233 lines
12 KiB
Markdown
233 lines
12 KiB
Markdown
<a href="https://www.ultralytics.com/"><img src="https://raw.githubusercontent.com/ultralytics/assets/main/logo/Ultralytics_Logotype_Original.svg" width="320" alt="Ultralytics logo"></a>
|
||
|
||
# ClearML Integration with Ultralytics YOLO
|
||
|
||
<img align="center" src="https://github.com/thepycoder/clearml_screenshots/raw/main/logos_dark.png#gh-light-mode-only" alt="ClearML"><img align="center" src="https://github.com/thepycoder/clearml_screenshots/raw/main/logos_light.png#gh-dark-mode-only" alt="ClearML">
|
||
|
||
## ℹ️ About ClearML
|
||
|
||
[ClearML](https://clear.ml/) is an [open-source MLOps platform](https://github.com/clearml/clearml) designed to streamline your machine learning workflow and maximize productivity. Integrating ClearML with [Ultralytics YOLO](https://docs.ultralytics.com/models/yolov5/) unlocks a robust suite of tools for experiment tracking, data management, and scalable deployment:
|
||
|
||
- **Experiment Management:** Effortlessly track every [YOLO training run](https://docs.ultralytics.com/modes/train/), including parameters, metrics, and outputs. Explore the [Ultralytics ClearML integration guide](https://docs.ultralytics.com/integrations/clearml/) for step-by-step instructions.
|
||
- **Data Versioning:** Manage and access your custom training data with ClearML's Data Versioning Tool, similar to [DVC integration](https://docs.ultralytics.com/integrations/dvc/).
|
||
- **Remote Execution:** [Remotely train and monitor models](https://docs.ultralytics.com/hub/cloud-training/) using ClearML Agent for seamless scaling.
|
||
- **Hyperparameter Optimization:** Boost your [mean average precision (mAP)](https://docs.ultralytics.com/guides/yolo-performance-metrics/) with ClearML's [hyperparameter tuning](https://docs.ultralytics.com/guides/hyperparameter-tuning/) capabilities.
|
||
- **Model Deployment:** Deploy your trained YOLO model as an API with ClearML Serving, complementing [Ultralytics model deployment options](https://docs.ultralytics.com/guides/model-deployment-options/).
|
||
|
||
You can use ClearML's experiment manager alone or combine these features into a comprehensive [MLOps pipeline](https://www.ultralytics.com/glossary/machine-learning-operations-mlops).
|
||
|
||
|
||
|
||
## 🦾 Setting Up ClearML
|
||
|
||
ClearML requires a server to track experiments and data. You have two main options:
|
||
|
||
1. **ClearML Hosted Service:** Sign up for a free account at [app.clear.ml](https://app.clear.ml/).
|
||
2. **Self-Hosted Server:** Deploy your own ClearML server using the [official setup guide](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server). The server is open-source, ensuring data privacy and control.
|
||
|
||
To get started:
|
||
|
||
1. **Install the ClearML Python package:**
|
||
|
||
```bash
|
||
pip install clearml
|
||
```
|
||
|
||
_Note: The `clearml` package is included in the YOLO requirements._
|
||
|
||
2. **Connect the ClearML SDK to your server:**
|
||
[Create credentials](https://app.clear.ml/settings/workspace-configuration) (Settings → Workspace → Create new credentials), then run:
|
||
|
||
```bash
|
||
clearml-init
|
||
```
|
||
|
||
Follow the prompts to complete setup.
|
||
|
||
For a general Ultralytics setup, see the [Quickstart Guide](https://docs.ultralytics.com/quickstart/).
|
||
|
||
## 🚀 Training YOLO with ClearML
|
||
|
||
When the `clearml` package is installed, experiment tracking is automatically enabled for every [YOLO training run](https://docs.ultralytics.com/modes/train/). All experiment details are captured and stored in the ClearML experiment manager.
|
||
|
||
To customize your project or task name in ClearML, use the `--project` and `--name` arguments. By default, the project is `YOLO` and the task is `Training`. ClearML uses `/` as a delimiter for subprojects.
|
||
|
||
**Example Training Command:**
|
||
|
||
```bash
|
||
# Train YOLO on COCO128 dataset for 3 epochs
|
||
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||
```
|
||
|
||
**Example with Custom Project and Task Names:**
|
||
|
||
```bash
|
||
# Train with custom project and experiment names
|
||
python train.py --project my_yolo_project --name experiment_001 --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
|
||
```
|
||
|
||
ClearML automatically logs:
|
||
|
||
- Source code and uncommitted changes
|
||
- Installed Python packages
|
||
- Hyperparameters and configuration settings
|
||
- Model checkpoints (use `--save-period n` to save every `n` epochs)
|
||
- Console output logs
|
||
- Performance metrics ([precision, recall](https://docs.ultralytics.com/guides/yolo-performance-metrics/), [losses](https://docs.ultralytics.com/reference/utils/loss/), [learning rates](https://www.ultralytics.com/glossary/learning-rate), mAP<sub>0.5</sub>, mAP<sub>0.5:0.95</sub>)
|
||
- System details (hardware specs, runtime, creation date)
|
||
- Generated plots (label correlogram, [confusion matrix](https://www.ultralytics.com/glossary/confusion-matrix))
|
||
- Images with bounding boxes per epoch
|
||
- Mosaic augmentation previews per epoch
|
||
- Validation images per epoch
|
||
|
||
All this information can be visualized in the ClearML UI. You can customize table views, sort experiments by metrics, and compare multiple runs. This enables advanced features like hyperparameter optimization and remote execution.
|
||
|
||
## 🔗 Dataset Version Management
|
||
|
||
Versioning your [datasets](https://docs.ultralytics.com/datasets/) independently from code is essential for reproducibility and collaboration. ClearML's Data Versioning Tool streamlines this process. YOLO supports ClearML dataset version IDs, automatically downloading data as needed. The dataset ID is saved as a task parameter, ensuring traceability for every experiment.
