W&B: refactor W&B tables (#5737)
* update * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * reformat * Single-line argparser argument * Update README.md * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Update README.md * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>pull/5804/head
parent
4c7b2bdc30
commit
f2ca30a407
utils/loggers/wandb
2
train.py
2
train.py
|
|
@ -475,7 +475,7 @@ def parse_opt(known=False):
|
|||
|
||||
# Weights & Biases arguments
|
||||
parser.add_argument('--entity', default=None, help='W&B: Entity')
|
||||
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
|
||||
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
|
||||
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
|
||||
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
|
||||
|
||||
|
|
|
|||
|
|
@ -2,6 +2,7 @@
|
|||
* [About Weights & Biases](#about-weights-&-biases)
|
||||
* [First-Time Setup](#first-time-setup)
|
||||
* [Viewing runs](#viewing-runs)
|
||||
* [Disabling wandb](#disabling-wandb)
|
||||
* [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
|
||||
* [Reports: Share your work with the world!](#reports)
|
||||
|
||||
|
|
@ -49,14 +50,30 @@ Run information streams from your environment to the W&B cloud console as you tr
|
|||
* Environment: OS and Python types, Git repository and state, **training command**
|
||||
|
||||
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
## Disabling wandb
|
||||
* training after running `wandb disabled` inside that directory creates no wandb run
|
||||
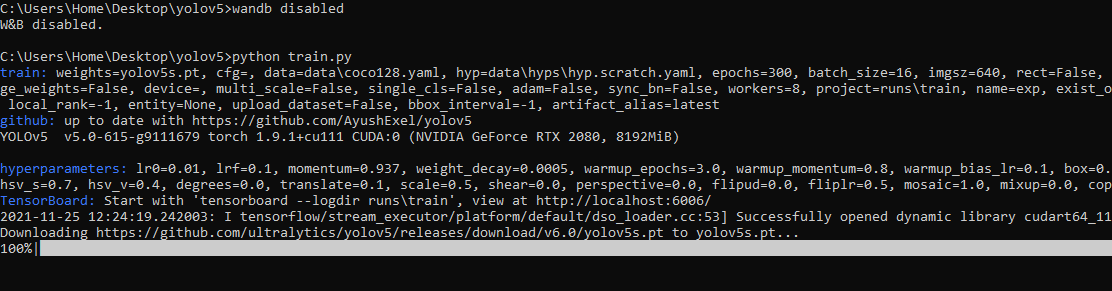
|
||||
|
||||
* To enable wandb again, run `wandb online`
|
||||
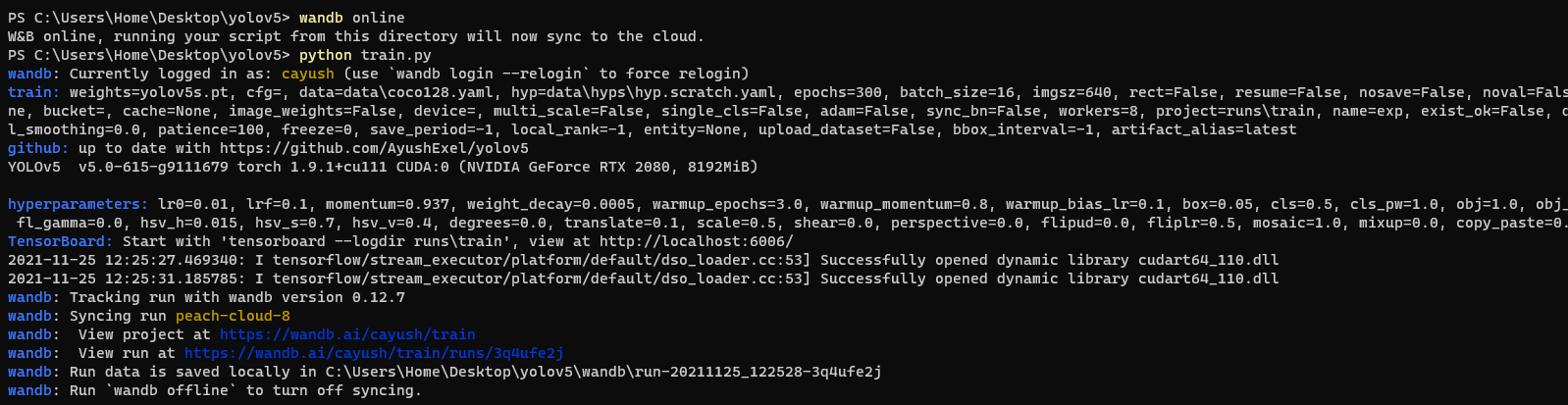
|
||||
|
||||
## Advanced Usage
|
||||
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
|
||||
<details open>
|
||||
<h3>1. Visualize and Version Datasets</h3>
|
||||
<h3> 1: Train and Log Evaluation simultaneousy </h3>
|
||||
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
|
||||
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
|
||||
so no images will be uploaded from your system more than once.
