Update Dockerfile `FROM pytorch/pytorch:latest` (#10902)
* Update Dockerfile `FROM pytorch/pytorch:latest` Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> * isort * precommit * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * spelling * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update .pre-commit-config.yaml Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> * Cleanup * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Cleanup * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Cleanup * Cleanup * Cleanup * Cleanup --------- Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>pull/10916/head
parent
d02ee60512
commit
b8a2c47fa9
|
|
@ -4,6 +4,7 @@
|
|||
default_language_version:
|
||||
python: python3.8
|
||||
|
||||
exclude: 'docs/'
|
||||
# Define bot property if installed via https://github.com/marketplace/pre-commit-ci
|
||||
ci:
|
||||
autofix_prs: true
|
||||
|
|
@ -28,13 +29,13 @@ repos:
|
|||
hooks:
|
||||
- id: pyupgrade
|
||||
name: Upgrade code
|
||||
args: [ --py37-plus ]
|
||||
args: [--py37-plus]
|
||||
|
||||
- repo: https://github.com/PyCQA/isort
|
||||
rev: 5.11.4
|
||||
hooks:
|
||||
- id: isort
|
||||
name: Sort imports
|
||||
# - repo: https://github.com/PyCQA/isort
|
||||
# rev: 5.11.4
|
||||
# hooks:
|
||||
# - id: isort
|
||||
# name: Sort imports
|
||||
|
||||
- repo: https://github.com/pre-commit/mirrors-yapf
|
||||
rev: v0.32.0
|
||||
|
|
@ -50,15 +51,22 @@ repos:
|
|||
additional_dependencies:
|
||||
- mdformat-gfm
|
||||
- mdformat-black
|
||||
exclude: "README.md|README.zh-CN.md"
|
||||
|
||||
- repo: https://github.com/asottile/yesqa
|
||||
rev: v1.4.0
|
||||
hooks:
|
||||
- id: yesqa
|
||||
# exclude: "README.md|README.zh-CN.md|CONTRIBUTING.md"
|
||||
|
||||
- repo: https://github.com/PyCQA/flake8
|
||||
rev: 6.0.0
|
||||
rev: 5.0.4
|
||||
hooks:
|
||||
- id: flake8
|
||||
name: PEP8
|
||||
|
||||
#- repo: https://github.com/codespell-project/codespell
|
||||
# rev: v2.2.2
|
||||
# hooks:
|
||||
# - id: codespell
|
||||
# args:
|
||||
# - --ignore-words-list=crate,nd
|
||||
|
||||
#- repo: https://github.com/asottile/yesqa
|
||||
# rev: v1.4.0
|
||||
# hooks:
|
||||
# - id: yesqa
|
||||
|
|
|
|||
107
README.md
107
README.md
|
|
@ -4,9 +4,10 @@
|
|||
<img width="850" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov5/v70/splash.png"></a>
|
||||
</p>
|
||||
|
||||
[English](README.md) | [简体中文](README.zh-CN.md)
|
||||
<br>
|
||||
<div>
|
||||
[English](README.md) | [简体中文](README.zh-CN.md)
|
||||
<br>
|
||||
|
||||
<div>
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv5 Citation"></a>
|
||||
<a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
|
@ -21,7 +22,7 @@ YOLOv5 🚀 is the world's most loved vision AI, representing <a href="https://u
|
|||
|
||||
To request an Enterprise License please complete the form at <a href="https://ultralytics.com/license">Ultralytics Licensing</a>.
|
||||
|
||||
<div align="center">
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
|
|
@ -49,7 +50,7 @@ To request an Enterprise License please complete the form at <a href="https://ul
|
|||
|
||||
<div align="center">
|
||||
|
||||
⚡️ Stay tuned for [Ultralytics Live Session 4](https://www.youtube.com/watch?v=FXIbVnat2eU) ⚡️
|
||||
⚡️ Stay tuned for [Ultralytics Live Session 4](https://www.youtube.com/watch?v=FXIbVnat2eU) ⚡️
|
||||
|
||||
Over the past couple of years we found that 22% percent of you experience difficulty in deploying your vision AI models. To improve this step in the ML pipeline, we've partnered with [Neural Magic](https://bit.ly/yolov5-neuralmagic), whose DeepSparse tool takes advantage of sparsity and low-precision arithmetic within neural networks to offer exceptional performance on commodity hardware.
|
||||
|
||||
|
|
@ -78,13 +79,13 @@ Our new YOLOv5 [release v7.0](https://github.com/ultralytics/yolov5/releases/v7.
|
|||
|
||||
We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640 using A100 GPUs. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) notebooks for easy reproducibility.
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Train time<br><sup>300 epochs<br>A100 (hours) | Speed<br><sup>ONNX CPU<br>(ms) | Speed<br><sup>TRT A100<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
|----------------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|-----------------------------------------------|--------------------------------|--------------------------------|--------------------|------------------------|
|
||||
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
||||
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
||||
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
||||
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
||||
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Train time<br><sup>300 epochs<br>A100 (hours) | Speed<br><sup>ONNX CPU<br>(ms) | Speed<br><sup>TRT A100<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| ------------------------------------------------------------------------------------------ | --------------------- | -------------------- | --------------------- | --------------------------------------------- | ------------------------------ | ------------------------------ | ------------------ | ---------------------- |
|
||||
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
||||
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
||||
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
||||
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
||||
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
||||
|
||||
- All checkpoints are trained to 300 epochs with SGD optimizer with `lr0=0.01` and `weight_decay=5e-5` at image size 640 and all default settings.<br>Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official
|
||||
- **Accuracy** values are for single-model single-scale on COCO dataset.<br>Reproduce by `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
|
||||
|
|
@ -97,6 +98,7 @@ We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640
|
|||
<summary>Segmentation Usage Examples <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/segment/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
||||
|
||||
### Train
|
||||
|
||||
YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with `--data coco128-seg.yaml` argument and manual download of COCO-segments dataset with `bash data/scripts/get_coco.sh --train --val --segments` and then `python train.py --data coco.yaml`.
|
||||
|
||||
```bash
|
||||
|
|
@ -108,33 +110,41 @@ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train
|
|||
```
|
||||
|
||||
### Val
|
||||
|
||||
Validate YOLOv5s-seg mask mAP on COCO dataset:
|
||||
|
||||
```bash
|
||||
bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
|
||||
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
|
||||
```
|
||||
|
||||
### Predict
|
||||
|
||||
Use pretrained YOLOv5m-seg.pt to predict bus.jpg:
|
||||
|
||||
```bash
|
||||
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg
|
||||
```
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5m-seg.pt') # load from PyTorch Hub (WARNING: inference not yet supported)
|
||||
model = torch.hub.load(
|
||||
"ultralytics/yolov5", "custom", "yolov5m-seg.pt"
|
||||
) # load from PyTorch Hub (WARNING: inference not yet supported)
|
||||
```
|
||||
|
||||
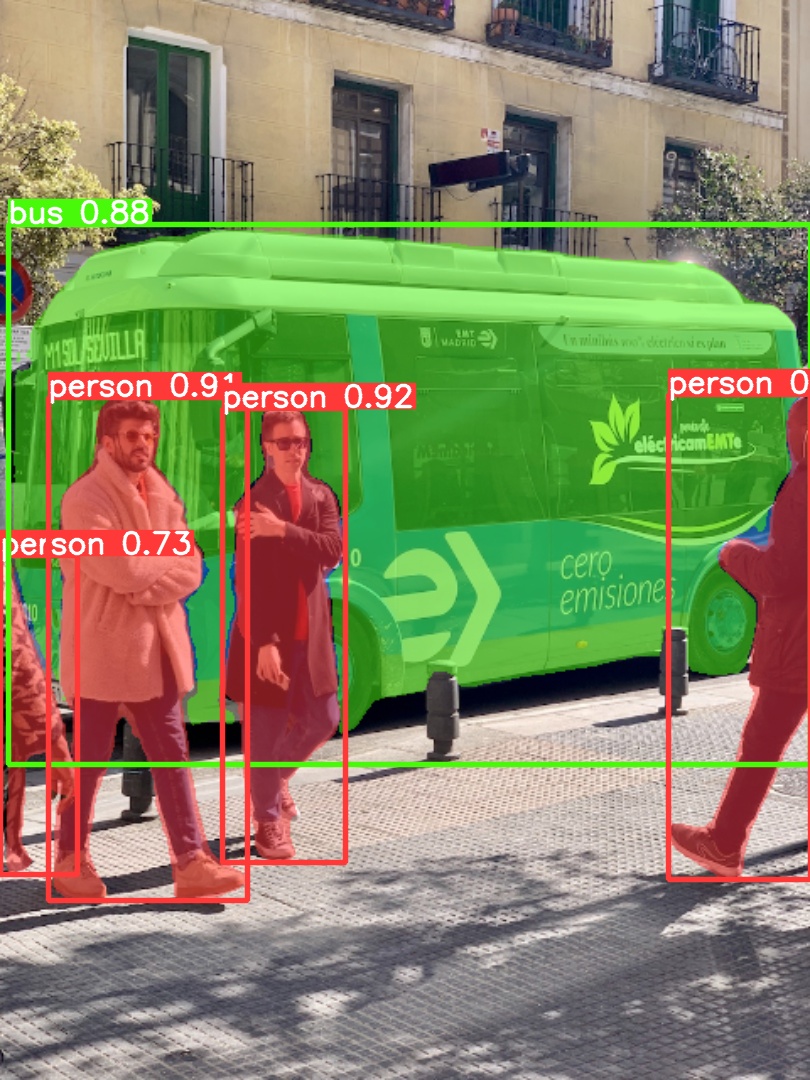
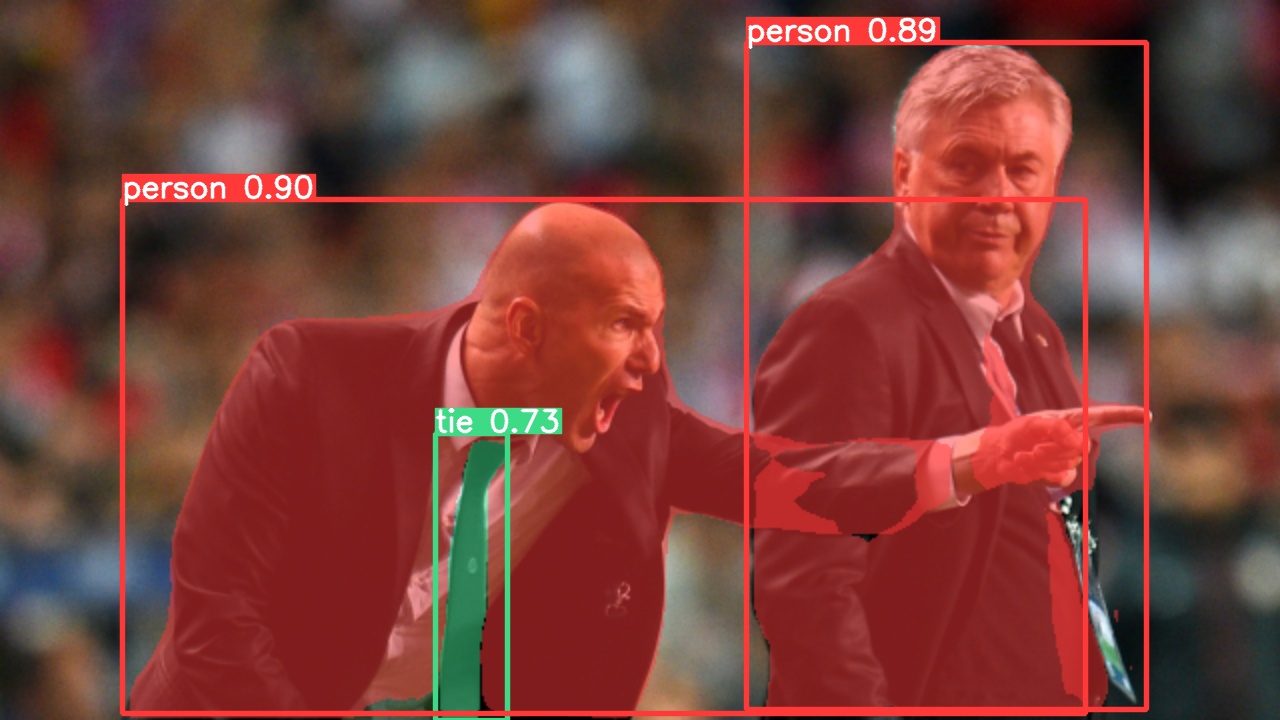 | 
|
||||
--- |---
|
||||
|  |  |
|
||||
| ---------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
|
||||
### Export
|
||||
|
||||
Export YOLOv5s-seg model to ONNX and TensorRT:
|
||||
|
||||
```bash
|
||||
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## <div align="center">Documentation</div>
|
||||
|
||||
See the [YOLOv5 Docs](https://docs.ultralytics.com) for full documentation on training, testing and deployment. See below for quickstart examples.
