From f50e7684303f1edaf4fc1e80b92d2f9bb0e264ab Mon Sep 17 00:00:00 2001
From: RE-OWOD <95522332+RE-OWOD@users.noreply.github.com>
Date: Tue, 4 Jan 2022 13:41:19 +0800
Subject: [PATCH] Add files via upload
---
projects/DeepLab/README.md | 100 ++
.../Base-DeepLabV3-OS16-Semantic.yaml | 36 +
...lab_v3_R_103_os16_mg124_poly_90k_bs16.yaml | 19 +
...3_plus_R_103_os16_mg124_poly_90k_bs16.yaml | 24 +
projects/DeepLab/deeplab/__init__.py | 5 +
projects/DeepLab/deeplab/build_solver.py | 28 +
projects/DeepLab/deeplab/config.py | 27 +
projects/DeepLab/deeplab/loss.py | 40 +
projects/DeepLab/deeplab/lr_scheduler.py | 62 ++
projects/DeepLab/deeplab/resnet.py | 157 +++
projects/DeepLab/deeplab/semantic_seg.py | 326 +++++++
projects/DeepLab/train_net.py | 141 +++
projects/Panoptic-DeepLab/README.md | 105 ++
.../Base-PanopticDeepLab-OS16.yaml | 65 ++
...s16_mg124_poly_90k_bs32_crop_512_1024.yaml | 20 +
.../panoptic_deeplab/__init__.py | 10 +
.../panoptic_deeplab/config.py | 50 +
.../panoptic_deeplab/dataset_mapper.py | 116 +++
.../panoptic_deeplab/panoptic_seg.py | 526 ++++++++++
.../panoptic_deeplab/post_processing.py | 234 +++++
.../panoptic_deeplab/target_generator.py | 161 +++
projects/Panoptic-DeepLab/train_net.py | 196 ++++
projects/PointRend/README.md | 134 +++
.../Base-PointRend-RCNN-FPN.yaml | 22 +
...pointrend_rcnn_R_50_FPN_1x_cityscapes.yaml | 22 +
.../pointrend_rcnn_R_50_FPN_1x_coco.yaml | 8 +
.../pointrend_rcnn_R_50_FPN_3x_coco.yaml | 12 +
.../Base-PointRend-Semantic-FPN.yaml | 20 +
...rend_semantic_R_101_FPN_1x_cityscapes.yaml | 33 +
projects/PointRend/point_rend/__init__.py | 6 +
.../PointRend/point_rend/coarse_mask_head.py | 92 ++
.../point_rend/color_augmentation.py | 98 ++
projects/PointRend/point_rend/config.py | 48 +
.../PointRend/point_rend/point_features.py | 216 +++++
projects/PointRend/point_rend/point_head.py | 157 +++
projects/PointRend/point_rend/roi_heads.py | 227 +++++
projects/PointRend/point_rend/semantic_seg.py | 135 +++
projects/PointRend/train_net.py | 154 +++
projects/README.md | 38 +
projects/TensorMask/README.md | 63 ++
.../TensorMask/configs/Base-TensorMask.yaml | 25 +
.../configs/tensormask_R_50_FPN_1x.yaml | 5 +
.../configs/tensormask_R_50_FPN_6x.yaml | 11 +
projects/TensorMask/setup.py | 69 ++
projects/TensorMask/tensormask/__init__.py | 3 +
projects/TensorMask/tensormask/arch.py | 913 ++++++++++++++++++
projects/TensorMask/tensormask/config.py | 50 +
.../TensorMask/tensormask/layers/__init__.py | 4 +
.../layers/csrc/SwapAlign2Nat/SwapAlign2Nat.h | 54 ++
.../csrc/SwapAlign2Nat/SwapAlign2Nat_cuda.cu | 526 ++++++++++
.../tensormask/layers/csrc/vision.cpp | 19 +
.../tensormask/layers/swap_align2nat.py | 61 ++
projects/TensorMask/tests/__init__.py | 1 +
.../TensorMask/tests/test_swap_align2nat.py | 32 +
projects/TensorMask/train_net.py | 70 ++
projects/TridentNet/README.md | 60 ++
.../configs/Base-TridentNet-Fast-C4.yaml | 29 +
.../configs/tridentnet_fast_R_101_C4_3x.yaml | 9 +
.../configs/tridentnet_fast_R_50_C4_1x.yaml | 6 +
.../configs/tridentnet_fast_R_50_C4_3x.yaml | 9 +
projects/TridentNet/train_net.py | 67 ++
projects/TridentNet/tridentnet/__init__.py | 9 +
projects/TridentNet/tridentnet/config.py | 26 +
.../TridentNet/tridentnet/trident_backbone.py | 223 +++++
.../TridentNet/tridentnet/trident_conv.py | 107 ++
.../TridentNet/tridentnet/trident_rcnn.py | 116 +++
projects/TridentNet/tridentnet/trident_rpn.py | 32 +
67 files changed, 6469 insertions(+)
create mode 100644 projects/DeepLab/README.md
create mode 100644 projects/DeepLab/configs/Cityscapes-SemanticSegmentation/Base-DeepLabV3-OS16-Semantic.yaml
create mode 100644 projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_R_103_os16_mg124_poly_90k_bs16.yaml
create mode 100644 projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml
create mode 100644 projects/DeepLab/deeplab/__init__.py
create mode 100644 projects/DeepLab/deeplab/build_solver.py
create mode 100644 projects/DeepLab/deeplab/config.py
create mode 100644 projects/DeepLab/deeplab/loss.py
create mode 100644 projects/DeepLab/deeplab/lr_scheduler.py
create mode 100644 projects/DeepLab/deeplab/resnet.py
create mode 100644 projects/DeepLab/deeplab/semantic_seg.py
create mode 100644 projects/DeepLab/train_net.py
create mode 100644 projects/Panoptic-DeepLab/README.md
create mode 100644 projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/Base-PanopticDeepLab-OS16.yaml
create mode 100644 projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/__init__.py
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/config.py
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/dataset_mapper.py
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/panoptic_seg.py
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/post_processing.py
create mode 100644 projects/Panoptic-DeepLab/panoptic_deeplab/target_generator.py
create mode 100644 projects/Panoptic-DeepLab/train_net.py
create mode 100644 projects/PointRend/README.md
create mode 100644 projects/PointRend/configs/InstanceSegmentation/Base-PointRend-RCNN-FPN.yaml
create mode 100644 projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_cityscapes.yaml
create mode 100644 projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml
create mode 100644 projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco.yaml
create mode 100644 projects/PointRend/configs/SemanticSegmentation/Base-PointRend-Semantic-FPN.yaml
create mode 100644 projects/PointRend/configs/SemanticSegmentation/pointrend_semantic_R_101_FPN_1x_cityscapes.yaml
create mode 100644 projects/PointRend/point_rend/__init__.py
create mode 100644 projects/PointRend/point_rend/coarse_mask_head.py
create mode 100644 projects/PointRend/point_rend/color_augmentation.py
create mode 100644 projects/PointRend/point_rend/config.py
create mode 100644 projects/PointRend/point_rend/point_features.py
create mode 100644 projects/PointRend/point_rend/point_head.py
create mode 100644 projects/PointRend/point_rend/roi_heads.py
create mode 100644 projects/PointRend/point_rend/semantic_seg.py
create mode 100644 projects/PointRend/train_net.py
create mode 100644 projects/TensorMask/README.md
create mode 100644 projects/TensorMask/configs/Base-TensorMask.yaml
create mode 100644 projects/TensorMask/configs/tensormask_R_50_FPN_1x.yaml
create mode 100644 projects/TensorMask/configs/tensormask_R_50_FPN_6x.yaml
create mode 100644 projects/TensorMask/setup.py
create mode 100644 projects/TensorMask/tensormask/__init__.py
create mode 100644 projects/TensorMask/tensormask/arch.py
create mode 100644 projects/TensorMask/tensormask/config.py
create mode 100644 projects/TensorMask/tensormask/layers/__init__.py
create mode 100644 projects/TensorMask/tensormask/layers/csrc/SwapAlign2Nat/SwapAlign2Nat.h
create mode 100644 projects/TensorMask/tensormask/layers/csrc/SwapAlign2Nat/SwapAlign2Nat_cuda.cu
create mode 100644 projects/TensorMask/tensormask/layers/csrc/vision.cpp
create mode 100644 projects/TensorMask/tensormask/layers/swap_align2nat.py
create mode 100644 projects/TensorMask/tests/__init__.py
create mode 100644 projects/TensorMask/tests/test_swap_align2nat.py
create mode 100644 projects/TensorMask/train_net.py
create mode 100644 projects/TridentNet/README.md
create mode 100644 projects/TridentNet/configs/Base-TridentNet-Fast-C4.yaml
create mode 100644 projects/TridentNet/configs/tridentnet_fast_R_101_C4_3x.yaml
create mode 100644 projects/TridentNet/configs/tridentnet_fast_R_50_C4_1x.yaml
create mode 100644 projects/TridentNet/configs/tridentnet_fast_R_50_C4_3x.yaml
create mode 100644 projects/TridentNet/train_net.py
create mode 100644 projects/TridentNet/tridentnet/__init__.py
create mode 100644 projects/TridentNet/tridentnet/config.py
create mode 100644 projects/TridentNet/tridentnet/trident_backbone.py
create mode 100644 projects/TridentNet/tridentnet/trident_conv.py
create mode 100644 projects/TridentNet/tridentnet/trident_rcnn.py
create mode 100644 projects/TridentNet/tridentnet/trident_rpn.py
diff --git a/projects/DeepLab/README.md b/projects/DeepLab/README.md
new file mode 100644
index 0000000..bd03cf1
--- /dev/null
+++ b/projects/DeepLab/README.md
@@ -0,0 +1,100 @@
+# DeepLab in Detectron2
+
+In this repository, we implement DeepLabV3 and DeepLabV3+ in Detectron2.
+
+## Installation
+Install Detectron2 following [the instructions](https://detectron2.readthedocs.io/tutorials/install.html).
+
+## Training
+
+To train a model with 8 GPUs run:
+```bash
+cd /path/to/detectron2/projects/DeepLab
+python train_net.py --config-file configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml --num-gpus 8
+```
+
+## Evaluation
+
+Model evaluation can be done similarly:
+```bash
+cd /path/to/detectron2/projects/DeepLab
+python train_net.py --config-file configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
+```
+
+## Cityscapes Semantic Segmentation
+Cityscapes models are trained with ImageNet pretraining.
+
+
+
+
+| Method |
+Backbone |
+Output
resolution |
+mIoU |
+model id |
+download |
+
+ | DeepLabV3 |
+R101-DC5 |
+1024×2048 |
+ 76.7 |
+ - |
+ - | - |
+
+ | DeepLabV3 |
+R103-DC5 |
+1024×2048 |
+ 78.5 |
+ 28041665 |
+model | metrics |
+
+ | DeepLabV3+ |
+R101-DC5 |
+1024×2048 |
+ 78.1 |
+ - |
+ - | - |
+
+ | DeepLabV3+ |
+R103-DC5 |
+1024×2048 |
+ 80.0 |
+28054032 |
+model | metrics |
+
+
+
+Note:
+- [R103](https://dl.fbaipublicfiles.com/detectron2/DeepLab/R-103.pkl): a ResNet-101 with its first 7x7 convolution replaced by 3 3x3 convolutions.
+This modification has been used in most semantic segmentation papers. We pre-train this backbone on ImageNet using the default recipe of [pytorch examples](https://github.com/pytorch/examples/tree/master/imagenet).
+- DC5 means using dilated convolution in `res5`.
+
+## Citing DeepLab
+
+If you use DeepLab, please use the following BibTeX entry.
+
+* DeepLabv3+:
+
+```
+@inproceedings{deeplabv3plus2018,
+ title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
+ author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
+ booktitle={ECCV},
+ year={2018}
+}
+```
+
+* DeepLabv3:
+
+```
+@article{deeplabv32018,
+ title={Rethinking atrous convolution for semantic image segmentation},
+ author={Chen, Liang-Chieh and Papandreou, George and Schroff, Florian and Adam, Hartwig},
+ journal={arXiv:1706.05587},
+ year={2017}
+}
+```
diff --git a/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/Base-DeepLabV3-OS16-Semantic.yaml b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/Base-DeepLabV3-OS16-Semantic.yaml
new file mode 100644
index 0000000..fa6edb5
--- /dev/null
+++ b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/Base-DeepLabV3-OS16-Semantic.yaml
@@ -0,0 +1,36 @@
+_BASE_: "../../../../configs/Base-RCNN-DilatedC5.yaml"
+MODEL:
+ META_ARCHITECTURE: "SemanticSegmentor"
+ BACKBONE:
+ FREEZE_AT: 0
+ SEM_SEG_HEAD:
+ NAME: "DeepLabV3Head"
+ IN_FEATURES: ["res5"]
+ ASPP_CHANNELS: 256
+ ASPP_DILATIONS: [6, 12, 18]
+ ASPP_DROPOUT: 0.1
+ CONVS_DIM: 256
+ COMMON_STRIDE: 16
+ NUM_CLASSES: 19
+ LOSS_TYPE: "hard_pixel_mining"
+DATASETS:
+ TRAIN: ("cityscapes_fine_sem_seg_train",)
+ TEST: ("cityscapes_fine_sem_seg_val",)
+SOLVER:
+ BASE_LR: 0.01
+ MAX_ITER: 90000
+ LR_SCHEDULER_NAME: "WarmupPolyLR"
+ IMS_PER_BATCH: 16
+INPUT:
+ MIN_SIZE_TRAIN: (512, 768, 1024, 1280, 1536, 1792, 2048)
+ MIN_SIZE_TRAIN_SAMPLING: "choice"
+ MIN_SIZE_TEST: 1024
+ MAX_SIZE_TRAIN: 4096
+ MAX_SIZE_TEST: 2048
+ CROP:
+ ENABLED: True
+ TYPE: "absolute"
+ SIZE: (512, 1024)
+ SINGLE_CATEGORY_MAX_AREA: 1.0
+DATALOADER:
+ NUM_WORKERS: 10
diff --git a/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_R_103_os16_mg124_poly_90k_bs16.yaml b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_R_103_os16_mg124_poly_90k_bs16.yaml
new file mode 100644
index 0000000..a2f5a54
--- /dev/null
+++ b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_R_103_os16_mg124_poly_90k_bs16.yaml
@@ -0,0 +1,19 @@
+_BASE_: Base-DeepLabV3-OS16-Semantic.yaml
+MODEL:
+ WEIGHTS: "detectron2://DeepLab/R-103.pkl"
+ PIXEL_MEAN: [123.675, 116.280, 103.530]
+ PIXEL_STD: [58.395, 57.120, 57.375]
+ BACKBONE:
+ NAME: "build_resnet_deeplab_backbone"
+ RESNETS:
+ DEPTH: 101
+ NORM: "SyncBN"
+ RES5_MULTI_GRID: [1, 2, 4]
+ STEM_TYPE: "deeplab"
+ STEM_OUT_CHANNELS: 128
+ STRIDE_IN_1X1: False
+ SEM_SEG_HEAD:
+ NAME: "DeepLabV3Head"
+ NORM: "SyncBN"
+INPUT:
+ FORMAT: "RGB"
diff --git a/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml
new file mode 100644
index 0000000..c03a72d
--- /dev/null
+++ b/projects/DeepLab/configs/Cityscapes-SemanticSegmentation/deeplab_v3_plus_R_103_os16_mg124_poly_90k_bs16.yaml
@@ -0,0 +1,24 @@
+_BASE_: Base-DeepLabV3-OS16-Semantic.yaml
+MODEL:
+ WEIGHTS: "detectron2://DeepLab/R-103.pkl"
+ PIXEL_MEAN: [123.675, 116.280, 103.530]
+ PIXEL_STD: [58.395, 57.120, 57.375]
+ BACKBONE:
+ NAME: "build_resnet_deeplab_backbone"
+ RESNETS:
+ DEPTH: 101
+ NORM: "SyncBN"
+ OUT_FEATURES: ["res2", "res5"]
+ RES5_MULTI_GRID: [1, 2, 4]
+ STEM_TYPE: "deeplab"
+ STEM_OUT_CHANNELS: 128
+ STRIDE_IN_1X1: False
+ SEM_SEG_HEAD:
+ NAME: "DeepLabV3PlusHead"
+ IN_FEATURES: ["res2", "res5"]
+ PROJECT_FEATURES: ["res2"]
+ PROJECT_CHANNELS: [48]
+ NORM: "SyncBN"
+ COMMON_STRIDE: 4
+INPUT:
+ FORMAT: "RGB"
diff --git a/projects/DeepLab/deeplab/__init__.py b/projects/DeepLab/deeplab/__init__.py
new file mode 100644
index 0000000..ca9aa6e
--- /dev/null
+++ b/projects/DeepLab/deeplab/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+from .build_solver import build_lr_scheduler
+from .config import add_deeplab_config
+from .resnet import build_resnet_deeplab_backbone
+from .semantic_seg import DeepLabV3Head, DeepLabV3PlusHead
diff --git a/projects/DeepLab/deeplab/build_solver.py b/projects/DeepLab/deeplab/build_solver.py
new file mode 100644
index 0000000..56c9322
--- /dev/null
+++ b/projects/DeepLab/deeplab/build_solver.py
@@ -0,0 +1,28 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import torch
+
+from detectron2.config import CfgNode
+from detectron2.solver import build_lr_scheduler as build_d2_lr_scheduler
+
+from .lr_scheduler import WarmupPolyLR
+
+
+def build_lr_scheduler(
+ cfg: CfgNode, optimizer: torch.optim.Optimizer
+) -> torch.optim.lr_scheduler._LRScheduler:
+ """
+ Build a LR scheduler from config.
+ """
+ name = cfg.SOLVER.LR_SCHEDULER_NAME
+ if name == "WarmupPolyLR":
+ return WarmupPolyLR(
+ optimizer,
+ cfg.SOLVER.MAX_ITER,
+ warmup_factor=cfg.SOLVER.WARMUP_FACTOR,
+ warmup_iters=cfg.SOLVER.WARMUP_ITERS,
+ warmup_method=cfg.SOLVER.WARMUP_METHOD,
+ power=cfg.SOLVER.POLY_LR_POWER,
+ constant_ending=cfg.SOLVER.POLY_LR_CONSTANT_ENDING,
+ )
+ else:
+ return build_d2_lr_scheduler(cfg, optimizer)
diff --git a/projects/DeepLab/deeplab/config.py b/projects/DeepLab/deeplab/config.py
new file mode 100644
index 0000000..adc4939
--- /dev/null
+++ b/projects/DeepLab/deeplab/config.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+
+def add_deeplab_config(cfg):
+ """
+ Add config for DeepLab.
+ """
+ # We retry random cropping until no single category in semantic segmentation GT occupies more
+ # than `SINGLE_CATEGORY_MAX_AREA` part of the crop.
+ cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA = 1.0
+ # Used for `poly` learning rate schedule.
+ cfg.SOLVER.POLY_LR_POWER = 0.9
+ cfg.SOLVER.POLY_LR_CONSTANT_ENDING = 0.0
+ # Loss type, choose from `cross_entropy`, `hard_pixel_mining`.
+ cfg.MODEL.SEM_SEG_HEAD.LOSS_TYPE = "hard_pixel_mining"
+ # DeepLab settings
+ cfg.MODEL.SEM_SEG_HEAD.PROJECT_FEATURES = ["res2"]
+ cfg.MODEL.SEM_SEG_HEAD.PROJECT_CHANNELS = [48]
+ cfg.MODEL.SEM_SEG_HEAD.ASPP_CHANNELS = 256
+ cfg.MODEL.SEM_SEG_HEAD.ASPP_DILATIONS = [6, 12, 18]
+ cfg.MODEL.SEM_SEG_HEAD.ASPP_DROPOUT = 0.1
+ # Backbone new configs
+ cfg.MODEL.RESNETS.RES4_DILATION = 1
+ cfg.MODEL.RESNETS.RES5_MULTI_GRID = [1, 2, 4]
+ # ResNet stem type from: `basic`, `deeplab`
+ cfg.MODEL.RESNETS.STEM_TYPE = "deeplab"
diff --git a/projects/DeepLab/deeplab/loss.py b/projects/DeepLab/deeplab/loss.py
new file mode 100644
index 0000000..11e6096
--- /dev/null
+++ b/projects/DeepLab/deeplab/loss.py
@@ -0,0 +1,40 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import torch
+import torch.nn as nn
+
+
+class DeepLabCE(nn.Module):
+ """
+ Hard pixel mining with cross entropy loss, for semantic segmentation.
+ This is used in TensorFlow DeepLab frameworks.
+ Paper: DeeperLab: Single-Shot Image Parser
+ Reference: https://github.com/tensorflow/models/blob/bd488858d610e44df69da6f89277e9de8a03722c/research/deeplab/utils/train_utils.py#L33 # noqa
+ Arguments:
+ ignore_label: Integer, label to ignore.
+ top_k_percent_pixels: Float, the value lies in [0.0, 1.0]. When its
+ value < 1.0, only compute the loss for the top k percent pixels
+ (e.g., the top 20% pixels). This is useful for hard pixel mining.
+ weight: Tensor, a manual rescaling weight given to each class.
+ """
+
+ def __init__(self, ignore_label=-1, top_k_percent_pixels=1.0, weight=None):
+ super(DeepLabCE, self).__init__()
+ self.top_k_percent_pixels = top_k_percent_pixels
+ self.ignore_label = ignore_label
+ self.criterion = nn.CrossEntropyLoss(
+ weight=weight, ignore_index=ignore_label, reduction="none"
+ )
+
+ def forward(self, logits, labels, weights=None):
+ if weights is None:
+ pixel_losses = self.criterion(logits, labels).contiguous().view(-1)
+ else:
+ # Apply per-pixel loss weights.
