 矩阵再通过 `top-k` 的方式动态决定样本选取以及样本个数。通过这种方式,
在网络优化的过程中会自动选取对分类或者回归更加敏感有效的位置的样本, 它不再只依赖先验的静态的信息, 而是使用当前的预测结果去动态寻找最优的匹配, 只要模型的预测越准确, 匹配算法求得的结果也会更优秀。但是在网络训练的初期, 网络的分类以及回归是随机初始化, 这个时候还是需要 `先验` 来约束, 以达到 `冷启动` 的效果。
`RTMDet` 作者也是采用了动态的 `SimOTA` 做法,不过其对动态的正负样本分配策略进行了改进。 之前的动态匹配策略( `HungarianAssigner` 、`OTA` )往往使用与 `Loss` 完全一致的代价函数作为匹配的依据,但我们经过实验发现这并不一定时最优的。 使用更多 `Soften` 的 `Cost` 以及先验,能够提升性能。
#### 1.3.1 Bbox 编解码过程
RTMDet 的 BBox Coder 采用的是 `mmdet.DistancePointBBoxCoder`。
该类的 docstring 为 `This coder encodes gt bboxes (x1, y1, x2, y2) into (top, bottom, left, right) and decode it back to the original.`
编码器将 gt bboxes (x1, y1, x2, y2) 编码为 (top, bottom, left, right),并且解码至原图像上。
MMDet 编码的核心源码:
```python
def bbox2distance(points: Tensor, bbox: Tensor, ...) -> Tensor:
"""
points (Tensor): 相当于 scale 值 stride ,且每个预测点仅为一个正方形 anchor 的 anchor point [x, y],Shape (n, 2) or (b, n, 2).
bbox (Tensor): Bbox 为乘上 stride 的网络预测值,格式为 xyxy,Shape (n, 4) or (b, n, 4).
"""
# 计算点距离四边的距离
left = points[..., 0] - bbox[..., 0]
top = points[..., 1] - bbox[..., 1]
right = bbox[..., 2] - points[..., 0]
bottom = bbox[..., 3] - points[..., 1]
...
return torch.stack([left, top, right, bottom], -1)
```
MMDetection 解码的核心源码:
```python
def distance2bbox(points: Tensor, distance: Tensor, ...) -> Tensor:
"""
通过距离反算 bbox 的 xyxy
points (Tensor): 正方形的预测 anchor 的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
distance (Tensor): 距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
"""
# 反算 bbox xyxy
x1 = points[..., 0] - distance[..., 0]
y1 = points[..., 1] - distance[..., 1]
x2 = points[..., 0] + distance[..., 2]
y2 = points[..., 1] + distance[..., 3]
bboxes = torch.stack([x1, y1, x2, y2], -1)
...
return bboxes
```
#### 1.3.2 匹配策略
`RTMDet` 提出了 `Dynamic Soft Label Assigner` 来实现标签的动态匹配策略, 该方法主要包括使用 **位置先验信息损失** , **样本回归损失** , **样本分类损失** , 同时对三个损失进行了 `Soft` 处理进行参数调优, 以达到最佳的动态匹配效果。
该方法 Matching Cost 矩阵由如下损失构成:
```python
cost_matrix = soft_cls_cost + iou_cost + soft_center_prior
```
1. Soft_Center_Prior
```{math}
C\_{center} = \\alpha^{|x\_{pred}-x\_{gt}|-\\beta}
```
```python
# valid_prior Tensor[N,4] 表示anchor point
# 4分别表示 x, y, 以及对应的特征层的 stride, stride
gt_center = (gt_bboxes[:, :2] + gt_bboxes[:, 2:]) / 2.0
valid_prior = priors[valid_mask]
strides = valid_prior[:, 2]
# 计算gt与anchor point的中心距离并转换到特征图尺度
distance = (valid_prior[:, None, :2] - gt_center[None, :, :]
).pow(2).sum(-1).sqrt() / strides[:, None]
