20 KiB
实用工具
我们在 tools/ 文件夹下提供很多实用工具。 除此之外,你也可以通过 MIM 来快速运行 OpenMMLab 的其他开源库。
以 MMDetection 为例,如果想利用 print_config.py,你可以直接采用如下命令,而无需复制源码到 MMYOLO 库中。
mim run mmdet print_config ${CONFIG}
可视化
可视化 COCO 标签
脚本 tools/analysis_tools/browse_coco_json.py 能够使用可视化显示 COCO 标签在图片的情况。
python tools/analysis_tools/browse_coco_json.py [--data-root ${DATA_ROOT}] \
[--img-dir ${IMG_DIR}] \
[--ann-file ${ANN_FILE}] \
[--wait-time ${WAIT_TIME}] \
[--disp-all] [--category-names CATEGORY_NAMES [CATEGORY_NAMES ...]] \
[--shuffle]
其中,如果图片、标签都在同一个文件夹下的话,可以指定 --data-root 到该文件夹,然后 --img-dir 和 --ann-file 指定该文件夹的相对路径,代码会自动拼接。
如果图片、标签文件不在同一个文件夹下的话,则无需指定 --data-root ,直接指定绝对路径的 --img-dir 和 --ann-file 即可。
例子:
- 查看
COCO全部类别,同时展示bbox、mask等所有类型的标注:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--disp-all
如果图片、标签不在同一个文件夹下的话,可以使用绝对路径:
python tools/analysis_tools/browse_coco_json.py --img-dir '/dataset/image/coco/train2017' \
--ann-file '/label/instances_train2017.json' \
--disp-all
- 查看
COCO全部类别,同时仅展示bbox类型的标注,并打乱显示:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--shuffle
- 只查看
bicycle和person类别,同时仅展示bbox类型的标注:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--category-names 'bicycle' 'person'
- 查看
COCO全部类别,同时展示bbox、mask等所有类型的标注,并打乱显示:
python tools/analysis_tools/browse_coco_json.py --data-root './data/coco' \
--img-dir 'train2017' \