+ pixel_losses = self.criterion(logits, labels) * weights
+ pixel_losses = pixel_losses.contiguous().view(-1)
+ if self.top_k_percent_pixels == 1.0:
+ return pixel_losses.mean()
+
+ top_k_pixels = int(self.top_k_percent_pixels * pixel_losses.numel())
+ pixel_losses, _ = torch.topk(pixel_losses, top_k_pixels)
+ return pixel_losses.mean()
diff --git a/projects/DeepLab/deeplab/lr_scheduler.py b/projects/DeepLab/deeplab/lr_scheduler.py
new file mode 100644
index 0000000..0647c03
--- /dev/null
+++ b/projects/DeepLab/deeplab/lr_scheduler.py
@@ -0,0 +1,62 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import math
+from typing import List
+import torch
+
+from detectron2.solver.lr_scheduler import _get_warmup_factor_at_iter
+
+# NOTE: PyTorch's LR scheduler interface uses names that assume the LR changes
+# only on epoch boundaries. We typically use iteration based schedules instead.
+# As a result, "epoch" (e.g., as in self.last_epoch) should be understood to mean
+# "iteration" instead.
+
+# FIXME: ideally this would be achieved with a CombinedLRScheduler, separating
+# MultiStepLR with WarmupLR but the current LRScheduler design doesn't allow it.
+
+
+class WarmupPolyLR(torch.optim.lr_scheduler._LRScheduler):
+ """
+ Poly learning rate schedule used to train DeepLab.
+ Paper: DeepLab: Semantic Image Segmentation with Deep Convolutional Nets,
+ Atrous Convolution, and Fully Connected CRFs.
+ Reference: https://github.com/tensorflow/models/blob/21b73d22f3ed05b650e85ac50849408dd36de32e/research/deeplab/utils/train_utils.py#L337 # noqa
+ """
+
+ def __init__(
+ self,
+ optimizer: torch.optim.Optimizer,
+ max_iters: int,
+ warmup_factor: float = 0.001,
+ warmup_iters: int = 1000,
+ warmup_method: str = "linear",
+ last_epoch: int = -1,
+ power: float = 0.9,
+ constant_ending: float = 0.0,
+ ):
+ self.max_iters = max_iters
+ self.warmup_factor = warmup_factor
+ self.warmup_iters = warmup_iters
+ self.warmup_method = warmup_method
+ self.power = power
+ self.constant_ending = constant_ending
+ super().__init__(optimizer, last_epoch)
+
+ def get_lr(self) -> List[float]:
+ warmup_factor = _get_warmup_factor_at_iter(
+ self.warmup_method, self.last_epoch, self.warmup_iters, self.warmup_factor
+ )
+ if self.constant_ending > 0 and warmup_factor == 1.0:
+ # Constant ending lr.
+ if (
+ math.pow((1.0 - self.last_epoch / self.max_iters), self.power)
+ < self.constant_ending
+ ):
+ return [base_lr * self.constant_ending for base_lr in self.base_lrs]
+ return [
+ base_lr * warmup_factor * math.pow((1.0 - self.last_epoch / self.max_iters), self.power)
+ for base_lr in self.base_lrs
+ ]
+
+ def _compute_values(self) -> List[float]:
+ # The new interface
+ return self.get_lr()
diff --git a/projects/DeepLab/deeplab/resnet.py b/projects/DeepLab/deeplab/resnet.py
new file mode 100644
index 0000000..b592ccb
--- /dev/null
+++ b/projects/DeepLab/deeplab/resnet.py
@@ -0,0 +1,157 @@
+import fvcore.nn.weight_init as weight_init
+import torch.nn.functional as F
+
+from detectron2.layers import CNNBlockBase, Conv2d, get_norm
+from detectron2.modeling import BACKBONE_REGISTRY
+from detectron2.modeling.backbone.resnet import (
+ BasicStem,
+ BottleneckBlock,
+ DeformBottleneckBlock,
+ ResNet,
+)
+
+
+class DeepLabStem(CNNBlockBase):
+ """
+ The DeepLab ResNet stem (layers before the first residual block).
+ """
+
+ def __init__(self, in_channels=3, out_channels=128, norm="BN"):
+ """
+ Args:
+ norm (str or callable): norm after the first conv layer.
+ See :func:`layers.get_norm` for supported format.
+ """
+ super().__init__(in_channels, out_channels, 4)
+ self.in_channels = in_channels
+ self.conv1 = Conv2d(
+ in_channels,
+ out_channels // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False,
+ norm=get_norm(norm, out_channels // 2),
+ )
+ self.conv2 = Conv2d(
+ out_channels // 2,
+ out_channels // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm=get_norm(norm, out_channels // 2),
+ )
+ self.conv3 = Conv2d(
+ out_channels // 2,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm=get_norm(norm, out_channels),
+ )
+ weight_init.c2_msra_fill(self.conv1)
+ weight_init.c2_msra_fill(self.conv2)
+ weight_init.c2_msra_fill(self.conv3)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = F.relu_(x)
+ x = self.conv2(x)
+ x = F.relu_(x)
+ x = self.conv3(x)
+ x = F.relu_(x)
+ x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
+ return x
+
+
+@BACKBONE_REGISTRY.register()
+def build_resnet_deeplab_backbone(cfg, input_shape):
+ """
+ Create a ResNet instance from config.
+ Returns:
+ ResNet: a :class:`ResNet` instance.
+ """
+ # need registration of new blocks/stems?
+ norm = cfg.MODEL.RESNETS.NORM
+ if cfg.MODEL.RESNETS.STEM_TYPE == "basic":
+ stem = BasicStem(
+ in_channels=input_shape.channels,
+ out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
+ norm=norm,
+ )
+ elif cfg.MODEL.RESNETS.STEM_TYPE == "deeplab":
+ stem = DeepLabStem(
+ in_channels=input_shape.channels,
+ out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
+ norm=norm,
+ )
+ else:
+ raise ValueError("Unknown stem type: {}".format(cfg.MODEL.RESNETS.STEM_TYPE))
+
+ # fmt: off
+ freeze_at = cfg.MODEL.BACKBONE.FREEZE_AT
+ out_features = cfg.MODEL.RESNETS.OUT_FEATURES
+ depth = cfg.MODEL.RESNETS.DEPTH
+ num_groups = cfg.MODEL.RESNETS.NUM_GROUPS
+ width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP
+ bottleneck_channels = num_groups * width_per_group
+ in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
+ out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS
+ stride_in_1x1 = cfg.MODEL.RESNETS.STRIDE_IN_1X1
+ res4_dilation = cfg.MODEL.RESNETS.RES4_DILATION
+ res5_dilation = cfg.MODEL.RESNETS.RES5_DILATION
+ deform_on_per_stage = cfg.MODEL.RESNETS.DEFORM_ON_PER_STAGE
+ deform_modulated = cfg.MODEL.RESNETS.DEFORM_MODULATED
+ deform_num_groups = cfg.MODEL.RESNETS.DEFORM_NUM_GROUPS
+ res5_multi_grid = cfg.MODEL.RESNETS.RES5_MULTI_GRID
+ # fmt: on
+ assert res4_dilation in {1, 2}, "res4_dilation cannot be {}.".format(res4_dilation)
+ assert res5_dilation in {1, 2, 4}, "res5_dilation cannot be {}.".format(res5_dilation)
+ if res4_dilation == 2:
+ # Always dilate res5 if res4 is dilated.
+ assert res5_dilation == 4
+
+ num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
+
+ stages = []
+
+ # Avoid creating variables without gradients
+ # It consumes extra memory and may cause allreduce to fail
+ out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
+ max_stage_idx = max(out_stage_idx)
+ for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
+ if stage_idx == 4:
+ dilation = res4_dilation
+ elif stage_idx == 5:
+ dilation = res5_dilation
+ else:
+ dilation = 1
+ first_stride = 1 if idx == 0 or dilation > 1 else 2
+ stage_kargs = {
+ "num_blocks": num_blocks_per_stage[idx],
+ "stride_per_block": [first_stride] + [1] * (num_blocks_per_stage[idx] - 1),
+ "in_channels": in_channels,
+ "out_channels": out_channels,
+ "norm": norm,
+ }
+ stage_kargs["bottleneck_channels"] = bottleneck_channels
+ stage_kargs["stride_in_1x1"] = stride_in_1x1
+ stage_kargs["dilation"] = dilation
+ stage_kargs["num_groups"] = num_groups
+ if deform_on_per_stage[idx]:
+ stage_kargs["block_class"] = DeformBottleneckBlock
+ stage_kargs["deform_modulated"] = deform_modulated
+ stage_kargs["deform_num_groups"] = deform_num_groups
+ else:
+ stage_kargs["block_class"] = BottleneckBlock
+ if stage_idx == 5:
+ stage_kargs.pop("dilation")
+ stage_kargs["dilation_per_block"] = [dilation * mg for mg in res5_multi_grid]
+ blocks = ResNet.make_stage(**stage_kargs)
+ in_channels = out_channels
+ out_channels *= 2
+ bottleneck_channels *= 2
+ stages.append(blocks)
+ return ResNet(stem, stages, out_features=out_features).freeze(freeze_at)
diff --git a/projects/DeepLab/deeplab/semantic_seg.py b/projects/DeepLab/deeplab/semantic_seg.py
new file mode 100644
index 0000000..4333d21
--- /dev/null
+++ b/projects/DeepLab/deeplab/semantic_seg.py
@@ -0,0 +1,326 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+from typing import Callable, Dict, List, Optional, Tuple, Union
+import fvcore.nn.weight_init as weight_init
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from detectron2.config import configurable
+from detectron2.layers import ASPP, Conv2d, ShapeSpec, get_norm
+from detectron2.modeling import SEM_SEG_HEADS_REGISTRY
+
+from .loss import DeepLabCE
+
+
+@SEM_SEG_HEADS_REGISTRY.register()
+class DeepLabV3PlusHead(nn.Module):
+ """
+ A semantic segmentation head described in :paper:`DeepLabV3+`.
+ """
+
+ @configurable
+ def __init__(
+ self,
+ input_shape: Dict[str, ShapeSpec],
+ *,
+ in_features: List[str],
+ project_channels: List[int],
+ aspp_dilations: List[int],
+ aspp_dropout: float,
+ decoder_channels: List[int],
+ common_stride: int,
+ norm: Union[str, Callable],
+ train_size: Optional[Tuple],
+ loss_weight: float = 1.0,
+ loss_type: str = "cross_entropy",
+ ignore_value: int = -1,
+ num_classes: Optional[int] = None,
+ ):
+ """
+ NOTE: this interface is experimental.
+
+ Args:
+ input_shape (ShapeSpec): shape of the input feature
+ in_features (list[str]): a list of input feature names, the last
+ name of "in_features" is used as the input to the decoder (i.e.
+ the ASPP module) and rest of "in_features" are low-level feature
+ the the intermediate levels of decoder. "in_features" should be
+ ordered from highest resolution to lowest resolution. For
+ example: ["res2", "res3", "res4", "res5"].
+ project_channels (list[int]): a list of low-level feature channels.
+ The length should be len(in_features) - 1.
+ aspp_dilations (list(int)): a list of 3 dilations in ASPP.
+ aspp_dropout (float): apply dropout on the output of ASPP.
+ decoder_channels (list[int]): a list of output channels of each
+ decoder stage. It should have the same length as "in_features"
+ (each element in "in_features" corresponds to one decoder stage).
+ common_stride (int): output stride of decoder.
+ norm (str or callable): normalization for all conv layers.
+ train_size (tuple): (height, width) of training images.
+ loss_weight (float): loss weight.
+ loss_type (str): type of loss function, 2 opptions:
+ (1) "cross_entropy" is the standard cross entropy loss.
+ (2) "hard_pixel_mining" is the loss in DeepLab that samples
+ top k% hardest pixels.
+ ignore_value (int): category to be ignored during training.
+ num_classes (int): number of classes, if set to None, the decoder
+ will not construct a predictor.
+ """
+ super().__init__()
+
+ # fmt: off
+ self.in_features = in_features # starting from "res2" to "res5"
+ in_channels = [input_shape[f].channels for f in self.in_features]
+ aspp_channels = decoder_channels[-1]
+ self.ignore_value = ignore_value
+ self.common_stride = common_stride # output stride
+ self.loss_weight = loss_weight
+ self.loss_type = loss_type
+ self.decoder_only = num_classes is None
+ # fmt: on
+
+ assert (
+ len(project_channels) == len(self.in_features) - 1
+ ), "Expected {} project_channels, got {}".format(
+ len(self.in_features) - 1, len(project_channels)
+ )
+ assert len(decoder_channels) == len(
+ self.in_features
+ ), "Expected {} decoder_channels, got {}".format(
+ len(self.in_features), len(decoder_channels)
+ )
+ self.decoder = nn.ModuleDict()
+
+ use_bias = norm == ""
+ for idx, in_channel in enumerate(in_channels):
+ decoder_stage = nn.ModuleDict()
+
+ if idx == len(self.in_features) - 1:
+ # ASPP module
+ if train_size is not None:
+ train_h, train_w = train_size
+ encoder_stride = input_shape[self.in_features[-1]].stride
+ if train_h % encoder_stride or train_w % encoder_stride:
+ raise ValueError("Crop size need to be divisible by encoder stride.")
+ pool_h = train_h // encoder_stride
+ pool_w = train_w // encoder_stride
+ pool_kernel_size = (pool_h, pool_w)
+ else:
+ pool_kernel_size = None
+ project_conv = ASPP(
+ in_channel,
+ aspp_channels,
+ aspp_dilations,
+ norm=norm,
+ activation=F.relu,
+ pool_kernel_size=pool_kernel_size,
+ dropout=aspp_dropout,
+ )
+ fuse_conv = None
+ else:
+ project_conv = Conv2d(
+ in_channel,
+ project_channels[idx],
+ kernel_size=1,
+ bias=use_bias,
+ norm=get_norm(norm, project_channels[idx]),
+ activation=F.relu,
+ )
+ fuse_conv = nn.Sequential(
+ Conv2d(
+ project_channels[idx] + decoder_channels[idx + 1],
+ decoder_channels[idx],
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, decoder_channels[idx]),
+ activation=F.relu,
+ ),
+ Conv2d(
+ decoder_channels[idx],
+ decoder_channels[idx],
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, decoder_channels[idx]),
+ activation=F.relu,
+ ),
+ )
+ weight_init.c2_xavier_fill(project_conv)
+ weight_init.c2_xavier_fill(fuse_conv[0])
+ weight_init.c2_xavier_fill(fuse_conv[1])
+
+ decoder_stage["project_conv"] = project_conv
+ decoder_stage["fuse_conv"] = fuse_conv
+
+ self.decoder[self.in_features[idx]] = decoder_stage
+
+ if not self.decoder_only:
+ self.predictor = Conv2d(
+ decoder_channels[0], num_classes, kernel_size=1, stride=1, padding=0
+ )
+ nn.init.normal_(self.predictor.weight, 0, 0.001)
+ nn.init.constant_(self.predictor.bias, 0)
+
+ if self.loss_type == "cross_entropy":
+ self.loss = nn.CrossEntropyLoss(reduction="mean", ignore_index=self.ignore_value)
+ elif self.loss_type == "hard_pixel_mining":
+ self.loss = DeepLabCE(ignore_label=self.ignore_value, top_k_percent_pixels=0.2)
+ else:
+ raise ValueError("Unexpected loss type: %s" % self.loss_type)
+
+ @classmethod
+ def from_config(cls, cfg, input_shape):
+ if cfg.INPUT.CROP.ENABLED:
+ assert cfg.INPUT.CROP.TYPE == "absolute"
+ train_size = cfg.INPUT.CROP.SIZE
+ else:
+ train_size = None
+ decoder_channels = [cfg.MODEL.SEM_SEG_HEAD.CONVS_DIM] * (
+ len(cfg.MODEL.SEM_SEG_HEAD.IN_FEATURES) - 1
+ ) + [cfg.MODEL.SEM_SEG_HEAD.ASPP_CHANNELS]
+ ret = dict(
+ input_shape=input_shape,
+ in_features=cfg.MODEL.SEM_SEG_HEAD.IN_FEATURES,
+ project_channels=cfg.MODEL.SEM_SEG_HEAD.PROJECT_CHANNELS,
+ aspp_dilations=cfg.MODEL.SEM_SEG_HEAD.ASPP_DILATIONS,
+ aspp_dropout=cfg.MODEL.SEM_SEG_HEAD.ASPP_DROPOUT,
+ decoder_channels=decoder_channels,
+ common_stride=cfg.MODEL.SEM_SEG_HEAD.COMMON_STRIDE,
+ norm=cfg.MODEL.SEM_SEG_HEAD.NORM,
+ train_size=train_size,
+ loss_weight=cfg.MODEL.SEM_SEG_HEAD.LOSS_WEIGHT,
+ loss_type=cfg.MODEL.SEM_SEG_HEAD.LOSS_TYPE,
+ ignore_value=cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
+ num_classes=cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES,
+ )
+ return ret
+
+ def forward(self, features, targets=None):
+ """
+ Returns:
+ In training, returns (None, dict of losses)
+ In inference, returns (CxHxW logits, {})
+ """
+ y = self.layers(features)
+ if self.decoder_only:
+ # Output from self.layers() only contains decoder feature.
+ return y
+ if self.training:
+ return None, self.losses(y, targets)
+ else:
+ y = F.interpolate(
+ y, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ return y, {}
+
+ def layers(self, features):
+ # Reverse feature maps into top-down order (from low to high resolution)
+ for f in self.in_features[::-1]:
+ x = features[f]
+ proj_x = self.decoder[f]["project_conv"](x)
+ if self.decoder[f]["fuse_conv"] is None:
+ # This is aspp module
+ y = proj_x
+ else:
+ # Upsample y
+ y = F.interpolate(y, size=proj_x.size()[2:], mode="bilinear", align_corners=False)
+ y = torch.cat([proj_x, y], dim=1)
+ y = self.decoder[f]["fuse_conv"](y)
+ if not self.decoder_only:
+ y = self.predictor(y)
+ return y
+
+ def losses(self, predictions, targets):
+ predictions = F.interpolate(
+ predictions, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ loss = self.loss(predictions, targets)
+ losses = {"loss_sem_seg": loss * self.loss_weight}
+ return losses
+
+
+@SEM_SEG_HEADS_REGISTRY.register()
+class DeepLabV3Head(nn.Module):
+ """
+ A semantic segmentation head described in :paper:`DeepLabV3`.
+ """
+
+ def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
+ super().__init__()
+
+ # fmt: off
+ self.in_features = cfg.MODEL.SEM_SEG_HEAD.IN_FEATURES
+ in_channels = [input_shape[f].channels for f in self.in_features]
+ aspp_channels = cfg.MODEL.SEM_SEG_HEAD.ASPP_CHANNELS
+ aspp_dilations = cfg.MODEL.SEM_SEG_HEAD.ASPP_DILATIONS
+ self.ignore_value = cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE
+ num_classes = cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES
+ conv_dims = cfg.MODEL.SEM_SEG_HEAD.CONVS_DIM
+ self.common_stride = cfg.MODEL.SEM_SEG_HEAD.COMMON_STRIDE # output stride
+ norm = cfg.MODEL.SEM_SEG_HEAD.NORM
+ self.loss_weight = cfg.MODEL.SEM_SEG_HEAD.LOSS_WEIGHT
+ self.loss_type = cfg.MODEL.SEM_SEG_HEAD.LOSS_TYPE
+ train_crop_size = cfg.INPUT.CROP.SIZE
+ aspp_dropout = cfg.MODEL.SEM_SEG_HEAD.ASPP_DROPOUT
+ # fmt: on
+
+ assert len(self.in_features) == 1
+ assert len(in_channels) == 1
+
+ # ASPP module
+ if cfg.INPUT.CROP.ENABLED:
+ assert cfg.INPUT.CROP.TYPE == "absolute"
+ train_crop_h, train_crop_w = train_crop_size
+ if train_crop_h % self.common_stride or train_crop_w % self.common_stride:
+ raise ValueError("Crop size need to be divisible by output stride.")
+ pool_h = train_crop_h // self.common_stride
+ pool_w = train_crop_w // self.common_stride
+ pool_kernel_size = (pool_h, pool_w)
+ else:
+ pool_kernel_size = None
+ self.aspp = ASPP(
+ in_channels[0],
+ aspp_channels,
+ aspp_dilations,
+ norm=norm,
+ activation=F.relu,
+ pool_kernel_size=pool_kernel_size,
+ dropout=aspp_dropout,
+ )
+
+ self.predictor = Conv2d(conv_dims, num_classes, kernel_size=1, stride=1, padding=0)
+ nn.init.normal_(self.predictor.weight, 0, 0.001)
+ nn.init.constant_(self.predictor.bias, 0)
+
+ if self.loss_type == "cross_entropy":
+ self.loss = nn.CrossEntropyLoss(reduction="mean", ignore_index=self.ignore_value)
+ elif self.loss_type == "hard_pixel_mining":
+ self.loss = DeepLabCE(ignore_label=self.ignore_value, top_k_percent_pixels=0.2)
+ else:
+ raise ValueError("Unexpected loss type: %s" % self.loss_type)
+
+ def forward(self, features, targets=None):
+ """
+ Returns:
+ In training, returns (None, dict of losses)
+ In inference, returns (CxHxW logits, {})
+ """
+ x = features[self.in_features[0]]
+ x = self.aspp(x)
+ x = self.predictor(x)
+ if self.training:
+ return None, self.losses(x, targets)
+ else:
+ x = F.interpolate(
+ x, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ return x, {}
+
+ def losses(self, predictions, targets):
+ predictions = F.interpolate(
+ predictions, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ loss = self.loss(predictions, targets)
+ losses = {"loss_sem_seg": loss * self.loss_weight}
+ return losses
diff --git a/projects/DeepLab/train_net.py b/projects/DeepLab/train_net.py
new file mode 100644
index 0000000..0789903
--- /dev/null
+++ b/projects/DeepLab/train_net.py
@@ -0,0 +1,141 @@
+#!/usr/bin/env python3
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+"""
+DeepLab Training Script.