|
||
|
||
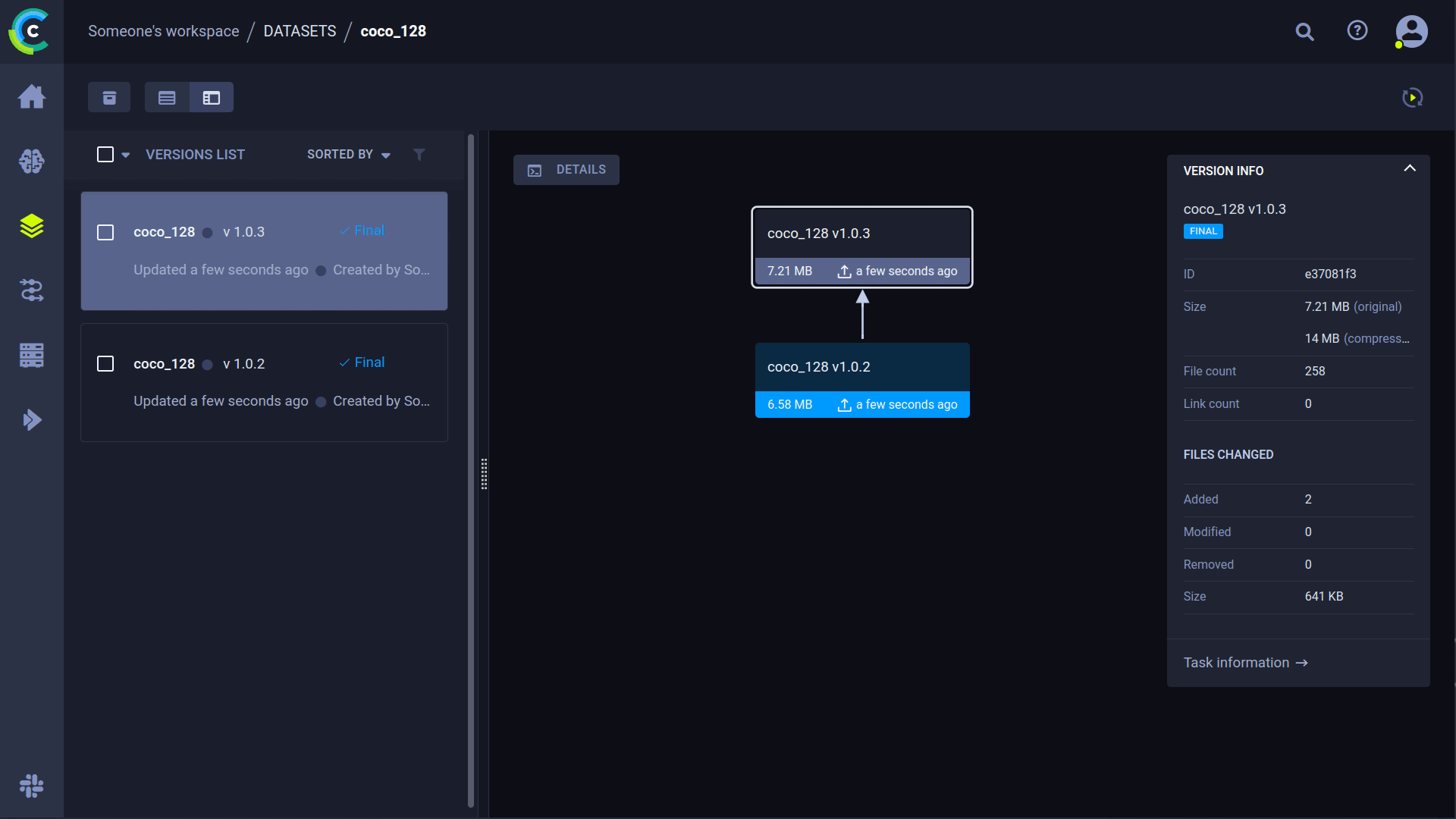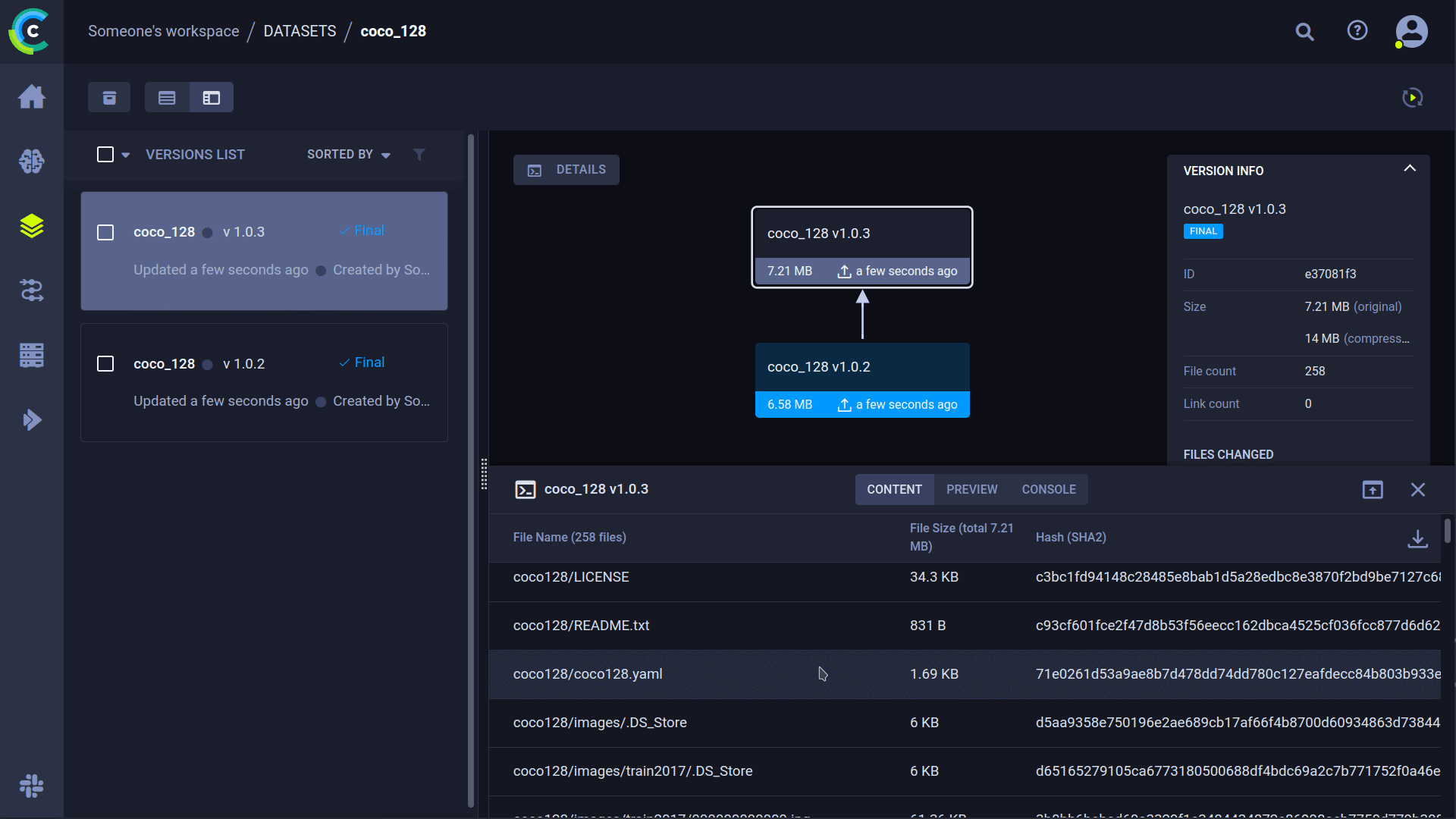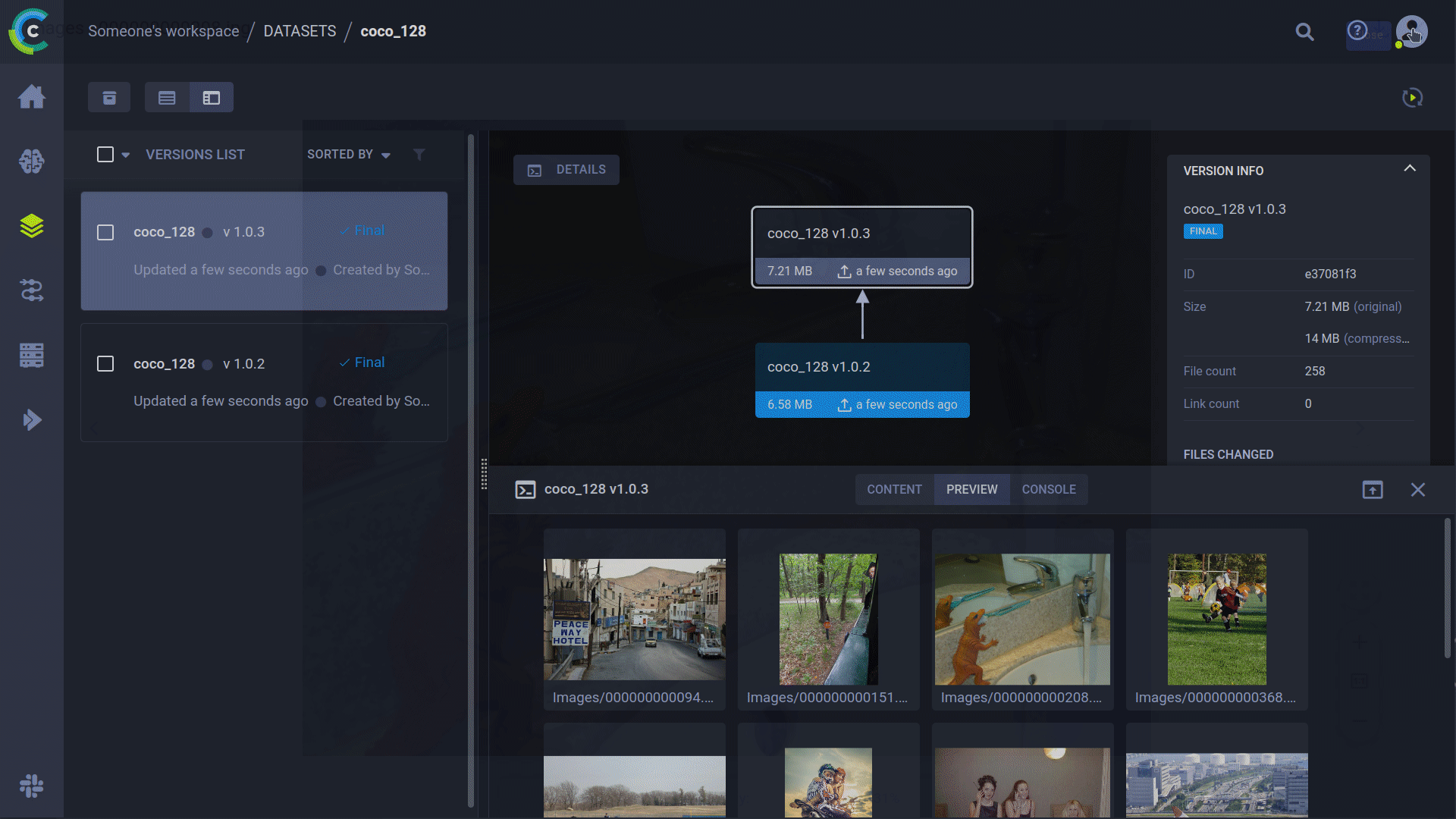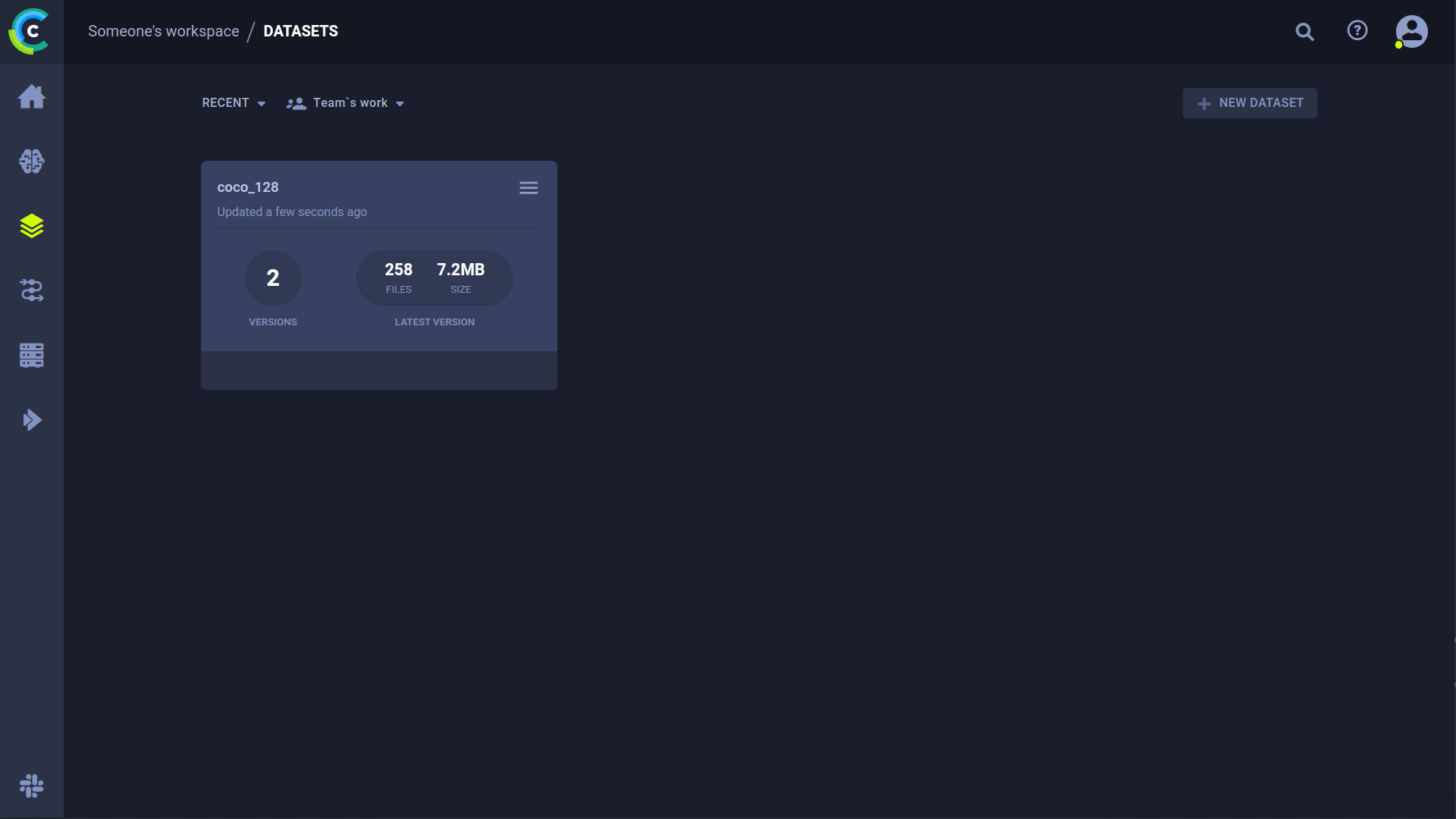
|
||
|
||
### Prepare Your Dataset
|
||
|
||
YOLO uses [YAML files](https://www.ultralytics.com/glossary/yaml) to define dataset configurations. By default, datasets are expected in the `../datasets` directory relative to the repository root. For example, the [COCO128 dataset](https://docs.ultralytics.com/datasets/detect/coco128/) structure:
|
||
|
||
```
|
||
../
|
||
├── yolov5/ # Your YOLO repository clone