|
||||
<details open>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python train.py --upload_data val</code>
|
||||
|
||||
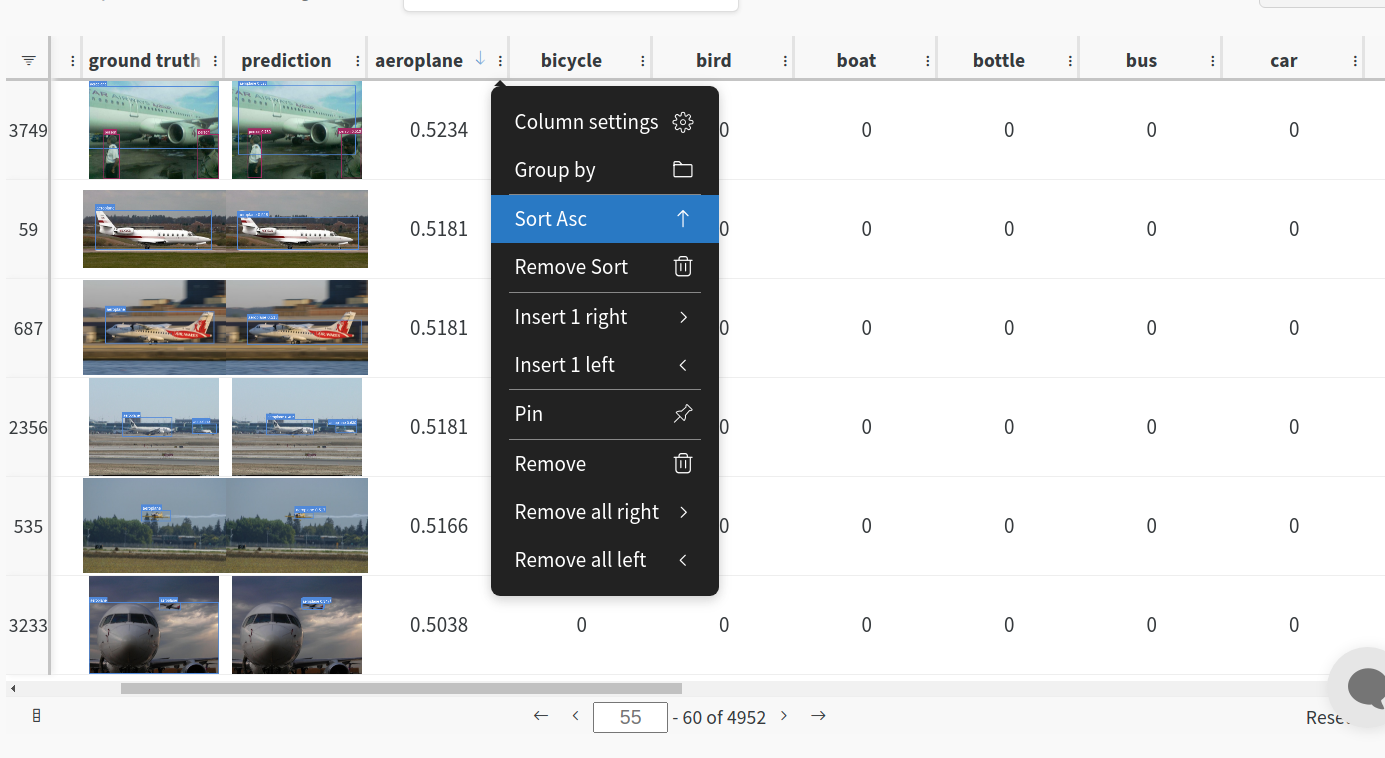
|
||||
</details>
|
||||
|
||||
<h3>2. Visualize and Version Datasets</h3>
|
||||
Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
|
|
@ -65,23 +82,12 @@ You can leverage W&B artifacts and Tables integration to easily visualize and ma
|
|||

|
||||
</details>
|
||||
|
||||
<h3> 2: Train and Log Evaluation simultaneousy </h3>
|
||||
This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
|
||||
Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
|
||||
so no images will be uploaded from your system more than once.
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --data .. --upload_data </code>
|
||||
|
||||

|
||||
</details>
|
||||
|
||||
<h3> 3: Train using dataset artifact </h3>
|
||||
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
|
||||
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
|
||||
<details>
|
||||
<summary> <b>Usage</b> </summary>
|
||||
<b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --data {data}_wandb.yaml </code>
|
||||
<b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>
|
||||
|
||||

|
||||
</details>
|
||||
|
|
@ -123,7 +129,6 @@ Any run can be resumed using artifacts if the <code>--resume</code> argument sta
|
|||
|
||||
</details>
|
||||
|
||||
|
||||
<h3> Reports </h3>
|
||||
W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)).
|
||||
|
||||
|
|
|
|||
|
|
@ -202,7 +202,6 @@ class WandbLogger():
|
|||
config_path = self.log_dataset_artifact(opt.data,
|
||||
opt.single_cls,
|
||||
'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
|
||||
LOGGER.info(f"Created dataset config file {config_path}")
|
||||
with open(config_path, errors='ignore') as f:
|
||||
wandb_data_dict = yaml.safe_load(f)
|
||||
return wandb_data_dict
|
||||
|
|
@ -244,7 +243,9 @@ class WandbLogger():
|
|||
|
||||
if self.val_artifact is not None:
|
||||
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
|
||||
self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
|
||||
columns = ["epoch", "id", "ground truth", "prediction"]
|
||||
columns.extend(self.data_dict['names'])
|
||||
self.result_table = wandb.Table(columns)
|
||||
self.val_table = self.val_artifact.get("val")
|
||||
if self.val_table_path_map is None:
|
||||
self.map_val_table_path()
|
||||
|
|
@ -331,28 +332,41 @@ class WandbLogger():
|
|||
returns:
|
||||