+
+This script is a simplified version of the training script in detectron2/tools.
+"""
+
+import os
+import torch
+
+import detectron2.data.transforms as T
+import detectron2.utils.comm as comm
+from detectron2.checkpoint import DetectionCheckpointer
+from detectron2.config import get_cfg
+from detectron2.data import DatasetMapper, MetadataCatalog, build_detection_train_loader
+from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
+from detectron2.evaluation import CityscapesSemSegEvaluator, DatasetEvaluators, SemSegEvaluator
+from detectron2.projects.deeplab import add_deeplab_config, build_lr_scheduler
+
+
+def build_sem_seg_train_aug(cfg):
+ augs = [
+ T.ResizeShortestEdge(
+ cfg.INPUT.MIN_SIZE_TRAIN, cfg.INPUT.MAX_SIZE_TRAIN, cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING
+ )
+ ]
+ if cfg.INPUT.CROP.ENABLED:
+ augs.append(
+ T.RandomCrop_CategoryAreaConstraint(
+ cfg.INPUT.CROP.TYPE,
+ cfg.INPUT.CROP.SIZE,
+ cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA,
+ cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
+ )
+ )
+ augs.append(T.RandomFlip())
+ return augs
+
+
+class Trainer(DefaultTrainer):
+ """
+ We use the "DefaultTrainer" which contains a number pre-defined logic for
+ standard training workflow. They may not work for you, especially if you
+ are working on a new research project. In that case you can use the cleaner
+ "SimpleTrainer", or write your own training loop.
+ """
+
+ @classmethod
+ def build_evaluator(cls, cfg, dataset_name, output_folder=None):
+ """
+ Create evaluator(s) for a given dataset.
+ This uses the special metadata "evaluator_type" associated with each builtin dataset.
+ For your own dataset, you can simply create an evaluator manually in your
+ script and do not have to worry about the hacky if-else logic here.
+ """
+ if output_folder is None:
+ output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
+ evaluator_list = []
+ evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
+ if evaluator_type == "sem_seg":
+ return SemSegEvaluator(
+ dataset_name,
+ distributed=True,
+ num_classes=cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES,
+ ignore_label=cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
+ output_dir=output_folder,
+ )
+ if evaluator_type == "cityscapes_sem_seg":
+ assert (
+ torch.cuda.device_count() >= comm.get_rank()
+ ), "CityscapesEvaluator currently do not work with multiple machines."
+ return CityscapesSemSegEvaluator(dataset_name)
+ if len(evaluator_list) == 0:
+ raise NotImplementedError(
+ "no Evaluator for the dataset {} with the type {}".format(
+ dataset_name, evaluator_type
+ )
+ )
+ if len(evaluator_list) == 1:
+ return evaluator_list[0]
+ return DatasetEvaluators(evaluator_list)
+
+ @classmethod
+ def build_train_loader(cls, cfg):
+ if "SemanticSegmentor" in cfg.MODEL.META_ARCHITECTURE:
+ mapper = DatasetMapper(cfg, is_train=True, augmentations=build_sem_seg_train_aug(cfg))
+ else:
+ mapper = None
+ return build_detection_train_loader(cfg, mapper=mapper)
+
+ @classmethod
+ def build_lr_scheduler(cls, cfg, optimizer):
+ """
+ It now calls :func:`detectron2.solver.build_lr_scheduler`.
+ Overwrite it if you'd like a different scheduler.
+ """
+ return build_lr_scheduler(cfg, optimizer)
+
+
+def setup(args):
+ """
+ Create configs and perform basic setups.
+ """
+ cfg = get_cfg()
+ add_deeplab_config(cfg)
+ cfg.merge_from_file(args.config_file)
+ cfg.merge_from_list(args.opts)
+ cfg.freeze()
+ default_setup(cfg, args)
+ return cfg
+
+
+def main(args):
+ cfg = setup(args)
+
+ if args.eval_only:
+ model = Trainer.build_model(cfg)
+ DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
+ cfg.MODEL.WEIGHTS, resume=args.resume
+ )
+ res = Trainer.test(cfg, model)
+ return res
+
+ trainer = Trainer(cfg)
+ trainer.resume_or_load(resume=args.resume)
+ return trainer.train()
+
+
+if __name__ == "__main__":
+ args = default_argument_parser().parse_args()
+ print("Command Line Args:", args)
+ launch(
+ main,
+ args.num_gpus,
+ num_machines=args.num_machines,
+ machine_rank=args.machine_rank,
+ dist_url=args.dist_url,
+ args=(args,),
+ )
diff --git a/projects/Panoptic-DeepLab/README.md b/projects/Panoptic-DeepLab/README.md
new file mode 100644
index 0000000..29ce944
--- /dev/null
+++ b/projects/Panoptic-DeepLab/README.md
@@ -0,0 +1,105 @@
+# Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
+
+Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang-Chieh Chen
+
+[[`arXiv`](https://arxiv.org/abs/1911.10194)] [[`BibTeX`](#CitingPanopticDeepLab)] [[`Reference implementation`](https://github.com/bowenc0221/panoptic-deeplab)]
+
+
+

+
+
+## Installation
+Install Detectron2 following [the instructions](https://detectron2.readthedocs.io/tutorials/install.html).
+
+## Training
+
+To train a model with 8 GPUs run:
+```bash
+cd /path/to/detectron2/projects/Panoptic-DeepLab
+python train_net.py --config-file config/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml --num-gpus 8
+```
+
+## Evaluation
+
+Model evaluation can be done similarly:
+```bash
+cd /path/to/detectron2/projects/Panoptic-DeepLab
+python train_net.py --config-file config/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
+```
+
+## Cityscapes Panoptic Segmentation
+Cityscapes models are trained with ImageNet pretraining.
+
+
+
+
+| Method |
+Backbone |
+Output
resolution |
+PQ |
+SQ |
+RQ |
+mIoU |
+AP |
+Memory (M) |
+model id |
+download |
+
+ | Panoptic-DeepLab |
+R50-DC5 |
+1024×2048 |
+ 58.6 |
+ 80.9 |
+ 71.2 |
+ 75.9 |
+ 29.8 |
+ 8668 |
+ - |
+model | metrics |
+
+ | Panoptic-DeepLab |
+R52-DC5 |
+1024×2048 |
+ 60.3 |
+ 81.5 |
+ 72.9 |
+ 78.2 |
+ 33.2 |
+ 9682 |
+ |
+model | metrics |
+
+
+
+Note:
+- [R52](https://dl.fbaipublicfiles.com/detectron2/DeepLab/R-52.pkl): a ResNet-50 with its first 7x7 convolution replaced by 3 3x3 convolutions. This modification has been used in most semantic segmentation papers. We pre-train this backbone on ImageNet using the default recipe of [pytorch examples](https://github.com/pytorch/examples/tree/master/imagenet).
+- DC5 means using dilated convolution in `res5`.
+- We use a smaller training crop size (512x1024) than the original paper (1025x2049), we find using larger crop size (1024x2048) could further improve PQ by 1.5% but also degrades AP by 3%.
+
+## Citing Panoptic-DeepLab
+
+If you use Panoptic-DeepLab, please use the following BibTeX entry.
+
+* CVPR 2020 paper:
+
+```
+@inproceedings{cheng2020panoptic,
+ title={Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation},
+ author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
+ booktitle={CVPR},
+ year={2020}
+}
+```
+
+* ICCV 2019 COCO-Mapillary workshp challenge report:
+
+```
+@inproceedings{cheng2019panoptic,
+ title={Panoptic-DeepLab},
+ author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
+ booktitle={ICCV COCO + Mapillary Joint Recognition Challenge Workshop},
+ year={2019}
+}
+```
diff --git a/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/Base-PanopticDeepLab-OS16.yaml b/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/Base-PanopticDeepLab-OS16.yaml
new file mode 100644
index 0000000..b737998
--- /dev/null
+++ b/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/Base-PanopticDeepLab-OS16.yaml
@@ -0,0 +1,65 @@
+MODEL:
+ META_ARCHITECTURE: "PanopticDeepLab"
+ BACKBONE:
+ FREEZE_AT: 0
+ RESNETS:
+ OUT_FEATURES: ["res2", "res3", "res5"]
+ RES5_DILATION: 2
+ SEM_SEG_HEAD:
+ NAME: "PanopticDeepLabSemSegHead"
+ IN_FEATURES: ["res2", "res3", "res5"]
+ PROJECT_FEATURES: ["res2", "res3"]
+ PROJECT_CHANNELS: [32, 64]
+ ASPP_CHANNELS: 256
+ ASPP_DILATIONS: [6, 12, 18]
+ ASPP_DROPOUT: 0.1
+ HEAD_CHANNELS: 256
+ CONVS_DIM: 256
+ COMMON_STRIDE: 4
+ NUM_CLASSES: 19
+ LOSS_TYPE: "hard_pixel_mining"
+ NORM: "SyncBN"
+ INS_EMBED_HEAD:
+ NAME: "PanopticDeepLabInsEmbedHead"
+ IN_FEATURES: ["res2", "res3", "res5"]
+ PROJECT_FEATURES: ["res2", "res3"]
+ PROJECT_CHANNELS: [32, 64]
+ ASPP_CHANNELS: 256
+ ASPP_DILATIONS: [6, 12, 18]
+ ASPP_DROPOUT: 0.1
+ HEAD_CHANNELS: 32
+ CONVS_DIM: 128
+ COMMON_STRIDE: 4
+ NORM: "SyncBN"
+ CENTER_LOSS_WEIGHT: 200.0
+ OFFSET_LOSS_WEIGHT: 0.01
+ PANOPTIC_DEEPLAB:
+ STUFF_AREA: 2048
+ CENTER_THRESHOLD: 0.1
+ NMS_KERNEL: 7
+ TOP_K_INSTANCE: 200
+DATASETS:
+ TRAIN: ("cityscapes_fine_panoptic_train",)
+ TEST: ("cityscapes_fine_panoptic_val",)
+SOLVER:
+ OPTIMIZER: "ADAM"
+ BASE_LR: 0.001
+ WEIGHT_DECAY: 0.0
+ WEIGHT_DECAY_NORM: 0.0
+ WEIGHT_DECAY_BIAS: 0.0
+ MAX_ITER: 60000
+ LR_SCHEDULER_NAME: "WarmupPolyLR"
+ IMS_PER_BATCH: 32
+INPUT:
+ MIN_SIZE_TRAIN: (512, 640, 704, 832, 896, 1024, 1152, 1216, 1344, 1408, 1536, 1664, 1728, 1856, 1920, 2048)
+ MIN_SIZE_TRAIN_SAMPLING: "choice"
+ MIN_SIZE_TEST: 1024
+ MAX_SIZE_TRAIN: 4096
+ MAX_SIZE_TEST: 2048
+ CROP:
+ ENABLED: True
+ TYPE: "absolute"
+ SIZE: (1024, 2048)
+DATALOADER:
+ NUM_WORKERS: 10
+VERSION: 2
diff --git a/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml b/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml
new file mode 100644
index 0000000..fde902b
--- /dev/null
+++ b/projects/Panoptic-DeepLab/configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024.yaml
@@ -0,0 +1,20 @@
+_BASE_: Base-PanopticDeepLab-OS16.yaml
+MODEL:
+ WEIGHTS: "detectron2://DeepLab/R-52.pkl"
+ PIXEL_MEAN: [123.675, 116.280, 103.530]
+ PIXEL_STD: [58.395, 57.120, 57.375]
+ BACKBONE:
+ NAME: "build_resnet_deeplab_backbone"
+ RESNETS:
+ DEPTH: 50
+ NORM: "SyncBN"
+ RES5_MULTI_GRID: [1, 2, 4]
+ STEM_TYPE: "deeplab"
+ STEM_OUT_CHANNELS: 128
+ STRIDE_IN_1X1: False
+SOLVER:
+ MAX_ITER: 90000
+INPUT:
+ FORMAT: "RGB"
+ CROP:
+ SIZE: (512, 1024)
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/__init__.py b/projects/Panoptic-DeepLab/panoptic_deeplab/__init__.py
new file mode 100644
index 0000000..f9a6b2b
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+from .config import add_panoptic_deeplab_config
+from .dataset_mapper import PanopticDeeplabDatasetMapper
+from .panoptic_seg import (
+ PanopticDeepLab,
+ INS_EMBED_BRANCHES_REGISTRY,
+ build_ins_embed_branch,
+ PanopticDeepLabSemSegHead,
+ PanopticDeepLabInsEmbedHead,
+)
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/config.py b/projects/Panoptic-DeepLab/panoptic_deeplab/config.py
new file mode 100644
index 0000000..3838175
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/config.py
@@ -0,0 +1,50 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+from detectron2.config import CfgNode as CN
+from detectron2.projects.deeplab import add_deeplab_config
+
+
+def add_panoptic_deeplab_config(cfg):
+ """
+ Add config for Panoptic-DeepLab.
+ """
+ # Reuse DeepLab config.
+ add_deeplab_config(cfg)
+ # Target generation parameters.
+ cfg.INPUT.GAUSSIAN_SIGMA = 10
+ cfg.INPUT.IGNORE_STUFF_IN_OFFSET = True
+ cfg.INPUT.SMALL_INSTANCE_AREA = 4096
+ cfg.INPUT.SMALL_INSTANCE_WEIGHT = 3
+ cfg.INPUT.IGNORE_CROWD_IN_SEMANTIC = False
+ # Optimizer type.
+ cfg.SOLVER.OPTIMIZER = "ADAM"
+ # Panoptic-DeepLab semantic segmentation head.
+ # We add an extra convolution before predictor.
+ cfg.MODEL.SEM_SEG_HEAD.HEAD_CHANNELS = 256
+ cfg.MODEL.SEM_SEG_HEAD.LOSS_TOP_K = 0.2
+ # Panoptic-DeepLab instance segmentation head.
+ cfg.MODEL.INS_EMBED_HEAD = CN()
+ cfg.MODEL.INS_EMBED_HEAD.NAME = "PanopticDeepLabInsEmbedHead"
+ cfg.MODEL.INS_EMBED_HEAD.IN_FEATURES = ["res2", "res3", "res5"]
+ cfg.MODEL.INS_EMBED_HEAD.PROJECT_FEATURES = ["res2", "res3"]
+ cfg.MODEL.INS_EMBED_HEAD.PROJECT_CHANNELS = [32, 64]
+ cfg.MODEL.INS_EMBED_HEAD.ASPP_CHANNELS = 256
+ cfg.MODEL.INS_EMBED_HEAD.ASPP_DILATIONS = [6, 12, 18]
+ cfg.MODEL.INS_EMBED_HEAD.ASPP_DROPOUT = 0.1
+ # We add an extra convolution before predictor.
+ cfg.MODEL.INS_EMBED_HEAD.HEAD_CHANNELS = 32
+ cfg.MODEL.INS_EMBED_HEAD.CONVS_DIM = 128
+ cfg.MODEL.INS_EMBED_HEAD.COMMON_STRIDE = 4
+ cfg.MODEL.INS_EMBED_HEAD.NORM = "SyncBN"
+ cfg.MODEL.INS_EMBED_HEAD.CENTER_LOSS_WEIGHT = 200.0
+ cfg.MODEL.INS_EMBED_HEAD.OFFSET_LOSS_WEIGHT = 0.01
+ # Panoptic-DeepLab post-processing setting.
+ cfg.MODEL.PANOPTIC_DEEPLAB = CN()
+ # Stuff area limit, ignore stuff region below this number.
+ cfg.MODEL.PANOPTIC_DEEPLAB.STUFF_AREA = 2048
+ cfg.MODEL.PANOPTIC_DEEPLAB.CENTER_THRESHOLD = 0.1
+ cfg.MODEL.PANOPTIC_DEEPLAB.NMS_KERNEL = 7
+ cfg.MODEL.PANOPTIC_DEEPLAB.TOP_K_INSTANCE = 200
+ # If set to False, Panoptic-DeepLab will not evaluate instance segmentation.
+ cfg.MODEL.PANOPTIC_DEEPLAB.PREDICT_INSTANCES = True
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/dataset_mapper.py b/projects/Panoptic-DeepLab/panoptic_deeplab/dataset_mapper.py
new file mode 100644
index 0000000..a99fd45
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/dataset_mapper.py
@@ -0,0 +1,116 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import copy
+import logging
+import numpy as np
+from typing import Callable, List, Union
+import torch
+from panopticapi.utils import rgb2id
+
+from detectron2.config import configurable
+from detectron2.data import MetadataCatalog
+from detectron2.data import detection_utils as utils
+from detectron2.data import transforms as T
+
+from .target_generator import PanopticDeepLabTargetGenerator
+
+__all__ = ["PanopticDeeplabDatasetMapper"]
+
+
+class PanopticDeeplabDatasetMapper:
+ """
+ The callable currently does the following:
+
+ 1. Read the image from "file_name" and label from "pan_seg_file_name"
+ 2. Applies random scale, crop and flip transforms to image and label
+ 3. Prepare data to Tensor and generate training targets from label
+ """
+
+ @configurable
+ def __init__(
+ self,
+ *,
+ augmentations: List[Union[T.Augmentation, T.Transform]],
+ image_format: str,
+ panoptic_target_generator: Callable,
+ ):
+ """
+ NOTE: this interface is experimental.
+
+ Args:
+ augmentations: a list of augmentations or deterministic transforms to apply
+ image_format: an image format supported by :func:`detection_utils.read_image`.
+ panoptic_target_generator: a callable that takes "panoptic_seg" and
+ "segments_info" to generate training targets for the model.
+ """
+ # fmt: off
+ self.augmentations = T.AugmentationList(augmentations)
+ self.image_format = image_format
+ # fmt: on
+ logger = logging.getLogger(__name__)
+ logger.info("Augmentations used in training: " + str(augmentations))
+
+ self.panoptic_target_generator = panoptic_target_generator
+
+ @classmethod
+ def from_config(cls, cfg):
+ augs = [
+ T.ResizeShortestEdge(
+ cfg.INPUT.MIN_SIZE_TRAIN,
+ cfg.INPUT.MAX_SIZE_TRAIN,
+ cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING,
+ )
+ ]
+ if cfg.INPUT.CROP.ENABLED:
+ augs.append(T.RandomCrop(cfg.INPUT.CROP.TYPE, cfg.INPUT.CROP.SIZE))
+ augs.append(T.RandomFlip())
+
+ # Assume always applies to the training set.
+ dataset_names = cfg.DATASETS.TRAIN
+ meta = MetadataCatalog.get(dataset_names[0])
+ panoptic_target_generator = PanopticDeepLabTargetGenerator(
+ ignore_label=meta.ignore_label,
+ thing_ids=list(meta.thing_dataset_id_to_contiguous_id.values()),
+ sigma=cfg.INPUT.GAUSSIAN_SIGMA,
+ ignore_stuff_in_offset=cfg.INPUT.IGNORE_STUFF_IN_OFFSET,
+ small_instance_area=cfg.INPUT.SMALL_INSTANCE_AREA,
+ small_instance_weight=cfg.INPUT.SMALL_INSTANCE_WEIGHT,
+ ignore_crowd_in_semantic=cfg.INPUT.IGNORE_CROWD_IN_SEMANTIC,
+ )
+
+ ret = {
+ "augmentations": augs,
+ "image_format": cfg.INPUT.FORMAT,
+ "panoptic_target_generator": panoptic_target_generator,
+ }
+ return ret
+
+ def __call__(self, dataset_dict):
+ """
+ Args:
+ dataset_dict (dict): Metadata of one image, in Detectron2 Dataset format.
+
+ Returns:
+ dict: a format that builtin models in detectron2 accept
+ """
+ dataset_dict = copy.deepcopy(dataset_dict) # it will be modified by code below
+ # Load image.
+ image = utils.read_image(dataset_dict["file_name"], format=self.image_format)
+ utils.check_image_size(dataset_dict, image)
+ # Panoptic label is encoded in RGB image.
+ pan_seg_gt = utils.read_image(dataset_dict.pop("pan_seg_file_name"), "RGB")
+
+ # Reuses semantic transform for panoptic labels.
+ aug_input = T.AugInput(image, sem_seg=pan_seg_gt)
+ _ = self.augmentations(aug_input)
+ image, pan_seg_gt = aug_input.image, aug_input.sem_seg
+
+ # Pytorch's dataloader is efficient on torch.Tensor due to shared-memory,
+ # but not efficient on large generic data structures due to the use of pickle & mp.Queue.
+ # Therefore it's important to use torch.Tensor.
+ dataset_dict["image"] = torch.as_tensor(np.ascontiguousarray(image.transpose(2, 0, 1)))
+
+ # Generates training targets for Panoptic-DeepLab.
+ targets = self.panoptic_target_generator(rgb2id(pan_seg_gt), dataset_dict["segments_info"])
+ dataset_dict.update(targets)
+
+ return dataset_dict
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/panoptic_seg.py b/projects/Panoptic-DeepLab/panoptic_deeplab/panoptic_seg.py
new file mode 100644
index 0000000..3526fb3
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/panoptic_seg.py
@@ -0,0 +1,526 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import numpy as np
+from typing import Callable, Dict, List, Union
+import fvcore.nn.weight_init as weight_init
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from detectron2.config import configurable
+from detectron2.data import MetadataCatalog
+from detectron2.layers import Conv2d, ShapeSpec, get_norm
+from detectron2.modeling import (
+ META_ARCH_REGISTRY,
+ SEM_SEG_HEADS_REGISTRY,
+ build_backbone,
+ build_sem_seg_head,
+)
+from detectron2.modeling.postprocessing import sem_seg_postprocess
+from detectron2.projects.deeplab import DeepLabV3PlusHead
+from detectron2.projects.deeplab.loss import DeepLabCE
+from detectron2.structures import BitMasks, ImageList, Instances
+from detectron2.utils.registry import Registry
+
+from .post_processing import get_panoptic_segmentation
+
+__all__ = ["PanopticDeepLab", "INS_EMBED_BRANCHES_REGISTRY", "build_ins_embed_branch"]
+
+
+INS_EMBED_BRANCHES_REGISTRY = Registry("INS_EMBED_BRANCHES")
+INS_EMBED_BRANCHES_REGISTRY.__doc__ = """
+Registry for instance embedding branches, which make instance embedding
+predictions from feature maps.