|
||
└── datasets/
|
||
└── coco128/
|
||
├── images/
|
||
├── labels/
|
||
├── LICENSE
|
||
└── README.txt
|
||
```
|
||
|
||
Ensure your custom dataset follows a similar structure.
|
||
|
||
Next, ⚠️ **copy the corresponding dataset `.yaml` file into the root of your dataset folder**. This file contains essential information (`path`, `train`, `test`, `val`, `nc`, `names`) required by ClearML.
|
||
|
||
```
|
||
../
|
||
└── datasets/
|
||
└── coco128/
|
||
├── images/
|
||
├── labels/
|
||
├── coco128.yaml # <---- Place the YAML file here!
|
||
├── LICENSE
|
||
└── README.txt
|
||
```
|
||
|
||
### Upload Your Dataset
|
||
|
||
Navigate to your dataset's root directory and use the `clearml-data` CLI tool:
|
||
|
||
```bash
|
||
cd ../datasets/coco128
|
||
clearml-data sync --project YOLO_Datasets --name coco128 --folder .
|
||
```
|
||
|
||
Alternatively, use the following commands:
|
||
|
||
```bash
|
||
# Create a new dataset entry in ClearML
|
||
clearml-data create --project YOLO_Datasets --name coco128
|
||
|
||
# Add the dataset files (use '.' for the current directory)
|
||
clearml-data add --files .