the new .yaml file with artifact links. it can be used to start training directly from artifacts
|
||||
"""
|
||||
upload_dataset = self.wandb_run.config.upload_dataset
|
||||
log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
|
||||
self.data_dict = check_dataset(data_file) # parse and check
|
||||
data = dict(self.data_dict)
|
||||
nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
|
||||
names = {k: v for k, v in enumerate(names)} # to index dictionary
|
||||
self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
|
||||
data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
|
||||
|
||||
# log train set
|
||||
if not log_val_only:
|
||||
self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
|
||||
data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
|
||||
if data.get('train'):
|
||||
data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
|
||||
|
||||
self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
|
||||
data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
|
||||
if data.get('train'):
|
||||
data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
|
||||
if data.get('val'):
|
||||
data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
|
||||
path = Path(data_file).stem
|
||||
path = (path if overwrite_config else path + '_wandb') + '.yaml' # updated data.yaml path
|
||||
data.pop('download', None)
|
||||
data.pop('path', None)
|
||||
with open(path, 'w') as f:
|
||||
yaml.safe_dump(data, f)
|
||||
|
||||
path = Path(data_file)
|
||||
# create a _wandb.yaml file with artifacts links if both train and test set are logged
|
||||
if not log_val_only:
|
||||
path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
|
||||
path = Path('data') / path
|
||||
data.pop('download', None)
|
||||
data.pop('path', None)
|
||||
with open(path, 'w') as f:
|
||||
yaml.safe_dump(data, f)
|
||||
LOGGER.info(f"Created dataset config file {path}")
|
||||
|
||||
if self.job_type == 'Training': # builds correct artifact pipeline graph
|
||||
if not log_val_only:
|
||||
self.wandb_run.log_artifact(
|
||||
self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
|
||||
self.wandb_run.use_artifact(self.val_artifact)
|
||||
self.wandb_run.use_artifact(self.train_artifact)
|
||||
self.val_artifact.wait()
|
||||
self.val_table = self.val_artifact.get('val')
|
||||
self.map_val_table_path()
|
||||
|
|
@ -371,7 +385,7 @@ class WandbLogger():
|
|||
for i, data in enumerate(tqdm(self.val_table.data)):
|
||||
self.val_table_path_map[data[3]] = data[0]