+"""
+
+
+@META_ARCH_REGISTRY.register()
+class PanopticDeepLab(nn.Module):
+ """
+ Main class for panoptic segmentation architectures.
+ """
+
+ def __init__(self, cfg):
+ super().__init__()
+ self.backbone = build_backbone(cfg)
+ self.sem_seg_head = build_sem_seg_head(cfg, self.backbone.output_shape())
+ self.ins_embed_head = build_ins_embed_branch(cfg, self.backbone.output_shape())
+ self.register_buffer("pixel_mean", torch.Tensor(cfg.MODEL.PIXEL_MEAN).view(-1, 1, 1))
+ self.register_buffer("pixel_std", torch.Tensor(cfg.MODEL.PIXEL_STD).view(-1, 1, 1))
+ self.meta = MetadataCatalog.get(cfg.DATASETS.TRAIN[0])
+ self.stuff_area = cfg.MODEL.PANOPTIC_DEEPLAB.STUFF_AREA
+ self.threshold = cfg.MODEL.PANOPTIC_DEEPLAB.CENTER_THRESHOLD
+ self.nms_kernel = cfg.MODEL.PANOPTIC_DEEPLAB.NMS_KERNEL
+ self.top_k = cfg.MODEL.PANOPTIC_DEEPLAB.TOP_K_INSTANCE
+ self.predict_instances = cfg.MODEL.PANOPTIC_DEEPLAB.PREDICT_INSTANCES
+
+ @property
+ def device(self):
+ return self.pixel_mean.device
+
+ def forward(self, batched_inputs):
+ """
+ Args:
+ batched_inputs: a list, batched outputs of :class:`DatasetMapper`.
+ Each item in the list contains the inputs for one image.
+ For now, each item in the list is a dict that contains:
+ * "image": Tensor, image in (C, H, W) format.
+ * "sem_seg": semantic segmentation ground truth
+ * "center": center points heatmap ground truth
+ * "offset": pixel offsets to center points ground truth
+ * Other information that's included in the original dicts, such as:
+ "height", "width" (int): the output resolution of the model (may be different
+ from input resolution), used in inference.
+ Returns:
+ list[dict]:
+ each dict is the results for one image. The dict contains the following keys:
+
+ * "instances": see :meth:`GeneralizedRCNN.forward` for its format.
+ * "sem_seg": see :meth:`SemanticSegmentor.forward` for its format.
+ * "panoptic_seg": see :func:`combine_semantic_and_instance_outputs` for its format.
+ """
+ images = [x["image"].to(self.device) for x in batched_inputs]
+ images = [(x - self.pixel_mean) / self.pixel_std for x in images]
+ size_divisibility = self.backbone.size_divisibility
+ images = ImageList.from_tensors(images, size_divisibility)
+
+ features = self.backbone(images.tensor)
+
+ losses = {}
+ if "sem_seg" in batched_inputs[0]:
+ targets = [x["sem_seg"].to(self.device) for x in batched_inputs]
+ targets = ImageList.from_tensors(
+ targets, size_divisibility, self.sem_seg_head.ignore_value
+ ).tensor
+ if "sem_seg_weights" in batched_inputs[0]:
+ # The default D2 DatasetMapper may not contain "sem_seg_weights"
+ # Avoid error in testing when default DatasetMapper is used.
+ weights = [x["sem_seg_weights"].to(self.device) for x in batched_inputs]
+ weights = ImageList.from_tensors(weights, size_divisibility).tensor
+ else:
+ weights = None
+ else:
+ targets = None
+ weights = None
+ sem_seg_results, sem_seg_losses = self.sem_seg_head(features, targets, weights)
+ losses.update(sem_seg_losses)
+
+ if "center" in batched_inputs[0] and "offset" in batched_inputs[0]:
+ center_targets = [x["center"].to(self.device) for x in batched_inputs]
+ center_targets = ImageList.from_tensors(
+ center_targets, size_divisibility
+ ).tensor.unsqueeze(1)
+ center_weights = [x["center_weights"].to(self.device) for x in batched_inputs]
+ center_weights = ImageList.from_tensors(center_weights, size_divisibility).tensor
+
+ offset_targets = [x["offset"].to(self.device) for x in batched_inputs]
+ offset_targets = ImageList.from_tensors(offset_targets, size_divisibility).tensor
+ offset_weights = [x["offset_weights"].to(self.device) for x in batched_inputs]
+ offset_weights = ImageList.from_tensors(offset_weights, size_divisibility).tensor
+ else:
+ center_targets = None
+ center_weights = None
+
+ offset_targets = None
+ offset_weights = None
+
+ center_results, offset_results, center_losses, offset_losses = self.ins_embed_head(
+ features, center_targets, center_weights, offset_targets, offset_weights
+ )
+ losses.update(center_losses)
+ losses.update(offset_losses)
+
+ if self.training:
+ return losses
+
+ processed_results = []
+ for sem_seg_result, center_result, offset_result, input_per_image, image_size in zip(
+ sem_seg_results, center_results, offset_results, batched_inputs, images.image_sizes
+ ):
+ height = input_per_image.get("height")
+ width = input_per_image.get("width")
+ r = sem_seg_postprocess(sem_seg_result, image_size, height, width)
+ c = sem_seg_postprocess(center_result, image_size, height, width)
+ o = sem_seg_postprocess(offset_result, image_size, height, width)
+ # Post-processing to get panoptic segmentation.
+ panoptic_image, _ = get_panoptic_segmentation(
+ r.argmax(dim=0, keepdim=True),
+ c,
+ o,
+ thing_ids=self.meta.thing_dataset_id_to_contiguous_id.values(),
+ label_divisor=self.meta.label_divisor,
+ stuff_area=self.stuff_area,
+ void_label=-1,
+ threshold=self.threshold,
+ nms_kernel=self.nms_kernel,
+ top_k=self.top_k,
+ )
+ # For semantic segmentation evaluation.
+ processed_results.append({"sem_seg": r})
+ panoptic_image = panoptic_image.squeeze(0)
+ semantic_prob = F.softmax(r, dim=0)
+ # For panoptic segmentation evaluation.
+ processed_results[-1]["panoptic_seg"] = (panoptic_image, None)
+ # For instance segmentation evaluation.
+ if self.predict_instances:
+ instances = []
+ panoptic_image_cpu = panoptic_image.cpu().numpy()
+ for panoptic_label in np.unique(panoptic_image_cpu):
+ if panoptic_label == -1:
+ continue
+ pred_class = panoptic_label // self.meta.label_divisor
+ isthing = pred_class in list(
+ self.meta.thing_dataset_id_to_contiguous_id.values()
+ )
+ # Get instance segmentation results.
+ if isthing:
+ instance = Instances((height, width))
+ # Evaluation code takes continuous id starting from 0
+ instance.pred_classes = torch.tensor(
+ [pred_class], device=panoptic_image.device
+ )
+ mask = panoptic_image == panoptic_label
+ instance.pred_masks = mask.unsqueeze(0)
+ # Average semantic probability
+ sem_scores = semantic_prob[pred_class, ...]
+ sem_scores = torch.mean(sem_scores[mask])
+ # Center point probability
+ mask_indices = torch.nonzero(mask).float()
+ center_y, center_x = (
+ torch.mean(mask_indices[:, 0]),
+ torch.mean(mask_indices[:, 1]),
+ )
+ center_scores = c[0, int(center_y.item()), int(center_x.item())]
+ # Confidence score is semantic prob * center prob.
+ instance.scores = torch.tensor(
+ [sem_scores * center_scores], device=panoptic_image.device
+ )
+ # Get bounding boxes
+ instance.pred_boxes = BitMasks(instance.pred_masks).get_bounding_boxes()
+ instances.append(instance)
+ if len(instances) > 0:
+ processed_results[-1]["instances"] = Instances.cat(instances)
+
+ return processed_results
+
+
+@SEM_SEG_HEADS_REGISTRY.register()
+class PanopticDeepLabSemSegHead(DeepLabV3PlusHead):
+ """
+ A semantic segmentation head described in :paper:`Panoptic-DeepLab`.
+ """
+
+ @configurable
+ def __init__(
+ self,
+ input_shape: Dict[str, ShapeSpec],
+ *,
+ decoder_channels: List[int],
+ norm: Union[str, Callable],
+ head_channels: int,
+ loss_weight: float,
+ loss_type: str,
+ loss_top_k: float,
+ ignore_value: int,
+ num_classes: int,
+ **kwargs,
+ ):
+ """
+ NOTE: this interface is experimental.
+
+ Args:
+ input_shape (ShapeSpec): shape of the input feature
+ decoder_channels (list[int]): a list of output channels of each
+ decoder stage. It should have the same length as "in_features"
+ (each element in "in_features" corresponds to one decoder stage).
+ norm (str or callable): normalization for all conv layers.
+ head_channels (int): the output channels of extra convolutions
+ between decoder and predictor.
+ loss_weight (float): loss weight.
+ loss_top_k: (float): setting the top k% hardest pixels for
+ "hard_pixel_mining" loss.
+ loss_type, ignore_value, num_classes: the same as the base class.
+ """
+ super().__init__(
+ input_shape,
+ decoder_channels=decoder_channels,
+ norm=norm,
+ ignore_value=ignore_value,
+ **kwargs,
+ )
+ assert self.decoder_only
+
+ self.loss_weight = loss_weight
+ use_bias = norm == ""
+ # `head` is additional transform before predictor
+ self.head = nn.Sequential(
+ Conv2d(
+ decoder_channels[0],
+ decoder_channels[0],
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, decoder_channels[0]),
+ activation=F.relu,
+ ),
+ Conv2d(
+ decoder_channels[0],
+ head_channels,
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, head_channels),
+ activation=F.relu,
+ ),
+ )
+ weight_init.c2_xavier_fill(self.head[0])
+ weight_init.c2_xavier_fill(self.head[1])
+ self.predictor = Conv2d(head_channels, num_classes, kernel_size=1)
+ nn.init.normal_(self.predictor.weight, 0, 0.001)
+ nn.init.constant_(self.predictor.bias, 0)
+
+ if loss_type == "cross_entropy":
+ self.loss = nn.CrossEntropyLoss(reduction="mean", ignore_index=ignore_value)
+ elif loss_type == "hard_pixel_mining":
+ self.loss = DeepLabCE(ignore_label=ignore_value, top_k_percent_pixels=loss_top_k)
+ else:
+ raise ValueError("Unexpected loss type: %s" % loss_type)
+
+ @classmethod
+ def from_config(cls, cfg, input_shape):
+ ret = super().from_config(cfg, input_shape)
+ ret["head_channels"] = cfg.MODEL.SEM_SEG_HEAD.HEAD_CHANNELS
+ ret["loss_top_k"] = cfg.MODEL.SEM_SEG_HEAD.LOSS_TOP_K
+ return ret
+
+ def forward(self, features, targets=None, weights=None):
+ """
+ Returns:
+ In training, returns (None, dict of losses)
+ In inference, returns (CxHxW logits, {})
+ """
+ y = self.layers(features)
+ if self.training:
+ return None, self.losses(y, targets, weights)
+ else:
+ y = F.interpolate(
+ y, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ return y, {}
+
+ def layers(self, features):
+ assert self.decoder_only
+ y = super().layers(features)
+ y = self.head(y)
+ y = self.predictor(y)
+ return y
+
+ def losses(self, predictions, targets, weights=None):
+ predictions = F.interpolate(
+ predictions, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ loss = self.loss(predictions, targets, weights)
+ losses = {"loss_sem_seg": loss * self.loss_weight}
+ return losses
+
+
+def build_ins_embed_branch(cfg, input_shape):
+ """
+ Build a instance embedding branch from `cfg.MODEL.INS_EMBED_HEAD.NAME`.
+ """
+ name = cfg.MODEL.INS_EMBED_HEAD.NAME
+ return INS_EMBED_BRANCHES_REGISTRY.get(name)(cfg, input_shape)
+
+
+@INS_EMBED_BRANCHES_REGISTRY.register()
+class PanopticDeepLabInsEmbedHead(DeepLabV3PlusHead):
+ """
+ A instance embedding head described in :paper:`Panoptic-DeepLab`.
+ """
+
+ @configurable
+ def __init__(
+ self,
+ input_shape: Dict[str, ShapeSpec],
+ *,
+ decoder_channels: List[int],
+ norm: Union[str, Callable],
+ head_channels: int,
+ center_loss_weight: float,
+ offset_loss_weight: float,
+ **kwargs,
+ ):
+ """
+ NOTE: this interface is experimental.
+
+ Args:
+ input_shape (ShapeSpec): shape of the input feature
+ decoder_channels (list[int]): a list of output channels of each
+ decoder stage. It should have the same length as "in_features"
+ (each element in "in_features" corresponds to one decoder stage).
+ norm (str or callable): normalization for all conv layers.
+ head_channels (int): the output channels of extra convolutions
+ between decoder and predictor.
+ center_loss_weight (float): loss weight for center point prediction.
+ offset_loss_weight (float): loss weight for center offset prediction.
+ """
+ super().__init__(input_shape, decoder_channels=decoder_channels, norm=norm, **kwargs)
+ assert self.decoder_only
+
+ self.center_loss_weight = center_loss_weight
+ self.offset_loss_weight = offset_loss_weight
+ use_bias = norm == ""
+ # center prediction
+ # `head` is additional transform before predictor
+ self.center_head = nn.Sequential(
+ Conv2d(
+ decoder_channels[0],
+ decoder_channels[0],
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, decoder_channels[0]),
+ activation=F.relu,
+ ),
+ Conv2d(
+ decoder_channels[0],
+ head_channels,
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, head_channels),
+ activation=F.relu,
+ ),
+ )
+ weight_init.c2_xavier_fill(self.center_head[0])
+ weight_init.c2_xavier_fill(self.center_head[1])
+ self.center_predictor = Conv2d(head_channels, 1, kernel_size=1)
+ nn.init.normal_(self.center_predictor.weight, 0, 0.001)
+ nn.init.constant_(self.center_predictor.bias, 0)
+
+ # offset prediction
+ # `head` is additional transform before predictor
+ self.offset_head = nn.Sequential(
+ Conv2d(
+ decoder_channels[0],
+ decoder_channels[0],
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, decoder_channels[0]),
+ activation=F.relu,
+ ),
+ Conv2d(
+ decoder_channels[0],
+ head_channels,
+ kernel_size=3,
+ padding=1,
+ bias=use_bias,
+ norm=get_norm(norm, head_channels),
+ activation=F.relu,
+ ),
+ )
+ weight_init.c2_xavier_fill(self.offset_head[0])
+ weight_init.c2_xavier_fill(self.offset_head[1])
+ self.offset_predictor = Conv2d(head_channels, 2, kernel_size=1)
+ nn.init.normal_(self.offset_predictor.weight, 0, 0.001)
+ nn.init.constant_(self.offset_predictor.bias, 0)
+
+ self.center_loss = nn.MSELoss(reduction="none")
+ self.offset_loss = nn.L1Loss(reduction="none")
+
+ @classmethod
+ def from_config(cls, cfg, input_shape):
+ if cfg.INPUT.CROP.ENABLED:
+ assert cfg.INPUT.CROP.TYPE == "absolute"
+ train_size = cfg.INPUT.CROP.SIZE
+ else:
+ train_size = None
+ decoder_channels = [cfg.MODEL.INS_EMBED_HEAD.CONVS_DIM] * (
+ len(cfg.MODEL.INS_EMBED_HEAD.IN_FEATURES) - 1
+ ) + [cfg.MODEL.INS_EMBED_HEAD.ASPP_CHANNELS]
+ ret = dict(
+ input_shape=input_shape,
+ in_features=cfg.MODEL.INS_EMBED_HEAD.IN_FEATURES,
+ project_channels=cfg.MODEL.INS_EMBED_HEAD.PROJECT_CHANNELS,
+ aspp_dilations=cfg.MODEL.INS_EMBED_HEAD.ASPP_DILATIONS,
+ aspp_dropout=cfg.MODEL.INS_EMBED_HEAD.ASPP_DROPOUT,
+ decoder_channels=decoder_channels,
+ common_stride=cfg.MODEL.INS_EMBED_HEAD.COMMON_STRIDE,
+ norm=cfg.MODEL.INS_EMBED_HEAD.NORM,
+ train_size=train_size,
+ head_channels=cfg.MODEL.INS_EMBED_HEAD.HEAD_CHANNELS,
+ center_loss_weight=cfg.MODEL.INS_EMBED_HEAD.CENTER_LOSS_WEIGHT,
+ offset_loss_weight=cfg.MODEL.INS_EMBED_HEAD.OFFSET_LOSS_WEIGHT,
+ )
+ return ret
+
+ def forward(
+ self,
+ features,
+ center_targets=None,
+ center_weights=None,
+ offset_targets=None,
+ offset_weights=None,
+ ):
+ """
+ Returns:
+ In training, returns (None, dict of losses)
+ In inference, returns (CxHxW logits, {})
+ """
+ center, offset = self.layers(features)
+ if self.training:
+ return (
+ None,
+ None,
+ self.center_losses(center, center_targets, center_weights),
+ self.offset_losses(offset, offset_targets, offset_weights),
+ )
+ else:
+ center = F.interpolate(
+ center, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ offset = (
+ F.interpolate(
+ offset, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ * self.common_stride
+ )
+ return center, offset, {}, {}
+
+ def layers(self, features):
+ assert self.decoder_only
+ y = super().layers(features)
+ # center
+ center = self.center_head(y)
+ center = self.center_predictor(center)
+ # offset
+ offset = self.offset_head(y)
+ offset = self.offset_predictor(offset)
+ return center, offset
+
+ def center_losses(self, predictions, targets, weights):
+ predictions = F.interpolate(
+ predictions, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ loss = self.center_loss(predictions, targets) * weights
+ if weights.sum() > 0:
+ loss = loss.sum() / weights.sum()
+ else:
+ loss = loss.sum() * 0
+ losses = {"loss_center": loss * self.center_loss_weight}
+ return losses
+
+ def offset_losses(self, predictions, targets, weights):
+ predictions = (
+ F.interpolate(
+ predictions, scale_factor=self.common_stride, mode="bilinear", align_corners=False
+ )
+ * self.common_stride
+ )
+ loss = self.offset_loss(predictions, targets) * weights
+ if weights.sum() > 0:
+ loss = loss.sum() / weights.sum()
+ else:
+ loss = loss.sum() * 0
+ losses = {"loss_offset": loss * self.offset_loss_weight}
+ return losses
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/post_processing.py b/projects/Panoptic-DeepLab/panoptic_deeplab/post_processing.py
new file mode 100644
index 0000000..6de3bf3
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/post_processing.py
@@ -0,0 +1,234 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+# Reference: https://github.com/bowenc0221/panoptic-deeplab/blob/master/segmentation/model/post_processing/instance_post_processing.py # noqa
+
+from collections import Counter
+import torch
+import torch.nn.functional as F
+
+
+def find_instance_center(center_heatmap, threshold=0.1, nms_kernel=3, top_k=None):
+ """
+ Find the center points from the center heatmap.
+ Args:
+ center_heatmap: A Tensor of shape [1, H, W] of raw center heatmap output.
+ threshold: A float, threshold applied to center heatmap score.
+ nms_kernel: An integer, NMS max pooling kernel size.
+ top_k: An integer, top k centers to keep.
+ Returns:
+ A Tensor of shape [K, 2] where K is the number of center points. The
+ order of second dim is (y, x).
+ """
+ # Thresholding, setting values below threshold to -1.
+ center_heatmap = F.threshold(center_heatmap, threshold, -1)
+
+ # NMS
+ nms_padding = (nms_kernel - 1) // 2
+ center_heatmap_max_pooled = F.max_pool2d(
+ center_heatmap, kernel_size=nms_kernel, stride=1, padding=nms_padding
+ )
+ center_heatmap[center_heatmap != center_heatmap_max_pooled] = -1
+
+ # Squeeze first two dimensions.
+ center_heatmap = center_heatmap.squeeze()
+ assert len(center_heatmap.size()) == 2, "Something is wrong with center heatmap dimension."
+
+ # Find non-zero elements.
+ if top_k is None:
+ return torch.nonzero(center_heatmap > 0)
+ else:
+ # find top k centers.
+ top_k_scores, _ = torch.topk(torch.flatten(center_heatmap), top_k)
+ return torch.nonzero(center_heatmap > top_k_scores[-1].clamp_(min=0))
+
+
+def group_pixels(center_points, offsets):
+ """
+ Gives each pixel in the image an instance id.
+ Args:
+ center_points: A Tensor of shape [K, 2] where K is the number of center points.
+ The order of second dim is (y, x).
+ offsets: A Tensor of shape [2, H, W] of raw offset output. The order of
+ second dim is (offset_y, offset_x).
+ Returns:
+ A Tensor of shape [1, H, W] with values in range [1, K], which represents
+ the center this pixel belongs to.
+ """
+ height, width = offsets.size()[1:]
+
+ # Generates a coordinate map, where each location is the coordinate of
+ # that location.