# 以10为底计算位置的软化损失,限定在gt的6个单元格以内
soft_center_prior = torch.pow(10, distance - 3)
```
2. IOU_Cost
```{math}
C\_{reg} = -log(IOU)
```
```python
# 计算回归 bboxes 和 gts 的 iou
pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
# 将 iou 使用 log 进行 soft , iou 越小 cost 更小
iou_cost = -torch.log(pairwise_ious + EPS) * 3
```
3. Soft_Cls_Cost
```{math}
C\_{cls} = CE(P,Y\_{soft}) \*(Y\_{soft}-P)^2
```
```python
# 生成分类标签
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64),
pred_scores.shape[-1]).float().unsqueeze(0).repeat(
num_valid, 1, 1))
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1)
# 不单单将分类标签为01,而是换成与 gt 的 iou
soft_label = gt_onehot_label * pairwise_ious[..., None]
# 使用 quality focal loss 计算分类损失 cost ,与实际的分类损失计算保持一致
scale_factor = soft_label - valid_pred_scores.sigmoid()
soft_cls_cost = F.binary_cross_entropy_with_logits(
valid_pred_scores, soft_label,
reduction='none') * scale_factor.abs().pow(2.0)
soft_cls_cost = soft_cls_cost.sum(dim=-1)
```
通过计算上述三个损失的和得到最终的 `cost_matrix` 后, 再使用 `SimOTA` 决定每一个 `GT` 匹配的样本的个数并决定最终的样本。具体操作如下所示:
1. 首先通过自适应计算每一个 `gt` 要选取的样本数量: 取每一个 `gt` 与所有 `bboxes` 前 `13` 大的 `iou`, 得到它们的和取整后作为这个 `gt` 的 `样本数目` , 最少为 `1` 个, 记为 `dynamic_ks`。
2. 对于每一个 `gt` , 将其 `cost_matrix` 矩阵前 `dynamic_ks` 小的位置作为该 `gt` 的正样本。
3. 对于某一个 `bbox`, 如果被匹配到多个 `gt` 就将与这些 `gts` 的 `cost_marix` 中最小的那个作为其 `label`。
在网络训练初期,因参数初始化,回归和分类的损失值 `Cost` 往往较大, 这时候 `IOU` 比较小, 选取的样本较少,主要起作用的是 `Soft_center_prior` 也就是位置信息,优先选取位置距离 `GT` 比较近的样本作为正样本,这也符合人们的理解,在网络前期给少量并且有足够质量的样本,以达到冷启动。
当网络进行训练一段时间过后,分类分支和回归分支都进行了一定的优化后,这时 `IOU` 变大, 选取的样本也逐渐增多,这时网络也有能力学习到更多的样本,同时因为 `IOU_Cost` 以及 `Soft_Cls_Cost` 变小,网络也会动态的找到更有利优化分类以及回归的样本点。
在 `Resnet50-1x` 的三种损失的消融实验:
| Soft_cls_cost | Soft_center_prior | Log_IoU_cost | mAP |
| :------------ | :---------------- | :----------- | :--- |
| × | × | × | 39.9 |
| √ | × | × | 40.3 |
| √ | √ | × | 40.8 |
| √ | √ | √ | 41.3 |
与其他主流 `Assign` 方法在 `Resnet50-1x` 的对比实验:
| method | mAP |
| :-----------: | :--- |
| ATSS | 39.2 |
| PAA | 40.4 |
| OTA | 40.7 |
| TOOD(w/o TAH) | 40.7 |
| Ours | 41.3 |
无论是 `Resnet50-1x` 还是标准的设置下,还是在`300epoch` + `havy augmentation`, 相比于 `SimOTA` 、 `OTA` 以及 `TOOD` 中的 `TAL` 均有提升。
| 300e + Mosaic & MixUP | mAP |
| :-------------------- | :--- |
| RTMDet-s + SimOTA | 43.2 |
| RTMDet-s + DSLA | 44.5 |
### 1.4 Loss 设计
参与 Loss 计算的共有两个值:`loss_cls` 和 `loss_bbox`,其各自使用的 Loss 方法如下:
- `loss_cls`:`mmdet.QualityFocalLoss`
- `loss_bbox`:`mmdet.GIoULoss`
权重比例是:`loss_cls` : `loss_bbox` = `1 : 2`