|
||||
|
|
@ -164,10 +174,10 @@ YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
|||
import torch
|
||||
|
||||
# Model
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
|
||||
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
|
||||
|
||||
# Images
|
||||
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
|
||||
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
|
||||
|
||||
# Inference
|
||||
results = model(img)
|
||||
|
|
@ -245,7 +255,6 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
|
|||
|
||||
</details>
|
||||
|
||||
|
||||
## <div align="center">Integrations</div>
|
||||
|
||||
<br>
|
||||
|
|
@ -268,10 +277,9 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
|
|||
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-neuralmagic.png" width="10%" /></a>
|
||||
</div>
|
||||
|
||||
|Roboflow|ClearML ⭐ NEW|Comet ⭐ NEW|Neural Magic ⭐ NEW|
|
||||
|:-:|:-:|:-:|:-:|
|
||||
|Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics)|Automatically track, visualize and even remotely train YOLOv5 using [ClearML](https://cutt.ly/yolov5-readme-clearml) (open-source!)|Free forever, [Comet](https://bit.ly/yolov5-readme-comet2) lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions|Run YOLOv5 inference up to 6x faster with [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic)|
|
||||
|
||||
| Roboflow | ClearML ⭐ NEW | Comet ⭐ NEW | Neural Magic ⭐ NEW |
|
||||
| :--------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: |
|
||||
| Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics) | Automatically track, visualize and even remotely train YOLOv5 using [ClearML](https://cutt.ly/yolov5-readme-clearml) (open-source!) | Free forever, [Comet](https://bit.ly/yolov5-readme-comet2) lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions | Run YOLOv5 inference up to 6x faster with [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic) |
|
||||
|
||||
## <div align="center">Ultralytics HUB</div>
|
||||
|
||||
|
|
@ -280,7 +288,6 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
|
|||
<a align="center" href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
||||
|
||||
|
||||
## <div align="center">Why YOLOv5</div>
|
||||
|
||||
YOLOv5 has been designed to be super easy to get started and simple to learn. We prioritize real-world results.
|
||||
|
|
@ -303,19 +310,19 @@ YOLOv5 has been designed to be super easy to get started and simple to learn. We
|
|||
|
||||
### Pretrained Checkpoints
|
||||
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | Speed<br><sup>CPU b1<br>(ms) | Speed<br><sup>V100 b1<br>(ms) | Speed<br><sup>V100 b32<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
|------------------------------------------------------------------------------------------------------|-----------------------|----------------------|-------------------|------------------------------|-------------------------------|--------------------------------|--------------------|------------------------|
|
||||
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
||||
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
||||
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
||||
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
||||
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
||||
| | | | | | | | | |
|
||||
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
||||
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
||||
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
||||
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
||||
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt)<br>+ [TTA][tta] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
||||
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | Speed<br><sup>CPU b1<br>(ms) | Speed<br><sup>V100 b1<br>(ms) | Speed<br><sup>V100 b32<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| ----------------------------------------------------------------------------------------------- | --------------------- | -------------------- | ----------------- | ---------------------------- | ----------------------------- | ------------------------------ | ------------------ | ---------------------- |
|
||||
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
||||
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
||||
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
||||
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
||||
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
||||
| | | | | | | | | |
|
||||
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
||||
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
||||
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
||||
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
||||
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt)<br>+ [TTA] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
||||
|
||||
<details>
|
||||
<summary>Table Notes</summary>
|
||||
|
|
@ -327,7 +334,6 @@ YOLOv5 has been designed to be super easy to get started and simple to learn. We
|
|||
|
||||
</details>
|
||||
|
||||
|
||||
## <div align="center">Classification ⭐ NEW</div>
|
||||
|
||||
YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) brings support for classification model training, validation and deployment! See full details in our [Release Notes](https://github.com/ultralytics/yolov5/releases/v6.2) and visit our [YOLOv5 Classification Colab Notebook](https://github.com/ultralytics/yolov5/blob/master/classify/tutorial.ipynb) for quickstart tutorials.
|
||||
|
|
@ -340,18 +346,18 @@ YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) brings sup
|
|||
We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) for easy reproducibility.
|
||||
|
||||
| Model | size<br><sup>(pixels) | acc<br><sup>top1 | acc<br><sup>top5 | Training<br><sup>90 epochs<br>4xA100 (hours) | Speed<br><sup>ONNX CPU<br>(ms) | Speed<br><sup>TensorRT V100<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@224 (B) |
|
||||
|----------------------------------------------------------------------------------------------------|-----------------------|------------------|------------------|----------------------------------------------|--------------------------------|-------------------------------------|--------------------|------------------------|
|
||||
| -------------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | -------------------------------------------- | ------------------------------ | ----------------------------------- | ------------------ | ---------------------- |
|
||||
| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
|
||||
| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
|
||||
| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
|
||||
| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
|
||||
| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
|
||||
| |
|
||||
| | | | | | | | | |
|
||||
| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
|
||||
| [ResNet34](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
|
||||
| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
|
||||
| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
|
||||
| |
|
||||
| | | | | | | | | |
|
||||
| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
|
||||
| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
|
||||
| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
|
||||
|
|
@ -364,6 +370,7 @@ We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4x
|
|||
- **Accuracy** values are for single-model single-scale on [ImageNet-1k](https://www.image-net.org/index.php) dataset.<br>Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224`
|
||||
- **Speed** averaged over 100 inference images using a Google [Colab Pro](https://colab.research.google.com/signup) V100 High-RAM instance.<br>Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
|
||||
- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`. <br>Reproduce by `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
|
||||
|
||||
</details>
|
||||
</details>
|
||||
|
||||
|
|
@ -371,6 +378,7 @@ We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4x
|
|||
<summary>Classification Usage Examples <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/classify/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
||||
|
||||
### Train
|
||||
|
||||
YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the `--data` argument. To start training on MNIST for example use `--data mnist`.
|
||||
|
||||
```bash
|
||||
|
|
@ -382,28 +390,37 @@ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/trai
|
|||
```
|
||||
|
||||
### Val
|
||||
|
||||
Validate YOLOv5m-cls accuracy on ImageNet-1k dataset:
|
||||
|
||||
```bash
|
||||
bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
|
||||
python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate
|
||||
```
|
||||
|
||||
### Predict
|
||||
|
||||
Use pretrained YOLOv5s-cls.pt to predict bus.jpg:
|
||||
|
||||
```bash
|
||||
python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpg
|
||||
```
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-cls.pt') # load from PyTorch Hub
|
||||
model = torch.hub.load(
|
||||
"ultralytics/yolov5", "custom", "yolov5s-cls.pt"
|
||||
) # load from PyTorch Hub
|
||||
```
|
||||
|
||||
### Export
|
||||
|
||||
Export a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT:
|
||||
|
||||
```bash
|
||||
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224
|
||||
```
|
||||
</details>
|
||||
|
||||
</details>
|
||||
|
||||
## <div align="center">Environments</div>
|
||||
|
||||
|
|
@ -436,14 +453,13 @@ Run YOLOv5 models on your iOS or Android device by downloading the [Ultralytics
|
|||
<a align="center" href="https://ultralytics.com/app_install" target="_blank">
|
||||
<img width="100%" alt="Ultralytics mobile app" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-app.png">
|
||||
|
||||
|
||||
## <div align="center">Contribute</div>
|
||||
|
||||
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our [Contributing Guide](CONTRIBUTING.md) to get started, and fill out the [YOLOv5 Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) to send us feedback on your experiences. Thank you to all our contributors!
|
||||
|
||||
<!-- SVG image from https://opencollective.com/ultralytics/contributors.svg?width=990 -->
|
||||
<a href="https://github.com/ultralytics/yolov5/graphs/contributors"><img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-contributors-1280.png" /></a>
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/graphs/contributors"><img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-contributors-1280.png" /></a>
|
||||
|
||||
## <div align="center">License</div>
|
||||
|
||||
|
|
@ -452,7 +468,6 @@ YOLOv5 is available under two different licenses:
|
|||
- **GPL-3.0 License**: See [LICENSE](https://github.com/ultralytics/yolov5/blob/master/LICENSE) file for details.
|
||||
- **Enterprise License**: Provides greater flexibility for commercial product development without the open-source requirements of GPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at [Ultralytics Licensing](https://ultralytics.com/license).
|
||||
|
||||
|
||||
## <div align="center">Contact</div>
|
||||
|
||||
For YOLOv5 bugs and feature requests please visit [GitHub Issues](https://github.com/ultralytics/yolov5/issues). For professional support please [Contact Us](https://ultralytics.com/contact).