+ y_coord, x_coord = torch.meshgrid(
+ torch.arange(height, dtype=offsets.dtype, device=offsets.device),
+ torch.arange(width, dtype=offsets.dtype, device=offsets.device),
+ )
+ coord = torch.cat((y_coord.unsqueeze(0), x_coord.unsqueeze(0)), dim=0)
+
+ center_loc = coord + offsets
+ center_loc = center_loc.flatten(1).T.unsqueeze_(0) # [1, H*W, 2]
+ center_points = center_points.unsqueeze(1) # [K, 1, 2]
+
+ # Distance: [K, H*W].
+ distance = torch.norm(center_points - center_loc, dim=-1)
+
+ # Finds center with minimum distance at each location, offset by 1, to
+ # reserve id=0 for stuff.
+ instance_id = torch.argmin(distance, dim=0).reshape((1, height, width)) + 1
+ return instance_id
+
+
+def get_instance_segmentation(
+ sem_seg, center_heatmap, offsets, thing_seg, thing_ids, threshold=0.1, nms_kernel=3, top_k=None
+):
+ """
+ Post-processing for instance segmentation, gets class agnostic instance id.
+ Args:
+ sem_seg: A Tensor of shape [1, H, W], predicted semantic label.
+ center_heatmap: A Tensor of shape [1, H, W] of raw center heatmap output.
+ offsets: A Tensor of shape [2, H, W] of raw offset output. The order of
+ second dim is (offset_y, offset_x).
+ thing_seg: A Tensor of shape [1, H, W], predicted foreground mask,
+ if not provided, inference from semantic prediction.
+ thing_ids: A set of ids from contiguous category ids belonging
+ to thing categories.
+ threshold: A float, threshold applied to center heatmap score.
+ nms_kernel: An integer, NMS max pooling kernel size.
+ top_k: An integer, top k centers to keep.
+ Returns:
+ A Tensor of shape [1, H, W] with value 0 represent stuff (not instance)
+ and other positive values represent different instances.
+ A Tensor of shape [1, K, 2] where K is the number of center points.
+ The order of second dim is (y, x).
+ """
+ center_points = find_instance_center(
+ center_heatmap, threshold=threshold, nms_kernel=nms_kernel, top_k=top_k
+ )
+ if center_points.size(0) == 0:
+ return torch.zeros_like(sem_seg), center_points.unsqueeze(0)
+ ins_seg = group_pixels(center_points, offsets)
+ return thing_seg * ins_seg, center_points.unsqueeze(0)
+
+
+def merge_semantic_and_instance(
+ sem_seg, ins_seg, semantic_thing_seg, label_divisor, thing_ids, stuff_area, void_label
+):
+ """
+ Post-processing for panoptic segmentation, by merging semantic segmentation
+ label and class agnostic instance segmentation label.
+ Args:
+ sem_seg: A Tensor of shape [1, H, W], predicted category id for each pixel.
+ ins_seg: A Tensor of shape [1, H, W], predicted instance id for each pixel.
+ semantic_thing_seg: A Tensor of shape [1, H, W], predicted foreground mask.
+ label_divisor: An integer, used to convert panoptic id =
+ semantic id * label_divisor + instance_id.
+ thing_ids: Set, a set of ids from contiguous category ids belonging
+ to thing categories.
+ stuff_area: An integer, remove stuff whose area is less tan stuff_area.
+ void_label: An integer, indicates the region has no confident prediction.
+ Returns:
+ A Tensor of shape [1, H, W].
+ """
+ # In case thing mask does not align with semantic prediction.
+ pan_seg = torch.zeros_like(sem_seg) + void_label
+ is_thing = (ins_seg > 0) & (semantic_thing_seg > 0)
+
+ # Keep track of instance id for each class.
+ class_id_tracker = Counter()
+
+ # Paste thing by majority voting.
+ instance_ids = torch.unique(ins_seg)
+ for ins_id in instance_ids:
+ if ins_id == 0:
+ continue
+ # Make sure only do majority voting within `semantic_thing_seg`.
+ thing_mask = (ins_seg == ins_id) & is_thing
+ if torch.nonzero(thing_mask).size(0) == 0:
+ continue
+ class_id, _ = torch.mode(sem_seg[thing_mask].view(-1))
+ class_id_tracker[class_id.item()] += 1
+ new_ins_id = class_id_tracker[class_id.item()]
+ pan_seg[thing_mask] = class_id * label_divisor + new_ins_id
+
+ # Paste stuff to unoccupied area.
+ class_ids = torch.unique(sem_seg)
+ for class_id in class_ids:
+ if class_id.item() in thing_ids:
+ # thing class
+ continue
+ # Calculate stuff area.
+ stuff_mask = (sem_seg == class_id) & (ins_seg == 0)
+ if stuff_mask.sum().item() >= stuff_area:
+ pan_seg[stuff_mask] = class_id * label_divisor
+
+ return pan_seg
+
+
+def get_panoptic_segmentation(
+ sem_seg,
+ center_heatmap,
+ offsets,
+ thing_ids,
+ label_divisor,
+ stuff_area,
+ void_label,
+ threshold=0.1,
+ nms_kernel=7,
+ top_k=200,
+ foreground_mask=None,
+):
+ """
+ Post-processing for panoptic segmentation.
+ Args:
+ sem_seg: A Tensor of shape [1, H, W] of predicted semantic label.
+ center_heatmap: A Tensor of shape [1, H, W] of raw center heatmap output.
+ offsets: A Tensor of shape [2, H, W] of raw offset output. The order of
+ second dim is (offset_y, offset_x).
+ thing_ids: A set of ids from contiguous category ids belonging
+ to thing categories.
+ label_divisor: An integer, used to convert panoptic id =
+ semantic id * label_divisor + instance_id.
+ stuff_area: An integer, remove stuff whose area is less tan stuff_area.
+ void_label: An integer, indicates the region has no confident prediction.
+ threshold: A float, threshold applied to center heatmap score.
+ nms_kernel: An integer, NMS max pooling kernel size.
+ top_k: An integer, top k centers to keep.
+ foreground_mask: Optional, A Tensor of shape [1, H, W] of predicted
+ binary foreground mask. If not provided, it will be generated from
+ sem_seg.
+ Returns:
+ A Tensor of shape [1, H, W], int64.
+ """
+ if sem_seg.dim() != 3 and sem_seg.size(0) != 1:
+ raise ValueError("Semantic prediction with un-supported shape: {}.".format(sem_seg.size()))
+ if center_heatmap.dim() != 3:
+ raise ValueError(
+ "Center prediction with un-supported dimension: {}.".format(center_heatmap.dim())
+ )
+ if offsets.dim() != 3:
+ raise ValueError("Offset prediction with un-supported dimension: {}.".format(offsets.dim()))
+ if foreground_mask is not None:
+ if foreground_mask.dim() != 3 and foreground_mask.size(0) != 1:
+ raise ValueError(
+ "Foreground prediction with un-supported shape: {}.".format(sem_seg.size())
+ )
+ thing_seg = foreground_mask
+ else:
+ # inference from semantic segmentation
+ thing_seg = torch.zeros_like(sem_seg)
+ for thing_class in list(thing_ids):
+ thing_seg[sem_seg == thing_class] = 1
+
+ instance, center = get_instance_segmentation(
+ sem_seg,
+ center_heatmap,
+ offsets,
+ thing_seg,
+ thing_ids,
+ threshold=threshold,
+ nms_kernel=nms_kernel,
+ top_k=top_k,
+ )
+ panoptic = merge_semantic_and_instance(
+ sem_seg, instance, thing_seg, label_divisor, thing_ids, stuff_area, void_label
+ )
+
+ return panoptic, center
diff --git a/projects/Panoptic-DeepLab/panoptic_deeplab/target_generator.py b/projects/Panoptic-DeepLab/panoptic_deeplab/target_generator.py
new file mode 100644
index 0000000..5a9fe1f
--- /dev/null
+++ b/projects/Panoptic-DeepLab/panoptic_deeplab/target_generator.py
@@ -0,0 +1,161 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+# Reference: https://github.com/bowenc0221/panoptic-deeplab/blob/aa934324b55a34ce95fea143aea1cb7a6dbe04bd/segmentation/data/transforms/target_transforms.py#L11 # noqa
+import numpy as np
+import torch
+
+
+class PanopticDeepLabTargetGenerator(object):
+ """
+ Generates training targets for Panoptic-DeepLab.
+ """
+
+ def __init__(
+ self,
+ ignore_label,
+ thing_ids,
+ sigma=8,
+ ignore_stuff_in_offset=False,
+ small_instance_area=0,
+ small_instance_weight=1,
+ ignore_crowd_in_semantic=False,
+ ):
+ """
+ Args:
+ ignore_label: Integer, the ignore label for semantic segmentation.
+ thing_ids: Set, a set of ids from contiguous category ids belonging
+ to thing categories.
+ sigma: the sigma for Gaussian kernel.
+ ignore_stuff_in_offset: Boolean, whether to ignore stuff region when
+ training the offset branch.
+ small_instance_area: Integer, indicates largest area for small instances.
+ small_instance_weight: Integer, indicates semantic loss weights for
+ small instances.
+ ignore_crowd_in_semantic: Boolean, whether to ignore crowd region in
+ semantic segmentation branch, crowd region is ignored in the original
+ TensorFlow implementation.
+ """
+ self.ignore_label = ignore_label
+ self.thing_ids = set(thing_ids)
+ self.ignore_stuff_in_offset = ignore_stuff_in_offset
+ self.small_instance_area = small_instance_area
+ self.small_instance_weight = small_instance_weight
+ self.ignore_crowd_in_semantic = ignore_crowd_in_semantic
+
+ # Generate the default Gaussian image for each center
+ self.sigma = sigma
+ size = 6 * sigma + 3
+ x = np.arange(0, size, 1, float)
+ y = x[:, np.newaxis]
+ x0, y0 = 3 * sigma + 1, 3 * sigma + 1
+ self.g = np.exp(-((x - x0) ** 2 + (y - y0) ** 2) / (2 * sigma ** 2))
+
+ def __call__(self, panoptic, segments_info):
+ """Generates the training target.
+ reference: https://github.com/mcordts/cityscapesScripts/blob/master/cityscapesscripts/preparation/createPanopticImgs.py # noqa
+ reference: https://github.com/facebookresearch/detectron2/blob/master/datasets/prepare_panoptic_fpn.py#L18 # noqa
+ Args:
+ panoptic: numpy.array, panoptic label, we assume it is already
+ converted from rgb image by panopticapi.utils.rgb2id.
+ segments_info: List, a list of dictionary containing information of
+ every segment, it has fields:
+ - id: panoptic id, this is the compact id that encode both
+ category and instance id by:
+ category_id * label_divisor + instance_id.
+ - category_id: category id, like semantic segmentation, it is
+ the class id for each pixel. It is expected to by contiguous
+ category id, conveted when registering panoptic datasets.
+ - iscrowd: crowd region.
+ Returns:
+ A dictionary with fields:
+ - sem_seg: Tensor, semantic label, shape=(H, W).
+ - center: Tensor, center heatmap, shape=(H, W).
+ - center_points: List, center coordinates, with tuple
+ (y-coord, x-coord).
+ - offset: Tensor, offset, shape=(2, H, W), first dim is
+ (offset_y, offset_x).
+ - sem_seg_weights: Tensor, loss weight for semantic prediction,
+ shape=(H, W).
+ - center_weights: Tensor, ignore region of center prediction,
+ shape=(H, W), used as weights for center regression 0 is
+ ignore, 1 is has instance. Multiply this mask to loss.
+ - offset_weights: Tensor, ignore region of offset prediction,
+ shape=(H, W), used as weights for offset regression 0 is
+ ignore, 1 is has instance. Multiply this mask to loss.
+ """
+ height, width = panoptic.shape[0], panoptic.shape[1]
+ semantic = np.zeros_like(panoptic, dtype=np.uint8) + self.ignore_label
+ center = np.zeros((height, width), dtype=np.float32)
+ center_pts = []
+ offset = np.zeros((2, height, width), dtype=np.float32)
+ y_coord, x_coord = np.meshgrid(
+ np.arange(height, dtype=np.float32), np.arange(width, dtype=np.float32), indexing="ij"
+ )
+ # Generate pixel-wise loss weights
+ semantic_weights = np.ones_like(panoptic, dtype=np.uint8)
+ # 0: ignore, 1: has instance
+ # three conditions for a region to be ignored for instance branches:
+ # (1) It is labeled as `ignore_label`
+ # (2) It is crowd region (iscrowd=1)
+ # (3) (Optional) It is stuff region (for offset branch)
+ center_weights = np.zeros_like(panoptic, dtype=np.uint8)
+ offset_weights = np.zeros_like(panoptic, dtype=np.uint8)
+ for seg in segments_info:
+ cat_id = seg["category_id"]
+ if not (self.ignore_crowd_in_semantic and seg["iscrowd"]):
+ semantic[panoptic == seg["id"]] = cat_id
+ if not seg["iscrowd"]:
+ # Ignored regions are not in `segments_info`.
+ # Handle crowd region.
+ center_weights[panoptic == seg["id"]] = 1
+ if not self.ignore_stuff_in_offset or cat_id in self.thing_ids:
+ offset_weights[panoptic == seg["id"]] = 1
+ if cat_id in self.thing_ids:
+ # find instance center
+ mask_index = np.where(panoptic == seg["id"])
+ if len(mask_index[0]) == 0:
+ # the instance is completely cropped
+ continue
+
+ # Find instance area
+ ins_area = len(mask_index[0])
+ if ins_area < self.small_instance_area:
+ semantic_weights[panoptic == seg["id"]] = self.small_instance_weight
+
+ center_y, center_x = np.mean(mask_index[0]), np.mean(mask_index[1])
+ center_pts.append([center_y, center_x])
+
+ # generate center heatmap
+ y, x = int(round(center_y)), int(round(center_x))
+ sigma = self.sigma
+ # upper left
+ ul = int(np.round(x - 3 * sigma - 1)), int(np.round(y - 3 * sigma - 1))
+ # bottom right
+ br = int(np.round(x + 3 * sigma + 2)), int(np.round(y + 3 * sigma + 2))
+
+ # start and end indices in default Gaussian image
+ gaussian_x0, gaussian_x1 = max(0, -ul[0]), min(br[0], width) - ul[0]
+ gaussian_y0, gaussian_y1 = max(0, -ul[1]), min(br[1], height) - ul[1]
+
+ # start and end indices in center heatmap image
+ center_x0, center_x1 = max(0, ul[0]), min(br[0], width)
+ center_y0, center_y1 = max(0, ul[1]), min(br[1], height)
+ center[center_y0:center_y1, center_x0:center_x1] = np.maximum(
+ center[center_y0:center_y1, center_x0:center_x1],
+ self.g[gaussian_y0:gaussian_y1, gaussian_x0:gaussian_x1],
+ )
+
+ # generate offset (2, h, w) -> (y-dir, x-dir)
+ offset[0][mask_index] = center_y - y_coord[mask_index]
+ offset[1][mask_index] = center_x - x_coord[mask_index]
+
+ center_weights = center_weights[None]
+ offset_weights = offset_weights[None]
+ return dict(
+ sem_seg=torch.as_tensor(semantic.astype("long")),
+ center=torch.as_tensor(center.astype(np.float32)),
+ center_points=center_pts,
+ offset=torch.as_tensor(offset.astype(np.float32)),
+ sem_seg_weights=torch.as_tensor(semantic_weights.astype(np.float32)),
+ center_weights=torch.as_tensor(center_weights.astype(np.float32)),
+ offset_weights=torch.as_tensor(offset_weights.astype(np.float32)),
+ )
diff --git a/projects/Panoptic-DeepLab/train_net.py b/projects/Panoptic-DeepLab/train_net.py
new file mode 100644
index 0000000..d888f25
--- /dev/null
+++ b/projects/Panoptic-DeepLab/train_net.py
@@ -0,0 +1,196 @@
+#!/usr/bin/env python3
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+"""
+Panoptic-DeepLab Training Script.
+This script is a simplified version of the training script in detectron2/tools.
+"""
+
+import os
+from typing import Any, Dict, List, Set
+import torch
+
+import detectron2.data.transforms as T
+import detectron2.utils.comm as comm
+from detectron2.checkpoint import DetectionCheckpointer
+from detectron2.config import get_cfg
+from detectron2.data import MetadataCatalog, build_detection_train_loader
+from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
+from detectron2.evaluation import (
+ CityscapesInstanceEvaluator,
+ CityscapesSemSegEvaluator,
+ COCOEvaluator,
+ COCOPanopticEvaluator,
+ DatasetEvaluators,
+)
+from detectron2.projects.deeplab import build_lr_scheduler
+from detectron2.projects.panoptic_deeplab import (
+ PanopticDeeplabDatasetMapper,
+ add_panoptic_deeplab_config,
+)
+from detectron2.solver.build import maybe_add_gradient_clipping
+
+
+def build_sem_seg_train_aug(cfg):
+ augs = [
+ T.ResizeShortestEdge(
+ cfg.INPUT.MIN_SIZE_TRAIN, cfg.INPUT.MAX_SIZE_TRAIN, cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING
+ )
+ ]
+ if cfg.INPUT.CROP.ENABLED:
+ augs.append(T.RandomCrop(cfg.INPUT.CROP.TYPE, cfg.INPUT.CROP.SIZE))
+ augs.append(T.RandomFlip())
+ return augs
+
+
+class Trainer(DefaultTrainer):
+ """
+ We use the "DefaultTrainer" which contains a number pre-defined logic for
+ standard training workflow. They may not work for you, especially if you
+ are working on a new research project. In that case you can use the cleaner
+ "SimpleTrainer", or write your own training loop.
+ """
+
+ @classmethod
+ def build_evaluator(cls, cfg, dataset_name, output_folder=None):
+ """
+ Create evaluator(s) for a given dataset.
+ This uses the special metadata "evaluator_type" associated with each builtin dataset.
+ For your own dataset, you can simply create an evaluator manually in your
+ script and do not have to worry about the hacky if-else logic here.
+ """
+ if output_folder is None:
+ output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
+ evaluator_list = []
+ evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
+ if evaluator_type in ["cityscapes_panoptic_seg", "coco_panoptic_seg"]:
+ evaluator_list.append(COCOPanopticEvaluator(dataset_name, output_folder))
+ if evaluator_type == "cityscapes_panoptic_seg":
+ assert (
+ torch.cuda.device_count() >= comm.get_rank()
+ ), "CityscapesEvaluator currently do not work with multiple machines."
+ evaluator_list.append(CityscapesSemSegEvaluator(dataset_name))
+ evaluator_list.append(CityscapesInstanceEvaluator(dataset_name))
+ if evaluator_type == "coco_panoptic_seg":
+ # Evaluate bbox and segm.
+ cfg.defrost()
+ cfg.MODEL.MASK_ON = True
+ cfg.MODEL.KEYPOINT_ON = False
+ cfg.freeze()
+ evaluator_list.append(COCOEvaluator(dataset_name, cfg, True, output_folder))
+ if len(evaluator_list) == 0:
+ raise NotImplementedError(
+ "no Evaluator for the dataset {} with the type {}".format(
+ dataset_name, evaluator_type
+ )
+ )
+ elif len(evaluator_list) == 1:
+ return evaluator_list[0]
+ return DatasetEvaluators(evaluator_list)
+
+ @classmethod
+ def build_train_loader(cls, cfg):
+ mapper = PanopticDeeplabDatasetMapper(cfg, augmentations=build_sem_seg_train_aug(cfg))
+ return build_detection_train_loader(cfg, mapper=mapper)
+
+ @classmethod
+ def build_lr_scheduler(cls, cfg, optimizer):
+ """
+ It now calls :func:`detectron2.solver.build_lr_scheduler`.
+ Overwrite it if you'd like a different scheduler.
+ """
+ return build_lr_scheduler(cfg, optimizer)
+
+ @classmethod
+ def build_optimizer(cls, cfg, model):
+ """
+ Build an optimizer from config.
+ """
+ norm_module_types = (
+ torch.nn.BatchNorm1d,
+ torch.nn.BatchNorm2d,
+ torch.nn.BatchNorm3d,
+ torch.nn.SyncBatchNorm,
+ # NaiveSyncBatchNorm inherits from BatchNorm2d
+ torch.nn.GroupNorm,
+ torch.nn.InstanceNorm1d,
+ torch.nn.InstanceNorm2d,
+ torch.nn.InstanceNorm3d,
+ torch.nn.LayerNorm,
+ torch.nn.LocalResponseNorm,
+ )
+ params: List[Dict[str, Any]] = []
+ memo: Set[torch.nn.parameter.Parameter] = set()
+ for module in model.modules():
+ for key, value in module.named_parameters(recurse=False):
+ if not value.requires_grad:
+ continue
+ # Avoid duplicating parameters
+ if value in memo:
+ continue
+ memo.add(value)
+ lr = cfg.SOLVER.BASE_LR
+ weight_decay = cfg.SOLVER.WEIGHT_DECAY
+ if isinstance(module, norm_module_types):
+ weight_decay = cfg.SOLVER.WEIGHT_DECAY_NORM
+ elif key == "bias":
+ lr = cfg.SOLVER.BASE_LR * cfg.SOLVER.BIAS_LR_FACTOR
+ weight_decay = cfg.SOLVER.WEIGHT_DECAY_BIAS
+ params += [{"params": [value], "lr": lr, "weight_decay": weight_decay}]
+
+ optimizer_type = cfg.SOLVER.OPTIMIZER
+ if optimizer_type == "SGD":
+ optimizer = torch.optim.SGD(
+ params,
+ cfg.SOLVER.BASE_LR,
+ momentum=cfg.SOLVER.MOMENTUM,
+ nesterov=cfg.SOLVER.NESTEROV,
+ )
+ elif optimizer_type == "ADAM":
+ optimizer = torch.optim.Adam(params, cfg.SOLVER.BASE_LR)
+ else:
+ raise NotImplementedError(f"no optimizer type {optimizer_type}")
+ optimizer = maybe_add_gradient_clipping(cfg, optimizer)
+ return optimizer
+
+
+def setup(args):
+ """
+ Create configs and perform basic setups.