|
||
|
||
# Finalize and upload the dataset version
|
||
clearml-data close
|
||
```
|
||
|
||
_Tip: Use `--parent <parent_dataset_id>` with `clearml-data create` to link versions and avoid re-uploading unchanged files._
|
||
|
||
### Run Training Using a ClearML Dataset
|
||
|
||
Once your dataset is versioned in ClearML, you can use it for training by providing the dataset ID via the `--data` argument with the `clearml://` prefix:
|
||
|
||
```bash
|
||
# Replace YOUR_DATASET_ID with the actual ID from ClearML
|
||
python train.py --img 640 --batch 16 --epochs 3 --data clearml://YOUR_DATASET_ID --weights yolov5s.pt --cache
|
||
```
|
||
|
||
## 👀 Hyperparameter Optimization
|
||
|
||
With experiments and data versioned, you can leverage ClearML for [hyperparameter optimization](https://docs.ultralytics.com/guides/hyperparameter-tuning/). ClearML captures all necessary information (code, packages, environment), making experiments fully reproducible. Its HPO tools clone an existing experiment, modify hyperparameters, and rerun it automatically.
|
||
|
||
To run HPO locally, use the provided script `utils/loggers/clearml/hpo.py`. You'll need the ID of a previously run training task (the "template task") to clone. Update the script with this ID and run:
|
||
|
||
```bash
|
||
# Install Optuna for advanced optimization strategies (optional)
|
||
# pip install optuna
|
||
|
||
# Run the HPO script
|
||
python utils/loggers/clearml/hpo.py
|
||
```
|
||
|
||
The script uses [Optuna](https://optuna.org/) by default if installed, or falls back to `RandomSearch`. You can modify `task.execute_locally()` to `task.execute()` in the script to enqueue HPO tasks for a remote ClearML agent.
|
||
|
||
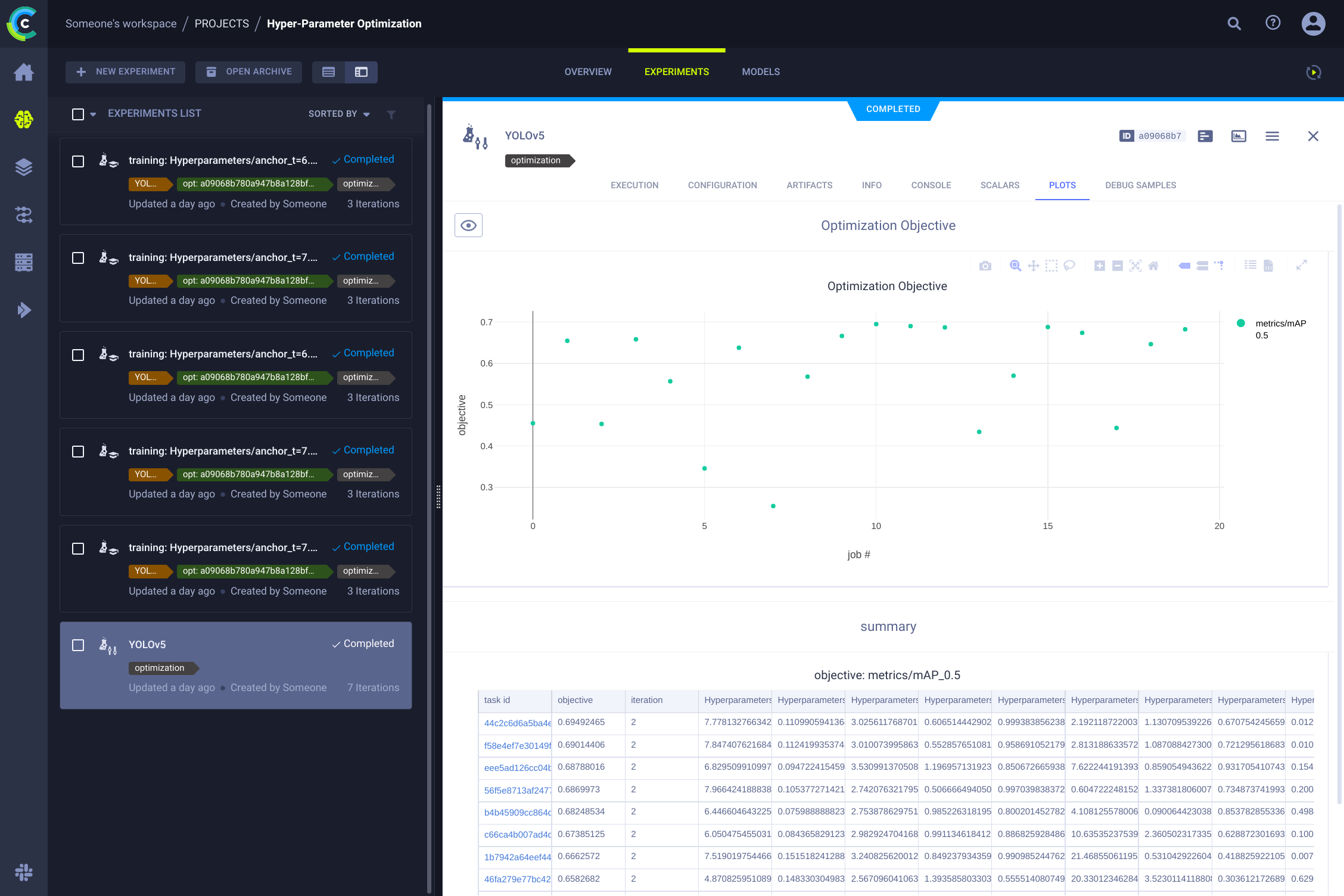
|
||
|
||
## 🤯 Remote Execution (Advanced)
|
||
|
||
ClearML Agent enables you to execute experiments on remote machines, including on-premise servers or cloud GPUs such as [AWS](https://aws.amazon.com/), [Google Cloud](https://cloud.google.com/), or [Azure](https://azure.microsoft.com/). The agent listens to task queues, reproduces the experiment environment, runs the task, and reports results back to the ClearML server.