--ann-file 'annotations/instances_train2017.json' \
--disp-all \
--shuffle
可视化数据集
python tools/analysis_tools/browse_dataset.py \
${CONFIG_FILE} \
[-o, --output-dir ${OUTPUT_DIR}] \
[-p, --phase ${DATASET_PHASE}] \
[-n, --show-number ${NUMBER_IMAGES_DISPLAY}] \
[-i, --show-interval ${SHOW_INTERRVAL}] \
[-m, --mode ${DISPLAY_MODE}] \
[--cfg-options ${CFG_OPTIONS}]
所有参数的说明:
config: 模型配置文件的路径。-o, --output-dir: 保存图片文件夹,如果没有指定,默认为'./output'。-p, --phase: 可视化数据集的阶段,只能为['train', 'val', 'test']之一,默认为'train'。-n, --show-number: 可视化样本数量。如果没有指定,默认展示数据集的所有图片。-m, --mode: 可视化的模式,只能为['original', 'transformed', 'pipeline']之一。 默认为'transformed'。--cfg-options: 对配置文件的修改,参考学习配置文件。
`-m, --mode` 用于设置可视化的模式,默认设置为 'transformed'。
- 如果 `--mode` 设置为 'original',则获取原始图片;
- 如果 `--mode` 设置为 'transformed',则获取预处理后的图片;
- 如果 `--mode` 设置为 'pipeline',则获得数据流水线所有中间过程图片。
示例:
- 'original' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py --phase val --output-dir tmp --mode original
--phase val: 可视化验证集, 可简化为-p val;--output-dir tmp: 可视化结果保存在 "tmp" 文件夹, 可简化为-o tmp;--mode original: 可视化原图, 可简化为-m original;--show-number 100: 可视化100张图,可简化为-n 100;
2.'transformed' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py
3.'pipeline' 模式 :
python ./tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_balloon.py -m pipeline
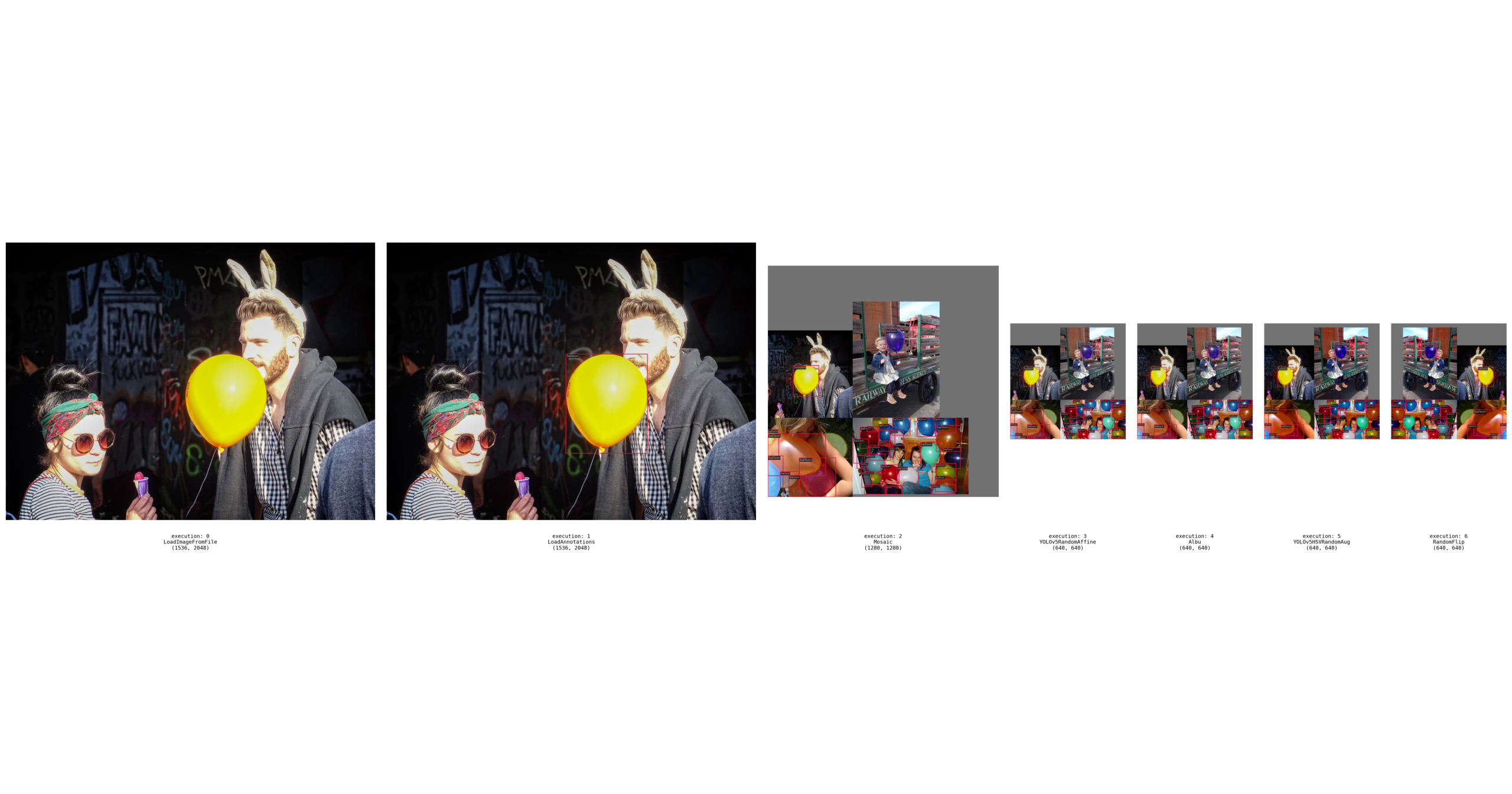