+ """
+ cfg = get_cfg()
+ add_panoptic_deeplab_config(cfg)
+ cfg.merge_from_file(args.config_file)
+ cfg.merge_from_list(args.opts)
+ cfg.freeze()
+ default_setup(cfg, args)
+ return cfg
+
+
+def main(args):
+ cfg = setup(args)
+
+ if args.eval_only:
+ model = Trainer.build_model(cfg)
+ DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
+ cfg.MODEL.WEIGHTS, resume=args.resume
+ )
+ res = Trainer.test(cfg, model)
+ return res
+
+ trainer = Trainer(cfg)
+ trainer.resume_or_load(resume=args.resume)
+ return trainer.train()
+
+
+if __name__ == "__main__":
+ args = default_argument_parser().parse_args()
+ print("Command Line Args:", args)
+ launch(
+ main,
+ args.num_gpus,
+ num_machines=args.num_machines,
+ machine_rank=args.machine_rank,
+ dist_url=args.dist_url,
+ args=(args,),
+ )
diff --git a/projects/PointRend/README.md b/projects/PointRend/README.md
new file mode 100644
index 0000000..594577d
--- /dev/null
+++ b/projects/PointRend/README.md
@@ -0,0 +1,134 @@
+# PointRend: Image Segmentation as Rendering
+
+Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
+
+[[`arXiv`](https://arxiv.org/abs/1912.08193)] [[`BibTeX`](#CitingPointRend)]
+
+
+
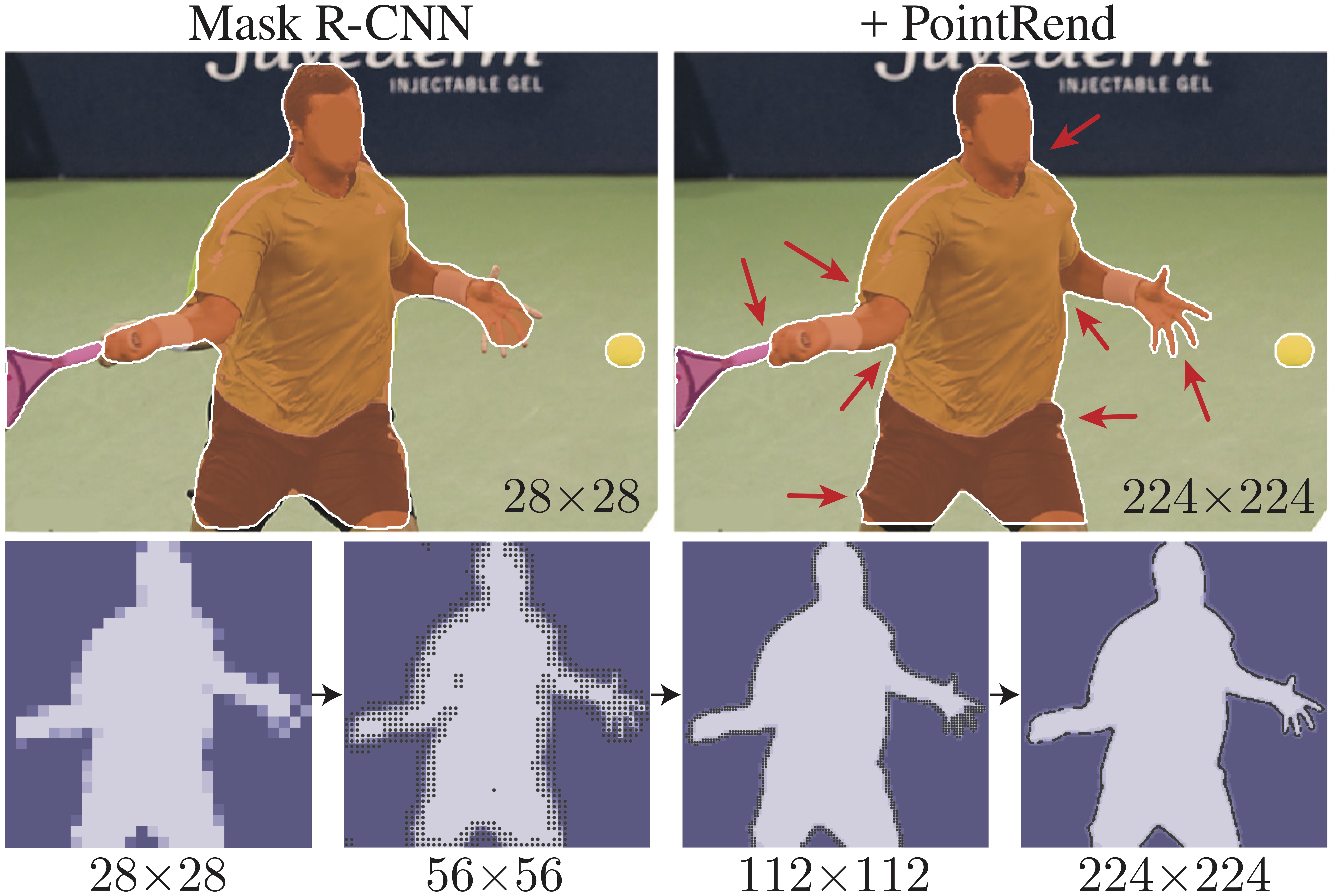
+
+
+In this repository, we release code for PointRend in Detectron2. PointRend can be flexibly applied to both instance and semantic segmentation tasks by building on top of existing state-of-the-art models.
+
+## Quick start and visualization
+
+This [Colab Notebook](https://colab.research.google.com/drive/1isGPL5h5_cKoPPhVL9XhMokRtHDvmMVL) tutorial contains examples of PointRend usage and visualizations of its point sampling stages.
+
+## Training
+
+To train a model with 8 GPUs run:
+```bash
+cd /path/to/detectron2/projects/PointRend
+python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --num-gpus 8
+```
+
+## Evaluation
+
+Model evaluation can be done similarly:
+```bash
+cd /path/to/detectron2/projects/PointRend
+python train_net.py --config-file configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
+```
+
+# Pretrained Models
+
+## Instance Segmentation
+#### COCO
+
+
+
+
+Mask
head |
+Backbone |
+lr
sched |
+Output
resolution |
+mask
AP |
+mask
AP* |
+model id |
+download |
+
+ | PointRend |
+R50-FPN |
+1× |
+224×224 |
+36.2 |
+39.7 |
+164254221 |
+model | metrics |
+
+ | PointRend |
+R50-FPN |
+3× |
+224×224 |
+38.3 |
+41.6 |
+164955410 |
+model | metrics |
+
+
+
+AP* is COCO mask AP evaluated against the higher-quality LVIS annotations; see the paper for details.
+Run `python detectron2/datasets/prepare_cocofied_lvis.py` to prepare GT files for AP* evaluation.
+Since LVIS annotations are not exhaustive, `lvis-api` and not `cocoapi` should be used to evaluate AP*.
+
+#### Cityscapes
+Cityscapes model is trained with ImageNet pretraining.
+
+
+
+
+Mask
head |
+Backbone |
+lr
sched |
+Output
resolution |
+mask
AP |
+model id |
+download |
+
+ | PointRend |
+R50-FPN |
+1× |
+224×224 |
+35.9 |
+164255101 |
+model | metrics |
+
+
+
+
+## Semantic Segmentation
+
+#### Cityscapes
+Cityscapes model is trained with ImageNet pretraining.
+
+
+
+## Citing PointRend
+
+If you use PointRend, please use the following BibTeX entry.
+
+```BibTeX
+@InProceedings{kirillov2019pointrend,
+ title={{PointRend}: Image Segmentation as Rendering},
+ author={Alexander Kirillov and Yuxin Wu and Kaiming He and Ross Girshick},
+ journal={ArXiv:1912.08193},
+ year={2019}
+}
+```
diff --git a/projects/PointRend/configs/InstanceSegmentation/Base-PointRend-RCNN-FPN.yaml b/projects/PointRend/configs/InstanceSegmentation/Base-PointRend-RCNN-FPN.yaml
new file mode 100644
index 0000000..480f1b5
--- /dev/null
+++ b/projects/PointRend/configs/InstanceSegmentation/Base-PointRend-RCNN-FPN.yaml
@@ -0,0 +1,22 @@
+_BASE_: "../../../../configs/Base-RCNN-FPN.yaml"
+MODEL:
+ MASK_ON: true
+ ROI_HEADS:
+ NAME: "PointRendROIHeads"
+ IN_FEATURES: ["p2", "p3", "p4", "p5"]
+ ROI_BOX_HEAD:
+ TRAIN_ON_PRED_BOXES: True
+ ROI_MASK_HEAD:
+ NAME: "CoarseMaskHead"
+ FC_DIM: 1024
+ NUM_FC: 2
+ OUTPUT_SIDE_RESOLUTION: 7
+ IN_FEATURES: ["p2"]
+ POINT_HEAD_ON: True
+ POINT_HEAD:
+ FC_DIM: 256
+ NUM_FC: 3
+ IN_FEATURES: ["p2"]
+INPUT:
+ # PointRend for instance segmenation does not work with "polygon" mask_format.
+ MASK_FORMAT: "bitmask"
diff --git a/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_cityscapes.yaml b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_cityscapes.yaml
new file mode 100644
index 0000000..0402d6d
--- /dev/null
+++ b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_cityscapes.yaml
@@ -0,0 +1,22 @@
+_BASE_: Base-PointRend-RCNN-FPN.yaml
+MODEL:
+ WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-50.pkl
+ RESNETS:
+ DEPTH: 50
+ ROI_HEADS:
+ NUM_CLASSES: 8
+ POINT_HEAD:
+ NUM_CLASSES: 8
+DATASETS:
+ TEST: ("cityscapes_fine_instance_seg_val",)
+ TRAIN: ("cityscapes_fine_instance_seg_train",)
+SOLVER:
+ BASE_LR: 0.01
+ IMS_PER_BATCH: 8
+ MAX_ITER: 24000
+ STEPS: (18000,)
+INPUT:
+ MAX_SIZE_TEST: 2048
+ MAX_SIZE_TRAIN: 2048
+ MIN_SIZE_TEST: 1024
+ MIN_SIZE_TRAIN: (800, 832, 864, 896, 928, 960, 992, 1024)
diff --git a/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml
new file mode 100644
index 0000000..0249b49
--- /dev/null
+++ b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_1x_coco.yaml
@@ -0,0 +1,8 @@
+_BASE_: Base-PointRend-RCNN-FPN.yaml
+MODEL:
+ WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-50.pkl
+ RESNETS:
+ DEPTH: 50
+# To add COCO AP evaluation against the higher-quality LVIS annotations.
+# DATASETS:
+# TEST: ("coco_2017_val", "lvis_v0.5_val_cocofied")
diff --git a/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco.yaml b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco.yaml
new file mode 100644
index 0000000..a571b4c
--- /dev/null
+++ b/projects/PointRend/configs/InstanceSegmentation/pointrend_rcnn_R_50_FPN_3x_coco.yaml
@@ -0,0 +1,12 @@
+_BASE_: Base-PointRend-RCNN-FPN.yaml
+MODEL:
+ WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-50.pkl
+ RESNETS:
+ DEPTH: 50
+SOLVER:
+ STEPS: (210000, 250000)
+ MAX_ITER: 270000
+# To add COCO AP evaluation against the higher-quality LVIS annotations.
+# DATASETS:
+# TEST: ("coco_2017_val", "lvis_v0.5_val_cocofied")
+
diff --git a/projects/PointRend/configs/SemanticSegmentation/Base-PointRend-Semantic-FPN.yaml b/projects/PointRend/configs/SemanticSegmentation/Base-PointRend-Semantic-FPN.yaml
new file mode 100644
index 0000000..9b7a1b4
--- /dev/null
+++ b/projects/PointRend/configs/SemanticSegmentation/Base-PointRend-Semantic-FPN.yaml
@@ -0,0 +1,20 @@
+_BASE_: "../../../../configs/Base-RCNN-FPN.yaml"
+MODEL:
+ META_ARCHITECTURE: "SemanticSegmentor"
+ BACKBONE:
+ FREEZE_AT: 0
+ SEM_SEG_HEAD:
+ NAME: "PointRendSemSegHead"
+ POINT_HEAD:
+ NUM_CLASSES: 54
+ FC_DIM: 256
+ NUM_FC: 3
+ IN_FEATURES: ["p2"]
+ TRAIN_NUM_POINTS: 1024
+ SUBDIVISION_STEPS: 2
+ SUBDIVISION_NUM_POINTS: 8192
+ COARSE_SEM_SEG_HEAD_NAME: "SemSegFPNHead"
+ COARSE_PRED_EACH_LAYER: False
+DATASETS:
+ TRAIN: ("coco_2017_train_panoptic_stuffonly",)
+ TEST: ("coco_2017_val_panoptic_stuffonly",)
diff --git a/projects/PointRend/configs/SemanticSegmentation/pointrend_semantic_R_101_FPN_1x_cityscapes.yaml b/projects/PointRend/configs/SemanticSegmentation/pointrend_semantic_R_101_FPN_1x_cityscapes.yaml
new file mode 100644
index 0000000..6be11fa
--- /dev/null
+++ b/projects/PointRend/configs/SemanticSegmentation/pointrend_semantic_R_101_FPN_1x_cityscapes.yaml
@@ -0,0 +1,33 @@
+_BASE_: Base-PointRend-Semantic-FPN.yaml
+MODEL:
+ WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-101.pkl
+ RESNETS:
+ DEPTH: 101
+ SEM_SEG_HEAD:
+ NUM_CLASSES: 19
+ POINT_HEAD:
+ NUM_CLASSES: 19
+ TRAIN_NUM_POINTS: 2048
+ SUBDIVISION_NUM_POINTS: 8192
+DATASETS:
+ TRAIN: ("cityscapes_fine_sem_seg_train",)
+ TEST: ("cityscapes_fine_sem_seg_val",)
+SOLVER:
+ BASE_LR: 0.01
+ STEPS: (40000, 55000)
+ MAX_ITER: 65000
+ IMS_PER_BATCH: 32
+INPUT:
+ MIN_SIZE_TRAIN: (512, 768, 1024, 1280, 1536, 1792, 2048)
+ MIN_SIZE_TRAIN_SAMPLING: "choice"
+ MIN_SIZE_TEST: 1024
+ MAX_SIZE_TRAIN: 4096
+ MAX_SIZE_TEST: 2048
+ CROP:
+ ENABLED: True
+ TYPE: "absolute"
+ SIZE: (512, 1024)
+ SINGLE_CATEGORY_MAX_AREA: 0.75
+ COLOR_AUG_SSD: True
+DATALOADER:
+ NUM_WORKERS: 10
diff --git a/projects/PointRend/point_rend/__init__.py b/projects/PointRend/point_rend/__init__.py
new file mode 100644
index 0000000..c9a6c22
--- /dev/null
+++ b/projects/PointRend/point_rend/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+from .config import add_pointrend_config
+from .coarse_mask_head import CoarseMaskHead
+from .roi_heads import PointRendROIHeads
+from .semantic_seg import PointRendSemSegHead
+from .color_augmentation import ColorAugSSDTransform
diff --git a/projects/PointRend/point_rend/coarse_mask_head.py b/projects/PointRend/point_rend/coarse_mask_head.py
new file mode 100644
index 0000000..3f1cffb
--- /dev/null
+++ b/projects/PointRend/point_rend/coarse_mask_head.py
@@ -0,0 +1,92 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import fvcore.nn.weight_init as weight_init
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from detectron2.layers import Conv2d, ShapeSpec
+from detectron2.modeling import ROI_MASK_HEAD_REGISTRY
+
+
+@ROI_MASK_HEAD_REGISTRY.register()
+class CoarseMaskHead(nn.Module):
+ """
+ A mask head with fully connected layers. Given pooled features it first reduces channels and
+ spatial dimensions with conv layers and then uses FC layers to predict coarse masks analogously
+ to the standard box head.
+ """
+
+ def __init__(self, cfg, input_shape: ShapeSpec):
+ """
+ The following attributes are parsed from config:
+ conv_dim: the output dimension of the conv layers
+ fc_dim: the feature dimenstion of the FC layers
+ num_fc: the number of FC layers
+ output_side_resolution: side resolution of the output square mask prediction
+ """
+ super(CoarseMaskHead, self).__init__()
+
+ # fmt: off
+ self.num_classes = cfg.MODEL.ROI_HEADS.NUM_CLASSES
+ conv_dim = cfg.MODEL.ROI_MASK_HEAD.CONV_DIM
+ self.fc_dim = cfg.MODEL.ROI_MASK_HEAD.FC_DIM
+ num_fc = cfg.MODEL.ROI_MASK_HEAD.NUM_FC
+ self.output_side_resolution = cfg.MODEL.ROI_MASK_HEAD.OUTPUT_SIDE_RESOLUTION
+ self.input_channels = input_shape.channels
+ self.input_h = input_shape.height
+ self.input_w = input_shape.width
+ # fmt: on
+
+ self.conv_layers = []
+ if self.input_channels > conv_dim:
+ self.reduce_channel_dim_conv = Conv2d(
+ self.input_channels,
+ conv_dim,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=True,
+ activation=F.relu,
+ )
+ self.conv_layers.append(self.reduce_channel_dim_conv)
+
+ self.reduce_spatial_dim_conv = Conv2d(
+ conv_dim, conv_dim, kernel_size=2, stride=2, padding=0, bias=True, activation=F.relu
+ )
+ self.conv_layers.append(self.reduce_spatial_dim_conv)
+
+ input_dim = conv_dim * self.input_h * self.input_w
+ input_dim //= 4
+
+ self.fcs = []
+ for k in range(num_fc):
+ fc = nn.Linear(input_dim, self.fc_dim)
+ self.add_module("coarse_mask_fc{}".format(k + 1), fc)
+ self.fcs.append(fc)
+ input_dim = self.fc_dim
+
+ output_dim = self.num_classes * self.output_side_resolution * self.output_side_resolution
+
+ self.prediction = nn.Linear(self.fc_dim, output_dim)
+ # use normal distribution initialization for mask prediction layer
+ nn.init.normal_(self.prediction.weight, std=0.001)
+ nn.init.constant_(self.prediction.bias, 0)
+
+ for layer in self.conv_layers:
+ weight_init.c2_msra_fill(layer)
+ for layer in self.fcs:
+ weight_init.c2_xavier_fill(layer)
+
+ def forward(self, x):
+ # unlike BaseMaskRCNNHead, this head only outputs intermediate
+ # features, because the features will be used later by PointHead.
+ N = x.shape[0]
+ x = x.view(N, self.input_channels, self.input_h, self.input_w)
+ for layer in self.conv_layers:
+ x = layer(x)
+ x = torch.flatten(x, start_dim=1)
+ for layer in self.fcs:
+ x = F.relu(layer(x))
+ return self.prediction(x).view(
+ N, self.num_classes, self.output_side_resolution, self.output_side_resolution
+ )
diff --git a/projects/PointRend/point_rend/color_augmentation.py b/projects/PointRend/point_rend/color_augmentation.py
new file mode 100644
index 0000000..27344c4
--- /dev/null
+++ b/projects/PointRend/point_rend/color_augmentation.py
@@ -0,0 +1,98 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import numpy as np
+import random
+import cv2
+from fvcore.transforms.transform import Transform
+
+
+class ColorAugSSDTransform(Transform):
+ """
+ A color related data augmentation used in Single Shot Multibox Detector (SSD).
+
+ Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy,
+ Scott Reed, Cheng-Yang Fu, Alexander C. Berg.
+ SSD: Single Shot MultiBox Detector. ECCV 2016.
+
+ Implementation based on:
+
+ https://github.com/weiliu89/caffe/blob
+ /4817bf8b4200b35ada8ed0dc378dceaf38c539e4
+ /src/caffe/util/im_transforms.cpp
+
+ https://github.com/chainer/chainercv/blob
+ /7159616642e0be7c5b3ef380b848e16b7e99355b/chainercv
+ /links/model/ssd/transforms.py
+ """
+
+ def __init__(
+ self,
+ img_format,
+ brightness_delta=32,
+ contrast_low=0.5,
+ contrast_high=1.5,
+ saturation_low=0.5,
+ saturation_high=1.5,
+ hue_delta=18,
+ ):
+ super().__init__()
+ assert img_format in ["BGR", "RGB"]
+ self.is_rgb = img_format == "RGB"
+ del img_format
+ self._set_attributes(locals())
+
+ def apply_coords(self, coords):
+ return coords
+
+ def apply_segmentation(self, segmentation):
+ return segmentation
+
+ def apply_image(self, img, interp=None):
+ if self.is_rgb:
+ img = img[:, :, [2, 1, 0]]
+ img = self.brightness(img)
+ if random.randrange(2):
+ img = self.contrast(img)
+ img = self.saturation(img)
+ img = self.hue(img)
+ else:
+ img = self.saturation(img)
+ img = self.hue(img)
+ img = self.contrast(img)
+ if self.is_rgb:
+ img = img[:, :, [2, 1, 0]]
+ return img
+
+ def convert(self, img, alpha=1, beta=0):
+ img = img.astype(np.float32) * alpha + beta
+ img = np.clip(img, 0, 255)
+ return img.astype(np.uint8)
+
+ def brightness(self, img):
+ if random.randrange(2):
+ return self.convert(
+ img, beta=random.uniform(-self.brightness_delta, self.brightness_delta)
+ )
+ return img
+
+ def contrast(self, img):
+ if random.randrange(2):
+ return self.convert(img, alpha=random.uniform(self.contrast_low, self.contrast_high))
+ return img
+
+ def saturation(self, img):
+ if random.randrange(2):
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
+ img[:, :, 1] = self.convert(
+ img[:, :, 1], alpha=random.uniform(self.saturation_low, self.saturation_high)
+ )
+ return cv2.cvtColor(img, cv2.COLOR_HSV2BGR)
+ return img
+
+ def hue(self, img):
+ if random.randrange(2):
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
+ img[:, :, 0] = (
+ img[:, :, 0].astype(int) + random.randint(-self.hue_delta, self.hue_delta)
+ ) % 180
+ return cv2.cvtColor(img, cv2.COLOR_HSV2BGR)
+ return img
diff --git a/projects/PointRend/point_rend/config.py b/projects/PointRend/point_rend/config.py
new file mode 100644
index 0000000..74f6367
--- /dev/null
+++ b/projects/PointRend/point_rend/config.py
@@ -0,0 +1,48 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+from detectron2.config import CfgNode as CN
+
+
+def add_pointrend_config(cfg):
+ """
+ Add config for PointRend.