|
||
|
||
Learn more about ClearML Agent:
|
||
|
||
- [YouTube Introduction to ClearML Agent](https://www.youtube.com/watch?v=MX3BrXnaULs)
|
||
- [Official ClearML Agent Documentation](https://clear.ml/docs/latest/docs/clearml_agent)
|
||
|
||
Turn any machine into a ClearML agent by running:
|
||
|
||
```bash
|
||
# Replace QUEUES_TO_LISTEN_TO with your queue name(s)
|
||
clearml-agent daemon --queue QUEUES_TO_LISTEN_TO [--docker] # Use --docker to run in a Docker container
|
||
```
|
||
|
||
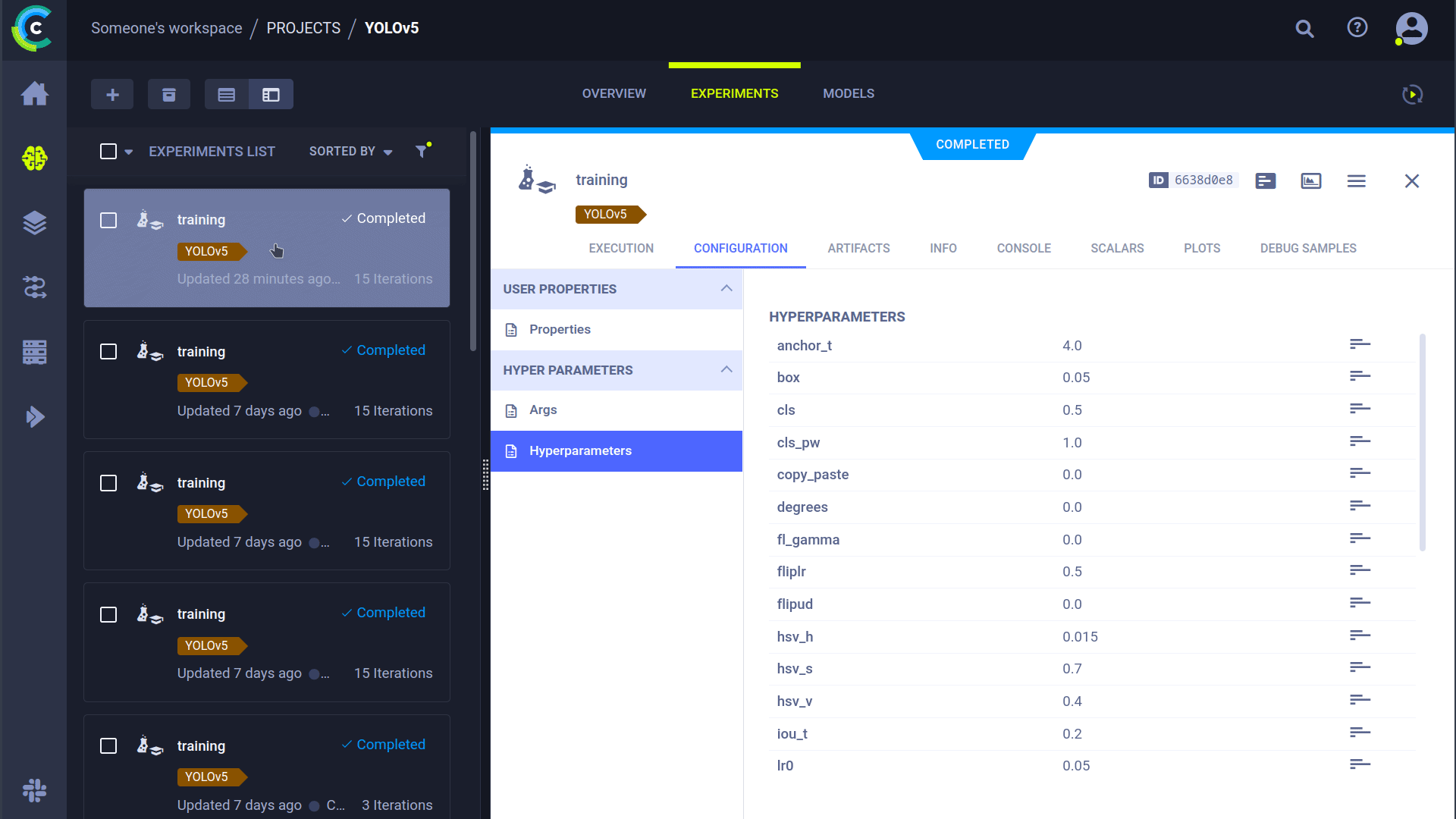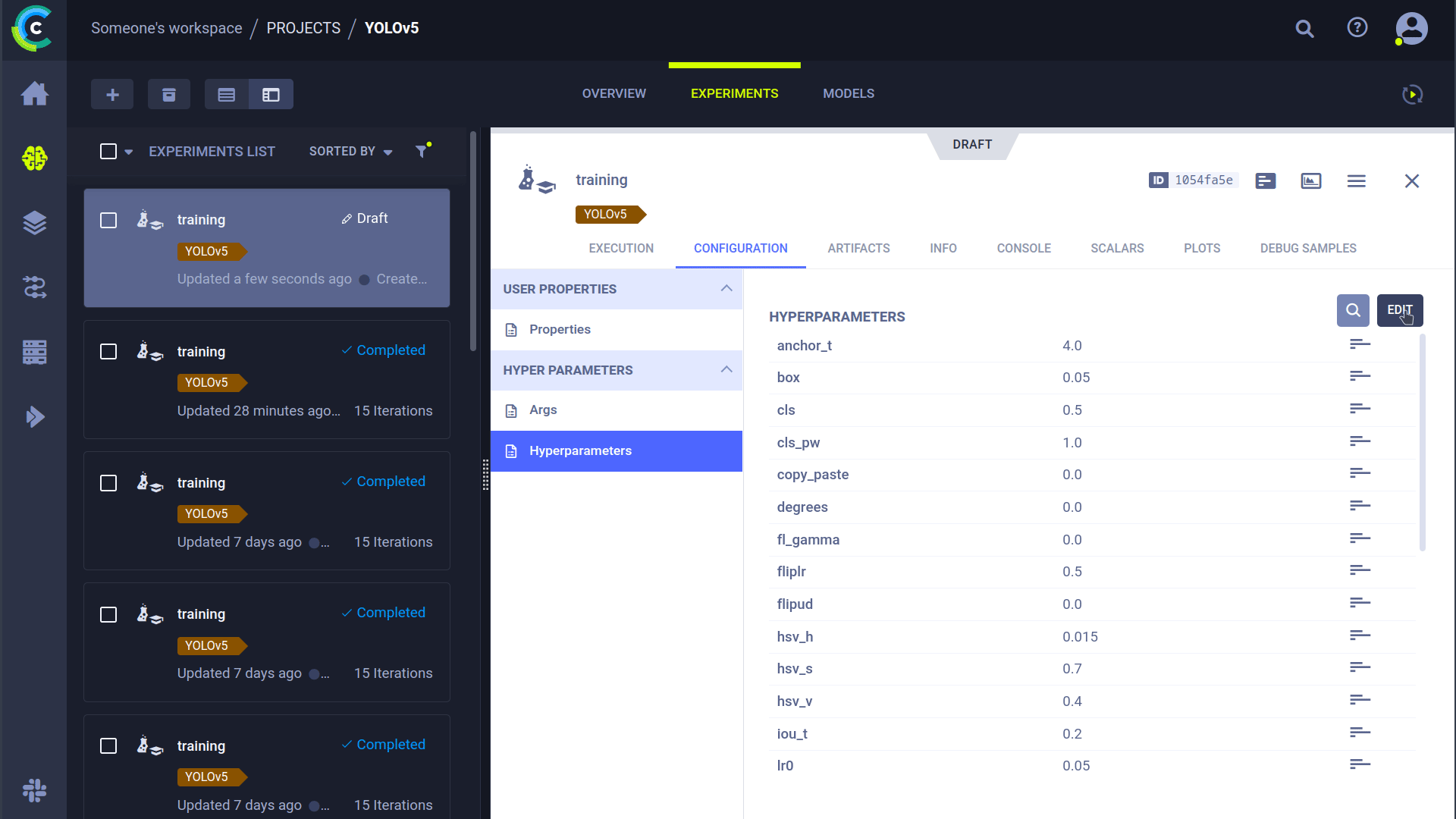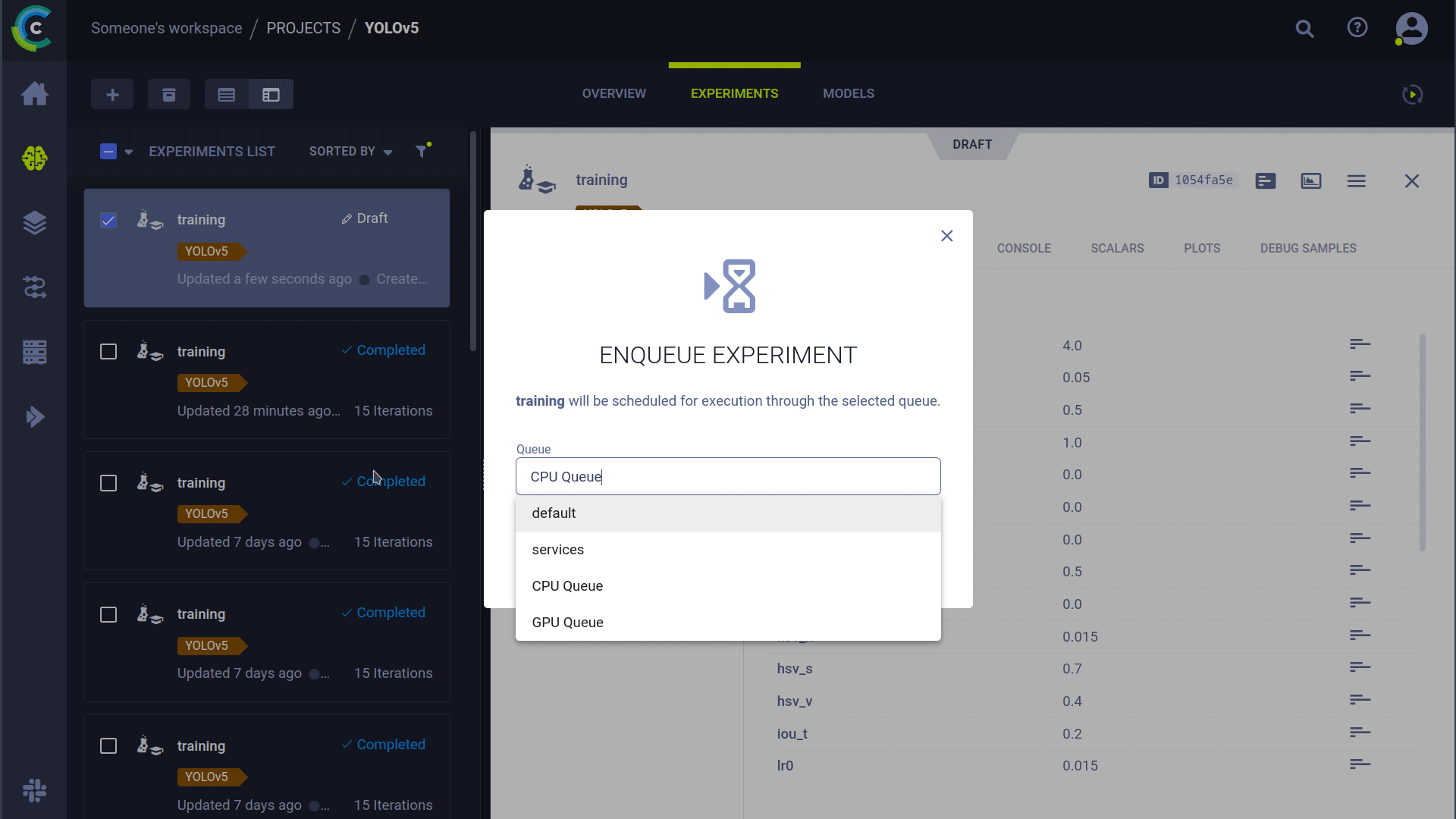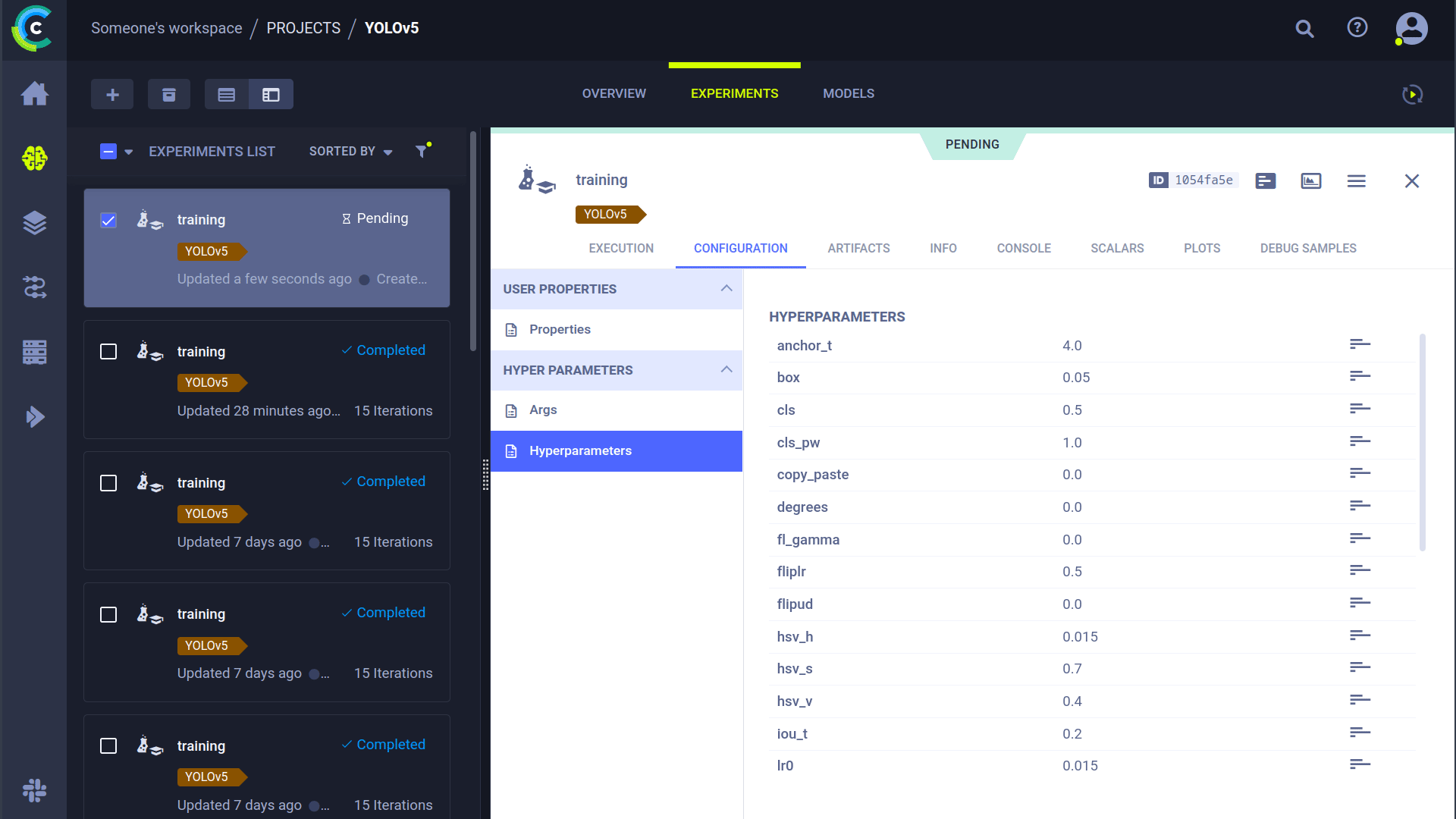
### Cloning, Editing, and Enqueuing Tasks
|
||
|
||
You can manage remote execution directly from the ClearML web UI:
|
||
|
||
1. **Clone:** Right-click an existing experiment to clone it.
|
||
2. **Edit:** Modify hyperparameters or other settings in the cloned task.