可视化数据集分析
脚本 tools/analysis_tools/dataset_analysis.py 能够帮助用户得到四种功能的结果图,并将图片保存到当前运行目录下的 dataset_analysis 文件夹中。
关于该脚本的功能的说明:
通过 main() 的数据准备,得到每个子函数所需要的数据。
功能一:显示类别和 bbox 实例个数的分布图,通过子函数 show_bbox_num 生成。
功能二:显示类别和 bbox 实例宽、高的分布图,通过子函数 show_bbox_wh 生成。
功能三:显示类别和 bbox 实例宽/高比例的分布图,通过子函数 show_bbox_wh_ratio 生成。
功能四:基于面积规则下,显示类别和 bbox 实例面积的分布图,通过子函数 show_bbox_area 生成。
打印列表显示,通过脚本中子函数 show_class_list 和 show_data_list 生成。
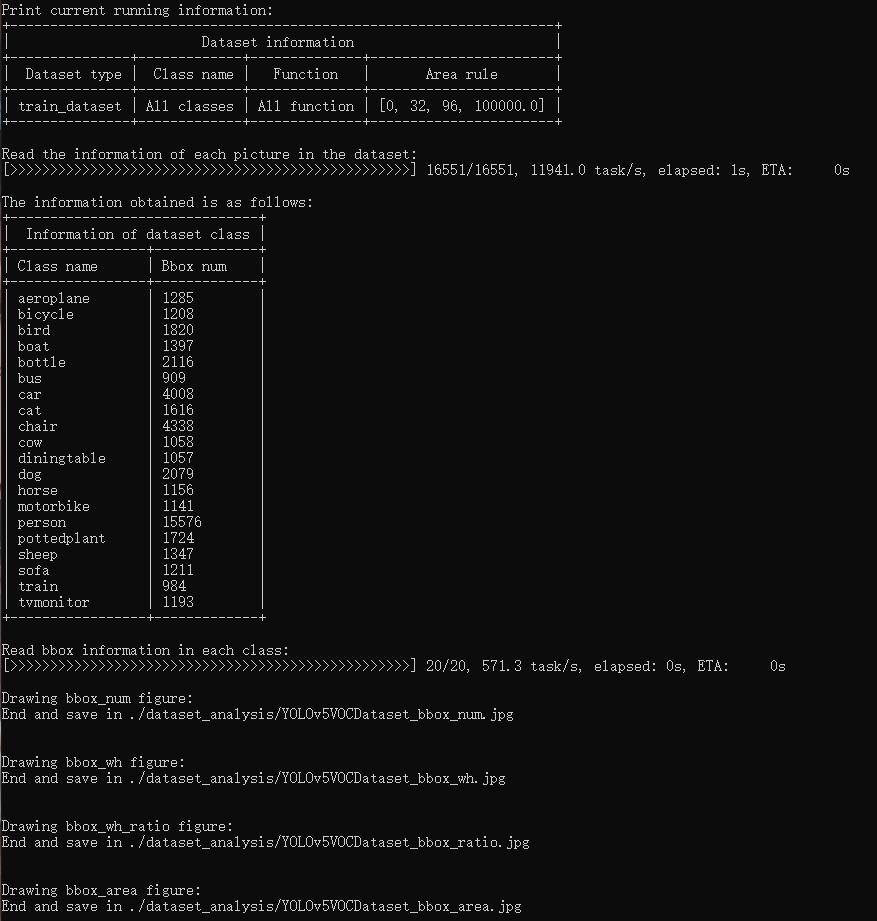
python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
[-h] \
[--val-dataset ${TYPE}] \
[--class-name ${CLASS_NAME}] \
[--area-rule ${AREA_RULE}] \
[--func ${FUNC}] \
[--out-dir ${OUT_DIR}]
例子:
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,其中默认设置:数据加载类型为train_dataset,面积规则设置为[0,32,96,1e5],生成包含所有类的结果图并将图片保存到当前运行目录下./dataset_analysis文件夹中:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--val-dataset设置将数据加载类型由默认的train_dataset改为val_dataset:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--val-dataset
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--class-name设置将生成所有类改为特定类显示,以显示person为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--class-name person
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--area-rule重新定义面积规则,以30 70 125为例,面积规则变为[0,30,70,125,1e5]:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--area-rule 30 70 125