|
||||
|
||||
def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int,str], name: str = 'dataset'):
|
||||
def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
|
||||
"""
|
||||
Create and return W&B artifact containing W&B Table of the dataset.
|
||||
|
||||
|
|
@ -424,23 +438,34 @@ class WandbLogger():
|
|||
"""
|
||||
class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
|
||||
box_data = []
|
||||
total_conf = 0
|
||||
avg_conf_per_class = [0] * len(self.data_dict['names'])
|
||||
pred_class_count = {}
|
||||
for *xyxy, conf, cls in predn.tolist():
|
||||
if conf >= 0.25:
|
||||
cls = int(cls)
|
||||
box_data.append(
|
||||
{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
|
||||
"class_id": int(cls),
|
||||
"class_id": cls,
|
||||
"box_caption": f"{names[cls]} {conf:.3f}",
|
||||
"scores": {"class_score": conf},
|
||||
"domain": "pixel"})
|
||||
total_conf += conf
|
||||
avg_conf_per_class[cls] += conf
|
||||
|
||||
if cls in pred_class_count:
|
||||
pred_class_count[cls] += 1
|
||||
else:
|
||||
pred_class_count[cls] = 1
|
||||
|
||||
for pred_class in pred_class_count.keys():
|
||||
avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
|
||||
|
||||
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
|
||||
id = self.val_table_path_map[Path(path).name]
|
||||
self.result_table.add_data(self.current_epoch,
|
||||
id,
|
||||
self.val_table.data[id][1],
|
||||
wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
|
||||
total_conf / max(1, len(box_data))
|
||||
*avg_conf_per_class
|
||||
)
|
||||
|
||||
def val_one_image(self, pred, predn, path, names, im):
|
||||
|
|
@ -490,7 +515,8 @@ class WandbLogger():
|
|||
try:
|
||||
wandb.log(self.log_dict)
|
||||
except BaseException as e:
|
||||
LOGGER.info(f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
|
||||
LOGGER.info(
|
||||
f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
|
||||
self.wandb_run.finish()
|
||||
self.wandb_run = None
|
||||
|
||||
|
|
@ -502,7 +528,9 @@ class WandbLogger():
|
|||
('best' if best_result else '')])
|
||||
|
||||
wandb.log({"evaluation": self.result_table})
|
||||
self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
|
||||
columns = ["epoch", "id", "ground truth", "prediction"]
|
||||
columns.extend(self.data_dict['names'])
|
||||
self.result_table = wandb.Table(columns)
|
||||
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
|
||||
|
||||
def finish_run(self):
|
||||
|
|
|
|||
Loading…
Reference in New Issue