|
||
3. **Enqueue:** Right-click the modified task and select "Enqueue" to assign it to a specific queue for an agent to pick up.
|
||
|
||
|
||
|
||
### Executing a Task Remotely via Code
|
||
|
||
You can also modify your training script to automatically enqueue tasks for remote execution. Add `task.execute_remotely()` after the ClearML logger is initialized in `train.py`:
|
||
|
||
```python
|
||
# Inside train.py, after logger initialization...
|
||
if RANK in {-1, 0}:
|
||
# Initialize loggers
|
||
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER)
|
||
|
||
# Check if ClearML logger is active and enqueue the task
|
||
if loggers.clearml:
|
||
# Specify the queue name for the remote agent
|
||
loggers.clearml.task.execute_remotely(queue_name="my_remote_queue") # <------ ADD THIS LINE
|
||
# data_dict might be populated by ClearML if using a ClearML dataset
|
||
data_dict = loggers.clearml.data_dict
|
||
```
|
||
|
||
Running the script with this modification will package the code and its environment and send it to the specified queue, rather than executing locally.
|
||
|
||
### Autoscaling Workers
|
||
|
||
ClearML provides Autoscalers that automatically manage cloud resources (AWS, GCP, Azure). They spin up new virtual machines as ClearML agents when tasks appear in a queue, and shut them down when the queue is empty, optimizing cost.
|
||
|
||
Watch the Autoscalers getting started video:
|
||
|
||
[](https://youtu.be/j4XVMAaUt3E)
|
||
|
||
## 🤝 Contributing
|
||
|
||
Contributions to enhance the ClearML integration are welcome! Please see the [Ultralytics Contributing Guide](https://docs.ultralytics.com/help/contributing/) for details on how to get involved.
|
||
|
||
---
|
||
|
||
[](https://github.com/ultralytics/ultralytics/graphs/contributors)
|