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--func设置,将显示四个功能效果图改为只显示功能一为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--func show_bbox_num
- 使用
config文件configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py分析数据集,通过--out-dir设置修改图片保存地址,以work_dirs/dataset_analysis地址为例:
python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
--out-dir work_dirs/dataset_analysis
优化器参数策略可视化
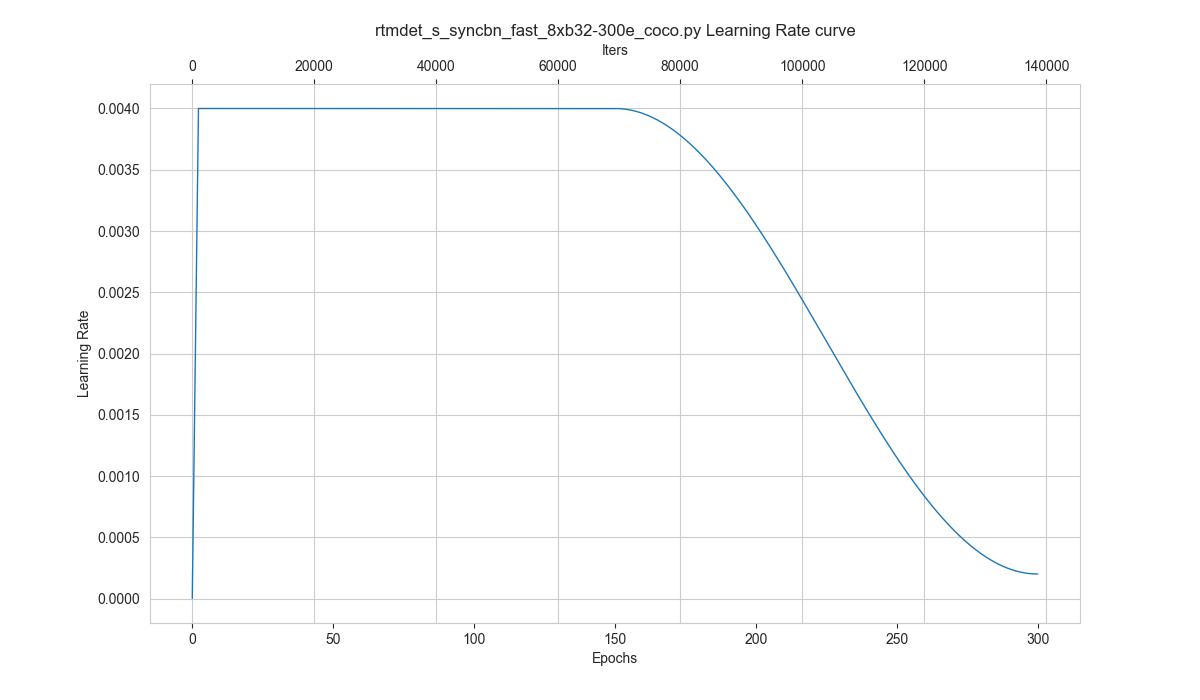
tools/analysis_tools/vis_scheduler.py 旨在帮助用户检查优化器的超参数调度器(无需训练),支持学习率(learning rate)、动量(momentum)和权值衰减(weight decay)。
python tools/analysis_tools/vis_scheduler.py \
${CONFIG_FILE} \
[-p, --parameter ${PARAMETER_NAME}] \
[-d, --dataset-size ${DATASET_SIZE}] \
[-n, --ngpus ${NUM_GPUs}] \
[-o, --out-dir ${OUT_DIR}] \
[--title ${TITLE}] \
[--style ${STYLE}] \
[--window-size ${WINDOW_SIZE}] \
[--cfg-options]
所有参数的说明:
config: 模型配置文件的路径。-p, parameter: 可视化参数名,只能为["lr", "momentum", "wd"]之一, 默认为"lr".-d, --dataset-size: 数据集的大小。如果指定,DATASETS.build将被跳过并使用这个数值作为数据集大小,默认使用DATASETS.build所得数据集的大小。-n, --ngpus: 使用 GPU 的数量, 默认为1。-o, --out-dir: 保存的可视化图片的文件夹路径,默认不保存。--title: 可视化图片的标题,默认为配置文件名。--style: 可视化图片的风格,默认为whitegrid。--window-size: 可视化窗口大小,如果没有指定,默认为12*7。如果需要指定,按照格式'W*H'。--cfg-options: 对配置文件的修改,参考学习配置文件。
部分数据集在解析标注阶段比较耗时,推荐直接将 `-d, dataset-size` 指定数据集的大小,以节约时间。