|
||||
|
|
|
|||
168
README.zh-CN.md
168
README.zh-CN.md
|
|
@ -4,9 +4,9 @@
|
|||
<img width="850" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov5/v70/splash.png"></a>
|
||||
</p>
|
||||
|
||||
[英文](README.md)\|[简体中文](README.zh-CN.md)<br>
|
||||
[英文](README.md)|[简体中文](README.zh-CN.md)<br>
|
||||
|
||||
<div>
|
||||
<div>
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv5 Citation"></a>
|
||||
<a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
|
@ -21,7 +21,7 @@ YOLOv5 🚀 是世界上最受欢迎的视觉 AI,代表<a href="https://ultral
|
|||
|
||||
如果要申请企业许可证,请填写表格<a href="https://ultralytics.com/license">Ultralytics 许可</a>.
|
||||
|
||||
<div align="center">
|
||||
<div align="center">
|
||||
<a href="https://github.com/ultralytics" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%" alt="" />
|
||||
|
|
@ -61,18 +61,18 @@ YOLOv5 🚀 是世界上最受欢迎的视觉 AI,代表<a href="https://ultral
|
|||
|
||||
我们使用 A100 GPU 在 COCO 上以 640 图像大小训练了 300 epochs 得到 YOLOv5 分割模型。我们将所有模型导出到 ONNX FP32 以进行 CPU 速度测试,并导出到 TensorRT FP16 以进行 GPU 速度测试。为了便于再现,我们在 Google [Colab Pro](https://colab.research.google.com/signup) 上进行了所有速度测试。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | 训练时长<br><sup>300 epochs<br>A100 GPU(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TRT A100<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| ------------------------------------------------------------------------------------------ | ------------------- | -------------------- | --------------------- | --------------------------------------------- | --------------------------------- | --------------------------------- | ----------------- | ---------------------- |
|
||||
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
||||
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
||||
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
||||
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
||||
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | 训练时长<br><sup>300 epochs<br>A100 GPU(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TRT A100<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| ------------------------------------------------------------------------------------------ | --------------- | -------------------- | --------------------- | --------------------------------------- | ----------------------------- | ----------------------------- | --------------- | ---------------------- |
|
||||
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
||||
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
||||
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
||||
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
||||
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
||||
|
||||
- 所有模型使用 SGD 优化器训练, 都使用 `lr0=0.01` 和 `weight_decay=5e-5` 参数, 图像大小为 640 。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5_v70_official
|
||||
- **准确性**结果都在 COCO 数据集上,使用单模型单尺度测试得到。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
|
||||
- **推理速度**是使用 100 张图像推理时间进行平均得到,测试环境使用 [Colab Pro](https://colab.research.google.com/signup) 上 A100 高 RAM 实例。结果仅表示推理速度(NMS 每张图像增加约 1 毫秒)。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
|
||||
- **模型转换**到 FP32 的 ONNX 和 FP16 的 TensorRT 脚本为 `export.py`.<br>运行命令 `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
|
||||
- 所有模型使用 SGD 优化器训练, 都使用 `lr0=0.01` 和 `weight_decay=5e-5` 参数, 图像大小为 640 。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5_v70_official
|
||||
- **准确性**结果都在 COCO 数据集上,使用单模型单尺度测试得到。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
|
||||
- **推理速度**是使用 100 张图像推理时间进行平均得到,测试环境使用 [Colab Pro](https://colab.research.google.com/signup) 上 A100 高 RAM 实例。结果仅表示推理速度(NMS 每张图像增加约 1 毫秒)。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
|
||||
- **模型转换**到 FP32 的 ONNX 和 FP16 的 TensorRT 脚本为 `export.py`.<br>运行命令 `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
|
||||
|
||||
</details>
|
||||
|
||||
|
|
@ -109,7 +109,9 @@ python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg
|
|||
```
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5m-seg.pt') # 从load from PyTorch Hub 加载模型 (WARNING: 推理暂未支持)
|
||||
model = torch.hub.load(
|
||||
"ultralytics/yolov5", "custom", "yolov5m-seg.pt"
|
||||
) # 从load from PyTorch Hub 加载模型 (WARNING: 推理暂未支持)
|
||||
```
|
||||
|
||||
|  |  |
|
||||
|
|
@ -152,10 +154,10 @@ YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载。
|
|||
import torch
|
||||
|
||||
# Model
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
|
||||
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
|
||||
|
||||
# Images
|
||||
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
|
||||
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
|
||||
|
||||
# Inference
|
||||
results = model(img)
|
||||
|
|
@ -212,22 +214,22 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
|
|||
<details open>
|
||||
<summary>教程</summary>
|
||||
|
||||
- [训练自定义数据](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data)🚀 推荐
|
||||
- [获得最佳训练结果的技巧](https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results)☘️ 推荐
|
||||
- [多 GPU 训练](https://github.com/ultralytics/yolov5/issues/475)
|
||||
- [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36)🌟 新
|
||||
- [TFLite、ONNX、CoreML、TensorRT 导出](https://github.com/ultralytics/yolov5/issues/251)🚀
|
||||
- [NVIDIA Jetson Nano 部署](https://github.com/ultralytics/yolov5/issues/9627)🌟 新
|
||||
- [测试时数据增强 (TTA)](https://github.com/ultralytics/yolov5/issues/303)
|
||||
- [模型集成](https://github.com/ultralytics/yolov5/issues/318)
|
||||
- [模型修剪/稀疏度](https://github.com/ultralytics/yolov5/issues/304)
|
||||
- [超参数进化](https://github.com/ultralytics/yolov5/issues/607)
|
||||
- [使用冻结层进行迁移学习](https://github.com/ultralytics/yolov5/issues/1314)
|
||||
- [架构总结](https://github.com/ultralytics/yolov5/issues/6998)🌟 新
|
||||
- [用于数据集、标签和主动学习的 Roboflow](https://github.com/ultralytics/yolov5/issues/4975)🌟 新
|
||||
- [ClearML 记录](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml)🌟 新
|
||||
- [Deci 平台](https://github.com/ultralytics/yolov5/wiki/Deci-Platform)🌟 新
|
||||
- [Comet Logging](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/comet)🌟 新
|
||||
- [训练自定义数据](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data)🚀 推荐
|
||||
- [获得最佳训练结果的技巧](https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results)☘️ 推荐
|
||||
- [多 GPU 训练](https://github.com/ultralytics/yolov5/issues/475)
|
||||
- [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36)🌟 新
|
||||
- [TFLite、ONNX、CoreML、TensorRT 导出](https://github.com/ultralytics/yolov5/issues/251)🚀
|
||||
- [NVIDIA Jetson Nano 部署](https://github.com/ultralytics/yolov5/issues/9627)🌟 新
|
||||
- [测试时数据增强 (TTA)](https://github.com/ultralytics/yolov5/issues/303)
|
||||
- [模型集成](https://github.com/ultralytics/yolov5/issues/318)
|
||||
- [模型修剪/稀疏度](https://github.com/ultralytics/yolov5/issues/304)
|
||||
- [超参数进化](https://github.com/ultralytics/yolov5/issues/607)
|
||||
- [使用冻结层进行迁移学习](https://github.com/ultralytics/yolov5/issues/1314)
|
||||
- [架构总结](https://github.com/ultralytics/yolov5/issues/6998)🌟 新
|
||||
- [用于数据集、标签和主动学习的 Roboflow](https://github.com/ultralytics/yolov5/issues/4975)🌟 新
|
||||
- [ClearML 记录](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml)🌟 新
|
||||
- [Deci 平台](https://github.com/ultralytics/yolov5/wiki/Deci-Platform)🌟 新
|
||||
- [Comet Logging](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/comet)🌟 新
|
||||
|
||||
</details>
|
||||
|
||||
|
|
@ -253,8 +255,8 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
|
|||
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-neuralmagic.png" width="10%" /></a>
|
||||
</div>
|
||||
|
||||
| Roboflow | ClearML ⭐ 新 | Comet ⭐ 新 | Neural Magic ⭐ 新 |
|
||||
| :-----------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------: |
|
||||
| Roboflow | ClearML ⭐ 新 | Comet ⭐ 新 | Neural Magic ⭐ 新 |
|
||||
| :--------------------------------------------------------------------------------: | :-------------------------------------------------------------------------: | :-------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
|
||||
| 将您的自定义数据集进行标注并直接导出到 YOLOv5 以进行训练 [Roboflow](https://roboflow.com/?ref=ultralytics) | 自动跟踪、可视化甚至远程训练 YOLOv5 [ClearML](https://cutt.ly/yolov5-readme-clearml)(开源!) | 永远免费,[Comet](https://bit.ly/yolov5-readme-comet)可让您保存 YOLOv5 模型、恢复训练以及交互式可视化和调试预测 | 使用 [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic),运行 YOLOv5 推理的速度最高可提高6倍 |
|
||||
|
||||
## <div align="center">Ultralytics HUB</div>
|
||||
|
|
@ -277,36 +279,36 @@ YOLOv5 超级容易上手,简单易学。我们优先考虑现实世界的结
|
|||
<details>
|
||||
<summary>图表笔记</summary>
|
||||
|
||||
- **COCO AP val** 表示 mAP@0.5:0.95 指标,在 [COCO val2017](http://cocodataset.org) 数据集的 5000 张图像上测得, 图像包含 256 到 1536 各种推理大小。
|
||||
- **显卡推理速度** 为在 [COCO val2017](http://cocodataset.org) 数据集上的平均推理时间,使用 [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100实例,batchsize 为 32 。
|
||||
- **EfficientDet** 数据来自 [google/automl](https://github.com/google/automl) , batchsize 为32。
|
||||
- **复现命令** 为 `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
|
||||
- **COCO AP val** 表示 mAP@0.5:0.95 指标,在 [COCO val2017](http://cocodataset.org) 数据集的 5000 张图像上测得, 图像包含 256 到 1536 各种推理大小。
|
||||
- **显卡推理速度** 为在 [COCO val2017](http://cocodataset.org) 数据集上的平均推理时间,使用 [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100实例,batchsize 为 32 。
|
||||
- **EfficientDet** 数据来自 [google/automl](https://github.com/google/automl) , batchsize 为32。
|
||||
- **复现命令** 为 `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
|
||||
|
||||
</details>
|
||||
|
||||
### 预训练模型
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | 推理速度<br><sup>CPU b1<br>(ms) | 推理速度<br><sup>V100 b1<br>(ms) | 速度<br><sup>V100 b32<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| --------------------------------------------------------------------------------------------------- | ------------------- | -------------------- | ------------------- | ------------------------------- | -------------------------------- | ------------------------------ | ----------------- | ---------------------- |
|
||||
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
||||
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
||||
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
||||
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
||||
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
||||
| | | | | | | | | |
|
||||
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
||||
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
||||
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
||||
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
||||