#### QualityFocalLoss
Quality Focal Loss (QFL) 是 [Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection](https://arxiv.org/abs/2006.04388) 的一部分。
普通的 Focal Loss 公式:
```{math}
{FL}(p) = -(1-p_t)^\gamma\log(p_t),p_t = \begin{cases}
p, & {when} \ y = 1 \\
1 - p, & {when} \ y = 0
\end{cases}
```
其中 {math}`y\in{1,0}` 指定真实类,{math}`p\in[0,1]` 表示标签 {math}`y = 1` 的类估计概率。{math}`\gamma` 是可调聚焦参数。具体来说,FL 由标准交叉熵部分 {math}`-\log(p_t)` 和动态比例因子部分 {math}`-(1-p_t)^\gamma` 组成,其中比例因子 {math}`-(1-p_t)^\gamma` 在训练期间自动降低简单类对于 loss 的比重,并且迅速将模型集中在困难类上。
首先 {math}`y = 0` 表示质量得分为 0 的负样本,{math}`0 < y \leq 1` 表示目标 IoU 得分为 y 的正样本。为了针对连续的标签,扩展 FL 的两个部分:
1. 交叉熵部分 {math}`-\log(p_t)` 扩展为完整版本 {math}`-((1-y)\log(1-\sigma)+y\log(\sigma))`
2. 比例因子部分 {math}`-(1-p_t)^\gamma` 被泛化为估计 {math}`\gamma` 与其连续标签 {math}`y` 的绝对距离,即 {math}`|y-\sigma|^\beta (\beta \geq 0)` 。
结合上面两个部分之后,我们得出 QFL 的公式:
```{math}
{QFL}(\sigma) = -|y-\sigma|^\beta((1-y)\log(1-\sigma)+y\log(\sigma))
```
具体作用是:可以将离散标签的 `focal loss` 泛化到连续标签上,将 bboxes 与 gt 的 IoU 的作为分类分数的标签,使得分类分数为表征回归质量的分数。
MMDetection 实现源码的核心部分:
```python
@weighted_loss
def quality_focal_loss(pred, target, beta=2.0):
"""
pred (torch.Tensor): 用形状(N,C)联合表示预测分类和质量(IoU),C是类的数量。
target (tuple([torch.Tensor])): 目标类别标签的形状为(N,),目标质量标签的形状是(N,,)。
beta (float): 计算比例因子的 β 参数.
"""
...
# label表示类别id,score表示质量分数
label, score = target
# 负样本质量分数0来进行监督
pred_sigmoid = pred.sigmoid()
scale_factor = pred_sigmoid
zerolabel = scale_factor.new_zeros(pred.shape)
# 计算交叉熵部分的值
loss = F.binary_cross_entropy_with_logits(
pred, zerolabel, reduction='none') * scale_factor.pow(beta)
# 得出 IoU 在区间 (0,1] 的 bbox
# FG cat_id: [0, num_classes -1], BG cat_id: num_classes
bg_class_ind = pred.size(1)
pos = ((label >= 0) & (label < bg_class_ind)).nonzero().squeeze(1)
pos_label = label[pos].long()
# 正样本由 IoU 范围在 (0,1] 的 bbox 来监督
# 计算动态比例因子
scale_factor = score[pos] - pred_sigmoid[pos, pos_label]
# 计算两部分的 loss
loss[pos, pos_label] = F.binary_cross_entropy_with_logits(
pred[pos, pos_label], score[pos],
reduction='none') * scale_factor.abs().pow(beta)
# 得出最终 loss
loss = loss.sum(dim=1, keepdim=False)
return loss
```
#### GIoULoss
论文:[Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression](https://arxiv.org/abs/1902.09630)
GIoU Loss 用于计算两个框重叠区域的关系,重叠区域越大,损失越小,反之越大。而且 GIoU 是在 \[0,2\] 之间,因为其值被限制在了一个较小的范围内,所以网络不会出现剧烈的波动,证明了其具有比较好的稳定性。
下图是基本的实现流程图:
MMDetection 实现源码的核心部分:
```python
def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):
...