你可以使用如下命令来绘制配置文件 configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py 将会使用的学习率变化曲线:
python tools/analysis_tools/vis_scheduler.py \
configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
--dataset-size 118287 \
--ngpus 8 \
--out-dir ./output
数据集转换
文件夹 tools/data_converters/ 目前包含 ballon2coco.py、yolo2coco.py 和 labelme2coco.py 三个数据集转换工具。
ballon2coco.py将balloon数据集(该小型数据集仅作为入门使用)转换成 COCO 的格式。
关于该脚本的详细说明,请看 YOLOv5 从入门到部署全流程 中 数据集准备 小节。
python tools/dataset_converters/balloon2coco.py
yolo2coco.py将yolo-style.txt 格式的数据集转换成 COCO 的格式,请按如下方式使用:
python tools/dataset_converters/yolo2coco.py /path/to/the/root/dir/of/your_dataset
使用说明:
image_dir是需要你传入的待转换的 yolo 格式数据集的根目录,内应包含images、labels和classes.txt文件,classes.txt是当前 dataset 对应的类的声明,一行一个类别。image_dir结构如下例所示:
.
└── $ROOT_PATH
├── classes.txt
├── labels
│ ├── a.txt
│ ├── b.txt
│ └── ...
├── images
│ ├── a.jpg
│ ├── b.png
│ └── ...
└── ...
- 脚本会检测
image_dir下是否已有的train.txt、val.txt和test.txt。若检测到文件,则会按照类别进行整理, 否则默认不需要分类。故请确保对应的train.txt、val.txt和test.txt要在image_dir内。文件内的图片路径必须是绝对路径。 - 脚本会默认在
image_dir目录下创建annotations文件夹并将转换结果存在这里。如果在image_dir下没找到分类文件,输出文件即为一个result.json,反之则会生成需要的train.json、val.json、test.json,脚本完成后annotations结构可如下例所示:
.
└── $ROOT_PATH
├── annotations
│ ├── result.json
│ └── ...
├── classes.txt
├── labels
│ ├── a.txt
│ ├── b.txt
│ └── ...
├── images
│ ├── a.jpg
│ ├── b.png
│ └── ...
└── ...