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt)<br>+[TTA][tta] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | 推理速度<br><sup>CPU b1<br>(ms) | 推理速度<br><sup>V100 b1<br>(ms) | 速度<br><sup>V100 b32<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| ---------------------------------------------------------------------------------------------- | --------------- | -------------------- | ----------------- | --------------------------- | ---------------------------- | --------------------------- | --------------- | ---------------------- |
|
||||
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
||||
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
||||
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
||||
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
||||
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
||||
| | | | | | | | | |
|
||||
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
||||
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
||||
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
||||
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
||||
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt)<br>+[TTA] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
||||
|
||||
<details>
|
||||
<summary>笔记</summary>
|
||||
|
||||
- 所有模型都使用默认配置,训练 300 epochs。n和s模型使用 [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) ,其他模型都使用 [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml) 。
|
||||
- **mAP<sup>val</sup>**在单模型单尺度上计算,数据集使用 [COCO val2017](http://cocodataset.org) 。<br>复现命令 `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
|
||||
- **推理速度**在 COCO val 图像总体时间上进行平均得到,测试环境使用[AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/)实例。 NMS 时间 (大约 1 ms/img) 不包括在内。<br>复现命令 `python val.py --data coco.yaml --img 640 --task speed --batch 1`
|
||||
- **TTA** [测试时数据增强](https://github.com/ultralytics/yolov5/issues/303) 包括反射和尺度变换。<br>复现命令 `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
|
||||
- 所有模型都使用默认配置,训练 300 epochs。n和s模型使用 [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) ,其他模型都使用 [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml) 。
|
||||
- \*\*mAP<sup>val</sup>\*\*在单模型单尺度上计算,数据集使用 [COCO val2017](http://cocodataset.org) 。<br>复现命令 `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
|
||||
- **推理速度**在 COCO val 图像总体时间上进行平均得到,测试环境使用[AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/)实例。 NMS 时间 (大约 1 ms/img) 不包括在内。<br>复现命令 `python val.py --data coco.yaml --img 640 --task speed --batch 1`
|
||||
- **TTA** [测试时数据增强](https://github.com/ultralytics/yolov5/issues/303) 包括反射和尺度变换。<br>复现命令 `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
|
||||
|
||||
</details>
|
||||
|
||||
|
|
@ -321,33 +323,33 @@ YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) 带来对
|
|||
|
||||
我们使用 4xA100 实例在 ImageNet 上训练了 90 个 epochs 得到 YOLOv5-cls 分类模型,我们训练了 ResNet 和 EfficientNet 模型以及相同的默认训练设置以进行比较。我们将所有模型导出到 ONNX FP32 以进行 CPU 速度测试,并导出到 TensorRT FP16 以进行 GPU 速度测试。为了便于重现,我们在 Google 上进行了所有速度测试 [Colab Pro](https://colab.research.google.com/signup) 。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | acc<br><sup>top1 | acc<br><sup>top5 | 训练时长<br><sup>90 epochs<br>4xA100(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TensorRT V100<br>(ms) | 参数<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| -------------------------------------------------------------------------------------------------- | ------------------- | ---------------- | ---------------- | ------------------------------------------ | --------------------------------- | -------------------------------------- | --------------- | -----------------------|
|
||||
| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
|
||||
| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
|
||||
| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
|
||||
| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
|
||||
| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
|
||||
| | | | | | | | | |
|
||||
| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
|
||||
| [Resnetzch](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
|
||||
| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
|
||||
| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
|
||||
| | | | | | | | | |
|
||||
| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
|
||||
| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
|
||||
| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
|
||||
| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
|
||||
| 模型 | 尺寸<br><sup>(像素) | acc<br><sup>top1 | acc<br><sup>top5 | 训练时长<br><sup>90 epochs<br>4xA100(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TensorRT V100<br>(ms) | 参数<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
||||
| -------------------------------------------------------------------------------------------------- | --------------- | ---------------- | ---------------- | ------------------------------------ | ----------------------------- | ---------------------------------- | -------------- | ---------------------- |
|
||||
| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
|
||||
| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
|
||||
| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
|
||||
| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
|
||||
| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
|
||||
| | | | | | | | | |
|
||||
| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
|
||||
| [Resnetzch](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
|
||||
| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
|
||||
| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
|
||||
| | | | | | | | | |
|
||||
| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
|
||||
| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
|
||||
| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
|
||||
| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
|
||||
|
||||
<details>
|
||||
<summary>Table Notes (点击以展开)</summary>
|
||||
|
||||
- 所有模型都使用 SGD 优化器训练 90 个 epochs,都使用 `lr0=0.001` 和 `weight_decay=5e-5` 参数, 图像大小为 224 ,且都使用默认设置。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
|
||||
- **准确性**都在单模型单尺度上计算,数据集使用 [ImageNet-1k](https://www.image-net.org/index.php) 。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224`
|
||||
- **推理速度**是使用 100 个推理图像进行平均得到,测试环境使用谷歌 [Colab Pro](https://colab.research.google.com/signup) V100 高 RAM 实例。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
|
||||
- **模型导出**到 FP32 的 ONNX 和 FP16 的 TensorRT 使用 `export.py` 。<br>复现命令 `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
|
||||
</details>
|
||||
</details>
|
||||
- 所有模型都使用 SGD 优化器训练 90 个 epochs,都使用 `lr0=0.001` 和 `weight_decay=5e-5` 参数, 图像大小为 224 ,且都使用默认设置。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
|
||||
- **准确性**都在单模型单尺度上计算,数据集使用 [ImageNet-1k](https://www.image-net.org/index.php) 。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224`
|
||||
- **推理速度**是使用 100 个推理图像进行平均得到,测试环境使用谷歌 [Colab Pro](https://colab.research.google.com/signup) V100 高 RAM 实例。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
|
||||
- **模型导出**到 FP32 的 ONNX 和 FP16 的 TensorRT 使用 `export.py` 。<br>复现命令 `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
|
||||
</details>
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>分类训练示例 <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/classify/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
||||
|
|
@ -382,7 +384,9 @@ python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpg
|
|||
```
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-cls.pt') # load from PyTorch Hub
|
||||
model = torch.hub.load(
|
||||
"ultralytics/yolov5", "custom", "yolov5s-cls.pt"
|
||||
) # load from PyTorch Hub
|
||||
```
|
||||
|
||||
### 模型导出
|
||||
|
|
@ -438,8 +442,8 @@ python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --inclu
|
|||
|
||||
YOLOv5 在两种不同的 License 下可用:
|
||||
|
||||
- **GPL-3.0 License**: 查看 [License](https://github.com/ultralytics/yolov5/blob/master/LICENSE) 文件的详细信息。
|
||||
- **企业License**:在没有 GPL-3.0 开源要求的情况下为商业产品开发提供更大的灵活性。典型用例是将 Ultralytics 软件和 AI 模型嵌入到商业产品和应用程序中。在以下位置申请企业许可证 [Ultralytics 许可](https://ultralytics.com/license) 。
|
||||
- **GPL-3.0 License**: 查看 [License](https://github.com/ultralytics/yolov5/blob/master/LICENSE) 文件的详细信息。
|
||||
- **企业License**:在没有 GPL-3.0 开源要求的情况下为商业产品开发提供更大的灵活性。典型用例是将 Ultralytics 软件和 AI 模型嵌入到商业产品和应用程序中。在以下位置申请企业许可证 [Ultralytics 许可](https://ultralytics.com/license) 。
|
||||
|
||||
## <div align="center">联系我们</div>
|
||||
|
||||
|
|
|
|||
|
|
@ -78,7 +78,7 @@
|
|||
"source": [
|
||||
"# 1. Predict\n",
|
||||
"\n",
|
||||
"`classify/predict.py` runs YOLOv5 Classifcation inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/predict-cls`. Example inference sources are:\n",
|
||||
"`classify/predict.py` runs YOLOv5 Classification inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/predict-cls`. Example inference sources are:\n",
|
||||
"\n",
|
||||
"```shell\n",
|
||||
"python classify/predict.py --source 0 # webcam\n",
|
||||
|
|
|
|||
|
|
@ -128,9 +128,9 @@ def run(
|
|||
LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
|
||||
LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
|
||||
for i, c in model.names.items():
|
||||
aci = acc[targets == i]
|
||||
top1i, top5i = aci.mean(0).tolist()
|
||||
LOGGER.info(f"{c:>24}{aci.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}")
|
||||
acc_i = acc[targets == i]
|
||||
top1i, top5i = acc_i.mean(0).tolist()
|
||||
LOGGER.info(f"{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}")
|
||||
|
||||
# Print results
|
||||
t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
|
||||
|
|
|
|||
|
|
@ -3,23 +3,33 @@
|
|||
# Image is CUDA-optimized for YOLOv5 single/multi-GPU training and inference
|
||||
|
||||
# Start FROM NVIDIA PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
|
||||
FROM nvcr.io/nvidia/pytorch:22.12-py3
|
||||
RUN rm -rf /opt/pytorch # remove 1.2GB dir
|
||||
# FROM docker.io/pytorch/pytorch:latest
|
||||
FROM pytorch/pytorch:latest
|
||||
|
||||
# Downloads to user config dir
|
||||
ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
|
||||
|
||||
# Install linux packages
|
||||
RUN apt update && apt install --no-install-recommends -y zip htop screen libgl1-mesa-glx
|
||||
ENV DEBIAN_FRONTEND noninteractive
|
||||
RUN apt update
|
||||
RUN TZ=Etc/UTC apt install -y tzdata
|
||||
RUN apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg
|
||||
# RUN alias python=python3
|
||||
|
||||
# Install pip packages (uninstall torch nightly in favor of stable)
|
||||
# Create working directory
|
||||
RUN mkdir -p /usr/src/app
|
||||
WORKDIR /usr/src/app
|
||||
|
||||
# Copy contents
|
||||
# COPY . /usr/src/app (issues as not a .git directory)
|
||||
RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
|
||||
|
||||
# Install pip packages
|
||||
COPY requirements.txt .