+ """
+ # We retry random cropping until no single category in semantic segmentation GT occupies more
+ # than `SINGLE_CATEGORY_MAX_AREA` part of the crop.
+ cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA = 1.0
+ # Color augmentatition from SSD paper for semantic segmentation model during training.
+ cfg.INPUT.COLOR_AUG_SSD = False
+
+ # Names of the input feature maps to be used by a coarse mask head.
+ cfg.MODEL.ROI_MASK_HEAD.IN_FEATURES = ("p2",)
+ cfg.MODEL.ROI_MASK_HEAD.FC_DIM = 1024
+ cfg.MODEL.ROI_MASK_HEAD.NUM_FC = 2
+ # The side size of a coarse mask head prediction.
+ cfg.MODEL.ROI_MASK_HEAD.OUTPUT_SIDE_RESOLUTION = 7
+ # True if point head is used.
+ cfg.MODEL.ROI_MASK_HEAD.POINT_HEAD_ON = False
+
+ cfg.MODEL.POINT_HEAD = CN()
+ cfg.MODEL.POINT_HEAD.NAME = "StandardPointHead"
+ cfg.MODEL.POINT_HEAD.NUM_CLASSES = 80
+ # Names of the input feature maps to be used by a mask point head.
+ cfg.MODEL.POINT_HEAD.IN_FEATURES = ("p2",)
+ # Number of points sampled during training for a mask point head.
+ cfg.MODEL.POINT_HEAD.TRAIN_NUM_POINTS = 14 * 14
+ # Oversampling parameter for PointRend point sampling during training. Parameter `k` in the
+ # original paper.
+ cfg.MODEL.POINT_HEAD.OVERSAMPLE_RATIO = 3
+ # Importance sampling parameter for PointRend point sampling during training. Parametr `beta` in
+ # the original paper.
+ cfg.MODEL.POINT_HEAD.IMPORTANCE_SAMPLE_RATIO = 0.75
+ # Number of subdivision steps during inference.
+ cfg.MODEL.POINT_HEAD.SUBDIVISION_STEPS = 5
+ # Maximum number of points selected at each subdivision step (N).
+ cfg.MODEL.POINT_HEAD.SUBDIVISION_NUM_POINTS = 28 * 28
+ cfg.MODEL.POINT_HEAD.FC_DIM = 256
+ cfg.MODEL.POINT_HEAD.NUM_FC = 3
+ cfg.MODEL.POINT_HEAD.CLS_AGNOSTIC_MASK = False
+ # If True, then coarse prediction features are used as inout for each layer in PointRend's MLP.
+ cfg.MODEL.POINT_HEAD.COARSE_PRED_EACH_LAYER = True
+ cfg.MODEL.POINT_HEAD.COARSE_SEM_SEG_HEAD_NAME = "SemSegFPNHead"
diff --git a/projects/PointRend/point_rend/point_features.py b/projects/PointRend/point_rend/point_features.py
new file mode 100644
index 0000000..320a33d
--- /dev/null
+++ b/projects/PointRend/point_rend/point_features.py
@@ -0,0 +1,216 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import torch
+from torch.nn import functional as F
+
+from detectron2.layers import cat
+from detectron2.structures import Boxes
+
+
+"""
+Shape shorthand in this module:
+
+ N: minibatch dimension size, i.e. the number of RoIs for instance segmenation or the
+ number of images for semantic segmenation.
+ R: number of ROIs, combined over all images, in the minibatch
+ P: number of points
+"""
+
+
+def point_sample(input, point_coords, **kwargs):
+ """
+ A wrapper around :function:`torch.nn.functional.grid_sample` to support 3D point_coords tensors.
+ Unlike :function:`torch.nn.functional.grid_sample` it assumes `point_coords` to lie inside
+ [0, 1] x [0, 1] square.
+
+ Args:
+ input (Tensor): A tensor of shape (N, C, H, W) that contains features map on a H x W grid.
+ point_coords (Tensor): A tensor of shape (N, P, 2) or (N, Hgrid, Wgrid, 2) that contains
+ [0, 1] x [0, 1] normalized point coordinates.
+
+ Returns:
+ output (Tensor): A tensor of shape (N, C, P) or (N, C, Hgrid, Wgrid) that contains
+ features for points in `point_coords`. The features are obtained via bilinear
+ interplation from `input` the same way as :function:`torch.nn.functional.grid_sample`.
+ """
+ add_dim = False
+ if point_coords.dim() == 3:
+ add_dim = True
+ point_coords = point_coords.unsqueeze(2)
+ output = F.grid_sample(input, 2.0 * point_coords - 1.0, **kwargs)
+ if add_dim:
+ output = output.squeeze(3)
+ return output
+
+
+def generate_regular_grid_point_coords(R, side_size, device):
+ """
+ Generate regular square grid of points in [0, 1] x [0, 1] coordinate space.
+
+ Args:
+ R (int): The number of grids to sample, one for each region.
+ side_size (int): The side size of the regular grid.
+ device (torch.device): Desired device of returned tensor.
+
+ Returns:
+ (Tensor): A tensor of shape (R, side_size^2, 2) that contains coordinates
+ for the regular grids.
+ """
+ aff = torch.tensor([[[0.5, 0, 0.5], [0, 0.5, 0.5]]], device=device)
+ r = F.affine_grid(aff, torch.Size((1, 1, side_size, side_size)), align_corners=False)
+ return r.view(1, -1, 2).expand(R, -1, -1)
+
+
+def get_uncertain_point_coords_with_randomness(
+ coarse_logits, uncertainty_func, num_points, oversample_ratio, importance_sample_ratio
+):
+ """
+ Sample points in [0, 1] x [0, 1] coordinate space based on their uncertainty. The unceratinties
+ are calculated for each point using 'uncertainty_func' function that takes point's logit
+ prediction as input.
+ See PointRend paper for details.
+
+ Args:
+ coarse_logits (Tensor): A tensor of shape (N, C, Hmask, Wmask) or (N, 1, Hmask, Wmask) for
+ class-specific or class-agnostic prediction.
+ uncertainty_func: A function that takes a Tensor of shape (N, C, P) or (N, 1, P) that
+ contains logit predictions for P points and returns their uncertainties as a Tensor of
+ shape (N, 1, P).
+ num_points (int): The number of points P to sample.
+ oversample_ratio (int): Oversampling parameter.
+ importance_sample_ratio (float): Ratio of points that are sampled via importnace sampling.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (N, P, 2) that contains the coordinates of P
+ sampled points.
+ """
+ assert oversample_ratio >= 1
+ assert importance_sample_ratio <= 1 and importance_sample_ratio >= 0
+ num_boxes = coarse_logits.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(num_boxes, num_sampled, 2, device=coarse_logits.device)
+ point_logits = point_sample(coarse_logits, point_coords, align_corners=False)
+ # It is crucial to calculate uncertainty based on the sampled prediction value for the points.
+ # Calculating uncertainties of the coarse predictions first and sampling them for points leads
+ # to incorrect results.
+ # To illustrate this: assume uncertainty_func(logits)=-abs(logits), a sampled point between
+ # two coarse predictions with -1 and 1 logits has 0 logits, and therefore 0 uncertainty value.
+ # However, if we calculate uncertainties for the coarse predictions first,
+ # both will have -1 uncertainty, and the sampled point will get -1 uncertainty.
+ point_uncertainties = uncertainty_func(point_logits)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(num_boxes, dtype=torch.long, device=coarse_logits.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ num_boxes, num_uncertain_points, 2
+ )
+ if num_random_points > 0:
+ point_coords = cat(
+ [
+ point_coords,
+ torch.rand(num_boxes, num_random_points, 2, device=coarse_logits.device),
+ ],
+ dim=1,
+ )
+ return point_coords
+
+
+def get_uncertain_point_coords_on_grid(uncertainty_map, num_points):
+ """
+ Find `num_points` most uncertain points from `uncertainty_map` grid.
+
+ Args:
+ uncertainty_map (Tensor): A tensor of shape (N, 1, H, W) that contains uncertainty
+ values for a set of points on a regular H x W grid.
+ num_points (int): The number of points P to select.
+
+ Returns:
+ point_indices (Tensor): A tensor of shape (N, P) that contains indices from
+ [0, H x W) of the most uncertain points.
+ point_coords (Tensor): A tensor of shape (N, P, 2) that contains [0, 1] x [0, 1] normalized
+ coordinates of the most uncertain points from the H x W grid.
+ """
+ R, _, H, W = uncertainty_map.shape
+ h_step = 1.0 / float(H)
+ w_step = 1.0 / float(W)
+
+ num_points = min(H * W, num_points)
+ point_indices = torch.topk(uncertainty_map.view(R, H * W), k=num_points, dim=1)[1]
+ point_coords = torch.zeros(R, num_points, 2, dtype=torch.float, device=uncertainty_map.device)
+ point_coords[:, :, 0] = w_step / 2.0 + (point_indices % W).to(torch.float) * w_step
+ point_coords[:, :, 1] = h_step / 2.0 + (point_indices // W).to(torch.float) * h_step
+ return point_indices, point_coords
+
+
+def point_sample_fine_grained_features(features_list, feature_scales, boxes, point_coords):
+ """
+ Get features from feature maps in `features_list` that correspond to specific point coordinates
+ inside each bounding box from `boxes`.
+
+ Args:
+ features_list (list[Tensor]): A list of feature map tensors to get features from.
+ feature_scales (list[float]): A list of scales for tensors in `features_list`.
+ boxes (list[Boxes]): A list of I Boxes objects that contain R_1 + ... + R_I = R boxes all
+ together.
+ point_coords (Tensor): A tensor of shape (R, P, 2) that contains
+ [0, 1] x [0, 1] box-normalized coordinates of the P sampled points.
+
+ Returns:
+ point_features (Tensor): A tensor of shape (R, C, P) that contains features sampled
+ from all features maps in feature_list for P sampled points for all R boxes in `boxes`.
+ point_coords_wrt_image (Tensor): A tensor of shape (R, P, 2) that contains image-level
+ coordinates of P points.
+ """
+ cat_boxes = Boxes.cat(boxes)
+ num_boxes = [len(b) for b in boxes]
+
+ point_coords_wrt_image = get_point_coords_wrt_image(cat_boxes.tensor, point_coords)
+ split_point_coords_wrt_image = torch.split(point_coords_wrt_image, num_boxes)
+
+ point_features = []
+ for idx_img, point_coords_wrt_image_per_image in enumerate(split_point_coords_wrt_image):
+ point_features_per_image = []
+ for idx_feature, feature_map in enumerate(features_list):
+ h, w = feature_map.shape[-2:]
+ scale = torch.tensor([w, h], device=feature_map.device) / feature_scales[idx_feature]
+ point_coords_scaled = point_coords_wrt_image_per_image / scale
+ point_features_per_image.append(
+ point_sample(
+ feature_map[idx_img].unsqueeze(0),
+ point_coords_scaled.unsqueeze(0),
+ align_corners=False,
+ )
+ .squeeze(0)
+ .transpose(1, 0)
+ )
+ point_features.append(cat(point_features_per_image, dim=1))
+
+ return cat(point_features, dim=0), point_coords_wrt_image
+
+
+def get_point_coords_wrt_image(boxes_coords, point_coords):
+ """
+ Convert box-normalized [0, 1] x [0, 1] point cooordinates to image-level coordinates.
+
+ Args:
+ boxes_coords (Tensor): A tensor of shape (R, 4) that contains bounding boxes.
+ coordinates.
+ point_coords (Tensor): A tensor of shape (R, P, 2) that contains
+ [0, 1] x [0, 1] box-normalized coordinates of the P sampled points.
+
+ Returns:
+ point_coords_wrt_image (Tensor): A tensor of shape (R, P, 2) that contains
+ image-normalized coordinates of P sampled points.
+ """
+ with torch.no_grad():
+ point_coords_wrt_image = point_coords.clone()
+ point_coords_wrt_image[:, :, 0] = point_coords_wrt_image[:, :, 0] * (
+ boxes_coords[:, None, 2] - boxes_coords[:, None, 0]
+ )
+ point_coords_wrt_image[:, :, 1] = point_coords_wrt_image[:, :, 1] * (
+ boxes_coords[:, None, 3] - boxes_coords[:, None, 1]
+ )
+ point_coords_wrt_image[:, :, 0] += boxes_coords[:, None, 0]
+ point_coords_wrt_image[:, :, 1] += boxes_coords[:, None, 1]
+ return point_coords_wrt_image
diff --git a/projects/PointRend/point_rend/point_head.py b/projects/PointRend/point_rend/point_head.py
new file mode 100644
index 0000000..4a4616f
--- /dev/null
+++ b/projects/PointRend/point_rend/point_head.py
@@ -0,0 +1,157 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import fvcore.nn.weight_init as weight_init
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from detectron2.layers import ShapeSpec, cat
+from detectron2.structures import BitMasks
+from detectron2.utils.events import get_event_storage
+from detectron2.utils.registry import Registry
+
+from .point_features import point_sample
+
+POINT_HEAD_REGISTRY = Registry("POINT_HEAD")
+POINT_HEAD_REGISTRY.__doc__ = """
+Registry for point heads, which makes prediction for a given set of per-point features.
+
+The registered object will be called with `obj(cfg, input_shape)`.
+"""
+
+
+def roi_mask_point_loss(mask_logits, instances, points_coord):
+ """
+ Compute the point-based loss for instance segmentation mask predictions.
+
+ Args:
+ mask_logits (Tensor): A tensor of shape (R, C, P) or (R, 1, P) for class-specific or
+ class-agnostic, where R is the total number of predicted masks in all images, C is the
+ number of foreground classes, and P is the number of points sampled for each mask.
+ The values are logits.
+ instances (list[Instances]): A list of N Instances, where N is the number of images
+ in the batch. These instances are in 1:1 correspondence with the `mask_logits`. So, i_th
+ elememt of the list contains R_i objects and R_1 + ... + R_N is equal to R.
+ The ground-truth labels (class, box, mask, ...) associated with each instance are stored
+ in fields.
+ points_coords (Tensor): A tensor of shape (R, P, 2), where R is the total number of
+ predicted masks and P is the number of points for each mask. The coordinates are in
+ the image pixel coordinate space, i.e. [0, H] x [0, W].
+ Returns:
+ point_loss (Tensor): A scalar tensor containing the loss.
+ """
+ with torch.no_grad():
+ cls_agnostic_mask = mask_logits.size(1) == 1
+ total_num_masks = mask_logits.size(0)
+
+ gt_classes = []
+ gt_mask_logits = []
+ idx = 0
+ for instances_per_image in instances:
+ if len(instances_per_image) == 0:
+ continue
+ assert isinstance(
+ instances_per_image.gt_masks, BitMasks
+ ), "Point head works with GT in 'bitmask' format. Set INPUT.MASK_FORMAT to 'bitmask'."
+
+ if not cls_agnostic_mask:
+ gt_classes_per_image = instances_per_image.gt_classes.to(dtype=torch.int64)
+ gt_classes.append(gt_classes_per_image)
+
+ gt_bit_masks = instances_per_image.gt_masks.tensor
+ h, w = instances_per_image.gt_masks.image_size
+ scale = torch.tensor([w, h], dtype=torch.float, device=gt_bit_masks.device)
+ points_coord_grid_sample_format = (
+ points_coord[idx : idx + len(instances_per_image)] / scale
+ )
+ idx += len(instances_per_image)
+ gt_mask_logits.append(
+ point_sample(
+ gt_bit_masks.to(torch.float32).unsqueeze(1),
+ points_coord_grid_sample_format,
+ align_corners=False,
+ ).squeeze(1)
+ )
+
+ if len(gt_mask_logits) == 0:
+ return mask_logits.sum() * 0
+
+ gt_mask_logits = cat(gt_mask_logits)
+ assert gt_mask_logits.numel() > 0, gt_mask_logits.shape
+
+ if cls_agnostic_mask:
+ mask_logits = mask_logits[:, 0]
+ else:
+ indices = torch.arange(total_num_masks)
+ gt_classes = cat(gt_classes, dim=0)
+ mask_logits = mask_logits[indices, gt_classes]
+
+ # Log the training accuracy (using gt classes and 0.0 threshold for the logits)
+ mask_accurate = (mask_logits > 0.0) == gt_mask_logits.to(dtype=torch.uint8)
+ mask_accuracy = mask_accurate.nonzero().size(0) / mask_accurate.numel()
+ get_event_storage().put_scalar("point_rend/accuracy", mask_accuracy)
+
+ point_loss = F.binary_cross_entropy_with_logits(
+ mask_logits, gt_mask_logits.to(dtype=torch.float32), reduction="mean"
+ )
+ return point_loss
+
+
+@POINT_HEAD_REGISTRY.register()
+class StandardPointHead(nn.Module):
+ """
+ A point head multi-layer perceptron which we model with conv1d layers with kernel 1. The head
+ takes both fine-grained and coarse prediction features as its input.
+ """
+
+ def __init__(self, cfg, input_shape: ShapeSpec):
+ """
+ The following attributes are parsed from config:
+ fc_dim: the output dimension of each FC layers
+ num_fc: the number of FC layers
+ coarse_pred_each_layer: if True, coarse prediction features are concatenated to each
+ layer's input
+ """
+ super(StandardPointHead, self).__init__()
+ # fmt: off
+ num_classes = cfg.MODEL.POINT_HEAD.NUM_CLASSES
+ fc_dim = cfg.MODEL.POINT_HEAD.FC_DIM
+ num_fc = cfg.MODEL.POINT_HEAD.NUM_FC
+ cls_agnostic_mask = cfg.MODEL.POINT_HEAD.CLS_AGNOSTIC_MASK
+ self.coarse_pred_each_layer = cfg.MODEL.POINT_HEAD.COARSE_PRED_EACH_LAYER
+ input_channels = input_shape.channels
+ # fmt: on
+
+ fc_dim_in = input_channels + num_classes
+ self.fc_layers = []
+ for k in range(num_fc):
+ fc = nn.Conv1d(fc_dim_in, fc_dim, kernel_size=1, stride=1, padding=0, bias=True)
+ self.add_module("fc{}".format(k + 1), fc)
+ self.fc_layers.append(fc)
+ fc_dim_in = fc_dim
+ fc_dim_in += num_classes if self.coarse_pred_each_layer else 0
+
+ num_mask_classes = 1 if cls_agnostic_mask else num_classes
+ self.predictor = nn.Conv1d(fc_dim_in, num_mask_classes, kernel_size=1, stride=1, padding=0)
+
+ for layer in self.fc_layers:
+ weight_init.c2_msra_fill(layer)
+ # use normal distribution initialization for mask prediction layer
+ nn.init.normal_(self.predictor.weight, std=0.001)
+ if self.predictor.bias is not None:
+ nn.init.constant_(self.predictor.bias, 0)
+
+ def forward(self, fine_grained_features, coarse_features):
+ x = torch.cat((fine_grained_features, coarse_features), dim=1)
+ for layer in self.fc_layers:
+ x = F.relu(layer(x))
+ if self.coarse_pred_each_layer:
+ x = cat((x, coarse_features), dim=1)
+ return self.predictor(x)
+
+
+def build_point_head(cfg, input_channels):
+ """
+ Build a point head defined by `cfg.MODEL.POINT_HEAD.NAME`.
+ """
+ head_name = cfg.MODEL.POINT_HEAD.NAME
+ return POINT_HEAD_REGISTRY.get(head_name)(cfg, input_channels)
diff --git a/projects/PointRend/point_rend/roi_heads.py b/projects/PointRend/point_rend/roi_heads.py
new file mode 100644
index 0000000..4f7225b
--- /dev/null
+++ b/projects/PointRend/point_rend/roi_heads.py
@@ -0,0 +1,227 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import numpy as np
+import torch
+
+from detectron2.layers import ShapeSpec, cat, interpolate
+from detectron2.modeling import ROI_HEADS_REGISTRY, StandardROIHeads
+from detectron2.modeling.roi_heads.mask_head import (
+ build_mask_head,
+ mask_rcnn_inference,
+ mask_rcnn_loss,
+)
+from detectron2.modeling.roi_heads.roi_heads import select_foreground_proposals
+
+from .point_features import (
+ generate_regular_grid_point_coords,
+ get_uncertain_point_coords_on_grid,
+ get_uncertain_point_coords_with_randomness,
+ point_sample,
+ point_sample_fine_grained_features,
+)
+from .point_head import build_point_head, roi_mask_point_loss
+
+
+def calculate_uncertainty(logits, classes):
+ """
+ We estimate uncerainty as L1 distance between 0.0 and the logit prediction in 'logits' for the
+ foreground class in `classes`.
+
+ Args:
+ logits (Tensor): A tensor of shape (R, C, ...) or (R, 1, ...) for class-specific or
+ class-agnostic, where R is the total number of predicted masks in all images and C is
+ the number of foreground classes. The values are logits.
+ classes (list): A list of length R that contains either predicted of ground truth class
+ for eash predicted mask.
+
+ Returns:
+ scores (Tensor): A tensor of shape (R, 1, ...) that contains uncertainty scores with
+ the most uncertain locations having the highest uncertainty score.