# 求两个区域的面积
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (
bboxes1[..., 3] - bboxes1[..., 1])
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (
bboxes2[..., 3] - bboxes2[..., 1])
if is_aligned:
# 得出两个 bbox 重合的左上角 lt 和右下角 rb
lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [B, rows, 2]
rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [B, rows, 2]
# 求重合面积
wh = fp16_clamp(rb - lt, min=0)
overlap = wh[..., 0] * wh[..., 1]
if mode in ['iou', 'giou']:
...
else:
union = area1
if mode == 'giou':
# 得出两个 bbox 最小凸闭合框的左上角 lt 和右下角 rb
enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])
enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])
else:
...
# 求重合面积 / gt bbox 面积 的比率,即 IoU
eps = union.new_tensor([eps])
union = torch.max(union, eps)
ious = overlap / union
...
# 求最小凸闭合框面积
enclose_wh = fp16_clamp(enclosed_rb - enclosed_lt, min=0)
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
enclose_area = torch.max(enclose_area, eps)
# 计算 giou
gious = ious - (enclose_area - union) / enclose_area
return gious
@weighted_loss
def giou_loss(pred, target, eps=1e-7):
gious = bbox_overlaps(pred, target, mode='giou', is_aligned=True, eps=eps)
loss = 1 - gious
return loss
```
### 1.5 优化策略和训练过程
### 1.6 推理和后处理过程
**(1) 特征图输入**
预测的图片输入大小为 640 x 640, 通道数为 3 ,经过 CSPNeXt, CSPNeXtPAFPN 层的 8 倍、16 倍、32 倍下采样得到 80 x 80, 40 x 40, 20 x 20 三个尺寸的特征图。以 rtmdet-l 模型为例,此时三层通道数都为 256,经过 `bbox_head` 层得到两个分支,分别为 `rtm_cls` 类别预测分支,将通道数从 256 变为 80,80 对应所有类别数量; `rtm_reg` 边框回归分支将通道数从 256 变为 4,4 代表框的坐标。
**(2) 初始化网格**
根据特征图尺寸初始化三个网格,大小分别为 6400 (80 x 80)、1600 (40 x 40)、400 (20 x 20),如第一个层 shape 为 torch.Size(\[ 6400, 2 \]),最后一个维度是 2,为网格点的横纵坐标,而 6400 表示当前特征层的网格点数量。
**(3) 维度变换**
经过 `_predict_by_feat_single` 函数,将从 head 提取的单一图像的特征转换为 bbox 结果输入,得到三个列表 `cls_score_list`,`bbox_pred_list`,`mlvl_priors`,详细大小如图所示。之后分别遍历三个特征层,分别对 class 类别预测分支、bbox 回归分支进行处理。以第一层为例,对 bbox 预测分支 \[ 4,80,80 \] 维度变换为 \[ 6400,4 \],对类别预测分支 \[ 80,80,80 \] 变化为 \[ 6400,80 \],并对其做归一化,确保类别置信度在 0 - 1 之间。
**(4) 阈值过滤**
先使用一个 `nms_pre` 操作,先过滤大部分置信度比较低的预测结果(比如 `score_thr` 阈值设置为 0.05,则去除当前预测置信度低于 0.05 的结果),然后得到 bbox 坐标、所在网格的坐标、置信度、标签的信息。经过三个特征层遍历之后,分别整合这三个层得到的的四个信息放入 results 列表中。
**(5) 还原到原图尺度**
最后将网络的预测结果映射到整图当中,得到 bbox 在整图中的坐标值
**(6) NMS**
进行 nms 操作,最终预测得到的返回值为经过后处理的每张图片的检测结果,包含分类置信度,框的 labels,框的四个坐标
## 2 总结
本文对 RTMDet 原理和在 MMYOLO 实现进行了详细解析,希望能帮助用户理解算法实现过程。同时请注意:由于 RTMDet 本身也在不断更新,
本开源库也会不断迭代,请及时阅读和同步最新版本。