|
||||
RUN python -m pip install --upgrade pip wheel
|
||||
RUN pip uninstall -y Pillow torchtext torch torchvision
|
||||
RUN pip install --no-cache -U pycocotools # install --upgrade
|
||||
RUN pip install --no-cache -r requirements.txt albumentations comet gsutil notebook 'opencv-python<4.6.0.66' \
|
||||
Pillow>=9.1.0 ultralytics \
|
||||
--extra-index-url https://download.pytorch.org/whl/cu113
|
||||
RUN python3 -m pip install --upgrade pip wheel
|
||||
RUN pip install --no-cache -r requirements.txt albumentations comet gsutil notebook \
|
||||
coremltools onnx onnx-simplifier onnxruntime openvino-dev>=2022.3
|
||||
# tensorflow tensorflowjs \
|
||||
|
||||
# Create working directory
|
||||
RUN mkdir -p /usr/src/app
|
||||
|
|
@ -32,6 +42,9 @@ RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
|
|||
# Set environment variables
|
||||
ENV OMP_NUM_THREADS=1
|
||||
|
||||
# Cleanup
|
||||
ENV DEBIAN_FRONTEND teletype
|
||||
|
||||
|
||||
# Usage Examples -------------------------------------------------------------------------------------------------------
|
||||
|
||||
|
|
|
|||
|
|
@ -84,10 +84,6 @@ class Loggers():
|
|||
self.csv = True # always log to csv
|
||||
|
||||
# Messages
|
||||
# if not wandb:
|
||||
# prefix = colorstr('Weights & Biases: ')
|
||||
# s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
|
||||
# self.logger.info(s)
|
||||
if not clearml:
|
||||
prefix = colorstr('ClearML: ')
|
||||
s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML"
|
||||
|
|
@ -105,14 +101,8 @@ class Loggers():
|
|||
|
||||
# W&B
|
||||
if wandb and 'wandb' in self.include:
|
||||
wandb_artifact_resume = isinstance(self.opt.resume, str) and self.opt.resume.startswith('wandb-artifact://')
|
||||
run_id = torch.load(self.weights).get('wandb_id') if self.opt.resume and not wandb_artifact_resume else None
|
||||
self.opt.hyp = self.hyp # add hyperparameters
|
||||
self.wandb = WandbLogger(self.opt, run_id)
|
||||
# temp warn. because nested artifacts not supported after 0.12.10
|
||||
# if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
|
||||
# s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
|
||||
# self.logger.warning(s)
|
||||
self.wandb = WandbLogger(self.opt)
|
||||
else:
|
||||
self.wandb = None
|
||||
|
||||
|
|
@ -175,7 +165,7 @@ class Loggers():
|
|||
self.comet_logger.on_pretrain_routine_end(paths)
|
||||
|
||||
def on_train_batch_end(self, model, ni, imgs, targets, paths, vals):
|
||||
log_dict = dict(zip(self.keys[0:3], vals))
|
||||
log_dict = dict(zip(self.keys[:3], vals))
|
||||
# Callback runs on train batch end
|
||||
# ni: number integrated batches (since train start)
|
||||
if self.plots:
|
||||
|
|
@ -221,10 +211,10 @@ class Loggers():
|
|||
# Callback runs on val end
|
||||
if self.wandb or self.clearml:
|
||||
files = sorted(self.save_dir.glob('val*.jpg'))
|
||||
if self.wandb:
|
||||
self.wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in files]})
|
||||
if self.clearml:
|
||||
self.clearml.log_debug_samples(files, title='Validation')
|
||||
if self.wandb:
|
||||
self.wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in files]})
|
||||
if self.clearml:
|
||||
self.clearml.log_debug_samples(files, title='Validation')
|
||||
|
||||
if self.comet_logger:
|
||||
self.comet_logger.on_val_end(nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
|
||||
|
|
@ -253,7 +243,7 @@ class Loggers():
|
|||
for i, name in enumerate(self.best_keys):
|
||||
self.wandb.wandb_run.summary[name] = best_results[i] # log best results in the summary
|
||||
self.wandb.log(x)
|
||||
self.wandb.end_epoch(best_result=best_fitness == fi)
|
||||
self.wandb.end_epoch()
|
||||
|
||||
if self.clearml:
|
||||
self.clearml.current_epoch_logged_images = set() # reset epoch image limit
|
||||
|
|
|
|||
|
|
@ -23,7 +23,6 @@ And so much more. It's up to you how many of these tools you want to use, you ca
|
|||
|
||||

|
||||
|
||||
|
||||
<br />
|
||||
<br />
|
||||
|
||||
|
|
@ -35,15 +34,15 @@ Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-t
|
|||
|
||||
1. Install the `clearml` python package:
|
||||
|
||||
```bash
|
||||
pip install clearml
|
||||
```
|
||||
```bash
|
||||
pip install clearml
|
||||
```
|
||||
|
||||
1. Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:
|
||||
|
||||
```bash
|
||||
clearml-init
|
||||
```
|
||||
```bash
|
||||
clearml-init
|
||||
```
|
||||
|
||||
That's it! You're done 😎
|
||||
|
||||
|
|
@ -60,18 +59,20 @@ pip install clearml>=1.2.0
|
|||
This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager.
|
||||
|
||||
If you want to change the `project_name` or `task_name`, use the `--project` and `--name` arguments of the `train.py` script, by default the project will be called `YOLOv5` and the task `Training`.
|
||||
PLEASE NOTE: ClearML uses `/` as a delimter for subprojects, so be careful when using `/` in your project name!
|
||||
PLEASE NOTE: ClearML uses `/` as a delimiter for subprojects, so be careful when using `/` in your project name!
|
||||
|
||||
```bash
|
||||
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||||
```
|
||||
|
||||
or with custom project and task name:
|
||||
|
||||
```bash
|
||||
python train.py --project my_project --name my_training --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||||
```
|
||||
|
||||
This will capture:
|
||||
|
||||
- Source code + uncommitted changes
|
||||
- Installed packages
|
||||
- (Hyper)parameters
|
||||
|
|
@ -94,7 +95,7 @@ There even more we can do with all of this information, like hyperparameter opti
|
|||
|
||||
## 🔗 Dataset Version Management
|
||||
|
||||
Versioning your data separately from your code is generally a good idea and makes it easy to aqcuire the latest version too. This repository supports supplying a dataset version ID and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!
|
||||
Versioning your data separately from your code is generally a good idea and makes it easy to acquire the latest version too. This repository supports supplying a dataset version ID, and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!
|
||||
|
||||

|
||||
|
||||
|
|
@ -112,6 +113,7 @@ The YOLOv5 repository supports a number of different datasets by using yaml file
|
|||
|_ LICENSE
|
||||
|_ README.txt
|
||||
```
|
||||
|
||||
But this can be any dataset you wish. Feel free to use your own, as long as you keep to this folder structure.
|
||||
|
||||
Next, ⚠️**copy the corresponding yaml file to the root of the dataset folder**⚠️. This yaml files contains the information ClearML will need to properly use the dataset. You can make this yourself too, of course, just follow the structure of the example yamls.
|
||||
|
|
@ -132,13 +134,15 @@ Basically we need the following keys: `path`, `train`, `test`, `val`, `nc`, `nam
|
|||
|
||||
### Upload Your Dataset
|
||||
|
||||
To get this dataset into ClearML as a versionned dataset, go to the dataset root folder and run the following command:
|
||||
To get this dataset into ClearML as a versioned dataset, go to the dataset root folder and run the following command:
|
||||
|
||||
```bash
|
||||
cd coco128
|
||||
clearml-data sync --project YOLOv5 --name coco128 --folder .
|
||||
```
|
||||
|
||||
The command `clearml-data sync` is actually a shorthand command. You could also run these commands one after the other:
|
||||
|
||||
```bash
|
||||
# Optionally add --parent <parent_dataset_id> if you want to base
|
||||
# this version on another dataset version, so no duplicate files are uploaded!
|
||||
|
|
@ -177,7 +181,7 @@ python utils/loggers/clearml/hpo.py
|
|||
|
||||
## 🤯 Remote Execution (advanced)
|
||||
|
||||
Running HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site or you have some budget to use cloud GPUs.
|
||||
Running HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site, or you have some budget to use cloud GPUs.
|
||||
This is where the ClearML Agent comes into play. Check out what the agent can do here:
|
||||
|
||||
- [YouTube video](https://youtu.be/MX3BrXnaULs)
|
||||
|
|
@ -186,6 +190,7 @@ This is where the ClearML Agent comes into play. Check out what the agent can do
|
|||
In short: every experiment tracked by the experiment manager contains enough information to reproduce it on a different machine (installed packages, uncommitted changes etc.). So a ClearML agent does just that: it listens to a queue for incoming tasks and when it finds one, it recreates the environment and runs it while still reporting scalars, plots etc. to the experiment manager.
|
||||
|
||||
You can turn any machine (a cloud VM, a local GPU machine, your own laptop ... ) into a ClearML agent by simply running:
|
||||
|
||||
```bash
|
||||
clearml-agent daemon --queue <queues_to_listen_to> [--docker]
|
||||
```
|
||||
|
|
@ -194,11 +199,11 @@ clearml-agent daemon --queue <queues_to_listen_to> [--docker]
|
|||
|
||||
With our agent running, we can give it some work. Remember from the HPO section that we can clone a task and edit the hyperparameters? We can do that from the interface too!
|
||||
|
||||
🪄 Clone the experiment by right clicking it
|
||||
🪄 Clone the experiment by right-clicking it
|
||||
|
||||
🎯 Edit the hyperparameters to what you wish them to be
|
||||
|
||||
⏳ Enqueue the task to any of the queues by right clicking it
|
||||
⏳ Enqueue the task to any of the queues by right-clicking it
|
||||
|
||||

|
||||
|
||||
|
|
@ -206,7 +211,8 @@ With our agent running, we can give it some work. Remember from the HPO section
|
|||
|
||||
Now you can clone a task like we explained above, or simply mark your current script by adding `task.execute_remotely()` and on execution it will be put into a queue, for the agent to start working on!
|
||||
|
||||
To run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instatiated:
|
||||
To run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instantiated:
|
||||
|
||||
```python
|
||||
# ...
|
||||
# Loggers
|
||||
|
|
@ -214,16 +220,17 @@ data_dict = None
|
|||
if RANK in {-1, 0}:
|
||||
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
|
||||
if loggers.clearml:
|
||||
loggers.clearml.task.execute_remotely(queue='my_queue') # <------ ADD THIS LINE
|
||||
loggers.clearml.task.execute_remotely(queue="my_queue") # <------ ADD THIS LINE
|
||||
# Data_dict is either None is user did not choose for ClearML dataset or is filled in by ClearML
|
||||
data_dict = loggers.clearml.data_dict
|
||||
# ...
|
||||
```
|
||||
|
||||
When running the training script after this change, python will run the script up until that line, after which it will package the code and send it to the queue instead!
|
||||
|
||||
### Autoscaling workers
|
||||
|
||||
ClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines and you stop paying!
|
||||
ClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines, and you stop paying!
|
||||
|
||||
Check out the autoscalers getting started video below.