数据集下载
脚本 tools/misc/download_dataset.py 支持下载数据集,例如 COCO、VOC、LVIS 和 Balloon.
python tools/misc/download_dataset.py --dataset-name coco2017
python tools/misc/download_dataset.py --dataset-name voc2007
python tools/misc/download_dataset.py --dataset-name voc2012
python tools/misc/download_dataset.py --dataset-name lvis
python tools/misc/download_dataset.py --dataset-name balloon [--save-dir ${SAVE_DIR}] [--unzip]
模型转换
文件夹 tools/model_converters/ 下的六个脚本能够帮助用户将对应YOLO官方的预训练模型中的键转换成 MMYOLO 格式,并使用 MMYOLO 对模型进行微调。
YOLOv5
下面以转换 yolov5s.pt 为例:
- 将 YOLOv5 官方代码克隆到本地(目前支持的最高版本为
v6.1):
git clone -b v6.1 https://github.com/ultralytics/yolov5.git
cd yolov5
- 下载官方权重:
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- 将
tools/model_converters/yolov5_to_mmyolo.py文件复制到 YOLOv5 官方代码克隆的路径:
cp ${MMDET_YOLO_PATH}/tools/model_converters/yolov5_to_mmyolo.py yolov5_to_mmyolo.py
- 执行转换:
python yolov5_to_mmyolo.py --src ${WEIGHT_FILE_PATH} --dst mmyolov5.pt
转换好的 mmyolov5.pt 即可以为 MMYOLO 所用。 YOLOv6 官方权重转化也是采用一样的使用方式。
YOLOX
YOLOX 模型的转换不需要下载 YOLOX 官方代码,只需要下载权重即可。下面以转换 yolox_s.pth 为例:
- 下载权重:
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
- 执行转换:
python tools/model_converters/yolox_to_mmyolo.py --src yolox_s.pth --dst mmyolox.pt
转换好的 mmyolox.pt 即可以在 MMYOLO 中使用。
优化锚框尺寸
脚本 tools/analysis_tools/optimize_anchors.py 支持 YOLO 系列中三种锚框生成方式,分别是 k-means、Differential Evolution、v5-k-means.
k-means
在 k-means 方法中,使用的是基于 IoU 表示距离的聚类方法,具体使用命令如下:
python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
--algorithm k-means \
--input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
--out-dir ${OUT_DIR}
Differential Evolution
在 Differential Evolution 方法中,使用的是基于差分进化算法(简称 DE 算法)的聚类方式,其最小化目标函数为 avg_iou_cost,具体使用命令如下:
python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
--algorithm DE \
--input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
--out-dir ${OUT_DIR}
v5-k-means
在 v5-k-means 方法中,使用的是 YOLOv5 中基于 shape-match 的聚类方式,具体使用命令如下:
python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
--algorithm v5-k-means \
--input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
--prior-match-thr ${PRIOR_MATCH_THR} \
--out-dir ${OUT_DIR}
提取 COCO 子集
COCO2017 数据集训练数据集包括 118K 张图片,验证集包括 5K 张图片,数据集比较大。在调试或者快速验证程序是否正确的场景下加载 json 会需要消耗较多资源和带来较慢的启动速度,这会导致程序体验不好。
extract_subcoco.py 脚本提供了按指定图片数量、类别、锚框尺寸来切分图片的功能,用户可以通过 --num-img, --classes, --area-size 参数来得到指定条件的 COCO 子集,从而满足上述需求。
例如通过以下脚本切分图片:
python tools/misc/extract_subcoco.py \
${ROOT} \
${OUT_DIR} \
--num-img 20 \
--classes cat dog person \
--area-size small
会切分出 20 张图片,且这 20 张图片只会保留同时满足类别条件和锚框尺寸条件的标注信息, 没有满足条件的标注信息的图片不会被选择,保证了这 20 张图都是有 annotation info 的。
注意: 本脚本目前仅仅支持 COCO2017 数据集,未来会支持更加通用的 COCO JSON 格式数据集
输入 root 根路径文件夹格式如下所示:
├── root
│ ├── annotations
│ ├── train2017
│ ├── val2017
│ ├── test2017
- 仅仅使用 5K 张验证集切分出 10 张训练图片和 10 张验证图片
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 10
- 使用训练集切分出 20 张训练图片,使用验证集切分出 20 张验证图片
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set
- 设置全局种子,默认不设置
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
- 按指定类别切分图片
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
- 按指定锚框尺寸切分图片
python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small