+ """
+ if logits.shape[1] == 1:
+ gt_class_logits = logits.clone()
+ else:
+ gt_class_logits = logits[
+ torch.arange(logits.shape[0], device=logits.device), classes
+ ].unsqueeze(1)
+ return -(torch.abs(gt_class_logits))
+
+
+@ROI_HEADS_REGISTRY.register()
+class PointRendROIHeads(StandardROIHeads):
+ """
+ The RoI heads class for PointRend instance segmentation models.
+
+ In this class we redefine the mask head of `StandardROIHeads` leaving all other heads intact.
+ To avoid namespace conflict with other heads we use names starting from `mask_` for all
+ variables that correspond to the mask head in the class's namespace.
+ """
+
+ def __init__(self, cfg, input_shape):
+ # TODO use explicit args style
+ super().__init__(cfg, input_shape)
+ self._init_mask_head(cfg, input_shape)
+
+ def _init_mask_head(self, cfg, input_shape):
+ # fmt: off
+ self.mask_on = cfg.MODEL.MASK_ON
+ if not self.mask_on:
+ return
+ self.mask_coarse_in_features = cfg.MODEL.ROI_MASK_HEAD.IN_FEATURES
+ self.mask_coarse_side_size = cfg.MODEL.ROI_MASK_HEAD.POOLER_RESOLUTION
+ self._feature_scales = {k: 1.0 / v.stride for k, v in input_shape.items()}
+ # fmt: on
+
+ in_channels = np.sum([input_shape[f].channels for f in self.mask_coarse_in_features])
+ self.mask_coarse_head = build_mask_head(
+ cfg,
+ ShapeSpec(
+ channels=in_channels,
+ width=self.mask_coarse_side_size,
+ height=self.mask_coarse_side_size,
+ ),
+ )
+ self._init_point_head(cfg, input_shape)
+
+ def _init_point_head(self, cfg, input_shape):
+ # fmt: off
+ self.mask_point_on = cfg.MODEL.ROI_MASK_HEAD.POINT_HEAD_ON
+ if not self.mask_point_on:
+ return
+ assert cfg.MODEL.ROI_HEADS.NUM_CLASSES == cfg.MODEL.POINT_HEAD.NUM_CLASSES
+ self.mask_point_in_features = cfg.MODEL.POINT_HEAD.IN_FEATURES
+ self.mask_point_train_num_points = cfg.MODEL.POINT_HEAD.TRAIN_NUM_POINTS
+ self.mask_point_oversample_ratio = cfg.MODEL.POINT_HEAD.OVERSAMPLE_RATIO
+ self.mask_point_importance_sample_ratio = cfg.MODEL.POINT_HEAD.IMPORTANCE_SAMPLE_RATIO
+ # next two parameters are use in the adaptive subdivions inference procedure
+ self.mask_point_subdivision_steps = cfg.MODEL.POINT_HEAD.SUBDIVISION_STEPS
+ self.mask_point_subdivision_num_points = cfg.MODEL.POINT_HEAD.SUBDIVISION_NUM_POINTS
+ # fmt: on
+
+ in_channels = np.sum([input_shape[f].channels for f in self.mask_point_in_features])
+ self.mask_point_head = build_point_head(
+ cfg, ShapeSpec(channels=in_channels, width=1, height=1)
+ )
+
+ def _forward_mask(self, features, instances):
+ """
+ Forward logic of the mask prediction branch.
+
+ Args:
+ features (dict[str, Tensor]): #level input features for mask prediction
+ instances (list[Instances]): the per-image instances to train/predict masks.
+ In training, they can be the proposals.
+ In inference, they can be the predicted boxes.
+
+ Returns:
+ In training, a dict of losses.
+ In inference, update `instances` with new fields "pred_masks" and return it.
+ """
+ if not self.mask_on:
+ return {} if self.training else instances
+
+ if self.training:
+ proposals, _ = select_foreground_proposals(instances, self.num_classes)
+ proposal_boxes = [x.proposal_boxes for x in proposals]
+ mask_coarse_logits = self._forward_mask_coarse(features, proposal_boxes)
+
+ losses = {"loss_mask": mask_rcnn_loss(mask_coarse_logits, proposals)}
+ losses.update(self._forward_mask_point(features, mask_coarse_logits, proposals))
+ return losses
+ else:
+ pred_boxes = [x.pred_boxes for x in instances]
+ mask_coarse_logits = self._forward_mask_coarse(features, pred_boxes)
+
+ mask_logits = self._forward_mask_point(features, mask_coarse_logits, instances)
+ mask_rcnn_inference(mask_logits, instances)
+ return instances
+
+ def _forward_mask_coarse(self, features, boxes):
+ """
+ Forward logic of the coarse mask head.
+ """
+ point_coords = generate_regular_grid_point_coords(
+ np.sum(len(x) for x in boxes), self.mask_coarse_side_size, boxes[0].device
+ )
+ mask_coarse_features_list = [features[k] for k in self.mask_coarse_in_features]
+ features_scales = [self._feature_scales[k] for k in self.mask_coarse_in_features]
+ # For regular grids of points, this function is equivalent to `len(features_list)' calls
+ # of `ROIAlign` (with `SAMPLING_RATIO=2`), and concat the results.
+ mask_features, _ = point_sample_fine_grained_features(
+ mask_coarse_features_list, features_scales, boxes, point_coords
+ )
+ return self.mask_coarse_head(mask_features)
+
+ def _forward_mask_point(self, features, mask_coarse_logits, instances):
+ """
+ Forward logic of the mask point head.
+ """
+ if not self.mask_point_on:
+ return {} if self.training else mask_coarse_logits
+
+ mask_features_list = [features[k] for k in self.mask_point_in_features]
+ features_scales = [self._feature_scales[k] for k in self.mask_point_in_features]
+
+ if self.training:
+ proposal_boxes = [x.proposal_boxes for x in instances]
+ gt_classes = cat([x.gt_classes for x in instances])
+ with torch.no_grad():
+ point_coords = get_uncertain_point_coords_with_randomness(
+ mask_coarse_logits,
+ lambda logits: calculate_uncertainty(logits, gt_classes),
+ self.mask_point_train_num_points,
+ self.mask_point_oversample_ratio,
+ self.mask_point_importance_sample_ratio,
+ )
+
+ fine_grained_features, point_coords_wrt_image = point_sample_fine_grained_features(
+ mask_features_list, features_scales, proposal_boxes, point_coords
+ )
+ coarse_features = point_sample(mask_coarse_logits, point_coords, align_corners=False)
+ point_logits = self.mask_point_head(fine_grained_features, coarse_features)
+ return {
+ "loss_mask_point": roi_mask_point_loss(
+ point_logits, instances, point_coords_wrt_image
+ )
+ }
+ else:
+ pred_boxes = [x.pred_boxes for x in instances]
+ pred_classes = cat([x.pred_classes for x in instances])
+ # The subdivision code will fail with the empty list of boxes
+ if len(pred_classes) == 0:
+ return mask_coarse_logits
+
+ mask_logits = mask_coarse_logits.clone()
+ for subdivions_step in range(self.mask_point_subdivision_steps):
+ mask_logits = interpolate(
+ mask_logits, scale_factor=2, mode="bilinear", align_corners=False
+ )
+ # If `mask_point_subdivision_num_points` is larger or equal to the
+ # resolution of the next step, then we can skip this step
+ H, W = mask_logits.shape[-2:]
+ if (
+ self.mask_point_subdivision_num_points >= 4 * H * W
+ and subdivions_step < self.mask_point_subdivision_steps - 1
+ ):
+ continue
+ uncertainty_map = calculate_uncertainty(mask_logits, pred_classes)
+ point_indices, point_coords = get_uncertain_point_coords_on_grid(
+ uncertainty_map, self.mask_point_subdivision_num_points
+ )
+ fine_grained_features, _ = point_sample_fine_grained_features(
+ mask_features_list, features_scales, pred_boxes, point_coords
+ )
+ coarse_features = point_sample(
+ mask_coarse_logits, point_coords, align_corners=False
+ )
+ point_logits = self.mask_point_head(fine_grained_features, coarse_features)
+
+ # put mask point predictions to the right places on the upsampled grid.
+ R, C, H, W = mask_logits.shape
+ point_indices = point_indices.unsqueeze(1).expand(-1, C, -1)
+ mask_logits = (
+ mask_logits.reshape(R, C, H * W)
+ .scatter_(2, point_indices, point_logits)
+ .view(R, C, H, W)
+ )
+ return mask_logits
diff --git a/projects/PointRend/point_rend/semantic_seg.py b/projects/PointRend/point_rend/semantic_seg.py
new file mode 100644
index 0000000..edd37ee
--- /dev/null
+++ b/projects/PointRend/point_rend/semantic_seg.py
@@ -0,0 +1,135 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+import numpy as np
+from typing import Dict
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from detectron2.layers import ShapeSpec, cat
+from detectron2.modeling import SEM_SEG_HEADS_REGISTRY
+
+from .point_features import (
+ get_uncertain_point_coords_on_grid,
+ get_uncertain_point_coords_with_randomness,
+ point_sample,
+)
+from .point_head import build_point_head
+
+
+def calculate_uncertainty(sem_seg_logits):
+ """
+ For each location of the prediction `sem_seg_logits` we estimate uncerainty as the
+ difference between top first and top second predicted logits.
+
+ Args:
+ mask_logits (Tensor): A tensor of shape (N, C, ...), where N is the minibatch size and
+ C is the number of foreground classes. The values are logits.
+
+ Returns:
+ scores (Tensor): A tensor of shape (N, 1, ...) that contains uncertainty scores with
+ the most uncertain locations having the highest uncertainty score.
+ """
+ top2_scores = torch.topk(sem_seg_logits, k=2, dim=1)[0]
+ return (top2_scores[:, 1] - top2_scores[:, 0]).unsqueeze(1)
+
+
+@SEM_SEG_HEADS_REGISTRY.register()
+class PointRendSemSegHead(nn.Module):
+ """
+ A semantic segmentation head that combines a head set in `POINT_HEAD.COARSE_SEM_SEG_HEAD_NAME`
+ and a point head set in `MODEL.POINT_HEAD.NAME`.
+ """
+
+ def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
+ super().__init__()
+
+ self.ignore_value = cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE
+
+ self.coarse_sem_seg_head = SEM_SEG_HEADS_REGISTRY.get(
+ cfg.MODEL.POINT_HEAD.COARSE_SEM_SEG_HEAD_NAME
+ )(cfg, input_shape)
+ self._init_point_head(cfg, input_shape)
+
+ def _init_point_head(self, cfg, input_shape: Dict[str, ShapeSpec]):
+ # fmt: off
+ assert cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES == cfg.MODEL.POINT_HEAD.NUM_CLASSES
+ feature_channels = {k: v.channels for k, v in input_shape.items()}
+ self.in_features = cfg.MODEL.POINT_HEAD.IN_FEATURES
+ self.train_num_points = cfg.MODEL.POINT_HEAD.TRAIN_NUM_POINTS
+ self.oversample_ratio = cfg.MODEL.POINT_HEAD.OVERSAMPLE_RATIO
+ self.importance_sample_ratio = cfg.MODEL.POINT_HEAD.IMPORTANCE_SAMPLE_RATIO
+ self.subdivision_steps = cfg.MODEL.POINT_HEAD.SUBDIVISION_STEPS
+ self.subdivision_num_points = cfg.MODEL.POINT_HEAD.SUBDIVISION_NUM_POINTS
+ # fmt: on
+
+ in_channels = np.sum([feature_channels[f] for f in self.in_features])
+ self.point_head = build_point_head(cfg, ShapeSpec(channels=in_channels, width=1, height=1))
+
+ def forward(self, features, targets=None):
+ coarse_sem_seg_logits = self.coarse_sem_seg_head.layers(features)
+
+ if self.training:
+ losses = self.coarse_sem_seg_head.losses(coarse_sem_seg_logits, targets)
+
+ with torch.no_grad():
+ point_coords = get_uncertain_point_coords_with_randomness(
+ coarse_sem_seg_logits,
+ calculate_uncertainty,
+ self.train_num_points,
+ self.oversample_ratio,
+ self.importance_sample_ratio,
+ )
+ coarse_features = point_sample(coarse_sem_seg_logits, point_coords, align_corners=False)
+
+ fine_grained_features = cat(
+ [
+ point_sample(features[in_feature], point_coords, align_corners=False)
+ for in_feature in self.in_features
+ ],
+ dim=1,
+ )
+ point_logits = self.point_head(fine_grained_features, coarse_features)
+ point_targets = (
+ point_sample(
+ targets.unsqueeze(1).to(torch.float),
+ point_coords,
+ mode="nearest",
+ align_corners=False,
+ )
+ .squeeze(1)
+ .to(torch.long)
+ )
+ losses["loss_sem_seg_point"] = F.cross_entropy(
+ point_logits, point_targets, reduction="mean", ignore_index=self.ignore_value
+ )
+ return None, losses
+ else:
+ sem_seg_logits = coarse_sem_seg_logits.clone()
+ for _ in range(self.subdivision_steps):
+ sem_seg_logits = F.interpolate(
+ sem_seg_logits, scale_factor=2, mode="bilinear", align_corners=False
+ )
+ uncertainty_map = calculate_uncertainty(sem_seg_logits)
+ point_indices, point_coords = get_uncertain_point_coords_on_grid(
+ uncertainty_map, self.subdivision_num_points
+ )
+ fine_grained_features = cat(
+ [
+ point_sample(features[in_feature], point_coords, align_corners=False)
+ for in_feature in self.in_features
+ ]
+ )
+ coarse_features = point_sample(
+ coarse_sem_seg_logits, point_coords, align_corners=False
+ )
+ point_logits = self.point_head(fine_grained_features, coarse_features)
+
+ # put sem seg point predictions to the right places on the upsampled grid.
+ N, C, H, W = sem_seg_logits.shape
+ point_indices = point_indices.unsqueeze(1).expand(-1, C, -1)
+ sem_seg_logits = (
+ sem_seg_logits.reshape(N, C, H * W)
+ .scatter_(2, point_indices, point_logits)
+ .view(N, C, H, W)
+ )
+ return sem_seg_logits, {}
diff --git a/projects/PointRend/train_net.py b/projects/PointRend/train_net.py
new file mode 100644
index 0000000..2df0723
--- /dev/null
+++ b/projects/PointRend/train_net.py
@@ -0,0 +1,154 @@
+#!/usr/bin/env python3
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+"""
+PointRend Training Script.
+
+This script is a simplified version of the training script in detectron2/tools.
+"""
+
+import os
+import torch
+
+import detectron2.data.transforms as T
+import detectron2.utils.comm as comm
+from detectron2.checkpoint import DetectionCheckpointer
+from detectron2.config import get_cfg
+from detectron2.data import DatasetMapper, MetadataCatalog, build_detection_train_loader
+from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
+from detectron2.evaluation import (
+ CityscapesInstanceEvaluator,
+ CityscapesSemSegEvaluator,
+ COCOEvaluator,
+ DatasetEvaluators,
+ LVISEvaluator,
+ SemSegEvaluator,
+ verify_results,
+)
+from detectron2.projects.point_rend import ColorAugSSDTransform, add_pointrend_config
+
+
+def build_sem_seg_train_aug(cfg):
+ augs = [
+ T.ResizeShortestEdge(
+ cfg.INPUT.MIN_SIZE_TRAIN, cfg.INPUT.MAX_SIZE_TRAIN, cfg.INPUT.MIN_SIZE_TRAIN_SAMPLING
+ )
+ ]
+ if cfg.INPUT.CROP.ENABLED:
+ augs.append(
+ T.RandomCrop_CategoryAreaConstraint(
+ cfg.INPUT.CROP.TYPE,
+ cfg.INPUT.CROP.SIZE,
+ cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA,
+ cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
+ )
+ )
+ if cfg.INPUT.COLOR_AUG_SSD:
+ augs.append(ColorAugSSDTransform(img_format=cfg.INPUT.FORMAT))
+ augs.append(T.RandomFlip())
+ return augs
+
+
+class Trainer(DefaultTrainer):
+ """
+ We use the "DefaultTrainer" which contains a number pre-defined logic for
+ standard training workflow. They may not work for you, especially if you
+ are working on a new research project. In that case you can use the cleaner
+ "SimpleTrainer", or write your own training loop.
+ """
+
+ @classmethod
+ def build_evaluator(cls, cfg, dataset_name, output_folder=None):
+ """
+ Create evaluator(s) for a given dataset.
+ This uses the special metadata "evaluator_type" associated with each builtin dataset.
+ For your own dataset, you can simply create an evaluator manually in your
+ script and do not have to worry about the hacky if-else logic here.
+ """
+ if output_folder is None:
+ output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
+ evaluator_list = []
+ evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
+ if evaluator_type == "lvis":
+ return LVISEvaluator(dataset_name, cfg, True, output_folder)
+ if evaluator_type == "coco":
+ return COCOEvaluator(dataset_name, cfg, True, output_folder)
+ if evaluator_type == "sem_seg":
+ return SemSegEvaluator(
+ dataset_name,
+ distributed=True,
+ num_classes=cfg.MODEL.SEM_SEG_HEAD.NUM_CLASSES,
+ ignore_label=cfg.MODEL.SEM_SEG_HEAD.IGNORE_VALUE,
+ output_dir=output_folder,
+ )
+ if evaluator_type == "cityscapes_instance":
+ assert (
+ torch.cuda.device_count() >= comm.get_rank()
+ ), "CityscapesEvaluator currently do not work with multiple machines."
+ return CityscapesInstanceEvaluator(dataset_name)
+ if evaluator_type == "cityscapes_sem_seg":
+ assert (
+ torch.cuda.device_count() >= comm.get_rank()
+ ), "CityscapesEvaluator currently do not work with multiple machines."
+ return CityscapesSemSegEvaluator(dataset_name)
+ if len(evaluator_list) == 0:
+ raise NotImplementedError(
+ "no Evaluator for the dataset {} with the type {}".format(
+ dataset_name, evaluator_type
+ )
+ )
+ if len(evaluator_list) == 1:
+ return evaluator_list[0]
+ return DatasetEvaluators(evaluator_list)
+
+ @classmethod
+ def build_train_loader(cls, cfg):
+ if "SemanticSegmentor" in cfg.MODEL.META_ARCHITECTURE:
+ mapper = DatasetMapper(cfg, is_train=True, augmentations=build_sem_seg_train_aug(cfg))
+ else:
+ mapper = None
+ return build_detection_train_loader(cfg, mapper=mapper)
+
+
+def setup(args):
+ """
+ Create configs and perform basic setups.
+ """
+ cfg = get_cfg()
+ add_pointrend_config(cfg)
+ cfg.merge_from_file(args.config_file)
+ cfg.merge_from_list(args.opts)
+ cfg.freeze()
+ default_setup(cfg, args)
+ return cfg
+
+
+def main(args):
+ cfg = setup(args)
+
+ if args.eval_only:
+ model = Trainer.build_model(cfg)
+ DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
+ cfg.MODEL.WEIGHTS, resume=args.resume
+ )
+ res = Trainer.test(cfg, model)
+ if comm.is_main_process():
+ verify_results(cfg, res)
+ return res
+
+ trainer = Trainer(cfg)
+ trainer.resume_or_load(resume=args.resume)
+ return trainer.train()
+
+
+if __name__ == "__main__":
+ args = default_argument_parser().parse_args()
+ print("Command Line Args:", args)
+ launch(
+ main,
+ args.num_gpus,
+ num_machines=args.num_machines,
+ machine_rank=args.machine_rank,
+ dist_url=args.dist_url,
+ args=(args,),
+ )
diff --git a/projects/README.md b/projects/README.md
index 8b13789..446994e 100644
--- a/projects/README.md
+++ b/projects/README.md
@@ -1 +1,39 @@
+Here are a few projects that are built on detectron2.
+They are examples of how to use detectron2 as a library, to make your projects more
+maintainable.
+
+## Projects by Facebook
+
+Note that these are research projects, and therefore may not have the same level
+of support or stability as detectron2.
+
++ [DensePose: Dense Human Pose Estimation In The Wild](DensePose)
++ [Scale-Aware Trident Networks for Object Detection](TridentNet)
++ [TensorMask: A Foundation for Dense Object Segmentation](TensorMask)
++ [Mesh R-CNN](https://github.com/facebookresearch/meshrcnn)
++ [PointRend: Image Segmentation as Rendering](PointRend)
++ [Momentum Contrast for Unsupervised Visual Representation Learning](https://github.com/facebookresearch/moco/tree/master/detection)
++ [DETR: End-to-End Object Detection with Transformers](https://github.com/facebookresearch/detr/tree/master/d2)
++ [Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation](Panoptic-DeepLab)
+
+
+## External Projects
+
+External projects in the community that use detectron2:
+
+
+
++ [AdelaiDet](https://github.com/aim-uofa/adet), a detection toolbox including FCOS, BlendMask, etc.
++ [CenterMask](https://github.com/youngwanLEE/centermask2)
++ [Res2Net backbones](https://github.com/Res2Net/Res2Net-detectron2)
++ [VoVNet backbones](https://github.com/youngwanLEE/vovnet-detectron2)
++ [FsDet](https://github.com/ucbdrive/few-shot-object-detection), Few-Shot Object Detection.
diff --git a/projects/TensorMask/README.md b/projects/TensorMask/README.md
new file mode 100644
index 0000000..e81307c
--- /dev/null
+++ b/projects/TensorMask/README.md
@@ -0,0 +1,63 @@
+
+# TensorMask in Detectron2
+**A Foundation for Dense Object Segmentation**
+
+Xinlei Chen, Ross Girshick, Kaiming He, Piotr Dollár
+
+[[`arXiv`](https://arxiv.org/abs/1903.12174)] [[`BibTeX`](#CitingTensorMask)]
+
+
+

+
+

+