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ pip install comet_ml
|
|||
|
||||
There are two ways to configure Comet with YOLOv5.
|
||||
|
||||
You can either set your credentials through enviroment variables
|
||||
You can either set your credentials through environment variables
|
||||
|
||||
**Environment Variables**
|
||||
|
||||
|
|
@ -49,11 +49,12 @@ project_name=<Your Comet Project Name> # This will default to 'yolov5'
|
|||
python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
|
||||
```
|
||||
|
||||
That's it! Comet will automatically log your hyperparameters, command line arguments, training and valiation metrics. You can visualize and analyze your runs in the Comet UI
|
||||
That's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI
|
||||
|
||||
<img width="1920" alt="yolo-ui" src="https://user-images.githubusercontent.com/26833433/202851203-164e94e1-2238-46dd-91f8-de020e9d6b41.png">
|
||||
|
||||
# Try out an Example!
|
||||
|
||||
Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||
|
||||
Or better yet, try it out yourself in this Colab Notebook
|
||||
|
|
@ -65,6 +66,7 @@ Or better yet, try it out yourself in this Colab Notebook
|
|||
By default, Comet will log the following items
|
||||
|
||||
## Metrics
|
||||
|
||||
- Box Loss, Object Loss, Classification Loss for the training and validation data
|
||||
- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
|
||||
- Precision and Recall for the validation data
|
||||
|
|
@ -121,7 +123,6 @@ You can control the frequency of logged predictions and the associated images by
|
|||
|
||||
Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||
|
||||
|
||||
```shell
|
||||
python train.py \
|
||||
--img 640 \
|
||||
|
|
@ -192,6 +193,7 @@ If you would like to use a dataset from Comet Artifacts, set the `path` variable
|
|||
# contents of artifact.yaml file
|
||||
path: "comet://<workspace name>/<artifact name>:<artifact version or alias>"
|
||||
```
|
||||
|
||||
Then pass this file to your training script in the following way
|
||||
|
||||
```shell
|
||||
|
|
@ -221,7 +223,7 @@ python train.py \
|
|||
|
||||
## Hyperparameter Search with the Comet Optimizer
|
||||
|
||||
YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualie hyperparameter sweeps in the Comet UI.
|
||||
YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.
|
||||
|
||||
### Configuring an Optimizer Sweep
|
||||
|
||||
|
|
|
|||
|
|
@ -1,162 +0,0 @@
|
|||
📚 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 🚀. UPDATED 29 September 2021.
|
||||
|
||||
- [About Weights & Biases](#about-weights-&-biases)
|
||||
- [First-Time Setup](#first-time-setup)
|
||||
- [Viewing runs](#viewing-runs)
|
||||
- [Disabling wandb](#disabling-wandb)
|
||||
- [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
|
||||
- [Reports: Share your work with the world!](#reports)
|
||||
|
||||
## About Weights & Biases
|
||||
|
||||
Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models — architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
|
||||
|
||||
Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
|
||||
|
||||
- [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
|
||||
- [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
|
||||
- [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
|
||||
- [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
|
||||
- [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
|
||||
- [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
|
||||
|
||||
## First-Time Setup
|
||||
|
||||
<details open>
|
||||
<summary> Toggle Details </summary>
|
||||
When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.
|
||||
|
||||
W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as:
|
||||
|
||||
```shell
|
||||
$ python train.py --project ... --name ...
|
||||
```
|
||||
|
||||
YOLOv5 notebook example: <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
<img width="960" alt="Screen Shot 2021-09-29 at 10 23 13 PM" src="https://user-images.githubusercontent.com/26833433/135392431-1ab7920a-c49d-450a-b0b0-0c86ec86100e.png">
|
||||
|
||||
</details>
|
||||
|
||||
## Viewing Runs
|
||||
|
||||
<details open>
|
||||
<summary> Toggle Details </summary>
|
||||
Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in <b>realtime</b> . All important information is logged:
|
||||
|
||||
- Training & Validation losses
|
||||
- Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
|
||||
- Learning Rate over time
|
||||
- A bounding box debugging panel, showing the training progress over time
|
||||
- GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage**
|
||||
- System: Disk I/0, CPU utilization, RAM memory usage
|
||||
- Your trained model as W&B Artifact
|
||||
- Environment: OS and Python types, Git repository and state, **training command**
|
||||
|
||||
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
|
||||
</details>
|
||||
|
||||
## Disabling wandb
|
||||
|
||||
- training after running `wandb disabled` inside that directory creates no wandb run
|
||||
|
||||
|
||||
- To enable wandb again, run `wandb online`
|
||||
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
|
||||
|
||||
<details open>
|
||||
<h3> 1: Train and Log Evaluation simultaneousy </h3>
|
||||
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
|
||||
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
|
||||
so no images will be uploaded from your system more than once.
|
||||
<details open>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --upload_data val</code>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<h3>2. Visualize and Version Datasets</h3>
|
||||
Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<h3> 3: Train using dataset artifact </h3>
|
||||
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
|
||||
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<h3> 4: Save model checkpoints as artifacts </h3>
|
||||
To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval.
|
||||
You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged
|
||||
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --save_period 1 </code>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
</details>
|
||||
|
||||
<h3> 5: Resume runs from checkpoint artifacts. </h3>
|
||||
Any run can be resumed using artifacts if the <code>--resume</code> argument starts with <code>wandb-artifact://</code> prefix followed by the run path, i.e, <code>wandb-artifact://username/project/runid </code>. This doesn't require the model checkpoint to be present on the local system.
|
||||
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --resume wandb-artifact://{run_path} </code>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<h3> 6: Resume runs from dataset artifact & checkpoint artifacts. </h3>
|
||||
<b> Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device </b>
|
||||
The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot <code>--upload_dataset</code> or
|
||||
train from <code>_wandb.yaml</code> file and set <code>--save_period</code>
|
||||
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --resume wandb-artifact://{run_path} </code>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
</details>
|
||||
|
||||
<h3> Reports </h3>
|
||||
W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)).
|
||||
|
||||
<img width="900" alt="Weights & Biases Reports" src="https://user-images.githubusercontent.com/26833433/135394029-a17eaf86-c6c1-4b1d-bb80-b90e83aaffa7.png">
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Google Colab and Kaggle** notebooks with free GPU: <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
## Status
|
||||
|
||||

|
||||
|
||||
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
import argparse
|
||||
|
||||
from wandb_utils import WandbLogger
|
||||
|
||||
from utils.general import LOGGER
|
||||
|
||||
WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
|
||||
|
||||
|
||||
def create_dataset_artifact(opt):
|
||||
logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
|
||||
if not logger.wandb:
|
||||
LOGGER.info("install wandb using `pip install wandb` to log the dataset")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
|
||||
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
|
||||
parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
|
||||
parser.add_argument('--entity', default=None, help='W&B entity')
|
||||
parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
|
||||
|
||||
opt = parser.parse_args()
|
||||
opt.resume = False # Explicitly disallow resume check for dataset upload job
|
||||
|
||||
create_dataset_artifact(opt)
|
||||
|
|
@ -1,41 +0,0 @@
|
|||
import sys
|
||||
from pathlib import Path
|
||||
|
||||
import wandb
|
||||
|
||||
FILE = Path(__file__).resolve()
|
||||
ROOT = FILE.parents[3] # YOLOv5 root directory
|
||||
if str(ROOT) not in sys.path:
|
||||
sys.path.append(str(ROOT)) # add ROOT to PATH
|
||||
|
||||
from train import parse_opt, train
|
||||
from utils.callbacks import Callbacks
|
||||
from utils.general import increment_path
|
||||
from utils.torch_utils import select_device
|
||||
|
||||
|
||||
def sweep():
|
||||
wandb.init()
|
||||
# Get hyp dict from sweep agent. Copy because train() modifies parameters which confused wandb.
|
||||
hyp_dict = vars(wandb.config).get("_items").copy()
|
||||
|
||||
# Workaround: get necessary opt args
|
||||
opt = parse_opt(known=True)
|
||||
opt.batch_size = hyp_dict.get("batch_size")
|
||||
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
|
||||
opt.epochs = hyp_dict.get("epochs")
|
||||
opt.nosave = True
|
||||
opt.data = hyp_dict.get("data")
|
||||
opt.weights = str(opt.weights)
|
||||
opt.cfg = str(opt.cfg)
|
||||
opt.data = str(opt.data)
|
||||
opt.hyp = str(opt.hyp)
|
||||
opt.project = str(opt.project)
|
||||
device = select_device(opt.device, batch_size=opt.batch_size)
|
||||
|
||||
# train
|
||||
train(hyp_dict, opt, device, callbacks=Callbacks())
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sweep()
|
||||
|
|
@ -1,143 +0,0 @@
|
|||
# Hyperparameters for training
|
||||
# To set range-
|
||||
# Provide min and max values as:
|
||||
# parameter:
|
||||
#
|
||||
# min: scalar
|
||||
# max: scalar
|
||||
# OR
|
||||
#
|
||||
# Set a specific list of search space-
|
||||
# parameter:
|
||||
# values: [scalar1, scalar2, scalar3...]
|
||||
#
|
||||
# You can use grid, bayesian and hyperopt search strategy
|
||||
# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
|
||||
|
||||
program: utils/loggers/wandb/sweep.py
|
||||
method: random
|
||||
metric:
|
||||
name: metrics/mAP_0.5
|
||||
goal: maximize
|
||||
|
||||
parameters:
|
||||
# hyperparameters: set either min, max range or values list
|
||||
data:
|
||||
value: "data/coco128.yaml"
|
||||
batch_size:
|
||||
values: [64]
|
||||
epochs:
|
||||
values: [10]
|
||||
|
||||
lr0:
|
||||
distribution: uniform
|
||||
min: 1e-5
|
||||
max: 1e-1
|
||||
lrf:
|
||||
distribution: uniform
|
||||
min: 0.01
|
||||
max: 1.0
|
||||
momentum:
|
||||
distribution: uniform
|
||||
min: 0.6
|
||||
max: 0.98
|
||||
weight_decay:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.001
|
||||
warmup_epochs:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 5.0
|
||||
warmup_momentum:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.95
|
||||
warmup_bias_lr:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.2
|
||||
box:
|
||||
distribution: uniform
|
||||
min: 0.02
|
||||
max: 0.2
|
||||
cls:
|
||||
distribution: uniform
|
||||
min: 0.2
|
||||
max: 4.0
|
||||
cls_pw:
|
||||
distribution: uniform
|
||||
min: 0.5
|
||||
max: 2.0
|
||||
obj:
|
||||
distribution: uniform
|
||||
min: 0.2
|
||||
max: 4.0
|
||||
obj_pw:
|
||||
distribution: uniform
|
||||
min: 0.5
|
||||
max: 2.0
|
||||
iou_t:
|
||||
distribution: uniform
|
||||
min: 0.1
|
||||
max: 0.7
|
||||
anchor_t:
|
||||
distribution: uniform
|
||||
min: 2.0
|
||||
max: 8.0
|
||||
fl_gamma:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 4.0
|
||||
hsv_h:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.1
|
||||
hsv_s:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.9
|
||||
hsv_v:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.9
|
||||
degrees:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 45.0
|
||||
translate:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.9
|
||||
scale:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.9
|
||||
shear:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 10.0
|
||||
perspective:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 0.001
|
||||
flipud:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 1.0
|
||||
fliplr:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 1.0
|
||||
mosaic:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 1.0
|
||||
mixup:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 1.0
|
||||
copy_paste:
|
||||
distribution: uniform
|
||||
min: 0.0
|
||||
max: 1.0
|
||||
|
|
@ -1,110 +1,32 @@
|
|||
"""Utilities and tools for tracking runs with Weights & Biases."""
|
||||
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||
|
||||
# WARNING ⚠️ wandb is deprecated and will be removed in future release.
|
||||
# See supported integrations at https://github.com/ultralytics/yolov5#integrations
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
from contextlib import contextmanager
|
||||
from pathlib import Path
|
||||
from typing import Dict
|
||||
|
||||
import yaml
|
||||
from tqdm import tqdm
|
||||
from utils.general import LOGGER, colorstr
|
||||
|
||||
FILE = Path(__file__).resolve()
|
||||
ROOT = FILE.parents[3] # YOLOv5 root directory
|
||||
if str(ROOT) not in sys.path:
|
||||
sys.path.append(str(ROOT)) # add ROOT to PATH
|
||||
|
||||
from utils.dataloaders import LoadImagesAndLabels, img2label_paths
|
||||
from utils.general import LOGGER, check_dataset, check_file
|
||||
RANK = int(os.getenv('RANK', -1))
|
||||
DEPRECATION_WARNING = f"{colorstr('wandb')}: WARNING ⚠️ wandb is deprecated and will be removed in a future release. " \
|
||||
f"See supported integrations at https://github.com/ultralytics/yolov5#integrations."
|
||||
|
||||
try:
|
||||
import wandb
|
||||
|
||||
assert hasattr(wandb, '__version__') # verify package import not local dir
|
||||
LOGGER.warning(DEPRECATION_WARNING)
|
||||
except (ImportError, AssertionError):
|
||||
wandb = None
|
||||
|
||||
RANK = int(os.getenv('RANK', -1))
|
||||
WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
|
||||
|
||||
|
||||
def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
|
||||
return from_string[len(prefix):]
|
||||
|
||||
|
||||
def check_wandb_config_file(data_config_file):
|
||||
wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
|
||||
if Path(wandb_config).is_file():
|
||||
return wandb_config
|
||||
return data_config_file
|
||||
|
||||
|
||||
def check_wandb_dataset(data_file):
|
||||
is_trainset_wandb_artifact = False
|
||||
is_valset_wandb_artifact = False
|
||||
if isinstance(data_file, dict):
|
||||
# In that case another dataset manager has already processed it and we don't have to
|
||||
return data_file
|
||||
if check_file(data_file) and data_file.endswith('.yaml'):
|
||||
with open(data_file, errors='ignore') as f:
|
||||
data_dict = yaml.safe_load(f)
|
||||
is_trainset_wandb_artifact = isinstance(data_dict['train'],
|
||||
str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX)
|
||||
is_valset_wandb_artifact = isinstance(data_dict['val'],
|
||||
str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX)
|
||||
if is_trainset_wandb_artifact or is_valset_wandb_artifact:
|
||||
return data_dict
|
||||
else:
|
||||
return check_dataset(data_file)
|
||||
|
||||
|
||||
def get_run_info(run_path):
|
||||
run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
|
||||
run_id = run_path.stem
|
||||
project = run_path.parent.stem
|
||||
entity = run_path.parent.parent.stem
|
||||
model_artifact_name = 'run_' + run_id + '_model'
|
||||
return entity, project, run_id, model_artifact_name
|
||||
|
||||
|
||||
def check_wandb_resume(opt):
|
||||
process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
|
||||
if isinstance(opt.resume, str):
|
||||
if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
|
||||
if RANK not in [-1, 0]: # For resuming DDP runs
|
||||
entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
|
||||
api = wandb.Api()
|
||||
artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
|
||||
modeldir = artifact.download()
|
||||
opt.weights = str(Path(modeldir) / "last.pt")
|
||||
return True
|
||||
return None
|
||||
|
||||
|
||||
def process_wandb_config_ddp_mode(opt):
|
||||
with open(check_file(opt.data), errors='ignore') as f:
|
||||
data_dict = yaml.safe_load(f) # data dict
|
||||
train_dir, val_dir = None, None
|
||||
if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
|
||||
api = wandb.Api()
|
||||
train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
|
||||
train_dir = train_artifact.download()
|
||||
train_path = Path(train_dir) / 'data/images/'
|
||||
data_dict['train'] = str(train_path)
|
||||
|
||||
if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
|
||||
api = wandb.Api()
|
||||
val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
|
||||
val_dir = val_artifact.download()
|
||||
val_path = Path(val_dir) / 'data/images/'
|
||||
data_dict['val'] = str(val_path)
|
||||
if train_dir or val_dir:
|
||||
ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
|
||||
with open(ddp_data_path, 'w') as f:
|
||||
yaml.safe_dump(data_dict, f)
|
||||
opt.data = ddp_data_path
|
||||
|
||||
|
||||
class WandbLogger():
|
||||
"""Log training runs, datasets, models, and predictions to Weights & Biases.
|
||||
|
|
@ -132,38 +54,16 @@ class WandbLogger():
|
|||
job_type (str) -- To set the job_type for this run
|
||||
|
||||
"""
|
||||
# Temporary-fix
|
||||
if opt.upload_dataset:
|
||||
opt.upload_dataset = False
|
||||
# LOGGER.info("Uploading Dataset functionality is not being supported temporarily due to a bug.")
|
||||
|
||||
# Pre-training routine --
|
||||
self.job_type = job_type
|
||||
self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
|
||||
self.wandb, self.wandb_run = wandb, wandb.run if wandb else None
|
||||
self.val_artifact, self.train_artifact = None, None
|
||||
self.train_artifact_path, self.val_artifact_path = None, None
|
||||
self.result_artifact = None
|
||||
self.val_table, self.result_table = None, None
|
||||
self.bbox_media_panel_images = []
|
||||
self.val_table_path_map = None
|
||||
self.max_imgs_to_log = 16
|
||||
self.wandb_artifact_data_dict = None
|
||||
self.data_dict = None
|
||||
# It's more elegant to stick to 1 wandb.init call,
|
||||
# but useful config data is overwritten in the WandbLogger's wandb.init call
|
||||
if isinstance(opt.resume, str): # checks resume from artifact
|
||||
if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
|
||||
entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
|
||||
model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
|
||||
assert wandb, 'install wandb to resume wandb runs'
|
||||
# Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
|
||||
self.wandb_run = wandb.init(id=run_id,
|
||||
project=project,
|
||||
entity=entity,
|
||||
resume='allow',
|
||||
allow_val_change=True)
|
||||
opt.resume = model_artifact_name
|
||||
elif self.wandb:
|
||||
if self.wandb:
|
||||
self.wandb_run = wandb.init(config=opt,
|
||||
resume="allow",
|
||||
project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
|
||||
|
|
@ -172,51 +72,15 @@ class WandbLogger():
|
|||
job_type=job_type,
|
||||
id=run_id,
|
||||
allow_val_change=True) if not wandb.run else wandb.run
|
||||
|
||||
if self.wandb_run:
|
||||
if self.job_type == 'Training':
|
||||
if opt.upload_dataset:
|
||||
if not opt.resume:
|
||||
self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
|
||||
|
||||
if isinstance(opt.data, dict):
|
||||
# This means another dataset manager has already processed the dataset info (e.g. ClearML)
|
||||
# and they will have stored the already processed dict in opt.data
|
||||
self.data_dict = opt.data
|
||||
elif opt.resume:
|
||||
# resume from artifact
|
||||
if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
|
||||
self.data_dict = dict(self.wandb_run.config.data_dict)
|
||||
else: # local resume
|
||||
self.data_dict = check_wandb_dataset(opt.data)
|
||||
else:
|
||||
self.data_dict = check_wandb_dataset(opt.data)
|
||||
self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
|
||||
|
||||
# write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
|
||||
self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict}, allow_val_change=True)
|
||||
self.setup_training(opt)
|
||||
|
||||
if self.job_type == 'Dataset Creation':
|
||||
self.wandb_run.config.update({"upload_dataset": True})
|
||||
self.data_dict = self.check_and_upload_dataset(opt)
|
||||
|
||||
def check_and_upload_dataset(self, opt):
|
||||
"""
|
||||
Check if the dataset format is compatible and upload it as W&B artifact
|
||||
|
||||
arguments:
|
||||
opt (namespace)-- Commandline arguments for current run
|
||||
|
||||
returns:
|
||||
Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
|
||||
"""
|
||||
assert wandb, 'Install wandb to upload dataset'
|
||||
config_path = self.log_dataset_artifact(opt.data, opt.single_cls,
|
||||
'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
|
||||
with open(config_path, errors='ignore') as f:
|
||||
wandb_data_dict = yaml.safe_load(f)
|
||||
return wandb_data_dict
|
||||
|
||||
def setup_training(self, opt):
|
||||
"""
|
||||
Setup the necessary processes for training YOLO models:
|
||||
|
|
@ -231,81 +95,18 @@ class WandbLogger():
|
|||
self.log_dict, self.current_epoch = {}, 0
|
||||
self.bbox_interval = opt.bbox_interval
|
||||
if isinstance(opt.resume, str):
|
||||
modeldir, _ = self.download_model_artifact(opt)
|
||||
if modeldir:
|
||||
self.weights = Path(modeldir) / "last.pt"
|
||||
model_dir, _ = self.download_model_artifact(opt)
|
||||
if model_dir:
|
||||
self.weights = Path(model_dir) / "last.pt"
|
||||
config = self.wandb_run.config
|
||||
opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
|
||||
self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs,\
|
||||
self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
|
||||
config.hyp, config.imgsz
|
||||
data_dict = self.data_dict
|
||||
if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
|
||||
self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(
|
||||
data_dict.get('train'), opt.artifact_alias)
|
||||
self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(
|
||||
data_dict.get('val'), opt.artifact_alias)
|
||||
|
||||
if self.train_artifact_path is not None:
|
||||
train_path = Path(self.train_artifact_path) / 'data/images/'
|
||||
data_dict['train'] = str(train_path)
|
||||
if self.val_artifact_path is not None:
|
||||
val_path = Path(self.val_artifact_path) / 'data/images/'
|
||||
data_dict['val'] = str(val_path)
|
||||
|
||||
if self.val_artifact is not None:
|
||||
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
|
||||
columns = ["epoch", "id", "ground truth", "prediction"]
|
||||
columns.extend(self.data_dict['names'])
|
||||
self.result_table = wandb.Table(columns)
|
||||
self.val_table = self.val_artifact.get("val")
|
||||
if self.val_table_path_map is None:
|
||||
self.map_val_table_path()
|
||||
if opt.bbox_interval == -1:
|
||||
self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
|
||||
if opt.evolve or opt.noplots:
|
||||
self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
|
||||
train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
|
||||
# Update the the data_dict to point to local artifacts dir
|
||||
if train_from_artifact:
|
||||
self.data_dict = data_dict
|
||||
|
||||
def download_dataset_artifact(self, path, alias):
|
||||
"""
|
||||
download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
|
||||
|
||||
arguments:
|
||||
path -- path of the dataset to be used for training
|
||||
alias (str)-- alias of the artifact to be download/used for training
|
||||
|
||||
returns:
|
||||
(str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
|
||||
is found otherwise returns (None, None)
|
||||
"""
|
||||
if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
|
||||
artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
|
||||
dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
|
||||
assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
|
||||
datadir = dataset_artifact.download()
|
||||
return datadir, dataset_artifact
|
||||
return None, None
|
||||
|
||||
def download_model_artifact(self, opt):
|
||||
"""
|
||||
download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
|
||||
|
||||
arguments:
|
||||
opt (namespace) -- Commandline arguments for this run
|
||||
"""
|
||||
if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
|
||||
model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
|
||||
assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
|
||||
modeldir = model_artifact.download()
|
||||
# epochs_trained = model_artifact.metadata.get('epochs_trained')
|
||||
total_epochs = model_artifact.metadata.get('total_epochs')
|
||||
is_finished = total_epochs is None
|
||||
assert not is_finished, 'training is finished, can only resume incomplete runs.'
|
||||
return modeldir, model_artifact
|
||||
return None, None
|
||||
|
||||
def log_model(self, path, opt, epoch, fitness_score, best_model=False):
|
||||
"""
|
||||
|
|
@ -332,190 +133,8 @@ class WandbLogger():
|
|||
aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
|
||||
LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
|
||||
|
||||
def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
|
||||
"""
|
||||
Log the dataset as W&B artifact and return the new data file with W&B links
|
||||
|
||||
arguments:
|
||||
data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
|
||||
single_class (boolean) -- train multi-class data as single-class
|
||||
project (str) -- project name. Used to construct the artifact path
|
||||
overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
|
||||
file with _wandb postfix. Eg -> data_wandb.yaml
|
||||
|
||||
returns:
|
||||
the new .yaml file with artifact links. it can be used to start training directly from artifacts
|
||||
"""
|
||||
upload_dataset = self.wandb_run.config.upload_dataset
|
||||
log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
|
||||
self.data_dict = check_dataset(data_file) # parse and check
|
||||
data = dict(self.data_dict)
|
||||
nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
|
||||
names = {k: v for k, v in enumerate(names)} # to index dictionary
|
||||
|
||||
# log train set
|
||||
if not log_val_only:
|
||||
self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(data['train'], rect=True, batch_size=1),
|
||||
names,
|
||||
name='train') if data.get('train') else None
|
||||
if data.get('train'):
|
||||
data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
|
||||
|
||||
self.val_artifact = self.create_dataset_table(
|
||||
LoadImagesAndLabels(data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
|
||||
if data.get('val'):
|
||||
data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
|
||||
|
||||
path = Path(data_file)
|
||||
# create a _wandb.yaml file with artifacts links if both train and test set are logged
|
||||
if not log_val_only:
|
||||
path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
|
||||
path = ROOT / 'data' / path
|
||||
data.pop('download', None)
|
||||
data.pop('path', None)
|
||||
with open(path, 'w') as f:
|
||||
yaml.safe_dump(data, f)
|
||||
LOGGER.info(f"Created dataset config file {path}")
|
||||
|
||||
if self.job_type == 'Training': # builds correct artifact pipeline graph
|
||||
if not log_val_only:
|
||||
self.wandb_run.log_artifact(
|
||||
self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
|
||||
self.wandb_run.use_artifact(self.val_artifact)
|
||||
self.val_artifact.wait()
|
||||
self.val_table = self.val_artifact.get('val')
|
||||
self.map_val_table_path()
|
||||
else:
|
||||
self.wandb_run.log_artifact(self.train_artifact)
|
||||
self.wandb_run.log_artifact(self.val_artifact)
|
||||
return path
|
||||
|
||||
def map_val_table_path(self):
|
||||
"""
|
||||
Map the validation dataset Table like name of file -> it's id in the W&B Table.
|
||||
Useful for - referencing artifacts for evaluation.
|
||||
"""
|
||||
self.val_table_path_map = {}
|
||||
LOGGER.info("Mapping dataset")
|
||||
for i, data in enumerate(tqdm(self.val_table.data)):
|
||||
self.val_table_path_map[data[3]] = data[0]
|
||||
|
||||
def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
|
||||
"""
|
||||
Create and return W&B artifact containing W&B Table of the dataset.
|
||||
|
||||
arguments:
|
||||
dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
|
||||
class_to_id -- hash map that maps class ids to labels
|
||||
name -- name of the artifact
|
||||
|
||||
returns:
|
||||
dataset artifact to be logged or used
|
||||
"""
|
||||
# TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
|
||||
artifact = wandb.Artifact(name=name, type="dataset")
|
||||
img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
|
||||
img_files = tqdm(dataset.im_files) if not img_files else img_files
|
||||
for img_file in img_files:
|
||||
if Path(img_file).is_dir():
|
||||
artifact.add_dir(img_file, name='data/images')
|
||||
labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
|
||||
artifact.add_dir(labels_path, name='data/labels')
|
||||
else:
|
||||
artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
|
||||
label_file = Path(img2label_paths([img_file])[0])
|
||||
artifact.add_file(str(label_file), name='data/labels/' +
|
||||
label_file.name) if label_file.exists() else None
|
||||
table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
|
||||
class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
|
||||
for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
|
||||
box_data, img_classes = [], {}
|
||||
for cls, *xywh in labels[:, 1:].tolist():
|
||||
cls = int(cls)
|
||||
box_data.append({
|
||||
"position": {
|
||||
"middle": [xywh[0], xywh[1]],
|
||||
"width": xywh[2],
|
||||
"height": xywh[3]},
|
||||
"class_id": cls,
|
||||
"box_caption": "%s" % (class_to_id[cls])})
|
||||
img_classes[cls] = class_to_id[cls]
|
||||
boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
|
||||
table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
|
||||
Path(paths).name)
|
||||
artifact.add(table, name)
|
||||
return artifact
|
||||
|
||||
def log_training_progress(self, predn, path, names):
|
||||
"""
|
||||
Build evaluation Table. Uses reference from validation dataset table.
|
||||
|
||||
arguments:
|
||||
predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
|
||||
path (str): local path of the current evaluation image
|
||||
names (dict(int, str)): hash map that maps class ids to labels
|
||||
"""
|
||||
class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
|
||||
box_data = []
|
||||
avg_conf_per_class = [0] * len(self.data_dict['names'])
|
||||
pred_class_count = {}
|
||||
for *xyxy, conf, cls in predn.tolist():
|
||||
if conf >= 0.25:
|
||||
cls = int(cls)
|
||||
box_data.append({
|
||||
"position": {
|
||||
"minX": xyxy[0],
|
||||
"minY": xyxy[1],
|
||||
"maxX": xyxy[2],
|
||||
"maxY": xyxy[3]},
|
||||
"class_id": cls,
|
||||
"box_caption": f"{names[cls]} {conf:.3f}",
|
||||
"scores": {
|
||||
"class_score": conf},
|
||||
"domain": "pixel"})
|
||||
avg_conf_per_class[cls] += conf
|
||||
|
||||
if cls in pred_class_count:
|
||||
pred_class_count[cls] += 1
|
||||
else:
|
||||
pred_class_count[cls] = 1
|
||||
|
||||
for pred_class in pred_class_count.keys():
|
||||
avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
|
||||
|
||||
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
|
||||
id = self.val_table_path_map[Path(path).name]
|
||||
self.result_table.add_data(self.current_epoch, id, self.val_table.data[id][1],
|
||||
wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
|
||||
*avg_conf_per_class)
|
||||
|
||||
def val_one_image(self, pred, predn, path, names, im):
|
||||
"""
|
||||
Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
|
||||
|
||||
arguments:
|
||||
pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
|
||||
predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
|
||||
path (str): local path of the current evaluation image
|
||||
"""
|
||||
if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
|
||||
self.log_training_progress(predn, path, names)
|
||||
|
||||
if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
|
||||
if self.current_epoch % self.bbox_interval == 0:
|
||||
box_data = [{
|
||||
"position": {
|
||||
"minX": xyxy[0],
|
||||
"minY": xyxy[1],
|
||||
"maxX": xyxy[2],
|
||||
"maxY": xyxy[3]},
|
||||
"class_id": int(cls),
|
||||
"box_caption": f"{names[int(cls)]} {conf:.3f}",
|
||||
"scores": {
|
||||
"class_score": conf},
|
||||
"domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
|
||||
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
|
||||
self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
|
||||
pass
|
||||
|
||||
def log(self, log_dict):
|
||||
"""
|
||||
|
|
@ -528,7 +147,7 @@ class WandbLogger():
|
|||
for key, value in log_dict.items():
|
||||
self.log_dict[key] = value
|
||||
|
||||
def end_epoch(self, best_result=False):
|
||||
def end_epoch(self):
|
||||
"""
|
||||
commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
|
||||
|
||||
|
|
@ -537,8 +156,6 @@ class WandbLogger():
|
|||
"""
|
||||
if self.wandb_run:
|
||||
with all_logging_disabled():
|
||||
if self.bbox_media_panel_images:
|
||||
self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
|
||||
try:
|
||||
wandb.log(self.log_dict)
|
||||
except BaseException as e:
|
||||
|
|
@ -547,21 +164,7 @@ class WandbLogger():
|
|||
)
|
||||
self.wandb_run.finish()
|
||||
self.wandb_run = None
|
||||
|
||||
self.log_dict = {}
|
||||
self.bbox_media_panel_images = []
|
||||
if self.result_artifact:
|
||||
self.result_artifact.add(self.result_table, 'result')
|
||||
wandb.log_artifact(self.result_artifact,
|
||||
aliases=[
|
||||
'latest', 'last', 'epoch ' + str(self.current_epoch),
|
||||
('best' if best_result else '')])
|
||||
|
||||
wandb.log({"evaluation": self.result_table})
|
||||
columns = ["epoch", "id", "ground truth", "prediction"]
|
||||
columns.extend(self.data_dict['names'])
|
||||
self.result_table = wandb.Table(columns)
|
||||
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
|
||||
|
||||
def finish_run(self):
|
||||
"""
|
||||
|
|
@ -572,6 +175,7 @@ class WandbLogger():
|
|||
with all_logging_disabled():
|
||||
wandb.log(self.log_dict)
|
||||
wandb.run.finish()
|
||||
LOGGER.warning(DEPRECATION_WARNING)
|
||||
|
||||
|
||||
@contextmanager
|
||||
|
|
|
|||
Loading…
Reference in New Issue